

A Classification Method for Electronic Components Based on Siamese Network

Abstract
:1. Introduction
2. Siamese Network Architecture and Dataset
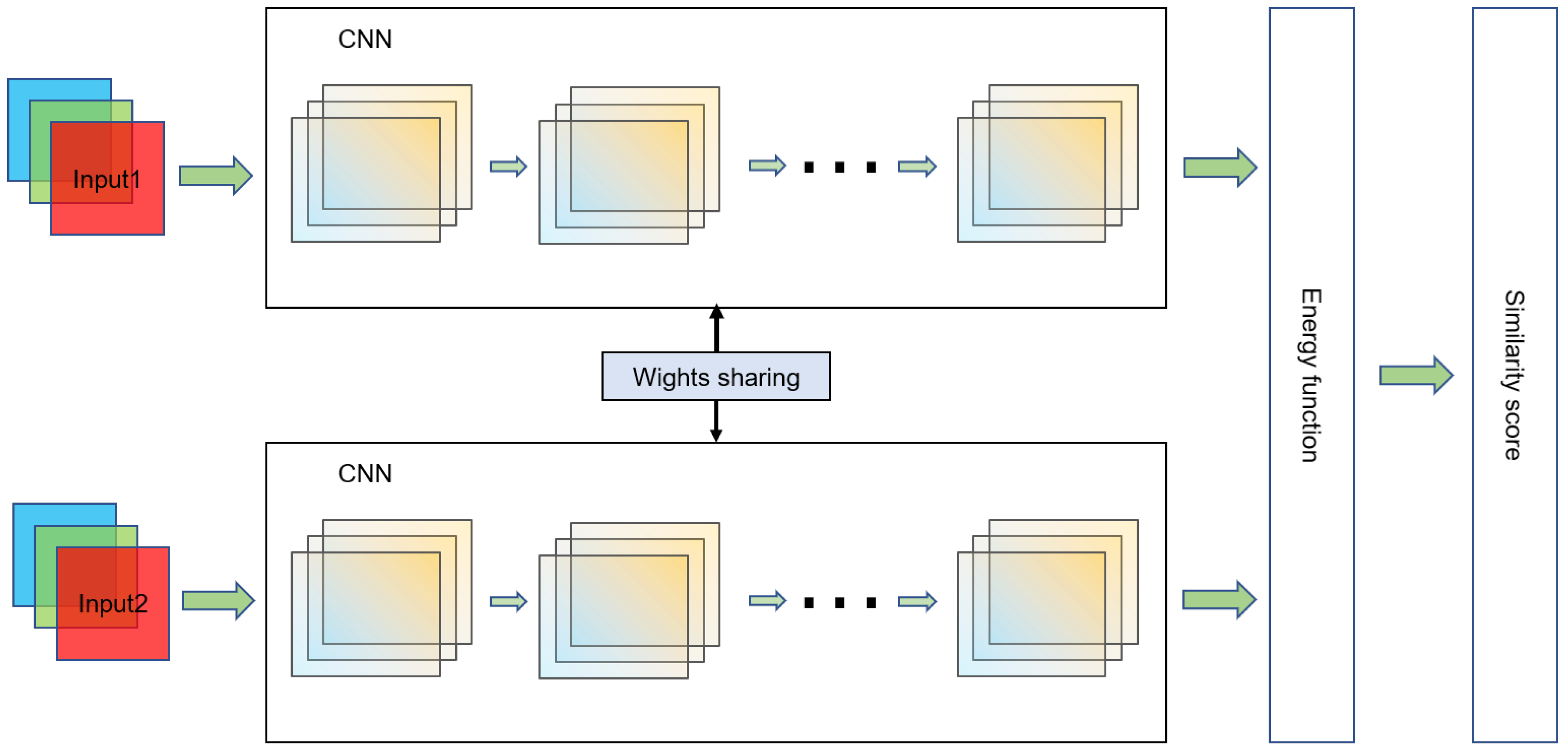
2.1. Siamese Network
2.2. Dataset
3. Method
3.1. Improved VGG-16 Model
3.2. Loss Function
4. Experiment Results and Discussion
4.1. Experimental Details
4.2. Evaluation Metrics
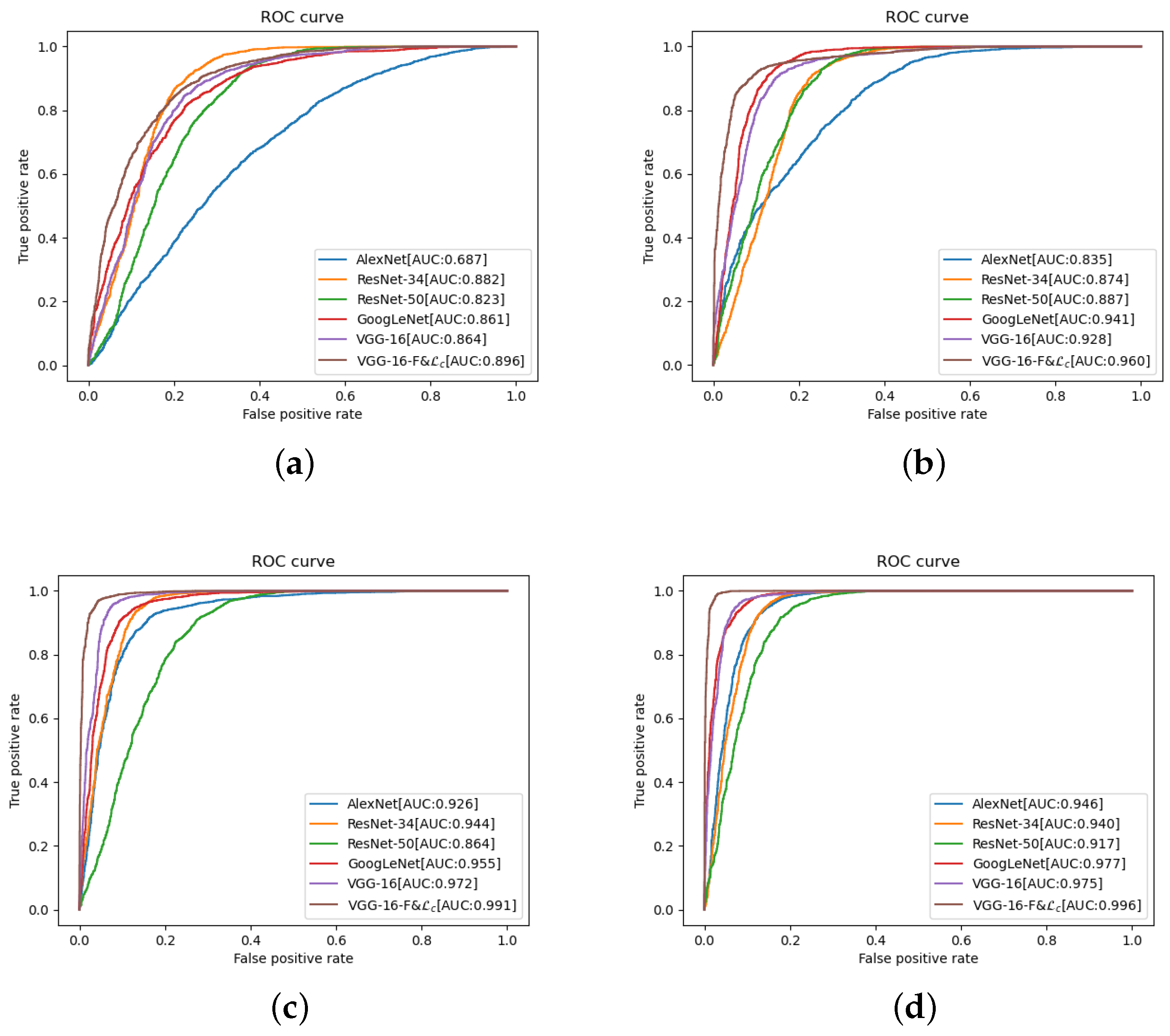
4.3. Experimental Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Kiddee, P.; Naidu, R.; Wong, M.H. Electronic waste management approaches: An overview. Waste Manag. 2013, 33, 1237–1250. [Google Scholar] [CrossRef] [PubMed]
- Tanskanen, P. Management and recycling of electronic waste. Acta Mater. 2013, 61, 1001–1011. [Google Scholar] [CrossRef]
- Rawat, W.; Wang, Z. Deep Convolutional Neural Networks for Image Classification: A Comprehensive Review. Neural Comput. 2017, 29, 1–98. [Google Scholar] [CrossRef] [PubMed]
- Alsaffar, A.; Tao, H.; Talab, M. Review of deep convolution neural network in image classification. In Proceedings of the 2017 International Conference on Radar, Antenna, Microwave, Electronics, and Telecommunications (ICRAMET), Jakarta, Indonesia, 23–24 October 2017; pp. 26–31. [Google Scholar] [CrossRef]
- Li, L.; Zhang, S.; Wang, B. Apple Leaf Disease Identification with a Small and Imbalanced Dataset Based on Lightweight Convolutional Networks. Sensors 2022, 22, 173. [Google Scholar] [CrossRef] [PubMed]
- Masci, J.; Meier, U.; Ciresan, D.; Schmidhuber, J.; Fricout, G. Steel defect classification with Max-Pooling Convolutional Neural Networks. In Proceedings of the 2012 International Joint Conference on Neural Networks (IJCNN), Brisbane, Australia, 10–15 June 2012; pp. 1–6. [Google Scholar] [CrossRef]
- Zhang, Y.D.; Satapathy, S.C.; Guttery, D.S.; Górriz, J.M.; Wang, S.H. Improved Breast Cancer Classification Through Combining Graph Convolutional Network and Convolutional Neural Network. Inf. Process. Manag. 2021, 58, 102439. [Google Scholar] [CrossRef]
