
ST-DeepGait: A Spatiotemporal Deep Learning Model for Human Gait Recognition


Abstract
1. Introduction
2. Related Work
2.1. RGB-Based Methods
2.2. Depth-Based Methods
2.3. Spatiotemporal Deep Learning Methods
3. Proposed Method
3.1. Problem Definition
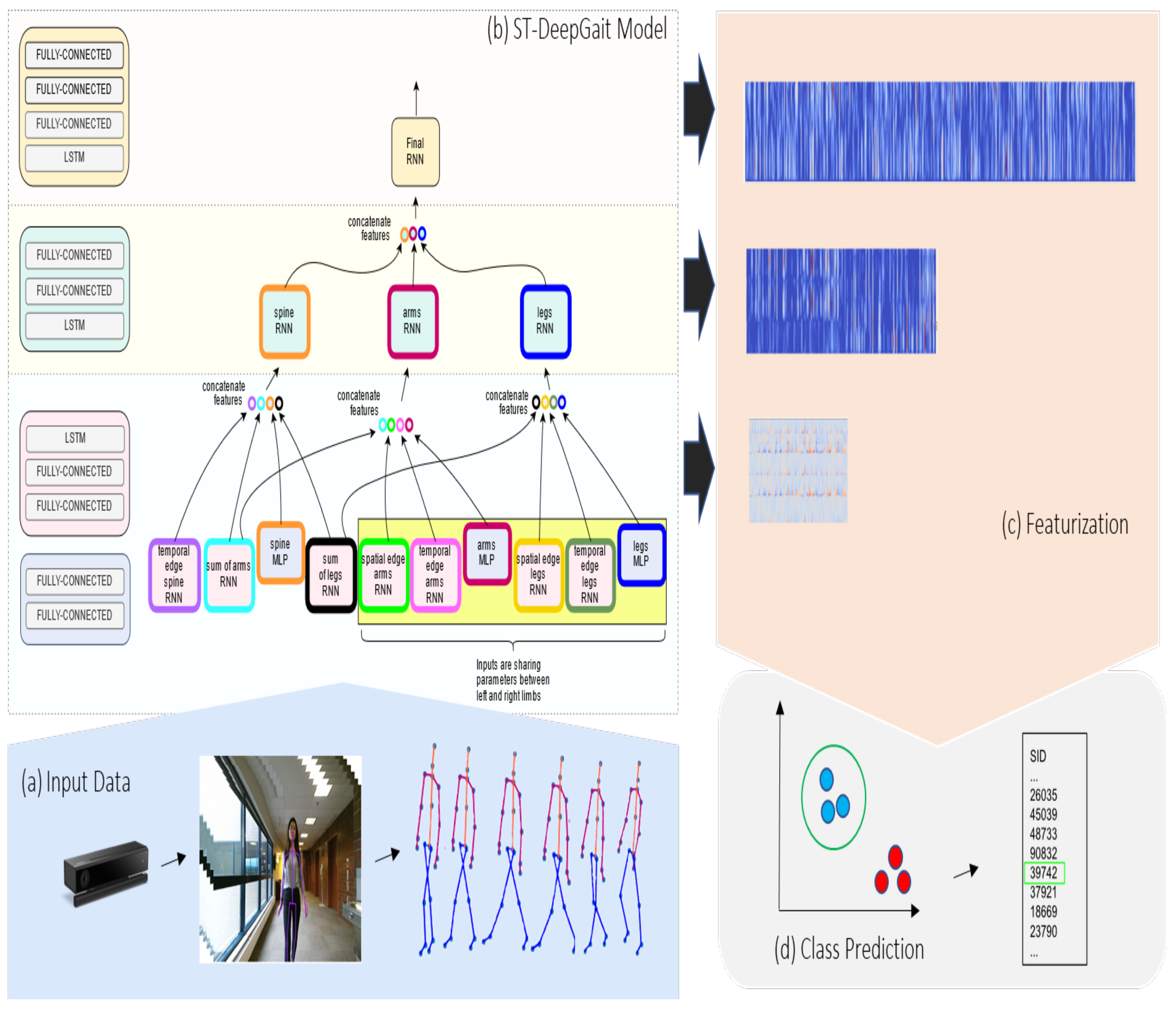
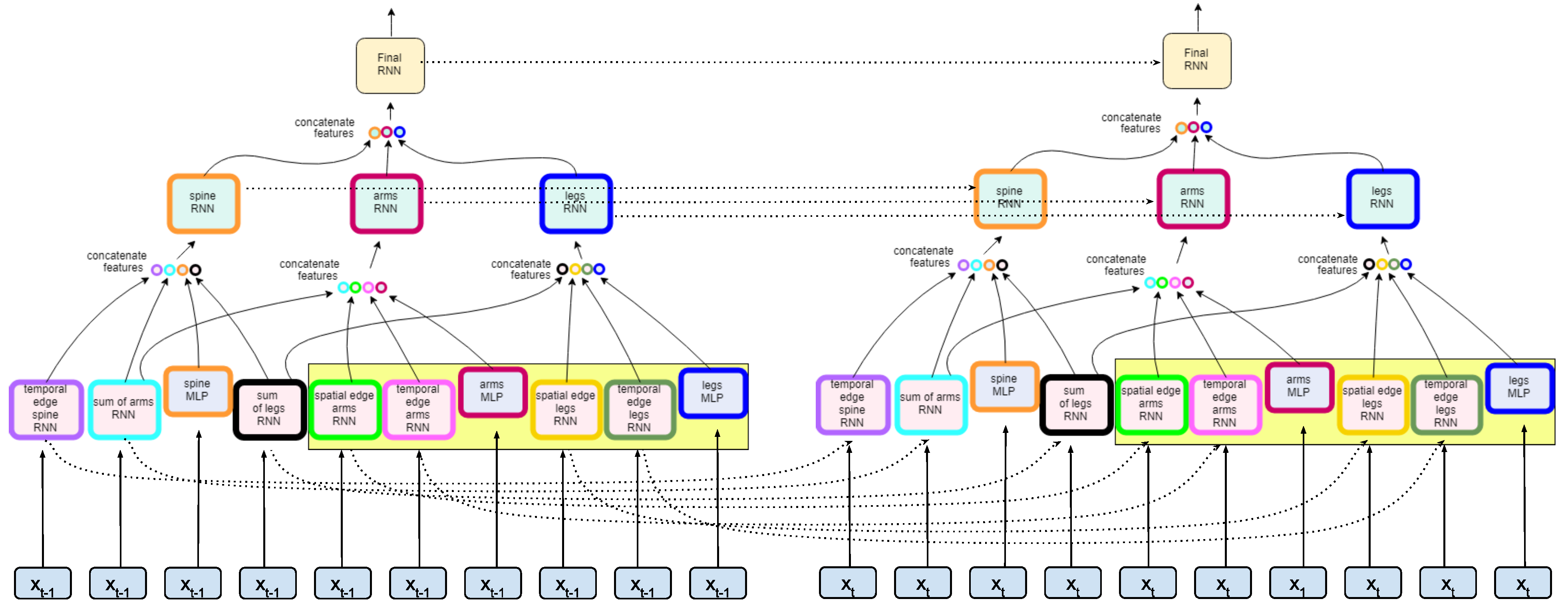
4. ST-DeepGait
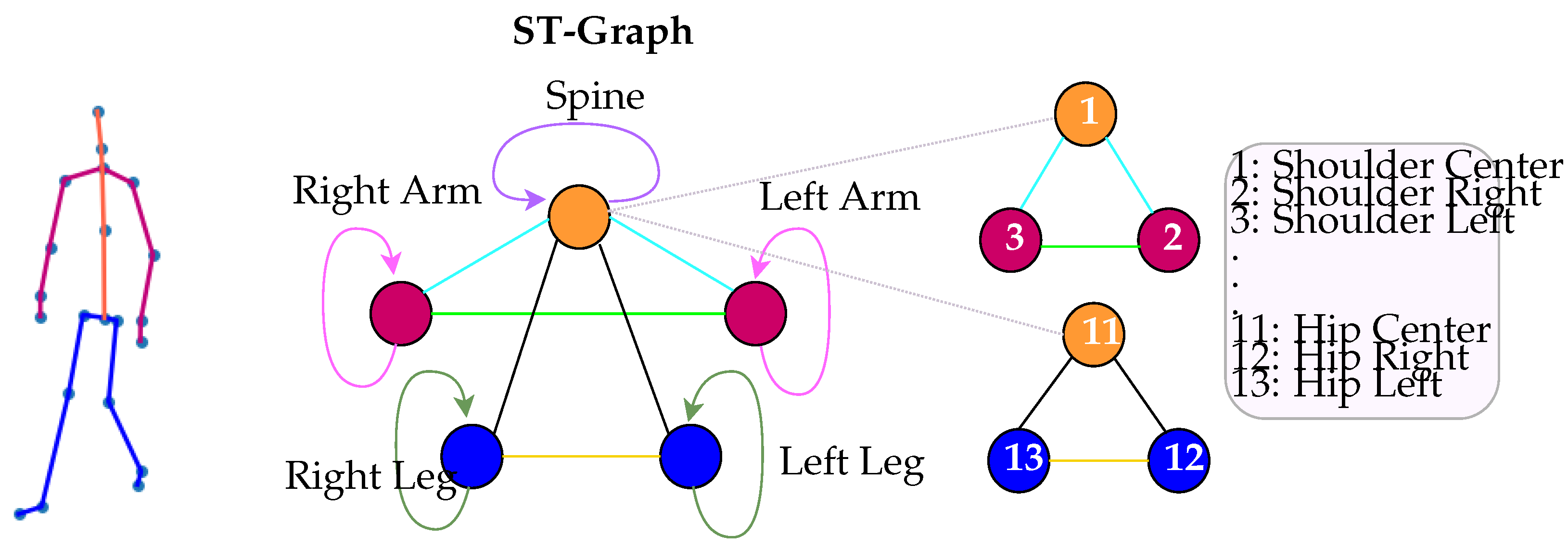
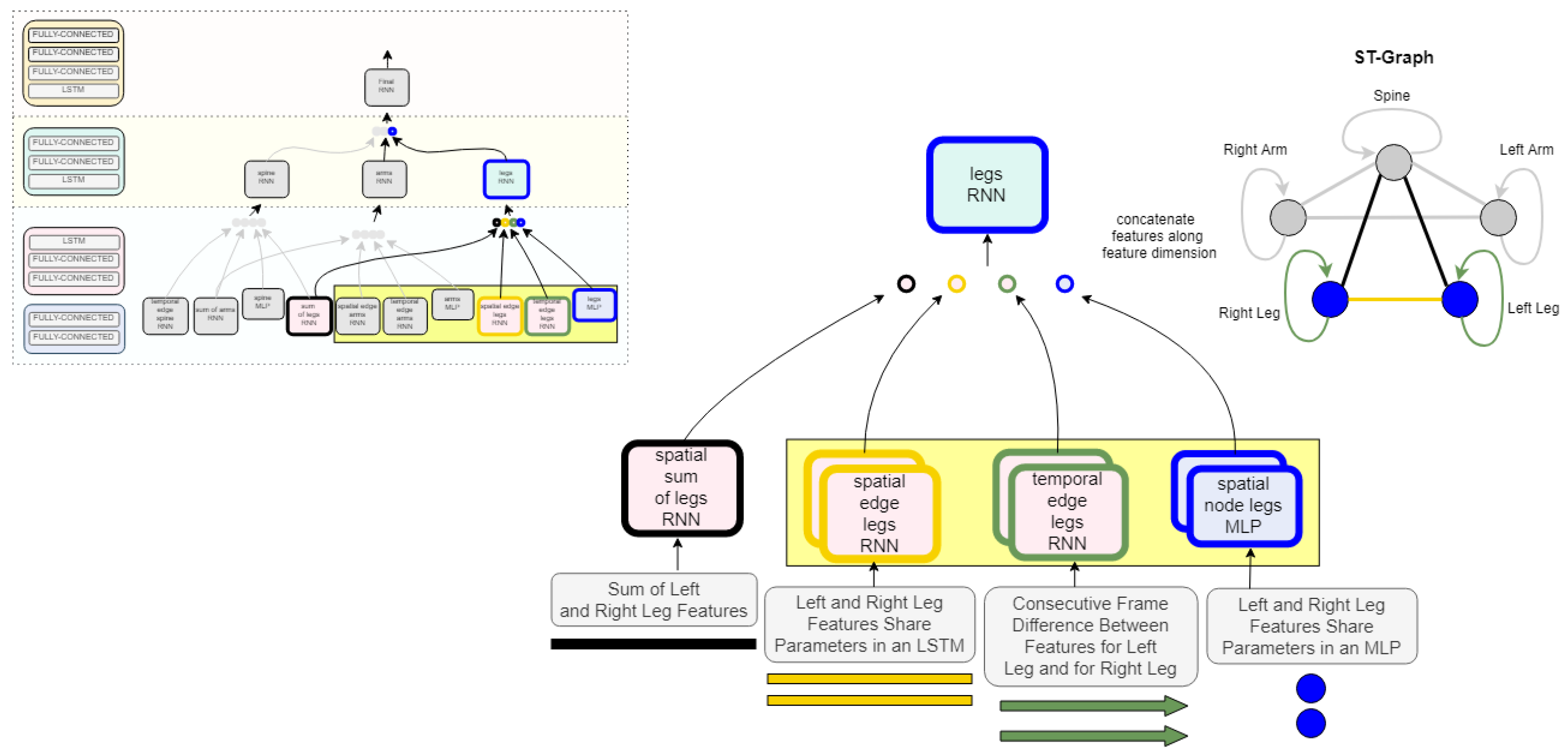
4.1. Spatial Representation
4.2. Temporal Representation
4.3. Inference
4.4. Formalization
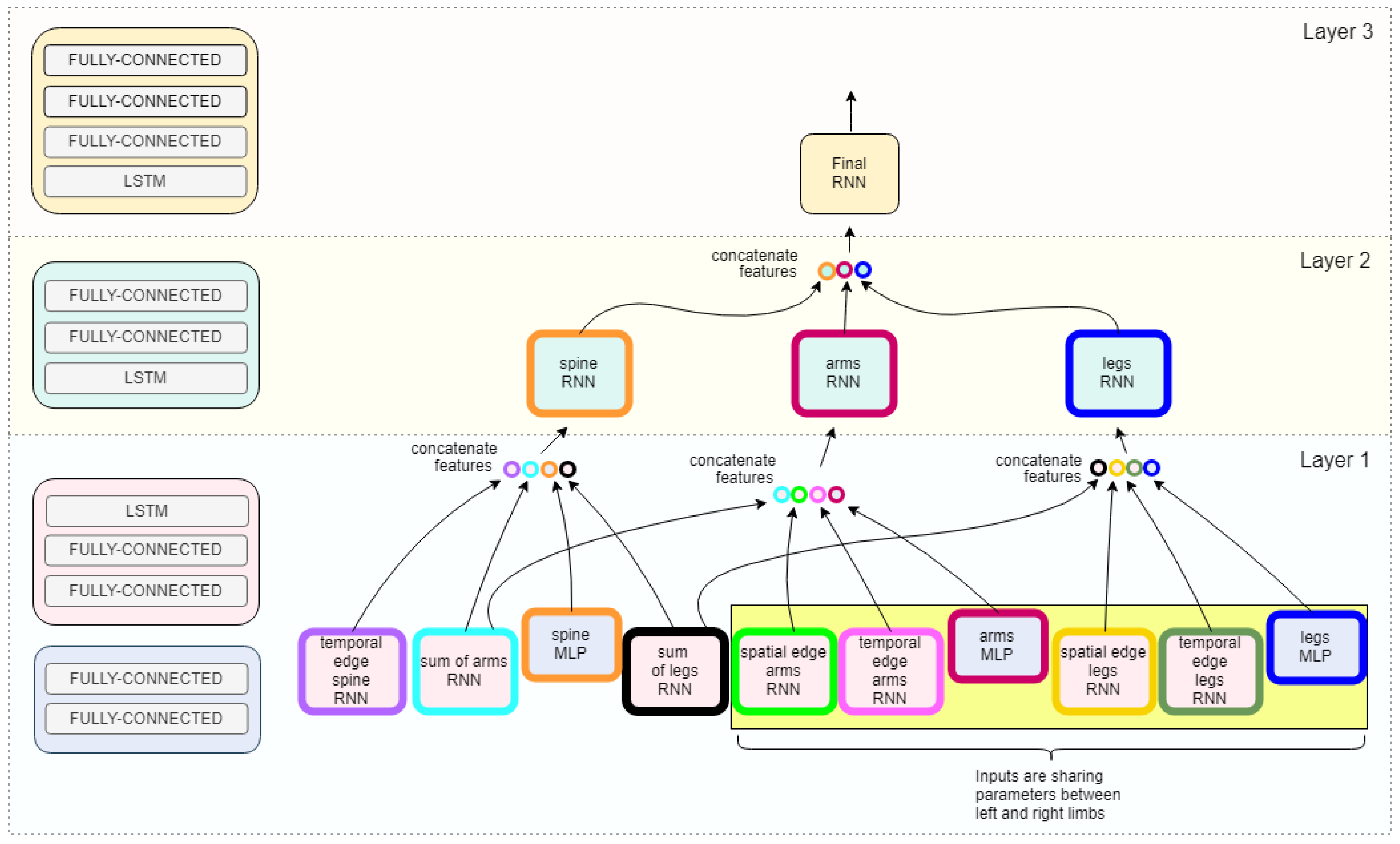
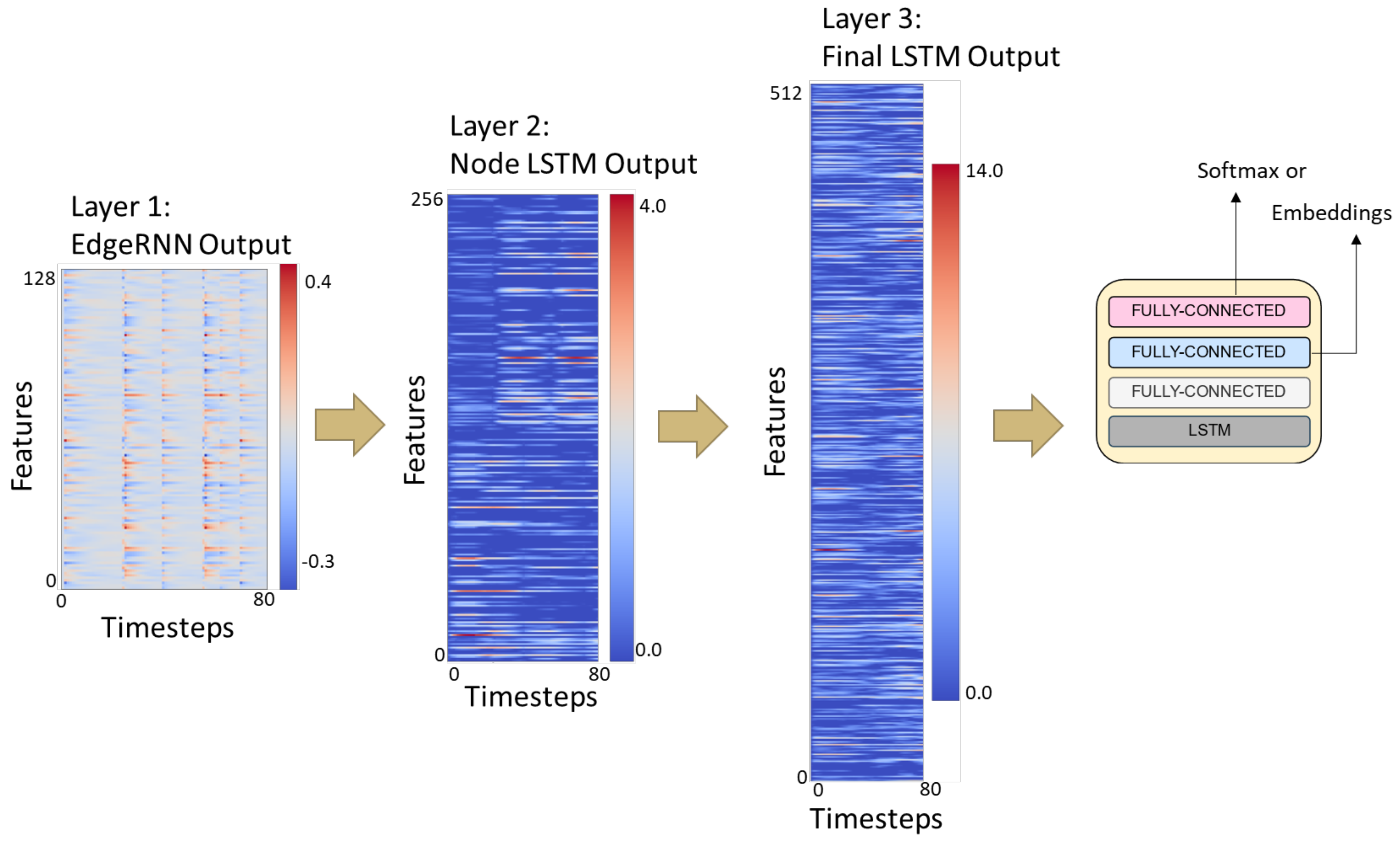
4.5. Model Architecture
5. Experimental Study
5.1. Dataset
5.2. Implementation
5.3. Model Hyperparameters
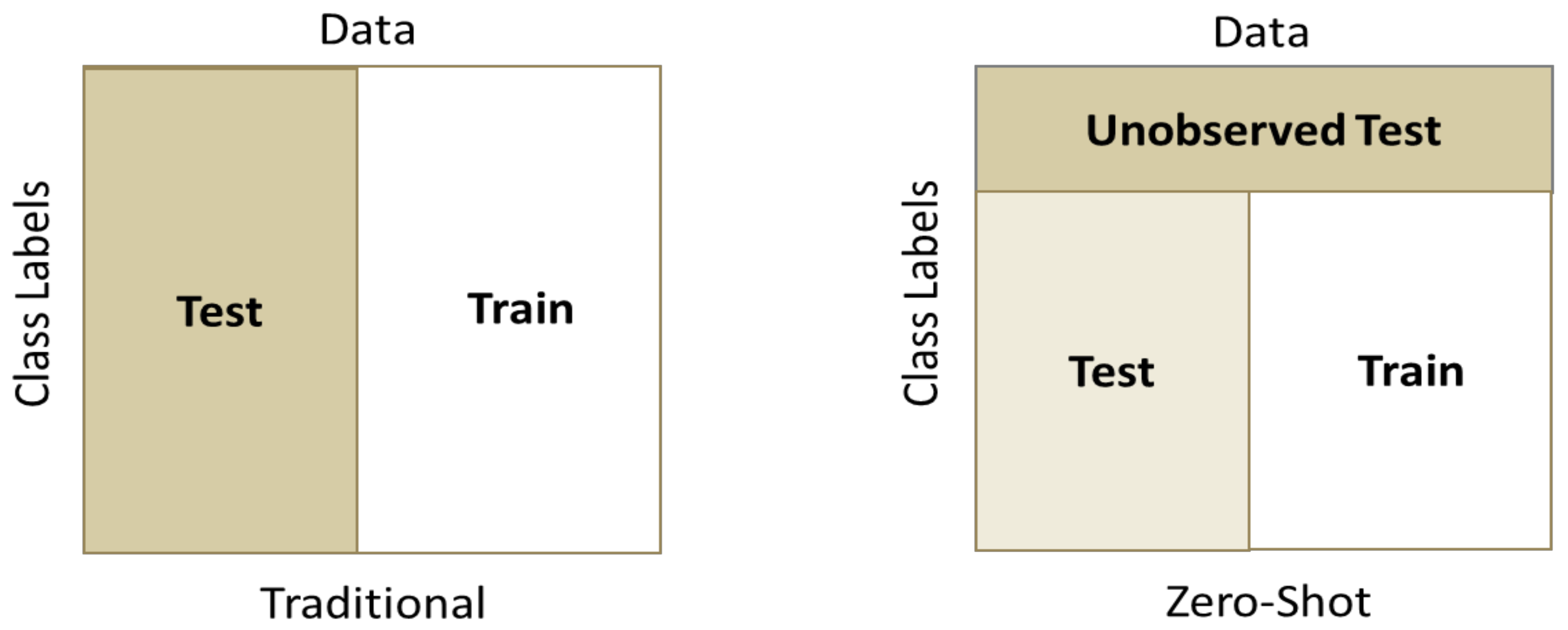
5.4. Experimental Methodology
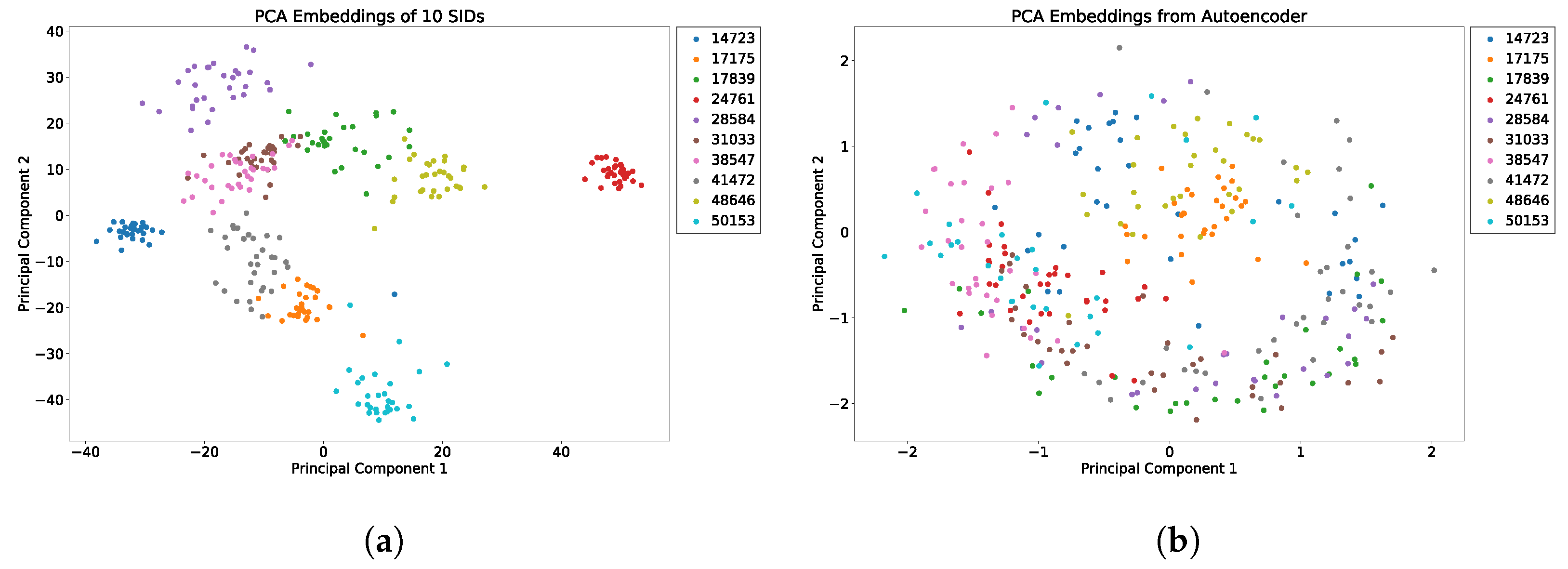
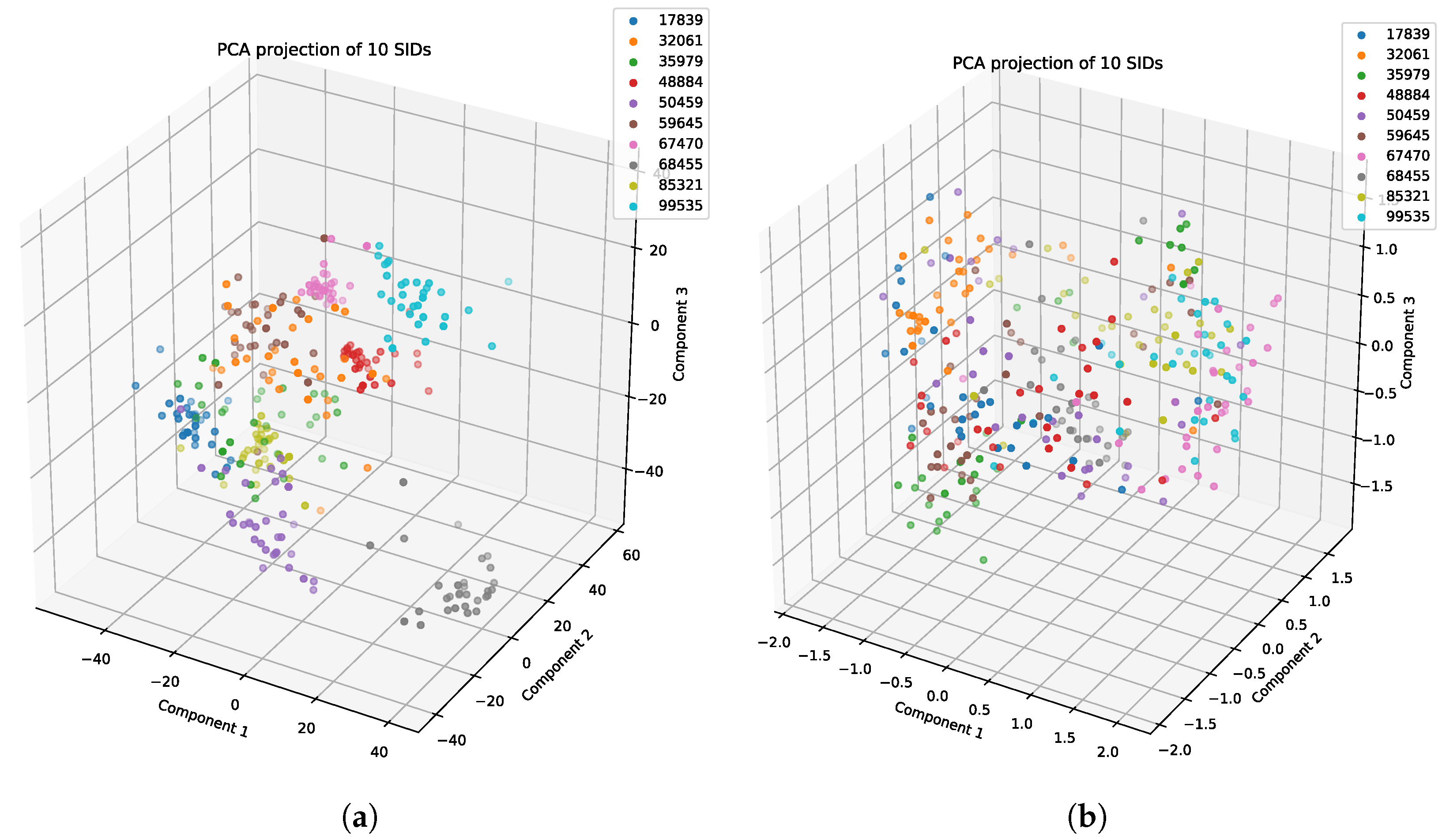
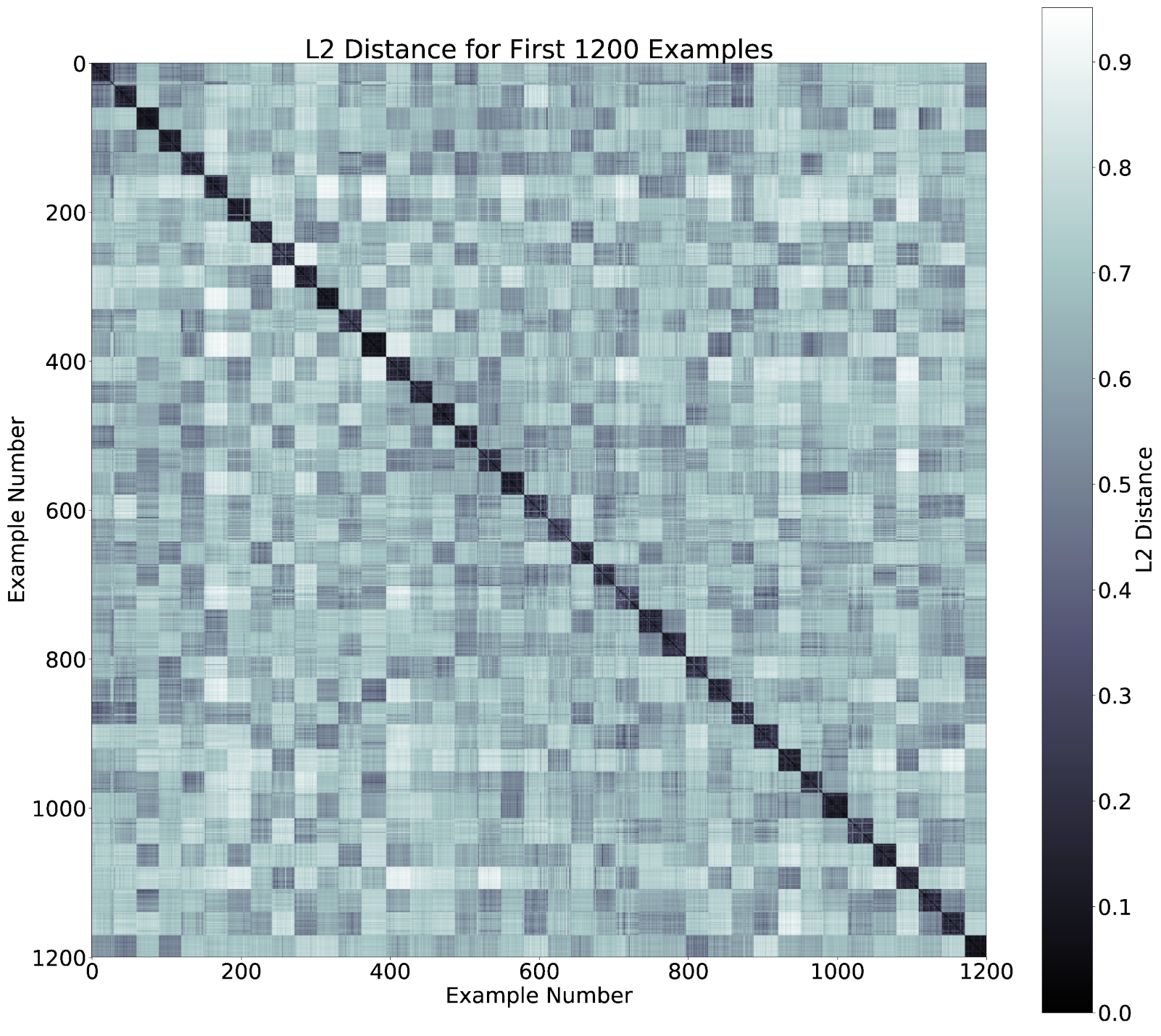
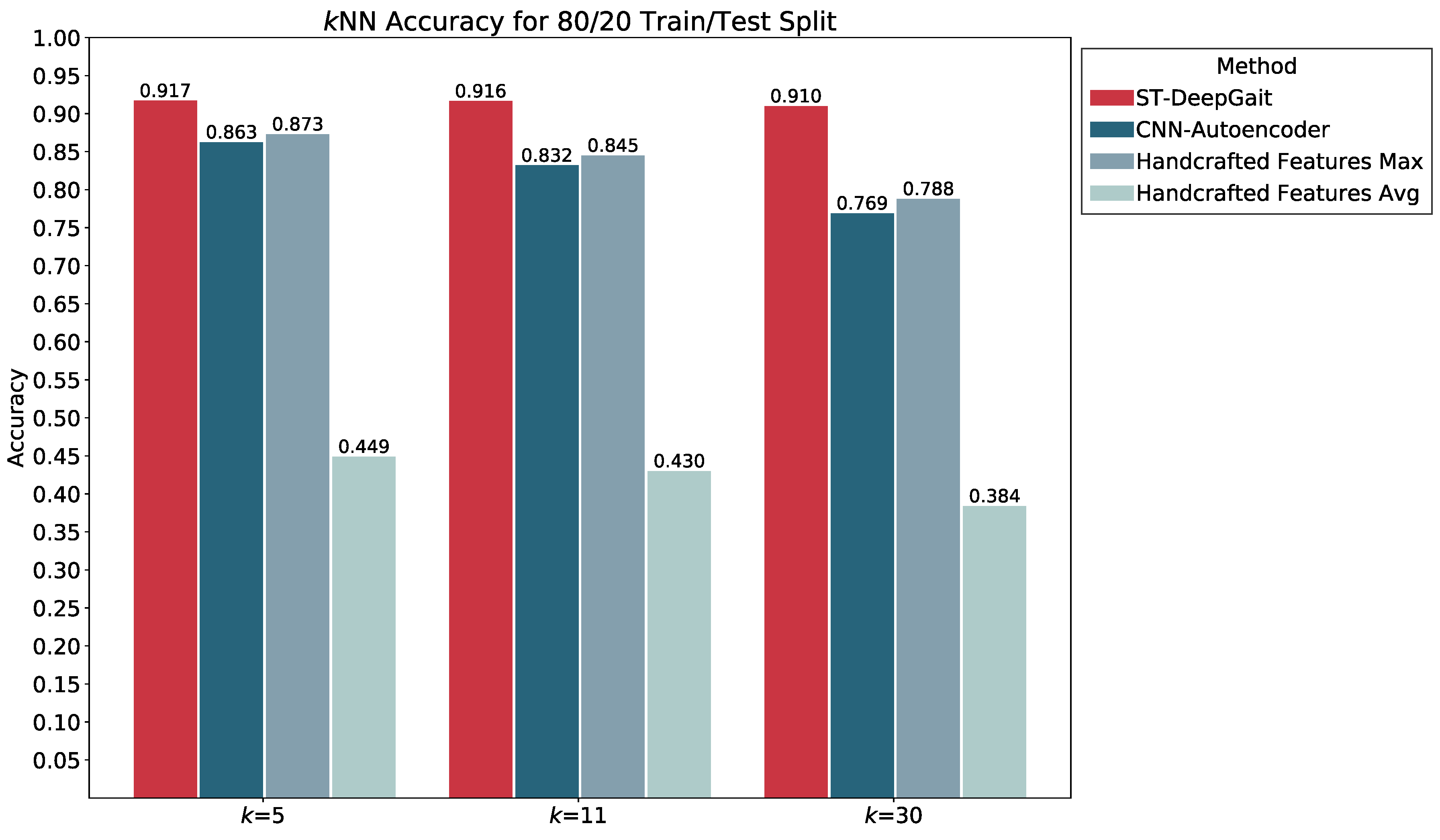
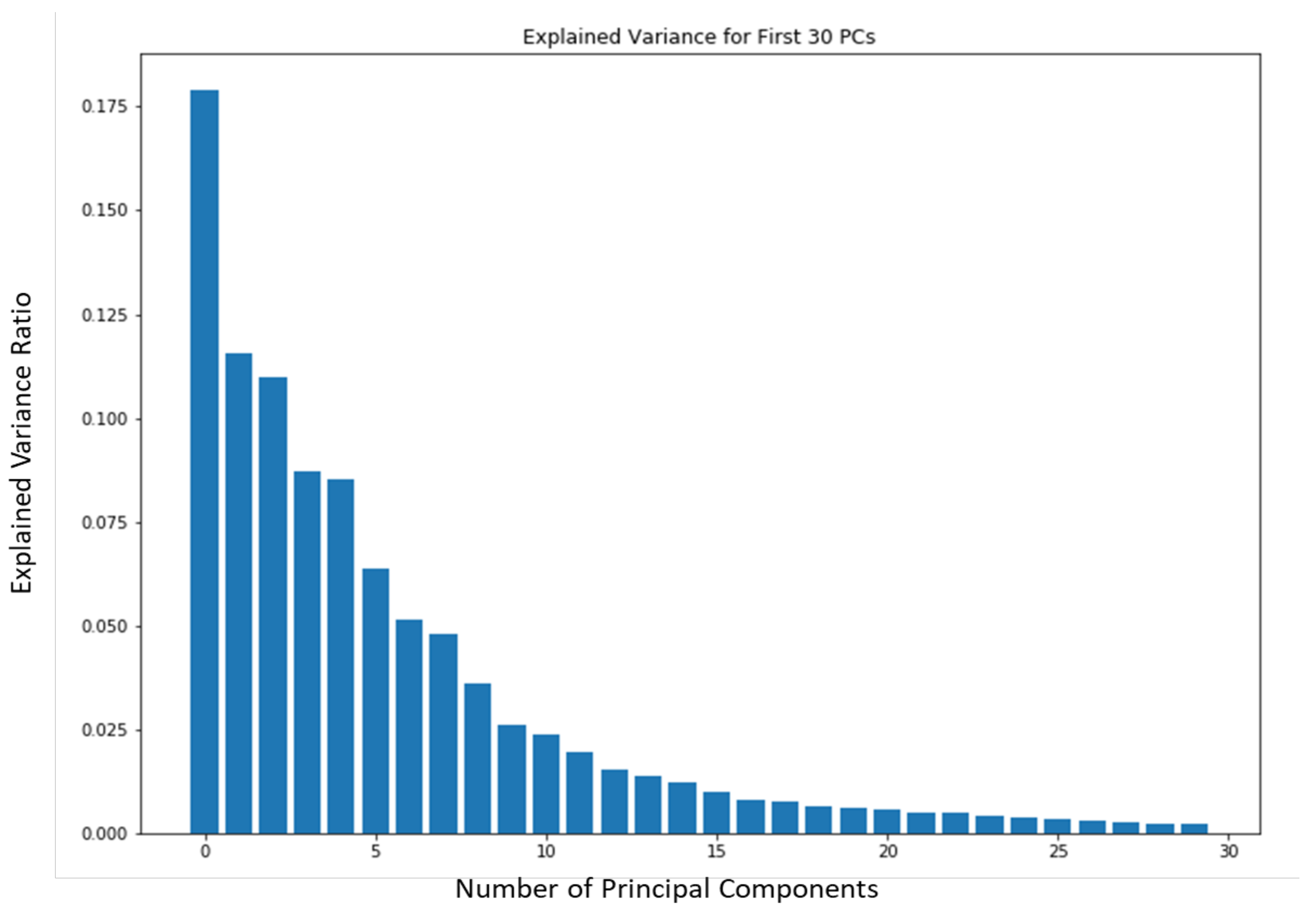
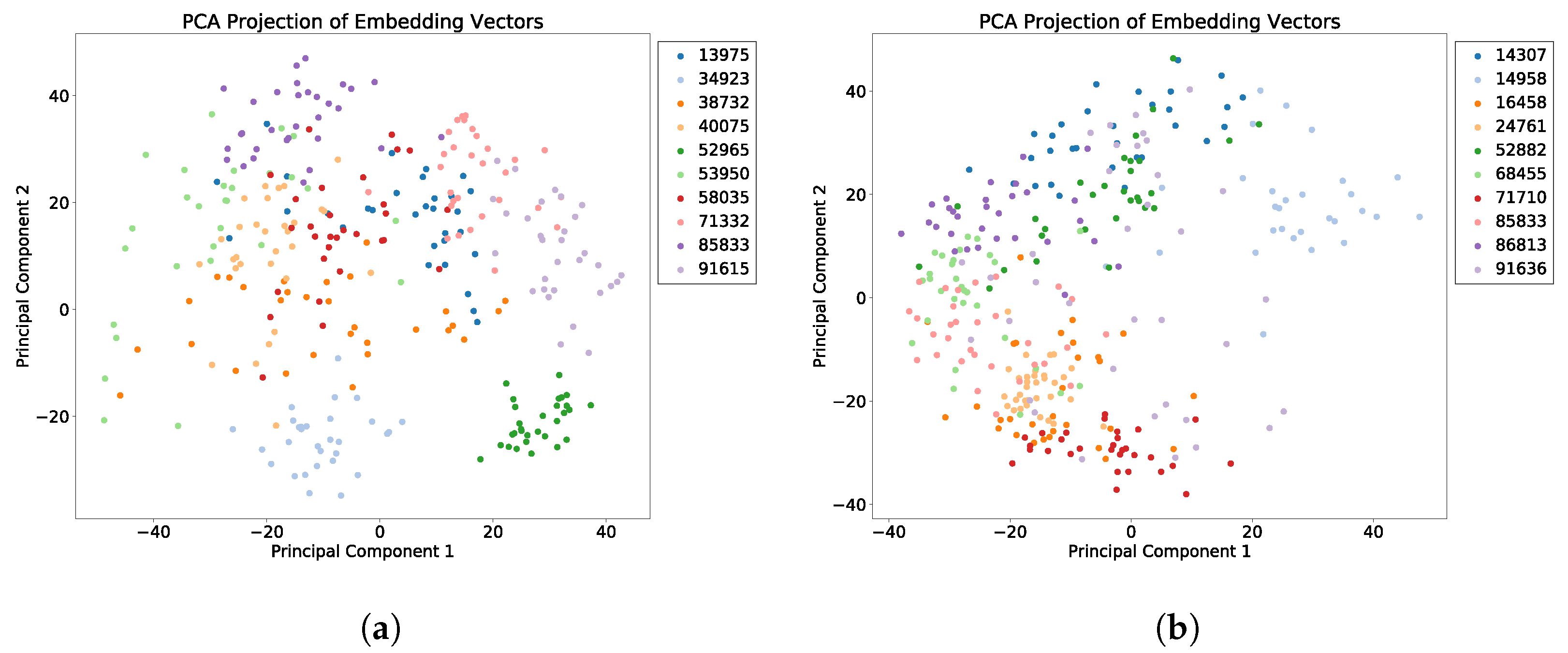
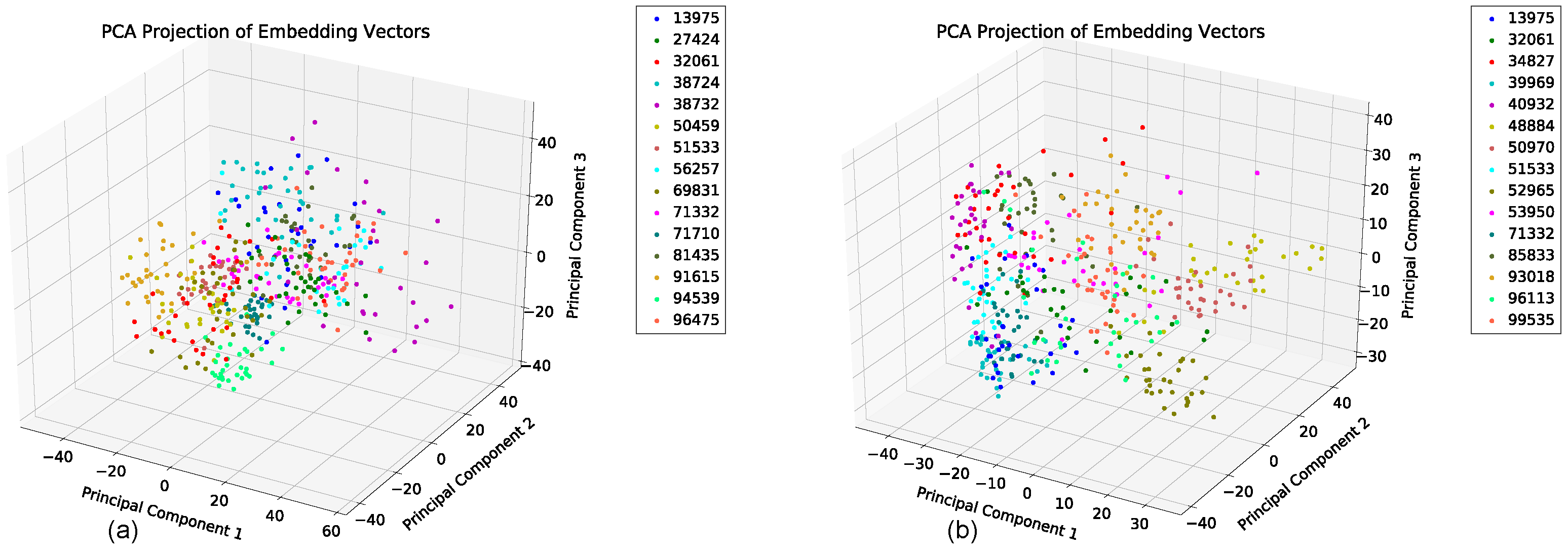
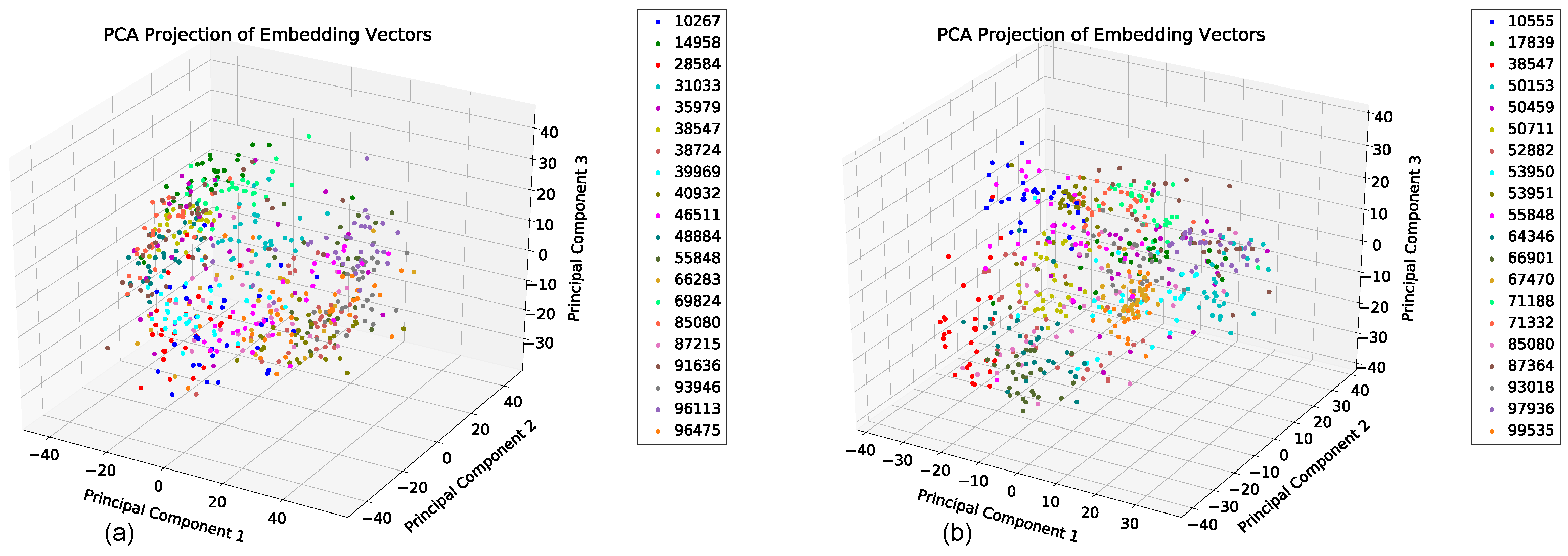
