1. Introduction
Cardiovascular disease (CVD) is a term for disorders related to the heart and blood vessels. According to statistics released by the American Heart Association in 2019, CVDs have become the dominant global cause of death. In 2016, there were over 17.6 million deaths (31% of global deaths), estimated to reach 23.6 million in 2030.
In clinical diagnostics, the electrocardiogram (ECG) is the most commonly used tool to assess cardiovascular function. The choice of ECG is based on its widespread availability, as well as its non-invasive nature, repeatability, and low cost of the exam. The idea of ECG measurement is to analyze the electrocardiographic signal, which reflects the change in electrical potential generated by the heart during each work cycle. During the ECG test, the frequency of contractions is determined, thus showing abnormal heartbeat rhythm and activity. This test helps diagnose many heart diseases that damage the function of the heart muscle, including arrhythmia, myocardial infarction, and coronary artery disease. Early detection helps prevent complications, such as an increased risk of stroke or sudden death.
Over the past decade, numerous attempts have been made to identify the ECG signal. This has been possible mainly due to the availability of large, public open-source ECG datasets. The literature indicates the application of various approaches to ECG signal classification. Existing ECG signal classification models can be divided into two main categories: classical methods and deep learning methods. Many proposed approaches explore the Accuracy of classification algorithms, such as Support Vector Machines (SVM), Naive Bayes classifier, k-nearest neighbors algorithm (kNN), Decision Trees (DT), and group classifiers. A common aspect of these algorithms is the need to extract features from the input ECG signal. These features are multimodal, e.g., temporal, frequency, and statistical. The magnitude of these features is of variable importance in recognizing different classes of arrhythmias and is used to train Machine Learning (ML) algorithms.
The success of ECG classification using the classical ML method depends largely on selecting features, which must be carefully designed for different algorithms. In addition, the selected input dataset for which the classification process is also performed has a great influence. The second approach is based on deep learning techniques, which are increasingly used in computer-aided diagnosis of almost all diseases. Common deep learning networks used in ECG signal analysis are Convolutional Neural Networks (CNN) and Recurrent Neural Network (RNN), as well as Long Short Term Memory (LSTM) and their combinations.
Most classification studies are performed using the MIT-BIH Arrhythmia database and PTB Diagnostic ECG. Classification is usually performed using two or five classes of arrhythmias. For classical methods, SVM classifiers [
1,
2,
3] combined with genetic algorithms [
4], Wavelet Transform (WT) [
5], or Discrete Wavelet Transform [
6,
7] have been used for most of them. The evaluation metric was most often Accuracy (ACC), for which the results took values of 91–93% up to five classes of arrhythmias and above five classes, with values between 95.92 and 99.66%. The authors also used models based on k-NN algorithms [
7,
8], taking into account prior extraction of morphological features of QRS complexes and Decision Tree (DT) algorithms [
9]. In the area, five to seven different arrhythmias were subjected to these classifications, yielding an ACC of 99%. Convergent procedural scenarios are noticeable for the deep learning network. The authors undertook classifications of a similar number of arrhythmia classes. Mostly they used the CNN model [
10,
11]. The authors of the work [
12] implemented a 1-D CNN to combine the feature extraction and classification process. A similar approach was used in the article [
13], limited to classifying two arrhythmia classes, focusing on myocardial infarction detection. In [
14], the authors used two different CNNs trained with 2-s and 5-s segments of ECG data to classify atrial fibrillation, atrial flutter, ventricular fibrillation, and normal rhythms. Improving the Accuracy in classification was undertaken by the authors of the article [
15] using Short-Time Fourier Transform (STFT) and Stationary Wavelet Transform (SWT) to obtain 2D CNN. A combination of CNN with LSTM was presented by the authors of the article [
16] for detecting five types of heartbeats, relying on variable-length ECG segments for feature generation. Continued work using the LSTM model was proposed by the authors of the article [
17,
18], undertaking the classification of two and eight classes of arrhythmias, respectively. An Accuracy of 99% was gained when they focused their research on aspects including atrial fibrillation. The new RNN architecture model has been successfully used to classify five types of ECG beats [
19,
20].
From the application perspective, ECG signal classification is important in remote patient monitoring devices. Their development and diffusion promote the prevention and treatment of cardiovascular diseases. Mobile solutions, i.e., small and discrete devices for long-term ECG monitoring, are associated with limitations. Especially when their purpose is to measure, analyze, archive, and transmit real-time data containing clinical information. This area was successfully recognized during the SARS-CoV-2 pandemic (COVID-19).
The correct interpretation of ECG signals is complex and clinically challenging, and misinterpretation can result in inappropriate treatment. Recommendations for standardization and interpretation of ECG are well known. However, the ubiquity of this test and the transition from analog to digital recordings have affected its detailed interpretation. Traditional approaches have increasingly focused on memorizing the morphological patterns of individual components of the ECG signal and associating them with a disease symptom. The idea seems to shift to automatic analysis of ECG signal fragments with the simultaneous classification of disease entities.
The process of diagnosing heart disease uses the information contained in electrocardiographic signals. The starting point in the evaluation of the ECG is the heart rate and the type of rhythm. The former is regulated by the heart rate and is related to the rate at which another follows one wave of the heart beat. The heart rhythm is the pattern in which the heart beats. It can be described as regular or irregular, fast or slow. A normal heart rhythm is called sinus rhythm. Its rate corresponds to the pulse, and accurate interpretation requires the evaluation of electrocardiographic signals. Various cardiovascular diseases can be detected with the help of the widely used electrocardiogram. Several parameters have clinical significance in the ECG, including PR interval, QRS complex, ST segment, and QT interval.
The authors often emphasized that data from single, small, or relatively homogeneous datasets, further limited by the small number of patients and rhythm, prevented the creation of reliable algorithms in Machine Learning models. To some extent, the PTB-XL database [
21,
22], for which multi-class classification work is already known [
23,
24,
25], has become a solution to the problem of data inaccessibility.
This study aimed to find the best possible classifiers of classical Machine Learning methods for disease entities belonging to 2, 5, and 15 classes of heart disease. In addition, a new method for R-wave determination and QRS complex extraction was used in this study. This method uses a 12-lead signal for which an estimate of the R-peak position is generated using R-wave detection [
23,
24]. In this article, we used the Feature Selection Method approach [
26] to perform the study in steps. The research was based on finding the optimal parameters from predefined parameters. Each stage was carried out for different classifier models, input data, dictionaries, and parameters, and four aggregation methods were developed. For this purpose, it was proposed to study nine classical Machine Learning classifiers using the Orthogonal Matching Pursuit algorithm.
This article is organized as follows. After the introduction,
Section 2 presents the research methodology. The characteristics of the databases and the methods used in the article are discussed. Then, the feature detection from ECG signal and the application of classical Machine Learning models are specified. Implementation details and experimental results are described in
Section 3. The conclusion and discussion are given after that.
2. Materials and Methods
Based on Feature Selection Methods [
26], the different classification steps were planned. The study aimed to find the optimal classification model for 2, 5, and 15 classes related to heart disease. The number of classes should be interpreted as follows: 2 classes—NORM class and others from PTB-XL database, 5 classes—disease classes from PTB-XL database, and 15 classes—subclasses of diseases from PTB-XL database.
