
Automatically Annotated Dataset of a Ground Mobile Robot in Natural Environments via Gazebo Simulations

 , , , and
, , , and
Abstract
:1. Introduction
- A new dataset obtained from realistic Gazebo simulations of a UGV moving on natural environments is presented.
- The released dataset contains 3D point clouds and images that have been automatically annotated without errors.
2. Gazebo Modeling
2.1. Husky Mobile Robot
- Tachometers.
- A Gazebo plugin reads the angular speed of each wheel and publishes it in an ROS topic at a rate of 10 .
- IMU.
- A generic IMU has been included inside the robot to provide its linear accelerations, angular velocities and 3D attitude. The data, composed of nine values in total, is generated directly from the physics engine ODE during the simulations with an output rate of 50 .
- GNSS.
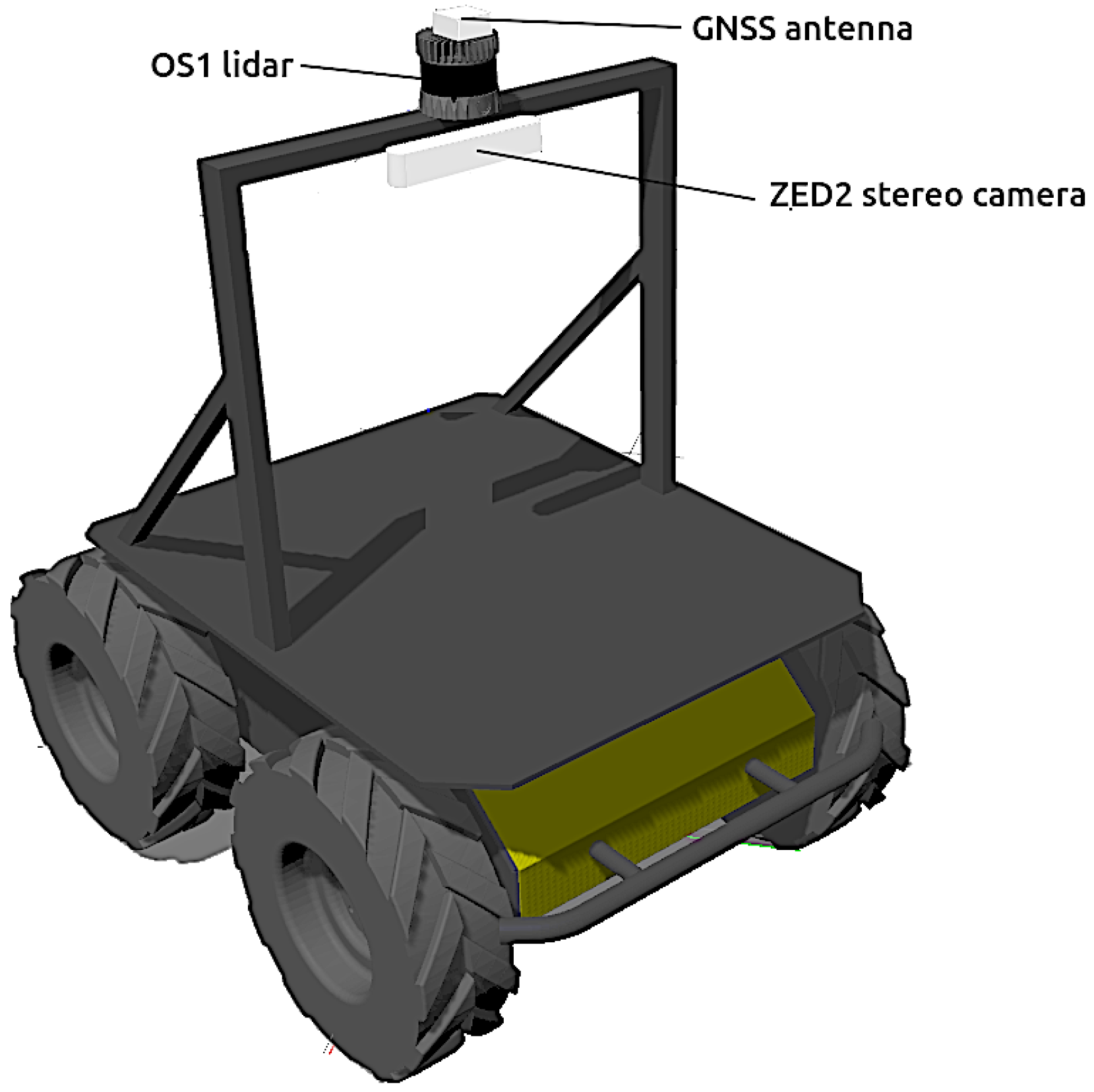
- The antenna of a generic GNSS receiver is incorporated on top of the vehicle (see Figure 2). The latitude , longitude and height h coordinates are directly calculated from the Gazebo simulation state at a rate of 2 .
