


Sound Classification and Processing of Urban Environments: A Systematic Literature Review

 , ,
, ,  and
and 
Abstract
:1. Introduction
2. Systematic Literature Review—Methodology
- Used datasets.
- Proposed models’ architecture, particularly if it is original or modified.
- Metrics used to evaluate the models’ performance.
2.1. Search Method
2.2. Sound Classification Methods
Neural Networks
3. Research Results
- Time stretching: slows down or speeds up the audio samples, but the pitch remains unchanged.
- Pitch shifting: the audio samples’ pitch is raised or lowered while keeping the duration unchanged.
- Dynamic range compression: compress the dynamic range of the audio using parameterizations from the Dolby E standard and the Icecast online radio streaming server.
- Background noise addition: mix background sounds’ recordings from different scenes with the audio samples.
- An increase in the number of epochs led to an exponential decrease in the validation error for training and testing data.
- LSTM model had better performance, in most cases than the CNN, which becomes more notable with the data augmentation techniques because the LSTM memory cell encompasses constant error backpropagation, which allows dealing better with noisy data.
- Focusing on the influence of the different used features, the one which led to the best accuracy was the MFCC; however, it was possible to outperform the achieved accuracy by using a stack of different features, mainly of MFCC and Chroma STFT.
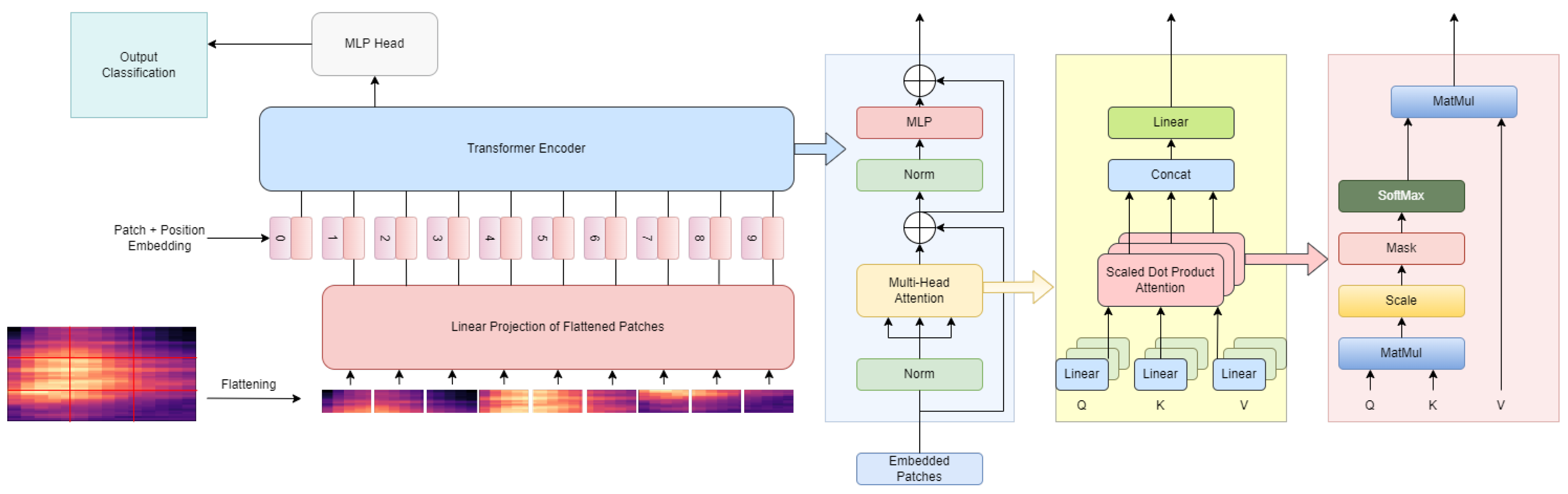
3.1. Transformers
- An input transformation baseline allows for choice of the embedding dimension and is constituted of a batch normalization layer, followed by a linear layer. This linear layer allows it to scale up or down one of the dimensions of audio features to a chosen dimension. After passing through the linear layer, a positional embedding is added to the feature vector to incorporate positional information into the prediction.
- A classic Transformer body which is a downsized version of BERT.
- A prediction head, after which three layers: a mean, a linear and a Softmax are used. The mean layer does a global average pooling of the output. The other two layers enable the mapping of the features to output classes before training using cross-entropy loss.
3.2. Sound Segmentation Methods
- Feature extraction: The audio input is divided into overlapping frames to allow extraction of the parametric feature vector from each frame.
- Initial detection: It is an optional step where the objective is to remove the silent parts and reject the parts of the signal that are not useful for the task.
- Segmentation: The vector sequence of features is segmented into sub-sequences with common acoustic characteristics. Two main approaches can be employed: distance-based and model-based techniques.
- Post-processing or smoothing: It is also an optional step where the goal is to correct the errors associated with detecting segments with a duration shorter than the specified threshold.
