
A Vehicle Trajectory Privacy Preservation Method Based on Caching and Dummy Locations in the Internet of Vehicles



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
- The problem of vehicle trajectory privacy preservation in IoVs is studied. And a vehicle trajectory privacy preservation method based on caching and dummy locations is proposed. When a vehicle user requests the continuous LBS, the location privacy preservation method based on dummy locations is used to protect the vehicle location. And the caching deployed at the RSU with active and passive cache update mechanisms is utilized to protect the vehicle trajectory. Compared with the exiting dummy location-based methods [9,10], our proposed method deploys the caching at RSU so that both the RSU and LBS server cannot obtain all the data since a single RSU can only cover a part of the area. Moreover, the proposed method still applies dummy locations to protect trajectory privacy within a single RSU region. Hence, our proposed method can preserve trajectory privacy under LSA and LCA.
- Compared with the caching-based trajectory privacy preservation methods relying on users’ collaborative caching [27,28], this paper addresses the cache update mechanisms based on data popularity and dummy locations to protect location privacy, as well as improving the cache hit rate. In the initialized and periodic cache update phases, RSUs cache the hotspot data pushed by the LBS server. In the service-providing phase, RSUs cache the requested data sent by the LBS server. However, for the collaborative caching mechanism in [27,28], the validity of the cache cannot be guaranteed due to the high mobility of vehicles; the communication among users increases the risk of privacy exposure.
- The performance of the proposed vehicle trajectory privacy preservation method, in terms of security, computation overhead, communication overhead, and storage overhead at the RSUs, is analyzed. Furthermore, extensive simulations are conducted to evaluate the performance of the proposed method. The results show that the proposed method achieves a lower trajectory privacy disclosure probability and a higher cache hit rate.
2. Related Work
3. Preliminaries and Problem Formulation
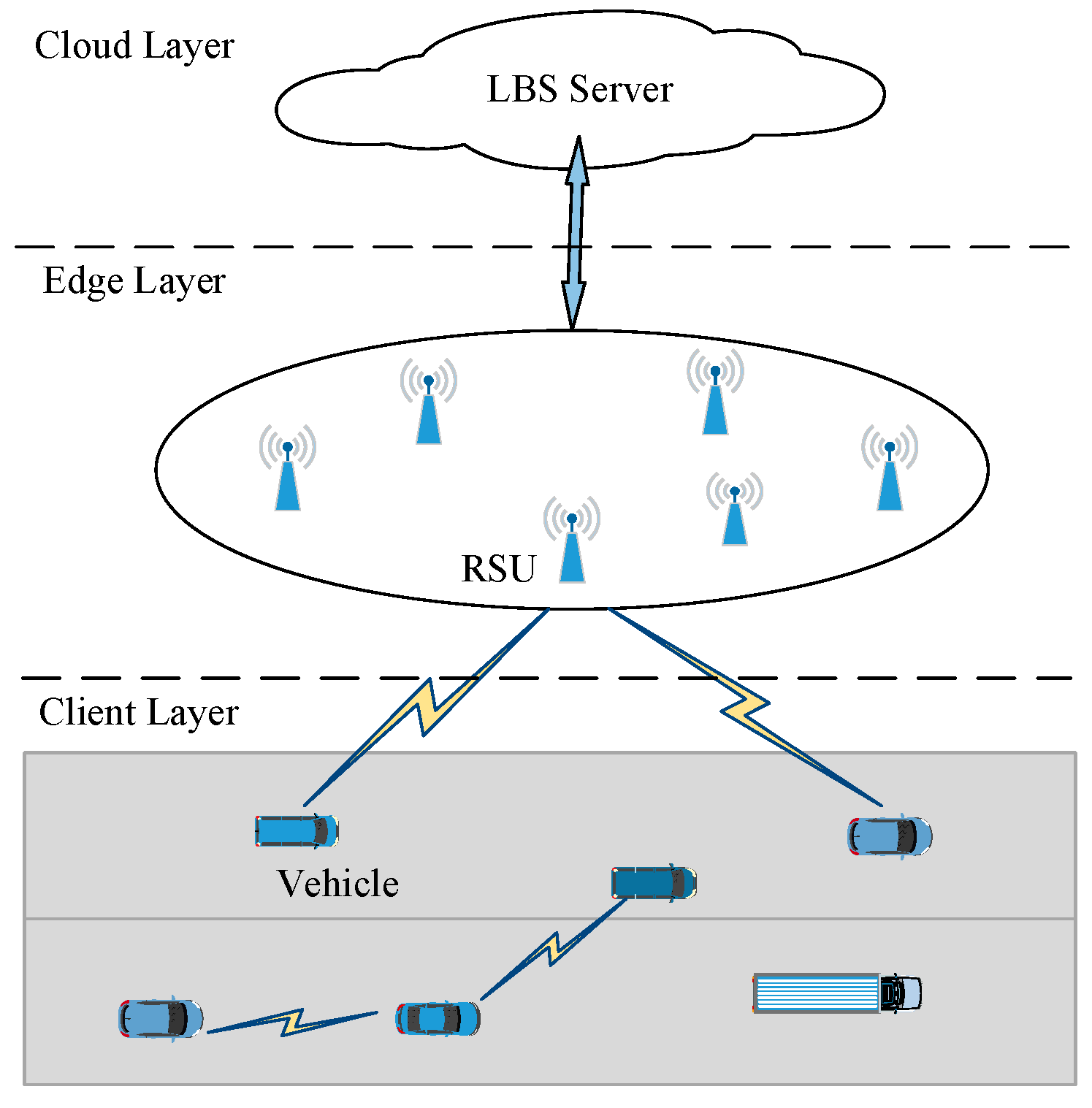
3.1. System Model
3.2. LBS Query
3.3. Service Semantics
3.4. Adversary Model
3.5. Problem Statement
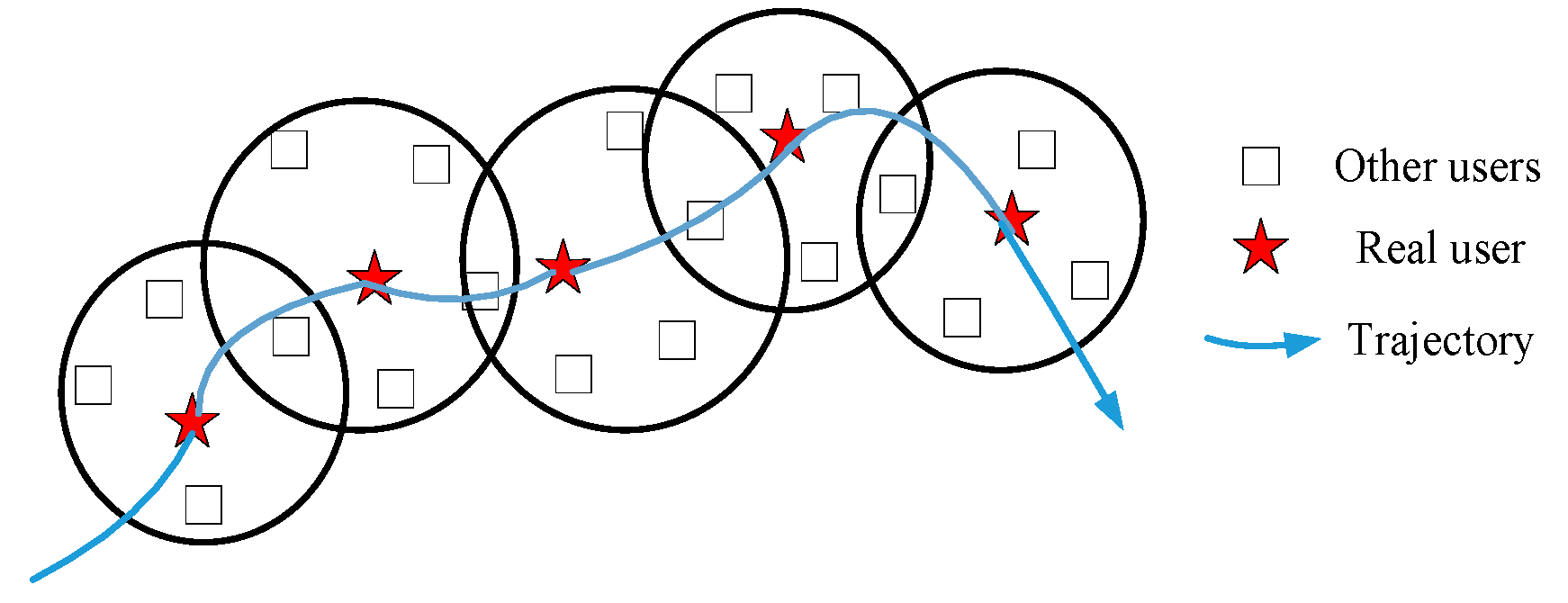
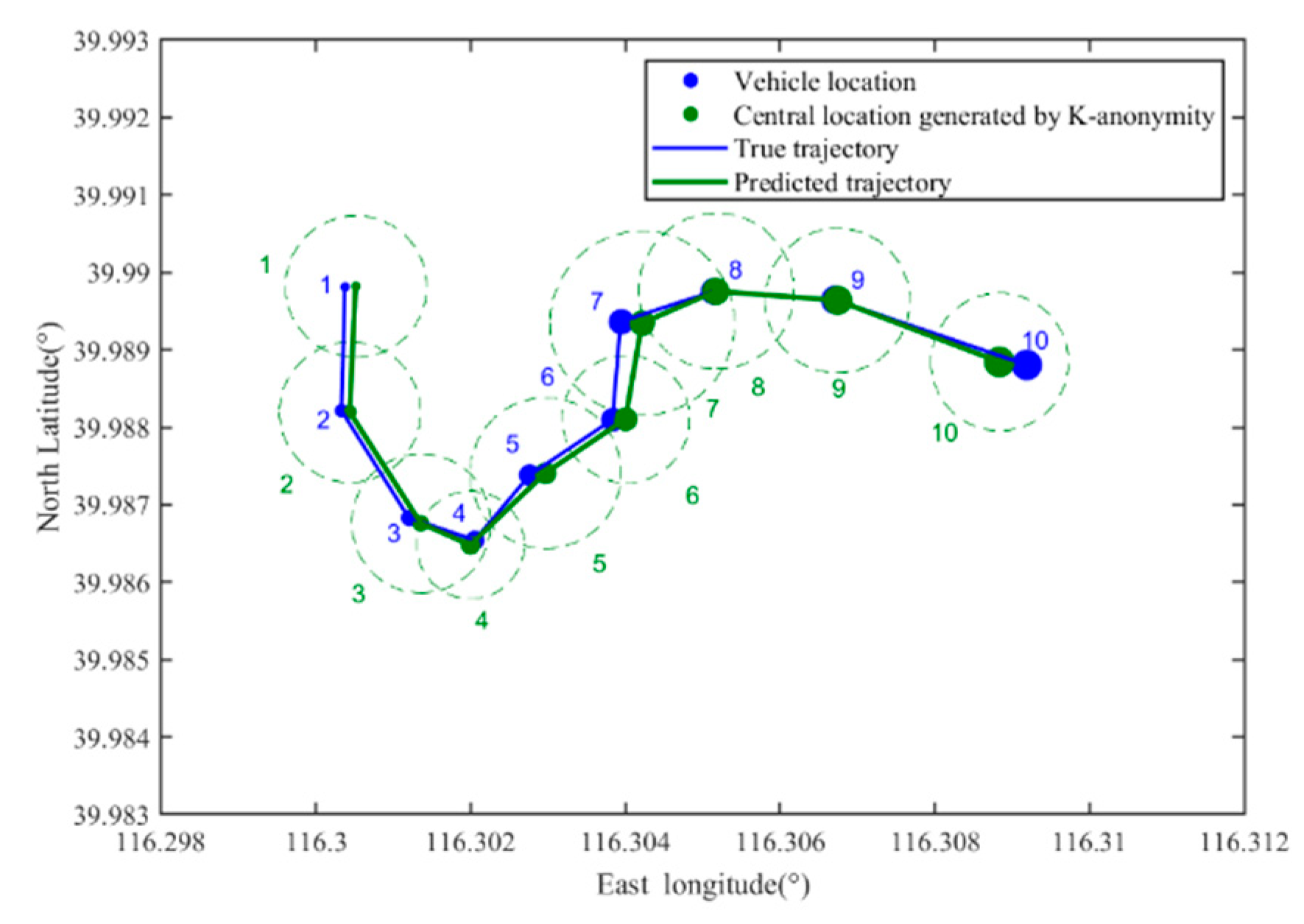
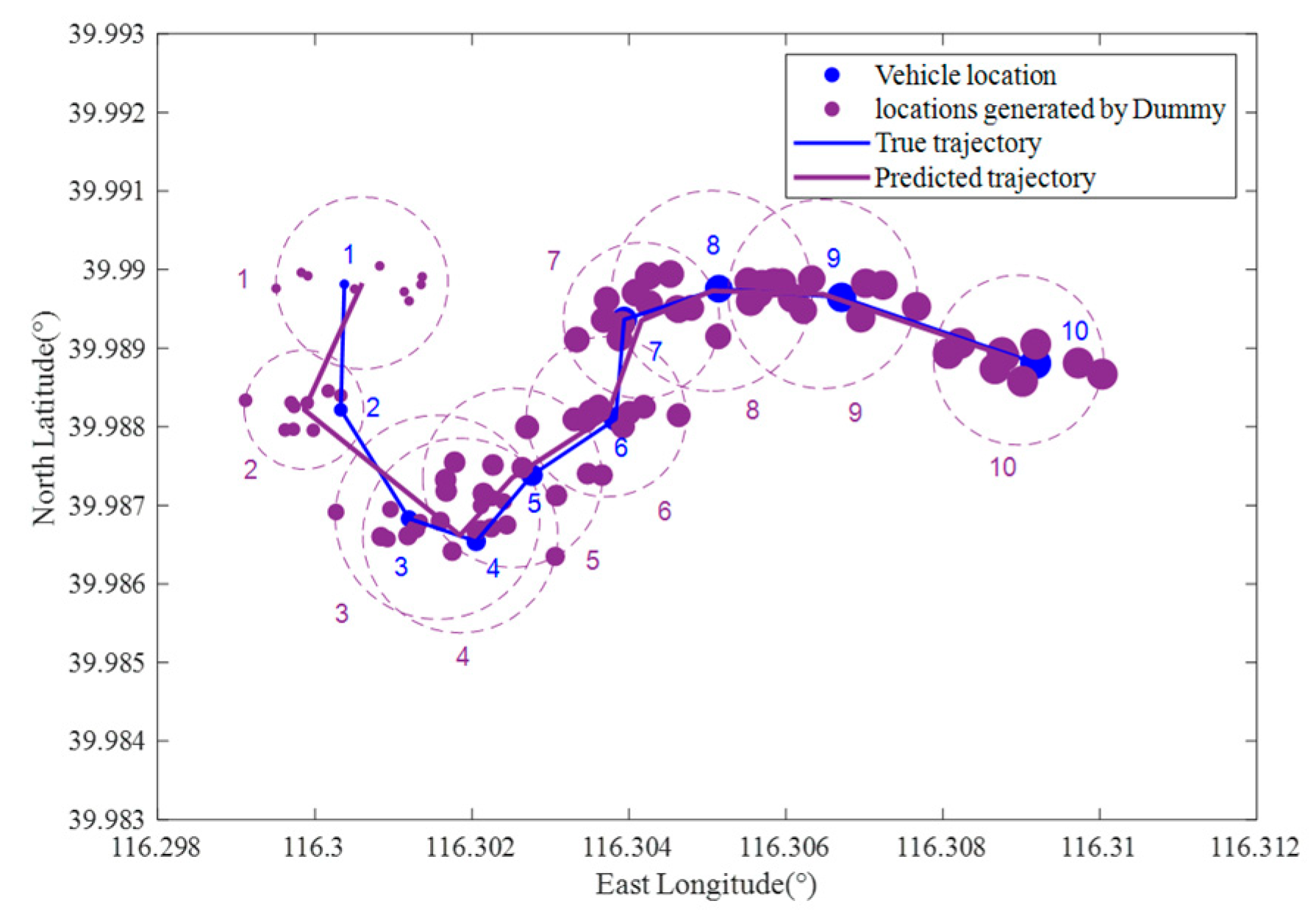
3.5.1. Long-Term Statistical Attack (LSA)
3.5.2. Location Correlation Attack (LCA)
4. Proposed Trajectory Privacy Preservation Method Based on Caching and Dummy Locations
4.1. Parameter Setting
4.2. Cache Initialization Mechanism
4.3. Dummy Locations Generation Algorithm
4.4. Cache and Information Matrix Update Mechanism
4.5. LBS Query Response Mechanism
4.6. Overall Procedure of TPPCD
- (1)
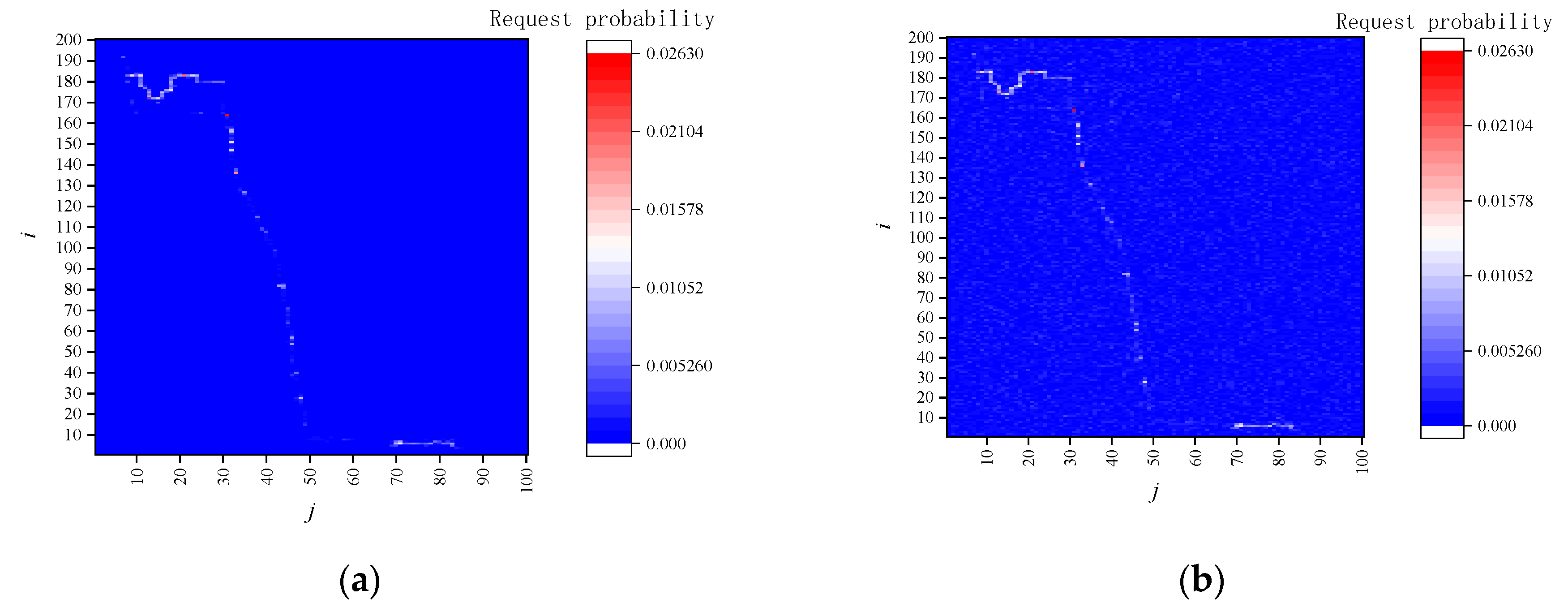
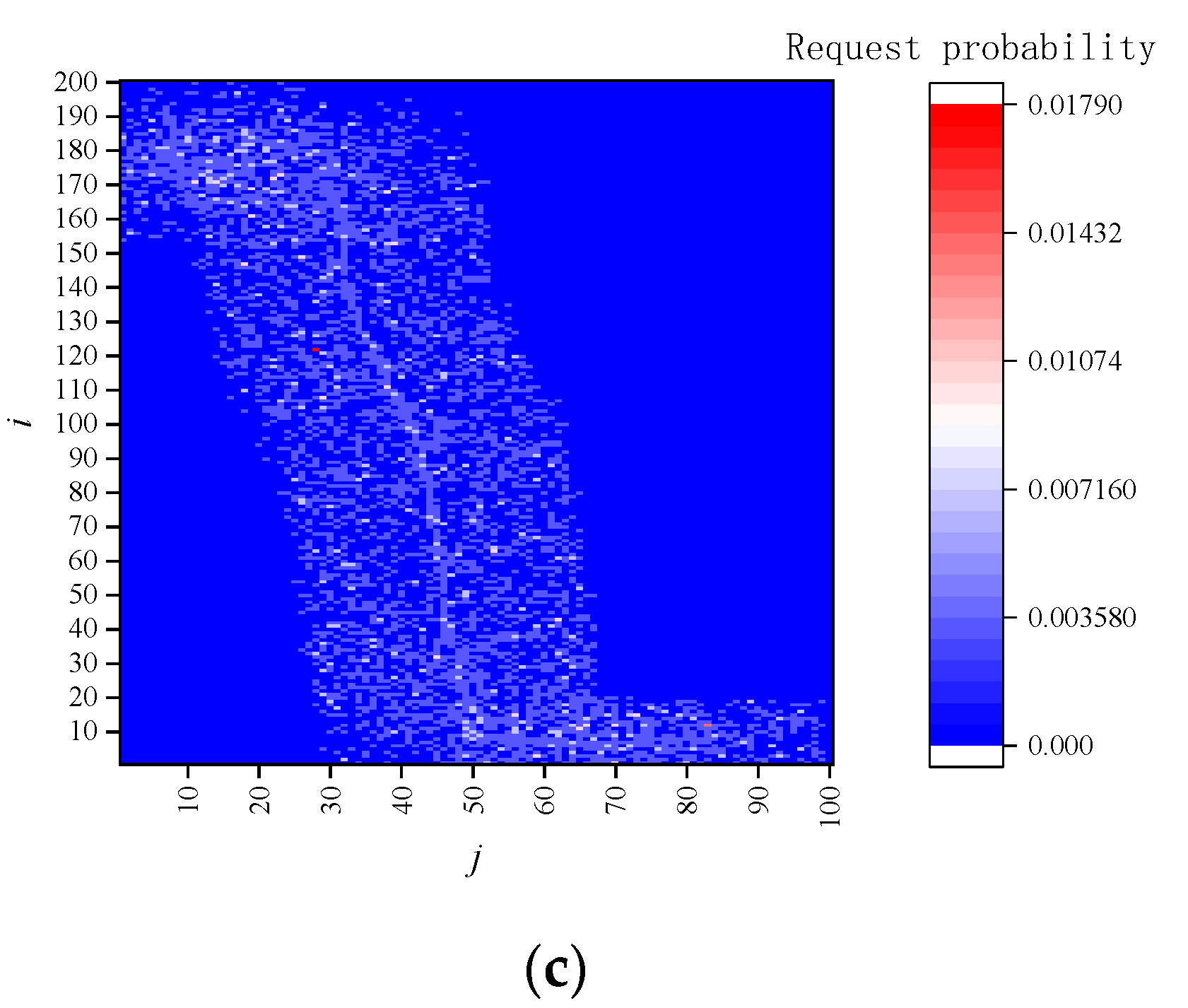
