



A Deep Learning Framework for Accurate Vehicle Yaw Angle Estimation from a Monocular Camera Based on Part Arrangement

 ,
,
Abstract
1. Introduction
2. Related Work
2.1. Pose Estimation
2.2. Dataset of Vehicle Poses
- We propose a framework for accurate yaw angle estimation, YAEN, based on the arrangement of parts. YAEN can quickly and accurately predict the yaw angle of a vehicle based on a single RGB image;
- A novel loss function is proposed to deal with the problem caused by the periodicity of the angle; and
- To test the accuracy of our network, we created a vehicle yaw angle dataset—the Yaw Angle Dataset, which comprised 17,258 images containing 15,863 yaw angle annotations, 17,258 2D BBox annotations of vehicles, and 73,191 2D BBox annotations of parts of vehicle parts. This dataset was used to validate the effectiveness of YAEN.
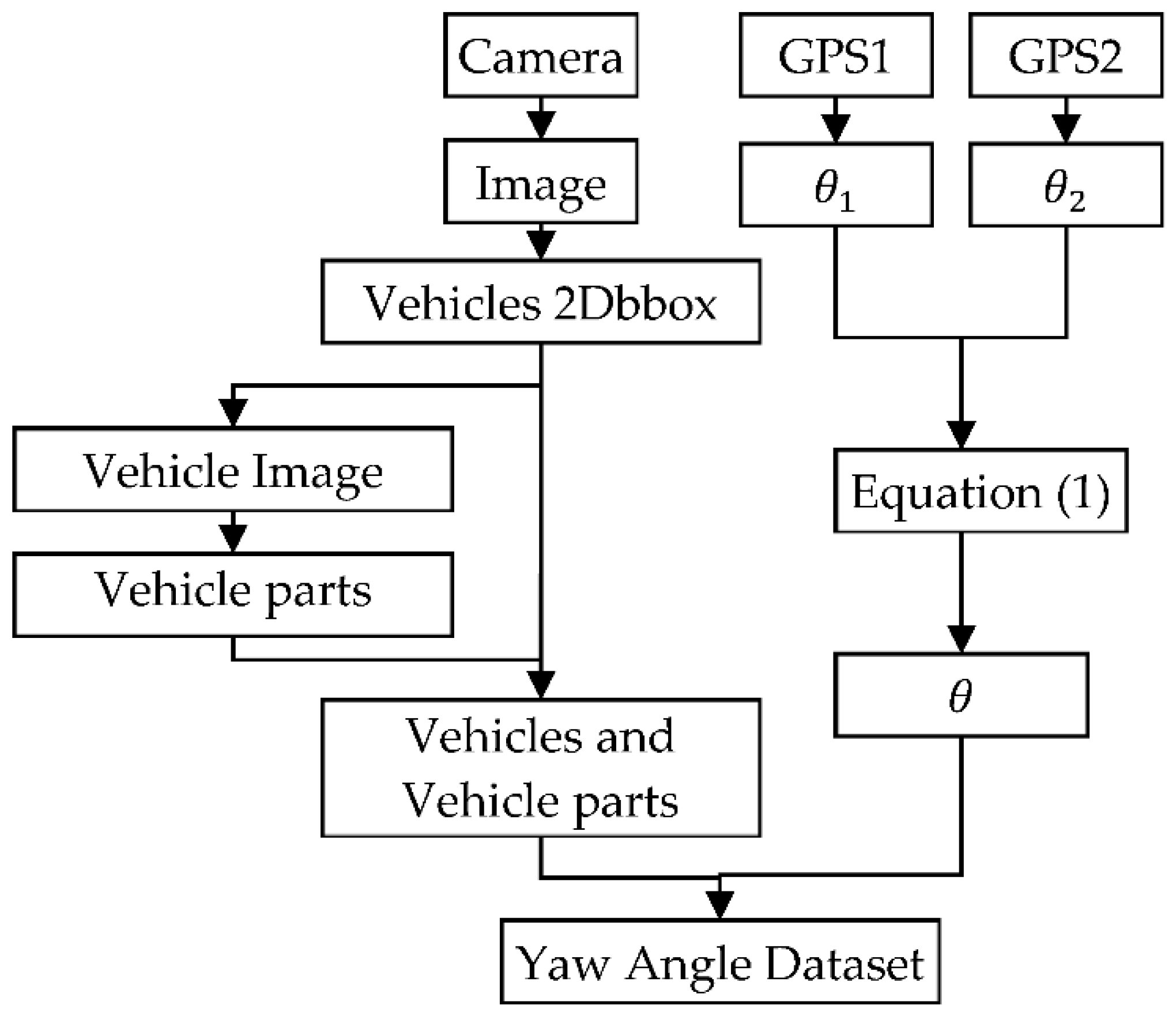
3. Yaw Angle Dataset
3.1. Devices
3.2. Data Collection
3.2.1. Time Synchronization
3.2.2. Collected Scenes
3.2.3. Data Processing
3.2.4. Annotations
4. YAEN
4.1. Part-Encoding Network
4.2. Yaw Angle Decoding Network
4.2.1. Design of the Network Structure
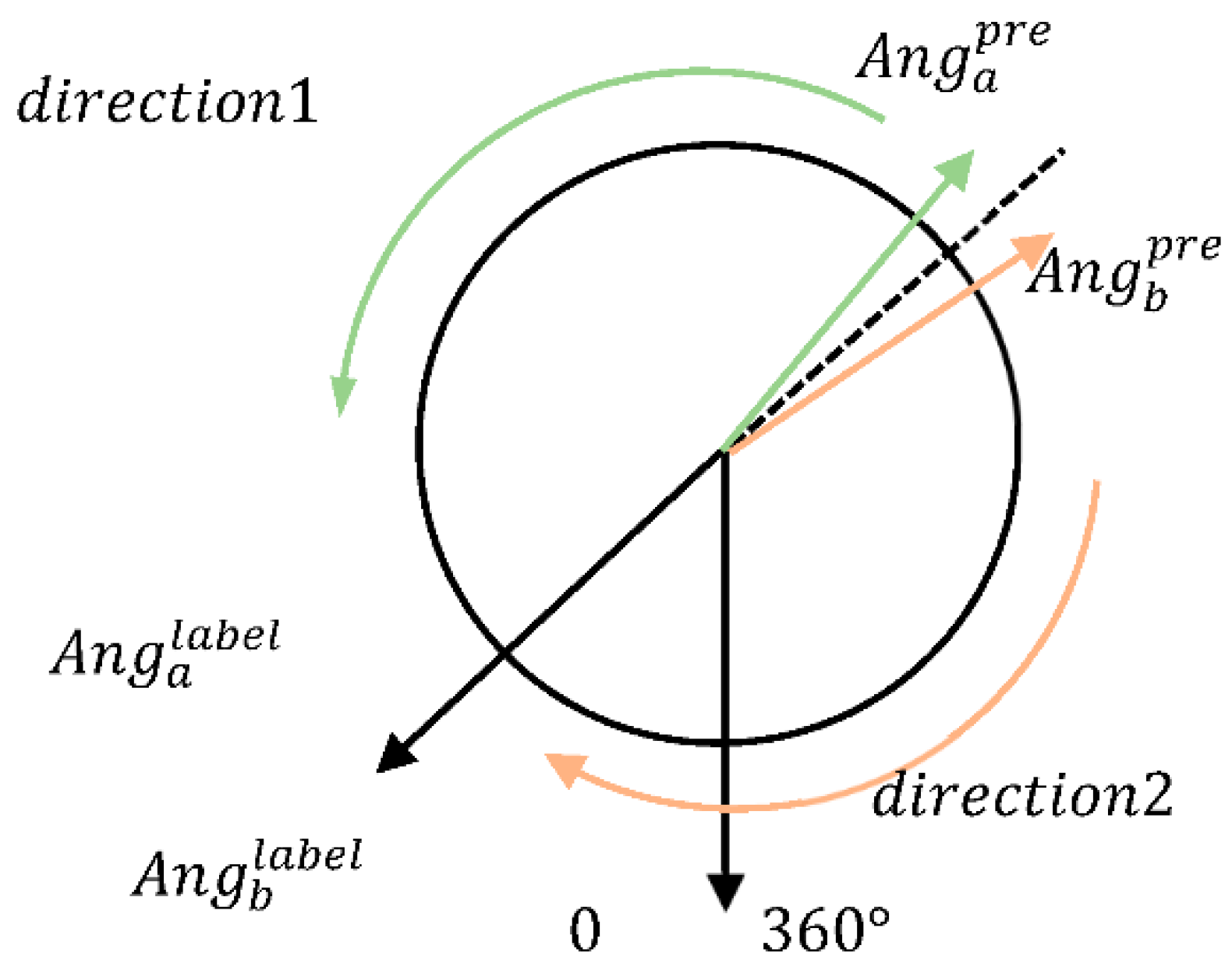
4.2.2. Design of Loss Functions
- (a)
- SSE Loss Function of Angle:
- (b)
- SSE Loss Function of Minimum Angle:
- (c)
- SSE Loss Function of Adding the Sign:
5. Experiment and Analysis
5.1. Evaluation Metrics
5.2. Experiment with Object-Encoding Network
5.3. Experiment with Yaw Angle Decoding Network
5.3.1. Ablation of Network Structure
5.3.2. Ablation of Tricks
5.4. Visualization of Detection
5.5. Analysis and Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bao, W.T.; Xu, B.; Chen, Z.Z. MonoFENet: Monocular 3D Object Detection With Feature Enhancement Networks. IEEE Trans. Image Process. 2020, 29, 2753–2765. [Google Scholar] [CrossRef] [PubMed]
- Zeng, K.; Wang, Y.N.; Mao, J.X.; Liu, C.P.; Peng, W.X.; Yang, Y. Deep Stereo Matching with Hysteresis Attention and Supervised Cost Volume Construction. IEEE Trans. Image Process. 2022, 31, 812–822. [Google Scholar] [CrossRef] [PubMed]