3.2.1. Attention Mechanisms
3.2.2. Autoencoders
3.2.3. Methods for Spectrogram Representation
4. Applications
5. Datasets
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| 1D | one-dimensional |
| 2D | two-dimensional |
| AAML | Additive Angular Margin Loss |
| ANN | Artificial Neural Network |
| APNet | Audio Prototype Network |
| AST | Audio Spectrogram Transformer |
| B-GRU | Bidirectional Gated Recurrent Unit |
| BERT | Bidirectional Encoder Representations from Transformers |
| BLSTM | Bidirectional Long-Short Term Memory |
| CENS | Chroma Energy Normalized Statistics |
| CNN | Convolutional Neural Network |
| CNN-Transformer | Convolutional Neural Network Transformer |
| CQT | Constant Q-transform |
| CRNN | Convolutional Recurrent Neural Networks |
| dB | decibel |
| DCNN | Deep Convolutional Neural Network |
| DeiT | Data efficiency image Transformer |
| DenseNet | Dense Convolutional Network |
| DL | Deep Learning |
| ERDF | European Regional Development Fund |
| ESC | Environmental Sound Classification |
| GFCC | Gammatone Frequency Cepstral Coefficient |
| GMM | Guassian Mixture Model |
| HMM | Hidden Markov Model |
| HPSS | Harmonic Percussive Source Separation |
| k-NN | k-Nearest Neighbor |
| LSTM | Long-Short Term Memory |
| M2M-AST | Many-to-Many Audio Spectrogram Transformer |
| MFCC | Mel Frequency Cepstral Coefficients |
| MIL-NCE | Multiple Instance Learning NCE |
| ML | Machine Learning |
| MSE | Mean Squared Error |
| NCE | Noise Contrastive Estimation |
| PRISMA | Preferred Reporting Items for Systematic Reviews and Meta-Analyses |
| RBF | Radial Basis Function |
| ResNet | Residual Neural Network |
| RGB | Red-Green-Blue |
| RNN | Recurrent Neural Network |
| SIF | Spectrogram Image Features |
| SSLS | Sound Source Localization and Separation |
| SSSC | Sound Source Separation and Classification |
| STFT | Short-Term Fourier Transformation |
| SVM | Support Vector Machine |
| TFCNN | Temporal-frequency attention based Convolutional Neural Network |
| VATT | Video-Audio-Text Transformer |
| ViT | Vision Transformer |
| VQ-VAE | Vector-quantized varitional autoencoders |
| YOHO | You Only Hear Once |
References
- Syed, A.S.; Sierra-Sosa, D.; Kumar, A.; Elmaghraby, A. IoT in Smart Cities: A Survey of Technologies, Practices and Challenges. Smart Cities 2021, 4, 429–475. [Google Scholar] [CrossRef]
- Bello, J.P.; Mydlarz, C.; Salamon, J. Sound Analysis in Smart Cities. In Computational Analysis of Sound Scenes and Events; Virtanen, T., Plumbley, M.D., Ellis, D., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 373–397. [Google Scholar]
- Mushtaq, Z.; Su, S.F. Efficient Classification of Environmental Sounds through Multiple Features Aggregation and Data Enhancement Techniques for Spectrogram Images. Symmetry 2020, 12, 1822. [Google Scholar] [CrossRef]
- Das, J.K.; Chakrabarty, A.; Piran, M.J. Environmental sound classification using convolution neural networks with different integrated loss functions. Expert Syst. 2021, 39. [Google Scholar] [CrossRef]
- Das, J.K.; Ghosh, A.; Pal, A.K.; Dutta, S.; Chakrabarty, A. Urban Sound Classification Using Convolutional Neural Network and Long Short Term Memory Based on Multiple Features. In Proceedings of the 2020 Fourth International Conference On Intelligent Computing in Data Sciences (ICDS), Hong Kong, China, 27–29 July 2020; pp. 1–9. [Google Scholar]
- Mu, W.; Yin, B.; Huang, X.; Xu, J.; Du, Z. Environmental sound classification using temporal-frequency attention based convolutional neural network. Sci. Rep. 2021, 11, 21552. [Google Scholar] [CrossRef] [PubMed]
- Giannakopoulos, T.; Spyrou, E.; Perantonis, S.J. Recognition of Urban Sound Events Using Deep Context-Aware Feature Extractors and Handcrafted Features. In Proceedings of the Artificial Intelligence Applications and Innovations; MacIntyre, J., Maglogiannis, I., Iliadis, L., Pimenidis, E., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 184–195. [Google Scholar]
- Luz, J.S.; Oliveira, M.C.; Araújo, F.H.; Magalhães, D.M. Ensemble of handcrafted and deep features for urban sound classification. Appl. Acoust. 2021, 175, 107819. [Google Scholar] [CrossRef]
- Gong, Y.; Chung, Y.; Glass, J.R. AST: Audio Spectrogram Transformer. CoRR. 2021. Available online: http://xxx.lanl.gov/abs/2104.01778 (accessed on 1 October 2022).
- Akbari, H.; Yuan, L.; Qian, R.; Chuang, W.; Chang, S.; Cui, Y.; Gong, B. VATT: Transformers for Multimodal Self-Supervised Learning from Raw Video, Audio and Text. CoRR. 2021. Available online: http://xxx.lanl.gov/abs/2104.11178 (accessed on 1 October 2022).
- Elliott, D.; Otero, C.E.; Wyatt, S.; Martino, E. Tiny Transformers for Environmental Sound Classification at the Edge. CoRR. 2021. Available online: http://xxx.lanl.gov/abs/2103.12157 (accessed on 1 October 2022).
- Wyatt, S.; Elliott, D.; Aravamudan, A.; Otero, C.E.; Otero, L.D.; Anagnostopoulos, G.C.; Smith, A.O.; Peter, A.M.; Jones, W.; Leung, S.; et al. Environmental Sound Classification with Tiny Transformers in Noisy Edge Environments. In Proceedings of the 2021 IEEE 7th World Forum on Internet of Things (WF-IoT), New Orleans, LA, USA, 14–31 July 2021; pp. 309–314. [Google Scholar]
- Park, S.; Jeong, Y.; Lee, T. Many-to-Many Audio Spectrogram Tansformer: Transformer for Sound Event Localization and Detection. In Proceedings of the DCASE, Barcelona, Spain, 15–19 November 2021; pp. 105–109. [Google Scholar]
- Koutini, K.; Schlüter, J.; Eghbal-zadeh, H.; Widmer, G. Efficient Training of Audio Transformers with Patchout. CoRR. 2021. Available online: http://xxx.lanl.gov/abs/2110.05069 (accessed on 1 October 2022).
