5.2. Evaluation Metrics
We used the IoU, precision, recall, and
mAP evaluation metrics related to object detection to evaluate the proposed system. Additionally, the average data volume exchange between the ADSs for collaborative perception was measured in kilobit (kbit). The IoU measures the spatial similarity between the estimated ground truth boxes and the actual ground truth set. The IoU can be defined as follows:
where
and
are defined as the actual ground truth and the estimated ground truth bounding boxes.
includes a set of all positive boxes identified by the Faster R-CNN-based object detection model. Each bounding box has confidence above the set thresholds. The IoU takes the size, location, and orientation of both bounding boxes (i.e.,
). The value of IoU ranges between 0 and 1, where IoU is defined to be 0 if the
both do not have any overlapping regions. On the other hand, if the value of the IoU is 1, then it means the location, size, and orientation of both
are equal and completely overlapped. When the value of the IoU metric for the
is above a certain threshold, then
can be defined as the matching estimation of
. Note that we can set the IoU threshold by our choice. A typical value for the threshold can be 0.5, 0.7, or 0.95.
The precision metrics used in our systems are average precision (
AP) and
mAP. The precision metric is the ratio of matched estimated bounding boxes to the total number of bounding boxes in the estimated set by the model. Similarly, the recall metric can be obtained by taking the ratio of matched estimated bounding boxes to the total number of bounding boxes in the ground truth set. The
AP is the weighted sum of all precision at each threshold which can be defined using Equation (8). The weight is defined as an increase in recall.
where the
is the total number of the estimated boxes and the recall value
∈ (
) in Equation (8) can be obtained by assuming that the thresholds and the confidence score of the bounding box at
position are equal.
The
can be obtained by using the
for each class considered in the object detection model. The mean of all classes is the
which can be obtained by Equation (9).
where
is the average precision of the class
and
is the total number of classes.
5.3. Top-Level Performance Evaluation of Proposed System
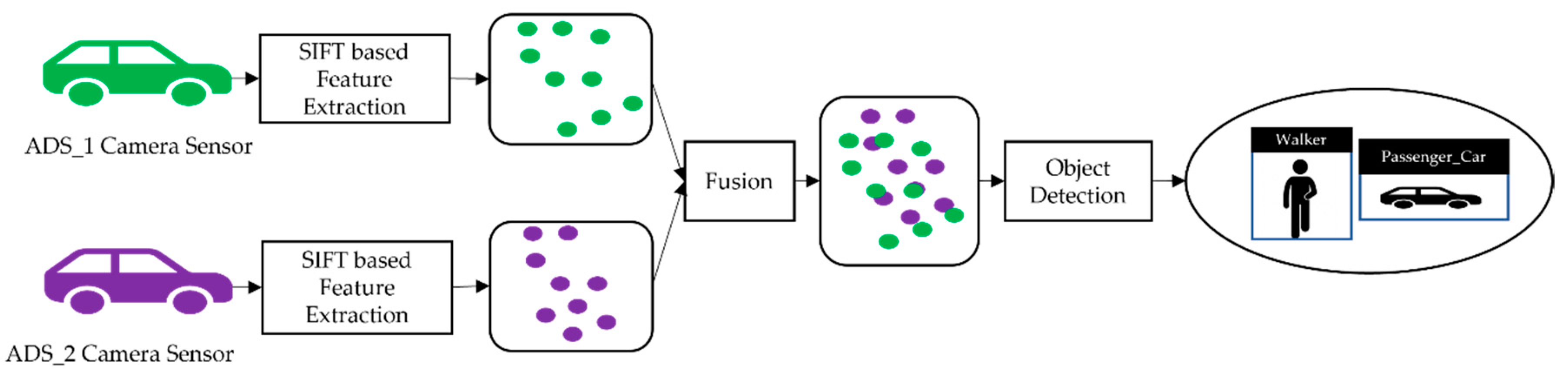
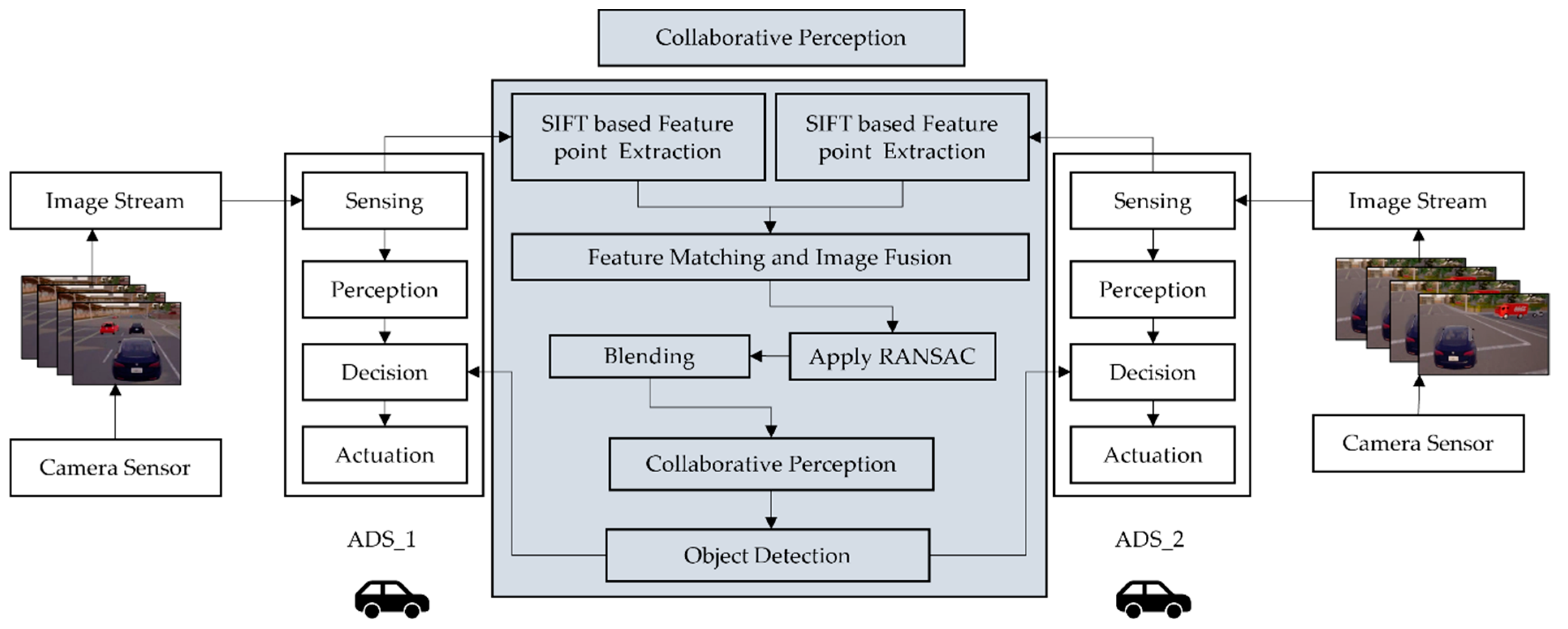
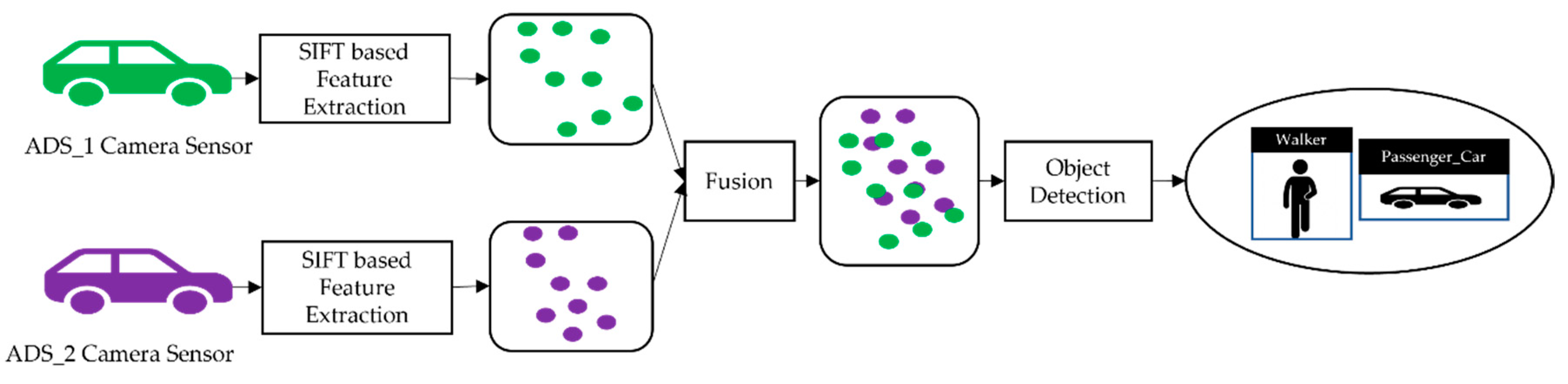
In order to evaluate the performance of the collaborative perception, we analyzed the performance of the models individually as well as the performance of the model in collaborative perception. We used the term “top-level performance evaluation” as an alternative to the visual analysis of proposed systems. We can see the result of the image fusion of two ADSs in
Figure 4 and
Figure 5, with receiving ADS (i.e., ADS_1) and data sender ADS (i.e., ADS_2).
