In this section, first, an overview of the proposed concatenating spatial and temporal features method is stated, showing and explaining the system architecture. Second, the descriptions on the data pre-processing, including synchronizing data collection, labeling and building dataset are addressed. Last, the design of CCLN consisting of three functional blocks, CNN Block, LSTM Block and Output Block, is presented.
2.1. System Overview
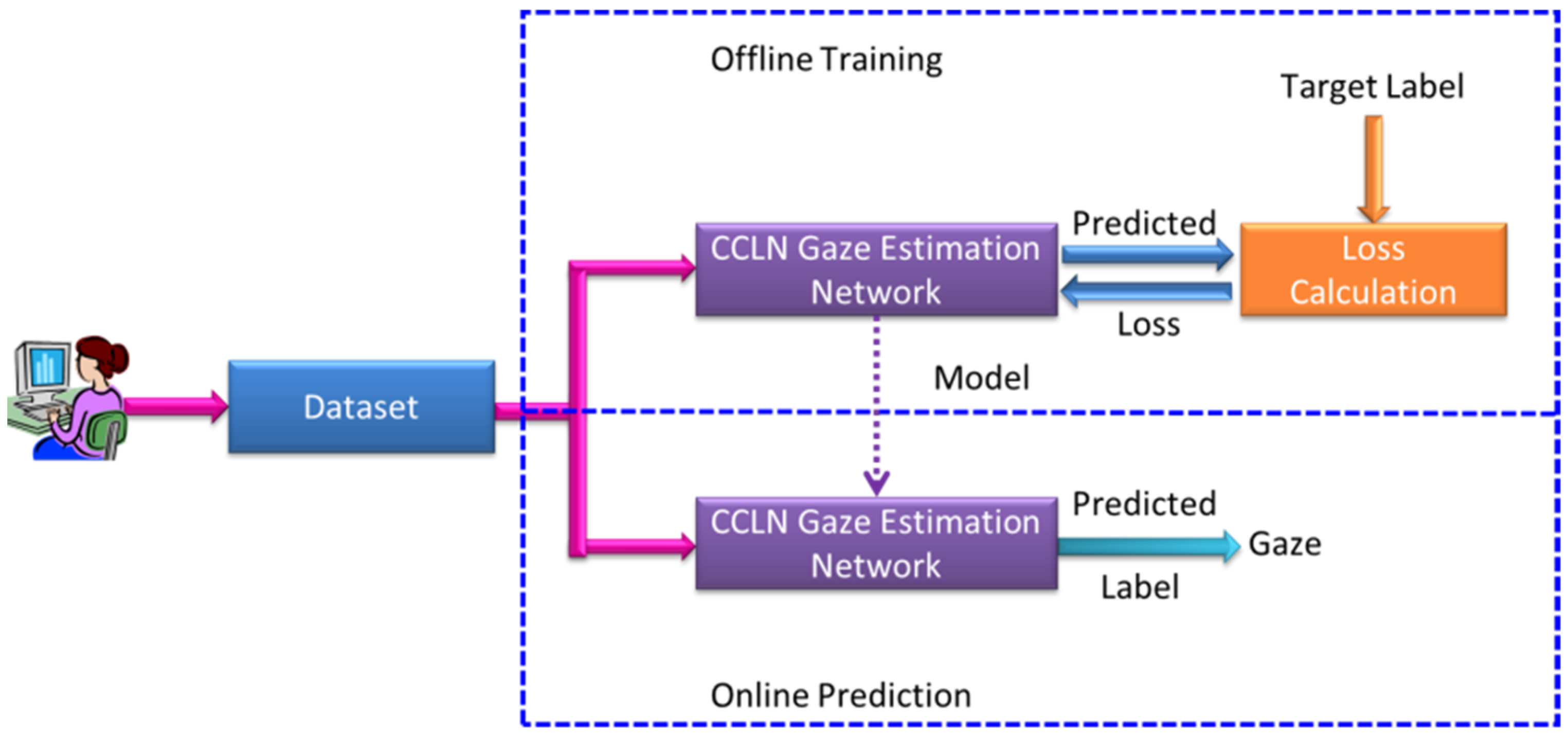
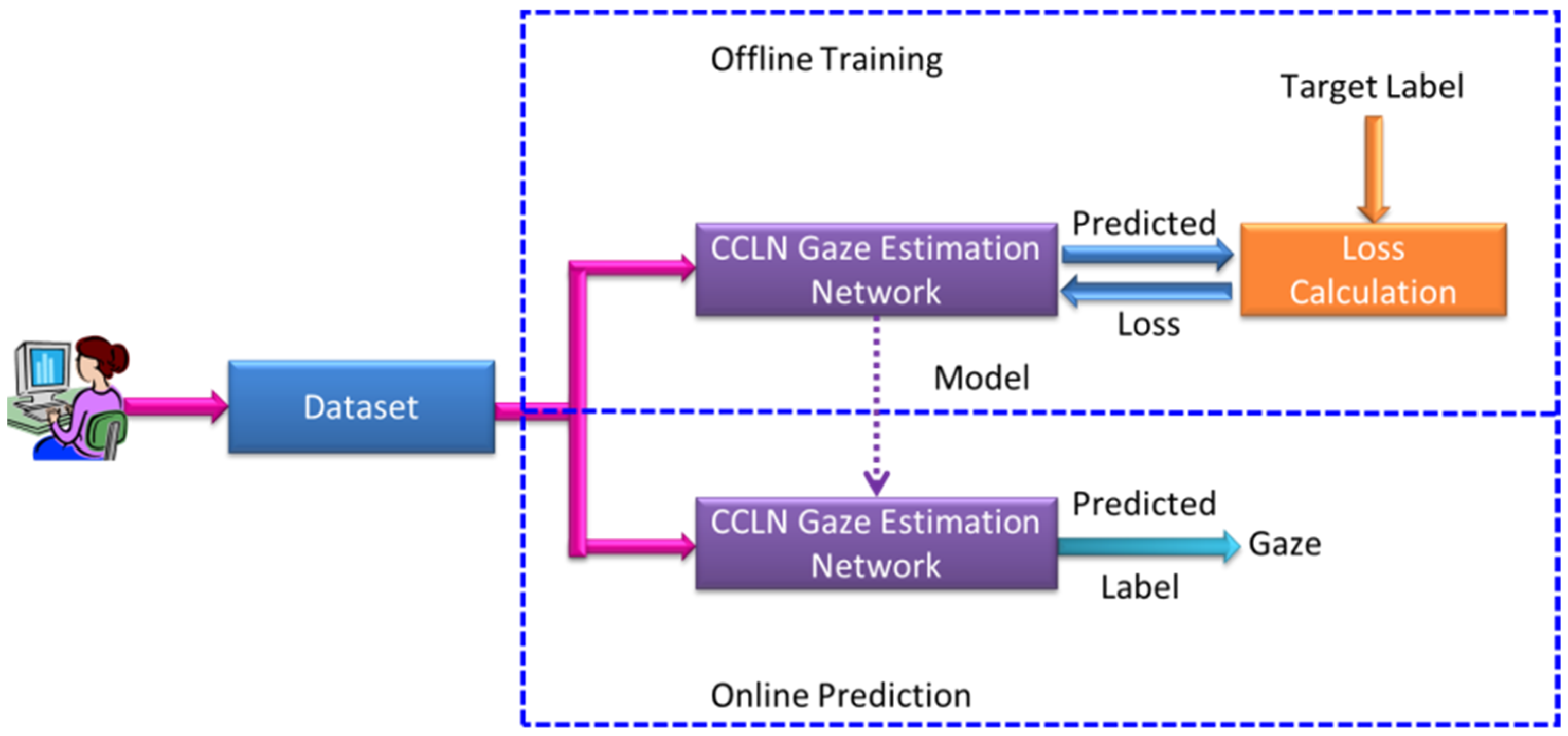
Figure 1 shows the system architecture for gaze point estimation based on concatenating spatial and temporal futures, including Offline Training and Online Prediction procedures. There are three function blocks consisting of the proposed Dataset, CCLN Gaze Estimation Network, and Loss Calculation. In the Online Prediction procedure, the prediction model is transferred when the Offline Training procedure is terminated. In our previous research [
15], the input model of the face image was the best output result; therefore, this study continues to use such type of images as the training and prediction data.
