1. Introduction
This section illustrates the research’s motivation, target and framework, followed by a relevant literature review of the recent research about the fault diagnosis of power transformers. After that, we state the research gap, our contributions and this paper’s organisation.
1.1. Motivation, Target and Framework
Power transformers are important equipment in electrical power systems, and transformer failures will negatively impact whole systems. An early-stage diagnosis of transformer fault type can save the high cost of repairing and downtime. The three-phase grounding currents of the iron core generated during the turning on of transformers are important indexes to assess the states of power transformers. The value of the normal grounding current of the iron core is quite small, while the abnormal grounding current value will increase substantially. The warning threshold for the grounding current of the iron core is 100 mA for the 110 kV power transformers and the faults are caused by Phases A, B, C and ABC to ground fault. This research aims to construct a reliable model that can analyse the fault type after 10 min from fault occurrence based on the abnormal three-phase grounding current data of the iron core, and the model can be quickly transferred to different devices with quick retraining to obtain good performance.
Benefiting from the evolution of machine learning, more and more supervised or unsupervised models have been adopted to pinpoint the linear or nonlinear relationships between electrical features and fault types [
1]. This paper proposes a new fault diagnosis framework based on convolutional neural networks (CNN) [
2,
3,
4], an attention mechanism [
5] and bidirectional long short-term memory networks (BiLSTM) [
6,
7].
Besides that, we compose a new framework of semi-supervised transfer learning called adaptive reinforcement (AR). This technique aims to solve the problem of unbalanced and undefined fault type data in the target power transformer, which negatively affects the transferring process. The first step of AR is pretraining the source model’s classifier and then giving pseudolabels to the unlabelled data by the trained model. After that, we supplement the unbalanced fault data from the source domain based on the probability distribution. To overcome the problem of overfitting the complemented data, we replay the training experience of the main type of fault. Finally, we fine-tune the whole network’s weights with few epochs to fit the target device.
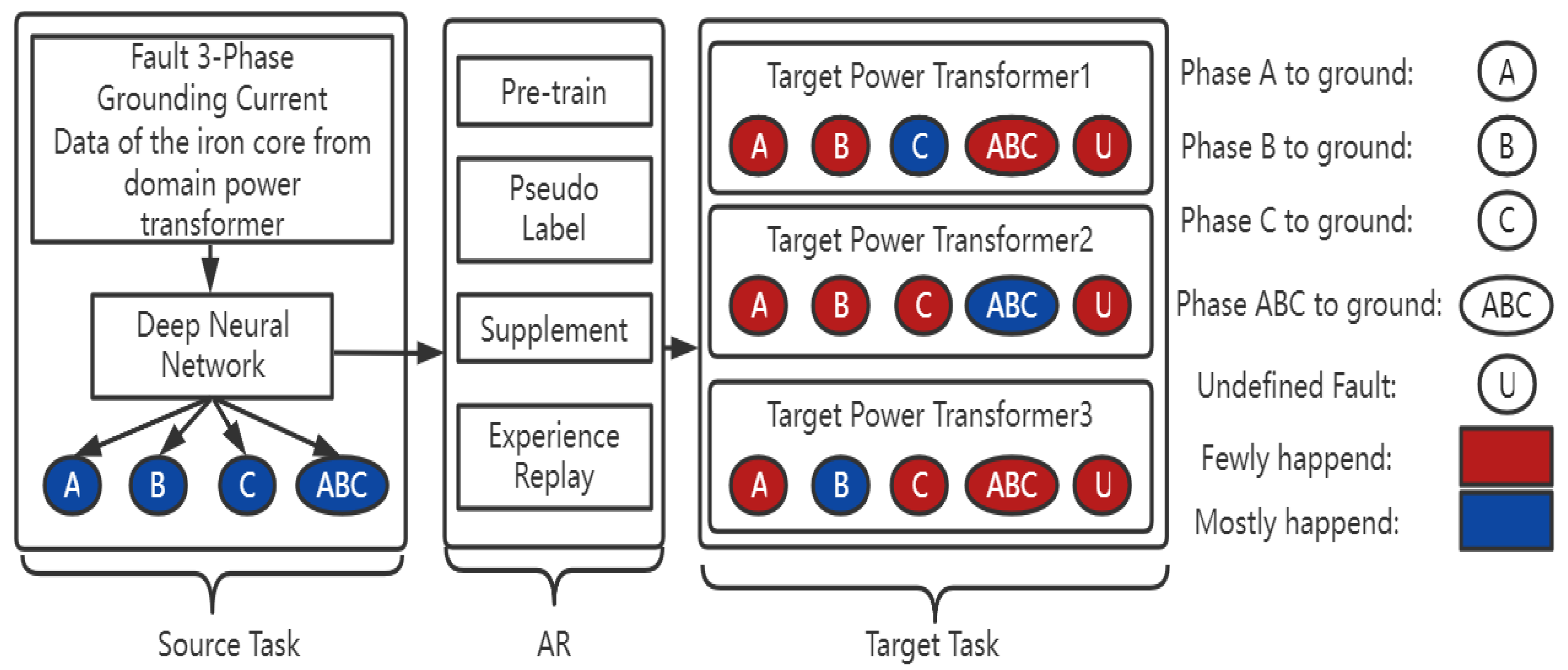
The comprehensive framework of the methodology is shown in
Figure 1. The source domain’s data are the three-phase fault grounding current data of the iron core after the fault happens from one 110 kV main power transformer with the corresponding four types of faults: Faults A, B, C and ABC to ground. In addition, the fault classes are balanced. We train the proposed deep neural network to classify the fault type and then transfer the model to the target domain in the framework of AR. There are three 110 kV target power transformers for the target task, and each of them contains undefined fault data. Moreover, the fault types in the target power transformer are unbalanced. The blue color indicates the fault type which mostly happened in that device, the red color indicates the fault type which rarely happened and U indicates the undefined fault type.
