
FDMLNet: A Frequency-Division and Multiscale Learning Network for Enhancing Low-Light Image

(This article belongs to the Section Intelligent Sensors)
Abstract
1. Introduction
- (1)
- We present a novel LLIE approach for creating visually satisfying images. The superior performance of this FDMLNet is verified by extensive experiments validated on several public benchmarks.
- (2)
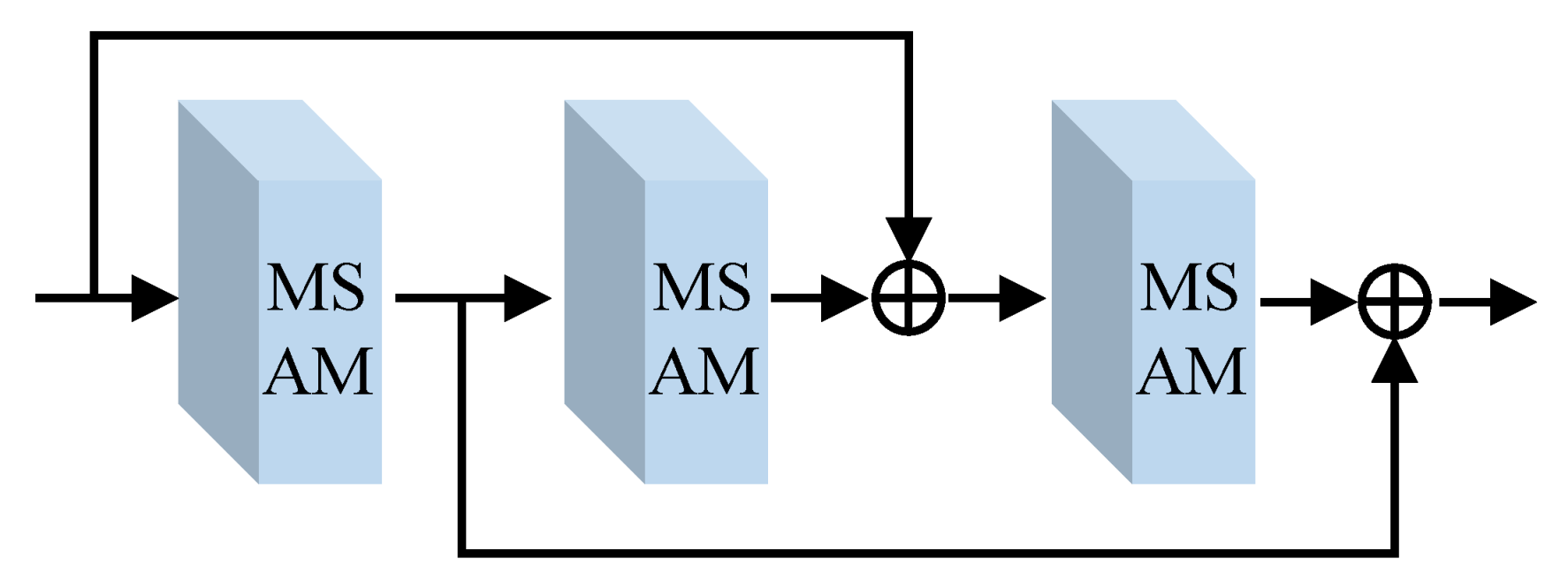
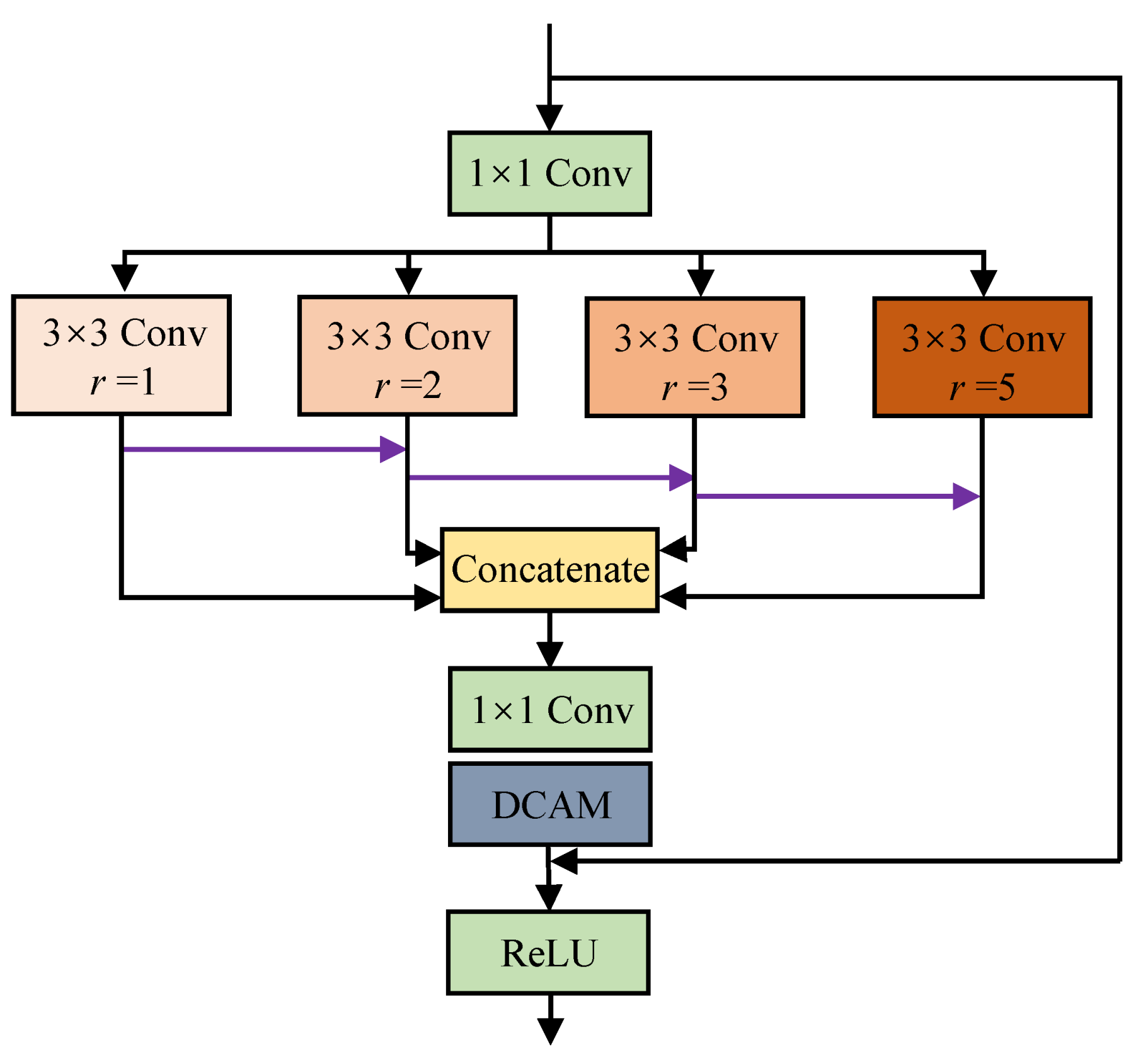
