
A PID-Based kNN Query Processing Algorithm for Spatial Data


Abstract
1. Introduction
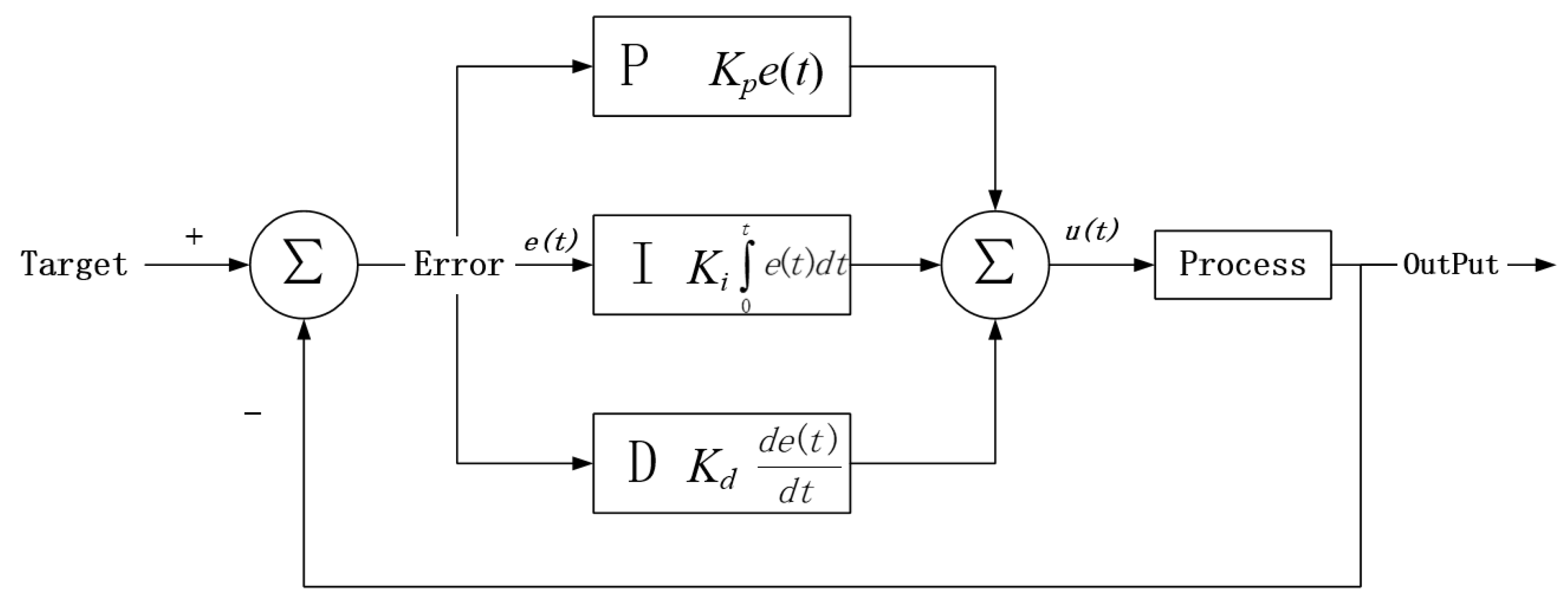
- We introduce the PID controller technology to the calculation of the kNN query radius growth step and realize the kNN query processing with a variable query radius growth step. This is the first time that the PID controller technique is introduced into the kNN query processing, making full use of the feedback mechanism of the PID controller, significantly improving the efficiency of spatial kNN query processing.
- We use the grid partitioning method and row sorting encoding to realize the partitioning and encoding of spatial data and construct a grid-based data index, which fully utilizes the advantages of simple structure and fast positioning of the grid index. We used a grid-based density peak clustering algorithm to optimize the setting of PID parameters and further improve the processing efficiency of spatial kNN queries.
- We conduct extensive performance evaluations using real and synthetic datasets. A series of experimental results show that our PIDKNN algorithm has good query processing performance and scalability and outperforms the existing kNN query algorithms.