5.5. Featurization Evaluation
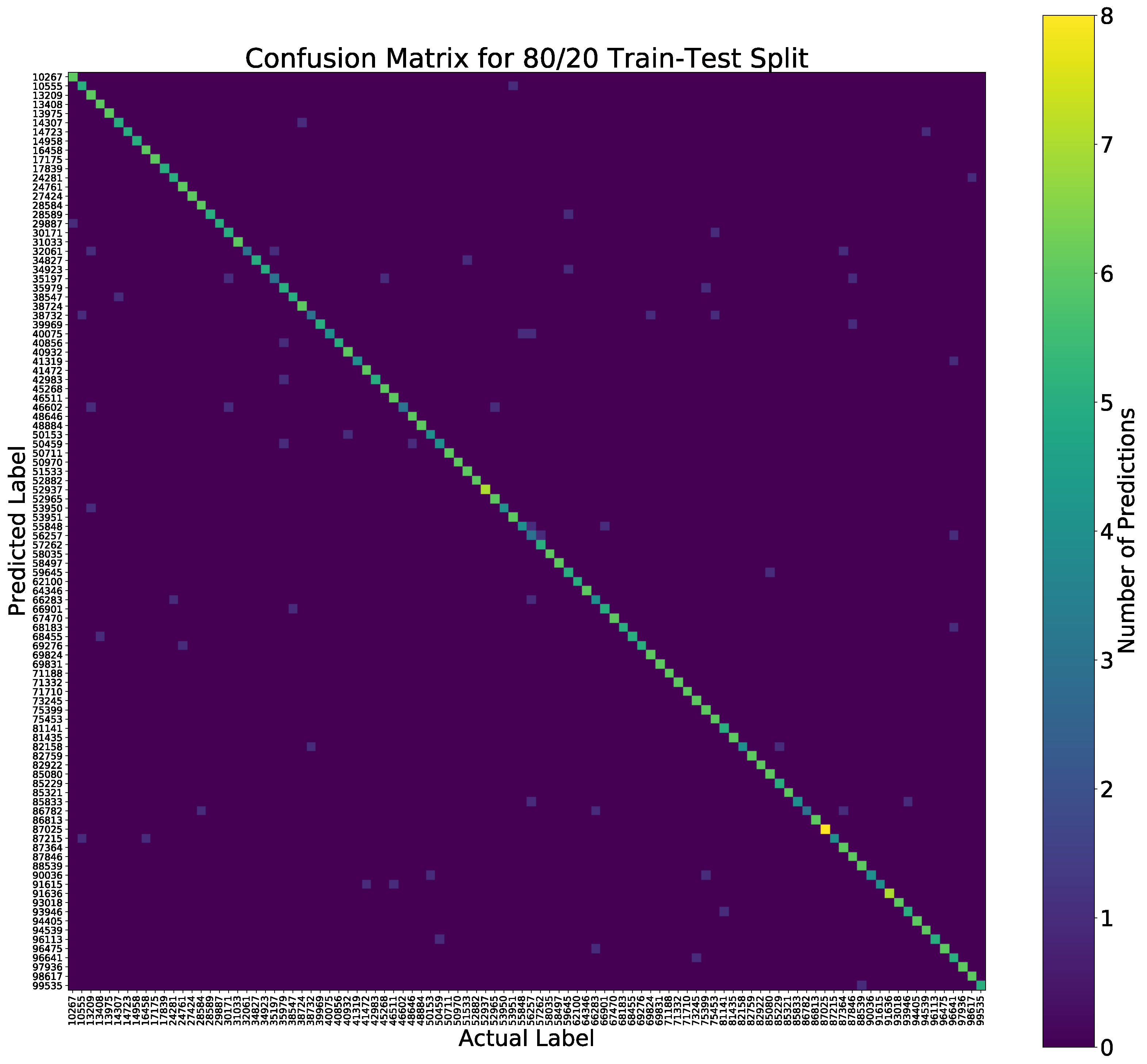
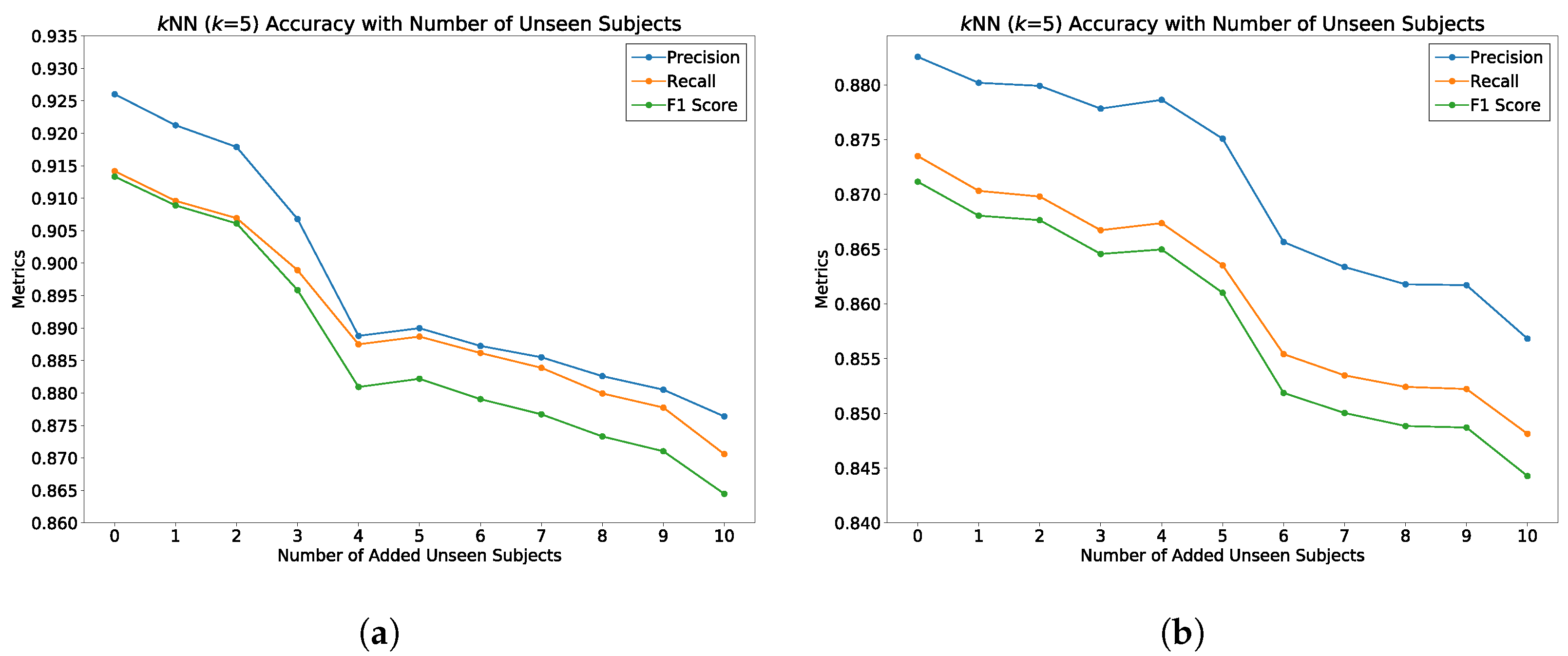
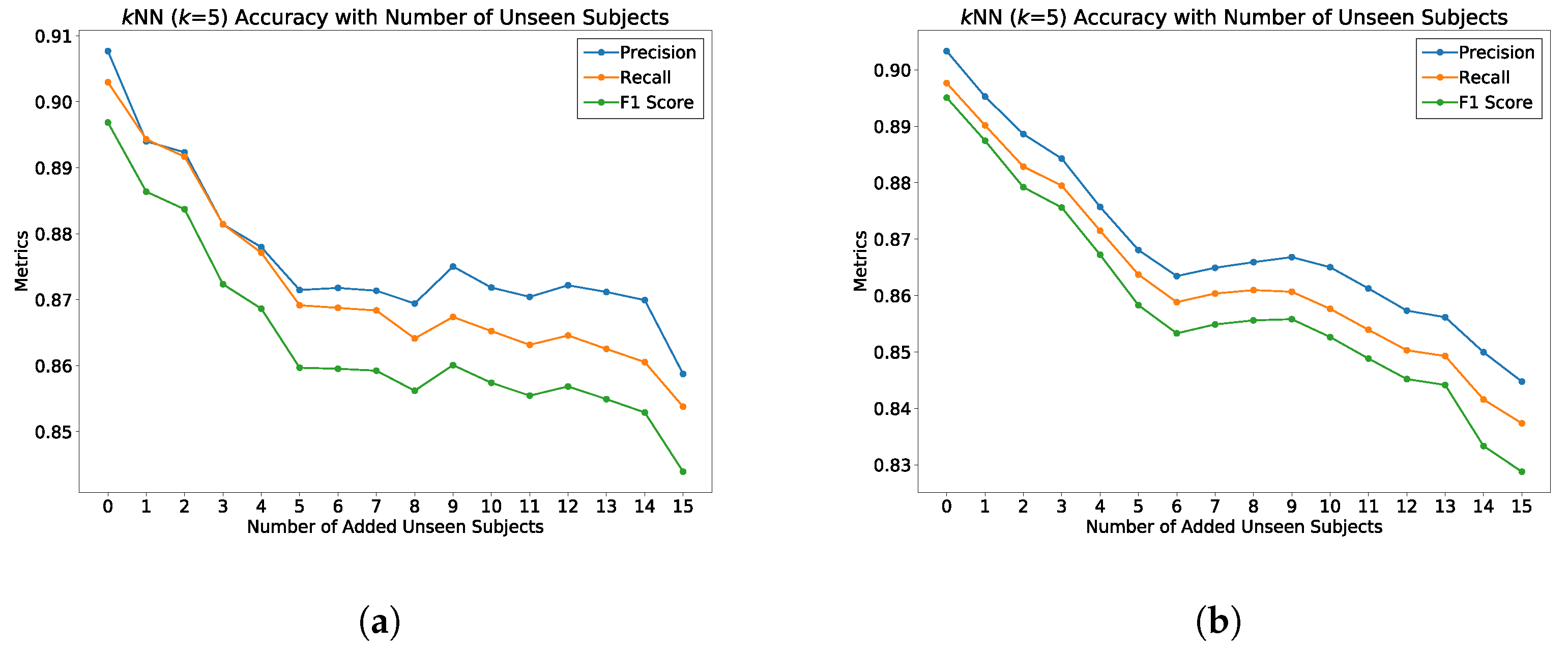
5.6. Behavioral Study
5.7. Summary of Results
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Johansson, G. Visual perception of biological motion and a model for its analysis. Percept. Psychophys. 1973, 14, 201–211. [Google Scholar] [CrossRef]
- Stevenage, S.V.; Nixon, M.S.; Vince, K. Visual analysis of gait as a cue to identity. Appl. Cogn. Psychol. 1999, 13, 513–526. [Google Scholar] [CrossRef]
- Boyd, J.E.; Little, J.J. Biometric Gait Recognition; Springer: Berlin/Heidelberg, Germany, 2005; pp. 19–42. [Google Scholar]
- Steinmetzer, T.; Bonninger, I.; Priwitzer, B.; Reinhardt, F.; Reckhardt, M.C.; Erk, D.; Travieso, C.M. Clustering of Human Gait with Parkinson’s Disease by Using Dynamic Time Warping. In Proceedings of the 2018 IEEE International Work Conference on Bioinspired Intelligence (IWOBI), San Carlos, Alajuela, Costa Rica, 18–20 July 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Staranowicz, A.; Brown, G.R.; Mariottini, G.L. Evaluating the Accuracy