
RNN-Based Sequence to Sequence Decoder for Run-Length Limited Codes in Visible Light Communication

Abstract
:1. Introduction
- •
- We exploited RNN technology for RLL decoding based on seq2seq models and found that a well-trained seq2seq model can achieve MAP-based decoding performance, thereby improving the reliability of VLC.
- •
- We show that the proposed decoder has sufficient capacity to handle multiple RLL-coded frames and implement multi-frame parallel decoding with only one-shot decoding, which largely improves the system throughput and reduces parallel decoding complexity.
- •
- We found that the number of frames for parallel decoding impacts the fitting of the decoder due to its restricted learning abilities, and further analyzed the saturation frame of the decoder based on our proposed criterion.
2. Related Background
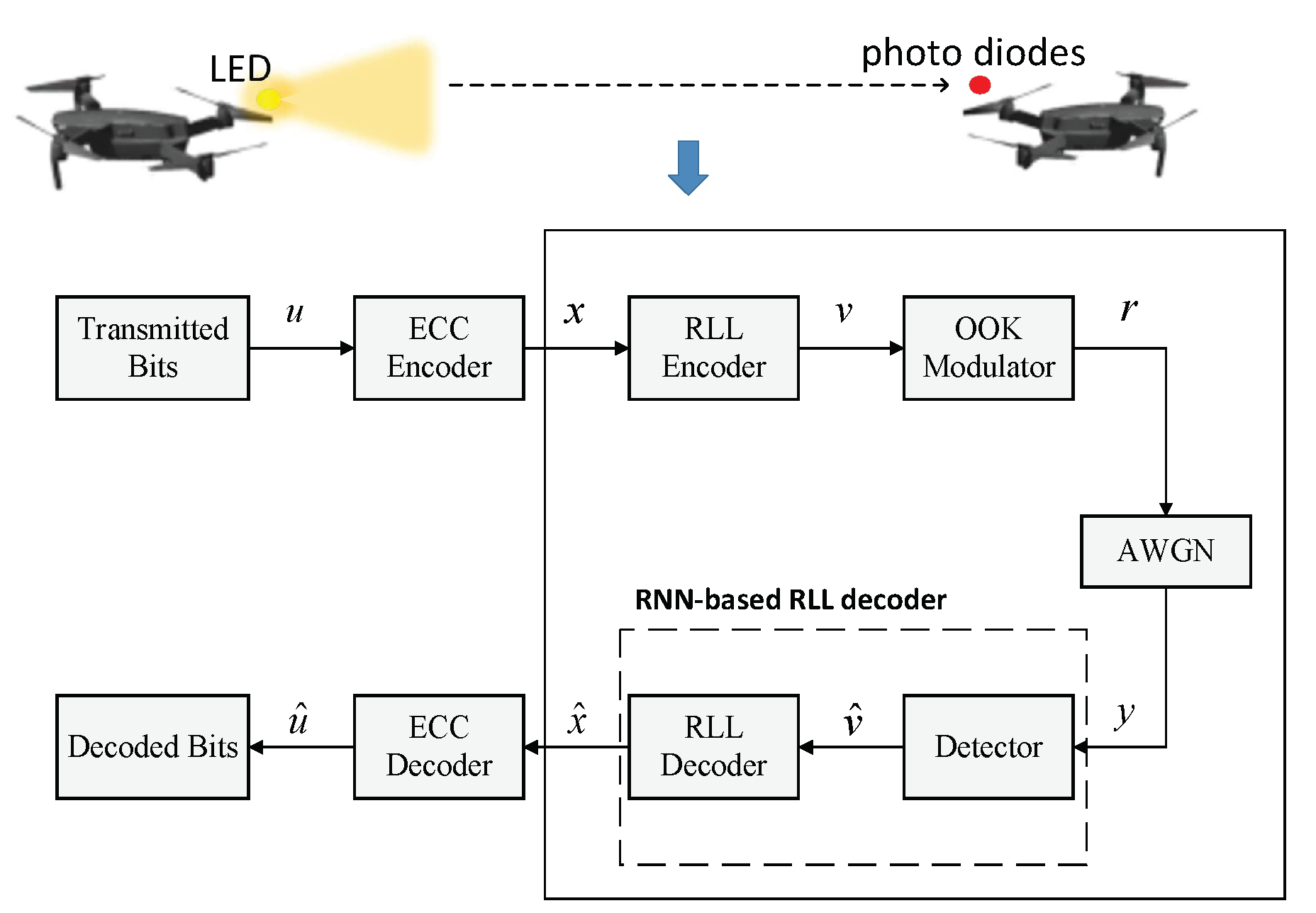
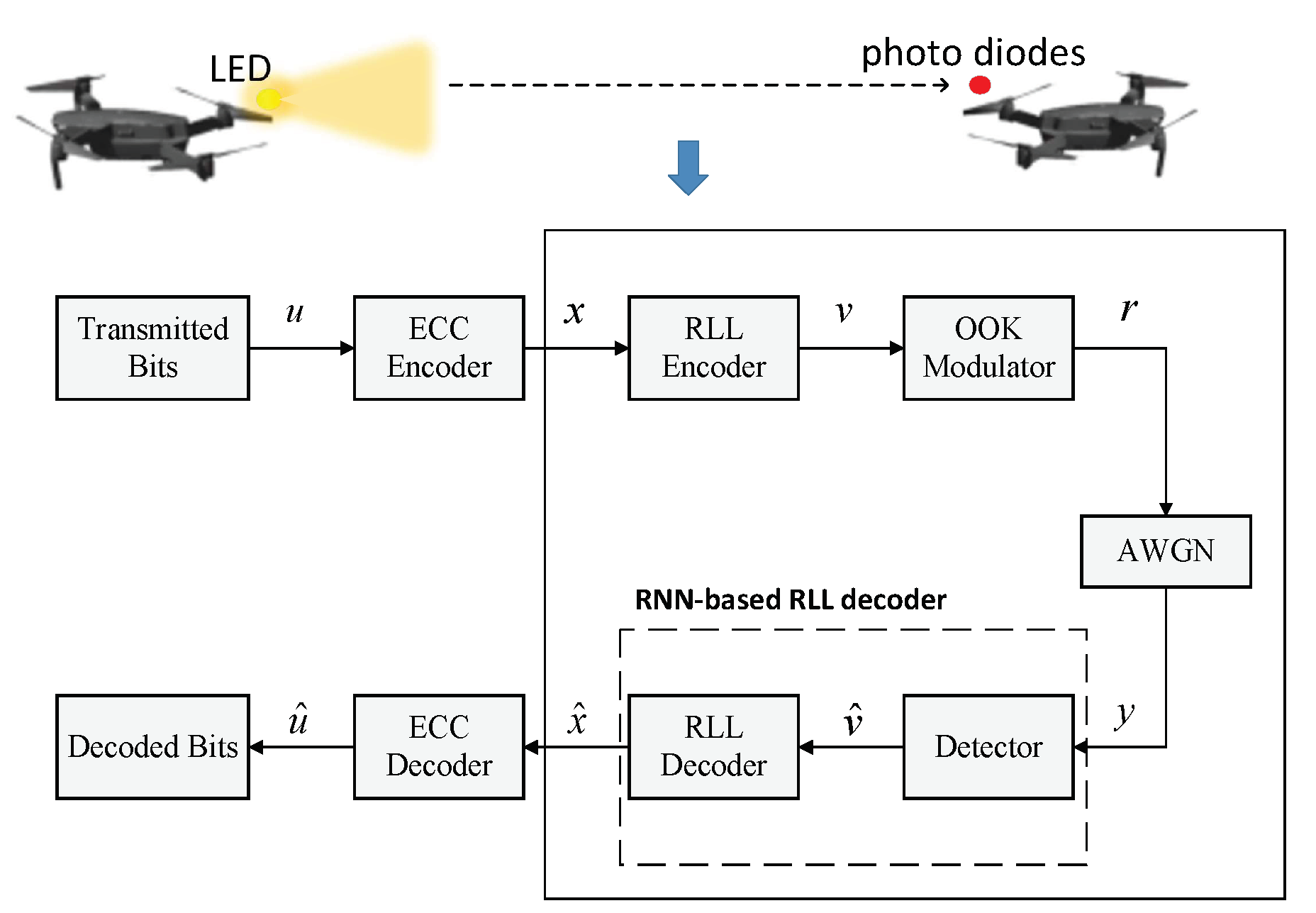
2.1. The Commucation System Model of UAVs with VLC
2.2. RLL Codes
3. Learning to RLL Decode
3.1. Problem Formulation
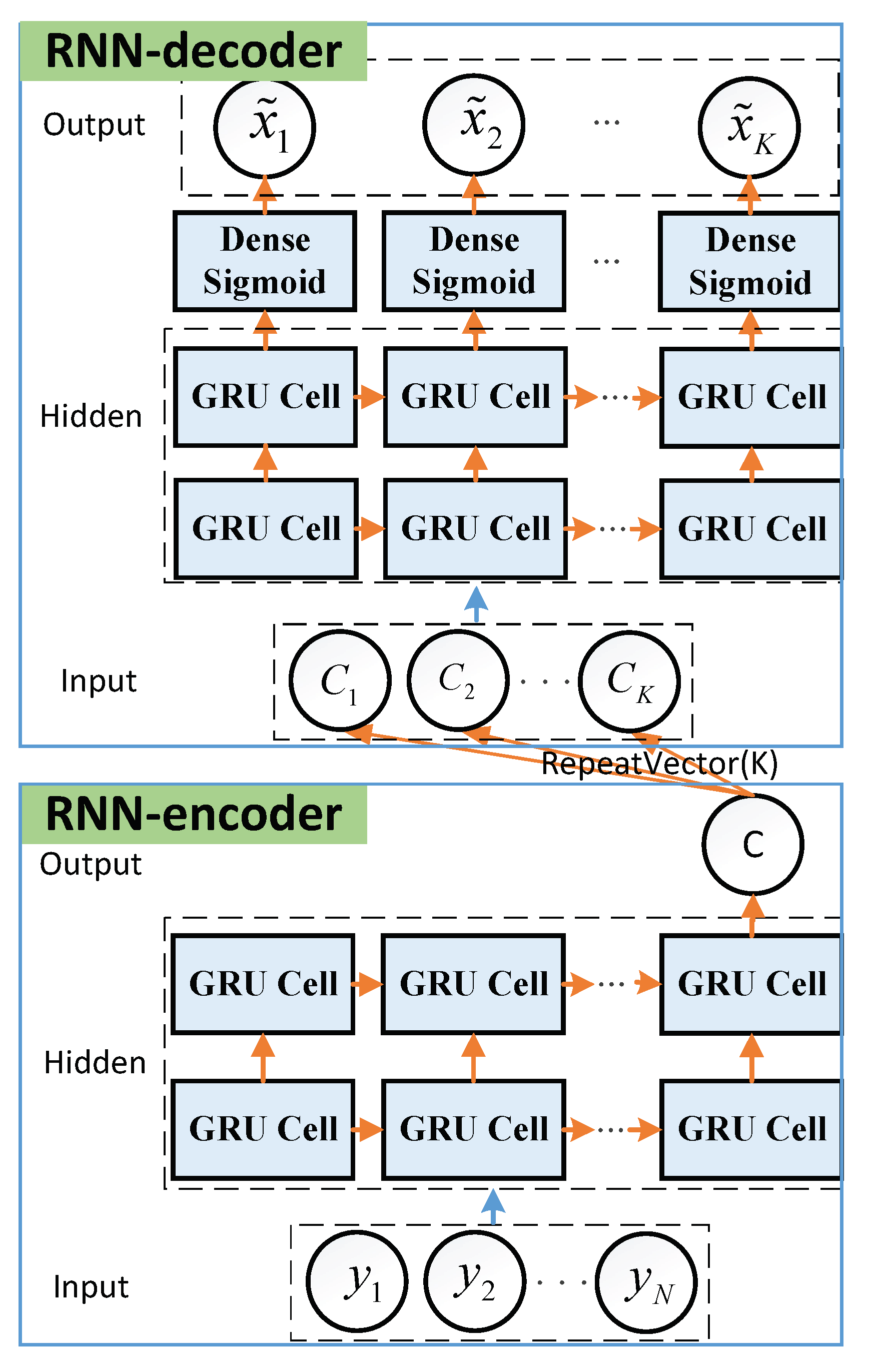
