
Multilayer Reversible Information Hiding with Prediction-Error Expansion and Dynamic Threshold Analysis


Abstract
:1. Introduction
2. Related Works
2.1. Prediction-Error Expansion
2.2. Dynamic Search for Expandable Difference in Horizontal and Vertical Difference Image
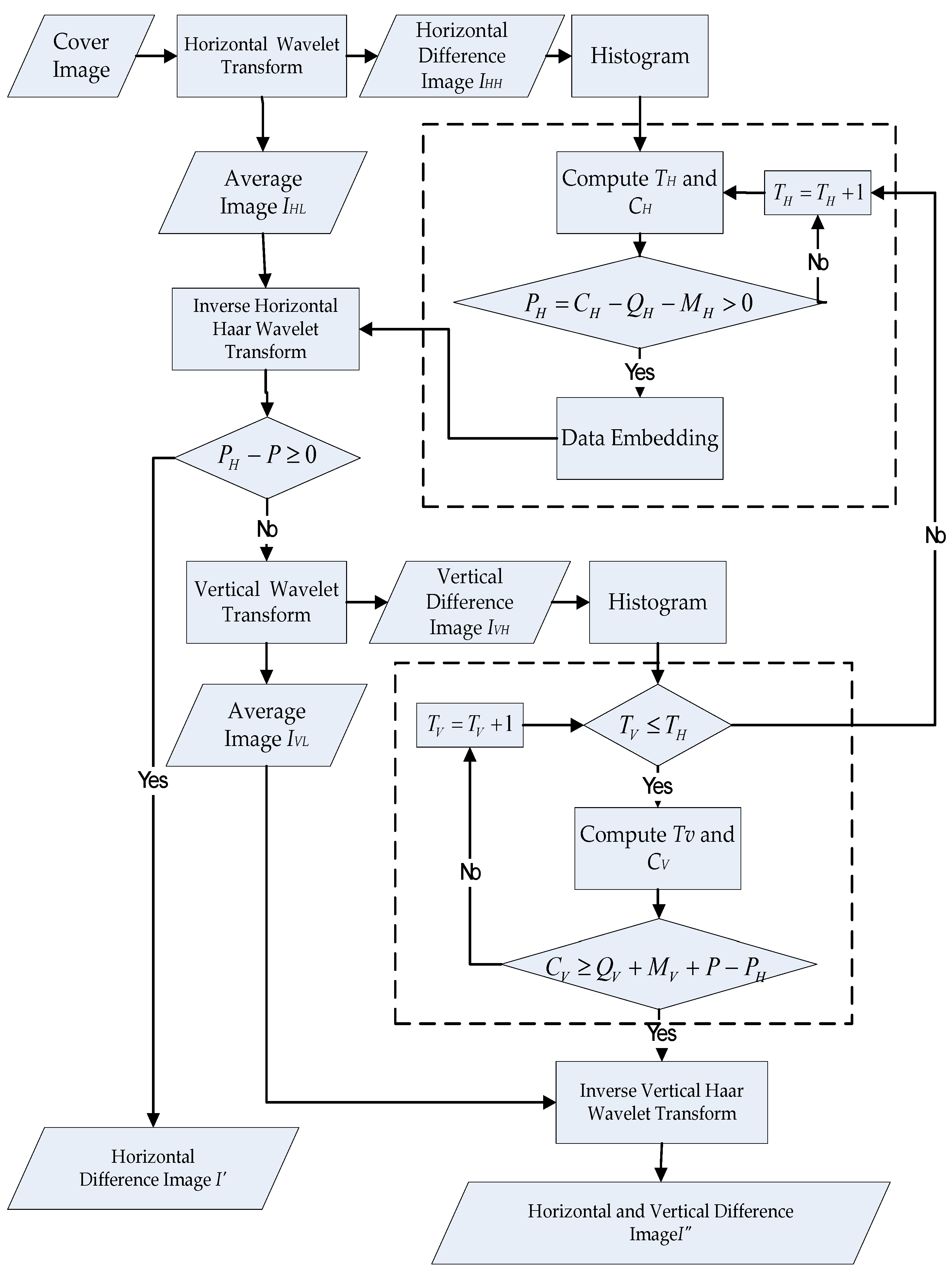
- For a cover image, the integer Haar wavelet transform (IHWT) is just performed in the row direction, and the horizontal difference image, , can be obtained. In addition, the histogram of is calculated.
- Supposing the payload is P, and the payload in the row direction is , the selection of all extendable differences provides spare space for the payload. In addition, there are sufficient locations for the auxiliary data, which consists of the header file, , and the location map, , in the horizontal direction. Assuming the present threshold and the horizontal embedding capacity are and , respectively, then the initial difference selection threshold is zero. If , the horizontal capacity under is sufficiently large for P, and no more locations are required. If , the horizontal capacity under is not sufficiently large for P. Therefore, only the partial payload, i.e., , will be embedded in the horizontal direction. Thus, they need the additional embedding capacity and must look into the image of the vertical difference.
- In Figure 2, the horizontal embedded image, , is obtained by synthesizing and the average image, .The integer Haar wavelet transform is performed on in the column direction to obtain the vertical difference image, . In this way, the difference histogram of is calculated.
- In the vertical direction, supposing the current threshold and the vertical embedding capacity are defined as and , respectively, then . The authors use another inner search loop to test whether . Once , it means that the vertical difference image can provide enough embedding capability for the remainder of the payload. As a result, one can hide the data and obtain the embedded vertical difference image, . If the final embedding capacity is larger than zero (), the search round under the current fails. We have to increase by 1 and repeat Steps (2)–(4) again. Note that, no matter how we increase , the vertical selection threshold should not be higher than the horizontal threshold, defined as
- By converting the Haar wavelet transform, the embedded vertical difference image, , can be synthesized, as well as the average image, , in Figure 2, to obtain the output image, .
