1. Introduction
With the rapid development of computer information technology, the research on time series clustering is gradually rising in various fields such as finance, biology, medicine, meteorology, electricity, industry, and agriculture [
1,
2,
3]. To better summarize and discover the effective information on these time series data, time series clustering technology has received extensive attention from researchers [
4]. Through clustering, we can mine the key hidden information in time series data and find some regularities between time series sample points. It provides indispensable preparation for forecasting and anomaly detection of time series data. Consequently, the study of time series clustering is of great significance.
The data is often imperfect. Due to some human errors, machine failures, or unavoidable natural influences, noise points and outlier samples may appear in the data, this phenomenon also exists in time series data.To better avoid the impact of abnormal fluctuations in time series data onto clustering, some researchers try to smooth the data before clustering. Abraha et al. (2003) [
5] proposed using B-spline fitting function data and using a K-means algorithm to divide the estimated model coefficients, which proved the strong consistency and effectiveness of the clustering method. Iorio et al. (2016) [
6] used a P-spline smoother to model the raw data and then used the k-means algorithm to cluster the fitted data objects according to the best spline coefficients. D’Urso et al. (2021) [
7,
8] applied the B-spline fitting coefficient to the robust fuzzy clustering method and proposed four different robust fuzzy clustering methods of time series data, then applied them to the clustering of COVID-19 time series. The above studies all smooth the data to reduce the negative effects of noise. In this paper, we fit the time series in the original data using P-splines [
9]. P-spline shrinks the difference penalty based on B-spline. This method will be described in detail in
Section 2.1.
With the extensive research on time series clustering, many targeted methods have been proposed, such as model-based clustering, feature-based clustering, deep learning-based clustering, and fuzzy theory-based clustering. Among them, the Fuzzy C-Means (FCM) algorithm is the classical representative of fuzzy clustering [
10], which adds the fuzzy concept to the k-means algorithm, and is widely used in the clustering of time series [
11]. The membership value between the sample point and the cluster center is calculated to indicate the closeness of each sample point in the cluster center [
12]. The FCM algorithm provides a more flexible clustering criterion so that time series samples with greater similarity can also be classified into the class to which they belong [
13,
14]. Compared with the K-means algorithm, FCM provides a better clustering effect [
15,
16]. In addition, different fuzzy systems are also applied to time series data. Pattanayak et al. (2020) [
17] used FCM to determine intervals of unequal lengths, and the support vector machine also considered the membership value when modeling fuzzy logical relationships. Kumar et al. (2021) [
18] proposed the nested Particle Swarm Optimization algorithm and exhaustive search Particle Swarm Optimization algorithm for fuzzy time series prediction. Xian et al. (2021) [
19] proposed a fuzzy c-means clustering method based on n-Pythagorean fuzzy sets, and effectively improved the prediction accuracy by using the clustering results. Al-qaness et al. (2022) [
20,
21] proposed optimizing the adaptive neuro-fuzzy inference system using the enhanced marine predator algorithm, and then again proposed combining the improved Aquila optimizer with adversarial-based learning techniques to optimize the adaptive neuro-fuzzy inference system. These fuzzy systems have excellent performance on time series data, which shows that the research on time series based on fuzzy theory has far-reaching significance.
Due to the high-dimension and complexity of time series data, there will inevitably be some noise sample points in the dataset, which affects the updating of fuzzy clustering centers. To solve this problem, a new clustering algorithm is derived based on FCM, called Fuzzy C-medoids (FCMdd) [
22,
23]. The center of each cluster in the FCMdd algorithm is a real object in the selected data set, which greatly reduces the influence of noise data onto the new medoids, and can better deal with the problem that the FCM algorithm is sensitive to noise data [
24,
25,
26]. Therefore, FCMdd can obtain higher quality clustering results, which makes many researchers apply FCMdd to time series clustering [
27]. Izakian H et al. (2015) [
28] proposed a hybrid technique using the advantages of FCM and FCMdd and used dynamic time warping distance to cluster time series. Liu et al. (2018) [
29] proposed two incremental FCMdd algorithms based on dynamic time warping distance, which can easily obtain higher-quality clustering results in the face of time-shifted time series data. D’Urso P et al. (2021) [
30] clustered multivariate financial time series through an appropriate cutting process, in which the Medoids surrounding partition strategy combined with dynamic time warping distances was used in the clustering process. The above studies have improved the performance of the FCMdd algorithm in different aspects, but they did not consider the impact of outlier samples on the FCMdd algorithm. In this paper, We define a new method to update the weights of each sample to improve the FCMdd algorithm, which reduces the impact of outlier samples on the clustering process and improves the robustness of our algorithm.
