
Comparison of Different Convolutional Neural Network Activation Functions and Methods for Building Ensembles for Small to Midsize Medical Data Sets




Abstract
:1. Introduction
- (1)
- The performance of twenty individual activation functions is assessed using two CNNs (VGG16 and ResNet50) across fifteen different medical data sets.
- (2)
- The performance of ensembles composed of the CNNs examined in #1 and four other topologies is evaluated.
- (3)
- Six new activation functions are proposed.
2. Related Work with Activation Functions
3. Activation Functions
3.1. Rectified Activation Functions
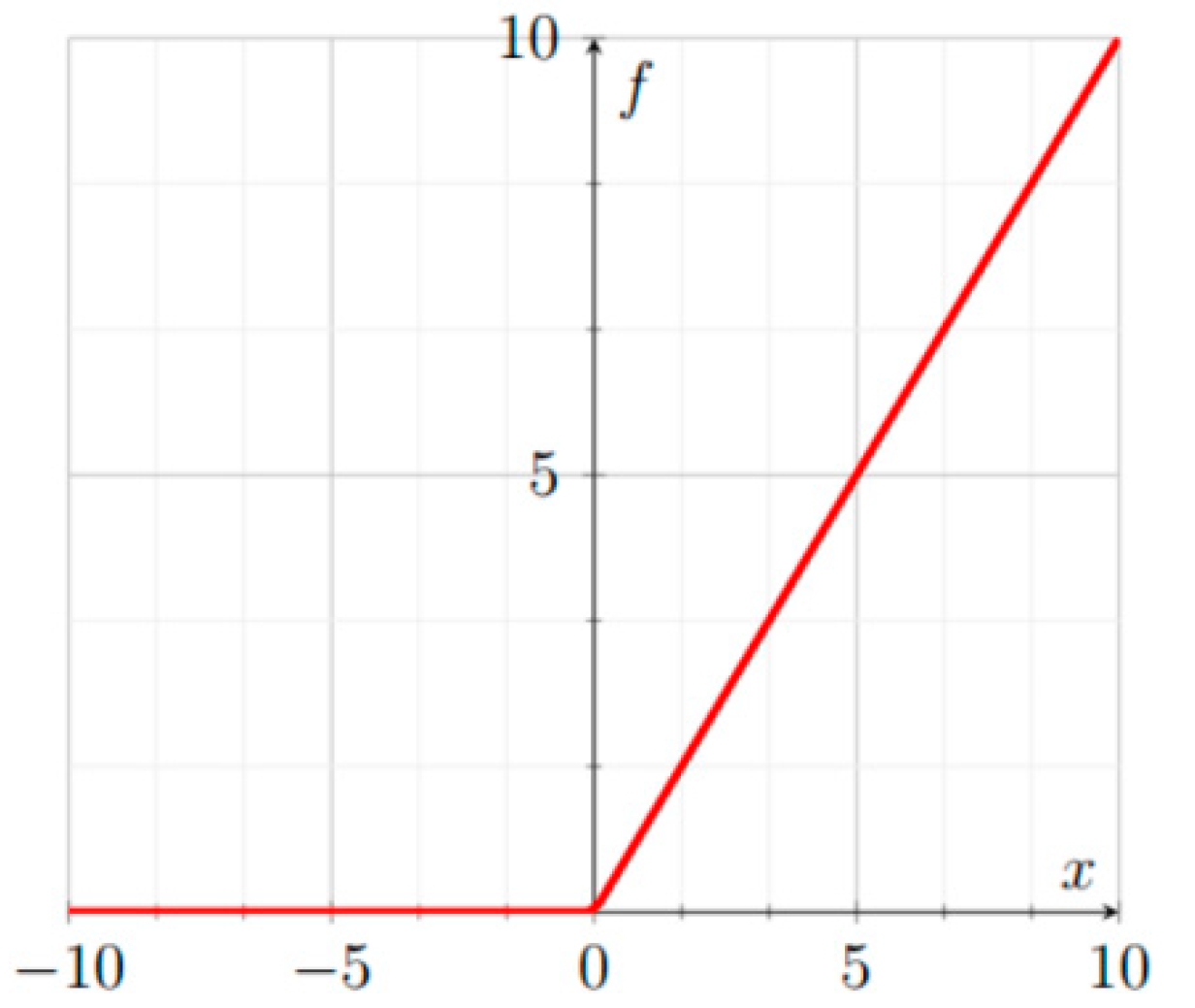
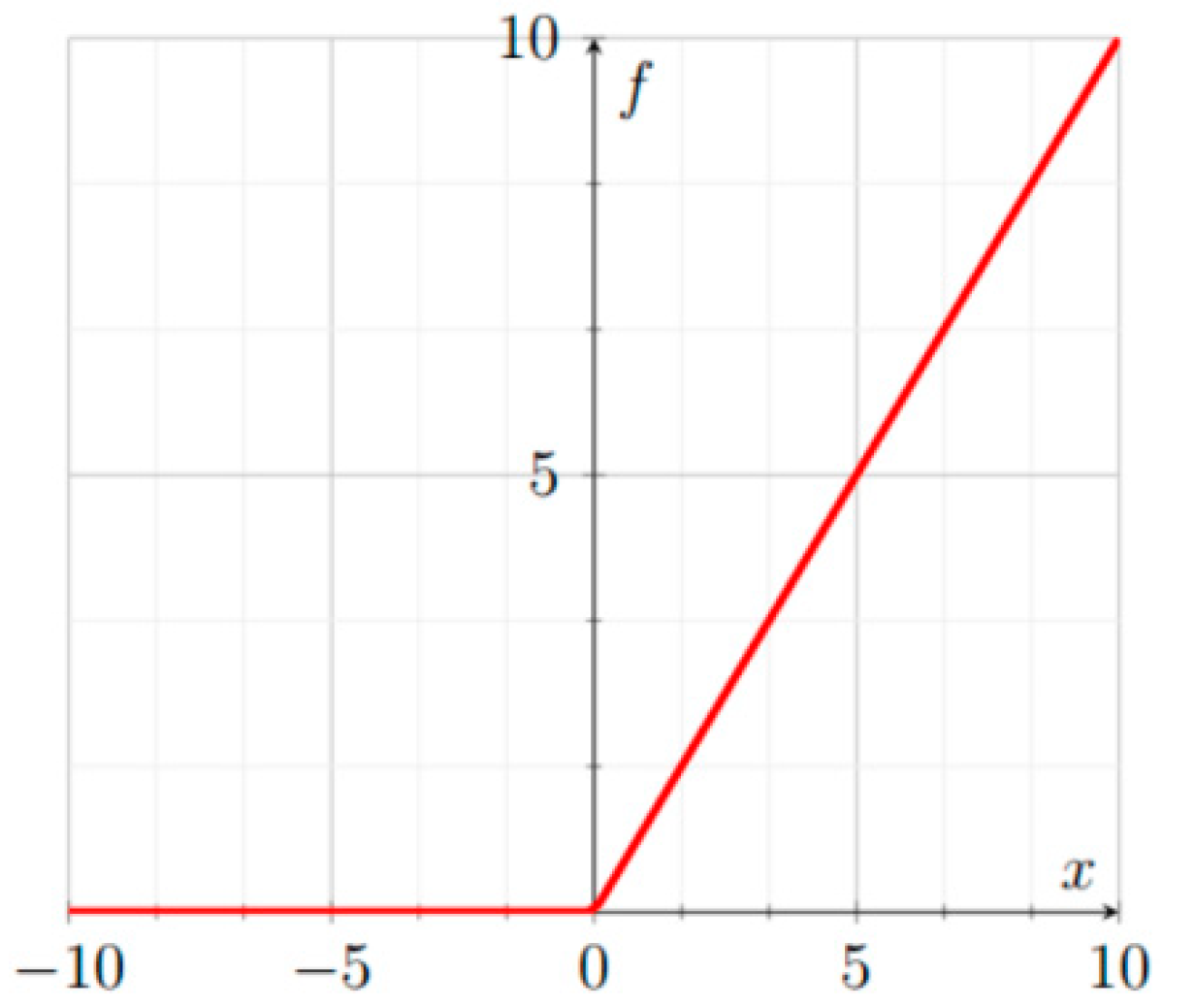
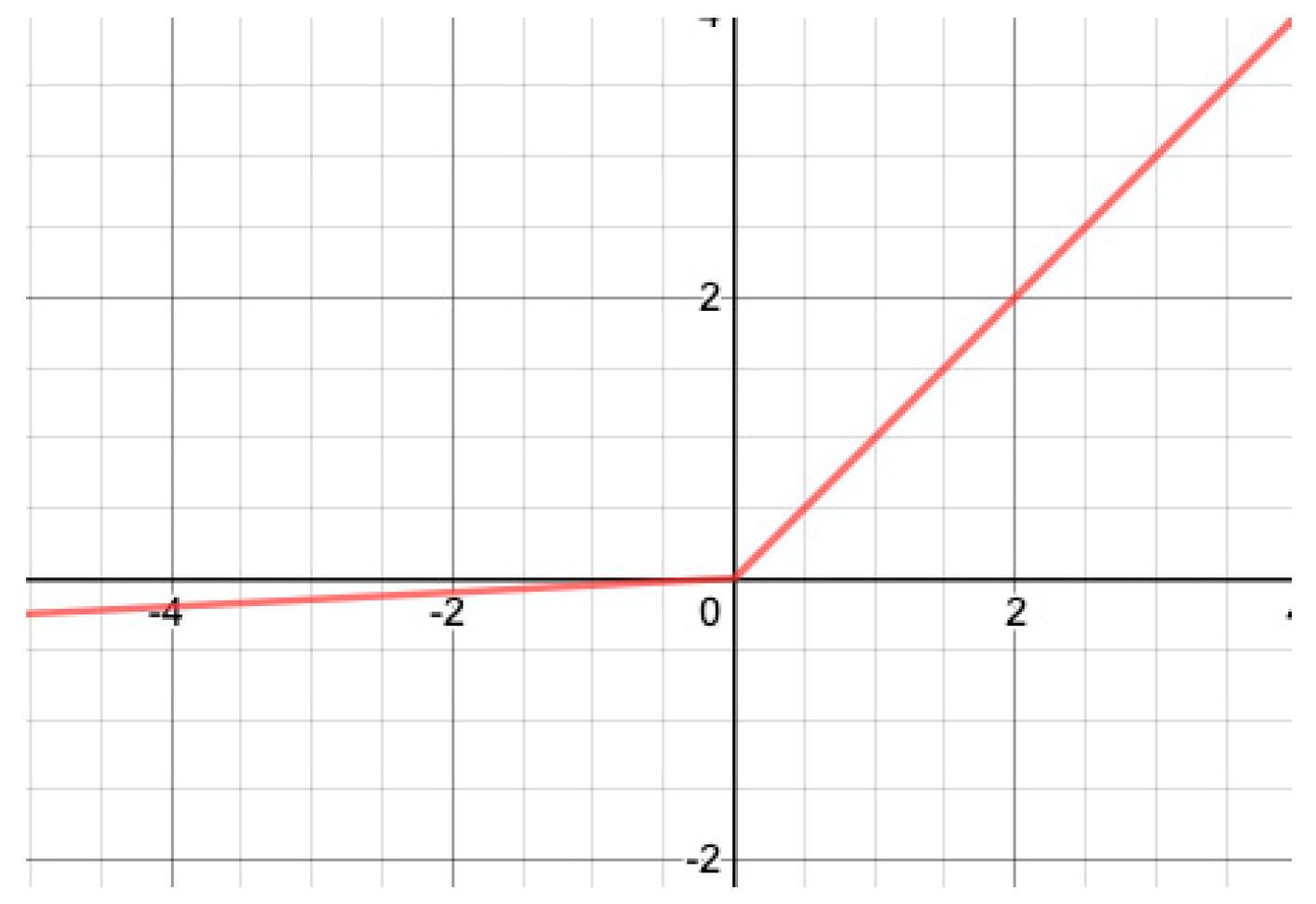
3.1.1. ReLU
3.1.2. Leaky ReLU
3.1.3. PReLU
3.2. Exponential Activation Functions
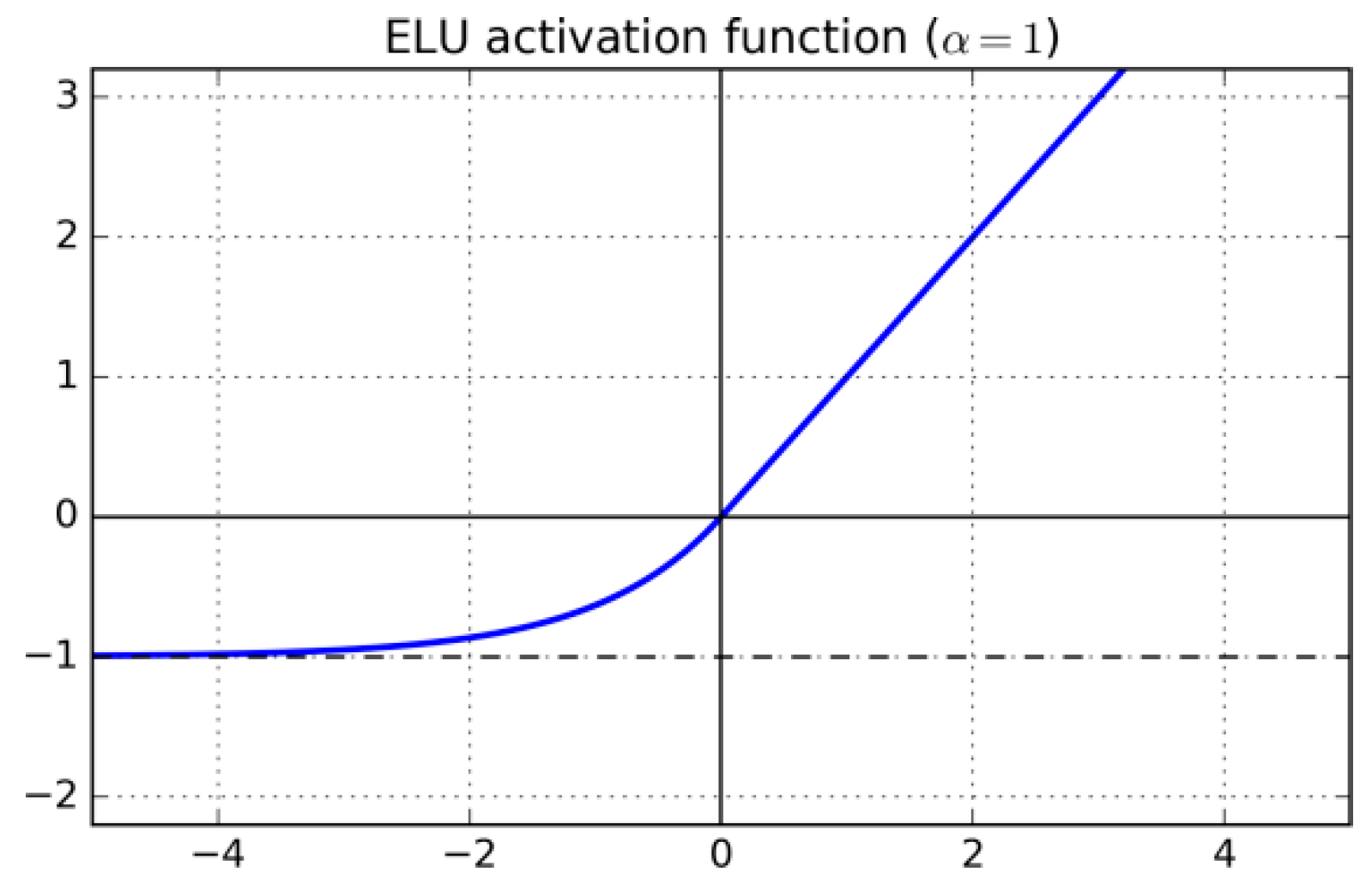
3.2.1. ELU
3.2.2. PDELU
3.3. Logistic Sigmoid and Tanh-Based AFs
3.3.1. Swish
3.3.2. Mish
3.3.3. TanELU (New)
3.4. Learning/Adaptive Activation Functions
3.4.1. SReLU
3.4.2. APLU
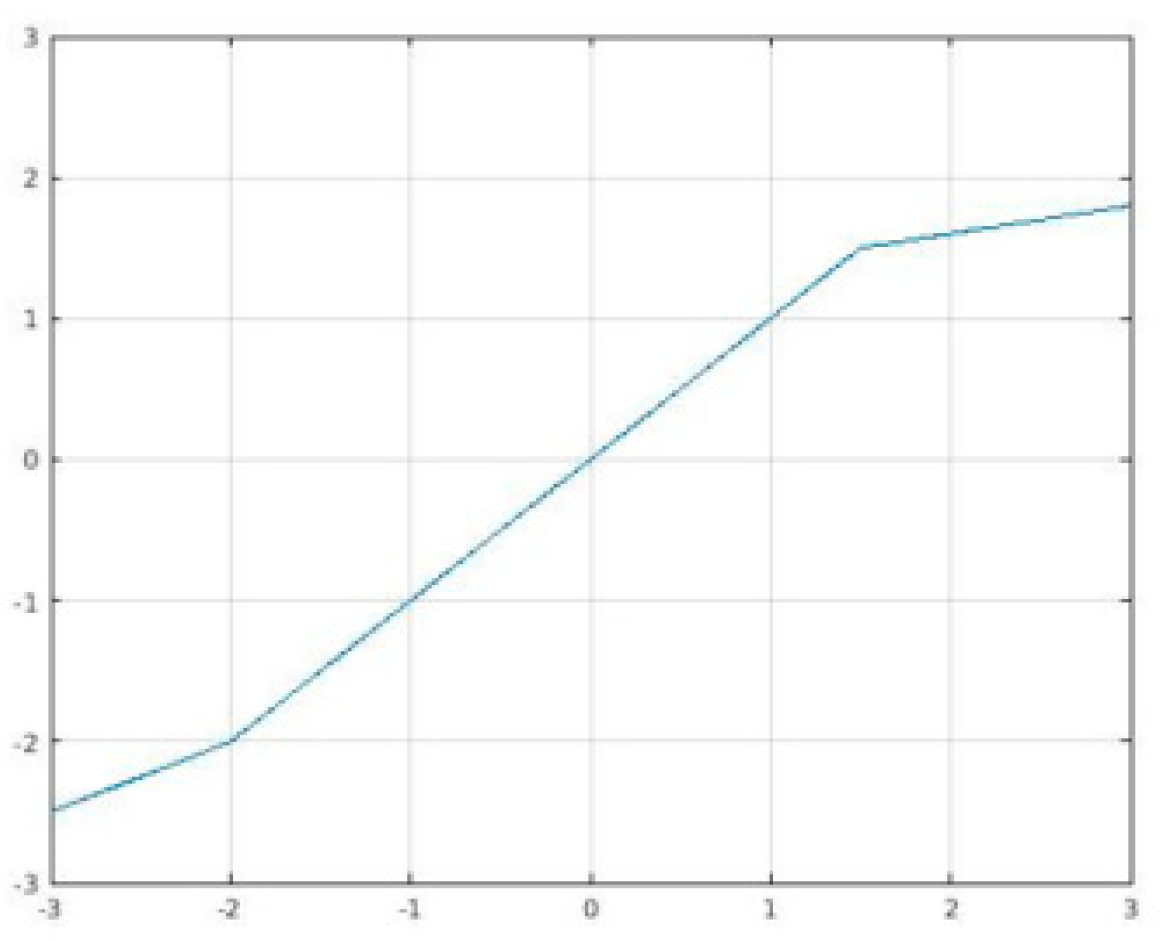
3.4.3. MeLU
3.4.4. GaLU
3.4.5. SRS
3.4.6. Soft Learnable
3.4.7. Splash
3.4.8. 2D MeLU (New)
3.4.9. MeLU + GaLU (New)
3.4.10. Symmetric MeLU (New)
3.4.11. Symmetric GaLU (New)
3.4.12. Flexible MeLU (New)
4. Building CNN Ensembles
4.1. Sequential Forward Floating Selection (SFFS)
4.2. Stochastic Method (Stoc)
5. Experimental Results
5.1. Biomedical Data Sets
- CH (CHO data set [72]): this is a data set containing 327 fluorescence microscopy images of Chinese hamster ovary cells divided into five classes: antigiantin, Hoechst 33,258 (DNA), antilamp2, antinop4, and antitubulin.
- HE (2D HeLa data set [72]): this is a balanced data set containing 862 fluorescence microscopy images of HeLa cells stained with various organelle-specific fluorescent dyes. The images are divided into ten classes of organelles: DNA (Nuclei); ER (Endoplasmic reticulum); Giantin, (cis/medial Golgi); GPP130 (cis Golgi); Lamp2 (Lysosomes); Nucleolin (Nucleoli); Actin, TfR (Endosomes); Mitochondria; and Tubulin.
- RN (RNAi data set [73]): this is a data set of 200 fluorescence microscopy images of fly cells (D. melanogaster) divided into ten classes. Each class contains 1024 × 1024 TIFF images of phenotypes produced from one of ten knock-down genes, the IDs of which form the class labels.
- MA (C. elegans Muscle Age data set [73]): this data set is for classifying the age of a nematode given twenty-five images of C. elegans muscles collected at four ages representing the classes.
- TB (Terminal Bulb Aging data set [73]): this is the companion data set to MA and contains 970 images of C. elegans terminal bulbs collected at seven ages representing the classes.