3. Proposed Scheme
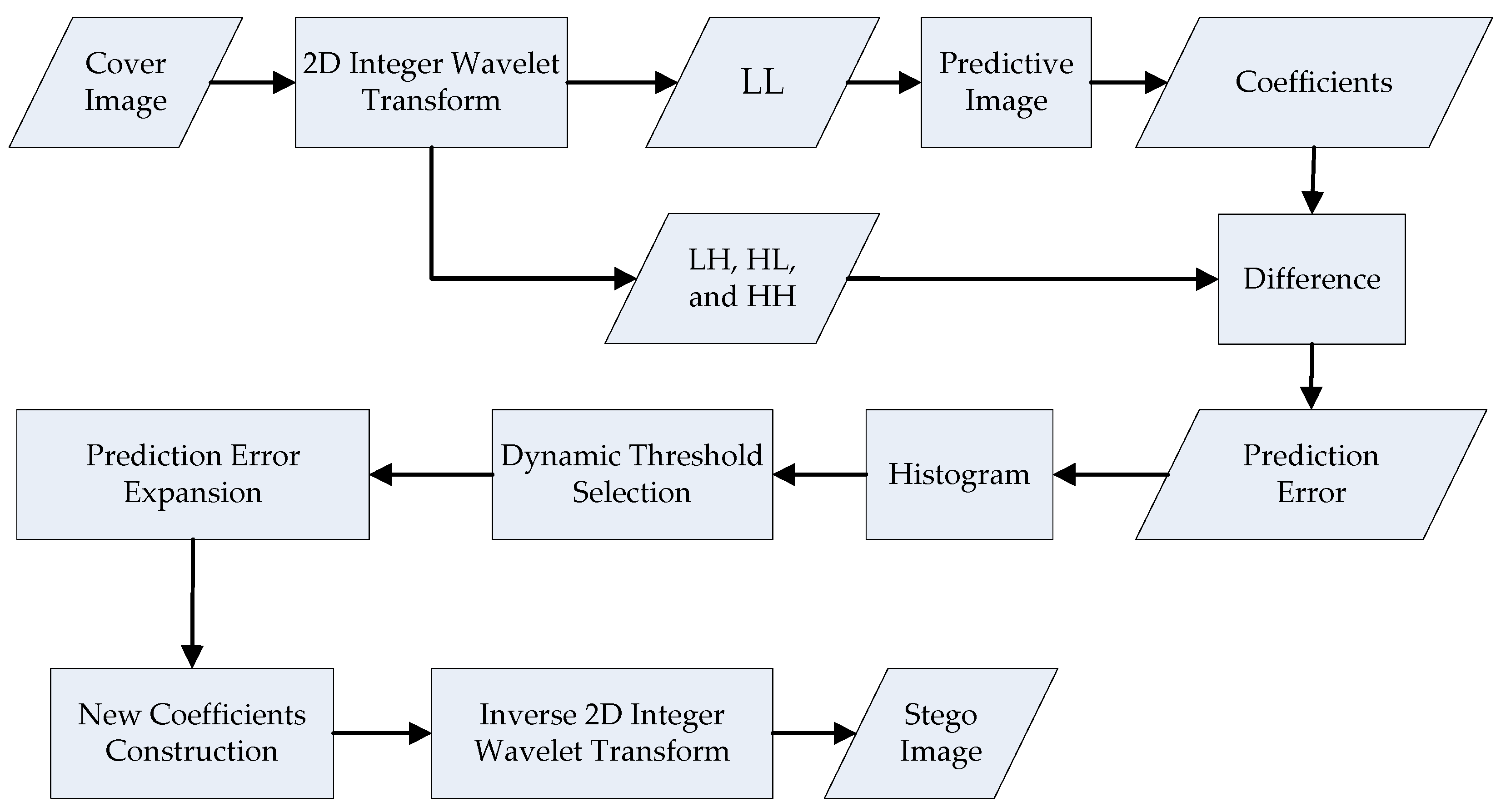
3.1. Predicted Model Construction
- The edge coefficients of the low-frequency coefficients (LL) in the cover image are duplicated.
- Equations (6)–(9) are used to produce the predictive image PI. In Figure 5, from each low-frequency coefficient, PI (2i, 2j), PI (2i−1, 2j), PI (2i, 2j−1), and PI (2i−1, 2j−1) denote the four neighboring pixels. For example, the original and predictive images of the “Airplane” image are shown in Figure 4, where PSNR is approximately 30 dB.
3.2. Dynamic Threshold Analysis
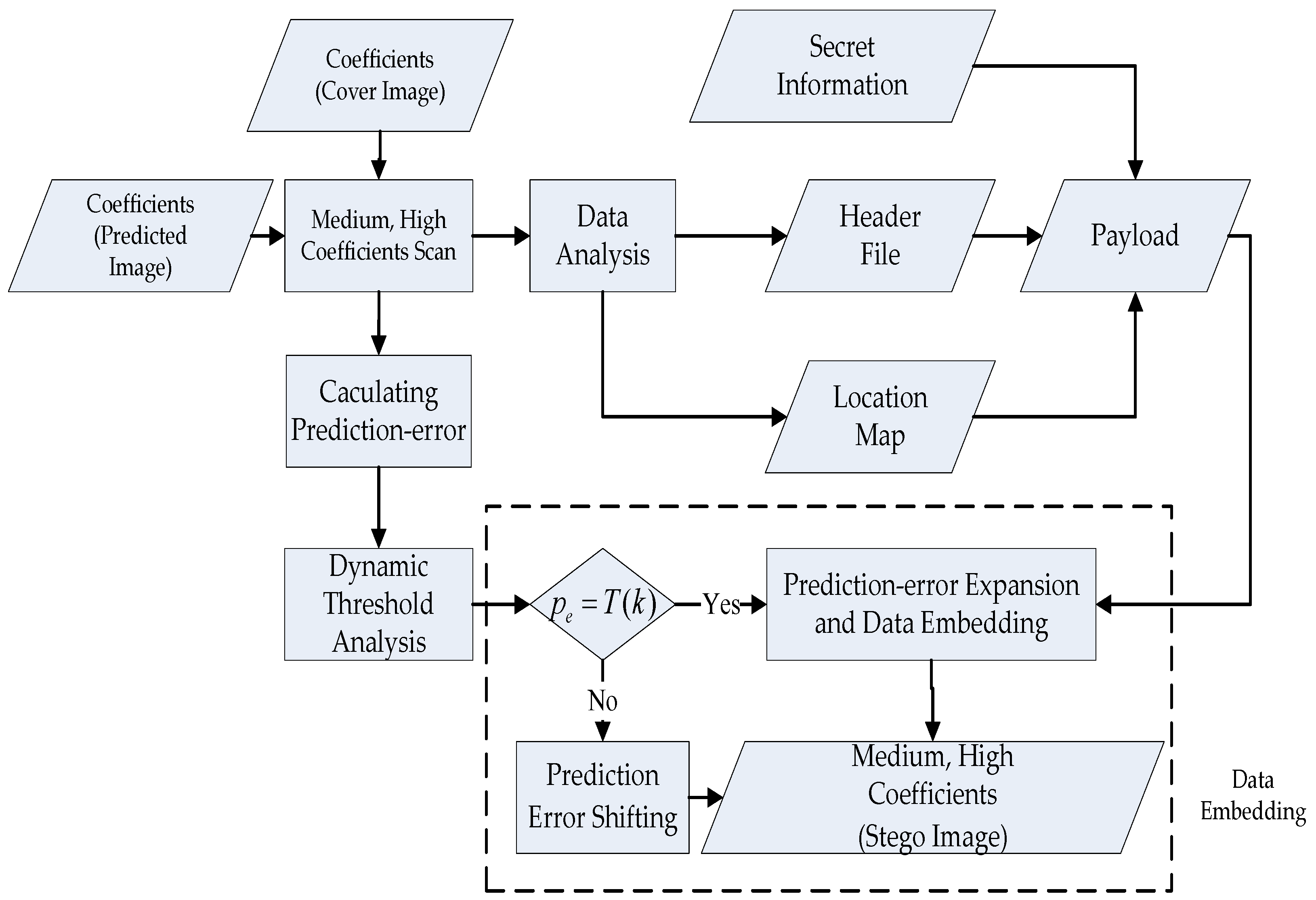
- 1.
- The multilayer embedding algorithm calculates the prediction error and difference histogram for the coefficients of the medium and high frequencies in the L layer. The initial difference selection threshold is zero. We use a difference histogram to describe the statistical distribution of the expandable differences.
- 2.
- To avoid unexpected shift, we apply a dynamic threshold analysis. The dynamic threshold, T(k), is shown in Equation (10). The initial value, T(0), is zero, and k is the number of the threshold analysis. To achieve a higher image quality, we define the marginal value, kE. During the experiment, we initially assume eight numbers of the dynamic threshold T(1) to T(16), as shown in Table 1. Each threshold indicates the value of the prediction error for each layer. We apply the value of initial prediction error, which is zero. Then, we expand both sides starting