
Effective TCP Flow Management Based on Hierarchical Feedback Learning in Complex Data Center Network


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- For recognizing the entire network condition, the proposed scheme uses the hierarchical information which has been fed back from bottom to top components.
- Learning said information, the proposed scheme makes the empirical rule of efficient TCP flow establishments, and tries to establish TCP flows for optimizing TCP throughput in the entire data center network.
- Applying deep reinforcement learning approach into the learning algorithm, the proposed scheme can handle a massive number of TCP flows effectively.
2. Related Work
3. Design of TCP Flow Management Based on Hierarchical Feedback Learning
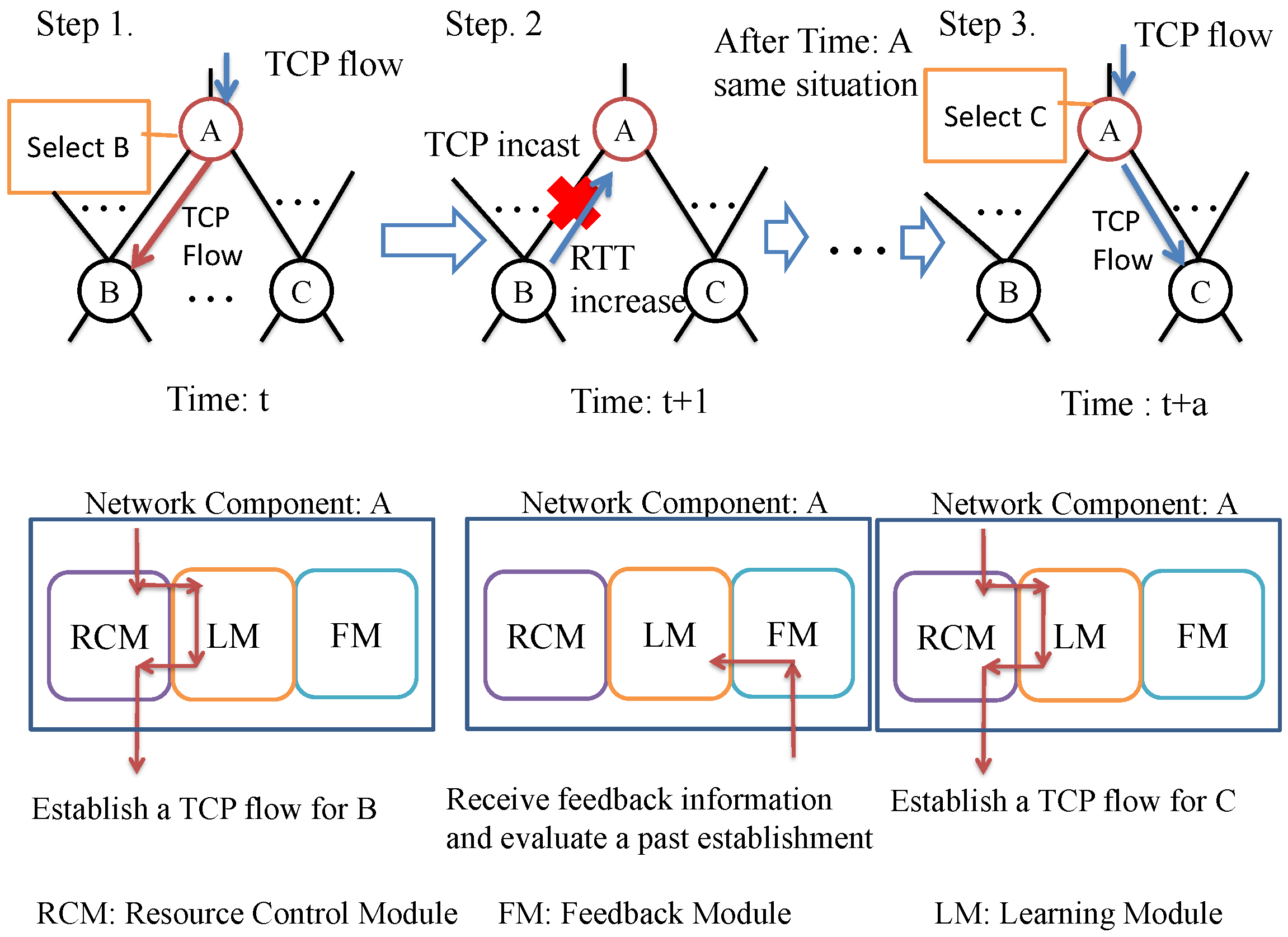
- Step 1:
- When network component A receives a client’s TCP flow at time t, the resource-control module in the network component A selects child component (i.e., the lower connected component) to establish the TCP flow. This selection is determined by loading the connection states from the learning module. After this selection, network component A establishes a TCP flow to network component B.
- Step 2:
- Next, network component A receives the feedback information containing child network components’ network state (e.g., RTT and the number of held TCP connections) from network component B through a feedback module. If a previous TCP establishment causes TCP incast, the Round Trip Time (RTT) increases exponentially so that network component A learns its situation with the fed back information sent from network component B.
- Step 3:
- After a prescribed period of time elapses, if network component A detects the same situation observed at time t (in time ), the learning module predicts that TCP flow establishment for network component B causes TCP incast. Then, the resource-control module of network A does not establish TCP flow to the network component B; instead, the resource-control module establishes TCP flow to network component C.
