1. Introduction
With the wide application of various three-dimensional (3D) sensors, as a basic 3D data format, point clouds are frequently appearing in many actual scenes, including 3D modeling [
1,
2,
3,
4,
5,
6,
7], indoor navigation [
8], and autonomous driving [
9,
10]. Therefore, the demand to understand the shapes represented by 3D point clouds through deep neural networks has gradually emerged.
Unlike the regular grid structure of the two-dimensional (2D) image, the point cloud is a set of unordered spatial points, making it unsuitable for the convolution operation based on the local patch arranged by the grid index. Although deep learning networks such as CNNs have obtained remarkable achievements in processing 2D images [
11,
12,
13,
14], it is non-trivial to directly transplant the success of CNN to 3D point cloud analysis. Some alternative approaches have been proposed to alleviate this critical issue. Some methods such as [
15,
16,
17,
18,
19,
20,
21] attempt to transform the point cloud into regular voxel format in order to apply 3D CNNs and inherit the advantages of 2D CNNs. However, the performance of voxelization methods is primarily limited by the cubical growth in the computational cost with the increase in resolution. There are also other methods such as [
22,
23,
24,
25,
26] to render the point cloud from multiple perspectives to obtain a set of images to directly introduce the CNN to process 3D point cloud analysis, which leads to spatial information loss and causes difficulties for tasks such as semantic segmentation.
Since the conversion of point clouds causes information loss and brings extra burdens on storage and computation, it is feasible to directly use the point cloud as the input of deep networks. The point cloud analysis network closely follows the development of image processing technology. The core problem of point cloud analysis is aggregating and extracting features within the perceptual field. There are many methods devoted to designing sophisticated local feature extraction modules, representative works are MLP-based (such as PointNet [
27] and PointNet++ [
28]), convolution-based (PointConv [
29]), graph-based (DGCNN [
30]), relation-based (RPNet [
31]), and transformer-based (point transformer [
32]; PCT [
33]) methods. These methods have contributed to the advancement of the point cloud analysis community. However, the pursuit of sophisticated local feature extractors also has its limitations. Delicate modules often correspond to complex modules, resulting in huge computational costs, which hinders the application of these methods to 3D point cloud analysis. In addition, the performance gains from more sophisticated extractors have also been saturated recently. Experiments in [
34] show that under similar network frameworks, the performance improvements brought by most refined local feature extractors are not significantly different. Therefore, this paper aims to design a lightweight and efficient network instead of pursuing more refined feature extractors.
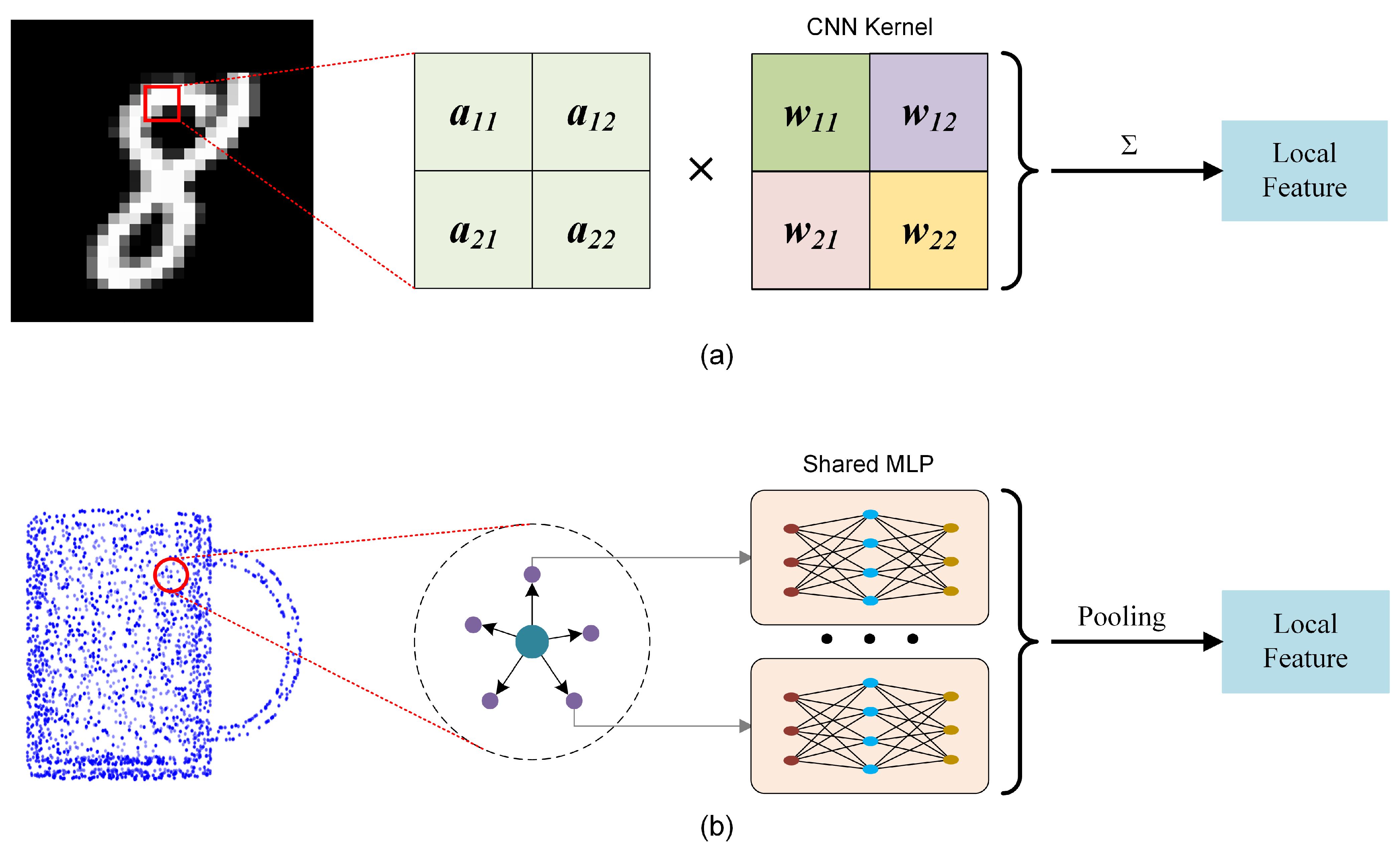
It is feasible to rethink MLP-based methods, analyze their inherent limitations, and modify them to improve feature extraction capabilities significantly. The advantage of simple MLP-based methods is that they do not require complex operations such as building graphs to extract edge features or generating adaptive convolution kernels. In addition, shared MLP regards all points in the receptive field as equivalent, extracts point features, and then obtains local aggregated features through a symmetric function, which makes the MLP-based methods less computationally expensive and can well adapt to the disorder of point clouds. However, treating all points as equivalent tends to ignore the difference in the spatial distribution, which leads to the deterioration of features. Looking back at the process of CNN using convolution kernels to perform convolution operations on the image patch to extract local features, the weight values in the convolution kernels are usually different, which means that pixels at different positions in the feature map correspond to different weights. Even if the features at different locations are the same, different activation values will be output due to different weights, so the distribution characteristics of elements in the local area also have a potential impact on the extraction of local features. Local features are not only the aggregation of input features in the local receptive field but also potentially encode the spatial distribution information of each element in the local area, see
Figure 1a. When performing MLP-based point cloud analysis, shared MLP is usually implemented with a 1 × 1 convolution kernel, which is equivalent to forcing the weights of the convolution kernels corresponding to each position in the local area of the 2D image to be the same. Thus, the feature extraction is independent of the relative position of the pixels, which seriously weakens the feature extraction ability of the convolution kernel, see
Figure 1b.
Typical MLP-based methods such as PointNet [
27] first extract features for each point independently and then aggregate over the global receptive field to obtain shape-level features. In addition to ignoring local geometric properties, PointNet [
27] completely ignores spatial distribution information when aggregating all point features. PointNet++ [
28] is an upgraded version of PointNet [
27], PointNet++ [
28] uses mini-PointNet to aggregate point features in local areas, and only splices the features and relative coordinates in the input layer of mini-PointNet, so PointNet++ [
28] does not inherently overcome the limitations of PointNet [
27]. Although DGCNN [
30] is a graph-based method, it still uses the MLP operation for local feature extraction. DGCNN [
30] is aware of the role of spatial distribution information, so it adds the relative coordinates of the neighborhood points and the absolute coordinates of the centroid to the input, which makes the local features depend on the absolute position of the centroid, thus reducing the representation ability of the local features. In addition, DGCNN [
30] dynamically builds graphs in Euclidean space and feature space, which introduces much computational consumption. Although CNN-based methods can extract local characteristics based on the spatial distribution information of points, the process of adaptively learning convolution kernels is still computationally expensive compared to MLP-based methods. A concise and effective way to alleviate the limitation of shared MLPs ignoring spatial distribution information is to explicitly provide the relative coordinates of the current receptive field at each MLP layer (for PointNet [
27], the receptive field is the entire point cloud, so global coordinates need to be provided). Although this modification is simple, experiments validate its effectiveness. This design allows us to achieve outstanding performance with fewer layers and a more lightweight network.
