
CLSQL: Improved Q-Learning Algorithm Based on Continuous Local Search Policy for Mobile Robot Path Planning



Abstract
:1. Introduction
- 1
- We introduce the concept of the local environment and establish the improved Q-learning based on a continuous local search policy. Specifically, the local environment and intermediate points are gradually determined in the search process to improve the search efficiency and reduce the number of iterations.
- 2
- Based on the local search policy, the proposed method adds a prior knowledge and optimizes a dynamically adjusting policy.
- 3
- We prove that compared with other RL algorithms, the proposed algorithm can not only ensure the search efficiency and the iteration number but also achieve satisfying results under different sizes and complexity of the map. The multigroup simulation results verify our analysis.
2. Related Work
2.1. The QL-Based Path Planning Method
| Algorithm 1: The Q-learning Algorithm |
| 1 (n states and m actions) |
| 2 |
| 3 Using to select a from present state s; |
| 4 Take action a, get r, ; |
| 5 Update by (1) |
| 6 |
| 7 s is destination |
2.2. The RL-Based Path Planning Method
3. Environment Modeling Based on Grid Map
3.1. Grid Method for 2D Environment Modeling
3.2. Problem Formulation
- •
- n: number of points of the planned path,
- •
- m: number of in the global environment,
- •
- k: number of ,
- •
- : point of the planned path.