from the origin. Supposing the payload is P, the current selection threshold and the embedding capacity are T(k) and C, respectively. Then, if C ≥ P and k < kE, the capacity under T(k) is sufficiently large for P. We do not require any more locations. If C < P and k < kE, this implies that the difference image cannot provide sufficient embedding capacity for the rest of the payload (). We increase the parameter of threshold, k, by 1 and repeat the previous steps. If we find C < P and k < kE, we must calculate the prediction error and histogram of the medium- and high-frequency coefficients in the next layer.
- 3.
- If the payload size continues to increase, this method cannot satisfy the capacity requirement in the single-layer embedding, whereas the multilayer embedding method is able to do so.
3.3. Predicted Parameter Adjustment of Multiple Layers
3.4. Secret Data Embedding and Extraction
3.4.1. Secret Data Embedding
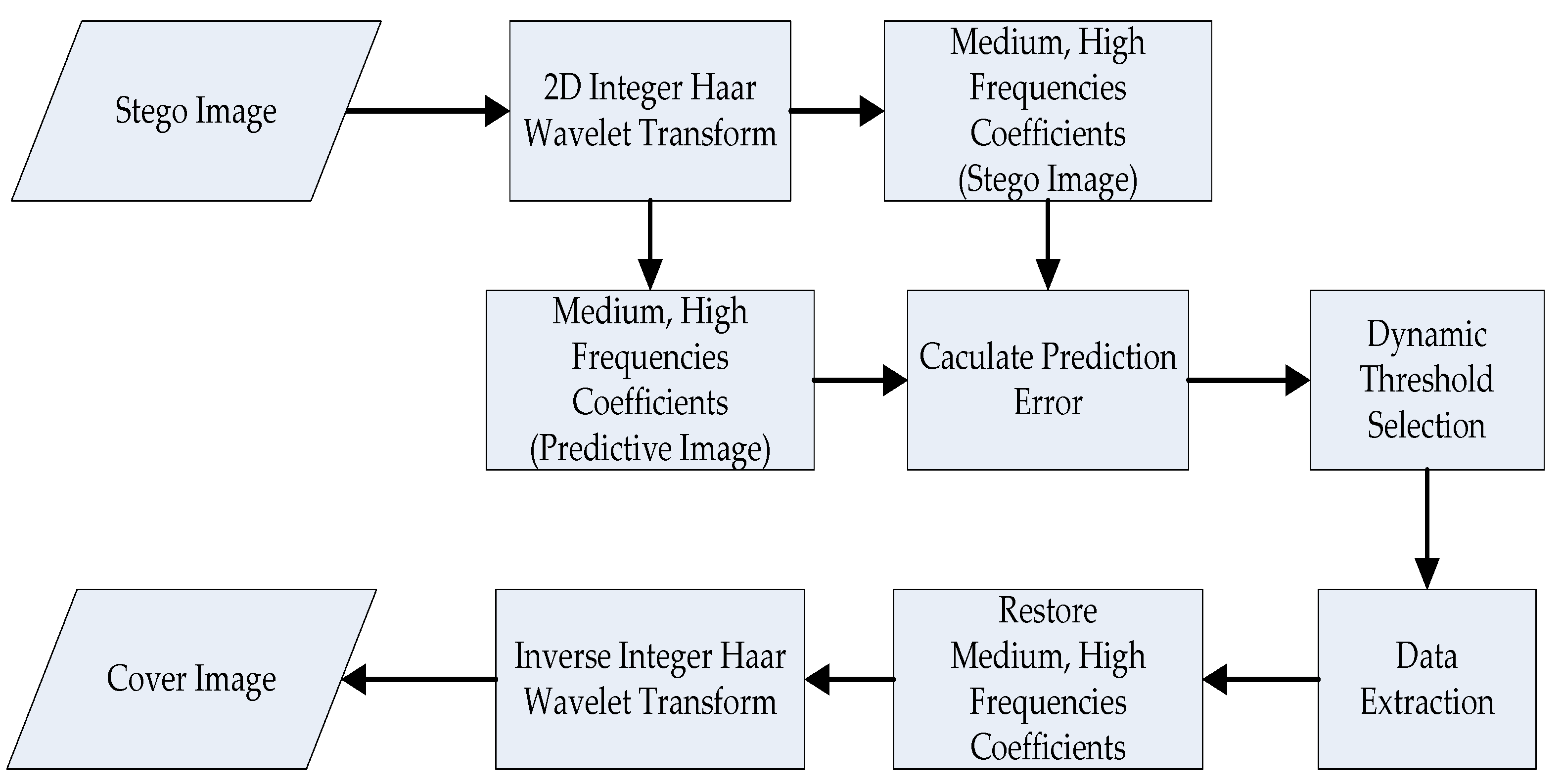
3.4.2. Information Extraction
4. Experiment and Discussion
- Increasing the security of data embedding:We proposed the predicted model construction using integer Haar wavelet transform decomposition. Then, we constructed the predicted image from low-frequency coefficients (LL). If someone attempts to steal the embedding information, they must use the key of the predicted model and parameters to extract the perfect information. Otherwise, some imperfect information or random unrecognizable characters and numbers may be found.