- The LBS server collects the number and types of services provided by the RSU using cached data and counts the number of various types of service requests sent by vehicle users in each cell. Hence, for each location, the LBS server can calculate the corresponding historical query probability , where denotes the number of queries in location cellij, F is the total number of service requests in the area under the jurisdiction of RSU. The request probability of service u is , where is the number of queries of service u in location cellij, u = 1, 2, …, U. The LBS server constructs the information matrix Q(r, q, e). Moreover, the LBS server selects the hotspot data based on the results of problem (5). Finally, the LBS server sends the information matrix Q(r, q, e) and the hotspot data to the RSU.
- (2)
- The RSU broadcasts information such as Q(r, q, e), R and to vehicle users in its jurisdiction and constructs a cached information matrix based on the existing times of cached data. Meanwhile, the RSU begins to count the existence time tq of the information matrix.
- (3)
- The vehicle users store the information matrix according to the broadcast information.
- (1)
- Using the privacy protection level V and the threshold of cache hit rate , the vehicle user calculates the privacy parameter k according to Equation (4). As described in Section 4.3, the vehicle user generates k – 1 dummy locations with the information matrix Q(r, q, e) and road information R, and RR-DLS. And a service query is constructed and sent to the RSU.
- (2)
- After receiving , the RSU retrieves the cached data for service queries. The number of queries hit by the cached data is kc. The existing times of hit data are reset to 0 s. If , the service results are returned directly to the vehicle user. Otherwise, if , it goes to Step (4).
- (3)
- The vehicle user filters the service results based on its location. If the user’s real query result is obtained, it goes to Step (8). Otherwise, the vehicle user sets the NoCache identifier, constructs the service query and sends it to the RSU.
- (4)
- The RSU selects kc locations and their corresponding services according to the result of the problem (8). The RSU replaces the queries hit by the cached data in with the locations in set obtained in problem (8) and the corresponding services to construct the service query . The RSU sends to the LBS server.
- (5)
- Receiving , the LBS server retrieves the database and returns the service results to the RSU.
- (6)
- The RSU caches the results of Lq* and deletes the cached data whose existing times are larger than TD. Then, the RSU screens out the results required by the vehicle user and adds the queries hit by the cached data in Step (2) to construct the user’s service results and returns them to the vehicle user.
- (7)
- The vehicle user filters the service result according to its location.
- (8)
- If , the RSU perform the information matrix update step as described in Step 1).
