
Multi-Floor Indoor Localization Based on Multi-Modal Sensors


Abstract
:1. Introduction
- Signal-Feature-Assisted VBL. The conventional hybrid SFBL and VBL scheme, simply, selects some candidate regions using SFBL, to restrict the processing complexities in the VBL stage. If we regard the region index identification as a ‘hard decision’, a more reasonable scheme is to consider a ‘soft decision’, instead. Hence, in this paper, we propose a joint visual and wireless signal feature-based localization (JVWL), by considering the likelihood distribution of potential positions, which eventually helps to improve the localization accuracy.
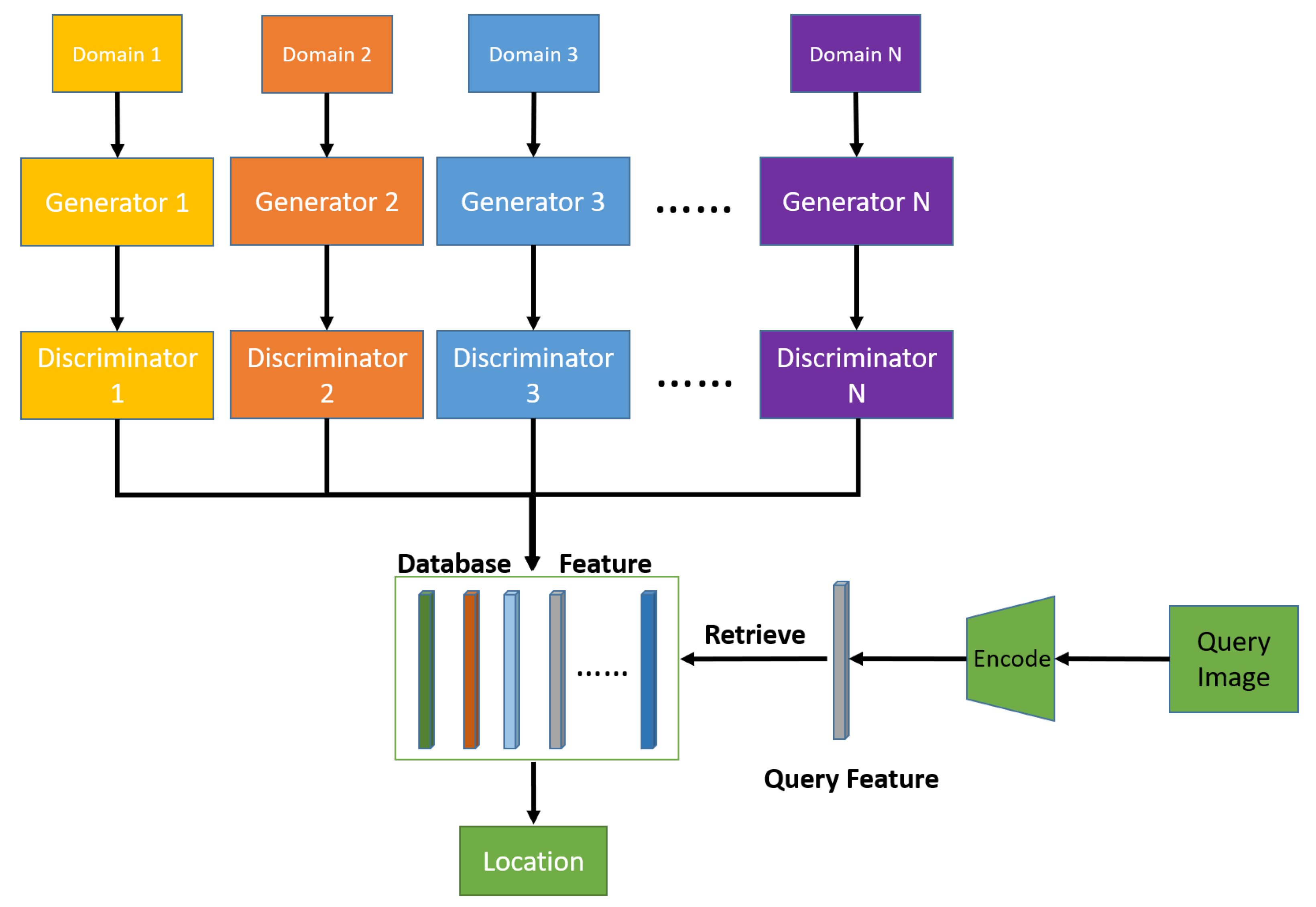
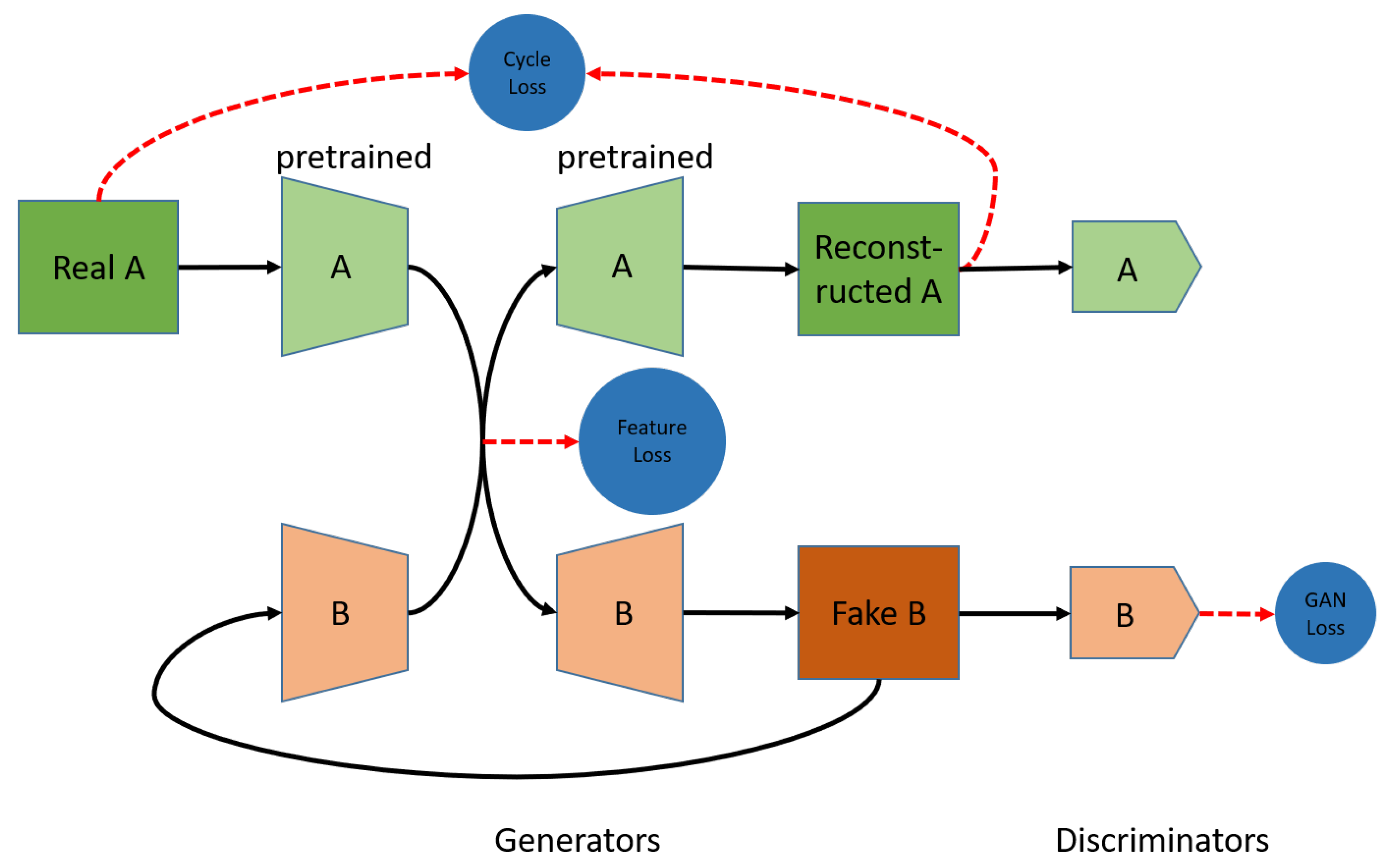
- Single-Floor to Multi-Floor Extension. Different from the single-floor cases, where the horizontal dimension is neglected, multi-floor localization raises many challenging issues, regarding the existing localization mechanisms. For example, the floor structure is more or less the same for different floors, which is generally difficult for VBL. Therefore, we utilize a multi-domain translation architecture, on top of signal-feature-based coarse localization, to learn the minor changes in different floor environments.
- Low-Complexity Few-Shot Learning. In addition, we study a low-complexity dataset construction mechanism and, numerically, analyze the relationship between the localization accuracy and the number of sampling images. Through some numerical results, we show that high-accuracy localization results can be achieved with low-complexity few-shot learning methods.