- Improving the payload of the location map:After the integer Haar wavelet transform decomposition, the low-frequency image is one quarter compared to the original image. For a 512 × 512 image, the location map size is 256 × 256. Hence, the embedding rate is 0.25 bits per pixel (bpp) when it is not compressed compared with Tian’s method [3] where the embedding rate is 0.5 bpp. Evidently, not all pairs can be used for data hiding. The location map indicates whether the pairs are expanded. Compared with Hu’s method [35], where the embedding rate is near 0.5 bpp with embedding the over- and under-flow location map for one layer, our proposed scheme can reach to 0.75 bpp, at best, in one layer.
- To improve the quality (PSNR) of the stego image. There are some lists for our proposed method:First, the dynamic threshold analysis calculates the PE and histogram of the median and high-frequency coefficients in each layer. The initial difference selection threshold is zero. When the payload is completely embedded into the cover image, the dynamic threshold analysis and other unexpected shifts are stopped. Therefore, the quality of the stego image can be improved. Second, we constrict the predicted model to low-frequency coefficients (LL). The low-frequency coefficients contain the most important information of the original image. During the secret data embedding and extraction, we not only never change the predictive image but also perfectly reconstruct it. After constructing the predicted image, we only find the median and high-frequency coefficients to finish the reversible data hiding and increase the quality of the stego image. Third, we improve the location map size such that we not only can use significantly lower extra information during the same data embedding but can also embed more payload. As we can see in Table 6, Chang et al. [43] used a more significant amount of extra information for performing reversible data hiding. Fourth, to obtain a higher image quality, we not only perform the dynamic threshold analysis but also define the predicted parameters of the multiple layers.
- After the integer Haar wavelet transform decomposition, we duplicate the edge coefficients of the low-frequency coefficients (LL) of the cover image to construct the predicted image. The detected features of the different texture complexities of the predicted image are important. For example, during the data embedding, we set the threshold to 8 and the predicted parameters to a = 1 and b = 0 with one layer embedding. Under the same conditions (the embedding rate is 0.38 bpp), the PSNRs of the “Baboon” and “Airplane” image were 32.24 and 44.52 dB, respectively. The PSNR of the “Airplane” image was significantly better than that of the “Baboon” image. Thus, a method that maintains the high-frequency coefficients, decreases prediction errors, and avoids under- and over-flow scenarios is crucial for future endeavors.
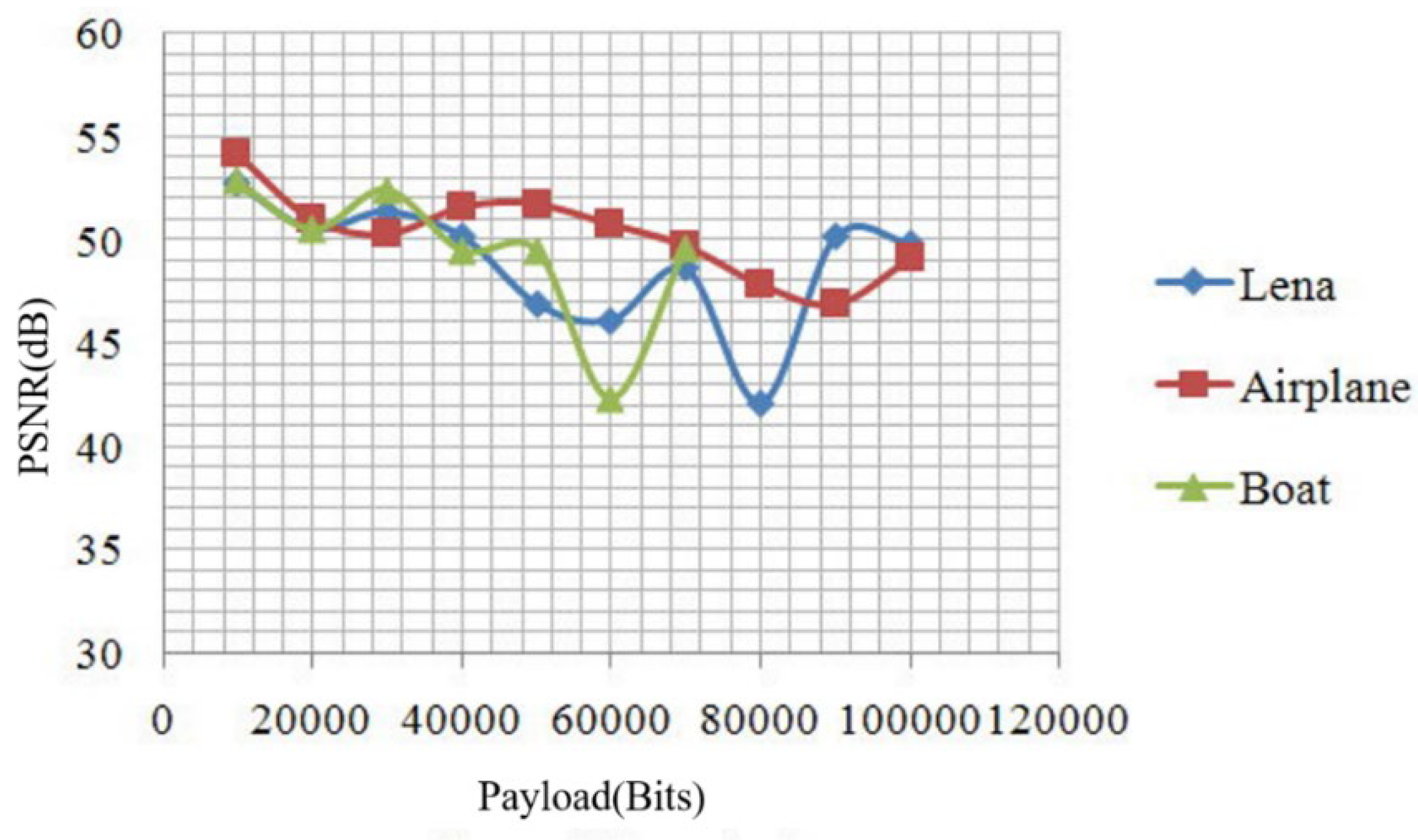
- If we use different predicted parameters, sometimes we can obtain better PSNRs but worse embedding rates, and at times we may find better embedding rates along with worse PSNRs. In Figure 11, under the same conditions, the embedding rate was 0.4 bpp, and we used the fourth and sixth parameters to determine that the PSNRs were 48.378 and 40.393 dB, respectively. An algorithm capable of searching the best parameters will be a key research endeavor in the future. In addition, a quick decision method for the selection of predicted parameters may be the next step for our research. Finally, this approach can be applied to copyright protection and digital archives.