- Cai, D.; Chen, K.; Qian, Y.; Kämäräinen, J.K. Convolutional low-resolution fine-grained classification. Pattern Recognit. Lett. 2019, 119, 166–171. [Google Scholar] [CrossRef]
- Wu, X.; Hong, D.; Chanussot, J. Convolutional Neural Networks for Multimodal Remote Sensing Data Classification. IEEE Trans. Geosci. Remote. Sens. 2022, 60, 5517010. [Google Scholar] [CrossRef]
- Mou, L.; Lu, X.; Li, X.; Zhu, X.X. Nonlocal Graph Convolutional Networks for Hyperspectral Image Classification. IEEE Trans. Geosci. Remote. Sens. 2020, 58, 8246–8257. [Google Scholar] [CrossRef]
- Lefkaditis, D.; Tsirigotis, G. Morphological feature selection and neural classification. J. Eng. Sci. Technol. Rev. 2009, 2, 151–156. [Google Scholar] [CrossRef]
- Atik, I. Classification of Electronic Components Based on Convolutional Neural Network Architecture. Energies 2022, 15, 2347. [Google Scholar] [CrossRef]
- Salvador, R.; Bandala, A.; Javel, I.; Bedruz, R.A.; Dadios, E.; Vicerra, R. DeepTronic: An Electronic Device Classification Model using Deep Convolutional Neural Networks. In Proceedings of the 2018 IEEE 10th International Conference on Humanoid, Nanotechnology, Information Technology, Communication and Control, Environment and Management (HNICEM), Baguio City, Philippines, 29 November–2 December 2018; pp. 1–5. [Google Scholar] [CrossRef]
- Wang, Y.J.; Chen, Y.T.; Jiang, Y.S.F.; Horng, M.F.; Shieh, C.S.; Wang, H.Y.; Ho, J.H.; Cheng, Y.M. An Artificial Neural Network to Support Package Classification for SMT Components. In Proceedings of the 2018 3rd International Conference on Computer and Communication Systems (ICCCS), Nagoya, Japan, 27–30 April 2018; pp. 130–134. [Google Scholar] [CrossRef]
- Hu, X.; Xu, J.; Wu, J. A Novel Electronic Component Classification Algorithm Based on Hierarchical Convolution Neural Network. In Proceedings of the IOP Conference Series: Earth and Environmental Science, Changchun, China, 21–23 August 2020; Volume 474, p. 052081. [Google Scholar] [CrossRef]
