
Real-Time Oil Leakage Detection on Aftermarket Motorcycle Damping System with Convolutional Neural Networks

 ,
, {kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
2. Related Work
3. Proposed Approach
3.1. Overview of CNNs
3.1.1. Structure of CNNs
3.1.2. CNNs for Computer Vision
3.1.3. CNNs and Transfer Learning
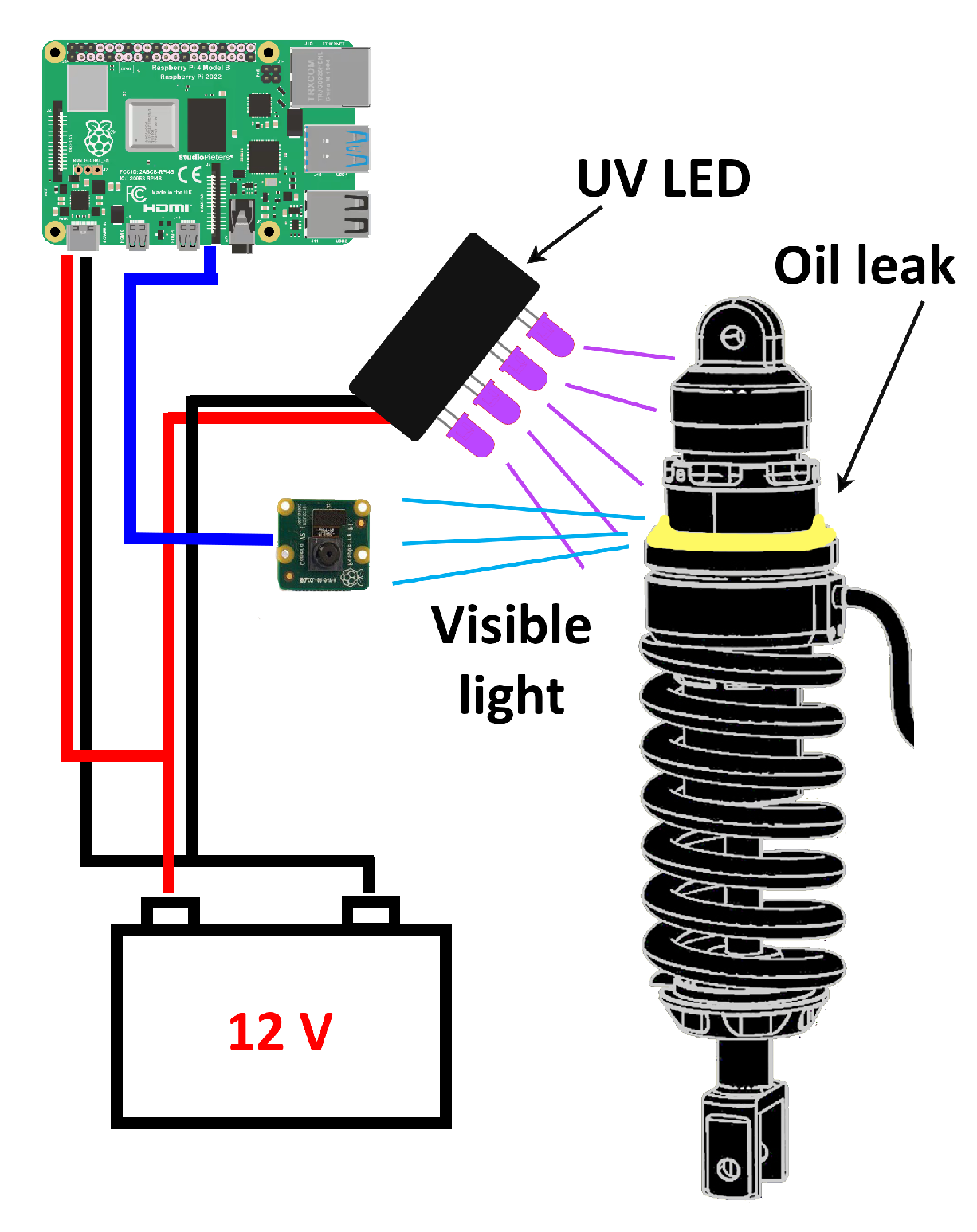
3.2. Experimental Setup
3.3. Dataset
3.4. Method
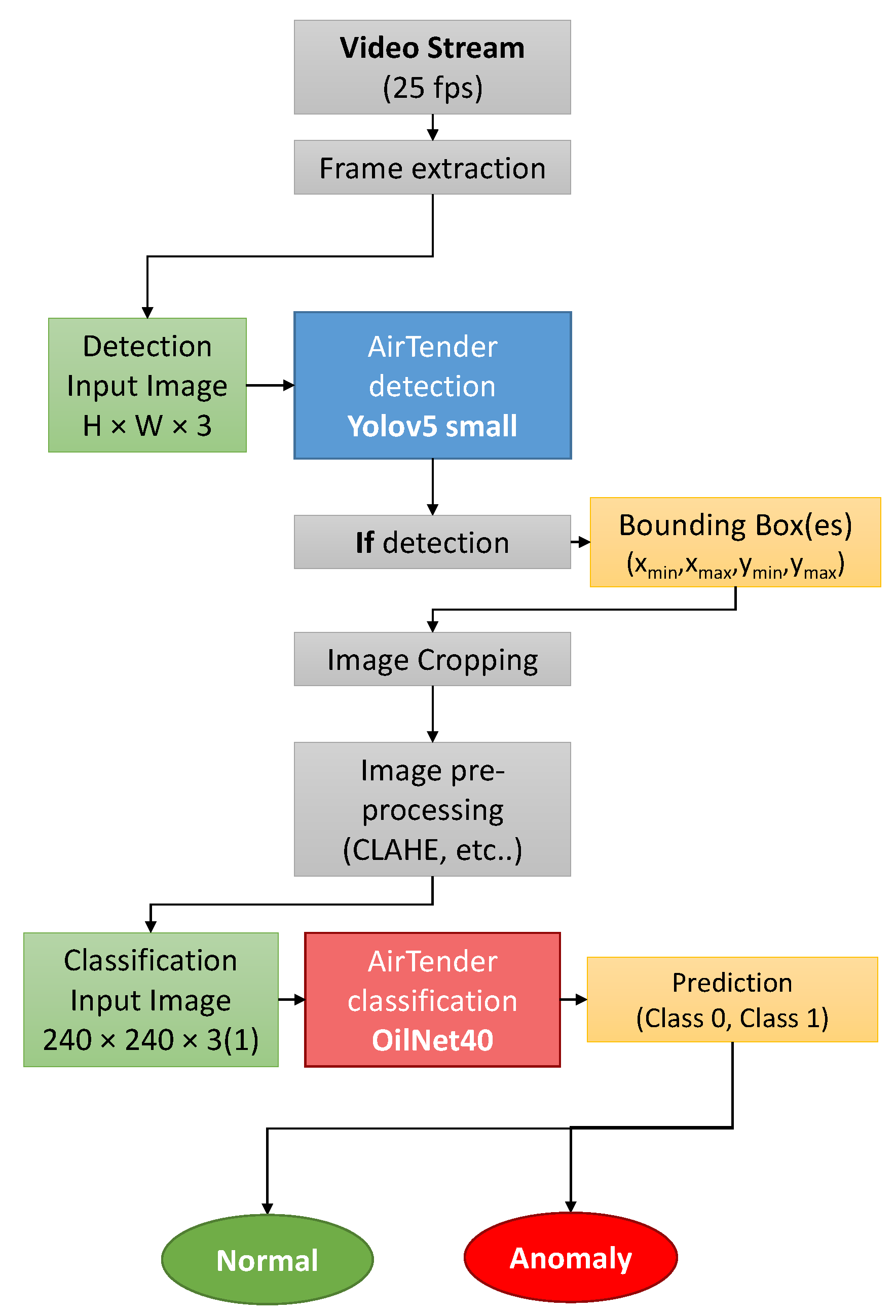
3.4.1. Workflow
3.4.2. Image Preprocessing
3.4.3. Image Normalization
3.4.4. Data Augmentation
3.5. Model Architectures
3.5.1. Model Architecture for AirTender Detection: Yolov5
3.5.2. CNN Model for Binary Classification: OilNet40
4. Results
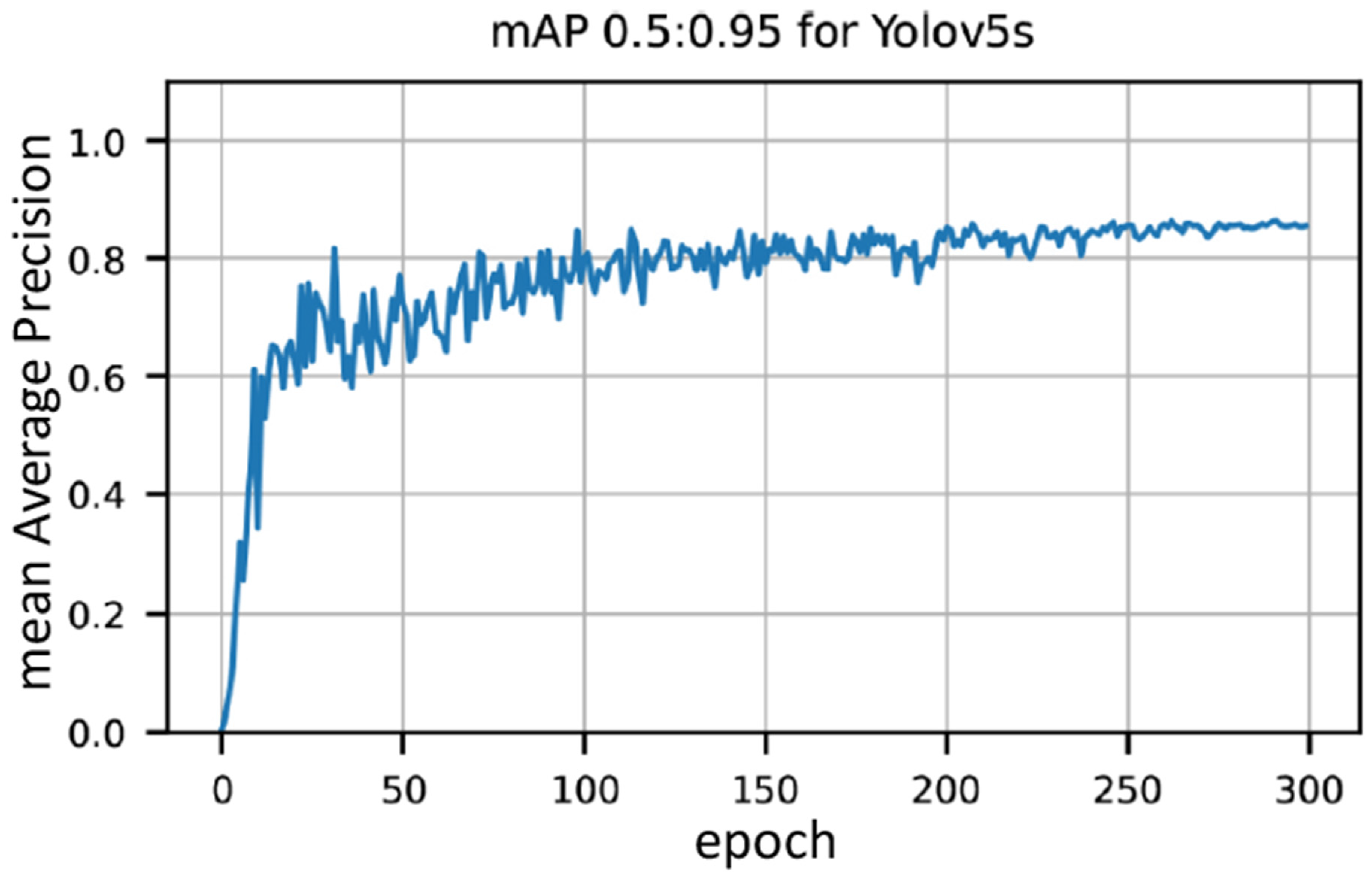
4.1. AirTender Detection
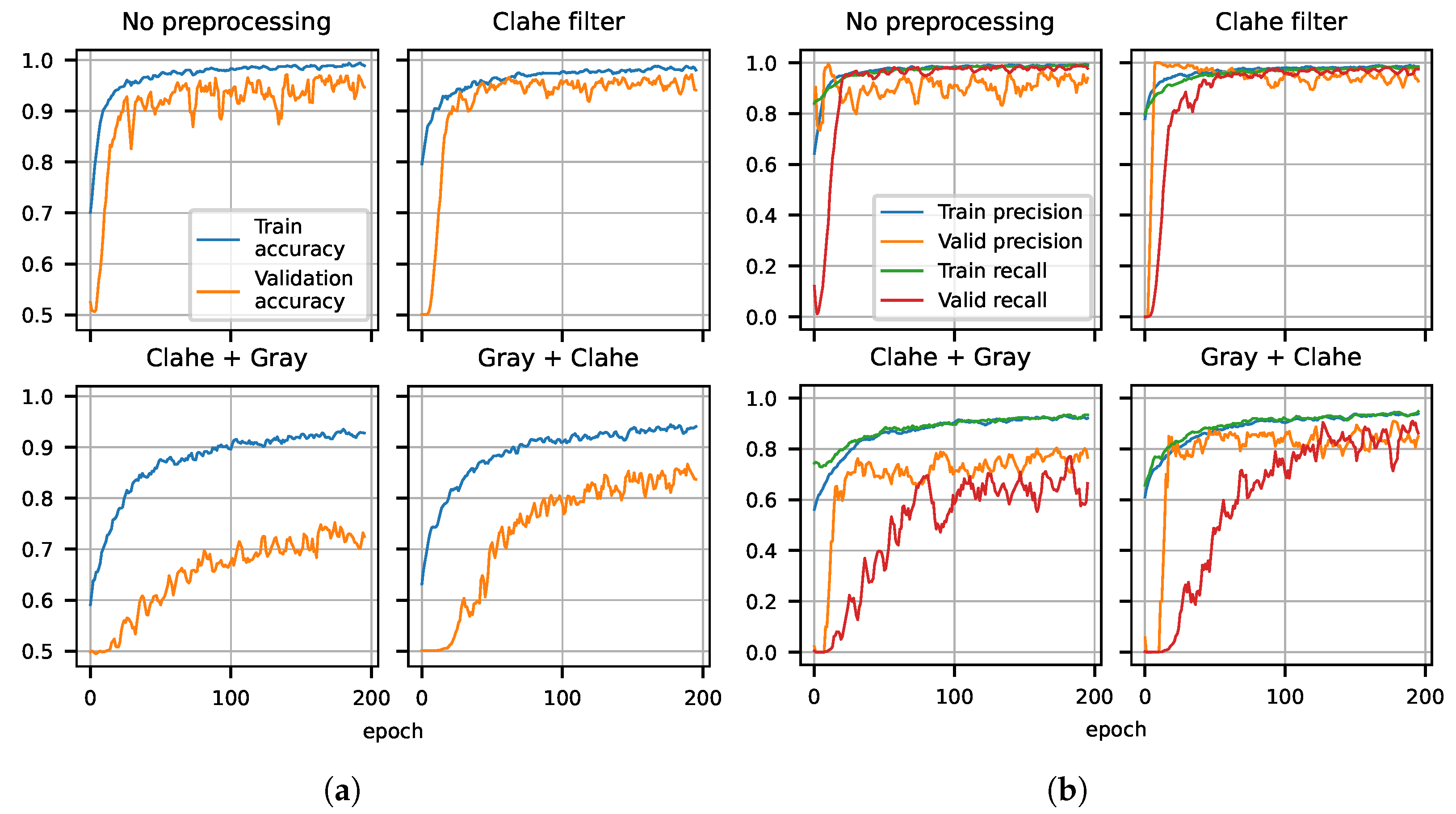
4.2. AirTender Classification
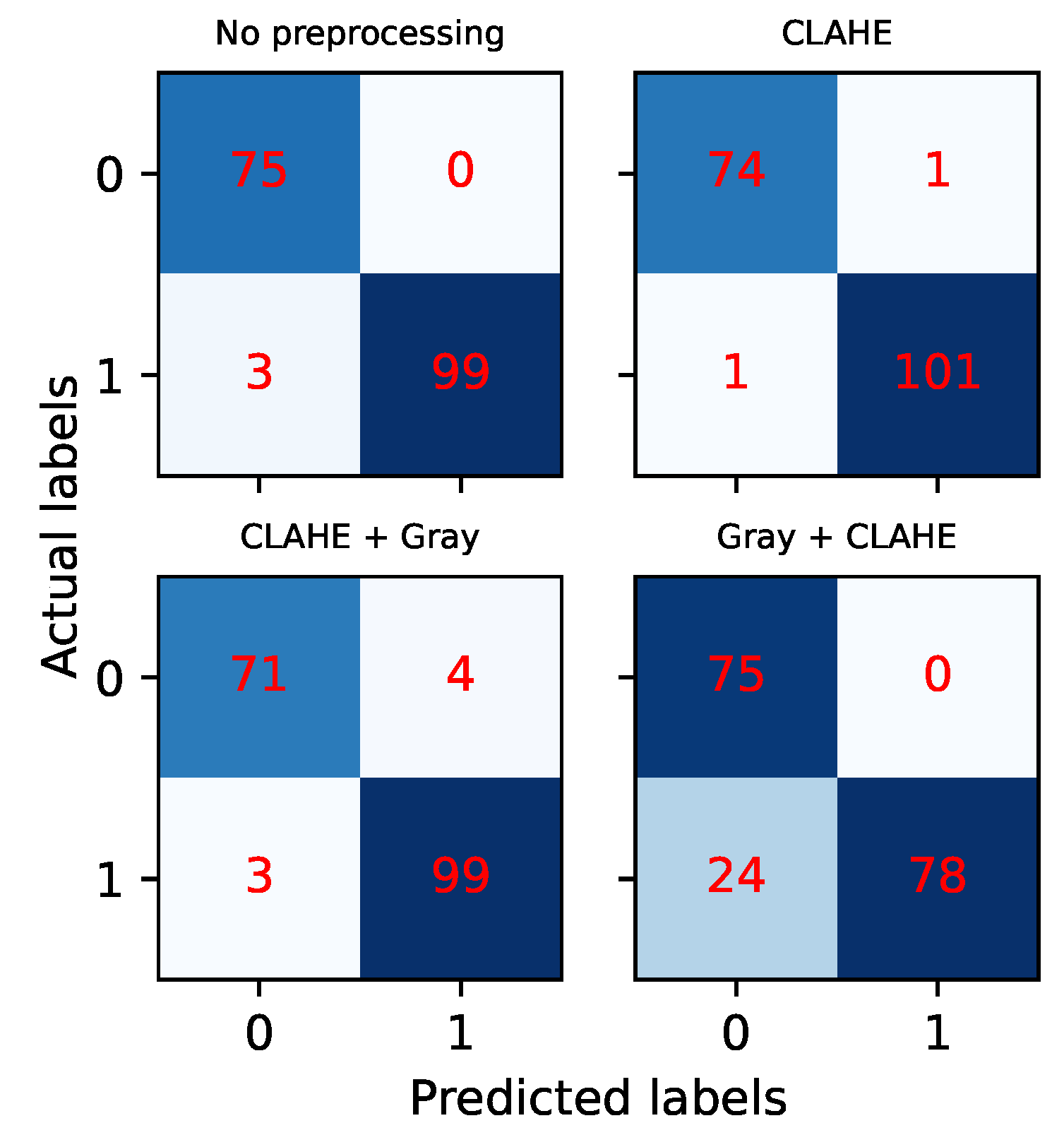
4.3. Robustness of the Results
5. Concluding Remarks
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kothamasu, R.; Huang, S.H.; VerDuin, W.H. System health monitoring and prognostics—A review of current paradigms and practices. Int. J. Adv. Manuf. Technol. 2006, 28, 1012–1024. [Google Scholar] [CrossRef]