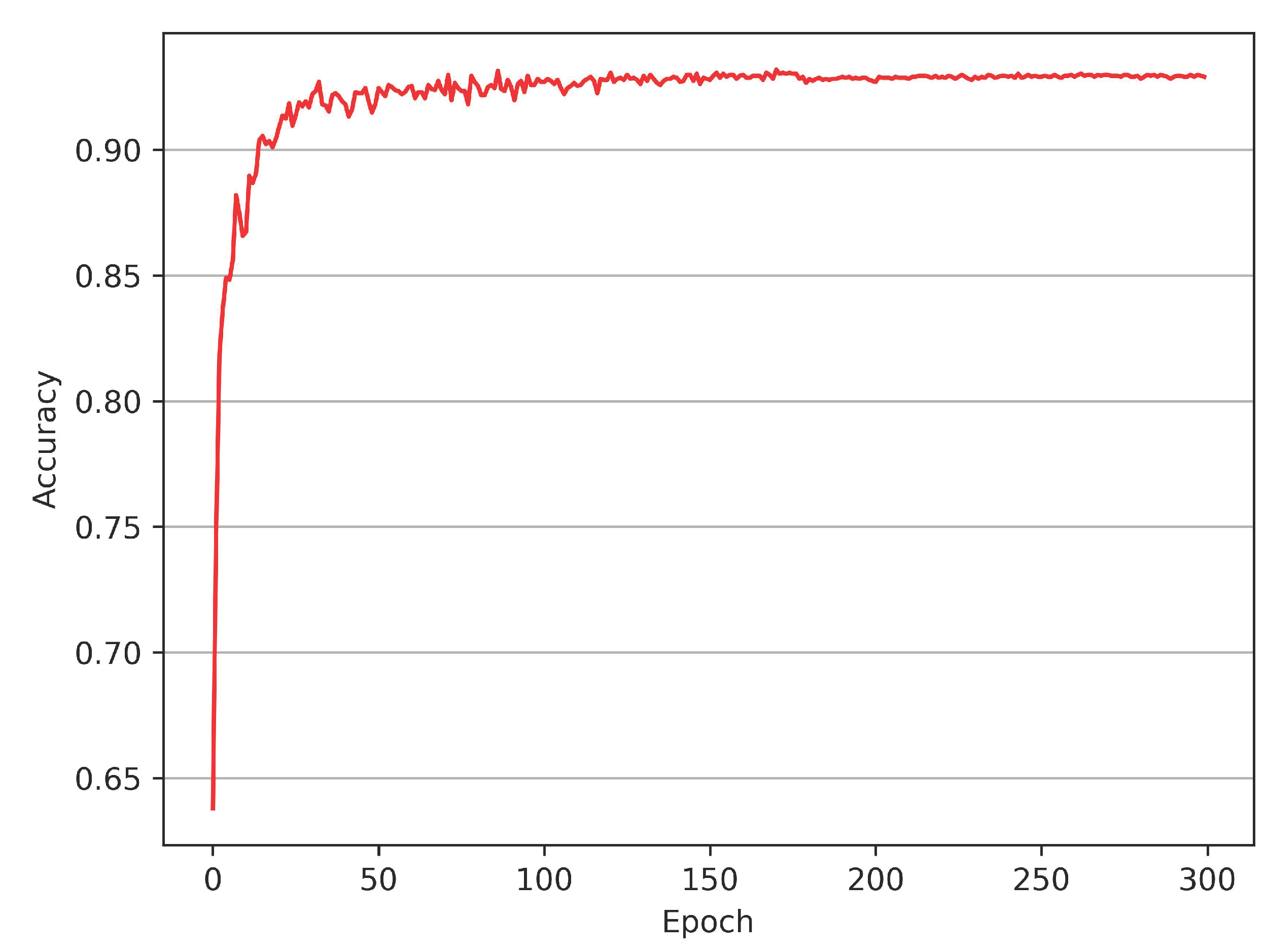
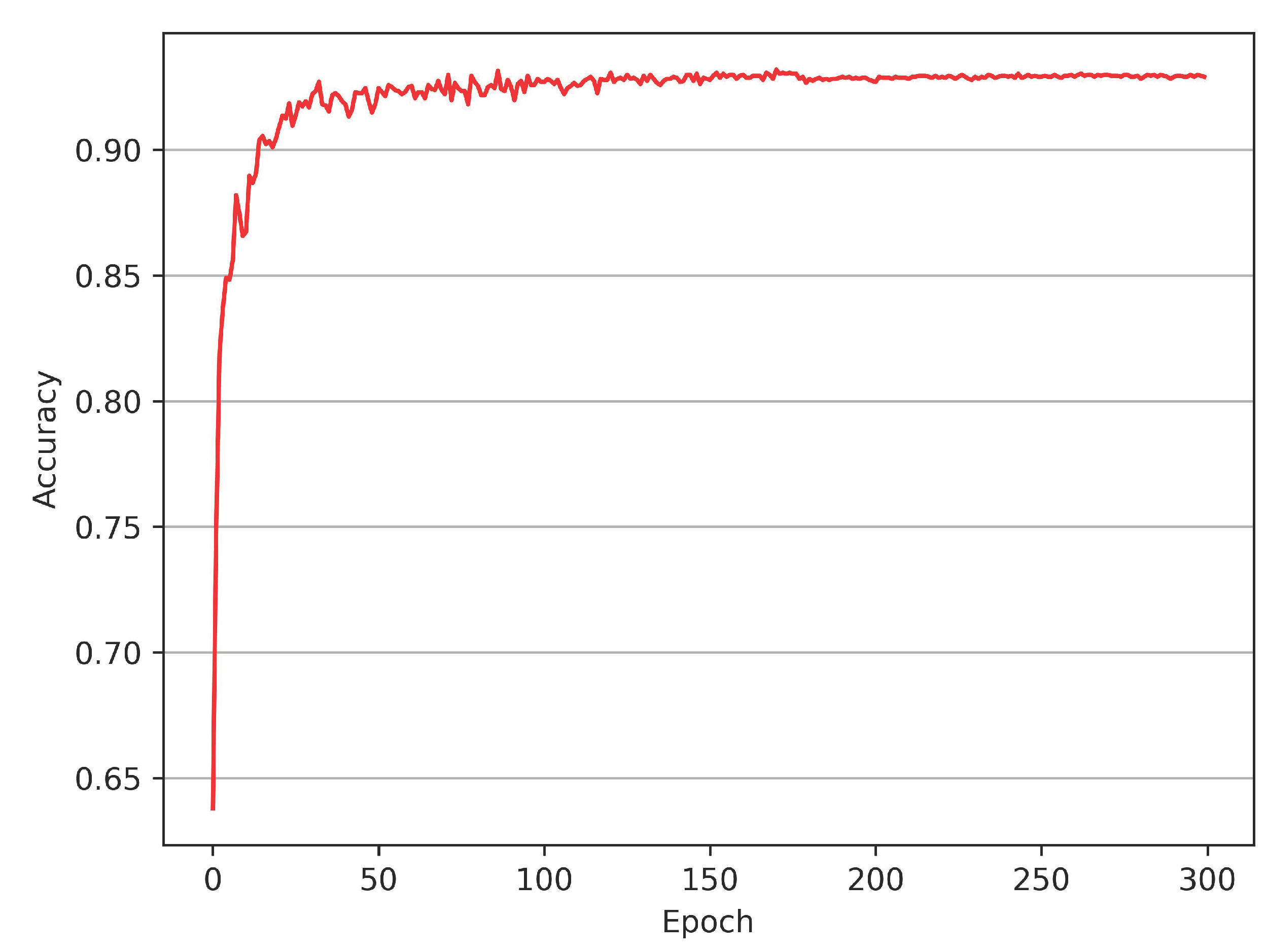
Moreover, the vanilla version of the proposed model with an exponential decay learning schedule exhibits rapid convergence, see
Figure 2, which implies that performance gains are limited for most epochs beyond the initial growth, accompanied by unnecessary cost of computing resources. We introduce the snapshot ensemble technology to the proposed model to address this issue. Snapshot ensemble can integrate a series of trained models in one complete training session without additional computation cost and fully utilize the model’s rapid convergence to improve the performance further. However, for the snapshot ensemble, the commonly used cosine annealing learning rate cannot be flexibly adjusted when the annealing cycle is fixed, so we propose a novel learning schedule denoted as Rectified-Tanh (Re-Tanh) with an adjustable parameter that can flexibly adapt to different scenarios. Ablation studies also demonstrate that the learning strategy is beneficial to improving the performance of the ensemble model.