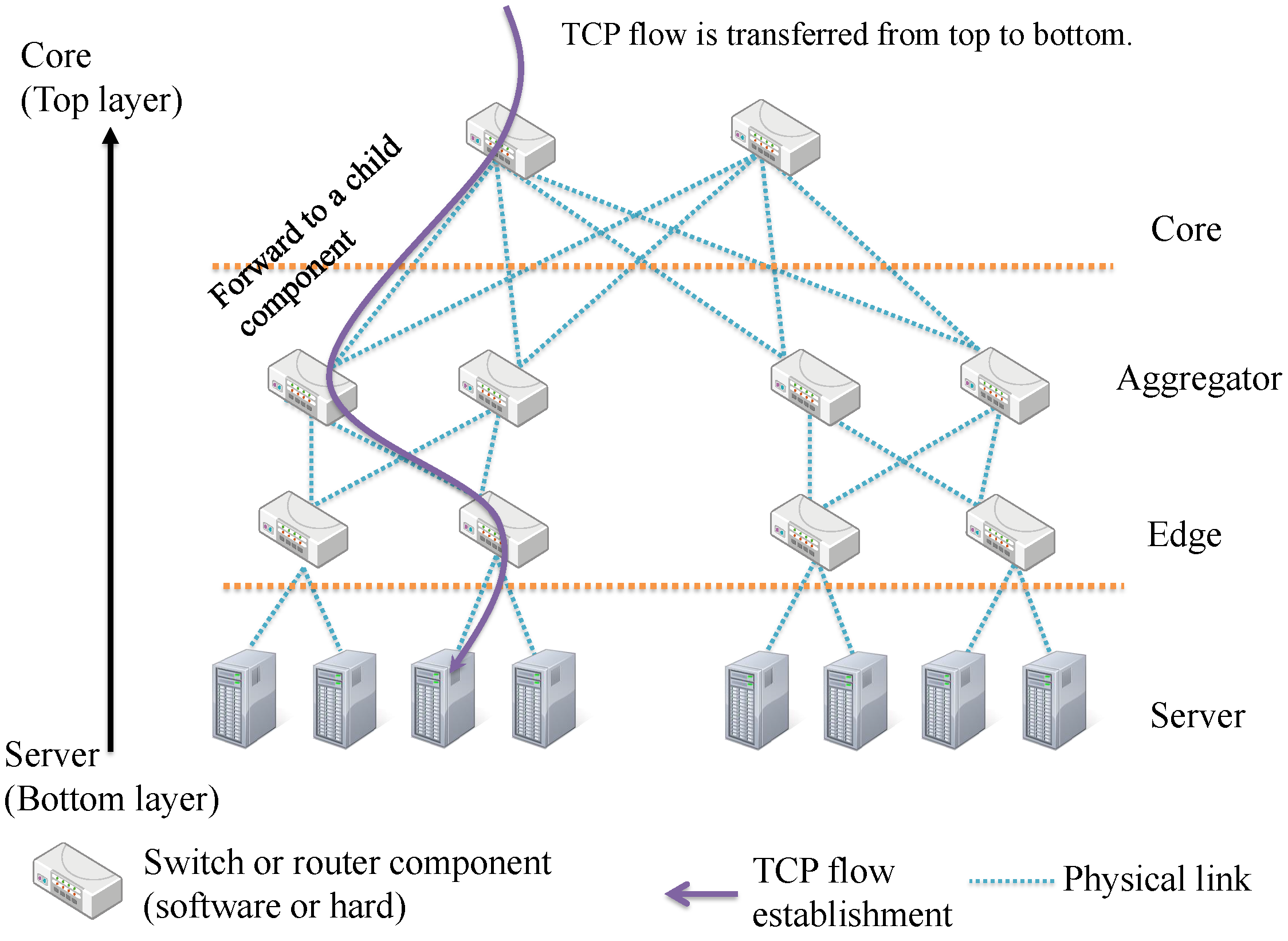
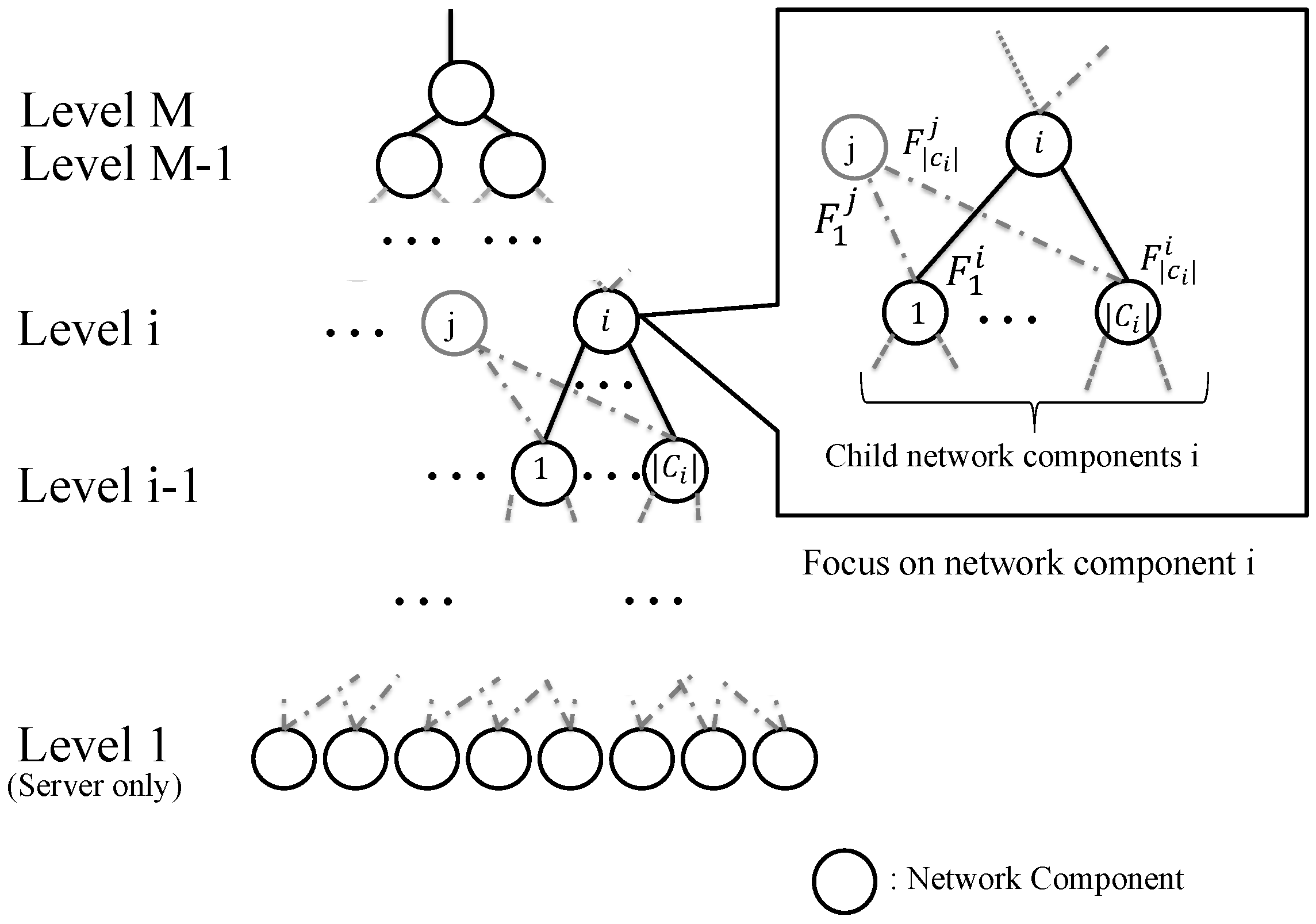
3.1. Data Center Model
- A data center network consists of network components, which figures hierarchical architecture, and the height of the hierarchy is M, noting that a network component in zero height indicates an end-host server.
