
Topic Break Detection in Interview Dialogues Using Sentence Embedding of Utterance and Speech Intention Based on Multitask Neural Networks

Abstract
1. Introduction
2. Related Works
2.1. Studies on Dialogue System
2.2. Studies on Topic Segmentation
3. Interview Dialogue Corpus
3.1. Data Collection
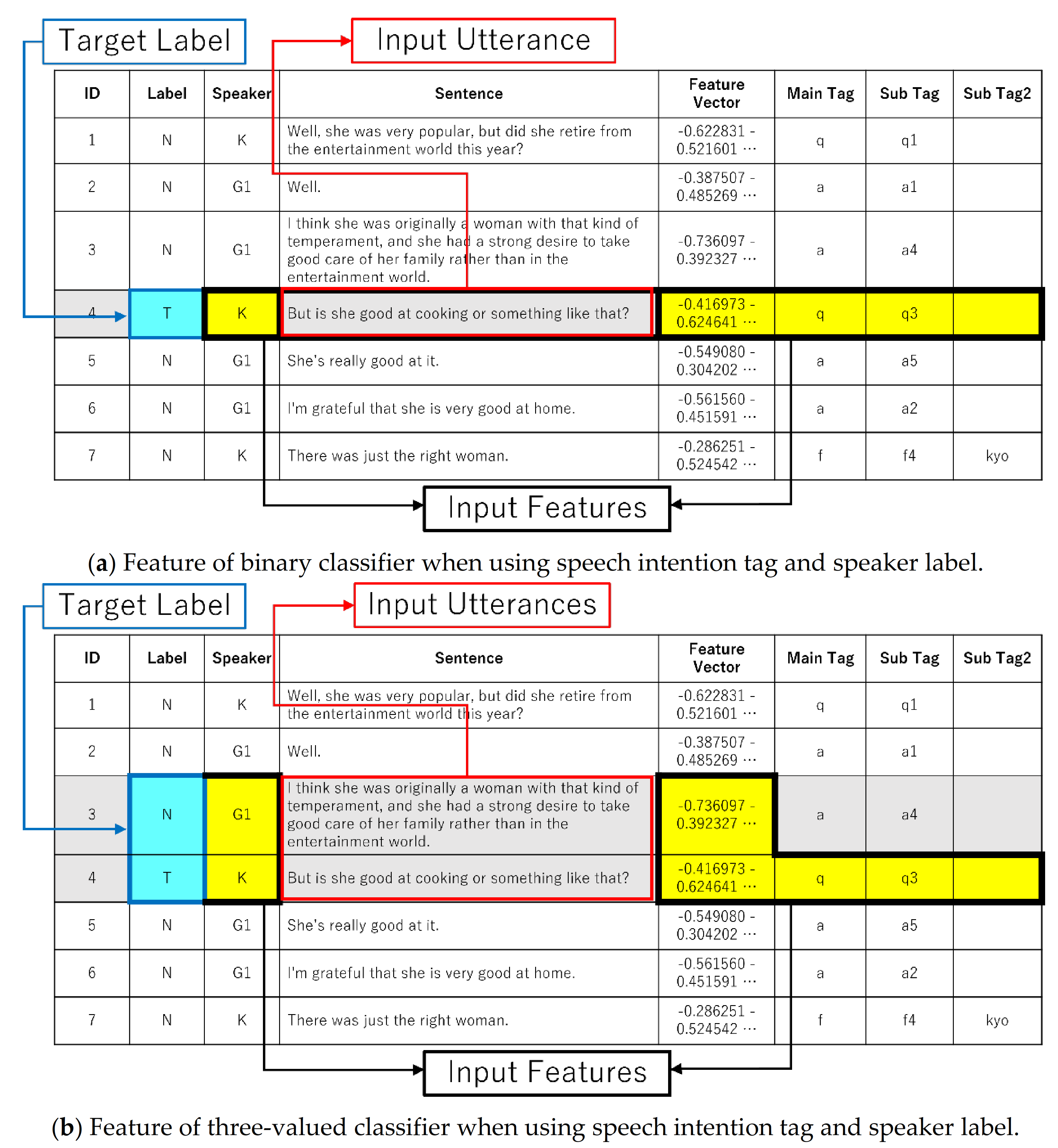
3.2. Speech Intention Tag Annotation
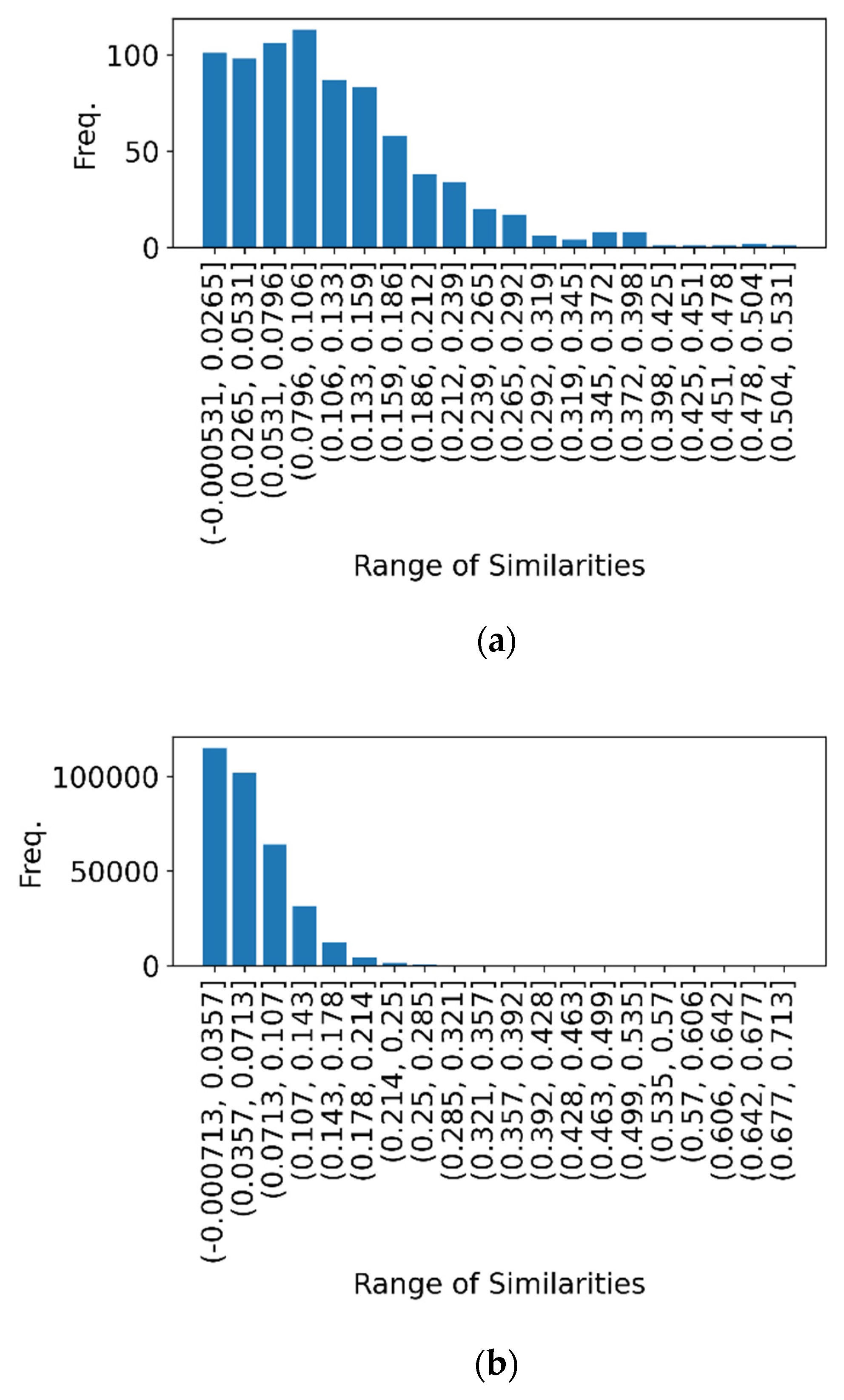
3.3. Corpus Analysis Based on TF-IDF Document Vector
4. Topic Segmentation Model
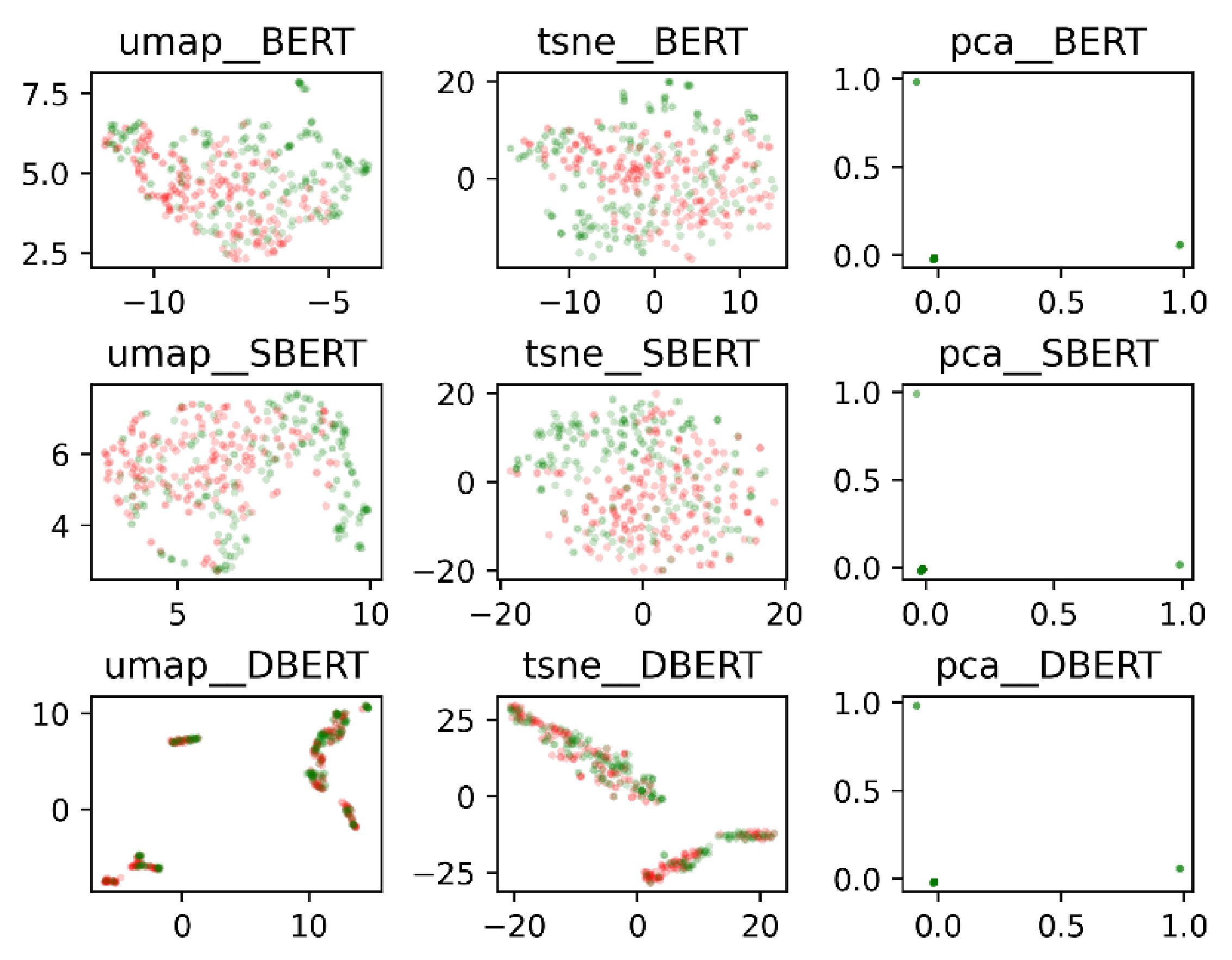
4.1. Vectorization of Dialogue Utterance Text
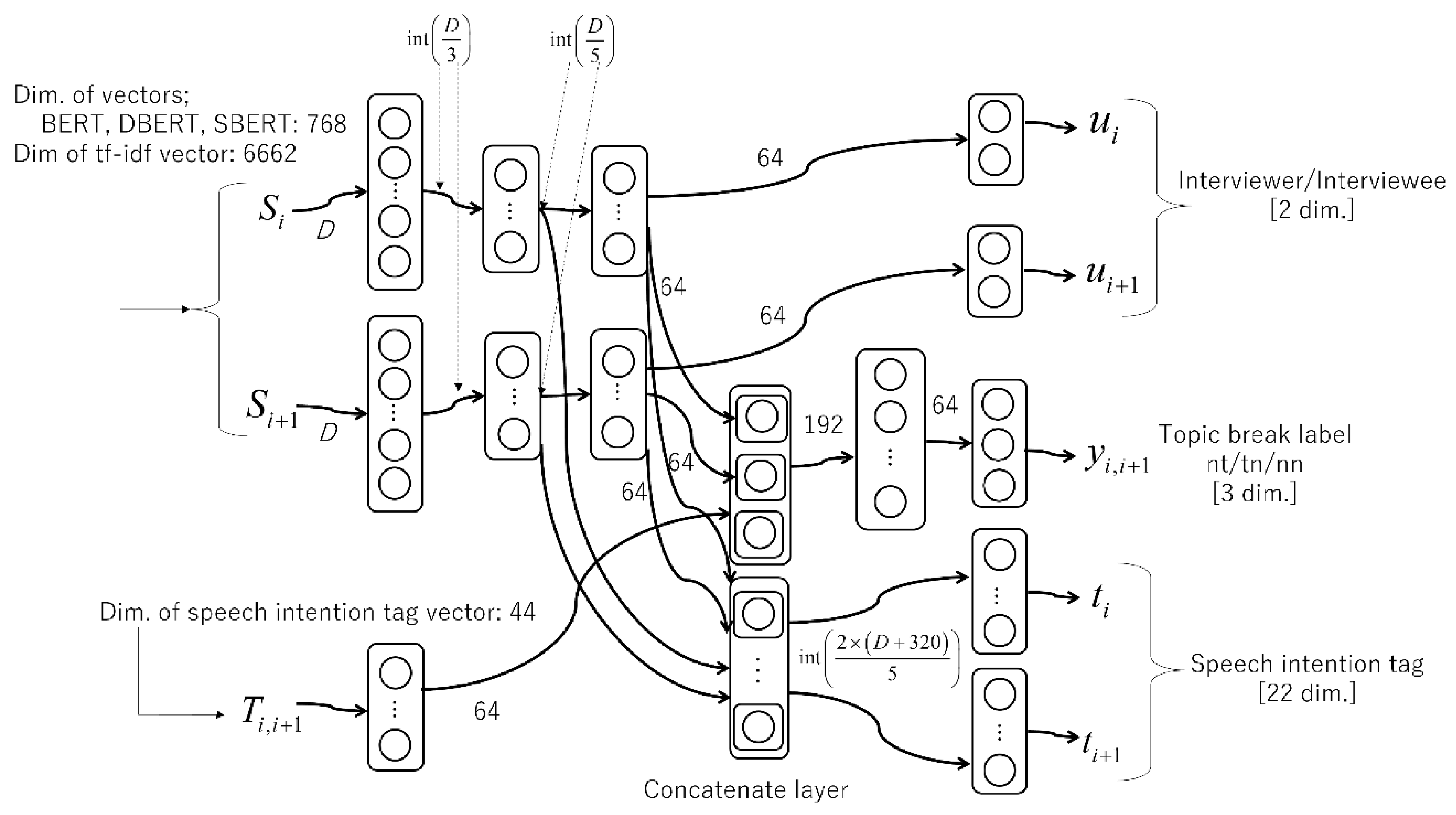
