Abstract
To avoid the potential safety hazards of electric vehicles caused by the mechanical fault deterioration of the in-wheel motor (IWM), this paper proposes an intelligent diagnosis based on double-optimized artificial hydrocarbon networks (AHNs) to identify the mechanical faults of IWM, which employs a K-means clustering and AdaBoost algorithm to solve the lower accuracy and poorer stability of traditional AHNs. Firstly, K-means clustering is used to improve the interval updating method of any adjacent AHNs molecules, and then simplify the complexity of the AHNs model. Secondly, the AdaBoost algorithm is utilized to adaptively distribute the weights for multiple weak models, then reconstitute the network structure of the AHNs. Finally, double-optimized AHNs are used to build an intelligent diagnosis system, where two cases of bearing datasets from Paderborn University and a self-made IWM test stand are processed to validate the better performance of the proposed method, especially in multiple rotating speeds and the load conditions of the IWM. The double-optimized AHNs provide a higher accuracy for identifying the mechanical faults of the IWM than the traditional AHNs, K-means-based AHNs (K-AHNs), support vector machine (SVM), and particle swarm optimization-based SVM (PSO-SVM).
1. Introduction
With the outbreak of the oil crisis, many policies and measures have been introduced to promote the development of the new energy vehicle (NEV) from countries all over the world. As a result, many new driving technologies have become research hotspots, one of which is the in-wheel motor (IWM), which has the advantages of high efficiency, fast response, and full-time wire control. The IWM-based driving system can reduce vehicle energy consumption, improve vehicle performance, and optimize spatial layout. Therefore, the IWM-based driving system has been recognized as the ideal configuration of future NEV power systems [1,2]. However, the unique installation between the IWM and the suspension must increase the unsprung mass of a vehicle, whereby the vibration isolation performance of the suspension is deteriorated, and the operational stability and safety are compromised. Moreover, as each IWM must directly withstand the intermittent strong impact load from the road, its local structure, such as the bearing, can be broken very easily, and it is difficult to detect the subtle damage. At present, there is no system for monitoring the IWM’s condition. Once a fault occurs to one or more of the IWMs in the driving system, local driving performance should deteriorate, which creates a security threat for the safe operation of the whole vehicle [3,4]. Therefore, it is urgent to explore efficient and reliable diagnosis methods for monitoring IWM’s fault condition [5,6,7].
In recent years, studies have been performed on signal processing, feature extraction, intelligent diagnosis, and the condition recognition of the common motor. For example, an intelligent fault diagnosis algorithm has been proposed by adaptive transfer affinity propagation clustering, which can extract potential energy features from the intrinsic mode functions of vibration signals using complete ensemble empirical mode decomposition (EMD) with adaptive noise [8]. A dual-tree complex wavelet transform (WT) is employed to acquire the multiscale signal’s features, which improve the classification accuracy of a fault’s characteristic signal [9]. A novel intelligent fault diagnosis approach based on principal component analysis (PCA) and a deep belief network (DBN) has been presented to extract the fault signatures in terms of primary eigenvalues and eigenvectors [10]. Ensemble EMD, wavelet packet transform (WPT), and sparse representation (SR) are utilized to accurately extract the information of fault features which are buried in vibration signals [11,12]. The method of attribute selection and feature extraction based on random forest (RF) combined with PCA has a faster recognition time and a higher recognition accuracy than other algorithms [13]. The integrated time-domain, frequency-domain statistical characteristics, EMD, and deep learning methods are proposed to realize the automatic recognition of different fault states of rotating machinery [14,15]. These methods of signal processing and feature extraction have the advantages of high resolution and strong interference suppression ability.
Moreover, Lagrange particle swarm optimization (L-PSO) has been improved to establish the multiple fault diagnosis model, which verifies the effectiveness and stability by sensor data-based multiple fault diagnosis [16]. Support vector machines (SVMs) have been applied to report the health states of railway turnout with high accuracy and self-adaptability [17,18]. A neural network (NN) is used establish the fault diagnosis model of large-scale ship engines, which has a higher diagnostic accuracy and use value [19,20]. The convolutional NN is modified with transfer learning for analyzing the thermal images of the rotor-bearing system under different working conditions [21]. The ensemble deep auto-encoders (EDAEs) method is proposed to intelligently diagnose the faults of rolling bearings [22]. A novel model with continuous WT and a local binary convolutional NN is applied to intelligently diagnose the faults of rotating machinery [23,24,25]. An improved particle swarm optimization variational mode decomposition (IPVMD) and improved convolutional neural network (I-CNN) are proposed to solve the problem of planetary gearbox composite fault diagnosis [26]. The improved convolutional neural network–support vector machine (CNN-SVM) method is presented to extract representative features from the multichannel vibration signals of the rolling bearing [27]. A novel tracking deep wavelet auto-encoder (TDWAE) method is introduced for the intelligent fault diagnosis of electric locomotive bearings [28]. The diagnosis method based on the auto-encoder and extreme learning machines is proposed for diagnosing faults in bearings so to overcome the deficiencies of longer training times [29]. A new real-time diagnosis method based on the dynamic Bayesian network (DBN) is used to distinguish the IWM’s mechanical faults [30]. The above methods have good classification effects or better applicability for specific application scenarios, but it is essential to establish the operation classification model and summarize the algorithm that can play better roles for specific scenarios [31,32,33]. However, as IWMs are often working in variable and complex conditions, the methods directly applied for fault diagnosis show neither superior performance nor acclimatization [34,35]. Therefore, it is urgent to make some improvement and achievement with respect to the existing artificial intelligence technologies so to establish the optimal intelligent diagnosis model for IWMs [36].
Artificial hydrocarbon networks (AHNs) are a new artificial intelligence algorithm that have excellent information encapsulation and integration ability. AHNs can not only realize the classifier function by using the target information in adjacent molecules, but also have the advantages of a clear network topology and strong adaptability [37]. However, while better performance would be achieved by training large samples, AHNs are confronted with large computational quantities and response times in these application [38,39,40].