In the past, video was rarely used as the input data for gaze point estimation. This paper proposes to record facial images while participants watching a movie, supplemented by the gaze point coordinates labelled by the eye tracker, to create a dataset with time-series-synchronized data. This dataset will be used as the training sample of the CCLN proposed in this paper. CCLN Gaze Estimation Network is designed for concatenating spatial and temporal features. In the prediction procedure, video (i.e., Stimulus video) is used as an estimation unit.
This paper mainly completes several tasks including the following:
Both the quantity and the content of training data are important factors that affect the final performance of machine learning. Data labeling is a heavy task. Designing an automatic labeling method can speed up and increase the construction of a training dataset.
- 2.
Constructing a dataset by watching movies
There are some public datasets built for viewing moving objects, mainly known objects such as small circles. They made participants gaze on the small circle on the screen, and then mark the connection coordinating this known object and the eye or face image. However, the visual behavior occurred in this kind of experimental environment setting is very different from that of generally watching a movie. There are few datasets that use videos (face) as the training data, so it is necessary to build a suitable time-series-related dataset. In this paper, the proposed method is to obtain the images taken by a webcam when participants viewing each movie frame. Further labeling the image to coordinate with the gaze point estimated by the infrared eye tracker to build a dataset of the synchronized time-series. However, such a taken image is still too messy and not suitable for direct use as a training sample, so the image needs to be cropped to a fixed size. In addition, a method is proposed to compose the taken images into a video with the consideration of an appropriate length.
- 3.
Designing the network architecture of CCLN
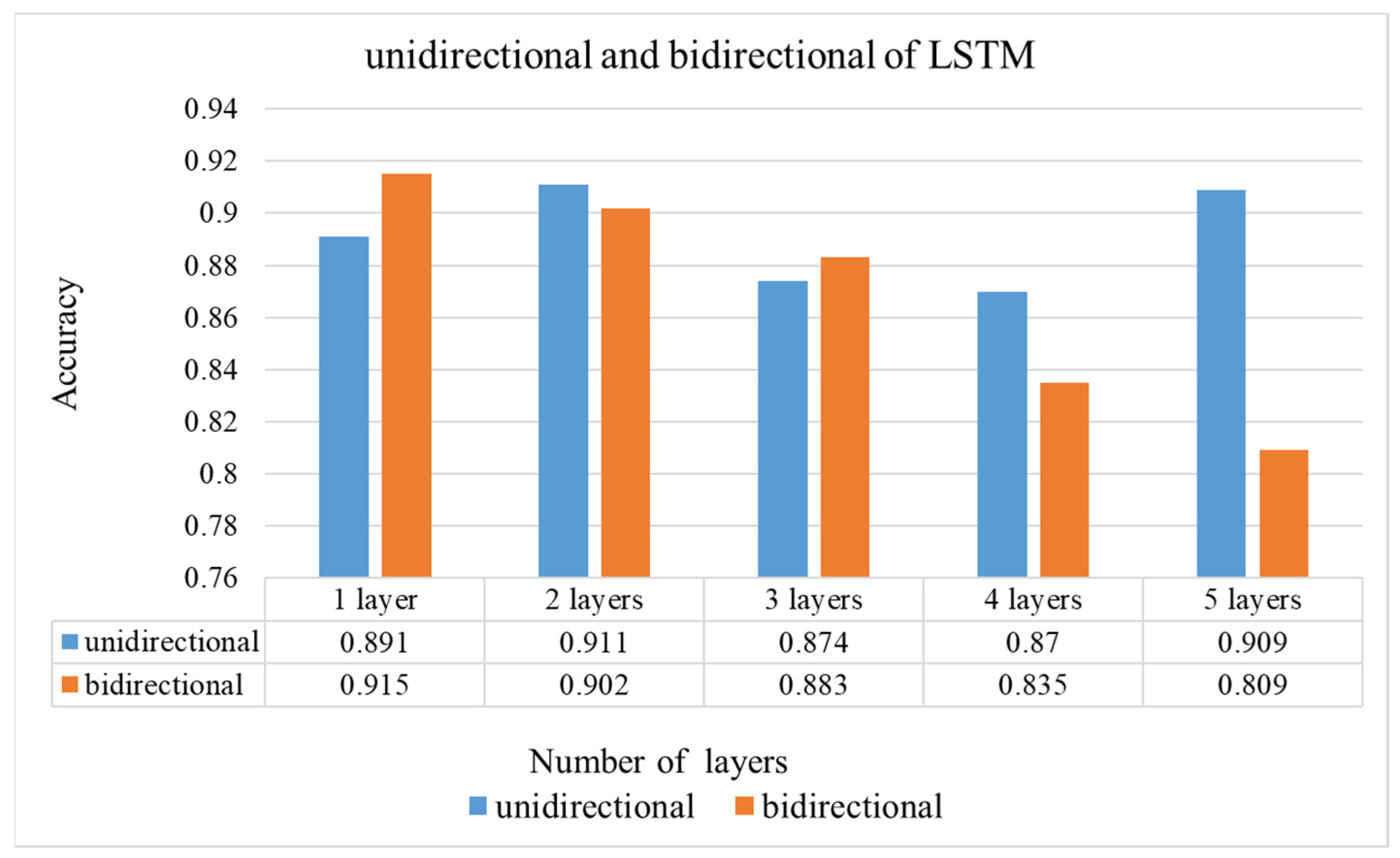
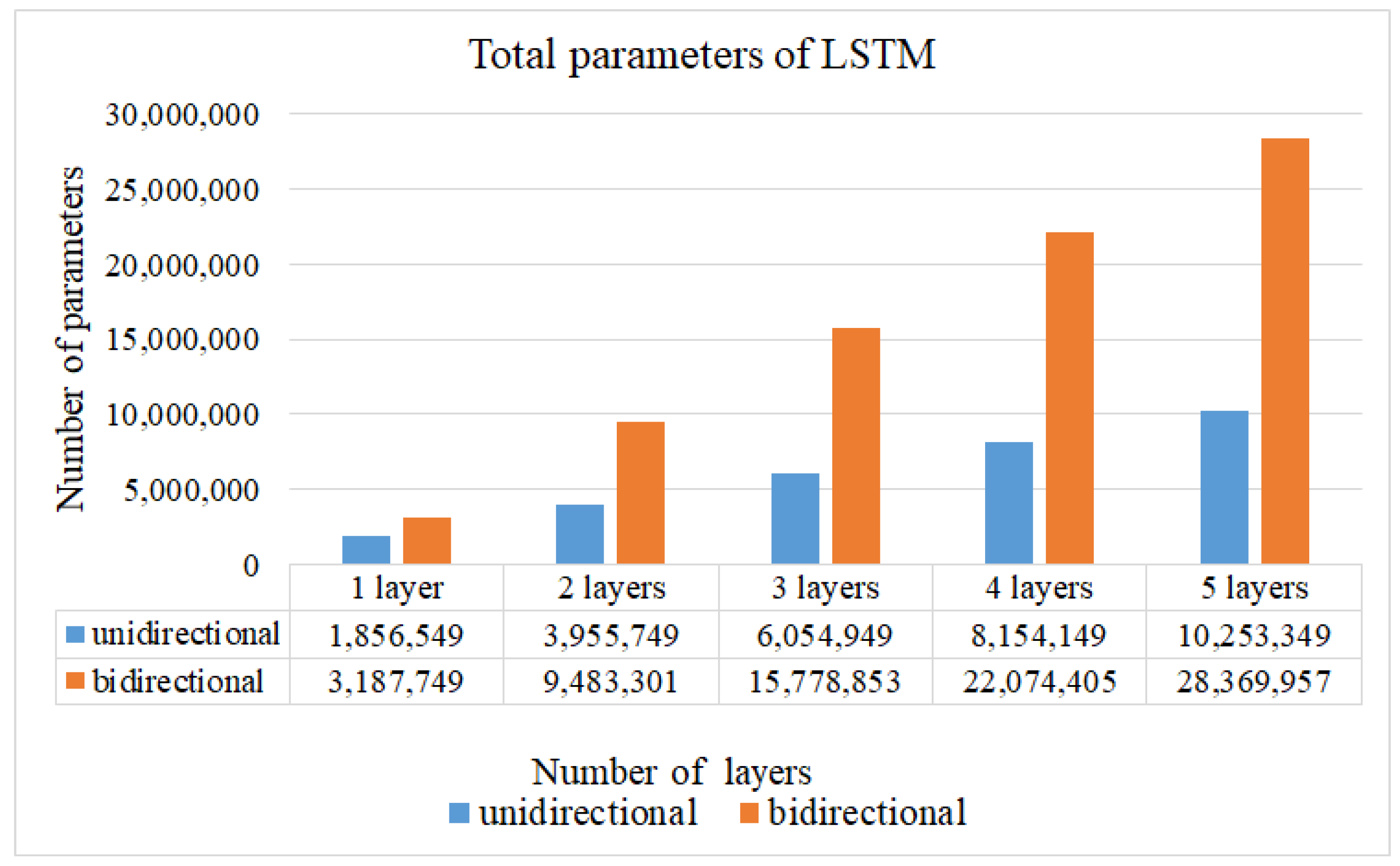
Other than using the eye image as the main extraction feature for gaze estimation, using the face image can overcome the influence caused by the head movement. Therefore, the training of CCLN will take the built video dataset as the training sample with the face image as the input image. Moreover, a complicated network architecture will easily lead to overfitting when the input image consists of few features. Hence, the number of LSTM layers, batch normalization and global average pooling are used to explore a model to obtain a balance between better prediction accuracy and reducing complexity. The performance, including accuracy, loss, recall, F1 score and precision, etc., are computed.