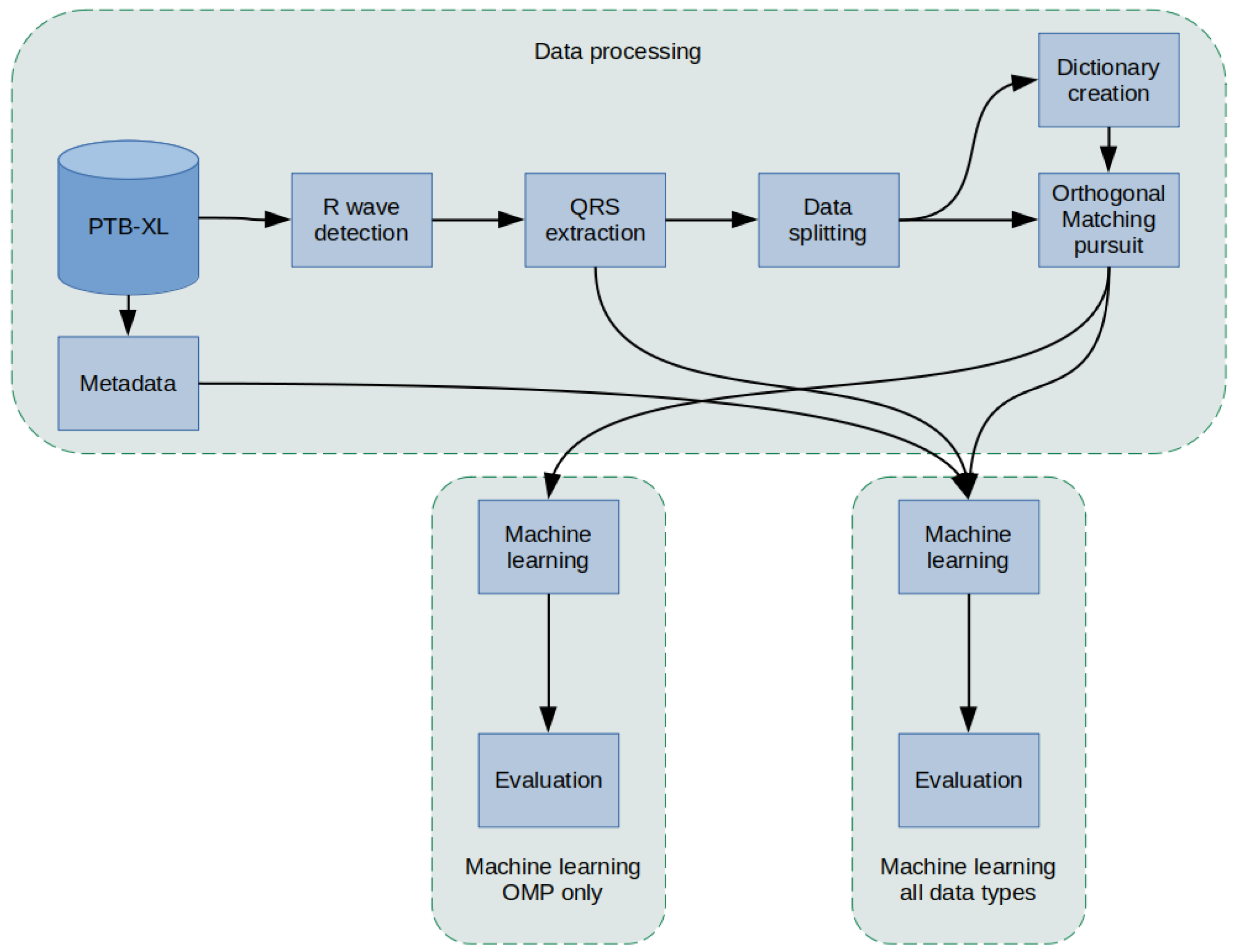
The methodology used in this article was as follows (
Figure 1): a PTB-XL dataset containing labeled 10-s ECG signal records was used for the study. First, the records in the database were filtered. Then, in the raw signal, R peaks were labeled and segmented so that there was precisely one QRS complex in each segment. In the next step, the data were divided into training data, validation, and test data (using cross-validation) and data for Dictionary Learning. In the next step, the dictionaries were created. Then, an Orthogonal Matching Pursuit operation was performed for the training data, resulting in the coefficients. Extracted QRS and coefficients were input for classifiers of 2, 5, and 15 heart disease classes. In the last step, an evaluation was conducted. The effectiveness of the proposed network methods was evaluated.
2.1. PTB-XL Dataset
In this study, all ECG data used are from the PTB-XL dataset [
21,
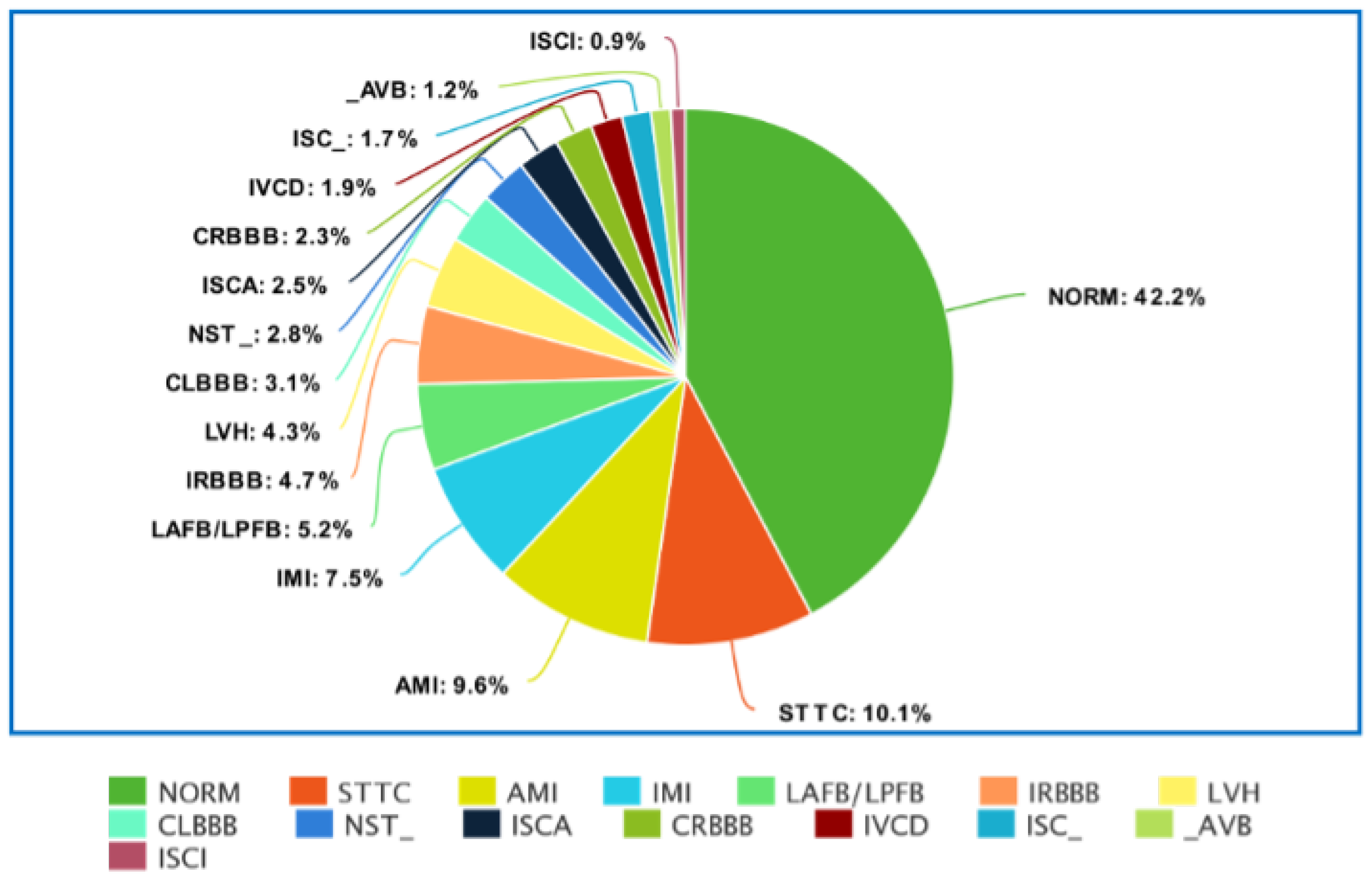
22]. The PTB-XL database is a clinical ECG dataset adapted for evaluating Machine Learning algorithms. Initially, PTB-XL consists of 21,837 records, corresponding to 12-lead ECG recordings. Each ECG signal is 10 s long and annotated by cardiologists. PTB-XL data are balanced by gender. The database contains 71 heart disease types with 5 relevant classes: normal ECG (NORM), myocardial infarction (CD), ST/T change (STTC), conduction abnormalities (MI), and hypertrophy (HYP).
Figure 2 and
Figure 3 show the detailed distribution of classes and subclasses used in the study. For
Figure 2, the data include the number and the percentage of records. In contrast, for
Figure 3, we are limited to the percentage of subclasses only.
2.2. Data Filtering
PTB-XL contained 21,837 ECG records. However, not all records have labels (assigned classes), and not all assigned classes have a specific 100% confidence (in terms of assigned medical diagnosis). For this reason, both cases were filtered from the original dataset. Each record has a specific class and subclass, defining cardiovascular disease. Records with less than 100 subclasses were also filtered out. This yielded 17,011 records, each belonging to one of 5 classes and one of 15 subclasses. For this study, it was decided to use ECG records with a sampling rate of 500 Hz.
2.3. R-Peak Detection
The classification studies were preceded by detecting features from the ECG signal. P wave, QRS complex, and T wave are its main components. The QRS complex was considered the leading one, for which the R-peak detection algorithm was developed. For R-peak detection, it was decided to investigate well-known detectors, such as: Hamilton [
27], Two Average [
28], Stationary Wavelet Transform [
29], Christov [
30], Pan-Tompkins [
31], and Engzee [
32] with modification [
33]. For a better illustration of the developed algorithm, Listing
A1 shows its implementation written in Python.