To solve the above problems, K-means clustering and the AdaBoost algorithm are employed to design double-optimized AHNs with the core idea to improve the interval updating method of any adjacent AHN’s molecules and the linear connection scheme of multiple molecules. Moreover, the iterative process and computing speed of the proposed methods are researched, and the classification accuracies are also compared with several existing methods under different operating conditions. The rest of the paper is organized as follows. The basic theory of traditional AHNs is introduced in Section 2, and the improved method of the double-optimized AHN algorithm is presented in Section 3. Experimental results and analysis are mainly described in Section 4. Conclusions are summarized and future research is determined in Section 5.
2. Artificial Hydrocarbon Networks
Artificial hydrocarbon networks (AHNs) are a new paradigm of computational algorithms whose framework is a chemically inspired technique based on organic chemistry, and many of the technical terms, such as atom, CH molecule, compound, and mixture, inherit from hydrocarbon networks. Therefore, many properties of organic chemistry become the main characteristics of the AHNs’ algorithm, such as structural organization, clustering information, inheritance of behavior, encapsulation of data, and stability in structure and response. There are some studies on the application of AHNs in the fields of signal processing and condition recognition [39,40].
In general, a linear and saturated chain of hydrocarbons, as shown in Figure 1, is used to establish the graph structure of an AHN that represents their physical properties, and the chemical behaviors of the components and their interactions are modeled through a mathematical object that can describe the nonlinear relationships between the input (attribute) and the output (target) variables. Certainly, these variables can be a number or vector. For convenience, let x (x ∈ [a, b]) be any chemical environment, f(x) be the corresponding chemical behaviors, and a mathematical model of an AHN can be described by
where K is the number of CH primitive molecules in the AHNs, Ck is the carbon atomic value in the k-th hydrocarbon molecule, and hkr is the r-th hydrogen atomic value around the carbon atomic Ck. According to chemical rules, r is a positive integer up to 4.
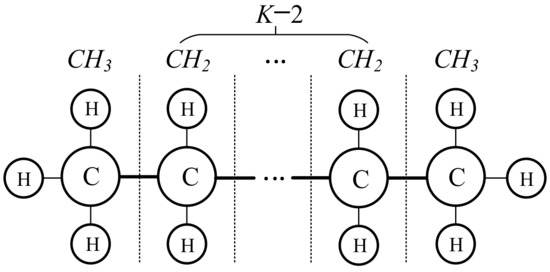
Figure 1.
Common graph structure of an AHN.
When two or more AHNs are mixed together, the resultant mixture contains more information. Suppose any number of AHNs can interact without sharing electrons, the optimal ratios of AHNs can be found to obtain the minimum loss energy in the whole structure. Then, the whole model of an AHNs can be defined by
where yj is the output value of the j-th AHN model, αj is the stoichiometric coefficient of the j-th AHN model, and J is the number of AHNs in a system.
In practical application, the number of hydrocarbons J and the number of each hydrocarbon molecule K are determined according to practical engineering problems. When AHNs are used to build the system of condition recognition, J depends on the engineering requirement and K hinges on the output class. Usually, it is easier to determine the values of J and K for specific classification, but harder to find the optimal values of carbon atomic Ck and hydrogen atomic hkr. This is because the input domain Dk excites the k-th molecule. For the input domain Dk, , , and the initial domain, Dk(0) is assigned by the equipartition method [34]; then, the criterion of minimizing the absolute errors is employed to determine the attribution domain of each sample. Suppose Σ = {(x, y)|x ∈ X, y ∈ Y} to be a training set, and M to be the number of training samples. Each sample (xm, ym) (m = 1, 2, …, M) includes the state parameter and the state label. Then, the attribution domain zk of each sample (xm, ym) can be expressed as follows:
In this way, all training samples are assigned to the different input domains, then the attribution set Z = {z1, z2, …, zk, …, zK} is obtained to activate the parameters of the AHN’s model. In this traditional approach, the least square method is used to determine the values Ck, hkr of the carbon atom, and the hydrogen atom in each hydrocarbon molecule, and an AHN’s model can be expressed as follows:
Similarly, the different training sets are used to build the corresponding AHN’s models. However, it is difficult to evaluate the stoichiometric coefficient of each AHN model. At present, the classification abilities of different training sets are compared, and the weight matching method is employed to confirm the coefficient αj, then multiple AHN models are synthesized into a complete classifier called AHNs.
In fact, there are two problems to confront in the renewal of the hydrocarbon molecular interval by the traditional AHN method: the single way and the slow convergence speed. Therefore, it is difficult for the traditional AHN method to be competent in a complex environment and attain the rapid response requirement. Based on this, K-means clustering and AdaBoost algorithms are employed to improve the clustering rule of the hydrocarbon molecular interval and linear connection scheme for hydrocarbons, as well as perfect the multistate classification model. Since the traditional AHN algorithm is optimized twice, the improved AHN is called the “double-optimized AHNs” in the paper. Figure 2 is the flow chart of double-optimized AHNs.
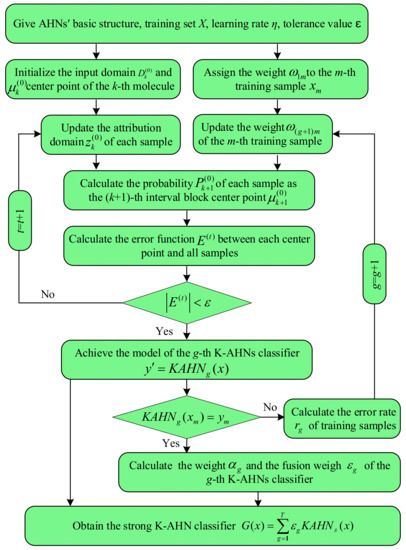
Figure 2.
