
Enhanced Multiscale Principal Component Analysis for Improved Sensor Fault Detection and Isolation


Abstract
1. Introduction
2. Theory and Background
2.1. PCA-Based Fault Detection and Detectability
2.2. PCA-Based Fault Isolation
2.2.1. General Decomposition Methods
2.2.2. Reconstruction Methods
2.2.3. Smearing Effect
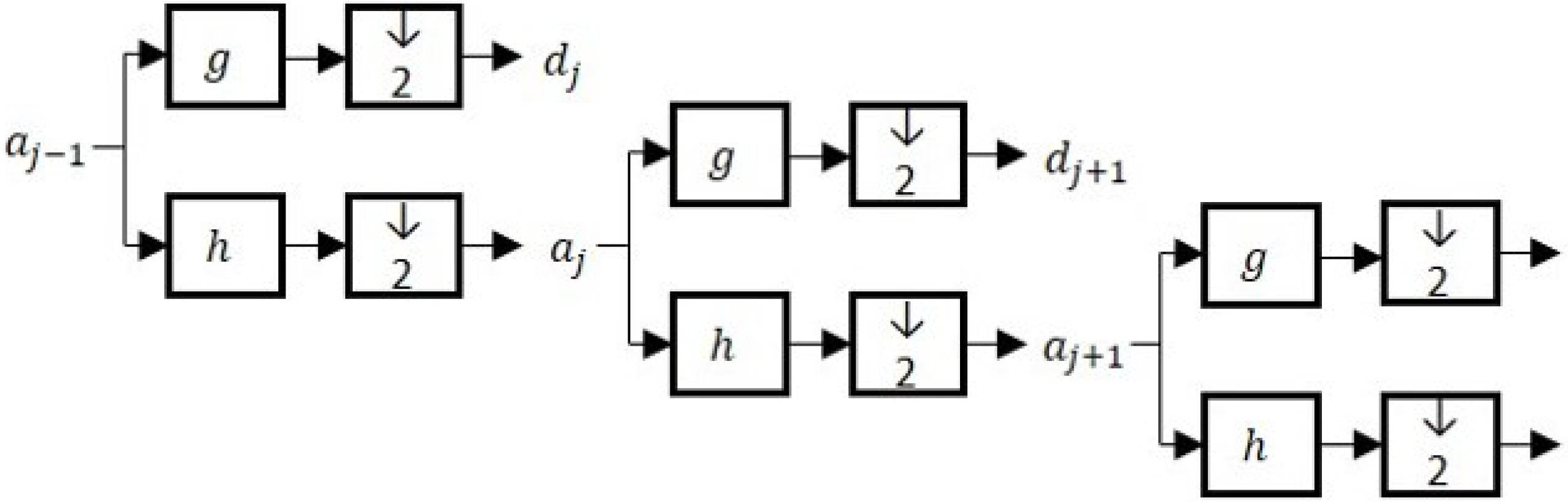
2.3. Wavlet-Based Analysis of Data
2.4. MSPCA Algorithm
3. New Coefficient Selection Criterion and Enhanced MSPCA (EMSPCA) Algorithm
- EMSPCA Coefficient Selection Criteria: Always select all coefficients of the approximate scale and select only the detail coefficients that violate the detection thresholds. Apply the same in both training and testing phases.
- MSPCA Coefficient Selection Criteria: Select all coefficients of a scale if a single limit violation occurs in that scale from the decomposed training data, and keep only the violating coefficients from the decomposed testing data. Apply the same for both details and approximate scales.
4. Fault Detection Performance of EMSPCA
4.1. Process Model and Simulation Conditions
- Theoretical limits with 99% and 98% confidence levels are used for thresholding the detail signals, and for the detection using the reconstructed data. These confidence level values are recommended by the original MSPCA work [7].
- The number of retained principal components is 3.
- At every iteration the fault location is randomized and the process model is generated randomly.
- The number of Monte Carlo realizations is 1000.