A robust time series clustering method not only handles the adverse effects of noise in the dataset, but also classifies sample points quickly. One of the main influencing factors of time series clustering is the complexity of the similarity metric for time series [
31]. So far, many effective similarity methods have been studied for time series data [
32], among which two main types are used. One is lock-step measures, its main representative method is Euclidean Distance (ED), the other is elastic measures, its main representative methods are Dynamic Time Warping (DTW) [
33] and Time Warp Edit Distance (TWED) [
34]. ED is simple and common, but it is susceptible to the time offset and has a small range of applications; DTW is a well-known time series similarity measurement criterion [
35], and it is also the most widely used and improved algorithm so far, but its computational cost is
when the sample object length is
N. Among the edit distances, there is the TWED algorithm that satisfies the triangular inequality relationship, which can deal with time series of different sampling rates, and is also an excellent time series similarity measurement method, but the time complexity is the same as DTW. Among these similarity measures, DTW and TWED are popular, but their high time complexity leads to low clustering efficiency. This paper chooses the MASS 3 algorithm [
36] in the matrix configuration file to measure the similarity between time series, which has certain robustness and can improve the accuracy of time series clustering. Moreover, the matrix configuration file has some outstanding advantages, such as simplicity, no parameters, time and space complexity are relatively low [
37].
In response to the problems discussed above, we propose a fast weighted fuzzy C-medoids clustering for time series data based on P-splines, named the PS-WFCMdd. PS-WFCMdd can well deal with the negative problems caused by noise and outliers in time series data, and has fast and efficient clustering performance. The main contributions of this paper include the following three aspects:
Abnormal fluctuations and noises in time series data usually make it challenging to define a suitable clustering model and increase the burden of related measurements. To solve these problems, we use the P-spline to fit clustering data. Smoothing the fitted data reduces abnormal fluctuations in the data compared to the original data. At the same time, the influence of noise on fuzzy clustering is avoided. Taking the fitting data as the input of the clustering algorithm, it is easier to find similar sample points in the clustering process;
In the traditional fuzzy clustering method, no matter how far the sample point is from the center of the data cluster, the membership degree of the sample point belonging to this class is not 0. This makes FCM vulnerable to boundary samples. In the proposed PS-WFCMdd, we design a new weighted fuzzy C-medoids, which can reduce the influence of outlier sample points on cluster center update by defining a new weighting method;
Among the time series similarity metrics, ED is simple and fast, but it is vulnerable to time offset. DTW algorithm has high time complexity and low efficiency in the face of a large-scale time-series data model. As a time-series measurement standard, MASS 3 has the characteristics of fast computing speed and small space overhead due to its unique segmented computing method. Therefore, we propose to apply MASS 3 to weighted fuzzy C-medoids to measure the similarity between time series data and medoids more accurately and quickly.
The rest of the paper is organized as follows: in
Section 2, we introduce some basic knowledge used in our algorithm.
Section 3 presents our method. The experimental results are presented in
Section 4, which also includes a discussion. Finally, the conclusions are presented in
Section 5.
3. Weighted Fuzzy C-Medoids Clustering Based on P-Splines
In the process of FCMdd algorithm clustering, after classifying an outlier sample into a certain cluster, in the next iterative update, because of the constraint condition A, the outlier sample will obtain a higher value of membership. In turn, the selected medoids are biased, and finally affect the clustering results. Although the traditional WFCMdd assigns different weights to each data sample point in the clustering process to obtain a better clustering effect. However, this method does not solve the negative impact of outlier samples on updating medoids. To solve this problem, we propose to judge the importance between different data and new medoids according to the distance. This increases the importance of data in more dense areas in the data space and reduces the importance of peripheral data (outlier data). To solve this problem, after the initial medoids
V is obtained, the update weight
of the sample point
and each cluster center
are obtained as:
where
is the standard deviation between the calculated input data. By updating the weights in this way, so that the data points are closer to the
point, then
will be larger, and
will be smaller on the contrary.