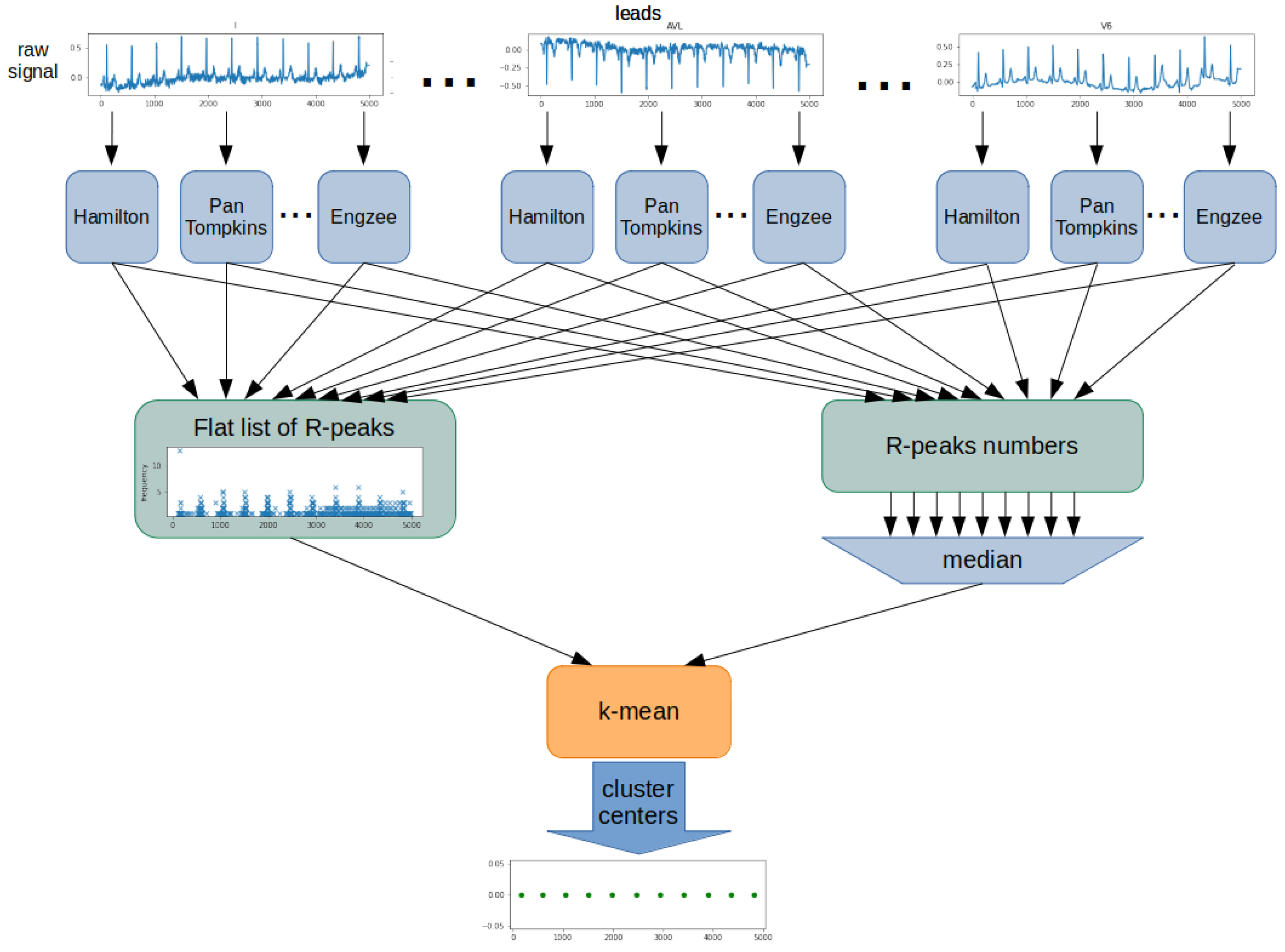
The proposed algorithm was based on determining the position and number of R-waves using all detectors for each ECG lead (
Figure 4). The result was a list of detected R-peaks for each detector and lead. From this, a flat list of R-peak numbers was created, including all leads and detectors. Next, the algorithm determined the number of R-peaks in the examined ECG signal. For this purpose, the list’s median containing all counted R-peak was used. The last step was to determine the position of each of the R-peaks. The k-mean algorithm was used for this purpose. A flat list of R-peaks is used as training data for the k-mean algorithm. A determined R-peaks number is used as a k-value. Cluster centers of the k-mean algorithm are the determined R-peak positions.
Similar approaches applying different detectors for the Wavelet Transform examples and a variable number of leads have been proposed in [
34]. The proposed approach combines three well-known algorithms operating on 1-lead ECG: Christov detectors, Pan-Tompkins, and Discrete Wavelet Transform. The aim of this procedure, as in the present work, was to obtain the best possible combination of different detectors for the highest Accuracy of R-wave detection.
This article’s test to evaluate the Accuracy of R-wave detection is presented in
Appendix B. The tests were related to both 1-lead ECG signal and 12-lead ECG signal. The combination of the Two Average, Christov, and Engzee detector for the research methodology was further used due to the Original Algorithm.
2.4. QRS Extraction
The determined positions of the R-peaks were used to extract the segments containing the QRS complexes. For a 10-s signal fragment, this operation consisted in determining the midpoint of the segments between consecutive R-peaks. The first and last segments obtained in this way were discarded. With this procedure, the R-peaks and thus the QRS complex would always be in the middle of the segment.
2.5. Description of the Implemented Method
Orthogonal Matching Pursuit was assumed to be the primary technique [
35,
36]. The Orthogonal Matching Pursuit (OMP) algorithm is an extension of the Matching Pursuit (MP) algorithm. The OMP algorithm, like MP, is based on a continuous search and matching of appropriate elements (atoms) of the dictionary that best reflect the desired features of the studied (original) signal. This process should maximize the correlation between an element from the dictionary and the rest of its part (residual) of the processed signal. The result of the OMP is a vector of coefficients. To give an idea of the process discussed above,
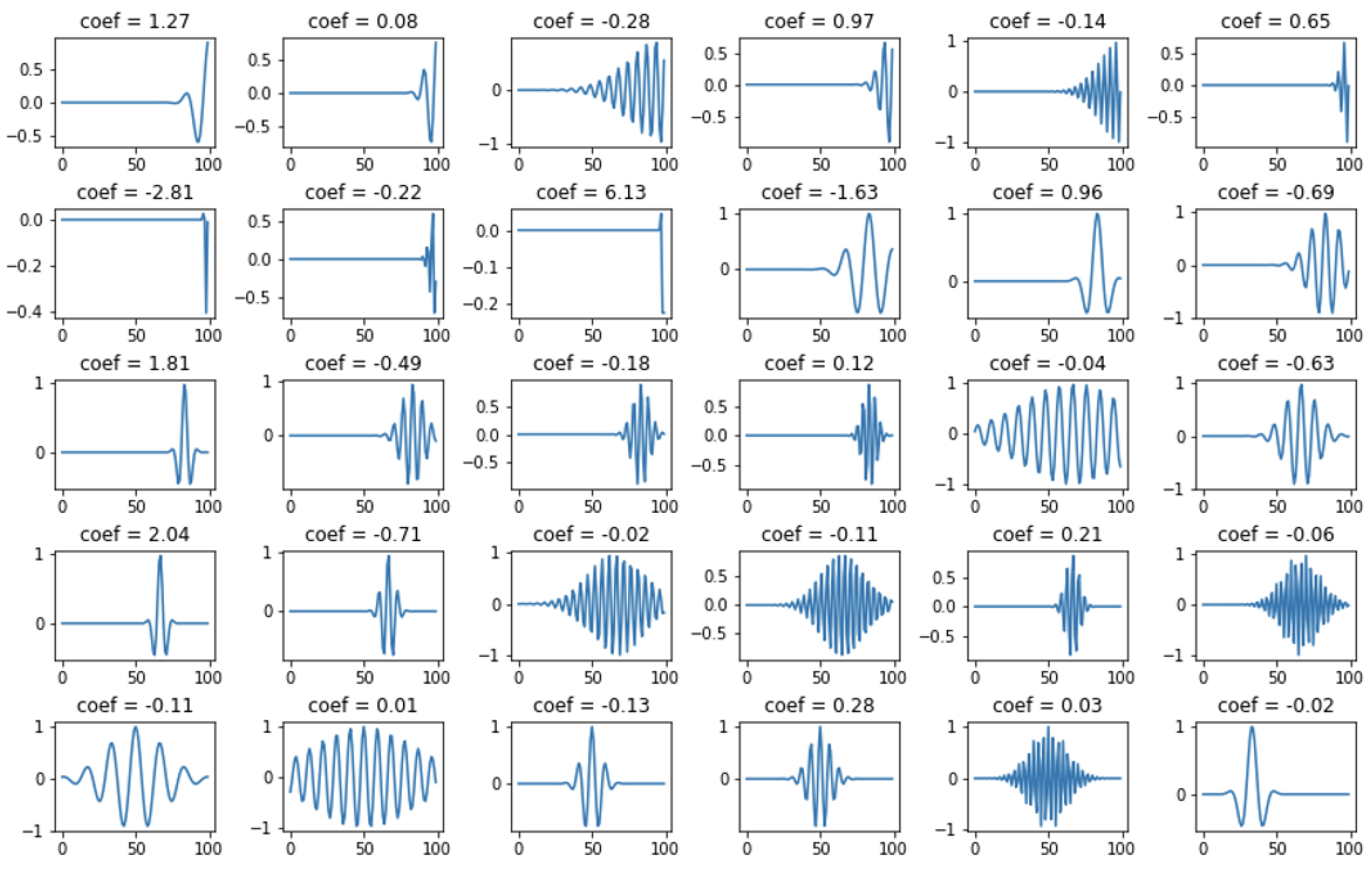
Figure 5 shows an example of the original (input) signal, the coefficients obtained from its decomposition, and the signal after reconstruction and the residual (the difference between the original signal). The blue color indicates the signal after reconstruction, and the orange color indicates the residual. The decomposition was performed with 6 non-zero coefficients.
Figure 6 shows the selected atoms with their coefficients. The expansion for this case is shown in
Figure 7 and
Figure 8, where 30 non-zero coefficients were used respectively.