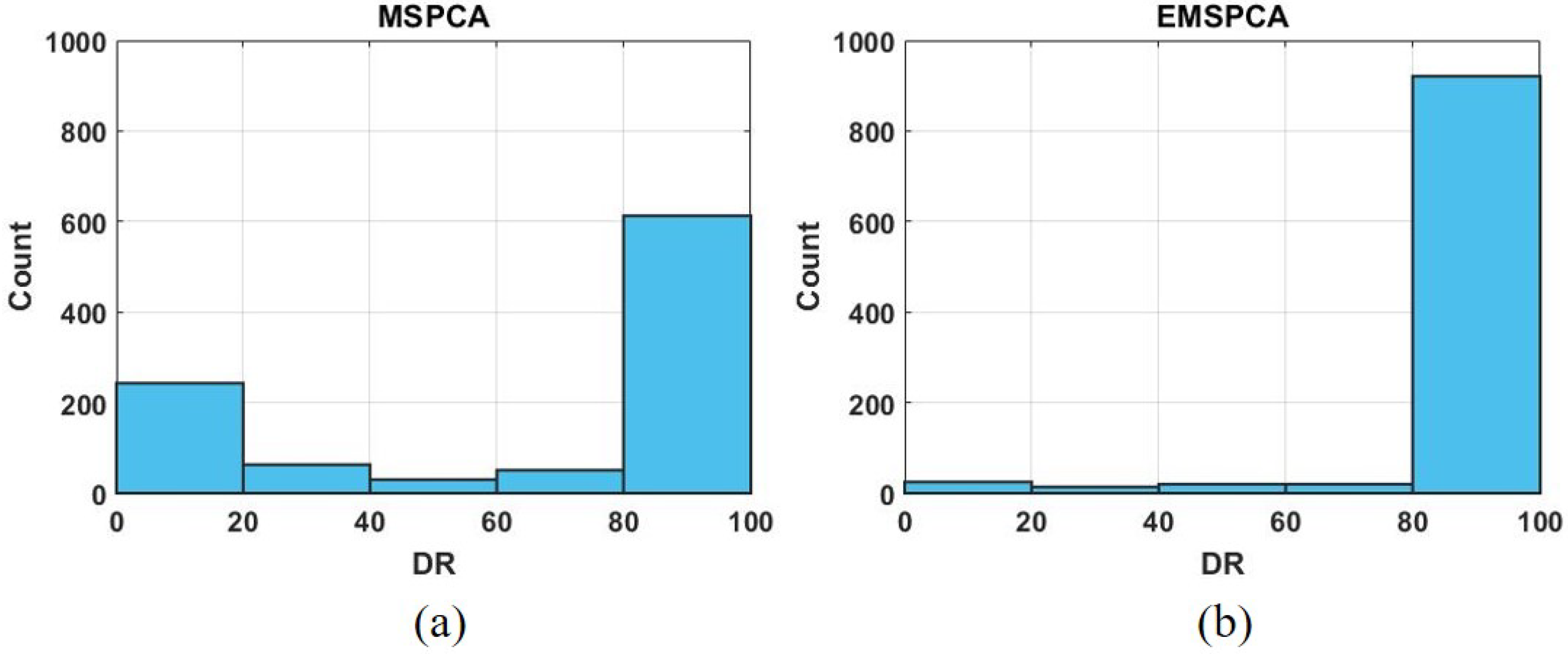
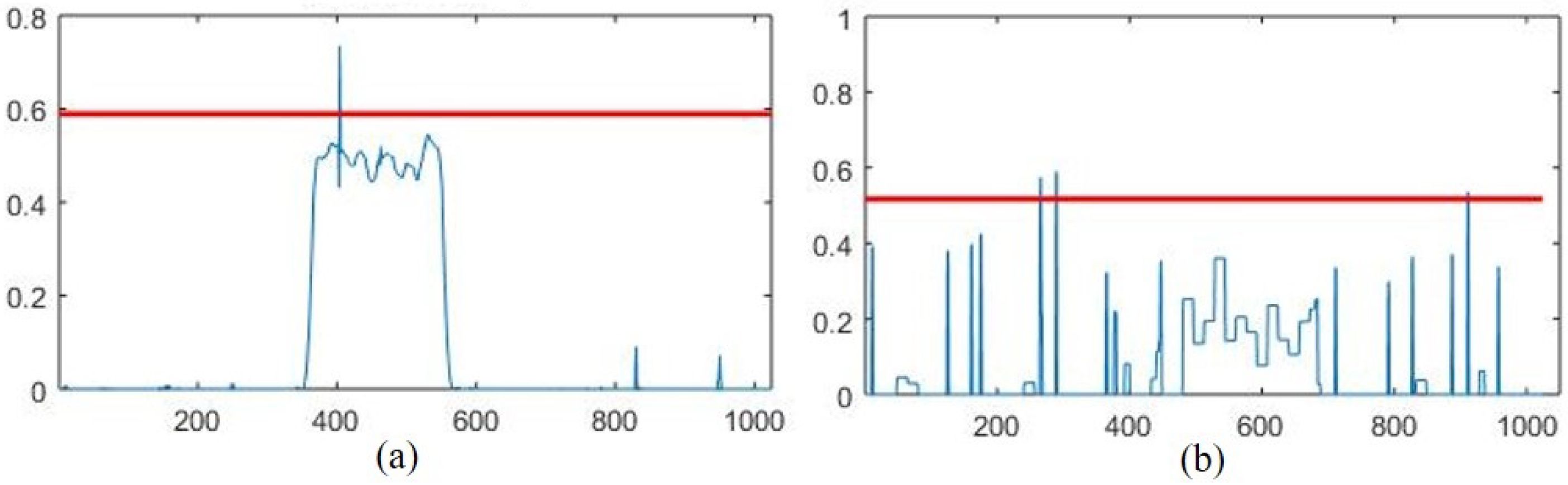
4.2. EMSPCA Motivation
4.3. Assessment of Fault Detection Performance of EMSPCA
5. Assessment of Fault Isolation Performance of EMSPCA
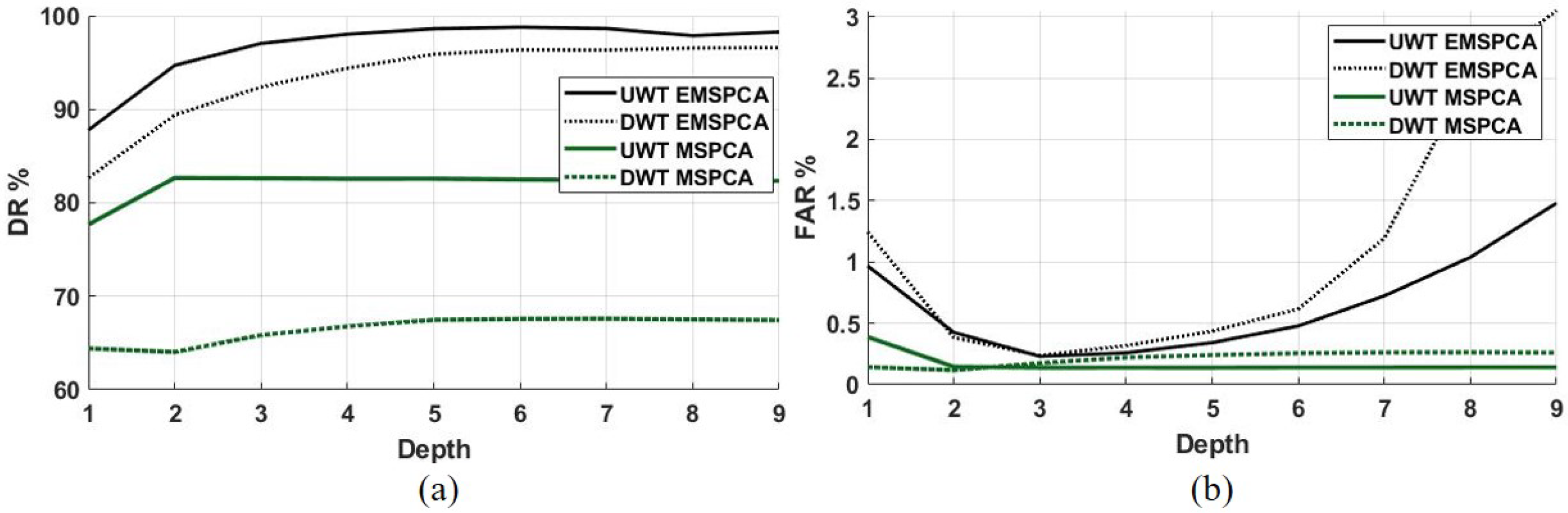
6. Impact of Decimated and Undecimated Wavelet Transforms
7. Assessment of Computational Time
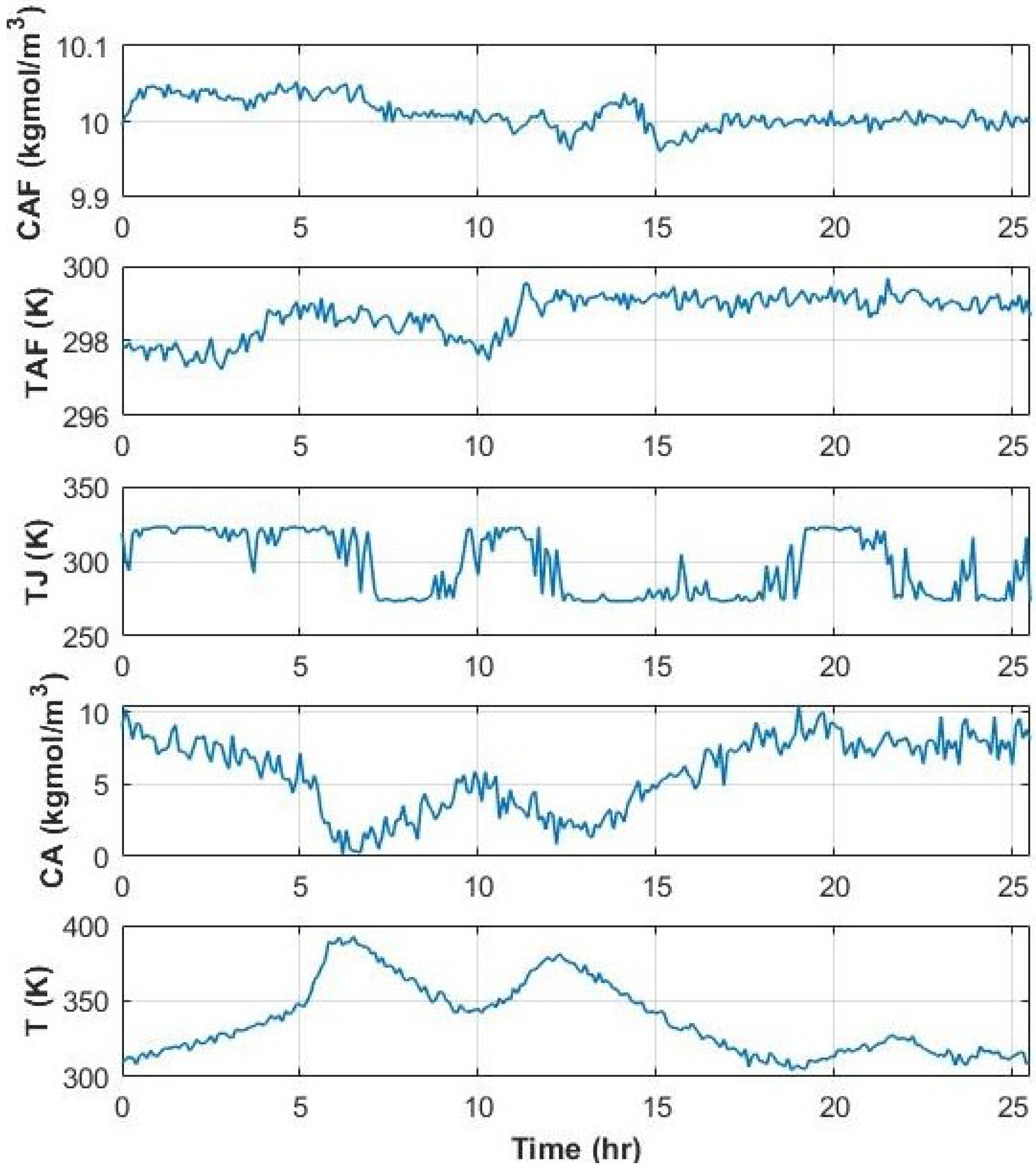
8. FDI in a CSTR Reactor Using EMSPCA
9. FDI in a Pilot Plant
10. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Nawaz, M.; Maulud, A.S.; Zabiri, H.; Taqvi, S.A.A.; Idris, A. Improved process monitoring using the CUSUM and EWMA-based multiscale PCA fault detection framework. Chin. J. Chem. Eng. 2021, 29, 253–265. [Google Scholar] [CrossRef]
- Lachouri, A.; Baiche, K.; Djeghader, R.; Doghmane, N.; Oulitati, S. Analyze and fault diagnosis by multi-scale PCA. In Proceedings of the 2008 3rd International Conference on Information and Communication Technologies: From Theory to Applications, ICTTA, Damascus, Syria, 7–11 April 2008. [Google Scholar] [CrossRef]
- Siti Nur, S.M.; Norhaliza, A.W. Fault detection and monitoring using multiscale principal component analysis at a sewage treatment plant. J. Teknol. 2014, 3, 87–92. [Google Scholar] [CrossRef][Green Version]
- Misra, M.; Yue, H.H.; Qin, S.J.; Ling, C. Multivariate process monitoring and fault diagnosis by multi-scale PCA. Comput. Chem. Eng. 2002, 26, 1281–1293. [Google Scholar] [CrossRef]
- Sheriff, M.Z.; Nounou, M.N. Improved Fault Detection and Process Safety Using Multiscale Shewhart Charts. J. Chem. Eng. Process. Technol. 2017, 8, 1–15. [Google Scholar] [CrossRef]