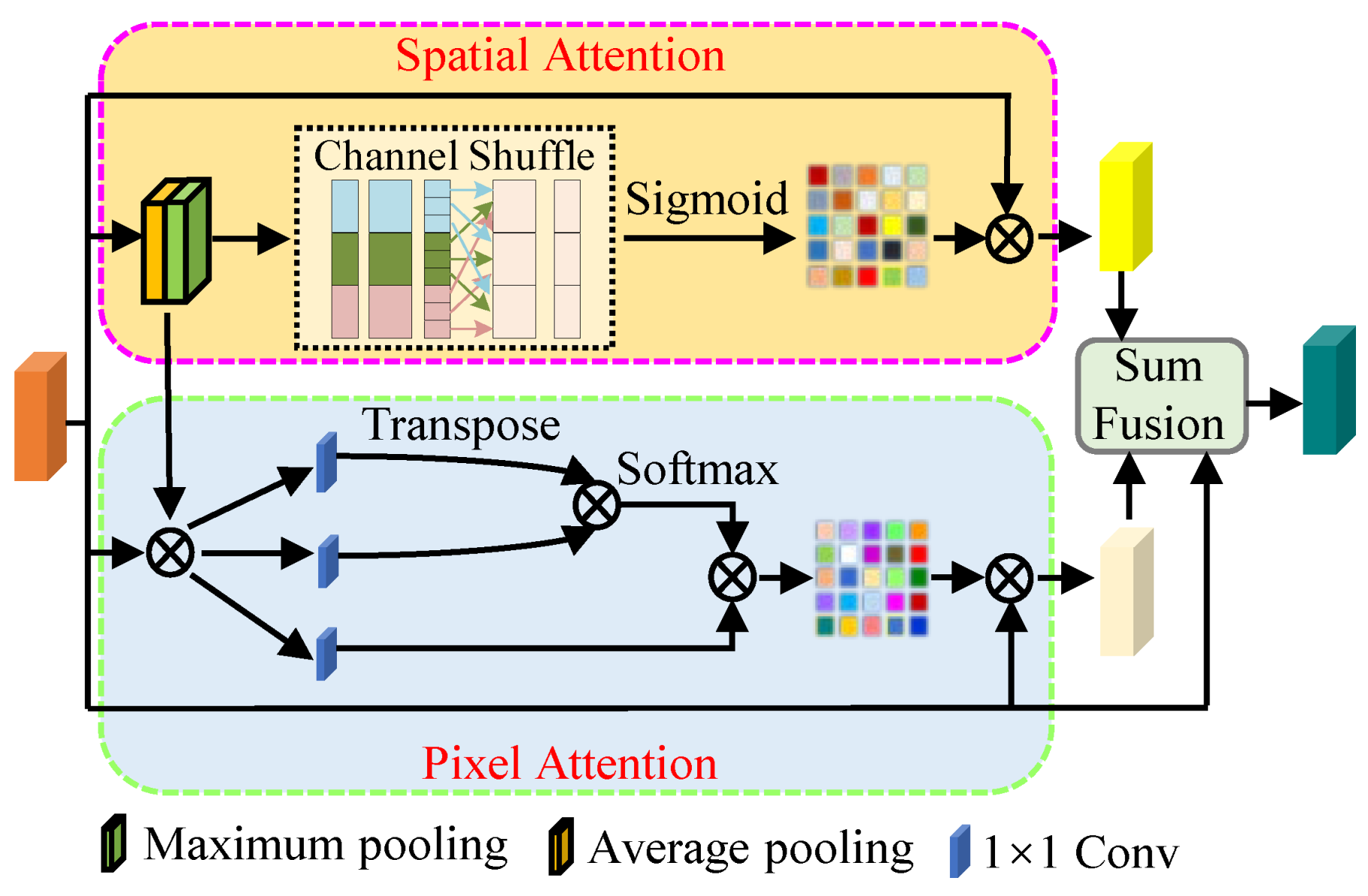
- We design a residual multiscale structure named MSAM, which is based on a residual multiscale learning (MSL) block and a dual-branch channel attention mechanism (DCAM). Furthermore, the former promotes the multiscale features learning ability of the FDMLNet, and the latter, including spatial attention and pixels attention, makes our model focus on areas that best characterize the image.