2.6. Dictionary Created Using Dictionary Learning Technique
Dictionary Learning dictionary creation is based on data [
37]. The task of the algorithms is to find a dictionary of atoms that best represents a given signal type.
Figure 9 shows an example of Dictionary Learning atoms.
2.7. Dictionary Created Using KSVD Technique
KSVD [
38] is an algorithm from the Dictionary Learning group that performs Singular Value Decomposition (SVD) to update the dictionary atoms, one by one, and is a kind of generalization of the k-means algorithm. An example of KSVD dictionary atoms is shown in
Figure 10.
2.8. Designed Machine Learning Algorithms
The following classifiers were examined: KNeighbors—k-Nearest Neighbors [
39], DecisionTree—Decision Tree [
40], RandomForest—Random Forest [
41], SVC—Support Vector Machine [
42], XGBoost, LGBM—LightGBM, MLP—Multi-Layer Perceptron [
43], AdaBoost [
44], and GaussianNB—Naive Bayesian Classifier.
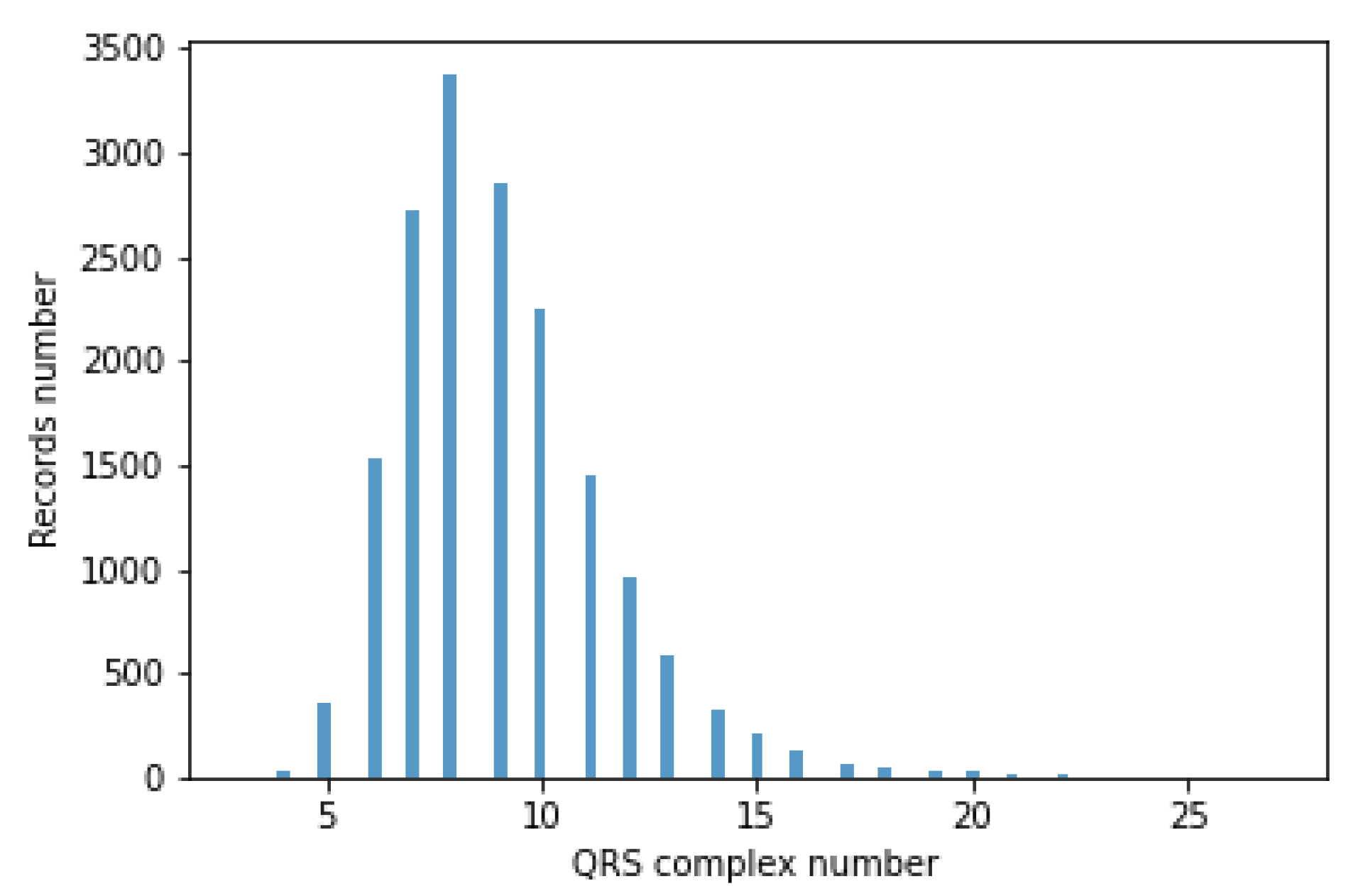
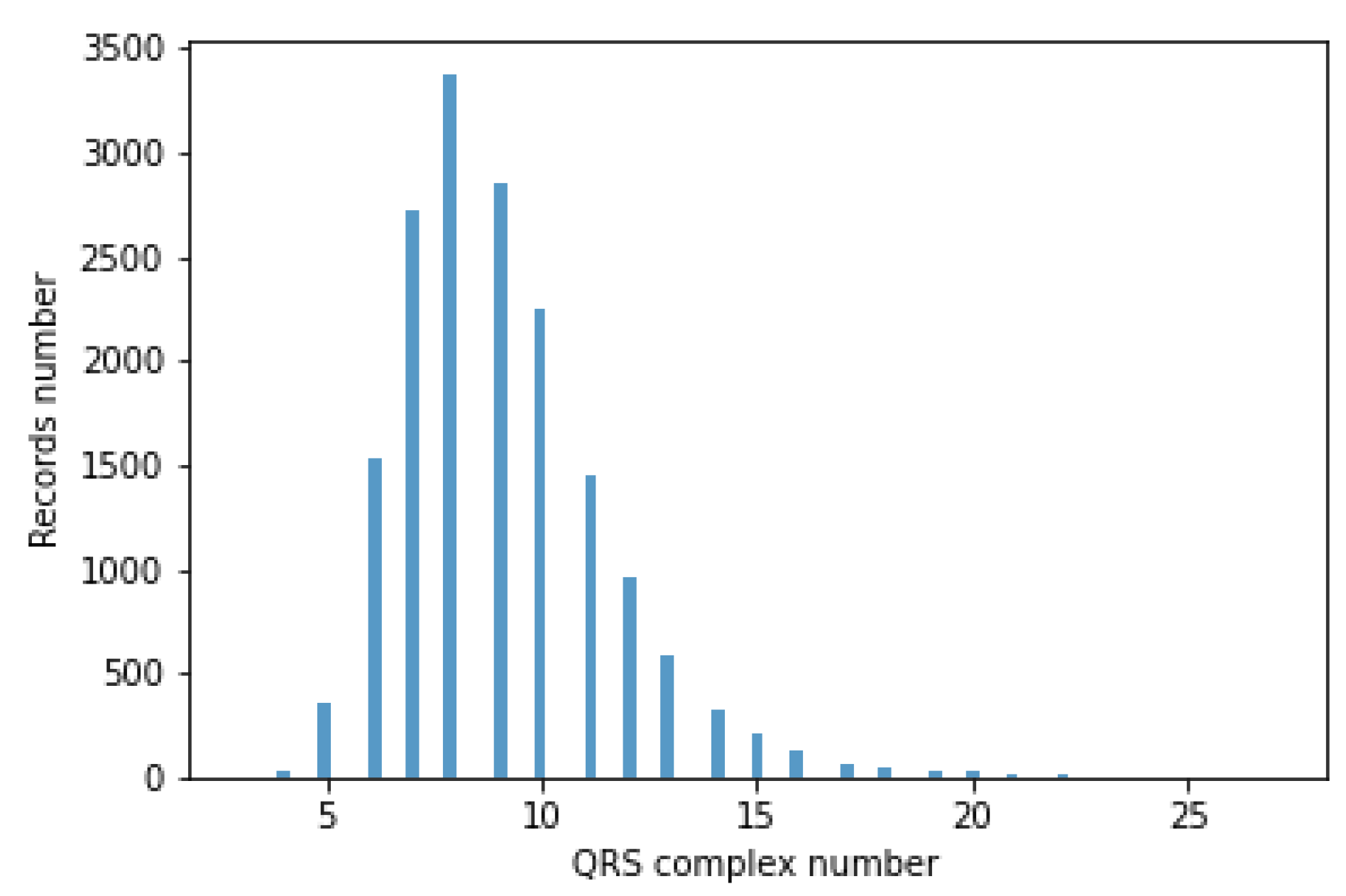
The classifiers take a fixed-size data vector as input. Unfortunately, for different records, the number of QRS episodes varies (BPM varies), ranging from 3 to 27. This causes the flat data vector with a different number of QRS to have a variable size. Accordingly, QRS episode aggregation methods have been proposed. A histogram of the number of segments containing the QRS complex is shown in
Figure 11.
The author’s 4 methods of aggregation, i.e., a grouping of episodes containing QRS complexes, were developed. In the rest of the article, the proposed aggregation methods are called Single, Mean, Max, and Voting.