Flow chart of double-optimized AHNs.
3. Double-Optimized AHNs
3.1. AHNs’ Model Optimization Based on K-Means
The K-means algorithm is a common clustering method which uses Euclidean distance to attribute the samples with a high similarity and a low difference to the same interval so as to form multiple interval blocks [41,42]. To make the distance between the center point as large as possible so to accelerate the convergence speed and improve the classification error in the subsequent iteration processing when the AHNs model is trained, the K-means algorithm is applied to optimize the update mode of the hydrocarbon molecular interval, and then improve the training speed of the AHNs model and reduce the strict requirements of the training sample set.
In the initialization process of the AHNs’ hydrocarbon molecular interval, the number of hydrocarbon molecules K is regarded as the number of clustering intervals, and the input sample set X and the center point of each hydrocarbon molecular interval block are made to classify the input activation parameters Z corresponding to different hydrocarbon molecular interval blocks.
In general, the number of K-means clusters is defined as the number of hydrocarbon molecules K of the AHN model, and a sample is selected randomly as the center point of the first interval block in the interval from the input sample set X. Secondly, the Euclidean distance between the remaining input samples xm and the center point of the existing interval block is calculated to obtain the probability P that each sample is selected as the center point of the next interval block, and then the input sample with the highest probability is selected as the center point of the next interval block, and so on until the initialization of K interval block centers is completed. Let be the probability of an input sample x is selected as the (k + 1)-th interval block center point in the initialization processing, then and are expressed as follows:
where is the k-th interval block center point in the initialization process, is the Euclidean distance, and M is the number of training samples. In that way, the K interval block center points have been obtained to complete the initialization of center point set of hydrocarbon molecule interval block, as follows:
In the following process, the interval block center point set in the t-th clustering process is used to find the interval block center point with the shortest Euclidean distance, then the input sample xm is classified into the corresponding interval blocks for obtaining the input activation parameter set Z corresponding to K interval blocks, in which the input activation parameter corresponding to the k-th interval block in the t-th clustering process can be expressed as follows:
The above algorithm is performed to satisfy the convergence condition of the improved AHN model. When the algorithm is iterating, the input activation parameters of each interval block is used to calculate the corresponding center point. Let be the error function of the improved AHN model in the t-th clustering process, where it is judged whether reaches the convergence condition. If the convergence condition is met, the training samples have been classified into the different hydrocarbon molecular interval. Otherwise, the k-th interval block center point in the (k + 1)-th clustering process is updated by the sum of the Euclidean distances between each center point and all samples in . The center point corresponding to the smallest one is confirmed as , as follows:
Then, the center point set in the t-th clustering process is used to drive each hydrocarbon molecule interval block , as follows:
Finally, the least square method is employed to determine new AHN model, such as Ck, hkr, and Dk. This has completed the first optimization of the AHN model based on the K-means algorithm. In this paper, the improved AHN model based on K-means is denoted as the K-AHNs model, and the output of the K-AHNs model is expressed as follows:
3.2. K-AHNs’ Model Optimization Based on AdaBoost
Adaptive boosting (AdaBoost) is a familiar iterative algorithm, where the core idea is to train different classifiers for the same training data and then combine these classifiers to form a stronger classifier [43,44]. In the process of algorithm improvement, each classifier will use an adaptive resampling technique to choose different samples, whereby the misclassified samples produced by previous classifiers are focused to form a new training sample with the other data. Moreover, the misclassified samples are endowed with higher weights to train the next classifier. The final classifier is a weighted sum of the ensemble predictions. Therefore, the AdaBoost algorithm is often applied to solve two-class problems, multiclass single-label problems, multiclass multilabel problems, categories of single-label problems, and regression problems [45].
In this paper, the AdaBoost algorithm is used to optimize the K-AHNs model for solving the strong dependence on the distribution of training samples. For the various samples, the sensitivities of these classifiers are made to assign the optimal weights for weak K-AHNs, then weaken the weight of the weak classifier and enhance the evaluation grade of stable one in the linear combination of all classifiers. In general, it takes four steps to achieve the optimization process of the K-AHNs model based on AdaBoost, as follows:
Step 1: Assign a weight to each training sample and obtain the first K-AHNs classifier. In the initial process, each example is endowed with the same weight. Suppose there are M samples in the training set X, the weight w1m of each sample xm (xm ∈ X, m = 1, 2, …, M) is set as , then all samples with the same weights are trained to obtain the first K-AHNs classifier. Usually, the classifier is weak.
Step 2: Calculate the error rate of the training samples and determine the weight of the corresponding classifier. The training result of the first K-AHNs classifier is analyzed, especially the misclassified samples, and the error rate rg of the training samples in the g-th K-AHNs classifier is defined as follows:
where KAHNg(·) is the output result of the g-th K-AHNs classifier and wgm is the weight of m-th sample in the g-th K-AHNs classifier. While the error rate rg is determined, the weight αg of the g-th K-AHNs classifier can be calculated for comprehensive evaluation, as follows:
where ln(·) is the natural logarithm function.
Step 3: Update the weights of each sample and K-AHN classifier in next process. According to the weight of each sample wgm and the K-AHN classifier αg in the g-th process, the weight of each sample w(g + 1) m in the (g + 1)-th process can be updated as follows:
where Zg is the normalization factor of the g-th K-AHN classifier. Based on this, the weights of the misclassified samples will be increased progressively in exponent regularity.
Step 4: Obtain the strong K-AHN classifier. When the above operation is repeated T times, these weak classifiers are weighted to fuse into a strong classifier G(x), as follows:
where is the fusion weigh of the g-th K-AHN classifier in the final classifier, .