of a Mobile Kinect-based Gait-monitoring System for Fall Prediction. In Proceedings of the 6th International Conference on PErvasive Technologies Related to Assistive Environments (PETRA ’13), Rhodes, Greece, 29–31 May 2013; ACM: New York, NY, USA, 2013; pp. 57:1–57:4. [Google Scholar] [CrossRef]
- Blumrosen, G.; Miron, Y.; Intrator, N.; Plotnik, M. A Real-Time Kinect Signature-Based Patient Home Monitoring System. Sensors 2016, 16, 1965. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Tan, T.; Ning, H.; Hu, W. Silhouette analysis-based gait recognition for human identification. IEEE Trans. Pattern Anal. Mach. Intell. 2003, 25, 1505–1518. [Google Scholar] [CrossRef]
- Collins, R.; Gross, R.; Shi, J. Silhouette-based human identification from body shape and gait. In Proceedings of the Fifth IEEE International Conference on Automatic Face Gesture Recognition, Washinton, DC, USA, 20–21 May 2002; pp. 366–371. [Google Scholar] [CrossRef]
- Yu, S.; Tan, D.; Tan, T. A Framework for Evaluating the Effect of View Angle, Clothing and Carrying Condition on Gait Recognition. In Proceedings of the 18th International Conference on Pattern Recognition (ICPR’06), Hong Kong, China, 20–24 August 2006; pp. 441–444. [Google Scholar] [CrossRef]