- (9)
- The whole service for a vehicle user is finished.
5. Performance Evaluation and Discussion
5.1. Security
5.1.1. Long-Term Statistical Attack
5.1.2. Location Correlation Attack
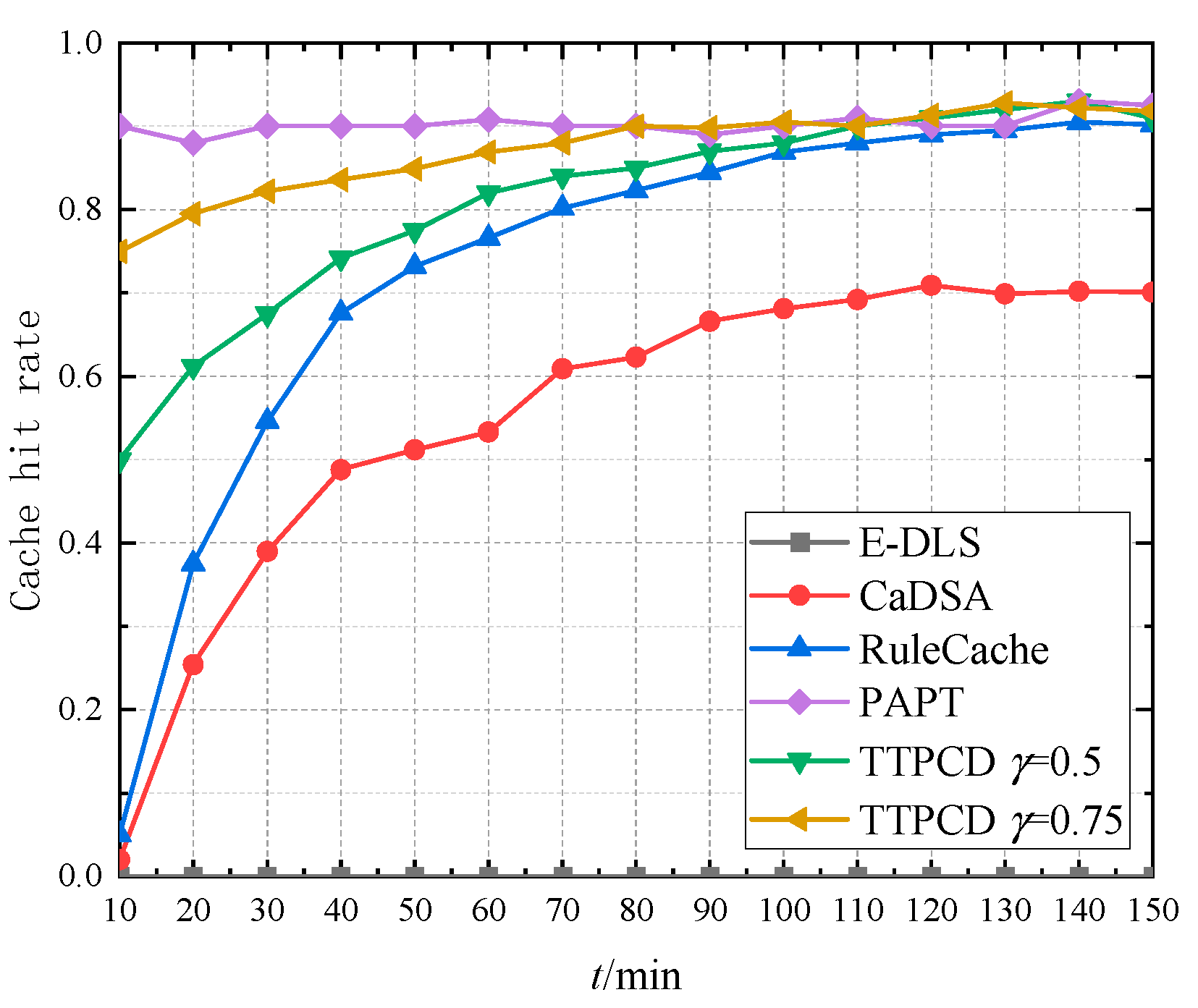
5.2. Cache Hit Rate
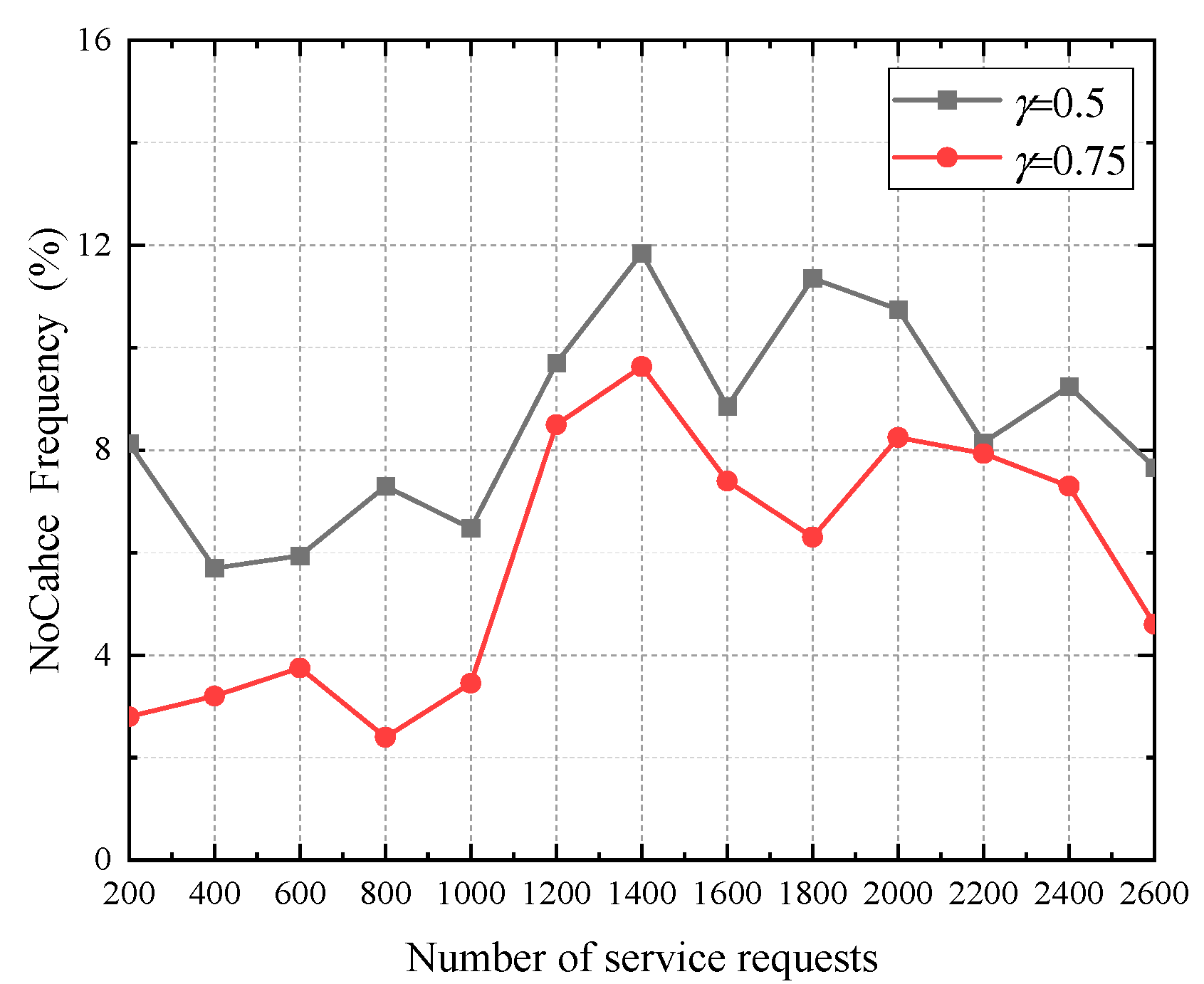
5.3. Service Failure Rate
5.4. Overhead Analysis
5.4.1. Computation Overhead
5.4.2. Communication Overhead
5.4.3. Storage Overhead
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Raya, M.; Hubaux, J.-P. Securing vehicular ad hoc networks. J. Comput. Secur. 2007, 15, 39–68. [Google Scholar] [CrossRef] [Green Version]
- Zhao, L.; Song, Y.; Zhang, C.; Liu, Y.; Wang, P.; Lin, T.; Deng, M.; Li, H. T-GCN: A temporal graph convolutional network for traffic prediction. IEEE Trans. Intell. Transp. 2020, 21, 3848–3858. [Google Scholar] [CrossRef] [Green Version]
- Qiu, H.; Qiu, M.; Lu, R. Secure V2X communication network based on intelligent PKI and edge computing. IEEE Netw. 2019, 34, 172–178. [Google Scholar] [CrossRef]
- Sun, G.; Sun, S.; Sun, J.; Yu, H.; Du, X.; Guizani, M. Security and privacy preservation in fog-based crowd sensing on the internet of vehicles. J. Netw. Comput. Appl. 2019, 134, 89–99. [Google Scholar] [CrossRef]
- Gupta, R.; Rao, U.P. An exploration to location based service and its privacy preserving techniques: A survey. Wirel. Pers. Commun. 2017, 96, 1973–2007. [Google Scholar] [CrossRef]
- Liu, J.; Jiang, X.; Zhang, S.; Wang, H.; Dou, W. FADBM: Frequency-aware dummy-based method in long-term location privacy protection. In Proceedings of the 2019 IEEE 25th International Conference on Parallel and Distributed Systems (ICPADS), Tianjin, China, 4–6 December 2019. [Google Scholar]
- Niu, J.; Zhu, X.; Shi, L.; Ma, J. Time-aware dummy-based privacy protection for continuous LBSs. In Proceedings of the 2019 International Conference on Networking and Network Applications (NaNA), Daegu, Korea, 10–13 October 2019. [Google Scholar]
- Zhang, J.; Wang, X.; Yuan, Y.; Ni, L. RcDT: Privacy preservation based on R-constrained dummy trajectory in mobile social networks. IEEE Access 2019, 7, 90476–90486. [Google Scholar] [CrossRef]
- Bindschaedler, V.; Shokri, R. Synthesizing plausible privacy-preserving location traces. In Proceedings of the 2016 IEEE Symposium on Security and Privacy, San Jose, CA, USA, 22–26 May 2016. [Google Scholar]
- Hara, T.; Suzuki, A.; Iwata, M.; Arase, Y.; Xie, X. Dummy-based user location anonymization under real-world constraints. IEEE Access 2016, 4, 673–687. [Google Scholar] [CrossRef]
- Choi, S.; Kim, J.; Yeo, H. TrajGAIL: Generating urban vehicle trajectories using generative adversarial imitation learning. Transp. Res. C Emerg. Technol. 2021, 128, 103091. [Google Scholar] [CrossRef]
- Cao, C.; Li, M. Generating mobility trajectories with retained Data Utility. In Proceedings of the 27th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 14–18 August 2021. [Google Scholar]
- Zhang, L.; Qian, Y.; Ding, M.; Ma, C.; Li, J.; Shaham, S. Location privacy preservation based on continuous queries for location-based services. In Proceedings of the IEEE INFOCOM 2019-IEEE Conference on Computer Communications Workshops, Paris, France, 29 April–2 May 2019. [Google Scholar]