2. Related Works
2.1. Learning-Based Visual Localization
2.2. Few-Shot Learning
2.3. Fusion-Based Localization
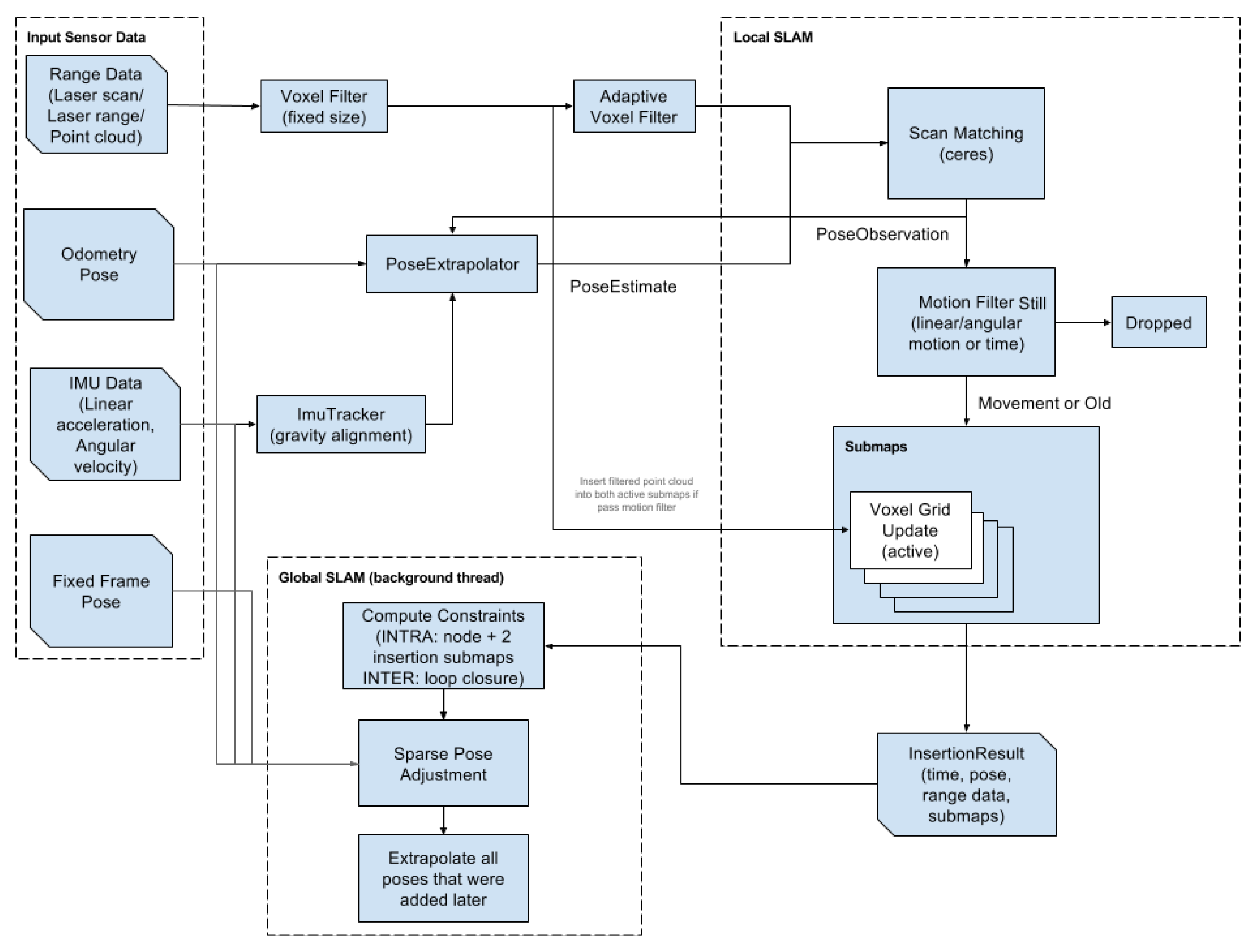
2.4. Lidar-Slam Localization
3. System Model
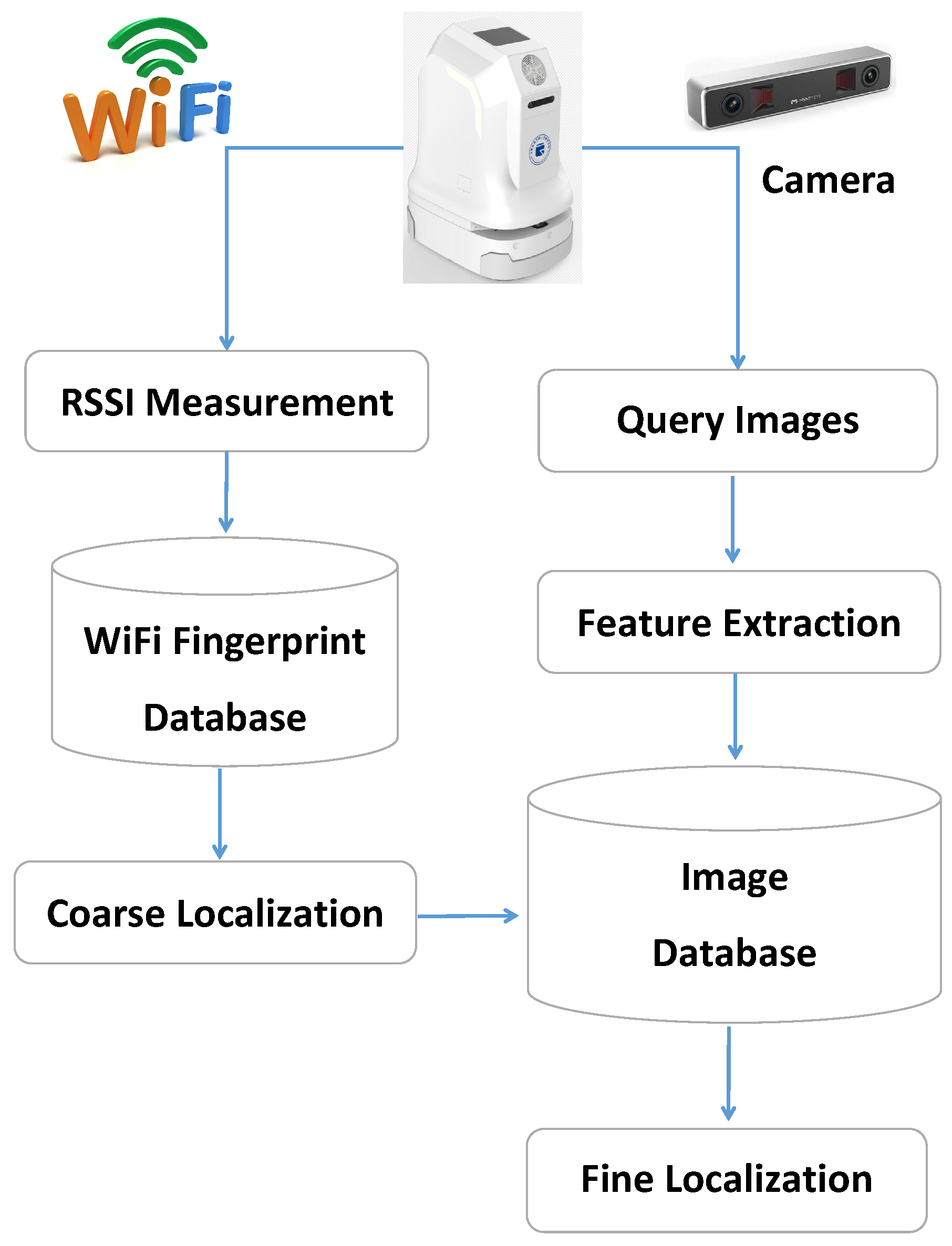
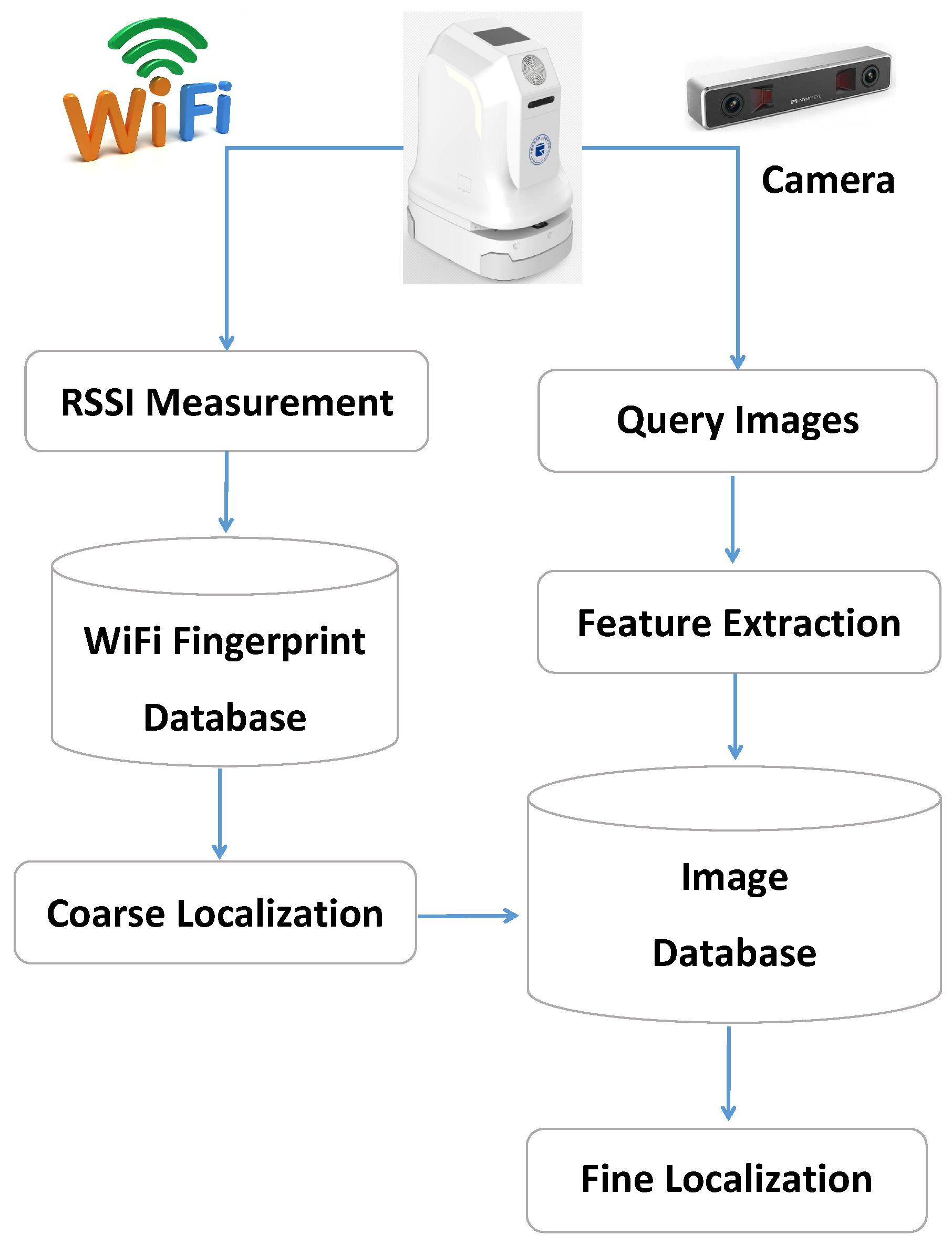
3.1. Overall Description
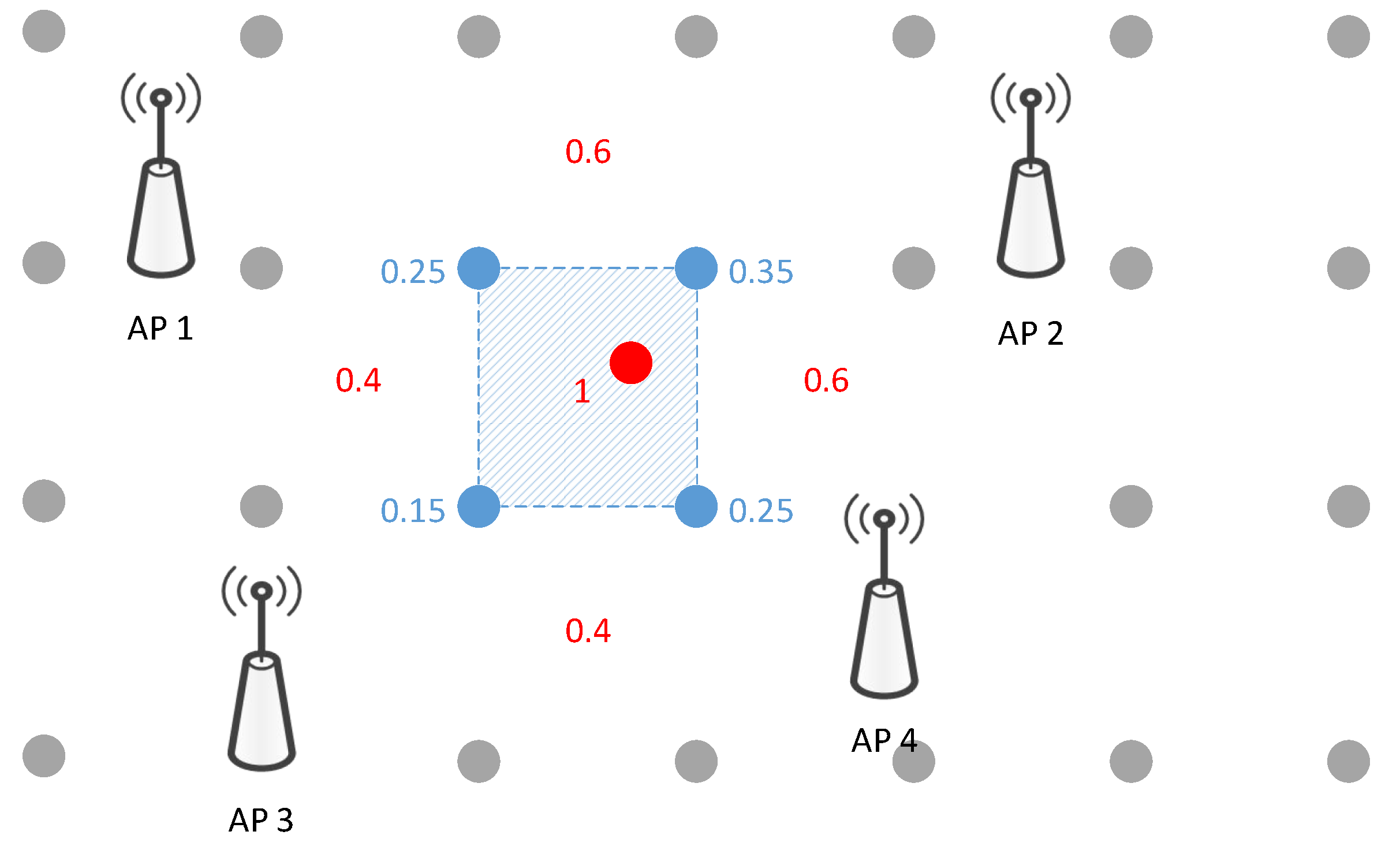
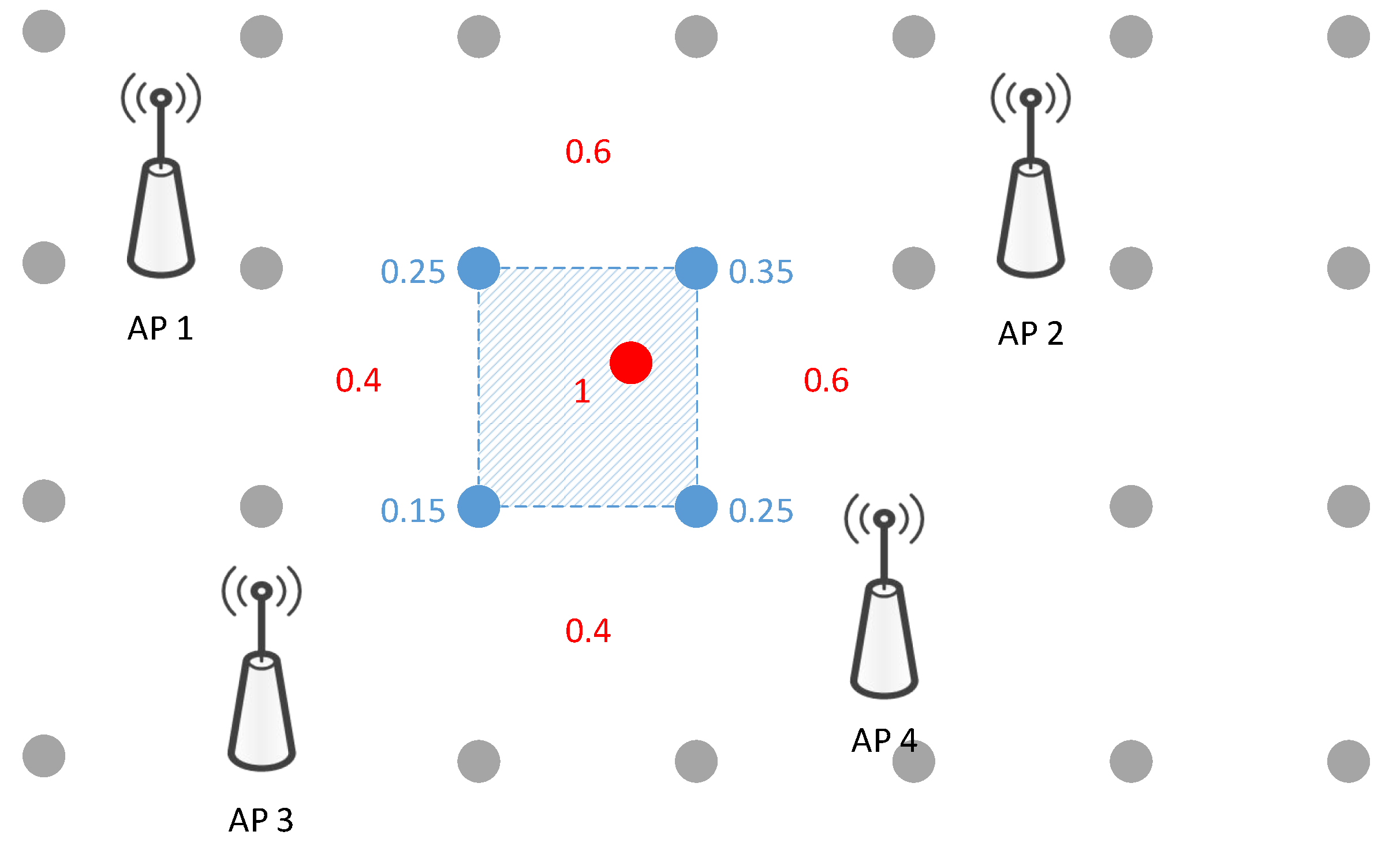
- Coarse Localization In the coarse localization, the proposed JVWL scheme first computes the likelihood probability with respect to (w.r.t.) RPs, i.e., , by inquiring the WiFi fingerprint database, . By comparison with the observed WiFi RSSIs, the likelihood probability w.r.t. the RP can be obtained via a standard support vector machine (SVM) scheme, which has proven to be effective in fingerprint classification tasks [43], e.g.,To reduce the searching complexity of the latter fine localization, we partition the target areas into consecutive areas based on RPs, , as shown in Figure 3. The likelihood probabilities of areas are, as follows:This can be calculated by summing over the likelihood probabilities of RPs, where each element is given by,The coarse localization results are, thus, given by selecting most possible areas according to the likelihood probabilities, . Mathematically, if we denote and to be the index set of selected areas and its complementary set, the candidate localization area and the corresponding likelihood probability can be expressed aswhere for any and , and the cardinality of is . By cascading (1)–(5), we denote the entire coarse localization process as
- Fine Localization In the fine localization, the proposed JVWL scheme maps the query images, , to the estimated location, , according to the image database . To control the searching complexity, we only use a subset of the entire image database in the practical deployment, e.g.,and the mathematical expression of the fine localization process is given by