The main contributions of this paper can be summarized below:
We take PointNet [
27] and PointNet++ [
28] as examples to study the difference in mechanism between shared MLP and CNN convolution kernels, analyze the defects of shared MLP, and reveal that the distribution information in the perceptual field is critical for feature extraction.
We propose a lightweight structure based on supplementing distribution information to extract discriminative features in a concise manner.
We introduce the snapshot ensemble to the model and propose a flexible learning schedule to improve the performance.
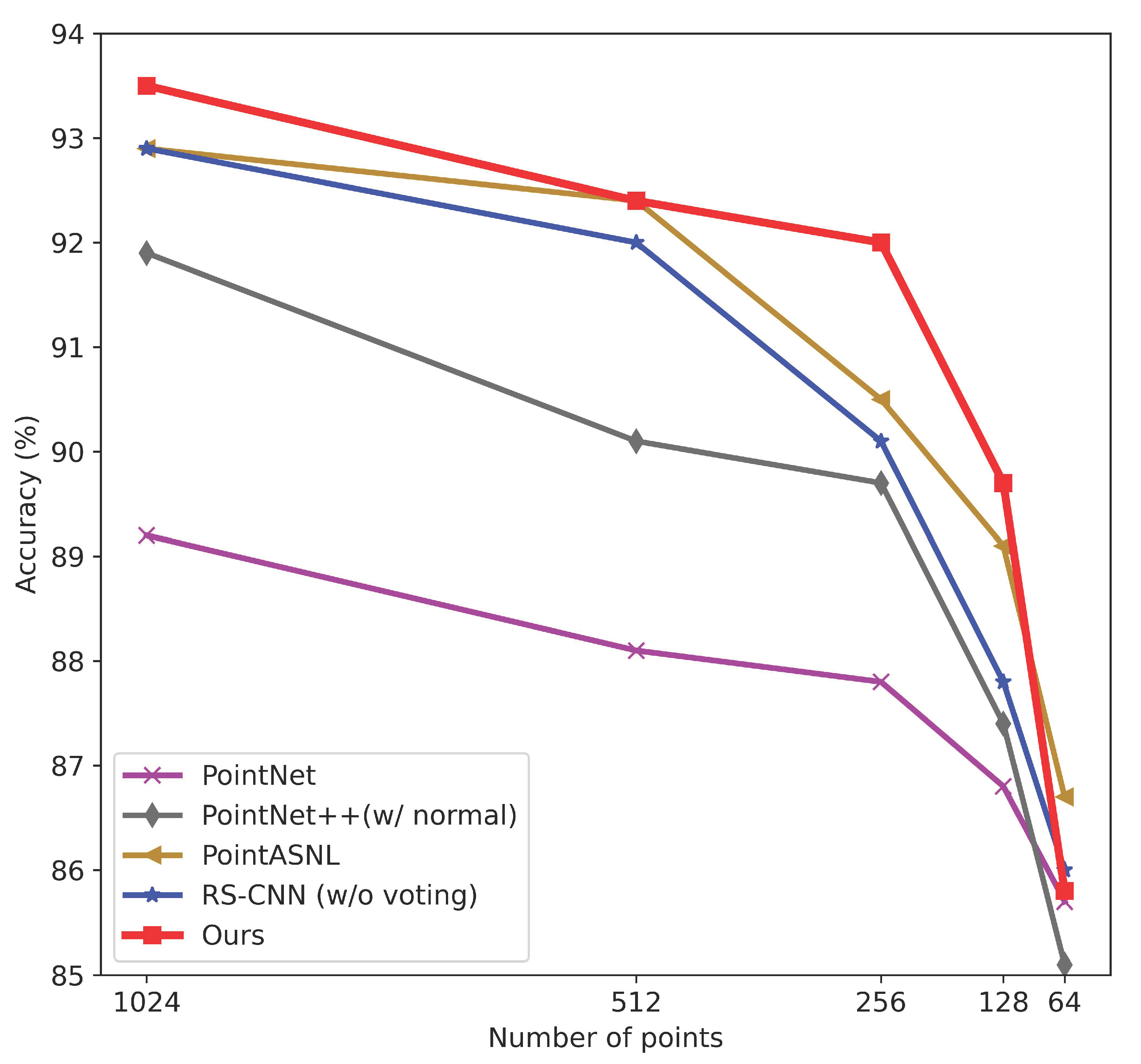
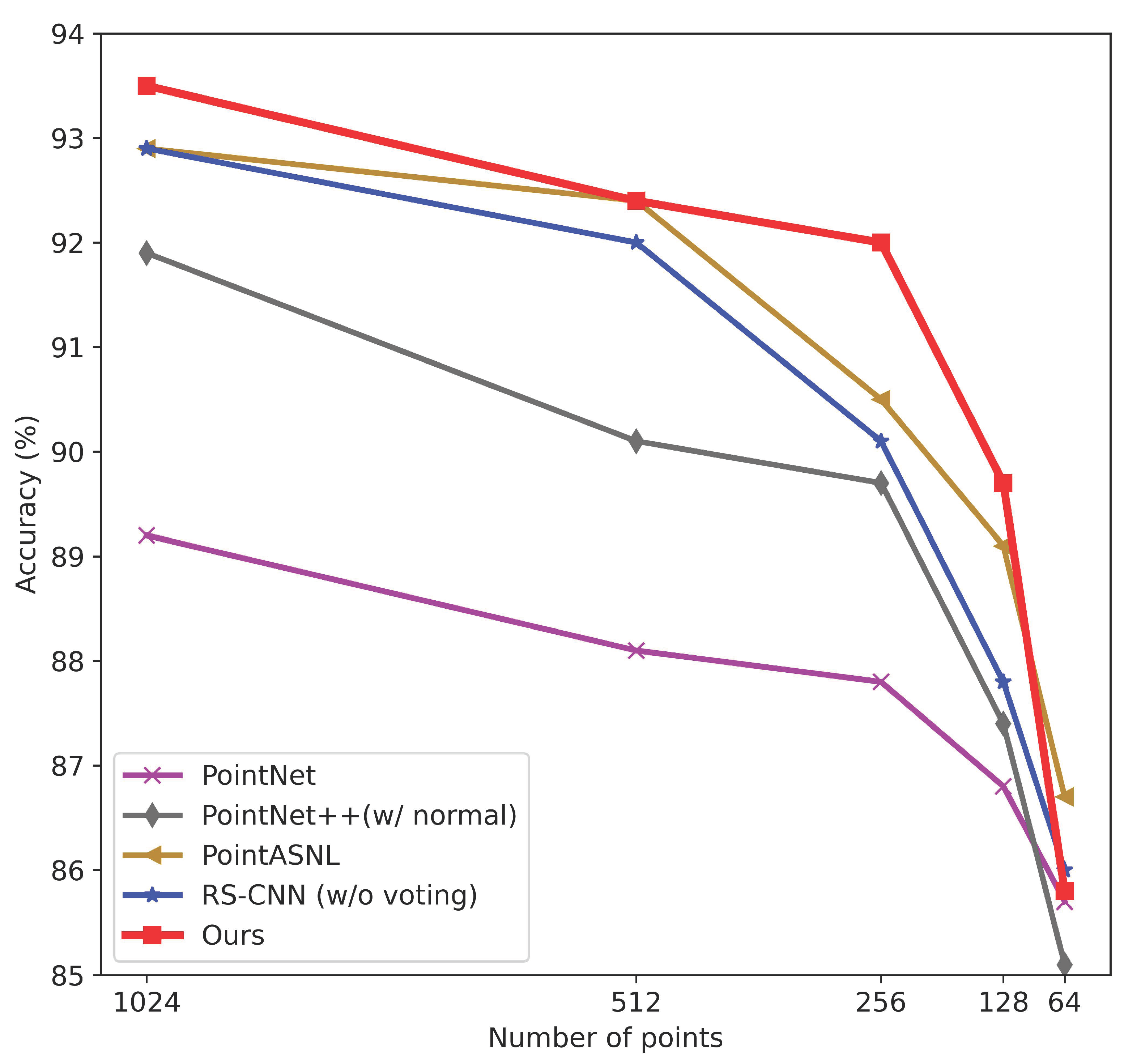
We evaluate our model on typical tasks, and the model with the minor parameters achieves on-par performance with the previous SOTA methods. Particularly, the models for ModelNet40 classification (93.5% accuracy) and S3DIS semantic segmentation (68.7% mIoU) have only about 1 million and 1.4 million parameters, respectively.