1.2. Literature Review
Research on fault diagnosis and the detection of power transformers focuses on different aspects and methodologies, separately. The frequency response analysis (FRA) technique is one main method to detect transformer tap changer faults. The experiment in [
8] was conducted on a three-phase 50 Hz, 11/0.415 kV, 500 kVA distribution transformer with a de-energized tap changer and simulated the tap changer fault to use FRA measurements to identify various contact faults such as coking and pitting. The work in [
9] was conducted on a three-phase 11/0.433 kV, 500 kVA distribution transformer and calculated the correlation coefficient of the deviation from the fingerprint signature to identify the fault type. The work in [
10] used the correlation between physical circuit parameters and various faults and quantified the impact of each fault with respect to the healthy signatures at different frequency regions. The work in [
11] proposed a deep-learning-based framework named SigdetNet, which takes the power spectrum as the network’s input to localize the spectral locations of the signals. The research in [
12] proposed an intrinsic time-scale decomposition (ITD)-based method for power transformer fault diagnosis based on dissolved gas analysis (DGA) parameters and used an XGBoost classifier to classify the optimal PRC feature set. The work in [
13] proposed an artificial neural network (ANN) to establish the power transformer fault classification based on DGA. The work in [
14] proposed a Hilbert–Huang transform (HHT)-based algorithm to effectively detect malfunctioning by revealing the instantaneous amplitude and frequency of nonlinear and nonstationary signals. The work in [
15] employed the algorithm using principal component analysis (PCA) to easily find the feature of the fast Fourier transform (FFT) signal and utilize
as an index for fault detection. The work in [
16] adopts the nonstationary signal processing techniques: wavelet transform (WT) to the application of industrial equipment and rotating machinery fault diagnosis (RMFD).
A well-trained model being adapted to similar tasks has become a popular technique with the advantages of saving time and having better model performance in the engineering area. Paper [
17] split the transfer learning work fault diagnosis into four categories: feature, GAN (generative adversarial network), example and parameters. The GAN-based transfer method generates fake samples, which is not suitable for our task, so we reviewed the other three types’ work here. Transfer learning for time series classification [
18] adopted a fully convolutional neural network model to pretrain UCR archive datasets. It then transferred the learned features (the networks’ weights) to a second network to be fine-tuned on a target dataset. In this paper, fine-tuning is still the main method while transferring the model. Domain adaption adjusts the weights of the pretrained model by the decision boundary between the source and target domains. Online and Offline Domain Adaptation for Reducing BCI Calibration Effort [
19] proposes an algorithm that originates from the work in [
20] that adapts the weights offline and online for unlabelled target data tasks. Adaptive Consistency Regularization for Semi-Supervised Transfer Learning [
21] proposes adaptive consistency regularization. It adapts the model weights based on the consistency between the source model and data with the target model and data. Transfer Learning Based Fault Diagnosis with Missing Data Due to Multi-Rate Sampling [
22] transfers the pretrained model from the missing sensors’ domain to complete data by completing the corresponding missing weights with random initial values. The work in [
23] imposed a Lautum-information-based regularization that relates the network weights to the target data. The work in [
24] offered a free-distribution-, kernel- and graph-Laplacian-based approach which optimizes empirical risk in the appropriate reproducing kernel Hilbert space. The work in [
25] proposed an expectation-maximization algorithm to solve the transferred model iteratively.
1.3. Research Gap
The literature review explored several novel works on fault diagnosis and transfer learning. FPA-based methods mostly focus on transformer tap changer faults by calculating the correlation coefficients. Deep-learning-based and machine-learning-based frameworks mostly utilize dissolved gas analysis (DGA) to establish fault classification. Transforming methods, including the Hilbert transform, fast Fourier transform and wavelet transform, study the information contained in the frequency to predict the occurrence of the fault. For transfer learning, fine-tuning is still the most popular method. For semi-supervised transfer learning, the novel proposed techniques are mostly based on the ideas of target domain adaption and consistency regularization.
This paper proposes a deep neural network to figure out the fault types of power transformers. The architecture is formed by the FCNN, attention mechanism and BiLSTM. For the semi-supervised transfer learning task, AR enhances the domain adaption step by mixing the dynamic time wrapping algorithm. In addition, the experience replay step reinforces the experience of training the major fault.
1.4. Contribution
Our main contributions can be summarized below:
To the best of our knowledge, we are the first to combine the semi-supervised transfer learning method with the experience replay idea and utilize this method to solve electrical system problems.
We combine fully convolutional neural networks (FCNN) with an attention mechanism followed by bidirectional long short-term memory (BiLSTM) networks as the diagnosis model’s architecture to classify the fault type accurately.
Considering the unbalanced and undefined fault data in the target task, we propose an enhancement on the pseudolabel method based on cross-entropy and dynamic time wrapping algorithms.
1.5. Organization
The rest of the paper is organized as follows:
Section 2 introduces the data and experiment’s setup, and
Section 3 details the architecture of the deep neural network.
Section 4 presents the framework of semi-supervised transfer learning. The evaluations of the experiments are carried out in
Section 5.
Section 6 discusses the results. The conclusion is drawn in
Section 7.
2. Materials and Methods
This section specifies the characteristics of the datasets, exploration methods and preprocessing steps as the setup for the experiments.
2.1. Dataset and Exploration
The datasets we employed for this research were the 3-phase fault grounding currents of the iron core data created by the main 110 kV power transformers owned by State Grid Shanghai Municipal Electric Power Company. We recorded the fault current after it reached the warning threshold, which was 100 mA. The source domain samples were the fault grounding current data of the iron core by one 110 kV main power transformer produced last year with four types of faults: Phase A to ground, Phase B to ground, Phase C to ground and Phase ABC to ground. The target domain samples were three different 110 kV power transformers’ fault data which contained labelled and unlabelled fault types. The value of the normal grounding current of the iron core was below 10 mA, and the abnormal current value increased substantially to about 150 mA. After the fault happened, as the abnormal current value appeared, we waited until the fault data had enough length and then input it into the model to classify the fault type.
2.1.1. Source Domain
The source data were collected from one main power transformer. Three detection devices monitored Phases A, B and C’s grounding currents of the iron cores individually. The detection devices recorded the corresponding grounding current data of the iron core simultaneously every twenty seconds. The maintenance worker found out the fault’s reason and recorded it each time.