- Rajesh, G.; Das, T.K.; Venkataraman, V. Wavelet-based multiscale statistical process monitoring: A literature review. IIE Trans. 2004, 36, 787–806. [Google Scholar] [CrossRef]
- Bakshi, B. Multiscale PCA with application to multivariate statistical process monitoring. AIChE J. 1998, 44, 1596–1610. [Google Scholar] [CrossRef]
- Li, S.; Yang, S.; Cao, Y.; Ji, Z. Nonlinear dynamic process monitoring using deep dynamic principal component analysis. Syst. Sci. Control Eng. 2022, 10, 55–64. [Google Scholar] [CrossRef]
- Zheng, D.; Zhou, L.; Song, Z. Kernel Generalization of Multi-Rate Probabilistic Principal Component Analysis for Fault Detection in Nonlinear Process. IEEE/CAA J. Autom. Sin. 2021, 8, 1465–1476. [Google Scholar] [CrossRef]
- Shahzad, F.; Huang, Z.; Memon, W.H. Process Monitoring Using Kernel PCA and Kernel Density Estimation-Based SSGLR Method for Nonlinear Fault Detection. Appl. Sci. 2022, 12, 2981. [Google Scholar] [CrossRef]
- Amin, M.T.; Khan, F.; Ahmed, S.; Imtiaz, S. A data-driven Bayesian network learning method for process fault diagnosis. Process. Saf. Environ. Prot. 2021, 150, 110–122. [Google Scholar] [CrossRef]
- Zhang, H.; Wang, Y. Improved MSPCA with application to process monitoring. In Proceedings of the International Technology and Innovation Conference 2006 (ITIC 2006), Hangzhou, China, 6–7 November 2006; pp. 2257–2261. [Google Scholar] [CrossRef]
- Beenamol, M.; Prabavathy, S.; Mohanalin, J. Wavelet based seismic signal de-noising using Shannon and Tsallis entropy. Comput. Math. Appl. 2012, 64, 3580–3593. [Google Scholar] [CrossRef]