3.2. Database Construction
4. Proposed Multi-Floor Scheme
4.1. Problem Formulation
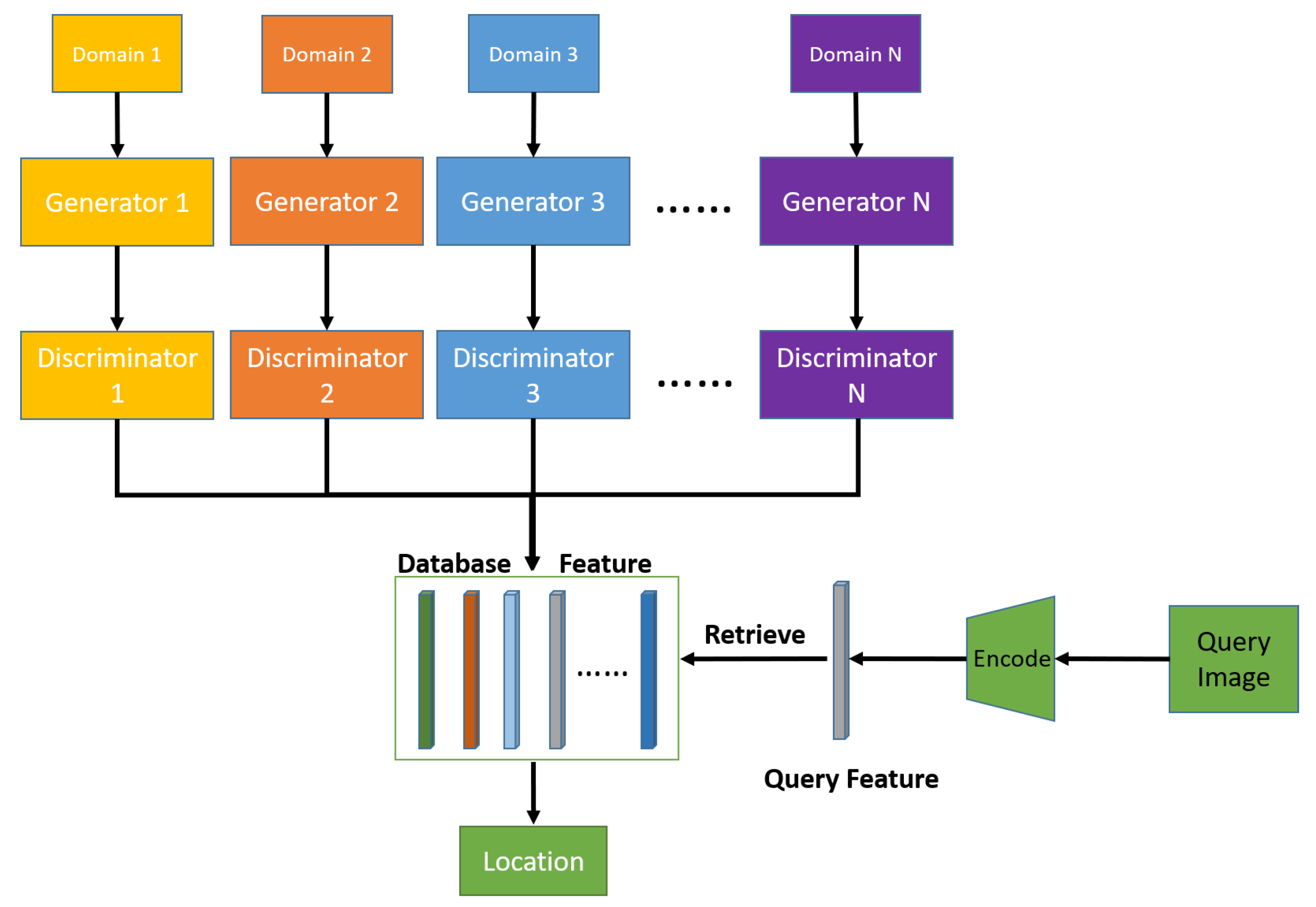
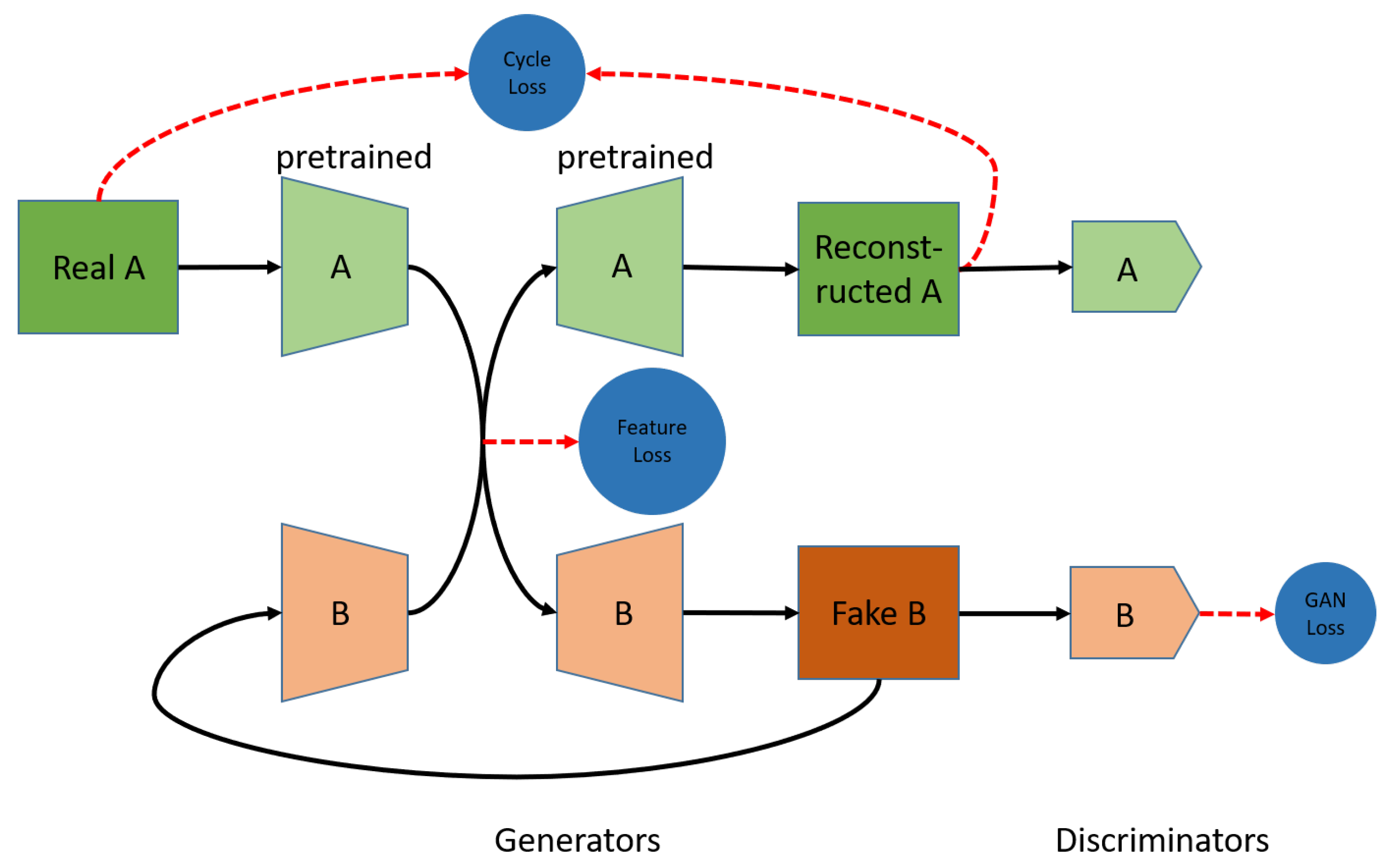
4.2. Multi-Floor-Model Architecture
5. Experiment Results
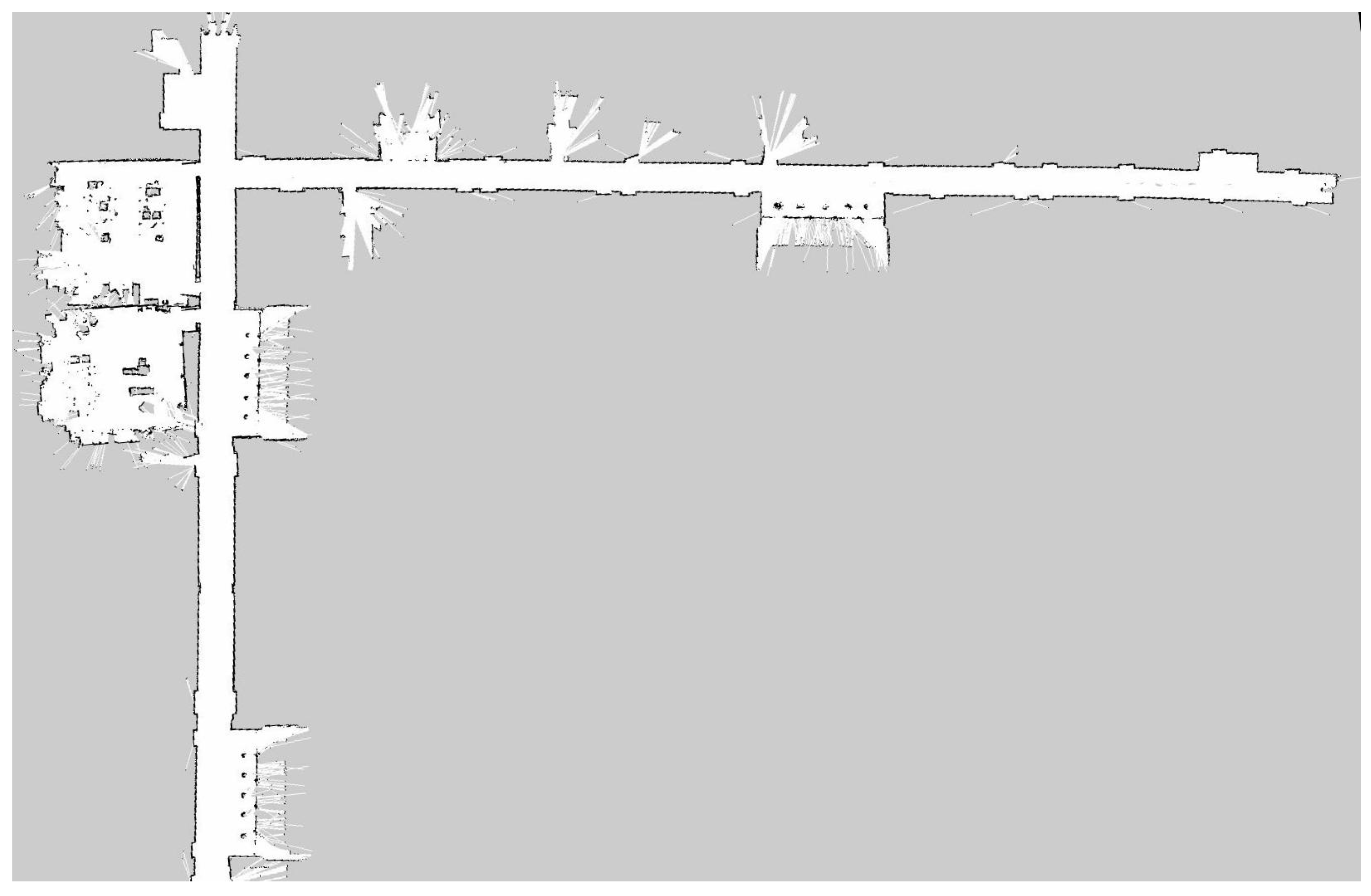
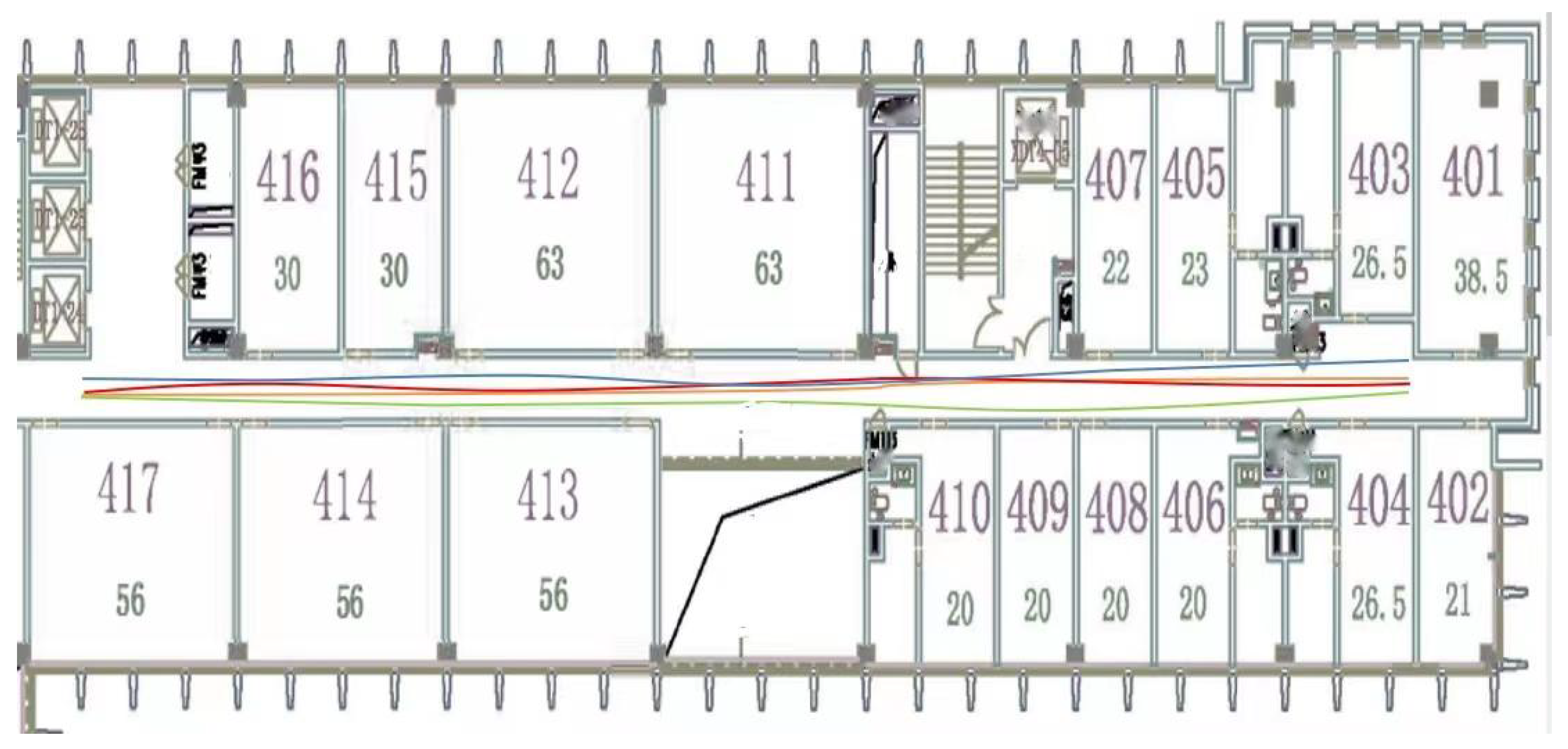
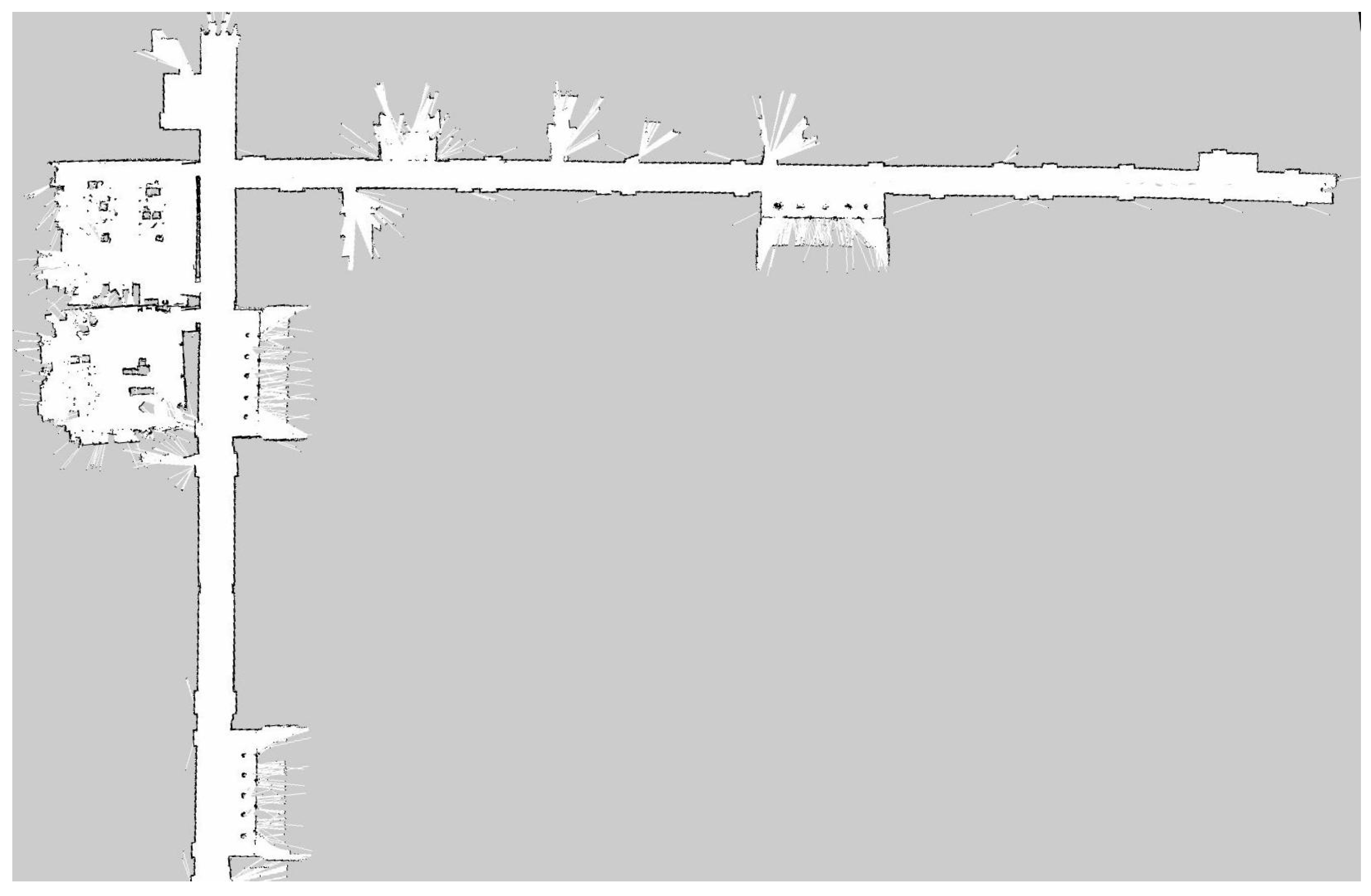
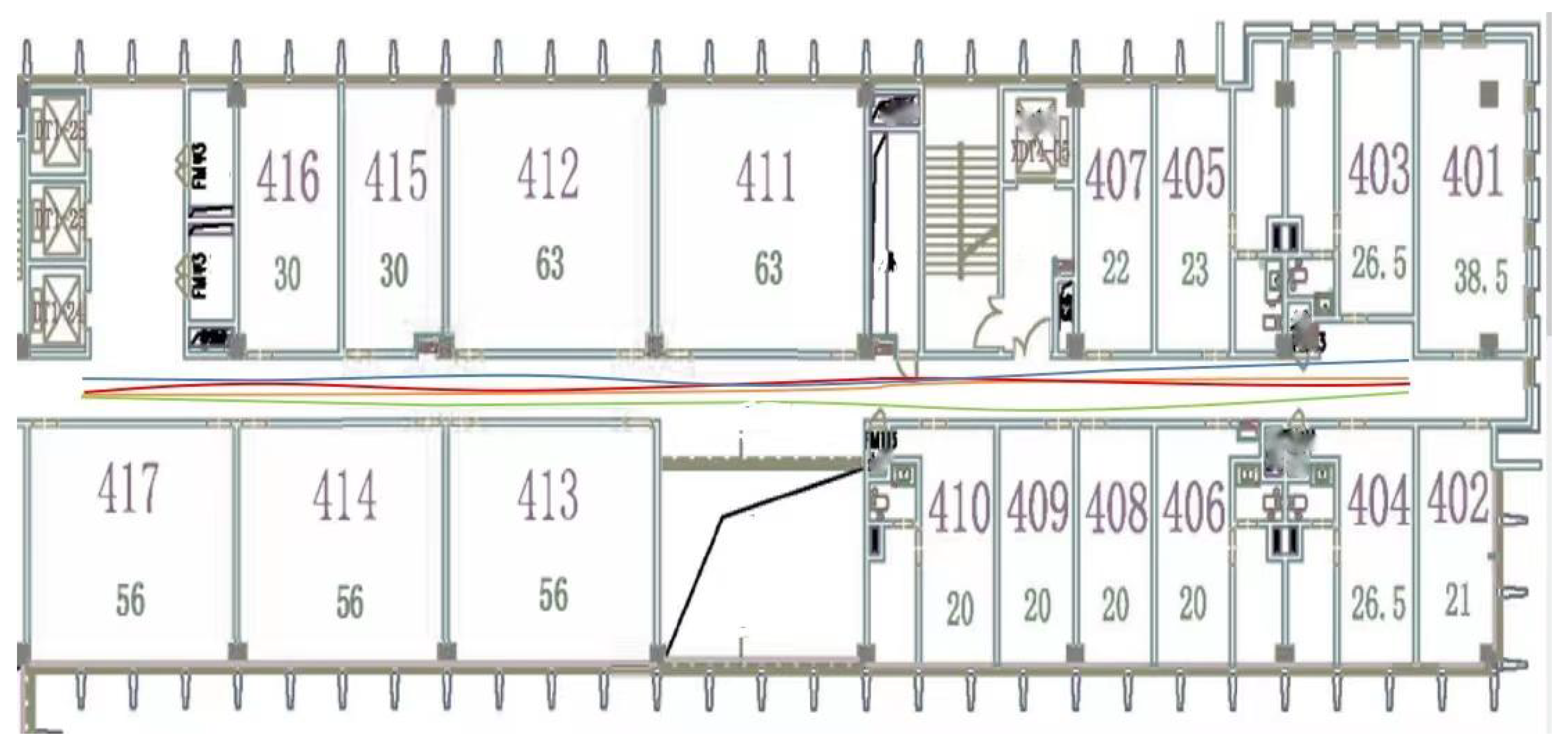
5.1. Experimental Environment
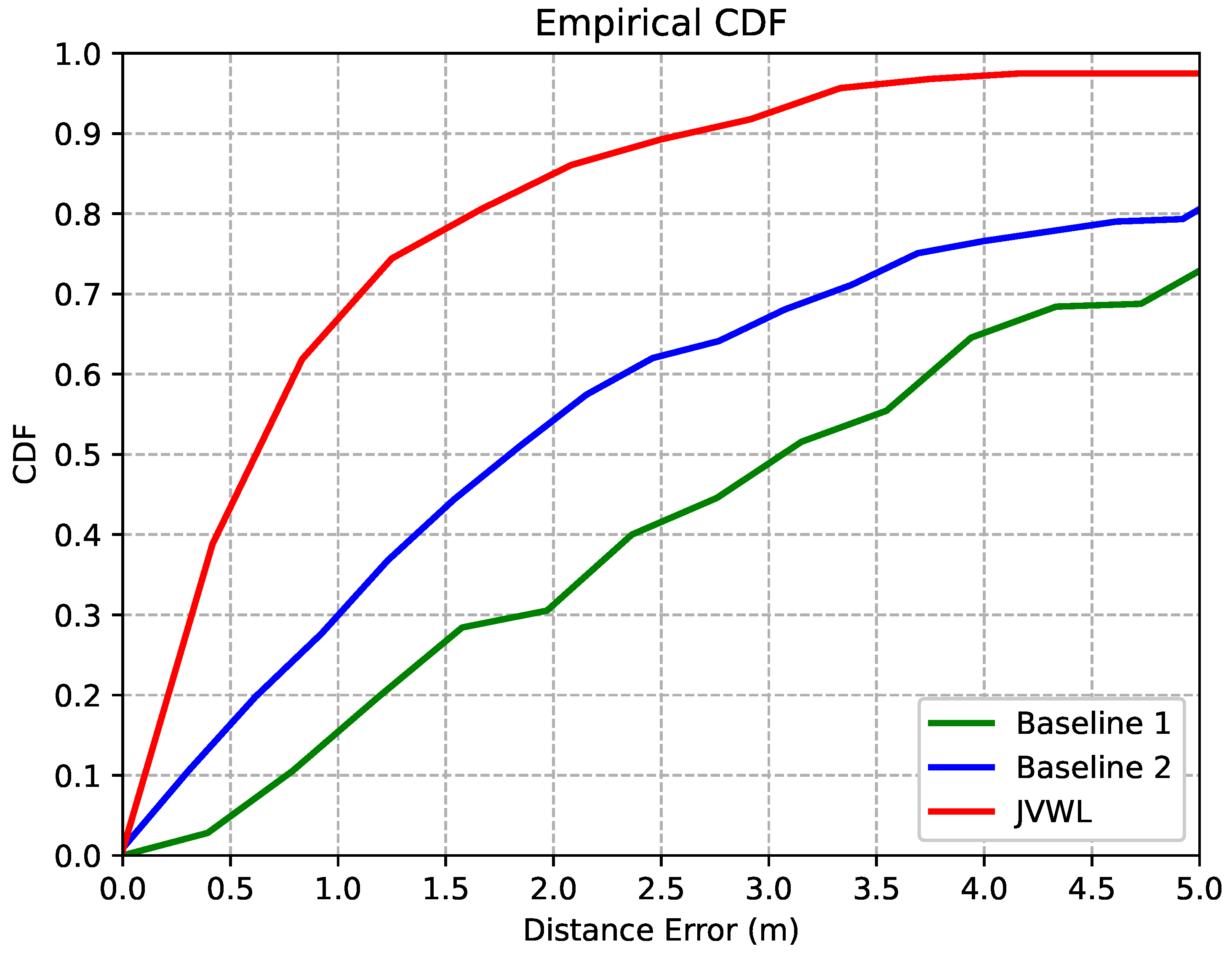
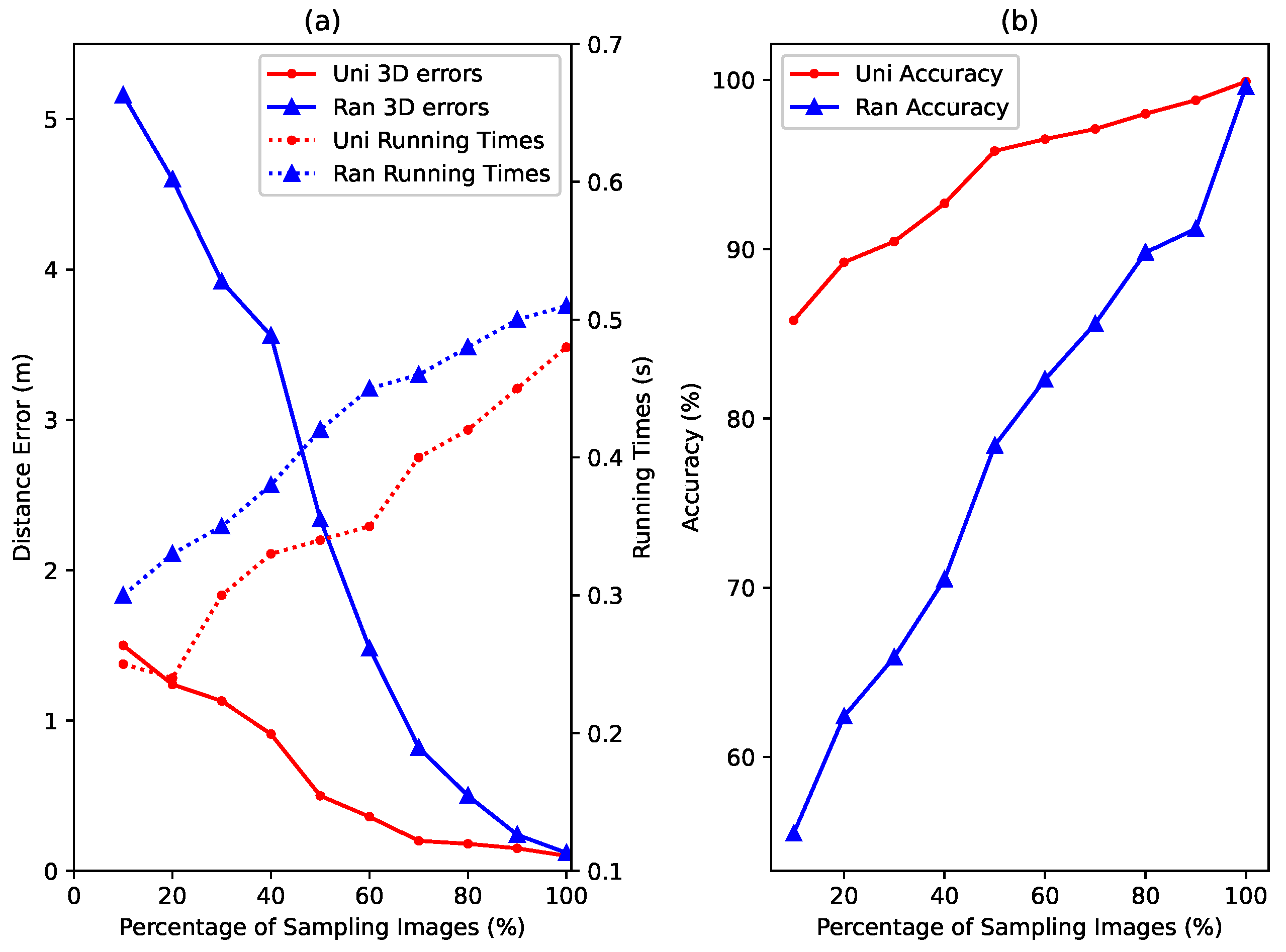
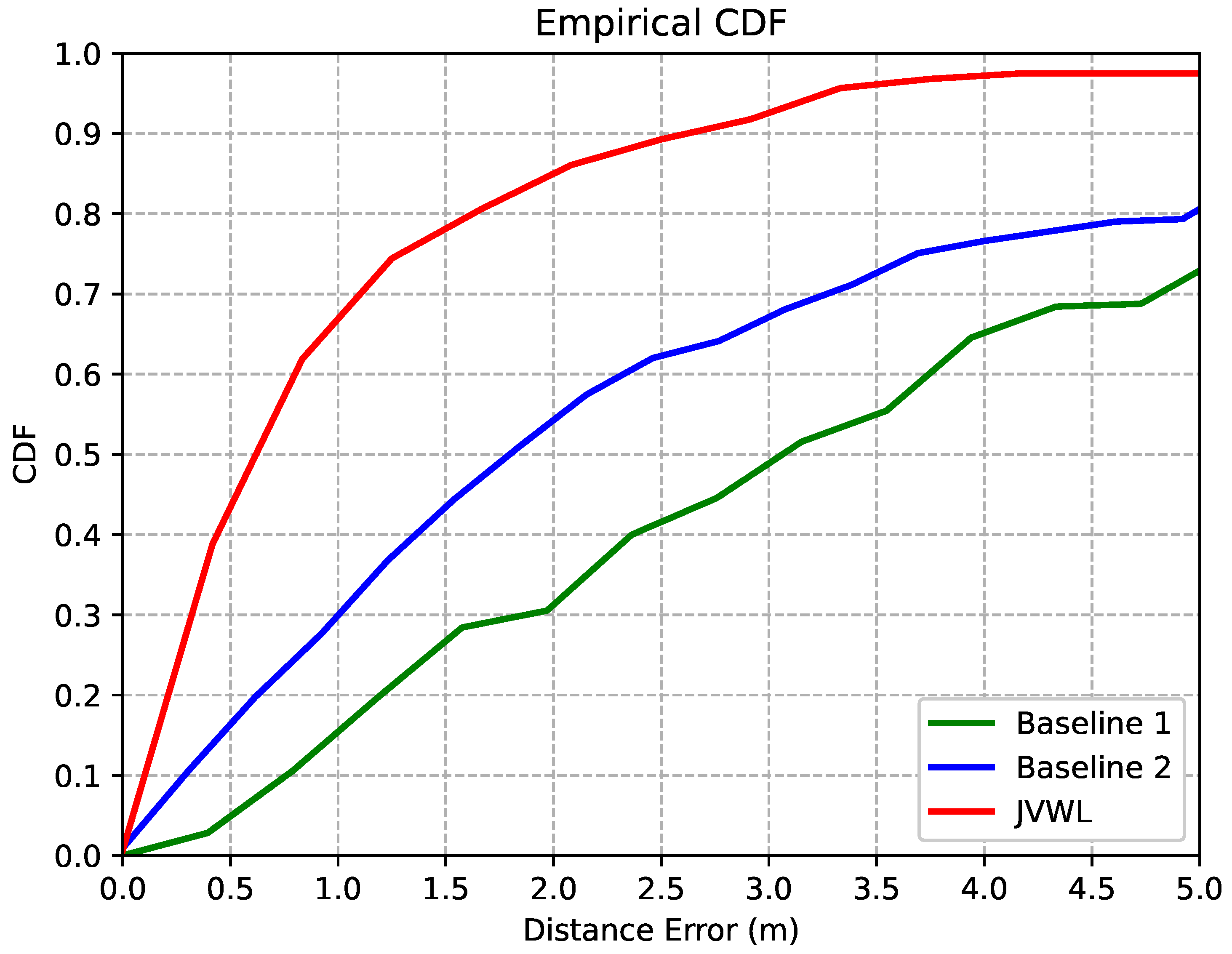
5.2. Localization Accuracy and Computational Complexity
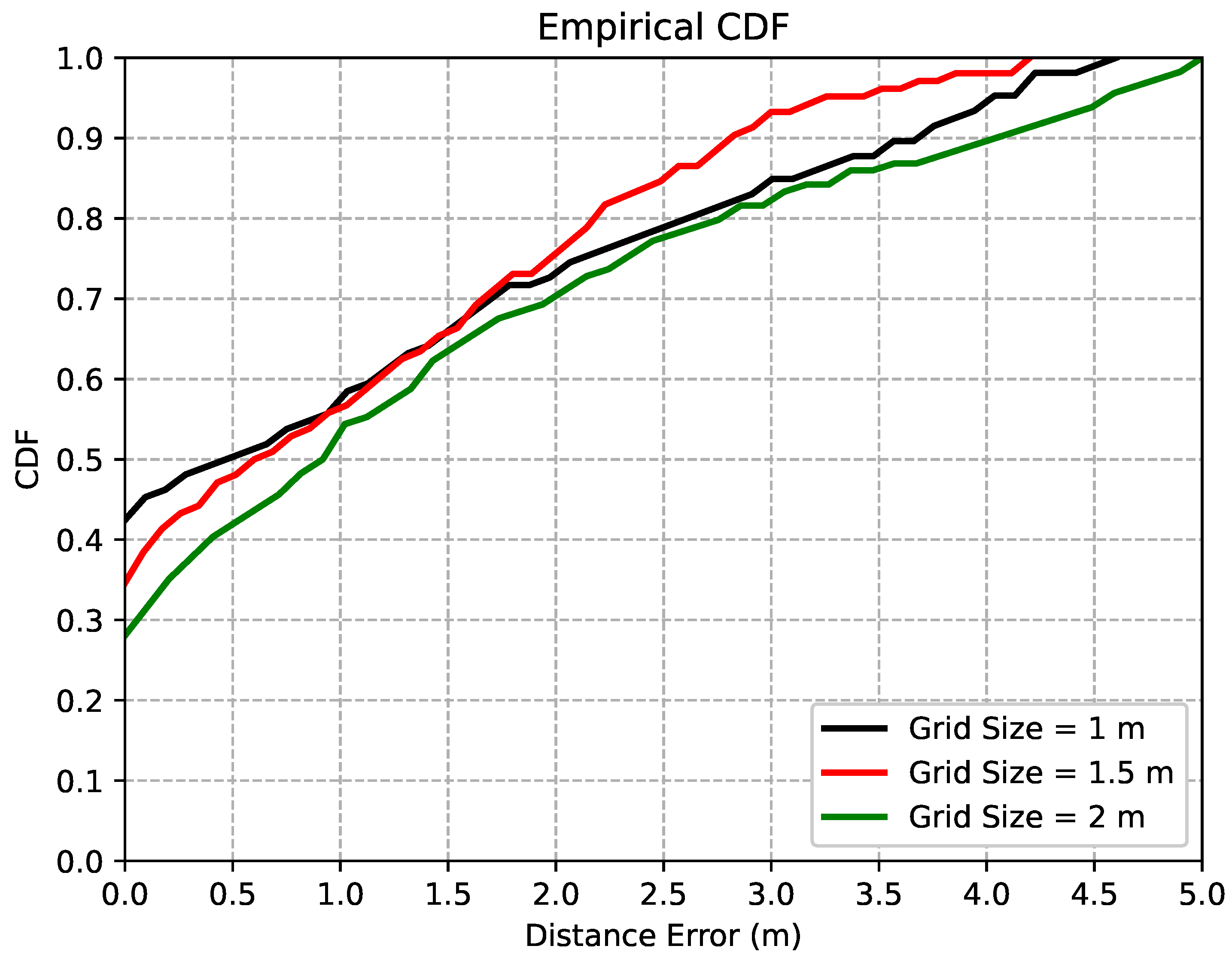
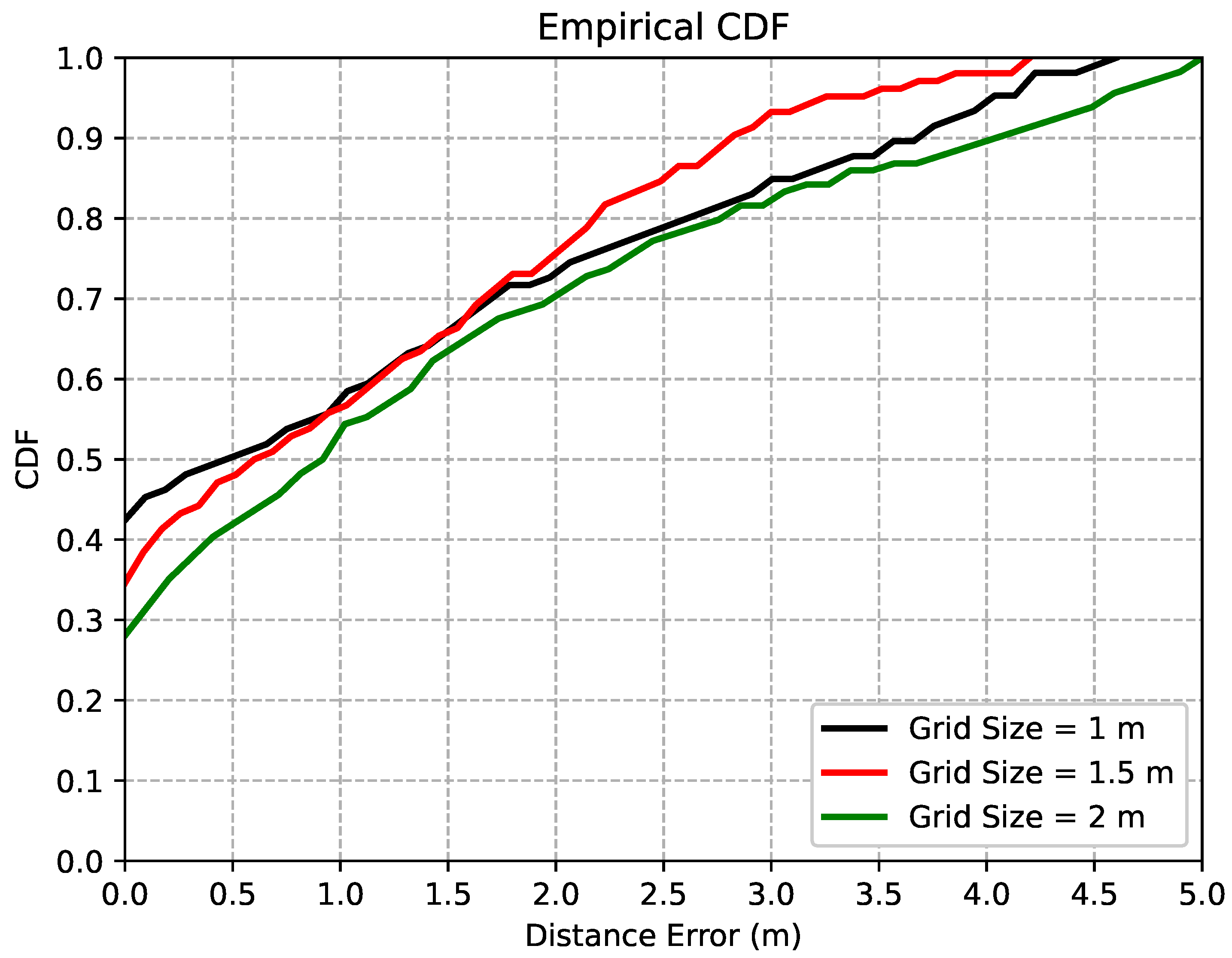
5.3. Effects of Grid Sizes
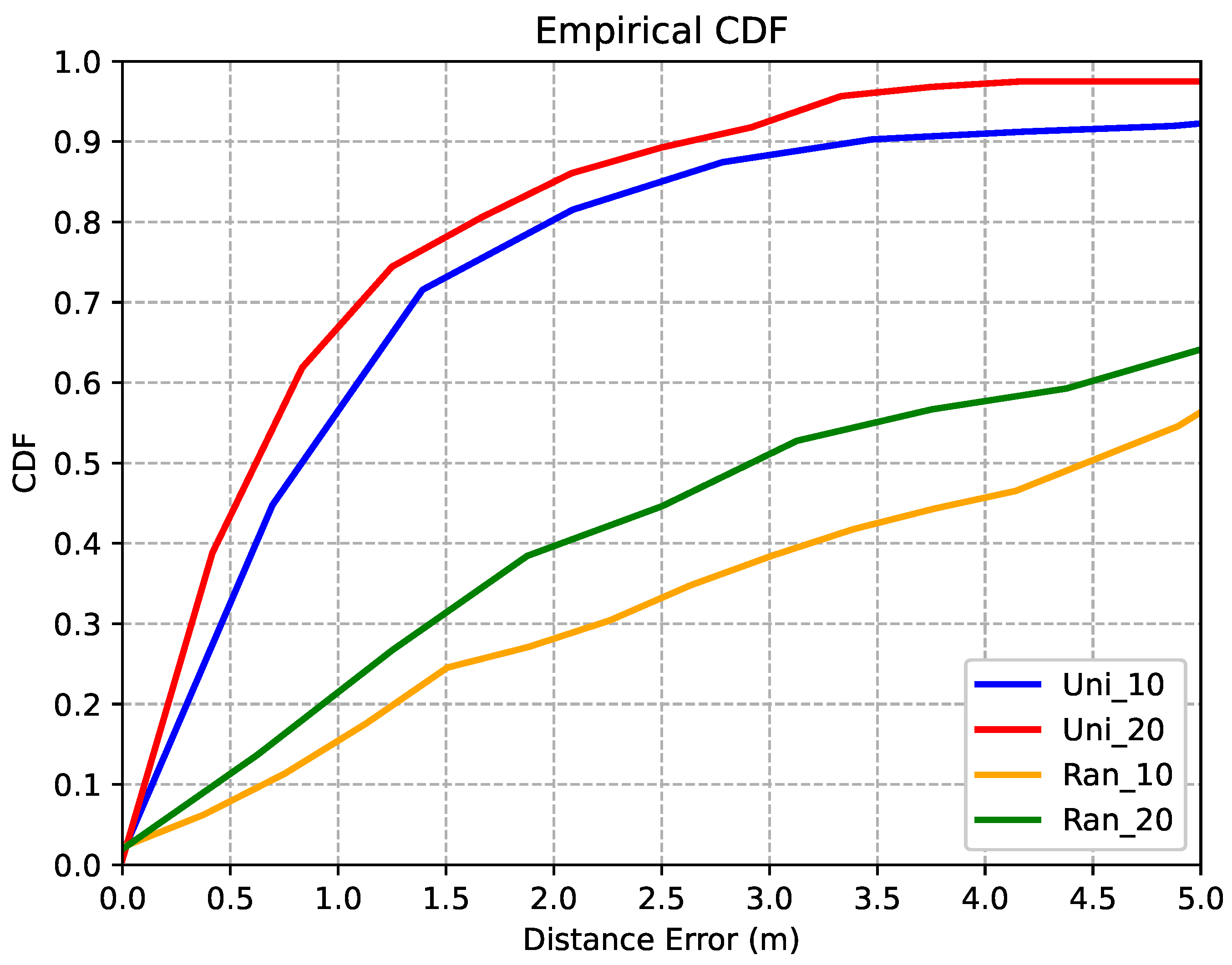
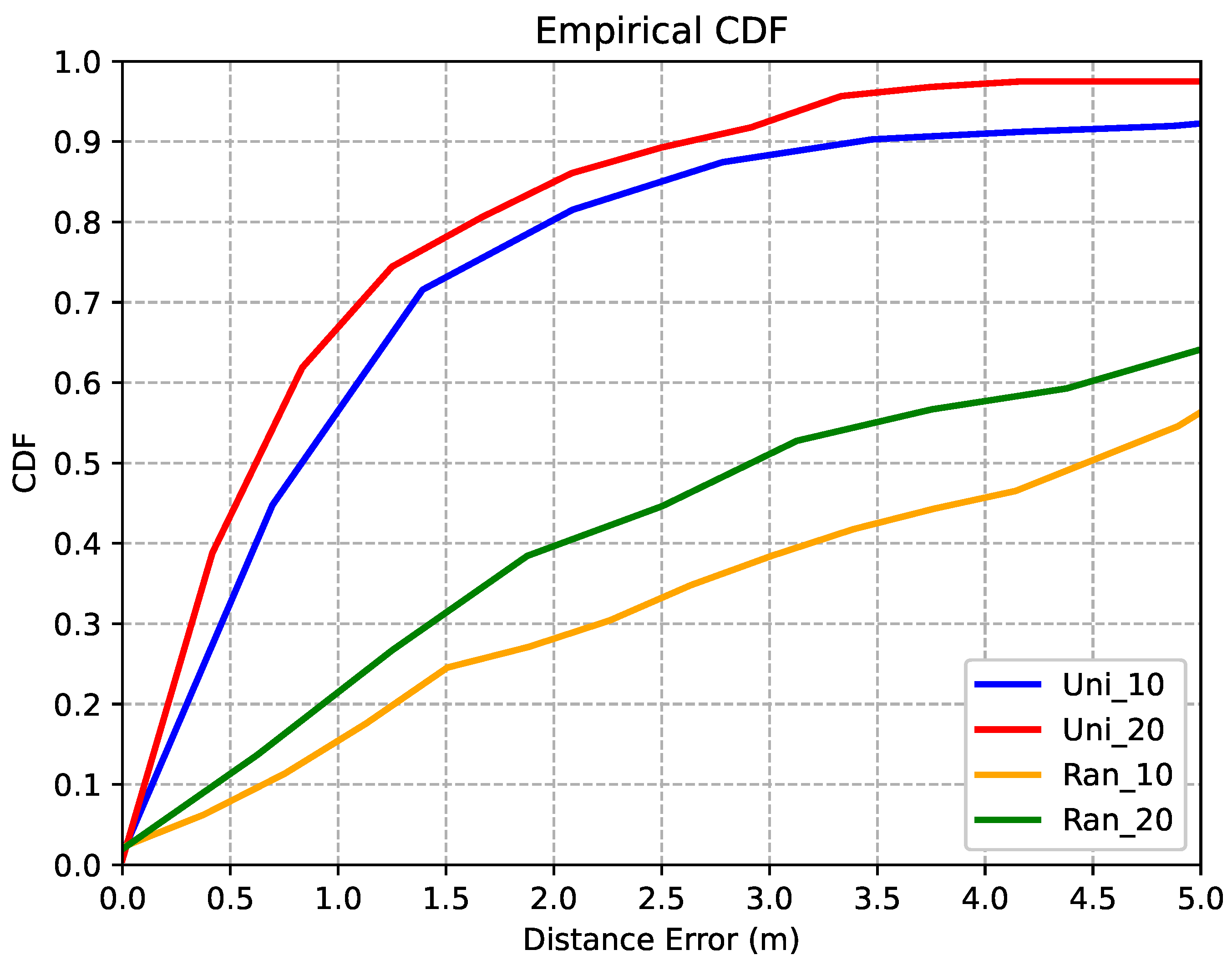
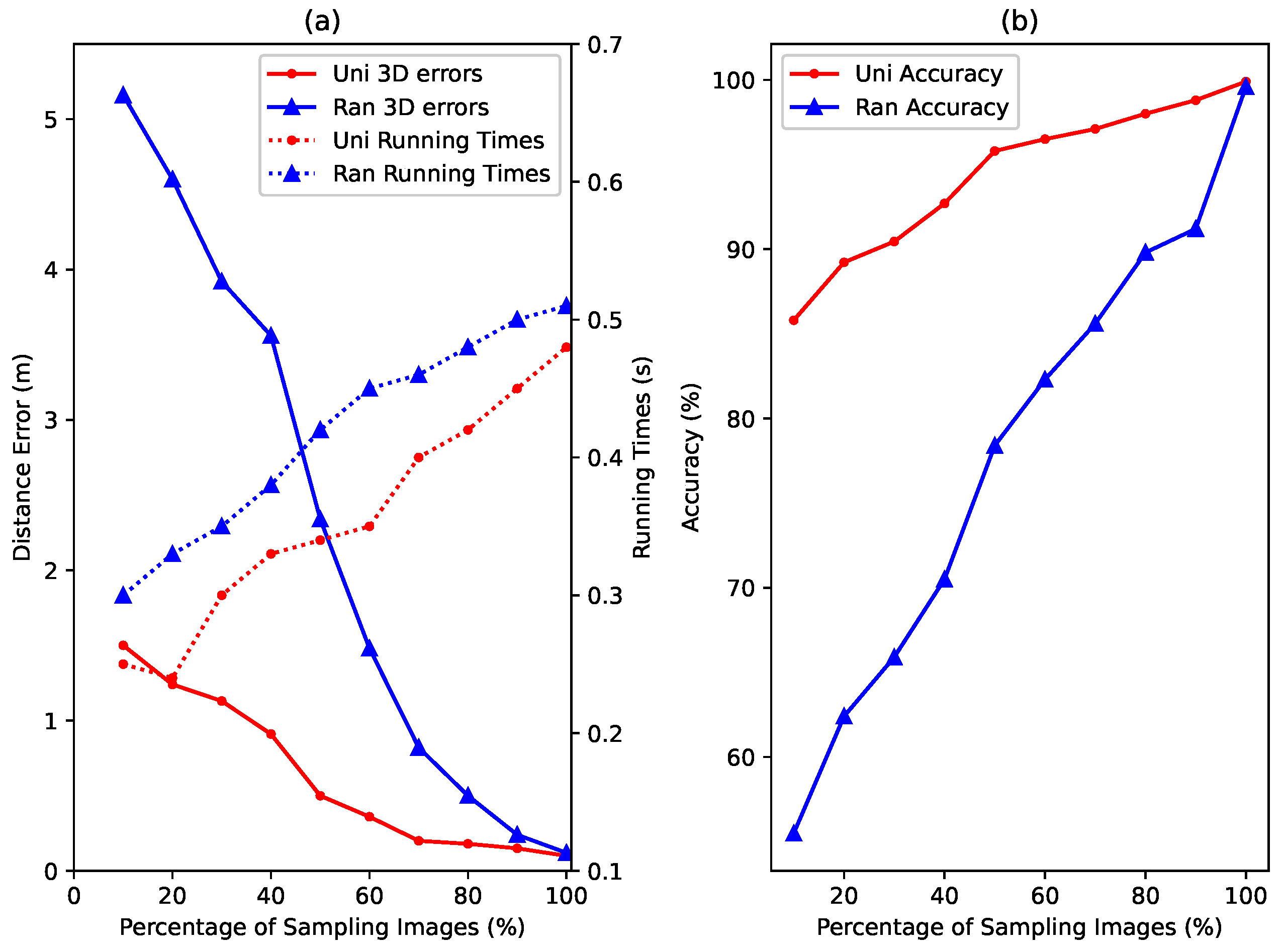
5.4. Effects of Few-Shot
6. Conclusions and Discussion
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Huang, H.; Gartner, G.; Krisp, J.M.; Raubal, M.; Van de Weghe, N. Location based services: Ongoing evolution and research agenda. J. Locat. Based Serv. 2018, 12, 63–93. [Google Scholar] [CrossRef]
- Elgendy, M.; Sik-Lanyi, C.; Kelemen, A. A novel marker detection system for people with visual impairment using the improved tiny-yolov3 model. Comput. Methods Programs Biomed. 2021, 205, 106112. [Google Scholar] [CrossRef] [PubMed]
- Al-Khalifa, S.; Al-Razgan, M. Ebsar: Indoor guidance for the visually impaired. Comput. Electr. Eng. 2016, 54, 26–39. [Google Scholar] [CrossRef]
- Tomai, S.; Krjanc, I. An automated indoor localization system for online bluetooth signal strength modeling using visual-inertial slam. Sensors 2021, 21, 2857. [Google Scholar]
- Xu, L.; Zhuang, W.; Yin, G.; Pi, D.; Liang, J.; Liu, Y.; Lu, Y. Geometry-based cooperative localization for connected vehicle subject to temporary loss of GNSS signals. IEEE Sens. J. 2021, 21, 23527–23536. [Google Scholar]