4.2. Topic Segmentation Model Based on Neural Networks
5. Experiments
5.1. Experimental Condition for Evaluation Experiment
5.2. Experimental Results
6. Discussions
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Masuda, A.; Ohara, Y.; Onishi, J. Development and Evaluation of a Robot with an Airport Guidance System, Proceedings of the 23rd HCI International Conference, HCII 2021, Virtual Event, 24–29 July 2021; Proceedings, Part II. Communications in Computer and Information Science 1420; Springer: Berlin, Germany, 2021; ISBN 978-3-030-78641-0. [Google Scholar]
- Ozaki, Y.; Ishihara, T.; Matsumura, N.; Nunobiki, T. Prediction of the decision-making that a pedestrian talks with a recep-tionist robot and Quantification of mental effects on the pedestrian. IEICE Tech. Rep. 2018, 117, 37–44. (In Japanese) [Google Scholar]
- ISHIGURO Symbiotic Human-Robot Interaction Project ERICA. Available online: http://www.jst.go.jp/erato/ishiguro/robot.html (accessed on 19 December 2021).
- Communication Robot Unibo. Available online: https://www.unirobot.com/unibo/ (accessed on 19 December 2021).
- Hashimoto, T.; Hiramatsu, S.; Tsuji, T.; Kobayashi, H. Realization and Evaluation of Realistic Nod with Receptionist Robot SAYA. In Proceedings of the 16th IEEE International Symposium on Robot and Human Interactive Communication RO-MAN, Jeju, Korea, 26–29 August 2007. [Google Scholar]
- Sutherland, C.J.; Ahn, B.K.; Brown, B.; Lim, J.; Johanson, D.L.; Broadbent, E.; Macdonald, B.A.; Ahn, H.S. The Doctor will See You Now: Could a Robot Be a medical Receptionist? In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 4310–4316. [Google Scholar]
- Narimatsu, H.; Sugiyama, H.; Mizukami, M.; Arimoto, T.; Miyazaki, N. Chat dialogue system with context understanding. NTT Tech. Rev. 2019, 17, 28–33. Available online: https://www.ntt-review.jp/archive/ntttechnical.php?contents=ntr201911fa5_s.html (accessed on 13 January 2022).
