


ArbGaze: Gaze Estimation from Arbitrary-Sized Low-Resolution Images



Abstract
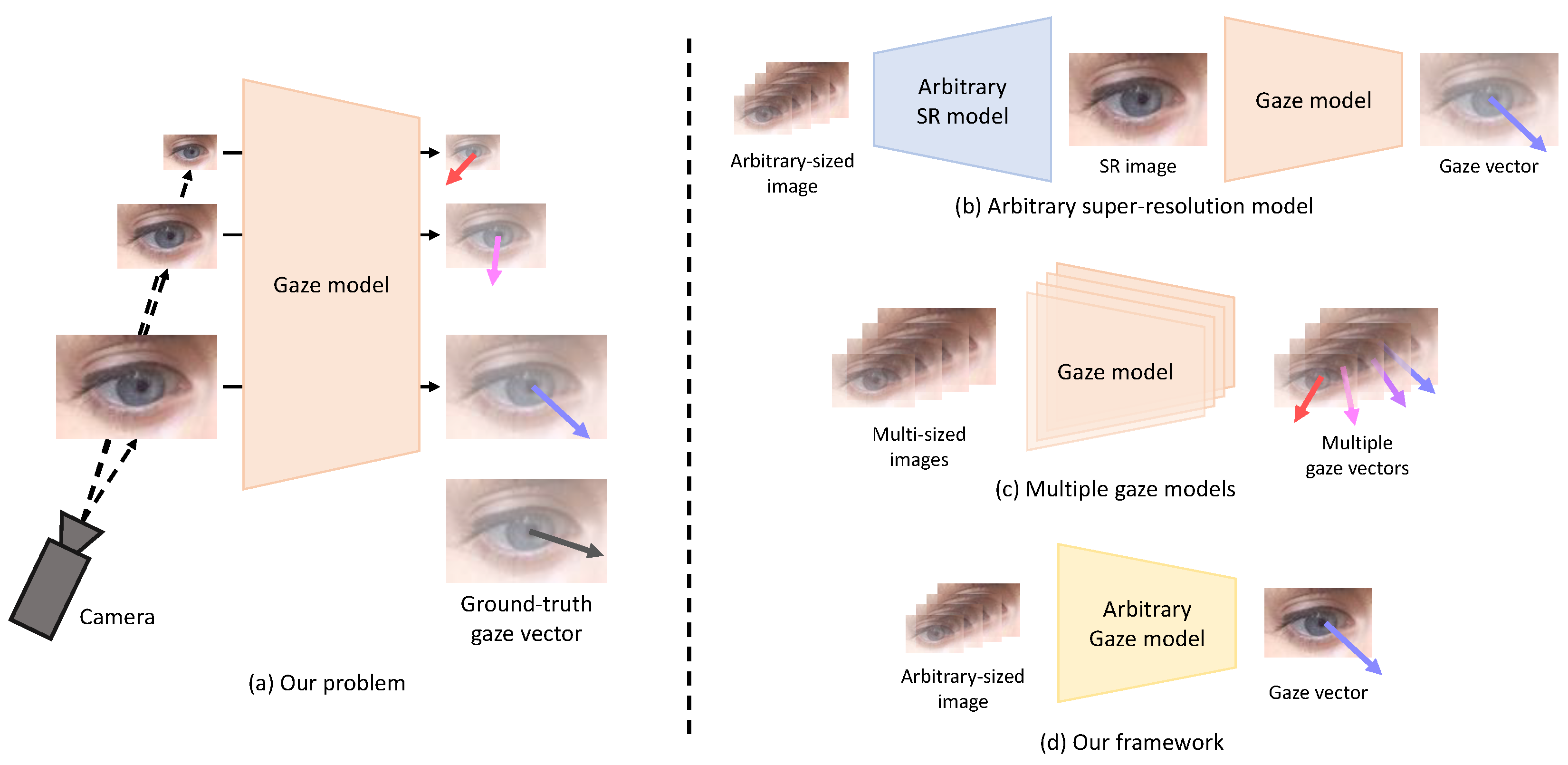
:1. Introduction
- A novel method is proposed to solve the problem of gaze estimation from low-resolution input images of arbitrary size, which has been rarely addressed previously.
