
Multiple-Attention Mechanism Network for Semantic Segmentation

 ,
,
Abstract
:1. Introduction
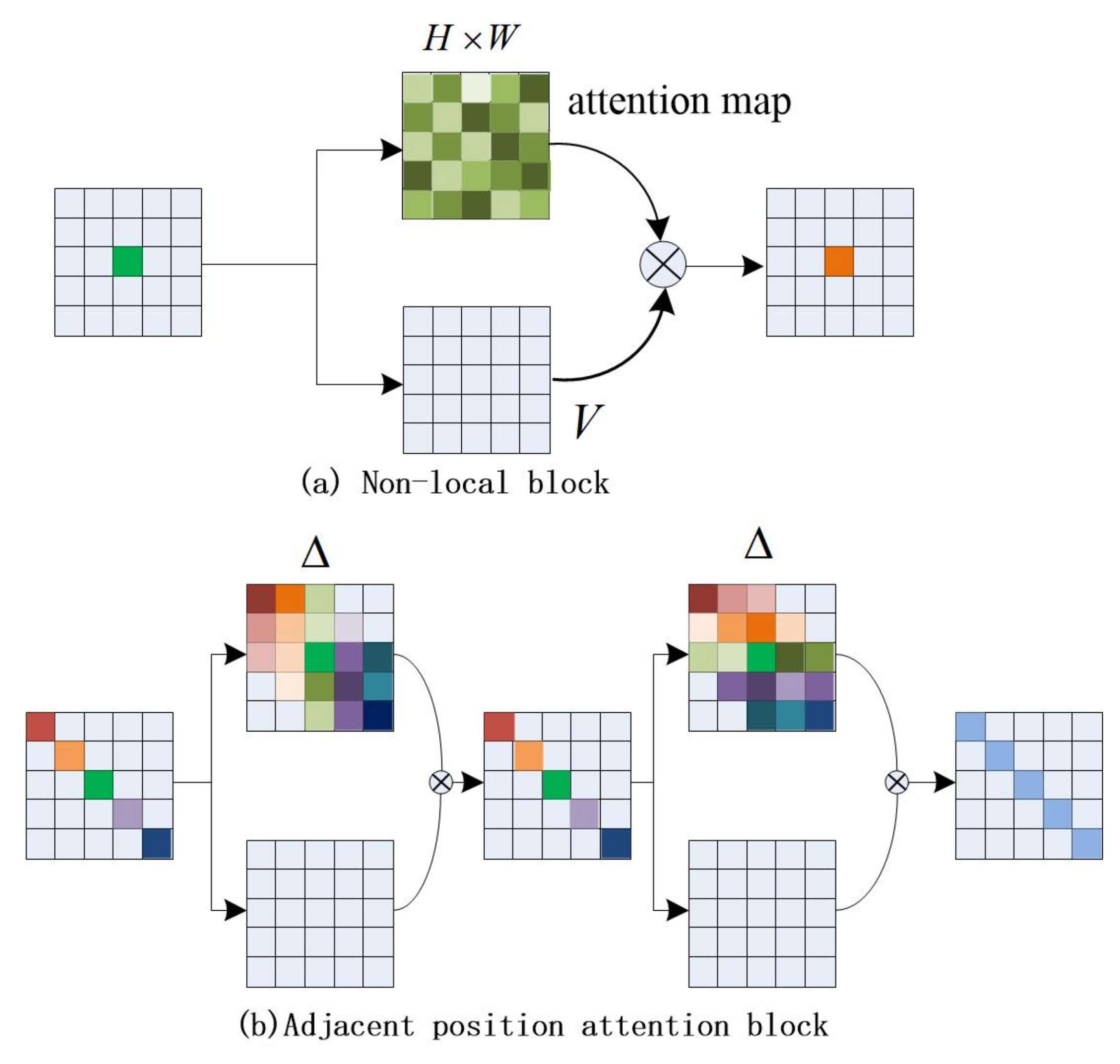
- To capture the long-distance dependence, we proposed the APAM, which combined with the Channel Attention Module to form a new dual-attention model (NDAM), which is lighter and more effective than DANet [8].