The inputs of aggregation methods were ECG signal records, episodes containing QRS complexes extracted on their basis, and the result of the OMP algorithm, i.e., coefficients obtained from them. In each aggregation method, the model’s output is a prediction corresponding to the disease entities.
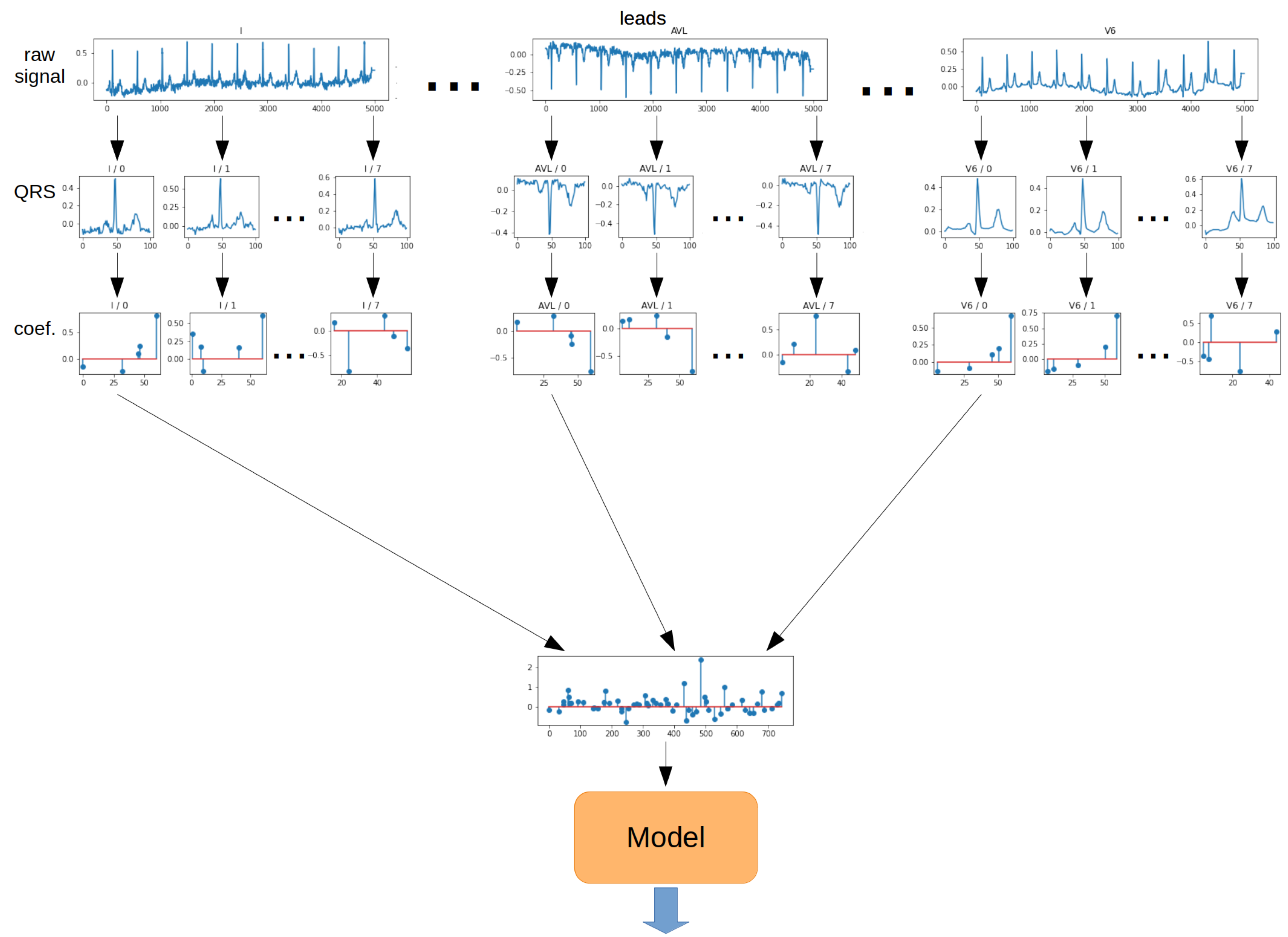
The
Single method is the most straightforward approach to QRS segment aggregation. The principle is to take a vector of coefficients obtained from the OMP algorithm for the first QRS segment from each lead. As a result, a 2-dimensional matrix was obtained. Then, such a matrix of coefficients was transformed into a 1-dimensional vector. The resulting vector was fed to the model input. The schematic for the Single method is shown in
Figure 12.
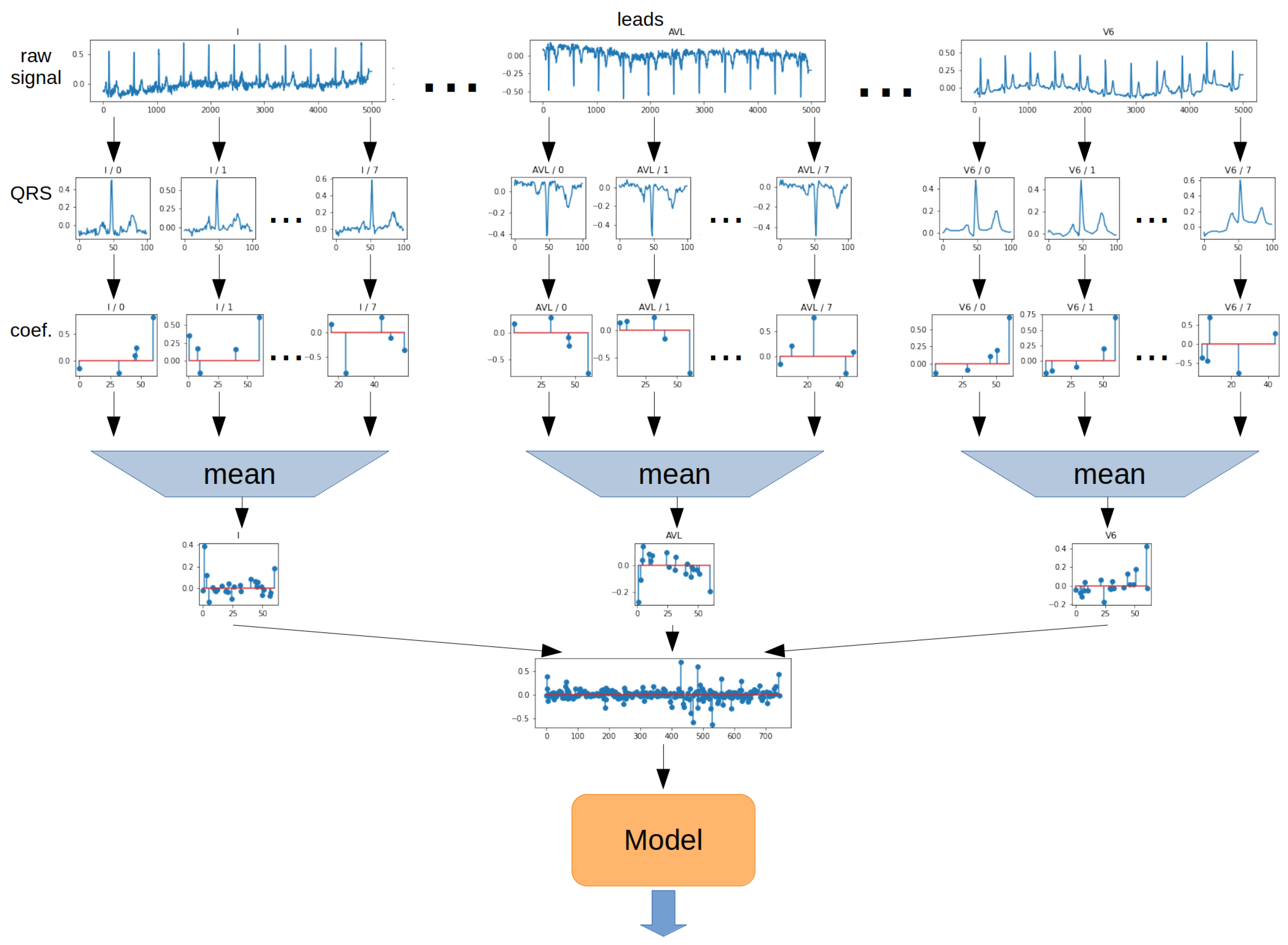
The
Mean method involves determining the arithmetic mean of the values of each ratio for all QRS segments. The operation was performed separately for each lead. The 2-dimensional matrix was then transformed into a 1-dimensional vector. In the next step, the vector was the model input. The schematic for the Mean method is shown in
Figure 13.
