The Wi-Fi received strength signal fingerprint-based positioning is identified as the most popular indoor positioning technique due to its low cost and ease of implementation, which consists of two phases: (a) training and (b) testing. During the training phase, RSS fingerprints known as radio maps are collected from each WiFi access point at multiple locations within the defined space of grid points (GPs), and a predictive model is trained on the RSS measurements of a grid point possibly from all Wi-Fi access points to characterize the ‘signal–location’ relationship, and its corresponding index of the location is stored in the database fingerprints (offline phase). This process is repeated for all GPs in order to characterize or store a grid point’s signal signature with its corresponding location. The learned model is then applied during the testing phase to infer the mobile user’s location based on the new measurement by mapping into the highest likelihood resemblance of signal-signature stored during the training phase time (online phase). To formulate the problem mathematically, let us conceive the general fingerprint-print-based positioning of the indoor environment scenario partitioned into
grid points. Each represent a mobile user’s location and each GP is indexed with a label
,
detectable Wi-Fi access points
were available, and the
ith Wi-Fi signal strength of fingerprints received at the
kth gird point of the
jth access point is a vector and the fingerprint database can be represented as a matrix
:
The above matrix can be described explicitly as:
and
is the corresponding coordinate to the associated location of the signal signature. The target instances would be received during the testing phase denoted as
and the offline source domain can be represented as:
called the labeled source data.
and
represent the numbers of measurements for the target and source data instances, respectively. In summary, the major challenges for Wi-Fi RSS-based fingerprint applications for indoor positions can be divided into three categories: (a) The inherent heterogeneity in measurement distribution at specific grid points or the dynamic nature of RSS value distributions (the sources of spreads can be: hardware devices, measurement time differences, user and antenna orientation, multipath channel conditions such as diffraction, shadowing, fading, interference, and others). (b) RSS fingerprints for a grid point may be duplicated from multiple Wi-Fi APs, causing interference of matched patterns with the actual user’s fingerprint, or irrelevant features may be generated and recorded in the database, inflating or degrading positioning performance. (c) Spending a significant amount of time during the training phase to establish a fairly stable ‘signal-signature to a location’ relationship, or their requirement for large sample size is so expensive. In this paper, we proposed a novel approach to solving the underlying problem associated with signal fluctuations by combining both techniques of principal component analysis (PCA) and correlation analysis with the help of heterogeneous transfer learning (HetTL), such that positive knowledge from the training phase could be leveraged, and only the most significant features would be considered to build the model, and we could establish fairly stable ‘signal-signature to a location’ relationship at the testing phase, respectively.
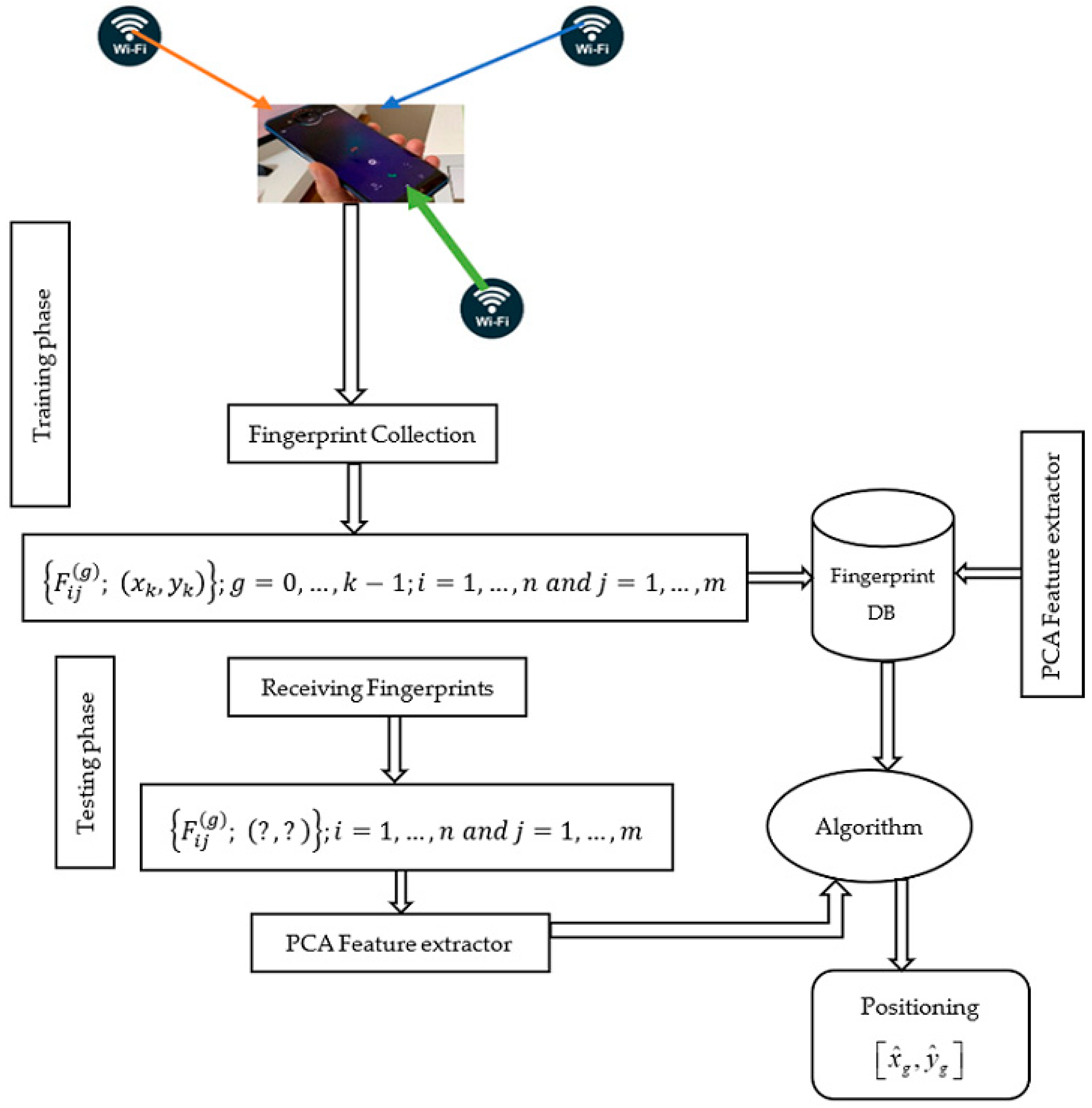
Figure 1 demonstrates the proposed framework of Wi-Fi received signal strength-based fingerprint for the indoor positioning system.
3.3. The Objective Function
Due to the inherent heterogeneity of hardware devices and the time difference between measurements for each grid point, there is no guarantee that the signals at any given position will be represented by a single value even using the same device. Two other challenges must also be addressed in heterogeneous transfer learning: it assumes that the Wi-Fi signals transmitted from different APs are independent so that the Wi-Fi signals transmitted from individual APs do not interfere with each other. Grid points’ RSS fingerprint values may be duplicates from multiple APs, which may interfere with matched patterns with the actual fingerprint of a user, or irrelevant features could be generated and recorded in our database, lowering positioning accuracy. Furthermore, the dimensions of the source feature spaces and target domains may be different. The noise caused by duplicated fingerprints and APs interdependence is handled by combining PCA and correlation coefficient techniques, which allow us to extract the most significant fingerprint features; thus, enabling the construction of a homogeneous independent feature vector. As a result, the objective function was minimized over the new feature vector to leverage the most significant features, independent features, and related source knowledge to the target domain. The Wi-Fi signal strength vectors of the source fingerprints can be given as:
and the target fingerprints also is given as:
The Minkowski is a generalized distance metric between two vectors and defined as:
where
denotes Manhattan [
77,
78] and Euclidean distances [
62,
63,
79], respectively. The transfer coefficients (
) constraint is to better minimize the signal measurements of differences between the samples of the source and target domains. The equality constraint mentioned in the objective function would assign higher weights to the most related source samples and the lesser weights would be assigned to the less related source samples. The weights are therefore updated as follows. The new feature vectors were used to minimize the received signal strength difference, such that the transfer coefficients can be estimated as:
The Lagrangian multiplier method was used to solve the constrained optimization problem of Equation (7) and we assumed that we obtained a location estimate
at the (
t − 1)th iteration, and now we need to estimate the coefficients
at the
tth iteration. By applying the Lagrangian multiplier method, we obtain:
where
is the Lagrangian multiplier. By letting the partial derivative of the Lagrangian with respect to
and
to be zeros, we obtain:
By adding up the first
terms in Equation (9), we can obtain:
Additionally, substituting Equation (10) into Equation (9) gives the estimated transfer coefficients as:
3.5. Analysis of Indoor Positioning Performance-Based Cramer–Rao Lower Bound (CRLB)
Recall the general RSS fingerprint-based positioning of the indoor environment scenario partitioned into grid points (GPs) such that defines the set of reference points associated to the coordinates representing the mobile user’s locations nearest by and each GP is indexed with a label , and there were M detectable Wi-Fi APs . Thus, the ith Wi-Fi signal strength of fingerprints received at the kth grid point of the jth access point is a vector and the fingerprint database from all Wi-Fi APs entirely can be represented as a matrix: and
is the corresponding coordinate to the associated location of the signal signature. Additionally, the target instances of signal strengths received during the testing phase can be represented as:
. The main goal of indoor positioning is to improve positioning performance mainly for better location-based services. In line with this, we applied the Cramer–Rao lower bound (CRLB) as it is widely used to evaluate the performance of the indoor positioning algorithm [
79] and estimates a lower limit for the variance of any unbiased estimator of an unknown parameter, which is widely used to analyze the localization performance [
80,
81,
82,
83]. Thus, the Wi-Fi received signal strengths were used to analyze the lower bound of the location estimation error and it is significantly important to characterize the properties of this lower bound in order to evaluate the impact of different parameters on the accuracy of target positioning. Furthermore, the lower bound analysis can also provide important system design suggestions by revealing error trends with the indoor localization system deployment. Suppose
is an unknown deterministic parameter which is to be estimated from
independent observations (measurements) of
, each from a distribution according to some probability density function
. The variance of any unbiased estimator
of
is then bounded by the reciprocal of the Fisher information
:
. Where the Fisher information
is defined as:
where
is the natural logarithm of the likelihood function for a single sample
and
denotes the expected value with respect to the density
of
. If
is twice differentiable and holds certain regularity conditions, then the Fisher information can also be defined as:
The efficiency of an unbiased estimator