- Zhang, Z.; Huang, M.; Zhao, Z.; Ji, F.; Chen, H.; Zhu, X. Memory-Augmented Dialogue Management for Task-Oriented Dialogue Systems. ACM Trans. Inf. Syst. 2019, 37, 1–30. [Google Scholar] [CrossRef]
- Hwang, E.J.; Macdonald, B.A.; Ahn, H.S. End-to-End Dialogue System with Multi Languages for Hospital Receptionist Robot. In Proceedings of the 16th International Conference on Ubiquitous Robots (UR), Jeju, Korea, 24–27 June 2019. [Google Scholar]
- Ivanovic, E. Automatic utterance segmentation in instant messaging dialogue. In Proceedings of the Australasian Language Technology Workshop, Sydney, Australia, 9–11 December 2005; pp. 241–249. [Google Scholar]
- Ogawa, H.; Nishikawa, H.; Tokunaga, T.; Yokono, H. Gamification platform for collecting task-oriented dialogue data. In Proceedings of the 12th Conference on Language Resources and Evaluation (LREC2020), Marseille, France, 11–16 May 2020; pp. 7084–7093. [Google Scholar]
- Sato, S.; Yoshinaga, N.; Toyoda, M.; Kitsuregawa, M. Modeling situations in neural chat bots. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics- Student Research Workshop, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 120–127. [Google Scholar]
- Park, S.; Kim, N.; Oh, A. Conversation Model Fine-Tuning for Classifying Client Utterances in Counseling Dialogues. In Proceedings of the NAACL-HLT 2019, Minneapolis, MI, USA, 2–7 June 2019; pp. 1448–1459. [Google Scholar]
- Traum, D.; Ittycheriah, M.; Henderer, J. What would you ask a conversational agent? Observations of human-agent dialogues in a museum setting. In Proceedings of the International Conference on Language Resources and Evaluation, LREC2008, Marrakech, Morocco, 28–30 May 2008. [Google Scholar]
- Zhai, K.; Williams, J.D. Discovering latent structure in task-oriented dialogues. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics, Baltimore, MA, USA, 23–25 June 2014; pp. 36–46. [Google Scholar]
- Wang, H.; Guo, B.; Wu, W.; Liu, S.; Yu, Z. Towards information-rich, logical dialogue systems with knowledge-enhanced neural models. Neurocomputing 2021, 465, 248–264. [Google Scholar] [CrossRef]
- Hong, Y.-J.; Piao, M.; Kim, J.; Lee, J.-H. Development and Evaluation of a Child Vaccination Chatbot Real-Time Consultation Messenger Service during the COVID-19 Pandemic. Appl. Sci. 2021, 11, 12142. [Google Scholar] [CrossRef]
- Boné, J.; Ferreira, J.C.; Ribeiro, R.; Cadete, G. DisBot: A Portuguese Disaster Support Dynamic Knowledge Chatbot. Appl. Sci. 2020, 10, 9082. [Google Scholar] [CrossRef]
- Chen, J.; Agbodike, O.; Wang, L. Memory-Based Deep Neural Attention (mDNA) for Cognitive Multi-Turn Response Retrieval in Task-Oriented Chatbots. Appl. Sci. 2020, 10, 5819. [Google Scholar] [CrossRef]
- Paul, A.; Latif, A.H.; Adnan, F.A.; Rahman, R.M. Focused domain contextual AI chatbot framework for resource poor languages. J. Inf. Telecommun. 2019, 3, 248–269. [Google Scholar] [CrossRef]
- Yuan, C.-C.; Li, C.-H.; Peng, C.-C. Development of mobile interactive courses based on an artificial intelligence chatbot on the communication software LINE. Interact. Learn. Environ. 2021, 1–15. [Google Scholar] [CrossRef]
- Daniel, G.; Cabot, J.; Deruelle, L.; Derras, M. Xatkit: A Multimodal Low-Code Chatbot Development Framework. IEEE Access 2020, 8, 15332–15346. [Google Scholar] [CrossRef]
- Garcia-Mendez, S.; De Arriba-Perez, F.; Gonzalez-Castano, F.J.; Regueiro-Janeiro, J.A.; Gil-Castineira, F. Entertainment Chatbot for the Digital Inclusion of Elderly People Without Abstraction Capabilities. IEEE Access 2021, 9, 75878–75891. [Google Scholar] [CrossRef]
- Wang, C.; Chen, D.; Hu, Y.; Ceng, Y.; Chen, J.; Li, H. Automatic Dialogue System of Marriage Law Based on the Parallel C4.5 Decision Tree. IEEE Access 2020, 8, 36061–36069. [Google Scholar] [CrossRef]
- Liu, W.; Tang, J.; Liang, X.; Cai, Q. Heterogeneous graph reasoning for knowledge-grounded medical dialogue system. Neurocomputing 2021, 442, 260–268. [Google Scholar] [CrossRef]
- Nakano, M.; Komatani, K. A framework for building closed-domain chat dialogue systems. Knowl. Based Syst. 2020, 204, 106212. [Google Scholar] [CrossRef]
