
Agrast-6: Abridged VGG-Based Reflected Lightweight Architecture for Binary Segmentation of Depth Images Captured by Kinect



Abstract
:1. Introduction
- An in-depth and organized examination of the most important deep learning models for semantic segmentation, their origins, and their contributions.
- A new convolutional deep learning model proposed for binary image segmentation.
- A comprehensive performance evaluation that collects quantitative metrics such as segmentation accuracy and execution time.
- A discussion of the aforementioned results as well as a list of potential future works that could set the course of future advances in semantic segmentation of depth images and a conclusion summarizing the field’s state of the art.
2. Previous Work on Semantic Image Segmentation
3. Methodology
3.1. Workflow
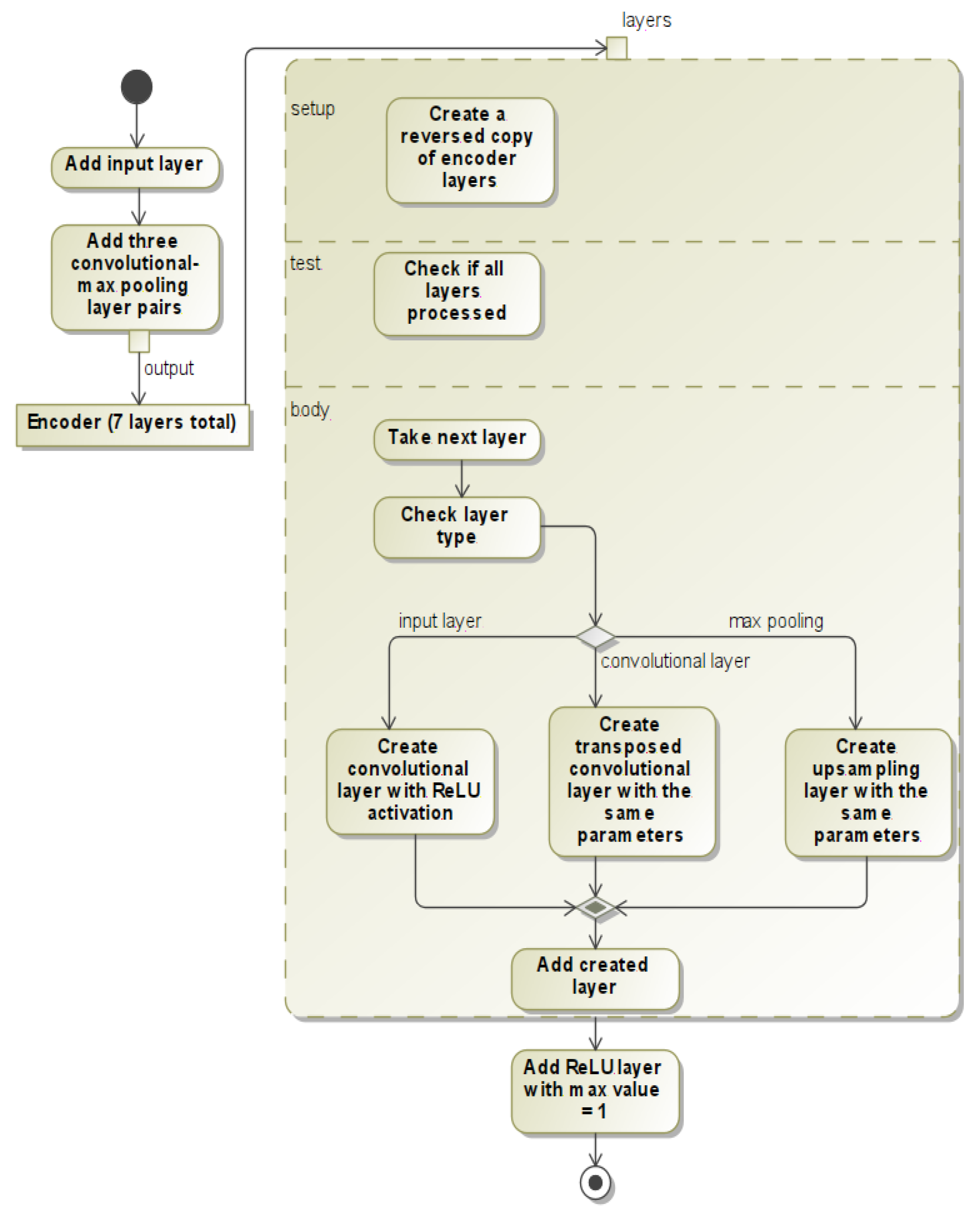
3.2. Suggested Neural Network—Agrast-6 Architecture
3.3. Neural Network Implementation
4. Neural Network Training and Evaluation
4.1. Dataset
4.2. Settings
4.3. Training
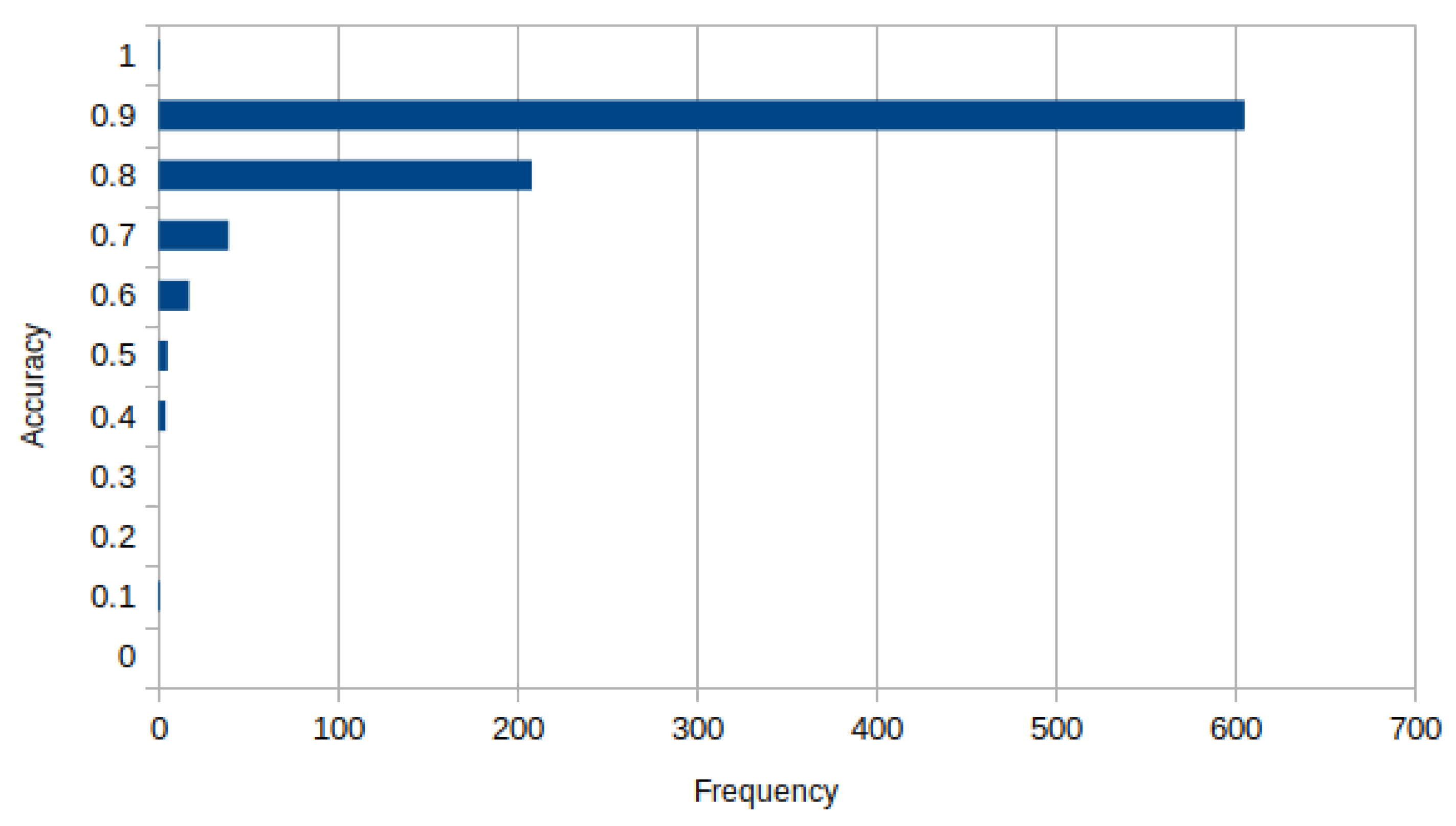
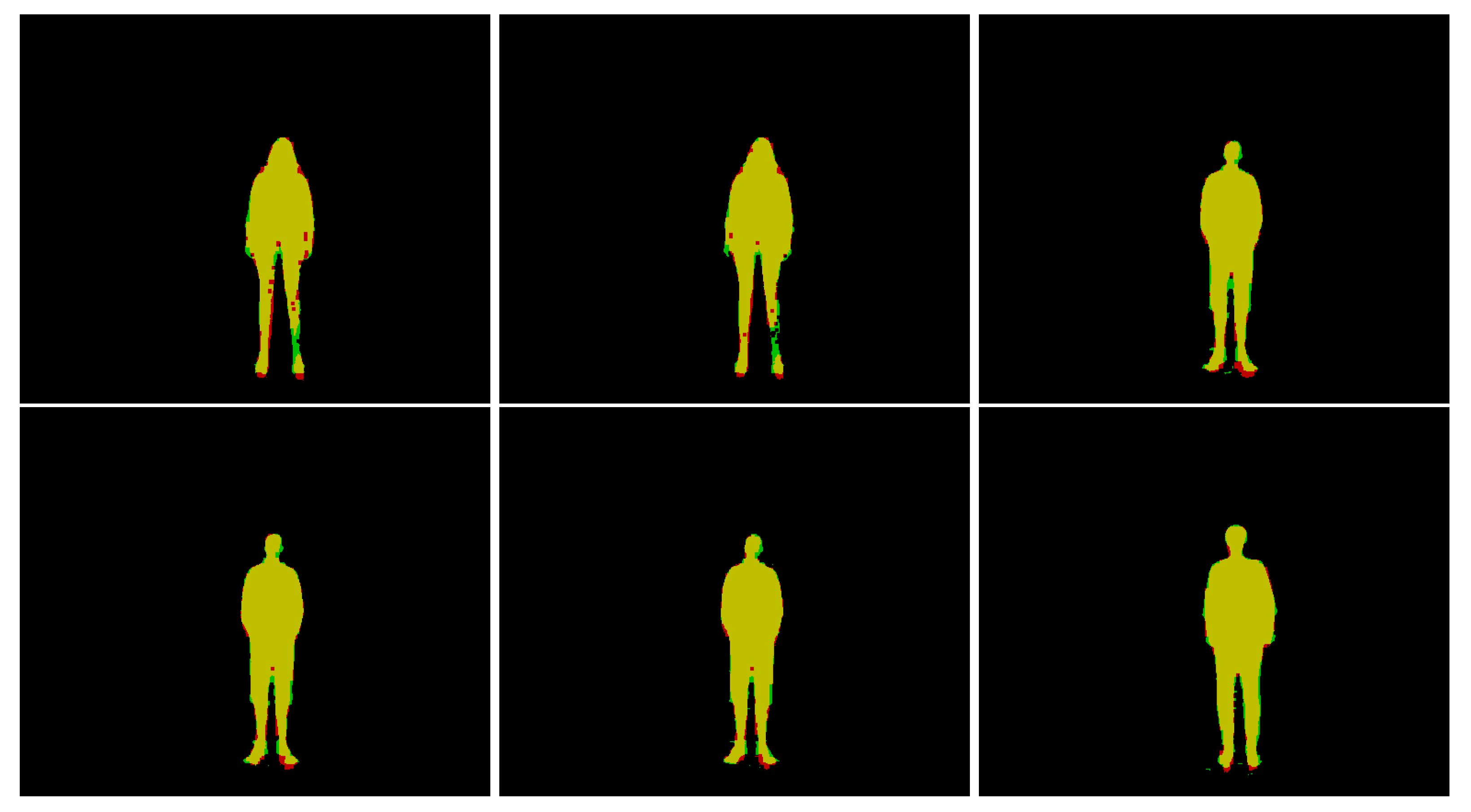
4.4. Quantitative and Qualitative Validation Analysis
4.5. Segmentation Evaluation via Cross-Intersection Accuracy and mIoU
4.6. Gender-Wise Accuracy Comparison
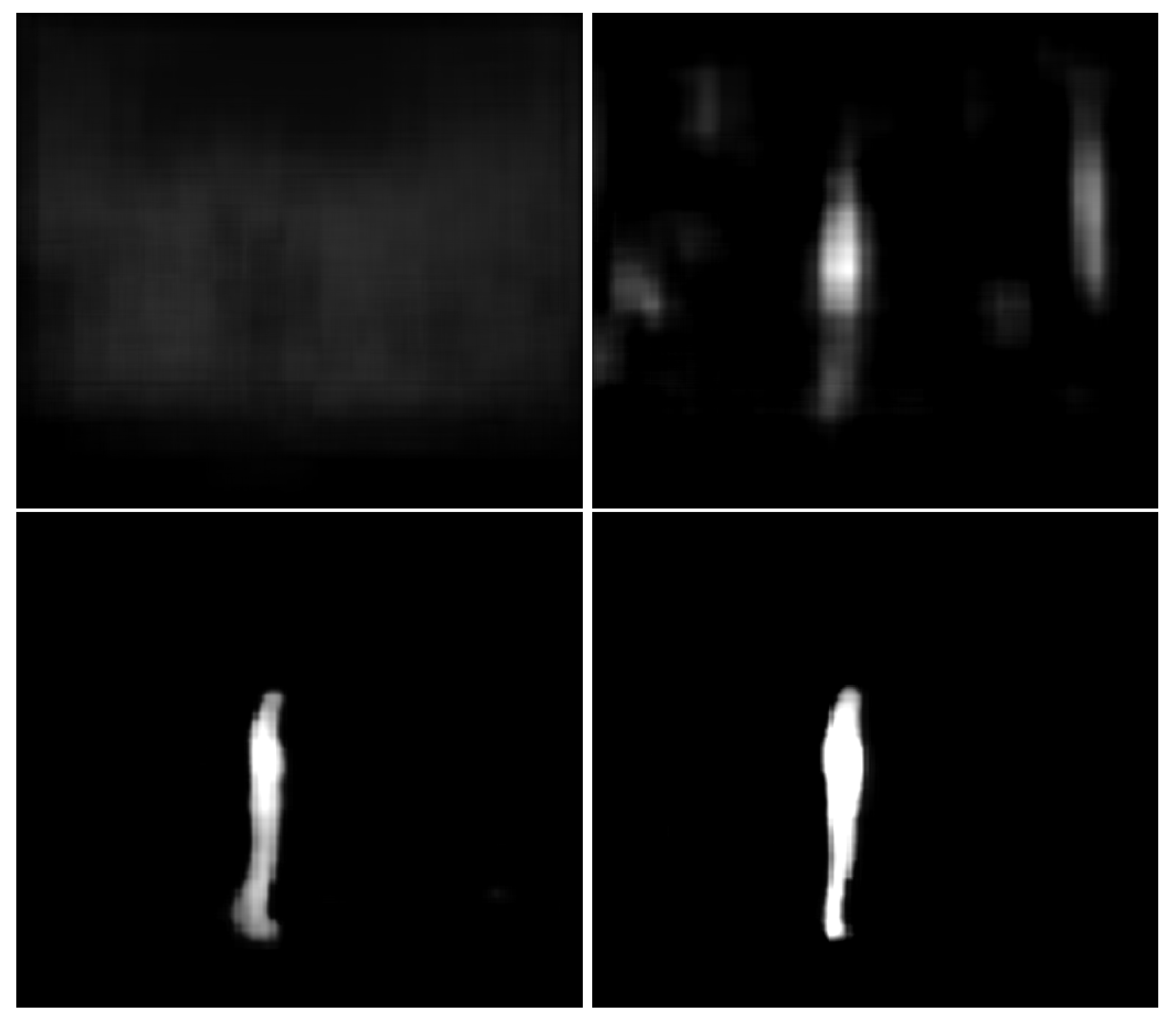
4.7. Qualitative Error Analysis
4.8. Prediction Performance
4.9. Comparison with Other Solutions
5. Discussion and Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Khanday, N.Y.; Sofi, S.A. Taxonomy, state-of-the-art, challenges and applications of visual understanding: A review. Comput. Sci. Rev. 2021, 40, 100374. [Google Scholar] [CrossRef]
- Garcia-Garcia, A.; Orts-Escolano, S.; Oprea, S.; Villena-Martinez, V.; Martinez-Gonzalez, P.; Garcia-Rodriguez, J. A survey on deep learning techniques for image and video semantic segmentation. Appl. Soft Comput. J. 2018, 70, 41–65. [Google Scholar] [CrossRef]
- Ulku, I.; Akagündüz, E. A Survey on Deep Learning-based Architectures for Semantic Segmentation on 2D Images. Appl. Artif. Intell. 2022, 36. [Google Scholar] [CrossRef]