We selected the fault data , where the number of time-steps with their corresponding fault types as the source dataset samples. We found that the whole-time length from the beginning of the fault happening until fixing was always more than one hour. In order to have enough training data for a deep neural network, we chose the abnormal phase grounding current data of the iron core from the beginning of faults every 10 min.
Figure 2 shows an example of the 3-phase grounding current data of the iron core. The fault type is Phase A to ground. The blue, orange and green lines indicate Phase A, Phase B and Phase C’s grounding currents of the iron cores individually.
The source domain collected four fault types’ data which are labelled. The next sample was one time-step shift from the last sample until the faults were fixed, where the time interval was twenty seconds. For example, the first sample was
and the next sample was
.
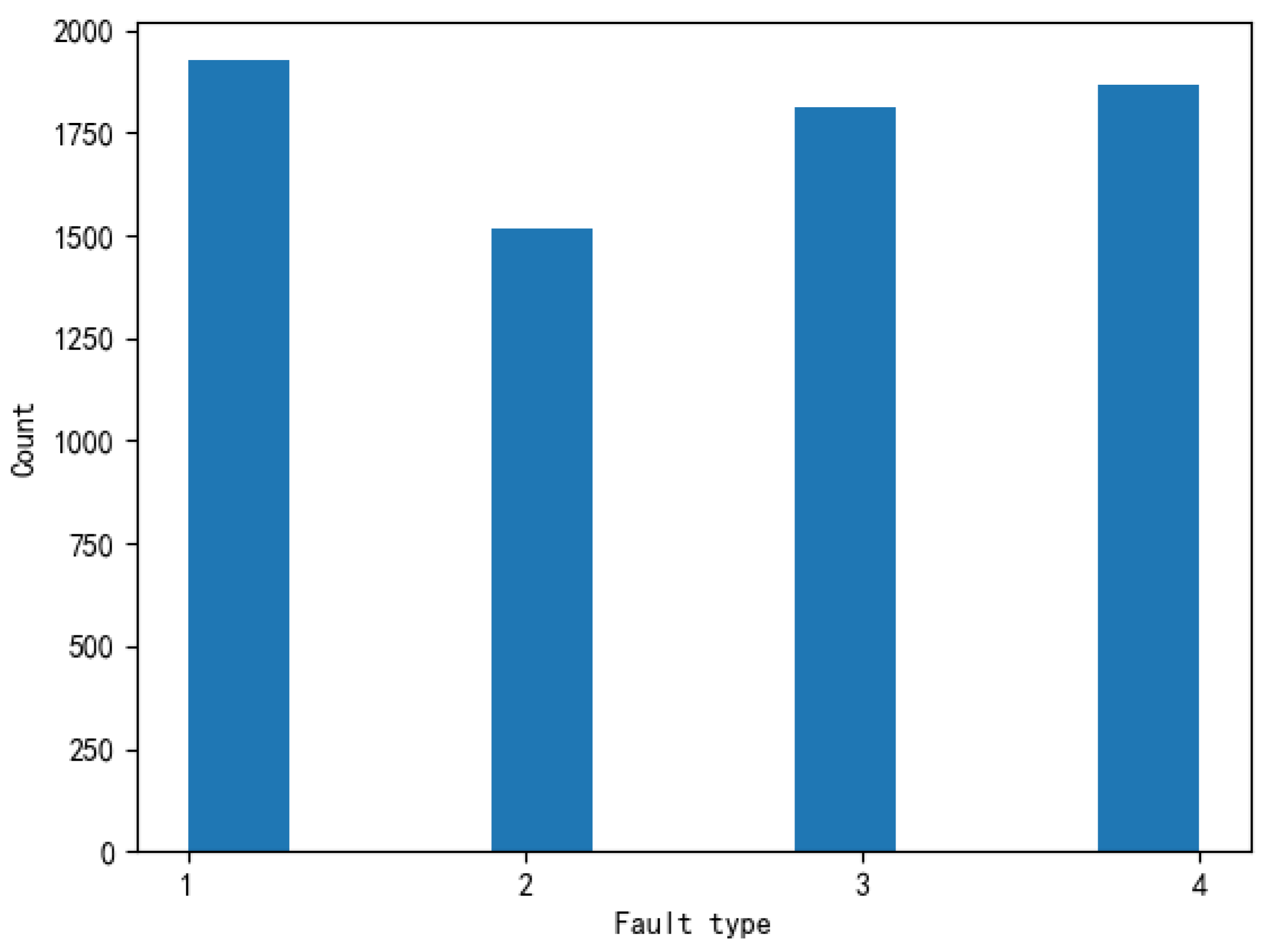
Figure 3 shows the distribution of all fault types in the source domain. The number 1 refers to Phase A to ground fault, 2 refers to Phase B to ground fault, 3 refers to Phase C to ground fault, and 4 refers to Phase ABC to ground fault. There were 1926 Type 1 fault data, 1516 Type 2 fault data, 1813 Type 3 fault data and 1867 Type 4 fault data.
2.1.2. Target Domain
The target domain’s 3-phase fault grounding currents of the iron core data were collected from three 110 kV diverse power transformers. The detecting conditions, the time-steps and the data shape were the same as those of the source domain. The values of the fault data were similar to the source domain’s data.
The difference is that the fault types’ data of the target domain were combined with unlabelled and labelled types’ data. The labelled data were heavily unbalanced as well.
Table 1 shows the distribution of fault type in the target domain of the three 110 kV different power transformers. Types 1, 2, 3 and 4 still refer to the same types as those of the source domain, and a Type 5 fault refers to unlabelled fault data. None means this kind of fault did not happen to this power transformer in the past year. The value means the sample size of each fault’s current data.
2.2. Preprocess
Data cleaning is the first step in data analysis. We pruned and checked the missing data and outliers due to the error of the detection device in the samples.
Three-phase currents are typical time series data. A time series
X =
is an ordered set of real values. The length of
X equals the number of real values
T. A key concept of time series prediction is that the data are expected to be stationary, which means the mean and variance of the data will not be varied too much with the passing of time. To improve the stationarity of the samples, we applied Lag2 differencing (
1) to preprocess the data.