- 4.
Studying the performance of commonly used models and the impact of transfer learning
This paper evaluates the performance of CNN when it is replaced by commonly used network models, including VGG16, VGG19, ResNet50, DenseNet121 and MobileNet. In addition, whether or not the effect of trained weights is initially used during training is evaluated, as a way to explore the generality of the network architecture proposed in this paper.
2.2. Synchronizing Data Collection, Labeling and Building Dataset
In order to obtain datasets of eye and face images for labeling, it is common to manage the viewable screen area into M × N regions with showing a predetermined target to be viewed, the target usually as a circle appearing in the center or moving toward the center of each region area in a random manner [
12,
13]. The eye images and the face images tracing the target to be viewed are recorded and marked during the viewing process. There are two problems with the abovementioned obtainment of the datasets. Firstly, the data obtained are limited to the center position of gazed region blocks, and the amount of data is relatively insufficient.
Secondly, by observing the results of static images [
28,
29], which have been marked with the gaze points, it can be found that the gaze points are actually concentrated on the objects of interest. For example, it can be proved from
Figure 2 [
28] that the position of the object in the image will affect the visual behavior, which will affect the area of interest for viewing, so the abovementioned obtainment of the datasets [
12,
13] is not favorable. Besides, although datasets such as [
28,
29] contain gaze point information, they lack the eye image at this time and cannot be directly used for training.
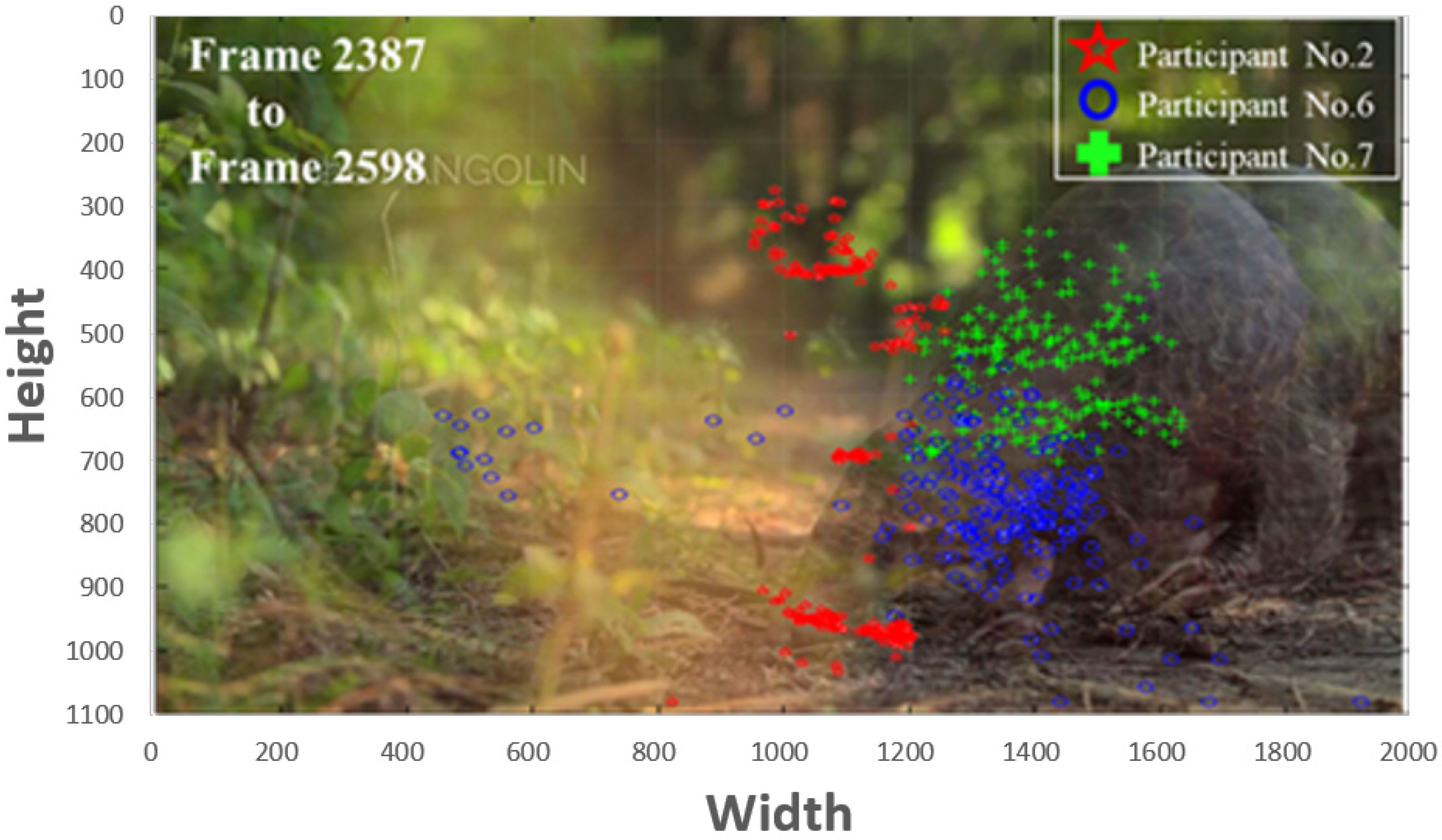
In addition, we have conducted an experiment on the gaze behavior of the participants while watching the arranged video regarding to the pangolin object.