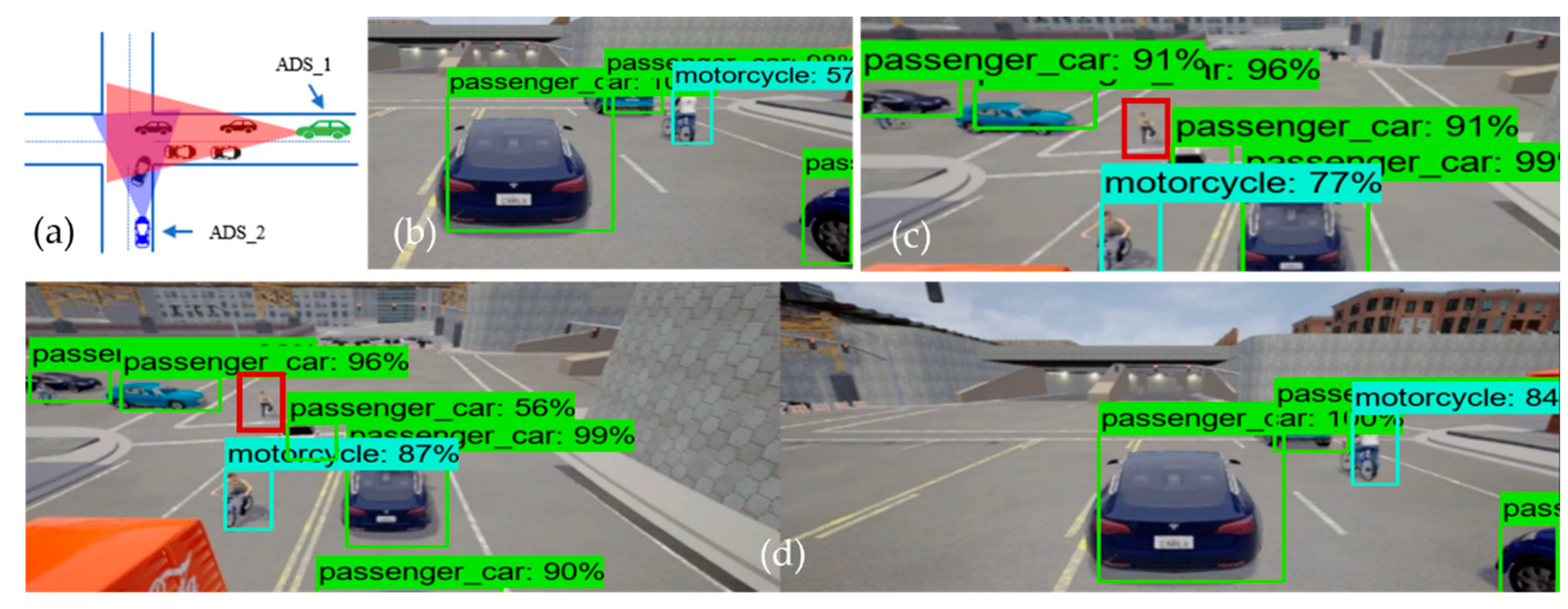
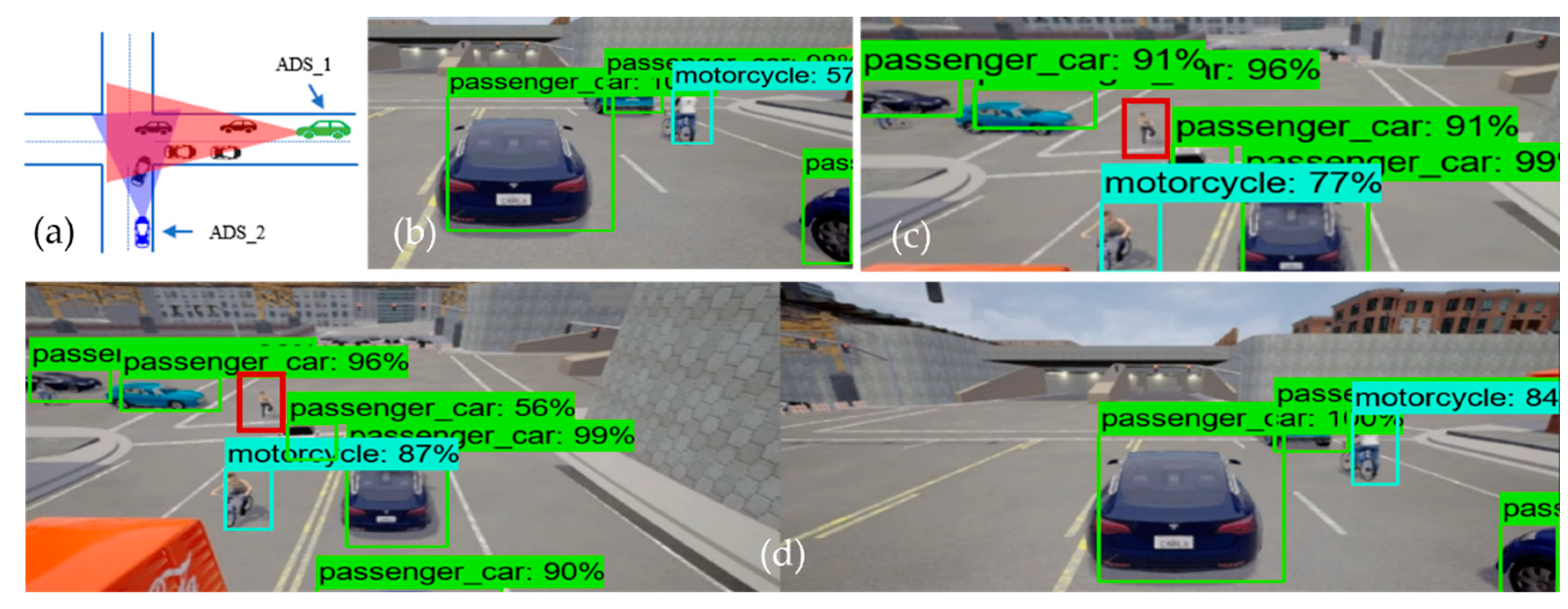
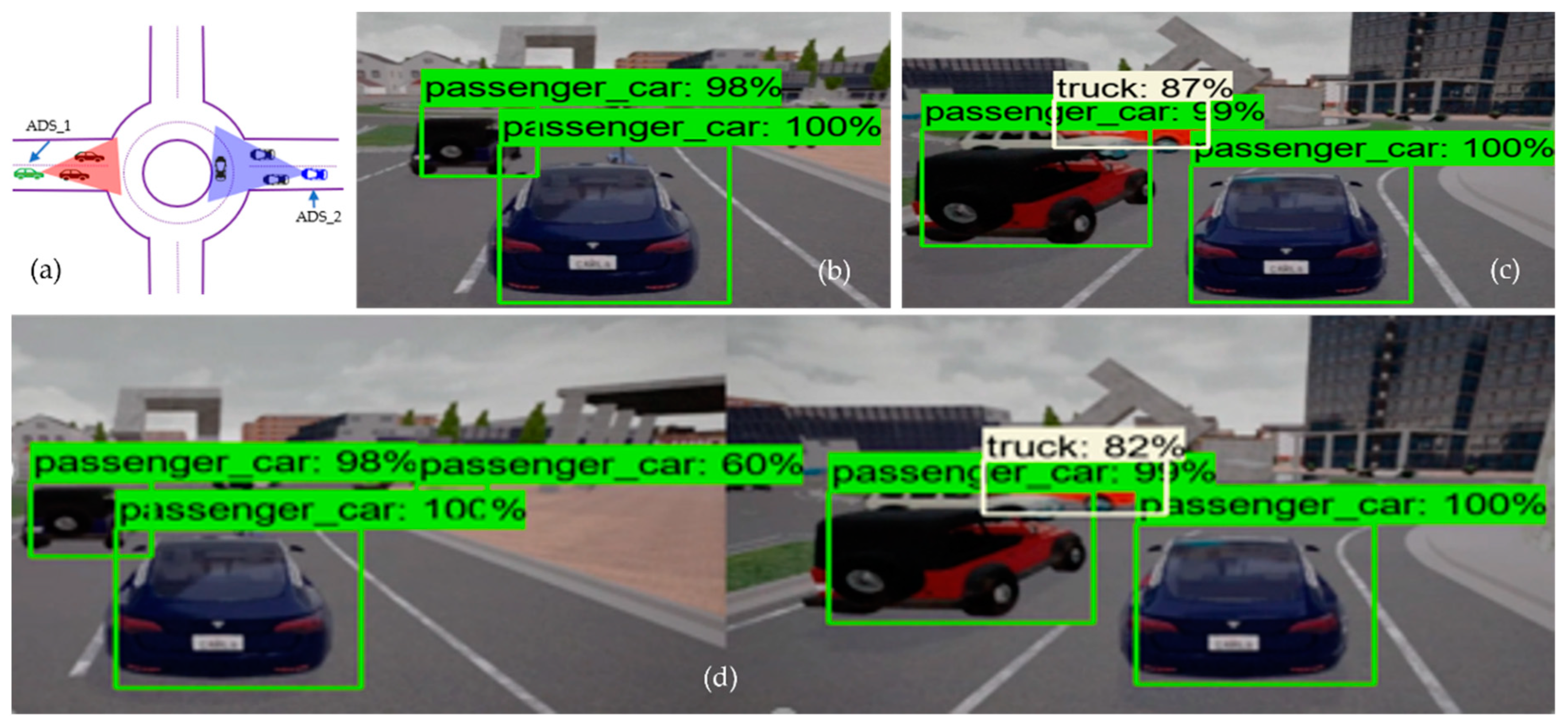
Figure 4 illustrates the performance of the object detection model at the intersection testing scenario, where
Figure 4a is the bird-eye view of the road intersection.
Figure 4b shows the detection result of ADS_1 (i.e., the receiver), just as
Figure 4c represents the sender ADSs (i.e., ADS_2) perception. Finally,
Figure 4d shows the detection result of the collaborative perception system of ADS_1. The performance evaluation was done based on the confidence threshold of 0.5, 0.7, and 0.95 for the object detection model on the individual system as well as the object detection model used in collaborative perception.
Figure 4 and
Figure 5 illustrate the top-level performance of the proposed systems with a confidence threshold of 0.7. When the confidence is above 0.7, the object detection model marks the bounding box for the detected object. In
Figure 4d and
Figure 5d, we can see the detection results of the object detection model used in collaborative perception for intersection and roundabout testing scenarios.
From
Figure 4b, we can see that the ADS_1 could only detect four objects (i.e., one motorcycle and three passenger cars), and
Figure 4c shows that the ADS_2 approaching the intersection from another road could detect five objects (i.e., one motorcycle and four passenger cars). However, it would be beneficial for both vehicles to know the information regarding the static and dynamic objects on their future trajectory, and such information may increase the situational awareness of both cars in terms of planning and decision. This can be achieved by fusing the perception of each ADS into collaborative perception where both the camera sensor data are fused in order to detect more objects, including occluded ones.