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lin, Y.-H.; Hsia, C.-H.; Chen, B.-Y.; Chen, Y.-Y. Visual IoT Security: Data Hiding in AMBTC Images Using Block-Wise Embedding Strategy. Sensors 2019, 19, 1974. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lin, C.C.; Tai, W.L.; Chang, C.C. Multilevel Reversible Data Hiding Based on Histogram Modification of Difference Images. Pattern Recognit. 2008, 41, 3582–3591. [Google Scholar] [CrossRef]
- Tian, J. Reversible Data Embedding Using a Difference Expansion. IEEE Trans. Circuits Syst. Video Technol. 2003, 13, 890–896. [Google Scholar] [CrossRef] [Green Version]
- Alattar, A.M. Reversible Watermark Using the Difference Expansion of a Generalized Integer Transform. IEEE Trans. Image Process 2004, 13, 1147–1156. [Google Scholar] [CrossRef]
- Ke, Y.; Zhang, M.Q.; Liu, J.; Su, T.T.; Yang, X.Y. Fully Homomorphic Encryption Encapsulated Difference Expansion for Reversible Data Hiding in Encrypted Domain. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 2353–2365. [Google Scholar] [CrossRef] [Green Version]
- Arham, A.; Hanung, A.N.; Teguh, B.A. Multiple Layer Data Hiding Scheme Based on Difference Expansion of Quad. Signal Process. 2017, 137, 52–62. [Google Scholar] [CrossRef]
- Ni, Z.; Shi, Y.Q.; Ansari, N.; Su, W. Reversible Data Hiding. IEEE Trans. Circuits Syst. Video Technol. 2006, 16, 354–362. [Google Scholar]
- Huang, H.C.; Fang, W.C. Authenticity Preservation with Histogram-Based Reversible Data Hiding and Quadtree Concepts. Sensors 2011, 11, 9717–9731. [Google Scholar] [CrossRef]
- Yang, C.-Y.; Wu, J.-L. Two-Bit Embedding Histogram-Prediction-Error Based Reversible Data Hiding for Medical Images with Smooth Area. Computers 2021, 10, 152. [Google Scholar] [CrossRef]
- Hou, X.; Min, L.; Yang, H. A Reversible Watermarking Scheme for Vector Maps Based on Multilevel Histogram Modification. Symmetry 2018, 10, 397. [Google Scholar] [CrossRef] [Green Version]
- Liu, W.-L.; Leng, H.-S.; Huang, C.-K.; Chen, D.-C. A Block-Based Division Reversible Data Hiding Method in Encrypted Images. Symmetry 2017, 9, 308. [Google Scholar] [CrossRef] [Green Version]
- Lu, T.-C.; Tseng, C.-Y.; Huang, S.-W.; Nhan Vo, T. Pixel-Value-Ordering based Reversible Information Hiding Scheme with Self-Adaptive Threshold Strategy. Symmetry 2018, 10, 764. [Google Scholar] [CrossRef] [Green Version]
- Kaur, G.; Singh, S.; Rani, R.; Kumar, R. A comprehensive study of reversible data hiding (RDH) schemes based on pixel value ordering (PVO). Arch. Comput. Methods Eng. 2020, 28, 3517–3568. [Google Scholar] [CrossRef]
- Kaur, G.; Singh, S.; Rani, R. PVO based reversible data hiding technique for roughly textured images. Multidimens. Syst. Signal Process. 2021, 32, 533–558. [Google Scholar] [CrossRef]
- Celik, M.U.; Sharma, G.; Tekalp, A.M.; Saber, E. Lossless Generalized-LSB Data Embedding. IEEE Trans. Image Process. 2005, 14, 253–266. [Google Scholar] [CrossRef] [PubMed]
- Faheem, Z.B.; Ali, M.; Raza, M.A.; Arslan, F.; Ali, J.; Masud, M.; Shorfuzzaman, M. Image Watermarking Scheme Using LSB and Image Gradient. Appl. Sci. 2022, 12, 4202. [Google Scholar] [CrossRef]
- Lin, J.-Y.; Horng, J.-H.; Chang, C.-C.; Li, Y.-H. Asymmetric Orientation Combination for Reversible and Authenticable Data Hiding of Dual Stego-images. Symmetry 2022, 14, 819. [Google Scholar] [CrossRef]
- Chang, C.-C.; Su, G.-D.; Lin, C.-C.; Li, Y.-H. Position-Aware Guided Hiding Data Scheme with Reversibility and Adaptivity for Dual Images. Symmetry 2022, 14, 509. [Google Scholar] [CrossRef]
- Yu, M.; Yao, H.; Qin, C. Reversible data hiding in encrypted images without additional information transmission. Signal Process. Image Commun. 2022, 105, 116696. [Google Scholar] [CrossRef]
- Motomura, R.; Imaizumi, S.; Kiya, H. A Reversible Data Hiding Method in Encrypted Images for Controlling Trade-Off between Hiding Capacity and Compression Efficiency. J. Imaging 2021, 7, 268. [Google Scholar] [CrossRef]