2. Related Work
3. Methods
3.1. The Definition of Space kNN Query
- (1)
- Data objects in KSet(k) satisfy the inequality , where represents the distance from query point q to the data object .
- (2)
- For any data object \, satisfies .
3.2. PID-Based Parallel kNN Query Processing Algorithm
3.2.1. Grid Index Construction
3.2.2. Calculation of PID-Based Query Radius Growth Step and PID Parameter Setting
- Calculation of query radius growth step based on PID
- 2.
- PID parameter setting
3.2.3. PIDKNN Algorithm
| Algorithm 1: PIDKNN Algorithm |
| Input: Spatial data object set: DataSet, query points: Queryset, grid cell length: L, the value of K: k, grid cell number: num Output: kNN query result set |
| // Initialization 1. Conf = new SparkConf ( ) 2. sc = new SparkContext (conf) 3. Data = sc.textFile (DataSet) 4. ResultBuffer = null 5. Index = Grid_index_build (Data, num) 6. Cell_Cluster = Grid_dense_peak clustering (Index) 7. pid_list = PID_build (Cell_Cluster) //Initial kNN query processing 8. Query = sc.textFile (QuerySet) 9. id = getID (query, Index) 10. r = L 11. Local_Result = kNN (query, 0, r, k) 12. answer = merged (Local_Result) 13. answer = answer.sort 14. ResultBuffer.save (answer, k) // PID-based kNN query processing 15. While (ResultBuffer.length < k and Queried_gridCells < num) 16. sum = ResultBuffer.length 17. pid_parameters = get_pid_parameters (k, id, pid_list) 18. r_new = r + PID (k, sum, r, pid_parameters) 19. h = ResultBuffer.length 20. Local_Result = kNN (query, r, r_new, k- h) 