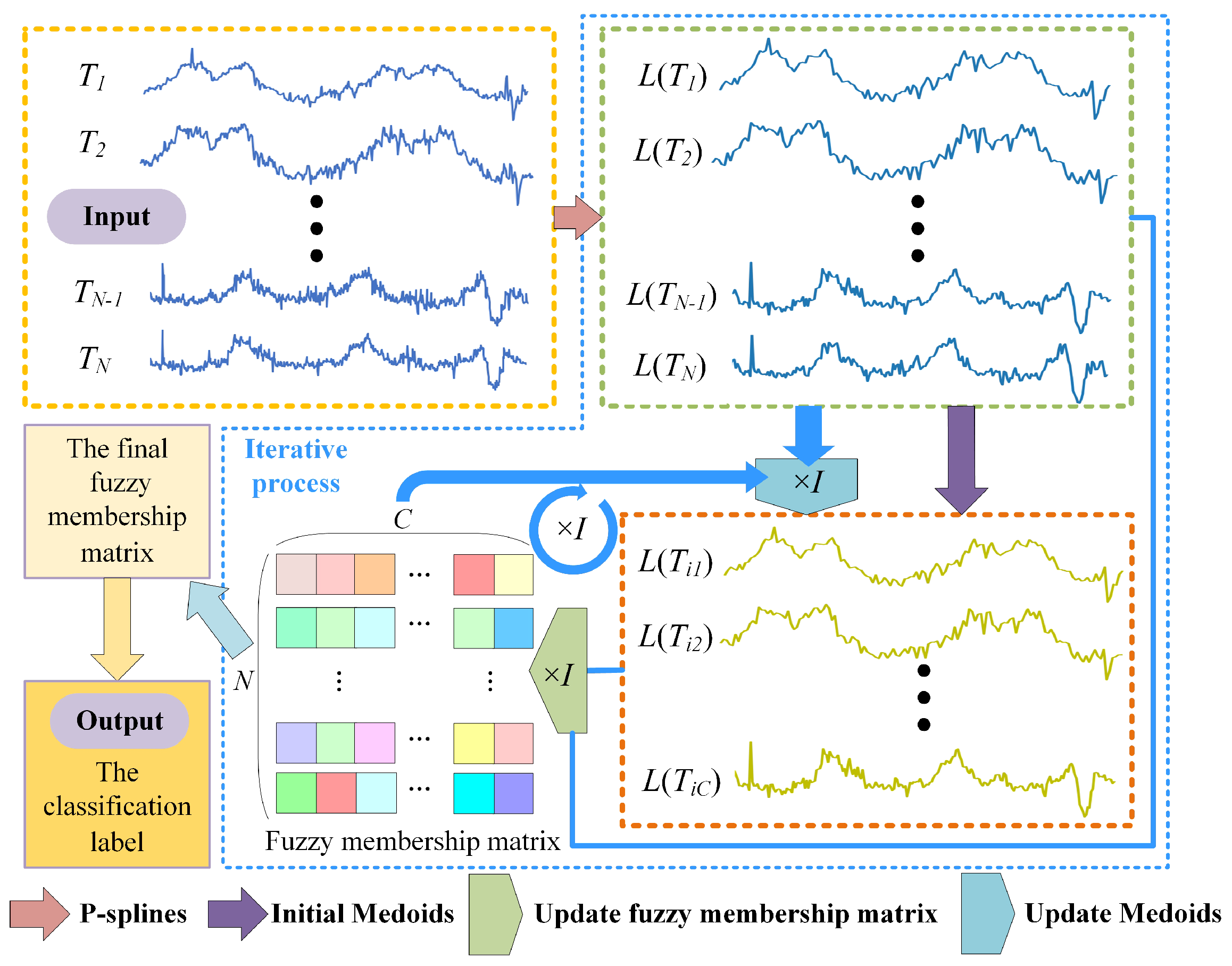
Based on the above research contents, we propose a fast weighted fuzzy C-medoids algorithm. The specific process of PS-WFCMdd is shown in
Figure 2. The input to the algorithm is the original time series dataset
. Then, use P-spline to fit each sample point in
T to obtain the fitted data set
. The P-spline will smooth the sample while preserving the main characteristics of the sample. The obtained fitting data set
L is used as the processing object of clustering, and initial medoids are randomly selected from it. MASS 3 is used to efficiently calculate the similarity between each fitting data object and medoids, and convert it into the corresponding fuzzy membership matrix. The
fuzzy membership matrix is generated after each iteration, and the intensity of the square color in the matrix represents the membership of each sample point relative to the cluster center. In the future medoids update, to solve the problem that FCMdd is sensitive to outlier samples, we propose a new weighting method to update the medoids. To redefine the weight relationship between different data objects and new medoids according to the distance, increase the weight of data objects close to medoids, and reduce the weight of outlier data objects farther from medoids. Thus, the clustering efficiency and robustness of PS-WFCMdd are improved.
In simple terms, after transforming the time series into projection coefficients on the basis of the P-spline function, it is clustered with new weights based on WFCMdd, and MASS 3 is used to measure the similarity between time series data and medoids in the clustering process. Then, the objective function of PS-WFCMdd is defined as:
The iterative expression to obtain the final membership matrix and medoids is:
According to Equations (
4), (
13), (
15) and (
16), the steps of PS-WFCMdd can be summarized as Algorithm 1.
| Algorithm 1 Weighted fuzzy C-medoids clustering algorithm based on P-splines(PS-WFCMdd). |
- Input:
Time series data set T, determine the values of parameters C, and max.iter; - Output:
Clustered sample class label Y. - 1:
Fit each sample in the cluster dataset T using Equation ( 4), the new fitted data is obtained as ; - 2:
Set = 0; - 3:
Randomly set C initial medoids: . - 4:
Repeat - 5:
Store the current centroids ; - 6:
Compute the fuzzy membership matrix U of in clusters ( C) using Equation ( 15); - 7:
Update the the new centroids using Equation ( 16); - 8:
Update the weight using Equation ( 13); - 9:
= + 1; - 10:
Until or iter=max.iter; - 11:
Calculate the classification label (Y) to which the sample belongs according to the final fuzzy membership U.
|
4. Experimental Results
4.1. Experiment Preparation and Evaluation Index
To demonstrate the effectiveness of our proposed method on time series datasets of different dimensions and data lengths, in the experiments, we selected 18 real-world datasets from the open time series database UCR for evaluation. Among them, 10 common time series data, whose detailed description is shown in
Table 1, and the detailed description of 8 large-scale time series data in
Table 2. The length of the time series in all datasets is between 96 and 2844, the size of the dataset is between 40 and 8236, and the number of classes in the dataset is between 2 and 8.