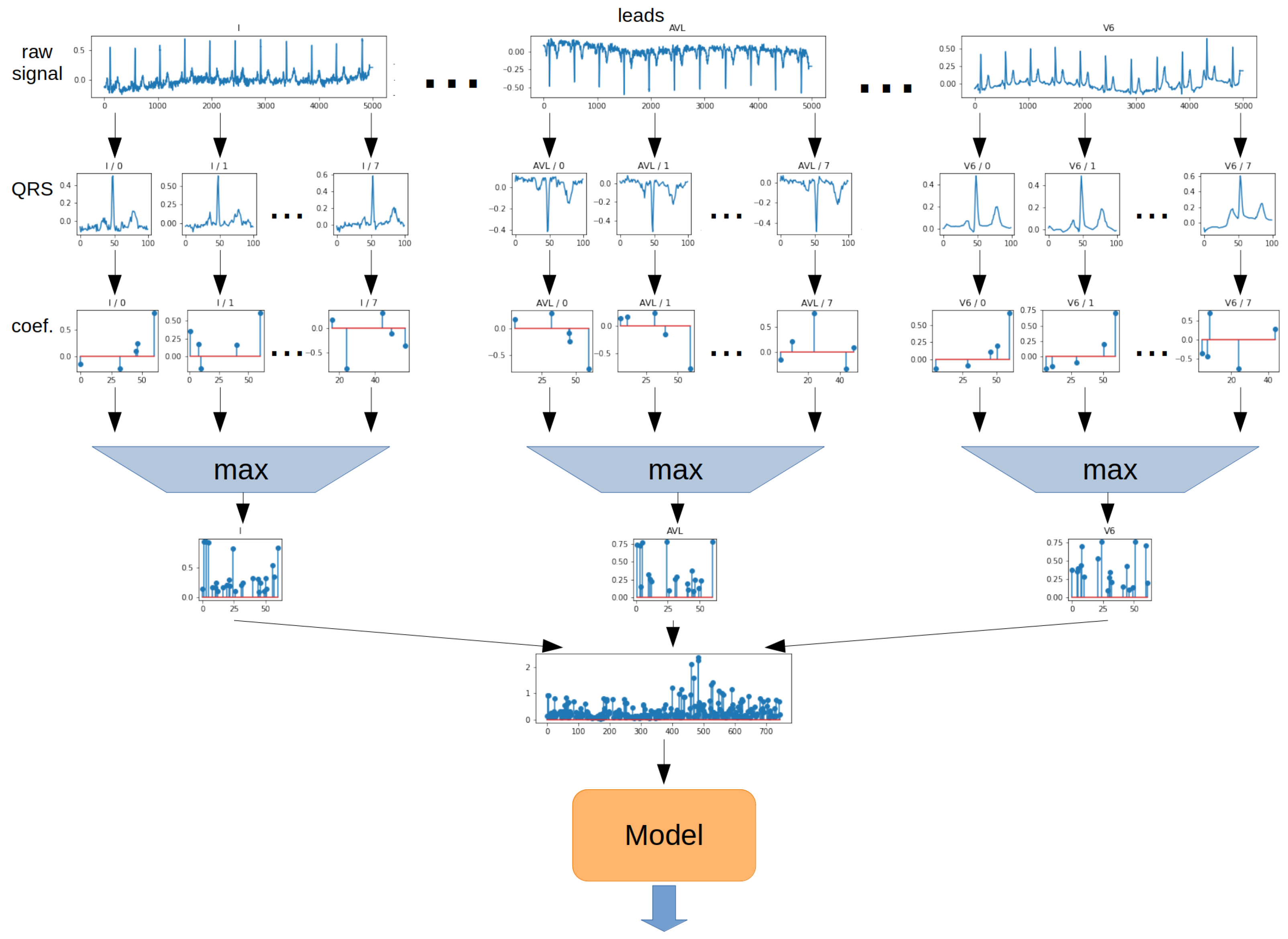
The
Max method determines the maximum from the absolute value of each ratio from all QRS episodes. The operation was performed separately for each lead. The 2-dimensional matrix was then transformed into a 1-dimensional vector. In the next step, the vector was the model input. The schematic for the Max method is shown in
Figure 14.
The
Voting method involves training model consisting of all QRS episodes. For this purpose, for each QRS segment, a 2-dimensional coefficient matrix is transformed into a 1-dimensional vector and given to the model input. In contrast, prediction is performed for each QRS segment separately. In the next step, the arithmetic mean of the prediction probabilities derived from each QRS segment is determined, and the prediction is made on this basis. The schematic for the Voting method is shown in
Figure 15.
2.9. Data Splitting
The following data were used for each record:
Metadata (sex, age, BPM, resampling ratio);
Segments containing QRS complexes;
Coefficients from the OMP algorithm;
Dictionary and its parameters, i.e., dictionary type (Dictionary Learning (DL), KSVD, Gabor), dictionary size (62, 125, 250, 500, 1000 elements), number of non-zero coefficients (5, 10, 20, 40);
Aggregation methods: Single, Mean, Max, Voting.
Records were divided into training, validation, and test data in proportions of 70%, 15%, and 15%. To improve the quality of testing, non-exhaustive cross-validation was used. For this purpose, the split function was called with 3 or 5 different seeds. This means that all tests were repeated five times for different data splits.
2.10. Metrics
Models were evaluated using the metrics described below [
45]. For simplicity of equations, specific acronyms have been created:
—True Positive,
—True Negative,
—False Positive, and
—False Negative.
The metrics used for network evaluation are:
Accuracy: ;
;
;
;
Balanced Accuracy: .
2.11. Used Tools
The computations were performed on a server equipped with 2 Intel Xeon Silver 4210R processors (192 GB of RAM), Nvidia Tesla A100 (40 GB RAM), and Nvidia Tesla A40 (48 GB RAM) GPUs. They were also performed on 5 servers, each of which was equipped with 2 Intel Xeon Gold 6132 processors (512 GB of RAM). In this research, Sklearn, Numpy, Pandas, and Jupyter Lab programming solutions were used.
4. Discussion
The classification of an ECG signal is a complex issue, for which many obstacles limit the high Accuracy of the conducted studies. The studies and analyses need to integrate available methods with feature extraction techniques from electrocardiographic signals. Only in this approach is it possible to achieve the objectives at the highest possible level from the clinical perspective and not only because of non-medical diagnostics.
Although different results are available for ECG classification experiments, it is difficult to compare directly due to different classification schemes and evaluation metrics. Furthermore, one can see differences in the adopted classification objectives, which are not always aimed at obtaining the highest possible scores and often show differences when using different classification models. Nevertheless, the methodology proposed for this work achieved relatively good results for the PTB-XL database compared to other works. However, to give an idea of the current state of the art, it was decided to present related studies using different classifiers within other databases.
ECG signal classification is known primarily from articles involving the diagnosis of myocardial infarction, atrial fibrillation, or ventricular fibrillation. An equally wide range of articles relates to the general definition of arrhythmias. For example, articles in myocardial infarction classification [
46,
47] based on classical SVM-type classifiers are known from research for the PTB Diagnostic ECG Database or MIT-BIH Arrhythmia [
48]. The test set results were ACC = 0.9958, ACC = 0.9874, and ACC = 0.976, respectively. Although they obtained high scores, the dataset dependencies remain uncertain for which, due to the small number of waveforms, it is possible that they used ECG signal segments from the same patient during model validation and testing. In addition, these results should not be interpreted as a classification for the two classes used in this study. The authors also chose to use models based on kNN algorithms [
6,
8], considering the previous extraction of QRS complexes and Decision Tree algorithms [
9]. The evaluation metric most commonly used was Accuracy, for which results took values of 0.910–0.930 for five classes of arrhythmias and above five classes, values ranging from 0.9592 to 0.9966.
This work implemented classification for 2, 5, and 15 classes. Each step was carried out for different classifier models, input data, and aggregation methods. The input data were enriched with features derived from the Orthogonal Matching Pursuit algorithm, including different dictionaries and their parameters. The author’s algorithm for R-wave determination and QRS complex extraction was also evaluated.
For the purpose of this article, tests were performed to assess the computational complexity of the study. The results are summarized in
Table A3, located in
Appendix C. The measured times correspond to the model training and prediction steps on the validation and test sets. The experiment was performed for the Single aggregation method and using only OMP coefficient vectors’ given inputs. For most of the classifiers considered, the length of computation was more dependent on the size of the dictionary than the number of classes. One can see a differential increase in these times depending on the model. For example, for the Decision Tree model, as the size of the dictionary and the number of classes increased, the computation increased slightly. The situation looks different for the XBoost model, where the calculation times increase significantly. The longest calculation times were observed for the SVC classifier.
In evaluating cardiac classification algorithms, it is important to evaluate the R-peak detection algorithm. Based on the results obtained, the Two Average detector showed the highest Accuracy in R-peak detection in the 1-lead approach, whereas the Engzee detector showed the lowest. Different combinations for the 12-lead signal significantly influenced the results obtained. An improvement in the Accuracy of R-peak detection could be observed with the 12-lead approach to the signal under study. For example, Two Average detector in the classical approach achieved MAE = 0.389, and in that proposed for this study MAE = 0.270. This was due to the simultaneous consideration of all leads from the examined 10-segment ECG signal. The results were completely different when all detectors were selected simultaneously, for which the MAE evaluation metric was 0.367. Although, concerning the classical best approach, i.e., MAE = 0.389, it still obtained a higher score. The solution proposed for this article indicates that there is undoubtedly some optimal combination of detectors that provides the best results. In the case of analyzed ECG signals, the highest Accuracy of R-peak detection was obtained by combining the Two Average detector, the Christov detector, and the Engzee detector.
The experiments conducted showed that the results on the test data differ little from the results on the validation data. The values of the ACC classification metric for grades 2 and 5 remain higher than the tests in the work [
23,
24], regardless of the approach used. In the case of the work [
25], they remain lower. The obtained Accuracy results for the classification of two and five classes achieved an Accuracy of 0.9023 and 0.7766, respectively. It is impossible to compare the classification for 15 classes, which has not been attempted so far by the authors of other works. The classification results for 15 classes achieved an Accuracy of 0.7079.