- Ling, Y.; Cai, F.; Hu, X.; Liu, J.; Chen, W.; Chen, H. Context-Controlled Topic-Aware Neural Response Generation for Open-Domain Dialog Systems. Inf. Process. Manag. 2020, 58, 102392. [Google Scholar] [CrossRef]
- Koo, S.; Yu, H.; Lee, G.G. Adversarial approach to domain adaptation for reinforcement learning on dialog systems. Pattern Recognit. Lett. 2019, 128, 467–473. [Google Scholar] [CrossRef]
- Ota, R.; Kimura, M. Proposal of Open-ended Dialog System Based on Topic Maps. Proc. Technol. 2014, 17, 122–129. [Google Scholar] [CrossRef][Green Version]
- Li, L.; Li, C.; Ji, D. Deep context modeling for multi-turn response selection in dialogue systems. Inf. Process. Manag. 2020, 58, 102415. [Google Scholar] [CrossRef]
- Ryu, S.; Kim, S.; Choi, J.; Yu, H.; Lee, G.G. Neural sentence embedding using only in-domain sentences for out-of-domain sentence detection in dialog systems. Pattern Recognit. Lett. 2017, 88, 26–32. [Google Scholar] [CrossRef]
- López-Cózar, R.; Callejas, Z.; Griol, D. Using knowledge of misunderstandings to increase the robustness of spoken dialogue systems. Knowl. Based Syst. 2010, 23, 471–485. [Google Scholar] [CrossRef]
- Giorgino, T.; Azzini, I.; Rognoni, C.; Quaglini, S.; Stefanelli, M.; Gretter, R.; Falavigna, D. Automated spoken dialogue system for hypertensive patient home management. Int. J. Med. Inform. 2005, 74, 159–167. [Google Scholar] [CrossRef]
- Miyamura, Y.; Tokunaga, T. Real-time topic segmentation of information seeking chat. IPSJ SIG Technical Report, 2008-NL-187, 71–76. (In Japanese).
- Tomiyama, K.; Nihei, F.; Nakano, Y.; Takase, Y. Identifying discourse boundaries in group discussions using multimodal embedding space. In Proceedings of the ACM IUI 2018 Workshops, Symbiotic Interaction and Harmonious Collaboration for Wisdom Computing (SymCollab), Tokyo, Japan, 7–11 March 2018. [Google Scholar]
- Tanaka, N. Classification of Discourse Signs for Starting a Topic from the Perspective of Discourse Understanding. Japanese Language Education, No. 170. Available online: https://www.jstage.jst.go.jp/article/nihongokyoiku/170/0/170_130/_article/-char/ja/ (accessed on 13 January 2022).
- Arguello, J.; Rosé, C. Topic segmentation of dialogue. In Proceedings of the HLT-NAACL 2006 Workshop on Analyzing Conversations in Text and Speech, New York, NY, USA, 8 June 2006; pp. 42–49. [Google Scholar]
- Zhang, L.; Zhou, Q. Topic Segmentation for Dialogue Stream. In Proceedings of the APSIPA Annual Summit and Conference, Lanzhou, China, 18–21 November 2019; pp. 1036–1043. [Google Scholar] [CrossRef]
- Sehikh, I.; Fohr, D.; Illina, I. Topic segmentation in ASR transcripts using bidirectional RNNs for change detection. In Proceedings of the IEEE Automatic Speech Recognition and Understanding Workshop, Okinawa, Japan, 16–20 December 2017; pp. 512–518. [Google Scholar] [CrossRef]
- Kimura, Y.; Maruyama, K. Providing topic candidates based on picking up terms and retrieving topics. Proc. IPSJ Interact. 2017, 269–273. [Google Scholar]
- Fayçal, N.; Hacene, B. A deep neural network model with multihop self-attention mechanism for topic segmentation of texts. Lect. Notes Data Eng. Commun. Technol. 2021, 72, 407–417. [Google Scholar]
- Solbiati, A.; Heffernan, K.; Damaskinos, G.; Poddar, S.; Modi, S.; Cali, J. Unsupervised topic segmentation of meetings with BERT embeddings. arXiv 2021, arXiv:2106.12978. [Google Scholar]
- Gnjatovic, M.; Macek, N. An Entropy Minimization Approach to Dialogue Segmentation. In Proceedings of the 11th IEEE International Conference on Cognitive Infocommunications (CogInfoCom), Mariehamn, Finland, 23–25 September 2020. [Google Scholar] [CrossRef]
- Ozaki, H.; Morishita, T.; Koreeda, Y.; Morio, G.; Yanai, K. Meeting support system with topic estimation by embeddings via predicate-argument structure analysis. In Proceedings of the 34th Annual Conference of the Japanese Society for Artificial Intelligence, Virtual, 9–12 June 2020. (In Japanese). [Google Scholar]
- Tamura, A.; Sumita, E. Bilingual segment topic model. IPSJ J. 2017, 58, 2080–2092. (In Japanese) [Google Scholar]