- Ilina, O.; Ziyadinov, V.; Klenov, N.; Tereshonok, M. A Survey on Symmetrical Neural Network Architectures and Applications. Symmetry 2022, 14, 1391. [Google Scholar] [CrossRef]
- Bromley, J.; Bentz, J.W.; Bottou, L.; Guyon, I.; LeCun, Y.; Moore, C.; Säckinger, E.; Shah, R. Signature verification using a“Siamese” time delay neural network. Int. J. Pattern Recognit. Artif. Intell. 1993, 7, 669–688. [Google Scholar] [CrossRef]
- Chopra, S.; Hadsell, R.; Lecun, Y. Learning a similarity metric discriminatively, with application to face verification. In Proceedings of the Computer Vision and Pattern Recognition Conference, San Diego, CA, USA, 20–25 June 2005; IEEE Press: Piscataway, NJ, USA, 2005; pp. 539–546. [Google Scholar]
- Hoffer, E.; Ailon, N. Deep Metric Learning Using Triplet Network. In Proceedings of the Similarity-Based Pattern Recognition, Copenhagen, Denmark, 12–14 October 2015; Feragen, A., Pelillo, M., Loog, M., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 84–92. [Google Scholar]
- Dong, X.; Shen, J.; Wu, D.; Guo, K.; Jin, X.; Porikli, F. Quadruplet Network With One-Shot Learning for Fast Visual Object Tracking. IEEE Trans. Image Process. 2019, 28, 3516–3527. [Google Scholar] [CrossRef]
- Liu, X.; Zhou, Y.; Zhao, J.; Yao, R.; Liu, B.; Zheng, Y. Siamese Convolutional Neural Networks for Remote Sensing Scene Classification. IEEE Geosci. Remote Sens. Lett. 2019, 16, 1200–1204. [Google Scholar] [CrossRef]
- Wang, B.; Wang, D. Plant Leaves Classification: A Few-Shot Learning Method Based on Siamese Network. IEEE Access 2019, 7, 151754–151763. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. Comput. Sci. 2014. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep Sparse Rectifier Neural Networks. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Ft. Lauderdale, FL, USA, 11–13 April 2011; Gordon, G., Dunson, D., Dudík, M., Eds.; PMLR: Fort Lauderdale, FL, USA, 2011; Volume 15, pp. 315–323. [Google Scholar]