- The proposed method significantly improves the gaze estimation performance for low-resolution images of various sizes by combining knowledge distillation and feature adaptation.
2. Related Works
2.1. Gaze Estimation
2.2. Knowledge Distillation
2.3. Scale- or Resolution-Dependent Feature Adaptation
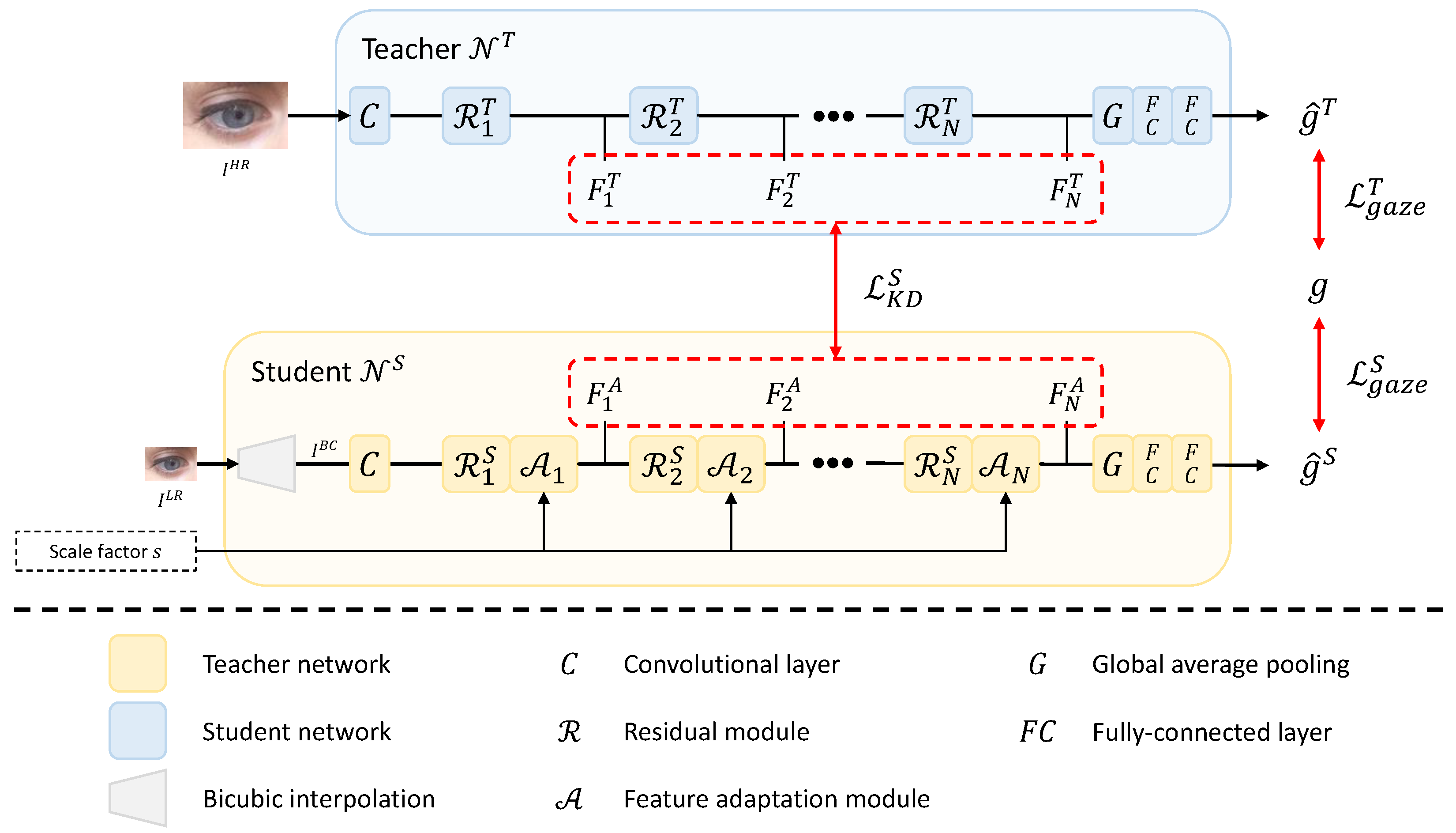
3. Proposed Method
3.1. Teacher Network
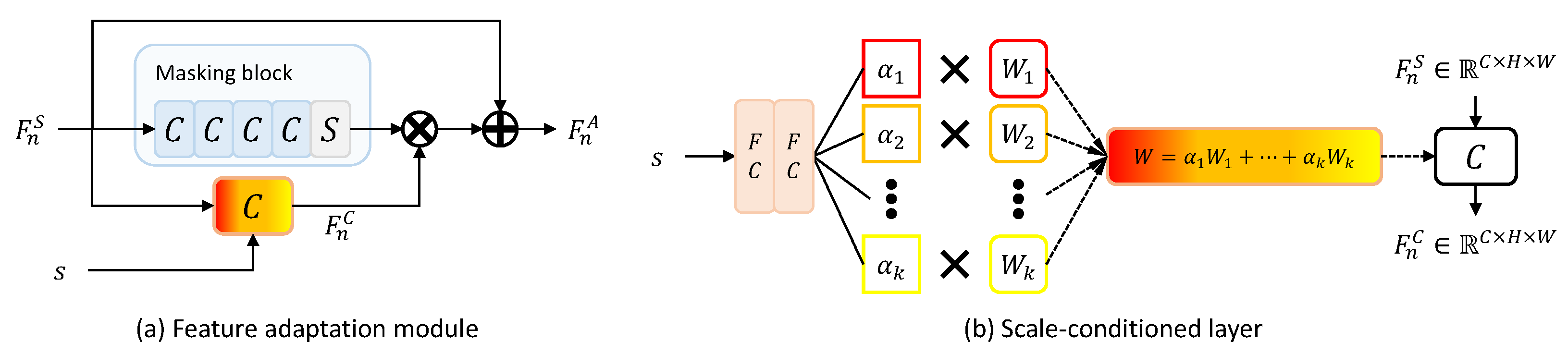
3.2. Student Network
3.3. Model Training and Testing
4. Experimental Results
4.1. Datasets
4.2. Implementation Details
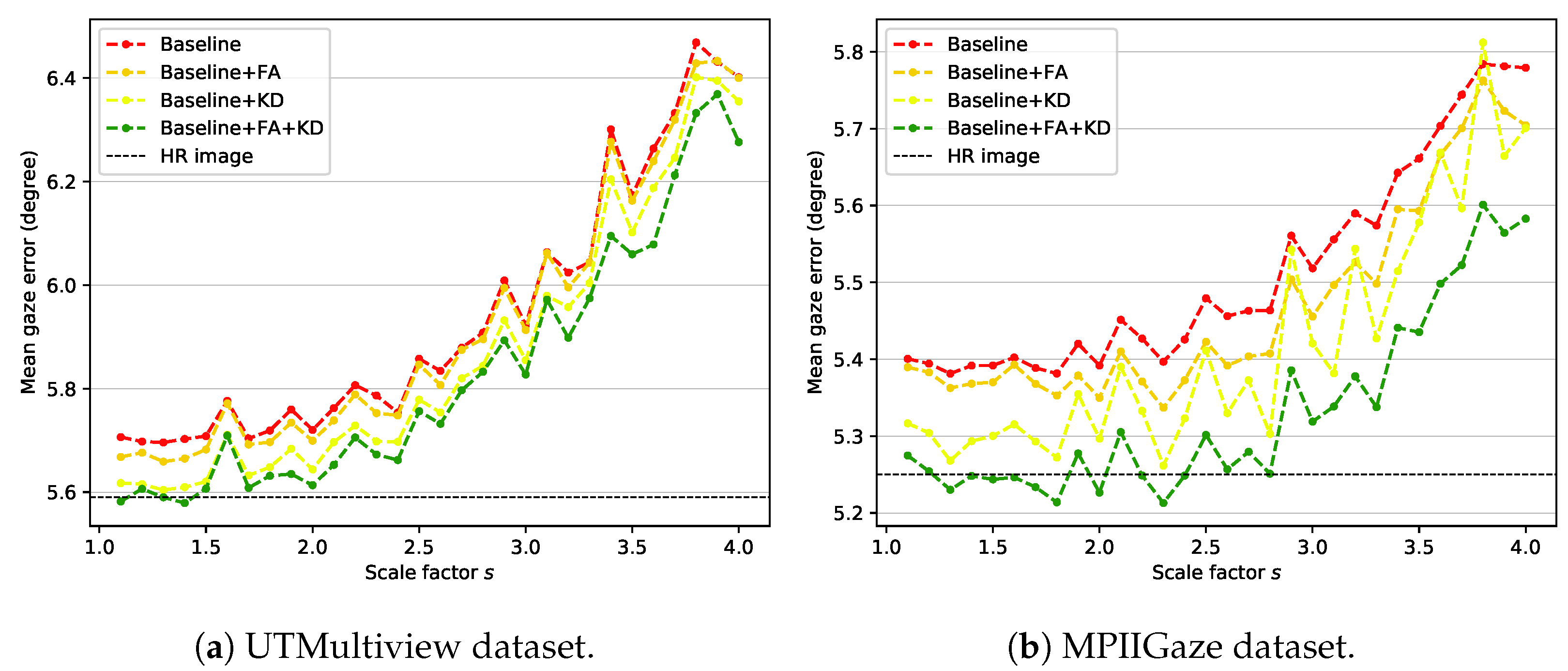
4.3. Ablation Study
4.4. Comparison to Baselines
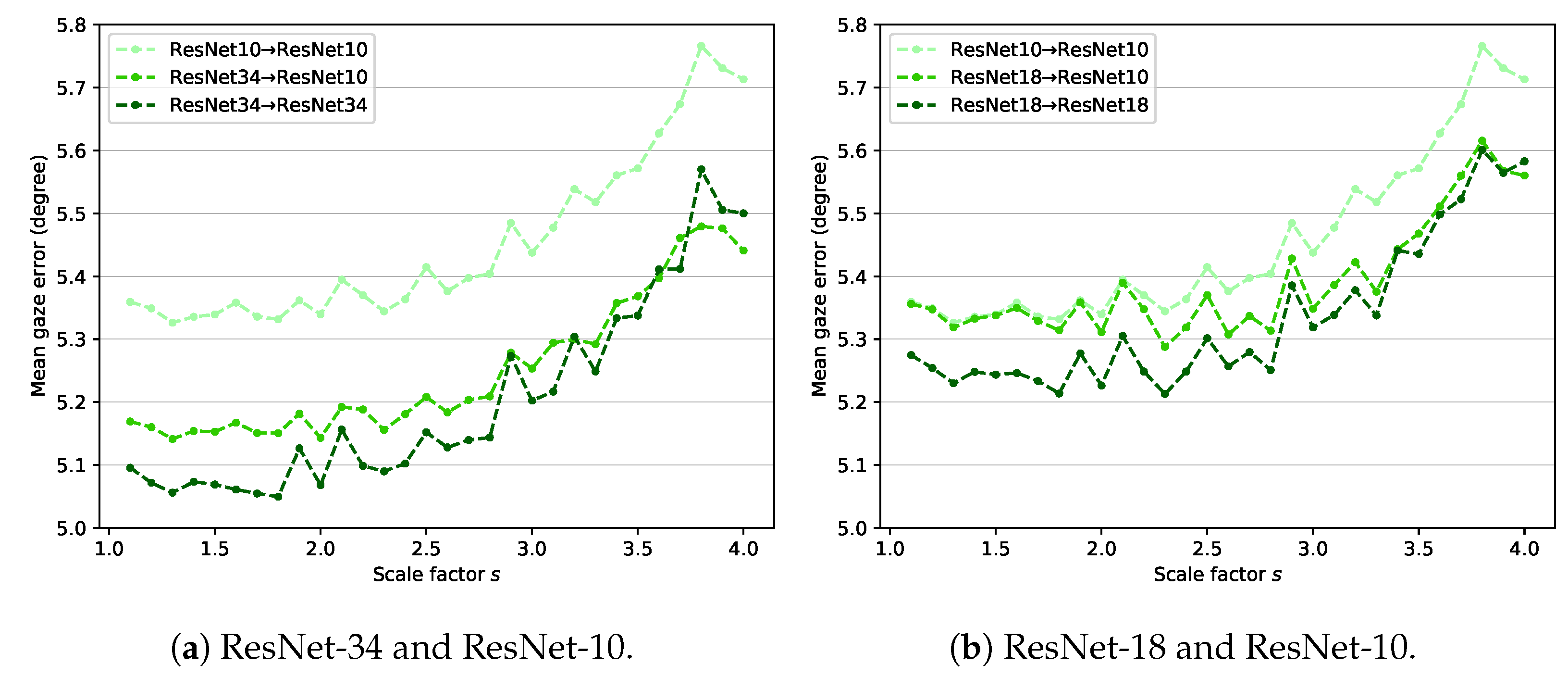
4.5. Generalization of the Proposed Method
4.6. Model Compression
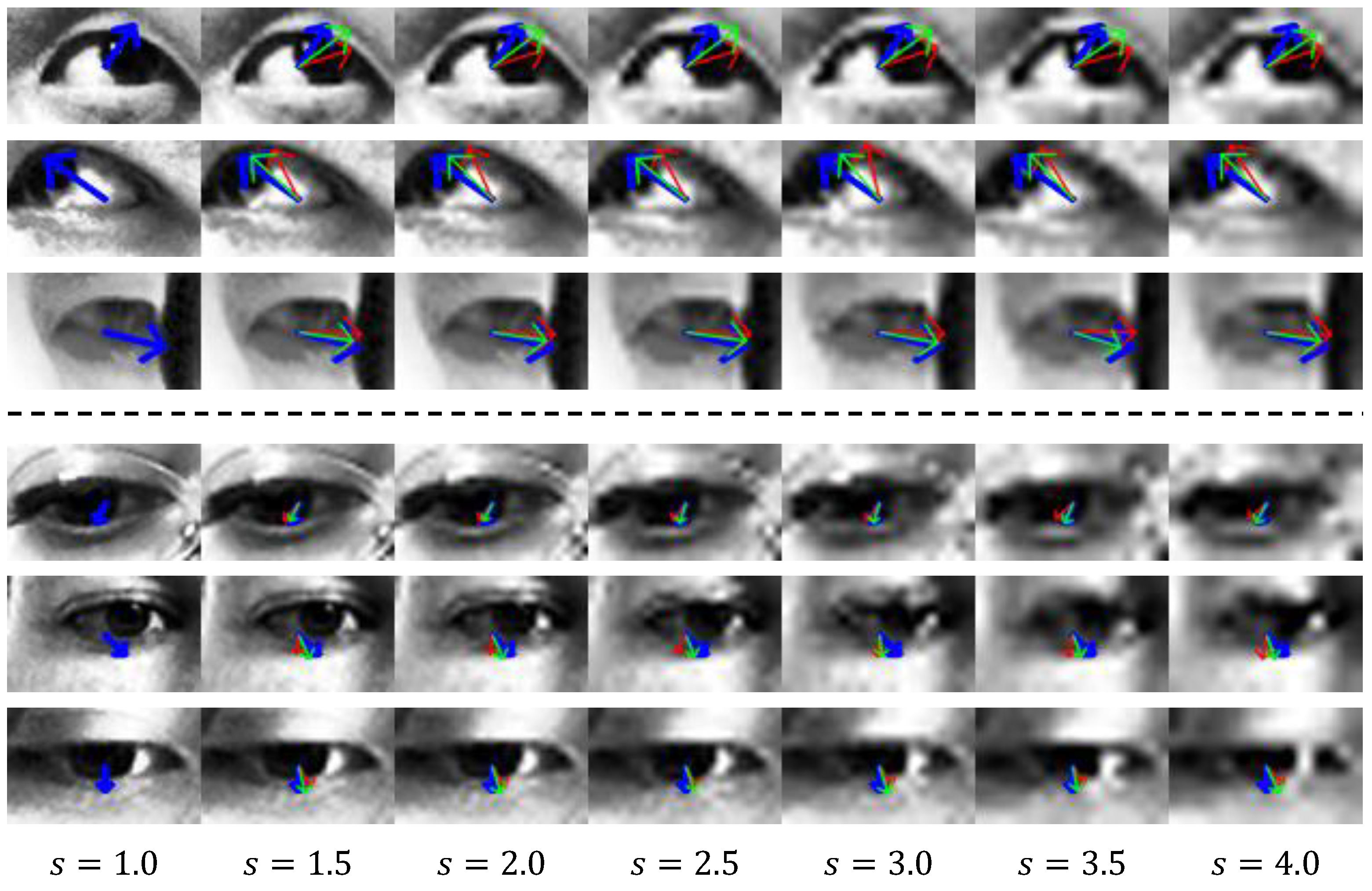
4.7. Qualitative Results
4.8. Quantitative Comparison with Gaze Estimation Methods from Fixed-Sized Images
4.9. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, W.X.; Cui, X.; Zheng, J.; Zhang, J.M.; Chen, S.; Yao, Y.D. Gaze Gestures and Their Applications in human-computer interaction with a head-mounted display. arXiv 2019, arXiv:1910.07428. [Google Scholar]
- Chakraborty, P.; Ahmed, S.; Yousuf, M.A.; Azad, A.; Alyami, S.A.; Moni, M.A. A Human-Robot Interaction System Calculating Visual Focus of Human’s Attention Level. IEEE Access 2021, 9, 93409–93421. [Google Scholar] [CrossRef]
- Liu, H.; Qin, H. Perceptual Self-Position Estimation Based on Gaze Tracking in Virtual Reality. Virtual Real. 2022, 26, 1359–4338. [Google Scholar] [CrossRef]
- Wang, Z.; Zhao, Y.; Lu, F. Gaze-Vergence-Controlled See-Through Vision in Augmented Reality. arXiv 2022, arXiv:2207.02645. [Google Scholar] [CrossRef] [PubMed]