- Vaskevicius, N.; Birk, A. Revisiting Superquadric Fitting: A Numerically Stable Formulation. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 41, 220–233. [Google Scholar] [CrossRef] [PubMed]
- Godard, C.; Mac Aodha, O.; Brostow, G.J.; IEEE. Unsupervised Monocular Depth Estimation with Left-Right Consistency. In Proceedings of the 30th IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2016. [Google Scholar]
- Fu, H.; Gong, M.M.; Wang, C.H.; Batmanghelich, K.; Tao, D.C.; IEEE. Deep Ordinal Regression Network for Monocular Depth Estimation. In Proceedings of the 31st IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18 June 2018. [Google Scholar]
- Luvizon, D.C.; Nassu, B.T.; Minetto, R. A Video-Based System for Vehicle Speed Measurement in Urban Roadways. IEEE Trans. Intell. Transp. Syst. 2017, 18, 1393–1404. [Google Scholar] [CrossRef]
- Lan, J.H.; Li, J.; Hu, G.D.; Ran, B.; Wang, L. Vehicle speed measurement based on gray constraint optical flow algorithm. Optik 2014, 125, 289–295. [Google Scholar] [CrossRef]
- Kehl, W.; Manhardt, F.; Tombari, F.; Ilic, S.; Navab, N.; IEEE. SSD-6D: Making RGB-Based 3D Detection and 6D Pose Estimation Great Again. In Proceedings of the 16th IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Peng, S.D.; Liu, Y.; Huang, Q.X.; Zhou, X.W.; Bao, H.J.; Soc, I.C. PVNet: Pixel-wise Voting Network for 6DoF Pose Estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Zheng, X.T.; Chen, X.M.; Lu, X.Q. A Joint Relationship Aware Neural Network for Single-Image 3D Human Pose Estimation. IEEE Trans. Image Process. 2020, 29, 4747–4758. [Google Scholar] [CrossRef]
- Bisogni, C.; Nappi, M.; Pero, C.; Ricciardi, S. FASHE: A FrActal Based Strategy for Head Pose Estimation. IEEE Trans. Image Process. 2021, 30, 3192–3203. [Google Scholar] [CrossRef]
- Deng, X.M.; Zhang, Y.D.; Yang, S.; Tan, P.; Chang, L.; Yuan, Y.; Wang, H.A. Joint Hand Detection and Rotation Estimation Using CNN. IEEE Trans. Image Process. 2018, 27, 1888–1900. [Google Scholar] [CrossRef]
- Fikes, R.; Hart, P.E.; Nilsson, N.J. Learning and Executing Generalized Robot Plans. Artif. Intell. 1972, 3, 251–288. [Google Scholar] [CrossRef]