- Türker, İ.; Aksu, S. Connectogram—A graph-based time dependent representation for sounds. Appl. Acoust. 2022, 191, 108660. [Google Scholar] [CrossRef]
- Kong, Q.; Xu, Y.; Plumbley, M. Sound Event Detection of Weakly Labelled Data With CNN-Transformer and Automatic Threshold Optimization. IEEE/Acm Trans. Audio Speech Lang. Process. 2020, 28, 2450–2460. [Google Scholar] [CrossRef]
- Salamon, J.; Bello, J.P. Deep Convolutional Neural Networks and Data Augmentation for Environmental Sound Classification. IEEE Signal Process. Lett. 2017, 24, 279–283. [Google Scholar] [CrossRef]
- Gimeno, P.; Viñals, I.; Ortega, A.; Miguel, A.; Lleida, E. Multiclass Audio Segmentation Based on Recurrent Neural Networks for Broadcast Domain Data. J Audio Speech Music Proc. 2020, 5, 1–19. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Xu, S.; Zhang, S.; Qiao, T.; Cao, S. Learning Attentive Representations for Environmental Sound Classification. IEEE Access 2019, 7, 130327–130339. [Google Scholar] [CrossRef]
- Zhang, Z.; Xu, S.; Zhang, S.; Qiao, T.; Cao, S. Attention based convolutional recurrent neural network for environmental sound classification. Neurocomputing 2020, 453, 896–903. [Google Scholar] [CrossRef]
- Qiao, T.; Zhang, S.; Cao, S.; Xu, S. High Accurate Environmental Sound Classification: Sub-Spectrogram Segmentation versus Temporal-Frequency Attention Mechanism. Sensors 2021, 21, 5500. [Google Scholar] [CrossRef] [PubMed]
- Tripathi, A.M.; Mishra, A. Environment sound classification using an attention-based residual neural network. Neurocomputing 2021, 460, 409–423. [Google Scholar] [CrossRef]
- Ristea, N.C.; Ionescu, R.T.; Khan, F.S. SepTr: Separable Transformer for Audio Spectrogram Processing. arXiv 2022, arXiv:2203.09581. [Google Scholar]
- Page, M.J.; McKenzie, J.E.; Bossuyt, P.M.M.; Boutron, I.; Hoffmann, T.C.; Mulrow, C.D.; Shamseer, L.; Tetzlaff, J.M.; Moher, D. Updating guidance for reporting systematic reviews: development of the PRISMA 2020 statement. J. Clin. Epidemiol. 2021, 134, 103–112. [Google Scholar] [CrossRef]
- Zinemanas, P.; Rocamora, M.; Miron, M.; Font, F.; Serra, X. An Interpretable Deep Learning Model for Automatic Sound Classification. Electronics 2021, 10, 850. [Google Scholar] [CrossRef]
- McFee, B.; Raffel, C.; Liang, D.; Ellis, D.P.; McVicar, M.; Battenberg, E.; Nieto, O. librosa: Audio and music signal analysis in python. In Proceedings of the 14th Python in Science Conference, Austin, TX, USA, 6–12 July 2015; Volume 8, pp. 18–25. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.u.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers); Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 4171–4186. [Google Scholar]
- Neath, A.A.; Cavanaugh, J.E. The Bayesian information criterion: background, derivation, and applications. Wiley Interdiscip. Rev. Comput. Stat. 2012, 4, 199–203. [Google Scholar] [CrossRef]
- Joyce, J.M. Kullback-leibler divergence. In International Encyclopedia of Statistical Science; Springer: Berlin/Heidelberg, Germany, 2011; pp. 720–722. [Google Scholar]
- Narasimhan, S.; Mah, R.S. Generalized likelihood ratio method for gross error identification. AIChE J. 1987, 33, 1514–1521. [Google Scholar] [CrossRef]
- Holloway, L.N.; Dunn, O.J. The robustness of hotelling’s T 2. J. Am. Stat. Assoc. 1967, 62, 124–136. [Google Scholar] [CrossRef]
- Theodorou, T.; Mporas, I.; Fakotakis, N. An Overview of Automatic Audio Segmentation. Int. J. Inf. Technol. Comput. Sci. 2014, 6, 1–9. [Google Scholar] [CrossRef] [Green Version]
- Tax, T.M.S.; Antich, J.L.D.; Purwins, H.; Maaløe, L. Utilizing Domain Knowledge in End-to-End Audio Processing. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Martín-Morató, I.; Cobos, M.; Ferri, F.J. Adaptive Distance-Based Pooling in Convolutional Neural Networks for Audio Event Classification. IEEE/Acm Trans. Audio Speech Lang. Process. 2020, 28, 1925–1935. [Google Scholar] [CrossRef]
- Sudo, Y.; Itoyama, K.; Nishida, K.; Nakadai, K. Multichannel environmental sound segmentation. Appl. Intell. 2021, 51, 8245–8259. [Google Scholar] [CrossRef]
- Venkatesh, S.; Moffat, D.; Miranda, E.R. You Only Hear Once: A YOLO-like Algorithm for Audio Segmentation and Sound Event Detection. 2021. Available online: http://xxx.lanl.gov/abs/2109.00962 (accessed on 1 October 2022).
- Fraiwan, M.; Fraiwan, L.; Alkhodari, M.; Hassanin, O. Recognition of pulmonary diseases from lung sounds using convolutional neural networks and long short-term memory. J. Ambient. Intell. Humaniz. Comput. 2022, 13, 4759–4771. [Google Scholar] [CrossRef]
- Tuncer, T.; Dogan, S.; Tan, R.S.; Acharya, U.R. Application of Petersen graph pattern technique for automated detection of heart valve diseases with PCG signals. Inf. Sci. 2021, 565, 91–104. [Google Scholar] [CrossRef]
- Er, M.B. Heart sounds classification using convolutional neural network with 1D-local binary pattern and 1D-local ternary pattern features. Appl. Acoust. 2021, 180, 108152. [Google Scholar] [CrossRef]
- Zeinali, Y.; Niaki, S.T.A. Heart sound classification using signal processing and machine learning algorithms. Mach. Learn. Appl. 2022, 7, 100206. [Google Scholar] [CrossRef]
- Grooby, E.; Sitaula, C.; Fattahi, D.; Sameni, R.; Tan, K.; Zhou, L.; King, A.; Ramanathan, A.; Malhotra, A.; Dumont, G.A.; et al. Real-Time Multi-Level Neonatal Heart and Lung Sound Quality Assessment for Telehealth Applications. IEEE Access 2022, 10, 10934–10948. [Google Scholar] [CrossRef]
- Soares, B.S.; Luz, J.S.; de Macêdo, V.F.; e Silva, R.R.V.; de Araújo, F.H.D.; Magalhães, D.M.V. MFCC-based descriptor for bee queen presence detection. Expert Syst. Appl. 2022, 201, 117104. [Google Scholar] [CrossRef]