- To obtain a better semantic segmentation effect, we designed a cross-dimensional interactive attention feature fusion module (CDIA-FFM) for fusing features from different stages in the decoder.
- Combining NDAM and CDIA-FFM, a new network MANet for semantic segmentation is proposed. It has obtained good results in the two benchmark tests PASCAL VOC 2012 and cityscapes.
2. Related Work
2.1. Semantic Segmentation
2.2. Encoding and Decoding
2.3. Attention Module
3. Method
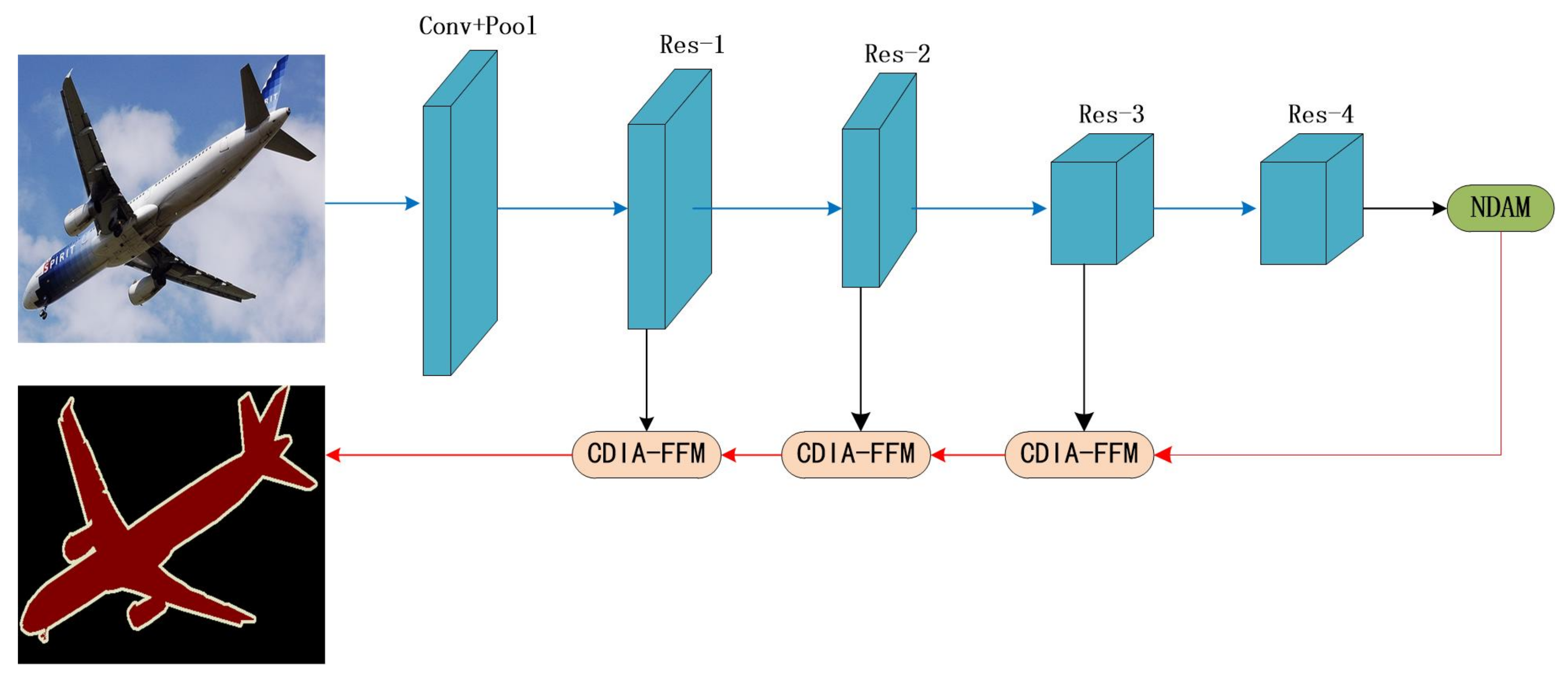
3.1. Network Architecture
3.2. New Dual-Attention Model
3.2.1. Overview of the New Dual-Attention Model
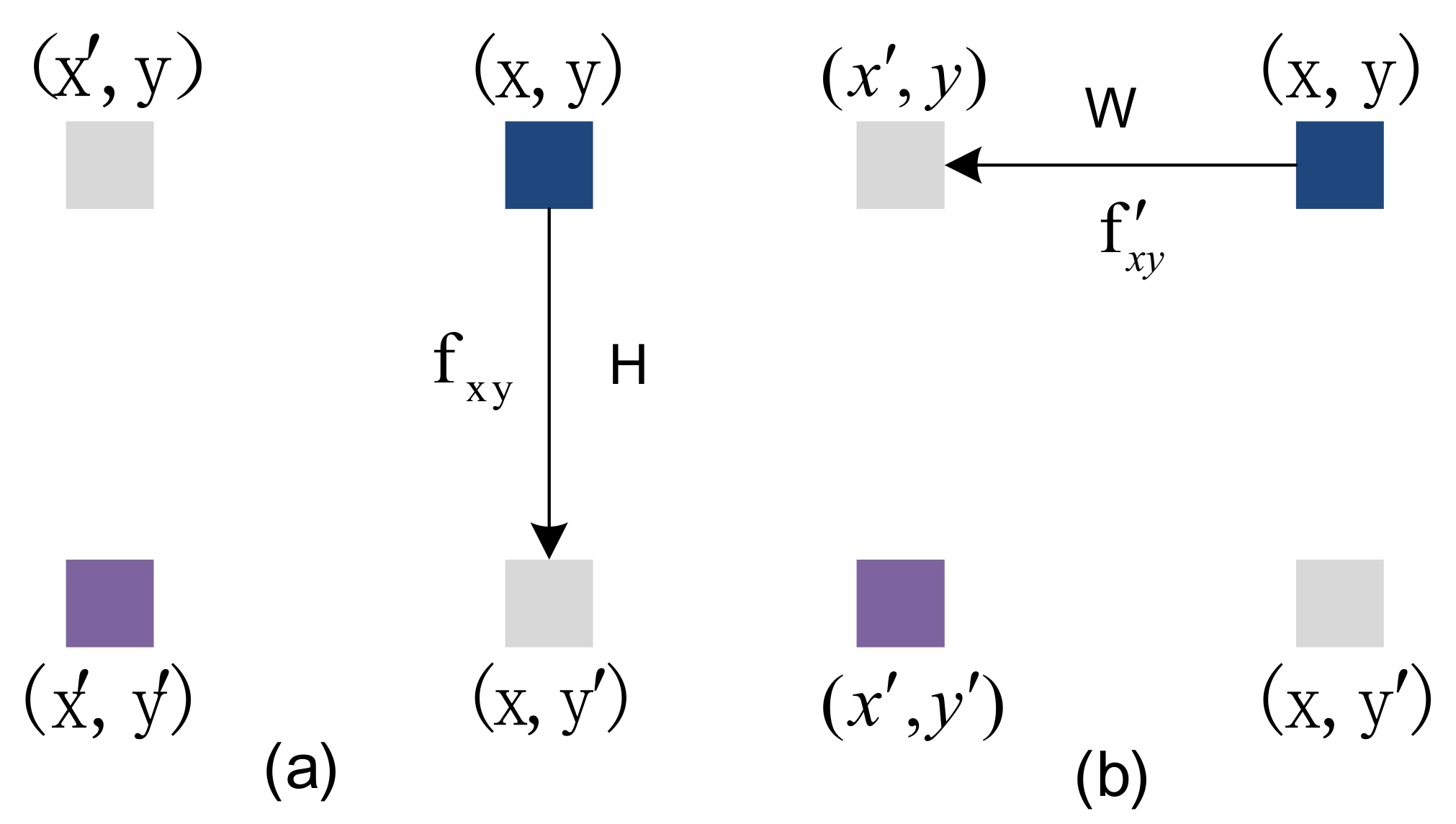
3.2.2. Details of Adjacent Position Attention
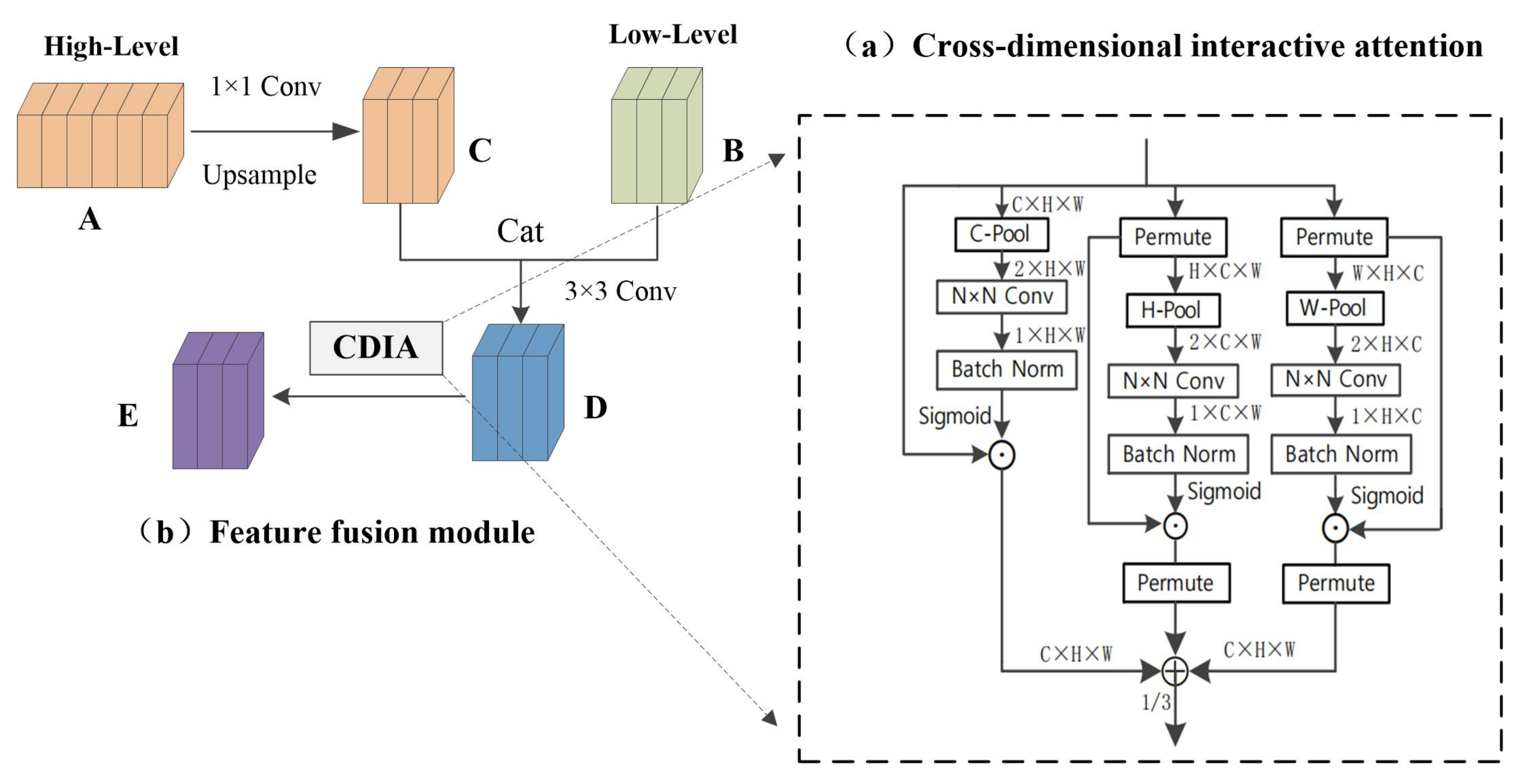
3.3. Cross-Dimensional Interactive Attention Feature Fusion Module
3.3.1. Cross-Dimensional Interactive Attention Mechanism
3.3.2. Feature Fusion Module
4. Experiments
4.1. Datasets and Implementation Details
4.2. Implementation Details
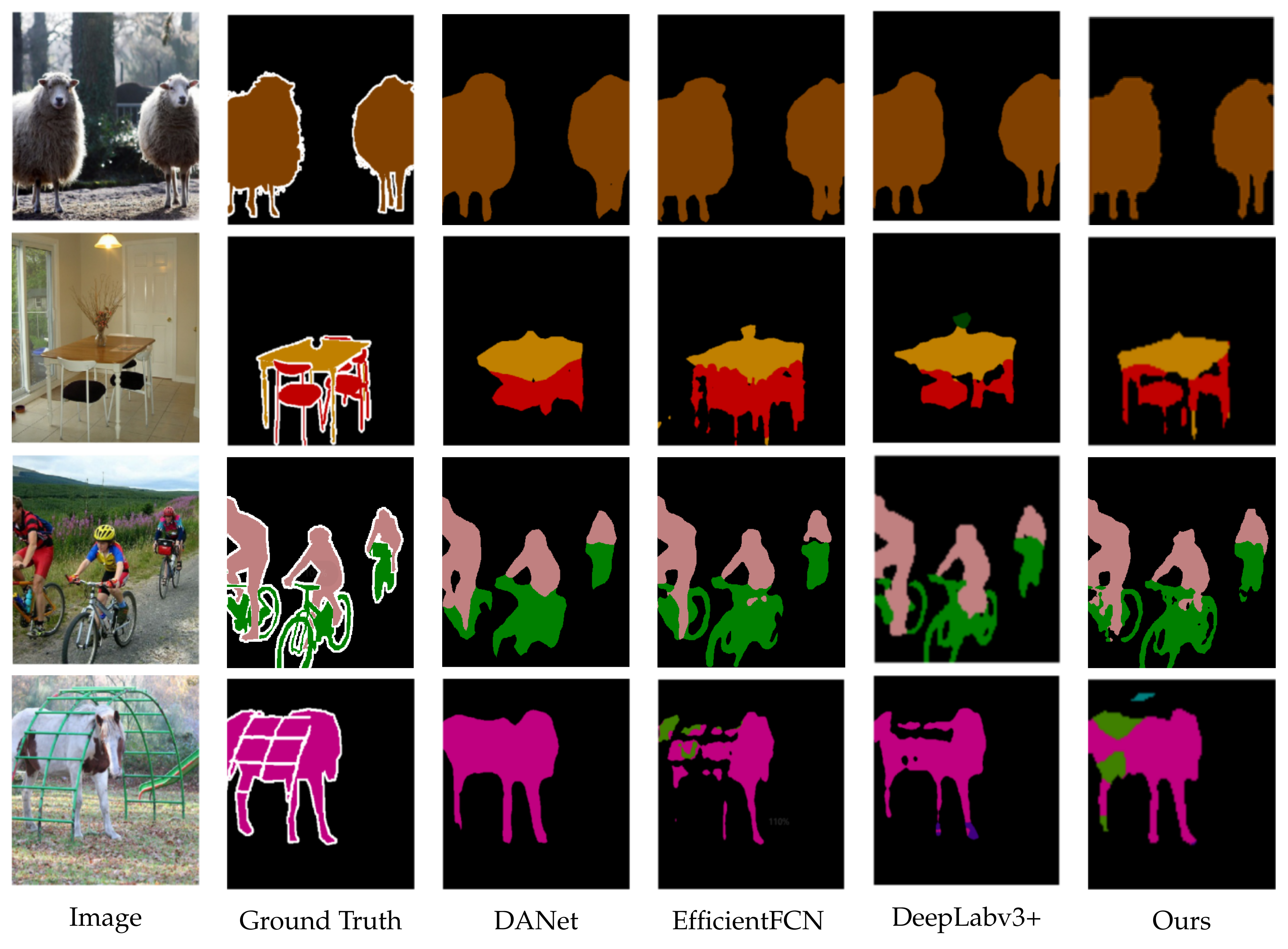
4.3. Results on PASCAL VOC 2012
4.3.1. New Dual-Attention Model
4.3.2. Cross-Dimensional Interactive Attention Feature Fusion Module
4.4. Results on Cityscapes
4.5. Compared with Transformer Method
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Fritsch, J.; Kuehnl, T.; Geiger, A. A new performance measure and evaluation benchmark for road detection algorithms. In Proceedings of the 16th International IEEE Conference on Intelligent Transportation Systems (ITSC 2013), The Hague, The Netherlands, 6–9 October 2013; pp. 1693–1700. [Google Scholar]