21. r = r_new 22. answer = merged (Local_Result) 23. answer = answer.sort 24. ResultBuffer.save (answer, k-h) 25. end while 26. Result = ResultBuffer.Saveastextfile (k) 27. Return Result 28. sc.stop def kNN (Query, r_old, r_new, k): 29. gridCells_list = getIntersectingCells (query, r_old, r_new) 30. traversed_gridCells = gridCells_list.length 31. result = null 32. for (gridCells_list: cell) 33. for (cell: point) 34. if (r_old < dist(Query, point)≤ r_new) then 35. result.add(point) 36. end if 37. end for 38. Return result |
4. Experiments
4.1. Experimental Environment
4.2. Experimental Data
4.3. Experimental Results
4.3.1. Ablation Experiments
4.3.2. Query Performance Comparison
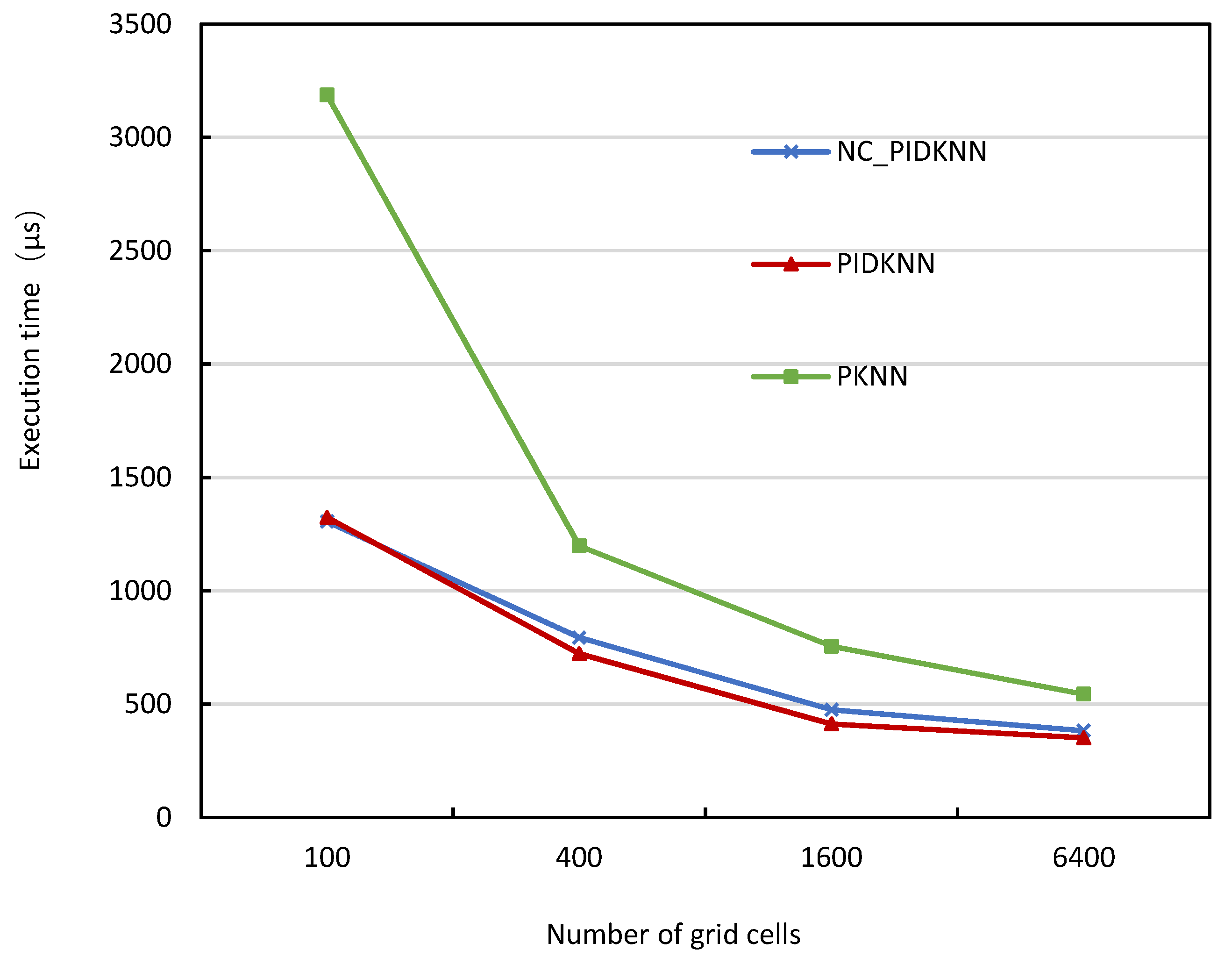
- 1.
- Execution time comparison with different numbers of grid cells
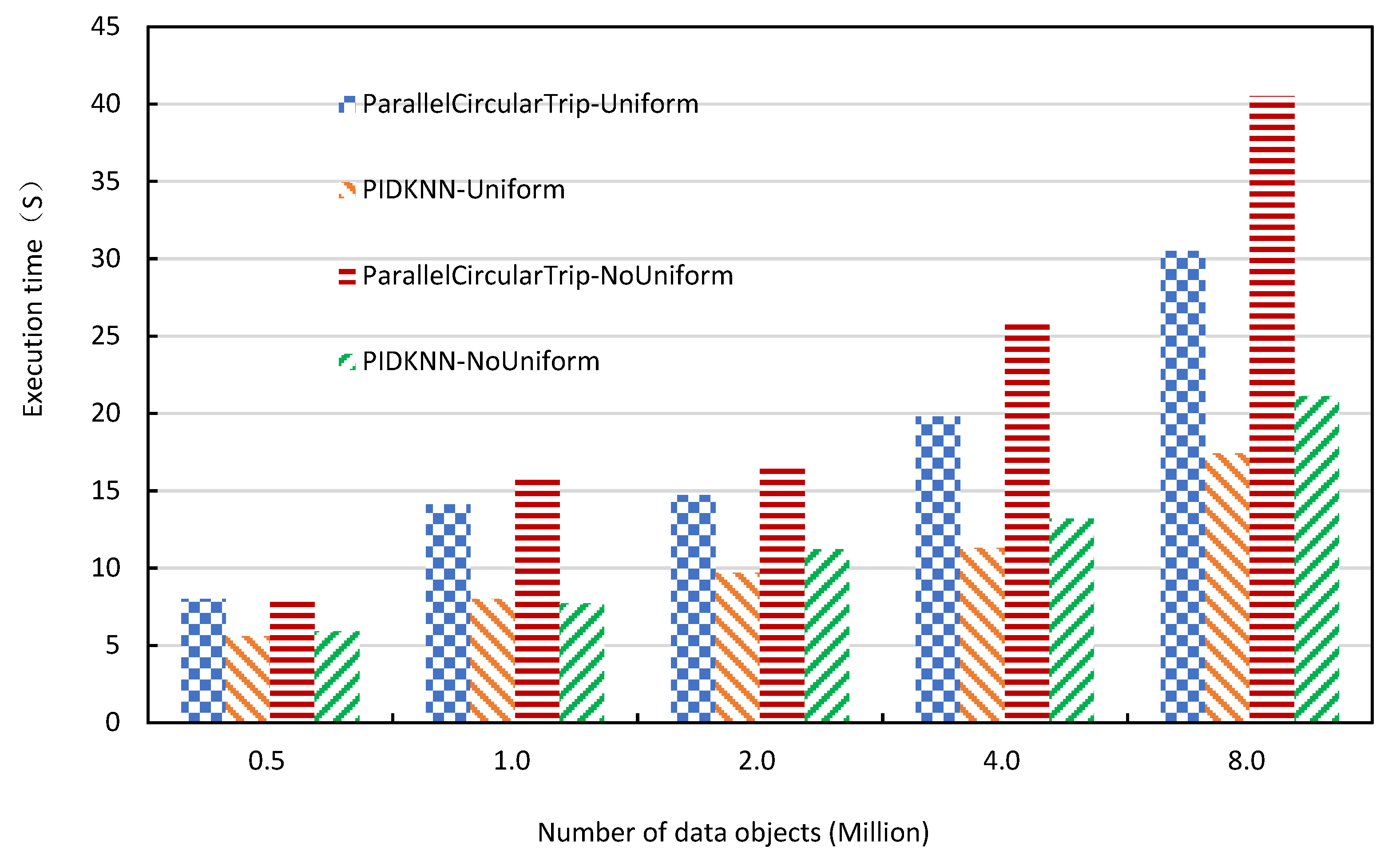
- 2.
- Execution time comparison with the size of data sets
- 3.
- Execution time comparison with the number of executors
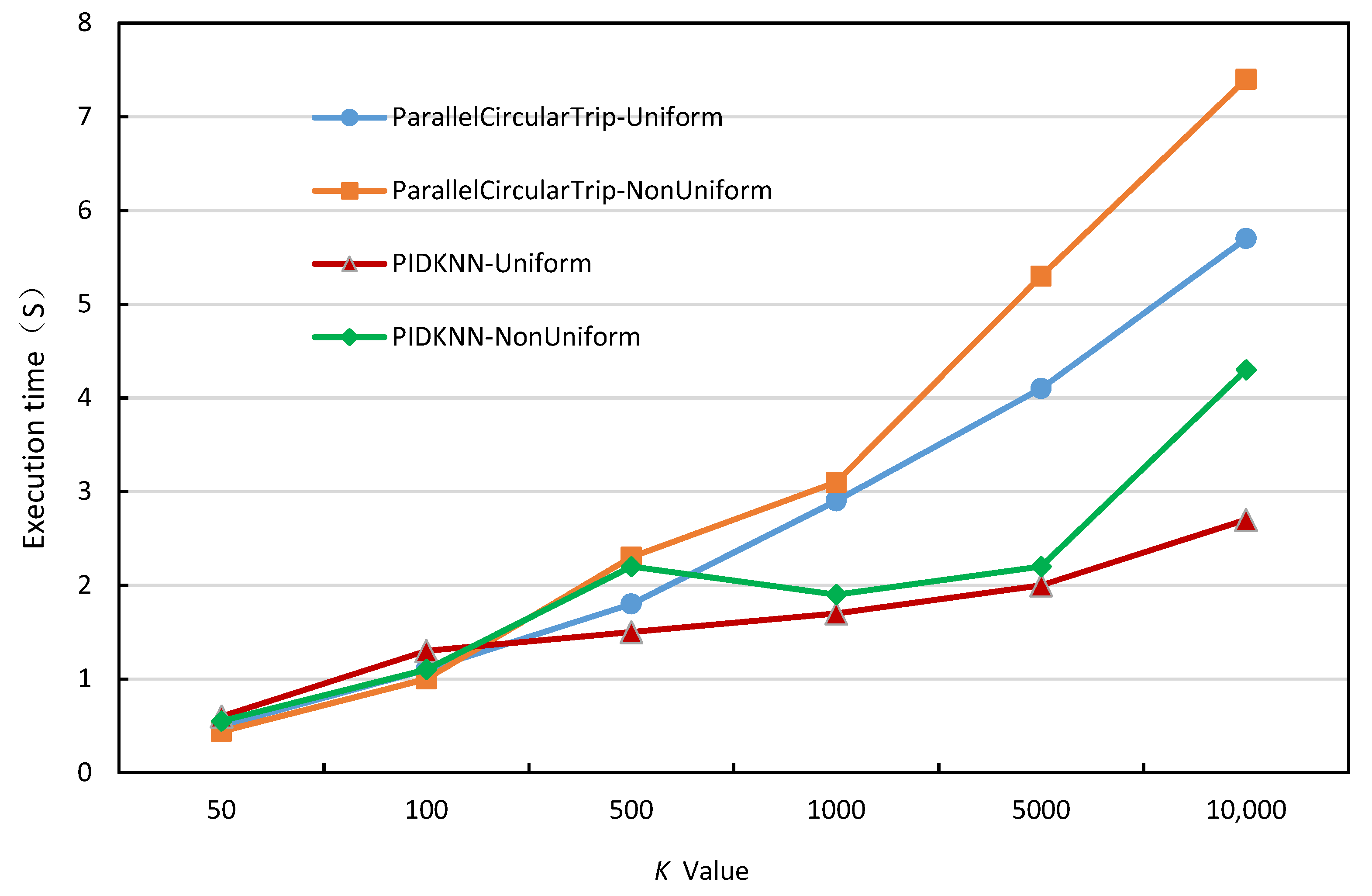
- 4.
- Execution time comparison with different values of k
- 5.
- Comparison of PIDKNN and SparkNN
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chi, Z.; Li, F.; Jestes, J. Efficient Parallel kNN Joins for Large Data in MapReduce. In Proceedings of the International Conference on Extending Database Technology, Berlin, Germany, 27–30 March 2012; pp. 38–49. [Google Scholar]
- Bagui, S.; Mondal, A.K. Improving the Performance of kNN in the MapReduce Framework Using Locality Sensitive Hashing. Int. J. Distrib. Syst. Technol. 2019, 10, 1–16. [Google Scholar] [CrossRef]