- A network component has physical connections to network components below it, which are called child components of i, and the set of the child network components of i is expressed as noting that the network component also includes other (), for example, network component 1 in Figure 3 has two upper links for two components located in higher layer (i.e., i and j).
- The number of established TCP flows from network component i to is denoted as .
3.2. Reinforcement Learning
3.3. Learning Module
3.4. Resource-Control Module
3.5. Feedback Module
3.6. Learning Algorithm of the Proposed Scheme
| Algorithm 1 The hierarchical feedback learning control of network component i |
| Inputs: |
| The measured state , |
| learning rate , |
| balanced factor , and discount factor . |
| Initialize: |
| deep reinforcement learning models |
| # Obtain next action and execute it. |
| # Suppose is establishing the TCP flow for component j. |
| # Calculate reward function with Measured RTT. |
| = |
| # Re-calculate reward function with the feedback reward. |
| += |
| # Calculate TD-error |
| # Update to |
3.7. Summary of the Proposed Scheme’s Behavior
4. Simulation Results
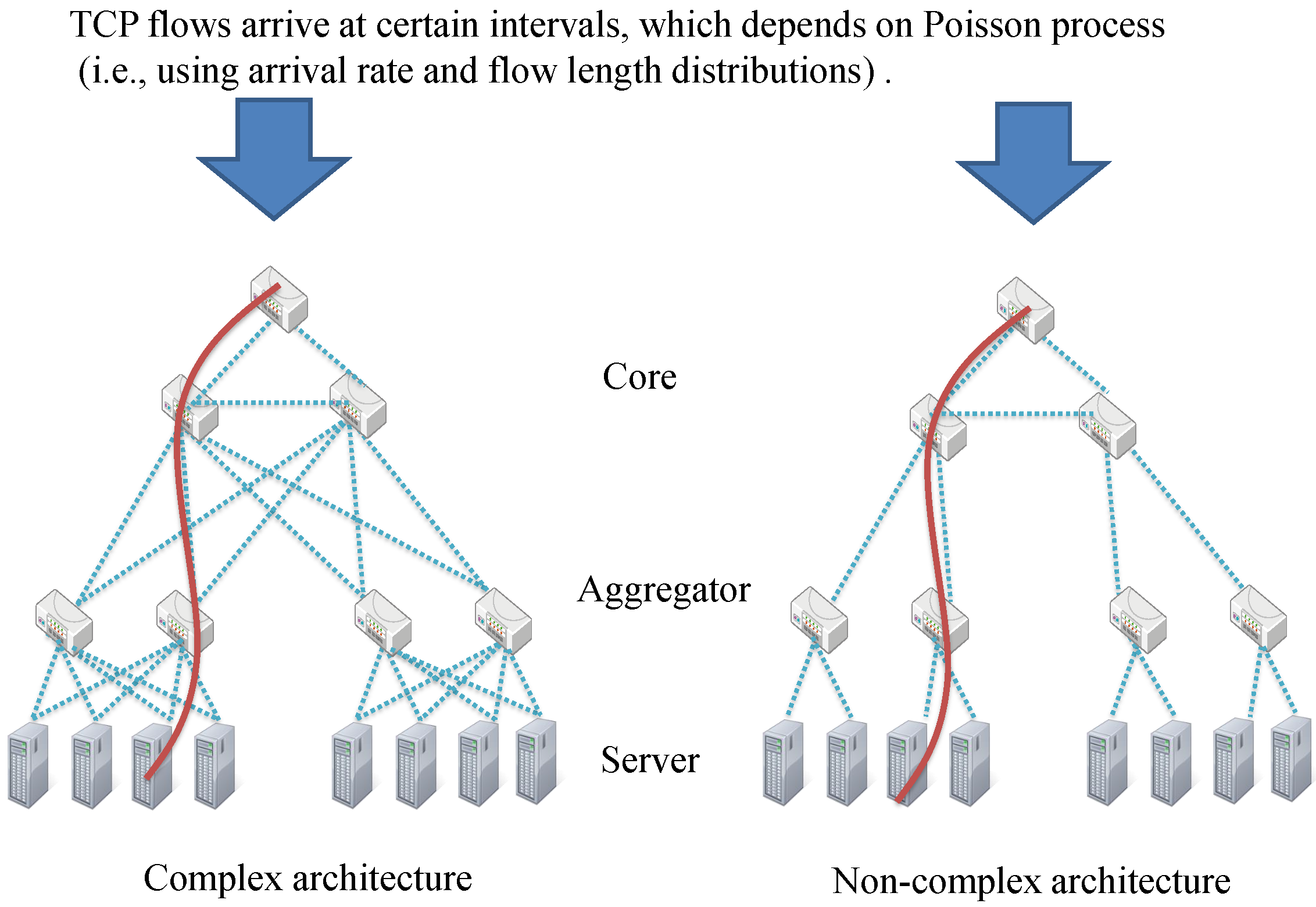
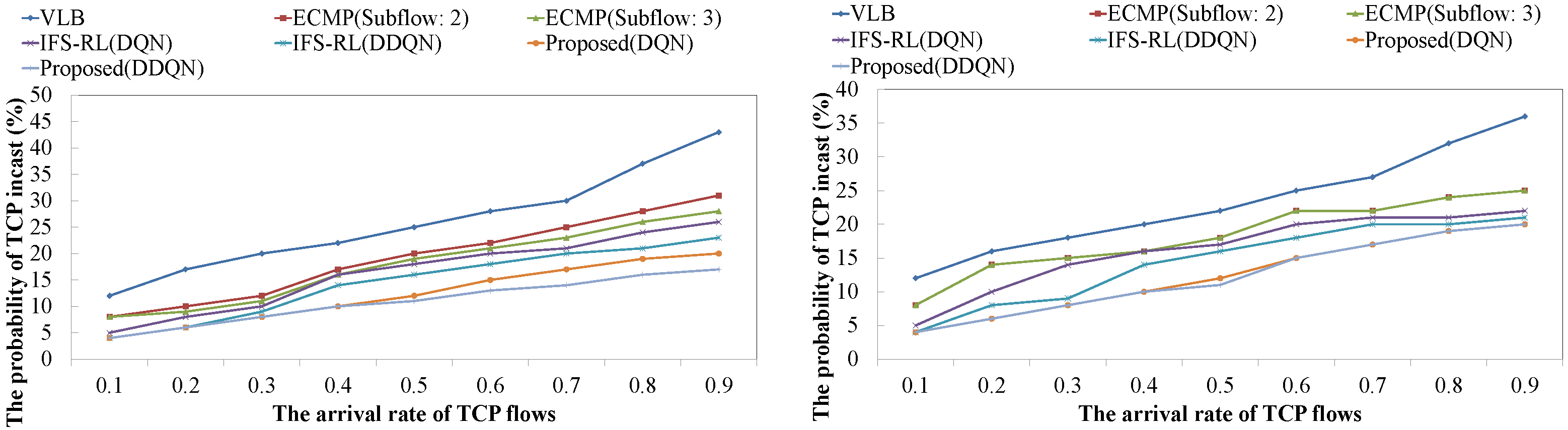
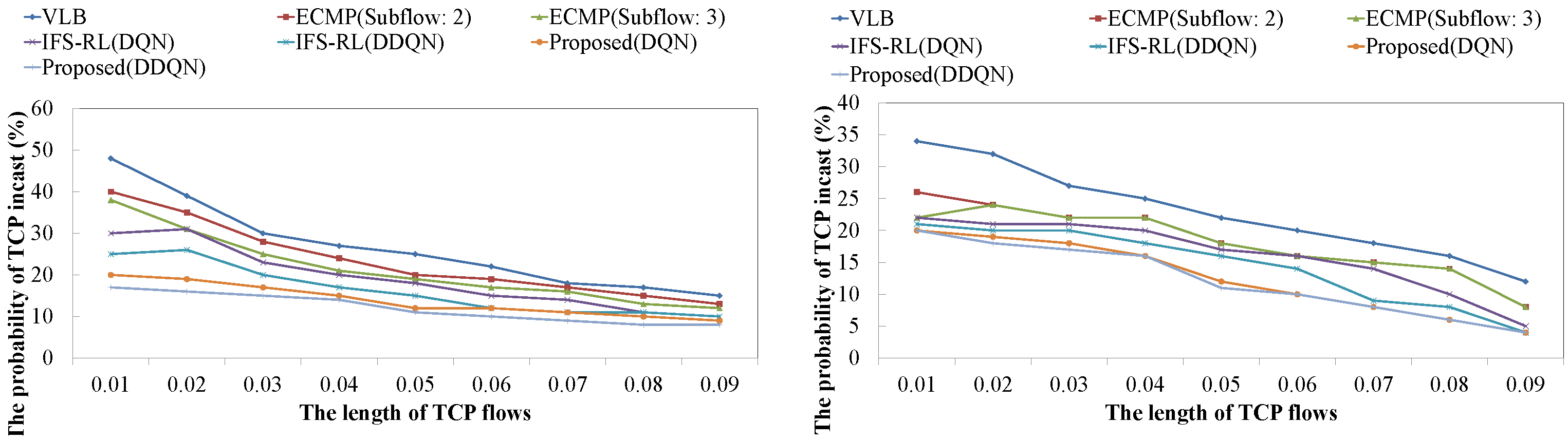
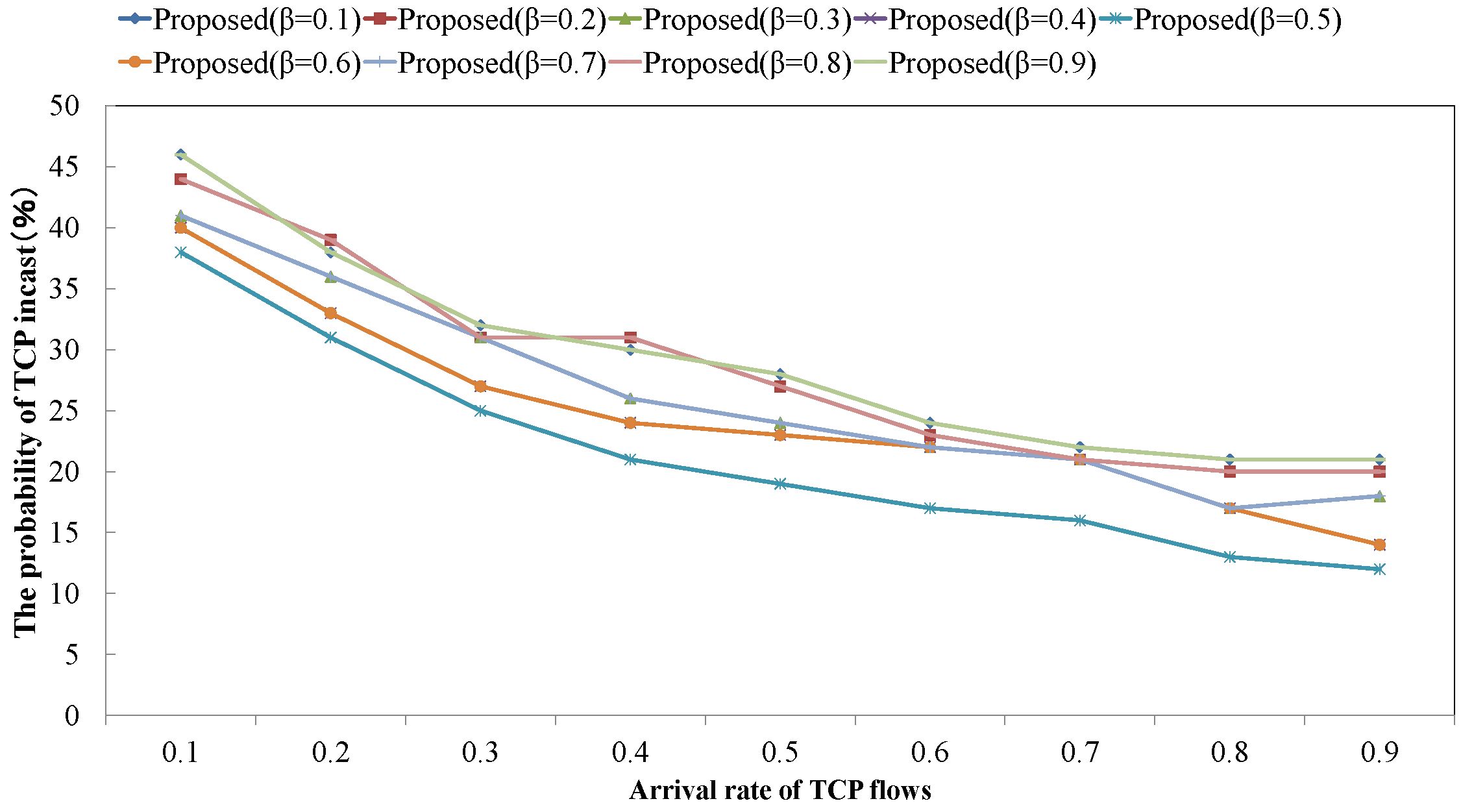
4.1. Probability of TCP Incast Occurrence for Changing TCP Flow’s Pattern
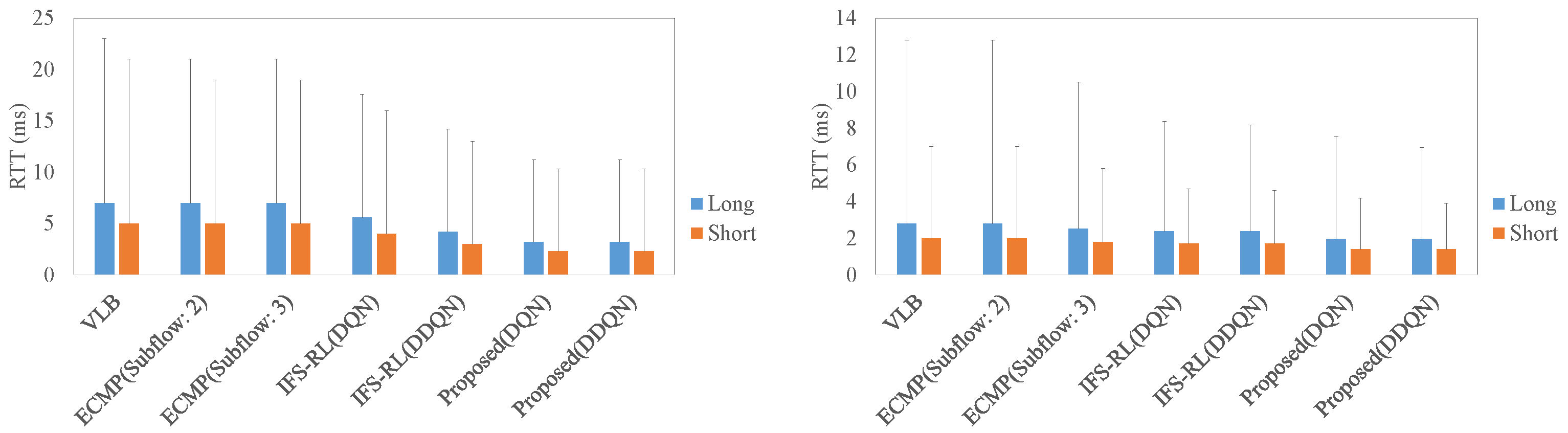
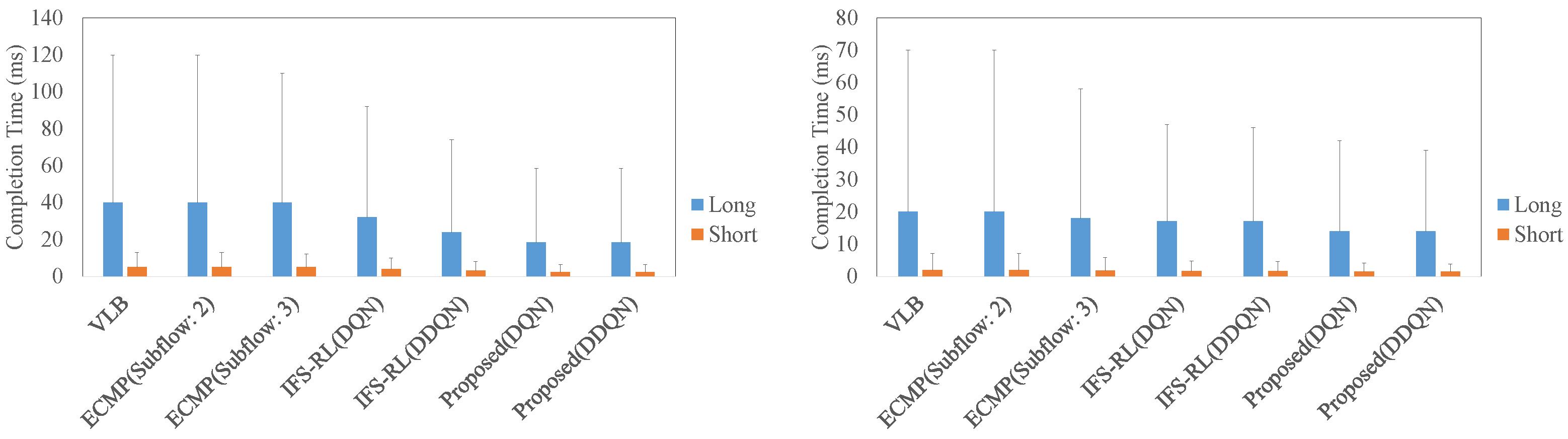
4.2. The Comparison of RTT, Throughput, and Flow Completion Time in Each Scheme
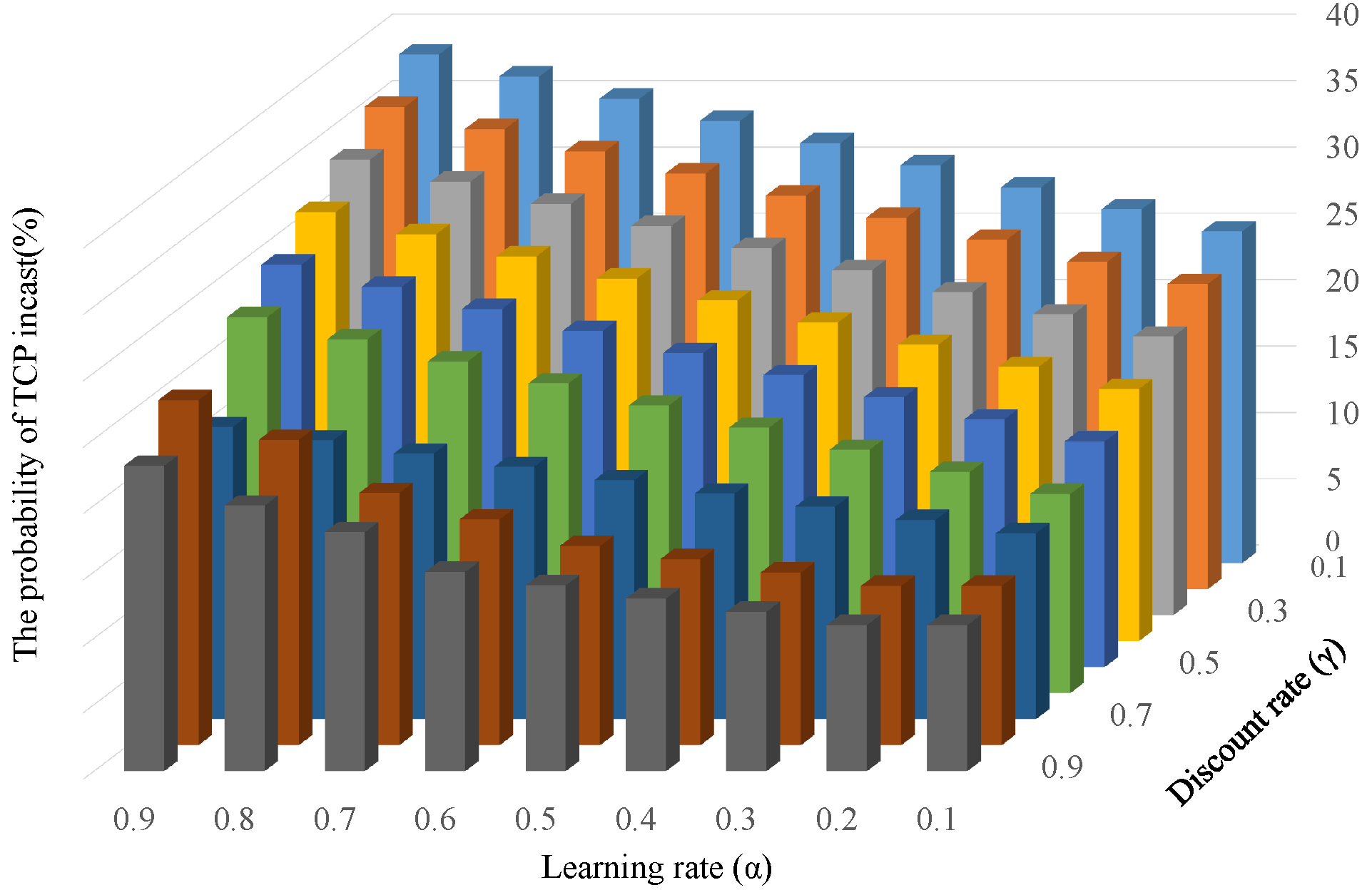
4.3. Probability of TCP Incast Occurrence for Changing Learning Parameters
4.4. Overhead for Reinforcement Learning
5. Conclusions
Funding
Conflicts of Interest
References
- Greenberg, A.; Hamilton, J.R.; Jain, N.; Kandula, S.; Kim, C.; Lahiri, P.; Maltz, D.A.; Patel, P.; Sengupta, S. VL2: A scalable and flexible data center network. ACM Spec. Interest Group Data Commun. (SIGCOMM) Comput. Commun. Rev. 2011, 54, 95–104. [Google Scholar] [CrossRef]