- (3)
- Finally, we merge three MSAMs in a novel dense skip-connection way to build an FFEM for fully exploring the image’s hierarchical information. In addition, we apply the dense connection strategy among FFEMs to further integrate multilevel features adequately.
2. Related Works
2.1. Traditional Approaches
2.2. Learning-Based Approaches
3. Methodology
3.1. Motivation
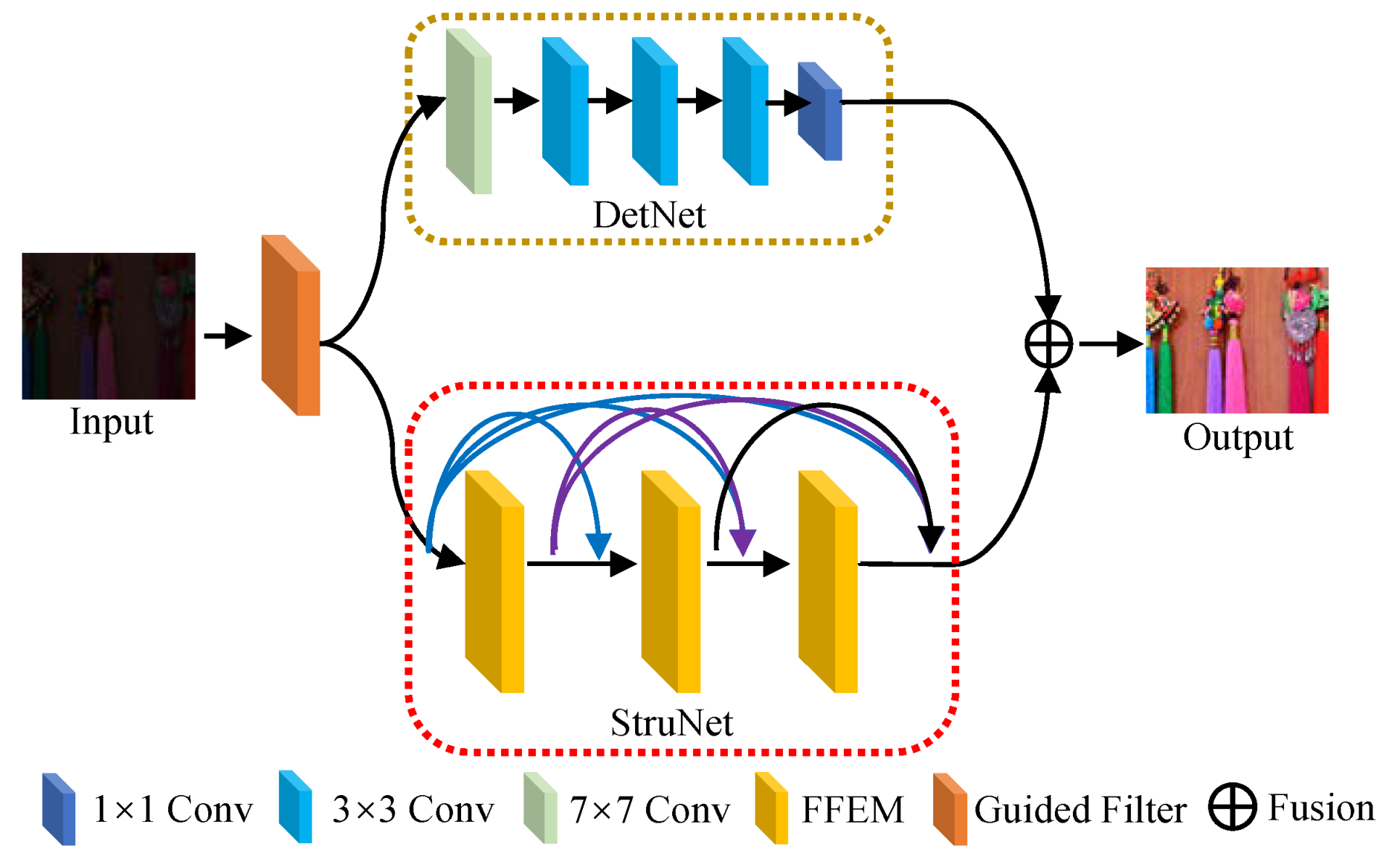
3.2. The Overall Model Framework
3.3. Frequency Division
3.4. Feasible Feature Extraction Module
3.5. Loss Function
3.6. Relation to Other Learning-Based Methods
- (1)
- The way the frequency division was performed: Xu et al. [21] employed a learning-based way, paying attention to the context encoding model (ACE), to adaptively decompose the high and low frequencies of the input image. However, a guided filter, a traditional preserving filer, was applied to achieve the image’s high and low frequencies in our work.