Figure 4d clearly illustrates the effectiveness of the collaborative perception system where the receiver ADS can detect more objects on the road that its sensors could not detect. Taking a closer look, we can see that there is occlusion for both ADSs. Those objects in the field of view of ADS_1 are not visible to ADS_2 and vice versa. Hence, by sharing the perception of ADS_2 with ADS_1, the ADS_1 can see the object on its future trajectory, which helps the ADS_1 make better planning and decisions. However, this is not the same for all cases, as some objects could not be detected by either ADS_1 and ADS_2 or the collaborative perception. The red-colored bounding box illustrates that neither ADSs detected the pedestrian and their collaborative perception. There could be many reasons for not detecting these objects, for instance that the object detection models’ performance varies with the object’s size. Other reasons could be the occlusion caused by other comparatively big objects.
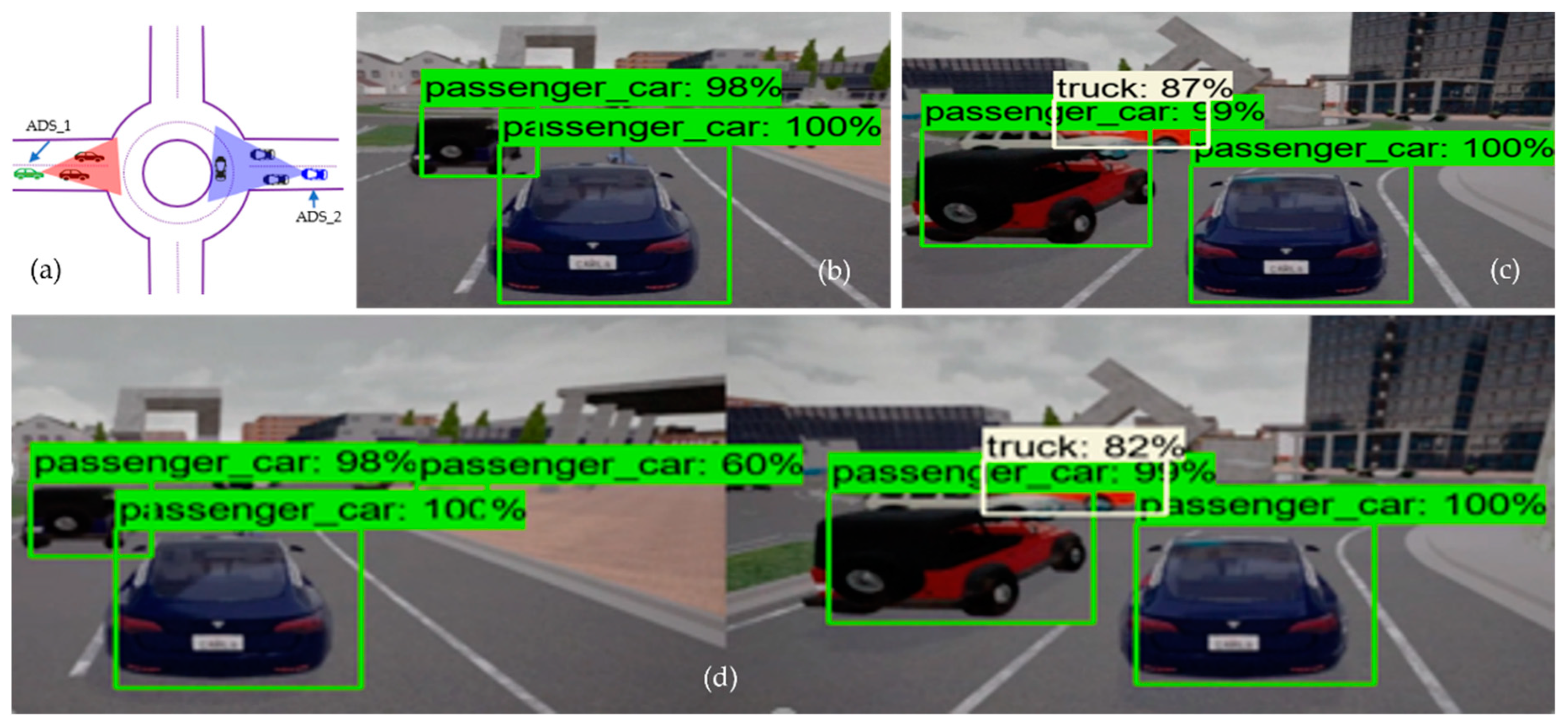
Similarly, in the roundabout driving scenario, where two ADSs are approaching the roundabout from the opposite direction, it would be suitable for both ADSs if they had more information about their surroundings. From
Figure 5b, we can see that ADS_1 detects only two passenger cars, and ADS_2 (i.e.,
Figure 5c) detects three objects (two passenger cars and one truck). However, after the fusion of the camera sensor data of both ADSs, we can see that the detection rate of ADS_1 increased drastically.