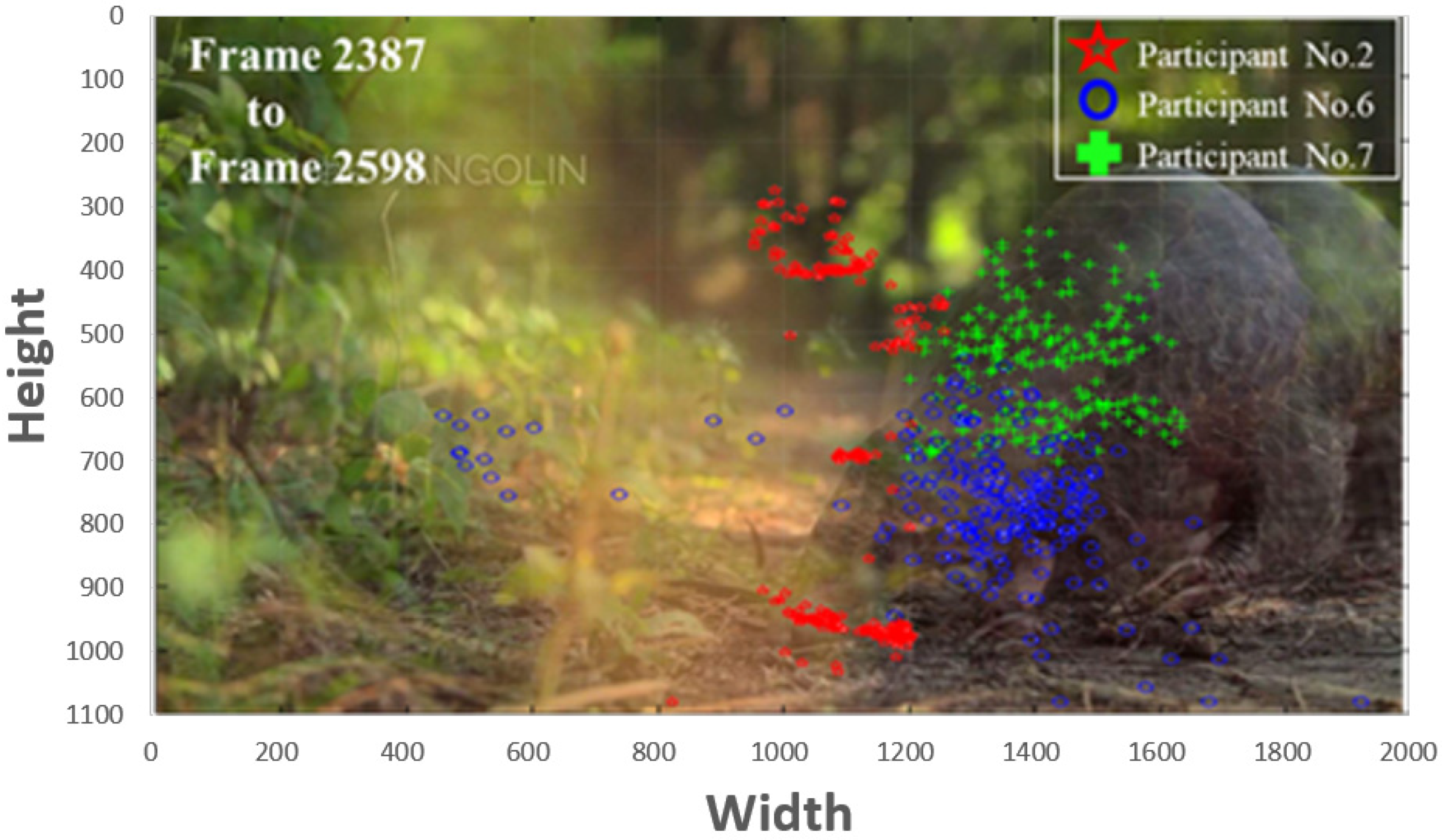
Figure 3 shows the examples that the visual behavior exhibits personal preferences with distinctly different distributions of gazes. It exhibits the result of comparing the gaze points of the different participants during frame 2387 to frame 2598 to express the attentions. Comparing to participant No. 2, the distributions of gaze points of participants No. 6 and No. 7 are more aggregated. Even though the areas of interest are different, all of the three participants have attended the pangolin object. This result also demonstrates that the gaze point is clustered and time-related.
For obtaining the training dataset, this research paper proposes to adopt an eye tracker to record gaze points of the participants while watching the video of general films. There are currently some eye trackers that use infrared light to detect gaze points with acceptable accuracy, and they have been adopted by some studies [
28]. For the eye tracker to achieve higher detection accuracy, a calibration process needs to be conducted prior to engaging the participant in the recording process initiated by the eye tracker. One should be also aware that the functionable distance for an eye tracker to detect gazes is relatively short as well as sever head and body movements might have impacts on detection accuracy. This infrared type of eye tracker is an acceptable auxiliary tool for acquiring gaze points to implement the proposed automatic labeling. Furthermore, a webcam along with the eye tracker is used for acquiring face images at the meantime to build the corresponding eye and face datasets.
To achieve the automatically labeling data for training, the acquired data of gaze points detected by the eye tracker and face images captured by the webcam must first be synchronized, in terms of the timestamps and the corresponding frame numbers. Therefore, this research paper designs a method for obtaining the synchronized data. In order to keep simultaneously with the frame rate of the video, the webcam is set to capture the face image of the participant while watching the video with one shot per frame. That is, the frequency of taking face images is the same as the frequency of the video frame rate. In the meantime, the (x, y) coordinates and time (frame number) of the current gaze point taken by eye tracker are recorded. The synchronization is implemented by using the frame number as the unit of time to associate the data between the coordinates of a gaze point and a captured face image. In order to achieve the purpose of automatically labeling data, in the program development, we first play the video and record the number of the frame, then capture the face image and get the gaze point detected by the gaze tracker at this time. Finally, the number of the frame, gaze point and face image serial number are combined into a record of data for storage. When training the input video, the corresponding relevant annotation data can be obtained at the same time.
Furthermore, the face images obtained by the webcam need to be cropped prior to be used as the training samples. Generally, facial recognition using facial landmarks for calibrating is to adjust the face to the center of the picture, the eyes of the face are on the horizontal line, and the face size of each picture is scaled to the same size. This study uses facial landmarks for facial recognition and using the center of the frame as the alignment base to crop the obtained face images. Since the heads and bodies of participants might move in pitch, roll and yaw with the distance changes from the camera or participants posse different eye heights, there are different image patterns of face and eye when participants look at the same position. These variations of different image patterns corresponding to the same gaze point should be regarded as visual behavior characteristics. If the obtained face image is cropped with the face as the alignment center, part of the features will be lost. To retain these features, the obtained face image will be cropped relative to the center of the frame.
It is observed that when gaze points gather on a certain object of interest in a short time, there will be no large-scale movement of adjacent positions. When the object of interest is changed, gaze points may shift away to another interested object with more movements. Based on the above observation on gathering effects and distinguished movements of shifting gaze points associated to the object of interests, this study proposes a method to composite the captured corresponding face images into the video as the training dataset. Gaze is dynamic and the probability of having consecutive gaze points with the same coordinates is extremely low. The face images are encoded into video to build the dataset with the following rule. This study presents the concept of a B × B macroblock, with size of width B pixels and height B pixels, as a basis for composing the training data. If the nth frame is the first frame of the video to be produced, we calculate the distance of the gaze points between the nth frame and the (n + 1)th frame. If the distance is within B/2 pixels, we record this frame and continue to calculate the next frame until it exceeds B/2 pixels, and then proceed to the next calculation procedure. The face images mapping to frames in the same recording are converted into a video, i.e., a training or test data in the dataset. The face images of the gaze points in a macroblock of B × B pixels are converted into a training data. The lengths of the composed training videos will adversely affect the training results. The built dataset is randomly split into 0.7, 0.2, and 0.1 for training, testing, and evaluation sets, respectively. A built dataset is a labelled folder storing data collected from each participant, respectively. Prior to performing training and testing the model, data in a respective dataset folder are randomly selected and split into 7:2:1 for training, testing, and evaluation sets. The approach of splitting the datasets into training and testing datasets can be reproducible.
The experimental tools for collecting data and 6 selected videos to watch are the same as used in [
15], including a 22-inch with 16:9 screen is used as the video playback device, Logitech C920r HD Pro Webcam and Tobii Eye Tracker 4C, respectively, for capturing face image and getting the gaze point. The participants watched 6 selected videos, each with a size of 1920 × 1080 pixels and a frame rate of 24 frames per second, played in a randomly selected manner. The detailed information of the videos is shown in
Table 1. The experiment and data are newly conducted in accordance to this research purpose. In this study experiment, there are 28 participants and face images of them are collected. However, the data type used in this paper is different. The input data use video instead of images, whereas [
15] used images.
