
Automatic Roadside Feature Detection Based on Lidar Road Cross Section Images



Abstract
:1. Introduction
Related Works
2. Materials and Methods
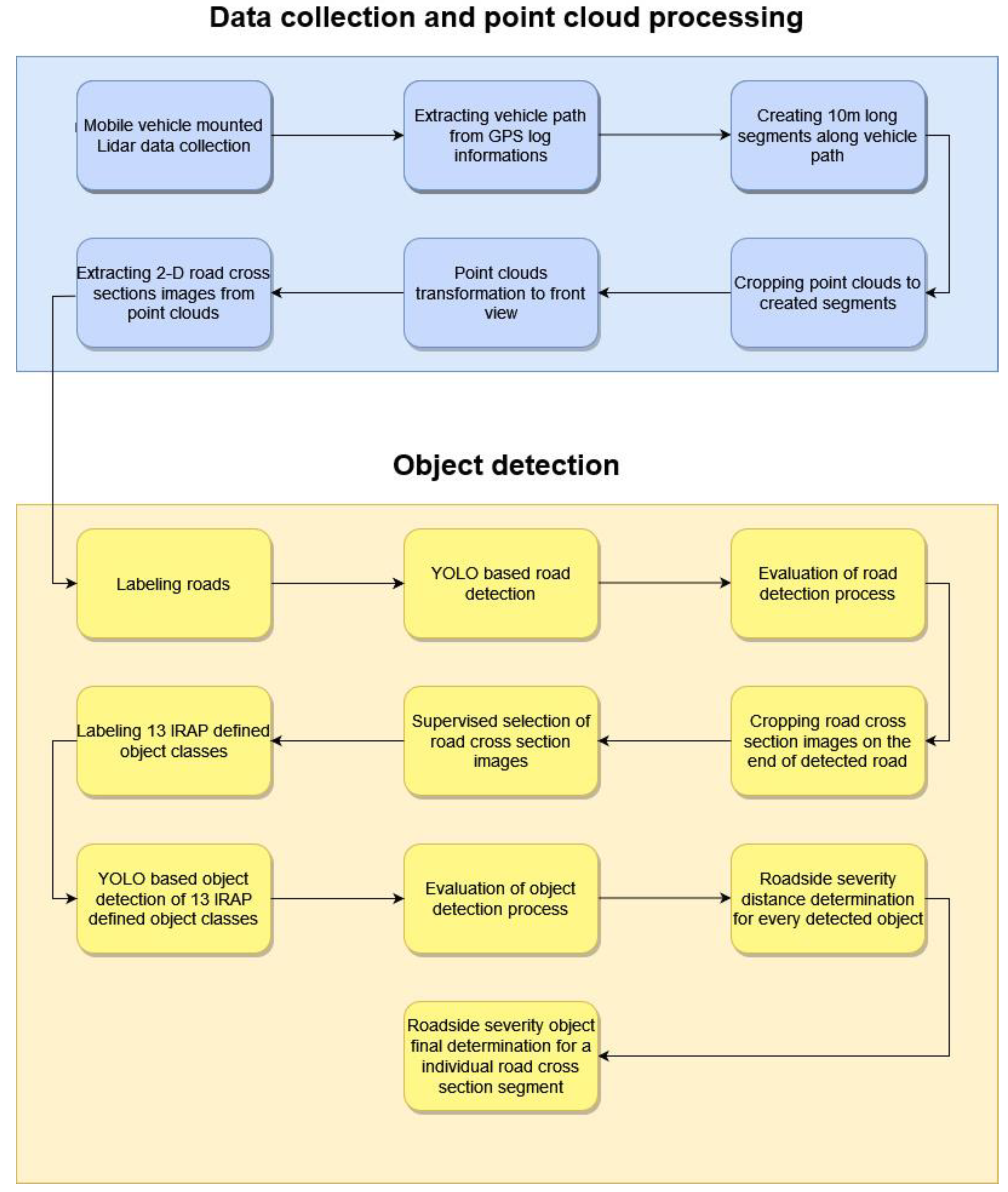
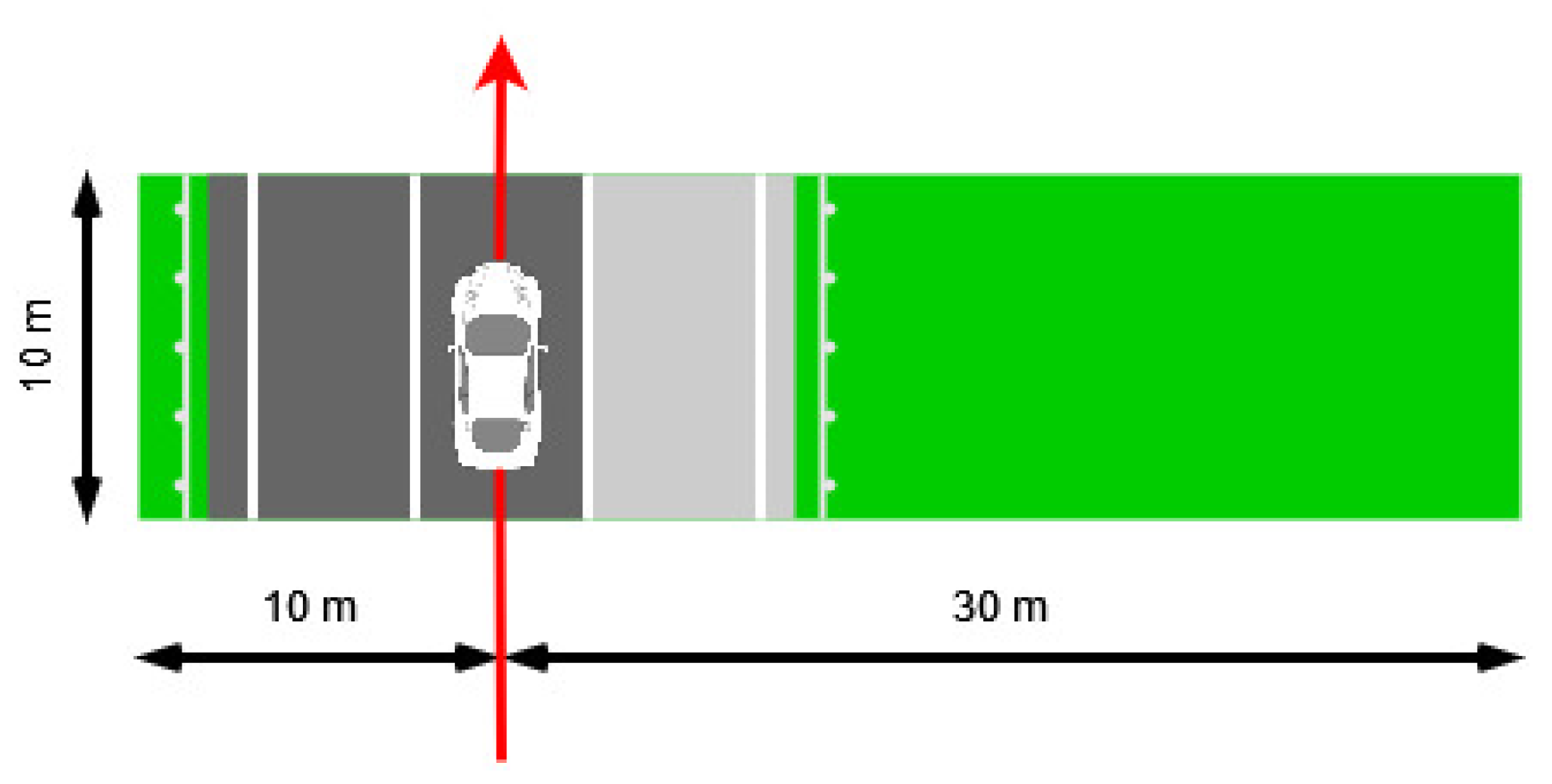