Figure 5d presents the collaborative perception of the receiver car (i.e., ADS_1) in the roundabout driving scenario. By closely inspecting the collaborative perception of ADS_1 at the roundabout scenario, we can see that it detected six objects, including one passenger car, that both ADS_1 and ADS_2 did not detect by their individual perception systems. From these comparisons, we can conclude that the average detection rate of collaborative perception was 45.4% more than the individual perception system of ADSs. The fusion of multiple ADSs camera sensor data increased the detection rate of occluded objects compared to individual perception systems.
5.4. Quantitative Performance Analysis of Collaborative Perception System
After taking the overview of the top-level performance analysis of our proposed collaborative perception systems, we now dive into the quantitative analysis of collaborative perception compared to the individual perception systems.
The data used to evaluate the collaborative perception comes from the dataset we collected using the CALRA simulator for testing scenarios. The results were reported using the IoU thresholds at 0.5, 0.7, and 0.95 for object detection. When the object detection confidence score for any object is above the IoU threshold, the model marks the bounding box on that object. The precision was calculated by comparing the detected objects with their ground truths using the evaluation metrics mentioned in
Section 5.2. The quantitative performance analysis was carried out for intersections, T-junctions, roundabouts, and multilane road-testing scenarios.
Effectiveness (RQ1): To answer the research question RQ1, we present the experimental results in
Figure 6 and
Table 1.
Table 1 and
Figure 6 report the efficacy of collaborative perception in detecting occluded objects on
mAP metrics. It also reports the superiority of collaborative perception over individual perception systems. The results show that the detection performance increased in terms of
mAP. We observed that the precision of the collaborative perception system was increased when the IoU threshold was set to 0.5. For example, in the T-junction driving scenarios, the increase in
mAP was 6.3% compared to ADS_1, and 5.2% compared to ADS_2. As in the intersection scenario, the gain in
mAP was 5.9% compared to ADS_1, and 4.6% compared to ADS_2. The same trends were recorded in another driving scenario (i.e.,
multilane road (same direction)). The increase in
mAP was 7% compared to ADS_1, and a 6.4% gain in
mAP was recorded compared to ADS_2. However, it can be observed that there are some variations in detection performances. For example, when IoU = 0.7 at T-junction, the gain in
mAP of collaborative perception was only 0.1% compared to ADS_1.
In most cases, no significant increase was observed in
mAP when the IoU threshold was set to 0.7. Only in two scenarios (i.e.,
roundabout and multilane road (same direction)) the
mAP was increased up to 6.7% compared to ADS_1, and a 6.2% increase in
mAP was observed compared to that of ADS_2 in the roundabout scenario. As in the
multilane road (same direction) testing scenario, the gain in
mAP was observed at 5% compared to ADS_2, while a 5.9% increase in
mAP was recorded compared to ADS_1. When we set the IoU threshold to 0.95, we observed a significant gain in all five driving scenarios except in
multilane road (opposite direction) driving scenarios. The gain in
mAP does not increase further as the performance gain reaches its saturation levels. The performance gain may increase if participating ADSs in collaborative perception systems increases. However, the average object detection rate of collaborative perception is 45.4% more than the individual perception system of ADS_1 and ADS_2, as shown in
Figure 6. We use only the front camera images for fusion. However, the front camera of both ADSs does not cover the large detection areas. As the detection area increases, the participation of more ADSs in collaborative perception systems would need to maintain the increasing trends in the performance gain. Although the participating ADSs in collaborative perception systems were only two in our current experiment, we can still observe a significant increase in the precision and object detection rate. More participating ADSs in collaborative perception systems can increase detection precision; however, the computational cost may also increase.
The location and alignment information of features for fusion has a significant impact on the object detection model’s performance. The change in alignment or translation may cause a bad impact on detection accuracy, despite the fact that in the dynamic driving environment, the precision of the object detection model is quite high in our experimental results. We can observe that the performance of the model in terms of mAP is stable. Meaning that there is no significant change in mAP with respect to driving scenarios on the same IoU thresholds. For example, the average difference between mAP at the same IoU thresholds is less than 4% in most cases. This shows the stability of object detection models in highly dynamic driving scenarios.
From
Table 1, we can see that the detection confidence sometimes varies in different scenarios. It is the location and dynamic driving environment that causes the small variation in detection confidence. However, from
Table 1, we can see that the object detection model performed extremely well in detecting objects in individual perception systems and collaborative perceptions. The highest
mAP (i.e., 80.1% and 80.4% when the IoU threshold was 0.5) was reported on the individual perception system of ADS_1 and ADS_2, respectively. On the other hand, the highest
mAP was recorded at 86.8% when the IoU threshold was set to 0.5 on the collaborative perception system of ADS_1. This indicates that the fusion of camera images increases the precision of object detection models. We believe that if the number of participating ADSs in collaborative perception systems increases, the
mAP will also increase.
Performance (RQ2): Moving to the comparative analysis of individual perception systems and collaborative perceptions in terms of detection rate, we can answer research question RQ2. The average number of the detected object in the collaborative perception system in each testing scenario is 45.4% more than in the individual perception system of both ADSs.