4. The Continuous Local Search Q-Learning Algorithm
4.1. Motivation
4.2. Environmental Prior Knowledge Based on Euclidean Distance
| Algorithm 2: Prior Knowledge |
| 1 Agent State , Destination State , Obstacle State |
| 2 |
| 3 s == |
| 4 |
| 5 |
| 6 |
| 7 All s traversal completed |
- 1
- First, determine the starting and destination points in the environment and calculate the distance between all points except obstacles and the starting point through the Euclidean function, such as shown in Figure 3, where the green circle, the red cross, and the black squares represent the starting point and destination point and obstacles, and the rest of the color squares from deep to shallow represent the size of the prior knowledge of the present points: the deeper the color, the further away from the destination point.
- 2
- Then, with the agent’s continuous search, the new state–action value is added to the Q-value of the relevant state, and the prior knowledge relevant to the present state is added, which is defined as:
- 3
- Finally, the Q-table with prior knowledge is used to learn and select the optimal action policy in the present environment.
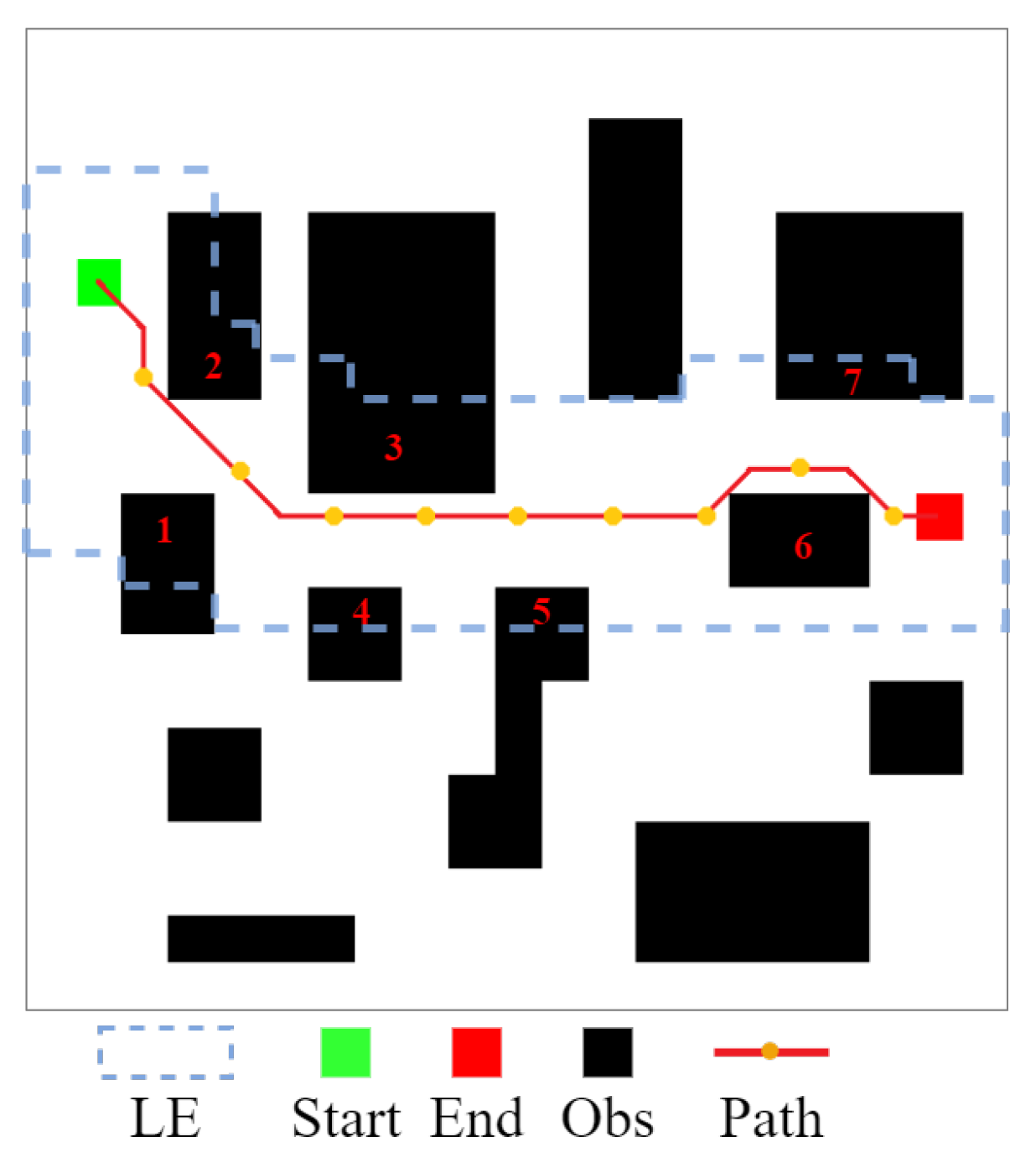
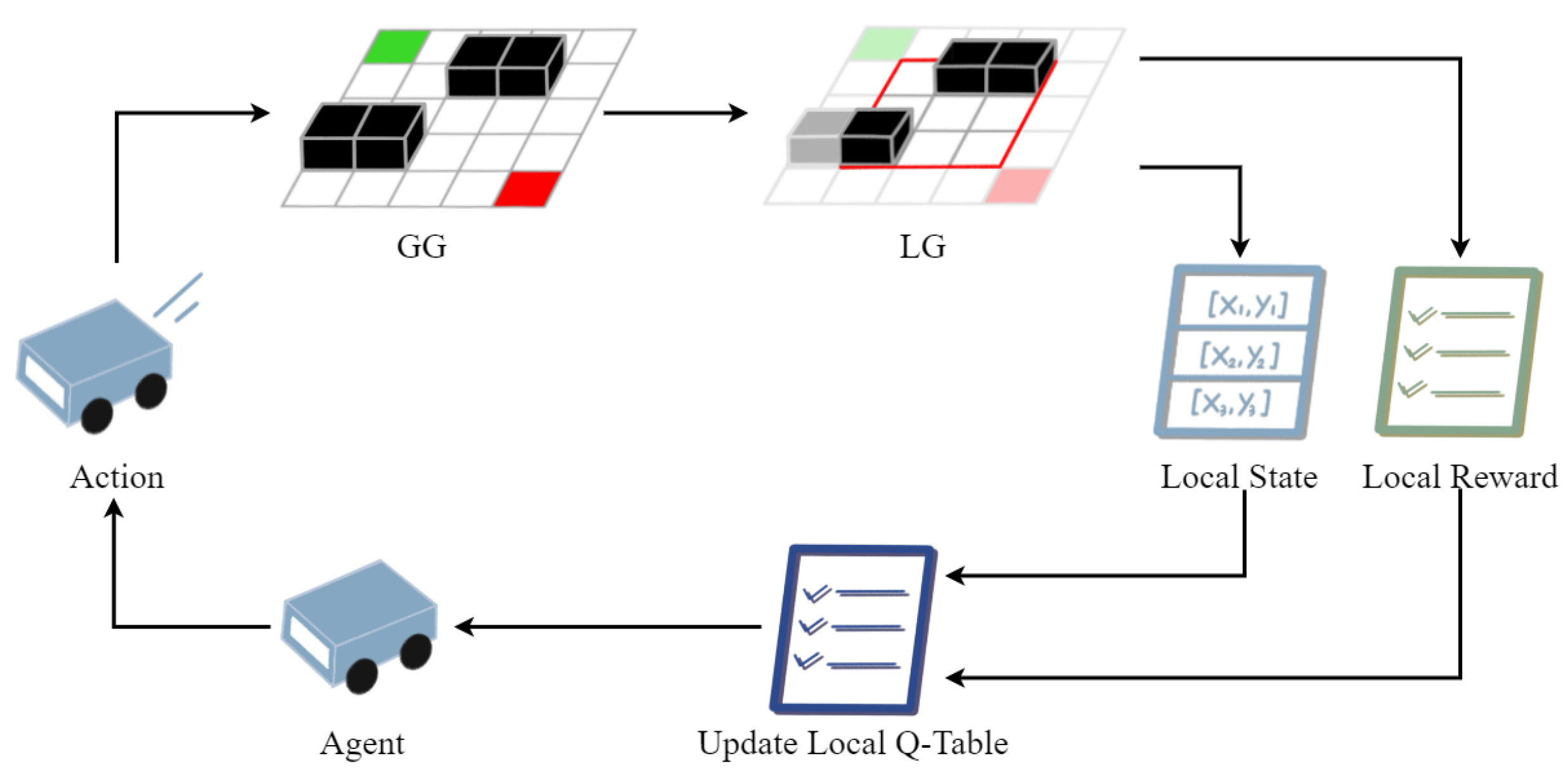
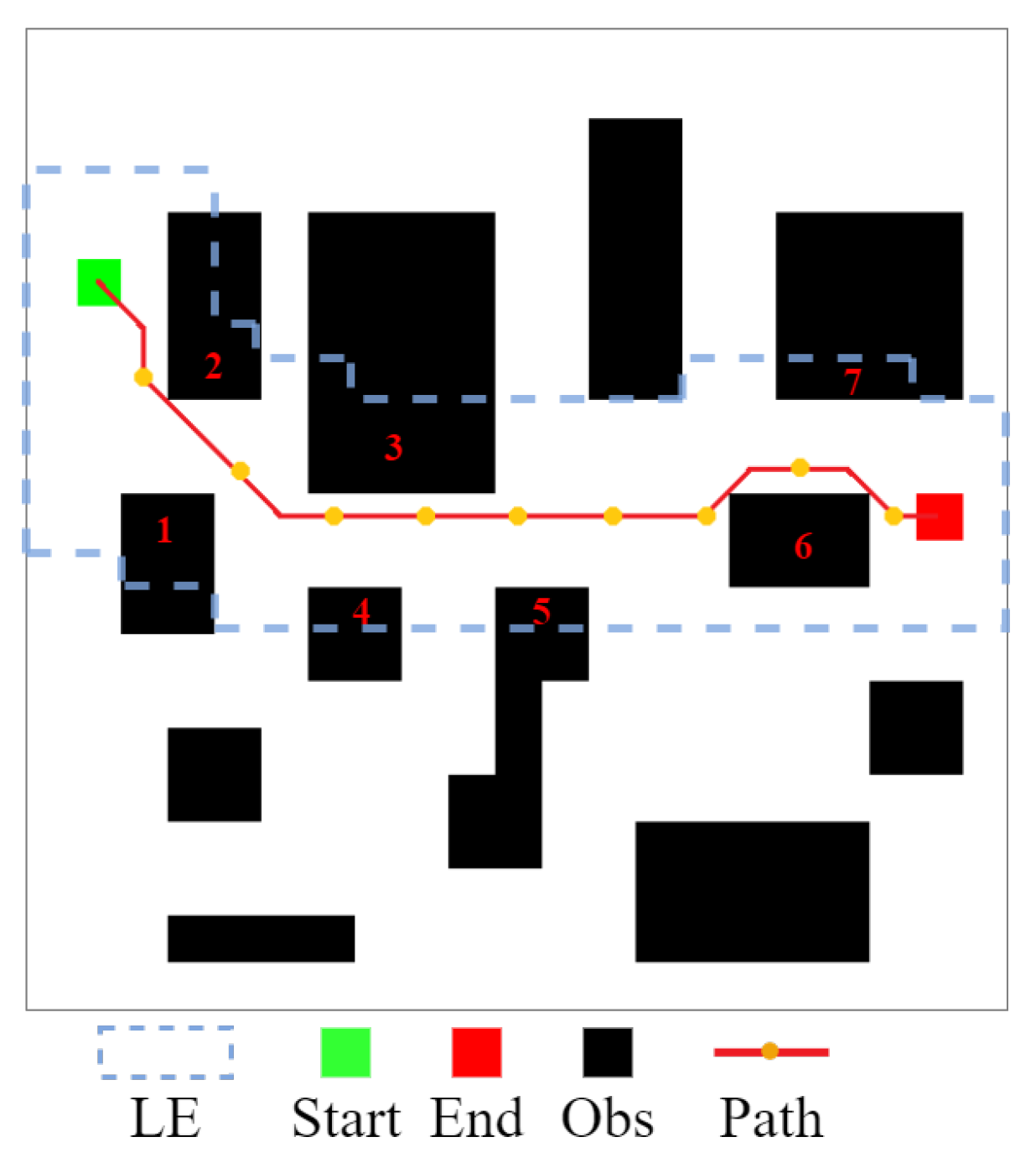
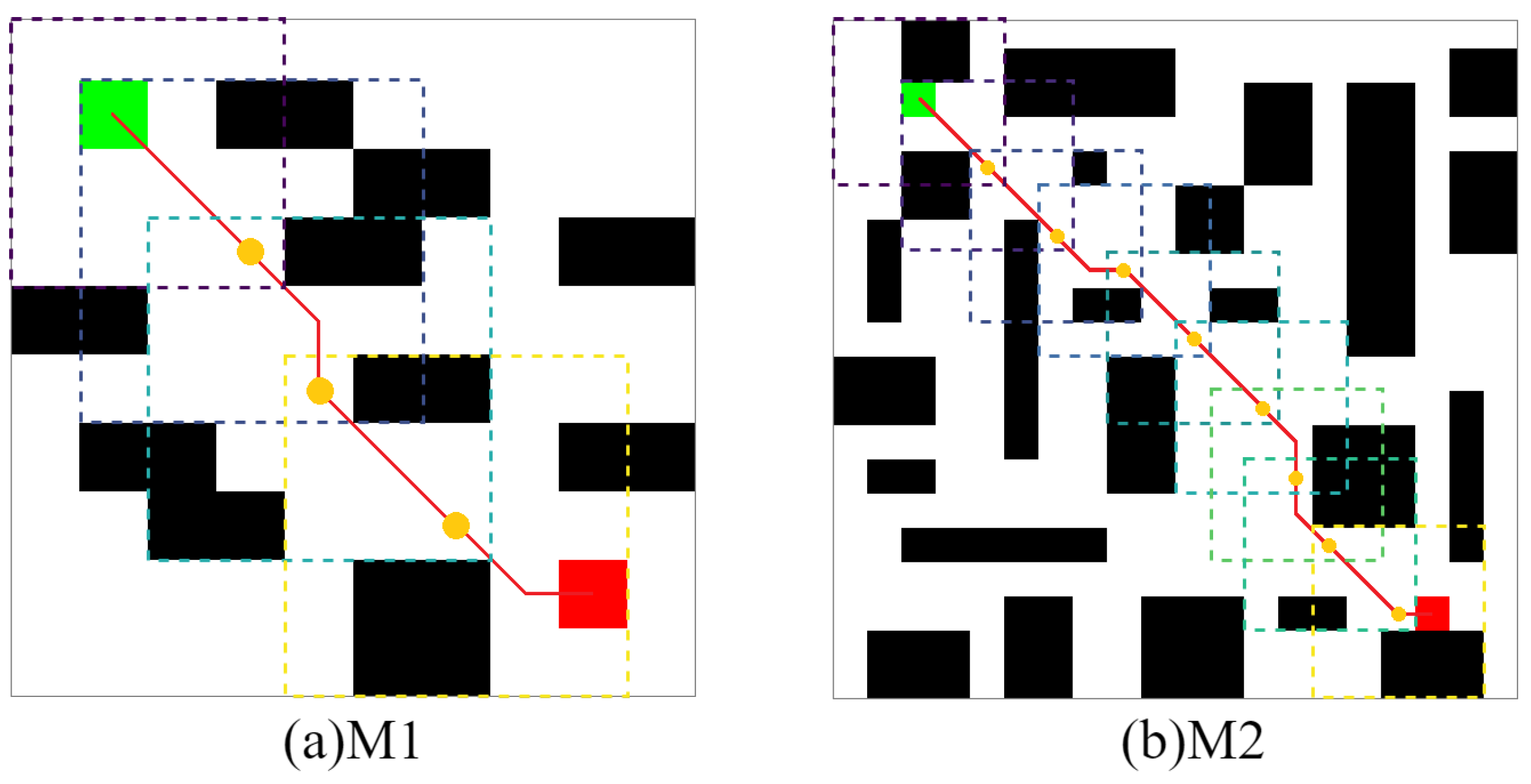
4.3. Efficient Local Search Policy
- 1
- By setting a Local Environment Size() size based on the start point or in the Global Environment Grid().