3. Model
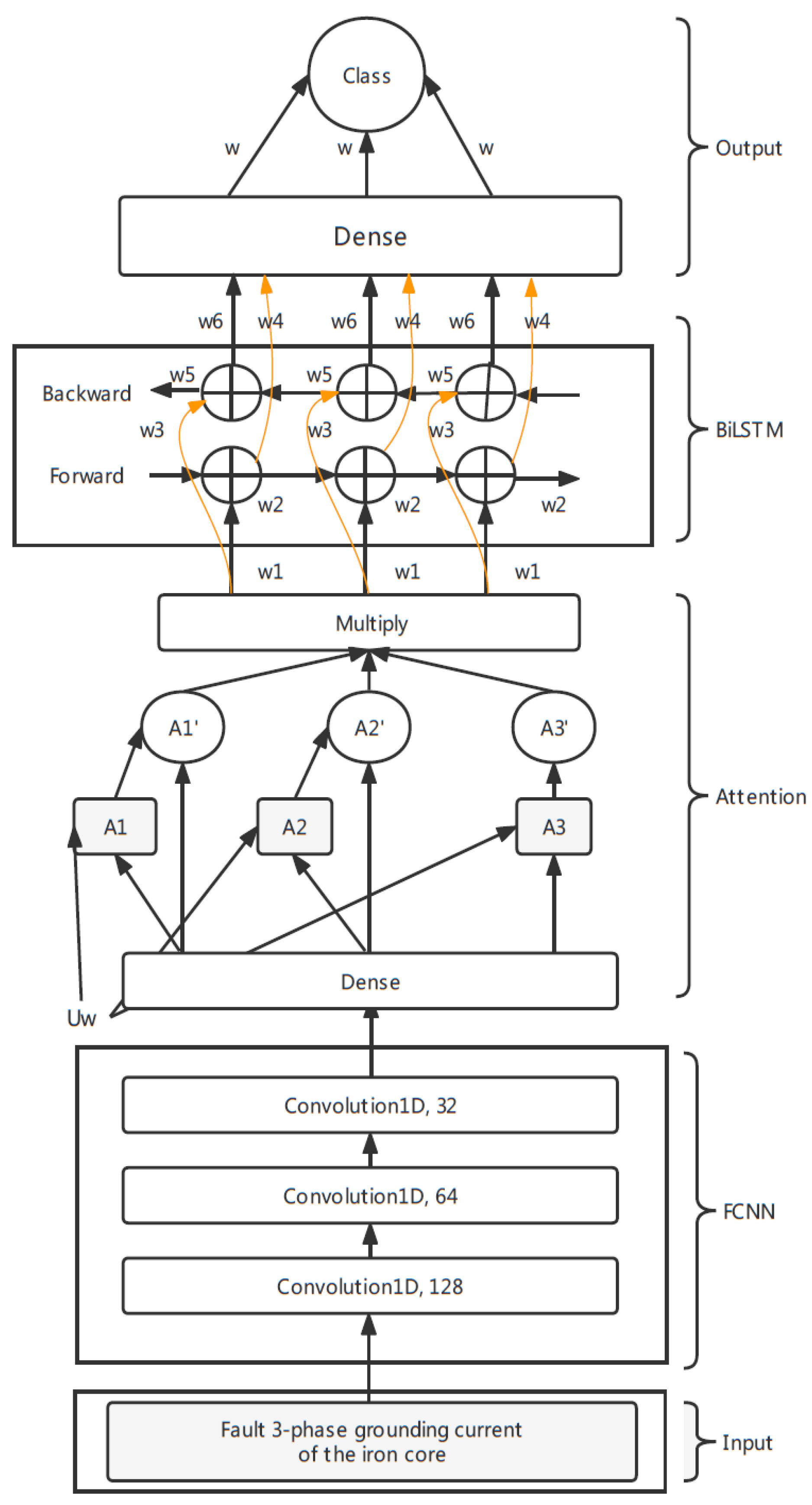
This section details the FCNN–Attention–BiLSTM model of transfer learning for fault classification in power transformers. The architecture of the model can be split into three parts: fully convolutional neural networks (FCNN), an attention mechanism and bidirectional long short-term memory (BiLSTM). The whole framework is shown in
Figure 4. The input of the network is the three-phase grounding current of the iron core series data in the length of time_steps, which is 28 after Lag2 differencing. The network’s output is a probability distribution over the four possible fault classes.
3.1. Fully Convolutional Neural Networks (FCNN)
The first architecture is the one-dimensional fully convolutional neural network for its robustness, as it gains good performance in multiple series tasks to extract the hidden information. The input of the networks is the three-phase fault grounding current of the iron core data in the shape of
. The first, second and third layers are convolutional layers with the rectified linear unit (Relu) [
26] as an activation function for feature selection and each layer is followed by a batch normalization operation and dropout of 0.3. The first convolution is composed of 128 filters of length 1, the second convolution is composed of 64 filters of length 1 and the last convolutional layer is composed of 32 filters of length 1. The strides of the three convolutional layers are all equal to 1. The output of each convolutional layer is a multivariate time series in the shape of
and will be normalized in the batch normalization layer and regularized in the dropout layer.
3.2. Attention Mechanism
The following is an attention mechanism [
5]. The location of the attention is also important, as the different location of the attention captures different essential messages. The popular way is putting the attention layer after BiLSTM [
7]. This paper adopts the method of transformed attention and sets the location of attention before BiLSTM but after FCNN to firstly extract feature importance.
The first layer of attention is a dense layer with the activation functions of softmax (
2). The dense layer’s input multiplies the dense output to complete the distribution of the weights. Because the input shape into the dense layer is (
,
), where input_dimension is the number of units of the last layer of convolution, we then permute the shape into (input_dimension, time_steps), which is reasonable for computing the weights of each feature.
The feature at one time point is multi_dimensional, and the multiple features change with time, so the computed weight vector is multi_dimensional. This paper averages the weight vector to compute the attention score
after softmax is activated (
3), where
A is a matrix consisting of output vectors
such that the FCNN layer is produced and
N is the input_dimension.
The last step is repermuting the weight vector-matrix back into a (time_steps, input_dimension) shape and then multiplying the input (
4). We add a dropout layer of 0.3 as well.