- Shao, Z.; Guo, W.; Qin, L. Trajectory privacy protection method based on multi-anonymizer. J. Comp. Res. Dev. 2019, 56, 576–584. [Google Scholar]
- Li, S.; Shen, H.; Sang, Y. An efficient model and algorithm for privacy-preserving trajectory data publishing. IEEE Trans. Mob. Comput. 2019, 18, 2315–2329. [Google Scholar]
- Xu, Z.; Zhang, J.; Tsai, P.; Lin, L.; Zhuo, C. Spatiotemporal mobility based trajectory privacy-preserving algorithm in location-based services. Sensors 2021, 21, 2021. [Google Scholar] [CrossRef] [PubMed]
- Gursoy, M.E.; Liu, L.; Truex, S.; Yu, L. Differentially private and utility preserving publication of trajectory data. IEEE Trans. Mob. Comput. 2018, 18, 2315–2329. [Google Scholar] [CrossRef]
- Andrés, M.; Bordenabe, N.; Chatzikokolakis, K.; Palamidessi, C. Geo-indistinguishability: Differential privacy for location-based systems. In Proceedings of the 2013 ACM SIGSAC Conference on Computer & Communications Security, New York, NY, USA, 4–8 November 2013. [Google Scholar]
- Al-Dhubhani, R.; Cazalas, J.M. An adaptive geo-indistinguishability mechanism for continuous LBS queries. Wirel. Netw. 2018, 24, 3221–3239. [Google Scholar] [CrossRef]
- Arif, M.; Chen, J.; Wang, G.; Geman, O.; Balas, V.E. Privacy preserving and data publication for vehicular trajectories with differential privacy. Measurement 2021, 173, 108675. [Google Scholar] [CrossRef]
- Liu, X.; Chen, H.; Andris, C. trajGANs: Using generative adversarial networks for geo-privacy protection of trajectory data (Vision paper). In Proceedings of the Location Privacy and Security Workshop 2018, Melbourne, Australia, 28–30 August 2018. [Google Scholar]
- Rao, J.; Gao, S.; Kang, Y.; Huang, Q. LSTM-TrajGAN: A deep learning approach to trajectory privacy protection. In Proceedings of the 11th International Conference on Geographic Information Science (GIScience’21), Online, 27–30 September 2021. [Google Scholar]
- Zhu, X.; Chi, H.; Niu, B.; Zhang, W.; Li, Z.; Li, H. MobiCache: When K-anonymity meets cache. In Proceedings of the IEEE Global Communications Conference (GLOBECOM), Atlanta, GA, USA, 9–13 December 2013. [Google Scholar]
- Niu, B.; Li, Q.; Zhu, X.; Cao, G.; Li, H. Enhancing privacy through caching in location-based services. In Proceedings of the 34th IEEE International Conference on Computer Communications (INFOCOM 2015), Hong Kong, China, 26 April–1 May 2015. [Google Scholar]
- Yang, Q.; Kong, P. RuleCache: A mobility pattern based multi-level cache approach for location privacy protection. In Proceedings of the 22nd IEEE International Conference on Parallel and Distributed Systems (ICPADS 2016), Wuhan, China, 13–16 December 2016. [Google Scholar]
- Zhang, S.; Li, X.; Tan, Z.; Peng, T.; Wang, G. A caching and spatial K-anonymity driven privacy enhancement scheme in continuous location-based services. Future Gener. Comput. Syst. 2019, 94, 40–50. [Google Scholar] [CrossRef] [Green Version]