- LY (Lymphoma data set [73]): this data set contains 375 images of malignant lymphoma representative of three types: Chronic Lymphocytic Leukemia (CLL), Follicular Lymphoma (FL), and Mantle Cell Lymphoma (MCL).
- LG (Liver Gender Caloric Restriction (CR) data set [73]): this data set contains 265 images of liver tissue sections from six-month-old male and female mice on a CR diet; the two classes represent the gender of the mice.
- LA (Liver Aging Ad libitum data set [73]): this data set contains 529 images of liver tissue sections from female mice on an ad libitum diet divided into four classes representing the age of the mice.
- CO (Colorectal Cancer [74]): this is a Zenodo data set (record: 53169#.WaXjW8hJaUm) of 5000 histological images (150 x 150 pixels each) of human colorectal cancer divided into eight classes.
- BGR (Breast Grading Carcinoma [75]): this is a Zenodo data set (record: 834910#.Wp1bQ-jOWUl) that contains 300 annotated histological images of twenty-one patients with invasive ductal carcinoma of the breast representing three classes/grades 1–3.
- LAR (Laryngeal data set [76]): this is a Zenodo data set (record: 1003200#.WdeQcnBx0nQ) containing 1320 images of thirty-three healthy and early-stage cancerous laryngeal tissues representative of four tissue classes.
- HP (set of immunohistochemistry images from the Human Protein Atlas [77]): this is a Zenodo data set (record: 3875786#.XthkoDozY2w) of 353 images of fourteen proteins in nine normal reproductive tissues belonging to seven subcellular locations. The data set in [77] is partitioned into two folds, one for training (177 images) and one for testing (176 images).
- RT (2D 3T3 Randomly CD-Tagged Images: Set 3 [78]): this collection of 304 2D 3T3 randomly CD-tagged images was created by randomly generating CD-tagged cell clones and imaging them by automated microscopy. The images are divided into ten classes. As in [78], the proteins are put into ten folds so that images in the training and testing sets never come from the same protein.
- LO (Locate Endogenous data set [79]): this fairly balanced data set contains 502 images of endogenous cells divided into ten classes: Actin-cytoskeleton, Endosomes, ER, Golgi, Lysosomes, Microtubule, Mitochondria, Nucleus, Peroxisomes, and PM. This data set is archived at https://integbio.jp/dbcatalog/en/record/nbdc00296 (accessed on 9 August 2022).
- TR (Locate Transfected data [79]): this is a companion data set to LO. TR contains 553 images divided into the set same ten classes as LO but with the additional class of Cytoplasm for a total of eleven classes.