- Sasayama, M.; Matsumoto, K. Tagging and analysis of utterance intention tag for interview dialogue corpus. JSAI Tech. Rep. 2021, 11, 56–61. (In Japanese) [Google Scholar]
- Sasayama, M.; Matsumoto, K. Annotation and Evaluation of Utterance Intention Tag for Interview Dialogue Corpus. In Proceedings of the 5th International Conference on Natural Language Processing and Information Retrieval (NLPIR2021), Virtual, 17–20 December 2021. [Google Scholar]
- Kirihara, T.; Matsumoto, K.; Sasayama, M.; Yoshida, M.; Kita, K. Topic segmentation for interview dialogue system. In Proceedings of the 5th International Conference on Natural Language Processing and Information Retrieval (NLPIR2021), Virtual, 17–20 December 2021. [Google Scholar]
- Matsumoto, K.; Sasayama, M.; Terazono, R.; Yoshida, M.; Kita, K. Analysis of utterance Intention and kansei on interview dialogue corpus. In Proceedings of the 15th Spring Annual Meeting of Japan Society of Kansei Engineering, Virtual, 5–6 March 2020. (In Japanese). [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. 2013, preprint. [Google Scholar]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching Word Vectors with Subword Information. Trans. Assoc. Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef]
- Pennington, J.; Socher, R.; Manning, C.D. GloVe: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1532–1543. [Google Scholar]
- Quoc Le, Q.; Mikolov, T. Distributed representations of sentences and documents. In Proceedings of the Machine Learning Research PMLR, Beijing, China, 22–24 June 2014; Volume 32, pp. 1188–1196. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language under-standing. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics, Human Language Technologies, Minneapolis, MI, USA, 2–7 June 2019; Volume 1, pp. 4171–4186. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP) 2019, Hong Kong, China, 3–7 November 2019; pp. 3973–3983. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2020, arXiv:1910.01108. [Google Scholar]
- McInnes, L.; Healy, J. UMAP: Uniform manifold approximation and projection for dimension reduction. arXiv 2020, arXiv:1802.03426. [Google Scholar]
- Maaten, L.; Hinton, G. Visualizing data using t-SNE. J. Mach. Learn. Res. 2008, 9, 2579–2605. [Google Scholar]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Main Tag | Sub-Tag | Sub-Tag 2 |
|---|---|---|
| “q”: Question | Pre-arranged question (“q1”) | Nest (“nest”) |
| Opinion (“q2”) | ||
| Others (“q3”) | ||
| “a”: Answer | Agreement/Disagreement (“a1”) | Nest (“nest”) Self-remark (“j”) |
| Self-disclosure (opinion) (“a2”) | ||
| Self-disclosure (others) (“a3”) | ||
| Explanation of another person (opinion) (“a4”) | ||
| Explanation of another person (others) (“a5”) | ||
| “f”: Feedback | Compliment (“f1”) | Empathy (“kyo”) |
| Help (“f2”) | ||
| Asking back/Repetition (“f3”) | ||
| Others (“f4”) | ||
| “c”: Comment | Compliment (“c1”) | Empathy (“kyo”) |
| Others (“c2”) | ||
| “b1”: Explanation to audience | ||
| “b2”: Filler | ||
| “b3”: Laughter | ||
| “b4”: Greeting |
| Main Tag | Interviewer | Interviewee |
|---|---|---|
| q | 2319 | 151 |
| a | 337 | 6442 |
| f | 2334 | 393 |
| c | 1548 | 3 |
| b1 | 401 | 6 |
| b2 | 42 | 96 |
| b3 | 173 | 118 |
| b4 | 160 | 238 |
| Speaker | Label (t) | Rate | Label (n) | Rate | Label(t)+Label(n) |
|---|---|---|---|---|---|
| Interviewer | 753 | 0.10 | 6749 | 0.90 | 7502 |
| Interviewee | 84 | 0.01 | 7684 | 0.99 | 7768 |
| Similarity | t-1 | t |
|---|---|---|
| 0.35 | player, violin, pressure, offer, strong, honor, dad, feeling | violin, musical performance, very, exception, wind instrument, drums, keyboard |
| 0.34 | son, mother, of course, think, good, that, not | language, but, news, anxiety stage, group, mother |
| Model | Parameters | Value |
|---|---|---|
| Neural Networks | epochs | 5–100 |
| optimizer | Adam | |
| loss function | categorical crossentropy | |
| SVM | kernel | rbf |
| regularization parameter C | 1.0 | |
| class weight | balanced | |