- Stereo camera.
- The popular ZED-2 stereo camera (https://www.stereolabs.com/assets/datasheets/zed2-camera-datasheet.pdf, accessed on 22 July 2022), with a baseline of , have been chosen (see Figure 1). The corresponding Gazebo model has been mounted centered on a stand above the robot (see Figure 2). The main characteristic of this sensor can be found in Table 1.
- 3D LiDAR.
- The selected 3D LiDAR is an Ouster OS1-64 (https://ouster.com/products/os1-lidar-sensor/, accessed on 22 July 2022)), which is a small high-performance multi-beam sensor (see Table 1) with an affordable cost (see Figure 1). It is also mounted on top of the stand to increase environment visibility (see Figure 2).
2.2. Natural Environments
2.2.1. Urban Park
2.2.2. Lake’s Shore
2.2.3. Dense Forest
2.2.4. Rugged Hillside
3. Simulated Experiments
4. Automatic Tagging
5. Dataset Description
- img_left, img_right, img_left_tag, img_right_tag.
- These folders contain all the generated left and right (both realistic and tagged) images, respectively. The stereo images have been saved with the Portable Network Graphics (PNG) format, where its time-stamp is part of the filename.
- lidar.
- This folder contains all the generated 3D point clouds. Every one has been saved in the Comma-Separated Values (CSV) format and with its time-stamp as its filename. Each line consists of the Cartesian coordinates with respect to the os1_lidar frame and the object reflectivity.
- imu_data, GNSS_data.
- The IMU and GNSS data have been saved separately as text files, where each sensor reading is written in a new line that starts with its corresponding time-stamp.
- tacho_data.
- The tachometer readings of each wheel are provided in four separated text files. Each line contains the time-stamp and the wheel speed in .
- pose_ground_truth.
- This text file contains the pose of the UGV, given for its base_link frame, published by the /gazebo/model_states topic. Each line begins with a time-stamp, continues with Cartesian coordinates and ends with a unit-quaternion.
- data_proportion.
- The exact label distribution among pixels and 3D points for the experiment are detailed in this Excel file.
Additional Material
- husky.
- A modified version of the Clearpath Husky stack that includes a customized version of the husky_gazebo package with the sensor setup described in the paper and the new package husky_tachometers with the plugin for wheel tachometers on Husky.
- geonav_transform.
- This package is required to simplify the integration of GNSS data into the ROS localization and navigation workflows.
- ouster_gazebo.
- The Ouster LiDAR model in Gazebo provided by the manufacturer.
- natural_environments.
- The description of each environment in Gazebo and their launch files. This folder also includes the way-point navigation node and the script for annotating images.