- Yellapu, V.S.; Zhang, W.; Vajpayee, V.; Xu, X. A multiscale data reconciliation approach for sensor fault detection. Prog. Nucl. Energy 2021, 135, 103707. [Google Scholar] [CrossRef]
- Chen, W.; Song, H. Automatic noise attenuation based on clustering and empirical wavelet transform. J. Appl. Geophys. 2018, 159, 649–665. [Google Scholar] [CrossRef]
- Li, X.; Dong, L.; Li, B.; Lei, Y.; Xu, N. Microseismic Signal Denoising via Empirical Mode Decomposition, Compressed Sensing, and Soft-thresholding. Appl. Sci. 2020, 10, 2191. [Google Scholar] [CrossRef]
- Peng, K.; Guo, H.; Shang, X. EEMD and Multiscale PCA-Based Signal Denoising Method and Its Application to Seismic P-Phase Arrival Picking. Sensors 2021, 21, 5271. [Google Scholar] [CrossRef] [PubMed]
- Yellapu, V.S.; Vajpayee, V.; Tiwari, A.P. Online Fault Detection and Isolation in Advanced Heavy Water Reactor Using Multiscale Principal Component Analysis. IEEE Trans. Nucl. Sci. 2019, 66, 1790–1803. [Google Scholar] [CrossRef]
- Yoon, S.; MacGregor, J.F. Fault diagnosis with multivariate statistical models part I: Using steady state fault signatures. J. Process Control 2001, 11, 387–400. [Google Scholar] [CrossRef]
- Alcala, C.F.; Qin, S.J. Reconstruction-based contribution for process monitoring. Automatica 2009, 45, 1593–1600. [Google Scholar] [CrossRef]
- Sheriff, M.Z.; Mansouri, M.; Karim, M.N.; Nounou, H.; Nounou, M. Fault detection using multiscale PCA-based moving window GLRT. J. Process Control 2017, 54, 47–64. [Google Scholar] [CrossRef]