- Yuan, G.; Wang, Y.; Yan, H.; Fu, X. Self-calibrated driver gaze estimation via gaze pattern learning. Knowl.-Based Syst. 2022, 235, 107630. [Google Scholar] [CrossRef]
- Krafka, K.; Khosla, A.; Kellnhofer, P.; Kannan, H.; Bhandarkar, S.; Matusik, W.; Torralba, A. Eye tracking for everyone. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2176–2184. [Google Scholar]
- Zhang, X.; Sugano, Y.; Fritz, M.; Bulling, A. It’s written all over your face: Full-face appearance-based gaze estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HL, USA, 21–26 July 2017; pp. 51–60. [Google Scholar]
- Huang, Q.; Veeraraghavan, A.; Sabharwal, A. TabletGaze: Dataset and analysis for unconstrained appearance-based gaze estimation in mobile tablets. Mach. Vis. Appl. 2017, 28, 445–461. [Google Scholar] [CrossRef]
- Smith, B.A.; Yin, Q.; Feiner, S.K.; Nayar, S.K. Gaze locking: Passive eye contact detection for human-object interaction. In Proceedings of the 26th Annual ACM Symposium On User Interface Software and Technology, St. Andrews, UK, 8–11 October 2013; pp. 271–280. [Google Scholar]
- Sugano, Y.; Matsushita, Y.; Sato, Y. Learning-by-synthesis for appearance-based 3d gaze estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1821–1828. [Google Scholar]
- Wood, E.; Baltrušaitis, T.; Morency, L.P.; Robinson, P.; Bulling, A. Learning an appearance-based gaze estimator from one million synthesised images. In Proceedings of the Ninth Biennial ACM Symposium on Eye Tracking Research & Applications, Charleston, SC, USA, 14–17 March 2016; pp. 131–138. [Google Scholar]
- Zhu, W.; Deng, H. Monocular free-head 3d gaze tracking with deep learning and geometry constraints. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 3143–3152. [Google Scholar]