- Khanam, F.-T.-Z.; Kim, S. Enhanced Joint and Separable Reversible Data Hiding in Encrypted Images with High Payload. Symmetry 2017, 9, 50. [Google Scholar] [CrossRef] [Green Version]
- Fragoso-Navarro, E.; Cedillo-Hernandez, M.; Garcia-Ugalde, F.; Morelos-Zaragoza, R. Reversible Data Hiding with a New Local Contrast Enhancement Approach. Mathematics 2022, 10, 841. [Google Scholar] [CrossRef]
- Lin, C.-C.; Nguyen, T.-S.; Chang, C.-C. LRW-CRDB: Lossless Robust Watermarking Scheme for Categorical Relational Databases. Symmetry 2021, 13, 2191. [Google Scholar] [CrossRef]
- Lin, J.-Y.; Horng, J.-H.; Chang, C.-C. A Novel (2, 3)-Threshold Reversible Secret Image Sharing Scheme Based on Optimized Crystal-Lattice Matrix. Symmetry 2021, 13, 2063. [Google Scholar] [CrossRef]
- Aryal, A.; Imaizumi, S.; Horiuchi, T.; Kiya, H. Integrated Model of Image Protection Techniques. J. Imaging. 2018, 4, 1. [Google Scholar] [CrossRef] [Green Version]
- Thodi, D.M.; Rodriguez, J.J. Expansion Embedding Techniques for Reversible Watermarking. IEEE Trans. Image Process. 2007, 16, 721–730. [Google Scholar] [CrossRef]
- Hung, C.-C.; Lin, C.-C.; Wu, H.-C.; Lin, C.-W. A Study on Reversible Data Hiding Technique Based on Three-Dimensional Prediction-Error Histogram Modification and a Multilayer Perceptron. Appl. Sci. 2022, 12, 2502. [Google Scholar] [CrossRef]
- Cai, S.; Li, X.; Liu, J.; Guo, Z. A new reversible data hiding scheme exploiting high-dimensional prediction-error histogram. In Proceedings of the IEEE International Conference on Image Processing (ICIP’16), Phoenix, AZ, USA, 25–28 September 2016; pp. 2732–2736. [Google Scholar]
- Ou, B.; Li, X.; Zhao, Y.; Ni, R.; Shi, Y.Q. Pairwise prediction-error expansion for efficient reversible data hiding. IEEE Trans. Image Process. 2013, 22, 5010–5021. [Google Scholar] [CrossRef]
- Zhan, Y.; Su, Y.; Wang, X.; Pei, Q. Three-dimensional prediction-error histograms based reversible data hiding algorithm for color images. Multimed. Tools Appl. 2019, 78, 35289–35311. [Google Scholar] [CrossRef]
- Jiang, R.; Zhang, W.; Hou, D.; Wang, H.; Yu, N. Reversible data hiding for 3D mesh models with three-dimensional prediction-error histogram modification. Multimed. Tools Appl. 2018, 77, 5263–5280. [Google Scholar] [CrossRef]
- Li, X.; Li, J.; Li, B.; Yang, B. High-fidelity reversible data hiding scheme based on pixel-value-ordering and prediction-error expansion. Signal Process. 2013, 93, 198–205. [Google Scholar] [CrossRef]
- Aljuaid, H.; Parah, S.A. Secure Patient Data Transfer Using Information Embedding and Hyperchaos. Sensors 2021, 21, 282. [Google Scholar] [CrossRef] [PubMed]
- Kaw, J.A.; Gull, S.; Parah, S.A. SVIoT: A Secure Visual-IoT Framework for Smart Healthcare. Sensors 2022, 22, 1773. [Google Scholar] [CrossRef] [PubMed]
- Hu, Y.; Lee, H.; Chen, K.; Li, J. Difference Expansion Based Reversible Data Hiding Using Two Embedding Directions. IEEE Trans. Multimed. 2008, 10, 1500–1512. [Google Scholar] [CrossRef]
- Kamstra, L.; Heijmans, H.J.A.M. Reversible data embedding into images using wavelet techniques and sorting. IEEE Trans. Image Process. 2005, 14, 2082–2090. [Google Scholar] [CrossRef] [PubMed]
- Wang, X.; Chang, C.C.; Lin, C.C.; Chang, C.C. Privacy-preserving Reversible Data Hiding Based on Quad-tree Block Encoding and Integer Wavelet Transform. J. Vis. Commun. Image Represent. 2021, 79, 103203. [Google Scholar] [CrossRef]
- Chang, C.C.; Lin, C.Y.; Fan, Y.H. Lossless data hiding for color images based on block truncation coding. Pattern Recognit. 2008, 41, 2347–2357. [Google Scholar] [CrossRef]
- Chan, Y.K.; Chen, W.T.; Yu, S.S.; Ho, Y.A.; Tsai, C.S.; Chu, Y.P. A HDWT-based Reversible Data Hiding Method. J. Syst. Softw. 2009, 82, 411–421. [Google Scholar] [CrossRef]