5.2. Experimental Results
- ENS: sum rule of {MeLU (), Leaky ReLU, ELU, MeLU (), PReLU, SReLU, APLU, ReLU} (if ) or {MeLU (), MeLU (), SReLU, APLU, ReLU} (if );
- eENS: sum rule of the methods that belong to ENS considering both and ;
- ENS_G: as in ENS but Small GaLU and GaLU are added, and in both cases or ;
- eENS_G: sum rule of the methods that belong to ENS_G but considering and ;
- ALL: sum rule among all the methods reported in Table 4 with or . Notice that when the methods with are combined, standard ReLU is also added to the fusion. Due to computation time, some activation functions are not combined with VGG16 and so are not considered;
- eALL: sum rule among all the methods, both with and . Due to computation time, some activation functions are not combined with VGG16 and thus are not considered in an ensemble;
- 15ReLU: ensemble obtained by the fusion of 15 ReLU models. Each network is different because of the stochasticity of the training process;
- Selection: ensemble selected using SFFS (see Section 3.1);
- Stoc_1: MeLU(), Leaky ReLU, ELU, MeLU(), PReLU, SReLU, APLU, GaLU, sGaLU. A has been used in the stochastic approach (see Section 3.2);
- Stoc_2: the same nine functions of Stoc_1 and an additional set of seven activation functions: ReLU, Soft Learnable, PDeLU, learnableMish, SRS, Swish Learnable, and Swish. A has been used;
- Stoc_4: the ensemble detailed in Section 4.
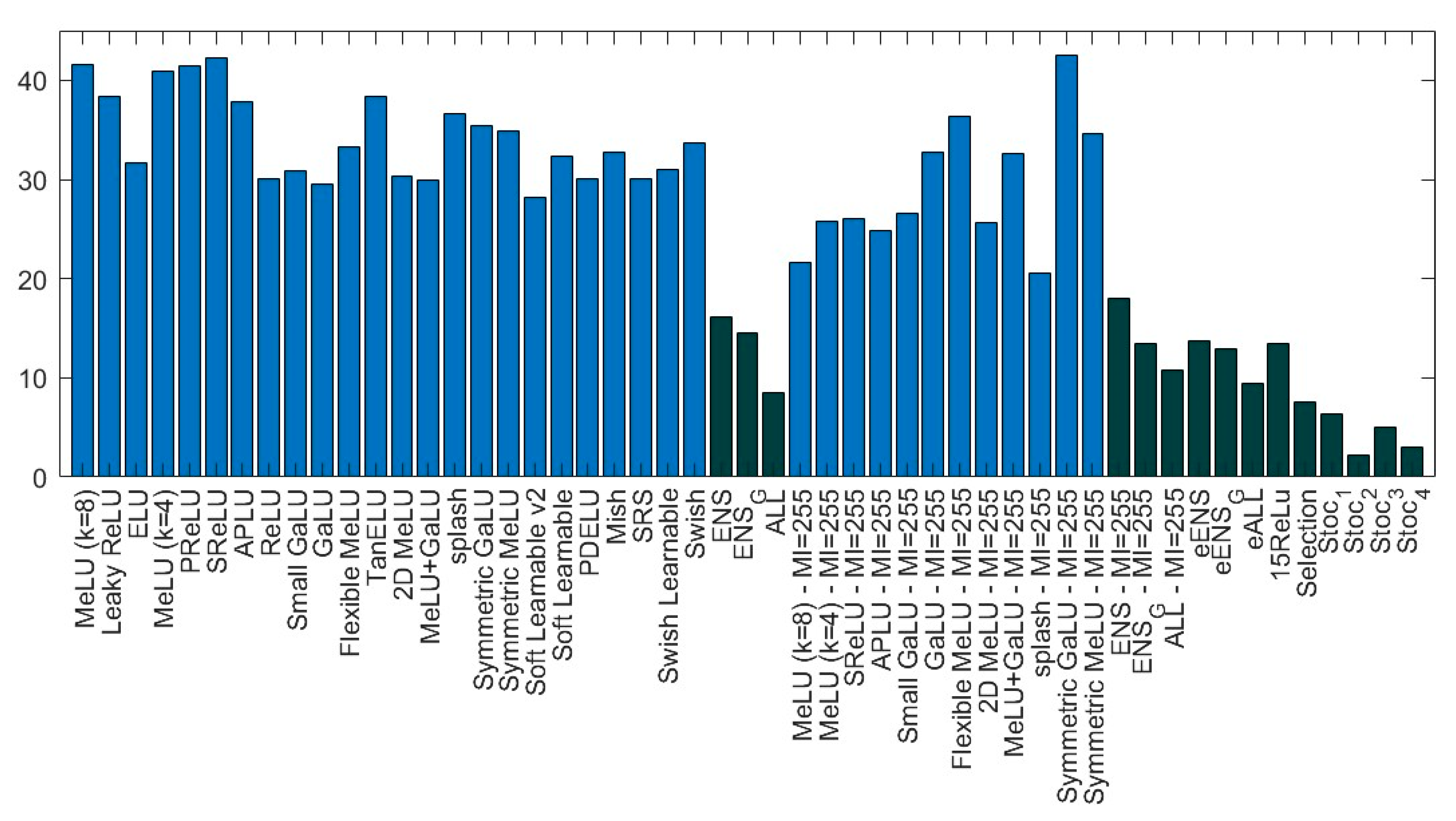
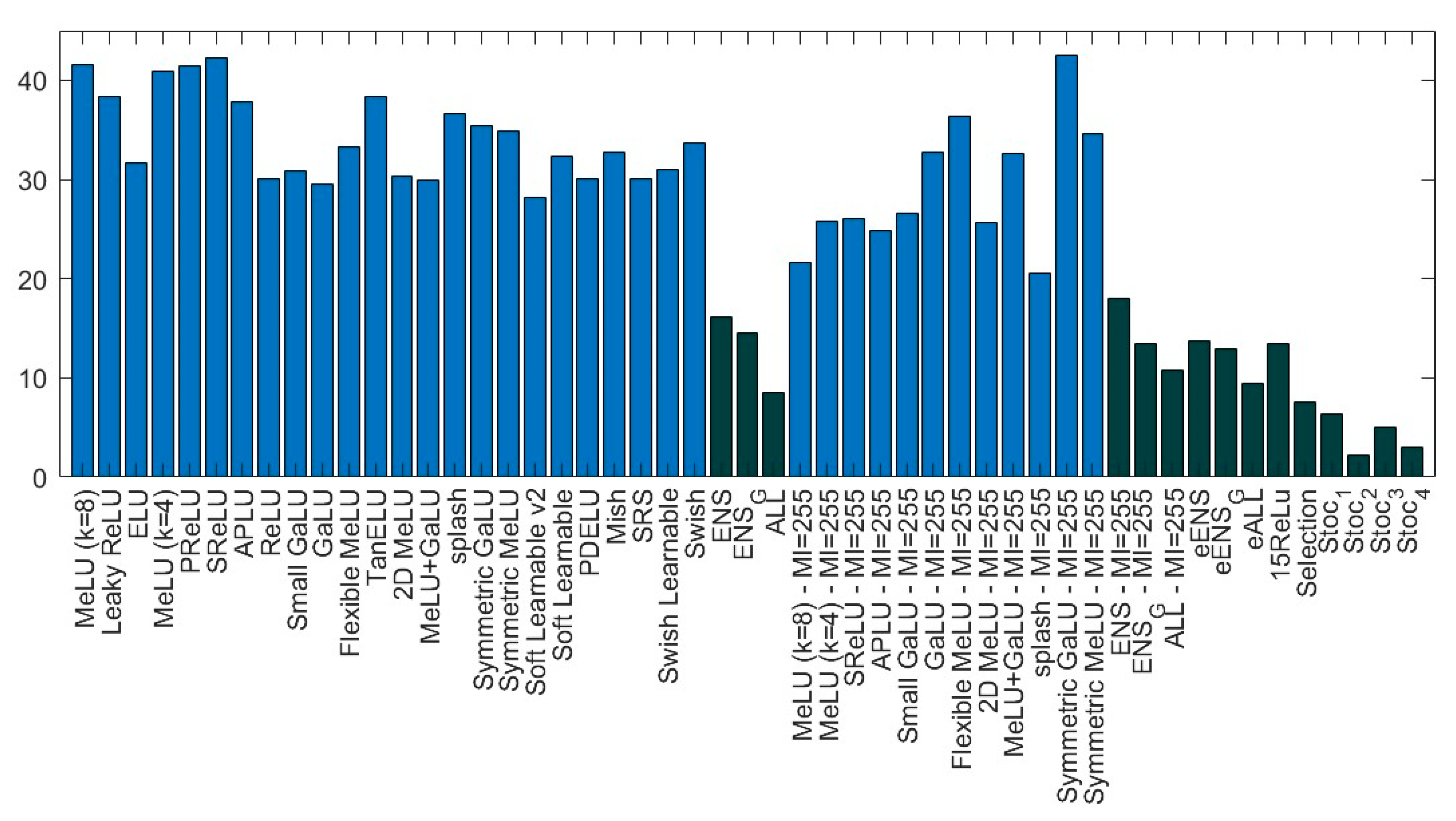
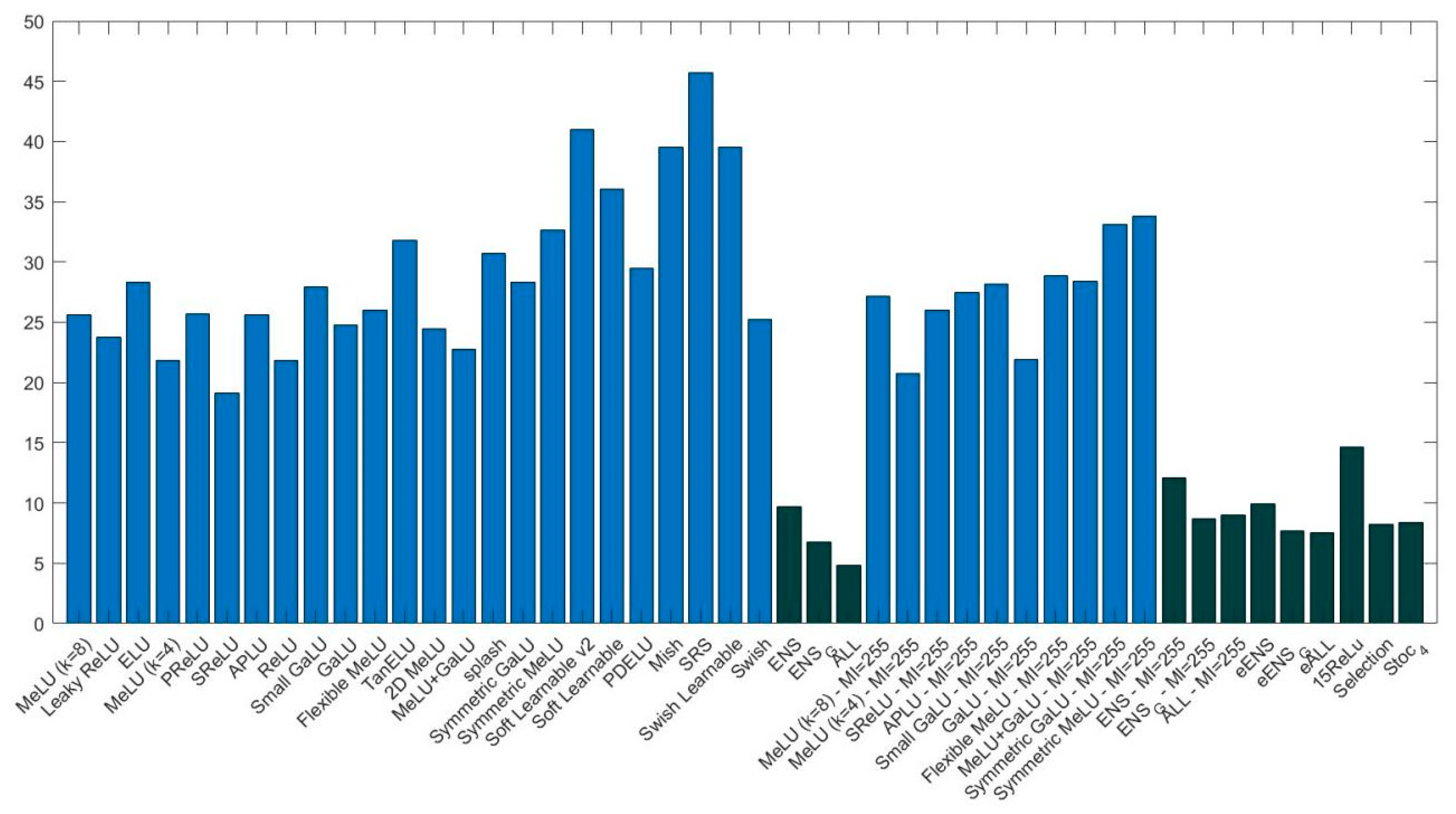
- ensemble methods outperform stand-alone networks. This result confirms previous research showing that changing activation functions is a viable method for creating ensembles of networks. Note how well 15ReLU outperforms (p-value of 0.01) the stand-alone ReLU;
- among the stand-alone ResNet50 networks, ReLU is not the best activation function. The two activations that reach the highest performance on ResNet50 are MeLU () with and Splash with . According to the Wilcoxon signed rank test, MeLU () with outperforms ReLU with a p-value of 0.1. There is no statistical difference between MeLU () and Splash (with for both);
- according to the Wilcoxon signed rank test, Stoc_4 and Stoc_2 are similar in performance, and both outperform the other stochastic approach with a p-value of 0.1;
- Stoc_4 outperforms eALL, 15ReLU, and Selection with a p-value of 0.1. Selection outperforms 15ReLU with p-value of 0.01, but Selection’s performance is similar to eALL.