- Wang, K.; Zhao, R.; Ji, Q. A hierarchical generative model for eye image synthesis and eye gaze estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 440–448. [Google Scholar]
- Fischer, T.; Chang, H.J.; Demiris, Y. Rt-gene: Real-time eye gaze estimation in natural environments. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 334–352. [Google Scholar]
- He, Z.; Spurr, A.; Zhang, X.; Hilliges, O. Photo-realistic monocular gaze redirection using generative adversarial networks. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6932–6941. [Google Scholar]
- Yu, Y.; Liu, G.; Odobez, J.M. Improving few-shot user-specific gaze adaptation via gaze redirection synthesis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 11937–11946. [Google Scholar]
- Zhang, X.; Sugano, Y.; Fritz, M.; Bulling, A. Appearance-based gaze estimation in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 4511–4520. [Google Scholar]
- Ranjan, R.; De Mello, S.; Kautz, J. Light-weight head pose invariant gaze tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2156–2164. [Google Scholar]
- Hu, X.; Mu, H.; Zhang, X.; Wang, Z.; Tan, T.; Sun, J. Meta-SR: A magnification-arbitrary network for super-resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 1575–1584. [Google Scholar]
- Wang, L.; Wang, Y.; Lin, Z.; Yang, J.; An, W.; Guo, Y. Learning a single network for scale-arbitrary super-resolution. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 4801–4810. [Google Scholar]
- Behjati, P.; Rodriguez, P.; Mehri, A.; Hupont, I.; Tena, C.F.; Gonzalez, J. Overnet: Lightweight multi-scale super-resolution with overscaling network. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2021; pp. 2694–2703. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the knowledge in a neural network. arXiv 2015, arXiv:1503.02531. [Google Scholar]