- 2
- Based on the centering of the point or , a 2D matrix was established and diffused to the size of , finally obtaining the Local Environment Grid(). Particularly, the first is determined by and then by .
- 3
- In the present local environment, the are determined based on prior knowledge.
- 4
- As the search progresses and point is updated, the complex environment can be transformed into several continuous local environments.
| Algorithm 3: Local Environment |
| 1 , , , |
| 2 i= |
| 3 j= |
| 4 |
| 5 |
| 6 |
| 7 |
| Algorithm 4: Intermediate Points |
| 1 |
| 2 |
| 3 |
| 4 |
| 5 using (9) to sort the priority of the local environment points; |
| 6 is the relevant point to the minimum value in PriQ. |
| 7 |
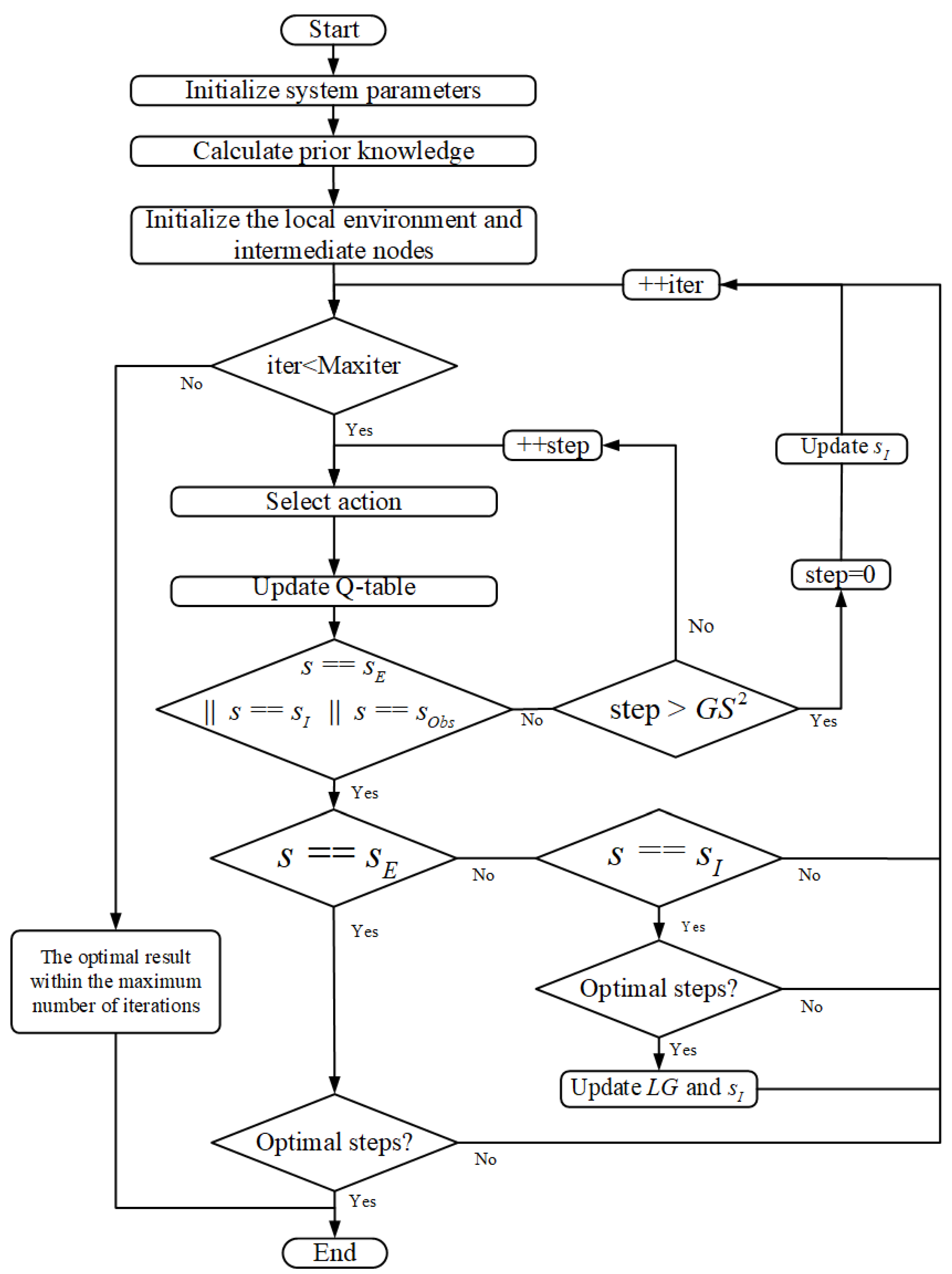
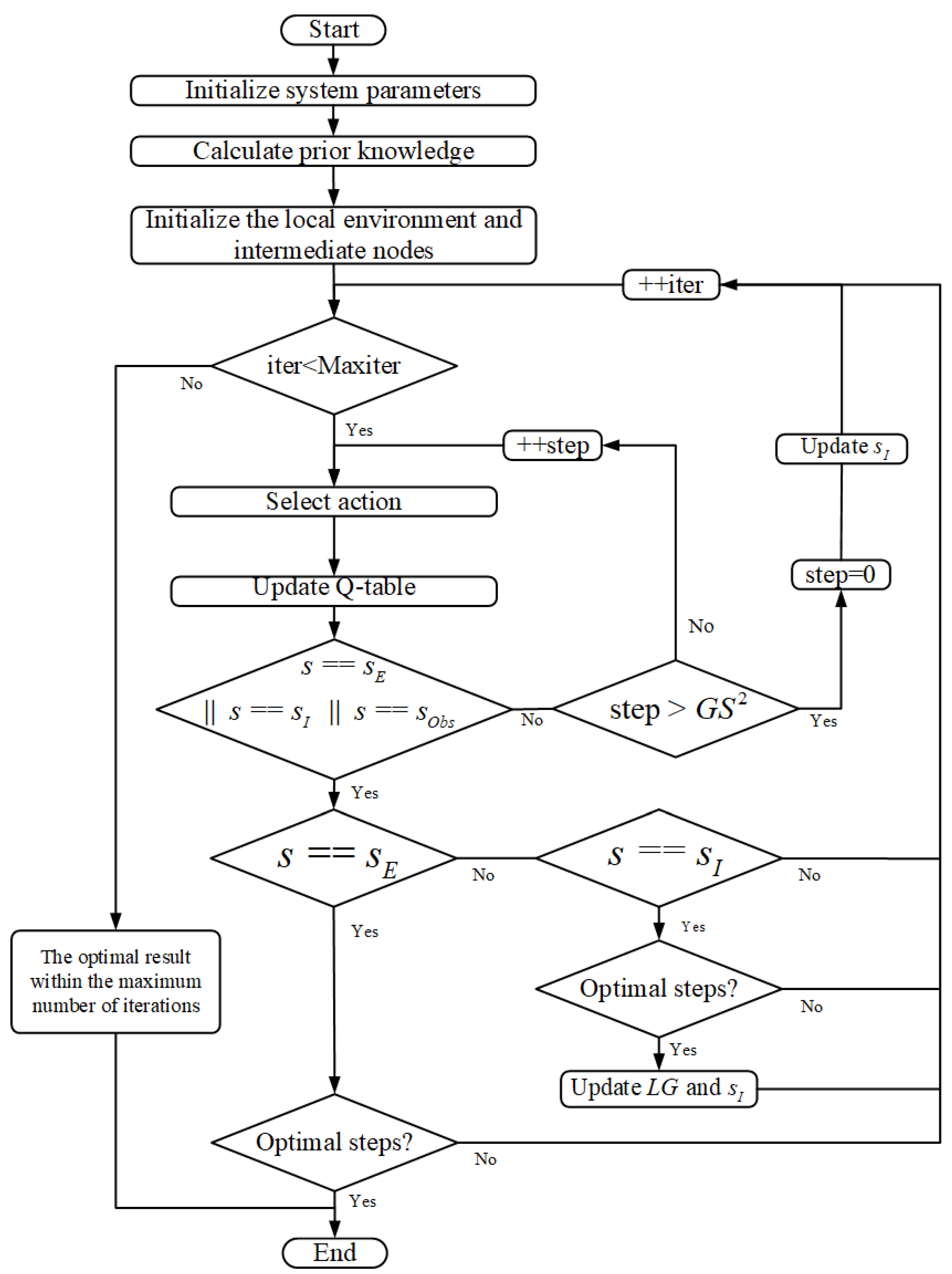
4.4. Search and Iteration Process of the CLSQL Algorithm
5. Experimental Results and Performance Analysis
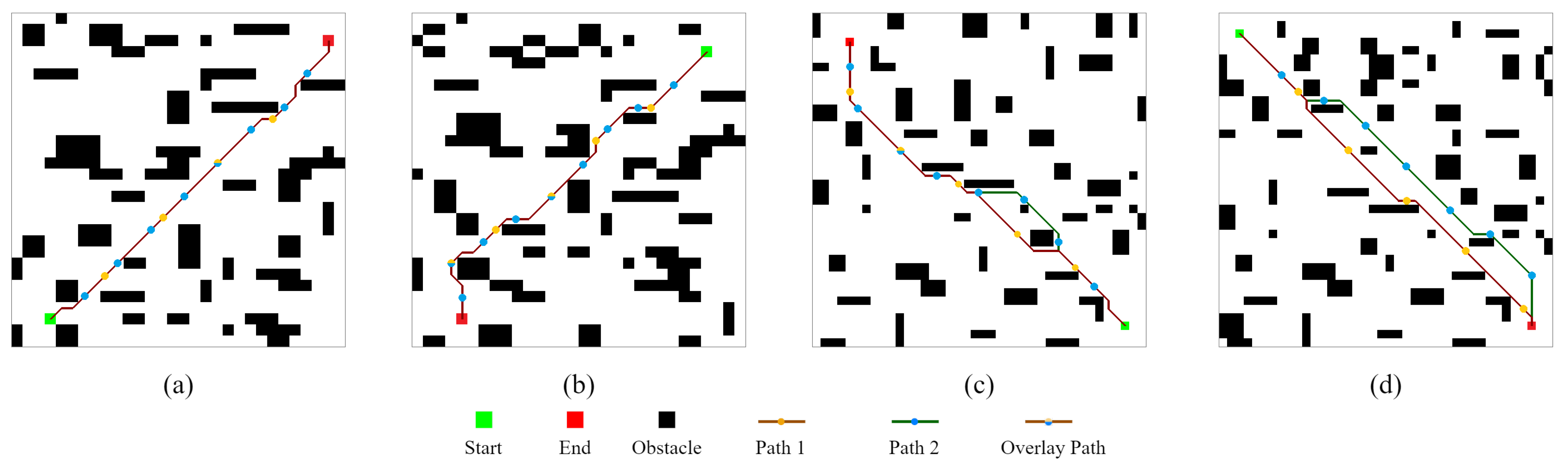
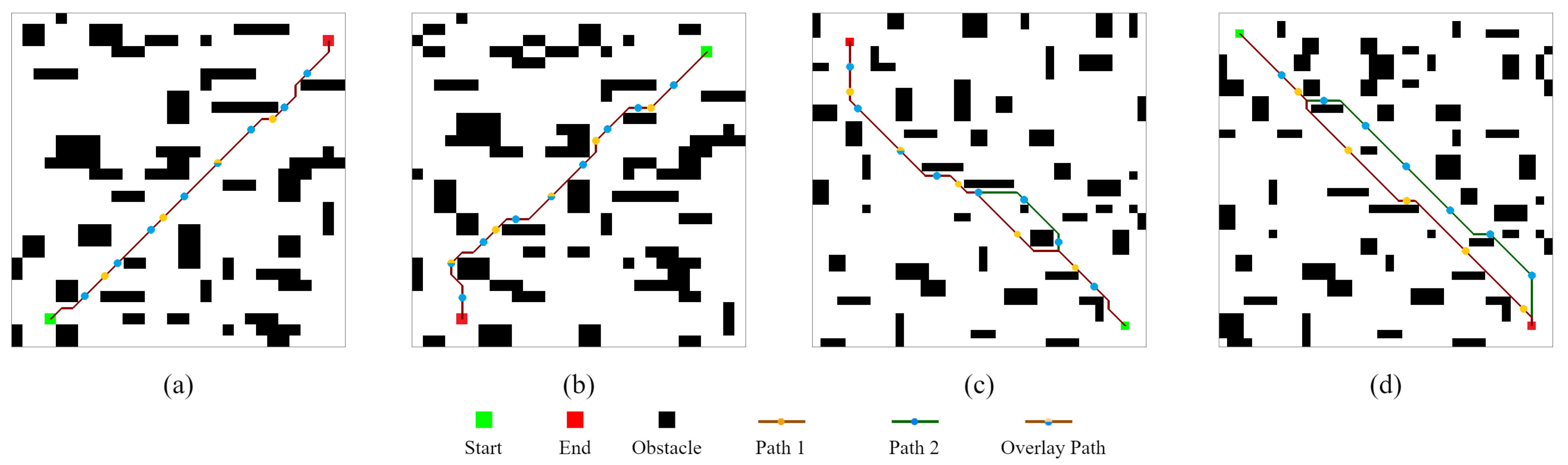
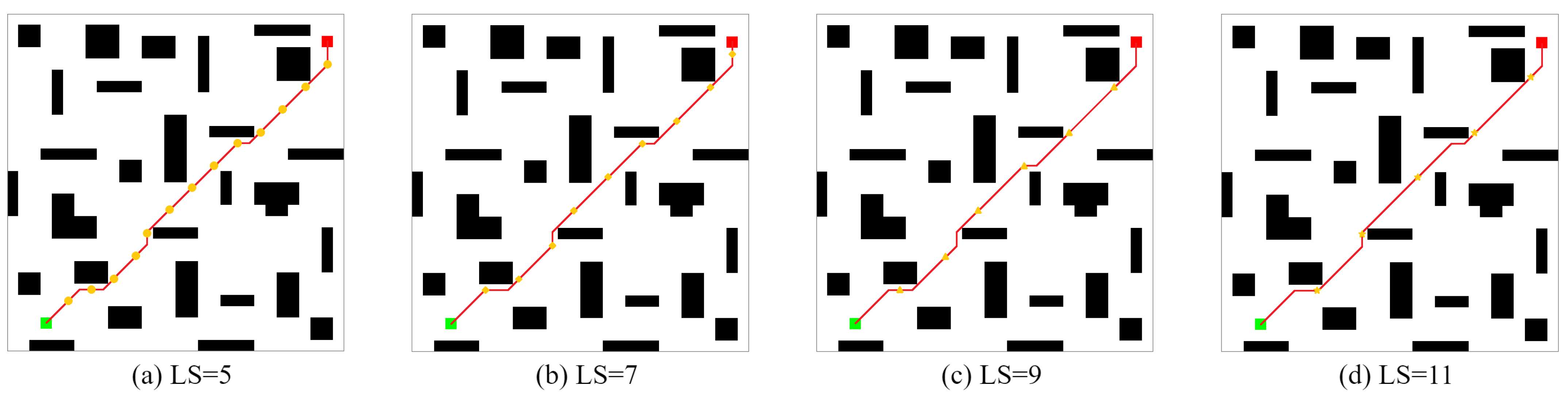
- Experiment 1 was conducted in four random static environments to verify the feasibility of CLSQL. It proves that different can be effectively applied in different environments and obtain satisfactory results.