- Shen, W.; Ji, N.; Yin, Y.; Dai, B.; Tu, D.; Sun, B.; Hou, H.; Kou, S.; Zhao, Y. Fusion of acoustic and deep features for pig cough sound recognition. Comput. Electron. Agric. 2022, 197, 106994. [Google Scholar] [CrossRef]
- Shen, W.; Ji, N.; Yin, Y.; Bao, J.; Dai, B.; Hou, H.; Kou, S.; Zhao, Y. Investigation of acoustic and visual features for pig cough classification. Biosyst. Eng. 2022, 219, 281–293. [Google Scholar]
- Tuncer, T.; Akbal, E.; Dogan, S. Multileveled ternary pattern and iterative ReliefF based bird sound classification. Appl. Acoust. 2021, 176, 107866. [Google Scholar] [CrossRef]
- Zhang, X.; Li, Y. Adaptive energy detection for bird sound detection in complex environments. Neurocomputing 2015, 155, 108–116. [Google Scholar] [CrossRef]
- Hsu, S.B.; Lee, C.H.; Chang, P.C.; Han, C.C.; Fan, K.C. Local Wavelet Acoustic Pattern: A Novel Time–Frequency Descriptor for Birdsong Recognition. IEEE Trans. Multimed. 2018, 20, 3187–3199. [Google Scholar] [CrossRef]
- Xie, J.; Indraswari, K.; Schwarzkopf, L.; Towsey, M.; Zhang, J.; Roe, P. Acoustic classification of frog within-species and species-specific calls. Appl. Acoust. 2018, 131, 79–86. [Google Scholar] [CrossRef]
- Xie, J.; Zhu, M.; Hu, K.; Zhang, J.; Hines, H.; Guo, Y. Frog calling activity detection using lightweight CNN with multi-view spectrogram: A case study on Kroombit tinker frog. Mach. Learn. Appl. 2022, 7, 100202. [Google Scholar] [CrossRef]
- Brodie, S.; Allen-Ankins, S.; Towsey, M.; Roe, P.; Schwarzkopf, L. Automated species identification of frog choruses in environmental recordings using acoustic indices. Ecol. Indic. 2020, 119, 106852. [Google Scholar] [CrossRef]
- Zhong, M.; LeBien, J.; Campos-Cerqueira, M.; Dodhia, R.; Lavista Ferres, J.; Velev, J.P.; Aide, T.M. Multispecies bioacoustic classification using transfer learning of deep convolutional neural networks with pseudo-labeling. Appl. Acoust. 2020, 166, 107375. [Google Scholar] [CrossRef]
- LeBien, J.; Zhong, M.; Campos-Cerqueira, M.; Velev, J.P.; Dodhia, R.; Ferres, J.L.; Aide, T.M. A pipeline for identification of bird and frog species in tropical soundscape recordings using a convolutional neural network. Ecol. Inform. 2020, 59, 101113. [Google Scholar] [CrossRef]
- Kim, C.I.; Cho, Y.; Jung, S.; Rew, J.; Hwang, E. Animal sounds classification scheme based on multi-feature network with mixed datasets. Ksii Trans. Internet Inf. Syst. 2020, 14, 3384–3398. [Google Scholar]
- Ghiurcau, M.V.; Rusu, C.; Bilcu, R.C.; Astola, J. Audio based solutions for detecting intruders in wild areas. Signal Process. 2012, 92, 829–840. [Google Scholar] [CrossRef]
- Bedoya, C.; Isaza, C.; Daza, J.M.; López, J.D. Automatic identification of rainfall in acoustic recordings. Ecol. Indic. 2017, 75, 95–100. [Google Scholar] [CrossRef]
- Wang, X.; Wang, M.; Liu, X.; Glade, T.; Chen, M.; Xie, Y.; Yuan, H.; Chen, Y. Rainfall observation using surveillance audio. Appl. Acoust. 2022, 186, 108478. [Google Scholar] [CrossRef]
- Shreyas, N.; Venkatraman, M.; Malini, S.; Chandrakala, S. Chapter 7—Trends of Sound Event Recognition in Audio Surveillance: A Recent Review and Study. In The Cognitive Approach in Cloud Computing and Internet of Things Technologies for Surveillance Tracking Systems; Peter, D., Alavi, A.H., Javadi, B., Fernandes, S.L., Eds.; Intelligent Data-Centric Systems, Academic Press: Cambridge, MA, USA, 2020; pp. 95–106. [Google Scholar]
- Laffitte, P.; Wang, Y.; Sodoyer, D.; Girin, L. Assessing the performances of different neural network architectures for the detection of screams and shouts in public transportation. Expert Syst. Appl. 2019, 117, 29–41. [Google Scholar] [CrossRef]
- Arnault, A.; Hanssens, B.; Riche, N. Urban Sound Classification: Striving towards a fair comparison. arXiv 2020, arXiv:2010.11805. [Google Scholar]
- Bello, J.P.; Silva, C.; Nov, O.; Dubois, R.L.; Arora, A.; Salamon, J.; Mydlarz, C.; Doraiswamy, H. SONYC: A System for Monitoring, Analyzing, and Mitigating Urban Noise Pollution. Commun. ACM 2019, 62, 68–77. [Google Scholar] [CrossRef] [Green Version]
- Scarpiniti, M.; Colasante, F.; Di Tanna, S.; Ciancia, M.; Lee, Y.C.; Uncini, A. Deep Belief Network based audio classification for construction sites monitoring. Expert Syst. Appl. 2021, 177, 114839. [Google Scholar] [CrossRef]
- Aziz, S.; Awais, M.; Akram, T.; Khan, U.; Alhussein, M.; Aurangzeb, K. Automatic Scene Recognition through Acoustic Classification for Behavioral Robotics. Electronics 2019, 8, 483. [Google Scholar] [CrossRef] [Green Version]
- Ibrahim, O.A.; Sciancalepore, S.; Di Pietro, R. Noise2Weight: On detecting payload weight from drones acoustic emissions. Future Gener. Comput. Syst. 2022, 134, 319–333. [Google Scholar] [CrossRef]
- Pramanick, D.; Ansar, H.; Kumar, H.; Pranav, S.; Tengshe, R.; Fatimah, B. Deep learning based urban sound classification and ambulance siren detector using spectrogram. In Proceedings of the 2021 12th International Conference on Computing Communication and Networking Technologies (ICCCNT), Kharagpur, India, 6–8 July 2021; pp. 1–6. [Google Scholar]
- Fatimah, B.; Preethi, A.; Hrushikesh, V.; Singh B., A.; Kotion, H.R. An automatic siren detection algorithm using Fourier Decomposition Method and MFCC. In Proceedings of the 2020 11th International Conference on Computing, Communication and Networking Technologies (ICCCNT), Kharagpur, India, 1–3 July 2020; pp. 1–6. [Google Scholar]
- Heittola, T.; Mesaros, A.; Virtanen, T. Acoustic scene classification in dcase 2020 challenge: Generalization across devices and low complexity solutions. arXiv 2020, arXiv:2005.14623. [Google Scholar]