To make the experiment more complete, the data objects we choose are diversified, and a brief introduction is given below. Car recorded the contours of four different types of cars extracted from the traffic video. Lightning2 is a transient electromagnetic event recorded by a suite of optical and radio frequency instruments. Wafer is a database of wafers recorded during the processing of silicon wafers for semiconductor manufacturing. StarLightCurves are recorded celestial brightness data over time. Car, Lightning2, Wafer, and StarLightCurves are all time-series databases constructed from collections of process control measurements recorded from various sensors. Beef, Meat, Strawberry, and Rock are the classification records of items made by various spectrometers. Beefly, Facefour, Fish, and Herring record image databases for contour problems. Both the ECG200 and ECG5000 track the electrical activity recorded during a heartbeat. ChlorineConcentration and Mallat are simulated datasets constructed by software applications. Gunpoint recorded the movement trajectory data of two actors with their hands. Hourstwenty is the dataset recorded using smart home devices.
A statement is required here, PS-WFCMdd, PS-k-means, and PS-WFCMdd-sD set the corresponding parameters of P-splines for each experimental dataset are consistent. Each series has been modeled by P-splines taking cubic bases and third-order penalties. For the P-spline modeling, a fixed smoothing parameter
is chosen for each dataset, and
ranges from 0.3 to 0.6. The distance metric criterion for both FCM and PS-k-means is ED. Note that the number of centers for each dataset is also fixed, here we specify the number of classes in
Table 1 and
Table 2 as the
C value.
In this experiment, our proposed PS-WFCMdd algorithm will be compared with six other time series clustering algorithms: traditional FCM algorithm; K-means based on P-splines [
6] (PS-k-means); based on soft-DTW [
39] (it is an improvement on the DTW algorithm as a differentiable loss function which can calculate all alignment costs Soft minimum) K-means algorithm (K-means-sD algorithm) [
40]; soft-DTW-based K-medoids algorithm (K-medoids-sD); K-shape algorithm based on cross-correlation distance metric [
41]; to better demonstrate the superiority of MASS 3, replace MASS 3 in PS-WFCMdd with softDTW, denoted as PS-WFCMdd-sD.
In the validation step, we use three widely used criteria to measure the performance of the clustering results. Due to the insufficient penalty of the Rand coefficient, the scores of the clustering algorithms are generally relatively high, and the performance of the algorithm cannot be significantly compared. Therefore, we use the adjusted Rand coefficient (ARI) [
42], which is a measure of the Rand coefficient. In an improved version, the purpose is to remove the influence of random labels on the Rand coefficient evaluation results. The Fowlkes–Mallows index (FMI) [
43] can be regarded as the geometric mean between precision and recall. This index shows similarity even if the number of clusters of the noisy dataset is different from that of the source data, making FMI one of the key metrics for evaluating the effectiveness of clustering. The amount of mutual information can be understood as the amount by which the uncertainty of the other decreases when guiding one. Normalized Mutual Information (NMI) is one of the most popular information-theoretic metrics in community detection methods. NMI is a normalization of the mutual information score used to scale the results between 0 (no mutual information) and 1 (perfect correlation). These standards are briefly described below.
The ARI score range is [−1, 1], negative scores indicate poor results, and a score equal to 1 indicates that the clustering results are completely consistent with the true labels. Where TP represents the number of true positive samples (the clustering results can group similar samples into the same cluster), TN represents the number of true negative samples (clustering results can group dissimilar samples into different clusters), FP represents the number of false positive samples (that is, the clustering results classify dissimilar samples into the same cluster), FN represents the number of false negative samples (clustering results group similar samples into different clusters). The definition of the ARI is:
The parameter in the expression of FMI has the same meaning as the parameter in Equation (
17) and can be defined as:
The minimum score of the Fowlkes–Mallows index is 0, indicating that the clustering results are different from the actual class labels; the highest score is 1, indicating that all data have been correctly classified.
NMI value range is between [0, 1], and the optimal value is 1. Given class labels
, and a result cluster labels
Y obtained by a clustering algorithm. The NMI is defined as:
where
means entropy; MI is given by
where
is the number of the samples in cluster
.
4.2. Experimental Comparison and Analysis
4.2.1. Results of PS-WFCMdd Method on Ten Common Time Series Datasets
To confirm that the PS-WFCMdd method is effective on common low-dimensional datasets, in the first part of this subsection, we compare the performance of PS-WFCMdd and six other clustering methods on the 10 low-dimensional datasets in
Table 1.