- Nounou, M.N.; Bakshi, B.R. On-line multiscale filtering of random and gross errors without process models. AIChE J. 1999, 45, 1041–1058. [Google Scholar] [CrossRef]
- Qin, L.; Tong, C.; Lan, T.; Chen, Y. Statistical process monitoring based on just-in-time feature analysis. Control Eng. Pract. 2021, 115, 104889. [Google Scholar] [CrossRef]
- Li, S.; Tong, C.; Chen, Y.; Lan, T. Dynamic statistical process monitoring based on online dynamic discriminative feature analysis. J. Process Control 2021, 103, 67–75. [Google Scholar] [CrossRef]
- Chen, H.; Jiang, B.; Lu, N.; Mao, Z. Deep PCA Based Real-Time Incipient Fault Detection and Diagnosis Methodology for Electrical Drive in High-Speed Trains. IEEE Trans. Veh. Technol. 2018, 67, 4819–4830. [Google Scholar] [CrossRef]
- Haitao Burrus, C.; Sidney, G.R.G. Orthogonal Wavelets via Filter Banks Theory and Applications; Rice University: Houston, TX, USA, 2000; p. 281. [Google Scholar]
- A unified geometric approach to process and sensor fault identification and reconstruction: The unidimensional fault case. Comput. Chem. Eng. 1998, 22, 927–943. [CrossRef]
- Jackson, J.E. A User’s Guide to Principal Components; John Wiley & Sons: Hoboken, NJ, USA, 2005; Volume 587. [Google Scholar]
- Eastment, H.T.; Krzanowski, W.J. Cross-Validatory Choice of the Number of Components from a Principal Component Analysis. Technometrics 1982, 24, 73–77. [Google Scholar] [CrossRef]
- Krzanowski, W.J. Cross-validatory choice in principal component analysis; some sampling results. J. Stat. Comput. Simul. 1983, 18, 299–314. [Google Scholar] [CrossRef]