- Yang, B.; Bender, G.; Le, Q.V.; Ngiam, J. Condconv: Conditionally parameterized convolutions for efficient inference. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Hansen, D.W.; Ji, Q. In the eye of the beholder: A survey of models for eyes and gaze. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 32, 478–500. [Google Scholar] [CrossRef] [PubMed]
- Pathirana, P.; Senarath, S.; Meedeniya, D.; Jayarathna, S. Eye gaze estimation: A survey on deep learning-based approaches. Expert Syst. Appl. 2022, 199, 116894. [Google Scholar] [CrossRef]
- Cheng, Y.; Wang, H.; Bao, Y.; Lu, F. Appearance-based Gaze Estimation with Deep Learning: A Review and Benchmark. arXiv 2021, arXiv:2104.12668. [Google Scholar]
- Cazzato, D.; Leo, M.; Distante, C.; Voos, H. When I Look into Your Eyes: A Survey on Computer Vision Contributions for Human Gaze Estimation and Tracking. Sensors 2020, 20, 3739. [Google Scholar] [CrossRef] [PubMed]
- Yoo, D.H.; Chung, M.J. A novel non-intrusive eye gaze estimation using cross-ratio under large head motion. Comput. Vis. Image Underst. 2005, 98, 25–51. [Google Scholar] [CrossRef]
- Chen, J.; Ji, Q. 3D gaze estimation with a single camera without IR illumination. In Proceedings of the 2008 19th International Conference on Pattern Recognition, Tampa, FL, USA, 8–11 December 2008; IEEE: Piscataway, NJ, USA, 2008; pp. 1–4. [Google Scholar]
- Hansen, D.W.; Pece, A.E. Eye tracking in the wild. Comput. Vis. Image Underst. 2005, 98, 155–181. [Google Scholar] [CrossRef]