- (a)
- there is not a clear winner among the different AFs;
- (b)
- ensembles work better with respect to stand-alone approaches;
- (c)
- the methods named Sto_x work better with respect to other ensembles.
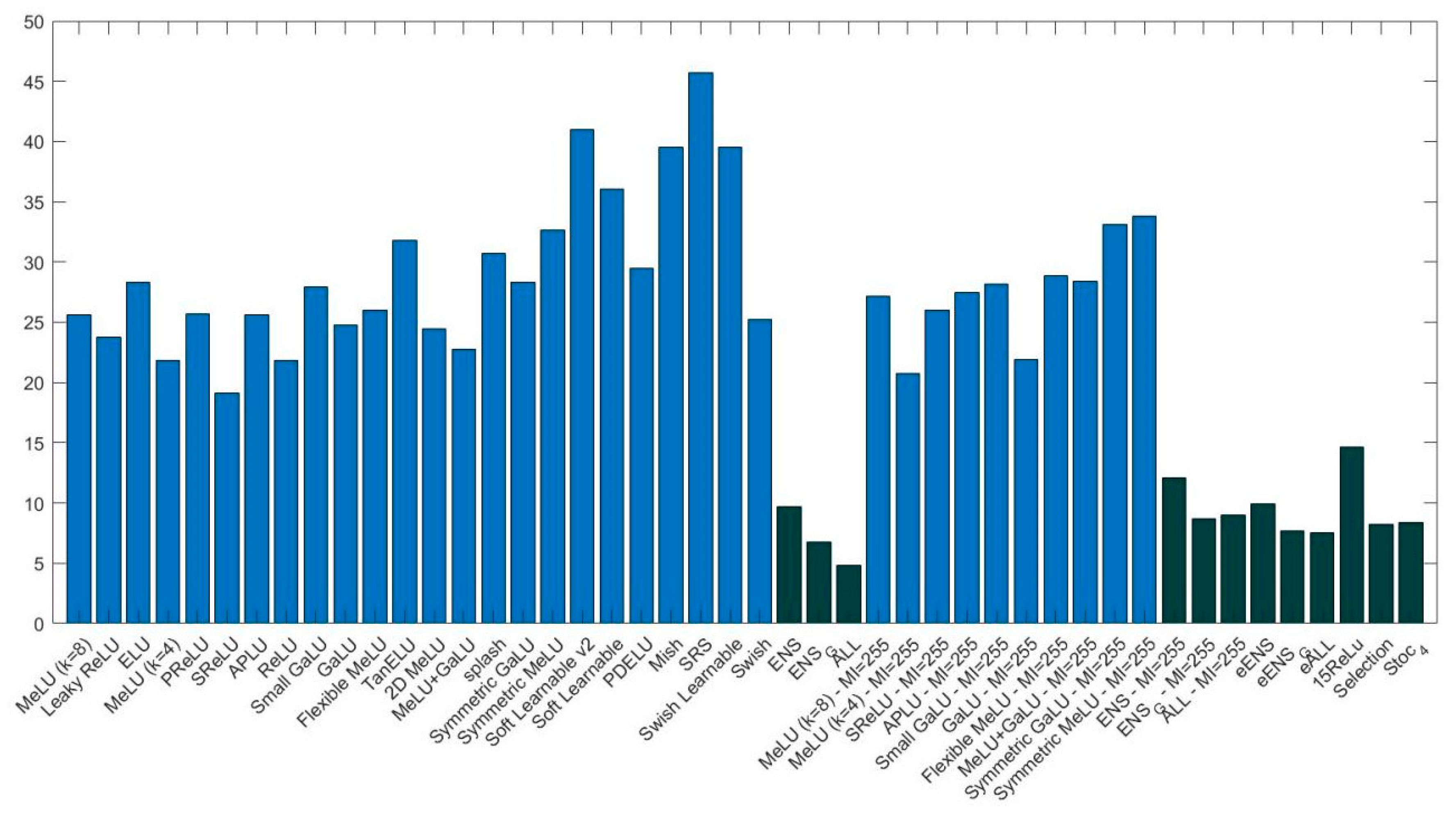
- again, the ensemble methods outperform the stand-alone CNNs. As was the case with ResNet50, 15ReLU strongly outperforms (p-value of 0.01) the stand-alone CNNs with ReLU;
- among the stand-alone VGG16 networks, ReLU is not the best activation function. The two activations that reach the highest performance on V6616 are MeLU () with and GaLU with . According to the Wilcoxon signed rank test, there is no statistical difference between ReLU, MeLU (), and GaLU, MI ;
- interestingly, ALL with 1 outperforms eALL with p-value of 0.05;
- Stoc_4 outperforms 15ReLU with p-value of 0.01, but the performance of Stoc_4 is similar to eALL, ALL (), and Selection.
- EfficientNetB0 [81]: this CNN does not have ReLU layers, so we only compare the stand-alone CNN with the ensemble labeled 15Reit (15 reiterations of the training).
- MobileNetV2 [82].
- DarkNet53, [83]: this deep network uses LeakyReLU with no ReLU layers; the fusion of 15 standard DarkNet53 models is labeled 15Leaky.
- DenseNet201 [84].
- ResNet50.
- the ensembles strongly outperform (p-value 0.01) the stand-alone CNN in each topology;
- in MobileNetV2, DenseNet201, and ResNet50, Stoc_4 outperforms 15ReLU (p-value 0.05);
- DarkNet53 behaved differently: on this network, 15Leaky and Stoc_4 obtained similar performance.
- CO—ResNet: the best is Swish Learnable;
- LAR—ResNet: the best is 2D MeLU;
- CO—VGG16: the best is MeLU + GaLU;
- LAR—VGG16: the best is MeLU (k = 4).
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Sony, S.; Dunphy, K.; Sadhu, A.; Capretz, M. A systematic review of convolutional neural network-based structural condition assessment techniques. Eng. Struct. 2021, 226, 111347. [Google Scholar] [CrossRef]
- Christin, S.; Hervet, É.; Lecomte, N. Applications for deep learning in ecology. Methods Ecol. Evol. 2019, 10, 1632–1644. [Google Scholar] [CrossRef]
- Min, S.; Lee, B.; Yoon, S. Deep learning in bioinformatics. Brief. Bioinform. 2016, 18, 851–869. [Google Scholar] [CrossRef] [PubMed]
- Kattenborn, T.; Leitloff, J.; Schiefer, F.; Hinz, S. Review on Convolutional Neural Networks (CNN) in vegetation remote sensing. ISPRS J. Photogramm. Remote Sens. 2021, 173, 24–49. [Google Scholar] [CrossRef]
- Yapici, M.M.; Tekerek, A.; Topaloğlu, N. Literature review of deep learning research areas. Gazi Mühendislik Bilimleri Derg. GMBD 2019, 5, 188–215. [Google Scholar]
- Bakator, M.; Radosav, D. Deep Learning and Medical Diagnosis: A Review of Literature. Multimodal Technol. Interact. 2018, 2, 47. Available online: https://www.mdpi.com/2414-4088/2/3/47 (accessed on 9 August 2022). [CrossRef]
- Wang, F.; Casalino, L.P.; Khullar, D. Deep learning in medicine—Promise, progress, and challenges. JAMA Intern. Med. 2019, 179, 293–294. [Google Scholar] [CrossRef]
- Ching, T.; Himmelstein, D.S.; Beaulieu-Jones, B.K.; Kalinin, A.A.; Do, B.T.; Way, G.P.; Ferrero, E.; Agapow, P.-M.; Zietz, M.; Hoffman, M.M.; et al. Opportunities and obstacles for deep learning in biology and medicine. J. R. Soc. Interface 2018, 15, 20170387. [Google Scholar] [CrossRef] [PubMed]
- Cai, L.; Gao, J.; Zhao, D. A review of the application of deep learning in medical image classification and segmentation. Ann. Transl. Med. 2020, 8, 713. [Google Scholar] [CrossRef]
- Rawat, W.; Wang, Z. Deep Convolutional Neural Networks for Image Classification: A Comprehensive Review. Neural Comput. 2017, 29, 2352–2449. [Google Scholar] [CrossRef] [PubMed]
- Dhillon, A.; Verma, G.K. Convolutional neural network: A review of models, methodologies and applications to object detection. Prog. Artif. Intell. 2020, 9, 85–112. [Google Scholar] [CrossRef]
- Zhao, Z.-Q.; Zheng, P.; Xu, S.-T.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [PubMed]
- Taskiran, M.; Kahraman, N.; Erdem, C.E. Face recognition: Past, present and future (a review). Digit. Signal Processing 2020, 106, 102809. [Google Scholar] [CrossRef]
- Kortli, Y.; Jridi, M.; al Falou, A.; Atri, M. Face recognition systems: A survey. Sensors 2020, 20, 342. [Google Scholar] [CrossRef]
- Bodapati, S.; Bandarupally, H.; Shaw, R.N.; Ghosh, A. Comparison and analysis of RNN-LSTMs and CNNs for social reviews classification. In Advances in Applications of Data-Driven Computing; Springer: Berlin/Heidelberg, Germany, 2021; pp. 49–59. [Google Scholar]
- Haggenmüller, S.; Maron, R.C.; Hekler, A.; Utikal, J.S.; Barata, C.; Barnhill, R.L.; Beltraminelli, H.; Berking, C.; Betz-Stablein, B.; Blum, A.; et al. Skin cancer classification via convolutional neural networks: Systematic review of studies involving human experts. Eur. J. Cancer 2021, 156, 202–216. [Google Scholar] [CrossRef] [PubMed]
- Haenssle, H.A.; Winkler, J.K.; Fink, C.; Toberer, F.; Enk, A.; Stolz, W.; Deinlein, T.; Hofmann-Wellenhof, R.; Kittler, H.; Tschandl, P.; et al. Skin lesions of face and scalp—Classification by a market-approved convolutional neural network in comparison with 64 dermatologists. Eur. J. Cancer 2021, 144, 192–199. [Google Scholar] [CrossRef]
- Zhang, S.M.; Wang, Y.J.; Zhang, S.T. Accuracy of artificial intelligence-assisted detection of esophageal cancer and neoplasms on endoscopic images: A systematic review and meta-analysis. J. Dig. Dis. 2021, 22, 318–328. [Google Scholar] [CrossRef]
- Singh, S.P.; Wang, L.; Gupta, S.; Goli, H.; Padmanabhan, P.; Gulyás, B. 3D Deep Learning on Medical Images: A Review. Sensors 2020, 20, 5097. [Google Scholar] [CrossRef]
- Gurovich, Y.; Hanani, Y.; Bar, O.; Nadav, G.; Fleischer, N.; Gelbman, D.; Basel-Salmon, L.; Krawitz, P.M.; Kamphausen, S.B.; Zenker, M.; et al. Identifying facial phenotypes of genetic disorders using deep learning. Nat. Med. 2019, 25, 60–64. [Google Scholar] [CrossRef]
- Oltu, B.; Karaca, B.K.; Erdem, H.; Özgür, A. A systematic review of transfer learning based approaches for diabetic retinopathy detection. arXiv 2021, arXiv:2105.13793. [Google Scholar]
- Kadan, A.B.; Subbian, P.S. Diabetic Retinopathy Detection from Fundus Images Using Machine Learning Techniques: A Review. Wirel. Pers. Commun. 2021, 121, 2199–2212. [Google Scholar] [CrossRef]
- Kapoor, P.; Arora, S. Applications of Deep Learning in Diabetic Retinopathy Detection and Classification: A Critical Review. In Proceedings of Data Analytics and Management; Springer: Singapore, 2021; pp. 505–535. [Google Scholar]
- Mirzania, D.; Thompson, A.C.; Muir, K.W. Applications of deep learning in detection of glaucoma: A systematic review. Eur. J. Ophthalmol. 2021, 31, 1618–1642. [Google Scholar] [CrossRef] [PubMed]
- Gumma, L.N.; Thiruvengatanadhan, R.; Kurakula, L.; Sivaprakasam, T. A Survey on Convolutional Neural Network (Deep-Learning Technique) -Based Lung Cancer Detection. SN Comput. Sci. 2021, 3, 66. [Google Scholar] [CrossRef]
- Abdelrahman, L.; al Ghamdi, M.; Collado-Mesa, F.; Abdel-Mottaleb, M. Convolutional neural networks for breast cancer detection in mammography: A survey. Comput. Biol. Med. 2021, 131, 104248. [Google Scholar] [CrossRef]
- Leng, X. Photoacoustic Imaging of Colorectal Cancer and Ovarian Cancer. Ph.D. Dissertation, Washington University in St. Louis, St. Louis, MO, USA, 2022. [Google Scholar]
- Yu, C.; Helwig, E.J. Artificial intelligence in gastric cancer: A translational narrative review. Ann. Transl. Med. 2021, 9, 269. [Google Scholar] [CrossRef]
- Kuntz, S.; Krieghoff-Henning, E.; Kather, J.N.; Jutzi, T.; Höhn, J.; Kiehl, L.; Hekler, A.; Alwers, E.; von Kalle, C.; Fröhling, S.; et al. Gastrointestinal cancer classification and prognostication from histology using deep learning: Systematic review. Eur. J. Cancer 2021, 155, 200–215. [Google Scholar] [CrossRef]
- Desai, M.; Shah, M. An anatomization on breast cancer detection and diagnosis employing multi-layer perceptron neural network (MLP) and Convolutional neural network (CNN). Clin. Ehealth 2021, 4, 1–11. [Google Scholar] [CrossRef]
- Senthil, K. Ovarian cancer diagnosis using pretrained mask CNN-based segmentation with VGG-19 architecture. Bio-Algorithms Med-Syst. 2021. [Google Scholar] [CrossRef]
- Soudy, M.; Alam, A.; Ola, O. Predicting the Cancer Recurrence Using Artificial Neural Networks. In Computational Intelligence in Oncology; Springer: Singapore, 2022; pp. 177–186. [Google Scholar]
- AbdulAzeem, Y.; Bahgat, W.M.; Badawy, M. A CNN based framework for classification of Alzheimer’s disease. Neural Comput. Appl. 2021, 33, 10415–10428. [Google Scholar] [CrossRef]
- Amini, M.; Pedram, M.M.; Moradi, A.; Ouchani, M. Diagnosis of Alzheimer’s Disease Severity with fMRI Images Using Robust Multitask Feature Extraction Method and Convolutional Neural Network (CNN). Comput. Math. Methods Med. 2021, 2021, 5514839. [Google Scholar] [CrossRef]
- Khanagar, S.B.; Naik, S.; Al Kheraif, A.A.; Vishwanathaiah, S.; Maganur, P.C.; Alhazmi, Y.; Mushtaq, S.; Sarode, S.C.; Sarode, G.S.; Zanza, A.; et al. Application and performance of artificial intelligence technology in oral cancer diagnosis and prediction of prognosis: A systematic review. Diagnostics 2021, 11, 1004. [Google Scholar] [CrossRef] [PubMed]