Table 3,
Table 4 and
Table 5, they show the ARI index scores, FMI index scores, and NMI index scores of the seven clustering methods on each dataset, where the bold content represents the best value in the comparison results.
Table 3 shows the clustering results under ARI. We can see that on the Beef, GunPoint, and Meat datasets, the PS-WFCMdd algorithm has an obvious score advantage. On the BeetleFly, Car, ECG200, FaceFour, and Lightning2 datasets, the PS-WFCMdd algorithm also has the best ARI scores, but the performance is not significant. On the Fish and Herring datasets, the ARI score of the K-means-sD algorithm is the best, followed by the SRFCM algorithm, PS-WFCMdd performs the next best. There is no significant difference in the performance of PS-WFCMdd-sD and PS-WFCMdd under ARI on the four datasets FaceFour, Fish, Lightning2, and Meat datasets.
Table 4 shows the clustering results under FMI. We can see that on the Beef and Meat datasets, the PS-WFCMdd algorithm has an obvious score advantage. On the BeetleFly, Fish, and GunPoint datasets, the FMI score of the PS-WFCMdd algorithm is also the best. On the Car, FaceFour, and Herring datasets, the FMI score of the PS-WFCMdd-sD algorithm is the best, and the SRFCM algorithm has a certain advantage over the remaining algorithms. On the ECG200 dataset, the FMI score of the K-means-sD algorithm is the best. On the Lightning2 dataset, the K-shape algorithm has the best score.
Table 5 shows the clustering results under NMI. We can see that on the Beef, BeetleFly, GunPoint, Car, ECG200, FaceFour, and Meat datasets, the PS-WFCMdd algorithm has obvious score advantages. On the Fish dataset, the NMI score of the K-means-sD algorithm is also the best value. On the Car, FaceFour, and Herring datasets, the NMI score of the K-means-sD algorithm is the best, and the PS-WFCMdd algorithm has a certain advantage over the remaining algorithms.
By analyzing the results of the above three tables, it can be concluded that our algorithm can obtain relatively excellent performance under the three evaluation indicators when faced with ordinary low-dimensional time series data sets. The improved algorithm based on the K-means algorithm also achieved good results in some indicators, indicating that the performance of the algorithm should not be underestimated. Although the PS-WFCMdd-sD algorithm achieves good performance under the FMI evaluation index, the overall performance is still inferior to the PS-WFCMdd algorithm. This shows that the MASS 3 we used has good performance on low-dimensional data in terms of clustering effect and the time complexity of the PS-WFCMdd-sD algorithm is high, we will further analyze it in