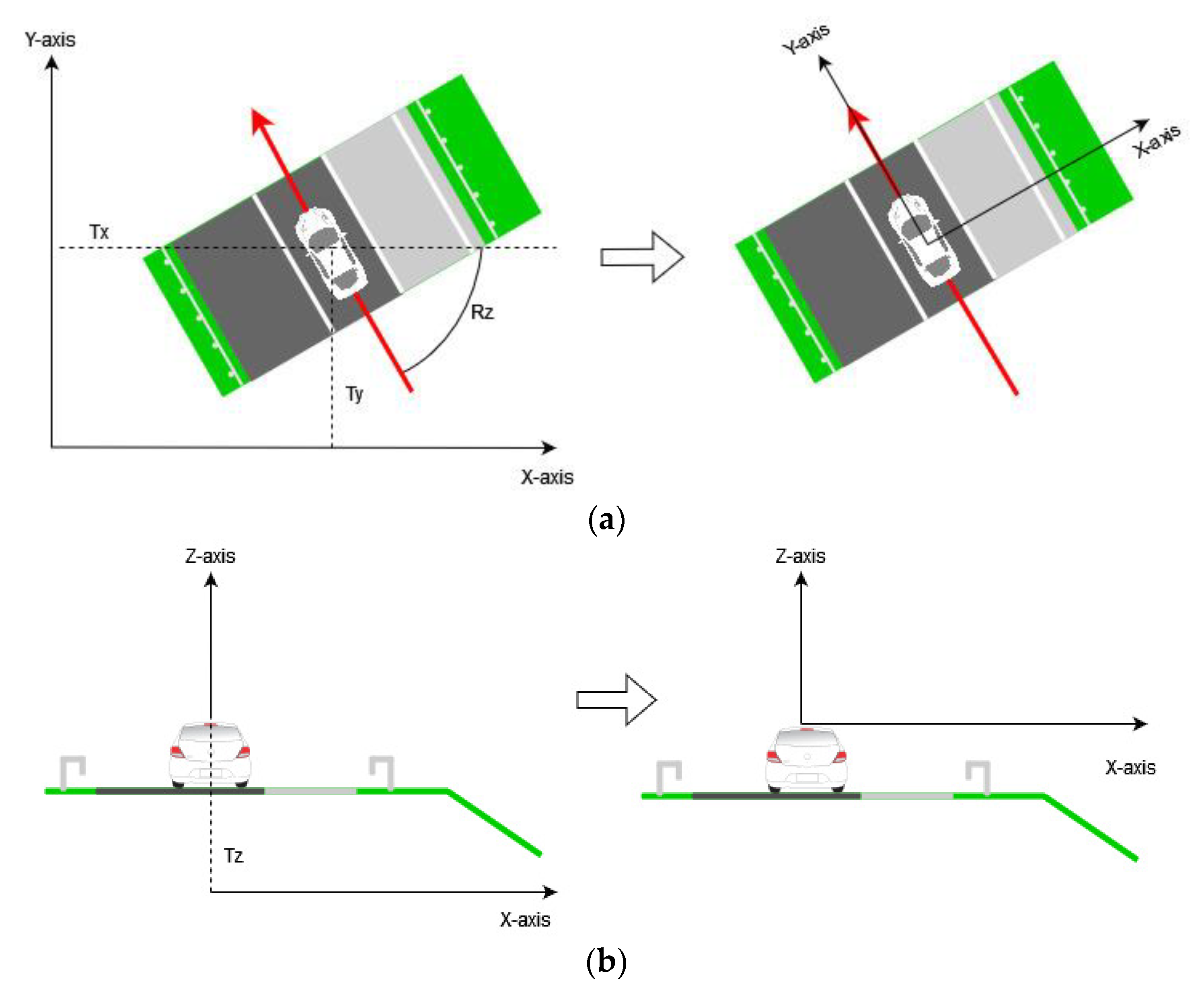
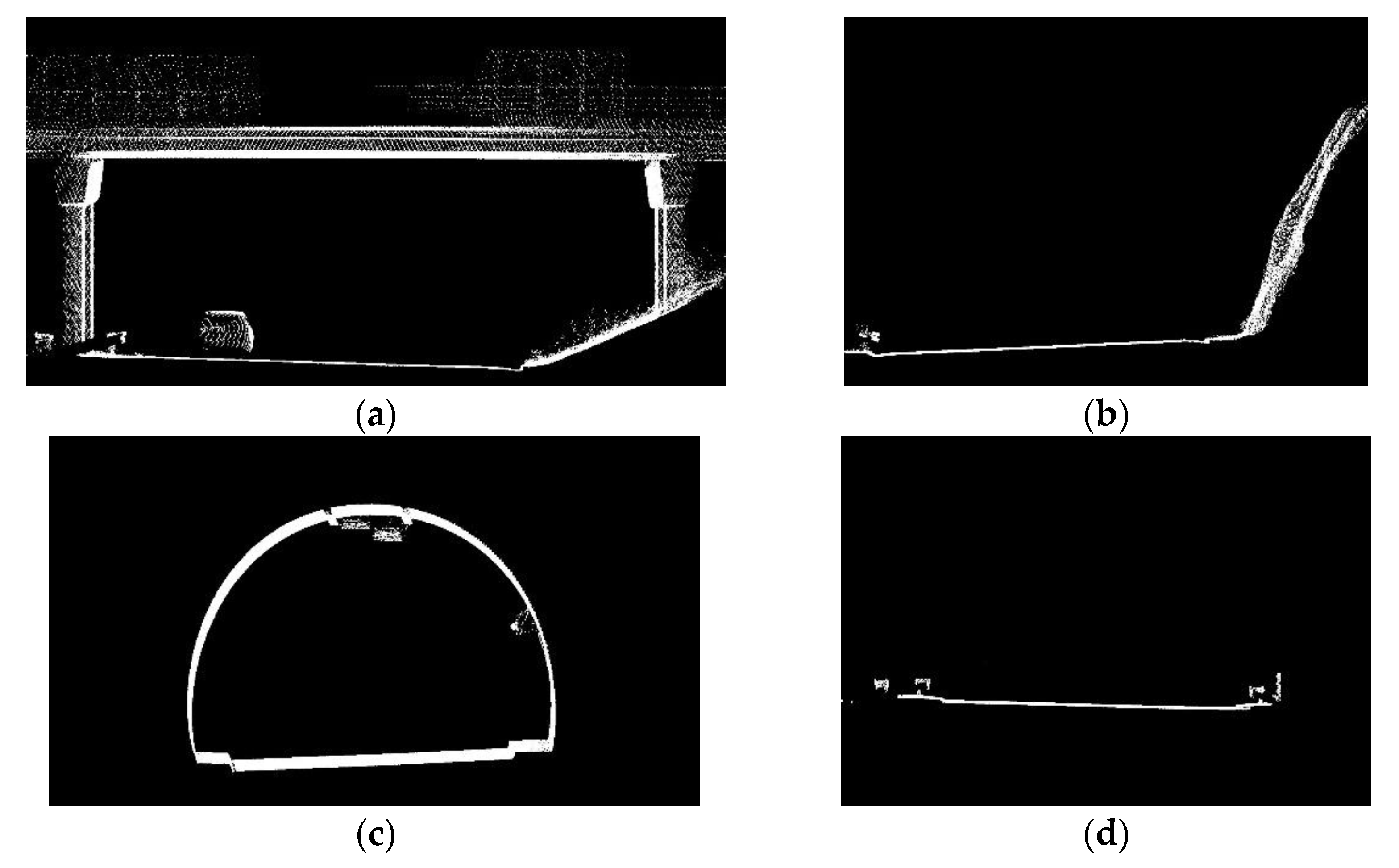
2.1. Data Collection with Point Cloud Processing
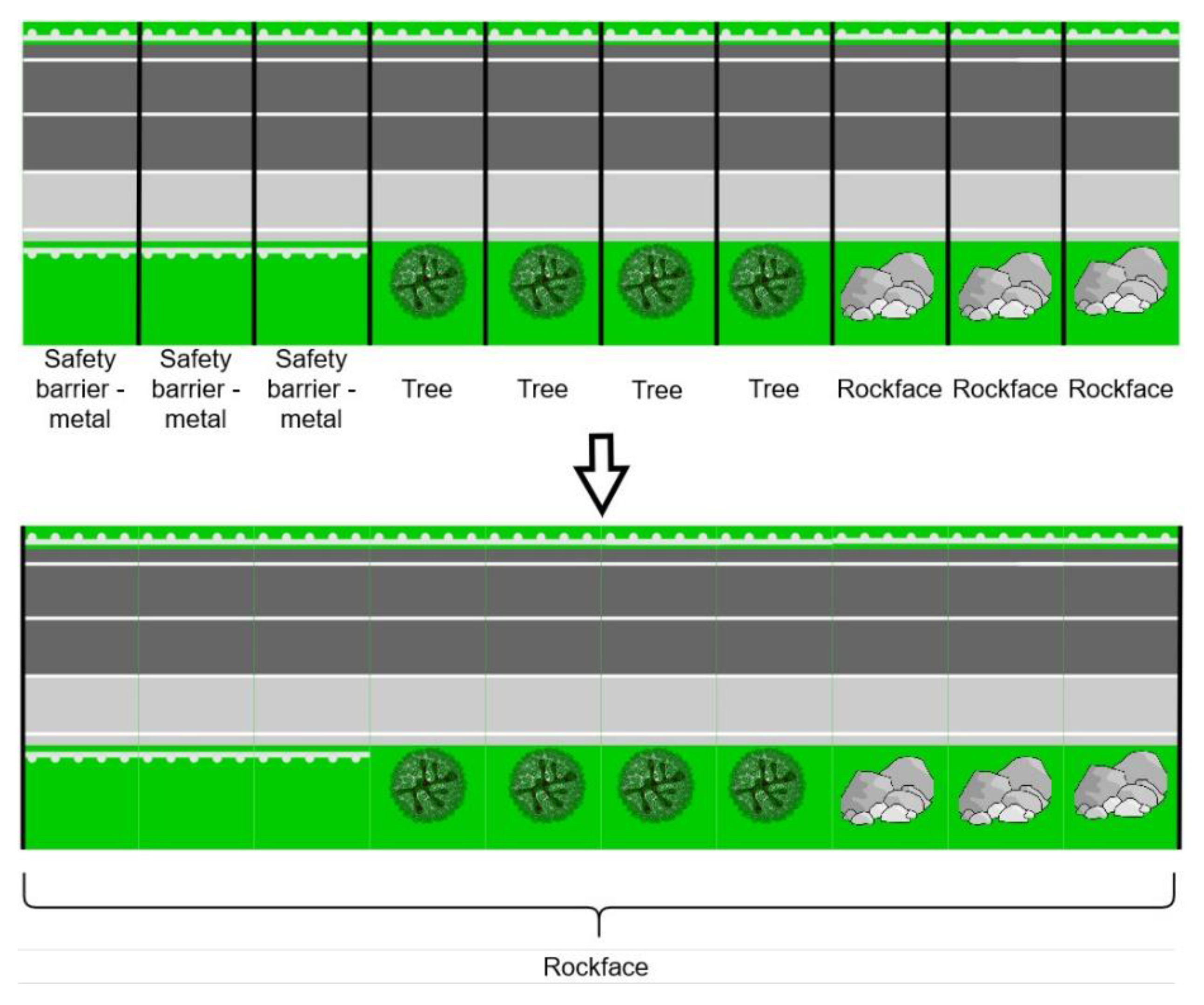
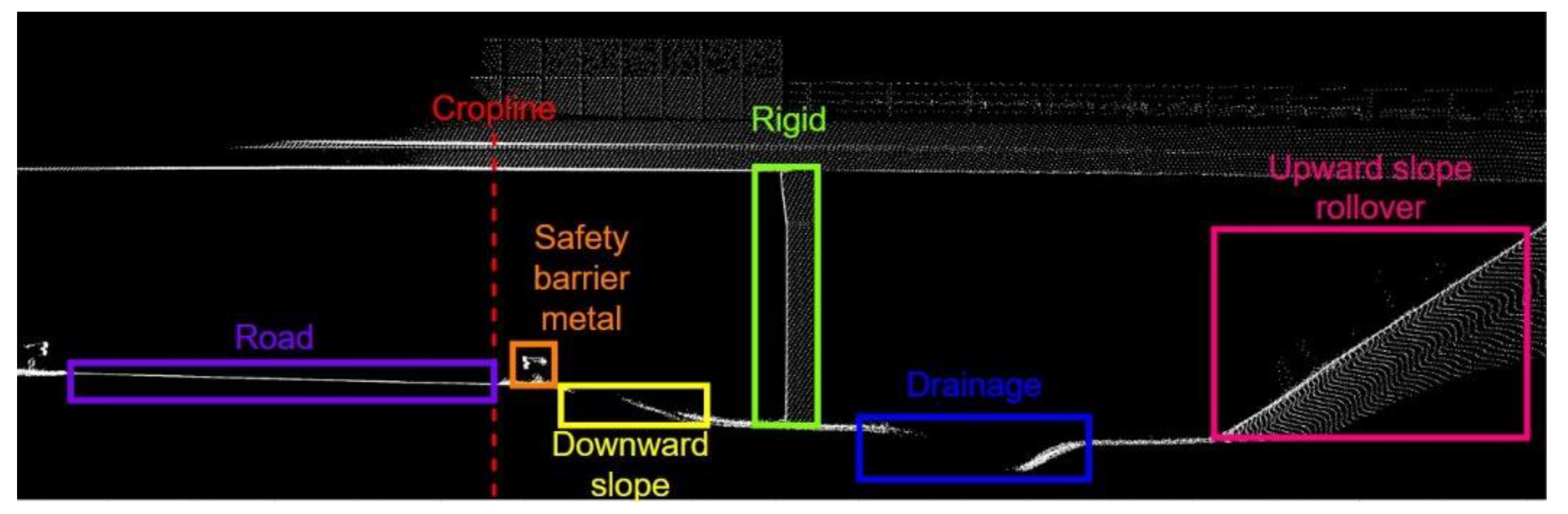
2.2. Object Detection