- Liu, B.; Zhou, W.; Zhu, T.; Gao, L.; Luan, T.H.; Zhou, H. Silence is golden: Enhancing privacy of location-based services by content broadcasting and active caching in wireless vehicular networks. IEEE Trans. Veh. Technol. 2016, 65, 9942–9953. [Google Scholar] [CrossRef]
- Peng, T.; Liu, Q.; Meng, D.; Wang, G. Collaborative trajectory privacy preserving scheme in location-based services. Inform. Sci. 2017, 387, 165–179. [Google Scholar] [CrossRef]
- Qian, Y.; Jiang, Y.; Hu, L.; Hossain, M.S.; Alrashoud, M.; Al-Hammadi, M. Blockchain-based privacy-aware content caching in cognitive Internet of Vehicles. IEEE Netw. 2020, 34, 46–51. [Google Scholar] [CrossRef]
- Guo, N.; Ma, L.; Gao, T. Independent mix zone for location privacy in vehicular networks. IEEE Access 2018, 6, 16842–16850. [Google Scholar] [CrossRef]
- Beresford, A.R.; Stajano, F. Location Privacy in Pervasive Computing. IEEE Pervasive Comput. 2003, 2, 46–55. [Google Scholar] [CrossRef] [Green Version]
- Palanisamy, B.; Liu, L. MobiMix: Protecting location privacy with mix-zones over road networks. In Proceedings of the 2011 IEEE 27th International Conference on Data Engineering, Washington, DC, USA, 11–16 April 2011. [Google Scholar]
- Chow, C.-Y.; Mokbel, M.; Aref, W. Casper*: Query processing for location services without compromising privacy. ACM Tran. Database Syst. 2009, 34, 1–48. [Google Scholar] [CrossRef]
- Liu, S.; Wang, J.H.; Wang, J.; Zhang, Q. Achieving user-defined location privacy preservation using a P2P system. IEEE Access 2020, 8, 45895–45912. [Google Scholar] [CrossRef]
- Ji, Y.; Gui, R.; Gui, X.; Liao, D.; Lin, X. Location privacy protection in online query based on privacy region replacement. In Proceedings of the 10th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 6–8 January 2020. [Google Scholar]
- Zhang, L.; Liu, D.; Chen, M.; Li, H.; Wang, C.; Zhang, Y.; Du, Y. A user collaboration privacy protection scheme with threshold scheme and smart contract. Inform. Sci. 2021, 560, 183–201. [Google Scholar] [CrossRef]
- Perazzo, P.; Skvortsov, P.; Dini, G. On designing resilient location-privacy obfuscators. Comput. J. 2015, 58, 2649–2664. [Google Scholar] [CrossRef] [Green Version]
- Kachore, V.; Lakshmi, J.; Nandy, S. Location obfuscation for location data privacy. In Proceedings of the 2015 IEEE World Congress on Services, New York, NY, USA, 27 June–2 July 2015. [Google Scholar]
- Qiu, C.; Squicciarini, A. Location privacy protection in vehicle-based spatial crowdsourcing via geo-indistinguishability. In Proceedings of the 2019 IEEE 39th International Conference on Distributed Computing Systems (ICDCS), Dallas, TX, USA, 7–10 July 2019. [Google Scholar]
- Luo, C.; Liu, X.; Xue, W.; Shen, Y.; Li, J.; Hu, W.; Liu, A. Predictable privacy-preserving mobile crowd sensing: A tale of two roles. IEEE/ACM Trans. Netw. 2019, 27, 361–374. [Google Scholar] [CrossRef]
- Zhou, L.; Yu, L.; Du, S.; Zhu, H.; Chen, C. Achieving differentially private location privacy in edge-assistant connected vehicles. IEEE Internet Things J. 2019, 6, 4472–4481. [Google Scholar] [CrossRef]