- Siegel, J.E.; Erb, D.C.; Sarma, S.E. A survey of the connected vehicle landscape—Architectures, enabling technologies, applications, and development areas. IEEE Trans. Intell. Transp. Syst. 2017, 19, 2391–2406. [Google Scholar] [CrossRef]
- Delvecchio, S.; Bonfiglio, P.; Pompoli, F. Vibro-acoustic condition monitoring of Internal Combustion Engines: A critical review of existing techniques. Mech. Syst. Signal Process. 2018, 99, 661–683. [Google Scholar] [CrossRef]
- Siegel, J.E.; Coda, U. Surveying off-board and extra-vehicular monitoring and progress towards pervasive diagnostics. arXiv 2020, arXiv:2007.03759. [Google Scholar]
- Zhao, R.; Yan, R.; Chen, Z.; Mao, K.; Wang, P.; Gao, R.X. Deep learning and its applications to machine health monitoring. Mech. Syst. Signal Process. 2019, 115, 213–237. [Google Scholar] [CrossRef]
- Zhao, G.; Zhang, G.; Ge, Q.; Liu, X. Research advances in fault diagnosis and prognostic based on deep learning. In Proceedings of the 2016 Prognostics and System Health Management Conference (PHM-Chengdu), Chengdu, China, 19–21 October 2016; pp. 1–6. [Google Scholar]
- Chase, C.; Lyra, G.; Green, M. Real time monitoring-the key to effective oil spill prevention and response. In Proceedings of the Rio Oil & Gas Expo and Conference, Rio de Janeiro, Brazil, 13–16 September 2010; pp. 1–10. [Google Scholar]