- Onyekpe, U.; Palade, V.; Kanarachos, S. Learning to localise automated vehicles in challenging environments using Inertial Navigation Systems (INS). Appl. Sci. 2021, 11, 1270. [Google Scholar] [CrossRef]
- Fischer, G.; Bordoy, J.; Schott, D.J.; Xiong, W.; Gabbrielli, A.; Hoflinger, F.; Fischer, K.; Schindelhauer, C.; Rupitsch, S.J. Multimodal Indoor Localization: Fusion Possibilities of Ultrasonic and Bluetooth Low-Energy Data. IEEE Sens. J. 2022, 22, 5857–5868. [Google Scholar] [CrossRef]
- Mohanty, S.; Tripathy, A.; Das, B. An overview of a low energy UWB localization in IoT based system. In Proceedings of the 2021 International Symposium of Asian Control Association on Intelligent Robotics and Industrial Automation (IRIA), Goa, India, 20–22 September 2021; pp. 293–296. [Google Scholar]
- Zhang, H.; Zhang, Z.; Zhang, S.; Xu, S.; Cao, S. Fingerprint-based localization using commercial lte signals: A field-trial study. In Proceedings of the IEEE Vehicular Technology Conference, Honolulu, HI, USA, 22–25 September 2019; pp. 1–5. [Google Scholar]
- Xiang, C.; Zhang, S.; Xu, S.; Chen, X.; Cao, S.; Alexropoulos, G.C.; Lau, V.K. Robust sub-meter level indoor localization with a single WiFi access point—Regression versus classification. IEEE Access 2019, 7, 146309–146321. [Google Scholar] [CrossRef]
- Morar, A.; Moldoveanu, A.; Mocanu, I.; Moldoveanu, F.; Radoi, I.E.; Asavei, V.; Gradinaru, A.; Butean, A. A comprehensive survey of indoor localization methods based on computer vision. Sensors 2020, 20, 2641. [Google Scholar] [CrossRef]
- Piasco, N.; Sidibé, D.; Demonceaux, C.; Gouet-Brunet, V. A survey on visual-based localization: On the benefit of heterogeneous data. Pattern Recognit. 2018, 74, 90–109. [Google Scholar] [CrossRef] [Green Version]
- Huang, B.; Zhao, J.; Liu, J. A survey of simultaneous localization and mapping. arXiv 2019, arXiv:1909.05214. [Google Scholar]