- Salamon, J.; Jacoby, C.; Bello, J.P. A dataset and taxonomy for urban sound research. In Proceedings of the 22nd ACM International Conference on Multimedia, Orlando, FL, USA, 3–7 November 2014; pp. 1041–1044. [Google Scholar]
- Piczak, K.J. ESC: Dataset for environmental sound classification. In Proceedings of the 23rd ACM international conference on Multimedia, Brisbane, Australia, 26–30 October 2015; pp. 1015–1018. [Google Scholar]
- Koizumi, Y.; Kawaguchi, Y.; Imoto, K.; Nakamura, T.; Nikaido, Y.; Tanabe, R.; Purohit, H.; Suefusa, K.; Endo, T.; Yasuda, M.; et al. Description and discussion on DCASE2020 challenge task2: Unsupervised anomalous sound detection for machine condition monitoring. arXiv 2020, arXiv:2006.05822. [Google Scholar]
- Cao, H.; Cooper, D.G.; Keutmann, M.K.; Gur, R.C.; Nenkova, A.; Verma, R. Crema-d: Crowd-sourced emotional multimodal actors dataset. IEEE Trans. Affect. Comput. 2014, 5, 377–390. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gemmeke, J.F.; Ellis, D.P.; Freedman, D.; Jansen, A.; Lawrence, W.; Moore, R.C.; Plakal, M.; Ritter, M. Audio set: An ontology and human-labeled dataset for audio events. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 776–780. [Google Scholar]
- Mesaros, A.; Heittola, T.; Virtanen, T. TUT Database for Acoustic Scene Classification and Sound Event Detection. In Proceedings of the 24th European Signal Processing Conference 2016 (EUSIPCO 2016), Budapest, Hungary, 29 August–2 September 2016. [Google Scholar]
- Rachman, F.H.; Sarno, R.; Fatichah, C. Music Emotion Classification based on Lyrics-Audio using Corpus based Emotion. Int. J. Electr. Comput. Eng. 2018, 8, 1720–1730. [Google Scholar] [CrossRef]
- Fonseca, E.; Favory, X.; Pons, J.; Font, F.; Serra, X. FSD50K: An open dataset of human-labeled sound events. IEEE/ACM Trans. Audio, Speech, Lang. Process. 2022, 30, 829–852. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Authors/Year | Model Features | Contributions/Benefits | Limitation(s) | Dataset/Metrics |
|---|---|---|---|---|
| Salamon and Bello (2017) [17] | DCNN combined with data augmentation techniques of time stretching, pitch shifting, dynamic range compression, and background noise. | Overcomes the problem of data scarcity; Shows that DL models produce better results due to their representational power and capacity combined with data augmentation. | Some augmentation techniques have a negative impact on the accuracy of some classes. | UrbanSound8K; Accuracy: 73% without data augmentation and 79% with data augmentation. |
| Das et al. (2020) [5] | CNN and LSTM models are used with a stack of multiple features as input and data augmentation techniques: pitch shift, time stretch and pitch shift along with time stretch. | Increasing the number of epochs leads to a decrease in the validation error until reaching convergence; LSTM deals better with data noise; The single feature input that allows the best result is MFCC; however, the stack of features of MFCC and Chroma STFT gave the best results out of all input features. | Needs large datasets; Execution time of 37.14 min with a GeForce RTX200 GPU with 6 Gigabytes of VRAM and boost clock of 1.68 GHz, consumes around 8 Gigabytes of RAM to train both models and requires large resources for inference. | UrbanSound8K; Accuracy: 98.81% for LSTM model using data augmentation and a stack of MFCC and Chroma STFT as input. |
| Das et al. (2021) [27] | CNN model is used with a single feature input (MFCC) and with a stack of features using as loss function a modified Softmax loss function. | The stack of MFCC and Chroma STFT as input provided the best results; A modified Softmax loss function showed to be more beneficial than the Softmax loss function; Additive angular margin loss was the loss function that gave the best results. | The sophisticated loss functions created an intelligible space to separate the different classes due to an increase in the compactness within classes. | UrbanSound8K; Accuracy: 99.60% of CNN model with an additive angular margin loss function without data augmentation. |
| Zinemanas et al. (2021) [25] | APNet is used with a time–frequency representation of the audio signal as input; prediction based on the resemblance between the encoded input and a collection of prototypes. | Provides insights into the decision-making process, helping the design of better models; Models are more explicit, allowing the possibility to understand what are the prototypes more representative of each class and which operation is more beneficial for identifying a specific sound. | The obtained results are not competitive with a noninterpretative DL model. | Medley-Solos-DB, Google Speech Commands, UrbanSound8K; Accuracy: 65.8% for Medley-Solos-DB, 89% for Google Speech Commands and 76.2% for UrbanSound8K. |
| Mu et al. (2021) [6] | TFCNN model is used, which is a CNN model with temporal and frequency attention mechanisms. | Attention mechanisms reduced the background noise and nonrelevant frequency bands influence; Low network structure complexity, and plain feature processing. | Did not show a similar improvement for all classes, negatively impacting the correct classification of some classes. | UrbanSound8K, ESC-50; Accuracy: 84.4% for ESC-50 and 93.1% for UrbanSound8K. |
| Authors/Year | Model Features | Contributions/Benefits | Limitation(s) | Dataset/Metrics |
|---|---|---|---|---|
| Kong et al. (2020) [16] | CNN-Transformer model and an automatic threshold optimization method are used. | Computations are done in parallel; Use weakly labeled datasets to train the model and outputs directly clip-level predictions; Automatic threshold optimization is employed. | CNN-based models need many parameters. | DCASE2017 Task4; F1-score: 64.6% for AT, 57.3% for SED; Precision: 69.1% for AT; Recall: 60.7% for AT; Error rate: 68% for SED. |