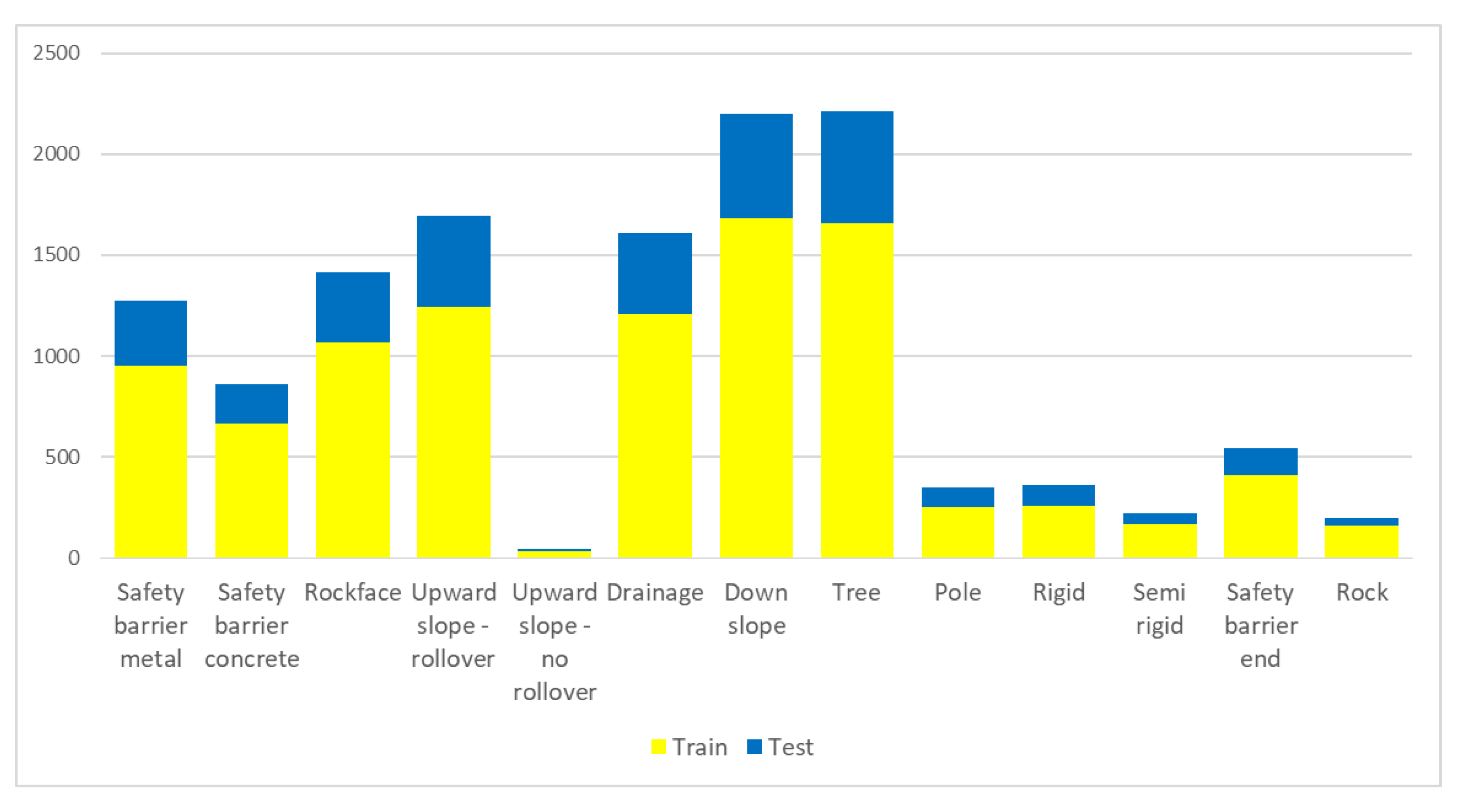
3. Results
3.1. Object Detection Evaluation
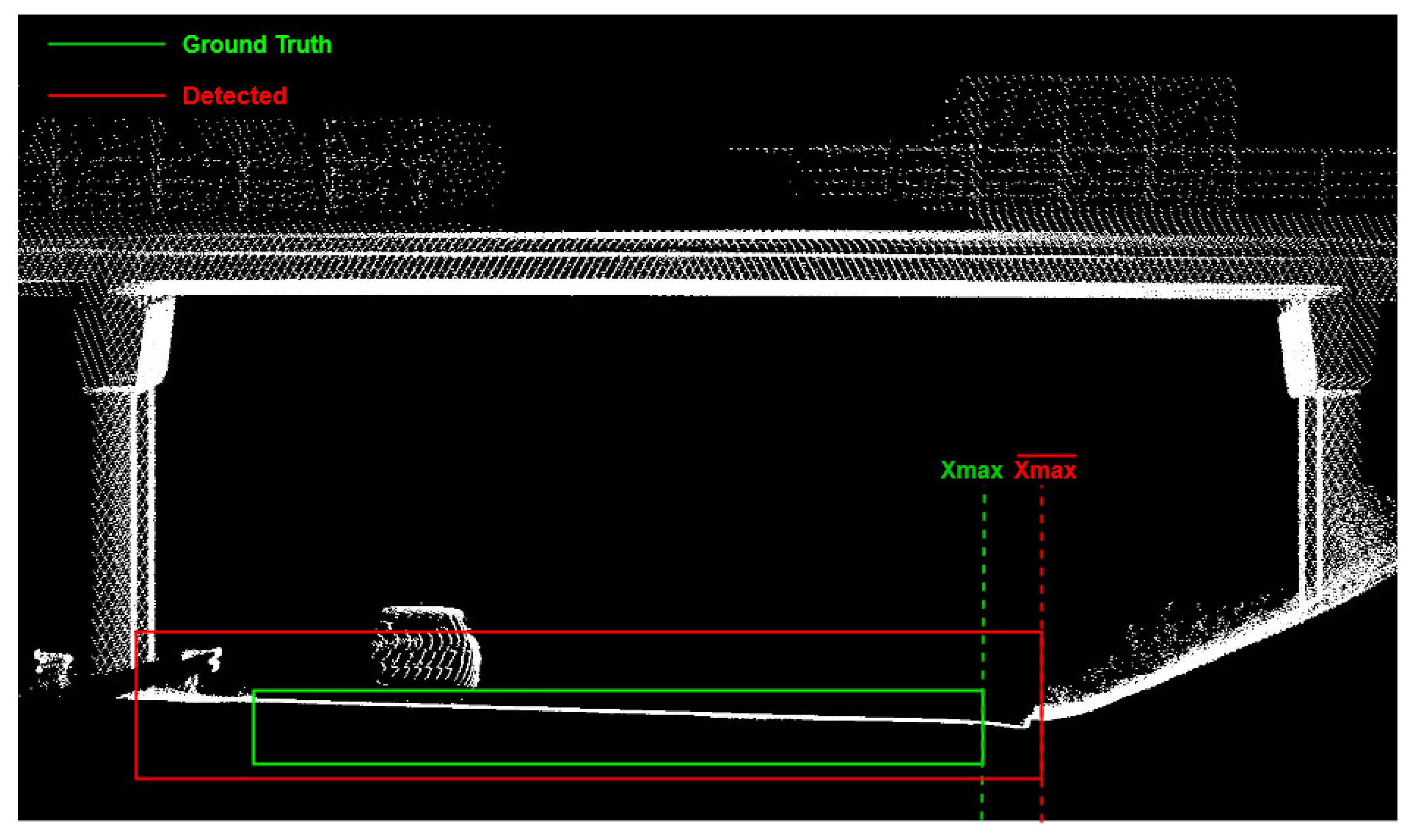
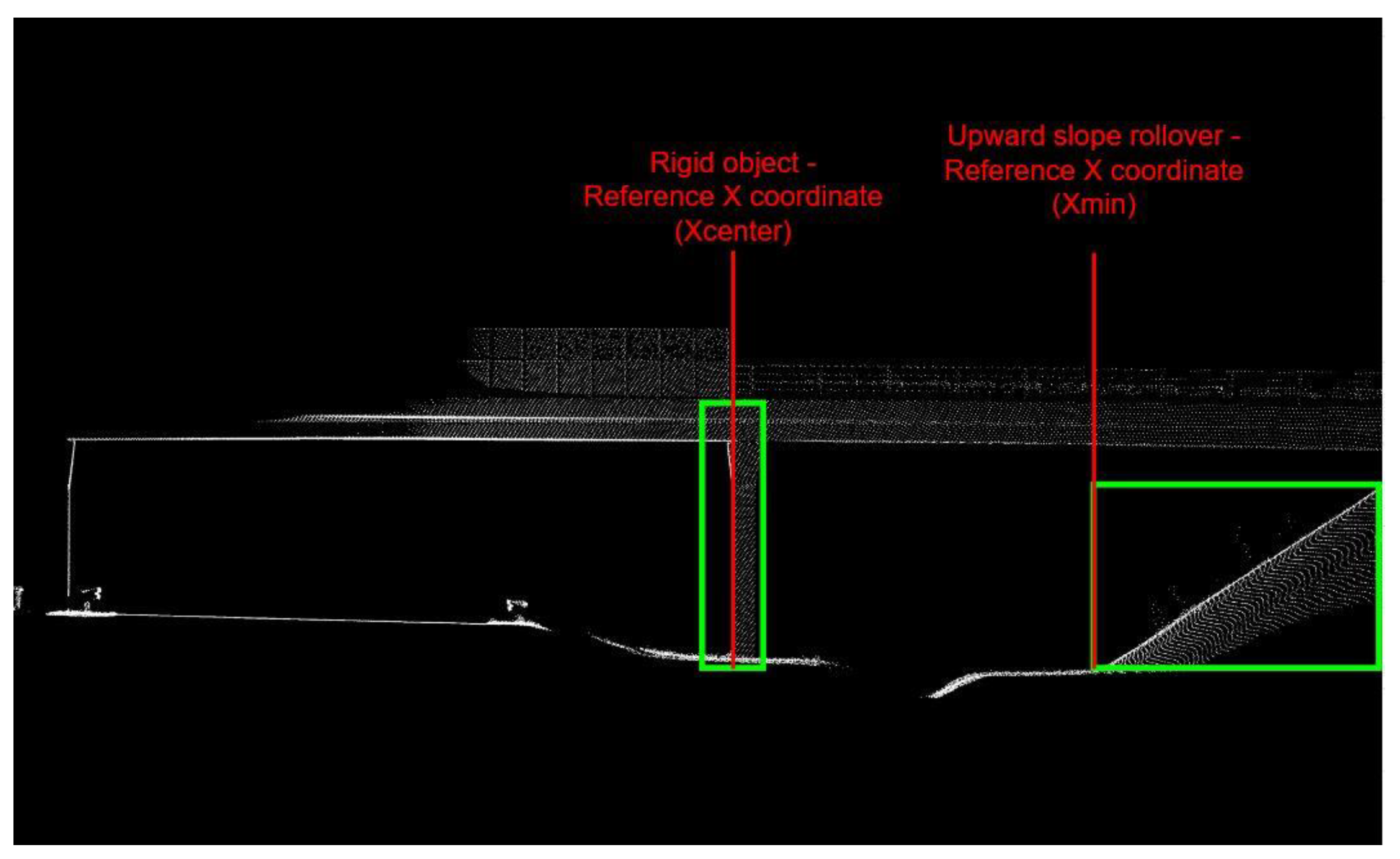
3.2. Spatial Accuracy of Detected Objects
3.3. Evaluation of Road Segments Classification
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Passmore, J.; Yon, Y.; Mikkelsen, B. Progress in Reducing Road-Traffic Injuries in the WHO European Region. Lancet Public Health 2019, 4, e272–e273. [Google Scholar] [CrossRef] [Green Version]
- World Health Organization (WHO). Global Status Report on Road Safety 2018 Summary. Available online: https://www.who.int/publications/i/item/9789241565684 (accessed on 25 April 2022).