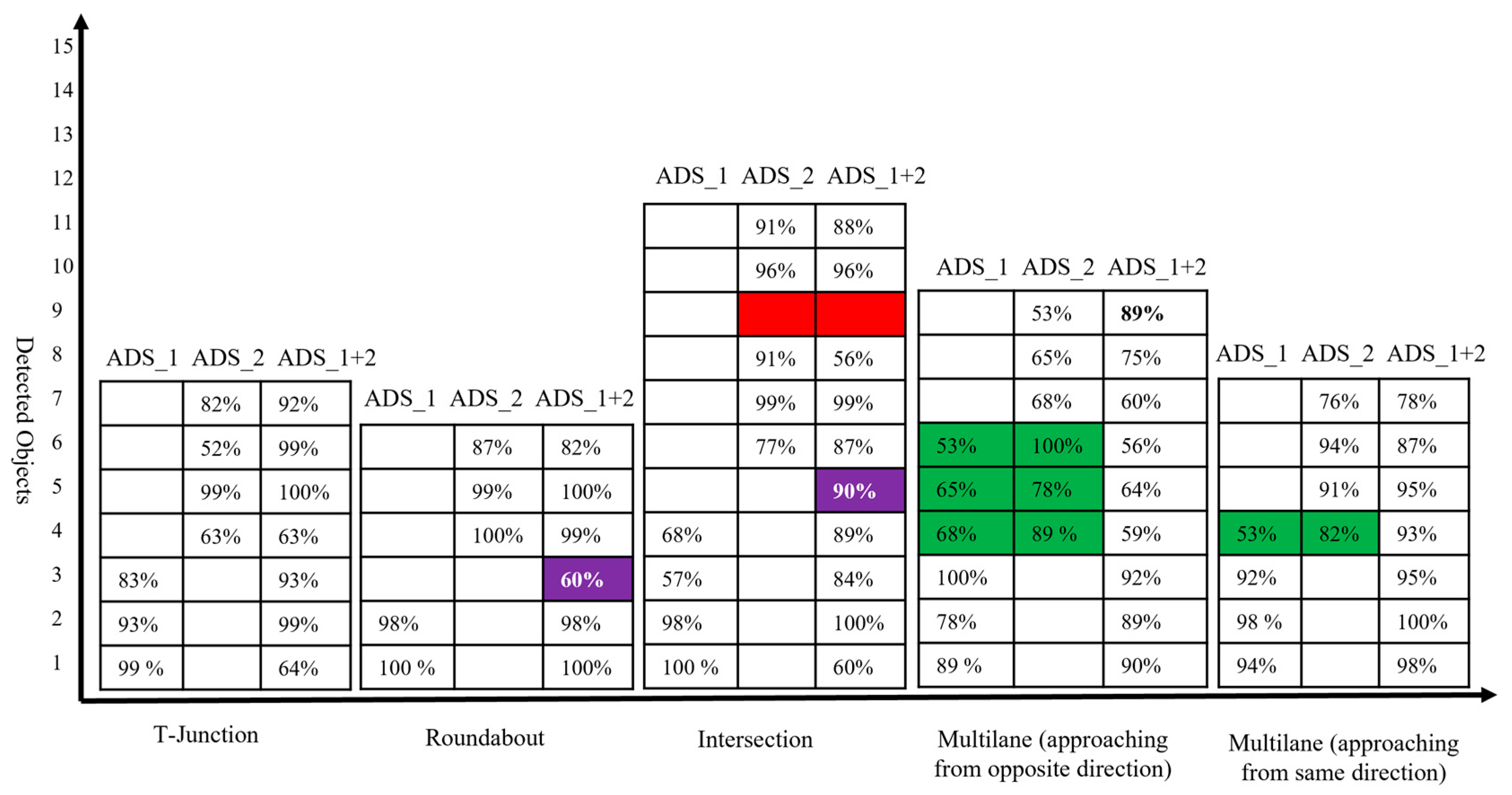
Figure 6 depicts the number of objects detected by the ADS_1 and ADS_2 and the collaborative perception system of ADS_1. In
Figure 6, the table presents the detection confidence in percentage in each testing scenario. The vertical axis represents the number of objects detected by each ADSs, and the collaborative perception of ADS_1 and the testing scenarios are given on the horizontal axis. The empty cell on the table represents that there are no more objects in the range of camera sensors. The red-colored cell represents the objects in the range of the camera sensor. However, the object detection models of both individual and collaborative perception systems could not detect them. The green-colored cells illustrate objects detected by both ADSs (i.e., all those objects in the range of both ADSs’ camera sensors.). Another important cell representation is the blue-colored cell. These blue-colored cells represent the objects that were not detected by the individual perception of both ADSs; however, due to the image fusion of both ADSs, the collaborative perception system detected those objects.
From
Figure 6, we can see that the collaborative perception systems outperformed the individual perception systems of both ADSs. Starting from the T-junctions testing scenario, it can be noted that the number of detected objects in the collaborative perception system of ADS_1 is two times more than its own perception system, as ADS_1 could only detect three objects by its own perception systems. Due to limited sensing range and occlusion, it could not detect more objects on its future trajectory. However, after fusing the camera sensor image of ADS_2, we can see a significant increase in the number of the detected object in collaborative perception. Now, the ADS_1 can detect four more objects those were not in its sensor range. As in the roundabout testing scenario, the collaborative perception system of ADS_1 detected four more objects due to image fusion. An interesting phenomenon was observed in both roundabout and intersection testing scenarios. In each case, the collaborative perception system detected one extra object, which was not detected by the individual perception systems of both ADSs. This phenomenon was very unexpected and interesting to analyze in our experiment, and the detected object and their confidence are given blue-colored cells in
Figure 6.
The intersection testing scenario has another interesting phenomenon to analyze, as expected. The collaborative perception system detected more objects (i.e., 10 objects compared to ADS_1, which detected only four objects, and ADS_2, which detected only five objects). However, one extra object (i.e., the blue-colored cell in
Figure 6 in the intersection testing scenario) that has 90% detection confidence has been detected. Another unique phenomenon to analyze in the intersection testing scenario is the red-colored cell representing objects that were not detected by either individual perception systems of ADSs or collaborative perception. Upon careful investigation of simulation logs and results, we observe that there was a pedestrian (i.e., the red bounding box in
Figure 4c,d) in the range of the camera sensor of ADS_2. However, it could be detected by neither the object detection model of ADS_2 nor the object detection model of the collaborative perception. There may be plenty of reasons for not detecting such objects. Firstly, this may happen due to the occlusion due to other big objects. As we can see in
Figure 4c,d, the pedestrian is surrounded by other big objects compared to its size and therefore causes occlusion and results in the pedestrian not being detected. Another reason is that the object detection models’ performance varies with the objects’ size. The object detection model performs worse when detecting small-sized objects than large objects [
11]. As expected, the collaborative perception system also outperformed the individual perception system of ADS_1 and ADS_2 in detecting more objects in
multilane (approaching from the opposite direction) and
multilane (approaching from the same direction) road testing scenarios. As we can see, some objects (i.e., cells with green color) in
Figure 6 were detected by both ADS_1 and ADS_2. We believe that these phenomena are due to the specific driving scenarios, as these objects were in the range of camera sensors of both ADS_1 and ADS_2. However, only a single instance of these redundant objects is detected in a collaborative perception system. Hence, this proves the effectiveness of the proposed collaborative perception, meaning that if more than one ADSs driving system detects a single object, then only a single instance of that object is detected in the collaborative perception.
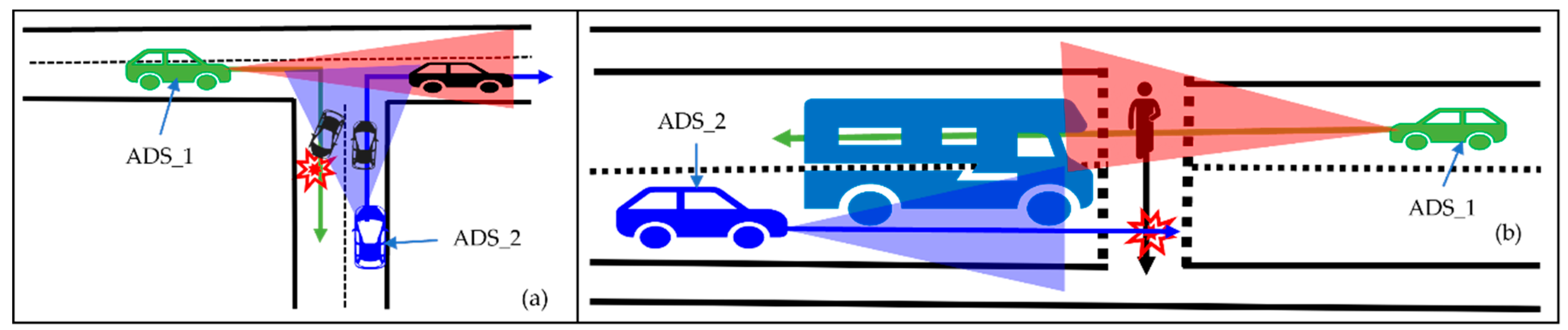
5.6. Impact of Collaborative Perception on Safety
To answer RQ3, we analyze the impact of collaborative perception on safety. While performing the safety analysis of collaborative perception, we consider a safety-critical scenario presented in our motivation, i.e.,
Figure 1b. The safety analysis in this article is based on time-based risk assessment methods. Generally, the forward collision algorithms with risk assessment methods have two approaches: time based and distance based. However, we considered a time-based approach in our experiment as time-based risk assessment methods are proven effective on the road [
41]. Time-based risk assessment is based on time-to-collision (TTC). In our collaborative perception, we used a forward collision avoidance algorithm based on a time-based risk assessment method to avoid collisions with pedestrians by considering the scenario presented in
Figure 1b. We simulated the scenario using two cars (i.e., ADS_1, the sender, and ADS_2, the receiver). To analyze the impact of collaborative perception on safety in such scenarios, we present two scenarios: hazardous scenarios and safe scenarios. In the following, we explain each scenario.