3. Methodology
In this section, we first introduce the methods of feature extraction and the supplement of distribution information, then review the snapshot ensemble and illustrate the proposed annealing schedule, and finally, we illustrate the network architecture in detail.
3.1. Extracting Local Features
3.1.1. K-Nearest Neighbor Points Search
For a 2D image, a local region of a particular pixel contains pixels located within a certain Manhattan distance from the central pixel that can be determined directly by the index. For a point cloud, a collection of unordered points without a regular grid structure, it is not feasible to directly determine the neighboring points with the index. The general method is k nearest neighbor (kNN) search which outputs a fixed number of nearest points around the centroid point in metric space.
Generally, a point cloud containing N points can be regarded as a point set denoted as , in which an element contains a point with its 3D coordinates and additional point feature vector such as normal, RGB and so on. For kNN research, the input point set is a tensor where N, d, and C represent the number of points, the dimensions of coordinates and features, and the outcome is a point set of size , where is the number of sampling points and k is the number of neighboring points in each local region.
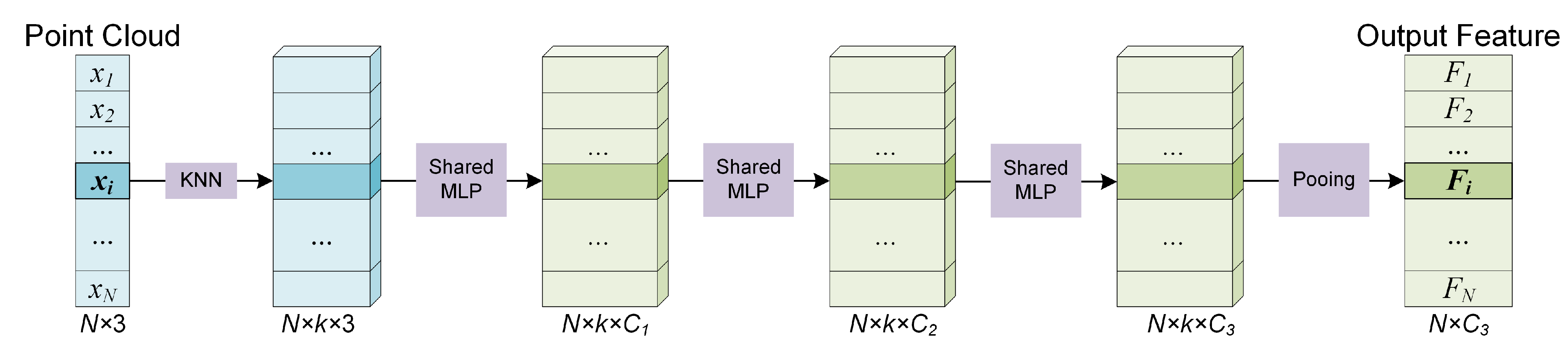
3.1.2. Local Feature Extraction
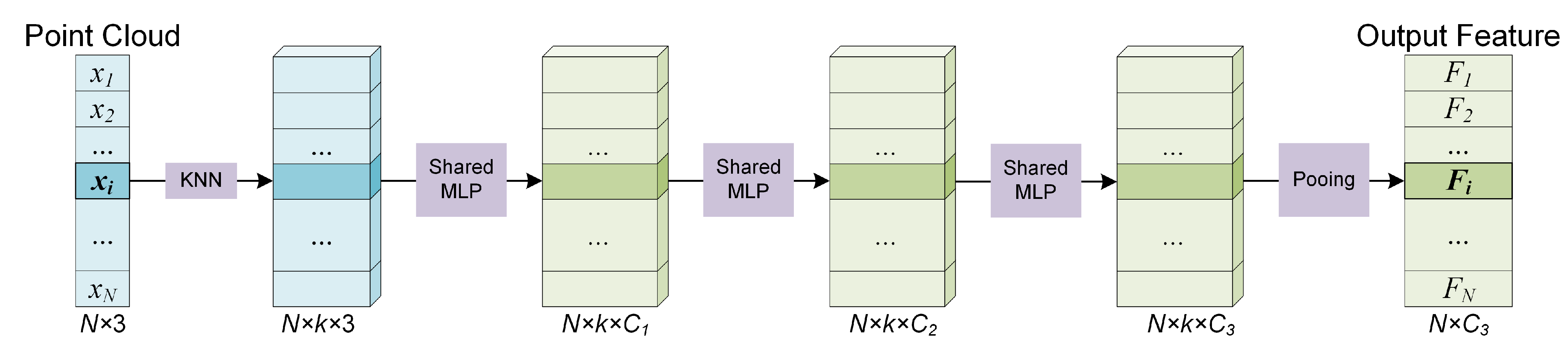
When the kNN search is completed, the neighboring points of a certain centroid point
are denoted as
. Our experiments found that shared MLP, even simple, is sufficient to obtain outstanding performance. Therefore, we choose shared MLP used in PointNet [
27] and PointNet++ [
28] as the local feature extractor in the trade-off between performance and model complexity. Given a neighbor set
with
k neighbor points
, the coordinates of points are firstly translated into local coordinates relative to the centroid point to make the local patterns independent of its spatial location. The local feature extractor for centroid
i can be defined as:
where
and
h represent the max-pooling operation and the stacked shared MLPs, respectively. See
Figure 3.
3.2. Supplement of the Distribution Information
From the analysis in
Section 1, it can be seen that for MLP-based methods, one of the main limitations is to regard points as equivalent and ignore the influence of point distribution on features. Therefore, it is vital to provide information about the spatial distribution of points within the receptive field to improve network performance. We adopt a concise manner by directly providing spatial coordinates as supplementary information to the intermediate layers of the network. The network automatically learns local features and spatial distribution characteristics simultaneously and fuses them to obtain aggregate features. Compared with the previous methods, the proposed model does not require an additional process of establishing complex data structures such as graphs and trees and avoids adding extra modules containing massive trainable parameters to extract distribution information, making our network effective and computationally efficient.