- (2)
- The way the enhancement was performed: Xu et al. [21] compressed the inherent noise and highlighted the details by the cross-domain transformation (CDT) model. However, we designed two subnets, i.e., DetNet and StruNet, to enhance the image, and the former processed the high-frequency components of the image to highlight its detail while the latter disposed of its low-frequency components to generate visually pleasing structural images.
- (3)
- Furthermore, we injected spatial attention and pixel attention mechanisms into our reported FDMLNet to fully exploit the inherent information in the image. In addition, the multiscale structure was also embedded to promote the multiscale representation ability of the proposed model.
4. Experimental Results and Analysis
4.1. Experimental Settings
4.2. Training Details
4.3. Ablation Studies
4.4. Comprehensive Assessment on Paired Datasets
4.5. Comprehensive Assessment on Unpaired Datasets
4.6. Comprehensive Analysis of Computational Complexity
4.7. Comprehensive Assessment on Real Images
5. Discussion and Limitation
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Li, C.; Guo, C.; Han, L.; Jiang, J.; Cheng, M.M.; Gu, J.; Loy, C.C. Low-Light Image and Video Enhancement Using Deep Learning: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021. [Google Scholar] [CrossRef] [PubMed]
- Liu, Y.; Wang, A.; Zhou, H.; Jia, P. Single nighttime image dehazing based on image decomposition. Signal Process. 2021, 183, 107986. [Google Scholar] [CrossRef]
- Wang, W.; Wu, X.; Yuan, X.; Gao, Z. An experiment-based review of low-light image enhancement methods. IEEE Access 2020, 8, 87884–87917. [Google Scholar] [CrossRef]
- Yu, X.; Li, H.; Yang, H. Two-stage image decomposition and color regulator for low-light image enhancement. Vis. Comput. 2022, 1–11. [Google Scholar] [CrossRef]
- Li, C.; Liu, J.; Zhu, J.; Zhang, W.; Bi, L. Mine image enhancement using adaptive bilateral gamma adjustment and double plateaus histogram equalization. Multimed. Tools Appl. 2022, 81, 12643–12660. [Google Scholar] [CrossRef]
- Yu, J.; Hao, X.; He, P. Single-stage Face Detection under Extremely Low-light Conditions. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 3523–3532. [Google Scholar]
- Liu, J.; Xu, D.; Yang, W.; Fan, M.; Huang, H. Benchmarking low-light image enhancement and beyond. Int. J. Comput. Vis. 2021, 129, 1153–1184. [Google Scholar] [CrossRef]
- Liu, S.; Long, W.; He, L.; Li, Y.; Ding, W. Retinex-based fast algorithm for low-light image enhancement. Entropy 2021, 23, 746. [Google Scholar] [CrossRef]
- Kong, X.Y.; Liu, L.; Qian, Y.S. Low-light image enhancement via poisson noise aware retinex model. IEEE Signal Process. Lett. 2021, 28, 1540–1544. [Google Scholar] [CrossRef]
- Ma, Q.; Wang, Y.; Zeng, T. Retinex-based variational framework for low-light image enhancement and denoising. IEEE Trans. Multimed. 2022. [Google Scholar] [CrossRef]
- Li, X.; Shang, J.; Song, W.; Chen, J.; Zhang, G.; Pan, J. Low-Light Image Enhancement Based on Constraint Low-Rank Approximation Retinex Model. Sensors 2022, 22, 6126. [Google Scholar] [CrossRef]
- Mittal, A.; Moorthy, A.K.; Bovik, A.C. No-reference image quality assessment in the spatial domain. IEEE Trans. Image Process. 2012, 21, 4695–4708. [Google Scholar] [CrossRef]
- Mittal, A.; Soundararajan, R.; Bovik, A.C. Making a “completely blind” image quality analyzer. IEEE Signal Process. Lett. 2012, 20, 209–212. [Google Scholar] [CrossRef]
- Wang, L.W.; Liu, Z.S.; Siu, W.C.; Lun, D.P. Lightening network for low-light image enhancement. IEEE Trans. Image Process. 2020, 29, 7984–7996. [Google Scholar] [CrossRef]