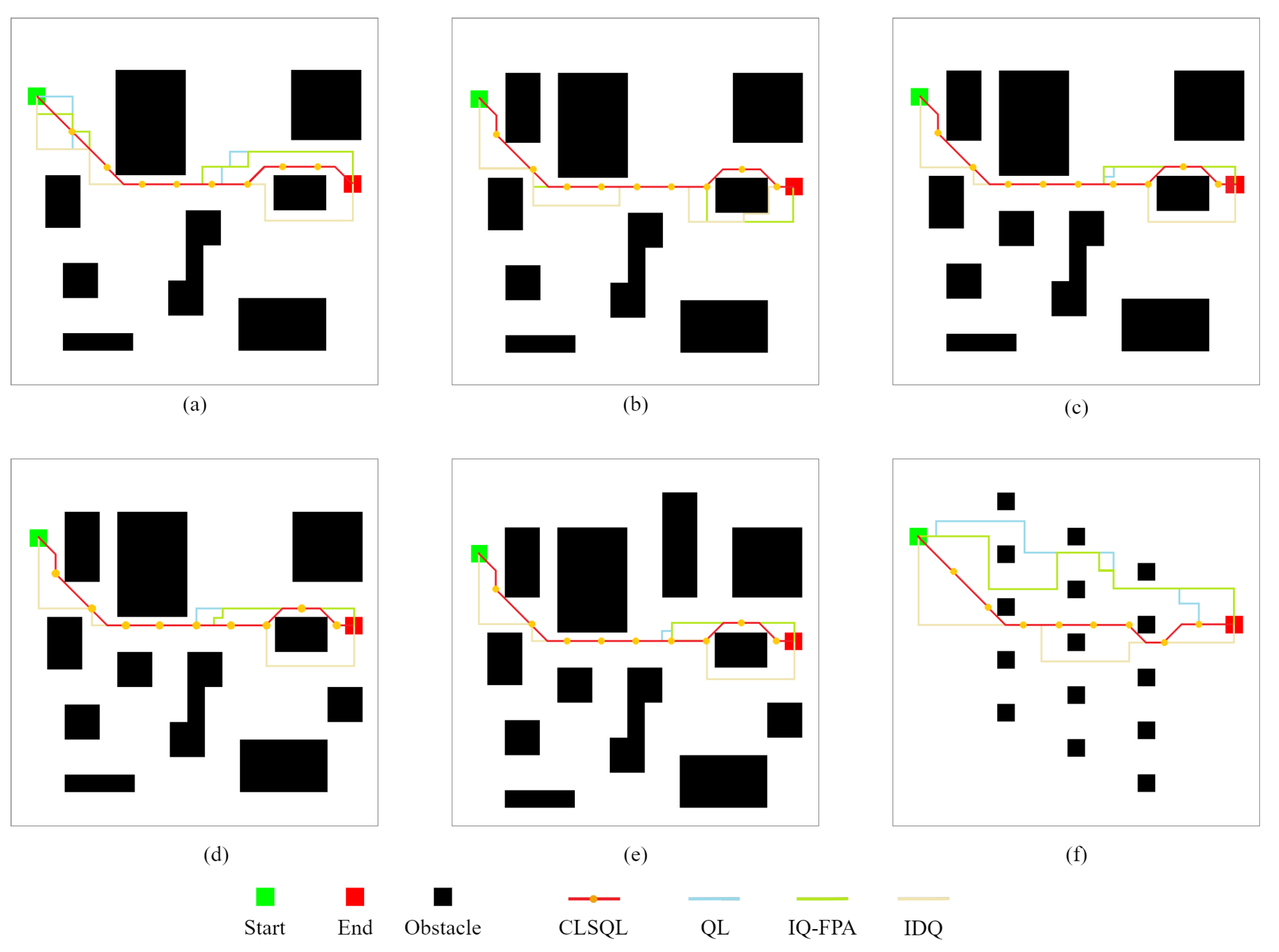
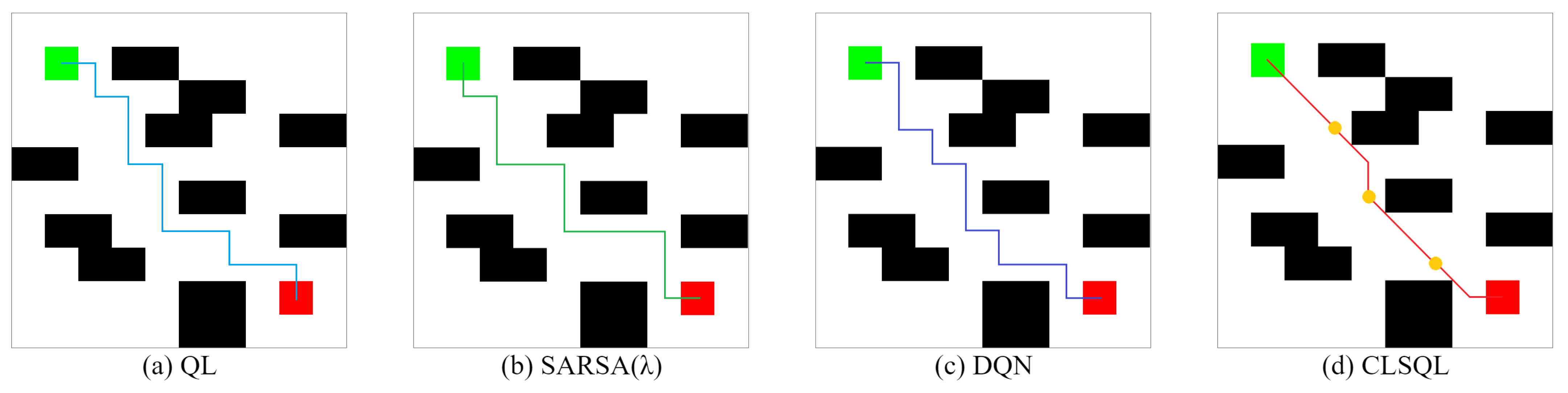
- Experiment 2 is based on the map proposed in the literature [23] for comparison. In this paper, we adopt a grid map for modeling, so rasterization of the map is required. Note that the approach presented in [23] is evaluated on a PC using MATLAB R2014a software for AMD A10 Quad Core with 2.5 GHz. Six different maps T1-T6 were tested, including the CLSQL algorithm, the Improved Q-learning with flower pollination algorithm (IQ-FPA), QL, and the Improved Decentralized QL (IDQ), to verify and compare the performance of different algorithms in terms of path length and computation time. This experiment can clearly show the advantages of the proposed algorithm in path planning and computation time.