| Elliott et al. (2021) [11] | BERT-based Transformer for ESC at the edge is used. | Evaluation of Transformers’ performance using several feature extraction techniques and data augmentation; Enables ESC on edge devices. | Models trained in traditional frameworks have little support to be converted to models that run at the edge; Lower competitive results when trained with small datasets. | ESC-50, Office Sounds; Accuracy: 67.71% for ESC-50, 95.31% for Office Sounds. |
| Wyatt et al. (2021) [12] | BERT-based Transformer used for ESC on a resource-constrained device applied in noisy environments. | The model trained with noise-augmented data can generalize to audio without noise and prevents having to construct custom acoustic filters to apply the model in real-life environments. | Needs large datasets; Only employed on small edge-end devices. | Office Sounds; Accuracy: 75.4% for non-noisy dataset, 81.2% for noisy dataset, Precision: 76.5% for non-noisy dataset, 79.7% for noisy dataset, Recall: 75.6% for non-noisy dataset, 80.6% for noisy dataset, F1-score: 75% for non-noisy dataset, 80% for noisy dataset. |
| Gong et al. (2021) [9] | Audio Spectogram Transformer, a purely attention-based audio classification model, is used. | Even in the lowest layers, it can capture long-range global context; Able to handle different input audio lengths without changing the architecture; Few parameters and fast convergence. | Cannot use rectangular patches due to the inexistence of a pre-trained model that used the same dataset as ViT; Unable to use only an AudioSet pre-trained model. | AudioSet, ESC-50, Speech Commands V2; mAP: 48.5% for AudioSet, Accuracy: 95.6% for ESC-50, 98.11% for Speech Commands V2. |
| Park et al. (2021) [13] | Audio Spectrogram Transformer that can handle various output resolutions is used. | Shows that Soft F-loss performs better than binary cross-entropy; Designed to deal with a multiplicity of output resolutions. | Large model size; Evaluates sound event localization and detection using only one dataset. | TAU-NIGENS Spatial Sound Events 2021; Error rate: 50%, F1-score: 65.7%, Recall dominant score: 74.7%. |
| Akbari et al. (2021) [10] | Transformers for multimodal self-supervised learning from raw video, audio and text are used. | Learns effectively semantic video, audio and text representations; DropToken technique reduces the pre-training complexity, which reduces computational costs, the training time and enables the hosting of large models on restricted hardware. | Needs large datasets to be trained due to the large size of the network. | Only 2 out of 10 datasets were from the audio domain: ESC-50, AudioSet. mAP: 39.4% for AudioSet, AUC: 97.1% for AudioSet, d-prime: 2.895 for AudioSet, Accuracy: 84.9% for ESC-50. |
| Koutini et al. (2021) [14] | Audio Transformer with Patchout which optimizes and regularizes Transformers on audio spectrograms is used. | Patchout improves the generalization and reduces the computation and memory complexity. | Increases the training time | AudioSet, OpenMIC, ESC-50, DCASE20; mAP: 49.6% for AudioSet, 84.3% for OpenMIC, Accuracy: 96.8% for ESC-50, 76.3% for DCASE20. |
| Authors/Year | Model Features | Contributions/Benefits | Limitation(s) | Dataset/Metrics |
|---|---|---|---|---|
| Tax et al. (2017) [34] | End-to-end CNN model classifier with the first layers initialized is used. | Training the first layers of a DCNN model using unlabeled data allows it to learn high-level audio representation; Incorporating knowledge from audio processing methods can enhance the performance of Neural Network-based models. | Not able to outperform the models trained on processed features. | ESC-50; Accuracy: around 50%. |
| Martín-Morató et al. (2020) [35] | CNN-based models with an adaptive pooling layer based on a non-linear transformation of the learned convolutional feature maps on the temporal axis are used. | Distance-based pooling layer to improve CNN-based models for audio classification in adverse scenarios; Allows the systems to a better generalization for mismatching test conditions; Learn more robustly from weakly labeled data; Enables a better propagation of the information about the actual event across the network. | Only uses isolated events with a clear beginning and end. | UrbanSound8K, ESC-30, DCASE2017 T4; Macro-averaging accuracy: 77% for ESC-30, 73.96% for UrbanSound8K, F1-score: 48.3% for DCASE2017 T4, Precision: 68.2% for DCASE2017 T4, Recall: 46.7% for DCASE2017 T4. |
| Gimeno et al. (2020) [18] | BLSTM with a Combination and Pooling block is used. | A combination of BLSTM modelling capabilities with HMM backend smooths the results and significantly reduces system error; Combination and Pooling block reduces redundant temporal information. | Needs large datasets; The proposed block could not outperform the model with HMM re-segmentation. | 3/24 TV, CARTV; Segmentation error rate: 11.80% for 3/24 TV, 24.93% for CARTV, Average class error: 19.25% for 3/24 TV, Accuracy: 16.05% for 3/24 TV. |
| Giannakopoulos et al. (2019) [7] | CNN is used to extract context-aware deep audio features and combine them in an early-fusion scheme with handcrafted audio features. | Using CNN as a feature extractor can improve the performance of the audio classifier by transference audio contextual knowledge without the need for CNN training. | Low accuracy results. | TUT Acoustic Scene (used to train), UrbanSound8K, ESC-50; Accuracy: 52.2% for ESC-50, 73.1% for UrbanSound8K. |
