


Transformers for Urban Sound Classification—A Comprehensive Performance Evaluation

 , ,
, ,  and
and 
Abstract
:1. Introduction
2. Related Works
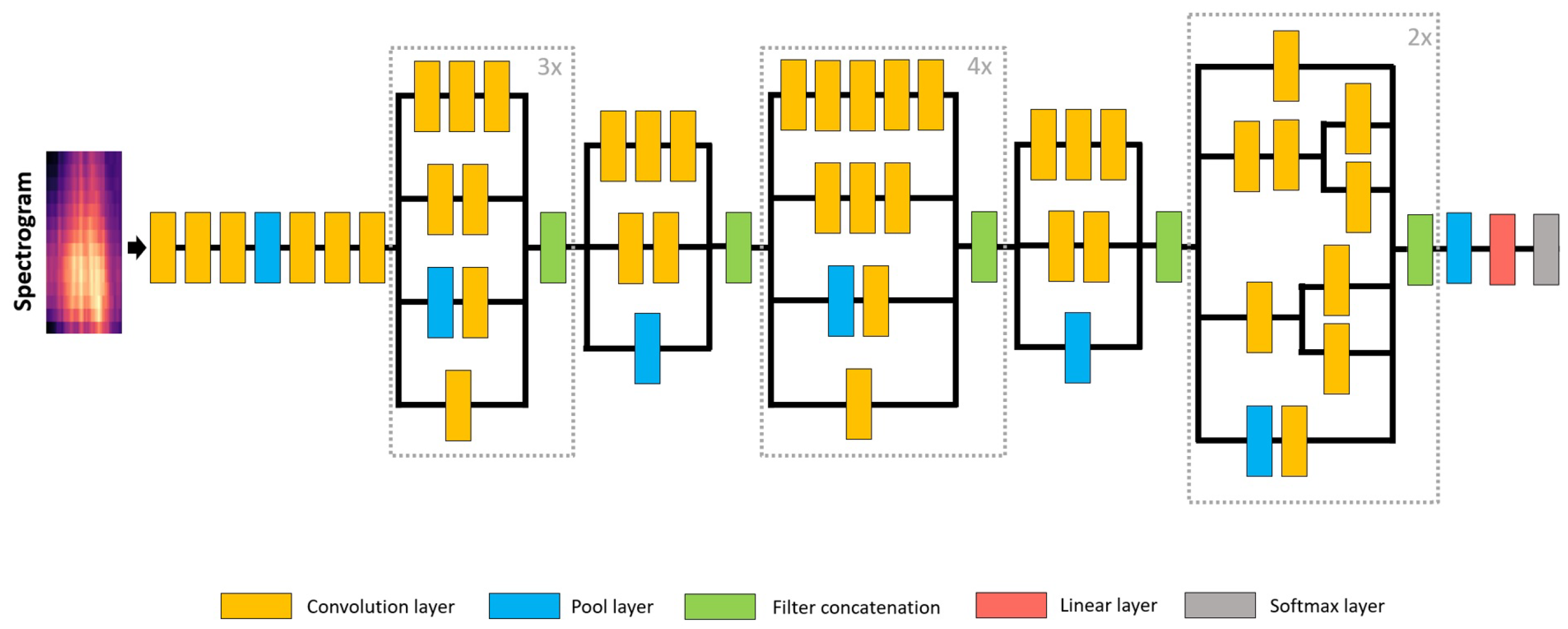
2.1. CNN for Audio Classification
2.2. RNN for Audio Classification
2.3. Transformers for Audio Classification
3. Proposed Approach
3.1. Feature-Based Models for Audio
3.2. CNN for Audio
3.3. Transformers for Audio
4. Experimental Validation
4.1. Datasets
4.2. Experimental Setup and Baselines
4.3. Metrics
4.4. Results and Discussion
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AAML | Additive Angular Margin Loss |
| AST | Audio Spectrogram Transformer |
| AUC | Area Under the Receiver Operating Characteristic (ROC) Curve |
| BERT | Bidirectional Encoder Representations from Transformers |
| CENS | Chroma Energy Normalized Statistics |
| CNN | Convolutional Neural Networks |
| CQT | Constant Q-Transform |
| CRNN | Convolutional Recurrent Neural Networks |
| DCNN | Deep Convolutional Neural Networks |
| DenseNet | Dense Convolutional Network |
| DL | Deep Learning |
| DNN | Deep Neural Network |
| ESC | Environmental Sound Classification |
| FN | False Negative |
| FP | False Positive |
| GPU | Graphics Processing Unit |
| LSTM | Long Short-Term Memory |
| M2M-AST | Many-to-Many Audio Spectrogram Transformer |
| MFCC | Mel Frequency Cepstral Coefficients |
| NLP | Natural Language Processing |
| pp | percentage points |
| ResNet | Residual Neural Network |
| RNN | Recurrent Neural Networks |
| STFT | Short-Term Fourier Transformation |
| TFCNN | Temporal-Frequency attention-based Convolutional Neural Network |
| TP | True Positive |
| VATT | Video–Audio–Text Transformer |
References
- Bello, J.P.; Mydlarz, C.; Salamon, J. Sound Analysis in Smart Cities. In Computational Analysis of Sound Scenes and Events; Virtanen, T., Plumbley, M.D., Ellis, D., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 373–397. [Google Scholar] [CrossRef]
- Zinemanas, P.; Rocamora, M.; Miron, M.; Font, F.; Serra, X. An Interpretable Deep Learning Model for Automatic Sound Classification. Electronics 2021, 10, 850. [Google Scholar] [CrossRef]
- Das, J.K.; Chakrabarty, A.; Piran, M.J. Environmental sound classification using convolution neural networks with different integrated loss functions. Expert Syst. 2021, 39, e12804. [Google Scholar] [CrossRef]
- Das, J.K.; Ghosh, A.; Pal, A.K.; Dutta, S.; Chakrabarty, A. Urban Sound Classification Using Convolutional Neural Network and Long Short Term Memory Based on Multiple Features. In Proceedings of the 2020 Fourth International Conference on Intelligent Computing in Data Sciences (ICDS), Fez, Morocco, 21–23 October 2020; pp. 1–9. [Google Scholar] [CrossRef]
- Mushtaq, Z.; Su, S.F. Efficient Classification of Environmental Sounds through Multiple Features Aggregation and Data Enhancement Techniques for Spectrogram Images. Symmetry 2020, 12, 1822. [Google Scholar] [CrossRef]