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| 3D | Three-Dimensional |
| CSV | Comma-Separated Values |
| GNSS | Global Navigation Satellite System |
| IMU | Inertial Measurement Unit |
| LiDAR | Light Detection and Ranging |
| ODE | Open Dynamics Engine |
| PNG | Portable Network Graphics |
| ROS | Robot Operating System |
| SAR | Search and Rescue |
| SLAM | Simultaneous Localization and Mapping |
| UGV | Unmanned Ground Vehicle |
References
- Guastella, D.C.; Muscato, G. Learning-Based Methods of Perception and Navigation for Ground Vehicles in Unstructured Environments: A Review. Sensors 2021, 21, 73. [Google Scholar] [CrossRef] [PubMed]
- Geiger, A.; Lenz, P.; Stiller, C.; Urtasun, R. Vision meets robotics: The KITTI dataset. Int. J. Robot. Res. 2013, 32, 1231–1237. [Google Scholar] [CrossRef] [Green Version]
- Hackel, T.; Savinov, N.; Ladicky, L.; Wegner, J.D.; Schindler, K.; Pollefeys, M. SEMANTIC3D.NET: A new large-scale point cloud classification benchmark. ISPRS Ann. Photogramm. Remote Sens. Spatial Inf. Sci. 2017, IV-1-W1, 91–98. [Google Scholar] [CrossRef] [Green Version]
- Maddern, W.; Pascoe, G.; Linegar, C.; Newman, P. 1 year, 1000 km: The Oxford RobotCar dataset. Int. J. Robot. Res. 2017, 36, 3–15. [Google Scholar] [CrossRef]
- Behley, J.; Garbade, M.; Milioto, A.; Quenzel, J.; Behnke, S.; Stachniss, C.; Gall, J. SemanticKITTI: A Dataset for Semantic Scene Understanding of LiDAR Sequences. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 9296–9306. [Google Scholar]
- Blanco, J.L.; Moreno, F.A.; González, J. A collection of outdoor robotic datasets with centimeter-accuracy ground truth. Auton. Robot. 2009, 27, 327–351. [Google Scholar] [CrossRef]
- Aybakan, A.; Haddeler, G.; Akay, M.C.; Ervan, O.; Temeltas, H. A 3D LiDAR Dataset of ITU Heterogeneous Robot Team. In Proceedings of the ACM 5th International Conference on Robotics and Artificial Intelligence, Singapore, 22–24 November 2019; pp. 12–17. [Google Scholar]
- Giusti, A.; Guzzi, J.; Ciresan, D.; He, F.L.; Rodriguez, J.; Fontana, F.; Faessler, M.; Forster, C.; Schmidhuber, J.; Caro, G.; et al. A Machine Learning Approach to Visual Perception of Forest Trails for Mobile Robots. IEEE Robot. Autom. Lett. 2016, 1, 661–667. [Google Scholar] [CrossRef] [Green Version]
- Pire, T.; Mujica, M.; Civera, J.; Kofman, E. The Rosario dataset: Multisensor data for localization and mapping in agricultural environments. Int. J. Robot. Res. 2019, 38, 633–641. [Google Scholar] [CrossRef] [Green Version]
- Potena, C.; Khanna, R.; Nieto, J.; Siegwart, R.; Nardi, D.; Pretto, A. AgriColMap: Aerial-Ground Collaborative 3D Mapping for Precision Farming. IEEE Robot. Autom. Lett. 2019, 4, 1085–1092. [Google Scholar] [CrossRef] [Green Version]
- Tong, C.H.; Gingras, D.; Larose, K.; Barfoot, T.D.; Dupuis, É. The Canadian planetary emulation terrain 3D mapping dataset. Int. J. Robot. Res. 2013, 32, 389–395. [Google Scholar] [CrossRef]
- Hewitt, R.A.; Boukas, E.; Azkarate, M.; Pagnamenta, M.; Marshall, J.A.; Gasteratos, A.; Visentin, G. The Katwijk beach planetary rover dataset. Int. J. Robot. Res. 2018, 37, 3–12. [Google Scholar] [CrossRef] [Green Version]
- Morales, J.; Vázquez-Martín, R.; Mandow, A.; Morilla-Cabello, D.; García-Cerezo, A. The UMA-SAR Dataset: Multimodal data collection from a ground vehicle during outdoor disaster response training exercises. Int. J. Robot. Res. 2021, 40, 835–847. [Google Scholar] [CrossRef]
- Tan, W.; Qin, N.; Ma, L.; Li, Y.; Du, J.; Cai, G.; Yang, K.; Li, J. Toronto-3D: A Large-scale Mobile LiDAR Dataset for Semantic Segmentation of Urban Roadways. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; pp. 797–806. [Google Scholar]