- Dong, T. Research on Spatial Data Index and kNN Query Technology under Big Data. M.D. Thesis, Dalian University of Technology, Dalian, China, 2013. [Google Scholar]
- Yu, J.; Wu, J.; Sarwat, M. Geospark: A Cluster Computing Framework for Processing Large-Scale Spatial Data. In Proceedings of the SIGSPATIAL International Conference on Advances in Geographic Information Systems, Seattle, WA, USA, 3–6 November 2015; p. 70. [Google Scholar]
- Armbrust, M. Spark sql: Relational Data Processing in Spark. In Proceedings of the ACM SIGMOD International Conference on Management of Data (SIGMOD), Melbourne, Australia, 31 May–4 June 2015; pp. 1383–1394. [Google Scholar]
- Xie, D.; Li, F.; Yao, B. Simba: Spatial in-memory Big Data Analysis. In Proceedings of the 24th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Burlingame, CA, USA, 31 October–3 November 2016; p. 86. [Google Scholar]
- Al Aghbari, Z.; Ismail, T.; Kamel, I. SparkNN: A Distributed In-Memory Data Partitioning for KNN Queries on Big Spatial Data. Data Sci. J. 2020, 19, 35. [Google Scholar] [CrossRef]
- Cheema, M.A.; Yuan, Y.; Lin, X. CircularTrip: An Effective Algorithm for Continuous kNN Queries. In Advances in Databases: Concepts, Systems and Applications, DASFAA 2007, Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2007; Volume 4443, pp. 863–869. [Google Scholar]
- He, D.; Wang, S.; Zhou, X. GLAD: A Grid and Labeling Framework with Scheduling for Conflict-Aware kNN Queries. IEEE Trans. Knowl. Data Eng. 2021, 33, 1554–1566. [Google Scholar] [CrossRef]