- Zhang, Z.; Deng, Y.; Min, G.; Xie, J.; Yang, L.T.; Zhou, Y. HSDC: A highly scalable data center network architecture for greater incremental scalability. IEEE Trans. Parallel Distrib. Syst. 2018, 30, 1105–1119. [Google Scholar] [CrossRef]
- Jain, N.; Bhatele, A.; Howell, L.H.; Böhme, D.; Karlin, I.; León, E.A.; Mubarak, M.; Wolfe, N.; Gamblin, T.; Leininger, M.L. Predicting the performance impact of different fat-tree configurations. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, Denver, CO, USA, 12–17 November 2017; pp. 1–13. [Google Scholar]
- Alipio, M.; Tiglao, N.M.; Bokhari, F.; Khalid, S. TCP incast solutions in data center networks: A classification and survey. J. Netw. Comput. Appl. 2019, 146, 102421. [Google Scholar] [CrossRef]
- Han, Z.; Yu, L. A survey of the bcube data center network topology. In Proceedings of the International Conference on Big Data Security on Cloud (BigDataSecurity), Omaha, NE, USA, 3–5 May 2018; pp. 229–231. [Google Scholar]
- Guo, C.; Wu, H.; Tan, K.; Shi, L.; Zhang, Y.; Lu, S. Dcell: A scalable and fault-tolerant network structure for data centers. In Proceedings of the ACM Special Interest Group on Data Communication (SIGCOMM) Annual Conference, Seattle, WA, USA, 17–22 August 2008; pp. 75–86. [Google Scholar]
- Hong, E.T.B.; Wey, C.Y. An optimized flow management mechanism in OpenFlow network. In Proceedings of the International Conference on Information Networking (ICOIN), Da Nang, Vietnam, 11–13 January 2017; pp. 143–147. [Google Scholar]
- Hollot, C.V.; Misra, V.; Towsley, D.; Gong, W.B. On designing improved controllers for AQM routers supporting TCP flows. In Proceedings of the IEEE International Conference on Computer Communications (INFOCOM), Anchorage, AK, USA, 22–26 April 2001; Volume 3, pp. 1726–1734. [Google Scholar]
- Zhang, Y.; Bai, B.; Xu, K.; Lei, K. IFS-RL: An Intelligent Forwarding Strategy Based on Reinforcement Learning in Named-Data Networking. In Proceedings of the ACM Special Interest Group on Data Communication (SIGCOMM) Workshop on Network Meets AI and ML (NetAI’18), Budapest, Hungary, 20–25 August 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 54–59. [Google Scholar] [CrossRef]