- Caesar, H.; Bankiti, V.; Lang, A.H.; Vora, S.; Liong, V.E.; Xu, Q.; Krishnan, A.; Pan, Y.; Baldan, G.; Beijbom, O. nuScenes: A Multimodal Dataset for Autonomous Driving. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, (CVPR), Seattle, WA, USA, 13–19 June 2020; pp. 11618–11628. [Google Scholar]
- Chang, M.F.; Lambert, J.W.; Sangkloy, P.; Singh, J.; Bak, S.; Hartnett, A.; Wang, D.; Carr, P.; Lucey, S.; Ramanan, D.; et al. Argoverse: 3D Tracking and Forecasting with Rich Maps. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 8740–8749. [Google Scholar]
- Sánchez, M.; Martínez, J.L.; Morales, J.; Robles, A.; Morán, M. Automatic Generation of Labeled 3D Point Clouds of Natural Environments with Gazebo. In Proceedings of the IEEE International Conference on Mechatronics (ICM), Ilmenau, Germany, 18–20 March 2019; pp. 161–166. [Google Scholar]
- Zhang, R.; Candra, S.A.; Vetter, K.; Zakhor, A. Sensor fusion for semantic segmentation of urban scenes. In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Seattle, WA, USA, 26–30 May 2015; pp. 1850–1857. [Google Scholar]
- Tong, G.; Li, Y.; Chen, D.; Sun, Q.; Cao, W.; Xiang, G. CSPC-Dataset: New LiDAR Point Cloud Dataset and Benchmark for Large-Scale Scene Semantic Segmentation. IEEE Access 2020, 8, 87695–87718. [Google Scholar] [CrossRef]
- Martínez, J.L.; Morán, M.; Morales, J.; Robles, A.; Sánchez, M. Supervised Learning of Natural-Terrain Traversability with Synthetic 3D Laser Scans. Appl. Sci. 2020, 10, 1140. [Google Scholar] [CrossRef] [Green Version]
- Griffiths, D.; Boehm, J. SynthCity: A large scale synthetic point cloud. arXiv 2019, arXiv:1907.04758. [Google Scholar]
- Nikolenko, S. Synthetic Simulated Environments. In Synthetic Data for Deep Learning; Springer Optimization and Its Applications; Springer: Cham, Switzerland, 2021; Volume 174, Chapter 7; pp. 195–215. [Google Scholar]
- Yue, X.; Wu, B.; Seshia, S.A.; Keutzer, K.; Sangiovanni-Vincentelli, A.L. A LiDAR Point Cloud Generator: From a Virtual World to Autonomous Driving. In Proceedings of the ACM International Conference on Multimedia Retrieval, Yokohama, Japan, 11–14 June 2018; pp. 458–464. [Google Scholar]
- Hurl, B.; Czarnecki, K.; Waslander, S. Precise Synthetic Image and LiDAR (PreSIL) Dataset for Autonomous Vehicle Perception. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Paris, France, 9–12 June 2019; pp. 2522–2529. [Google Scholar]
- Khan, S.; Phan, B.; Salay, R.; Czarnecki, K. ProcSy: Procedural Synthetic Dataset Generation Towards Influence Factor Studies Of Semantic Segmentation Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 88–96. [Google Scholar]
- Chavez-Garcia, R.O.; Guzzi, J.; Gambardella, L.M.; Giusti, A. Learning ground traversability from simulations. IEEE Robot. Autom. Lett. 2018, 3, 1695–1702. [Google Scholar] [CrossRef] [Green Version]
- Hewitt, R.A.; Ellery, A.; de Ruiter, A. Training a terrain traversability classifier for a planetary rover through simulation. Int. J. Adv. Robot. Syst. 2017, 14, 1–14. [Google Scholar] [CrossRef]
- Bechtsis, D.; Moisiadis, V.; Tsolakis, N.; Vlachos, D.; Bochtis, D. Unmanned Ground Vehicles in Precision Farming Services: An Integrated Emulation Modelling Approach. In Information and Communication Technologies in Modern Agricultural Development; Springer Communications in Computer and Information Science; Springer: Cham, Switzerland, 2019; Volume 953, pp. 177–190. [Google Scholar]
- Agüero, C.E.; Koenig, N.; Chen, I.; Boyer, H.; Peters, S.; Hsu, J.; Gerkey, B.; Paepcke, S.; Rivero, J.L.; Manzo, J.; et al. Inside the Virtual Robotics Challenge: Simulating Real-Time Robotic Disaster Response. IEEE Trans. Autom. Sci. Eng. 2015, 12, 494–506. [Google Scholar] [CrossRef]