- Hsu, T.C.; Yein, A.D.; Hsieh, W.S.; Chen, N.T.; Chiang, J.Y.; Su, T.S. Reversible Watermarking Algorithm Based on Embedding Pixel Dependence. J. Internet Technol. 2012, 13, 571–580. [Google Scholar]
- Kim, H.J.; Sachnev, V.; Shi, Y.Q.; Nam, J.; Choo, H.G. A Novel Difference Expansion Transform for Reversible Data Embedding. IEEE Trans. Inf. Forensics Secur. 2008, 3, 456–465. [Google Scholar]
- Hu, Y.; Lee, H.; Li, J. DE-Based Reversible Data Hiding with Improved Overflow Location Map. IEEE Trans. Circuits Syst. Video Technol. 2009, 2, 250–260. [Google Scholar]
- Chang, C.C.; Pai, P.Y.; Yeh, C.M.; Chan, Y.K. A High Payload Frequency-based Reversible Image Hiding Method. Inf. Sci. 2009, 180, 2286–2298. [Google Scholar] [CrossRef]
- Hong, W.; Chen, T.S. A Local Variance-controlled Reversible Data Hiding Method Using Prediction and Histogram-shifting. J. Syst. Softw. 2010, 83, 2653–2663. [Google Scholar] [CrossRef]
- Luo, L.; Chen, Z.; Chen, M.; Zeng, X.; Xiong, Z. Reversible Image Watermarking Using Interpolation Technique. IEEE Trans. Inf. Forensics Secur. 2010, 5, 187–193. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| T(1) | T(2) | T(3) | T(4) | T(5) | T(6) | T(7) | T(8) |
|---|---|---|---|---|---|---|---|
| 0 | −1 | 1 | −2 | 2 | −3 | 3 | −4 |
| L | Predicted Parameters | kE | Apply Location Map | The Length of Location Map | The Number of Embedded Payloads in the Last Layer | Total Bits | ||
|---|---|---|---|---|---|---|---|---|
| Does the last layer apply location map? | Yes | 4 | 16 | 12 | 1 | 16 | 16 | 65 |
| No | 4 | 16 | 12 | 1 | 0 | 16 | 49 | |
| Other Layer | ---- | 16 | 12 | ---- | ---- | ---- | 28 | |
| bpp | Peppers | Airplane | Baboon | Boat | Bridge | Couple | Crowd | Elain |
| 0.038 | 52.89 | 54.09 | 48.85 | 52.99 | 49.62 | 56.08 | 49.69 | 51.06 |
| 0.076 | 50.64 | 51.11 | 45.84 | 50.66 | 47.02 | 53.05 | 46.19 | 48.83 |
| 0.115 | 49.27 | 50.28 | 43.14 | 49.18 | 45.06 | 51.24 | 43.84 | 47.01 |
| 0.153 | 48.43 | 49.15 | 40.91 | 48.43 | 43.16 | 50.41 | 41.09 | 45.62 |
| 0.191 | 47.04 | 48.50 | 39.38 | 46.99 | 41.35 | 50.09 | 39.16 | 44.49 |
| 0.229 | 46.50 | 47.41 | 37.63 | 46.45 | 39.83 | 49.41 | 37.20 | 42.91 |
| 0.267 | 45.48 | 46.73 | 36.37 | 45.40 | 38.55 | 48.64 | 35.69 | 41.69 |
| 0.305 | 44.74 | 46.12 | 35.17 | 44.50 | 37.24 | 48.27 | 34.35 | 40.72 |
| 0.343 | 43.74 | 45.57 | 33.88 | 43.53 | 36.13 | 47.40 | 32.90 | 39.87 |
| 0.382 | 42.87 | 44.53 | 32.24 | 42.56 | 35.11 | 46.93 | 31.59 | 38.86 |
| 0.420 | 42.03 | 43.75 | 30.84 | 41.67 | 33.97 | 46.67 | 30.34 | 38.14 |
| 0.458 | 41.42 | 42.82 | 29.70 | 40.61 | 32.75 | 46.10 | 29.05 | 37.39 |
| 0.496 | 40.29 | 42.01 | 28.65 | 39.69 | 31.63 | 45.28 | 27.90 | 36.69 |
| 0.534 | 39.28 | 41.02 | 28.80 | 38.68 | 30.67 | 44.63 | 26.50 | 35.93 |
| 0.572 | 38.29 | 40.00 | 25.90 | 37.49 | 29.69 | 43.78 | 25.18 | 34.85 |
| 0.611 | 37.50 | 38.85 | 24.55 | 36.59 | 28.80 | 43.04 | 26.31 | 33.86 |
| 0.649 | 36.73 | 37.77 | 22.69 | 35.94 | 29.35 | 42.14 | 22.05 | 33.00 |
| bpp | Flower | Girl | Goldhill | Hat | Lake | Lena | Loco | Martha |
| 0.038 | 54.83 | 54.97 | 51.44 | 53.97 | 51.98 | 52.89 | 54.95 | 53.00 |
| 0.076 | 51.98 | 51.62 | 49.53 | 50.87 | 49.35 | 50.64 | 51.55 | 50.71 |
| 0.115 | 50.70 | 50.53 | 47.99 | 49.91 | 47.69 | 49.27 | 50.51 | 49.48 |
| 0.153 | 50.16 | 49.60 | 46.37 | 48.57 | 46.35 | 48.43 | 48.76 | 48.47 |
| 0.191 | 47.90 | 48.54 | 45.21 | 48.02 | 45.02 | 47.04 | 47.43 | 47.56 |
| 0.229 | 45.87 | 47.81 | 44.12 | 46.93 | 43.41 | 46.50 | 46.00 | 46.64 |
| 0.267 | 43.98 | 46.90 | 42.84 | 46.52 | 42.13 | 45.48 | 44.69 | 46.19 |
| 0.305 | 42.29 | 46.59 | 41.69 | 45.61 | 41.03 | 44.74 | 43.00 | 45.46 |
| 0.343 | 40.72 | 45.84 | 40.79 | 45.09 | 39.96 | 43.74 | 41.44 | 44.65 |
| 0.382 | 39.26 | 45.34 | 39.89 | 44.02 | 38.81 | 42.87 | 40.38 | 43.83 |
| 0.420 | 37.97 | 44.32 | 38.95 | 43.29 | 37.80 | 42.03 | 39.06 | 43.05 |