- Li, C.; Shen, D.; Zhu, M. A kNN Query Processing Method for Spatio-Temporal Information. Acta Softw. Sin. 2016, 27, 2278–2289. [Google Scholar]
- Kouiroukidis, N.; Evangelidis, G. The Effects of Dimensionality Curse in High Dimensional kNN Search. In Proceedings of the 2011 15th Panhellenic Conference on Informatics (PCI), Kastoria, Greece, 30 September–2 October 2011; pp. 41–45. [Google Scholar]
- Song, Y.; Gu, Y.; Zhang, R.; Yu, G. BrePartition: Optimized High-Dimensional kNN Search with Bregman Distances. IEEE Trans. Knowl. Data Eng. 2022, 34, 1053–1065. [Google Scholar] [CrossRef]
- Li, L.; Xu, J.; Li, Y.; Cai, J. HCTree+: A Workload-Guided Index for Approximate kNN Search. Inf. Sci. 2021, 581, 876–890. [Google Scholar] [CrossRef]
- Kolahdouzan, M.; Shahabi, C. Voronoi-Based k Nearest Neighbor Search for Spatial Network Databases. In Proceedings of the Thirtieth International Conference on Very Large Data Bases, VLDB Endowment, Toronto, ON, Canada, 31 August–3 September 2004; Volume 30, pp. 840–851. [Google Scholar]
- Zhang, C.; Almpanidis, G.; Hasibi, F. Gridvoronoi: An Efficient Spatial Index for Nearest Neighbor Query Processing. IEEE Access 2019, 7, 120997–121014. [Google Scholar] [CrossRef]
- Yu, Z.; Jiao, K. Incremental Processing of Continuous k Nearest Neighbor Queries Over Moving Objects. In Proceedings of the 2017 International Conference on Computer Systems, Electronics and, Control (ICCSEC), Dalian, China, 25–27 December 2017; pp. 1–4. [Google Scholar]