- Thrun, S.; Burgard, W.; Fox, D. Probabilistic Robotics; MIT Press: Cambridge, MA, USA, 2005; pp. 309–384. [Google Scholar]
- Grisetti, G.; Stachniss, C.; Burgard, W. Improved techniques for grid mapping with rao-blackwellized particle filters. IEEE Trans. Robot. 2007, 23, 34. [Google Scholar] [CrossRef] [Green Version]
- Hess, W.; Kohler, D.; Rapp, H.; Andor, D. Real time loop closure in 2d lidar slam. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 1271–1278. [Google Scholar]
- Jiao, J.; Deng, Z.; Arain, Q.A.; Li, F. Smart fusion of multi-sensor ubiquitous signals of mobile device for localization in gnss-denied scenarios. Wirel. Pers. Commun. 2021, 116, 1507–1523. [Google Scholar] [CrossRef]
- Dong, J.; Xiao, Y.; Noreikis, M.; Ou, Z.; Ylä-Jääski, A. iMoon: Using Smartphones for Image-based Indoor Navigation. ACM Conf. Embed. Netw. Sens. Syst. 2015, 11, 85–97. [Google Scholar]
- Xu, H.; Yang, Z.; Zhou, Z.; Shangguan, L.; Yi, K.; Liu, Y. Indoor Localization via Multi-modal Sensing on Smartphones. In Proceedings of the ACM International Joint Conference on Pervasive and Ubiquitous Computing, Heidelberg, Germany, 12–16 September 2016; pp. 208–219. [Google Scholar]
- Hu, Z.; Huang, G.; Hu, Y.; Yang, Z. WI-VI Fingerprint: WiFi and Vision Integrated Fingerprint for Smartphone-based Indoor Self-localization. In Proceedings of the IEEE International Conference on Image Processing, Beijing, China, 17–20 September 2017; pp. 4402–4406. [Google Scholar]
- Kendall, A.; Grimes, M.; Cipolla, R. Posenet: A convolutional network for real-time 6-dof camera relocalization. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 2938–2946. [Google Scholar]
- Walch, F.; Hazirbas, C.; Leal-Taixe, L.; Sattler, T.; Hilsenbeck, S.; Cremers, D. Image-based localization using lstms for structured feature correlation. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 627–637. [Google Scholar]