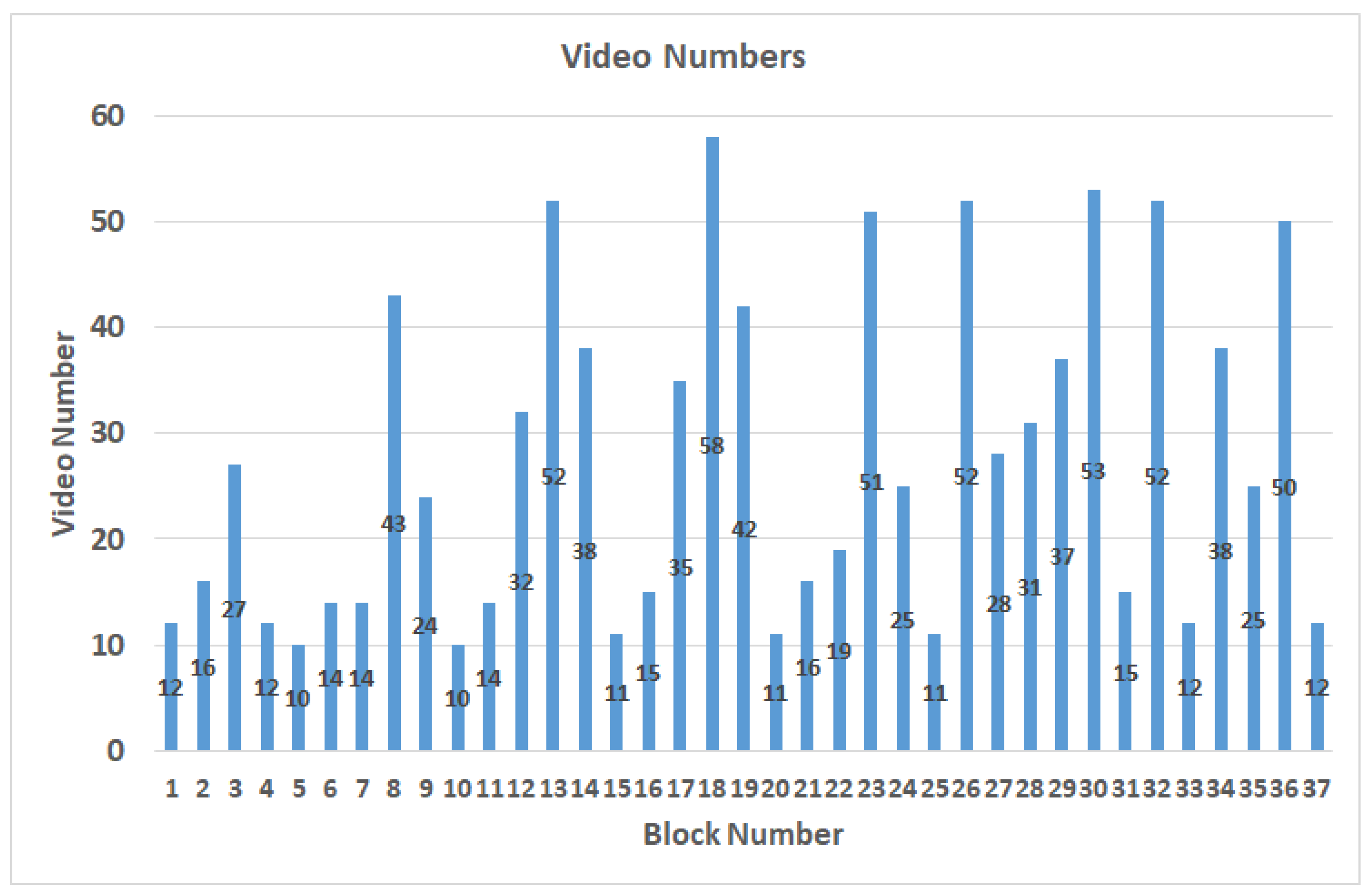
In the case of setting B to 30, after the production of the video, the video length distribution is less than 5 s, and 90% is within 1 s. Therefore, the threshold is set as 3 s, and if it exceeds, it will be divided into 2 equal segments. The dataset contains 1017 videos labeled with block numbers out of the 37 blocks proposed by [
15].
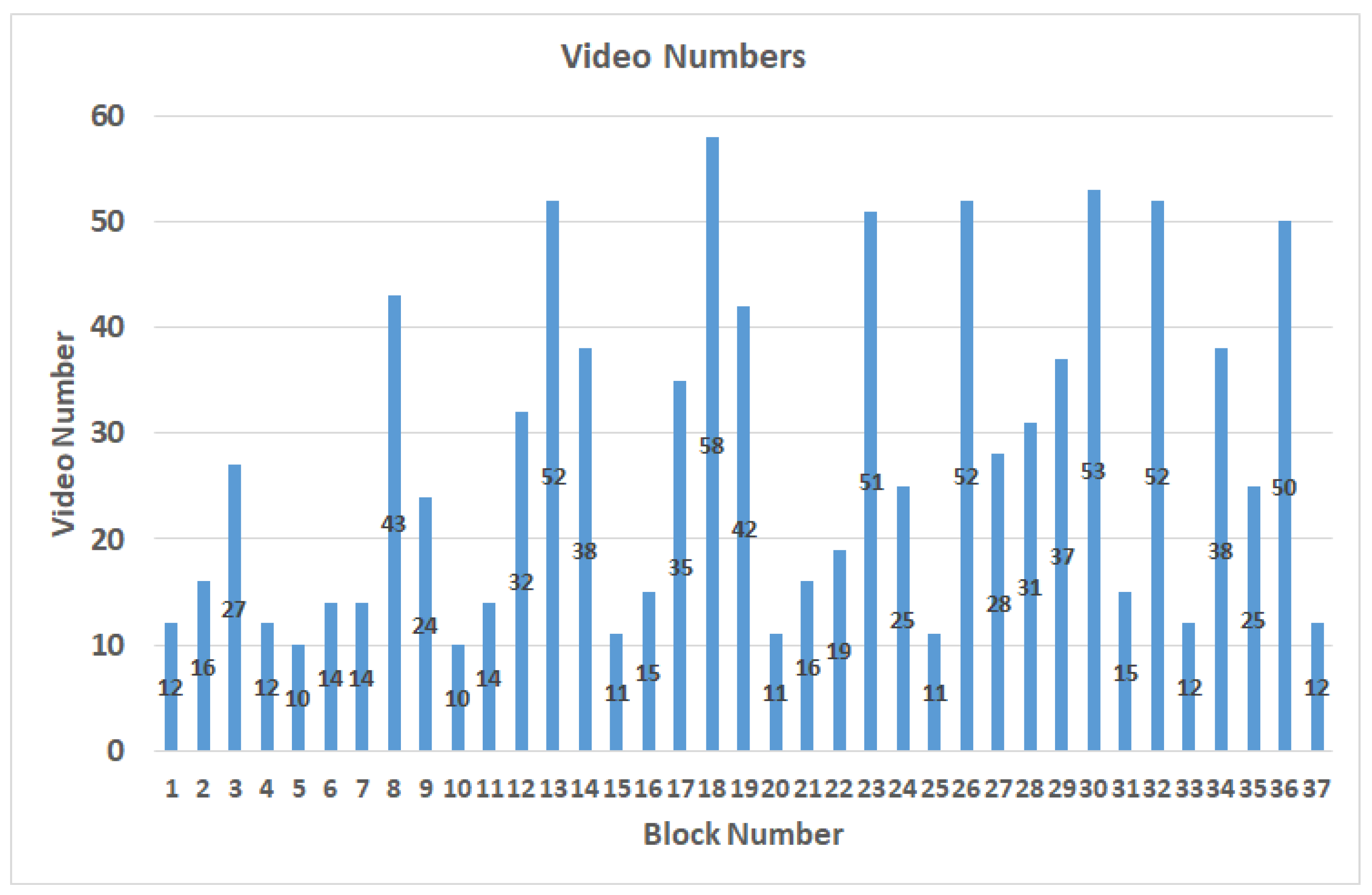
Figure 4 shows the distribution results after the videos are labeled as blocks. According to the proposed video splitting method, the length of each video is controlled within 3 s and the distribution is shown in