- Lan, R.; Sun, L.; Liu, Z.; Lu, H.; Pang, C.; Luo, X. MADNet: A fast and lightweight network for single-image super resolution. IEEE Trans. Cybern. 2020, 51, 1443–1453. [Google Scholar] [CrossRef]
- Paul, A.; Bhattacharya, P.; Maity, S.P. Histogram modification in adaptive bi-histogram equalization for contrast enhancement on digital images. Optik 2022, 259, 168899. [Google Scholar] [CrossRef]
- Lu, H.; Liu, Z.; Pan, X. An adaptive detail equalization for infrared image enhancement based on multi-scale convolution. IEEE Access 2020, 8, 156763–156773. [Google Scholar] [CrossRef]
- Ren, X.; Yang, W.; Cheng, W.H.; Liu, J. LR3M: Robust low-light enhancement via low-rank regularized retinex model. IEEE Trans. Image Process. 2020, 29, 5862–5876. [Google Scholar] [CrossRef]
- Fu, X.; Zeng, D.; Huang, Y.; Zhang, X.P.; Ding, X. A weighted variational model for simultaneous reflectance and illumination estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2782–2790. [Google Scholar]
- Ying, Z.; Li, G.; Gao, W. A bio-inspired multi-exposure fusion framework for low-light image enhancement. arXiv 2017, arXiv:1711.00591. [Google Scholar]
- Xu, K.; Yang, X.; Yin, B.; Lau, R.W. Learning to restore low-light images via decomposition-and-enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2281–2290. [Google Scholar]
- Jeon, J.J.; Eom, I.K. Low-light image enhancement using inverted image normalized by atmospheric light. Signal Process. 2022, 196, 108523. [Google Scholar] [CrossRef]
- Guo, L.; Jia, Z.; Yang, J.; Kasabov, N.K. Detail Preserving Low Illumination Image and Video Enhancement Algorithm Based on Dark Channel Prior. Sensors 2021, 22, 85. [Google Scholar] [CrossRef]
- Hong, S.; Kim, M.; Kang, M.G. Single image dehazing via atmospheric scattering model-based image fusion. Signal Process. 2021, 178, 107798. [Google Scholar] [CrossRef]
- Shin, J.; Park, H.; Park, J.; Paik, J.; Ha, J. Variational low-light image enhanc38ement based on a haze model. IEIE Trans. Smart Process. Comput. 2018, 7, 325–331. [Google Scholar] [CrossRef]
- Wang, Y.; Wan, R.; Yang, W.; Li, H.; Chau, L.P.; Kot, A. Low-light image enhancement with normalizing flow. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual. 6–10 November 2022; Volume 36, pp. 2604–2612. [Google Scholar]
- Lore, K.G.; Akintayo, A.; Sarkar, S. LLNet: A deep autoencoder approach to natural low-light image enhancement. Pattern Recognit. 2017, 61, 650–662. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhang, J.; Guo, X. Kindling the darkness: A practical low-light image enhancer. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 1632–1640. [Google Scholar]
- Jiang, Y.; Gong, X.; Liu, D.; Cheng, Y.; Fang, C.; Shen, X.; Yang, J.; Zhou, P.; Wang, Z. Enlightengan: Deep light enhancement without paired supervision. IEEE Trans. Image Process. 2021, 30, 2340–2349. [Google Scholar] [CrossRef] [PubMed]
- Ulyanov, D.; Vedaldi, A.; Lempitsky, V. Deep image prior. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 9446–9454. [Google Scholar]
- Qian, S.; Shi, Y.; Wu, H.; Liu, J.; Zhang, W. An adaptive enhancement algorithm based on visual saliency for low illumination images. Appl. Intell. 2022, 52, 1770–1792. [Google Scholar] [CrossRef]
- Du, N.; Luo, Q.; Du, Y.; Zhou, Y. Color Image Enhancement: A Metaheuristic Chimp Optimization Algorithm. Neural Process. Lett. 2022, 1–40. [Google Scholar] [CrossRef]
- Srinivas, S.; Siddharth, V.R.; Dutta, S.; Khare, N.S.; Krishna, L. Channel prior based Retinex model for underwater image enhancement. In Proceedings of the 2022 Second IEEE International Conference on Advances in Electrical, Computing, Communication and Sustainable Technologies (ICAECT), Bhilai, India, 21–22 April 2022; pp. 1–10. [Google Scholar]