| Luz et al. (2021) [8] | CNN model used to extract deep features that are combined with handcrafted features. As classifiers, Support Vector Machine and Random Forest were used. | Feature selection steps to reduce feature dimensionality and understand which handcrafted features could enrich deep features to better distinguish between Urban Sounds; Deep features hold more important information than handcrafted features. | Data augmentation techniques were not evaluated; To extract features from the Melspectrogram, only one not-too-deep CNN model was used. | ESC-10, UrbanSound8K; Accuracy: 86.2% for ESC-10, 96.8% for UrbanSound8K. |
| Authors/Year | Model Features | Contributions/Benefits | Limitation(s) | Dataset/Metrics |
|---|---|---|---|---|
| Zhang et al. (2019) [19] | CRNN model with temporal and channel attention mechanisms is used. | The two attention mechanisms enhance CNN’s representation capabilities and lead it to concentrate on the semantically significant portions of the sounds; The attention mechanism allows better outcomes when applied to lower layers rather than the higher-level layers. | Does not quantify the robustness to noise. | ESC-10, ESC-50, DCASE2016; Accuracy: 94.2% for ESC-10, 86.5% for ESC-50, 88.9% for DCASE2016. |
| Zhang et al. (2020) [20] | Frame-level attention mechanism based on CRNN is used. | The attention model automatically focuses on the semantically relevant frames and produces discriminative features; Low computational complexity. | Does not quantify the robustness to noise. | ESC-50, ESC-10; Accuracy: 93.7% for ESC-10, 86.1% for ESC-50. |
| Qiao et al. (2021) [21] | CRNN model is used with sub-spectrogram segmentation based feature extraction and score level fusion; CRNN model using temporal-frequency attention. | Score level fusion improves the accuracy in comparison with the uniform weights assignment; Low complexity when generating the temporal-frequency attention map when using the attention mechanism; High accuracy results when using temporal-frequency mechanisms. | Sub-spectrogram segmentation mechanism just considers frequency domain characteristics; Multi-dimensional search spaces are needed to optimize segmentation limits and the number of segments, which are, in general, computationally prohibitive. | ESC-50; Accuracy: 82.1% for ESC-50 with sub-spectrogram segmentation, 86.4% for ESC-50 with temporal-frequency attention. |
| Tripathi and Mishra (2021) [22] | Attention-guided residual network that efficiently learns spatio-temporal relationships of a signal’s spectrogram is used. | The attention module resolves the intra-class inconsistency; Identifies more semantically relevant parts of the spectrogram and correctly highlights them while providing a visual description. | Does not quantify the robustness to noise. | ESC-10, DCASE 2019 Task-1(A); For augmented datasets: Accuracy: 92.16% for ESC-10, 82.21% for DCASE 2019. For non-augmented datasets: 92% for ESC-10, 82% for DCASE 2019, Precision: 88.70% for ESC-10, 83.47% for DCASE 2019, Recall: 89.80% for ESC-10, 82.28% for DCASE 2019, F1-score: 87.93% for ESC-10, 82.39% for DCASE 2019. |
| Ristea et al. (2022) [23] | Separable Transformer, which separates the attention for the horizontal axis (time) from the vertical axis (frequency) of spectrograms, is used. | Reduces the number of learnable parameters, which reduces the memory footprint; Able to handle high-resolution spectrograms. | Does not quantify the robustness to noise. | ESC-50, Speech Commands V2, CREMA-D; Accuracy: 70.47% for CREMA-D, 98.51% for Speech Commands V2, 91.13% for ESC-50. |
| Authors/Year | Model Features | Contributions/Benefits | Limitation(s) | Dataset/Metrics |
|---|---|---|---|---|
| Sudo (2021) [36] | Multichannel environmental sound segmentation method constituted by a sound source localization block and a sound source separation and classification block is used. | No need to define in advance the number of sound sources; No overfitting between the direction of arrival and the class relationship; Sine and cosine of interchannel phase difference are optimum for sound source localization and separation. | Lack of sufficiently large datasets with separated sound source signals and direction of arrival labels. | The dataset is a combination of 10 datasets resulting in a dataset with 75 classes; Root Mean Square Error: 18.59. |
| Venkatesh et al. (2021) [37] | YOHO model, which is an end-to-end model with a CNN architecture adapted from the MobileNet architecture, is used. | Converts the detection of acoustic boundaries into a regression problem; The fast inference makes YOHO appropriate for real-time applications; Directly outputs the time boundaries. | Limited by the time resolution of the input. | BBC Radio Devon and MuSpeak, MIREX music-speech detection, TUT Sound Event Detection, Urban-SED; F1-score: 97.22% for BBC Radio Devon and MuSpeak, 90.20% for MIREX, 44% for TUT Sound Event Detection, ≈60% for Urban-SED; Error rate: 75.17% for TUT Sound Event Detection. |
| Authors/Year | Model Features | Contributions/Benefits | Limitation(s) | Dataset/Metrics |
|---|---|---|---|---|