- Arjelovic, R.; Gronat, P.; Torii, A.; Pajdla, T.; Sivic, J. Netvlad: Cnn architecture for weakly supervised place recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 6, 1437–1451. [Google Scholar]
- Hu, H.; Qiao, Z.; Cheng, M.; Liu, Z.; Wang, H. Dasgil: Domain adaptation for semantic and geometric-aware image-based localization. IEEE Trans. Image Process. 2020, 12, 1342–1353. [Google Scholar] [CrossRef] [PubMed]
- Liu, M.Y.; Breuel, T.; Kautz, J. Unsupervised image-to-image translation networks. arXiv 2017, arXiv:1703.00848. [Google Scholar]
- Kim, T.; Cha, M.; Kim, H.; Lee, J.K.; Kim, J. Learning to discover cross-domain relations with generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; Volume 3, pp. 1857–1865. [Google Scholar]
- Anoosheh, A.; Agustsson, E.; Timofte, R.; Van Gool, L. Combogan: Unrestrained scalability for image domain translation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Salt Lake City, UT, USA, 18–22 June 2018; pp. 896–8967. [Google Scholar]
- Anoosheh, A.; Sattler, T.; Timofte, R.; Pollefeys, M.; Van Gool, L. Night-to-day image translation for retrieval-based localization. In Proceedings of the 2019 International Conference on Robotics and Automation(ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 5958–5964. [Google Scholar]
- Hu, H.; Wang, H.; Liu, Z.; Yang, C.; Chen, W.; Xie, L. Retrieval-based localization based on domain-invariant feature learning under changing environments. In Proceedings of the 2019 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Macau, China, 3–8 November 2019; pp. 3684–3689. [Google Scholar]
- Wang, Y.; Yao, Q.; Kwok, J.T.; Ni, L.M. Generalizing from a few examples: A survey on few-shot learning. ACM Comput. Surv. (CSUR) 2020, 53, 1–34. [Google Scholar] [CrossRef]
- Ravi, S.; Larochelle, H. Optimization as a model for few-shot learning. In Proceedings of the International Conference on Learning Representations(ICLR), Toulon, France, 24–26 April 2017. [Google Scholar]