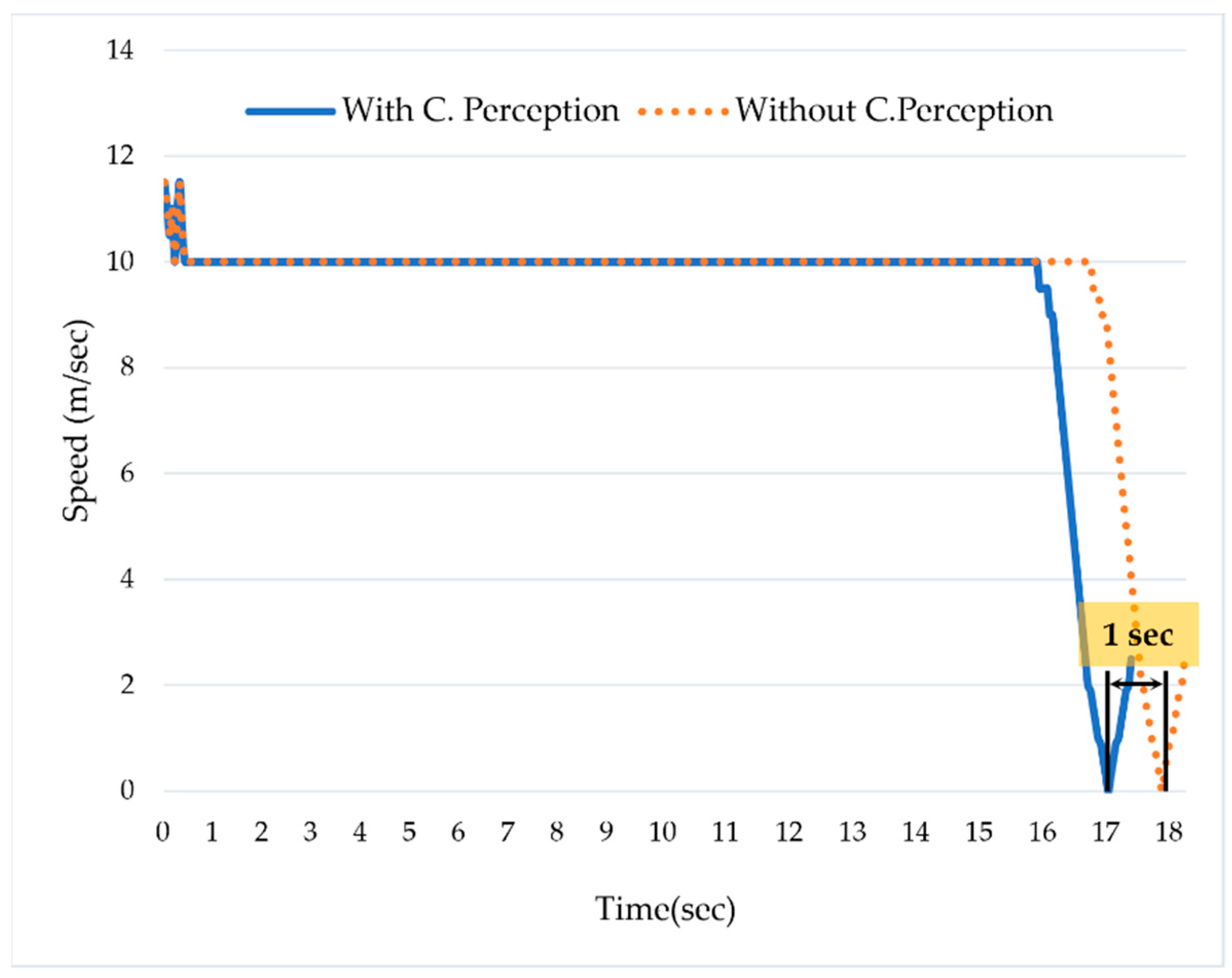
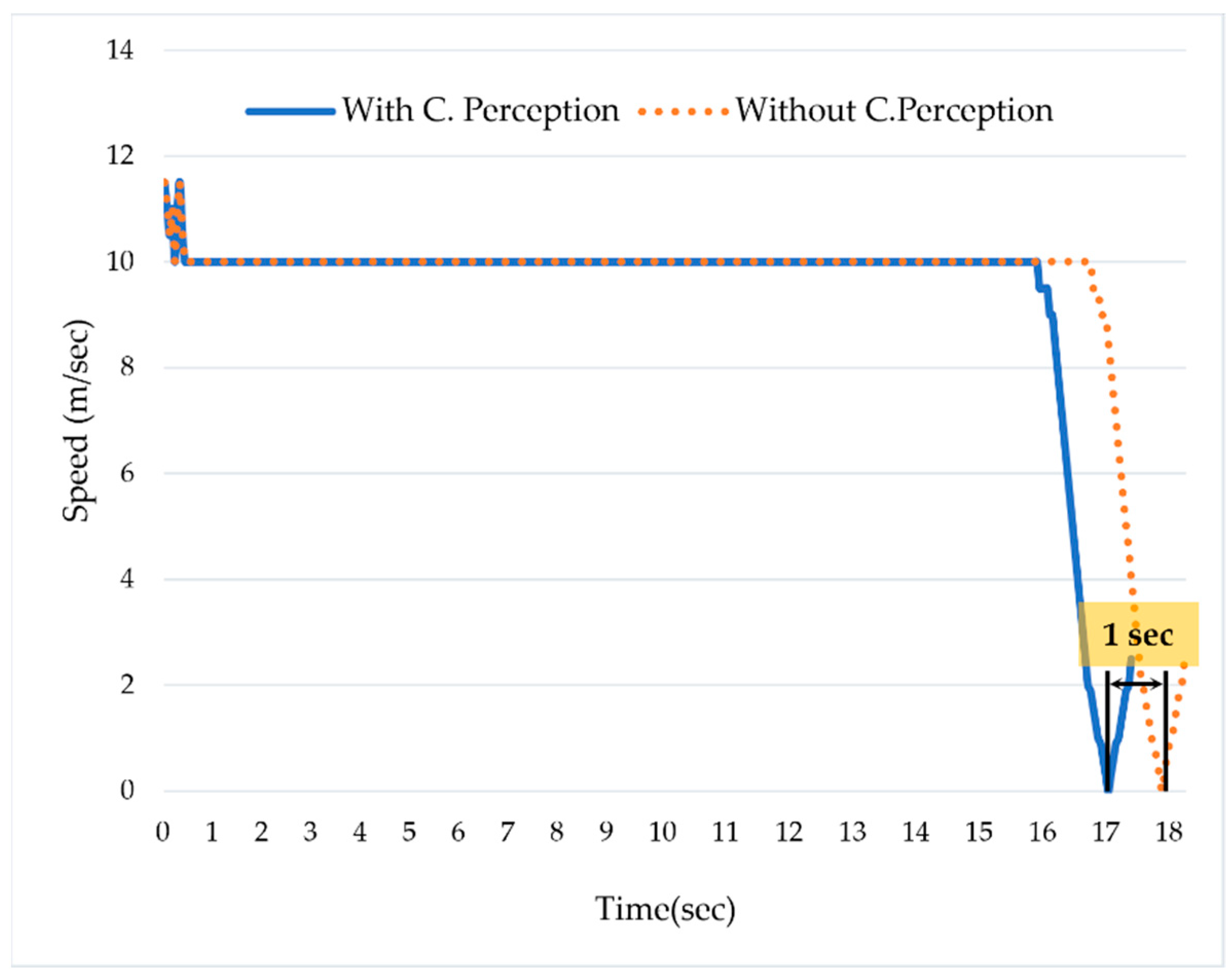
In order to simulate the hazardous scenario, we did not use the collaborative perception system. The ADS_2 was moving forward with a speed of 10 m/s. Due to occlusion caused by the bus, the ADS_2 could not detect the pedestrian, and, as a result, caused a hazardous scenario. Despite applying the emergency brake, we confirmed that the distance between the ADS_2 and the pedestrian was close to zero. This hazardous scenario was analyzed using the velocity logs and the distance between the ADS_2 and the pedestrian.