- Li, W.; Liu, J.; Wang, S.; Zhang, T.; Zou, S.; Hu, J.; Jiang, W.; Huang, J. Survey on Traffic Management in Data Center Network: From Link Layer to Application Layer. IEEE Access 2021, 9, 38427–38456. [Google Scholar] [CrossRef]
- Alizadeh, M.; Greenberg, A.; Maltz, D.; Padhye, J.; Patel, P.; Prabhakar, B.; Sengupta, S.; Sridharan, M. Data center TCP (DCTCP). In Proceedings of the ACM Special Interest Group on Data Communication (SIGCOMM) Annual Conference, Delhi, India, 30 August–3 September 2010; pp. 63–74. [Google Scholar]
- Chen, L.; Lingys, J.; Chen, K.; Liu, F. AuTO: Scaling Deep Reinforcement Learning for Datacenter-Scale Automatic Traffic Optimization. In Proceedings of the ACM Special Interest Group on Data Communication (SIGCOMM) Annual Conference, Budapest, Hungary, 20–25 August 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 191–205. [Google Scholar] [CrossRef]
- Wilson, C.; Ballani, H.; Karagiannis, T.; Rowtron, A. Better never than late: Meeting deadlines in datacenter networks. ACM Spec. Interest Group Data Commun. (SIGCOMM), Comput. Commun. Rev. 2011, 41, 50–61. [Google Scholar] [CrossRef]
- Wischik, D.; Raiciu, C.; Greenhalgh, A.; Handley, M. Design, Implementation and Evaluation of Congestion Control for Multipath TCP. In Proceedings of the USENIX Symposium on Networked Systems Design and Implementation (NSDI), San Jose, CA, USA, 25–27 April 2011; Volume 11, p. 8. [Google Scholar]
- Van Der Pol, R.; Boele, S.; Dijkstra, F.; Barczyk, A.; van Malenstein, G.; Chen, J.H.; Mambretti, J. Multipathing with MPTCP and OpenFlow. In Proceedings of the Super Computing (SC), High Performance Computing, Networking Storage and Analysis, Salt Lake City, UT, USA, 10–16 November 2012; pp. 1617–1624. [Google Scholar]