- Li, W.; Wang, L.; Xu, J.; Huo, J.; Gao, Y.; Luo, J. Revisiting local descriptor based image-to-class measure for few-shot learning. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 7253–7260. [Google Scholar]
- Sun, Q.; Liu, Y.; Chua, T.S.; Schiele, B. Meta-transfer learning for few-shot learning. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 403–412. [Google Scholar]
- Qi, H.; Brown, M.; Lowe, D.G. Low-shot learning with imprinted weights. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5822–5830. [Google Scholar]
- Qiao, S.; Liu, C.; Shen, W.; Yuille, A.L. Few-shot image recognition by predicting parameters from activations. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7229–7238. [Google Scholar]
- Gidaris, S.; Komodakis, N. Dynamic few-shot visual learning without forgetting. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4367–4375. [Google Scholar]
- Chen, W.Y.; Liu, Y.C.; Kira, Z.; Wang, Y.C.F.; Huang, J.B. A closer look at few-shot classification. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Zhang, H.; Li, Y. Lightgbm indoor positioning method based on merged wi-fi and image fingerprints. Sensors 2021, 21, 3662. [Google Scholar]
- Huang, G.; Hu, Z.; Wu, J.; Xiao, H.; Zhang, F. Wifi and vision-integrated fingerprint for smartphone-based self-localization in public indoor scenes. IEEE Internet Things J. 2020, 7, 6748–6761. [Google Scholar] [CrossRef]
- Jiao, J.; Wang, X.; Deng, Z. Build a robust learning feature descriptor by using a new image visualization method for indoor scenario recognition. Sensors 2017, 17, 1569. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Redžić, M.D.; Laoudias, C.; Kyriakides, I. Image and wlan bimodal integration for indoor user localization. IEEE Trans. Mob. Comput. 2020, 19, 1109–1122. [Google Scholar] [CrossRef] [Green Version]