- Zhang, M.; Fu, R.; Morris, D.D.; Wang, C. A Framework for Turning Behavior Classification at Intersections Using 3D LIDAR. IEEE Trans. Veh. Technol. 2019, 68, 7431–7442. [Google Scholar] [CrossRef]
- Lim, J.J.; Khosla, A.; Torralba, A. FPM: Fine Pose Parts-Based Model with 3D CAD Models. In Proceedings of the Computer Vision—ECCV 2014, Zurich, Switzerland, 6–12 September 2014. [Google Scholar]
- Hinterstoisser, S.; Cagniart, C.; Ilic, S.; Sturm, P.; Navab, N.; Fua, P.; Lepetit, V. Gradient Response Maps for Real-Time Detection of Textureless Objects. IEEE Trans. Pattern Anal. Mach. Intell. 2012, 34, 876–888. [Google Scholar] [CrossRef] [PubMed]
- Bay, H.; Tuytelaars, T.; Van Gool, L. SURF: Speeded Up Robust Features. In Proceedings of the Computer Vision—ECCV 2006, Graz, Austria, 7–13 May 2006. [Google Scholar]
- Lepetit, V.; Moreno-Noguer, F.; Fua, P. EPnP: An Accurate O(n) Solution to the PnP Problem. Int. J. Comput. Vis. 2009, 81, 155–166. [Google Scholar] [CrossRef]
- Fu, C.Y.; Hoseinnezhad, R.; Bab-Hadiashar, A.; Jazar, R.N. Direct yaw moment control for electric and hybrid vehicles with independent motors. Int. J. Veh. Des. 2015, 69, 1–24. [Google Scholar] [CrossRef]
- Xu, Q.; Li, X.; Sun, Z.; Hu, W.; Chang, B. A Novel Heading Angle Estimation Methodology for Land Vehicles Based on Deep Learning and Enhanced Digital Map. IEEE Access 2019, 7, 138567–138578. [Google Scholar] [CrossRef]
- Yurtsever, E.; Lambert, J.; Carballo, A.; Takeda, K. A Survey of Autonomous Driving: Common Practices and Emerging Technologies. IEEE Access 2020, 8, 58443–58469. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 8–16 October 2016. [Google Scholar]
- Chen, W.; Duan, J.; Basevi, H.; Chang, H.J.; Leonardis, A.; Soc, I.C. PointPoseNet: Point Pose Network for Robust 6D Object Pose Estimation. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision (WACV), Snowmass, CO, USA, 1–5 March 2020. [Google Scholar]