4. Experimental Verification
To verify the effectiveness of double-optimized AHNs for diagnosing some mechanical faults, two cases of bearing data are studied, including Case 1: the bearing data from Paderborn University, and Case 2: the bearing data from the self-made IWM test stand. The experimental data of Case 1 are representative in the field of fault diagnosis, where traditional AHNs, K-AHNs, and double-optimized AHNs will be used with the same training data and test data for comparison and discussion. However, the experimental data of Case 2 are especially particular in the application scenarios, where the robustness and diagnosis accuracy of double-optimized AHNs can be compared with the existing methods.
4.1. Case 1: The Bearing Data from Paderborn University
The experimental data of the bearing faults from Paderborn University [46] are firstly analyzed. Single faults with inner race and outer race defects were set on the testing bearing (ball bearing with Type 6203) separately, and the extent of the bearing defect was cut by an electric engraver into a trench of a 0.25 mm length in the rolling direction and a depth of 1–2 mm, respectively. The operating condition was that the rotational speed was 900, 1500 rpm, the load torque was 0.1, 0.7 Nm, and the radial force was 1000 N. The vibration was measured with the sampling frequency of 64 kHz.
The vibration signal in each condition was firstly processed by empirical wavelet transform (EWT) [47] to extract five highly sensitive symptom parameters (SPs), such as the root mean square (RMS), average peak, skewness, kurtosis, and waveform stability index, wherein the SPs are labeled with SP1, SP2, SP3, SP4, SP5 [37,48], respectively. Then, the five-dimensional vector, namely (SP1, SP2, SP3, SP4, SP5), is used to represent the bearing state within a certain time. In this paper, the five states of the bearing from Paderborn University are selected, including the normal state (State 1), the slight fault of inner ring (State 2), the severe fault of inner ring (State 3), the slight fault of outer ring (State 4), and the severe fault of outer ring (State 5). The vibration data of each state every 0.128 s are regarded as a sample to set s vector of SPs, then 30 samples are obtained in each state of bearing.
According to the actual condition of the above bearing experiment, the double-optimized AHNs model is built with a five-type classifier. The input xm is five-dimensional vector (SP1m, SP2m, SP3m, SP4m, SP5m), and the corresponding output is an integer of 1, 2, 3, 4, or 5 which maps into the state with the same number. Then, 70 percent of each of the state samples are randomly selected to associate with the corresponding label for the training samples {(SP1, SP2, SP3, SP4, SP5, y) | y = 1, 2, 3, 4, 5}, while the other samples are used to test the performance of the double-optimized AHNs classifier. Certainly, the basic parameters of each classifier are set in advance. In particular, the learning rate is 0.1, the tolerance value is 0.05, and the maximum number of iterations is 50. Therefore, the diagnosis system based on the double-optimized AHNs is performed. When the output value agrees with the defined label, it indexes the stipulated state, and the diagnosis result is correct. Otherwise, the state is a case of mistaken identity. Similarly, the diagnosis models based on the AHNs and K-AHNs are performed with the same training and test samples, respectively. Then, the diagnosis accuracies of all the test samples of the different bearing states under the three operating conditions are shown in Figure 3. Moreover, the average CPU times of the three methods in the training and test processes are shown as Table 1.
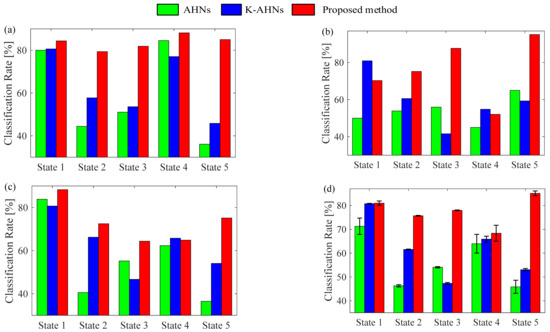
Figure 3.
The classification results of the five states of the motor bearing of Paderborn University under three operating conditions (a) Rotational speed = 1500 rpm, load torque = 0.7 Nm; (b) Rotational speed = 900 rpm, load torque = 0.7 Nm; (c) Rotational speed = 1500 rpm, load torque = 0.1 Nm; (d) Average classification rate and error degree.

Table 1.
The average CPU 1 times of the three methods in the training and test processes.
Obviously, there are great differences in the classification accuracies of three classifiers. In the first condition, with a rotational speed of 1500 rpm and load torque of 0.7 Nm, the diagnosis accuracies of the double-optimized AHNs proposed in this paper are all over 80%, and the classification results of the AHNs and K-AHNs are in fluctuation, especially the accuracies that are less than 60% for identifying State 2, State 3, and State 5. In the other operating conditions, the performances of these methods show a drop, but nearly all accuracies of the proposed method are still higher than 60%, and almost half of the results based on AHNs and K-AHNs are less than 60%. Using statistical analysis, the average accuracy of the proposed method is 7.35% more than the K-AHNs, and 11.99 % more than the AHNs. Moreover, the variance error of the proposed method is less than 0.39%. As far as the average CPU times are concerned, the training and test processes are discussed separately. In the training process, the processing rate of the proposed method is obviously faster than the traditional AHNs but slower than the K-AHNs. In the test process, the processing speed of the proposed method is well up to the leading level. On the whole, the performance of the proposed method is the highest, followed by the K-AHNs model.
4.2. Case 2: The Bearing Data from Self-Made IWM Test Stand
Figure 4 shows the self-made IWM test bench, which is mainly composed of batteries, the IWM, an inverter, and a magnetic powder brake. Since the bearing defect is a typical machine fault of IWMs, double-rowed tapered rolling bearings (Type: DU2505237) are artificially processed with a single damage (width 0.5 mm and depth 0.15 mm) across rolling element, inner ring, and outer ring, which are then fixed tightly on the stator axis of each IWM by a professional, respectively. In the process of the experiment, four IWMs are orderly operated with the same speed and load, including the normal state (State 1), the rolling element defect (State 2), the inner ring defect (State 3), and the outer ring defect (State 4). Moreover, the operating condition of each state is relatively fixed in different ways. For example, the single chip microcomputer is used to simulate the gas pedals of the NEV for controlling each IWM at the rotating speeds of 100, 200, …, 700 rpm (or thereabouts). The magnetic powder brake is adjusted by the tension controller to the different loads of 0, 10, 20, and 30 N m. The vibration from the stator axis of each IWM is collected with a sampling frequency of 12.8 kHz to last for 60 s. Figure 5 shows the part of the vibration signals of four IWMs at the rotating speed of 700 rpm and load torque of 30 N m.