- Hao, S.; Han, X.; Guo, Y.; Wang, M. Decoupled Low-Light Image Enhancement. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2022, 18, 1–19. [Google Scholar] [CrossRef]
- Liu, X.; Yang, Y.; Zhong, Y.; Xiong, D.; Huang, Z. Super-Pixel Guided Low-Light Images Enhancement with Features Restoration. Sensors 2022, 22, 3667. [Google Scholar] [CrossRef]
- Lu, Y.; Jung, S.W. Progressive Joint Low-Light Enhancement and Noise Removal for Raw Images. IEEE Trans. Image Process. 2022, 31, 2390–2404. [Google Scholar] [CrossRef]
- Yu, W.; Yao, H.; Li, D.; Li, G.; Shi, H. GLAGC: Adaptive Dual-Gamma Function for Image Illumination Perception and Correction in the Wavelet Domain. Sensors 2021, 21, 845. [Google Scholar] [CrossRef]
- Feng, H.; Ping, L.; Wang, B. Color image enhancement algorithm based on adaptive weight Retinex and wavelet transform. Radioengineering 2020, 4, 19. [Google Scholar]
- Zhang, B.; Wang, M.; Shen, X. Image haze removal algorithm based on nonsubsampled contourlet transform. IEEE Access 2021, 9, 21708–21720. [Google Scholar] [CrossRef]
- Kaur, K.; Jindal, N.; Singh, K. Fractional Fourier Transform based Riesz fractional derivative approach for edge detection and its application in image enhancement. Signal Process. 2021, 180, 107852. [Google Scholar] [CrossRef]
- Yang, J.; Xu, Y.; Yue, H.; Jiang, Z.; Li, K. Low-light image enhancement based on Retinex decomposition and adaptive gamma correction. IET Image Process. 2021, 15, 1189–1202. [Google Scholar] [CrossRef]
- Xu, Y.; Sun, Y.; Yang, Z.; Miao, J.; Yang, Y. H2FA R-CNN: Holistic and Hierarchical Feature Alignment for Cross-Domain Weakly Supervised Object Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 14329–14339. [Google Scholar]
- Han, G.; Huang, S.; Ma, J.; He, Y.; Chang, S.F. Meta faster r-cnn: Towards accurate few-shot object detection with attentive feature alignment. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual. 6–10 November 2022; Volume 36, pp. 780–789. [Google Scholar]
- Yang, X.; Yan, J. On the arbitrary-oriented object detection: Classification based approaches revisited. Int. J. Comput. Vis. 2022, 130, 1340–1365. [Google Scholar] [CrossRef]
- Zhang, X.; Shen, M.; Li, X.; Feng, F. A deformable CNN-based triplet model for fine-grained sketch-based image retrieval. Pattern Recognit. 2022, 125, 108508. [Google Scholar] [CrossRef]
- Lv, F.; Lu, F.; Wu, J.; Lim, C. MBLLEN: Low-Light Image/Video Enhancement Using CNNs. In Proceedings of the 2018 British Machine Vision Conference, Newcastle, UK, 3–6 September 2018; Volume 220, p. 4. [Google Scholar]
- Zhu, M.; Pan, P.; Chen, W.; Yang, Y. EEMEFN: Low-light image enhancement via edge-enhanced multi-exposure fusion network. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 13106–13113. [Google Scholar]
- Lu, K.; Zhang, L. TBEFN: A two-branch exposure-fusion network for low-light image enhancement. IEEE Trans. Multimed. 2020, 23, 4093–4105. [Google Scholar] [CrossRef]
- Lim, S.; Kim, W. DSLR: Deep stacked Laplacian restorer for low-light image enhancement. IEEE Trans. Multimed. 2020, 23, 4272–4284. [Google Scholar] [CrossRef]
- Li, J.; Feng, X.; Hua, Z. Low-light image enhancement via progressive-recursive network. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 4227–4240. [Google Scholar] [CrossRef]
- Panetta, K.; KM, S.K.; Rao, S.P.; Agaian, S.S. Deep Perceptual Image Enhancement Network for Exposure Restoration. IEEE Trans. Cybern. 2022. [Google Scholar] [CrossRef]
- Liang, D.; Li, L.; Wei, M.; Yang, S.; Zhang, L.; Yang, W.; Du, Y.; Zhou, H. Semantically contrastive learning for low-light image enhancement. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual. 6–10 November 2022; Volume 36, pp. 1555–1563. [Google Scholar]