- Chiu, M.T.; Xu, X.; Wei, Y.; Huang, Z.; Schwing, A.G.; Brunner, R.; Khachatrian, H.; Karapetyan, H.; Dozier, I.; Rose, G.; et al. Agriculture-vision: A large aerial image database for agricultural pattern analysis. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 2828–2838. [Google Scholar]
- Chiu, M.T.; Xu, X.; Wang, K.; Hobbs, J.; Hovakimyan, N.; Huang, T.S.; Shi, H. The 1st agriculture-vision challenge: Methods and results. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 13–19 June 2020; pp. 48–49. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhao, H.; Shi, J.; Qi, X.; Wang, X.; Jia, J. Pyramid scene parsing network. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2881–2890. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual attention network for scene segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 3146–3154. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-decoder with atrous separable convolution for semantic image segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Yu, C.; Wang, J.; Peng, C.; Gao, C.; Yu, G.; Sang, N. Learning a discriminative feature network for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1857–1866. [Google Scholar]
- Li, H.; Xiong, P.; An, J.; Wang, L. Pyramid attention network for semantic segmentation. arXiv 2018, arXiv:1805.10180. [Google Scholar]
- Lin, G.; Milan, A.; Shen, C.; Reid, I. Refinenet: Multi-path refinement networks for high-resolution semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1925–1934. [Google Scholar]
- Ke, T.W.; Hwang, J.J.; Liu, Z.; Yu, S.X. Adaptive affinity fields for semantic segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 587–602. [Google Scholar]
- Zhong, Z.; Lin, Z.Q.; Bidart, R.; Hu, X.; Daya, I.B.; Li, Z.; Zheng, W.S.; Li, J.; Wong, A. Squeeze-and-attention networks for semantic segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 13065–13074. [Google Scholar]
- Yuan, Y.; Chen, X.; Wang, J. Object-contextual representations for semantic segmentation. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Part VI 16, Glasgow, UK, 23–28 August 2020; pp. 173–190. [Google Scholar]
- Chen, X.; Yuan, Y.; Zeng, G.; Wang, J. Semi-Supervised Semantic Segmentation with Cross Pseudo Supervision. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 2613–2622. [Google Scholar]
- Jo, S.; Yu, I.J. Puzzle-CAM: Improved localization via matching partial and full features. arXiv 2021, arXiv:2101.11253. [Google Scholar]
- Min, J.; Kang, D.; Cho, M. Hypercorrelation squeeze for few-shot segmentation. arXiv 2021, arXiv:2104.01538. [Google Scholar]
- Huang, H.; Lin, L.; Tong, R.; Hu, H.; Zhang, Q.; Iwamoto, Y.; Han, X.; Chen, Y.W.; Wu, J. Unet 3+: A full-scale connected unet for medical image segmentation. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 1055–1059. [Google Scholar]
