1. Introduction
With the rise of the Internet, there has been an immense surge in Internet-based services [
1]. As a result, many of the physical systems or devices that are connected to the Internet can easily be operated and managed remotely. Client behaviour can then be monitored and documented, future decisions can be predicted, and useful services provided [
2]. The Internet of Things (IoT) is used in a variety of fields, including the smart home, smart city, smart healthcare, smart factories, smart supply chain, and smart retail.
Figure 1 depicts a few of IoT applications that may be found in everyday life. The goal of such a smart environment is to make people’s lives more productive and add value by addressing issues related to living conditions [
3]. However, because of increased interconnectedness, the network has become more complicated, making network security more difficult to sustain. Intruders consider security lapses to be an invitation to discover and exploit vulnerabilities in IoT networks. However, network security breaches can result in significant financial losses for businesses and consumers. Hence, it is essential to design a system that will ensure the security of the IoT network. Many tools and techniques are available to combat various cyber-attacks, such as spam filters, firewalls, anti-malware, intrusion detection systems (IDSs), intrusion prevention systems (IPSs), and so on [
4].
To ensure the security of an IoT network, an IDS can be an extremely effective and crucial solution. There are three key phases in the operation of an IDS. The first of these is monitoring, which is based on network or host sensors. The second phase is analysis, which involves feature extraction and pattern recognition. Finally, the third phase is detection, which detects any anomalies in a network.
Intrusion detection systems can be classified into two main groups: signature-based intrusion detection systems (SIDS) and anomaly-based intrusion detection systems (AIDS). Traditional SIDS methods involve examining network packets and attempting to match patterns to a signature database. A machine-learning (ML) approach is used in AIDS to train the model in normalised behaviour. Network activities are then compared with that normal behaviour. Anomaly-based intrusion detection systems are considered as a dynamic approach to anomaly detection, applying behaviour-oriented detection.
The AIDS strategy has in fact received more attention than any other approach [
5]. The capacity to detect unknown or zero-day attacks is the main benefit of AIDS. The majority of researchers choose anomaly detection, since it appears to be the most viable means [
6,
7]. However, designing efficient IDS for IoT devices remains challenging, due to the following reasons:
- (a)
Cyber-security datasets
The majority of existing datasets are outdated and may be inefficient for grasping the behavioural patterns of modern cyber-attacks. Moreover, there is a dearth of knowledge about the characteristics of recent attacks and their patterns of occurrence.
- (b)
Handling quality problems in Cyber-security datasets
Cyber-security datasets may be incomplete, unbalanced, noisy, or contain inconsistent instances related to a particular security incident. The quality of the learning process, and performance of ML-based models is affected by such dataset issues [
8].
- (c)
Low processing ability
Internet of Things devices are lightweight and energy-constrained with low computational capacity. However, teal-time data-processing is required by ML algorithms, which presents a problem to the implementation of such resource-constrained devices.
- (d)
Low memory capacity
Data is created in diverse ways in the IoT context, necessitating huge memory in IoT devices. As a result, being able to offer an efficient solution for varied data poses a hurdle.
Moreover, employing all features in the design of an IDS can lead to the introduction of redundant and irrelevant features into the model. Therefore, feature optimization must be used to achieve good IDS performance [
9]. There are three main approaches to feature optimization. The filter-based approach evaluates features according to predefined metrics, often using information theory. In contrast, a wrapper and embedded approach will evaluate features using an ML algorithm. In this current study, a wrapper-based feature optimization technique was used, specifically IDSBPSO as it gives efficient results as compare to other feature optimization methods [
10]. SBPSO is a recently proposed BPSO variant that updates a particle’s position, using the flipping probability rather than velocity. In SBPSO, a stickiness parameter is employed to maintain the momentum that is characteristic of PSO, meaning that a particle will tend to adhere to the position to which it has recently moved. PSO is a population-based stochastic optimization algorithm. Due to its easy feature-coding, computational reasonability, few parameters, and less demanding execution to address and select critical feature problems, the PSO algorithm is considered efficient and robustness to control parameters. There are various publicly available datasets for IoT networks, which include DARPA98, KDDCUP99, CAIDA (2007), ISCX 2012, ADFA-WD (2014), ADFA-LD (2014), CISIDS 2017, DS2OS (updated 20218), BOT-IoT (updated 2020) UNSW-NB15, and IoTID20.