| Mushtaq and Su (2020) [3] | DenseNet-161 fine-tuned with optimal learning rates and discriminative learning is used. | Introduction of L2M and L3M features; Novel data augmentation techniques: NA-1 and NA-2; Can achieve high results with few training epochs and less quantity of original data. | L2M and L3M are outperformed by other Mel filter-based features. Computationally heavy. | ESC-10, ESC-50, UrbanSound8K (US8K); Accuracy: 99.22% for ESC-10, 98.52% for ESC-50, 97.98% for US8K, Error rate: 0.777% for ESC-10, 1.476% for ESC-50, 2.018% for US8K, F1-score: 99.25% for ESC-10, 98.53% for ESC-50, 98.13% for US8K, Recall: 99.25% for ESC-10, 98.53% for ESC-50, 98.13% for US8K, Precision: 99.24% for ESC-10, 98.57% for ESC-50, 98.14% for US8K, Kappa score, Matthews Correlation Coefficient, False Discovery rate, Fowlkes-Mallows index, Miss rate. |
| İlker Türker and Aksu (2022) [15] | ResNet50 is used with a combination of two Melspectrogram with different parameters and Connectogram as input. | Introduces a time-convexity graph-based representation for sounds, Connectogram, capable of being fused with Melspectrograms to improve their representation capabilities. | Connectrogram is not a powerful representation when used solely. | ESC-10; Accuracy: 96.46% for ESC-10. |
| Authors | Dataset | Accuracy | Other Metrics |
|---|---|---|---|
| Salamon and Bello [17] | UrbanSound8k | 79% | - |
| Das et al. [5] | UrbanSound8k (unofficial splits) | 98.81% | - |
| Das et al. [4] | UrbanSound8k (unofficial splits) | 99.60% | - |
| Zinemanas et al. [25] | UrbanSound8k Google Speech Commands Medley-Solos-DB | 76.2% 89% 65.8% | - |
| Mu et al. [6] | UrbanSound8k ESC-50 | 93.1% 84.4% | - |
| Kong et al. [16] | DCASE2017 Task 4 | - | AT - F1-score: 64.6%, Precision: 69.1%, Recall: 60.7% Sound Event Detection - F1-score: 57.3%, Error rate: 68% |
| Elliott et al. [11] | ESC-50 Office Sounds | 67.71% 95.31% | - |
| Wyatt et al. [12] | Office Sounds | 81.2% | Precision: 79.7%, Recall: 80.6%, F1-score: 80% |
| Gong et al. [9] | ESC-50 Speech Commands V2 AudioSet | 95.6% 98.11% - | - - mAP: 48.5% |
| Park et al. [13] | TAU-NIGENS Spatial Sound Events 2021 | - | F1-score: 65.7%, Recall: 74.7%, Error rate: 50% |
| Akbari et al. [10] | ESC-50 AudioSet | 84.9% - | - mAP: 39.4%, AUC: 97.1%, d-prime: 2.895 |
| Koutini et al. [14] | ESC-50 AudioSet OpenMIC DCASE20 | 96.8% - - 76.3% | - mAP: 49.6% mAP: 84.3% - |
| Tax et al. [34] | ESC-50 | ≈50% | - |
| Martín-Morató et al. [35] | UrbanSound8K ESC-30 DCASE2017 T4 | 73.96% 77% - | - - F1-score: 48.3%, Precision: 68.2%, Recall: 46.7% |
| Gimeno et al. [18] | 3/24 TV CARTV | 16.05% - | Segmentation error: 11.80%, Average class error: 19.25% Segmentation error: 24.93% |
| Giannakopoulos et al. [7] | UrbanSound8K ESC-50 | 73.1% 52.2% | - |
| Luz et al. [8] | UrbanSound8K ESC-10 | 96.8% 86.2% | - |
| Zhang et al. [19] | ESC-50 ESC-10 DCASE2016 | 86.5% 94.2% 88.9% | - |
| Zhang et al. [20] | ESC-50 ESC-10 | 86.1% 93.7% | - |
| Qiao et al. [21] | ESC-50 | 86.4% | - |
| Tripathi and Mishra [22] | ESC-10 DCASE 2019 Task-1(A) | 92.16% 82.21% | - |
| Ristea et al. [23] | ESC-50 Speech Commands V2 CREMA-D | 91.13% 98.51% 70.47% | - |
| Sudo et al. [36] | 75-classes dataset combining 10 datasets | - | Root Mean Square Error: 18.59 |
| Venkatesh et al. [37] | Urban-SED TUT Sound Event Detection BBC Radio Devon and MuSpeak MIREX | - | F1-score: ≈60% F1-score: 44%, Error rate: 75.17% F1-score: 97.22% F1-score: 90.20% |
| UrbanSound8K | 97.98% | Error rate: 2.018%, F1-score: 98.13%, Recall: 98.13%, Precision: 98.14%, Kappa score: 97.09%, MCC: 97.73%, FDR: 1.854%, FM: 98.14%, Miss rate: 1.863% | |
| Mushtaq and Su [3] | ESC-50 | 98.52% | Error rate: 1.476%, F1-score: 98.53%, Recall: 98.53%, Precision: 98.57%, Kappa score: 98.95%, MCC: 98.49%, FDR: 1.469%, FM: 98.55%, Miss rate: 1.469% |
| ESC-10 | 99.22% | Error rate: 0.777%, F1-score: 99.25%, Recall: 99.25%, Precision: 99.24%, Kappa score: 98.93%, MCC: 99.13%, FDR: 0.758%, FM: 99.24%, Miss rate: 0.744% | |
| İlker Türker and Aksu [15] | ESC-10 | 96.46% | - |
| Reference | Name | Size | #Classes | Duration | Description |
|---|---|---|---|---|---|
| Salamon et al. [68] | UrbanSound8k | 8732 | 10 | ≤4 s | Contains the metadata, Imbalanced classes |
| Piczak [69] | ESC-50 | 2000 | 30 | ≤5 s | Contains the metadata, Balanced classes |
| Piczak [69] | ESC-10 | 400 | 10 | ≤5 s | Contains the metadata, Balanced classes |
| Piczak [69] | ESC-US | 250,000 | - | ≤5 s | Unlabeled Dataset |
| Koizumi et al. [70] | DCASE Task 2 | 8 | - | ≤10 s | Mechanical Anomalous Sounds |
| Cao et al. [71] | CREMA-D | 7442 | - | ≤10 s | A selection of 12 sentences with emotions |
| Gemmeke et al. [72] | AudioSet | +2 Million | 632 | ≤10 s | A large set of annotated sound categories |
| Mesaros et al. [73] | TUT Sound Event | 24 | 15 | ≤15 s | Chopped into small samples |
| Rachman et al. [74] | MIREX | 903 | 15 | - | Mood Dataset for Emotion Classification |
| Fonseca et al. [75] | FSD50K | 51,197 | 200 | ≤30 s | Human-labeled sound events |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nogueira, A.F.R.; Oliveira, H.S.; Machado, J.J.M.; Tavares, J.M.R.S. Sound Classification and Processing of Urban Environments: A Systematic Literature Review. Sensors 2022, 22, 8608. https://doi.org/10.3390/s22228608
Nogueira AFR, Oliveira HS, Machado JJM, Tavares JMRS. Sound Classification and Processing of Urban Environments: A Systematic Literature Review. Sensors. 2022; 22(22):8608. https://doi.org/10.3390/s22228608
Chicago/Turabian StyleNogueira, Ana Filipa Rodrigues, Hugo S. Oliveira, José J. M. Machado, and João Manuel R. S. Tavares. 2022. "Sound Classification and Processing of Urban Environments: A Systematic Literature Review" Sensors 22, no. 22: 8608. https://doi.org/10.3390/s22228608
APA StyleNogueira, A. F. R., Oliveira, H. S., Machado, J. J. M., & Tavares, J. M. R. S. (2022). Sound Classification and Processing of Urban Environments: A Systematic Literature Review. Sensors, 22(22), 8608. https://doi.org/10.3390/s22228608