- Martínez, J.L.; Morales, J.; Sánchez, M.; Morán, M.; Reina, A.J.; Fernández-Lozano, J.J. Reactive Navigation on Natural Environments by Continuous Classification of Ground Traversability. Sensors 2020, 20, 6423. [Google Scholar] [CrossRef]
- Koenig, K.; Howard, A. Design and use paradigms for Gazebo, an open-source multi-robot simulator. In Proceedings of the IEEE-RSJ International Conference on Intelligent Robots and Systems, Sendai, Japan, 28 September–2 October 2004; pp. 2149–2154. [Google Scholar]
- Hosseininaveh, A.; Remondino, F. An Imaging Network Design for UGV-Based 3D Reconstruction of Buildings. Remote Sens. 2021, 13, 1923. [Google Scholar] [CrossRef]
- Quigley, M.; Conley, K.; Gerkey, B.; Faust, J.; Foote, T.; Leibs, J.; Wheeler, R.; Ng, A. ROS: An open-source Robot Operating System. In Proceedings of the IEEE ICRA Workshop on Open Source Software, Kobe, Japan, 12–17 May 2009; Volume 3, pp. 1–6. [Google Scholar]
- Minaee, S.; Boykov, Y.Y.; Porikli, F.; Plaza, A.J.; Kehtarnavaz, N.; Terzopoulos, D. Image Segmentation Using Deep Learning: A Survey. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 44, 3523–3542. [Google Scholar] [CrossRef] [PubMed]
- Sickert, S.; Denzler, J. Semantic Segmentation of Outdoor Areas using 3D Moment Invariants and Contextual Cues. In Proceedings of the German Conference on Pattern Recognition (GCPR), Basel, Switzerland, 12–15 September 2017; pp. 165–176. [Google Scholar]
- Cadena, C.; Carlone, L.; Carrillo, H.; Latif, Y.; Scaramuzza, D.; Neira, J.; Reid, I.; Leonard, J.J. Past, Present, and Future of Simultaneous Localization and Mapping: Toward the Robust-Perception Age. IEEE Trans. Robot. 2016, 32, 1309–1332. [Google Scholar] [CrossRef] [Green Version]
- Dai, J.; Li, D.; Li, Y.; Zhao, J.; Li, W.; Liu, G. Mobile Robot Localization and Mapping Algorithm Based on the Fusion of Image and Laser Point Cloud. Sensors 2022, 22, 4114. [Google Scholar] [CrossRef] [PubMed]
- Dosovitskiy, A.; Ros, G.; Codevilla, F.; López, A.; Koltun, V. CARLA: An Open Urban Driving Simulator. In Proceedings of the 1st Conference on Robot Learning, Mountain View, CA, USA, 13–15 November 2017; pp. 1–16. [Google Scholar]
- Palafox, P.R.; Garzón, M.; Valente, J.; Roldán, J.J.; Barrientos, A. Robust Visual-Aided Autonomous Takeoff, Tracking, and Landing of a Small UAV on a Moving Landing Platform for Life-Long Operation. Appl. Sci. 2019, 9, 2661. [Google Scholar] [CrossRef] [Green Version]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ZED-2 | OS1-64 | |
|---|---|---|
| Field of view (horizontal × vertical) | ||
| Resolution (horizontal × vertical) | pixels | 3D points |
| Output rate | 25 | 10 |
| Coordinate System | x | y | z | Roll | Pitch | Yaw |
|---|---|---|---|---|---|---|
| (m) | (m) | (m) | (°) | (°) | (°) | |
| GNSS_link | 0.10 | 0 | 0.890 | 0 | 0 | 0 |
| os1_lidar | 0.09 | 0 | 0.826 | 0 | 0 | 0 |
| right_camera | 0.15 | −0.06 | 0.720 | 0 | 90 | 0 |
| left_camera | 0.15 | 0.06 | 0.720 | 0 | 90 | 0 |
| imu_link | 0.19 | 0 | 0.149 | 0 | −90 | 180 |
| front_right_wheel | 0.256 | −0.2854 | 0.03282 | 0 | 0 | 0 |
| rear_right_wheel | −0.256 | −0.2854 | 0.03282 | 0 | 0 | 0 |
| front_left_wheel | 0.256 | 0.2854 | 0.03282 | 0 | 0 | 0 |
| rear_left_wheel | −0.256 | 0.2854 | 0.03282 | 0 | 0 | 0 |
| base_footprint | 0 | 0 | −0.13228 | 0 | 0 | 0 |
| Element | Flat Color | Reflectivity | |
|---|---|---|---|
| Ground | (0, 255, 0) |  | 1 |
| Trunk and branch | (255, 0, 255) |  | 2 |
| Treetop | (255, 255, 0) |  | 3 |