- Guo, C.; Szemenyei, M.; Yi, Y.; Wang, W.; Chen, B.; Fan, C. Sa-unet: Spatial attention u-net for retinal vessel segmentation. In Proceedings of the 2020 25th International Conference on Pattern Recognition (ICPR), Milan, Italy, 10–15 January 2021; pp. 1236–1242. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked hourglass networks for human pose estimation. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; pp. 483–499. [Google Scholar]
- Ji, Y.; Zhang, H.; Zhang, Z.; Liu, M. CNN-based encoder-decoder networks for salient object detection: A comprehensive review and recent advances. Inf. Sci. 2021, 546, 835–857. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Huang, Z.; Wang, X.; Huang, L.; Huang, C.; Wei, Y.; Liu, W. Ccnet: Criss-cross attention for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 November 2019; pp. 603–612. [Google Scholar]
- Peng, C.; Tian, T.; Chen, C.; Guo, X.; Ma, J. Bilateral attention decoder: A lightweight decoder for real-time semantic segmentation. Neural Netw. 2021, 137, 188–199. [Google Scholar] [CrossRef] [PubMed]
- Strudel, R.; Garcia, R.; Laptev, I.; Schmid, C. Segmenter: Transformer for semantic segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 7262–7272. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Everingham, M.; Winn, J. The pascal visual object classes challenge 2012 (voc2012) development kit. Pattern Anal. Stat. Model. Comput. Learn. Tech. Rep. 2011, 8, 5. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Liu, J.; He, J.; Zhang, J.; Ren, J.S.; Li, H. Efficientfcn: Holistically-guided decoding for semantic segmentation. In Proceedings of the European Conference on Computer Vision, Glasgow, UK, 23–28 August 2020; pp. 1–17. [Google Scholar]
- Yu, C.; Gao, C.; Wang, J.; Yu, G.; Shen, C.; Sang, N. Bisenet v2: Bilateral network with guided aggregation for real-time semantic segmentation. Int. J. Comput. Vis. 2021, 129, 3051–3068. [Google Scholar] [CrossRef]
- Xie, E.; Wang, W.; Yu, Z.; Anandkumar, A.; Alvarez, J.M.; Luo, P. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 1–13. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | BaseNet | mIoU (%) |
|---|---|---|
| PAM [8] | ResNet101 | 72.80 |
| APAM | ResNet101 | 73.15 |
| CAM + PAM [8] | ResNet101 | 73.39 |
| CAM + APAM | ResNet101 | 73.13 |
| CAM + APAM | ResNet101 | 73.57 |
| Method | BaseNet | Parameters | FLOPs |
|---|---|---|---|
| DANet [8] | ResNet101 | 66.327 (M) | 80.774 (G) |
| NDAM | ResNet101 | 65.294 (M) | 79.738 (G) |
| Method | N | mIoU (%) |
|---|---|---|
| CDIA-FFM | 3, 3, 3 | 75.10 |
| CDIA-FFM | 5, 5, 5 | 75.34 |
| CDIA-FFM | 3, 5, 7 | 75.50 |
| Method | BaseNet | mIoU (%) |
|---|---|---|
| Dilated FCN | ResNet101 | 72.40 |
| DeepLabv3+ [9] | ResNet101 | 75.45 |
| DANet [8] | ResNet101 | 73.39 |