- Narayan, A.; Cangialosi, F.; Raghavan, D.; Goyal, P.; Narayana, S.; Mittal, R.; Alizadeh, M.; Balakrishnan, H. Restructuring endpoint congestion control. In Proceedings of the 2018 Conference of the ACM Special Interest Group on Data Communication (SIGCOMM), Budapest, Hungary, 20–25 August 2018; pp. 30–43. [Google Scholar]
- Tokui, S.; Oono, K.; Hido, S.; Clayton, J. Chainer: A next-generation open source framework for deep learning. In Proceedings of the Workshop on Machine Learning Systems (LEARNINGSYS) in the Twenty-Ninth Annual Conference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 2–8 December 2015; Volume 5, pp. 1–6. [Google Scholar]
- Jose, L.; Yan, L.; Alizadeh, M.; Varghese, G.; McKeown, N.; Katti, S. High speed networks need proactive congestion control. In Proceedings of the ACM Workshop on Hot Topics in Networks, Philadelphia, PA, USA, 16–17 November 2015; pp. 1–7. [Google Scholar]
- Wang, J.; Wen, J.; Li, C.; Xiong, Z.; Han, Y. DC-Vegas: A delay-based TCP congestion control algorithm for datacenter applications. J. Netw. Comput. Appl. 2015, 53, 103–114. [Google Scholar] [CrossRef]
- Jin, C.; Wei, D.; Low, S.H.; Bunn, J.; Choe, H.D.; Doylle, J.C.; Newman, H.; Ravot, S.; Singh, S.; Paganini, F.; et al. FAST TCP: From theory to experiments. IEEE Netw. 2005, 19, 4–11. [Google Scholar]
- Xia, Y.; Wu, J.; Xia, J.; Wang, T.; Mao, S. Multipath-aware TCP for Data Center Traffic Load-balancing. In Proceedings of the IEEE/ACM 29th International Symposium on Quality of Service (IWQOS), Tokyo, Japan, 25–28 June 2021; pp. 1–6. [Google Scholar]
- Xu, Z.; Tang, J.; Yin, C.; Wang, Y.; Xue, G. Experience-Driven Congestion Control: When Multi-Path TCP Meets Deep Reinforcement Learning. IEEE J. Sel. Areas Commun. 2019, 37, 1325–1336. [Google Scholar] [CrossRef]
- Naeem, F.; Srivastava, G.; Tariq, M. A software defined network based fuzzy normalized neural adaptive multipath congestion control for the Internet of Things. IEEE Trans. Netw. Sci. Eng. 2020, 7, 2155–2164. [Google Scholar] [CrossRef]
- Cao, Y.; Dai, B.; Mo, Y.; Xu, Y. IQoR: An Intelligent QoS-aware Routing Mechanism with Deep Reinforcement Learning. In Proceedings of the IEEE Conference on Local Computer Networks (LCN), Sydney, Australia, 16–19 November 2020; IEEE Computer Society: Los Alamitos, CA, USA, 2020; pp. 329–332. [Google Scholar] [CrossRef]