- Mu, W.; Yin, B.; Huang, X.; Xu, J.; Du, Z. Environmental sound classification using temporal-frequency attention based convolutional neural network. Sci. Rep. 2021, 11, 21552. [Google Scholar] [CrossRef] [PubMed]
- Giannakopoulos, T.; Spyrou, E.; Perantonis, S.J. Recognition of Urban Sound Events Using Deep Context-Aware Feature Extractors and Handcrafted Features. In IFIP International Conference on Artificial Intelligence Applications and Innovations; MacIntyre, J., Maglogiannis, I., Iliadis, L., Pimenidis, E., Eds.; Springer International Publishing: Cham, Switzerland, 2019; pp. 184–195. [Google Scholar]
- Luz, J.S.; Oliveira, M.C.; Araújo, F.H.; Magalhães, D.M. Ensemble of handcrafted and deep features for urban sound classification. Appl. Acoust. 2021, 175, 107819. [Google Scholar] [CrossRef]
- Gong, Y.; Chung, Y.; Glass, J.R. AST: Audio Spectrogram Transformer. arXiv 2021, arXiv:2104.01778. [Google Scholar]
- Türker, İ.; Aksu, S. Connectogram—A graph-based time dependent representation for sounds. Appl. Acoust. 2022, 191, 108660. [Google Scholar] [CrossRef]
- Kong, Q.; Xu, Y.; Plumbley, M. Sound Event Detection of Weakly Labelled Data with CNN-Transformer and Automatic Threshold Optimization. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 28, 2450–2460. [Google Scholar] [CrossRef]
- Gimeno, P.; Viñals, I.; Ortega, A.; Miguel, A.; Lleida, E. Multiclass audio segmentation based on recurrent neural networks for broadcast domain data. EURASIP J. Audio Speech Music Process. 2020, 2020, 5. [Google Scholar] [CrossRef]
- Zhang, Z.; Xu, S.; Zhang, S.; Qiao, T.; Cao, S. Learning Attentive Representations for Environmental Sound Classification. IEEE Access 2019, 7, 130327–130339. [Google Scholar] [CrossRef]
- Zhang, Z.; Xu, S.; Zhang, S.; Qiao, T.; Cao, S. Attention based convolutional recurrent neural network for environmental sound classification. Neurocomputing 2020, 453, 896–903. [Google Scholar] [CrossRef]
- Qiao, T.; Zhang, S.; Cao, S.; Xu, S. High Accurate Environmental Sound Classification: Sub-Spectrogram Segmentation versus Temporal-Frequency Attention Mechanism. Sensors 2021, 21, 5500. [Google Scholar] [CrossRef] [PubMed]
- Tripathi, A.M.; Mishra, A. Environment sound classification using an attention-based residual neural network. Neurocomputing 2021, 460, 409–423. [Google Scholar] [CrossRef]
- Ristea, N.C.; Ionescu, R.T.; Khan, F.S. SepTr: Separable Transformer for Audio Spectrogram Processing. arXiv 2022, arXiv:2203.09581. [Google Scholar] [CrossRef]
- Akbari, H.; Yuan, L.; Qian, R.; Chuang, W.; Chang, S.; Cui, Y.; Gong, B. VATT: Transformers for Multimodal Self-Supervised Learning from Raw Video, Audio and Text. arXiv 2021, arXiv:2104.11178. [Google Scholar]
- Elliott, D.; Otero, C.E.; Wyatt, S.; Martino, E. Tiny Transformers for Environmental Sound Classification at the Edge. arXiv 2021, arXiv:2103.12157. [Google Scholar]