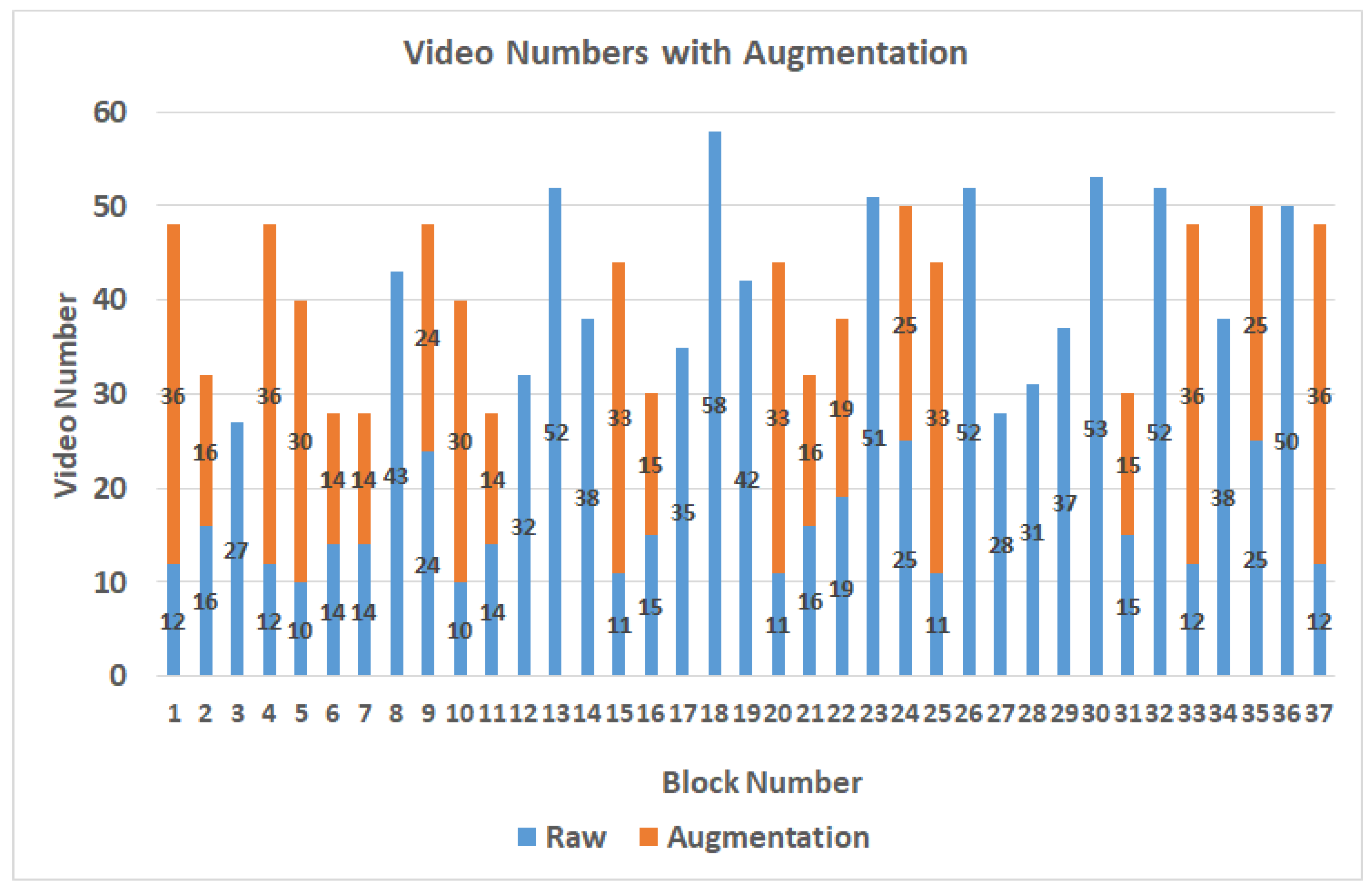
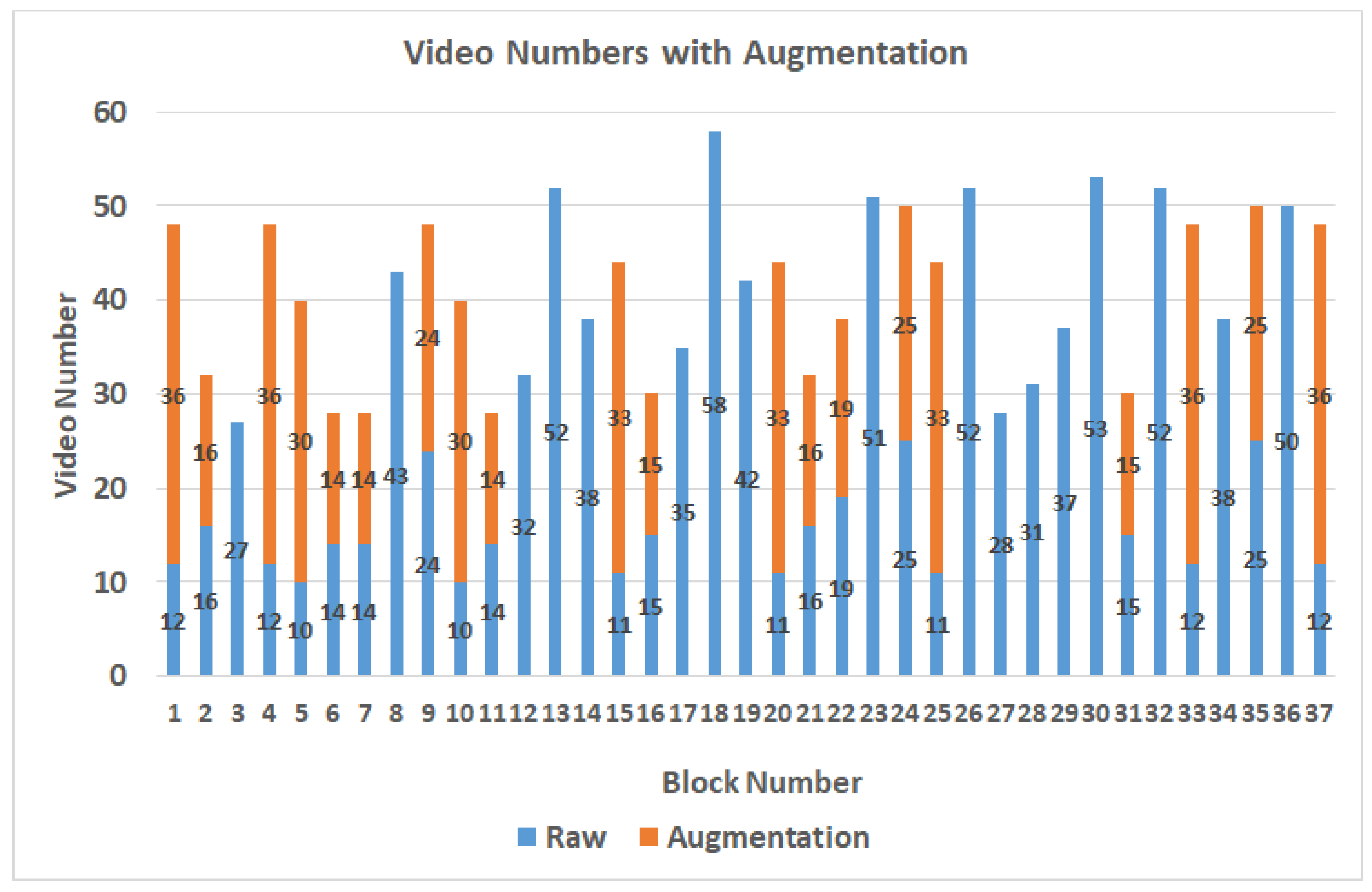
Table 2. When the participant is watching the video, the gaze points are usually in the area near the center of the screen, resulting in an uneven data distribution. The data augmentation method of brightness adjustments will be performed to expand the number of videos in blocks which contain fewer videos than the average number of videos in all blocks. Thus, the blocks with a lower number of videos can get enough data, and finally, there are 1517 videos after data augmentation, as shown in
Figure 5.