- Ren, R.; Luo, H.; Su, C.; Yao, Y.; Liao, W. Machine learning in dental, oral and craniofacial imaging: A review of recent progress. PeerJ 2021, 9, e11451. [Google Scholar] [CrossRef] [PubMed]
- Mohan, B.P.; Khan, S.R.; Kassab, L.L.; Ponnada, S.; Chandan, S.; Ali, T.; Dulai, P.S.; Adler, D.G.; Kochhar, G.S. High pooled performance of convolutional neural networks in computer-aided diagnosis of GI ulcers and/or hemorrhage on wireless capsule endoscopy images: A systematic review and meta-analysis. Gastrointest. Endosc. 2021, 93, 356–364.e4. [Google Scholar] [CrossRef] [PubMed]
- Esteva, A.; Chou, K.; Yeung, S.; Naik, N.; Madani, A.; Mottaghi, A.; Liu, Y.; Topol, E.; Dean, J.; Socher, R. Deep learning-enabled medical computer vision. NPJ Digit. Med. 2021, 4, 5. [Google Scholar] [CrossRef] [PubMed]
- Gonçalves, C.B.; Souza, J.R.; Fernandes, H. Classification of static infrared images using pre-trained CNN for breast cancer detection. In Proceedings of the 2021 IEEE 34th International Symposium on Computer-Based Medical Systems (CBMS), Aveiro, Portugal, 7–9 June 2021; pp. 101–106. [Google Scholar]
- Morid, M.A.; Borjali, A.; del Fiol, G. A scoping review of transfer learning research on medical image analysis using ImageNet. Comput. Biol. Med. 2021, 128, 104115. [Google Scholar] [CrossRef]
- Chlap, P.; Min, H.; Vandenberg, N.; Dowling, J.; Holloway, L.; Haworth, A. A review of medical image data augmentation techniques for deep learning applications. J. Med. Imaging Radiat. Oncol. 2021, 65, 545–563. [Google Scholar] [CrossRef]
- Papanastasopoulos, Z.; Samala, R.K.; Chan, H.-P.; Hadjiiski, L.; Paramagul, C.; Helvie, M.A.; Neal, C.H. Explainable AI for medical imaging: Deep-learning CNN ensemble for classification of estrogen receptor status from breast MRI. In Medical Imaging 2020: Computer-Aided Diagnosis; International Society for Optics and Photonics: Bellingham, WA, USA, 2020; p. 113140Z. [Google Scholar]
- Singh, R.K.; Gorantla, R. DMENet: Diabetic macular edema diagnosis using hierarchical ensemble of CNNs. PLoS ONE 2020, 15, e0220677. [Google Scholar]
- Coupé, P.; Mansencal, B.; Clément, M.; Giraud, R.; de Senneville, B.D.; Ta, V.; Lepetit, V.; Manjon, J.V. AssemblyNet: A large ensemble of CNNs for 3D whole brain MRI segmentation. NeuroImage 2020, 219, 117026. [Google Scholar] [CrossRef]
- Savelli, B.; Bria, A.; Molinara, M.; Marrocco, C.; Tortorella, F. A multi-context CNN ensemble for small lesion detection. Artif. Intell. Med. 2020, 103, 101749. [Google Scholar] [CrossRef]
- Maguolo, G.; Nanni, L.; Ghidoni, S. Ensemble of Convolutional Neural Networks Trained with Different Activation Functions. Expert Syst. Appl. 2021, 166, 114048. [Google Scholar] [CrossRef]
- Nanni, L.; Lumini, A.; Ghidoni, S.; Maguolo, G. Stochastic Selection of Activation Layers for Convolutional Neural Networks. Sensors 2020, 20, 1626. [Google Scholar] [CrossRef] [PubMed]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. Cornell Univ. arXiv 2014, arXiv:1409.1556v6 2014. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Glorot, X.; Bordes, A.; Bengio, Y. Deep Sparse Rectifier Neural Networks. In AISTATS; PMLR: Birmingham, UK, 2011; Available online: https://pdfs.semanticscholar.org/6710/7f78a84bdb2411053cb54e94fa226eea6d8e.pdf?_ga=2.211730323.729472771.1575613836-1202913834.1575613836 (accessed on 9 August 2022).
- Nair, V.; Hinton, G.E. Rectified Linear Units Improve Restricted Boltzmann Machines. In Proceedings of the 27th International Conference on Machine Learning, Haifa, Israel, 21 June 2010. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems; Pereira, F., Burges, C.J.C., Bottou, L., Weinberger, K.Q., Eds.; Curran Associates, Inc.: New Yoek, NY, USA, 2012; pp. 1097–1105. [Google Scholar]
- Maas, A.L. Rectifier Nonlinearities Improve Neural Network Acoustic Models. 2013. Available online: https://pdfs.semanticscholar.org/367f/2c63a6f6a10b3b64b8729d601e69337ee3cc.pdf?_ga=2.208124820.729472771.1575613836-1202913834.1575613836 (accessed on 9 August 2022).
- Clevert, D.-A.; Unterthiner, T.; Hochreiter, S. Fast and Accurate Deep Network Learning by Exponential Linear Units (ELUs). arXiv 2015, arXiv:1511.07289v5. [Google Scholar]
- Klambauer, G.; Unterthiner, T.; Mayr, A.; Hochreiter, S. Self-Normalizing Neural Networks. In Proceedings of the 31st Conference on Neural Information Processing Systems (NIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1026–1034. [Google Scholar]
- Agostinelli, F.; Hoffman, M.D.; Sadowski, P.J.; Baldi, P. Learning Activation Functions to Improve Deep Neural Networks. arXiv 2014, arXiv:1412.6830. [Google Scholar]
- Scardapane, S.; Vaerenbergh, S.V.; Uncini, A. Kafnets: Kernel-based non-parametric activation functions for neural networks. Neural Netw. Off. J. Int. Neural Netw. Soc. 2017, 110, 19–32. [Google Scholar] [CrossRef] [PubMed]
- Manessi, F.; Rozza, A. Learning Combinations of Activation Functions. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 61–66. [Google Scholar]
- Ramachandran, P.; Zoph, B.; Le, Q.V. Searching for Activation Functions. arXiv 2017, arXiv:1710.05941. [Google Scholar]
- Maguolo, G.; Nanni, L.; Ghidoni, S. Ensemble of convolutional neural networks trained with different activation functions. arXiv 2019, arXiv:1905.02473. [Google Scholar] [CrossRef]
- Junior, B.G.; da Rocha, S.V.; Gattass, M.; Silva, A.C.; de Paiva, A.C. A mass classification using spatial diversity approaches in mammography images for false positive reduction. Expert Syst. Appl. 2013, 40, 7534–7543. [Google Scholar] [CrossRef]
- Jin, X.; Xu, C.; Feng, J.; Wei, Y.; Xiong, J.; Yan, S. Deep learning with S-shaped rectified linear activation units. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12 February 2016. [Google Scholar]
- Tavakoli, M.; Agostinelli, F.; Baldi, P. SPLASH: Learnable Activation Functions for Improving Accuracy and Adversarial Robustness. arXiv 2020, arXiv:2006.08947. [Google Scholar] [CrossRef]
- Misra, D. Mish: A Self Regularized Non-Monotonic Activation Function. arXiv 2020, arXiv:1908.08681. [Google Scholar]
- Cheng, Q.; Li, H.; Wu, Q.; Ma, L.; Ngan, K.N. Parametric Deformable Exponential Linear Units for deep neural networks. Neural Netw. 2020, 125, 281–289. [Google Scholar] [CrossRef] [PubMed]
- Zhou, Y.; Li, D.; Huo, S.; Kung, S. Soft-Root-Sign Activation Function. arXiv 2020, arXiv:2003.00547. [Google Scholar]
- Berno, F.; Nanni, L.; Maguolo, G.; Brahnam, S. Ensembles of convolutional neural networks with different activation functions for small to medium size biomedical datasets. In Machine Learning in Medicine; CRC Press Taylor & Francis Group: Boca Raton, FL, USA, 2021; In Press. [Google Scholar]
- Duch, W.; Jankowski, N. Survey of neural transfer functions. Neural Comput. Surv. 1999, 2, 163–212. [Google Scholar]
- Nicolae, A. PLU: The Piecewise Linear Unit Activation Function. arXiv 2018, arXiv:2104.03693. [Google Scholar]
- Pudil, P.; Novovicova, J.; Kittler, J. Floating search methods in feature selection. Pattern Recognit Lett 1994, 5, 1119–1125. [Google Scholar] [CrossRef]
- Boland, M.V.; Murphy, R.F. A neural network classifier capable of recognizing the patterns of all major subcellular structures in fluorescence microscope images of HeLa cells. BioInformatics 2001, 17, 1213–1223. [Google Scholar] [CrossRef] [PubMed]
- Shamir, L.; Orlov, N.V.; Eckley, D.M.; Goldberg, I. IICBU 2008: A proposed benchmark suite for biological image analysis. Med. Biol. Eng. Comput. 2008, 46, 943–947. [Google Scholar] [CrossRef]
- Kather, J.N.; Weis, C.-A.; Bianconi, F.; Melchers, S.M.; Schad, L.R.; Gaiser, T.; Marx, A.; Zöllner, F.G. Multi-class texture analysis in colorectal cancer histology. Sci. Rep. 2016, 6, 27988. [Google Scholar] [CrossRef]
- Dimitropoulos, K.; Barmpoutis, P.; Zioga, C.; Kamas, A.; Patsiaoura, K.; Grammalidis, N. Grading of invasive breast carcinoma through Grassmannian VLAD encoding. PLoS ONE 2017, 12, e0185110. [Google Scholar] [CrossRef]
- Moccia, S.; De Momi, E.; Guarnaschelli, M.; Savazzi, M.; Laborai, A. Confident texture-based laryngeal tissue classification for early stage diagnosis support. J. Med. Imaging 2017, 4, 34502. [Google Scholar] [CrossRef]
- Yang, F.; Xu, Y.; Wang, S.; Shen, H. Image-based classification of protein subcellular location patterns in human reproductive tissue by ensemble learning global and local features. Neurocomputing 2014, 131, 113–123. [Google Scholar] [CrossRef]
- Coelho, L.P.; Kangas, J.D.; Naik, A.W.; Osuna-Highley, E.; Glory-Afshar, E.; Fuhrman, M.; Simha, R.; Berget, P.B.; Jarvik, J.W.; Murphy, R.F. Determining the subcellular location of new proteins from microscope images using local features. Bioinformatics 2013, 29, 2343–2352. [Google Scholar] [CrossRef] [PubMed]
- Hamilton, N.; Pantelic, R.; Hanson, K.; Teasdale, R.D. Fast automated cell phenotype classification. BMC Bioinform. 2007, 8, 110. [Google Scholar] [CrossRef] [PubMed]
- Demšar, J. Statistical comparisons of classifiers over multiple data sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. arXiv 2019, arXiv:1905.11946. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef]
- Joseph, R. Darknet: Open Source Neural Networks in C. Available online: https://pjreddie.com/darknet/ (accessed on 22 January 2022).