- Barrientos, R.J.; Riquelme, J.A. R Hernández-García; et al. Fast kNN Query Processing over a Multi-Node GPU Environment. J. Supercomput. 2021, 78, 3045–3071. [Google Scholar] [CrossRef]
- Barrientos, R.J.; Millaguir, F.; Sanchez, J.L.; Arias, E. Gpu-Based Exhaustive Algorithms Processing kNN Queries. J. Supercomput. 2017, 73, 4611–4634. [Google Scholar] [CrossRef]
- Jakob, J.; Guthe, M. Optimizing LBVH-Construction and Hierarchy-Traversal to accelerate kNN Queries on Point Clouds using the GPU. Comput. Graph. Forum 2020, 40, 124–137. [Google Scholar] [CrossRef]
- He, H.; Wang, L.; Zhou, L. pgi-distance: An Efficient Parallel KNN-Join Processing Method. Comput. Res. Dev. 2007, 44, 1774–1781. [Google Scholar] [CrossRef]
- Bareche, I.; Xia, Y. Selective Velocity Distributed Indexing for Continuously Moving Objects Model. In ICA3PP 2019. Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2019; Volume 11945. [Google Scholar]
- Yang, M.; Ma, K.; Yu, X. An Efficient Index Structure for Distributed k-Nearest Neighbours Query Processing. Soft Comput. 2020, 24, 5539–5550. [Google Scholar] [CrossRef]
- Jang, M.; Shin, Y.S.; Chang, J.W. A Grid-Based k-Nearest Neighbor Join for Large Scale Datasets on MapReduce. In Proceedings of the IEEE 17th International Conference on High Performance Computing and Communications, New York, NY, USA, 24–26 August 2015; pp. 888–891. [Google Scholar]
- Chen, Y.; Liu, N.; Xu, H.; Liu, M. Research on Spatial Range Query Index Based on Spark. Comput. Appl. Softw. 2018, 35, 96–101. [Google Scholar]