3.3. Bidirectional Long Short-Term Memory (BiLSTM)
The next layer is bidirectional long short-term memory (BiLSTM) [
6], which is composed of two LSTM networks and can capture the information of the series from back to front. The LSTM neural network is formed by the input data
, cell state
, temporary cell state
, hidden state
, forget gate
, memory gate
and output gate
at time
T. The computation process transfers the useful information from the cell state, drops the useless information and outputs the hidden state at each timestamp. The drop, memory and output are controlled by the last timestamp’s hidden state
, with the current forget gate, memory gate and output gate computed by the current input information
.
The joint of the forward LSTM outputs
and backward LSTM outputs
is the hidden state vector of BiLSTM. We set 512 neurons in this layer, which contains the information from front to back and from back to front. After that, we add a dropout layer of 0.3 to connect the final dense layer, whose activation is the softmax function (
2).
The output of the model is a probability distribution of the four fault types generated by the dense layer. The fault is classified according to the highest probability.
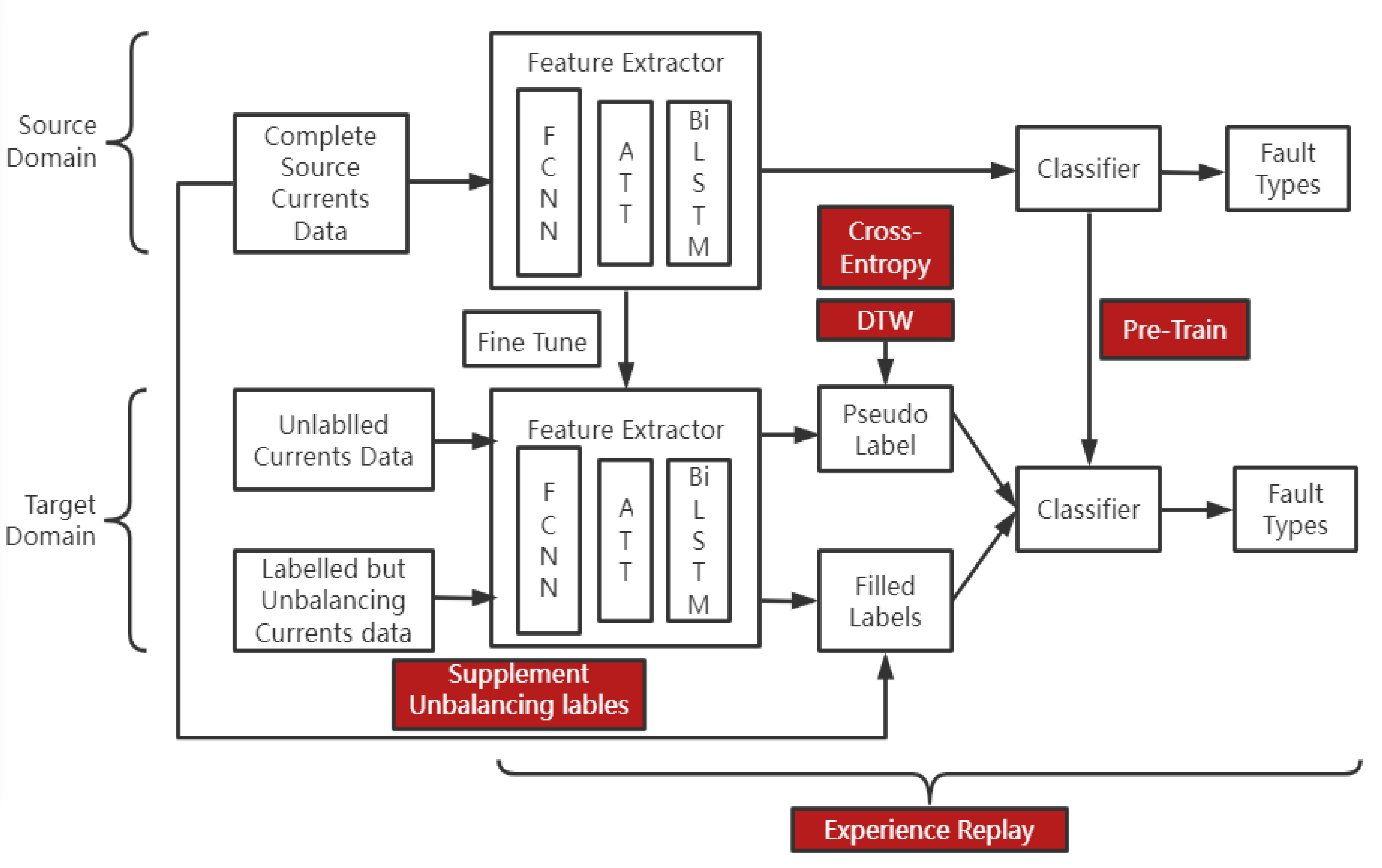
4. Semi-Supervised Transfer Learning
The whole framework of semi-supervised transfer learning, which we call adaptive reinforcement (AR), is shown in
Figure 5 below. The source domain and target domain are detailed in
Section 2. We split the architecture of the deep neural network into two parts: a feature extractor function
and a classifier function
.
is composed of the architecture as illustrated in
Section 3, and we denote its weights in the pretrained model from the source domain as
.
is the fully connected layer with respect to the fault types and we denote its weight in the pretrained model as
. The target dataset comprises labelled examples
, where
l indicates labelled and unlabelled examples
, where
u indicates unlabelled.
4.1. Pretrain
The first step of semi-supervised training is pretraining the target model. The feature extractor’s weights of the target model are initialized with , the same as in the source domain’s model. We fine-tune their parameters in the later training process.
For the classifier’s weights of the target model, which we denote as , we initialize them with random values for the weight columns and 0 for the bias column. Then, we fit the target model on the labelled examples with the Adam optimizer, whose learning rate is , and categorical-cross-entropy loss. We average the parameters of the last layer as the initial . For example, the No. 1 power transformer has 1328 labelled data over 1840 samples. We fit the model whose weights are composed of and randomly initialize with labelled samples ( training dataset, test dataset). Therefore, we obtain 1062 s and average the corresponding weight columns to obtain and recompose it with as the target model.