The following are the contributions of the paper:
The proposed IDSBPSO is based on a novel approach of dynamic bit-masking strategy to reduce the search space of the SBPSO. This approach iteratively applies a mask to features after a certain number of generations, in order to prevent those features from evolving further. Using such a method throughout the evolutionary process can significantly reduce the search space, allowing the IDSBPSO to identify better solutions within a smaller search space.
Some parameters are set to dynamic, in order to investigate how this strategy can help balance exploration with exploitation, thereby further improving the searchability of SBPSO for the problems of optimising feature selection.
The proposed strategy would be implemented on two IoT network datasets for feature optimization, since this strategy is proposed for the design of an anomaly detection system for IoT networks, as a means of reducing the computational cost of such networks when using devices of a constrained nature.
The proposed FS model will be tested on the 2 datasets, IoTID20 and UNSW-NB15. The proposed model obtain comparable or higher accuracy with reduced computational cost and less number of features compared to benchmark PSO based methods. The remainder of this paper is organised as follows: the literature review is presented in
Section 2;
Section 3 discusses the proposed framework architecture;
Section 4 describes the implementation and evaluation of the results of the system experiments, and
Section 5 concludes the paper, also making recommendations for future work.
2. Literature Review
Internet of Things network security remains a consistent research topic for security analysers. Hence, numerous IDSs have been proposed, based on various types of feature optimization and reduction methodologies. In [
11], the authors propose a novel two-tier classification model based on ML methodologies, for example, the Naive Bayes, K nearest neighbors (KNN) classifier with certainty factor voting, and linear discriminant analysis (LDA) for feature reduction. This model has a high detection rate for sophisticated attacks like User to Root (U2R) and Remote to Local (R2L), namely 34.81% and 67.16%, respectively. Conversely, in [
12], the authors propose an effective deep learning approach: a self-taught learning (STL) IDS. The NSL-KDD dataset was used in the above-mentioned study, but the authors suggest a hybrid method for more accurate results. In [
13], the authors suggest a feature selection technique using filter and wrapper methods, but these are computationally expensive. Meanwhile, in [
14], the authors propose three IDS on K-means clustering, a decision tree, and a hybrid of these methods to achieve a maximum detection rate of 70–93%.
In [
15], however, the authors propose a hybrid deep network, combining Convolutional Neural Network (CNN) with a gated recursive unit to detect intrusion. A PSO algorithm was utilised in the resulting study to select relevant features from the data, and a developing system successfully performed the feature selection and classification process automatically. Meanwhile, in [
16], the authors present a semi-supervised ML technique for distributed denial of service (DDoS) detection, based on network entropy estimation, co-clustering, information gain ratio, and an extra-tree algorithm. This demonstrated good accuracy but with increased complexity. Conversely, in [
17], the authors employed a variety of feature selection strategies, including a correlation coefficient, gain ratio, and information gain. The suggested experiment was carried out on random forest, rotation forest, and random committee classifiers.
Meanwhile, in [
18], the authors present a feature selection-based IDS. The feature classification algorithm was based on a linear correlation coefficient. The cuttlefish algorithm was also used in this method to select features based on filter and wrapper, respectively. The FCC-CFA (feature grouping according to the linear correlation coefficient-cuttlefish algorithm) approach was created to extract the optimal subset of features from the dataset. This is a hybrid form of filter and wrapper method, retaining the advantages of each. The KDD Cup99 dataset was then used to test the suggested approach. The results of utilising the FGLCC-CFA algorithm revealed that compared with the CFA and FGLCC algorithms, the hybrid method was able to improve the accuracy and detection rate, while also reducing the number of false alarms.
In contrast, using a two-phase approach, the authors in [
19] propose a hybrid intrusion detection model. Here, the first phase consisted of feature selection and the second, detecting an attack. A wrapper method called MGA-SVM was applied in the first phase. With multi-parent crossover and multi-parent mutation, this model combines the characteristics of SVM and GA (MGA). In the second phase, an artificial neural network (ANN) was used to detect attacks, and PSO was employed to improve the suggested model’s performance. The proposed name of this model is therefore MGA-SVMHGS-PSO-ANN. It has a high detection accuracy of 99.3%, according to data from the NSL-KDD dataset.