- United Nations (UN). Voluntary Global Performance Targets for Road Safety Risk Factors and Service Delivery Mechanisms and Corresponding Indicators. Available online: https://www.grsproadsafety.org/wp-content/uploads/Towards-the-12-Voluntary-Global-Targets-for-Road-Safety.pdf (accessed on 25 April 2022).
- United Nations (UN). Available online: https://www.un.org/sites/un2.un.org/files/2020/09/road_safety_strategy_booklet.pdf (accessed on 25 April 2022).
- International Road Assessment Programme (iRAP). IRAP Coding Manual Drive on the Right Edition. Available online: www.irap.org/specifications (accessed on 25 April 2022).
- International Road Assesment Programme (iRAP). IRAP Star Rating and Investment Plan Implementation Support Guide; iRAP: London, UK, 2021. [Google Scholar]
- The European Parliament and the Council of the European Union. Directives of the European Parliament and of the Council of 11 December 2013 on Union Guidelines for the Development of the Trans-European Transport Network and Repealing Decision; The European Parliament: Strasbourg, France, 2019. [Google Scholar]
- Brkić, I.; Miler, M.; Ševrović, M.; Medak, D. An Analytical Framework for Accurate Traffic Flow Parameter Calculation from UAV Aerial Videos. Remote Sens. 2020, 12, 3844. [Google Scholar] [CrossRef]
- Khan, M.A.; Ectors, W.; Bellemans, T.; Janssens, D.; Wets, G. Unmanned Aerial Vehicle-Based Traffic Analysis: A Case Study for Shockwave Identification and Flow Parameters Estimation at Signalized Intersections. Remote Sens. 2018, 10, 458. [Google Scholar] [CrossRef] [Green Version]
- Ke, R.; Li, Z.; Tang, J.; Pan, Z.; Wang, Y. Real-Time Traffic Flow Parameter Estimation from UAV Video Based on Ensemble Classifier and Optical Flow. IEEE Trans. Intell. Transp. Syst. 2019, 20, 54–64. [Google Scholar] [CrossRef]
- Chen, X.; Li, Z.; Yang, Y.; Qi, L.; Ke, R. High-Resolution Vehicle Trajectory Extraction and Denoising from Aerial Videos. IEEE Trans. Intell. Transp. Syst. 2021, 22, 3190–3202. [Google Scholar] [CrossRef]
- Leduc, G. Road Traffic Data: Collection Methods and Applications, Working Papers on Energy. Work. Pap. Energy Transp. Clim. Change 2008, 1, 1–55. [Google Scholar]
- Handscombe, J.; Yu, H.Q. Low-Cost and Data Anonymised City Traffic Flow. Sensors 2019, 19, 347. [Google Scholar] [CrossRef] [Green Version]
- Martinez, A.P. Freight Traffic Data in the City of Eindhoven, University of Technology Eindhoven. 2015. Available online: https://pure.tue.nl/ws/portalfiles/portal/47039665/801382-1.pdf (accessed on 25 April 2022).
- Kacan, M.; Oršic, M.; Šegvic, S.; Ševrovic, M. Multi-Task Learning for IRAP Attribute Classification and Road Safety Assessment. In Proceedings of the 2020 IEEE 23rd International Conference on Intelligent Transportation Systems, ITSC 2020, Rhodes, Greece, 20–23 September 2020. [Google Scholar] [CrossRef]
- Graf, S.; Pagany, R.; Dorner, W.; Weigold, A. Georeferencing of Road Infrastructure from Photographs Using Computer Vision and Deep Learning for Road Safety Applications. In Proceedings of the 5th International Conference on Geographical Information Systems Theory, Applications and Managem (GISTAM 2019), Heraklion, Crete, 3–5 May 2019. [Google Scholar] [CrossRef]
- Sanjeewani, P.; Verma, B. Optimization of Fully Convolutional Network for Road Safety Attribute Detection. IEEE Access 2021, 9, 120525–120536. [Google Scholar] [CrossRef]
- Sanjeewani, P.; Verma, B. Single Class Detection-Based Deep Learning Approach for Identification of Road Safety Attributes. Neural Comput. Appl. 2021, 33, 9691–9702. [Google Scholar] [CrossRef]
- Björnstig, U.; Björnstig, J. Flying Roadside Stones—A Deadly Risk in a Crash. Traffic Saf. Res. 2021, 1, 000002. [Google Scholar] [CrossRef]
- Song, W. Image-Based Roadway Assessment Using Convolutional Neural Networks. Master’s Theis, University of Kentucky, Lexington, Kentucky, 2019. [Google Scholar] [CrossRef]
- Ai-RAP–IRAP. Available online: https://irap.org/project/ai-rap/ (accessed on 26 April 2022).