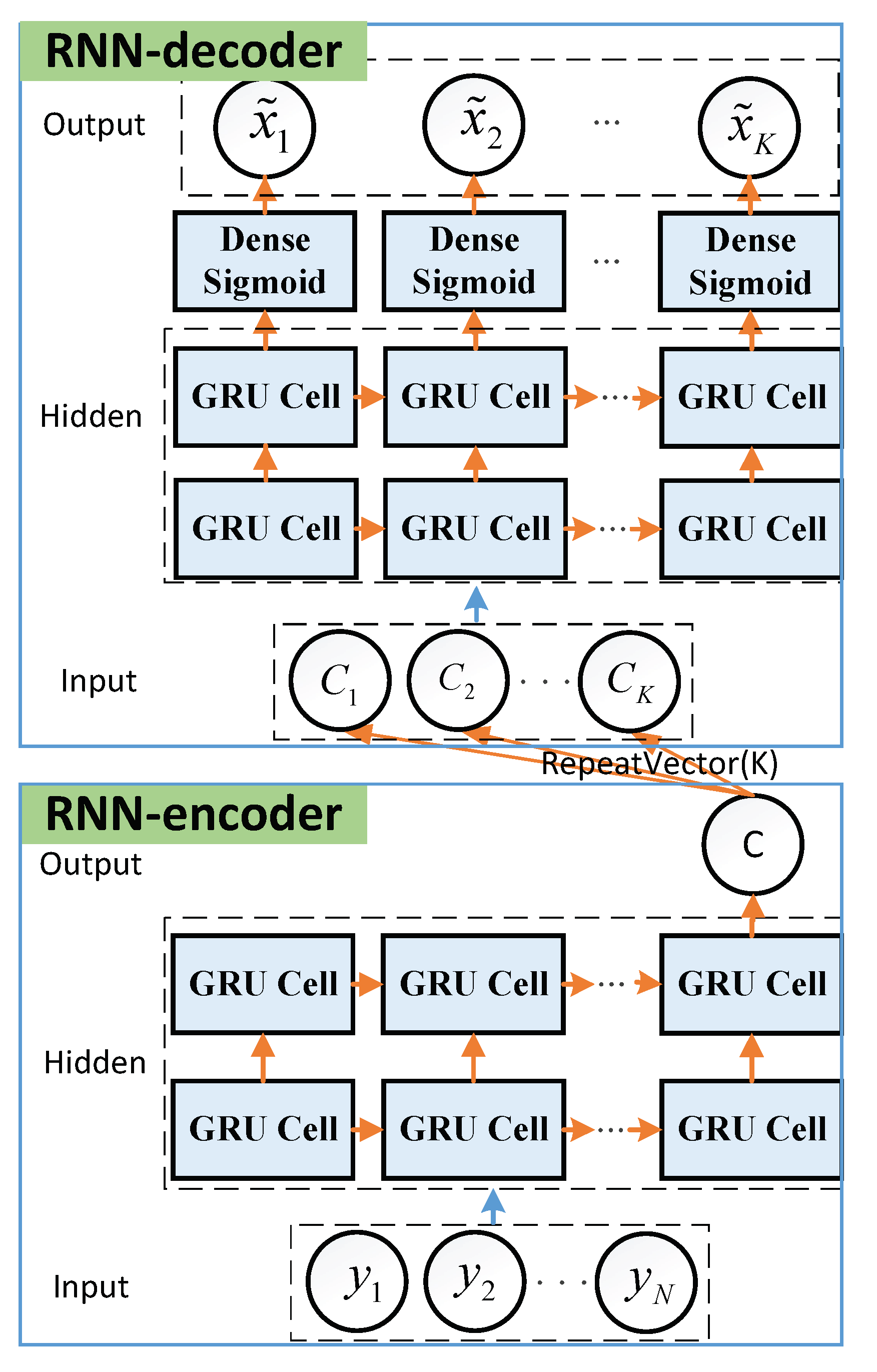
3.2. Seq2seq Decoder
- Encoder-Input: Denote as a training sample of dataset , with being the the received signal and being the corresponding label. Thus, the are fed into RNN-encoder as the inputs. The labels of the inputs can be given by , where . Here, the labels are the encoded sequences corresponding to the inputs .
- Encoder-Hidden States: The encoder has two hidden layers of size . In the hidden layers, the hidden state is computed as , where is a Relu activation function and is the j-th hidden unit of the first hidden layer. Then, is used to compute the second hidden layer, given by . For the RNN cell, long short-term memory (LSTM) cell and gated recurrent unit (GRU) cell are widely used to avoid gradient vanishing as the network deepens. Moreover, GRU has less training parameters than LSTM [20]. Thus, we employ GRU cell in our work.
- Encoder-Output: The encoder has an output layer of size 1, which only outputs the result c of the final hidden state in the second hidden layer. To realize the single output of RNN-encoder, we set return_sequences = False in Keras. Note that the final output c contains all information of the received signal so that the RNN-decoder can catch the information for further training.
- Decoder-Input:K repeated c are fed into RNN-decoder as its inputs, which are given by . Here, the are the same.
- Decoder-Hidden States: The decoder has two hidden layers of size . The working steps and its configure are the same as encoder-hidden states.
- Decoder-Output: The output layer is a fully-connected layer with the sigmoid activation function, given by , with z being the input of the sigmoid function and . Thus, the decoder outputs the final K soft estimates of transmitted data . Here, , which indicates the probabilities of the RLL-decoded bit being a “0” or a “1”. Therefore, we can output the final decoded sequence based on the rule (2).
- Loss and Update: Here, the mean square error (MSE) loss function is utilized to measure the uncertainty between the actual outputs and the desired outputs , such thatwhere is the i-th output of decoder.