Section 4.4.
4.2.2. Results of PS-WFCMdd Method on Nine Large-Scale Time Series Datasets
To confirm that the PS-WFCMdd method is also effective on large-scale datasets in
Table 2, in this section, we compare the clustering effects of PS-WFCMdd and six other clustering methods on the eight datasets in
Figure 3,
Figure 4 and
Figure 5 show the ARI scores, FMI scores, NMI scores of the seven clustering methods on each dataset.
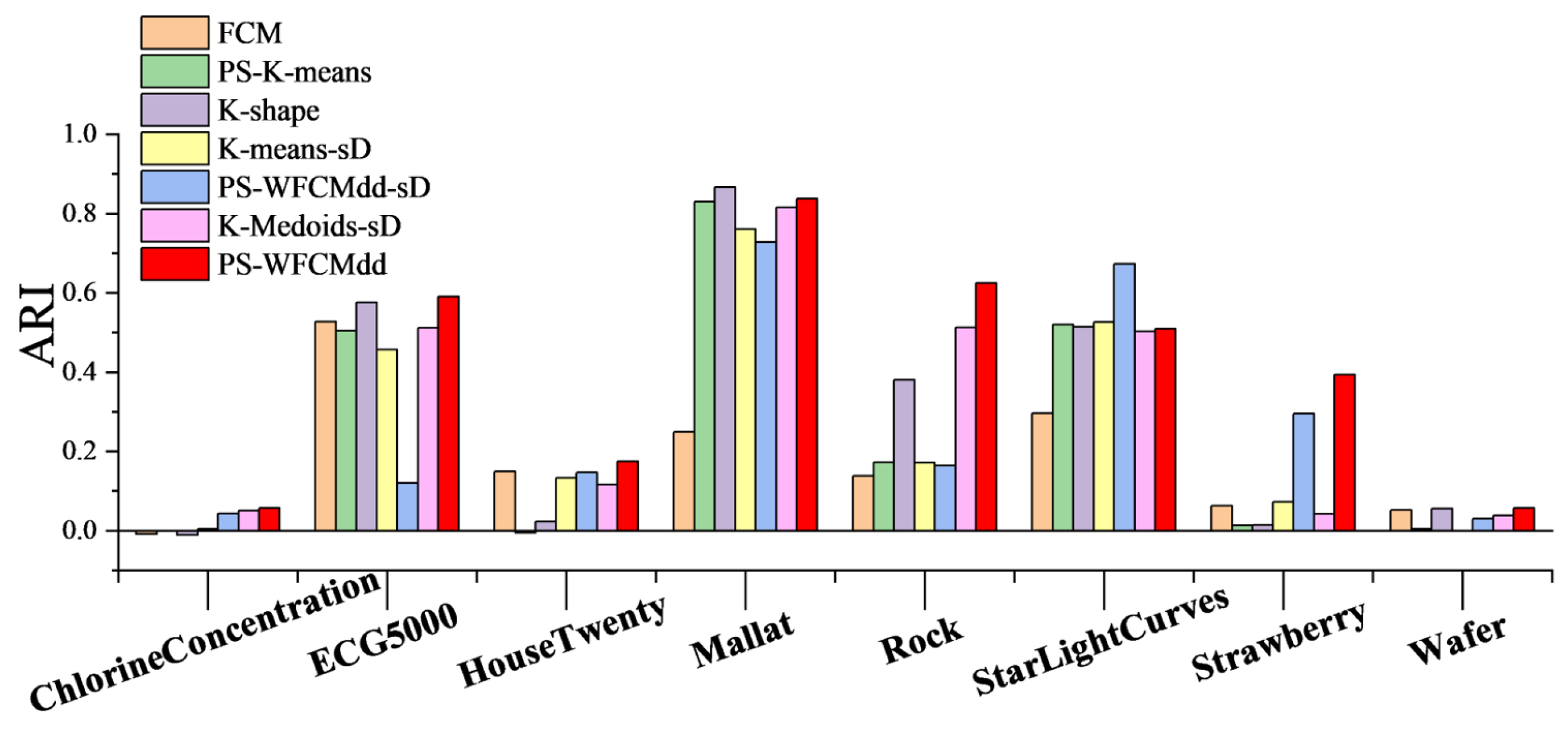
By looking at
Figure 3. We can see that on the ChlorineConcentration, Rock, and Strawberry datasets, the PS-WFCMdd algorithm has obvious score advantages. On the ECG5000, HouseTwenty, and Wafer datasets, the ARI score of the PS-WFCMdd algorithm is also the best. On the StarLightCurves dataset, the ARI score of the PS-WFCMdd-sD algorithm is the best. On the Mallat dataset, the ARI score of the K-shape algorithm is the best. The ARI scores of the PS-WFCMdd-sD and PS-WFCMdd algorithm on the ChlorineConcentration and HouseTwenty data have little difference.
According to the results in
Figure 4. On the Rock, StarLightCurves, and Strawberry datasets, the PS-WFCMdd algorithm has obvious advantages. On the ECG5000 and Mallat datasets, the PS-WFCMdd algorithm is barely optimal. The FCM algorithm achieves excellent performance on the ChlorineConcentration dataset, and the PS-K-means algorithm achieves the highest score on the HouseTwenty dataset. On the Wafer dataset, the FMI score of the PS-WFCMdd-sD algorithm is outstanding.
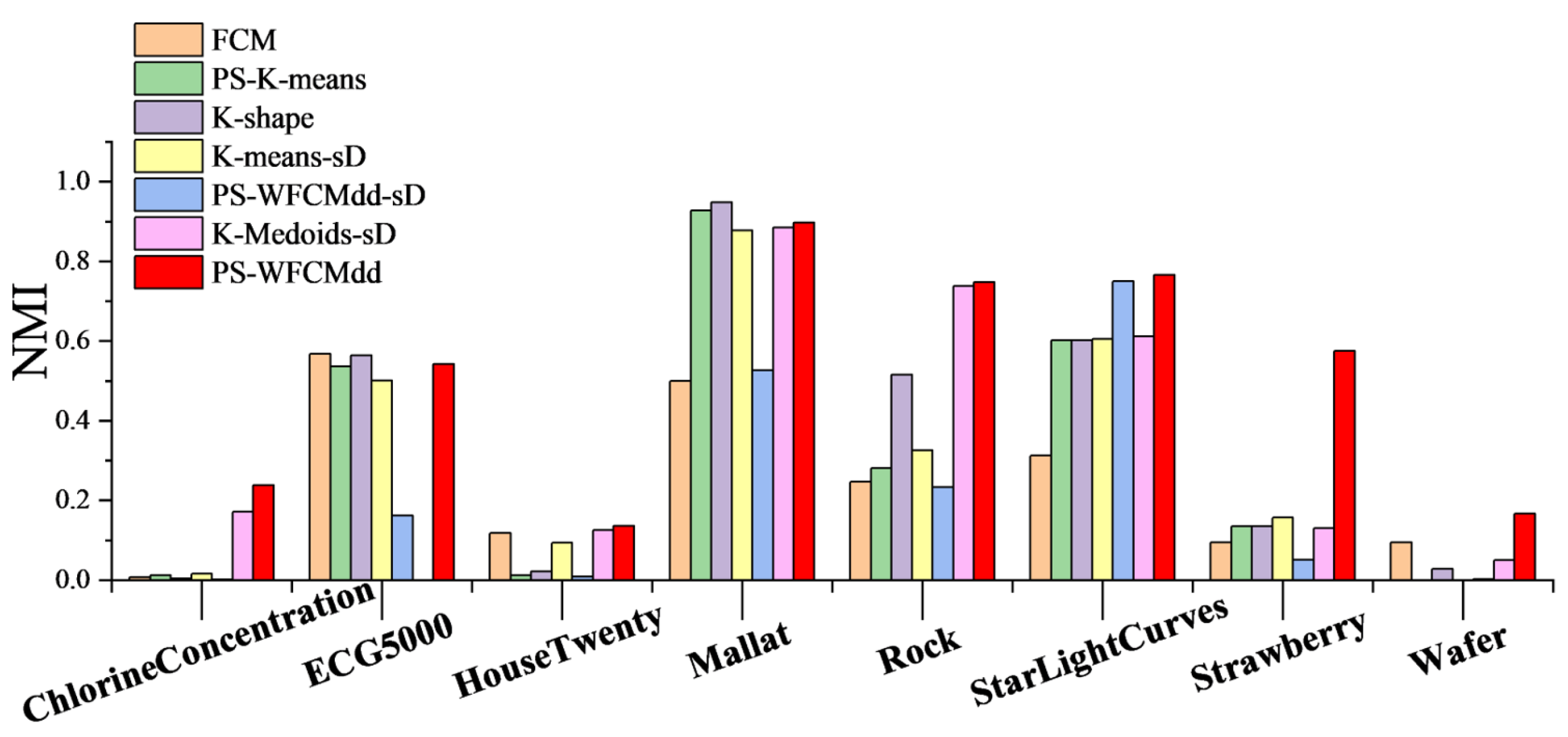
It can be seen from
Figure 5 that on the ChlorineConcentration, Rock, StarLightCurves, Strawberry, and Wafer datasets, the PS-WFCMdd algorithm has obvious score advantages; on the HouseTwenty dataset, the PS-WFCMdd algorithm achieves only a small advantage; on the ECG5000 dataset, the NMI score of the FCM algorithm is the optimal value; on the Mallat dataset, the K-shape algorithm has the best FMI score.