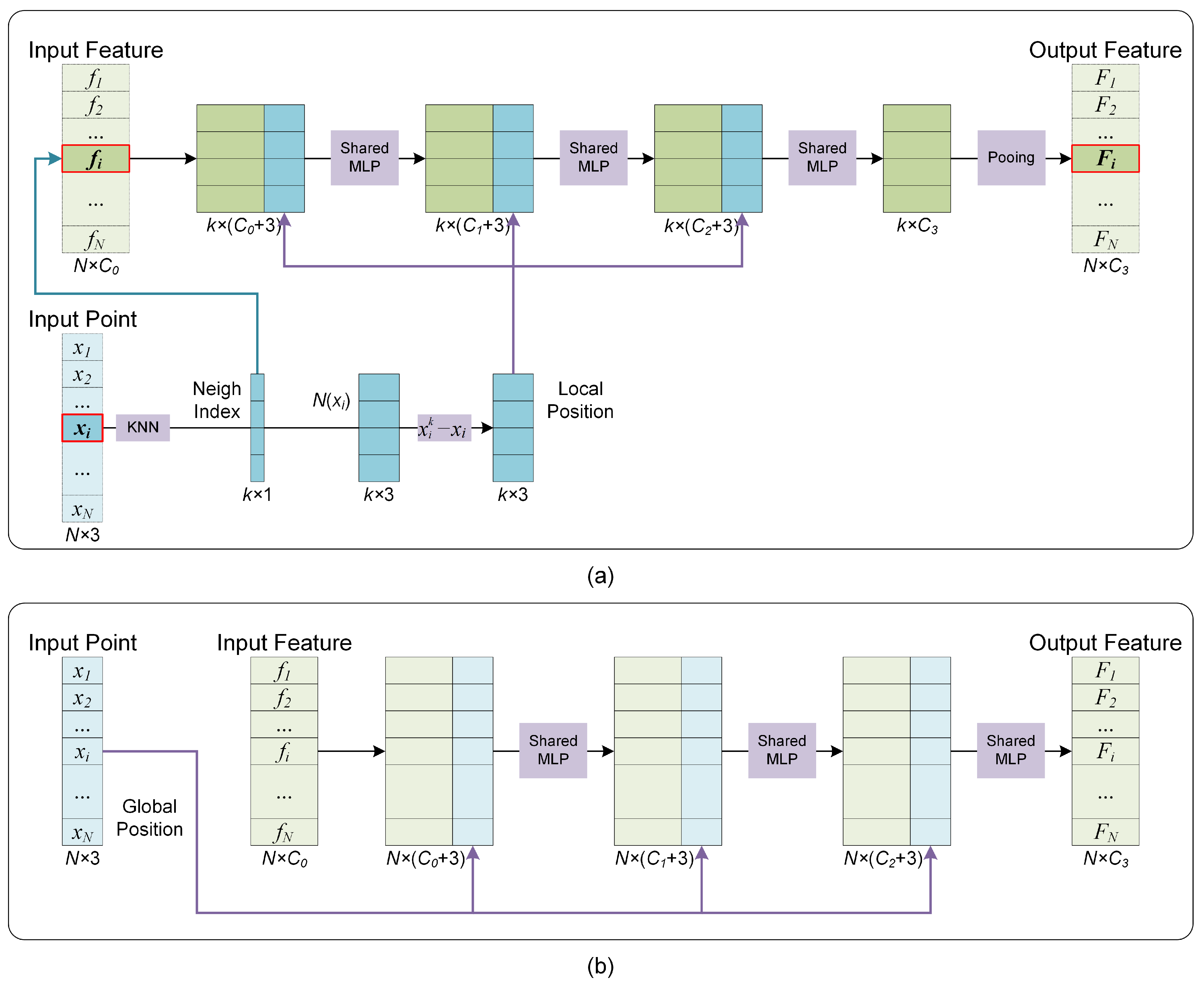
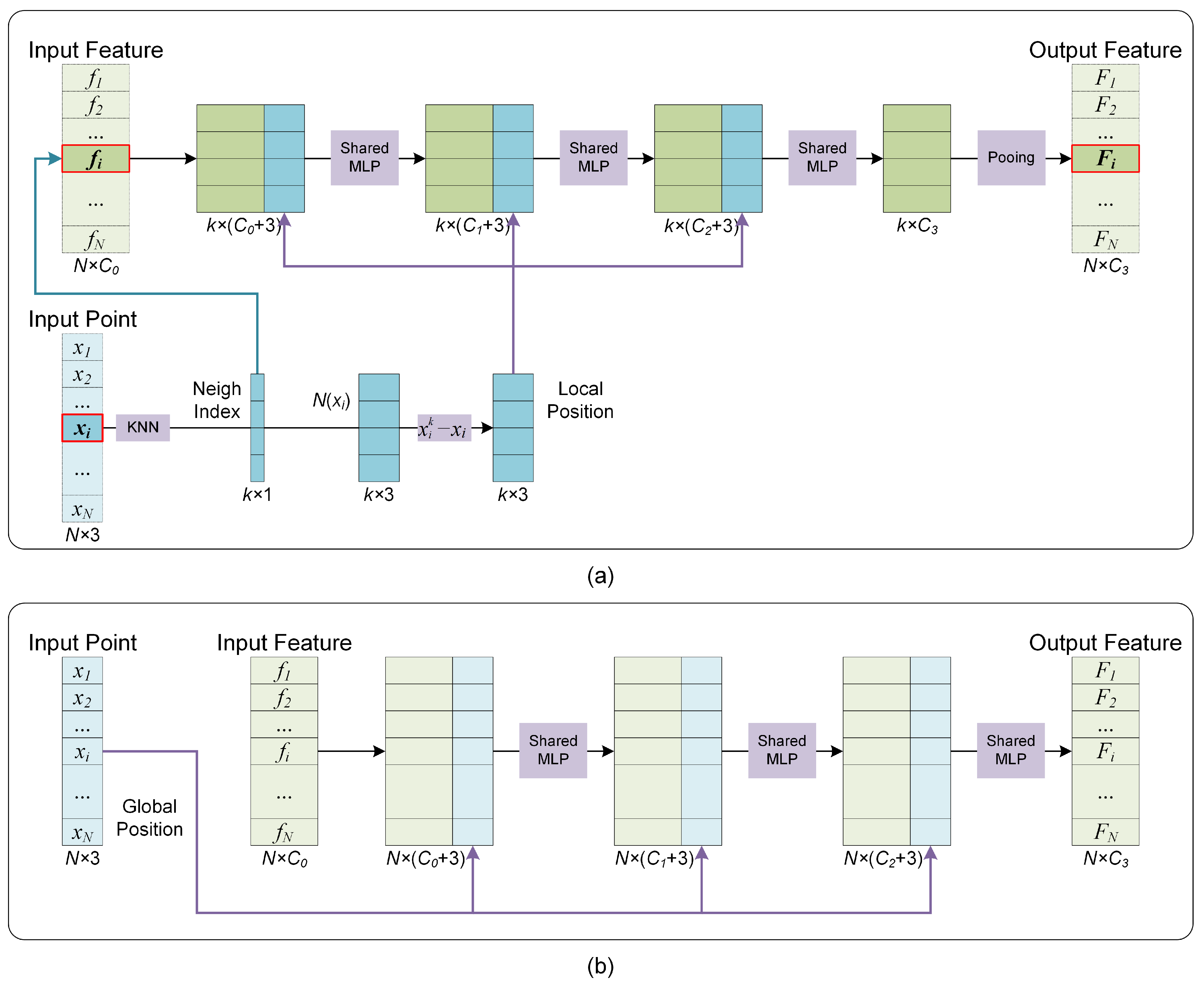
Since the supplement mechanism of distribution characteristics involves the fusion of features and their spatial distribution, the corresponding network module is denoted as the Fusion Module. There exist local and global receptive fields in point clouds, so the supplement mechanisms of distributional characteristics are also different.
Figure 4 shows the Fusion Modules utilized in this paper.
Figure 4a,b correspond to the Fusion Modules with the local and global perception fields. The main difference between the two modules is that the Fusion Module with local perception fields needs to explore the neighborhood points through kNN operation and then calculate the relative coordinates, and the Fusion Module with the global perception field only needs to provide the global coordinates directly.
Figure 4b can be seen as a particular case of
Figure 4a when the local receptive field is expanded to the entire point cloud.
3.3. The Proposed Learning Schedule for Snapshot Ensemble
Model ensemble technology is much more robust and accurate than individual networks. The ordinary method is to train several individual models and fuse the outputs of each model, which is computationally expensive. Snapshot ensemble [
62] is an effective method that can ensemble multiple neural networks without additional training cost. Snapshot ensemble follows a cyclic annealing schedule to converge to multiple local minima. The training process thus is split into
M cycles, and in each cycle, the learning rate starts with a higher value and gradually decreases to a lower learning rate. Starting with a higher value gives the network sufficient momentum to escape from a local minimum, and the subsequent smaller learning rate guarantees the network to converge smoothly to a new local minimum. The general form of the learning rate is:
where
and
are the initial and final learning rate in one cycle,
t is the iteration number,
T is the total number of training iterations in one cycle, and
f is a monotonically decreasing function. In general,
f is set to be the shifted cosine function:
The experiments reveal that the non-ensemble model rapidly converges when trained with an exponential decay learning rate, see
Figure 2. Rapid convergence implies that the proposed model can quickly reach a local minimum in several epochs, facilitating the introduction of the snapshot ensemble.
However, when
T,
and
are fixed, the commonly used cosine annealing learning schedule is also fixed, which makes it unable to be flexibly adjusted to adapt to diverse scenarios. Thus we need to design a function that decreases monotonically from 1 to 0 on the interval
like the shifted cosine, and the shape of the function can be flexibly adjusted. As shown in Equation (
4), the tanh function increases monotonically, and we introduce a new annealing schedule based on it.