measures how close this estimator’s variance comes to this lower bound; and efficiency of an estimator is defined as
Along with this, consider that the unknown position of the mobile user and the position of the
jth access point are denoted as
and
, respectively, then the distance between the mobile user and the
jth Wi-Fi access point can be calculated as
. Now, the Wi-Fi received signal strengths of a grid point from multiple access points is expected to have fluctuating signal values due to the complex nature of indoor environment possibly affected by the path loss, shadowing, and multipath effect propagation. Hence, the distribution of those measurements could be affected by a random heterogeneity over time such that it is paramount to know how to estimate the random effect of that variable on the overall process of the system modeling. In this case, we adopted the assumption that the random error or the noise could be introduced due to the random phenomenon following a normal distribution with mean zero and variance
and hence the RSS values can be modeled as:
where
and
. Additionally, the pdf (probability density function) of the measurements
is given by:
In RSS fingerprint-based indoor localization, we assume that the Wi-Fi received signal strengths from multiple APs at a reference point are independent and identically distributed such that the joint likelihood function for the measurements can be defined as:
By exponential property, Equation (18) can be rewritten as:
Take ln to get the log-likelihood function of the above Equation (19):
Apply the first partial derivative w.r.t L:
Take the second partial derivative of equation:
Additionally, one can see that the final result does not depend on the vector of observations
and the CRLB of the estimate is given as:
We proved that the variance of the location estimator
attained the lower boundary variance (CRLB) and this indicates our estimator is also the MVU (Minimum Variance Unbiased) estimator as no unbiased estimator could do better and the Fisher information matrix (FIM) [
82,
83] is given by
If
is twice differentiable and holds certain regularity conditions, then the Fisher information can also be rewritten as:
Therefore, the CRLB of MSE of the L can be calculated as
From Equations (19), (24), and (25), we see that:
On the other hand, the CRLB analysis can be restated using the concept of mean square error (MSE). Assume
is an unknown deterministic parameter which is to be estimated from
independent observations (measurements) of
, each from a distribution according to some probability density function
. The MSE of any estimator
of
is then defined as:
From properties of expectations of random variables, the last term of Equation (33) would give zero. Additionally, the term
represents the variance of the estimator
. Finally, as in Equation (33), the MSE is defined as the sum of two components of the variance of the estimator (
) and the square of the differences between the expectation of the estimator and the actual mobile user’s location
. Alternatively, for the unbiased estimator of
, its
must be equal to
and consequently the unbiased estimator of
, i.e.,
and to the right side of Equation (33) the second sum term would vanish for large samples. Moreover, let us recall the above scenario of the RSS fingerprint-based indoor positioning system such that
is the estimate of the unknown mobile user’s coordinates
, and the covariance matrix of the estimator can be given as:
where
is the covariance between
and
which can be represented as
and since the covariance is commutative it is equal with
. The term
refers to the Fisher information matrix (FIM) and Equation (28) holds the criterion of CRLB. Moreover, if
denotes the likelihood function of measurements
conditioned on L, then the score function is defined as the gradient of its log-likelihood function such that:
Additionally, the FIM can be defined as the variance of this score function
:
One can also observe that
From the above derivation, we noted that an interesting relationship for the FIM above and the signal model we considered in Equation (16) were revealed as a reciprocal multiplicative effect to the Gaussian random noise that might be introduced due to the heterogeneity nature of complex indoor environment settings and can be described as:














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}