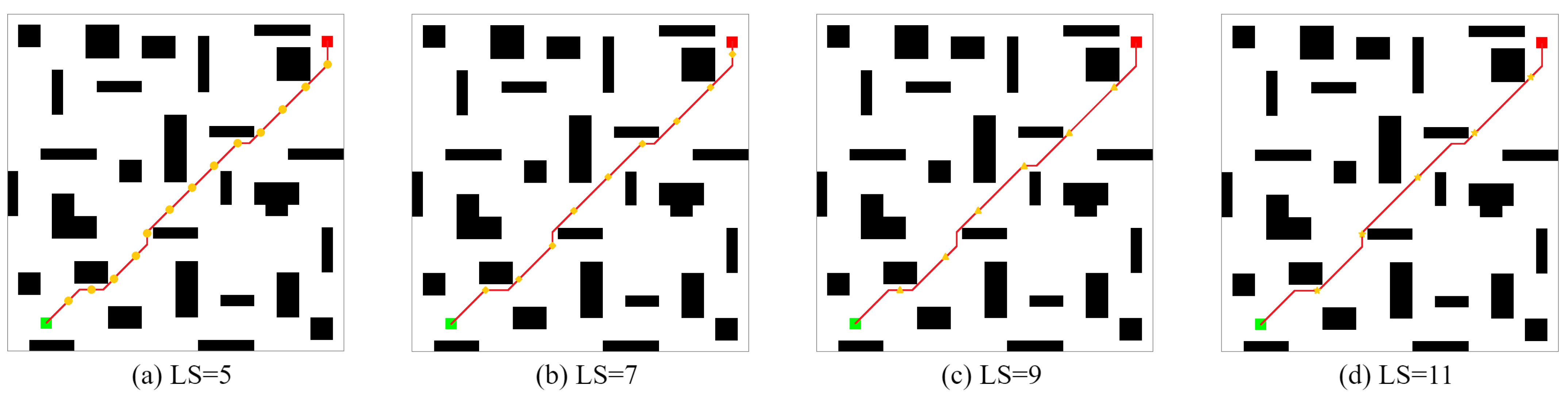
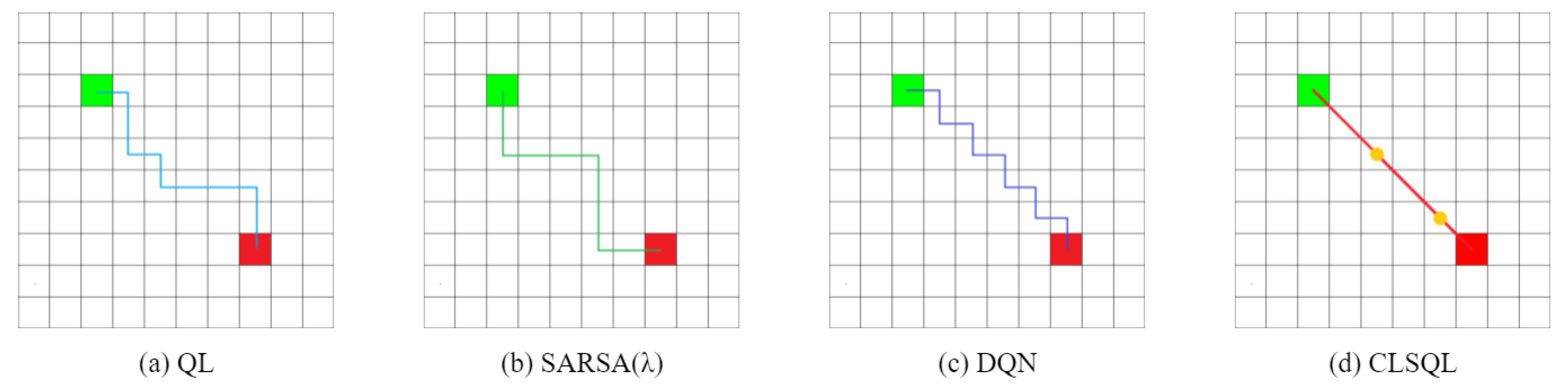
- Experiment 3 builds two kinds of environment maps and focuses on verifying the improvement in search efficiency and iteration times between the CLSQL algorithm and the QL-based algorithm in the obstacle-free or obstacle maps of different specifications. The experiment further proves that the proposed algorithm can achieve a better path effect and iteration efficiency for environment maps of any complexity. The other one, which sets different local environmental parameters, uses the CLSQL algorithm to conduct an ablation experiment in the same environment and sums up the effect of the proposed algorithm relevant to different local environmental parameters.
5.1. Feasibility Experiment
5.2. Effectiveness Experiment
5.3. Ablation Experiment
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Sherwani, F.; Asad, M.M.; Ibrahim, B.S.K.K. Collaborative robots and industrial revolution 4.0 (IR 4.0). In Proceedings of the 2020 International Conference on Emerging Trends in Smart Technologies (ICETST), Karachi, Pakistan, 26–27 March 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–5. [Google Scholar]
- Bai, X.; Yan, W.; Cao, M.; Xue, D. Distributed multi-vehicle task assignment in a time-invariant drift field with obstacles. IET Control Theory Appl. 2019, 13, 2886–2893. [Google Scholar] [CrossRef]
- Hart, P.E.; Nilsson, N.J.; Raphael, B. A formal basis for the heuristic determination of minimum cost paths. IEEE Trans. Syst. Sci. Cybern. 1968, 4, 100–107. [Google Scholar] [CrossRef]
- LaValle, S.M. Rapidly-Exploring Random Trees: A New Tool for Path Planning; Iowa State University: Ames, IA, USA, 1998. [Google Scholar]
- Grefenstette, J.J. Optimization of control parameters for genetic algorithms. IEEE Trans. Syst. Man. Cybern. 1986, 16, 122–128. [Google Scholar] [CrossRef]
- Song, B.; Wang, Z.; Zou, L. An improved PSO algorithm for smooth path planning of mobile robots using continuous high-degree Bezier curve. Appl. Soft Comput. 2021, 100, 106960. [Google Scholar] [CrossRef]
- Bai, X.; Yan, W.; Ge, S.S.; Cao, M. An integrated multi-population genetic algorithm for multi-vehicle task assignment in a drift field. Inf. Sci. 2018, 453, 227–238. [Google Scholar] [CrossRef]
- Bai, X.; Yan, W.; Cao, M. Clustering-based algorithms for multivehicle task assignment in a time-invariant drift field. IEEE Robot. Autom. Lett. 2017, 2, 2166–2173. [Google Scholar] [CrossRef] [Green Version]
- Hentout, A.; Maoudj, A.; Guir, D.; Saighi, S.; Harkat, M.A.; Hammouche, M.Z.; Bakdi, A. Collision-free path planning for indoor mobile robots based on rapidly-exploring random trees and piecewise cubic hermite interpolating polynomial. Int. J. Imaging Robot. 2019, 19, 74–97. [Google Scholar]
- Mohammadi, M.; Al-Fuqaha, A.; Sorour, S.; Guizani, M. Deep learning for IoT big data and streaming analytics: A survey. IEEE Commun. Surv. Tutorials 2018, 20, 2923–2960. [Google Scholar] [CrossRef] [Green Version]
- Zieliński, P.; Markowska-Kaczmar, U. 3D robotic navigation using a vision-based deep reinforcement learning model. Appl. Soft Comput. 2021, 110, 107602. [Google Scholar] [CrossRef]
- Peters, J.; Schaal, S. Reinforcement learning of motor skills with policy gradients. Neural Netw. 2008, 21, 682–697. [Google Scholar] [CrossRef] [Green Version]
- Wen, S.; Jiang, Y.; Cui, B.; Gao, K.; Wang, F. A Hierarchical Path Planning Approach with Multi-SARSA Based on Topological Map. Sensors 2022, 22, 2367. [Google Scholar] [CrossRef] [PubMed]
- Peters, J.; Schaal, S. Natural actor-critic. Neurocomputing 2008, 71, 1180–1190. [Google Scholar] [CrossRef]
- Watkins, C.J.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Kober, J.; Bagnell, J.A.; Peters, J. Reinforcement learning in robotics: A survey. Int. J. Robot. Res. 2013, 32, 1238–1274. [Google Scholar] [CrossRef] [Green Version]
- Wang, B.; Liu, Z.; Li, Q.; Prorok, A. Mobile robot path planning in dynamic environments through globally guided reinforcement learning. IEEE Robot. Autom. Lett. 2020, 5, 6932–6939. [Google Scholar] [CrossRef]
- Xie, R.; Meng, Z.; Wang, L.; Li, H.; Wang, K.; Wu, Z. Unmanned aerial vehicle path planning algorithm based on deep reinforcement learning in large-scale and dynamic environments. IEEE Access 2021, 9, 24884–24900. [Google Scholar] [CrossRef]