- Palmero, C.; Selva, J.; Bagheri, M.A.; Escalera, S. Recurrent cnn for 3d gaze estimation using appearance and shape cues. arXiv 2018, arXiv:1805.03064. [Google Scholar]
- Park, S.; Zhang, X.; Bulling, A.; Hilliges, O. Learning to find eye region landmarks for remote gaze estimation in unconstrained settings. In Proceedings of the 2018 ACM Symposium on Eye Tracking Research & Applications, Warsaw, Poland, 14–17 June 2018; pp. 1–10. [Google Scholar]
- Lu, F.; Sugano, Y.; Okabe, T.; Sato, Y. Adaptive linear regression for appearance-based gaze estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2014, 36, 2033–2046. [Google Scholar] [CrossRef]
- Kellnhofer, P.; Recasens, A.; Stent, S.; Matusik, W.; Torralba, A. Gaze360: Physically unconstrained gaze estimation in the wild. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 6912–6921. [Google Scholar]
- Zhang, X.; Park, S.; Beeler, T.; Bradley, D.; Tang, S.; Hilliges, O. Eth-xgaze: A large scale dataset for gaze estimation under extreme head pose and gaze variation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 365–381. [Google Scholar]
- Chang, Z.; Matias Di Martino, J.; Qiu, Q.; Espinosa, S.; Sapiro, G. Salgaze: Personalizing gaze estimation using visual saliency. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Guo, T.; Liu, Y.; Zhang, H.; Liu, X.; Kwak, Y.; In Yoo, B.; Han, J.J.; Choi, C. A generalized and robust method towards practical gaze estimation on smart phone. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- He, J.; Pham, K.; Valliappan, N.; Xu, P.; Roberts, C.; Lagun, D.; Navalpakkam, V. On-device few-shot personalization for real-time gaze estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Korea, 27–28 October 2019. [Google Scholar]