The problem of heart disease classification using classical models of Machine Learning methods was supported by underestimated Orthogonal Matching Pursuit (OMP) algorithms, showing the significant effect of concise representation parameters on improving the Accuracy of the classification process. Different combinations of dictionaries created for the operation of the OMP algorithm were investigated. Their optimal parameters were determined. The study shows that not only the type of dictionary is important. Its size and the number of non-zero coefficients are also important. The realized studies indicate that the hybrid system provides the highest ACC metric scores. For this system, the input data vector includes coefficients obtained from the OMP algorithm, segments containing QRS complexes in raw signal form, and metadata.
The RandomForest, XGBoost, or LightGBM classifiers proposed in this article are Decision Tree-based models designed to work with structured data. Thus, models cannot cope with unstructured data. This is the inability to recognize and detect shapes and displacements. It can be speculated that the approach proposed in this article, related to extraction of QRS complexes and resampling of the raw signal, contributes to locating the R-peak always in the same place and structures the data well enough for tree-based models to cope.
The realized experiments highlight the Accuracy of the proposed Voting aggregation method, for which the highest Accuracy results were obtained, regardless of the model or class size. A similar observation was noted in the comparison of dictionaries, where dictionaries created using Gabor functions were found to be the best. The performed experiments also emphasized the importance of using coefficients obtained from the OMP algorithm, for which the tested models obtained the highest Accuracy.
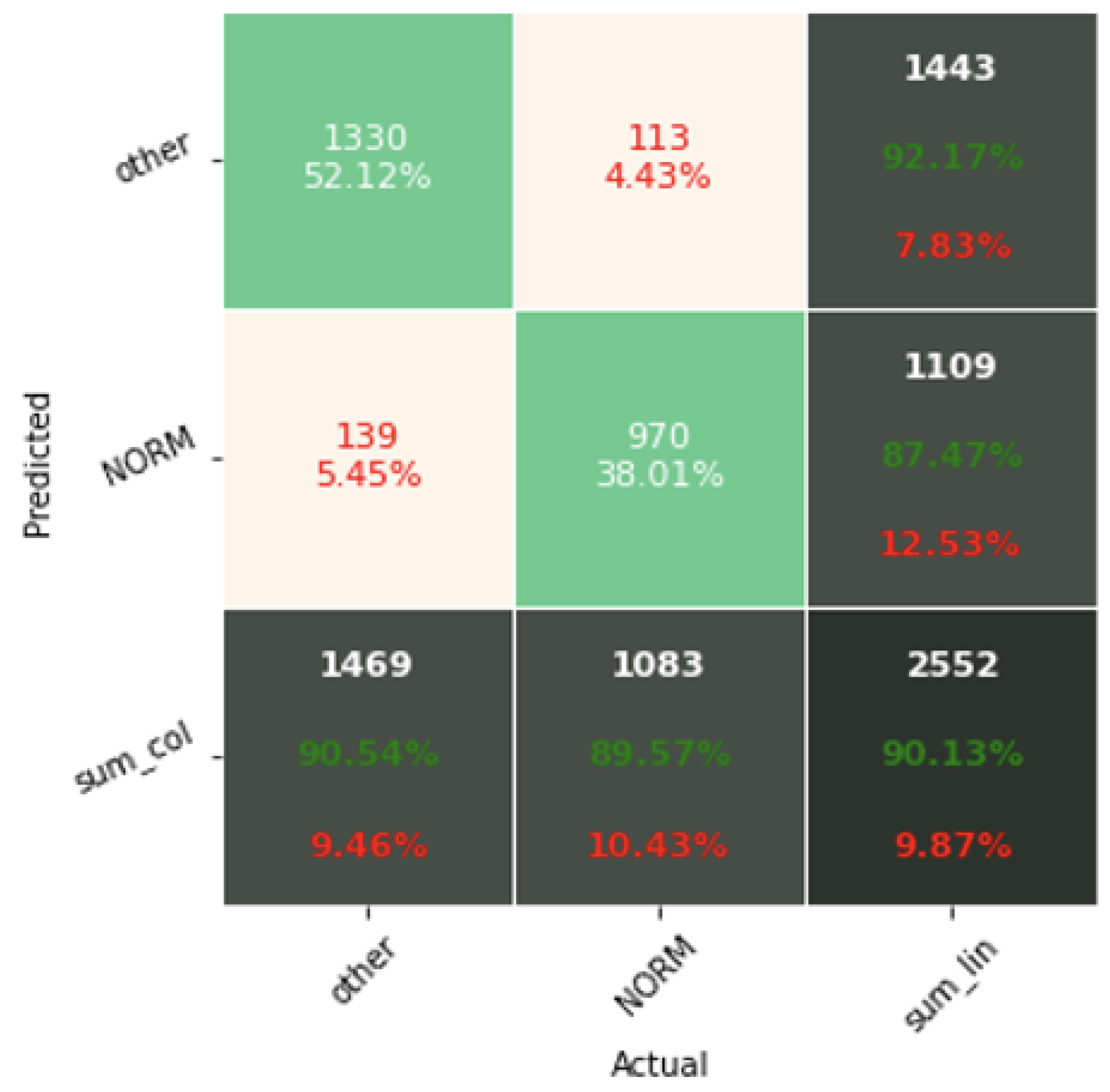
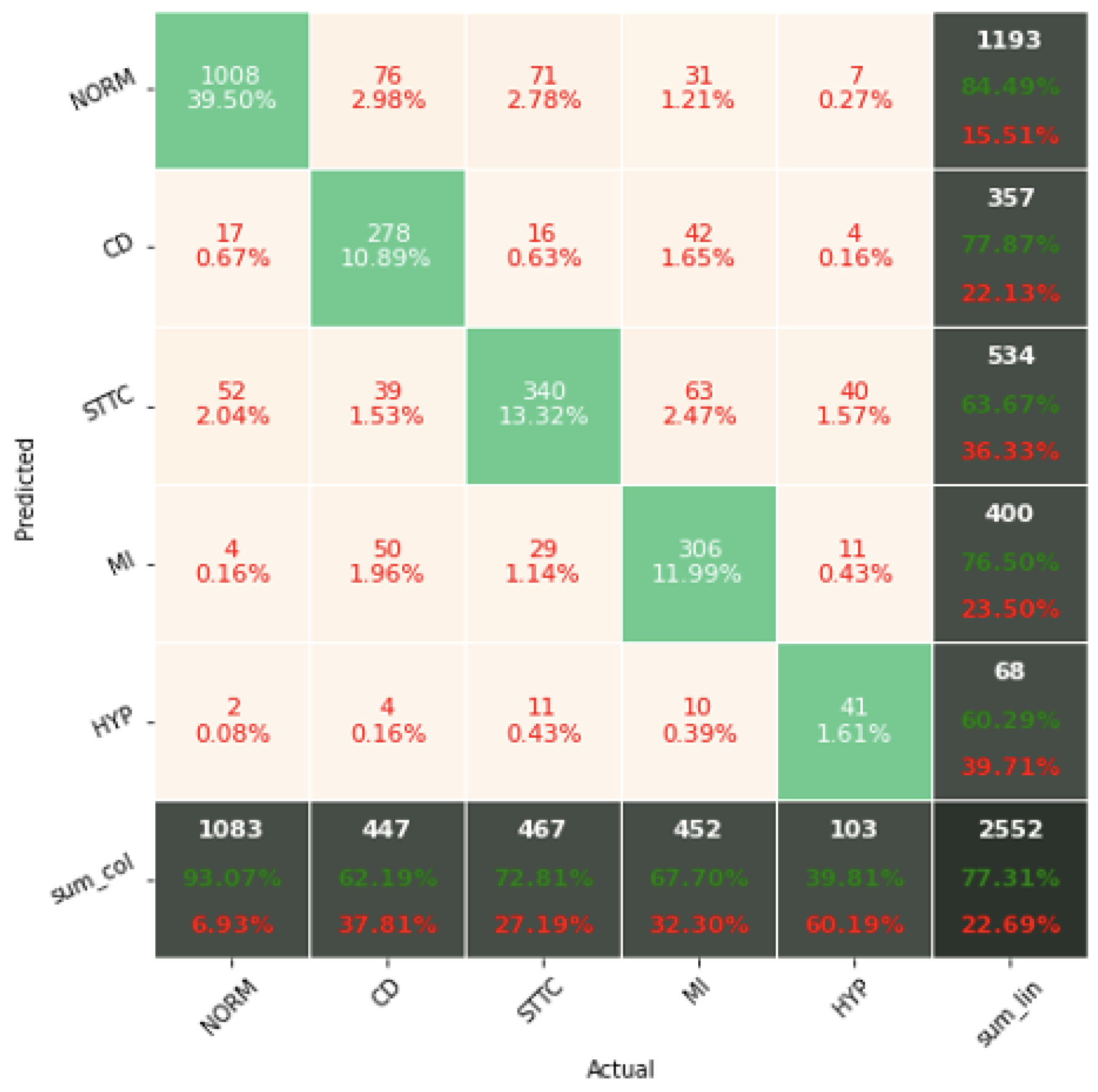