- Dong, Z.; Liu, S.; Zhou, T.; Cheng, H.; Zeng, L.; Yu, X.; Liu, H.; IEEE. PPR-Net: Point-wise Pose Regression Network for Instance Segmentation and 6D Pose Estimation in Bin-picking Scenarios. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 4–8 November 2019. [Google Scholar]
- Guo, Z.; Chai, Z.; Liu, C.; Xiong, Z.; IEEE. A Fast Global Method Combined with Local Features for 6D Object Pose Estimation. In Proceedings of the IEEE/ASME International Conference on Advanced Intelligent Mechatronics (AIM), Hong Kong, China, 8–12 July 2019. [Google Scholar]
- Chen, X.; Chen, Y.; You, B.; Xie, J.; Najjaran, H. Detecting 6D Poses of Target Objects From Cluttered Scenes by Learning to Align the Point Cloud Patches With the CAD Models. IEEE Access 2020, 8, 210640–210650. [Google Scholar] [CrossRef]
- Guo, J.W.; Xing, X.J.; Quan, W.Z.; Yan, D.M.; Gu, Q.Y.; Liu, Y.; Zhang, X.P. Efficient Center Voting for Object Detection and 6D Pose Estimation in 3D Point Cloud. IEEE Trans. Image Process. 2021, 30, 5072–5084. [Google Scholar] [CrossRef]
- Li, Z.G.; Wang, G.; Ji, X.Y.; IEEE. CDPN: Coordinates-Based Disentangled Pose Network for Real-Time RGB-Based 6-DoF Object Pose Estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Zhou, Y.; Liu, L.; Shao, L. Vehicle Re-Identification by Deep Hidden Multi-View Inference. IEEE Trans. Image Process. 2018, 27, 3275–3287. [Google Scholar] [CrossRef]
- Rad, M.; Lepetit, V.; IEEE. BB8: A Scalable, Accurate, Robust to Partial Occlusion Method for Predicting the 3D Poses of Challenging Objects without Using Depth. In Proceedings of the 16th IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017. [Google Scholar]
- Xiang, Y.; Schmidt, T.; Narayanan, V.; Fox, D. PoseCNN: A Convolutional Neural Network for 6D Object Pose Estimation in Cluttered Scenes. In Proceedings of the 14th Conference on Robotics—Science and Systems, Pittsburgh, PA, USA, 26–30 June 2018. [Google Scholar]
- Luo, Y.M.; Xu, Z.T.; Liu, P.Z.; Du, Y.Z.; Guo, J.M. Multi-Person Pose Estimation via Multi-Layer Fractal Network and Joints Kinship Pattern. IEEE Trans. Image Process. 2019, 28, 142–155. [Google Scholar] [CrossRef]