- Wyatt, S.; Elliott, D.; Aravamudan, A.; Otero, C.E.; Otero, L.D.; Anagnostopoulos, G.C.; Smith, A.O.; Peter, A.M.; Jones, W.; Leung, S.; et al. Environmental Sound Classification with Tiny Transformers in Noisy Edge Environments. In Proceedings of the 2021 IEEE 7th World Forum on Internet of Things (WF-IoT), New Orleans, LA, USA, 14 June–31 July 2021; pp. 309–314. [Google Scholar] [CrossRef]
- Park, S.; Jeong, Y.; Lee, T. Many-to-Many Audio Spectrogram Tansformer: Transformer for Sound Event Localization and Detection. In Proceedings of the Detection and Classification of Acoustic Scenes and Events 2021, Online, 15–19 November 2021; pp. 105–109. [Google Scholar]
- Koutini, K.; Schlüter, J.; Eghbal-zadeh, H.; Widmer, G. Efficient Training of Audio Transformers with Patchout. arXiv 2021, arXiv:2110.05069. [Google Scholar]
- Salamon, J.; Bello, J.P. Deep Convolutional Neural Networks and Data Augmentation for Environmental Sound Classification. arXiv 2021, arXiv:1608.04363. [Google Scholar] [CrossRef]
- Wolpert, D.; Macready, W. No free lunch theorems for optimization. IEEE Trans. Evol. Comput. 1997, 1, 67–82. [Google Scholar] [CrossRef] [Green Version]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies; Volume 1 (Long and Short Papers). Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.u.; Polosukhin, I. Attention is All you Need. In Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. arXiv 2016, arXiv:1608.06993. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper with Convolutions. arXiv 2014, arXiv:1409.4842. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | DA | PT-I | PT-A | Metrics | Discussion |
|---|---|---|---|---|---|
| Dataset: ESC-10 | |||||
| Baseline model + mms60 + Nadam + dr: 0.2 | - | - | - | acc: 74.8%, AUC: 94.8%, mf1: 74.8%, Mf1: 74.3%, prec: 77.7%, rec: 73.3%. | The combination of features gives more discriminating information to the baseline model. |
| DenseNet + AdamW | - | - | - | acc: 89.8%, AUC: 98.9%, mf1: 89.8%, Mf1: 89.3%, prec: 91.5%, rec: 89.8%. | Improves the baseline performance by 13.23 pp. on average. |
| ResNet + AdamW | - | ✓ | - | acc: 94.0%, AUC: 99.8%, mf1: 94.0%, Mf1: 93.8%, prec: 94.8%, rec: 94.0%. | The use of pre-training from ImageNet improves, on average, the end-to-end model performance by 3.55 pp. |
| DenseNet + Adam | ✓ | ✓ | - | acc: 95.0%, AUC: 99.8%, mf1: 95.0%, Mf1: 94.9%, prec: 95.8%, rec: 95.0%. | The addition of data augmentation techniques provides a slight improvement of 0.85 pp, on average. |
| Transformer + AdamW | ✓ | - | - | acc: 52.8%, AUC: 91.8%, mf1: 52.8%, Mf1: 50.7%, prec: 61.7%, rec: 52.8%. | The use of a Transformer model without pre-training cannot give competitive results. |
| Transformer + AdamW | ✓ | ✓ | - | acc: 93.8%, AUC: 99.8%, mf1: 93.8%, Mf1: 93.5%, prec: 98.2%, rec: 93.8%. | The use of pre-training from ImageNet gives the Transformer model an average boost of 35.05 pp, showing the need for large datasets to train. |