- Yue, H.H.; Qin, S.J. Reconstruction-based fault identification using a combined index. Ind. Eng. Chem. Res. 2001, 40, 4403–4414. [Google Scholar] [CrossRef]
- Alcala, C.F.; Qin, S.J. Analysis and generalization of fault diagnosis methods for process monitoring. J. Process Control 2011, 21, 322–330. [Google Scholar] [CrossRef]
- Nomikos, P.; MacGregor, J.F. Multivariate SPC charts for monitoring batch processes. Technometrics 1995, 37, 41–59. [Google Scholar] [CrossRef]
- Kourti, T.; MacGregor, J.F. Multivariate SPC Methods for Process and Product Monitoring. J. Qual. Technol. 1996, 28, 409–428. [Google Scholar] [CrossRef]
- Wang, S.; Xiao, F. Detection and diagnosis of AHU sensor faults using principal component analysis method. Energy Convers. Manag. 2004, 45, 2667–2686. [Google Scholar] [CrossRef]
- Xiao, D.; Gao, X.; Wang, J.; Mao, Y. Process Monitoring and Fault Diagnosis for Shell Rolling Production of Seamless Tube. Math. Probl. Eng. 2015, 2015, 219710. [Google Scholar] [CrossRef]
- Mnassri, B.; Adel, E.M.E.; Ouladsine, M. Reconstruction-based contribution approaches for improved fault diagnosis using principal component analysis. J. Process Control 2015, 33, 60–76. [Google Scholar] [CrossRef]
- Liu, J. Fault diagnosis using contribution plots without smearing effect on non-faulty variables. J. Process Control 2012, 22, 1609–1623. [Google Scholar] [CrossRef]
- Ji, H.; He, X.; Zhou, D. On the use of reconstruction-based contribution for fault diagnosis. J. Process Control 2016, 40, 24–34. [Google Scholar] [CrossRef]