- Antonio Martín-Jiménez, J.; Zazo, S.; Arranz Justel, J.J.; Rodríguez-Gonzálvez, P.; González-Aguilera, D. Road Safety Evaluation through Automatic Extraction of Road Horizontal Alignments from Mobile LiDAR System and Inductive Reasoning Based on a Decision Tree. ISPRS J. Photogramm. Remote Sens. 2018, 146, 334–346. [Google Scholar] [CrossRef] [Green Version]
- Zhong, M.; Verma, B.; Affum, J. Neural Information Processing; Gedeon, T., Wong, K.W., Lee, M., Eds.; Springer International Publishing: Cham, Switzerland, 2019; Volume 11954, ISBN 978 3 030 36710 7. [Google Scholar]
- Ziakopoulos, A.; Yannis, G. A Review of Spatial Approaches in Road Safety. Accid. Anal. Prev. 2020, 135, 105323. [Google Scholar] [CrossRef] [PubMed]
- Jan, Z.; Verma, B.; Affum, J.; Atabak, S.; Moir, L. A Convolutional Neural Network Based Deep Learning Technique for Identifying Road Attributes. In Proceedings of the 2018 International Conference on Image and Vision Computing New Zealand (IVCNZ), Auckland, New Zealand, 19–21 November 2018. [Google Scholar] [CrossRef]
- Sanjeewani, P.; Verma, B. An Optimisation Technique for the Detection of Safety Attributes Using Roadside Video Data. In Proceedings of the 2020 35th International Conference on Image and Vision Computing New Zealand (IVCNZ), Wellington, New Zealand, 25–27 November 2020. [Google Scholar] [CrossRef]
- Zhong, M.; Verma, B.; Affirm, J. Point Cloud Classification for Detecting Roadside Safety Attributes and Distances. In Proceedings of the 2019 IEEE Symposium Series on Computational Intelligence, SSCI 2019, Xiamen, China, 6–9 December 2019; pp. 1078–1084. [Google Scholar] [CrossRef]
- Pubudu Sanjeewani, T.G.; Verma, B. Learning and Analysis of AusRAP Attributes from Digital Video Recording for Road Safety. In Proceedings of the 2019 International Conference on Image and Vision Computing New Zealand (IVCNZ), Dunedin, New Zealand, 2–4 December 2019. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022. [Google Scholar]
- Ural, S.; Shan, J.; Romero, M.A.; Tarko, A. Road and Roadside Feature Extraction Using Imagery and Lidar Data for Transportation Operation. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2015, 2, 239–246. [Google Scholar] [CrossRef] [Green Version]
- Han, X.; Wang, H.; Lu, J.; Zhao, C. Road Detection Based on the Fusion of Lidar and Image Data. Int. J. Adv. Robot. Syst. 2017, 14. [Google Scholar] [CrossRef] [Green Version]
- Zeybek, M. Extraction of Road Lane Markings from Mobile LiDAR Data. Transp. Res. Rec. J. Transp. Res. Board 2021, 2675, 30–47. [Google Scholar] [CrossRef]
- Roodaki, H.; Bojnordi, M.N. Compressed Geometric Arrays for Point Cloud Processing. arXiv 2021, arXiv:2110.11616. [Google Scholar]
- Wu, Y.; Wang, Y.; Zhang, S.; Ogai, H. Deep 3D Object Detection Networks Using LiDAR Data: A Review. IEEE Sens. J. 2021, 21, 1152–1171. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Jiang, P.; Ergu, D.; Liu, F.; Cai, Y.; Ma, B. A Review of Yolo Algorithm Developments. Procedia Comput. Sci. 2021, 199, 1066–1073. [Google Scholar] [CrossRef]
- Henderson, P.; Ferrari, V. End-to-End Training of Object Class Detectors for Mean Average Precision. In Proceedings of the Asian Conference on Computer Vision 2016, Taipei, Taiwan, 20–24 November 2016. [Google Scholar] [CrossRef]
- Oksuz, K.; Cam, B.C.; Akbas, E.; Kalkan, S. Localization Recall Precision (LRP): A New Performance Metric for Object Detection. In Proceedings of the European Conference on Computer Vision (ECCV); Springer: Cham, Switzerland, 2018; ISBN 978-3-030-01234-2. [Google Scholar]
- Davis, J.; Goadrich, M. The Relationship Between Precision-Recall and ROC Curves. In Proceedings of the 23rd International Conference on Machine Learning 2006, New York, NY, USA, 25–29 June 2006. [Google Scholar] [CrossRef] [Green Version]
- Stitt, J.M.; Svancara, L.K.; Vierling, L.A.; Vierling, K.T. Smartphone LIDAR Can Measure Tree Cavity Dimensions for Wildlife Studies. Wildl. Soc. Bull. 2019, 43, 159–166. [Google Scholar] [CrossRef] [Green Version]
- Chan, J.; Raghunath, A.; Michaelsen, K.E.; Gollakota, S. Testing a Drop of Liquid Using Smartphone LiDAR. In Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies; ACM: New York, NY, USA, 2022; Volume 6, p. 27. [Google Scholar] [CrossRef]
- Tavani, S.; Billi, A.; Corradetti, A.; Mercuri, M.; Bosman, A.; Cuffaro, M.; Seers, T.; Carminati, E. Smartphone Assisted Fieldwork: Towards the Digital Transition of Geoscience Fieldwork Using LiDAR-Equipped IPhones. Earth-Sci. Rev. 2022, 227, 103969. [Google Scholar] [CrossRef]
- Wolcott, R.W.; Eustice, R.M. Robust LIDAR Localization Using Multiresolution Gaussian Mixture Maps for Autonomous Driving. Int. J. Robot. Res. 2017, 36, 292–319. [Google Scholar] [CrossRef]
- Li, Y.; Ma, L.; Zhong, Z.; Liu, F.; Chapman, M.A.; Cao, D.; Li, J. Deep Learning for LiDAR Point Clouds in Autonomous Driving: A Review. IEEE Trans. Neural Netw. Learn. Syst. 2021, 32, 3412–3432. [Google Scholar] [CrossRef] [PubMed]