- Zheng, S.; Gupta, G. Semantic-guided zero-shot learning for low-light image/video enhancement. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2022; pp. 581–590. [Google Scholar]
- Wei, C.; Wang, W.; Yang, W.; Liu, J. Deep retinex decomposition for low-light enhancement. arXiv 2018, arXiv:1808.04560. [Google Scholar]
- Wang, R.; Zhang, Q.; Fu, C.W.; Shen, X.; Zheng, W.S.; Jia, J. Underexposed photo enhancement using deep illumination estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6849–6857. [Google Scholar]
- Zhang, Y.; Guo, X.; Ma, J.; Liu, W.; Zhang, J. Beyond brightening low-light images. Int. J. Comput. Vis. 2021, 129, 1013–1037. [Google Scholar] [CrossRef]
- Yu, R.; Liu, W.; Zhang, Y.; Qu, Z.; Zhao, D.; Zhang, B. Deepexposure: Learning to expose photos with asynchronously reinforced adversarial learning. In Proceedings of the 32nd Annual Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Yang, W.; Wang, S.; Fang, Y.; Wang, Y.; Liu, J. From fidelity to perceptual quality: A semi-supervised approach for low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 3063–3072. [Google Scholar]
- Yang, W.; Wang, S.; Fang, Y.; Wang, Y.; Liu, J. Band Representation-Based Semi-Supervised Low-Light Image Enhancement: Bridging the Gap Between Signal Fidelity and Perceptual Quality. IEEE Trans. Image Process. 2021, 30, 3461–3473. [Google Scholar] [CrossRef]
- Zhu, A.; Zhang, L.; Shen, Y.; Ma, Y.; Zhao, S.; Zhou, Y. Zero-shot restoration of underexposed images via robust retinex decomposition. In Proceedings of the 2020 IEEE International Conference on Multimedia and Expo (ICME), London, UK, 6–10 July 2020; pp. 1–6. [Google Scholar]
- Liu, R.; Ma, L.; Zhang, J.; Fan, X.; Luo, Z. Retinex-inspired unrolling with cooperative prior architecture search for low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 10561–10570. [Google Scholar]
- Guo, C.; Li, C.; Guo, J.; Loy, C.C.; Hou, J.; Kwong, S.; Cong, R. Zero-reference deep curve estimation for low-light image enhancement. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1780–1789. [Google Scholar]
- Xu, X.; Wang, S.; Wang, Z.; Zhang, X.; Hu, R. Exploring image enhancement for salient object detection in low light images. ACM Trans. Multimed. Comput. Commun. Appl. (TOMM) 2021, 17, 1–19. [Google Scholar] [CrossRef]
- Xu, K.; Chen, H.; Xu, C.; Jin, Y.; Zhu, C. Structure-Texture aware network for low-light image enhancement. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 4983–4996. [Google Scholar] [CrossRef]
- Zamir, S.W.; Arora, A.; Khan, S.H.; Munawar, H.; Khan, F.S.; Yang, M.H.; Shao, L. Learning Enriched Features for Fast Image Restoration and Enhancement. arXiv 2022, arXiv:2205.01649. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Zhang, R.; Isola, P.; Efros, A.A.; Shechtman, E.; Wang, O. The unreasonable effectiveness of deep features as a perceptual metric. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 586–595. [Google Scholar]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | LOL | MIT-Adobe | ||
|---|---|---|---|---|
| PSNR ↑ | SSIM ↑ | PSNR ↑ | SSIM ↑ | |
| -w/o MSL | 24.519 | 0.875 | 17.845 | 0.881 |
| -w/o DCAM | 24.545 | 0.880 | 17.887 | 0.886 |
| Ours | 24.658 | 0.886 | 17.895 | 0.879 |
| Function | LOL | MIT-Adobe | |||
|---|---|---|---|---|---|
| PSNR ↑ | SSIM ↑ | PSNR ↑ | SSIM ↑ | ||
| Loss | -w/o L1 | 24.644 | 0.880 | 21.359 | 0.866 |
| -w/o TV | 24.599 | 0.879 | 21.353 | 0.869 | |
| -w/o SSIM | 23.979 | 0.869 | 21.288 | 0.858 | |
| -w/o Color | 24.656 | 0.881 | 21.358 | 0.870 | |
| Our | 24.658 | 0.886 | 21.361 | 0.879 | |
| Activate | LeakyReLU | 24.317 | 0.877 | 21.105 | 0.867 |
| Mish | 24.651 | 0.884 | 21.299 | 0.870 | |
| ReLU | 24.658 | 0.886 | 21.361 | 0.879 | |
| Method | LOL | MIT-Adobe | ||||||
|---|---|---|---|---|---|---|---|---|