- Cartographer. Available online: https://google-cartographer.readthedocs.io/en/latest/ (accessed on 12 March 2022).
- Zhou, R.; Lu, X.; Zhao, P.; Chen, J. Device-free Presence Detection and Localization with SVM and CSI Fingerprinting. IEEE Sens. J. 2017, 17, 7990–7999. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Module | Layers | Parameters |
|---|---|---|
| Generators | Conv1 | |
| Conv2 | ||
| Conv3 | ||
| Res1-9 | ||
| Uconv1 | ||
| Uconv2 | ||
| Uconv3 | ||
| Discriminator | Conv1 | |
| Conv2 | ||
| Conv3 | ||
| Conv4 | ||
| Conv5 |
| Parameter | Value | Parameter | Value |
|---|---|---|---|
| 50 | 5 | ||
| 492 | 752 | ||
| 780 | 3 | ||
| 24 | 15 | ||
| 2 | 2 | ||
| J | 4 | N | 4 |
| NVIDIA Titan X | Pytorch |
| Methods | Running Time | Memory Space | Accuracy | MSE |
|---|---|---|---|---|
| Baseline 1 | 0.01 s | 4.8 MB | 57.93% | 3.43 m |
| Baseline 2 | 1.2 s | 25 MB | 66.87% | 2.64 m |
| JVWL | 0.25 s | 10 MB | 89.22% | 1.24 m |
| Few-Shot Samples | Accuracy | MSE |
|---|---|---|
| Uni_10 | 85.80% | 1.50 m |
| Uni_20 | 89.22% | 1.24 m |
| Ran_10 | 55.49% | 5.16 m |
| Ran_20 | 62.40% | 4.60 m |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhou, G.; Xu, S.; Zhang, S.; Wang, Y.; Xiang, C. Multi-Floor Indoor Localization Based on Multi-Modal Sensors. Sensors 2022, 22, 4162. https://doi.org/10.3390/s22114162
Zhou G, Xu S, Zhang S, Wang Y, Xiang C. Multi-Floor Indoor Localization Based on Multi-Modal Sensors. Sensors. 2022; 22(11):4162. https://doi.org/10.3390/s22114162
Chicago/Turabian StyleZhou, Guangbing, Shugong Xu, Shunqing Zhang, Yu Wang, and Chenlu Xiang. 2022. "Multi-Floor Indoor Localization Based on Multi-Modal Sensors" Sensors 22, no. 11: 4162. https://doi.org/10.3390/s22114162
APA StyleZhou, G., Xu, S., Zhang, S., Wang, Y., & Xiang, C. (2022). Multi-Floor Indoor Localization Based on Multi-Modal Sensors. Sensors, 22(11), 4162. https://doi.org/10.3390/s22114162