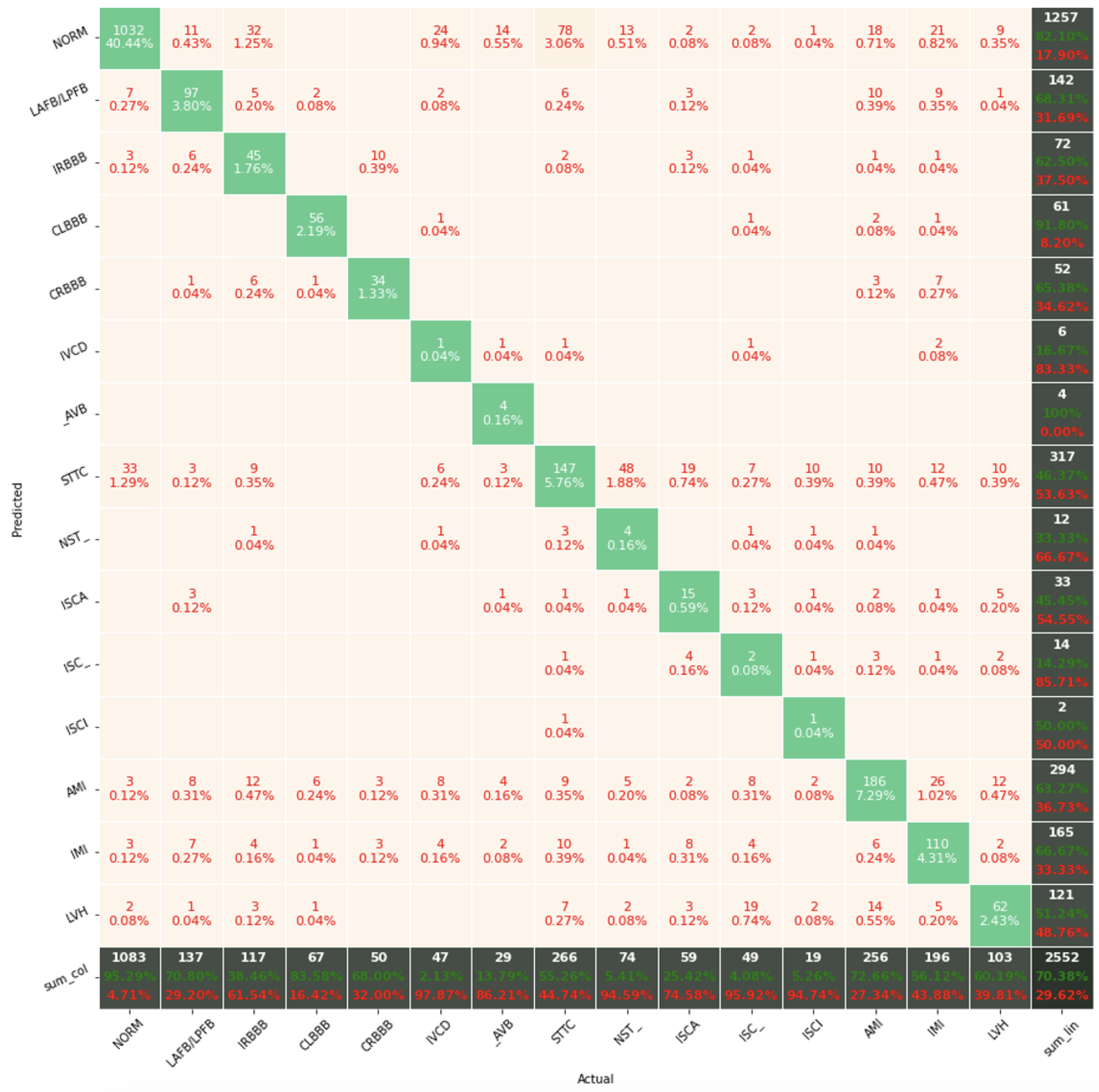
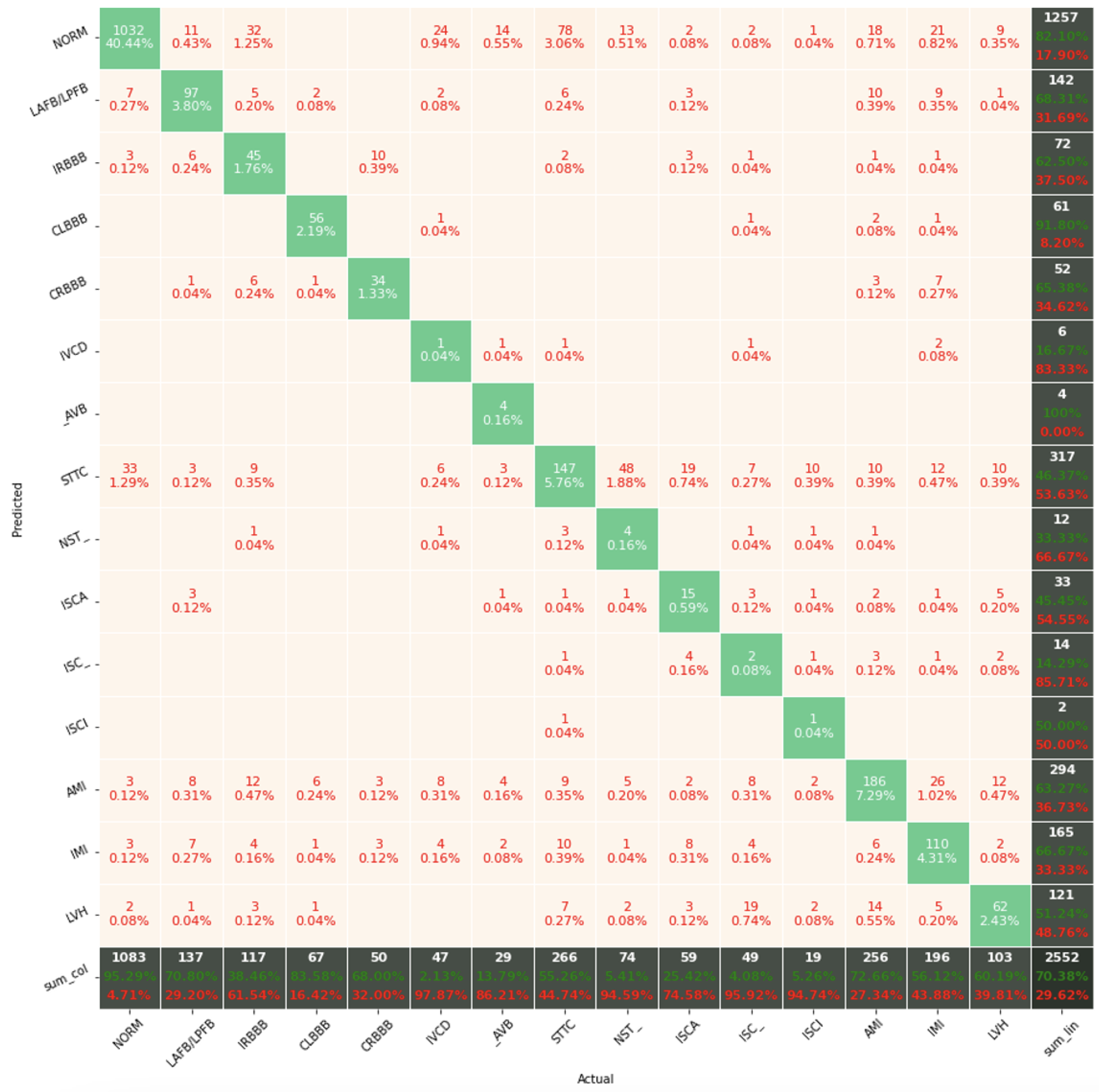
The confusion matrix analysis gives more possibilities to evaluate the obtained results. Classification Accuracy for two classes regardless of classifier type seems to be true. Although also, in this case, for subclasses with a small number of records, skipping occurs, which affects to some extent the skewness of the model. However, this explains the worse classification performance as the class size increases, i.e., 5 and 15 classes. What is particularly clear in
Figure 19 is that a large part of the misclassification is caused by an imbalanced dataset. Classes with a low record number (such as IVCD or ISCI) are less frequently selected by the model. The situation is different for classes with many records (such as NORM or STTC). The model more often selects them. The NORM class is the most numerous, which makes it the best internalized by the model. It has the highest Precision and Recall values (green percentages on the bottom and right matrix bars). This is confirmed by the balanced Accuracy presented in
Table 1,
Table 2,
Table 3,
Table 4,
Table 5,
Table 6,
Table 7 and
Table 8.
If the aim of the work was to evaluate the results obtained in terms of statistical significance, it would be necessary to carry out Levenes test, Annova test, and Tukey-Hsd test. In the analyzed article, such an approach was carried out for step 3, considering this step as final. In the case of classification for 2, 5, and 15 classes, the results of Levenes test reached p > 0.05 and the results of Annova test reached p < 0.05. Realizing the comparison of different combinations of models with the use of Tukey-Hsd test, it can be noticed that statistically significant differences of the ACC metric for two classes are obtained above 1%, and respectively for 5 classes and 15 classes, −2.5% and 3.8%.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}