- Konar, A.; Chakraborty, I.G.; Singh, S.J.; Jain, L.C.; Nagar, A.K. A deterministic improved Q-learning for path planning of a mobile robot. IEEE Trans. Syst. Man Cybern. Syst. 2013, 43, 1141–1153. [Google Scholar] [CrossRef] [Green Version]
- Zhang, B.; Li, G.; Zheng, Q.; Bai, X.; Ding, Y.; Khan, A. Path Planning for Wheeled Mobile Robot in Partially Known Uneven Terrain. Sensors 2022, 22, 5217. [Google Scholar] [CrossRef]
- Zhou, S.; Liu, X.; Xu, Y.; Guo, J. A deep Q-network (DQN) based path planning method for mobile robots. In Proceedings of the 2018 IEEE International Conference on Information and Automation (ICIA), Harbin, China, 20–23 June 2010; IEEE: Piscataway, NJ, USA, 2018; pp. 366–371. [Google Scholar]
- Low, E.S.; Ong, P.; Cheah, K.C. Solving the optimal path planning of a mobile robot using improved Q-learning. Robot. Auton. Syst. 2019, 115, 143–161. [Google Scholar] [CrossRef]
- Chen, C.; Chen, X.Q.; Ma, F.; Zeng, X.J.; Wang, J. A knowledge-free path planning approach for smart ships based on reinforcement learning. Ocean Eng. 2019, 189, 106299. [Google Scholar] [CrossRef]
- Zhao, M.; Lu, H.; Yang, S.; Guo, F. The experience-memory Q-learning algorithm for robot path planning in unknown environment. IEEE Access 2020, 8, 47824–47844. [Google Scholar] [CrossRef]
- Zhang, J.; Zhang, J.; Ma, Z.; He, Z. Using Partial-Policy Q-Learning to Plan Path for Robot Navigation in Unknown Enviroment. In Proceedings of the 2017 10th International Symposium on Computational Intelligence and Design (ISCID), Hangzhou, China, 9–10 December 2017; IEEE: Piscataway, NJ, USA, 2017; Volume 1, pp. 192–196. [Google Scholar]
- Maoudj, A.; Hentout, A. Optimal path planning approach based on Q-learning algorithm for mobile robots. Appl. Soft Comput. 2020, 97, 106796. [Google Scholar] [CrossRef]
- Das, P.K.; Mandhata, S.; Behera, H.; Patro, S. An improved Q-learning algorithm for path-planning of a mobile robot. Int. J. Comput. Appl. 2012, 51. [Google Scholar]
- Robards, M.; Sunehag, P.; Sanner, S.; Marthi, B. Sparse kernel-SARSA (λ) with an eligibility trace. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Athens, Greece, 5–9 September 2011; Springer: Berlin, Germany, 2011; pp. 1–17. [Google Scholar]
- Xu, C.; Zhao, W.; Chen, Q.; Wang, C. An actor-critic based learning method for decision-making and planning of autonomous vehicles. Sci. China Technol. Sci. 2021, 64, 984–994. [Google Scholar] [CrossRef]
- Woo, J.; Yu, C.; Kim, N. Deep reinforcement learning-based controller for path following of an unmanned surface vehicle. Ocean Eng. 2019, 183, 155–166. [Google Scholar] [CrossRef]
- Zhang, H.; Wang, Y.; Zheng, J.; Yu, J. Path planning of industrial robot based on improved RRT algorithm in complex environments. IEEE Access 2018, 6, 53296–53306. [Google Scholar] [CrossRef]
- Panov, A.I.; Yakovlev, K.S.; Suvorov, R. Grid path planning with deep reinforcement learning: Preliminary results. Procedia Comput. Sci. 2018, 123, 347–353. [Google Scholar] [CrossRef]
- Mao, G.; Gu, S. An Improved Q-Learning Algorithm and Its Application in Path Planning. J. Taiyuan Univ. Technol. 2021, 51, 40–46. [Google Scholar]
- Simsek, M.; Czylwik, A.; Galindo-Serrano, A.; Giupponi, L. Improved decentralized Q-learning algorithm for interference reduction in LTE-femtocells. In Proceedings of the 2011 Wireless Advanced, Surathkal, India, 16–18 December 2011; IEEE: Piscataway, NJ, USA, 2011; pp. 138–143. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Environment | (Unit) | Path Length (Unit) | Computation Time(s) |
|---|---|---|---|
| Env1 | 7 | 36.53 | 0.41 |
| 11 | 36.53 | 0.38 | |
| Env2 | 7 | 36.87 | 0.43 |
| 11 | 36.87 | 0.39 | |
| Env3 | 11 | 53.11 | 0.60 |
| 15 | 52.47 | 0.59 | |
| Env4 | 11 | 51.14 | 0.58 |
| 15 | 50.67 | 0.54 |
| Environment | Average Path Length (Unit) | Average Computation Time (s) | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| QL | IDQ | IQ-FPA | CLSQL | Improvement Percentage(%) | QL | IDQ | IQ-FPA | CLSQL | Improvement Percentage(%) | |
| T1(8 obstacles) | 28.93 | 26.27 | 29.33 | 20.90 | 20.44 | 4.06 | 9.26 | 3.52 | 0.30 | 91.48 |
| T2(9 obstacles) | 30.67 | 26.37 | 31.27 | 21.49 | 18.51 | 4.04 | 10.05 | 3.62 | 0.31 | 91.44 |
| T3(10 obstacles) | 30.00 | 26.00 | 29.60 | 21.49 | 17.35 | 3.89 | 10.28 | 3.88 | 0.32 | 91.75 |
| T4(11 obstacles) | 27.67 | 26.27 | 28.73 | 21.49 | 18.20 | 3.64 | 27.10 | 3.98 | 0.32 | 91.21 |