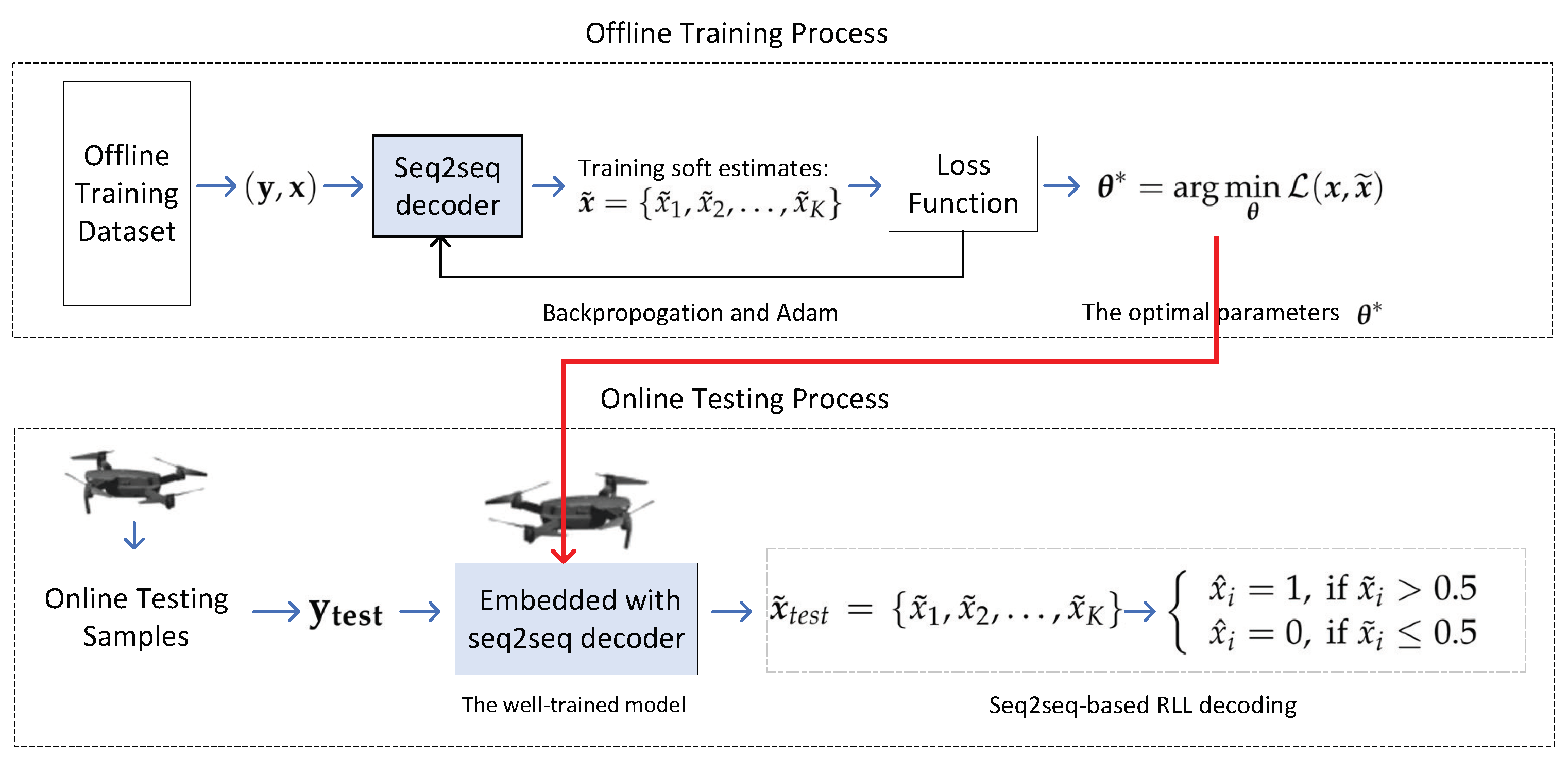
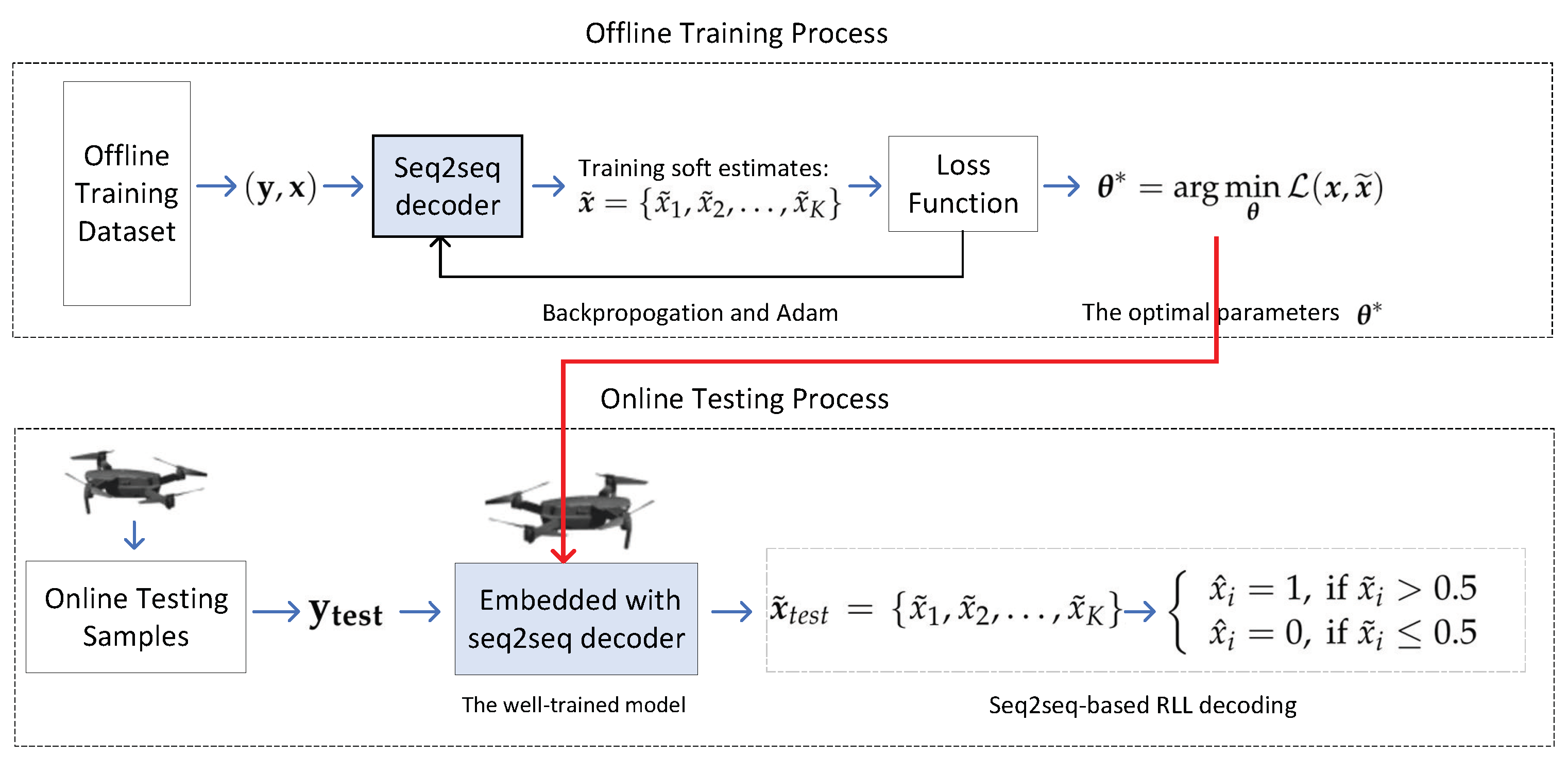
- Training procedure: To obtain the optimal parameter of the seq2seq decoder, a batch of the training dataset (i.e., a mini-batch) is randomly selected and fed into the decoder. As such, the loss function is computed using