- Camagni, P.; Colombo, G.; Koechler, C.; Pedrini, A.; Omenetto, N.; Rossi, G. Diagnostics of oil pollution by laser-induced fluorescence. IEEE Trans. Geosci. Remote Sens. 1988, 26, 22–26. [Google Scholar] [CrossRef]
- Fingas, M.; Brown, C. Review of oil spill remote sensing. Mar. Pollut. Bull. 2014, 83, 9–23. [Google Scholar] [CrossRef] [PubMed]
- Sato, T.; Suzuki, Y.; Kashiwagi, H.; Nanjo, M.; Kakui, Y. A method for remote detection of oil spills using laser-excited Raman backscattering and backscattered fluorescence. IEEE J. Ocean. Eng. 1978, 3, 1–4. [Google Scholar] [CrossRef]
- Ferreira, C.; Ventura, P.; Morais, R.; Valente, A.L.; Neves, C.; Reis, M.C. Sensing methodologies to determine automotive damper condition under vehicle normal operation. Sens. Actuators A Phys. 2009, 156, 237–244. [Google Scholar] [CrossRef]
- Hernandez-Alcantara, D.; Morales-Menendez, R.; Amezquita-Brooks, L. Fault detection for automotive shock absorber. In Journal of Physics: Conference Series; IOP Publishing: Bristol, UK, 2015; Volume 659, p. 012037. [Google Scholar]
- Hernandez-Alcantara, D.; Amezquita-Brooks, L.; Vivas-Lopez, C.; Morales-Menendez, R.; Ramirez-Mendoza, R. Fault detection for automotive semi-active dampers. In Proceedings of the 2013 Conference on Control and Fault-Tolerant Systems (SysTol), Nice, France, 9–11 October 2013; pp. 625–630. [Google Scholar]