Figure 7 shows that the ADS_2 was moving with a speed of 10 m/s; the ADS_1 detected a pedestrian in the middle of the road at 16th seconds. However, as the ADS_2 was not using the collaborative perception, it responded to the situation on the 17th. Despite applying the brake, the ADS_2 could not stop and collided with the pedestrian. We can see that the ADS_2 started deceleration at the 17th s and stopped at the 18th. Due to the late response, the safety distance between the ADS_2 and the pedestrian was close to zero.
In contrast to the hazardous scenario, we simulated the safe scenario using two ADSs that use collaborative perception.
Figure 7 shows that the ADS_2 was moving forward with a speed of 10 m/second. The ADS_1 detected the pedestrian at the 16th s and shared its real-time perception with ADS_2 via collaborative perception. The ADS_2 proactively responded to the situation one second earlier compared to the scenario in which it was not using the collaborative perception. Additionally, after analyzing the safety distance (i.e., distance to collision) between ADS_2 and the pedestrian, we confirmed that the safety distance was 1.2 m.
Figure 7 shows that ADS_2 proactively started reducing the speed at the 16th s right after detecting the pedestrian in collaborative perception. Therefore, it could stop at a safe distance, i.e., 1.2 m from the pedestrian. In contrast, while the ADS_2 was not using the collaborative perception, the safety distance was almost equal to zero.
However, the collaborative perception system is always prone to attack from malicious vehicles sending phantom information, which may cause hazards for participating ADSs. Therefore, in order to avoid the phantom information sent by malicious vehicles in collaborative perception, we use the chaotic map-based encryption technique. The logistic map is a chaos system with highly complex behavior [
42] and is very sensitive to the initial condition. Mathematically it can be described as:
The parameter
in the logistic map ranges between 0 and 4.
represents the initial value. Each iteration of the map in logistic chaos generates a value known as iterates.
represents the number of iterates and the variable
represents the chaotic output, and its values range between [0, 1]. The chaotic behavior in the logistic map can be achieved after several iterations. The value of
must remain less than the range to achieve chaotic behavior—the higher values of
r cause impossible to achieve chaotic behavior [
43].
In our proposed encryption scheme, we first generate the chaotic sequences followed by the confusion process in which the pixel values are confused and then shuffle the pixel position to generate the encrypted image. Consider that we have an image frame of camera sensors of ADS_2, which is to be transmitted to ADS_1 via collaborative perception. represents the size of the image frame, and the pixel of each image frame is . The represents the pixel value at the position We obtained the initial value for the logistic map from the secret key. The secret key used in the chaotic map-based encryption consists of 256bits in ASCII form. After defining the initial condition, we transformed the ) into an array and converted each pixel value to an integer ranging from 0–255. Following by transformation process, we generated the chaotic sequence using the equation . The confusion was achieved via XOR operation using the equation , where the variable denotes the array of pixel values. Finally, we shuffle the pixel values to get the encrypted image. For the decryption process, we follow the inverse of the encryption process as the decryption is the inverse of the encryption process.
The logistic chaos map-based encryption and decryption process can be summarized as follows: first, the pixel values of each image frame of the ADS_2 are transformed into an array, and secondly, we convert the pixels’ values into an integer between a range of 0 to 255 using mod operation. The third step is to generate the chaotic sequences, and finally, in the fourth step, confusion and diffusion are performed to get the required encrypted image. In contrast, the inverse encryption process is followed at the receiving end (i.e., ADS_1) to get the decrypted image.
In response to the second part of the RQ3, we analyze the impact of chaotic map-based encryption on safety by considering the key sensitivity, histogram, and adjacent pixel autocorrelation analysis. During the experiment, we set the initial value for the chaotic map at 0.1, and the value of the variable
r was set to 3.76. We used the 256-bit, i.e., 32 characters long encryption key. The image frames of ADS_2 were encrypted using the encryption key 1q2w3e4r5t6y7u8i9o0p!@#
$%^&*(){} and these image frames were shared with ADS_1. At receiving end, each image frame was decrypted using the same key.
Figure 8a–c depicts the encryption process and decryption process using the same key. We can see that there is no visual difference between encrypted and decrypted images when the key is the same for encryption and decryption.
The encryption and decryption technique should be key sensitive, and the system must produce entirely different patterns for any change in the key. From
Figure 8d–f, we can see that the proposed encryption technique is highly key sensitive. A minor change in the key produced an entirely different pattern and produced no visible information in the decrypted image. The encryption key was set to 1q2w3e4r5t6y7u8i9o0p!@#
$%^&*(){}, and while decrypting the image, the key was set to !q2w3e4r5t6y7u8i9o0p!@#
$%^&*(){}. Despite the fact that the difference between the encryption (1q2w3e4r5t6y7u8i9o0p!@#
$%^&*(){}) and decryption key(!q2w3e4r5t6y7u8i9o0p!@#
$%^&*(){}) was only one character (i.e.,!), the decrypted image contains no visual information. This indicates that the encryption scheme is very key-sensitive. If any malicious vehicle tries to access or send phantom information, the encryption technique will avoid such phantom information, thus enhancing safety.
The histogram analysis of both encrypted and decrypted image frames proves that our logistic map-based encryption techniques provide enough safety and security from malicious vehicles. Histograms describe the distribution of image pixels, and a good encryption technique must produce a uniform histogram for all encrypted image frames.
Figure 9 shows the histogram of the original (i.e.,
Figure 9b) and encrypted image (i.e.,
Figure 9d). As it can be seen that the histogram of the encrypted image has more uniform spikes as compared to the original image. We can see that the histogram of the original image is not uniform. These figures show no statistical similarity between the original and encrypted images, consequently providing no meaningful information for the malicious vehicle.