the outputs of decoder and the labels corresponding to the inputs. Later, the adaptive moment estimation (Adam) algorithm is executed to optimize the parameters of the NN. After repeated iterations with mini-batches, the parameters of NN converge and approach optimum values.
3.3. Dataset and Training Details
4. Results and Analysis
4.1. Simulation Setup
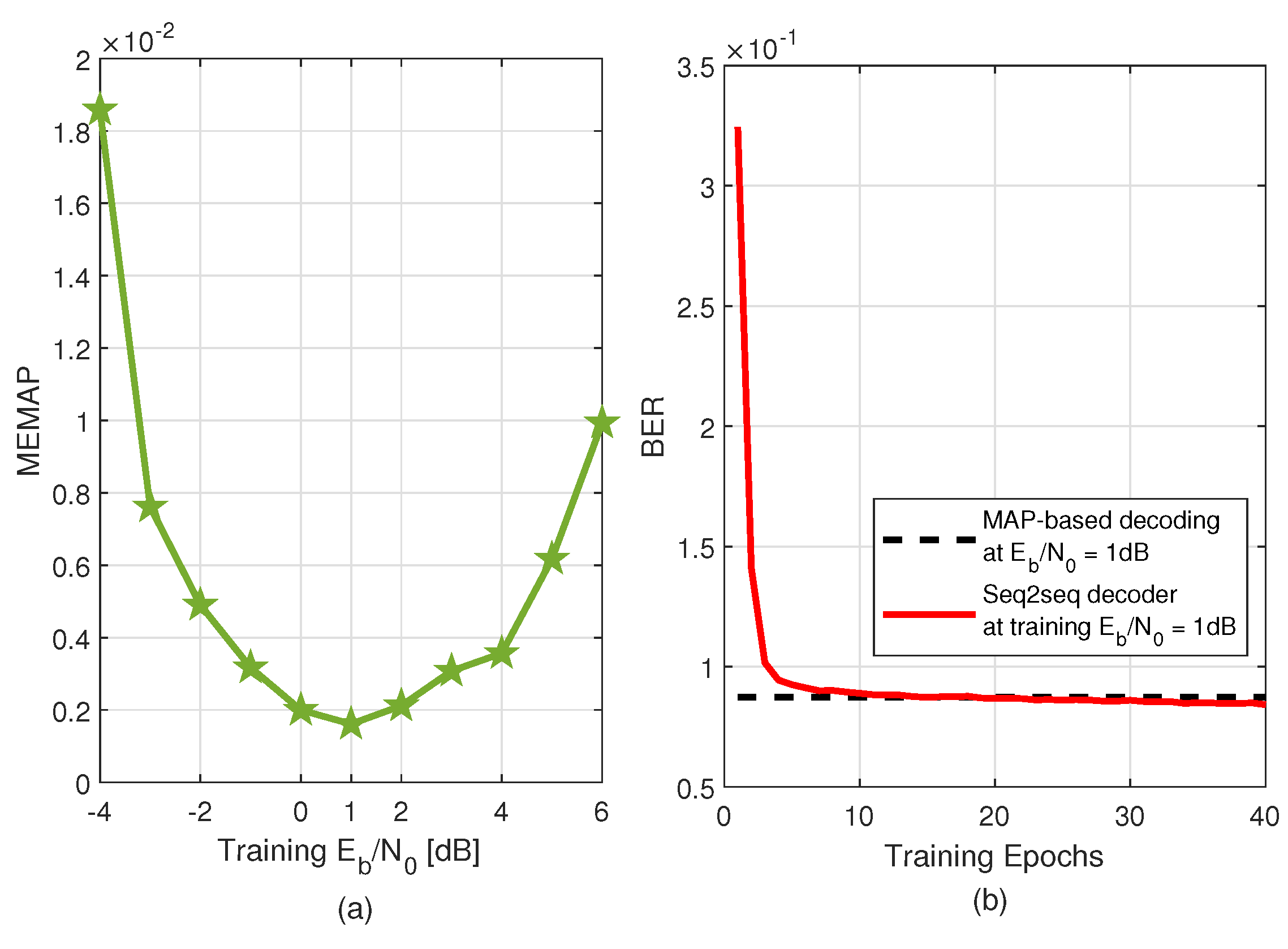
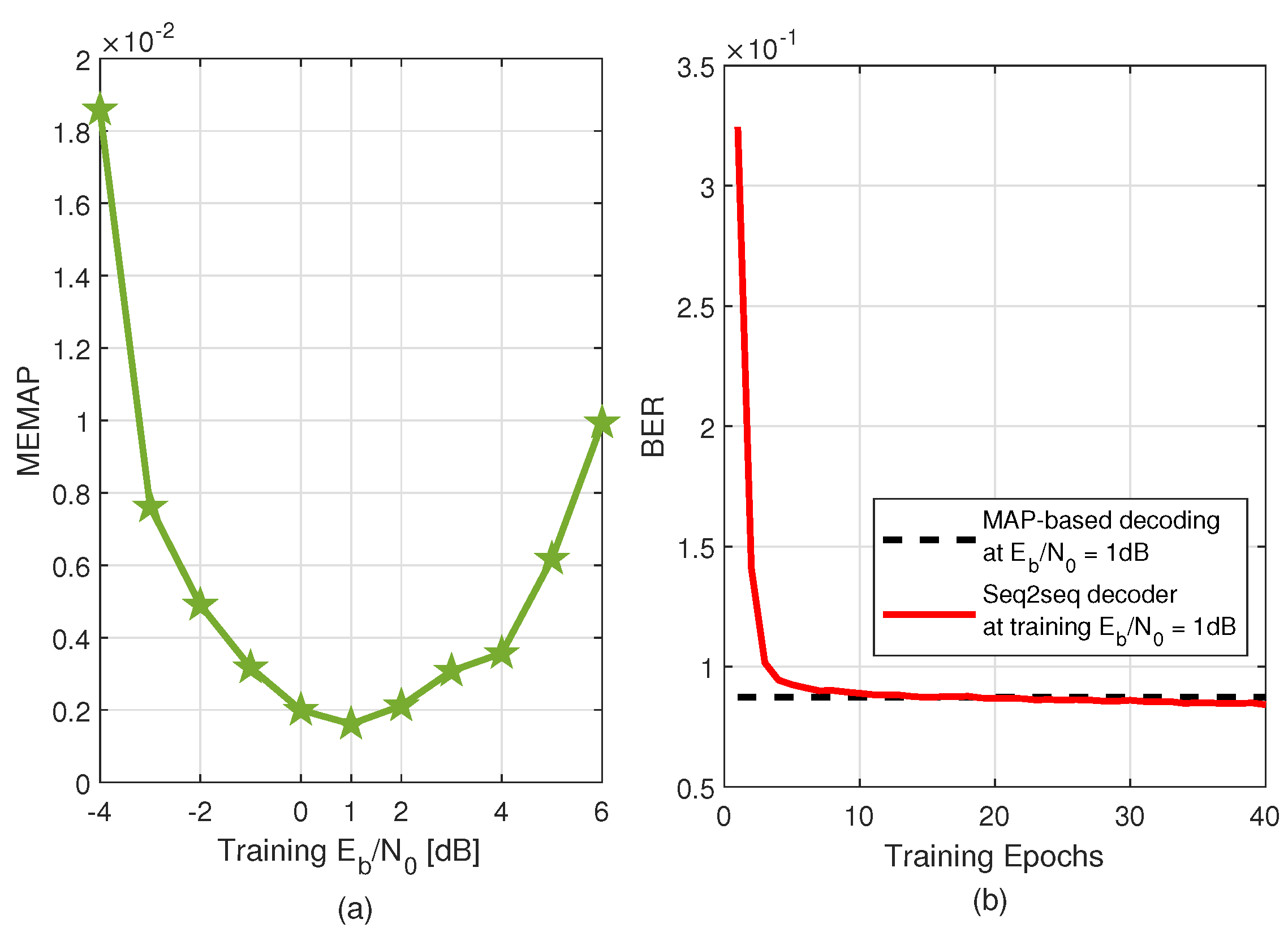
4.2. Optimal Training SNR
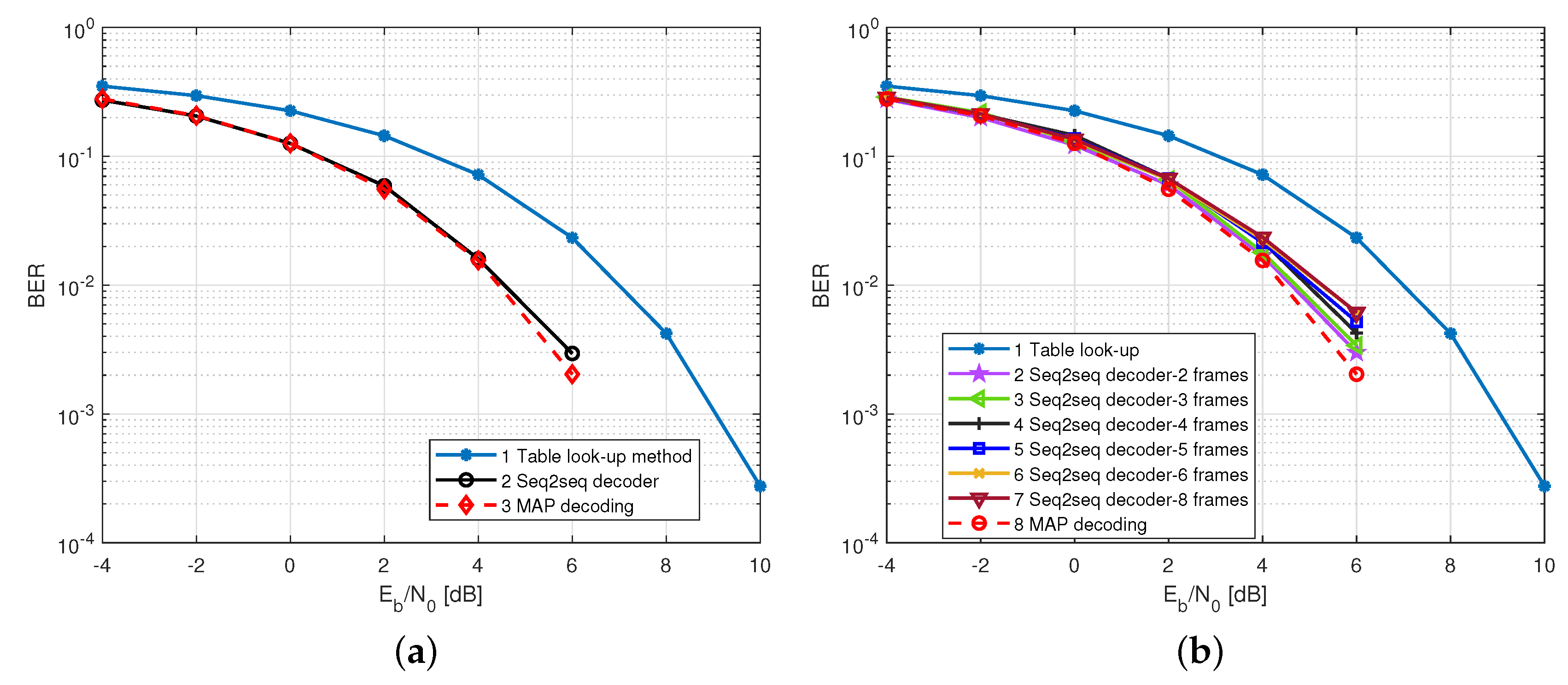
4.3. The BERs of the Seq2seq Decoder
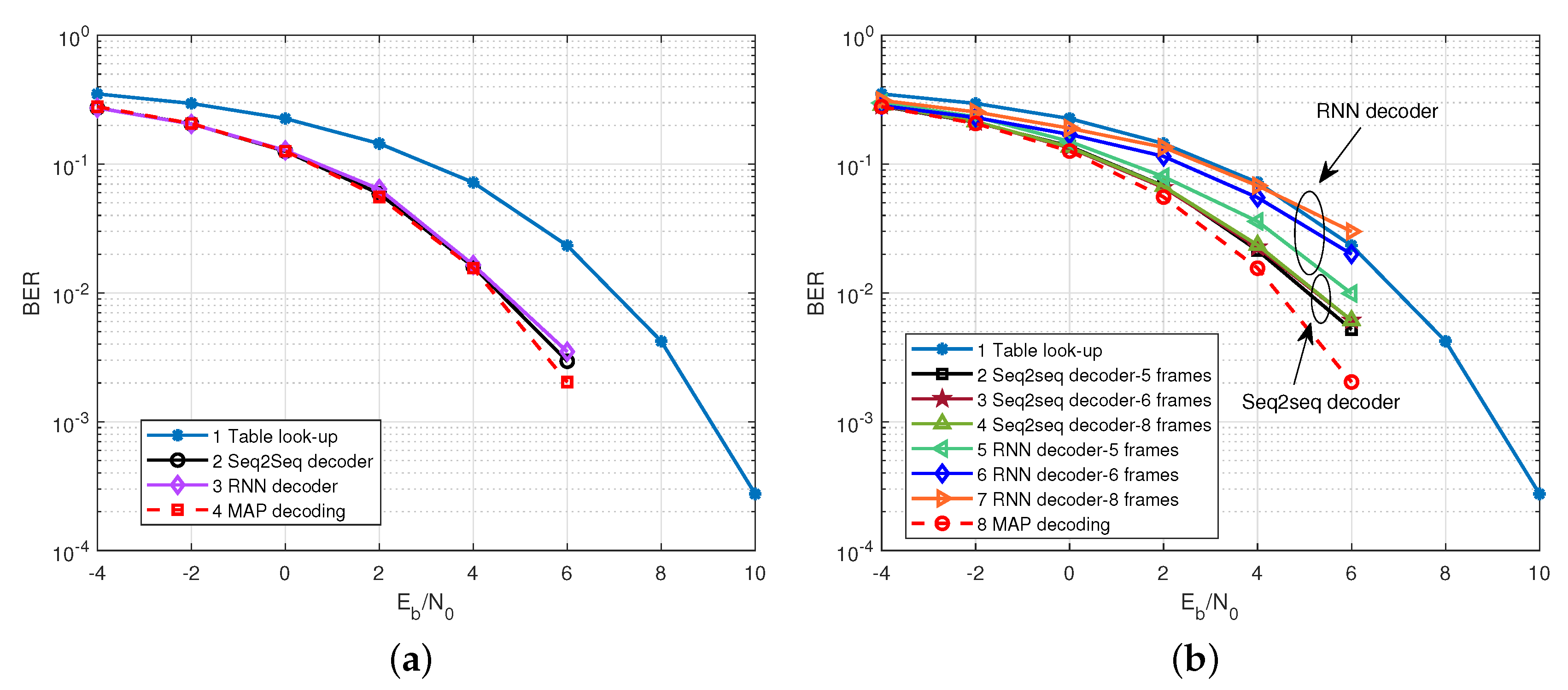
4.4. The BERs Comparison with Conventional RNN Decoder
4.5. Scalability
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- IEEE Standard 802.15.7; IEEE Standard for Local and Metropolitan Area Networks—Part 15.7:Short-Range Wireless Optical Communication Using Visible Light. IEEE: Piscataway, NJ, USA, 2011; pp. 248–271.
