
A Self-Regulating Power-Control Scheme Using Reinforcement Learning for D2D Communication Networks


Abstract
:1. Introduction
2. Related Works
3. A D2D Communication Network and Channel Model
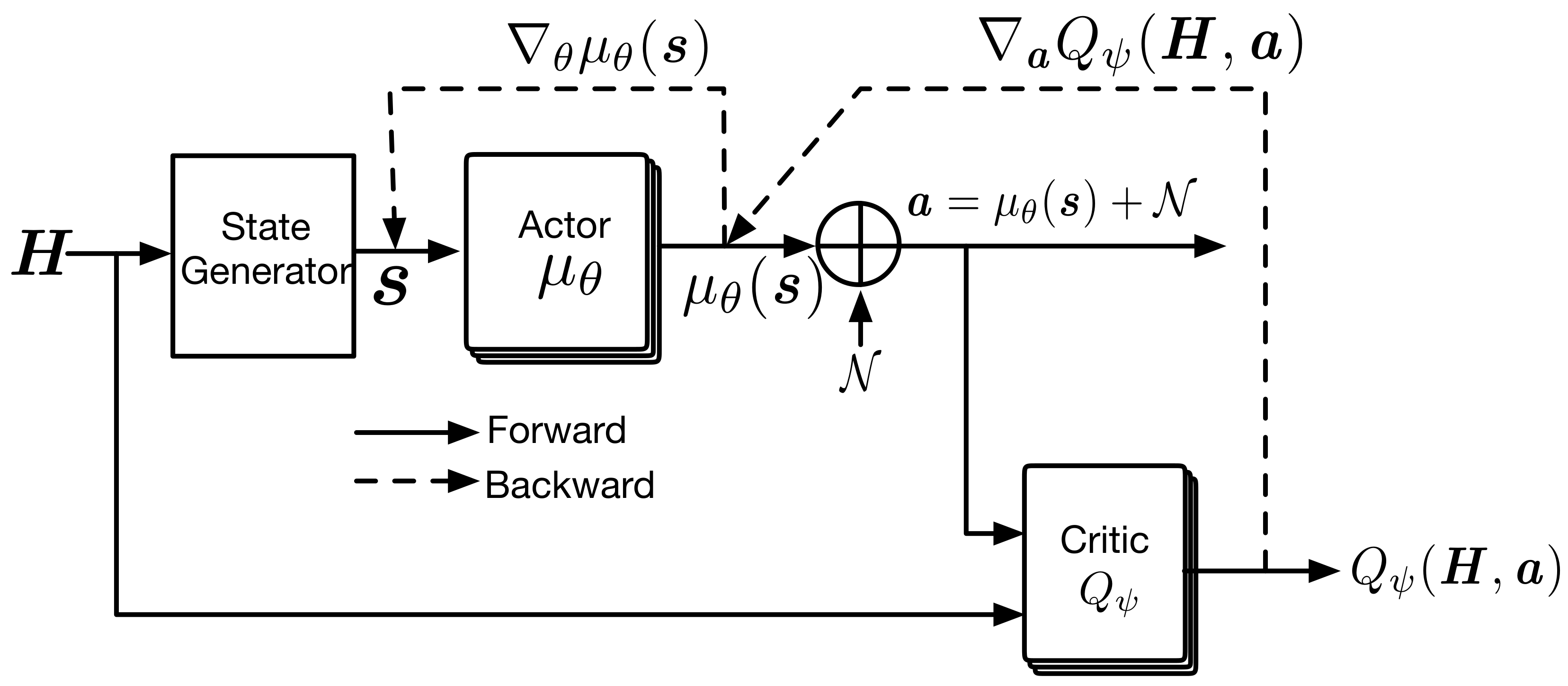
4. Proposed Power Control Scheme
| Algorithm 1 Proposed power control algorithm using DDPG |
|
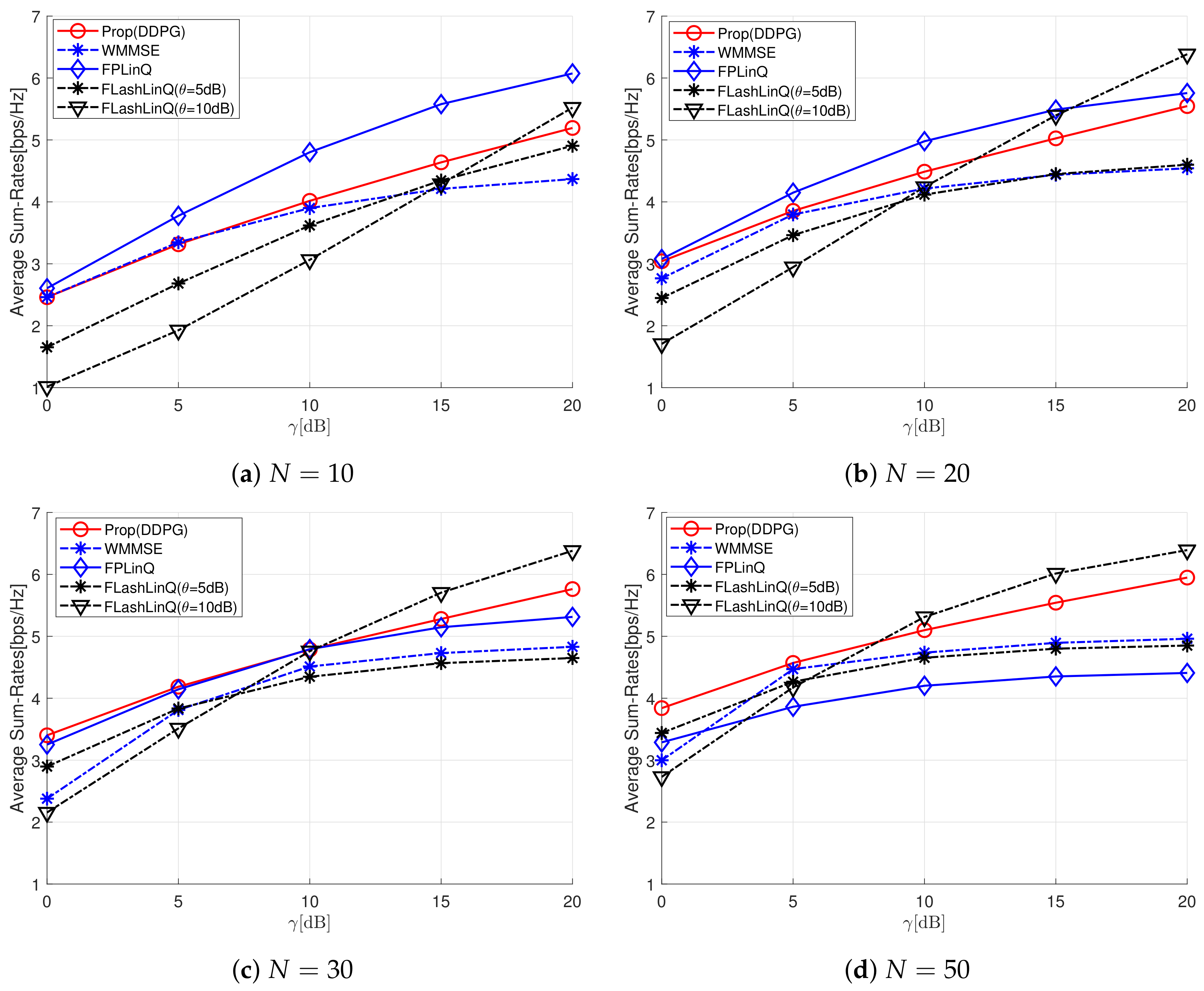
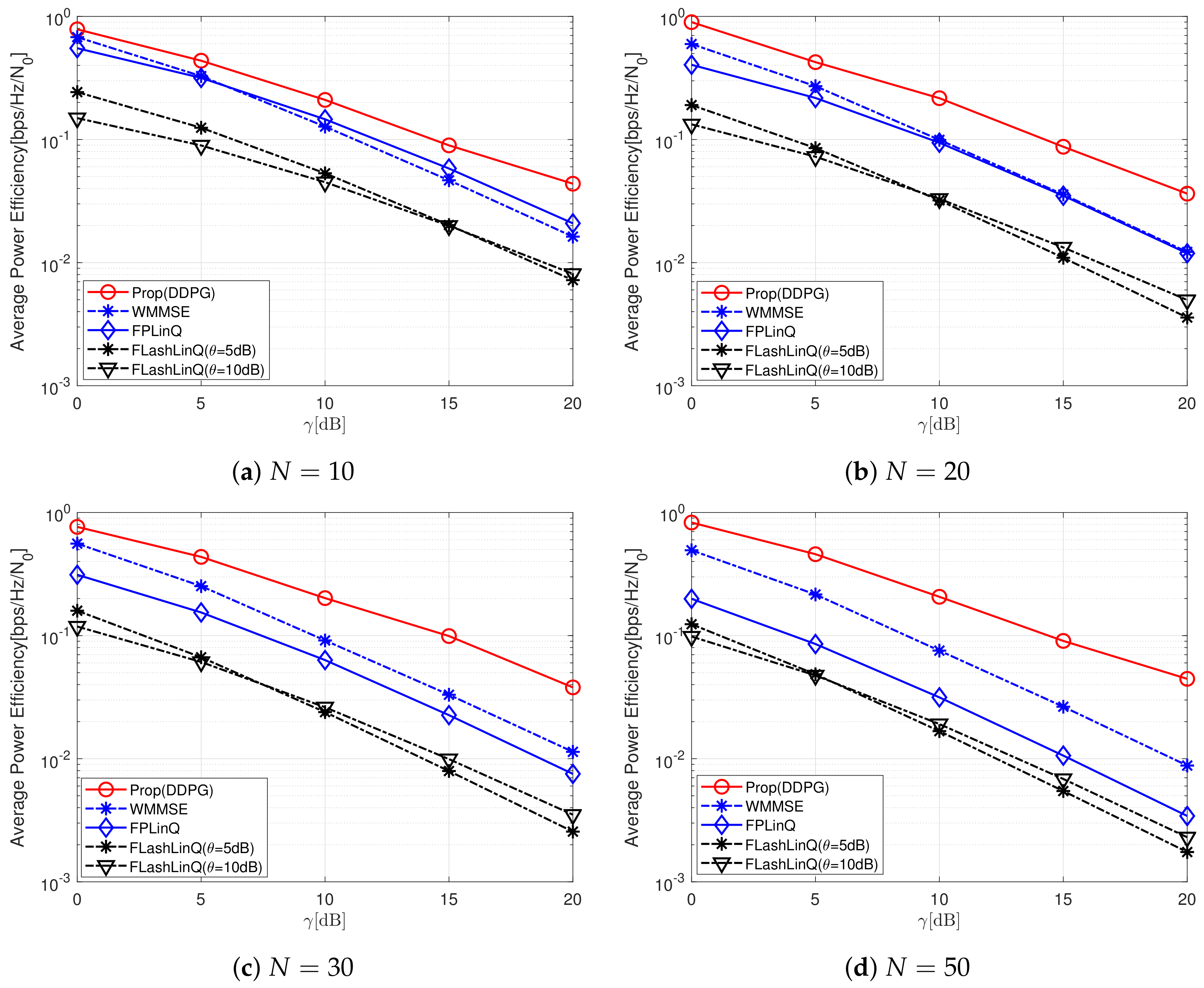
5. Numerical Results
6. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Qiao, Y.; Li, Y.; Li, J. An Economic Incentive for D2D Assisted Offloading Using Stackelberg Game. IEEE Access 2020, 8, 136684–136696. [Google Scholar] [CrossRef]
- Yasukawa, S.; Harada, H.; Nagata, S.; Zhao, Q. D2D communications in LTE advanced release 12. NTT Docomo Tech. J. 2015, 17, 56–64. [Google Scholar]
- Yeh, W.-C.; Jiang, Y.; Huang, C.-L.; Xiong, N.N.; Hu, C.-F.; Yeh, Y.-H. Improve Energy Consumption and Signal Transmission Quality of Routings in Wireless Sensor Networks. IEEE Access 2020, 8, 198254–198264. [Google Scholar] [CrossRef]
- Han, L.; Zhang, Y.; Zhang, X.; Mu, J. Power Control for Full-Duplex D2D Communications Underlaying Cellular Networks. IEEE Access 2019, 7, 111858–111865. [Google Scholar] [CrossRef]
- Shi, Q.; Razaviyayn, M.; Luo, Z.-Q.; He, C. An IterativelyWeighted MMSE Approach to Distributed Sum-UtilityMaximization for a MIMO Interfering Broadcast Channel. IEEE Trans. Signal Process. 2011, 59, 4331–4340. [Google Scholar] [CrossRef]