From the above analysis, it can be concluded that our algorithm can achieve excellent performance under three evaluation indicators when faced with large-scale time series datasets. On some datasets, the FCM algorithm and the K-shape algorithm have also achieved good results, indicating that these two algorithms have certain advantages in processing large-scale time series data. The PS-WFCMdd-sD algorithm has achieved good performance under the three evaluation indicators, but the overall performance is still better than the PS-WFCMdd algorithm.
4.3. Experimental Analysis from the Perspective of Data Characteristics
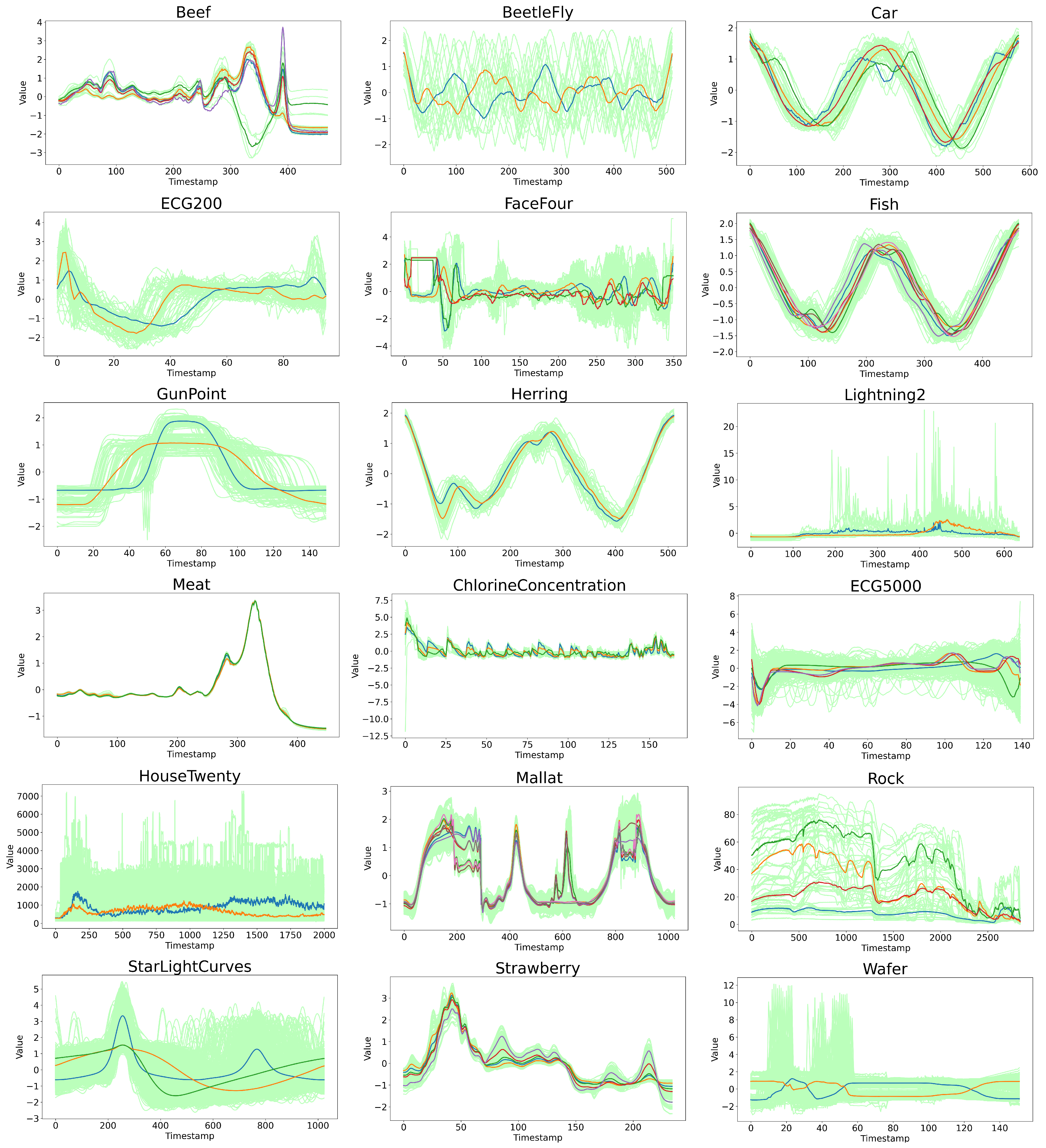
To more intuitively explain the robustness of the PS-WFCMdd algorithm from the data features, the trend of all experimental data and the cluster center results obtained by the PS-WFCMdd algorithm are shown in
Figure 6. The K-means-sD algorithm, which is generally used in time series clustering, is selected for the corresponding visual comparison, as shown in
Figure 7. In both figures, the colored lines represent cluster centers, and the light-colored lines represent the original sample set. In addition, the comprehensive performance of K-means-sD in the experiments in this paper is also relatively good. Let us first observe the clustering centers in the two visualization charts. Through comparison, we can see that since k-means-sd is the clustering center gradually generated in the clustering process, the trend of the clustering centers of some data is quite different from the original data, and the difference is more obvious in BeetleFly, HouseTwenty, and Wafer. However, PS-WFCMdd is the cluster center found in the corresponding original data, and the trend of the obtained cluster center is the same as that of the original data.
We then evaluate the data from the trend in the time series dynamic analysis. From the display of the source data set alone, it can be seen that BeetleFly, Car, Fish, Herring, and ChlorineConcentration all exhibit periodic changes, among which BeetleFly has a larger time series amplitude. In terms of the experimental results on Fish and Herring, PS-WFCMdd performs generally in the three evaluation indicators, while K-means-sD has better experimental results. In the experimental results of Car and ChlorineConcentration, the advantage of PS-WFCMdd is small. PS-WFCMdd performs well in the