- Mráček, Š.; Drahanskỳ, M.; Dvořák, R.; Provazník, I.; Váňa, J. 3D face recognition on low-cost depth sensors. In Proceedings of the 2014 International Conference of the Biometrics Special Interest Group (BIOSIG), Darmstadt, Germany, 10–12 September 2014; pp. 1–4. [Google Scholar]
- Cippitelli, E.; Fioranelli, F.; Gambi, E.; Spinsante, S. Radar and RGB-depth sensors for fall detection: A review. IEEE Sens. J. 2017, 17, 3585–3604. [Google Scholar] [CrossRef] [Green Version]
- Kurillo, G.; Chen, A.; Bajcsy, R.; Han, J.J. Evaluation of upper extremity reachable workspace using Kinect camera. Technol. Health Care 2013, 21, 641–656. [Google Scholar] [CrossRef] [Green Version]
- Chen, C.; Liu, K.; Jafari, R.; Kehtarnavaz, N. Home-based senior fitness test measurement system using collaborative inertial and depth sensors. In Proceedings of the 2014 36th Annual International Conference of the IEEE Engineering in Medicine and Biology Society, Chicago, IL, USA, 26–30 August 2014; pp. 4135–4138. [Google Scholar]
- Ryselis, K.; Petkus, T.; Blažauskas, T.; Maskeliūnas, R.; Damaševičius, R. Multiple Kinect based system to monitor and analyze key performance indicators of physical training. Hum-Centric Comput. Inf. Sci. 2020, 10, 51. [Google Scholar] [CrossRef]
- Ofli, F.; Kurillo, G.; Obdržálek, S.; Bajcsy, R.; Jimison, H.B.; Pavel, M. Design and evaluation of an interactive exercise coaching system for older adults: Lessons learned. IEEE J. Biomed. Health Inform. 2016, 20, 201–212. [Google Scholar] [CrossRef]
- Patalas-maliszewska, J.; Halikowski, D.; Damaševičius, R. An automated recognition of work activity in industrial manufacturing using convolutional neural networks. Electronics 2021, 10, 2946. [Google Scholar] [CrossRef]
- Tadic, V.; Toth, A.; Vizvari, Z.; Klincsik, M.; Sari, Z.; Sarcevic, P.; Sarosi, J.; Biro, I. Perspectives of RealSense and ZED Depth Sensors for Robotic Vision Applications. Machines 2022, 10, 183. [Google Scholar] [CrossRef]
- Long, N.; Wang, K.; Cheng, R.; Hu, W.; Yang, K. Unifying obstacle detection, recognition, and fusion based on millimeter wave radar and RGB-depth sensors for the visually impaired. Rev. Sci. Instrum. 2019, 90, 044102. [Google Scholar] [CrossRef]