- Dhurandher, S.K.; Singh, J.; Obaidat, M.S.; Woungang, I.; Srivastava, S.; Rodrigues, J.J. Reinforcement learning-based routing protocol for opportunistic networks. In Proceedings of the IEEE International Conference on Communications (ICC), Dublin, Ireland, 7–11 June 2020; pp. 1–6. [Google Scholar]
- Mizutani, K.; Akashi, O.; Terauchi, A.; Kugimoto, T.; Maruyama, M. A dynamic flow control mechanism based on a hierarchical feedback model for data center networks. In Proceedings of the IEEE Network Operations and Management Symposium, Maui, HI, USA, 16–20 April 2012; pp. 599–602. [Google Scholar]
- Abu-Libdeh, H.; Costa, P.; Rowstron, A.; O’Shea, G.; Donnelly, A. Symbiotic routing in future data centers. In Proceedings of the ACM Special Interest Group on Data Communication (SIGCOMM) Annual Conference, Delhi, India, 30 August–3 September 2010; pp. 51–62. [Google Scholar]
- Touihri, R.; Alwan, S.; Dandoush, A.; Aitsaadi, N.; Veillon, C. CRP: Optimized SDN routing protocol in server-only CamCube data-center networks. In Proceedings of the IEEE International Conference on Communications (ICC), Shanghai, China, 22–24 May 2019; pp. 1–6. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep reinforcement learning with double q-learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30, pp. 2094–2100. [Google Scholar]
- Pawelzik, K.; Kohlmorgen, J.; Müller, K.R. Annealed competition of experts for a segmentation and classification of switching dynamics. Neural Comput. 1996, 8, 340–356. [Google Scholar] [CrossRef]
- Mathis, M.; Semke, J.; Mahdavi, J.; Ott, T. The macroscopic behavior of the TCP congestion avoidance algorithm. ACM Spec. Interest Group Data Commun. (SIGCOMM) Comput. Commun. Rev. 1997, 27, 67–82. [Google Scholar] [CrossRef]
- Fujita, Y.; Nagarajan, P.; Kataoka, T.; Ishikawa, T. Chainerrl: A deep reinforcement learning library. J. Mach. Learn. Res. 2021, 22, 1–14. [Google Scholar]