- Alcantara, D.H.; Morales-Menendez, R.; Amezquita-Brooks, L. Fault diagnosis for an automotive suspension using particle filters. In Proceedings of the 2016 European Control Conference (ECC), Aalborg, Denmark, 29 June–1 July 2016; pp. 1898–1903. [Google Scholar]
- Xia, M.; Li, T.; Xu, L.; Liu, L.; De Silva, C.W. Fault diagnosis for rotating machinery using multiple sensors and convolutional neural networks. IEEE/ASME Trans. Mechatron. 2017, 23, 101–110. [Google Scholar] [CrossRef]
- Eren, L.; Ince, T.; Kiranyaz, S. A generic intelligent bearing fault diagnosis system using compact adaptive 1D CNN classifier. J. Signal Process. Syst. 2019, 91, 179–189. [Google Scholar] [CrossRef]
- Zilong, Z.; Wei, Q. Intelligent fault diagnosis of rolling bearing using one-dimensional multi-scale deep convolutional neural network based health state classification. In Proceedings of the 2018 IEEE 15th International conference on networking, sensing and control (ICNSC), Zhuhai, China, 27–29 March 2018; pp. 1–6. [Google Scholar]
- Janssens, O.; Slavkovikj, V.; Vervisch, B.; Stockman, K.; Loccufier, M.; Verstockt, S.; Van de Walle, R.; Van Hoecke, S. Convolutional neural network based fault detection for rotating machinery. J. Sound Vib. 2016, 377, 331–345. [Google Scholar] [CrossRef]