- Wu, X.; Tavildar, S.; Shakkottai, S.; Richardson, T.; Li, J.; Laroia, R.; Jovicic, A. FlashLinQ: A Synchronous Distributed Scheduler for Peer-to-Peer Ad Hoc Networks. IEEE/ACM Trans. Netw. 2013, 21, 1215–1228. [Google Scholar] [CrossRef]
- Shen, K.; Yu, W. FPLinQ: A cooperative spectrum sharing strategy for device-to-device communications. In Proceedings of the 2017 IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017; pp. 2323–2327. [Google Scholar] [CrossRef]
- Han, L.; Zhou, R.; Li, Y.; Zhang, B.; Zhang, X. Power Control for Two-Way AF Relay Assisted D2D Communications Underlaying Cellular Networks. IEEE Access 2020, 8, 151968–151975. [Google Scholar] [CrossRef]
- Lai, W.-K.; Wang, Y.-C.; Lin, H.-C.; Li, J.-W. Efficient Resource Allocation and Power Control for LTE-A D2D Communication with Pure D2D Model. IEEE Trans. Veh. Technol. 2020, 69, 3202–3216. [Google Scholar] [CrossRef]
- Lim, D.-W.; Kang, J.; Kim, H.-M. Adaptive Power Control for D2D Communications in Downlink SWIPT Networks with Partial CSI. IEEE Wirel. Commun. Lett. 2019, 8, 1333–1336. [Google Scholar] [CrossRef]
- Kumar, B.N.; Tyagi, S. Deep-Reinforcement-Learning-Based Proportional Fair Scheduling Control Scheme for Underlay D2D Communication. IEEE Internet Things J. 2021, 8, 3143–3156. [Google Scholar]