Figure 4.
The test bench system of IWM.
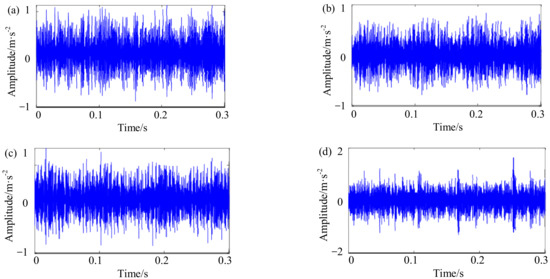
Figure 5.
Vibration signals of four IWMs at the rotating speed of 700 rpm and load torque of 30 N·m: (a) State 1—normal state; (b) State 2—rolling element defect; (c) State 3—inner ring defect; (d) State 4—outer ring defect.
All the raw signals are filtered with a 1–5 kHz band-pass filter. Since the fault features of the IWM at the lowest rotating speed are analyzed, the vibration data every 1.28 s are regarded as a sample to calculate the same SPs above, and then 45 samples of each IWM’s state are obtained in each operating condition. Based on the four states of the IWMs, the double-optimized AHNs model is set to a four-type classifier. The input xm is still a five-dimensional vector (SP1m, SP2m, SP3m, SP4m, SP5m), and the corresponding output becomes an integer of 1, 2, 3, or 4, which maps into the IWM’s state defined by the same number. Then, 70 percent of each state samples are randomly selected to associate with the corresponding label for the training samples {(SP1, SP2, SP3, SP4, SP5, y) | y = 1, 2, 3, 4}, while other samples are used to test the performance of the double-optimized AHNs classifier. Moreover, the learning rate is 0.1, the tolerance value is 0.05, and the maximum number of iterations is 50. Then, the double-optimized AHNs classifier is firstly performed and the classification results of four IWM’s states are computed in the same operating condition. For example, all test samples of the four IWMs at the rotating speed of 100 rpm and the no-load condition, that is, the load of 0 N m, are regarded as the different states of an IWM, and the IWM’s state is correctly judged as long as the output value agrees with the defined label. Then, the classification results are shown in Figure 6.
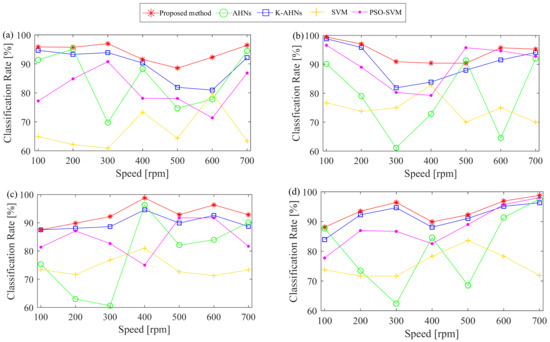
Figure 6.
The classification results of five methods under different operating conditions. (a) No-load condition, (b) 10 N·m load condition, (c) 20 N·m load condition, (d) 30 N·m load condition.
To reveal the effectiveness of the proposed method, four existing classifiers, the AHNs, K-AHNs, SVM [49], and the particle swarm optimization-based SVM (PSO-SVM), [50] are employed to build the diagnosis system. Here, the basic parameters of the AHNs and the K-AHNs are set as double-optimized AHNs. In this paper, two methods of the SVM and the PSO-SVM directly select the same configuration parameters of the relevant references to establish the classification systems, respectively. For example, Ref. [49] used the SVM with the Gaussian RBF function and the width parameter of 0.4, while Ref. [50] set the parameters of the PSO algorithm, such as two acceleration factors of 1.5, weight coefficient of 1, maximum iterations of 40, and population size of 20, to determine automatically the two key parameters of the SVM. Moreover, the same training samples above were used to train the classifier based on each method, then the same test samples were regarded as an unknown state to verify the classification performance of each method. The corresponding diagnosis results are shown in Figure 6.
Since the receiver operating characteristic (ROC) curve and the area under the curve (AUC) have a better sensitivity and specificity evaluation standard for each fault state, the ROC and AUC are used to judge the quality of the above classifiers. To better eliminate the contingency of the experiment and reflect the sensitivity and specificity of different operating states, seven random trials were conducted to show the ROCs and AUCs of bearing states from the self-made IWM test stand by the five methods shown in Figure 7.
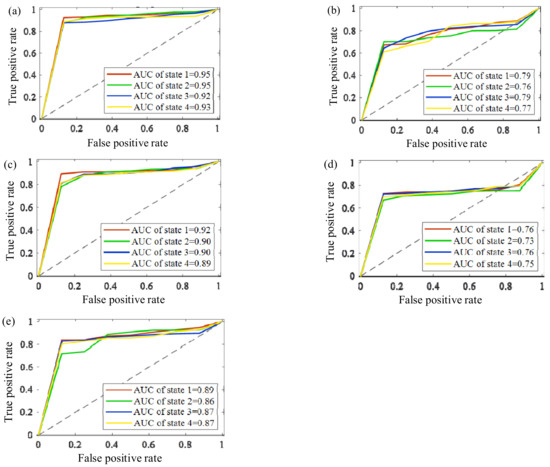
Figure 7.
The ROCs and AUCs of the bearing states from the self-made IWM test stand by five methods: (a) proposed method, (b) AHNs, (c) K-AHNs, (d) SVM, (e) PSO-SVM.