- Wen, L.; Li, X.; Gao, L.; Zhang, Y. A new convolutional neural network-based data-driven fault diagnosis method. IEEE Trans. Ind. Electron. 2017, 65, 5990–5998. [Google Scholar] [CrossRef]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Zhang, W.; Peng, G.; Li, C. Bearings fault diagnosis based on convolutional neural networks with 2-D representation of vibration signals as input. In Proceedings of the MATEC Web of Conferences, Seoul, Korea, 22–25 August 2017; EDP Sciences: Les Ulis, France, 2017; Volume 95, p. 13001. [Google Scholar]
- Liao, Y.; Zeng, X.; Li, W. Wavelet transform based convolutional neural network for gearbox fault classification. In Proceedings of the 2017 Prognostics and System Health Management Conference (PHM-Harbin), Harbin, China, 9–12 July 2017; pp. 1–6. [Google Scholar]
- Verstraete, D.; Ferrada, A.; Droguett, E.L.; Meruane, V.; Modarres, M. Deep learning enabled fault diagnosis using time-frequency image analysis of rolling element bearings. Shock Vib. 2017, 2017. [Google Scholar] [CrossRef]
- Zhang, W.; Zhang, F.; Chen, W.; Jiang, Y.; Song, D. Fault state recognition of rolling bearing based fully convolutional network. Comput. Sci. Eng. 2018, 21, 55–63. [Google Scholar] [CrossRef]