- Alanwar, A.; Shoukry, Y.; Chakraborty, S.; Martin, P.; Tabuada, P.; Srivastava, M. PrOLoc: Resilient localization with private observers using partial homomorphic encryption. In Proceedings of the 16th ACM/IEEE International Conference on Information Processing in Sensor Networks (IPSN), Pittsburgh, PA, USA, 18–20 April 2017. [Google Scholar]
- Negi, D.; Ray, S.; Lu, R. Pystin: Enabling secure LBS in smart cities with privacy-preserving top-k spatial-textual query. IEEE Internet Things J. 2019, 6, 7788–7799. [Google Scholar] [CrossRef]
- Farouk, F.; Alkady, Y.; Rizk, R. Efficient privacy-preserving scheme for location-based services in VANET system. IEEE Access 2020, 8, 60101–60116. [Google Scholar] [CrossRef]
- Niu, B.; Li, Q.; Zhu, X.; Cao, G.; Li, H. Achieving K-anonymity in privacy-aware location-based services. In Proceedings of the 2014 IEEE Conference on Computer Communications (INFOCOM), Toronto, ON, Canada, 27 April–2 May 2014. [Google Scholar]
- Pingley, A.; Zhang, N.; Fu, X.; Choi, H.; Subramaniam, S.; Zhao, W. Protection of query privacy for continuous location-based services. In Proceedings of the 30th IEEE International Conference on Computer Communications, Shanghai, China, 10–15 April 2011. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. Adv. Neural Inf. Process. Syst. 2014, 27, 2672–2680. [Google Scholar]
- Hu, L.; Qian, Y.; Chen, M.; Hossain, M.S.; Muhammad, G. Proactive cache-based location privacy preserving for vehicle networks. IEEE Wirel. Commun. 2018, 25, 77–83. [Google Scholar] [CrossRef]
- Sun, Y.; Chen, M.; Hu, L.; Qian, Y.; Hassan, M.M. ASA: Against statistical attacks for privacy-aware users in location based service. Future Gener. Comput. Syst. 2017, 70, 48–58. [Google Scholar] [CrossRef]
- Hwang, R.; Hsueh, Y.; Chung, H. A novel time-obfuscated algorithm for trajectory privacy protection. IEEE Trans. Serv. Comput. 2014, 7, 126–139. [Google Scholar] [CrossRef]
- Xu, X.; Chen, H.; Xie, L. A location privacy preservation method based on dummy locations in Internet of vehicles. Appl. Sci. 2021, 11, 4594. [Google Scholar] [CrossRef]
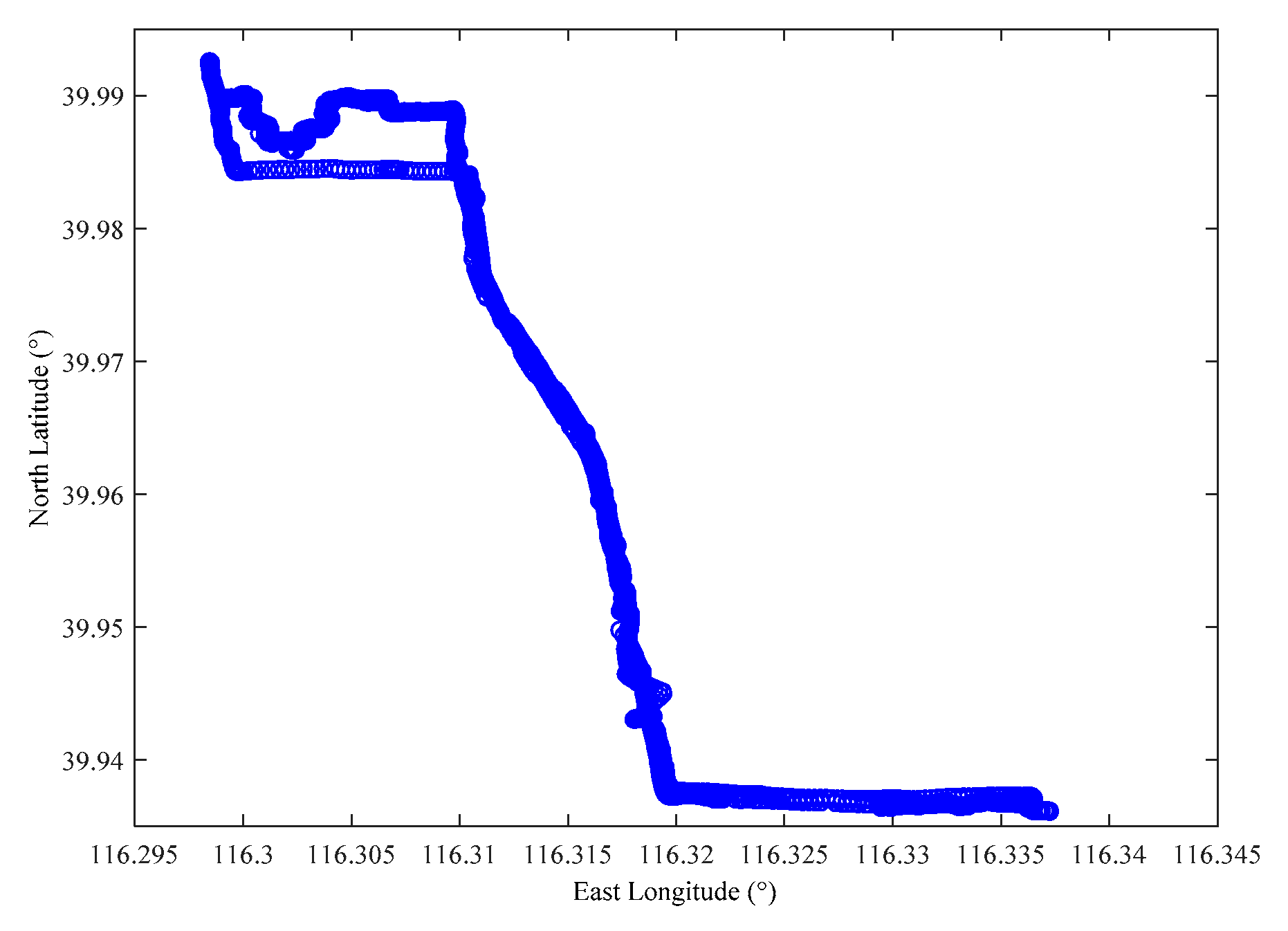
- Zheng, Y.; Xie, X.; Ma, W. GeoLife: A collaborative social networking service among user, location and trajectory. IEEE Data Eng. Bull. 2010, 33, 32–39. [Google Scholar]




Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Huang, Q.; Xu, X.; Chen, H.; Xie, L. A Vehicle Trajectory Privacy Preservation Method Based on Caching and Dummy Locations in the Internet of Vehicles. Sensors 2022, 22, 4423. https://doi.org/10.3390/s22124423
Huang Q, Xu X, Chen H, Xie L. A Vehicle Trajectory Privacy Preservation Method Based on Caching and Dummy Locations in the Internet of Vehicles. Sensors. 2022; 22(12):4423. https://doi.org/10.3390/s22124423
Chicago/Turabian StyleHuang, Qianyong, Xianyun Xu, Huifang Chen, and Lei Xie. 2022. "A Vehicle Trajectory Privacy Preservation Method Based on Caching and Dummy Locations in the Internet of Vehicles" Sensors 22, no. 12: 4423. https://doi.org/10.3390/s22124423
APA StyleHuang, Q., Xu, X., Chen, H., & Xie, L. (2022). A Vehicle Trajectory Privacy Preservation Method Based on Caching and Dummy Locations in the Internet of Vehicles. Sensors, 22(12), 4423. https://doi.org/10.3390/s22124423