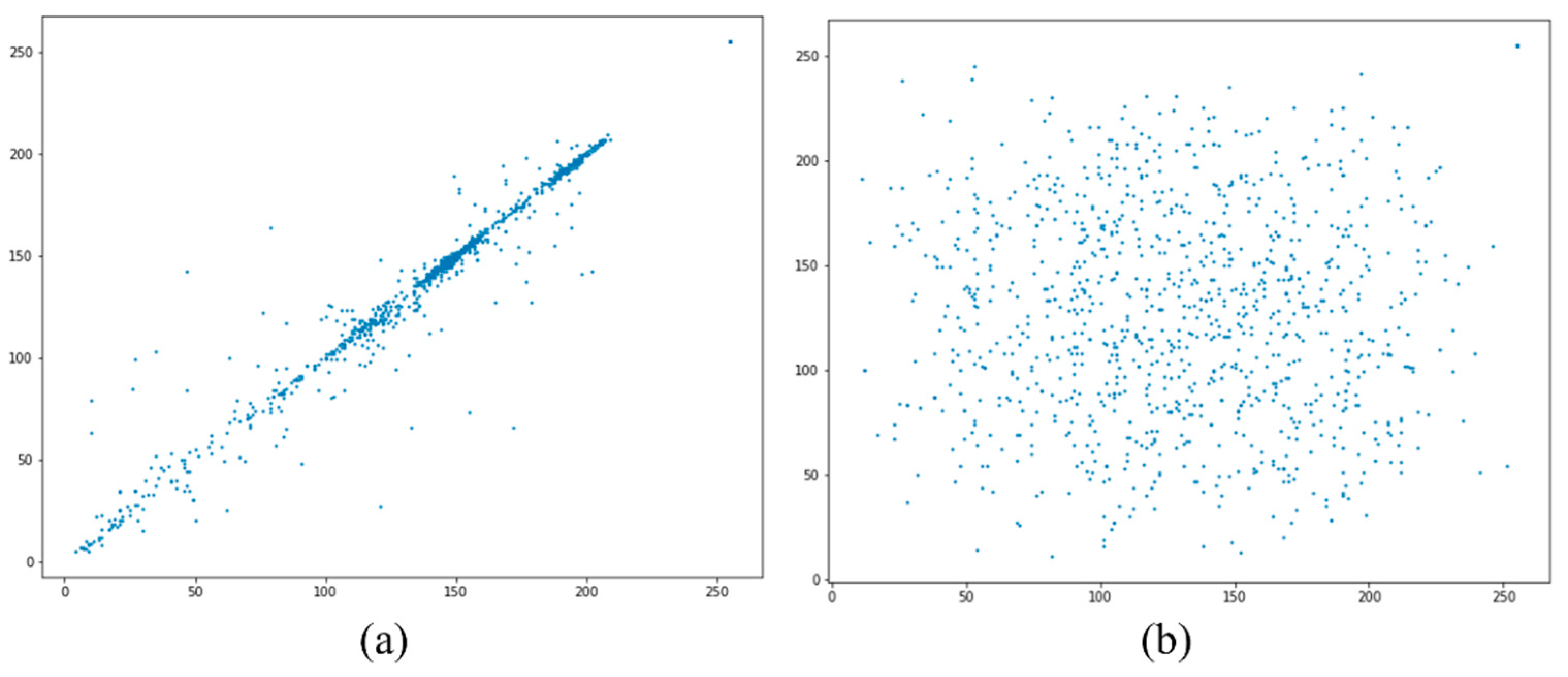
To avoid the attack from malicious vehicles on collaborative perception, the adjacent pixels in the encrypted image should be noncorrelated and the value of correlation should be close to zero. Higher correlation implies higher similarity between adjacent pixels, and
Figure 10 shows that the original image has a higher correlation than the encrypted image. From
Figure 10a, the correlation between the adjacent pixel is high in horizontal, vertical, and diagonal positions. In contrast,
Figure 10b shows a correlation graph of the encrypted image, indicating that the correlation between adjacent pixels is very low. The correlation graphs of original and encrypted image frames confirmed that the encrypted image achieved zero correlation, proving that the encryption technique is robust against correlation attacks of malicious vehicles.
5.7. Comparative Analysis with Existing Works
Comparison (RQ4): To compare our approach with the existing fusion-based collaborative/co-operative perception system, we choose F-Cooper [
10] and Cooper [
32]. However, the direct comparison of our approach with these fusion methods would not be meaningful due to the sensor type, position, and data used for fusion.
Table 3 presents the high-level comparative analysis of our approach with the existing baseline approaches. Additionally, we compare the object detection performance of Cooper and F-Cooper with our approach. F-Cooper reported their detection result in average precision. Both F-Cooper and Cooper reported the detection precision in two categories based on the distance between the camera sensor and the detected objects. The first category is the “Near” category, representing the object near the camera sensors. The second category is the “Far” category, representing the object far from the camera sensors. The cutoff between the “Near” and “Far” is 20 m. Regarding the detection performance of both F-Cooper and Cooper in multilane road-testing scenarios, the voxel feature fusion method was reported as the best-performing method from F-Cooper, with an average precision of 77.46% and 58.27% for the “Near” and “Far” category, respectively, when the IoU threshold was set to 0.7.
In contrast to the Cooper and F-Cooper, the detection confidence of our collaborative perception system was reported in
mAP. Compared to the average detection precision of F-Cooper, our collaborative perception system
mAP was reported at 79.9% in the multilane road-testing scenario. As in the road intersection scenario, the average detection precision of F-Cooper and Cooper reported for the voxel fusion method was 80.21% for the “Near” category and 72.37% for the “Far” category, respectively. On the other hand, the
mAP for the road intersection scenario in our collaborative perception system was reported at 78.8%. Although we reported the detection confidence in mean average precision, while F-Cooper and Cooper still reported detection confidence in average precision, our detection confidence outperformed both F-Cooper and Cooper in multilane road-testing scenarios when the IoU threshold was set to 0.7. We also evaluated the performance of collaborative perception with the IoU threshold at 0.5 and 0.95. The result showed that the detection confidence when the IoU threshold was set to 0.5, our proposed approach outperformed F-Cooper and Cooper in both testing scenarios. For example, the
mAP was 84.2% of our approach compared to F-Cooper, and Cooper’s average precision was 80.21% for “Near” and 72.37% for “Far” in the intersection scenario. Compared to the existing approach, each frame size in our proposed system was reported as less than 358 kbit, and the time required to process the image frames required less than 301 ms. We also compared the sensor placement techniques with [
33], in which all the sensors in co-operative perception were placed in fixed positions (i.e., roundabouts and T-junctions). The objects beyond the range of these fixed positioned sensors are still unknown to ADSs, posing safety threats. In contrast, the sensor placement in our approach is not location dependent, meaning that the camera sensors are mounted on the ADSs themselves, enabling them to extend the sensing range.
5.8. Threats to Validity
The first threat to validity is the network delay, although in this study, we did not consider communication and network delay. Regarding the network delay, the insights from our study are that it can cause problems in collaborative perception in terms of false detection or introduce more false positives due to the misalignment of frames or missing frames. Network delays should be rigorously investigated as missing frames, or misaligned incoming frames due to network delays can compromise the performance of object detection models. However, we handle this thread to validity by reducing the frame size through compression without losing important features. From the experimental result, we can observe that the average frame size was recorded as only 357 kbit. To process frames with the size of 357 kbit at the rate of 10 frames/s, we need only 3.7 MB/s bandwidth. The commercially available wireless communication system can easily support such a processing rate.
The second threat to validity is the broad security protocol and data integrity aspects. The article does not cover the broad aspect of the security protocol of data being transferred from one ADS_1 to another ADS_1. Data security and integrity are very important in connected vehicles and need to be thoroughly investigated. Malicious ADSs may send phantom information. Additionally, the participating ADSs in collaborative perception can be unintentionally malicious due to sensor degradation of faulty sensors. This may pose serious driving hazards causing accidents. However, this issue was minimized through the encryption technique. The communication between the two ADSs was secured through an end-to-end encryption technique. On the other hand, if the tampering in image frames happens before the encryption, the encryption systems cannot avoid such tampering, which is another external threat to the validity of this proposed system. Another important aspect is communication with low latency in practical applications. Latency is a big issue that needs to be solved in practical applications. We argue that the advancement in wireless communication has actively accommodated the latency issues. For example, the 5G and millimeter-wave communication provide extremely low latency [
44].
Testing safety-threatening scenarios, as shown in
Figure 1, with actual vehicles may pose a risk to human safety. Therefore, in general, these risk scenarios must be tested thoroughly by simulated-based testing to ensure safety. Typically, manufacturers perform very limited infield testing to test complex systems such as ADS [
45]. Simulation-based testing allows for the safe testing of hazardous scenarios. Hence, manufacturers test more risk scenarios by recording sensor data from infield testing and regenerating them in the simulation environment. Therefore, we decided to validate the proposed system in the simulation environment. We believe that testing the proposed system will yield the same results on real data since the simulator-generated data produces the same results as those obtained on the real data, as mentioned in [
46]. However, on-road testing is necessary for the final product to be released, which is done by professional field testers.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}