- Du, C.; Zhang, Z.; Wang, X.; An, J. Deep Learning Based Power Allocation for Workload Driven Full-Duplex D2D-Aided Underlaying Networks. IEEE Trans. Veh. Technol. 2020, 69, 15880–15892. [Google Scholar] [CrossRef]
- Bi, Z.; Zhou, W. Deep Reinforcement Learning Based Power Allocation for D2D Network. In Proceedings of the 2020 IEEE 91st Vehicular Technology Conference (VTC2020-Spring), Antwerp, Belgium, 25–28 May 2020; pp. 1–5. [Google Scholar]
- Tan, J.; Liang, Y.-C.; Zhang, L.; Feng, G. Deep Reinforcement Learning for Joint Channel Selection and Power Control in D2D Networks. IEEE Trans. Wirel. Commun. 2021, 20, 1363–1378. [Google Scholar] [CrossRef]
- Kim, D.; Jung, H.; Lee, I.-H. Deep Learning-Based Power Control Scheme with Partial Channel Information in Overlay Device-to-Device Communication Systems. IEEE Access 2021, 9, 122125–122137. [Google Scholar] [CrossRef]
- Shi, J.; Zhang, Q.; Liang, Y.-C.; Yuan, X. Distributed Deep Learning for Power Control in D2D Networks With Outdated Information. IEEE Trans. Wirel. Commun. 2021, 20, 5702–5713. [Google Scholar] [CrossRef]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Ban, T.-W.; Jung, B.C. On the Link Scheduling for Cellular-Aided Device-to-Device Networks. IEEE Trans. Veh. Technol. 2016, 65, 9404–9409. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
| [dB] | N | |||
|---|---|---|---|---|
| 10 | 20 | 30 | 50 | |
| 0 | 0.94 (FPLinQ) | 0.99 (FPLinQ) | 1.05 (FPLinQ) | 1.12 (FPLinQ) |
| 5 | 0.88 (FPLinQ) | 0.93 (FPLinQ) | 1.01 (FPLinQ) | 1.02 (WMMSE) |