- Levchenko, O.; Kolev, B.; Yagoubi, D.E. BestNeighbor: Efficient Evaluation of kNN Queries on Large Time Series Databases. Knowl. Inf. Syst. 2021, 63, 349–378. [Google Scholar] [CrossRef]
- Moutafis, P.; Mavrommatis, G.; Vassilakopoulos, M.; Corral, A. Efficient Group K Nearest-Neighbor Spatial Query Processing in Apache Spark. ISPRS Int. J. Geo-Inf. 2021, 10, 763. [Google Scholar] [CrossRef]
- Tang, M.; Yu, Y.; Mahmood, A.R.; Malluhi, Q.M.; Ouzzani, M.; Aref, W.G. LocationSpark: In-memory Distributed Spatial Query Processing and Optimization. Front. Big Data 2020, 3, 30. [Google Scholar] [CrossRef] [PubMed]
- Baig, F.; Vo, H.; Kurç, T.M.; Saltz, J.H.; Wang, F. SparkGIS: Resource Aware Efficient In-Memory Spatial Query Processing. In Proceedings of the 25th ACM SIGSPATIAL International Conference on Advances in Geographic Information Systems, Redondo Beach, CA, USA, 7–10 November 2017; pp. 28:1–28:10. [Google Scholar] [CrossRef]
- Kambiz, T.; Panda, R.; Tehrani, K.A. Introduction to PID Controllers—Theory, Tuning and Application to Frontier Areas (Chapter 9—PID Control Theory); BoD–Books on Demand: Norderstedt, Germany, 2012. [Google Scholar]
- Amirahmadi, A.; Rafiei, M.; Tehrani, K.; Griva, G.; Batarseh, I. Optimum Design of Integer and Fractional-Order PID Controllers for Boost Converter Using SPEA Look-up Tables. J. Power Electron. 2015, 15, 160–176. [Google Scholar] [CrossRef]