4.2. Pseudolabel
Compared to other pseudolabelling methods [
21,
27], we design an algorithm to mark the labels based on cross-entropy and dynamic time warping (
) [
28]. Cross-entropy is the distance between two probability distributions. If the distance is smaller, the two probability distributions are more similar. The
algorithm measures the distance between two series, and a smaller distance indicates higher similarity.
The source model’s output, composed of
and
, is a probability distribution
, where x is the sample current’s data.
is a one-dimensional vector with a length equal to the fault type number. For the the unlabelled sample data in the target domain, we compute each probability distribution
. Then, we calculate the cross-entropy (
5) between
with
.
C is the classification number, which is 4 in our task. is the source model’s probability distribution of each unlabelled sample data. is the probability distribution of the fault type, for example, (1,0,0,0) for the Type 1 fault. We compute the cross-entropy values between each with the four s. The lowest cross-entropy value over four results assigns the corresponding fault type to the unlabelled sample as the pseudolabel.
During the experiment, we found the cross-entropy values with different fault types were very close for a few unlabelled samples. For example, one unlabelled sample’s cross-entropy values with fault Type 2 and fault Type 3 are 0.34 and 0.35, separately. It would be unscientific to assign this sample to one type directly. We set an
, which equals 0.2 if the difference between two cross-entropy values is less than
(
6), and we use
(
7) to calculate the distance between the unlabelled samples with the confusing types of samples to determine the pseudolabel.
The principle of the algorithm is that for two series Q and C with lengths n and m, we construct a matrix of matrix where matrix (i,j) is the distance of and , which is the Euclidean distance: . We calculate the distance between the unlabelled sample with all the confusing types of samples from the source domain and average the distances. The lowest distance, called the warping path , assigns the unlabelled sample to the corresponding fault type.
4.3. Supplement Unbalancing Dataset
After pretraining and assigning the pseudolabels, we obtain a target model composed of
and
and a target dataset
, the size of which was
. To make the distributions of the source and the target domain similar so that the model fit better, we supplement the target dataset with the weak types’ fault data from the source domain based on the probability distribution of the number of the fault types, as shown in (
8).
is the number of supplement samples to weak types’ samples, and is the number of weak types’ samples in the target dataset. is the probability of the most common fault happening in the target power transformer, and is the probability of the weak type’s sample in the target domain.
4.4. Experience Replay
The complete target dataset becomes
.
, the samples of the main fault type in each power transformer, are the most important. The mass occurrence of that type of fault over last year means this fault is more likely to happen. For a specific power transformer, we should consider the different conditions and adapt the weights more inclined to predict the main fault of that one. For this reason, we employ the idea of experience replay, which is used in the reinforcement learning model DQN [
29].
For each batch during the training process, we denote the initial target model as
Q, the sample of the most common fault as
and the trained target model after the end of the training of each batch as
. We record the output vector in one dimension of the main fault’s sample as
. Before moving on to the next batch, we replay the training process (
9) as below.
We obtain a new output vector using the trained model Q for the specific sample during the replay process. We multiply the max value of the new output vector, which is the probability of predicting the most common fault, with a gamma which we set as 0.01. Then, we add the multiplication value to the raw vector’s corresponding fault probability as the new output vector for that sample and retrain the model on it.
5. Experimental Evaluation
This presents the results of the training processes on the source target and transfer learning results of the three target power transformers.
5.1. Model Training on the Source Domain
The source domain contains 7122 samples, which we shuffled randomly and split into training and validation sets. The model’s training process sets the batch sizes equal to 8 and 40 epochs with a loss function of categorical cross-entropy, Adam optimizer and accuracy metrics. The learning rate is changed during the training process since we found that the loss of train and validation datasets fluctuated after dozens of iterations. Therefore, we set the learning rate to be for the first ten epochs, for the following ten epochs, for the next ten and for the final ten epochs.
The training history of the validation dataset is shown in
Figure 6. We compare the proposed model architecture with three other models: FCNN–Attention, FCNN and FCNN–BiLSTM–Attention. The conditions of the training were all the same. We trained each model five times for fair conditions and picked the best one of them as the final model. The FCNN–Attention–BiLSTM mechanism outperformed the other three, ending with over
validation accuracy and about 0.1 validation loss.
For more
, we also calculated the
(
10),
(
11),
(
12) and
(
13) between the prediction values and true validation data.
,
,
and
stand for true positive, true negative, false positive and false negative, respectively. The evaluation results are shown in
Table 2.
5.2. Transfer Learning
We compare the proposed AR framework with the following state-of-the-art semi-supervised transfer learning methods. For a fair comparison, the learning process had the same framework of the learning rate as because we did not want to suddenly change the weights of the model layers by a significant factor that may adversely affect the model performance, loss function, epochs and metrics.
Fine-tuning [
18]: This is the pure supervised manner where unlabelled samples are deleted.
Pseudolabel [
27]: It assigns the unlabelled samples by the model trained from the source domain.
Freeze [
30]: This lets the feature extractor layers freeze and their parameters are untrainable during transfer learning. The unlabelled samples are ignored as well as fine-tuning.
ACR [
21]: It contains the techniques of adaptive knowledge consistency by the entropy-gate algorithm and adaptive representation consistency by the maximum mean discrepancies (MMD) algorithm to regularize the weights.
EM [
25]: The expectation maximization algorithm (EM) contains E and M steps. The posterior distribution is calculated in the E step by Bayes’s theorem. In the M step, the mixture distribution and the convolutional neural network parameters are updated.
LR [
23]: It calculates the cross-entropy test loss and decomposes to several derivations, leading to a new regularization term called Lautum regularization (LR).
We also compare AR with and without the experience replay step as well. The aim of this research is trying to find the fastest and most steady transfer learning method. For this reason, we do not compare the final accuracy of each algorithm but the shortest time to achieve over
accuracy over three successive epochs on each target domain. The results of the acquired epochs for each transfer learning method is shown in
Table 3. AR reached
accuracy with the least time consumption from retraining. In addition, the experience replay step accelerated the fitting process from the result.
The unlabelled data were given labels by the five semi-supervised transfer learning methods: pseudolabel, ACR, EM, LR and AR. We checked the target domain’s sample distribution after processing as shown in
Table 4. Even after fitting the labels, the fault types were still unbalanced for the pseudolabel and ACR methods.