- Brachmann, E.; Krull, A.; Michel, F.; Gumhold, S.; Shotton, J.; Rother, C. Learning 6D Object Pose Estimation Using 3D Object Coordinates; Springer International Publishing: Berlin/Heidelberg, Germany, 2014. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Ren, S.Q.; He, K.M.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 386–397. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Zhou, D.; Lu, F.; Fang, J.; Zhang, L. AutoShape: Real-Time Shape-Aware Monocular 3D Object Detection. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 11 October 2021. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-first AAAI conference on artificial intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Wu, D.; Zhuang, Z.; Xiang, C.; Zou, W.; Li, X. 6D-VNet: End-To-End 6DoF Vehicle Pose Estimation From Monocular RGB Images. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Song, X.; Wang, P.; Zhou, D.; Zhu, R.; Guan, C.; Dai, Y.; Su, H.; Li, H.; Yang, R.; Soc, I.C. ApolloCar3D: A Large 3D Car Instance Understanding Benchmark for Autonomous Driving. In Proceedings of the 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–21 June 2019. [Google Scholar]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The KITTI dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef]
- Geiger, A.; Lenz, P.; Urtasun, R.; IEEE. Are we ready for Autonomous Driving? The KITTI Vision Benchmark Suite. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Providence, RI, USA, 16–21 June 2012. [Google Scholar]
- Huang, X.; Wang, P.; Cheng, X.; Zhou, D.; Geng, Q.; Yang, R. The ApolloScape Open Dataset for Autonomous Driving and Its Application. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 2702–2719. [Google Scholar] [CrossRef]
- Xiang, Y.; Mottaghi, R.; Savarese, S. Beyond PASCAL: A benchmark for 3D object detection in the wild. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Steamboat Springs, CO, USA, 24–26 March 2014. [Google Scholar]
- Jocher, G.; Stoken, A.; Chaurasia, A. Ultralytics/yolov5: v6.0—YOLOv5n ‘Nano’ Models, Roboflow Integration, TensorFlow Export, OpenCV DNN Support. Available online: https://zenodo.org/record/5563715#.Y0Yf50xByUk (accessed on 12 October 2021).