- Camalan, S.; Sengul, G.; Misra, S.; Maskeliūnas, R.; Damaševičius, R. Gender detection using 3d anthropometric measurements by kinect. Metrol. Meas. Syst. 2018, 25, 253–267. [Google Scholar]
- Kulikajevas, A.; Maskeliunas, R.; Damasevicius, R.; Scherer, R. Humannet-a two-tiered deep neural network architecture for self-occluding humanoid pose reconstruction. Sensors 2021, 21, 3945. [Google Scholar] [CrossRef]
- Do Carmo Vilas-Boas, M.; Choupina, H.M.P.; Rocha, A.P.; Fernandes, J.M.; Cunha, J.P.S. Full-body motion assessment: Concurrent validation of two body tracking depth sensors versus a gold standard system during gait. J. Biomech. 2019, 87, 189–196. [Google Scholar] [CrossRef] [PubMed]
- Ma, Y.; Li, N.; Zhang, W.; Wang, S.; Ma, H. Image encryption scheme based on alternate quantum walks and discrete cosine transform. Opt. Express 2021, 29, 28338–28351. [Google Scholar] [CrossRef] [PubMed]
- Peng, H.; Li, B.; Xiong, W.; Hu, W.; Ji, R. RGBD salient object detection: A benchmark and algorithms. In European Conference on Computer Vision, Proceedings of the 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 92–109. [Google Scholar]
- Qi, X.; Liao, R.; Jia, J.; Fidler, S.; Urtasun, R. 3d graph neural networks for rgbd semantic segmentation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5199–5208. [Google Scholar]
- Wang, J.; Wang, Z.; Tao, D.; See, S.; Wang, G. Learning common and specific features for RGB-D semantic segmentation with deconvolutional networks. In European Conference on Computer Vision, Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Cham, Switzerland, 2016; pp. 664–679. [Google Scholar]
- Hu, X.; Yang, K.; Fei, L.; Wang, K. Acnet: Attention based network to exploit complementary features for rgbd semantic segmentation. In Proceedings of the IEEE International Conference on Image Processing (ICIP), Taipei, China, 22–25 September 2019; pp. 1440–1444. [Google Scholar]