- Ahmed, F.; Paul, P.P.; Gavrilova, M.L. DTW-based kernel and rank-level fusion for 3D gait recognition using Kinect. Vis. Comput. 2015, 31, 915–924. [Google Scholar] [CrossRef]
- Andersson, V.O.; Araujo, R.M. Person identification using anthropometric and gait data from kinect sensor. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Sutherland, D.H.; Olshen, R.; Cooper, L.; Woo, S.L. The development of mature gait. J. Bone Jt. Surg. Am. Vol. 1980, 62, 336–353. [Google Scholar] [CrossRef]
- Jain, L.C.; Medsker, L.R. Recurrent Neural Networks: Design and Applications, 1st ed.; CRC Press, Inc.: Boca Raton, FL, USA, 1999. [Google Scholar]
- Jain, A.; Zamir, A.R.; Savarese, S.; Saxena, A. Structural-RNN: Deep Learning on Spatio-Temporal Graphs. arXiv 2015, arXiv:1511.05298. [Google Scholar]
- Fragkiadaki, K.; Levine, S.; Felsen, P.; Malik, J. Recurrent network models for human dynamics. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 4346–4354. [Google Scholar]
- Sarkar, S.; Phillips, P.; Liu, Z.; Vega, I.; Grother, P.; Bowyer, K. The humanID gait challenge problem: Data sets, performance, and analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 162–177. [Google Scholar] [CrossRef] [PubMed]
- Han, J.; Bhanu, B. Individual recognition using gait energy image. IEEE Trans. Pattern Anal. Mach. Intell. 2006, 28, 316–322. [Google Scholar] [CrossRef] [PubMed]
- Chung, D.; Tahboub, K.; Delp, E.J. A Two Stream Siamese Convolutional Neural Network for Person Re-identification. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 1992–2000. [Google Scholar] [CrossRef]
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A Unified Embedding for Face Recognition and Clustering. arXiv 2015, arXiv:1503.03832. [Google Scholar]
- Whytock, T.; Belyaev, A.; Robertson, N.M. Dynamic distance-based shape features for gait recognition. J. Math. Imaging Vis. 2014, 50, 314–326. [Google Scholar] [CrossRef]
- Pavllo, D.; Feichtenhofer, C.; Auli, M.; Grangier, D. Modeling Human Motion with Quaternion-based Neural Networks. arXiv 2019, arXiv:1901.07677. [Google Scholar] [CrossRef]