- Kerkhof, P.V.D.; Vanlaer, J.; Gins, G.; Impe, J.F.V. Analysis of smearing-out in contribution plot based fault isolation for Statistical Process Control. Chem. Eng. Sci. 2013, 104, 285–293. [Google Scholar] [CrossRef]
- Perrin, C.; Walczak, B.; Massart, D.L. The Use of Wavelets for Signal Denoising in Capillary Electrophoresis. Anal. Chem. 2001, 73, 4903–4917. [Google Scholar] [CrossRef]
- Kehtarnavaz, N.; Kim, N. Chapter 7—Frequency Domain Processing; Newnes: Burlington, NJ, USA, 2005; pp. 139–145. [Google Scholar] [CrossRef]
- Valens, C. A Really Friendly Guide to Wavelets. 1999. Available online: http://www.staroceans.org/documents/A%20Really%20Friendly%20Guide%20to%20Wavelets.pdf (accessed on 1 January 2018).
- Nounou, H.N.; Nounou, M.N. Multiscale fuzzy Kalman filtering. Eng. Appl. Artif. Intell. 2006, 19, 439–450. [Google Scholar] [CrossRef]
- Gholizadeh, M.; Yazdizadeh, A.; Mohammad-Bagherpour, H. Fault detection and identification using combination of EKF and neuro-fuzzy network applied to a chemical process (CSTR). Pattern Anal. Appl. 2019, 22, 359–373. [Google Scholar] [CrossRef]
- Xu, F.; Puig, V.; Ocampo-Martinez, C.; Stoican, F.; Olaru, S. Actuator-fault detection and isolation based on set-theoretic approaches. J. Process Control 2014, 24, 947–956. [Google Scholar] [CrossRef]
- MathWorks. Non-Adiabatic Continuous Stirred Tank Reactor: MATLAB File Modeling with Simulations in Simulink. Available online: https://www.mathworks.com/help/ident/ug/non-adiabatic-continuous-stirred-tank-reactor-matlab-file-modeling-with-simulations-in-simulink.html (accessed on 16 January 2022).