- Ma, X.; Sun, X.; IEEE. Detection and Segmentation of Occluded Vehicles Based on Symmetry Analysis. In Proceedings of the 4th International Conference on Systems and Informatics (ICSAI), Hangzhou, China, 11–13 November 2017. [Google Scholar]
- Reddy, N.D.; Vo, M.; Narasimhan, S.G.; Soc, I.C. Occlusion-Net: 2D/3D Occluded Keypoint Localization Using Graph Networks. In Proceedings of the 32nd IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z.; IEEE. Rethinking the Inception Architecture for Computer Vision. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2016. [Google Scholar]
- Shelhamer, E.; Long, J.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 640–651. [Google Scholar] [CrossRef]
- Zheng, W.; Tang, W.; Jiang, L.; Fu, C.W. SE-SSD: Self-Ensembling Single-Stage Object Detector From Point Cloud. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Everingham, M.; Eslami, S.M.A.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The PASCAL Visual Object Classes Challenge: A Retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2015, arXiv:1412.6980. [Google Scholar]














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
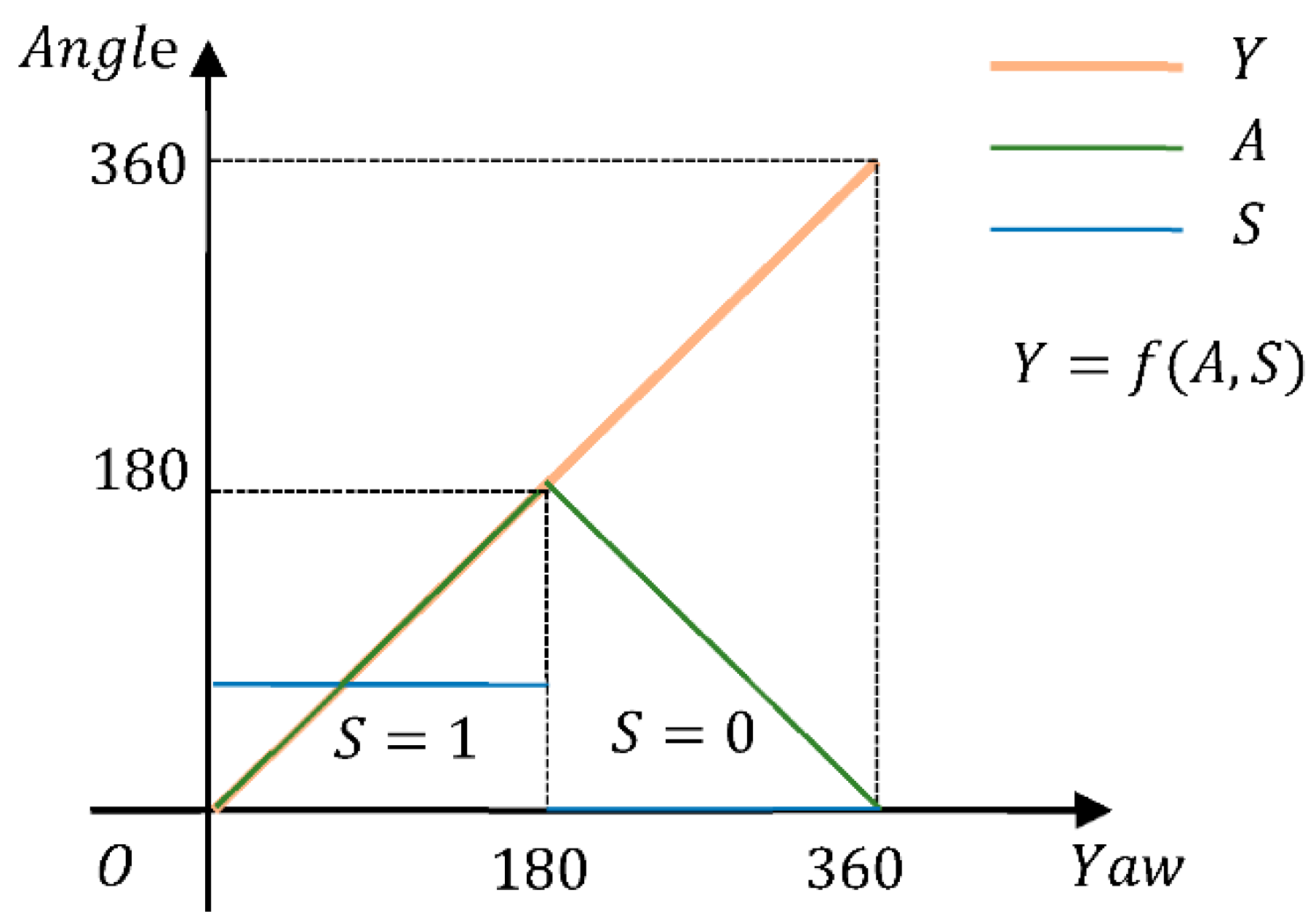{kind=link}
{kind=link}
{kind=link}
| Device | Quantity | Mounting Location | Function | Performance Parameters |
|---|---|---|---|---|
| OXTS GPS RT3000 v2 | 1 | Observing vehicle | Provide data on the latitude, longitude, yaw angle, roll angle, pitch angle, and speed of the observing vehicle | Location: Angle: |
| OXTS GPS RT3000 v2 | 1 | Observed vehicle | Provide data on the latitude, longitude, yaw angle, roll angle, pitch angle, and speed of the observed vehicle | Location: Angle: |
| OXTS RT-BASE | 1 | Near the test site | Improve the positioning accuracy of OXTS GPS RT3000 v2 | - |
| FLIR GS3-U3 | 2 | Observing vehicle | Provide pictures of the observed vehicle from the perspective of the observing vehicle | Resolution: 1920 × 1200 × 3 FPS: 160 |
| Velodyne VLP-32C | 1 | Observing vehicle | Provide the point cloud of the observed vehicle from the perspective of the observing vehicle | Horizontal angular resolution: to |