We predicted each raw target dataset without unlabelled samples to ensure that our model correctly predicted the raw dataset rather than overfitting. Then, we checked the accuracy, recall, precision and F1 score. The evaluation results are shown in
Table 5. The accuracy is a little below the raw performance, but the difference is not big and can be affordable.
6. Discussion
The experiment was conducted on two tasks: the source task and the target task. The source task contained enough three-phase fault grounding currents of the iron core and balanced class type from one main 110 kV power transformer. The target task contained three 110 kV power transformers’ three-phase fault grounding currents of the iron core, while the target classes were unbalanced and contained undefined fault types. The three-phase grounding current of the iron core, Phase A, Phase B and Phase C, were recorded by three detection devices at the same time every twenty seconds. There were 7122 samples in the source domain and we preprocessed each one with the Lag2 difference method. We trained the proposed network on the source task in the framework of FCNN–Attention–BiLSTM and compared its performance with three other deep neural network frameworks: FCNN–Attention, FCNN–BiLSTM–Att and FCNN. For each model, we trained five times under the same conditions and recorded the best one. We visualized their training histories of them in
Figure 6 and found out that our proposed model reached over
accuracy, which outperformed others. The model achieved
accuracy after four epochs but vibrates little. Its accuracy stabilized above
accuracy after 35 epochs and every epoch’s validation accuracy beat the other three models by more than 1–2% accuracy. For further comparison, we calculated the accuracy, recall, precision and F1 score of each model. The highest one was FCNN–Attention–BiLSTM, with about
accuracy, and the second one was the FCNN–Attention framework, with approximately
accuracy.
After we trained the model on the source task, we transferred it to the three target tasks. We compared our proposed semi-supervised transfer learning framework, AR, with six other state-of-the-art semi-supervised transfer learning methods: fine-tuning, pseudolabel, freeze, ACR, EM and LR. We also compared AR without the step of experience replay as well. The evaluation metrics were the fitting speeds of these frameworks. The quickest one was the AR framework, which just needed 9–10 epochs to stabilize over accuracy at each target task, while the second one was the EM algorithm, which needed about 15 epochs. We also checked the new distribution of the fault type in each target task by the generating label methods: pseudolabel, ACR, EM, LR and AR. AR supplemented all the lacking type’s data so it required more time to train each epoch, though the time consumption of fitting was still the lowest. When the model stabilized over accuracy, we stopped training and predicted the validation set’s classes with the raw dataset without the supplement samples. The accuracy for the three power transformers was about separately. Though it is a little lower than the accuracy on the training dataset, the difference is less than , which is affordable.
The aim of this investigation is classifying fault type after fault occurrence based on the three-phase grounding current of the iron core. The work focuses on quick semi-supervised transfer learning. For further research, we will try to predict fault preoccurrence with the dissolved gas data. The methodology can be improved with signal processing techniques, the frequency response analysis technique and loss optimization algorithms.
7. Conclusions
This research focuses on the task of classifying the fault types, Phases A, B, C and ABC to ground fault, based on the three-phase fault grounding current of the iron cores from 110 kV power transformers. The values of the data were recorded every twenty seconds and increased substantially after the fault occurred. After the abnormal current appeared and exceeded the warning threshold, which was 100 mA, we collected the sample of the fault current in the length of 30 and preprocessed it with the Lag2 difference method.
This paper proposes an FCNN–Attention–BiLSTM model to classify fault type based on fault data. This architecture achieves over accuracy. Apart from this, a semi-supervised transfer learning method called AR is illustrated to transfer the trained model to diverse power transformers. AR includes four steps: pretraining the classifier layer, generating a pseudolabel by and cross-entropy algorithms, supplementing unbalanced data by the probability distribution of the fault classes and relaying the training experience of the most-occurring fault. AR reduces the epochs required dramatically to achieve a high accuracy score in our target task.
For real-time diagnosis, while the current value exceeds the warning threshold, which is 100 mA, the system waits until enough data in the length of 30 (10 min from when the fault happens) are generated. The model inputs the preprocessed fault data and returns the probability distribution of the four types of faults. If the largest probability is higher than the confidence level, which we set as 0.7, the system will deliver the corresponding fault type message to the maintenance worker. On the other hand, if the four probabilities are close, the system will wait another twenty seconds until the next detection data are generated and then replicate the above steps.
Author Contributions
Conceptualization, W.M. and B.W.; methodology, X.X. and L.C.; software, T.W. and Z.P.; validation, C.R.; formal analysis, W.M., B.W. and X.X.; investigation, W.M. and L.C.; writing—original draft preparation, Z.P. and C.R.; writing—review and editing, B.W., C.R., X.X. and W.M.; visualization, T.W. and Z.P.; supervision, W.M.; project administration, W.M. All authors have read and agreed to the published version of the manuscript.
Funding
This research was supported in part by China’s State Grid Shanghai Electric Power Company under Grant 520940200067.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Not applicable.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Massaoudi, M.; Abu-Rub, H.; Refaat, S.S.; Chihi, I.; Oueslati, F.S. Deep learning in smart grid technology: A review of recent advancements and future prospects. IEEE Access 2021, 9, 54558–54578. [Google Scholar] [CrossRef]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a convolutional neural network. In Proceedings of the 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017; pp. 1–6. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Zou, G.; Liu, H.; Ren, K.; Deng, B.; Xue, J. Automatic Recognition of Faults in Mining Areas Based on Convolutional Neural Network. Energies 2022, 15, 3758. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.u.; Polosukhin, I. Attention is all you need. In Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30, Available online: https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf (accessed on 6 December 2017).