- Roesner, F.; Kohno, T.; Molnar, D. Security and privacy for augmented reality systems. Commun. ACM 2014, 57, 88–96. [Google Scholar] [CrossRef]
- Fu, K.; Lu, W.; Diao, W.; Yan, M.; Sun, H.; Zhang, Y.; Sun, X. WSF-NET: Weakly supervised feature-fusion network for binary segmentation in remote sensing image. Remote Sens. 2018, 10, 1970. [Google Scholar] [CrossRef] [Green Version]
- Barrowclough, O.J.; Muntingh, G.; Nainamalai, V.; Stangeby, I. Binary segmentation of medical images using implicit spline representations and deep learning. Comput. Aided Geom. Des. 2021, 85, 101972. [Google Scholar] [CrossRef]
- Hu, Y.T.; Huang, J.B.; Schwing, A. Maskrnn: Instance level video object segmentation. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. [Google Scholar]
- Shazeer, N.; Mirhoseini, A.; Maziarz, K.; Davis, A.; Le, Q.; Hinton, G.; Dean, J. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv 2017, arXiv:1701.06538. [Google Scholar]
- Huang, Y.; Cheng, Y.; Bapna, A.; Firat, O.; Chen, D.; Chen, M.; Lee, H.; Ngiam, J.; Le, Q.V.; Wu, Y.; et al. Gpipe: Efficient training of giant neural networks using pipeline parallelism. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, QC, Canada, 8–14 December 2019; Volume 32. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; Volume 25. [Google Scholar]
- Yu, W.; Yang, K.; Bai, Y.; Xiao, T.; Yao, H.; Rui, Y. Visualizing and comparing AlexNet and VGG using deconvolutional layers. In Proceedings of the 33 rd International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016. [Google Scholar]
- Canziani, A.; Paszke, A.; Culurciello, E. An analysis of deep neural network models for practical applications. arXiv 2016, arXiv:1605.07678. [Google Scholar]
- Paszke, A.; Chaurasia, A.; Kim, S.; Culurciello, E. Enet: A deep neural network architecture for real-time semantic segmentation. arXiv 2016, arXiv:1606.02147. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Alqazzaz, S.; Sun, X.; Yang, X.; Nokes, L. Automated brain tumor segmentation on multi-modal MR image using SegNet. Comput. Vis. Media 2019, 5, 209–219. [Google Scholar] [CrossRef] [Green Version]