| Transformer + AdamW | - | ✓ | ✓ | acc: 98.8%, AUC: 100%, mf1: 98.8%, Mf1: 98.7%, prec: 99.7%, rec: 98.8%. | Using pre-training from ImageNet and AudioSet gives a better performance than just an ImageNet pre-trained Transformer with an average increase of 3.65 pp. |
| Transformer + Adam | ✓ | ✓ | ✓ | acc: 99.0%, AUC: 100%, mf1: 99.0%, Mf1: 99.0%, prec: 99.9%, rec: 99.0%. | The addition of data augmentation to the pre-trained network from both domains gives, on average, a slight improvement of 0.18 pp. The average boost for the baseline model is 21.03 pp and for the best end-to-end model is 3.40 pp. |
| Dataset: ESC-50 | |||||
| Baseline model + mfccstft80 + Nadam + dr: 0.2 | - | - | - | acc: 38.1%, AUC: 82.4%, mf1: 38.1%, Mf1: 36.2%, prec: 43.9%, rec: 33.9%. | The combination of features gives more discriminating information to the baseline model. |
| DenseNet + Adam | - | - | - | acc: 76.1%, AUC: 98.7%, mf1: 76.1%, Mf1: 75.4%, prec: 78.0%, rec: 76.1%. | Improves the baseline performance by 34.63 pp, on average. |
| ResNet + Adam | - | ✓ | - | acc: 88.2%, AUC: 99.6%, mf1: 88.2%, Mf1: 87.7%, prec: 89.6%, rec: 88.2%. | The use of pre-training from ImageNet improves, on average, the end-to-end model performance by 10.18 pp. |
| ResNet + Adam | ✓ | ✓ | - | acc: 90.1%, AUC: 99.6%, mf1: 90.1%, Mf1: 89.9%, prec: 91.2%, rec: 90.1%. | The addition of data augmentation techniques gives a small increase of 1.58 pp, on average. |
| Transformer + AdamW | ✓ | - | - | acc: 43.9%, AUC: 93.6%, mf1: 43.9%, Mf1: 42.4%, prec: 46.8%, rec: 43.9%. | The use of a Transformer model without pre-training is not capable of giving good results; however, they are better than the baseline model. |
| Transformer + AdamW | ✓ | ✓ | - | acc: 88.6%, AUC: 99.6%, mf1: 88.6%, Mf1: 88.4%, prec: 92.7%, rec: 88.6%. | The use of pre-training from ImageNet gives a huge performance boost of 38.67 pp, on average, compared to the Transformer model without pre-training. |
| Transformer + AdamW | - | ✓ | ✓ | acc: 95.4%, AUC: 99.9%, mf1: 95.4%, Mf1: 95.3%, prec: 97.6%, rec: 95.4%. | Using pre-training from ImageNet and AudioSet gives an average improvement of 5.42 pp compared to the ImageNet pre-trained Transformer. |
| Transformer + AdamW | ✓ | ✓ | ✓ | acc: 95.8%, AUC: 99.9%, mf1: 95.8%, Mf1: 95.6%, prec: 97.8%, rec: 95.8%. | The addition of data augmentation gives a small improvement of 0.28 pp, on average. The average boost is for the baseline model of 51.35 pp and of 4.95 pp for the best end-to-end model. |
| Dataset: UrbanSound8K | |||||
| Baseline model + mmsqc + Nadam + dr: 0.6 | - | - | - | acc: 61.1%, AUC: 88.9%, mf1: 61.1%, Mf1: 63.2%, prec: 73.1%, rec: 49.2%. | The combination of features gives more discriminating information to the baseline model. |
| DenseNet + AdamW | - | - | - | acc: 74.2%, AUC: 95.4%, mf1: 74.2%, Mf1: 75.6%, prec: 75.2%, rec: 74.2%. | Improves the baseline performance by 12.03 pp, on average. |