- Alizadeh, M.; Yang, S.; Sharif, M.; Katti, S.; McKeown, N.; Prabhakar, B.; Shenker, S. pfabric: Minimal near-optimal datacenter transport. ACM Spec. Interest Group Data Commun. (SIGCOMM) Comput. Commun. Rev. 2013, 43, 435–446. [Google Scholar] [CrossRef]
- Liu, J.; Huang, J.; Lv, W.; Wang, J. APS: Adaptive packet spraying to isolate mix-flows in data center network. IEEE Trans. Cloud Comput. 2020. [Google Scholar] [CrossRef]
- Cho, I.; Jang, K.; Han, D. Credit-scheduled delay-bounded congestion control for datacenters. In Proceedings of the Conference of the ACM Special Interest Group on Data Communication (SIGCOMM), Los Angeles, CA, USA, 21–25 August 2017; pp. 239–252. [Google Scholar]
- Kodialam, M.; Lakshman, T.V.; Orlin, J.B.; Sengupta, S. A Versatile Scheme for Routing Highly Variable Traffic in Service Overlays and IP Backbones. In Proceedings of the IEEE International Conference on Computer Communications (INFOCOM), Barcelona, Spain, 23–29 April 2006; pp. 1–12. [Google Scholar] [CrossRef]
- Agiwal, M.; Roy, A.; Saxena, N. Next generation 5G wireless networks: A comprehensive survey. IEEE Commun. Surv. Tutor. 2016, 18, 1617–1655. [Google Scholar] [CrossRef]


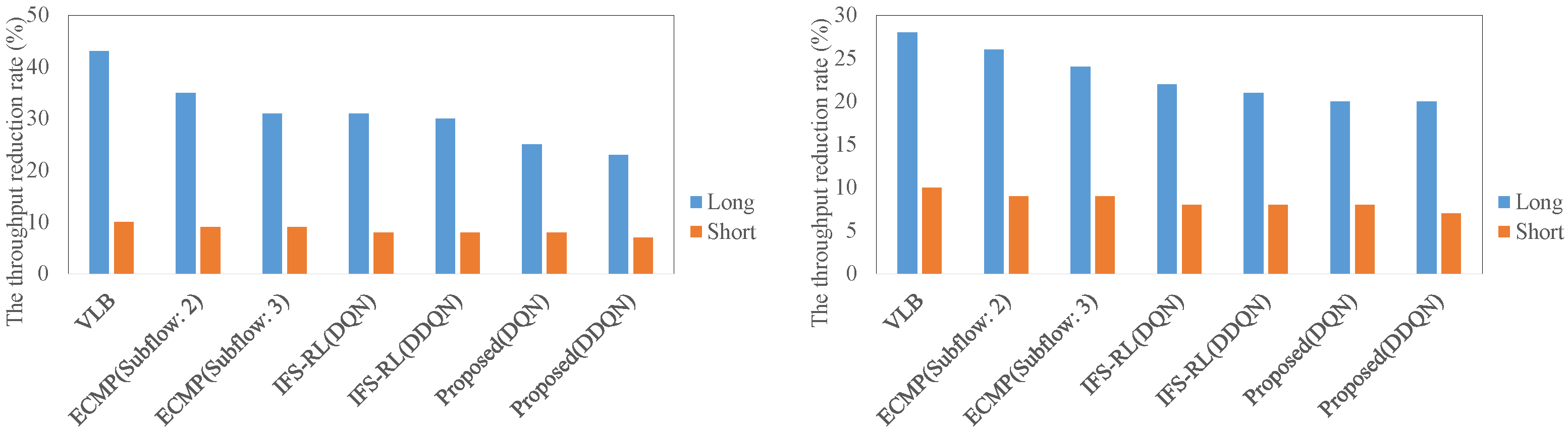
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mizutani, K. Effective TCP Flow Management Based on Hierarchical Feedback Learning in Complex Data Center Network. Sensors 2022, 22, 611. https://doi.org/10.3390/s22020611
Mizutani K. Effective TCP Flow Management Based on Hierarchical Feedback Learning in Complex Data Center Network. Sensors. 2022; 22(2):611. https://doi.org/10.3390/s22020611
Chicago/Turabian StyleMizutani, Kimihiro. 2022. "Effective TCP Flow Management Based on Hierarchical Feedback Learning in Complex Data Center Network" Sensors 22, no. 2: 611. https://doi.org/10.3390/s22020611
APA StyleMizutani, K. (2022). Effective TCP Flow Management Based on Hierarchical Feedback Learning in Complex Data Center Network. Sensors, 22(2), 611. https://doi.org/10.3390/s22020611