2.3. The Proposed CCLN Gaze Estimation Network
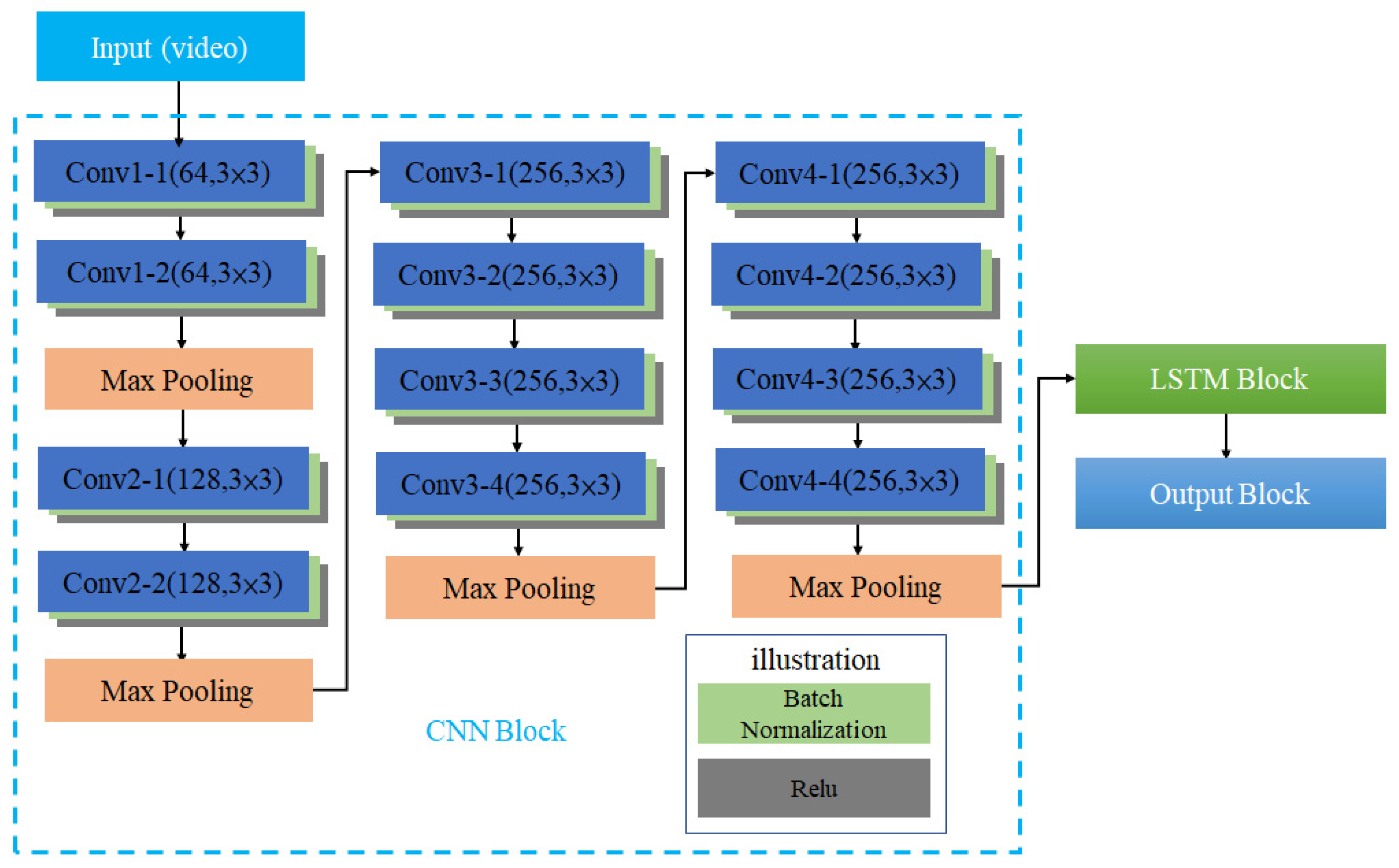
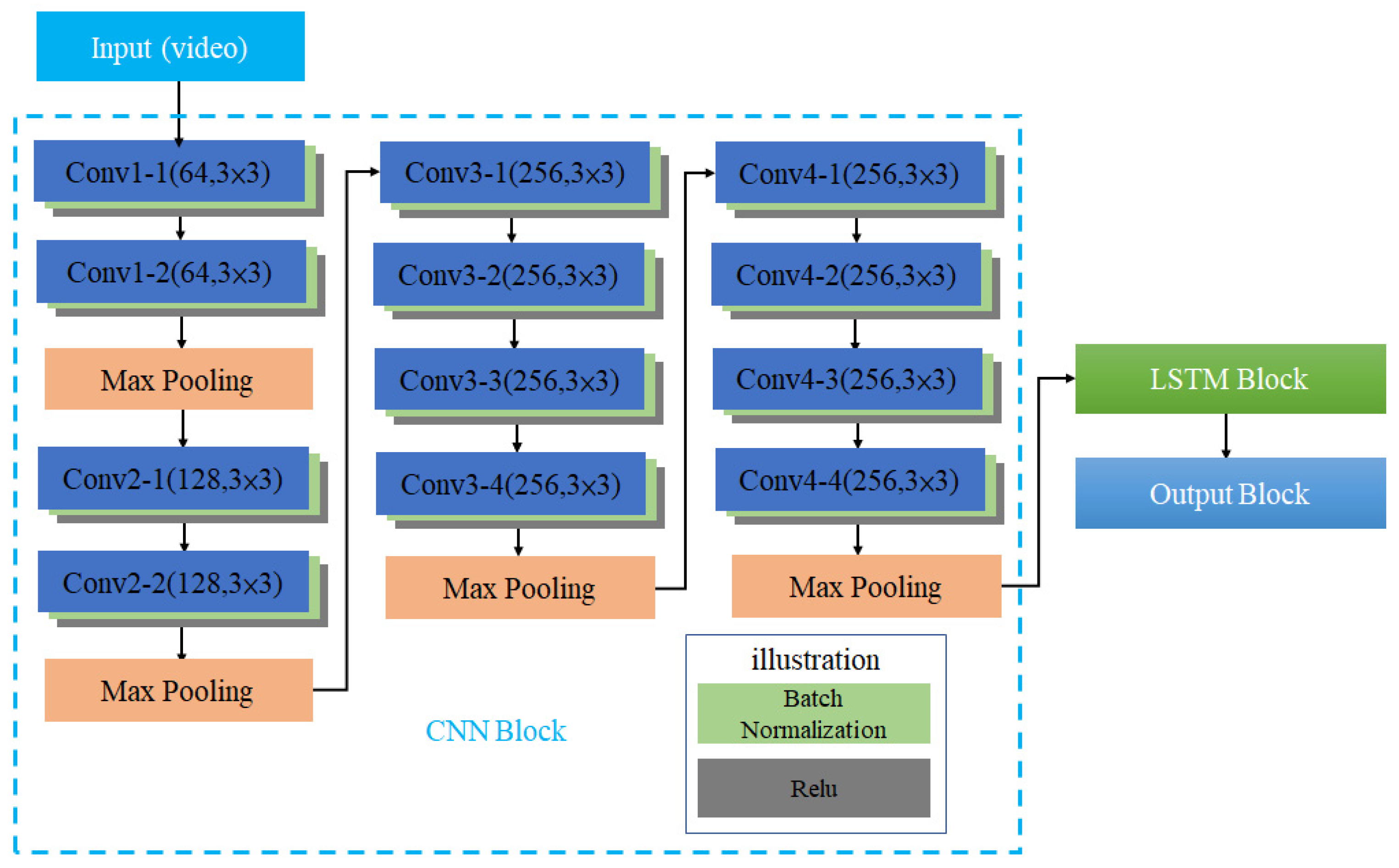
Figure 6 shows the architecture of CCLN Gaze Estimation Network consisted of 3 functional blocks, CNN Block, LSTM Block and Output Block. The architecture of CNN Block includes 12 layers of convolutional layers and 4 layers of Max Pooling. The number of convolutional layers is connected in series with 2, 2, 4, 4, and the middle is connected with the Max Pooling layer. After each convolutional layer in the model, batch normalization (BN) and Relu functions are added to reduce the computational complexity and are illustrated as light green and gray, respectively. The architecture of this CNN block is similar to that of [
15]. The difference is that there are no global average pooling (GAP) and Softmax layers, so it can have a better effect on transfer learning. The dataset built in this paper is randomly split into training, testing, and evaluation sets. According to the system architecture shown in
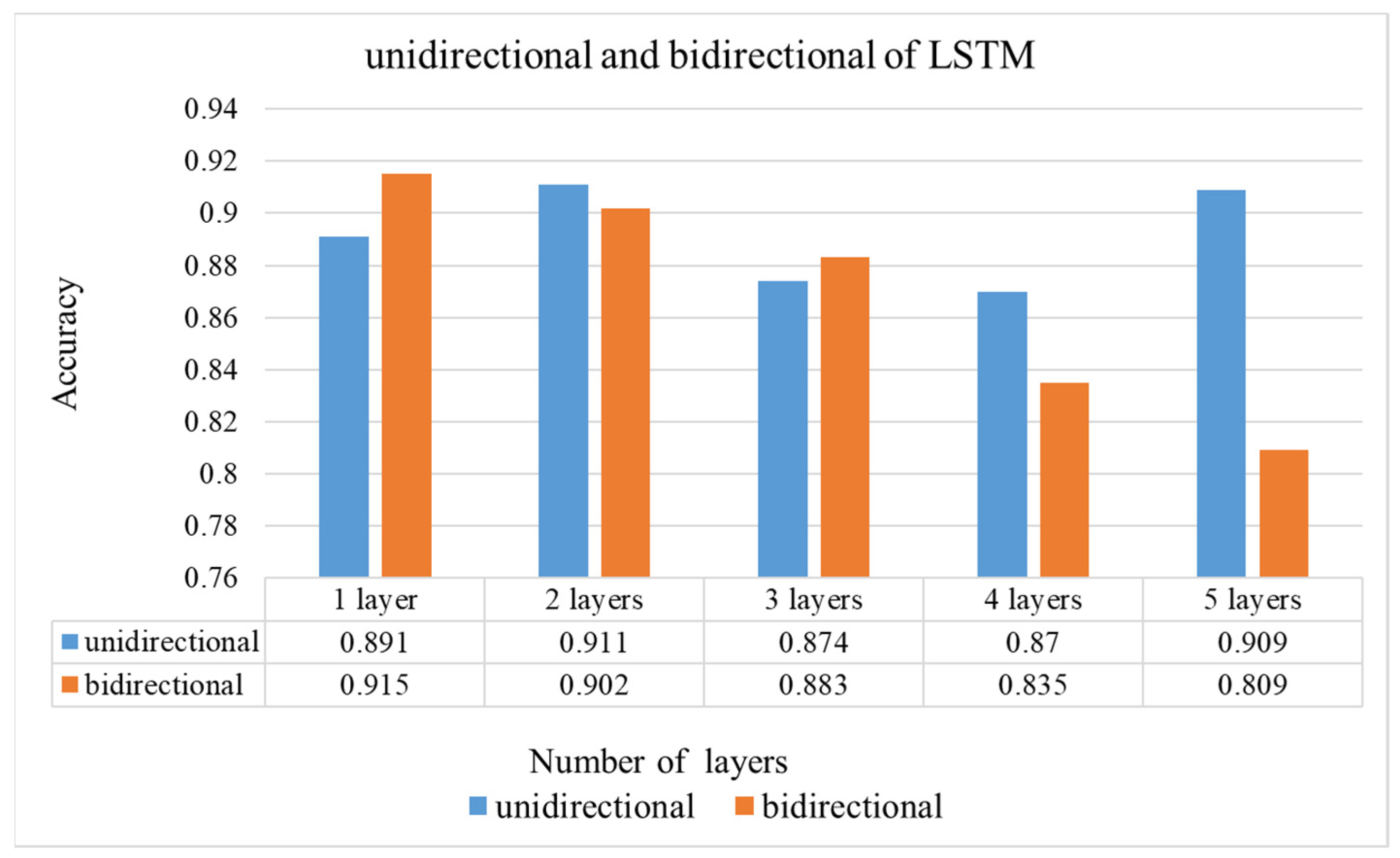
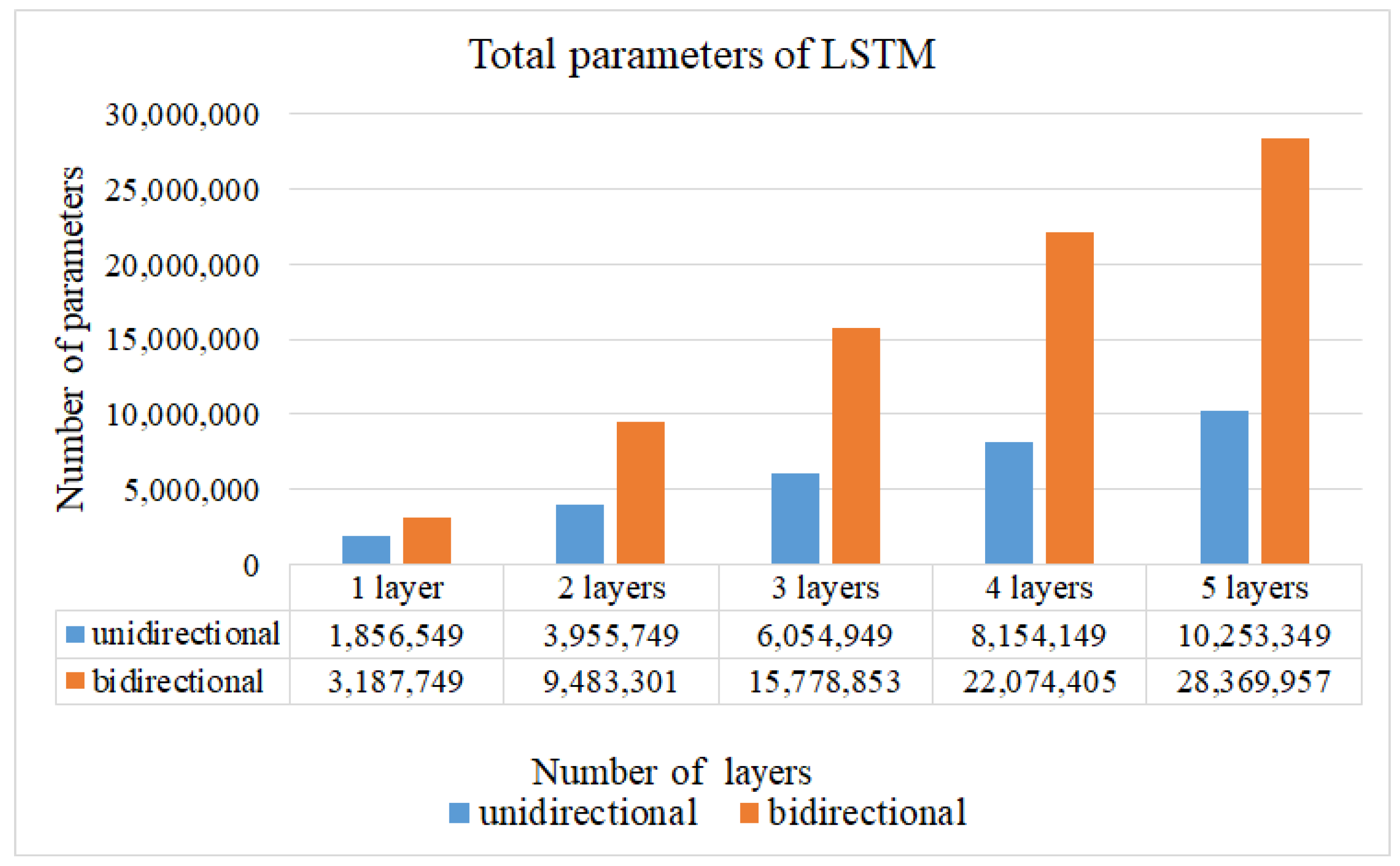
Figure 1, in the Offline Training state, a video in the training set is randomly selected and decoded into frames to input CCN in CCLN for training. For each built dataset, data collected from per participant, respectively, data in a respective dataset folder are randomly selected and split into 7:2:1 for training, testing, and evaluation sets. During performing Offline Training state, a video will be randomly selected from the training set, and then, the next one will be randomly selected, so forth and so on. Data for performing testing and evaluation are as well randomly selected with the same approach. In addition, the technique of early stopping is applied to end the training procedure. Then, the testing set is used to validate the performance of the trained model. Finally, the evaluation set is used to evaluate the effectiveness of the trained model including accuracy, loss, F1 score, recall and precision in the Online Prediction state. The LSTM Block analyzes the system performance including the following different conditions: the number of LSTM layers, the comparison of unidirectional and bidirectional LSTM architectures, and whether to use Dropout, BN. Usually, the Output Block includes fully connected (FC) and Softmax layers, the issue of the impact of replacing fully connected layer with GAP will be evaluated and presented in
Section 3.1.2.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}