- Park, S.; Mello, S.D.; Molchanov, P.; Iqbal, U.; Hilliges, O.; Kautz, J. Few-shot adaptive gaze estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 9368–9377. [Google Scholar]
- Yu, Y.; Odobez, J.M. Unsupervised representation learning for gaze estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7314–7324. [Google Scholar]
- Kothari, R.; De Mello, S.; Iqbal, U.; Byeon, W.; Park, S.; Kautz, J. Weakly-supervised physically unconstrained gaze estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 9980–9989. [Google Scholar]
- Liu, Y.; Liu, R.; Wang, H.; Lu, F. Generalizing gaze estimation with outlier-guided collaborative adaptation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 11–17 October 2021; pp. 3835–3844. [Google Scholar]
- Xu, X.; Chen, H.; Moreno-Noguer, F.; Jeni, L.A.; Torre, F.D.l. 3d human shape and pose from a single low-resolution image with self-supervised learning. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; Springer: Berlin/Heidelberg, Germany, 2020; pp. 284–300. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Chen, Z.; Shi, B.E. Appearance-based gaze estimation using dilated-convolutions. In Proceedings of the Asian Conference on Computer Vision, Perth, WA, Australia, 2–6 December 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 309–324. [Google Scholar]
- Zhang, X.; Sugano, Y.; Fritz, M.; Bulling, A. Mpiigaze: Real-world dataset and deep appearance-based gaze estimation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 41, 162–175. [Google Scholar] [CrossRef] [PubMed]
- Cheng, Y.; Lu, F.; Zhang, X. Appearance-Based Gaze Estimation via Evaluation-Guided Asymmetric Regression. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 105–121. [Google Scholar]