The steps to rectify tanh to generate a new annealing curve are displayed as follows:
Use
instead of
x to obtain a monotonically decreasing function
:
The
x is replaced by
to scale
, and then
is truncated on the interval
to obtain the function
:
By replacing
x with
, the function
is shifted to the right by
, thereby obtaining the function
defined on the interval
:
Since the values of
at both ends of the interval
are not strictly equal to
, it needs to be normalized to obtain the function
with a range of
:
Scale the value range of
to
and move it up by 0.5 to obtain a new annealing function Re-Tanh defined on
. The function value decreases monotonically from 1 to 0, and the shape can be adjusted by
s. The expression is:
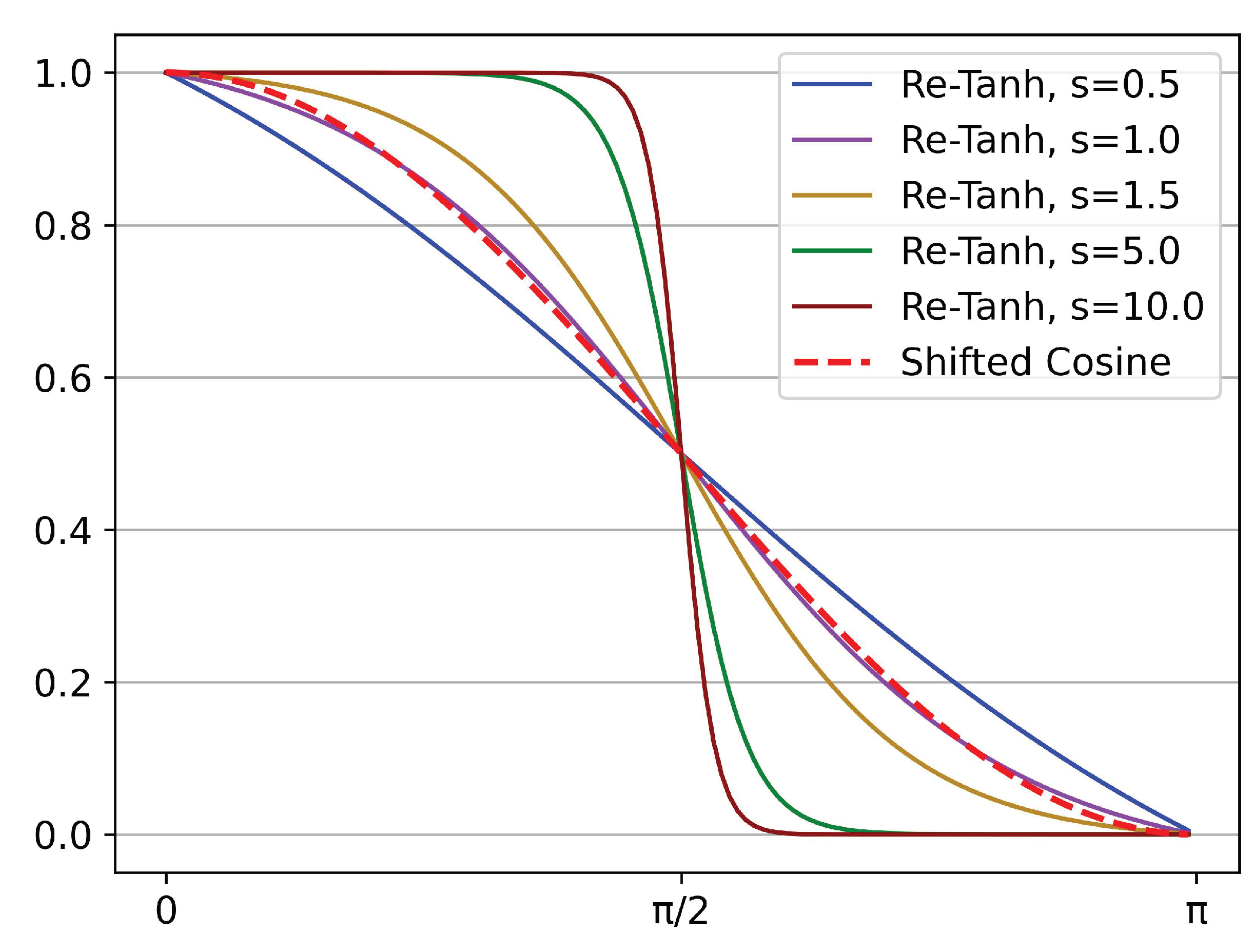
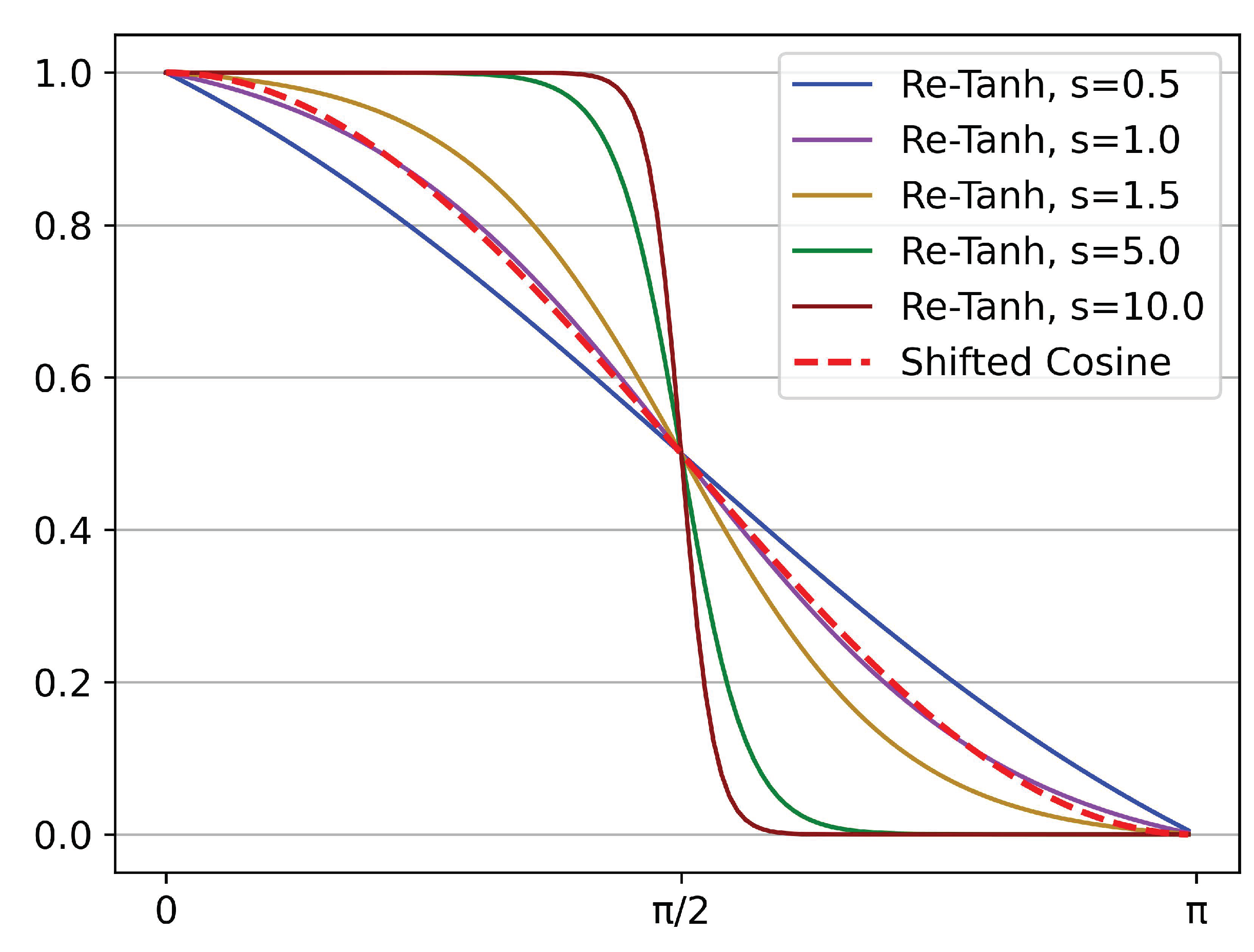
Figure 5 illustrates the Re-Tanh curves corresponding to different
s values. The shifted cosine is also shown for reference. It is noted that when
s equals 1, the middle part of the Re-Tanh and the shifted cosine are almost coincident. This phenomenon can prove mathematically that the slopes of the two curves are almost equal when they are close to the center of symmetry (
), which shows that the Re-Tanh can be regarded as a generalization of shifted cosine so that the learning schedule can be flexibly adjusted in specific scenarios to improve the performance of the model. In practical applications, the
x is usually replaced with
, where the mathematical quantities represented by
t and
T are the same as those in Equation (
2).
3.4. Network Architecture
Compared with the task of semantic segmentation of large-scale scenes, for classification and part segmentation tasks, the processed point cloud objects are complete discrete objects, and the scale of the point cloud is smaller, so a more lightweight network can be designed. The network structure for classification and part segmentation in this paper only consists of a Local Feature Module and a Fusion Module with a global perception field. The number of points is always huge for semantic segmentation tasks, and more abstract features are required, so a deeper network consisting of a Local Feature Module and multiple cascaded Fusion Modules with enlarged local perception fields is adopted.