| 10 | 0.84 (FPLinQ) | 0.90 (FPLinQ) | 1.00 (FPLinQ) | 0.96 (FLashLinQ) |
| 15 | 0.83 (FPLinQ) | 0.92 (FPLinQ) | 0.93 (FPLinQ) | 0.92 (FLashLinQ) |
| 20 | 0.85 (FPLinQ) | 0.87 (FPLinQ) | 0.90 (FLashLinQ) | 0.93 (FLashLinQ) |
| [dB] | N | |||
|---|---|---|---|---|
| 10 | 20 | 30 | 50 | |
| 0 | 1.16 (WMMSE) | 1.51 (WMMSE) | 1.37 (WMMSE) | 1.68 (WMMSE) |
| 5 | 1.33 (WMMSE) | 1.57 (WMMSE) | 1.73 (WMMSE) | 2.12 (WMMSE) |
| 10 | 1.44 (FPLinQ) | 2.18 (FPLinQ) | 2.21 (WMMSE) | 2.74 (WMMSE) |
| 15 | 1.54 (FPLinQ) | 2.44 (FPLinQ) | 2.99 (WMMSE) | 3.43 (WMMSE) |
| 20 | 2.09 (FPLinQ) | 2.98 (FPLinQ) | 3.32 (WMMSE) | 5.06 (WMMSE) |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ban, T.-W. A Self-Regulating Power-Control Scheme Using Reinforcement Learning for D2D Communication Networks. Sensors 2022, 22, 4894. https://doi.org/10.3390/s22134894
Ban T-W. A Self-Regulating Power-Control Scheme Using Reinforcement Learning for D2D Communication Networks. Sensors. 2022; 22(13):4894. https://doi.org/10.3390/s22134894
Chicago/Turabian StyleBan, Tae-Won. 2022. "A Self-Regulating Power-Control Scheme Using Reinforcement Learning for D2D Communication Networks" Sensors 22, no. 13: 4894. https://doi.org/10.3390/s22134894
APA StyleBan, T.-W. (2022). A Self-Regulating Power-Control Scheme Using Reinforcement Learning for D2D Communication Networks. Sensors, 22(13), 4894. https://doi.org/10.3390/s22134894