| MSE ↓ | PSNR ↑ | SSIM ↑ | LPIPS ↓ | MSE ↓ | PSNR ↑ | SSIM ↑ | LPIPS ↓ | |
| LR3M [18] | 4.928 | 16.998 | 0.301 | 0.580 | 4.117 | 17.917 | 0.699 | 0.241 |
| SRIE [19] | 4.902 | 17.162 | 0.235 | 0.552 | 4.206 | 17.819 | 0.690 | 0.249 |
| BIMEF [20] | 4.869 | 17.191 | 0.264 | 0.560 | 4.259 | 17.772 | 0.683 | 0.252 |
| RetinexNet [54] | 1.651 | 21.875 | 0.462 | 0.474 | 4.391 | 17.624 | 0.671 | 0.239 |
| DSLR [49] | 3.536 | 18.580 | 0.597 | 0.337 | 1.947 | 21.172 | 0.692 | 0.201 |
| KinD [28] | 1.431 | 22.509 | 0.766 | 0.143 | 2.675 | 19.908 | 0.799 | 0.167 |
| DLN [14] | 1.515 | 21.939 | 0.807 | 0.163 | 1.897 | 16.995 | 0.769 | 0.171 |
| DRBN [59] | 2.259 | 20.635 | 0.472 | 0.316 | 3.307 | 18.875 | 0.378 | 0.291 |
| EnlightenGAN [29] | 1.998 | 21.263 | 0.677 | 0.322 | 3.628 | 18.456 | 0.745 | 0.170 |
| MIRNet [65] | 1.226 | 23.191 | 0.816 | 0.253 | 1.864 | 21.361 | 0.690 | 0.238 |
| Zero DCE++ [1] | 3.300 | 14.859 | 0.587 | 0.360 | 3.481 | 13.197 | 0.704 | 0.212 |
| SCL-LLE [52] | 2.445 | 20.197 | 0.695 | 0.386 | 3.002 | 19.291 | 0.636 | 0.279 |
| Ours | 1.103 | 24.658 | 0.866 | 0.140 | 1.412 | 21.361 | 0.879 | 0.169 |
| Method | LIME | MEF | NPE | VV | ||||
|---|---|---|---|---|---|---|---|---|
| NIQE ↓ | PCQI ↑ | NIQE ↓ | PCQI ↑ | NIQE ↓ | PCQI ↑ | NIQE ↓ | PCQI ↑ | |
| LR3M [18] | 4.4259 | 0.7417 | 3.6001 | 0.9459 | 4.1490 | 0.7551 | 3.1233 | 0.9656 |
| SRIE [19] | 3.7870 | 1.1121 | 3.5936 | 0.9570 | 3.3383 | 0.9556 | 3.1361 | 0.9629 |
| BIMEF [20] | 3.8313 | 1.0647 | 3.5674 | 0.9293 | 3.4027 | 0.9116 | 3.1175 | 0.9271 |
| RetinexNet [54] | 4.9079 | 0.7947 | 3.7337 | 0.9112 | 4.2111 | 0.7320 | 3.2440 | 0.9163 |
| DSLR [49] | 5.8877 | 0.7286 | 4.1052 | 0.8998 | 4.2655 | 0.7802 | 3.6661 | 0.8116 |
| KinD [28] | 4.7619 | 0.9393 | 3.5954 | 0.9081 | 3.5060 | 0.8638 | 3.3689 | 0.8314 |
| DLN [14] | 3.8432 | 0.9990 | 3.5608 | 0.9002 | 3.4119 | 0.9036 | 3.1096 | 0.9292 |
| DRBN [59] | 3.8710 | 1.0059 | 3.5711 | 0.9225 | 3.5413 | 0.9201 | 3.2210 | 9.9199 |
| EnlightenGAN [29] | 4.6320 | 0.9392 | 3.2232 | 0.9691 | 3.5885 | 0.8897 | 2.5814 | 0.9774 |
| Zero DCE++ [1] | 3.7691 | 1.0956 | 3.5279 | 0.9398 | 3.2819 | 0.9598 | 2.4001 | 0.9799 |
| SCL-LLE [52] | 3.7800 | 0.7874 | 3.3115 | 0.8991 | 3.8776 | 0.7543 | 3.1649 | 0.9010 |
| Ours | 3.5996 | 1.2351 | 3.0010 | 0.9689 | 2.9998 | 0.9696 | 2.3369 | 0.9801 |
| Method | Param (M) ↓ | Flops (G) ↓ | Time (s) ↓ |
|---|---|---|---|
| LR3M [18] | - | - | 7.4802 |
| SRIE [19] | - | - | 5.1453 |
| BIMEF [20] | - | - | 0.5096 |
| RetinexNet [54] | 1.23 | 6.79 | 0.5217 |
| DSLR [49] | 14.31 | 22.95 | 0.0201 |
| KinD [28] | 8.49 | 7.44 | 0.6445 |
| DLN [14] | 91.19 | 198.56 | 0.9807 |
| DRBN [59] | 0.58 | 2.62 | 0.0711 |
| EnlightenGAN [29] | 8.64 | 7.88 | 0.6501 |
| Zero DCE++ [1] | 1.25 | 0.12 | 0.0028 |
| SCL-LLE [52] | 0.08 | 1.56 | 0.0048 |
| Ours | 2.91 | 3.08 | 0.0213 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lu, H.; Gong, J.; Liu, Z.; Lan, R.; Pan, X. FDMLNet: A Frequency-Division and Multiscale Learning Network for Enhancing Low-Light Image. Sensors 2022, 22, 8244. https://doi.org/10.3390/s22218244
Lu H, Gong J, Liu Z, Lan R, Pan X. FDMLNet: A Frequency-Division and Multiscale Learning Network for Enhancing Low-Light Image. Sensors. 2022; 22(21):8244. https://doi.org/10.3390/s22218244
Chicago/Turabian StyleLu, Haoxiang, Junming Gong, Zhenbing Liu, Rushi Lan, and Xipeng Pan. 2022. "FDMLNet: A Frequency-Division and Multiscale Learning Network for Enhancing Low-Light Image" Sensors 22, no. 21: 8244. https://doi.org/10.3390/s22218244
APA StyleLu, H., Gong, J., Liu, Z., Lan, R., & Pan, X. (2022). FDMLNet: A Frequency-Division and Multiscale Learning Network for Enhancing Low-Light Image. Sensors, 22(21), 8244. https://doi.org/10.3390/s22218244