3.4.1. Classification and Part Segmentation Network
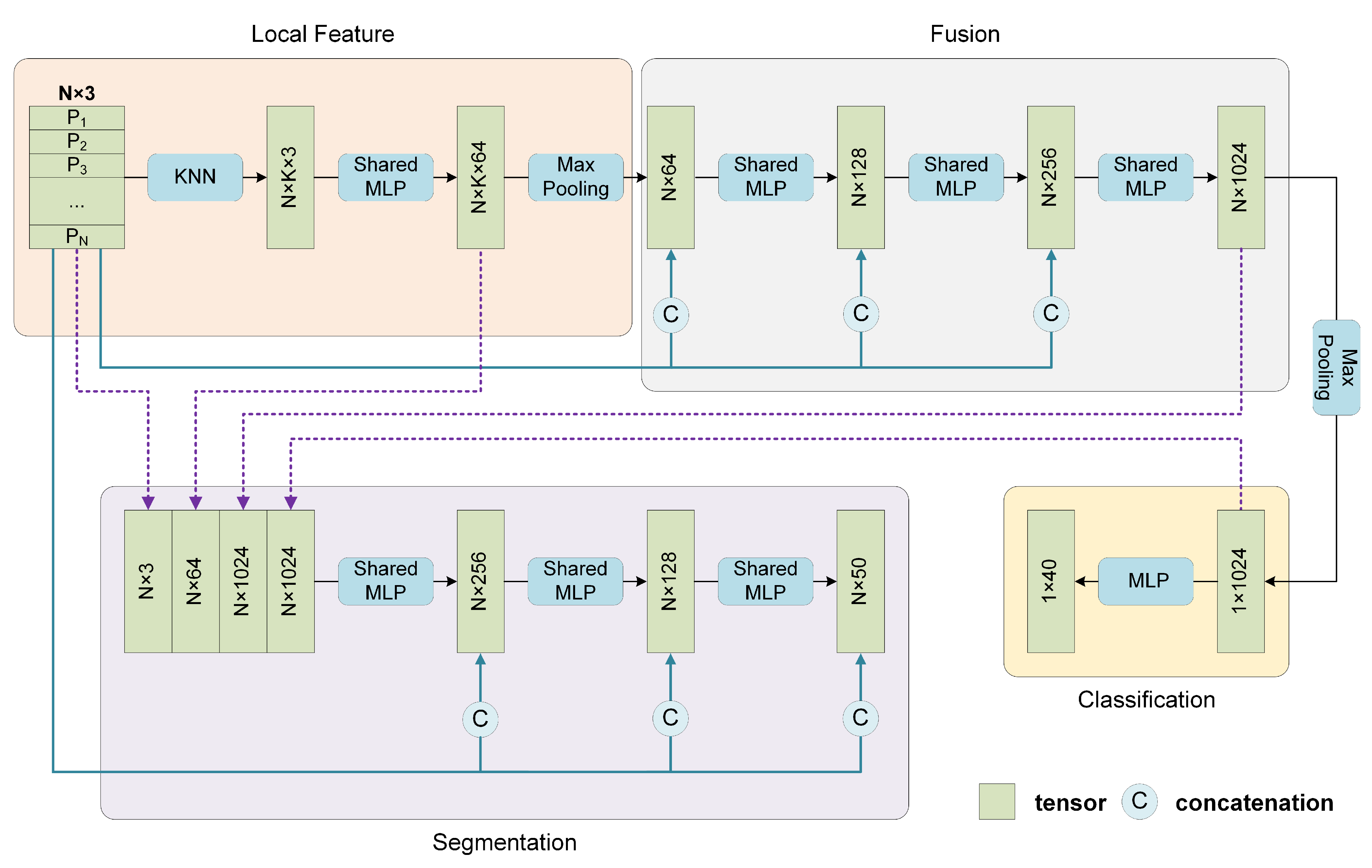
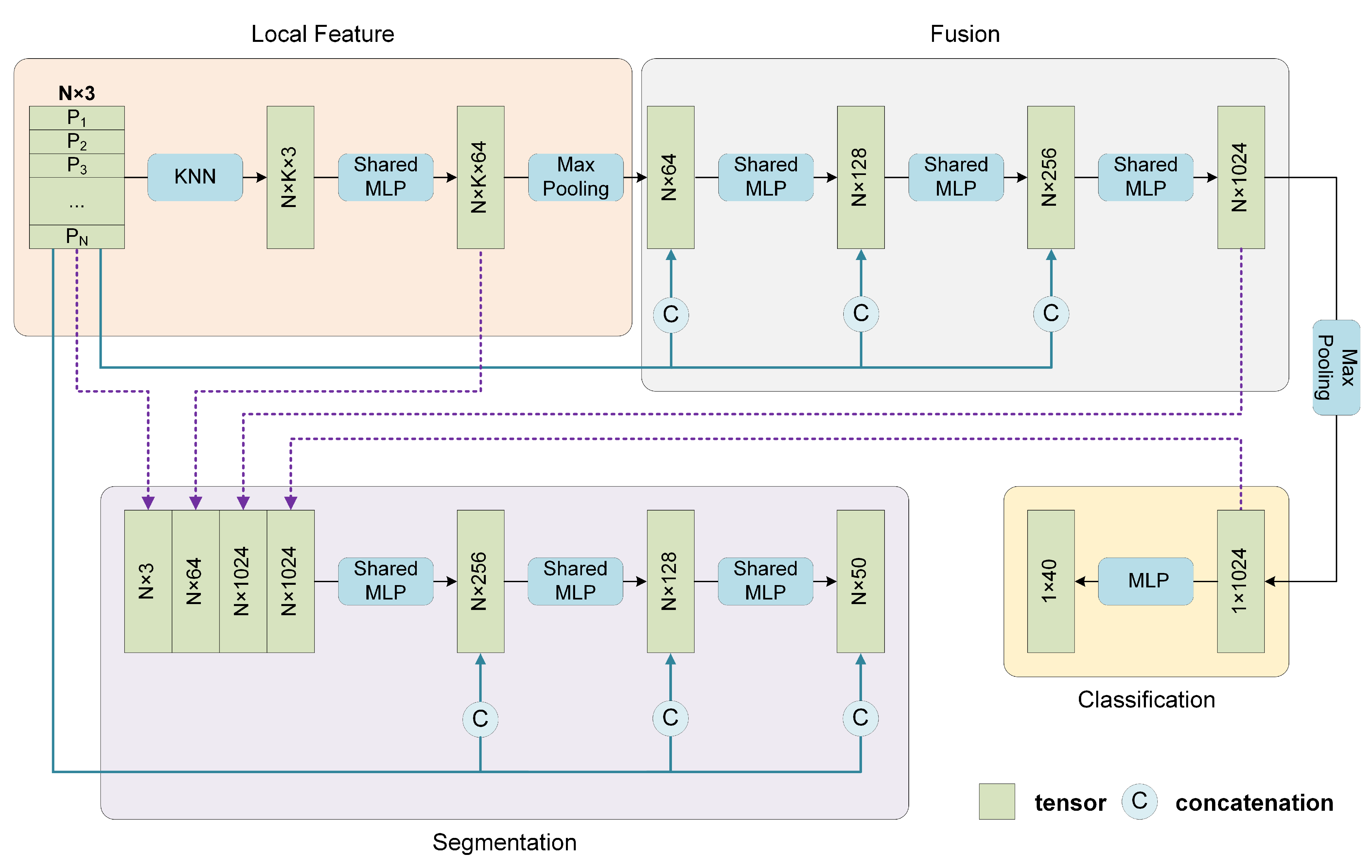
As shown in
Figure 6, the entire network mainly consists of three modules, which are used to extract the local features, fuse the local features with the supplementary global coordinates to obtain shape-level features, and perform classification or segmentation tasks, respectively. The classification network and segmentation network share the same first two modules.
For classification, first, the N points in the input point cloud are regarded as centroids without sampling, and then k neighboring points are searched. The grouped points are fed into the local feature extractor, containing three successive shared MLPs followed by a max-pooling layer to guarantee that the local features are permutation invariant. Each centroid corresponds to a group of neighboring points, and all the N groups share the same parameters. Subsequently, the N local features are sent to Fusion Module. It is noted that before each layer in the Fusion Module, the N local features and their N corresponding global coordinates are concatenated. Finally, the classification task is performed through three MLP layers. For part segmentation, the local features reflect the local geometric properties. The Fusion Module yields more abstract fusion features for each point which contain global and local information before the final max-pooling layer, and the shape-level feature acts as the output of the max-pooling layer. These features mentioned above contain complete information about an individual point: the object it belongs to, the local pattern it represents, and its spatial distribution. Then the shape-level feature is concatenated with each point’s local features and fusion features and output by the local feature extractor and Fusion Module, respectively. Then the combined feature is fed into Segmentation Module, in which the global coordinates are also provided to accomplish the segmentation tasks.