experimental results on BeetleFly. This shows that when faced with data with obvious periodicity and stable data trend, because there are few noise and abnormal samples in these data, PS-WFCMdd has no advantage in experimental results. The remaining 13 datasets contain a large number of irregular dynamic time series, which inevitably contain a lot of noise and edge data. From the experimental results of these data, the performance of PS-WFCMdd is relatively good. However, on Housetwenty and Wafer data with mutation frequencies, this type of data often presents more difficult modeling problems. PS-WFCMdd performs best among all comparison algorithms, but is not outstanding and does not make a practical solution for mutation frequency time series.
Based on the above experimental analysis, P-splines are used to fit time series data and use the fitted data as the input of clustering, which can effectively improve the final clustering effect. Under the influence of the new weight, the PS-WFCMdd algorithm can still obtain a higher clustering effectiveness index score under the condition of noise and outlier samples in the sample data. However, our algorithm also has some limitations. For example, compared with most algorithms, PS-WFCMdd needs to adjust more smoothing parameters, so the algorithm is not very concise. When faced with time series with obvious periodicity and stable data trends and irregularly changing data with mutation, our algorithm performs in general and needs further optimization and improvement.
4.4. Time Complexity Analysis
The time complexity of each comparison algorithm and PS-WFCMdd algorithm in this experiment is shown in
Table 6, where
N represents the number of sample data,
C represents the number of clusters, and
K represents the number of iterations. It can be seen that the time complexity of PS-WFCMdd is the same as that of K-shape, and it is second only to FCM and PS-K-means algorithm. The time complexity of the remaining clustering algorithms is higher. We can see that because of the difference in time complexity between soft-DTW and MASS 3, the running time consumption of PS-WFCMdd-sD and PS-WFCMdd is one order of magnitude different. Especially in the face of large time series, the advantages of the PS-WFCMdd algorithm are more obvious.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}