- Bequette, B.W. Process Dynamics: Modeling, Analysis, and Simulation. B. Wayne Bequette; Prentice Hall PTR: Hoboken, NJ, USA, 1998. [Google Scholar]



















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Time (s/run) | DR (%) | FAR (%) | RB FIR (%) |
|---|---|---|---|---|
| PCA | 0.01 | 65.21 | 2.15 | 0.79 |
| MSPCA UWT | 0.11 | 80.26 | 0.16 | 0.96 |
| MSPCA DWT | 0.06 | 65.20 | 0.23 | 0.89 |
| EMSPCA UWT | 0.23 | 97.21 | 0.25 | 0.97 |
| EMSPCA DWT | 0.12 | 93.23 | 0.31 | 0.96 |
| Symbol | Parameter Description | Units |
|---|---|---|
| F | Volumetric flow rate | m/h |
| V | Volume in reactor | m |
| Pre-exponential non-thermal factor | 1/h | |
| E | Activation energy | kcal/kgmol |
| R | Boltzmann’s gas constant | kcal/(kgmol K) |
| Heat of reaction | kcal/kgmol | |
| Heat capacity | kcal/(kg K) | |
| Density | kg/m | |
| Overall heat transfer coefficient times tank area | kcal/(K h) |
| Method | Shift-In-Mean | Complete Failure | Drift | Precision Degradation | Average | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| DR | FA | DR | FA | DR | FA | DR | FA | DR | FA | |
| PCA | 70 | 1.7 | 64 | 1.8 | 64 | 1.8 | 76 | 1.8 | 69 | 1.8 |
| MSPCA UWT | 76 | 0.4 | 71 | 0.4 | 68 | 0.5 | 74 | 0.5 | 72 | 0.5 |
| MSPCA DWT | 76 | 1.7 | 72 | 1.8 | 68 | 1.7 | 76 | 2 | 73 | 1.8 |
| EMSPCA UWT | 95 | 0.4 | 89 | 0.5 | 82 | 0.5 | 81 | 0.5 | 87 | 0.5 |
| EMSPCA DWT | 93 | 0.5 | 86 | 0.5 | 80 | 0.5 | 83 | 0.6 | 86 | 0.5 |
| Method | Shift-in-Mean | Complete Failure | Drift | Precision Degradation | Average | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| RB | CD | RB | CD | RB | CD | RB | CD | RB | CD | |
| PCA | 57 | 47 | 58 | 47 | 60 | 47 | 77 | 52 | 63 | 48 |
| MSPCA UWT | 66 | 48 | 68 | 50 | 70 | 48 | 79 | 52 | 71 | 50 |
| MSPCA DWT | 53 | 43 | 54 | 45 | 54 | 40 | 64 | 43 | 56 | 43 |
| EMSPCA UWT | 85 | 85 | 87 | 86 | 87 | 86 | 93 | 91 | 88 | 87 |
| EMSPCA DWT | 85 | 84 | 86 | 84 | 87 | 86 | 93 | 91 | 88 | 86 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Malluhi, B.; Nounou, H.; Nounou, M. Enhanced Multiscale Principal Component Analysis for Improved Sensor Fault Detection and Isolation. Sensors 2022, 22, 5564. https://doi.org/10.3390/s22155564
Malluhi B, Nounou H, Nounou M. Enhanced Multiscale Principal Component Analysis for Improved Sensor Fault Detection and Isolation. Sensors. 2022; 22(15):5564. https://doi.org/10.3390/s22155564
Chicago/Turabian StyleMalluhi, Byanne, Hazem Nounou, and Mohamed Nounou. 2022. "Enhanced Multiscale Principal Component Analysis for Improved Sensor Fault Detection and Isolation" Sensors 22, no. 15: 5564. https://doi.org/10.3390/s22155564
APA StyleMalluhi, B., Nounou, H., & Nounou, M. (2022). Enhanced Multiscale Principal Component Analysis for Improved Sensor Fault Detection and Isolation. Sensors, 22(15), 5564. https://doi.org/10.3390/s22155564