- Chen, T.; Cai, Z.; Zhao, X.; Chen, C.; Liang, X.; Zou, T.; Wang, P. Pavement crack detection and recognition using the architecture of segNet. J. Ind. Inf. Integr. 2020, 18, 100144. [Google Scholar] [CrossRef]
- Alonso, I.; Murillo, A.C. EV-SegNet: Semantic segmentation for event-based cameras. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Long Beach, CA, USA, 16–17 June 2019. [Google Scholar]
- Mou, L.; Hua, Y.; Zhu, X.X. A relation-augmented fully convolutional network for semantic segmentation in aerial scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 12416–12425. [Google Scholar]
- Gros, C.; Lemay, A.; Cohen-Adad, J. SoftSeg: Advantages of soft versus binary training for image segmentation. Med. Image Anal. 2021, 71, 102038. [Google Scholar] [CrossRef]
- Iglovikov, V.; Shvets, A. Ternausnet: U-net with vgg11 encoder pre-trained on imagenet for image segmentation. arXiv 2018, arXiv:1801.05746. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In International Conference on Medical Image Computing and Computer-Assisted Intervention, Proceedings of the 18th International Conference, Munich, Germany, 5–9 October 2015; Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics); Springer: Cham, Switzerland, 2015; Volume 9351, pp. 234–241. [Google Scholar]
- Seo, H.; Huang, C.; Bassenne, M.; Xiao, R.; Xing, L. Modified U-Net (mU-Net) with incorporation of object-dependent high level features for improved liver and liver-tumor segmentation in CT images. IEEE Trans. Med. Imaging 2019, 39, 1316–1325. [Google Scholar] [CrossRef] [Green Version]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef] [Green Version]
- Visin, F.; Romero, A.; Cho, K.; Matteucci, M.; Ciccone, M.; Kastner, K.; Bengio, Y.; Courville, A. ReSeg: A Recurrent Neural Network-Based Model for Semantic Segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 426–433. [Google Scholar]
- Shuai, B.; Zuo, Z.; Wang, B.; Wang, G. DAG-Recurrent Neural Networks for Scene Labeling. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; Volume 2016-December, pp. 3620–3629. [Google Scholar]