| TL-AP450GP | 1 | Near the test site | Construct a local area network for communication between devices | 2.4 GHz, 450 Mbps |
| Method | Car | Wheel | ||||
|---|---|---|---|---|---|---|
| Object Detector | 0.996 | 0.995 | 0.996 | 0.996 | 0.995 | 0.996 |
| Model | Method | Size | Val Yaw Angle Dataset | Image Dataset | ||||
|---|---|---|---|---|---|---|---|---|
| V | 10.41 | 58.01 | 79.00 | 10.06 | 59.74 | 81.46 | ||
| H | 6.76 | 68.35 | 88.59 | 7.01 | 69.77 | 90.97 | ||
| H + V | 7.30 | 66.02 | 86.76 | 7.87 | 70.08 | 90.29 | ||
| Model | Method | Tricks | Size | Val Yaw Angle Dataset | Image Dataset | ||||
|---|---|---|---|---|---|---|---|---|---|
| H | 6.76 | 68.35 | 88.59 | 7.01 | 69.77 | 90.97 | |||
| H | 6.69 | 54.29 | 76.17 | 6.41 | 55.35 | 80.05 | |||
| H | 3.64 | 78.31 | 93.63 | 3.33 | 82.56 | 96.14 | |||
| H | 3.40 | 78.69 | 93.63 | 3.09 | 83.19 | 96.45 | |||
| Platform | FPS: Yaw Angle Decoder | FPS: Complete Model | ||||
|---|---|---|---|---|---|---|
| Fastest | Average | Slowest | Fastest | Average | Slowest | |
| 503 | 497 | 465 | 98 | 97 | 93 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, W.; Li, W.; Tang, L.; Zhu, X.; Zou, B. A Deep Learning Framework for Accurate Vehicle Yaw Angle Estimation from a Monocular Camera Based on Part Arrangement. Sensors 2022, 22, 8027. https://doi.org/10.3390/s22208027
Huang W, Li W, Tang L, Zhu X, Zou B. A Deep Learning Framework for Accurate Vehicle Yaw Angle Estimation from a Monocular Camera Based on Part Arrangement. Sensors. 2022; 22(20):8027. https://doi.org/10.3390/s22208027
Chicago/Turabian StyleHuang, Wenjun, Wenbo Li, Luqi Tang, Xiaoming Zhu, and Bin Zou. 2022. "A Deep Learning Framework for Accurate Vehicle Yaw Angle Estimation from a Monocular Camera Based on Part Arrangement" Sensors 22, no. 20: 8027. https://doi.org/10.3390/s22208027
APA StyleHuang, W., Li, W., Tang, L., Zhu, X., & Zou, B. (2022). A Deep Learning Framework for Accurate Vehicle Yaw Angle Estimation from a Monocular Camera Based on Part Arrangement. Sensors, 22(20), 8027. https://doi.org/10.3390/s22208027