- Huang, G.; Liu, Z.; van der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. CVPR 2017, 1, 3. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| J | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|
| 512 | 256 | 768 | 128 | 384 | 640 | 896 | |
| 512 | 256 | 256 | 128 | 128 | 128 | 128 |
| J | 1 | 2 | 3 | 4 | 5 | 6 | 7 | |
|---|---|---|---|---|---|---|---|---|
| MELU | 2.00 | 1.00 | 3.00 | 0.50 | 1.50 | 2.50 | 3.50 | |
| 2.00 | 1.00 | 1.00 | 0.50 | 0.50 | 0.50 | 0.50 | ||
| GALU | 1.00 | 0.50 | 2.50 | 0.25 | 1.25 | 2.25 | 3.25 | |
| 1.00 | 0.50 | 0.50 | 0.25 | 0.25 | 0.25 | 0.25 |
| Short Name | Full Name | #Classes | #Samples | Protocol | Image Type |
|---|---|---|---|---|---|
| CH | CHO | 5 | 327 | 5CV | hamster ovary cells |
| HE | 2D HeLa | 10 | 862 | 5CV | subcellular location |
| RN | RNAi data set | 200 | 5CV | fly cells | |
| MA | Muscle aging | 4 | 237 | 5CV | muscles |
| TB | Terminal Bulb Aging | 7 | 970 | 5CV | terminal bulbs |
| LY | Lymphoma | 3 | 375 | 5CV | malignant lymphoma |
| LG | Liver Gender | 2 | 265 | 5CV | liver tissue |
| LA | Liver Aging | 4 | 529 | 5CV | liver tissue |
| CO | Colorectal Cancer | 8 | 5000 | 10CV | histological images |
| BGR | Breast grading carcinoma | 3 | 300 | 5CV | histological images |
| LAR | Laryngeal data set | 4 | 1320 | Tr-Te | laryngeal tissues |
| HP | Immunohistochemistry images from the human protein atlas | 7 | 353 | Tr-Te | reproductive tissues |
| RT | 2D 3T3 Randomly CD-Tagged Cell Clones | 10 | 304 | 10CV | CD-tagged cell clones |
| LO | Locate Endogenous | 10 | 502 | 5CV | subcellular location |
| TR | Locate Transfected | 11 | 553 | 5CV | subcellular location |
| Activation | CH | HE | LO | TR | RN | TB | LY | MA | LG | LA | CO | BG | LAR | RT | HP | Avg | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ResNet50 MaxInput = 1 | MeLU (k = 8) | 92.92 | 86.40 | 91.80 | 82.91 | 25.50 | 56.29 | 67.47 | 76.25 | 91.00 | 82.48 | 94.82 | 89.67 | 88.79 | 68.36 | 48.86 | 76.23 |
| Leaky ReLU | 89.23 | 87.09 | 92.80 | 84.18 | 34.00 | 57.11 | 70.93 | 79.17 | 93.67 | 82.48 | 95.66 | 90.33 | 87.27 | 69.72 | 45.45 | 77.27 | |
| ELU | 90.15 | 86.74 | 94.00 | 85.82 | 48.00 | 60.82 | 65.33 | 85.00 | 96.00 | 90.10 | 95.14 | 89.33 | 89.92 | 73.50 | 40.91 | 79.38 | |
| MeLU (k = 4) | 91.08 | 85.35 | 92.80 | 84.91 | 27.50 | 55.36 | 68.53 | 77.08 | 90.00 | 79.43 | 95.34 | 89.33 | 87.20 | 72.24 | 51.14 | 76.48 | |
| PReLU | 92.00 | 85.35 | 91.40 | 81.64 | 33.50 | 57.11 | 68.80 | 76.25 | 88.33 | 82.10 | 95.68 | 88.67 | 89.55 | 71.20 | 44.89 | 76.43 | |
| SReLU | 91.38 | 85.58 | 92.60 | 83.27 | 30.00 | 55.88 | 69.33 | 75.00 | 88.00 | 82.10 | 95.66 | 89.00 | 89.47 | 69.98 | 42.61 | 75.99 | |
| APLU | 92.31 | 87.09 | 93.20 | 80.91 | 25.00 | 54.12 | 67.20 | 76.67 | 93.00 | 82.67 | 95.46 | 90.33 | 88.86 | 71.65 | 48.30 | 76.45 | |
| ReLU | 93.54 | 89.88 | 95.60 | 90.00 | 55.00 | 58.45 | 77.87 | 90.00 | 93.00 | 85.14 | 94.92 | 88.67 | 87.05 | 69.77 | 48.86 | 81.18 | |
| Small GaLU | 92.31 | 87.91 | 93.20 | 91.09 | 52.00 | 60.00 | 72.53 | 90.00 | 95.33 | 87.43 | 95.38 | 87.67 | 88.79 | 67.57 | 44.32 | 80.36 | |
| GaLU | 92.92 | 88.37 | 92.20 | 90.36 | 41.50 | 57.84 | 73.60 | 89.17 | 92.67 | 88.76 | 94.90 | 90.33 | 90.00 | 72.98 | 48.86 | 80.29 | |
| Flexible MeLU | 91.69 | 88.49 | 93.00 | 91.64 | 38.50 | 60.31 | 73.33 | 88.33 | 95.67 | 87.62 | 94.72 | 89.67 | 86.67 | 67.35 | 44.32 | 79.42 | |
| TanELU | 93.54 | 86.16 | 90.60 | 90.91 | 40.00 | 58.56 | 69.60 | 86.25 | 95.33 | 83.05 | 94.80 | 87.67 | 86.89 | 73.95 | 43.18 | 78.69 | |
| 2D MeLU | 91.69 | 87.67 | 93.00 | 91.64 | 48.00 | 60.41 | 72.00 | 91.67 | 96.00 | 88.38 | 95.42 | 89.00 | 87.58 | 70.53 | 42.61 | 80.37 | |
| MeLU + GaLU | 93.23 | 88.02 | 93.40 | 92.91 | 54.50 | 59.18 | 72.53 | 89.58 | 95.33 | 86.29 | 95.34 | 88.64 | 88.64 | 69.29 | 43.18 | 80.67 | |
| Splash | 93.54 | 87.56 | 93.80 | 90.00 | 47.50 | 55.98 | 72.00 | 82.92 | 94.33 | 84.19 | 95.02 | 86.00 | 87.12 | 75.70 | 42.61 | 79.21 | |
| Symmetric GaLU | 93.85 | 84.19 | 92.80 | 89.45 | 47.50 | 58.66 | 72.80 | 87.08 | 95.33 | 82.67 | 94.44 | 87.33 | 87.80 | 71.52 | 52.84 | 79.88 | |
| Symmetric MeLU | 92.62 | 86.63 | 92.40 | 89.27 | 50.00 | 60.62 | 72.27 | 85.42 | 95.00 | 85.14 | 94.72 | 90.00 | 87.58 | 66.71 | 50.57 | 79.93 | |
| Soft Learnable v2 | 93.93 | 87.33 | 93.60 | 92.55 | 46.00 | 60.31 | 69.07 | 89.58 | 94.67 | 86.10 | 95.00 | 89.67 | 87.05 | 73.72 | 54.55 | 80.87 | |
| Soft Learnable | 94.15 | 87.44 | 93.40 | 90.36 | 47.00 | 59.18 | 67.73 | 88.33 | 95.00 | 85.52 | 95.52 | 89.33 | 88.26 | 72.04 | 46.59 | 79.99 | |
| PDELU | 94.15 | 87.21 | 92.00 | 91.64 | 51.50 | 56.70 | 70.93 | 89.58 | 96.33 | 86.67 | 95.08 | 89.67 | 88.18 | 72.76 | 46.59 | 80.59 | |
| Mish | 95.08 | 87.56 | 93.20 | 91.82 | 45.00 | 58.45 | 69.07 | 86.67 | 95.33 | 86.67 | 95.48 | 90.00 | 88.41 | 53.41 | 34.09 | 78.01 | |
| SRS | 93.23 | 88.84 | 93.40 | 91.09 | 51.50 | 60.10 | 69.87 | 88.75 | 95.00 | 86.48 | 95.72 | 88.33 | 89.47 | 54.06 | 48.86 | 79.64 | |
| Swish Learnable | 93.54 | 87.91 | 94.40 | 91.64 | 48.00 | 59.28 | 69.33 | 88.75 | 95.33 | 83.24 | 96.10 | 90.00 | 89.32 | 41.15 | 39.77 | 77.85 | |
| Swish | 94.15 | 88.02 | 94.20 | 90.73 | 48.50 | 59.90 | 70.13 | 89.17 | 92.67 | 86.10 | 95.66 | 87.67 | 87.65 | 65.05 | 32.39 | 78.79 | |
| ENS | 95.38 | 89.53 | 97.00 | 89.82 | 59.00 | 62.78 | 76.53 | 86.67 | 96.00 | 91.43 | 96.60 | 91.00 | 89.92 | 74.00 | 50.00 | 83.04 | |
| ENS_G | 93.54 | 90.70 | 97.20 | 92.73 | 56.00 | 63.92 | 77.60 | 90.83 | 96.33 | 91.43 | 96.42 | 90.00 | 90.00 | 73.76 | 50.00 | 83.36 | |
| ALL | 97.23 | 91.16 | 97.20 | 95.27 | 58.00 | 65.15 | 76.80 | 92.92 | 98.00 | 90.10 | 96.58 | 90.00 | 90.38 | 74.67 | 53.98 | 84.49 | |
| ResNet50 MaxInput = 255 | MeLU (k = 8) | 94.46 | 89.30 | 94.20 | 92.18 | 54.00 | 61.86 | 75.73 | 89.17 | 97.00 | 88.57 | 95.60 | 87.67 | 88.71 | 72.09 | 52.27 | 82.18 |
| MeLU (k = 4) | 92.92 | 90.23 | 95.00 | 91.82 | 57.00 | 59.79 | 78.40 | 87.50 | 97.33 | 85.14 | 95.72 | 89.33 | 88.26 | 66.20 | 48.30 | 81.52 | |
| SReLU | 92.31 | 89.42 | 93.00 | 90.73 | 56.50 | 59.69 | 73.33 | 91.67 | 98.33 | 88.95 | 95.52 | 89.67 | 87.88 | 68.94 | 48.30 | 81.61 | |
| APLU | 95.08 | 89.19 | 93.60 | 90.73 | 47.50 | 56.91 | 75.20 | 89.17 | 97.33 | 87.05 | 95.68 | 89.67 | 89.47 | 71.44 | 51.14 | 81.27 | |
| Small GaLU | 93.54 | 87.79 | 95.60 | 89.82 | 55.00 | 63.09 | 76.00 | 90.42 | 95.00 | 85.33 | 95.08 | 89.67 | 89.77 | 72.14 | 45.45 | 81.58 | |
| GaLU | 92.92 | 87.21 | 92.00 | 91.27 | 47.50 | 60.10 | 74.13 | 87.92 | 96.00 | 86.86 | 95.56 | 89.33 | 87.73 | 70.26 | 44.32 | 80.20 | |
| Flexible MeLU | 92.62 | 87.09 | 91.60 | 91.09 | 48.50 | 57.01 | 69.60 | 86.67 | 95.00 | 87.81 | 95.26 | 89.00 | 88.11 | 70.83 | 46.59 | 79.78 | |