- Zhang, S.; Ma, Z.; Zhang, G.; Lei, T.; Zhang, R.; Cui, Y. Semantic image segmentation with deep convolutional neural networks and quick shift. Symmetry 2020, 12, 427. [Google Scholar] [CrossRef] [Green Version]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Agarap, A.F. Deep learning using rectified linear units (relu). arXiv 2018, arXiv:1803.08375. [Google Scholar]
- Agarwal, M.; Gupta, S.; Biswas, K. A new Conv2D model with modified ReLU activation function for identification of disease type and severity in cucumber plant. Sustain. Comput. Inform. Syst. 2021, 30, 100473. [Google Scholar] [CrossRef]
- Karastergiou, K.; Smith, S.R.; Greenberg, A.S.; Fried, S.K. Sex differences in human adipose tissues—The biology of pear shape. Biol. Sex Differ. 2012, 3, 1–12. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Palmero, C.; Clapés, A.; Bahnsen, C.; Møgelmose, A.; Moeslund, T.B.; Escalera, S. Multi-modal rgb–depth–thermal human body segmentation. Int. J. Comput. Vis. 2016, 118, 217–239. [Google Scholar] [CrossRef] [Green Version]
- Zeppelzauer, M.; Poier, G.; Seidl, M.; Reinbacher, C.; Schulter, S.; Breiteneder, C.; Bischof, H. Interactive 3D segmentation of rock-art by enhanced depth maps and gradient preserving regularization. J. Comput. Cult. Herit. (JOCCH) 2016, 9, 1–30. [Google Scholar] [CrossRef]
- Wang, G.; Li, W.; Ourselin, S.; Vercauteren, T. Automatic brain tumor segmentation using cascaded anisotropic convolutional neural networks. In International MICCAI Brainlesion Workshop, Proceedings of the Third International Workshop, BrainLes 2017, Held in Conjunction with MICCAI 2017, Quebec City, QC, Canada, 14 September 2017; Springer: Cham, Switzerland, 2017; pp. 178–190. [Google Scholar]
- Ryselis, K.; Blažauskas, T.; Damaševičius, R.; Maskeliūnas, R. Computer-Aided Depth Video Stream Masking Framework for Human Body Segmentation in Depth Sensor Images. Sensors 2022, 22, 3531. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | Model | Novelty | Major Drawback |
|---|---|---|---|
| 2012 | AlexNet [28] | Depth of the model | Ineffective and lower accuracy than later models |