On the other hand, specifically for lightweight IoT devices, the performance of a lightweight ML-based IDS was tested in [
20], using a new feature selection technique. The technique was verified with a public dataset, acquired from an IoT environment for this work. In the above model, a new feature selection approach, referred to as correlated-set thresholding on gain-ratio (CST-GR), is proposed to create a lightweight system, while also positively affecting the detection rate.
In [
21], however, the authors propose supervised ML algorithms to create a three-layer intrusion detection system, capable of detecting a variety of cyber-attacks in IoT networks. The resulting solution was tested in a smart home scenario with eight IoT gadgets. In [
22], the authors designed a bottom-up EI architecture and proposed novel data driven dynamical control strategy. Moreover, Intelligent controllers augmented by deep reinforcement learning (DRL) techniques are adopted and the concept of curriculum learning (CL) is integrated into DRL to improve the sample efficiency and accelerate the training process. Similarly, in [
23], the authors created a novel hybrid intrusion detection system (HIDS) for IoT threats. The developed HIDS ensemble was utilised to secure IoT devices by merging SIDS with AIDS. The results of the generated model revealed that the HIDS was superior in its performance. Conversely, the model could not detect various types of attack on the IoT system.
According to the research cited above, various FS methods have been used in the past but when the data dimensionality increases then it cause serious challenge for optimisers, as search space increases dramatically. Choosing the right characteristics to maximise classification accuracy for anomaly detection in IoT networks, while at the same time reducing computational cost and prediction time, would still appear to be a work in progress. Various research exists on the design of anomaly detection systems for IoT networks, but these either use benchmark PSO-based methods, or a hybrid of optimization algorithms for feature selection. To close the gap in the literature, this study therefore provides an intelligent system, which uses novel approach to reduce search space and increase the exploration and exploitation ability of optimizer to select optimal features, while obtaining comparable or higher accuracy with reduced computational cost and prediction time.
3. The Proposed Model
This section proposes an enhanced approach to the design of an efficient and accurate IDS for IoT networks, using an IDSBPSO as an approach to feature selection. Particle swarm optimization (PSO) is a population-based stochastic optimization algorithm, proposed by Eberhart and Kennedy in 1995 [
24]. Because of its easy feature-coding, computational reasonability, few parameters, and less demanding execution to address and select critical feature problems, the PSO algorithm is considered efficient [
25]. The originally proposed PSO was a continuous one (CPSO), used to tackle a variety of continuous issues. The main drawback of PSO is that if a particle gets stuck in a local minimum (optimal), all the other particles will converge to that local minimum, resulting in erroneous solutions. Thus, before expanding the network, it is necessary to preserve particle diversity [
26].
Particles are employed in the PSO method to represent solutions from the population of particles in the relevant space. This population is referred to as a swarm. Each particle in the swarm is represented by vector
…
, where
d represents the number of features in the dataset, and each particle has
d dimensional velocity
…
. To enhance efficiency, PSO works randomly and travels in the search space to find relevant features by updating velocity and position with iterations. At each iteration, the particles’ velocity and position are updated according to
and
, which are the best personal and global fitness values up until that iteration. According to [
27], the position and velocity of particles is updated as in (1) and (2).
where
k represents
iteration and
d represents
feature in the vector space. In addition,
w represents the inertia factor that will give weightage to the previous velocity, and
and
are acceleration coefficients that give weightage to the cognitive and social term in the updated velocity. Meanwhile,
and
are uniform random numbers within [0, 1].
Velocity has three components, as illustrated in (1). The first component is momentum, depicting the influence of the present direction. Varying particles usually have different momentums, which help keep the swarm diverse, especially when everyone shares their finest experiences. Furthermore, momentum is the only factor that will allow a particle to continue seeking better solutions, once it has arrived at the best point discovered by the swarm so far. Conversely, the other two are cognitive and social components which guide particles towards an optimal experience, as well as that of each particle’s neighbours.
Binary PSO was developed to solve combinatorial problems, including job-shop scheduling and feature selection. In BPSO, rather than adding velocity to position, in order to obtain a new position, velocity is used to determine the probability of achieving the corresponding updated position values [
27], which can be seen in (3).