Obviously, the proposed method, K-AHNs and PSO-SVM, have better performances. Hence, their specific confusion matrixes among the IWM’s bearing states are further analyzed, as shown in Figure 8.
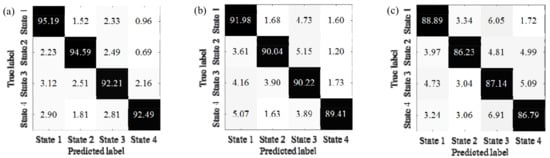
Figure 8.
The confusion matrixes among IWM’s bearing states by different methods: (a) proposed method, (b) K-AHNs, (c) PSO-SVM.
It is clear that the double-optimized AHNs method has a better identification capability and robustness thanks to the classification accuracies of more than 88%, with the AUCs and diagnosis accuracies of the IWM’s bearing states being over 92% no matter how the rotating speed and load condition change. The second is the K-AHNs method, which maintains a high classification accuracy above 80%, where the AUCs and diagnosis accuracies of the IWM’s bearing states are over 89% under four different operating conditions. The condition recognition level based on the PSO-SVM algorithm can hover around 85%, but the stability is not better than the K-AHNs. The traditional methods of the AHNs and SVM cannot meet the engineering requirements in the fault diagnosis of the IWM with a variable working condition.
5. Conclusions
To effectively identify the mechanical faults of the IWM under variable rotating speeds and load conditions, double-optimized AHNs are proposed to build an intelligent diagnosis system, and the effectiveness is experimentally verified by two case studies of using datasets from Paderborn University and a self-made IWM test stand. The superiority of the method proposed in this paper can be summarized by the following points:
- (1)
- K-means clustering and AdaBoost are used to optimize the AHNs algorithm, which not only simplify the complexity of the AHNs model, but also reconstitute the network structure of the AHNs; as a result, the double-optimized AHNs displays excellent performance due to the organic fusion of AHNs, K-means clustering, and AdaBoost mainly.
- (2)
- As long as the intelligent diagnosis system is built by the double-optimized AHNs, no matter how the rotating speed and load conditions of the IWM are altered, the high classification accuracy can be obtained. It is attributed primarily to the strong robustness of double-optimized AHNs.
- (3)
- The intelligent diagnosis method based on the double-optimized AHNs can avoid selecting configuration parameters and adaptively distribute the weight of multiple weak models for a strong classifier.
This paper has preliminarily verified the application of the double-optimized AHNs method in the field of the IWM’s condition recognition. The real operating conditions of the EV are more complex, the speed changes frequently, and the duration is not constant, which greatly increases the application difficulty of the double-optimized AHNs method. Certainly, the interpretability of AHNs is still an issue. In the future, the double-optimized AHNs algorithm will be further optimized to lay a better foundation for the field of the on-line fault diagnosis of the IWM in the real environment. Moreover, the performances of the double-optimized AHNs with different parameters will be discussed in detail and compared with the advanced network models such as the CNN, deep belief network (DBN), and stacked auto-encoder network (SAN).
Author Contributions
H.X. contributed to the conceptualization and methodology of the double-optimized AHNs, writing—review and editing, and funding acquisition; Z.S. and M.W. were responsible for some parts of the theoretical analysis, investigation, data curation, validation, original draft preparation, and some necessary experimental data; N.S. contributed writing—review and editing; H.W. was responsible for writing—review and editing and supervision. All authors have read and agreed to the published version of the manuscript.
Funding
This project is supported by National Natural Science Foundation of China (grant no. 51775245).
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Wang, F.; Zhang, J.; Xu, X.; Cai, Y.; Zhou, Z.; Sun, X. New teeth surface and back (TSB) modification method for transient torsional vibration suppression of planetary gear powertrain for an electric vehicle. Mech. Mach. Theory 2019, 140, 520–537. [Google Scholar] [CrossRef]
- Chen, L.; Xu, H.; Sun, X. A novel strategy of control performance improvement for six-phase permanent magnet synchronous hub motor drives of EVs under new European driving cycle. IEEE Trans. Veh. Technol. 2021, 70, 5628–5637. [Google Scholar] [CrossRef]
- Xue, H.; Ding, D.; Zhang, Z.; Wu, M.; Wang, H. A fuzzy system of operation safety assessment using multimodel linkage and multistage collaboration for in-wheel motor. IEEE Trans. Fuzzy Syst. 2022, 30, 999–1013. [Google Scholar] [CrossRef]
- Wang, H.; Chen, Y.; Cai, Y.; Chen, L.; Li, Y.; Sotelo, M.A.; Li, Z. SFNet-N: An improved SFNet algorithm for semantic segmentation of low-light autonomous driving road scenes. IEEE Trans. Intell. Transp. Syst. 2022, 1–13. [Google Scholar] [CrossRef]
- Ruan, J.; Song, Q.; Yang, W. The application of hybrid energy storage system with electrified continuously variable transmission in battery electric vehicle. Energy 2019, 183, 315–330. [Google Scholar] [CrossRef]