| 2014 | VGG-16 [27] | Small receptive fields | Heavy model, computationally expensive |
| 2015 | U-Net [39] | Encoder–decoder architecture | Blurred features, slower due to decoder |
| 2015 | SPP-Net [41] | Variable image size adaptation | Cannot fine-tune convolutional layers before SPP layer |
| 2015 | FCNN [45] | Adaptation into fully convolutional networks | - |
| 2016 | ReSeg [42] | Recurrent layer | Features must be extracted using other techniques |
| 2017 | SegNet [32] | Decoder non-linear upsampling | Slower due to decoder |
| 2021 | SoftSeg [37] | Normalized ReLU activation and regression loss function | Hard to evaluate due to fuzzy boundaries |
| Hyperparameter | Value |
|---|---|
| Convolutional layer kernel size | 3 × 3 |
| Convolutional layer activation function | ReLU |
| Max-pooling pool size | 4 × 4, 2 × 2 for last layer |
| Optimizer | Adam |
| Optimizer learning rate | 0.0001 |
| Loss function | Binary cross-entropy |
| Epoch | Train | Test | ||||||
|---|---|---|---|---|---|---|---|---|
| Loss | Precision | Accuracy | Recall | Loss | Precision | Accuracy | Recall | |
| 4 | 0.0161 | 0.9415 | 0.9939 | 0.9444 | 0.0430 | 0.9308 | 0.9916 | 0.9030 |
| 5 | 0.0150 | 0.9457 | 0.9944 | 0.9490 | 0.0347 | 0.9317 | 0.9920 | 0.9106 |
| 6 | 0.0158 | 0.9440 | 0.9940 | 0.9440 | 0.0329 | 0.9209 | 0.9919 | 0.9206 |
| 7 | 0.0152 | 0.9452 | 0.9942 | 0.9469 | 0.0351 | 0.9226 | 0.9915 | 0.9102 |
| 8 | 0.0164 | 0.9412 | 0.9938 | 0.9433 | 0.0324 | 0.9195 | 0.9921 | 0.9265 |
| 9 | 0.0162 | 0.9437 | 0.9939 | 0.9421 | 0.0325 | 0.9316 | 0.9925 | 0.9194 |
| Dataset | Gender | Mean Cross-Set Intersection | mIoU |
|---|---|---|---|
| Simple | male | 82.2% | 82.4% |
| Complex | male | 86.7% | 87.1% |
| Simple | female | 85.3% | 85.8% |
| Complex | female | 87.3% | 87.6% |
| Parameter | Value |
|---|---|
| Computational speed achieved on AMD Ryzen-9 3900X CPU | 469 GFlops |
| Computational speed achieved on NVidia GTX 1660 SUPER GPU | 5.03 TFlops |
| Average prediction time | 166 ms |
| Shortest prediction time | 154 ms |
| Longest prediction time | 229 ms |