| T5(12 obstacles) | 27.67 | 26.53 | 29.00 | 21.49 | 19.00 | 3.71 | 23.39 | 4.00 | 0.31 | 91.64 |
| T6(15 obstacles) | 30.07 | 26.00 | 26.80 | 21.04 | 19.08 | 3.23 | 2.87 | 3.66 | 0.33 | 88.50 |
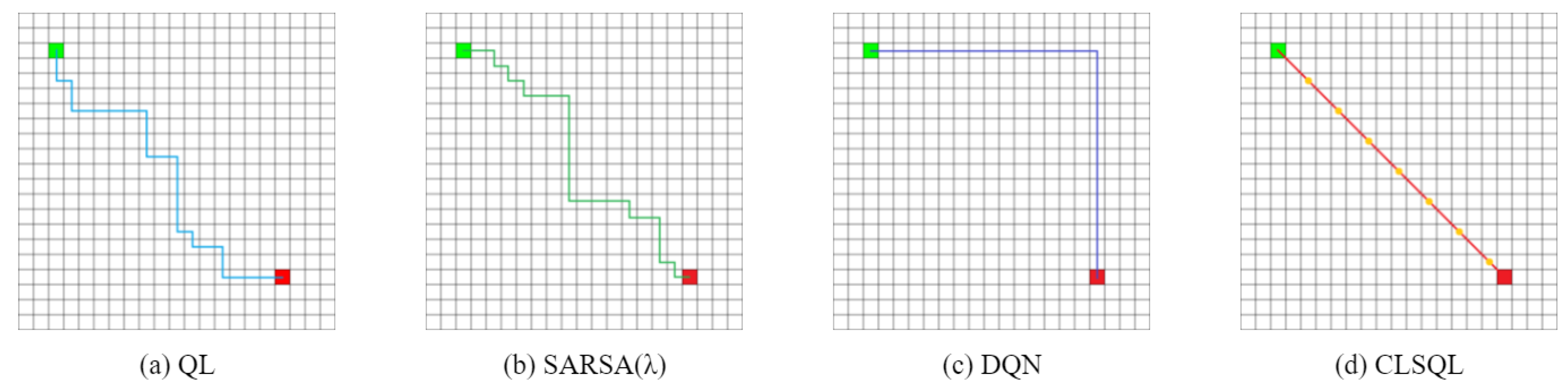
| Environment | Average Path Length (Unit) | Average Computation Time (s) | Average Iteration(Unit) | Average Total Step (Unit) | ||||
|---|---|---|---|---|---|---|---|---|
| B1 | B2 | B1 | B2 | B1 | B2 | B1 | B2 | |
| QL | 10 | 31.4 | 0.14 | 0.39 | 20.4 | 114.5 | 3592.0 | 52451.8 |
| SARSA() | 10 | 36.4 | 0.15 | 0.52 | 88.8 | 525.2 | 4699.0 | 28570.1 |
| DQN | 10 | 30 | 0.49 | 1.19 | 9.4 | 24.5 | 9058.0 | 15363.3 |
| CLSQL | 7.07 | 21.21 | 0.09 | 0.26 | 3.3 | 9.4 | 8.38 | 27.54 |
| Improvement (%) | 29.30 | 29.30 | 35.71 | 33.33 | 64.89 | 61.63 | 99.77 | 99.82 |
| Environment | Path Length (Unit) | Computation Time (s) | Iteration (Unit) | Total Step (Unit) | ||||
|---|---|---|---|---|---|---|---|---|
| B1 | B2 | B1 | B2 | B1 | B2 | B1 | B2 | |
| QL | 0.00 | 2.01 | 0.01 | 0.12 | 5.39 | 16.24 | 720.05 | 8783.63 |
| SARSA() | 0.00 | 4.45 | 0.02 | 0.06 | 65.05 | 397.83 | 1277.49 | 19974.05 |
| DQN | 0.00 | 0.00 | 0.15 | 0.03 | 4.25 | 18.90 | 2063.27 | 9622.40 |
| CLSQL | 0.00 | 0.00 | 0.01 | 0.02 | 0.46 | 0.92 | 2.03 | 4.73 |
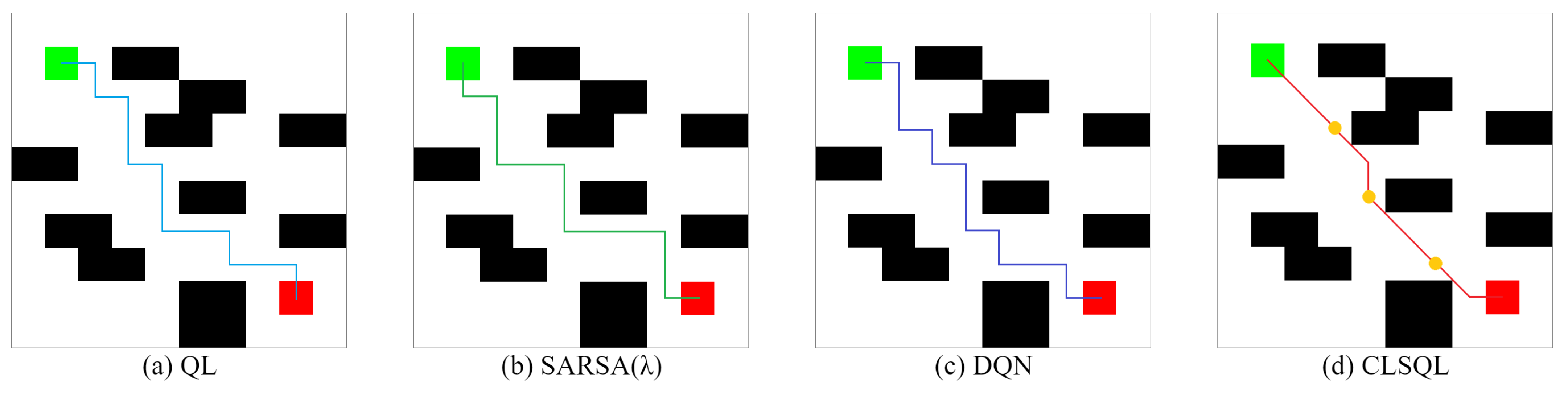
| Environment | Average Path Length (Unit) | Average Computation Time (s) | Average Iteration (Unit) | Average Total Step (Unit) | ||||
|---|---|---|---|---|---|---|---|---|
| M1 | M2 | M1 | M2 | M1 | M2 | M1 | M2 | |
| QL | 14 | 30 | 0.19 | 0.41 | 3.3 | 7.8 | 31.3 | 117 |
| SARSA() | 14 | 30 | 0.21 | 0.43 | 6.7 | 13.6 | 71.1 | 254.6 |
| DQN | 14 | 30.4 | 0.55 | 1.22 | 313.2 | 634.2 | 4149.9 | 8211 |
| CLSQL | 10.49 | 22.38 | 0.14 | 0.28 | 12.7 | 14.5 | 42.85 | 36.87 |
| Improvement (%) | 25.07 | 25.40 | 26.32 | 31.71 | −284.85 | −85.90 | −36.90 | 68.49 |
| Environment | Path Length (Unit) | Computation Time (s) | Iteration (Unit) | Total Step (Unit) | ||||
|---|---|---|---|---|---|---|---|---|
| M1 | M2 | M1 | M2 | M1 | M2 | M1 | M2 | |
| QL | 0 | 0 | 0.01 | 0.02 | 0.80 | 1.17 | 9.06 | 13.95 |
| SARSA() | 0 | 0 | 0.01 | 0.02 | 1.95 | 4.03 | 29.73 | 102.44 |
| DQN | 0 | 1.20 | 0.04 | 0.06 | 154.50 | 160.01 | 2322.13 | 5409.54 |
| CLSQL | 0 | 0 | 0.01 | 0.01 | 1.42 | 1.20 | 5.48 | 3.27 |
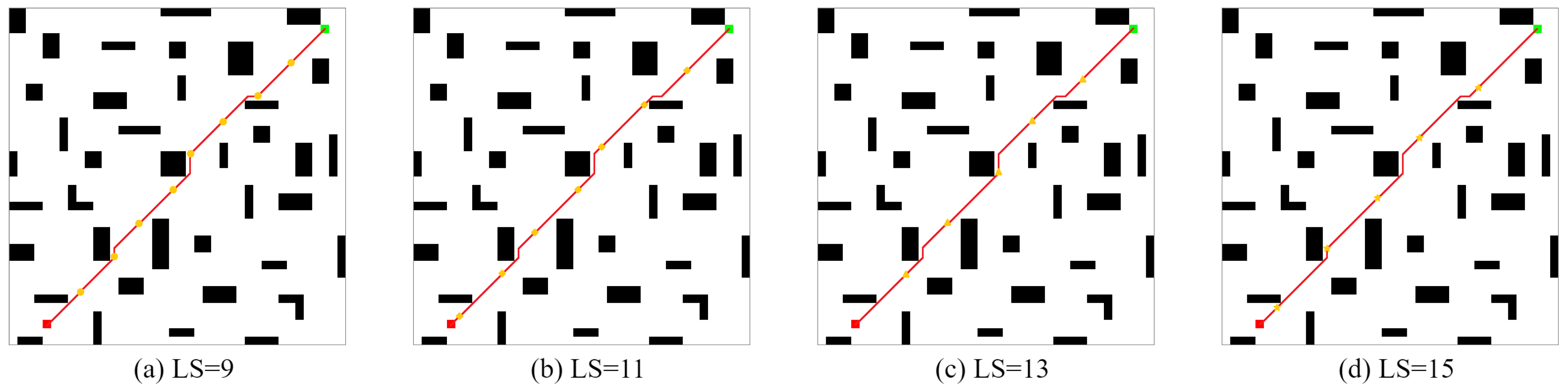
| Environment | (Unit) | Average Path Length (Unit) | Average Computation Time (s) | Average Iteration (Unit) | Average Total Step (Unit) |
|---|---|---|---|---|---|
| Map1 | 5 | 37.11 | 0.47 | 47.1 | 162.52 |
| 7 | 37.11 | 0.51 | 71.5 | 415.79 | |
| 9 | 37.11 | 0.47 | 57.2 | 362.83 | |
| 11 | 37.11 | 0.42 | 36.1 | 258.32 | |
| Map2 | 9 | 49.31 | 0.56 | 39.3 | 308.50 |
| 11 | 49.25 | 0.53 | 40.4 | 370.79 | |
| 13 | 49.31 | 0.52 | 35.9 | 389.57 | |
| 15 | 49.25 | 0.52 | 38.9 | 445.44 |
| Environment | (Unit) | Average Path Length (Unit) | Average Computation Time (s) | Average Iteration (Unit) | Average Total Step (Unit) |
|---|---|---|---|---|---|
| Map1 | 5 | 0 | 1.30 | 2.39 | 9.23 |
| 7 | 0 | 1.86 | 3.75 | 32.31 | |
| 9 | 0 | 2.45 | 4.77 | 28.60 | |
| 11 | 0 | 3.04 | 4.81 | 32.32 | |
| Map2 | 9 | 0.17 | 2.43 | 7.11 | 75.40 |
| 11 | 0 | 3.01 | 5.14 | 95.32 | |
| 13 | 0.17 | 3.59 | 14.66 | 192.21 | |
| 15 | 0 | 4.16 | 9.07 | 140.80 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ma, T.; Lyu, J.; Yang, J.; Xi, R.; Li, Y.; An, J.; Li, C. CLSQL: Improved Q-Learning Algorithm Based on Continuous Local Search Policy for Mobile Robot Path Planning. Sensors 2022, 22, 5910. https://doi.org/10.3390/s22155910
Ma T, Lyu J, Yang J, Xi R, Li Y, An J, Li C. CLSQL: Improved Q-Learning Algorithm Based on Continuous Local Search Policy for Mobile Robot Path Planning. Sensors. 2022; 22(15):5910. https://doi.org/10.3390/s22155910
Chicago/Turabian StyleMa, Tian, Jiahao Lyu, Jiayi Yang, Runtao Xi, Yuancheng Li, Jinpeng An, and Chao Li. 2022. "CLSQL: Improved Q-Learning Algorithm Based on Continuous Local Search Policy for Mobile Robot Path Planning" Sensors 22, no. 15: 5910. https://doi.org/10.3390/s22155910
APA StyleMa, T., Lyu, J., Yang, J., Xi, R., Li, Y., An, J., & Li, C. (2022). CLSQL: Improved Q-Learning Algorithm Based on Continuous Local Search Policy for Mobile Robot Path Planning. Sensors, 22(15), 5910. https://doi.org/10.3390/s22155910