Sticky BPSO (SBPSO) is a recently proposed BPSO variant that updates a particle’s position, using the flipping probability rather than velocity. In SBPSO, a stickiness parameter is employed to maintain the momentum that is characteristic of PSO, meaning that a particle will tend to adhere to the position to which it has recently moved [
28]. This is illustrated in (5).
where rand () is a random value in [0, 1] from the uniform distribution. Moreover,
is the flipping probability of the
particle in the
d dimension [
28], which may be written mathematically as per (6).
where
denotes the stickiness parameter of the
particle on the
dimension. Here,
denotes the personal best of the
particle on the
dimension, and
denotes the global best. Meanwhile,
,
, and
are the three parameters that give weightage to the particle’s stickiness ability and its tendency to move towards pbest and gbest. The stickiness parameter,
lowers over time, indicating that a bit is more likely to cling to its new position. According to [
28], the updated
mechanism is illustrated in (7).
where
M is the step parameter determining stickiness ability, which decreases from 1 to 0 as the number of iterations increases. Initially,
was set for
k = 0. Dynamic SBPSO is a further variant of the SBPSO variant, proposed to control the exploration and exploitation ability of particles. In dynamic SBPSO,
,
, and
are used to increase exploration at the outset and increase exploitation at the end. Here,
and
linearly decrease in relation to an increase in the number of iterations, which can be seen in (8) and (10), respectively. Meanwhile,
linearly increases alongside the rising number of iterations, which can be seen in (9).
where
and
are the maximum and minimum values for the
factor,
and
are the maximum and minimum values for the
factor, and
and
are the maximum and minimum values for the
factor. Ultimately,
k represents the
iteration, and
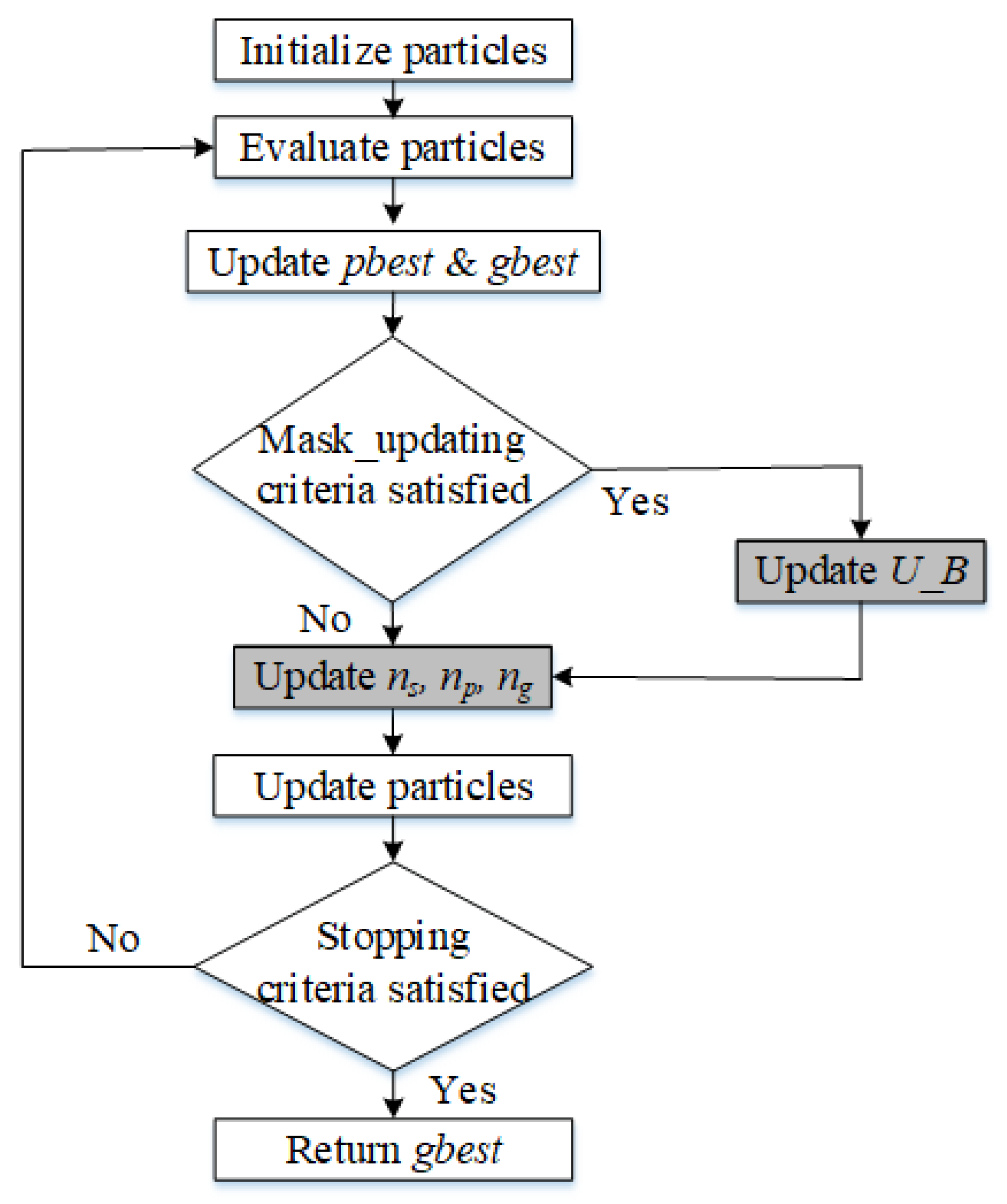
represents the maximum number of iterations. The values applied for all these parameters can be seen in the subsection, ‘Parameter Setup’.