- Ding, X.; He, Q. Energy-fluctuated multiscale feature learning with deep convnet for intelligent spindle bearing fault diagnosis. IEEE Trans. Instrum. Meas. 2017, 66, 1926–1935. [Google Scholar] [CrossRef]
- Zehelein, T.; Hemmert-Pottmann, T.; Lienkamp, M. Diagnosing automotive damper defects using convolutional neural networks and electronic stability control sensor signals. J. Sens. Actuator Netw. 2020, 9, 8. [Google Scholar] [CrossRef]
- LeCun, Y.; Boser, B.; Denker, J.; Henderson, D.; Howard, R.; Hubbard, W.; Jackel, L. Handwritten digit recognition with a back-propagation network. Adv. Neural Inf. Process. Syst. 1989, 2, 296–303. [Google Scholar]
- Géron, A. Hands-on Machine Learning with Scikit-Learn, Keras, and TensorFlow: Concepts, Tools, and Techniques to Build Intelligent Systems; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2019. [Google Scholar]
- Chollet, F. Deep Learning with Python; Simon and Schuster: New York, NY, USA, 2021. [Google Scholar]
- Mehta, P.; Bukov, M.; Wang, C.H.; Day, A.G.; Richardson, C.; Fisher, C.K.; Schwab, D.J. A high-bias, low-variance introduction to machine learning for physicists. Phys. Rep. 2019, 810, 1–124. [Google Scholar] [CrossRef]
- Bronstein, M.M.; Bruna, J.; LeCun, Y.; Szlam, A.; Vandergheynst, P. Geometric deep learning: Going beyond euclidean data. IEEE Signal Process. Mag. 2017, 34, 18–42. [Google Scholar] [CrossRef]