- Ndjiongue, A.R.; Ferreira, H.C.; Ngatched, T.M. Visible Light Communications (VLC) Technology. In Wiley Encyclopedia of Electrical and Electronics Engineering; Wiley: Hoboken, NJ, USA, 1999; pp. 1–5. [Google Scholar]
- Ndjiongue, A.R.; Ngatched, T.M.N.; Dobre, O.A.; Armada, A.G. VLC-Based Networking: Feasibility and Challenges. IEEE Netw. 2020, 34, 158–165. [Google Scholar] [CrossRef] [Green Version]
- Rajagopal, S.; Roberts, R.D.; Lim, S.-K. IEEE 802.15.7 visiblelight communication: Modulation schemes and dimming support. IEEE Commun. Mag. 2012, 53, 72–82. [Google Scholar] [CrossRef]
- Deng, H.; Li, J.; Sayegh, A.; Birolini, S.; Andreani, S. Twinkle: A flying lighting companion for urban safety. In Proceedings of the ACM 12th International Conference on Tangible, Embedded and Embodied Interactions, Stockholm, Sweden, 18–21 March 2018; pp. 567–573. [Google Scholar]
- Wang, Y.; Chen, M.; Yang, Z.; Luo, T.; Saad, W. Deep Learning for Optimal Deployment of UAVs With Visible Light Communications. IEEE Trans. Wirel. Commun. 2020, 19, 7049–7063. [Google Scholar] [CrossRef]
- O’Shea, T.; Hoydis, J. An Introduction to Deep Learning for the Physical Layer. IEEE Transactions on Cognitive Communications and Networking 2017, 3, 563–575. [Google Scholar] [CrossRef] [Green Version]
- Gruber, T.; Cammerer, S.; Hoydis, J.; Brink, S.T. On deep learning-based channel decoding. In Proceedings of the 2017 51st Annual Conference on Information Sciences and Systems (CISS), Baltimore, MA, USA, 22–24 March 2017; pp. 1–6. [Google Scholar]
- Lyu, W.; Zhang, Z.; Jiao, C.; Qin, K.; Zhang, H. Performance Evaluation of Channel Decoding with Deep Neural Networks. In Proceedings of the 2018 IEEE International Conference on Communications (ICC), Kansas City, MO, USA, 20–24 May 2018; pp. 1–6. [Google Scholar]
- Nachmani, E.; Be’ery, Y.; Burshtein, D. Learning to decode linear codes using deep learning. In Proceedings of the 2016 54th Annual Allerton Conference on Communication, Control, and Computing (Allerton), Monticello, IL, USA, 27–30 September 2016; pp. 341–346. [Google Scholar]
- Lugosch, L.; Gross, W.J. Neural offset min-sum decoding. In Proceedings of the 2017 IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017; pp. 1361–1365. [Google Scholar]
- Wang, H.; Kim, S. Soft-Input Soft-Output Run-Length Limited Decoding for Visible Light Communication. IEEE Photonics Technol. Lett. 2016, 28, 225–228. [Google Scholar] [CrossRef]
- Wang, H.; Kim, S. New RLL Decoding Algorithm for Multiple Candidates in Visible Light Communication. IEEE Photonics Technol. Lett. 2015, 27, 15–17. [Google Scholar] [CrossRef]
- Niu, G.; Zhang, J.; Guo, S.; Pun, M.-O.; Chen, C.S. UAV-Enabled 3D Indoor Positioning and Navigation Based on VLC. In Proceedings of the IEEE International Conference on Communications (ICC), Montreal, QC, Canada, 14–23 June 2021; pp. 1–6. [Google Scholar]
- Lin, B.; Ghassemlooy, Z.; Lin, C.; Tang, X.; Li, Y.; Zhang, S. An Indoor Visible Light Positioning System Based on Optical Camera Communications. IEEE Photonics Technol. Lett. 2017, 29, 579–582. [Google Scholar] [CrossRef]
- Babar, Z.; Izhar, M.A.M.; Nguyen, H.V.; Botsinis, P.; Alanis, D.; Chandra, D.; Ng, S.X.; Maunder, R.; Hanzo, L. Unary-Coded Dimming Control Improves ON-OFF Keying Visible Light Communication. IEEE Trans. Commun. 2018, 66, 255–264. [Google Scholar] [CrossRef] [Green Version]
- Li, Z.; Yu, H.; Shan, B.; Zou, D.; Li, S. New Run-Length Limited Codes in On—Off Keying Visible Light Communication Systems. IEEE Wirel. Commun. Lett. 2020, 9, 148–151. [Google Scholar] [CrossRef]
- Cho, K.; Merrienboer, B.V.; Gulcehre, C. Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation. arXiv 2014, arXiv:1406.1078. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems 27 (NIPS 2014), Montreal, QC, Canada, 8–13 December 2014. [Google Scholar]
- Goodfellow, I.; Bengio, Y.; Courville, A.; Bengio, Y. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Volume 1. [Google Scholar]
- Chollet, F. Keras. 2015. Available online: https://github.com/keras-team/keras (accessed on 10 December 2021).




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Source Word | Codeword | Source Word | Codeword |
|---|---|---|---|
| 0000 | 001110 | 1000 | 011001 |
| 0001 | 001101 | 1001 | 011010 |
| 0010 | 010011 | 1010 | 011100 |
| 0011 | 010110 | 1011 | 110001 |
| 0100 | 010101 | 1100 | 110010 |
| 0101 | 100011 | 1101 | 101001 |
| 0110 | 100110 | 1110 | 101010 |
| 0111 | 100101 | 1111 | 101100 |
| Parameters | Seq2seq Decoder | |
|---|---|---|
| RNN-Encoder | RNN-Decoder | |
| Input Neurons | N | K |
| Hidden Layer Units | [, ] | [, ] |
| Output Neurons | 1 | K |
| Training sets | ||
| Batch size | 100 | |
| Training epochs | 40 | |
| Optimizer | Adam (with learning rate = 0.01) | |
| Initializer | Xavier uniform | |
| Loss Function | MSE | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, X.; Yang, H. RNN-Based Sequence to Sequence Decoder for Run-Length Limited Codes in Visible Light Communication. Sensors 2022, 22, 4843. https://doi.org/10.3390/s22134843
Luo X, Yang H. RNN-Based Sequence to Sequence Decoder for Run-Length Limited Codes in Visible Light Communication. Sensors. 2022; 22(13):4843. https://doi.org/10.3390/s22134843
Chicago/Turabian StyleLuo, Xu, and Haifen Yang. 2022. "RNN-Based Sequence to Sequence Decoder for Run-Length Limited Codes in Visible Light Communication" Sensors 22, no. 13: 4843. https://doi.org/10.3390/s22134843
APA StyleLuo, X., & Yang, H. (2022). RNN-Based Sequence to Sequence Decoder for Run-Length Limited Codes in Visible Light Communication. Sensors, 22(13), 4843. https://doi.org/10.3390/s22134843