| Method | Accuracy | Input Type | Based on | Purpose | Parameters | Model File Size | Inference Time | Input Size |
|---|---|---|---|---|---|---|---|---|
| Multi-modal RF RGBD + T [49] | 78% | RGBD + T | Random forest + descriptors | Segmentation | - | - | - | - |
| Rock depth + RF [50] | 60% | Depth | Random forest + deviation maps | Depth segmentation | - | - | - | - |
| WNet [51] | 91% | Medical depth | CNN | Segmentation | - | - | - | - |
| AlexNet [28] | 60% | RGB | CNN | RGB classification | 62 M | 233 MB | 52 ms | 227 × 277 |
| VGG-16 [27] | 75% | RGB | CNN | RGB classification | 134 M | 528 MB | 215 ms | 224 × 224 |
| SegNet [32] | 60% | RGB | CNN | Semantic RGB segmentation | 32 M | 117 MB | 341 ms | 340 × 480 |
| U-Net [39] | 92% | RGB | CNN | RGB binary segmentation | 30 M | 386 MB | 676 ms | 512 × 512 |
| Auto-expanding BB [52] | 76% | Depth | Geometrical | Binary depth segmentation | - | - | 60 ms | 424 × 512 |
| Agrast-6 (this paper) | 86% | Depth | CNN | Binary depth segmentation | 1.25 M | 15.4 MB | 292 ms | 448 × 512 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ryselis, K.; Blažauskas, T.; Damaševičius, R.; Maskeliūnas, R. Agrast-6: Abridged VGG-Based Reflected Lightweight Architecture for Binary Segmentation of Depth Images Captured by Kinect. Sensors 2022, 22, 6354. https://doi.org/10.3390/s22176354
Ryselis K, Blažauskas T, Damaševičius R, Maskeliūnas R. Agrast-6: Abridged VGG-Based Reflected Lightweight Architecture for Binary Segmentation of Depth Images Captured by Kinect. Sensors. 2022; 22(17):6354. https://doi.org/10.3390/s22176354
Chicago/Turabian StyleRyselis, Karolis, Tomas Blažauskas, Robertas Damaševičius, and Rytis Maskeliūnas. 2022. "Agrast-6: Abridged VGG-Based Reflected Lightweight Architecture for Binary Segmentation of Depth Images Captured by Kinect" Sensors 22, no. 17: 6354. https://doi.org/10.3390/s22176354
APA StyleRyselis, K., Blažauskas, T., Damaševičius, R., & Maskeliūnas, R. (2022). Agrast-6: Abridged VGG-Based Reflected Lightweight Architecture for Binary Segmentation of Depth Images Captured by Kinect. Sensors, 22(17), 6354. https://doi.org/10.3390/s22176354