| Logistic Regression | default parameters | |
| Random Forest | default parameters | |
| Tag | Output (bin/tri) | Task | Feature | Epochs | Accuracy |
|---|---|---|---|---|---|
| without | bin | triple | DBERT | 70 | 0.79 |
| multi | DBERT | 90 | 0.79 | ||
| single | DBERT | 30 | 0.78 | ||
| tri | triple | DBERT | 90 | 0.70 | |
| multi | BERT | 20 | 0.69 | ||
| single | DBERT | 40 | 0.69 | ||
| with | bin | triple | DBERT | 20 | 0.83 |
| multi | DBERT | 20 | 0.84 | ||
| single | DBERT | 10 | 0.83 | ||
| tri | triple | DBERT | 20 | 0.76 | |
| multi | DBERT | 20 | 0.76 | ||
| single | BERT | 10 | 0.75 |
| Tag | Output (bin/tri) | Task | Feature | Epochs | F1-score |
|---|---|---|---|---|---|
| without | bin | triple | DBERT | 70 | 0.78 |
| multi | DBERT | 80 | 0.78 | ||
| single | DBERT | 50 | 0.77 | ||
| tri | triple | BERT | 30 | 0.74 | |
| multi | BERT | 20 | 0.73 | ||
| single | BERT | 5 | 0.73 | ||
| with | bin | triple | DBERT | 20 | 0.83 |
| multi | DBERT | 20 | 0.83 | ||
| single | DBERT | 20 | 0.83 | ||
| tri | triple | DBERT | 20 | 0.785 | |
| multi | DBERT | 30 | 0.795 | ||
| single | DBERT | 20 | 0.79 |
| Tag | Output (bin/tri) | Model | Feature | Accuracy |
|---|---|---|---|---|
| without | bin | SVM | BERT | 0.78 |
| Logistic Regression | BERT | 0.76 | ||
| Random Forest | BERT | 0.78 | ||
| tri | SVM | BERT | 0.75 | |
| Logistic Regression | BERT | 0.75 | ||
| Random Forest | BERT | 0.74 | ||
| with | bin | SVM | BERT | 0.83 |
| Logistic Regression | TFIDF | 0.82 | ||
| Random Forest | TFIDF | 0.81 | ||
| tri | SVM | BERT | 0.82 | |
| Logistic Regression | BERT | 0.82 | ||
| Random Forest | BERT | 0.81 |
| Tag | Output (bin/tri) | Model | Feature | F1-score |
|---|---|---|---|---|
| without | bin | SVM | BERT | 0.79 |
| Logistic Regression | BERT | 0.76 | ||
| Random Forest | BERT | 0.79 | ||
| tri | SVM | BERT | 0.76 | |
| Logistic Regression | BERT | 0.75 | ||
| Random Forest | BERT | 0.72 | ||
| with | bin | SVM | BERT | 0.83 |
| Logistic Regression | DBERT | 0.82 | ||
| Random Forest | BERT | 0.80 | ||
| tri | SVM | BERT | 0.82 | |
| Logistic Regression | BERT | 0.82 | ||
| Random Forest | BERT | 0.80 |
| Feature | SVM | Random Forest | Logistic Regression |
|---|---|---|---|
| tf-idf | dou, rassharu, you, irassharu, today, graduation, change, guest, mother, now, gurai, marriage, san, da, but, etc. | dou, rassharu, irassharu, you, today, yes, actor, aunt, guest, mother, gurai, kedo, marriage, this, san, Kuroyanagi, great, That’s right, that, it, da, but, etc. | dou, rassharu, irassharu, you, today, yes, actor, guest, gurai, marriage, say, san, great, That’s right, such, da, but, etc. |
| tf-idf + speech intention tag vector | you, bera, high, nice, <s>, <par>, <nest>, etc. | dou, yes, rassharu, irassharu, today, guest, mother, gurai, marriage, this, san, Kuroyanagi, That’s right, da, but, <a>, <d>, <k>, <q>, <s>, <else>, <iken>, <jik>, <par>, <yoi>, etc. | yes, everyone, you, kashira, That’s right, it, da, but, <k>, <q>, <s>, <par>, <yoi>, <kyo>, <nest>, etc. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Matsumoto, K.; Sasayama, M.; Kirihara, T. Topic Break Detection in Interview Dialogues Using Sentence Embedding of Utterance and Speech Intention Based on Multitask Neural Networks. Sensors 2022, 22, 694. https://doi.org/10.3390/s22020694
Matsumoto K, Sasayama M, Kirihara T. Topic Break Detection in Interview Dialogues Using Sentence Embedding of Utterance and Speech Intention Based on Multitask Neural Networks. Sensors. 2022; 22(2):694. https://doi.org/10.3390/s22020694
Chicago/Turabian StyleMatsumoto, Kazuyuki, Manabu Sasayama, and Taiga Kirihara. 2022. "Topic Break Detection in Interview Dialogues Using Sentence Embedding of Utterance and Speech Intention Based on Multitask Neural Networks" Sensors 22, no. 2: 694. https://doi.org/10.3390/s22020694
APA StyleMatsumoto, K., Sasayama, M., & Kirihara, T. (2022). Topic Break Detection in Interview Dialogues Using Sentence Embedding of Utterance and Speech Intention Based on Multitask Neural Networks. Sensors, 22(2), 694. https://doi.org/10.3390/s22020694