- Najjari, B.; Mirzaei, M.; Tahouni, A. Constrained stability control with optimal power management strategy for in-wheel electric vehicles. Proc. Inst. Mech. Eng. Part K J. Multi Body Dyn. 2019, 233, 1014–1032. [Google Scholar] [CrossRef]
- Tang, Z.; Xu, X.; Wang, F.; Jiang, X.; Jiang, H. Coordinated control for path following of two-wheel independently actuated autonomous ground vehicle. IET Intell. Transp. Syst. 2019, 13, 628–635. [Google Scholar] [CrossRef]
- Li, M.; Wang, Y.; Chen, Z.; Zhao, J. Intelligent fault diagnosis for rotating machinery based on potential energy feature and adaptive transfer affinity propagation clustering. Meas. Sci. Technol. 2021, 32, 1–13. [Google Scholar] [CrossRef]
- Sun, W.; Yao, B.; Zeng, N.; Chen, B.; He, Y.; Cao, X.; He, W. An intelligent gear fault diagnosis methodology using a complex wavelet enhanced convolutional neural network. Materials 2017, 10, 790. [Google Scholar] [CrossRef] [Green Version]
- Zhu, J.; Hu, T.; Jiang, B.; Yang, X. Intelligent bearing fault diagnosis using PCA–DBN framework. Neural Comput. Appl. 2020, 32, 10773–10781. [Google Scholar] [CrossRef]
- Wei, Z.; Wang, Y.; He, S.; Bao, J. A novel intelligent method for bearing fault diagnosis based on affinity propagation clustering and adaptive feature selection. Knowl. Based Syst. 2017, 116, 1–12. [Google Scholar] [CrossRef]
- Han, C.; Lu, W.; Wang, P.; Song, L.; Wang, H. A recursive sparse representation strategy for bearing fault diagnosis. Measurement 2022, 187, 110360. [Google Scholar] [CrossRef]
- Bian, K.; Zhou, M.; Hu, F.; Lai, W. RF-PCA: A new solution for rapid identification of breast cancer categorical data based on attribute selection and feature extraction. Front. Genet. 2020, 11, 566057. [Google Scholar] [CrossRef] [PubMed]
- Han, D.; Liang, K.; Shi, P. Intelligent fault diagnosis of rotating machinery based on deep learning with feature selection. J. Low Freq. Noise Vib. Act. Control. 2020, 39, 939–953. [Google Scholar] [CrossRef] [Green Version]
- Liu, Z.; Cai, Y.; Wang, H.; Chen, L.; Gao, H.; Jia, Y.; Li, Y. Robust target recognition and tracking of self-driving cars with radar and camera information fusion under severe weather conditions. In Proceedings of the IEEE Transactions on Intelligent Transportation Systems, Indianapolis, IN, USA, 19–22 September 2021; pp. 1–14. [Google Scholar] [CrossRef]
- Lv, X.; Zhou, D.; Ma, L.; Zhang, Y.; Tang, Y. An improved lagrange particle swarm optimization algorithm and its application in multiple fault diagnosis. Shock. Vib. 2020, 2020, 1091548. [Google Scholar] [CrossRef]
- Ji, W.; Cheng, C.; Xie, G.; Zhu, L.; Wang, Y.; Pan, L.; Hei, X. An intelligent fault diagnosis method based on curve segmentation and SVM for rail transit turnout. J. Intell. Fuzzy Syst. 2021, 41, 4275–4285. [Google Scholar] [CrossRef]
- Xue, H.; Wang, M.; Li, Z.; Chen, P. Sequential fault detection for sealed deep groove ball bearings of in-wheel motor in variable operating conditions. J. Vibroeng. 2018, 19, 5947–5959. [Google Scholar] [CrossRef]
- Feng, D.; Li, Y. Research on intelligent diagnosis method for large-scale ship engine fault in non-deterministic environment. Pol. Marit. Res. 2017, 24, 200–206. [Google Scholar] [CrossRef] [Green Version]
- Lin, T.; Wang, H.; Guo, X.; Wang, P.; Song, L. A novel prediction network for remaining useful life of rotating machinery. Int. J. Adv. Manuf. Technol. 2022, 1–10. [Google Scholar] [CrossRef]
- Lin, T.; Wang, H.; Guo, X.; Wang, P.; Song, L. Intelligent fault diagnosis of rotor-bearing system under varying working conditions with modified transfer convolutional neural network and thermal images. IEEE Trans. Ind. Inform. 2020, 17, 3488–3496. [Google Scholar]
- Shao, H.; Jiang, H.; Lin, Y.; Li, X. A novel method for intelligent fault diagnosis of rolling bearings using ensemble deep auto-encoders. Mech. Syst. Signal Processing 2018, 102, 278–297. [Google Scholar] [CrossRef]
- Cheng, Y.; Lin, M.; Wu, J.; Zhu, H.; Shao, X. Intelligent fault diagnosis of rotating machinery based on continuous wavelet transform-local binary convolutional neural network. Knowl. Based Syst. 2021, 216, 106796. [Google Scholar] [CrossRef]
- Wang, P.; Song, L.; Guo, X.; Wang, H.; Cui, L. A high-stability diagnosis model based on a multiscale feature fusion convolutional neural network. IEEE Trans. Instrum. Meas. 2021, 70, 3522709. [Google Scholar] [CrossRef]
- Wang, H.; Lin, T.; Cui, L.; Ma, B.; Dong, Z.; Song, L. Multi-task learning-based self-attention encoding atrous convolutional neural network for remaining useful life prediction. IEEE Trans. Instrum. Meas. 2022, 71, 3516108. [Google Scholar]
- Sun, G.-D.; Wang, Y.-R.; Sun, C.-F.; Jin, Q. Intelligent detection of a planetary gearbox composite fault based on adaptive separation and deep learning. Sensors 2019, 19, 5222. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Gong, W.; Chen, H.; Zhang, Z.; Zhang, M.; Wang, R.; Guan, C.; Wang, Q. A novel deep learning method for intelligent fault diagnosis of rotating machinery based on improved CNN-SVM and multichannel data fusion. Sensors 2019, 19, 1693. [Google Scholar] [CrossRef] [Green Version]
- Haidong, S.; Hongkai, J.; Ke, Z.; Dongdong, W.; Xingqiu, L. A novel tracking deep wavelet auto-encoder method for intelligent fault diagnosis of electric locomotive bearings. Mech. Syst. Signal Processing 2018, 110, 193–209. [Google Scholar] [CrossRef]