- Cheng, Y.; Zhang, X.; Lu, F.; Sato, Y. Gaze Estimation by Exploring Two-Eye Asymmetry. IEEE Trans. Image Process. 2020, 29, 5259–5272. [Google Scholar] [CrossRef] [PubMed]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Params (M) ↓ | FLOPs (G) ↓ | UTMV (Degree) ↓ | MPII (Degree) ↓ | ||||
|---|---|---|---|---|---|---|---|---|
| s = 2 | s = 3 | s = 4 | s = 2 | s = 3 | s = 4 | |||
| Arbitrary SR baseline | 33.36 | 23.51 | 5.60 | 5.73 | 5.97 | 5.21 | 5.26 | 5.37 |
| Multiple gaze baseline | 337.09 | 0.20 | 5.47 | 5.90 | 6.45 | 5.32 | 5.60 | 5.82 |
| ArbGaze (ours) | 12.08 | 0.22 | 5.61 | 5.83 | 6.28 | 5.23 | 5.32 | 5.58 |
| Method | Input | Gaze Error (Degree) ↓ |
|---|---|---|
| RF [10] | eye image | 7.99 |
| Mnist [17] | eye image | 6.30 |
| GazeNet [48] | eye image | 5.83 |
| ARE-Net [49] | eye image | 5.02 |
| Proposed (VGG13 + FA + KD) | eye image | 4.88 |
| Full Face [7] | face image | 4.90 |
| RT-Gaze [14] | face image | 4.30 |
| FAR-Net [50] | face image | 4.30 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kim, H.G.; Chang, J.Y. ArbGaze: Gaze Estimation from Arbitrary-Sized Low-Resolution Images. Sensors 2022, 22, 7427. https://doi.org/10.3390/s22197427
Kim HG, Chang JY. ArbGaze: Gaze Estimation from Arbitrary-Sized Low-Resolution Images. Sensors. 2022; 22(19):7427. https://doi.org/10.3390/s22197427
Chicago/Turabian StyleKim, Hee Gyoon, and Ju Yong Chang. 2022. "ArbGaze: Gaze Estimation from Arbitrary-Sized Low-Resolution Images" Sensors 22, no. 19: 7427. https://doi.org/10.3390/s22197427
APA StyleKim, H. G., & Chang, J. Y. (2022). ArbGaze: Gaze Estimation from Arbitrary-Sized Low-Resolution Images. Sensors, 22(19), 7427. https://doi.org/10.3390/s22197427