| 2D MeLU | 95.08 | 90.23 | 93.00 | 91.45 | 54.00 | 57.42 | 69.60 | 90.42 | 96.00 | 87.43 | 91.84 | 87.67 | 90.76 | 73.44 | 54.55 | 81.52 | |
| MeLU + GaLU | 93.23 | 87.33 | 92.20 | 90.91 | 54.00 | 58.66 | 73.87 | 89.58 | 95.33 | 88.76 | 95.42 | 86.33 | 86.74 | 70.91 | 48.86 | 80.92 | |
| Splash | 96.00 | 87.67 | 92.80 | 93.82 | 50.50 | 60.62 | 78.13 | 89.58 | 96.67 | 87.81 | 95.18 | 90.33 | 91.36 | 68.81 | 51.70 | 82.06 | |
| Symmetric GaLU | 92.00 | 85.58 | 91.20 | 89.64 | 43.50 | 57.94 | 70.93 | 79.58 | 91.33 | 85.14 | 95.34 | 87.33 | 85.98 | 69.37 | 47.16 | 78.13 | |
| Symmetric MeLU | 92.92 | 88.37 | 93.40 | 92.00 | 44.00 | 58.56 | 69.60 | 91.67 | 93.33 | 84.00 | 94.94 | 87.33 | 88.79 | 70.30 | 44.89 | 79.60 | |
| ENS | 93.85 | 91.28 | 96.20 | 93.27 | 59.00 | 63.30 | 77.60 | 91.67 | 98.00 | 87.43 | 96.30 | 89.00 | 89.17 | 71.11 | 50.00 | 83.14 | |
| ENS_G | 95.08 | 91.28 | 96.20 | 94.18 | 63.00 | 64.85 | 78.67 | 92.50 | 97.67 | 87.62 | 96.54 | 89.67 | 89.77 | 71.36 | 51.14 | 83.96 | |
| ALL | 96.00 | 91.16 | 96.60 | 94.55 | 60.50 | 64.74 | 77.60 | 92.92 | 97.67 | 89.52 | 96.62 | 89.33 | 90.68 | 74.37 | 52.27 | 84.30 | |
| eENS | 94.77 | 91.40 | 97.00 | 92.91 | 60.00 | 64.74 | 77.87 | 88.75 | 98.00 | 90.10 | 96.50 | 90.00 | 89.77 | 73.23 | 50.57 | 83.70 | |
| eENS_G | 95.08 | 91.28 | 96.80 | 93.45 | 62.50 | 65.26 | 78.93 | 91.67 | 96.67 | 90.48 | 96.60 | 89.33 | 89.85 | 73.60 | 50.00 | 84.10 | |
| eALL | 96.92 | 91.28 | 97.20 | 95.45 | 60.50 | 64.64 | 77.87 | 93.75 | 97.67 | 90.10 | 96.58 | 89.67 | 90.68 | 74.37 | 52.27 | 84.59 | |
| 15ReLU | 95.40 | 91.10 | 96.20 | 95.01 | 58.50 | 64.80 | 76.00 | 92.90 | 97.30 | 89.30 | 96.30 | 90.00 | 90.04 | 73.00 | 50.57 | 83.76 | |
| Selection | 96.62 | 91.40 | 97.00 | 95.09 | 60.00 | 64.85 | 77.87 | 93.75 | 98.00 | 90.29 | 96.78 | 90.00 | 90.98 | 74.04 | 54.55 | 84.74 | |
| Stoc_1 | 97.81 | 91.51 | 96.66 | 95.87 | 60.04 | 65.83 | 80.02 | 92.96 | 99.09 | 91.24 | 96.61 | 90.77 | 91.03 | 74.20 | 50.57 | 84.95 | |
| Stoc_2 | 98.82 | 93.42 | 97.87 | 96.48 | 65.58 | 66.92 | 85.65 | 92.94 | 99.77 | 94.33 | 96.63 | 91.36 | 92.34 | 76.83 | 54.55 | 86.89 | |
| Stoc_3 | 99.43 | 93.93 | 98.04 | 96.06 | 64.55 | 66.41 | 83.24 | 90.04 | 96.04 | 93.93 | 96.72 | 92.05 | 91.34 | 75.89 | 51.70 | 85.95 | |
| Stoc_4 | 98.77 | 92.09 | 97.40 | 96.55 | 63.00 | 67.01 | 81.87 | 93.33 | 100 | 93.52 | 96.72 | 93.00 | 92.27 | 76.38 | 51.70 | 86.24 |
| ACTIVATION | CH | HE | LO | TR | RN | TB | LY | MA | LG | LA | CO | BG | LAR | RT | HP | AVG | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| VGG16 MAXINPUT = 1 | MeLU (k = 8) | 99.69 | 92.09 | 98.00 | 92.91 | 59.00 | 60.93 | 78.67 | 87.92 | 86.67 | 93.14 | 95.20 | 89.67 | 90.53 | 73.73 | 42.61 | 82.71 |
| Leaky ReLU | 99.08 | 91.98 | 98.00 | 93.45 | 66.50 | 61.13 | 80.00 | 92.08 | 86.67 | 91.81 | 95.62 | 91.33 | 88.94 | 74.86 | 38.07 | 83.30 | |
| ELU | 98.77 | 93.95 | 97.00 | 92.36 | 56.00 | 59.69 | 81.60 | 90.83 | 78.33 | 85.90 | 95.78 | 93.00 | 90.45 | 71.55 | 40.91 | 81.74 | |
| MeLU (k = 4) | 99.38 | 91.16 | 97.60 | 92.73 | 64.50 | 62.37 | 81.07 | 89.58 | 86.00 | 89.71 | 95.82 | 89.67 | 93.18 | 75.20 | 42.61 | 83.37 | |
| PReLU | 99.08 | 90.47 | 97.80 | 94.55 | 64.00 | 60.00 | 81.33 | 92.92 | 78.33 | 91.05 | 95.80 | 92.67 | 90.38 | 73.74 | 35.23 | 82.49 | |
| SReLU | 99.08 | 91.16 | 97.00 | 93.64 | 65.50 | 60.62 | 82.67 | 90.00 | 79.33 | 93.33 | 96.10 | 94.00 | 92.58 | 76.80 | 45.45 | 83.81 | |
| APLU | 99.08 | 92.33 | 97.60 | 91.82 | 63.50 | 62.27 | 77.33 | 90.00 | 82.00 | 92.38 | 96.00 | 91.33 | 90.98 | 76.58 | 34.66 | 82.52 | |
| ReLU | 99.69 | 93.60 | 98.20 | 93.27 | 69.50 | 61.44 | 80.80 | 85.00 | 85.33 | 88.57 | 95.50 | 93.00 | 91.44 | 73.68 | 40.34 | 83.29 | |
| Small GaLU | 98.46 | 91.63 | 97.80 | 91.35 | 64.50 | 59.79 | 80.53 | 89.58 | 77.33 | 92.76 | 95.70 | 91.67 | 91.97 | 72.63 | 44.32 | 82.66 | |
| GaLU | 98.46 | 94.07 | 97.40 | 92.36 | 65.00 | 59.07 | 81.07 | 92.08 | 75.67 | 93.71 | 95.68 | 88.67 | 91.74 | 75.81 | 39.20 | 82.66 | |
| Flexible MeLU | 97.54 | 94.19 | 96.60 | 94.91 | 59.00 | 62.68 | 77.07 | 90.00 | 89.00 | 91.81 | 95.94 | 92.67 | 89.92 | 72.15 | 38.64 | 82.80 | |
| TanELU | 97.85 | 93.14 | 97.00 | 92.36 | 61.00 | 61.44 | 72.80 | 89.17 | 77.33 | 91.62 | 95.28 | 89.67 | 90.23 | 72.84 | 43.75 | 81.69 | |
| 2D MeLU | 97.85 | 93.72 | 97.20 | 92.73 | 61.00 | 61.34 | 81.60 | 91.25 | 92.33 | 94.48 | 95.86 | 89.67 | 92.35 | 71.91 | 38.64 | 83.46 | |
| MeLU + GaLU | 98.15 | 93.72 | 98.20 | 93.64 | 60.00 | 60.82 | 77.60 | 92.08 | 81.00 | 93.14 | 95.54 | 92.33 | 89.47 | 75.60 | 47.16 | 83.23 | |
| Splash | 97.85 | 92.79 | 97.80 | 92.18 | 58.50 | 62.06 | 75.73 | 88.33 | 83.67 | 85.90 | 95.02 | 91.67 | 90.15 | 74.29 | 42.05 | 81.86 | |
| Symmetric GaLU | 99.08 | 92.79 | 97.20 | 92.91 | 60.50 | 60.00 | 78.93 | 88.33 | 79.33 | 91.62 | 95.52 | 92.67 | 91.67 | 73.91 | 40.34 | 82.32 | |
| Symmetric MeLU | 98.46 | 92.91 | 96.60 | 92.18 | 56.50 | 59.69 | 74.93 | 90.00 | 85.00 | 87.05 | 94.76 | 90.33 | 90.68 | 72.87 | 41.48 | 81.56 | |
| Soft Learnable v2 | 95.69 | 87.91 | 94.60 | 93.45 | 34.50 | 55.57 | 50.67 | 77.50 | 64.67 | 29.71 | 94.08 | 67.67 | 92.35 | 68.96 | 35.80 | 69.54 | |
| Soft Learnable | 98.15 | 92.91 | 97.00 | 91.82 | 47.50 | 54.33 | 62.13 | 86.67 | 95.67 | 65.90 | 95.04 | 84.33 | 90.38 | 71.08 | 40.34 | 78.21 | |
| PDELU | 98.77 | 93.60 | 96.40 | 92.18 | 59.00 | 58.25 | 76.80 | 87.92 | 87.67 | 89.33 | 95.36 | 90.33 | 91.74 | 75.24 | 42.05 | 82.30 | |
| Mish | 96.31 | 90.70 | 94.60 | 93.64 | 18.50 | 46.80 | 54.13 | 66.67 | 73.67 | 56.38 | 93.88 | 80.00 | 82.73 | 73.89 | 44.32 | 71.08 | |
| SRS | 71.08 | 59.19 | 45.00 | 51.64 | 29.50 | 31.44 | 57.60 | 61.25 | 61.00 | 45.33 | 86.88 | 57.00 | 67.50 | 39.74 | 19.32 | 52.23 | |
| Swish Learnable | 97.54 | 91.86 | 97.00 | 93.64 | 43.50 | 54.64 | 66.67 | 87.08 | 81.00 | 79.43 | 94.46 | 81.00 | 85.23 | 70.02 | 35.23 | 77.22 | |
| Swish | 98.77 | 92.56 | 96.80 | 93.64 | 63.50 | 58.97 | 80.80 | 90.00 | 89.00 | 93.14 | 94.68 | 93.33 | 91.74 | 75.24 | 39.77 | 83.46 | |
| ENS | 99.38 | 93.84 | 98.40 | 95.64 | 68.00 | 65.67 | 85.07 | 92.08 | 85.00 | 96.38 | 96.74 | 94.33 | 92.65 | 75.55 | 44.89 | 85.57 | |
| ENS_G | 99.69 | 94.65 | 99.00 | 95.45 | 72.00 | 64.95 | 86.93 | 92.50 | 83.33 | 97.14 | 96.72 | 94.67 | 92.65 | 75.56 | 45.45 | 86.07 | |
| ALL | 99.69 | 95.35 | 98.80 | 95.45 | 72.00 | 66.80 | 84.00 | 94.17 | 85.67 | 97.14 | 96.66 | 95.00 | 93.18 | 75.85 | 48.30 | 86.53 | |
| VGG16 MAXINPUT = 255 | MeLU (k = 8) | 99.69 | 92.09 | 97.40 | 93.09 | 59.50 | 60.82 | 80.53 | 88.75 | 80.33 | 88.57 | 95.94 | 90.33 | 88.33 | 73.01 | 47.73 | 82.40 |
| MeLU (k = 4) | 99.38 | 91.98 | 98.60 | 92.55 | 66.50 | 59.59 | 84.53 | 91.67 | 88.00 | 94.86 | 95.46 | 93.00 | 93.03 | 72.21 | 38.64 | 84.00 | |