- Xu, G.; Meng, Y.; Qiu, X.; Yu, Z.; Wu, X. Sentiment analysis of comment texts based on bilstm. IEEE Access 2019, 7, 51522–51532. [Google Scholar] [CrossRef]
- Guan, R.; Wang, A.; Liang, Y.; Fu, J.; Han, X. International Natural Gas Price Trends Prediction with Historical Prices and Related News. Energies 2022, 15, 3573. [Google Scholar] [CrossRef]
- Al-Ameri, S.M.; Almutairi, A.; Kamarudin, M.S.; Yousof, M.F.M.; Abu-Siada, A.; Mosaad, M.I.; Alyami, S. Application of Frequency Response Analysis Technique to Detect Transformer Tap Changer Faults. Appl. Sci. 2021, 11, 3128. [Google Scholar] [CrossRef]
- Al-Ameri, S.M.; Kamarudin, M.S.; Yousof, M.F.M.; Salem, A.A.; Siada, A.A.; Mosaad, M.I. Interpretation of Frequency Response Analysis for Fault Detection in Power Transformers. Appl. Sci. 2021, 11, 2923. [Google Scholar] [CrossRef]
- Al-Ameri, S.M.A.N.; Kamarudin, M.S.; Yousof, M.F.M.; Salem, A.A.; Banakhr, F.A.; Mosaad, M.I.; Abu-Siada, A. Understanding the Influence of Power Transformer Faults on the Frequency Response Signature Using Simulation Analysis and Statistical Indicators. IEEE Access 2021, 9, 70935–70947. [Google Scholar] [CrossRef]
- Lin, M.; Zhang, X.; Tian, Y.; Huang, Y. Multi-Signal Detection Framework: A Deep Learning Based Carrier Frequency and Bandwidth Estimation. Sensors 2022, 22, 3909. [Google Scholar] [CrossRef] [PubMed]
- Sami, S.M.; Bhuiyan, M.I.H. Power Transformer Fault Diagnosis with Intrinsic Time-Scale Decomposition and XGBoost Classifier. In Proceedings of the International Conference on Big Data, IoT, and Machine Learning, Sydney, Australia; Cox’s Bazar, Bangladesh, 23–25 September 2021; Volume 95. [Google Scholar]
- Seifeddine, S.; Khmais, B.; Abdelkader, C. Power transformer fault diagnosis based on dissolved gas analysis by artificial neural network. In Proceedings of the 2012 First International Conference on Renewable Energies and Vehicular Technology, Nabeul, Tunisia, 26–28 March 2012; pp. 230–236. [Google Scholar] [CrossRef]
- German-Sallo, Z.; Grif, H.S. Hilbert-Huang Transform in Fault Detection. Procedia Manuf. 2019, 32, 591–595. [Google Scholar] [CrossRef]
- Yoo, Y.J. Fault Detection of Induction Motor Using Fast Fourier Transform with Feature Selection via Principal Component Analysis. Int. J. Precis. Eng. Manuf. 2019, 20, 1543–1552. [Google Scholar] [CrossRef]
- Chen, J.; Li, Z.; Pan, J.; Chen, G.; Zi, Y.; Yuan, J.; Chen, B.; He, Z. Wavelet transform based on inner product in fault diagnosis of rotating machinery: A review. Mech. Syst. Signal Process. 2016, 70–71, 1–5. [Google Scholar] [CrossRef]
- Lei, Y.; Yang, B.; Jiang, X.; Jia, F.; Li, N.; Nandi, A.K. Applications of machine learning to machine fault diagnosis: A review and roadmap. Mech. Syst. Signal Process. 2020, 138, 106587. [Google Scholar] [CrossRef]
- Fawaz, H.I.; Forestier, G.; Weber, J.; Idoumghar, L.; Muller, P.-A. Transfer learning for time series classification. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018. [Google Scholar] [CrossRef] [Green Version]
- Wu, D. Online and offline domain adaptation for reducing bci calibration effort. IEEE Trans. Hum. Mach. Syst. 2016, 47, 550–563. [Google Scholar] [CrossRef] [Green Version]
- Long, M.; Wang, J.; Ding, G.; Pan, S.J.; Philip, S.Y. Adaptation regularization: A general framework for transfer learning. IEEE Trans. Knowl. Data Eng. 2014, 26, 1076–1089. [Google Scholar] [CrossRef]
- Abuduweili, A.; Li, X.; Shi, H.; Xu, C.-Z.; Dou, D. Adaptive consistency regularization for semi-supervised transfer learning. arXiv 2021, arXiv:2103.02193. [Google Scholar]
- Chen, D.; Yang, S.; Zhou, F. Transfer learning based fault diagnosis with missing data due to multi-rate sampling. Sensors 2019, 19, 1826. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Jakubovitz, D.; Rodrigues, M.R.; Giryes, R. Lautum Regularization for Semi-Supervised Transfer Learning. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 763–767. [Google Scholar] [CrossRef] [Green Version]
- Deshmukh, A.A.; Laftchiev, E. Semi-Supervised Transfer Learning Using Marginal Predictors. In Proceedings of the 2018 IEEE Data Science Workshop (DSW), Lausanne, Switzerland, 2–6 June 2018. [Google Scholar] [CrossRef]
- Wei, W.; Meng, D.; Zhao, Q.; Xu, Z.; Wu, Y. Semi-Supervised Transfer Learning for Image Rain Removal. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3872–3881. [Google Scholar] [CrossRef] [Green Version]
- Agarap, A.F. Deep learning using rectified linear units (relu). arXiv 2018, arXiv:1803.08375. [Google Scholar]
- Ghamdi, M.A.; Li, M.; Abdel-Mottaleb, M.; Shousha, M.A. Semi-supervised Transfer Learning for Convolutional Neural Networks for Glaucoma Detection. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 3812–3816. [Google Scholar] [CrossRef]
- Giorgino, T. Computing and visualizing dynamic time warping align- ments in R: The dtw package. J. Stat. Softw. 2009, 31, 1–24. [Google Scholar] [CrossRef] [Green Version]
- Zuo, G.; Du, T.; Lu, J. Double DQN method for object detection. In Proceedings of the 2017 Chinese Automation Congress (CAC), Jinan, China, 20–22 October 2017; pp. 6727–6732. [Google Scholar] [CrossRef]
- Hu, R.; Wang, T.; Zhou, Y.; Snoussi, H.; Cherouat, A. FT-MDnet: A Deep-Frozen Transfer Learning Framework for Person Search. IEEE Trans. Inf. Forensics Secur. 2021, 16, 4721–4732. [Google Scholar] [CrossRef]
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).


 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}