| 0.458 | 36.75 | 43.56 | 38.22 | 42.56 | 36.84 | 41.42 | 37.80 | 42.30 |
| 0.496 | 35.71 | 42.79 | 37.41 | 41.95 | 36.02 | 40.66 | 36.54 | 41.81 |
| 0.534 | 35.29 | 42.17 | 36.64 | 41.24 | 35.97 | 40.02 | 35.82 | 41.15 |
| 0.572 | 34.86 | 41.42 | 35.71 | 40.46 | 34.13 | 39.22 | 35.45 | 40.42 |
| 0.611 | 34.27 | 40.53 | 34.94 | 39.71 | 33.40 | 38.44 | 34.68 | 39.81 |
| 0.649 | 34.05 | 39.53 | 34.09 | 38.88 | 32.55 | 37.50 | 34.32 | 39.00 |
| Peppers | Airplane | Baboon | Boat | Bridge | Couple | Crowd | Elain | |
| Layer 1 | 155,489 | 166,206 | 88,028 | 153,938 | 104,043 | 185,214 | 81,730 | 137,341 |
| Layer 2 | 46,557 | 33,836 | 49,935 | 47,872 | 63,101 | 17,155 | 49,233 | 63,037 |
| Layer 3 | 25,799 | 33,515 | 28,111 | |||||
| Layer 4 | 13,002 | 15,029 | ||||||
| payload | 202,046 | 200,042 | 176,764 | 201,810 | 200,659 | 202,369 | 174,103 | 200,378 |
| Flower | Girl | Goldhill | Hat | Lake | Lena | Loco | Martha | |
| Layer 1 | 127,797 | 174,779 | 145,195 | 174,660 | 130,152 | 166,059 | 133,218 | 177,391 |
| Layer 2 | 72,605 | 27,185 | 55,131 | 28,366 | 70,131 | 34,375 | 67,396 | 22,741 |
| Layer 3 | 1,592 | |||||||
| Layer 4 | ||||||||
| payload | 200,402 | 201,964 | 200,326 | 203,026 | 201,875 | 200,434 | 200,614 | 200,132 |
| Images and Parameters | Parameters of Each Layer | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | ||
| Lena | A | 1 | −2 | 3 | −2 | 3 | −3 | 4 | 3 | −4 |
| B | 0 | −2 | 8 | −2 | 3 | 0 | 6 | −4 | 10 | |
| k | 1 | 2 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |
| Airplane | A | 1 | −1 | −1 | 1 | - | - | - | - | - |
| B | 0 | 0 | −3 | 6 | - | - | - | - | - | |
| k | 1 | 3 | 1 | 1 | - | - | - | - | - | |
| Boat | A | 1 | −2 | −2 | −2 | 2 | −4 | −3 | −2 | −2 |
| B | 0 | 0 | 8 | 4 | 2 | −6 | −8 | 8 | 8 | |
| k | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 | |
| Images | Chang’s Method | Proposed Method | Compare | |
|---|---|---|---|---|
| Lena | Embedded Data | 62,784 | 99,767 | +36,983 |
| Extra Information | 68,288 | 273 | −68,015 | |
| PSNR (dB) | 43.73 | 49.85 | +6.12 | |
| Airplane | Embedded Data | 74,656 | 99,909 | +25,253 |
| Extra Information | 56,416 | 133 | −56,283 | |
| PSNR (dB) | 43.71 | 49.14 | +5.43 | |
| Boat | Embedded Data | 48,888 | 69,763 | +20,875 |
| Extra Information | 82,184 | 277 | −81,907 | |
| PSNR (dB) | 43.22 | 49.61 | +6.39 | |
| Image | Hung’s Method | Hong’s Method | Luo’s Method | Cai’s Method | Proposed Method | |
|---|---|---|---|---|---|---|
| Lena | Payload | 59,751 | 46,839 | 71,674 | 7964 | 100,040 |
| PSNR (dB) | 48.64 | 49.19 | 48.82 | 62.16 | 49.85 | |
| Airplane (F-16) | Payload | 66,465 | 64,863 | 84,050 | 21,300 | 70,042 |
| 100,042 | ||||||
| PSNR (dB) | 48.75 | 49.39 | 48.94 | 58.27 | 49.70 | |
| 49.14 | ||||||
| Boat | Payload | 37,938 | 29,824 | - | 2923 | 70,040 |
| PSNR (dB) | 48.41 | 49.02 | - | 66.26 | 49.62 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pan, I.-H.; Huang, P.-S.; Chang, T.-J.; Chen, H.-H. Multilayer Reversible Information Hiding with Prediction-Error Expansion and Dynamic Threshold Analysis. Sensors 2022, 22, 4872. https://doi.org/10.3390/s22134872
Pan I-H, Huang P-S, Chang T-J, Chen H-H. Multilayer Reversible Information Hiding with Prediction-Error Expansion and Dynamic Threshold Analysis. Sensors. 2022; 22(13):4872. https://doi.org/10.3390/s22134872
Chicago/Turabian StylePan, I-Hui, Ping-Sheng Huang, Te-Jen Chang, and Hsiang-Hsiung Chen. 2022. "Multilayer Reversible Information Hiding with Prediction-Error Expansion and Dynamic Threshold Analysis" Sensors 22, no. 13: 4872. https://doi.org/10.3390/s22134872
APA StylePan, I.-H., Huang, P.-S., Chang, T.-J., & Chen, H.-H. (2022). Multilayer Reversible Information Hiding with Prediction-Error Expansion and Dynamic Threshold Analysis. Sensors, 22(13), 4872. https://doi.org/10.3390/s22134872