- Horst, F.; Lapuschkin, S.; Samek, W.; Müller, K.; Schöllhorn, W.I. What is Unique in Individual Gait Patterns? Understanding and Interpreting Deep Learning in Gait Analysis. arXiv 2018, arXiv:1808.04308. [Google Scholar]
- Kastaniotis, D.; Theodorakopoulos, I.; Theoharatos, C.; Economou, G.; Fotopoulos, S. A framework for gait-based recognition using Kinect. Pattern Recognit. Lett. 2015, 68, 327–335. [Google Scholar] [CrossRef]
- Dikovski, B.; Madjarov, G.; Gjorgjevikj, D. Evaluation of different feature sets for gait recognition using skeletal data from Kinect. In Proceedings of the 2014 37th International Convention on Information and Communication Technology, Electronics and Microelectronics (MIPRO), Opatija, Croatia, 26–30 May 2014; pp. 1304–1308. [Google Scholar]
- Jiang, S.; Wang, Y.; Zhang, Y.; Sun, J. Real time gait recognition system based on kinect skeleton feature. In Proceedings of the Asian Conference on Computer Vision, Singapore, 1–5 November 2014; pp. 46–57. [Google Scholar]
- Mu, X.; Wu, Q. A complete dynamic model of five-link bipedal walking. In Proceedings of the 2003 American Control Conference, Denver, CO, USA, 4–6 June 2003; Volume 6, pp. 4926–4931. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; The MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Simonyan, K.; Zisserman, A. Two-Stream Convolutional Networks for Action Recognition in Videos. arXiv 2014, arXiv:1406.2199. [Google Scholar]
- Holden, D.; Saito, J.; Komura, T.; Joyce, T. Learning motion manifolds with convolutional autoencoders. In Proceedings of the SIGGRAPH Asia Technical Briefs, Kobe, Japan, 2–6 November 2015. [Google Scholar]
- Dehzangi, O.; Taherisadr, M.; ChangalVala, R. IMU-Based Gait Recognition Using Convolutional Neural Networks and Multi-Sensor Fusion. Sensors 2017, 17, 2735. [Google Scholar] [CrossRef] [PubMed]
- Martinez, J.; Black, M.J.; Romero, J. On human motion prediction using recurrent neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2891–2900. [Google Scholar]
- Koppula, H.S.; Saxena, A. Learning Spatio-Temporal Structure from RGB-D Videos for Human Activity Detection and Anticipation. Technical Report. 2013. Available online: https://proceedings.mlr.press/v28/koppula13.html (accessed on 15 March 2019).