| Bush | (0, 0, 255) |  | 4 |
| Rock | (255, 0, 0) |  | 5 |
| High grass | (97, 127, 56) |  | 6 |
| Sky | (127, 127, 127) |  | - |
| Trail | (76, 57, 48) |  | 7 |
| Lamp post | (204, 97, 20) |  | 8 |
| Trash bin | (102, 0, 102) |  | 9 |
| Table | (0, 0, 0) |  | 10 |
| Water | (33, 112, 178) |  | - |
| Bench | (255, 255, 255) |  | 11 |
| Post | (61, 59, 112) |  | 12 |
| Cable | (255, 153, 153) |  | 13 |
| Bag File | 3D Point | Stereo | GNSS | IMU | Length | Duration |
|---|---|---|---|---|---|---|
| Clouds | Images | Readings | Readings | (m) | (s) | |
| Park 1 | 2576 | 6464 | 10,344 | 12,650 | 76.08 | 253 |
| Park 2 | 7089 | 15,469 | 25,471 | 35,900 | 217.51 | 718 |
| Lake 1 | 6216 | 15,562 | 24,900 | 31,100 | 186.85 | 622 |
| Lake 2 | 6343 | 15,858 | 25,375 | 31,700 | 190.45 | 634 |
| Forest 1 | 2689 | 6723 | 10,758 | 13,450 | 80.52 | 269 |
| Forest 2 | 2451 | 6125 | 9802 | 12,250 | 73.38 | 245 |
| Hillside 1 | 5145 | 13,162 | 20,583 | 25,700 | 153.10 | 514 |
| Hillside 2 | 5111 | 13,056 | 20,444 | 25,550 | 159.34 | 511 |
| ROS Topic | Rate | Brief Description |
|---|---|---|
| {message} | (Hz) | |
| gazebo/model_states {gazebo/ModelStates} | 1000 | The pose of all objects in the environment, including Husky, with respect to the global coordinate frame of Gazebo. |
| imu/data {sensor_msgs/Imu} | 50 | 3D attitude, linear acceleration and angular velocities of the UGV measured by its IMU. |
| navsat/fix {sensor_msgs/NavSatFix} | 2 | Geodetic coordinates (, and h) of the GNSS antenna. |
| os1_cloud_node/points {sensor_msgs/PointCloud2} | 10 | A 3D point cloud generated by the LiDAR, including its intensity measurements. |
| /gazebo_client/front_left_speed {std_msgs/Float32} | 10 | Angular speed of the front left wheel in /. |
| /gazebo_client/front_right_speed {std_msgs/Float32} | 10 | Angular speed of the front right wheel in /. |
| /gazebo_client/rear_left_speed {std_msgs/Float32} | 10 | Angular speed of the rear left wheel in /. |
| /gazebo_client/rear_right_speed {std_msgs/Float32} | 10 | Angular speed of the rear right wheel in /. |
| stereo/camera/left/real/compressed {sensor_msgs/CompressedImage} | 25 | A compressed realistic image of the left camera. |
| stereo/camera/left/tag/img_raw {sensor_msgs/Image} | 25 | An annotated image of the left camera. |
| stereo/camera/right/real/compressed {sensor_msgs/CompressedImage} | 25 | A compressed realistic image of the right camera. |
| stereo/camera/right/tag/img_raw {sensor_msgs/Image} | 25 | An annotated image of the right camera. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sánchez, M.; Morales, J.; Martínez, J.L.; Fernández-Lozano, J.J.; García-Cerezo, A. Automatically Annotated Dataset of a Ground Mobile Robot in Natural Environments via Gazebo Simulations. Sensors 2022, 22, 5599. https://doi.org/10.3390/s22155599
Sánchez M, Morales J, Martínez JL, Fernández-Lozano JJ, García-Cerezo A. Automatically Annotated Dataset of a Ground Mobile Robot in Natural Environments via Gazebo Simulations. Sensors. 2022; 22(15):5599. https://doi.org/10.3390/s22155599
Chicago/Turabian StyleSánchez, Manuel, Jesús Morales, Jorge L. Martínez, J. J. Fernández-Lozano, and Alfonso García-Cerezo. 2022. "Automatically Annotated Dataset of a Ground Mobile Robot in Natural Environments via Gazebo Simulations" Sensors 22, no. 15: 5599. https://doi.org/10.3390/s22155599
APA StyleSánchez, M., Morales, J., Martínez, J. L., Fernández-Lozano, J. J., & García-Cerezo, A. (2022). Automatically Annotated Dataset of a Ground Mobile Robot in Natural Environments via Gazebo Simulations. Sensors, 22(15), 5599. https://doi.org/10.3390/s22155599