| OCRNet [17] | ResNet101 | 74.69 |
| EfficientFCN [33] | ResNet101 | 73.78 |
| Bisenet v2 [34] | no | 73.88 |
| Ours | ResNet101 | 75.50 |
| Method | BaseNet | mIoU (%) |
|---|---|---|
| Dilated FCN | ResNet101 | 66.61 |
| DeepLabv3+ [9] | ResNet101 | 71.21 |
| DANet [8] | ResNet101 | 69.08 |
| OCRNet [17] | ResNet101 | 68.14 |
| EfficientFCN [33] | ResNet101 | 68.65 |
| Bisenet v2 [34] | no | 68.50 |
| Ours | ResNet101 | 72.80 |
| Method | Backbone | PASCAL VOC 2012 (mIoU%) | Cityscapes (mIoU%) |
|---|---|---|---|
| Segformer | Mit-B2 | 74.9 | 78.1 |
| Ours | ResNet101 | 75.5 | 72.8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, D.; Xiang, S.; Zhou, Y.; Mu, J.; Zhou, H.; Irampaye, R. Multiple-Attention Mechanism Network for Semantic Segmentation. Sensors 2022, 22, 4477. https://doi.org/10.3390/s22124477
Wang D, Xiang S, Zhou Y, Mu J, Zhou H, Irampaye R. Multiple-Attention Mechanism Network for Semantic Segmentation. Sensors. 2022; 22(12):4477. https://doi.org/10.3390/s22124477
Chicago/Turabian StyleWang, Dongli, Shengliang Xiang, Yan Zhou, Jinzhen Mu, Haibin Zhou, and Richard Irampaye. 2022. "Multiple-Attention Mechanism Network for Semantic Segmentation" Sensors 22, no. 12: 4477. https://doi.org/10.3390/s22124477
APA StyleWang, D., Xiang, S., Zhou, Y., Mu, J., Zhou, H., & Irampaye, R. (2022). Multiple-Attention Mechanism Network for Semantic Segmentation. Sensors, 22(12), 4477. https://doi.org/10.3390/s22124477