| DenseNet + Adam | - | ✓ | - | acc: 83.3%, AUC: 97.7%, mf1: 83.3%, Mf1: 84.4%, prec: 84.1%, rec: 83.3%. | The use of pre-training from ImageNet improves the end-to-end model performance by 7.88 pp, on average. |
| ResNet + Adamax | ✓ | ✓ | - | acc: 82.2%, AUC: 97.4%, mf1: 82.2%, Mf1: 83.0%, prec: 82.5%, rec: 82.2%. | The use of data augmentation techniques was detrimental. |
| Transformer + Adamax | ✓ | ✓ | ✓ | acc: 89.8%, AUC: 98.6%, mf1: 89.8%, Mf1: 90.4%, prec: 93.8%, rec: 89.8%. | The Transformer model pre-trained with datasets from both domains and using data augmentation gives an average boost of 25.93 pp regarding the baseline model and of 6.02 pp compared to the best end-to-end model. |
| Model | DA | PT-I | PT-A | GPU Capacity (MiB) | Computational Time (min) |
|---|---|---|---|---|---|
| Dataset: ESC-10 | |||||
| Baseline model + mms60 + Nadam + dr: 0.2 | - | - | - | - | 8 |
| DenseNet + AdamW | - | - | - | 5913 | 29 |
| ResNet + AdamW | - | ✓ | - | 3591 | 18 |
| DenseNet + Adam | ✓ | ✓ | - | 5913 | 907 |
| Transformer + AdamW | ✓ | - | - | 39,444 | 32 |
| Transformer + AdamW | ✓ | ✓ | - | 39,444 | 37 |
| Transformer + AdamW | - | ✓ | ✓ | 39,444 | 34 |
| Transformer + Adam | ✓ | ✓ | ✓ | 39,444 | 32 |
| Dataset: ESC-50 | |||||
| Baseline model + mfccstft80 + Nadam + dr: 0.2 | - | - | - | - | 25 |
| DenseNet + Adam | - | - | - | 5904 | 130 |
| ResNet + Adam | - | ✓ | - | 3566 | 66 |
| ResNet + Adam | ✓ | ✓ | - | 3566 | 886 |
| Transformer + AdamW | ✓ | - | - | 39,712 | 74 |
| Transformer + AdamW | ✓ | ✓ | - | 39,712 | 64 |
| Transformer + AdamW | - | ✓ | ✓ | 39,712 | 68 |
| Transformer + AdamW | ✓ | ✓ | ✓ | 39,712 | 65 |
| Dataset: UrbanSound8K | |||||
| Baseline model + mmsqc + Nadam + dr: 0.6 | - | - | - | - | 46 |
| DenseNet + AdamW | - | - | - | 5902 | 762 |
| DenseNet + Adam | - | ✓ | - | 5902 | 733 |
| ResNet + Adamax | ✓ | ✓ | - | 3564 | 2541 |
| Transformer + Adamax | ✓ | ✓ | ✓ | 39,716 | 370 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nogueira, A.F.R.; Oliveira, H.S.; Machado, J.J.M.; Tavares, J.M.R.S. Transformers for Urban Sound Classification—A Comprehensive Performance Evaluation. Sensors 2022, 22, 8874. https://doi.org/10.3390/s22228874
Nogueira AFR, Oliveira HS, Machado JJM, Tavares JMRS. Transformers for Urban Sound Classification—A Comprehensive Performance Evaluation. Sensors. 2022; 22(22):8874. https://doi.org/10.3390/s22228874
Chicago/Turabian StyleNogueira, Ana Filipa Rodrigues, Hugo S. Oliveira, José J. M. Machado, and João Manuel R. S. Tavares. 2022. "Transformers for Urban Sound Classification—A Comprehensive Performance Evaluation" Sensors 22, no. 22: 8874. https://doi.org/10.3390/s22228874
APA StyleNogueira, A. F. R., Oliveira, H. S., Machado, J. J. M., & Tavares, J. M. R. S. (2022). Transformers for Urban Sound Classification—A Comprehensive Performance Evaluation. Sensors, 22(22), 8874. https://doi.org/10.3390/s22228874