- Mao, W.; He, J.; Li, Y.; Yan, Y. Bearing fault diagnosis with auto-encoder extreme learning machine: A comparative study. Proc. Inst. Mech. Eng. Part C: J. Mech. Eng. Sci. 2017, 231, 1560–1578. [Google Scholar] [CrossRef]
- Xue, H.; Zhou, J.; Chen, Z.; Li, Z. Real-time diagnosis of an in-wheel motor of an electric vehicle based on dynamic Bayesian networks. IEEE Access 2019, 7, 114685–114699. [Google Scholar] [CrossRef]
- Schmid, M.; Gebauer, E.; Hanzl, C.; Endisch, C. Active model-based fault diagnosis in reconfigurable battery systems. IEEE Trans. Power Electron. 2021, 36, 2584–2597. [Google Scholar] [CrossRef]
- Glowacz, A.; Tadeusiewicz, R.; Legutko, S.; Caesarendra, W.; Irfan, M.; Liu, H.; Brumercik, F.; Gutten, M.; Sulowicz, M.; Daviu, J.A.A.; et al. Fault diagnosis of angle grinders and electric impact drills using acoustic signals. Appl. Acoust. 2021, 179, 108070. [Google Scholar] [CrossRef]
- Cai, Y.; Luan, T.; Gao, H.; Wang, H.; Chen, L.; Li, Y.; Sotelo, M.A.; Li, Z. YOLOv4-5D: An effective and efficient object detector for autonomous driving. IEEE Trans. Instrum. Meas. 2021, 70, 4503613. [Google Scholar] [CrossRef]
- Lei, Y.; Jia, F.; Lin, J.; Xing, S.; Ding, S. An intelligent fault diagnosis method using unsupervised feature learning towards mechanical big data. IEEE Trans. Ind. Electron. 2016, 63, 3137–3147. [Google Scholar] [CrossRef]
- Wang, W.; Wang, M.; Li, J.; Song, L.; Hao, Y. A novel signal separation method based on improved sparse non-negative matrix factorization. Entropy 2019, 21, 445. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, X.-B.; Luo, L.; Tang, L.; Yang, Z.-X. Automatic representation and detection of fault bearings in in-wheel motors under variable load conditions. Adv. Eng. Inform. 2021, 49, 101321. [Google Scholar] [CrossRef]
- Xue, H.; Wu, M.; Zhang, Z.; Wang, H. Intelligent diagnosis of mechanical faults of in-wheel motor based on improved artificial hydrocarbon networks. ISA Trans. 2022, 120, 360–371. [Google Scholar] [CrossRef]
- Ponce, H.; Miralles-Pechuán, L.; Martínez-Villaseñor, M. A flexible approach for human activity recognition using artificial hydrocarbon networks. Sensors 2016, 16, 1715. [Google Scholar] [CrossRef] [Green Version]
- Ponce, H.; Martinez-Villasenor, M.; Miralles-Pechuan, L. A novel wearable sensor-based human activity recognition approach using artificial hydrocarbon networks. Sensors 2016, 16, 1033. [Google Scholar] [CrossRef]
- Ponce, H. A novel artificial hydrocarbon networks based value function approximation in hierarchical reinforcement learning. In Mexican International Conference on Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2016; pp. 211–225. [Google Scholar]
- Yu, K.; Lin, T.R.; Ma, H.; Li, X.; Li, X. A multi-stage semi-supervised learning approach for intelligent fault diagnosis of rolling bearing using data augmentation and metric learning. Mech. Syst. Signal Processing 2021, 146, 107043. [Google Scholar] [CrossRef]
- Glowacz, A.; Glowacz, Z. Diagnosis of the three-phase induction motor using thermal imaging. Infrared Phys. Technol. 2017, 81, 7–16. [Google Scholar] [CrossRef]
- He, Y.-L.; Zhao, Y.; Hu, X.; Yan, X.-N.; Zhu, Q.-X.; Xu, Y. Fault diagnosis using novel AdaBoost based discriminant locality preserving projection with resamples. Eng. Appl. Artif. Intell. 2020, 91, 103631. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, G.; Paul, P.; Zhang, J.; Wu, T.; Fan, S.; Xiong, X. Dissolved gas analysis for transformer fault based on learning spiking neural P system with belief AdaBoost. Int. J. Unconv. Comput. 2021, 16, 239–258. [Google Scholar]
- Long, Z.; Zhang, X.; Zhang, L.; Qin, G.; Huang, S.; Song, D.; Shao, H.; Wu, G. Motor fault diagnosis using attention mechanism and improved adaboost driven by multi-sensor information. Measurement 2021, 170, 108718. [Google Scholar] [CrossRef]
- Lessmeier, C.; Kimotho, J.; Zimmer, D.; Sextro, W. Condition monitoring of bearing damage in electromechanical drive systems by using motor current signals of electric motors: A benchmark data set for data-driven classification. In Proceedings of the European Conference of the Prognostics and Health Management Society (PHM Society), Bilbao, Spain, 5–7 July 2016. [Google Scholar]
- Chen, J.; Pan, J.; Li, Z.; Zi, Y.; Chen, X. Generator bearing fault diagnosis for wind turbine via empirical wavelet transform using measured vibration signals. Renew. Energy 2016, 89, 80–92. [Google Scholar] [CrossRef]
- Xue, H.T.; Liu, B.C.; Ding, D.Y.; Zhou, J.; Cui, X. Diagnosis method based on hidden Markov model and Weibull mixture model for mechanical faults of in-wheel motor. Meas. Sci. Technol. 2022, 33, 114002. [Google Scholar] [CrossRef]
- Xue, H.; Li, Z.; Li, Y.; Jiang, H.; Chen, P. A fuzzy diagnosis of multi-fault state based on information fusion from multiple sensors. J. Vibroeng. 2016, 18, 2135–2148. [Google Scholar] [CrossRef]
- Yan, X.; Jia, M. A novel optimized SVM classification algorithm with multi-domain feature and its application to fault diagnosis of rolling bearing. Neurocomputing 2018, 313, 47–64. [Google Scholar] [CrossRef]
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).