- Karpatne, A.; Watkins, W.; Read, J.S.; Kumar, V. Physics-guided Neural Networks (PGNN): An Application in Lake Temperature Modeling. arXiv 2017, arXiv:1710.11431. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Olver, F.W.J.; Daalhuis, A.B.O.; Lozier, D.W.; Schneider, B.I.; Boisvert, R.F.; Clark, C.W.; Miller, B.R.; Saunders, B.V. (Eds.) NIST Digital Library of Mathematical Functions; Release 1.0.22. Available online: http://dlmf.nist.gov/ (accessed on 15 March 2019).
- Konz, L.; Hill, A.; Banaei-Kashani, F. CU Denver Gait Dataset. Available online: https://cse.ucdenver.edu/~bdlab/datasets/gait/ (accessed on 15 March 2019).
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Masci, J.; Meier, U.; Cire¸san, D.C.; Schmidhuber, J. Stacked Convolutional Auto-Encoders for Hierarchical Feature Extraction. Technical Report. Available online: https://people.idsia.ch/~ciresan/data/icann2011.pdf (accessed on 15 March 2019).
- Rousseeuw, P.J. Silhouettes: A graphical aid to the interpretation and validation of cluster analysis. J. Comput. Appl. Math. 1987, 20, 53–65. [Google Scholar] [CrossRef]




















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
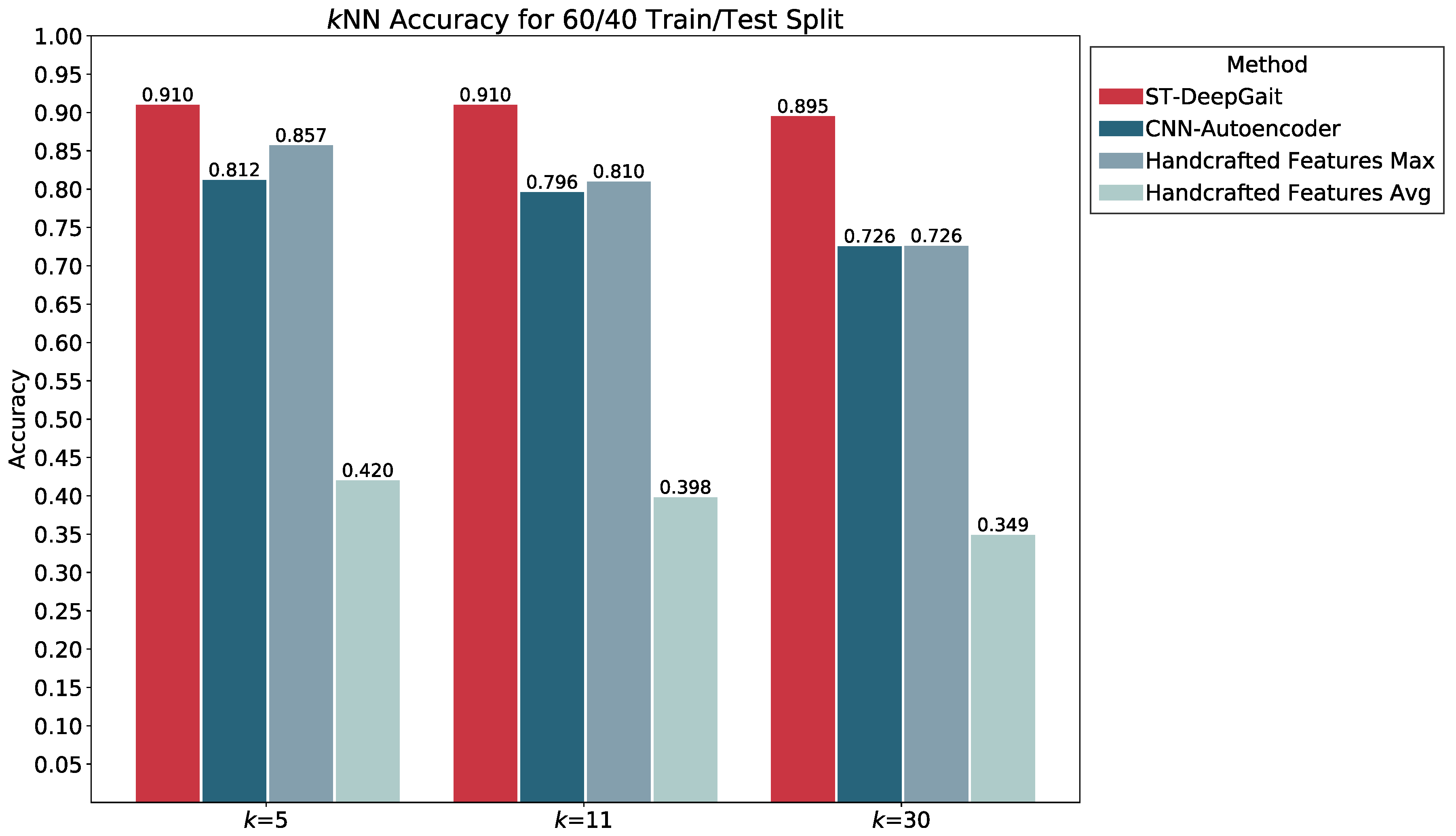{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| SID | ST-DeepGait | CAE |
|---|---|---|
| 14723 | 0.6036 | |
| 17175 | 0.5657 | 0.0876 |
| 17839 | 0.4162 | 0.0709 |
| 24761 | 0.8215 | 0.2288 |
| 28584 | 0.4494 | |
| 31033 | 0.5893 | 0.1659 |
| 38547 | 0.3969 | 0.1579 |
| 41472 | 0.7017 | 0.0865 |
| 48646 | 0.4435 | 0.0990 |
| 50153 | 0.3876 | 0.0737 |
| Classifier | Train Accuracy | Test Accuracy | Precision | Recall | F1-Score | EER | CMC (k = 5) |
|---|---|---|---|---|---|---|---|
| ST-DeepGait | 98.8% | 91.7% | 91.5% | 91.6% | 91.36 | 0.0034 | 0.956 |
| LSTM(128)-Dense(100) | 99.3% | 82.8% | 85.5% | 83.7% | 83.1% | 0.0322 | 0.957 |
| 3-Channel CNN | 98.6% | 76.0% | 81.4% | 76.0% | 76.2% | 0.017 | 0.891 |
| Classifier | Train Accuracy | Test Accuracy | Precision | Recall | F1-Score | EER | CMC (k = 5) |
|---|---|---|---|---|---|---|---|
| ST-DeepGait | 98.1% | 87.8% | 88.1% | 87.22% | 86.9% | 0.005 | 0.96 |
| LSTM(128)-Dense(100) | 98.2% | 77.4% | 79.2% | 78.5% | 78.2% | 0.377 | 0.94 |
| 3-Channel CNN | 98.6% | 69.1% | 72.4% | 69.1% | 69.1% | 0.0386 | 0.8855 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Konz, L.; Hill, A.; Banaei-Kashani, F. ST-DeepGait: A Spatiotemporal Deep Learning Model for Human Gait Recognition. Sensors 2022, 22, 8075. https://doi.org/10.3390/s22208075
Konz L, Hill A, Banaei-Kashani F. ST-DeepGait: A Spatiotemporal Deep Learning Model for Human Gait Recognition. Sensors. 2022; 22(20):8075. https://doi.org/10.3390/s22208075
Chicago/Turabian StyleKonz, Latisha, Andrew Hill, and Farnoush Banaei-Kashani. 2022. "ST-DeepGait: A Spatiotemporal Deep Learning Model for Human Gait Recognition" Sensors 22, no. 20: 8075. https://doi.org/10.3390/s22208075
APA StyleKonz, L., Hill, A., & Banaei-Kashani, F. (2022). ST-DeepGait: A Spatiotemporal Deep Learning Model for Human Gait Recognition. Sensors, 22(20), 8075. https://doi.org/10.3390/s22208075