- Bronstein, M.M.; Bruna, J.; Cohen, T.; Veličković, P. Geometric deep learning: Grids, groups, graphs, geodesics, and gauges. arXiv 2021, arXiv:2104.13478. [Google Scholar]
- Cohen, T.S. Equivariant Convolutional Networks. Ph.D. Thesis, Faculty of Science (FNWI), Amsterdam, The Netherlands, 2021. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the International Conference on Machine Learning (ICML), Haifa, Israel, 21–24 June 2010. [Google Scholar]
- Nagi, J.; Ducatelle, F.; Di Caro, G.A.; Cireşan, D.; Meier, U.; Giusti, A.; Nagi, F.; Schmidhuber, J.; Gambardella, L.M. Max-pooling convolutional neural networks for vision-based hand gesture recognition. In Proceedings of the 2011 IEEE International Conference on Signal and Image Processing Applications (ICSIPA), Kuala Lumpur, Malaysia, 16–18 November 2011; pp. 342–347. [Google Scholar]
- Lin, M.; Chen, Q.; Yan, S. Network in network. arXiv 2013, arXiv:1312.4400. [Google Scholar]
- Abu-Mostafa, Y.S.; Magdon-Ismail, M.; Lin, H.T. Learning from Data; AMLBook: New York, NY, USA, 2012; Volume 4. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Jocher, G.; Nishimura, K.; Mineeva, T.; Vilariño, R. yolov5. Code Repository. 2020. Available online: https://github.com/ultralytics/yolov5 (accessed on 11 September 2022).