- Wan, J.; He, B.; Wang, D.; Yan, T.; Shen, Y. Fractional-Order PID Motion Control for AUV Using Cloud-Model-Based Quantum Genetic Algorithm. IEEE Access 2019, 7, 124828–124843. [Google Scholar] [CrossRef]
- Shalaby, R.; El-Hossainy, M.; Abo-Zalam, B. Optimal Fractional-Order PID Controller Based on Fractional-Order Actor-Critic Algorithm. Neural Comput. Appl. 2022. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
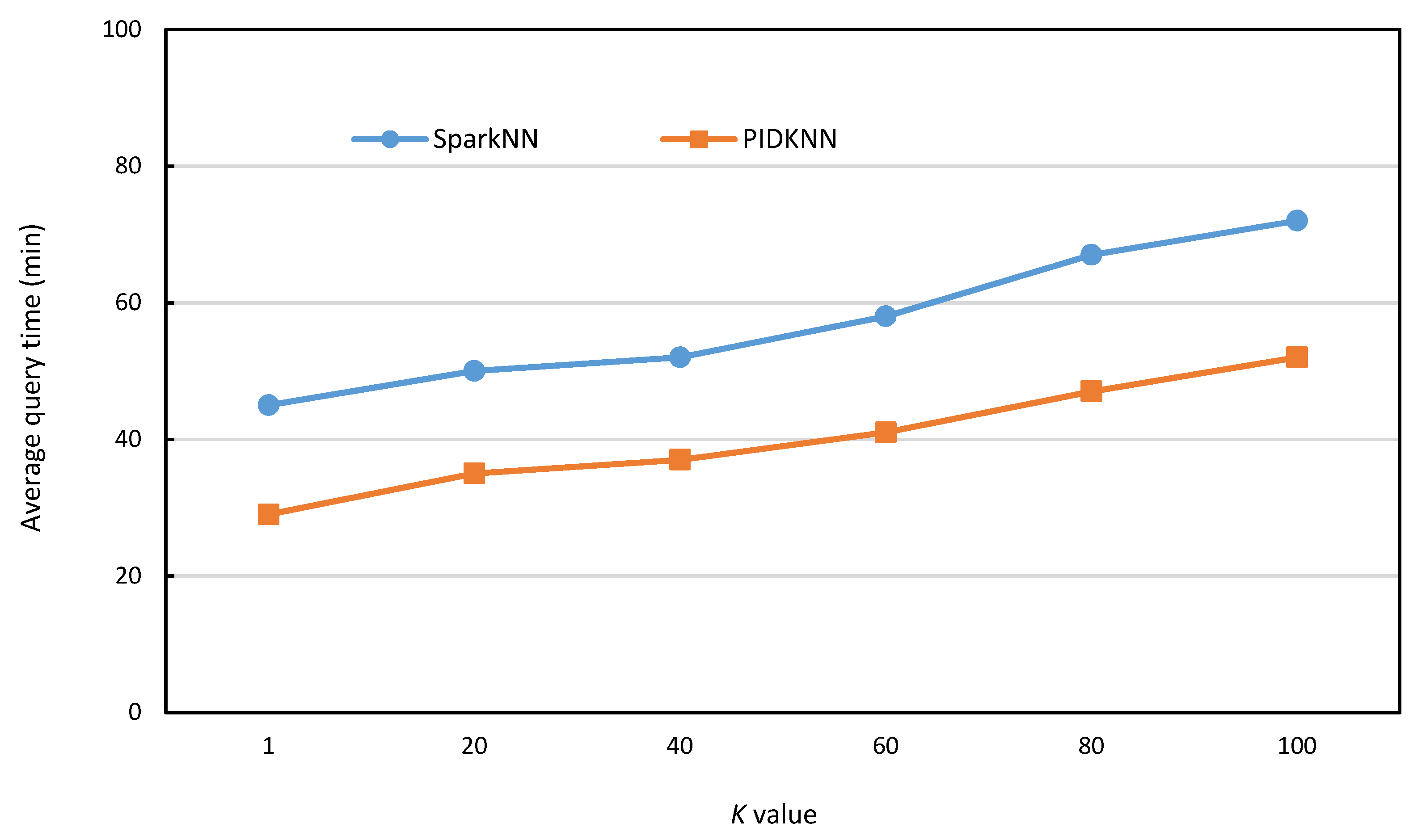{kind=link}
| Parameter Name | Parameter Value |
|---|---|
| The spatial range of synthetic data | 10,000 × 10,000 |
| Data size of synthetic data sets (million) Size of real data set (million) | 0.5 × 2, 1 × 2, 2 × 2, 4 × 2, 8 × 2 5 |
| Parallelism (Spark Executors) Number of grid cells | 6, 12, 24, 48, 72 100, 400, 1600, 6400 |
| K Value | 50, 100, 500, 1000, 5000, 10,000 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Qiao, B.; Ma, L.; Chen, L.; Hu, B. A PID-Based kNN Query Processing Algorithm for Spatial Data. Sensors 2022, 22, 7651. https://doi.org/10.3390/s22197651
Qiao B, Ma L, Chen L, Hu B. A PID-Based kNN Query Processing Algorithm for Spatial Data. Sensors. 2022; 22(19):7651. https://doi.org/10.3390/s22197651
Chicago/Turabian StyleQiao, Baiyou, Ling Ma, Linlin Chen, and Bing Hu. 2022. "A PID-Based kNN Query Processing Algorithm for Spatial Data" Sensors 22, no. 19: 7651. https://doi.org/10.3390/s22197651
APA StyleQiao, B., Ma, L., Chen, L., & Hu, B. (2022). A PID-Based kNN Query Processing Algorithm for Spatial Data. Sensors, 22(19), 7651. https://doi.org/10.3390/s22197651