Traditionally, during the evolutionary process, a BPSO algorithm searches in a fixed d-dimensional space (where d represents the number of original features). When d is large, setting a high number of particles or generations in the PSO algorithms demands significant processing resources. As a result, it is advantageous to include a search space reduction strategy, which can lower the computational resources required for the PSO applied to the feature selection task.
In this study, the dynamic bit-masking strategy was combined with DSBPSO. This first involved extracting information from the
of particles to determine which bits should be masked. During the evolutionary process, the number of selected traits of all particles decreases. Even before the halting criterion is met, noisy or irrelevant features can be determined. After a certain number of generations, if a feature (bit) is not selected by all
in the swarm, it is very probable that this feature is useless, since solutions containing this feature are very likely to be eliminated for their poor fitness. The parameter that decides when a mask should be updated is
. In this study, the mask update approach was adopted, because a bit is masked if it is not selected by all pbests in the swarm. This can be seen in Algorithm 1.
| Algorithm 1: Search Space Reduction Strategy |
![Sensors 22 04926 i001]() |
In this algorithm, the
of particles are represented by a set,
, and the mask is denoted by
, given that each element in this set corresponds to an unmasked bit. The
set is updated by obtaining information from the pbest of each swarm. A bit is removed from
if it is not selected by all
in the swarm. During the algorithm’s evolutionary phase, the set is updated. Some bits in
are masked each time the mask- update mechanism is run. The mask-update approach ensures a reduced search space, because only the bits in
can evolve. The position-updating mechanism can then be rewritten as in (11) [
28].
According to the third condition, if
, the position of that particle is assigned a value of 0, meaning that it is eliminated from the search space to reduce computational time and resources. This improvement can be seen in
Figure 2, where the grey blocks show the improved SBPSO strategies.