- Li, Y.; Ibanez-Guzman, J. Lidar for Autonomous Driving: The Principles, Challenges, and Trends for Automotive Lidar and Perception Systems. IEEE Signal Processing Mag. 2020, 37, 50–61. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| System Module | Parameter | Value |
|---|---|---|
| Laser scanning | Accuracy | 10 mm |
| Precision | 5 mm | |
| Frequency | Variable: 50–300 kHz (×2) | |
| Range | @50 kHz: 180 m σ ≥ 10%; 500 m σ ≥ 80% | |
| @300 kHz: 75 m σ ≥ 10%; 200 m σ ≥ 80% | ||
| Imaging modules | 15 MP Forward panorama | Yes |
| 15 MP Rear panorama | Optional | |
| 5 MP Oblique Surface | Yes | |
| Positioning | POS LV 420 |
| Ground Truth | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Safety Barrier Metal | Safety Barrier Concrete | Rockface | Upward Slope-Rollover | Upward Slone-No Rollover | Drainage | Down Slope | Tree | Pole | Rigid | Semi rigid | Safety Barrier End | Rock | Background False Positive | ||
| Predicted | Safety barrier metal | 92.9 | 0.5 | 8.3 | 7.4 | ||||||||||
| Safety barrier concrete | 98.0 | 0.2 | |||||||||||||
| Rockface | 78.5 | 3.6 | 10.7 | ||||||||||||
| Upward slope-rollover | 10.9 | 82.7 | 8.3 | 14.5 | |||||||||||
| Upward slope-no rollover | 83.3 | 0.2 | |||||||||||||
| Drainage | 94.3 | 0.2 | 12.1 | ||||||||||||
| Down slope | 81.3 | 19.9 | |||||||||||||
| Tree | 90.2 | 23.5 | |||||||||||||
| Pole | 75.0 | 2.4 | |||||||||||||
| Rigid | 8.3 | 79.8 | 1.8 | ||||||||||||
| Semi rigid | 1.0 | 89.3 | 2.6 | ||||||||||||
| Safety barrier end | 2.8 | 1.8 | 88.0 | 4.0 | |||||||||||
| Rock | 75.0 | 0.6 | |||||||||||||
| Background False Negative | 4.3 | 1.5 | 10.6 | 13.7 | 0.0 | 5.7 | 18.5 | 9.8 | 25.0 | 19.2 | 8.9 | 3.8 | 25.0 | ||
| Recall | Precision | AP | |
|---|---|---|---|
| Safety barrier metal | 0.87 | 0.92 | 0.91 |
| Safety barrier concrete | 0.99 | 0.98 | 0.98 |
| Rockface | 0.81 | 0.77 | 0.72 |
| Upward slope-rollover | 0.77 | 0.81 | 0.76 |
| Upward slope-no rollover | 0.90 | 0.83 | 0.83 |
| Drainage | 0.87 | 0.93 | 0.91 |
| Down slope | 0.78 | 0.89 | 0.85 |
| Tree | 0.81 | 0.88 | 0.82 |
| Pole | 0.87 | 0.71 | 0.73 |
| Rigid | 0.88 | 0.78 | 0.76 |
| Semi rigid | 0.78 | 0.89 | 0.87 |
| Safety barrier end | 0.79 | 0.88 | 0.85 |
| Rock | 0.90 | 0.75 | 0.74 |
| Mean | 0.85 | 0.85 | 0.83 |
| RMSE (m) | |
|---|---|
| Safety barrier metal | 0.05 |
| Safety barrier concrete | 0.06 |
| Rockface | 0.27 |
| Upward slope-rollover | 0.65 |
| Upward slope-no rollover | 0.12 |
| Drainage | 0.73 |
| Down slope | 0.36 |
| Tree | 0.65 |
| Pole | 0.09 |
| Rigid | 0.08 |
| Semi rigid | 0.15 |
| Safety barrier end | 0.05 |
| Rock | 0.05 |
| Mean | 0.25 |
| Ground Truth | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Safety Barrier Metal | Safety Barrier Concrete | Rockface | Upward Slope-Rollover | Upward Slone-No Rollover | Drainage | Down Slope | Tree | Pole | Rigid | Semi Rigid | Safety Barrier End | Rock | ||
| Predicted | Safety barrier metal | 78.6 | 0.4 | 0.6 | 0.5 | 1.1 | 1.3 | 2.8 | 2.4 | |||||
| Safety barrier concrete | 93.0 | 0.0 | 0.3 | 1.3 | 0.6 | |||||||||
| Rockface | 84.1 | 5.7 | 0.2 | 2.6 | 1.4 | 6.1 | 0.8 | 20.0 | ||||||
| Upward slope-rollover | 1.9 | 8.3 | 88.1 | 0.5 | 0.2 | 3.9 | 2.0 | 0.8 | ||||||
| Upward slope-no rollover | 90.0 | |||||||||||||
| Drainage | 2.9 | 0.9 | 0.7 | 0.3 | 85.2 | 4.2 | 1.3 | 1.4 | ||||||
| Down slope | 4.9 | 6.1 | 0.4 | 10.1 | 84.4 | 8.4 | 1.4 | 3.1 | ||||||
| Tree | 1.9 | 1.1 | 1.8 | 1.1 | 5.0 | 77.3 | 1.4 | 6.1 | 2.4 | |||||
| Pole | 1.9 | 0.3 | 0.6 | 86.1 | 0.8 | |||||||||
| Rigid | 0.3 | 10.0 | 1.4 | 81.6 | ||||||||||
| Semi rigid | 1.9 | 0.0 | 93.1 | |||||||||||
| Safety barrier end | 5.8 | 2.2 | 0.3 | 1.1 | 0.7 | 0.6 | 2.0 | 6.9 | 89.8 | |||||
| Rock | 1.3 | 77.1 | ||||||||||||
| None | 2.9 | 2.4 | 1.6 | 2.9 | 1.9 | 4.2 | 2.0 | 2.9 | ||||||
| Ground Truth | |||||
|---|---|---|---|---|---|
| 0–1 m | 1–5 m | 5–10 m | >10 m | ||
| Predicted | 0–1 m | 86.59 | 3.80 | 3.76 | 2.65 |
| 1–5 m | 9.96 | 88.43 | 11.65 | 15.04 | |
| 5–10 m | 2.03 | 4.17 | 78.20 | 6.19 | |
| >10 m | 0.81 | 1.30 | 4.14 | 70.80 | |
| None | 0.61 | 2.31 | 2.26 | 5.31 | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Brkić, I.; Miler, M.; Ševrović, M.; Medak, D. Automatic Roadside Feature Detection Based on Lidar Road Cross Section Images. Sensors 2022, 22, 5510. https://doi.org/10.3390/s22155510
Brkić I, Miler M, Ševrović M, Medak D. Automatic Roadside Feature Detection Based on Lidar Road Cross Section Images. Sensors. 2022; 22(15):5510. https://doi.org/10.3390/s22155510
Chicago/Turabian StyleBrkić, Ivan, Mario Miler, Marko Ševrović, and Damir Medak. 2022. "Automatic Roadside Feature Detection Based on Lidar Road Cross Section Images" Sensors 22, no. 15: 5510. https://doi.org/10.3390/s22155510
APA StyleBrkić, I., Miler, M., Ševrović, M., & Medak, D. (2022). Automatic Roadside Feature Detection Based on Lidar Road Cross Section Images. Sensors, 22(15), 5510. https://doi.org/10.3390/s22155510