- Srivastava, N.; Hinton, G.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Dropout: A Simple Way to Prevent Neural Networks from Overfitting. J. Mach. Learn. Res. 2014, 15, 1929–1958. [Google Scholar]
- Koch, G.; Zemel, R.; Salakhutdinov, R. Siamese Neural Networks for One-shot Image Recognition. In Proceedings of the ICML Deep Learning Workshop, Lille, France, 6–11 July 2015. [Google Scholar]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. Image Style Transfer Using Convolutional Neural Networks. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2414–2423. [Google Scholar] [CrossRef]
- Kingma, D.; Ba, J. Adam: A Method for Stochastic Optimization. Int. Conf. Learn. Represent. 2014. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef] [Green Version]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | ||||
|---|---|---|---|---|
| VGG-16 | 0.31 | 0.50 | 0.67 | 0.71 |
| VGG-16-F | 0.46 | 0.61 | 0.77 | 0.86 |
| VGG-16& | 0.38 | 0.56 | 0.75 | 0.84 |
| VGG-16-F& | 0.47 | 0.65 | 0.91 | 0.94 |
| Model | ||||
|---|---|---|---|---|
| AlexNet | 0.15 | 0.34 | 0.49 | 0.55 |
| ResNet-34 | 0.31 | 0.39 | 0.44 | 0.47 |
| ResNet-50 | 0.18 | 0.29 | 0.31 | 0.36 |
| GoogLeNet | 0.37 | 0.52 | 0.58 | 0.78 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, Y.; Wang, A.; Wu, L. A Classification Method for Electronic Components Based on Siamese Network. Sensors 2022, 22, 6478. https://doi.org/10.3390/s22176478
Cheng Y, Wang A, Wu L. A Classification Method for Electronic Components Based on Siamese Network. Sensors. 2022; 22(17):6478. https://doi.org/10.3390/s22176478
Chicago/Turabian StyleCheng, Yahui, Aimin Wang, and Long Wu. 2022. "A Classification Method for Electronic Components Based on Siamese Network" Sensors 22, no. 17: 6478. https://doi.org/10.3390/s22176478
APA StyleCheng, Y., Wang, A., & Wu, L. (2022). A Classification Method for Electronic Components Based on Siamese Network. Sensors, 22(17), 6478. https://doi.org/10.3390/s22176478