The overall IDSBPSO-based feature selection procedure can be seen in Algorithm 2. The proposed approach first adopts a search space reduction strategy to reduce the number of features involved in the iteration update, and the mask is updated every
.
K iterations, with
K as the maximum number of iterations.
| Algorithm 2: Pseudocode of the IDSBPSO-Based Feature Selection Method |
![Sensors 22 04926 i002]() |
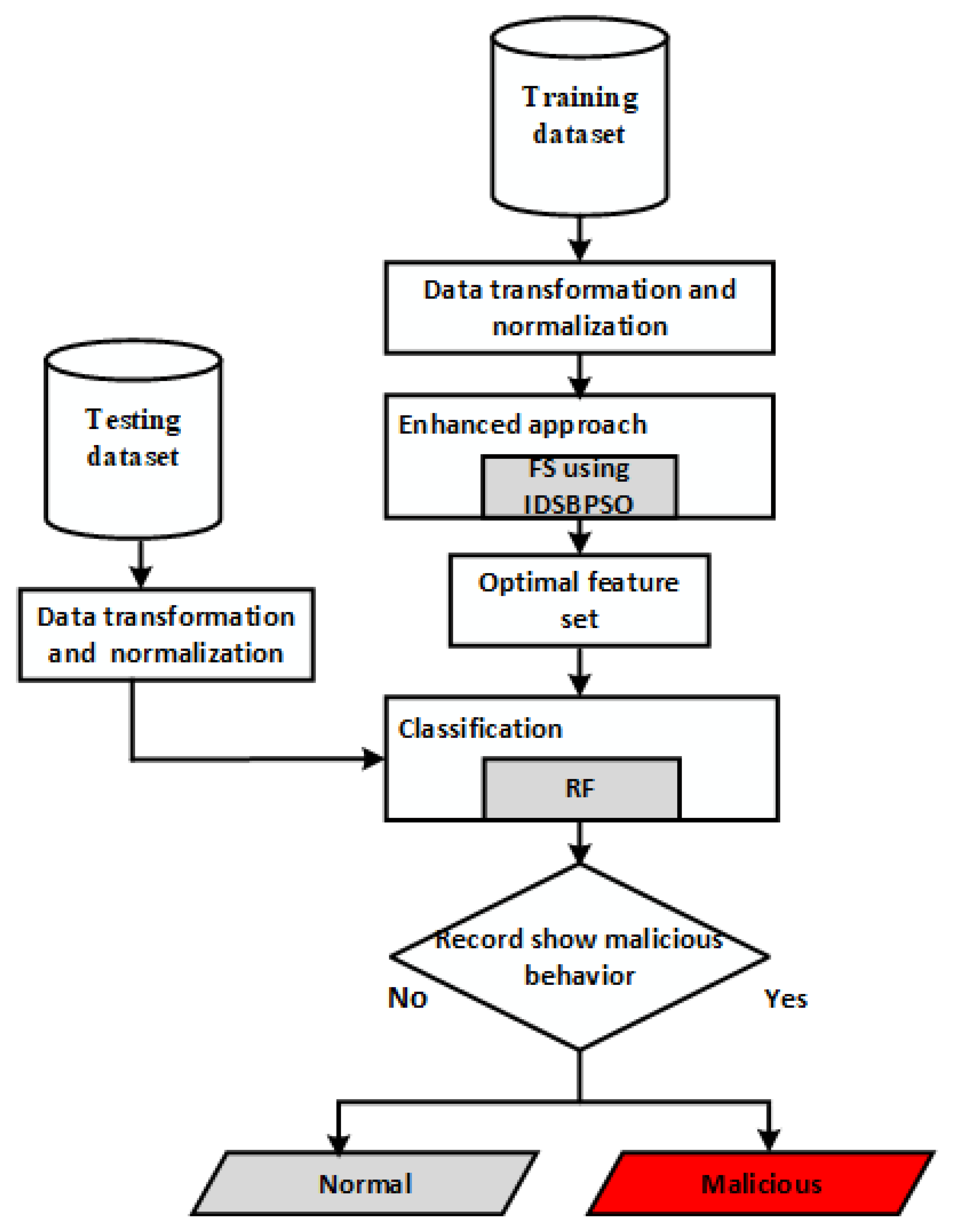
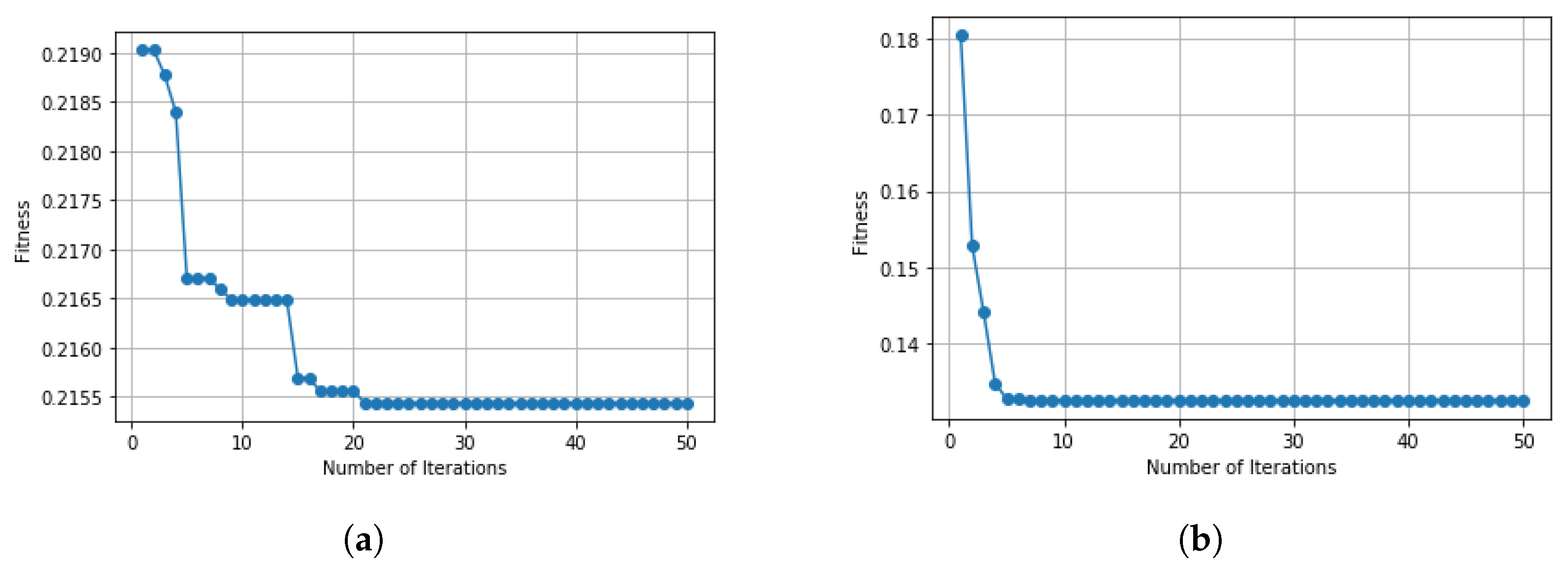
Figure 3 depicts the framework of the proposed model for a network IDS using IDSBPSO. The proposed system comprises a number of phases to obtain good accuracy and network suitability, as explained in this section.
The two IoT datasets included IoTID20 and UNSW-NB15. The IoTID20 dataset was generated in 2020 [
29] and contains a total of 83 network features. These network features can be seen in
Table 1. There are also three label features in this dataset: binary, category, and sub-category, and four main attacks: Scan, Mirai, denial of service (DoS), and man in the middle (MITM). These attacks and their subcategories can be seen in
Table 2.
The UNSW-NB15 is an advanced dataset used for IDS research. It is widely referenced in the literature. The UNSW-NB15 contains 42 network features, as listed in
Table 3. There are two label features in this dataset: binary and category. Moreover, nine attacks may be seen in
Table 4. Authentication, confidentiality, integrity, and availability are among the security needs targeted by these attacks. Accurate detection of these attacks is critical, as the consequences for IoT applications can be disastrous [
30].
Real-life datasets are high-dimensional because they incorporate vibrant information, received from a variety of IoT devices and sensors. When creating an ML model, it is essential to choose a set of meaningful, non-redundant features, because the quality of the features will reduce the performance of the ML classifier [
31,
32] and the data will be unsuitable for IoT devices to work on. For this purpose, IDSBPSO-based feature optimization was used in this study. The feature optimization problem may be formulated in different ways. In many cases, there is a need to optimise features to reduce computational cost, while also increasing performance accuracy to enhance the generalisation capability. When choosing the best optimization technique based solely on prediction accuracy, performance will vary between the training and test sets [