- Russakovsky, O.; Deng, J.; Su, H.; Krause, J.; Satheesh, S.; Ma, S.; Huang, Z.; Karpathy, A.; Khosla, A.; Bernstein, M.; et al. ImageNet Large Scale Visual Recognition Challenge. Int. J. Comput. Vis. (IJCV) 2015, 115, 211–252. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 84–90. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A.A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Zeng, X.; Ouyang, W.; Yan, J.; Li, H.; Xiao, T.; Wang, K.; Liu, Y.; Zhou, Y.; Yang, B.; Wang, Z.; et al. Crafting gbd-net for object detection. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 2109–2123. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28, 1137–1149. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Zhao, Z.Q.; Zheng, P.; Xu, S.t.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef]
- Lu, L.; Ichimura, S.; Yamagishi, A.; Rokunohe, T. Oil film detection under solar irradiation and image processing. IEEE Sens. J. 2019, 20, 3070–3077. [Google Scholar] [CrossRef]
- Tzutalin. LabelImg, Free Software; MIT License: West Hollywood, CA, USA, 2015. [Google Scholar]
- Bradski, G. The OpenCV Library. Dr. Dobb’s J. Softw. Tools Prof. Program. 2000, 25, 120–123. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. In Advances in Neural Information Processing Systems 32; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; pp. 8024–8035. [Google Scholar]
- Chollet, F. Keras. 2015. Available online: https://keras.io (accessed on 11 September 2022).
- Abadi, M.; Agarwal, A.; Barham, P.; Brevdo, E.; Chen, Z.; Citro, C.; Corrado, G.S.; Davis, A.; Dean, J.; Devin, M.; et al. TensorFlow: Large-Scale Machine Learning on Heterogeneous Systems. 2015. Available online: https://tensorflow.org (accessed on 11 September 2022).
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. In Proceedings of the International Conference on Machine Learning (PMLR), Lille, France, 7–9 July 2015; pp. 448–456. [Google Scholar]
- Dozat, T. Incorporating Nesterov Momentum into Adam. 2016. Available online: https://openreview.net/pdf?id=OM0jvwB8jIp57ZJjtNEZ (accessed on 11 September 2022).
- O’Malley, T.; Bursztein, E.; Long, J.; Chollet, F.; Jin, H.; Invernizzi, L. KerasTuner. 2019. Available online: https://github.com/keras-team/keras-tuner (accessed on 11 September 2022).
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 234–241. [Google Scholar]








Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bianchi, F.; Speziali, S.; Marini, A.; Proietti, M.; Menculini, L.; Garinei, A.; Bellani, G.; Marconi, M. Real-Time Oil Leakage Detection on Aftermarket Motorcycle Damping System with Convolutional Neural Networks. Sensors 2022, 22, 7951. https://doi.org/10.3390/s22207951
Bianchi F, Speziali S, Marini A, Proietti M, Menculini L, Garinei A, Bellani G, Marconi M. Real-Time Oil Leakage Detection on Aftermarket Motorcycle Damping System with Convolutional Neural Networks. Sensors. 2022; 22(20):7951. https://doi.org/10.3390/s22207951
Chicago/Turabian StyleBianchi, Federico, Stefano Speziali, Andrea Marini, Massimiliano Proietti, Lorenzo Menculini, Alberto Garinei, Gabriele Bellani, and Marcello Marconi. 2022. "Real-Time Oil Leakage Detection on Aftermarket Motorcycle Damping System with Convolutional Neural Networks" Sensors 22, no. 20: 7951. https://doi.org/10.3390/s22207951
APA StyleBianchi, F., Speziali, S., Marini, A., Proietti, M., Menculini, L., Garinei, A., Bellani, G., & Marconi, M. (2022). Real-Time Oil Leakage Detection on Aftermarket Motorcycle Damping System with Convolutional Neural Networks. Sensors, 22(20), 7951. https://doi.org/10.3390/s22207951