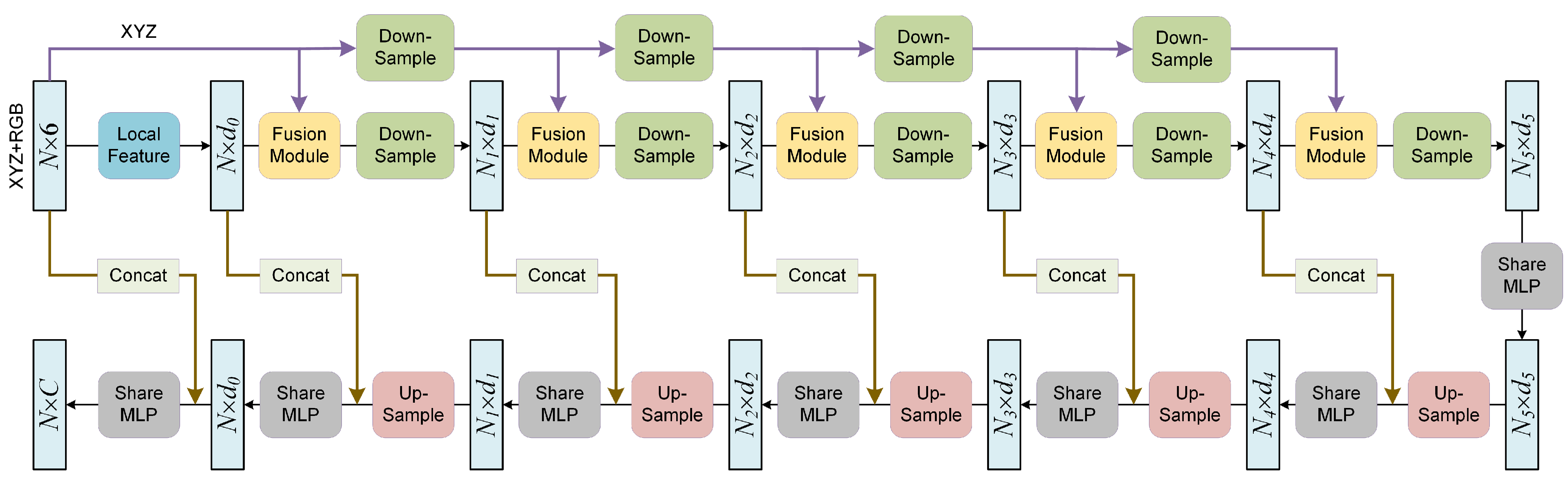
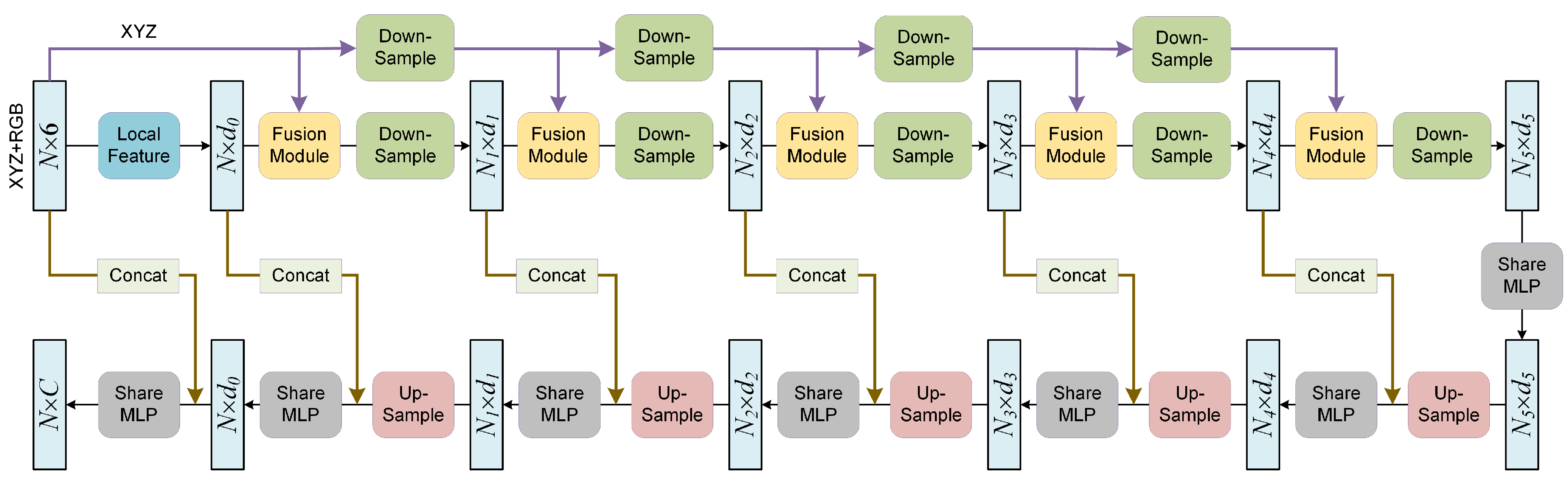
3.4.2. Semantic Segmentation Network
In addition to the initial Local Feature Module, the semantic segmentation network mainly includes five Fusion Modules followed by down-sampling operations and five subsequent up-sampling operations. Such a design is beneficial for reducing the amount of computation and extracting more abstract features. The entire network structure is shown in
Figure 7.
3.5. Implementation Details
The network is implemented on an NVIDIA TITAN Xp GPU with TensorFlow. For the three tasks, the batch size is set to 32, 32, and 8. For classification and part segmentation, the annealing cycle is 26 and 10 epochs, and the momentum of batch normalization (BN) starts at 0.5 and decays exponentially once every annealing cycle by a rate of 0.8. The scale factor of the Re-Tanh is set to 1.5. In each cycle, the learning rate starts at 0.01 and decreases monotonically to 0.00001. For semantic segmentation, the momentum of BN is fixed to 0.99, and a learning rate starts at 0.01 with an exponential decay rate of 0.95 per epoch is employed without ensemble technology.



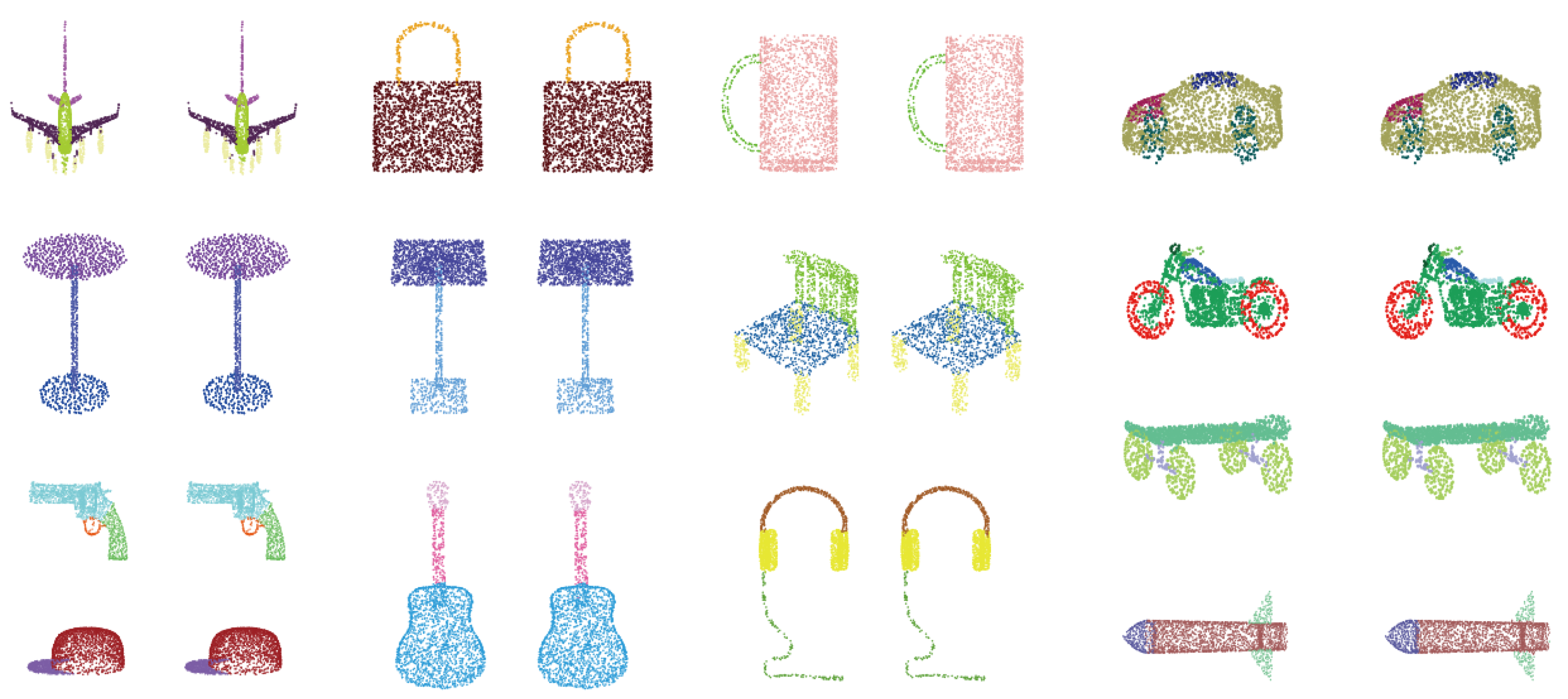


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}