33]. Therefore, there are two main goals in feature selection: to improve classification performance and reduce the number of selected features. In [
34], the aggregate fitness function is used to select best features with no change in accuracy, which can be shown in (12).
where
is the error rate,
a is a constant giving weightage to the terms, and
is the percentage of selected features, which can be seen in (13).
where
p represents the total number of selected features out of a total of N features. The value of
a has been adjusted to 0.8 since it was suggested as being between 0.7 and 0.9 [
35]. The selected features were then entered into the ML classifier. Random forest classification is used, this being a group of tree-structured classifiers in an ensemble technique. Each tree is built with a decision tree and different bootstrap sample from the original data. Each node of trees only selects a limited selection of features for the split. Out-of-bag (OOB) evaluation, which is an unbiased estimator of generalisation error, is performed on the learning samples that are not selected using the bootstrap. When a new sample needs to be classified after the forest has been built, it is fed into each tree in the forest. Each tree then casts a unit vote for a specific class, indicating the tree’s judgement. When compared to typical ML classifiers, ensemble classifiers are strategies that may be adopted to build a powerful classifier with improved classification accuracy. The mathematical expression representing the model can be seen in (14).
where
j represents each classifier and
m represents the total number of classifiers included in the classification or voting.
Random forest has the following advantages:
It demonstrates excellent performance in accuracy on structured data.
It is computationally efficient and can run on large-scale datasets with high dimensions.
In most cases, it does not overfit and is robust against noise.
It can handle unbalanced datasets.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}