| SReLU | 98.77 | 93.14 | 97.00 | 92.18 | 65.00 | 62.47 | 77.60 | 89.58 | 76.00 | 96.00 | 95.84 | 94.33 | 89.85 | 74.04 | 42.61 | 82.96 | |
| APLU | 98.77 | 92.91 | 97.40 | 93.09 | 63.00 | 57.32 | 82.67 | 90.42 | 77.00 | 90.67 | 94.90 | 93.00 | 91.21 | 75.65 | 36.36 | 82.29 | |
| Small GaLU | 99.38 | 92.91 | 97.00 | 92.73 | 50.50 | 62.16 | 78.40 | 90.42 | 73.00 | 94.48 | 95.32 | 92.00 | 90.98 | 73.61 | 42.61 | 81.70 | |
| GaLU | 98.77 | 92.91 | 97.60 | 93.09 | 66.50 | 59.48 | 83.47 | 90.83 | 95.00 | 85.52 | 95.96 | 91.67 | 93.41 | 75.45 | 38.64 | 83.88 | |
| Flexible MeLU | 99.08 | 95.00 | 97.20 | 93.45 | 62.00 | 55.98 | 76.80 | 89.17 | 83.00 | 88.57 | 95.64 | 91.33 | 91.29 | 73.00 | 37.50 | 81.93 | |
| MeLU + GaLU | 98.46 | 94.42 | 96.80 | 92.00 | 54.50 | 60.82 | 79.73 | 90.83 | 78.67 | 93.33 | 96.26 | 89.67 | 91.14 | 74.79 | 40.34 | 82.11 | |
| Symmetric GaLU | 97.85 | 92.21 | 97.40 | 93.64 | 58.00 | 58.14 | 73.87 | 91.67 | 79.33 | 91.43 | 95.18 | 90.33 | 89.55 | 74.47 | 34.09 | 81.14 | |
| Symmetric MeLU | 98.46 | 92.33 | 96.80 | 92.18 | 56.50 | 61.24 | 75.47 | 89.17 | 82.00 | 88.00 | 95.32 | 92.67 | 88.86 | 74.27 | 38.07 | 81.42 | |
| ENS | 99.38 | 93.84 | 98.80 | 95.27 | 68.50 | 64.23 | 84.53 | 92.50 | 81.33 | 96.57 | 96.66 | 95.00 | 92.20 | 75.27 | 43.75 | 85.18 | |
| ENS_G | 99.38 | 94.88 | 98.80 | 95.64 | 70.50 | 65.88 | 85.87 | 93.75 | 81.67 | 96.38 | 96.70 | 95.67 | 92.80 | 75.26 | 44.32 | 85.83 | |
| ALL | 99.69 | 95.47 | 98.40 | 95.45 | 70.00 | 63.92 | 83.73 | 94.17 | 82.67 | 96.38 | 96.60 | 95.00 | 92.73 | 75.78 | 45.45 | 85.69 | |
| EENS | 99.38 | 94.07 | 98.80 | 95.64 | 69.00 | 65.88 | 85.87 | 93.33 | 82.67 | 96.57 | 96.88 | 95.33 | 92.50 | 74.99 | 43.18 | 85.60 | |
| EENS_G | 99.69 | 94.65 | 99.00 | 95.27 | 70.50 | 65.57 | 86.93 | 92.92 | 83.33 | 97.71 | 96.82 | 95.00 | 92.42 | 76.09 | 44.32 | 86.01 | |
| EALL | 99.69 | 95.70 | 98.80 | 95.45 | 71.50 | 65.98 | 83.73 | 94.58 | 85.67 | 96.38 | 96.70 | 95.00 | 92.50 | 75.42 | 47.16 | 86.28 | |
| 15RELU | 99.08 | 95.35 | 98.60 | 94.91 | 64.50 | 64.64 | 79.20 | 95.00 | 83.00 | 92.76 | 96.38 | 94.00 | 92.42 | 74.34 | 50.57 | 84.98 | |
| SELECTION | 99.69 | 95.26 | 98.60 | 94.91 | 71.00 | 64.85 | 86.67 | 94.58 | 84.67 | 95.24 | 96.72 | 94.33 | 93.56 | 75.48 | 47.16 | 86.18 | |
| STOC_4 | 99.69 | 96.05 | 98.60 | 95.27 | 74.50 | 67.53 | 83.47 | 95.00 | 84.00 | 95.62 | 96.78 | 92.67 | 93.48 | 74.87 | 51.70 | 86.61 |
| EfficientNetB0 | CH | HE | LO | TR | RN | TB | LY | MA | LG | LA | CO | BG | LAR | RT | HP | Avg |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| ReLU | 94.46 | 91.28 | 94.80 | 92.18 | 68.50 | 62.58 | 88.80 | 92.50 | 97.33 | 96.76 | 95.04 | 90.67 | 87.35 | 71.21 | 52.27 | 85.05 |
| 15Reit | 96.00 | 92.09 | 95.40 | 93.82 | 74.00 | 65.98 | 89.07 | 93.33 | 97.00 | 98.29 | 95.60 | 90.00 | 88.94 | 71.61 | 61.36 | 86.83 |
| MobileNetV2 | CH | HE | LO | TR | RN | TB | LY | MA | LG | LA | CO | BG | LAR | RT | HP | Avg |
| ReLU | 98.15 | 92.91 | 97.40 | 92.91 | 69.00 | 64.54 | 76.00 | 91.67 | 96.67 | 96.76 | 94.54 | 89.00 | 90.23 | 69.53 | 50.57 | 84.65 |
| 15ReLU | 99.08 | 95.23 | 98.80 | 95.64 | 75.00 | 70.41 | 80.27 | 95.42 | 98.00 | 97.71 | 95.46 | 90.67 | 91.52 | 69.24 | 55.11 | 87.17 |
| Stoc_4 | 99.08 | 95.35 | 99.20 | 98.36 | 84.00 | 76.91 | 87.20 | 94.58 | 100 | 99.62 | 95.50 | 94.00 | 95.08 | 77.02 | 63.64 | 90.63 |
| DarkNet53 | CH | HE | LO | TR | RN | TB | LY | MA | LG | LA | CO | BG | LAR | RT | HP | Avg |
| ReLU | 98.77 | 93.60 | 98.00 | 95.82 | 71.00 | 67.84 | 81.33 | 71.25 | 98.00 | 96.95 | 92.02 | 91.67 | 91.44 | 67.12 | 53.98 | 84.58 |
| 15Leaky | 99.69 | 95.12 | 99.20 | 99.45 | 89.00 | 77.94 | 91.73 | 89.17 | 100 | 99.81 | 95.56 | 93.00 | 93.56 | 76.02 | 61.93 | 90.74 |
| Stoc_4 | 99.69 | 95.93 | 98.80 | 98.80 | 88.00 | 77.73 | 96.00 | 88.33 | 100 | 99.81 | 95.28 | 91.00 | 92.12 | 74.33 | 67.05 | 90.86 |
| ResNet50 | CH | HE | LO | TR | RN | TB | LY | MA | LG | LA | CO | BG | LAR | RT | HP | Avg |
| ReLU | 97.54 | 94.19 | 98.40 | 95.82 | 74.50 | 65.15 | 80.00 | 92.08 | 98.00 | 96.76 | 96.26 | 89.67 | 91.44 | 77.21 | 55.68 | 86.84 |
| 15ReLU | 99.08 | 95.70 | 99.20 | 97.27 | 79.00 | 69.38 | 84.27 | 95.42 | 97.33 | 98.10 | 97.00 | 91.00 | 93.79 | 77.15 | 59.66 | 88.89 |
| Stoc_4 | 99.69 | 95.47 | 99.20 | 98.00 | 85.00 | 75.26 | 91.47 | 95.00 | 99.00 | 99.62 | 97.02 | 93.00 | 94.85 | 75.18 | 62.50 | 90.68 |
| DenseNet201 | CH | HE | LO | TR | RN | TB | LY | MA | LG | LA | CO | BG | LAR | RT | HP | Avg |
| ReLU | 98.73 | 95.29 | 98.37 | 96.92 | 71.40 | 66.80 | 82.20 | 91.31 | 98.22 | 98.12 | 95.88 | 91.69 | 93.96 | 49.92 | 54.70 | 85.56 |
| 15ReLU | 99.38 | 96.40 | 98.40 | 98.55 | 79.00 | 71.24 | 86.40 | 94.58 | 99.67 | 99.24 | 97.84 | 95.33 | 96.14 | 77.57 | 61.36 | 90.07 |
| Stoc_4 | 99.69 | 94.88 | 99.20 | 99.27 | 84.00 | 76.29 | 93.87 | 96.67 | 100 | 100 | 97.84 | 93.00 | 95.38 | 77.67 | 69.89 | 91.84 |
| ResNet50 | CH | HE | MA | LAR | |
| ReLU | 98.15 | 95.93 | 95.83 | 94.77 | |
| 15ReLU | 99.08 | 96.28 | 97.08 | 95.91 | |
| Sto_4 | 99.69 | 96.40 | 97.50 | 96.74 |
| GPU | Year GPU | Single ResNet50 | Ensemble 15 ResNet50 |
|---|---|---|---|
| GTX 1080 | 2016 | 0.36 s | 5.58 s |
| Titan Xp | 2017 | 0.31 s | 4.12 s |
| Titan RTX | 2018 | 0.22 s | 2.71 s |
| Titan V100 | 2018 | 0.20 s | 2.42 s |
| Topology | MI | Top1r | Top2r | Top3r | Top4r |
|---|---|---|---|---|---|
| ResNet50 | 1 | MeLU + GaLU | SRS | PDELU | Soft Learnable v2 |
| ResNet50 | 255 | MeLU (k = 8) | Splash | MeLU (k = 4) | 2D MeLU |
| VGG16 | 1 | SReLU | MeLU + GaLU | MeLU (k = 4) | ReLU |
| VGG16 | 255 | GaLU | MeLU (k = 4) | SReLU | APLU |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nanni, L.; Brahnam, S.; Paci, M.; Ghidoni, S. Comparison of Different Convolutional Neural Network Activation Functions and Methods for Building Ensembles for Small to Midsize Medical Data Sets. Sensors 2022, 22, 6129. https://doi.org/10.3390/s22166129
Nanni L, Brahnam S, Paci M, Ghidoni S. Comparison of Different Convolutional Neural Network Activation Functions and Methods for Building Ensembles for Small to Midsize Medical Data Sets. Sensors. 2022; 22(16):6129. https://doi.org/10.3390/s22166129
Chicago/Turabian StyleNanni, Loris, Sheryl Brahnam, Michelangelo Paci, and Stefano Ghidoni. 2022. "Comparison of Different Convolutional Neural Network Activation Functions and Methods for Building Ensembles for Small to Midsize Medical Data Sets" Sensors 22, no. 16: 6129. https://doi.org/10.3390/s22166129
APA StyleNanni, L., Brahnam, S., Paci, M., & Ghidoni, S. (2022). Comparison of Different Convolutional Neural Network Activation Functions and Methods for Building Ensembles for Small to Midsize Medical Data Sets. Sensors, 22(16), 6129. https://doi.org/10.3390/s22166129