
Deep Learning-Based Dynamic Computation Task Offloading for Mobile Edge Computing Networks


Abstract
:1. Introduction
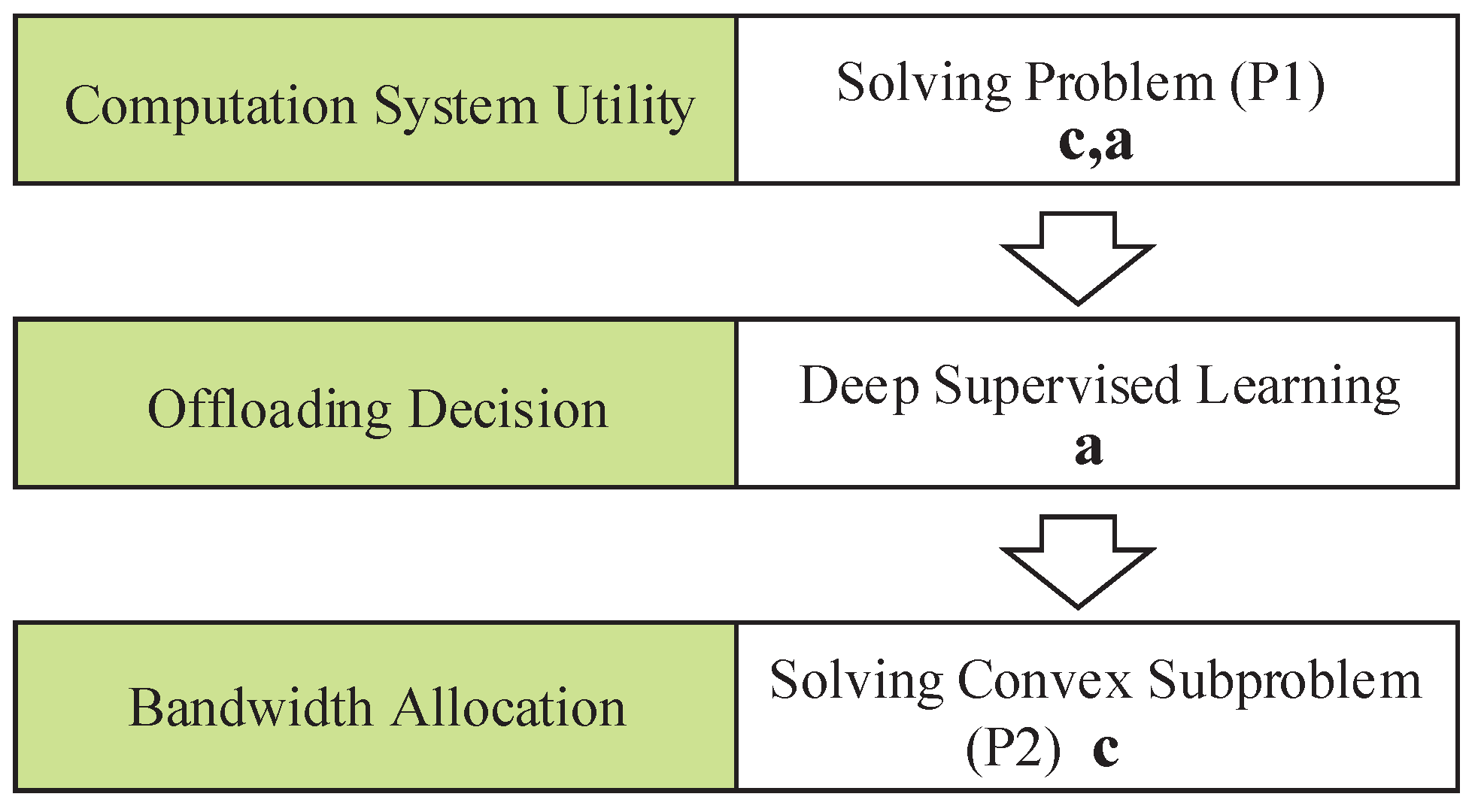
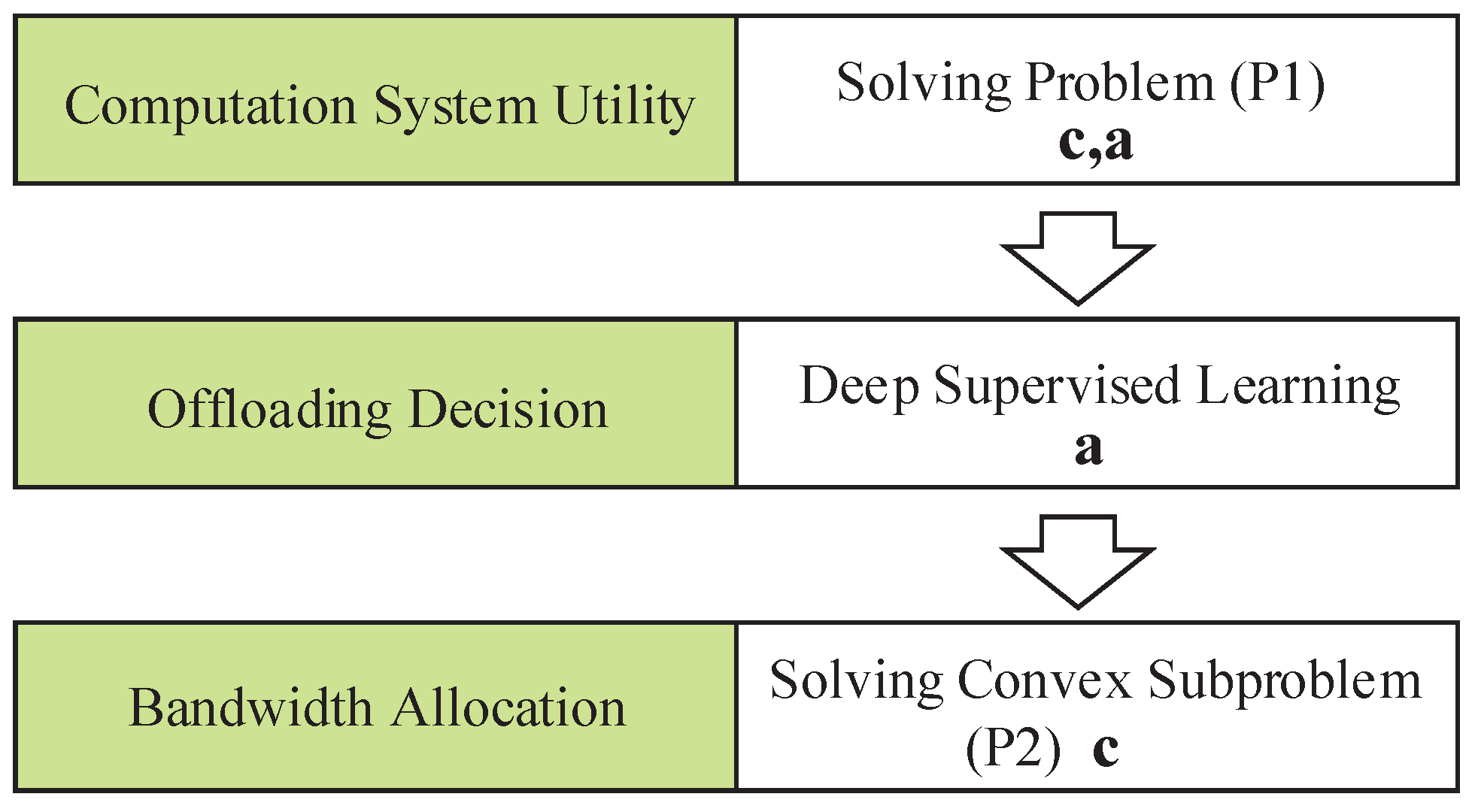
- We model the system utility of the MEC network with prioritized computing tasks such as the weighted sum of energy consumption and delay cost. To minimize the system utility, we decompose the joint optimization problem into the offloading decision subproblem and the transmission bandwidth allocation subproblem, which are further solved via deep learning and optimization methods, respectively.
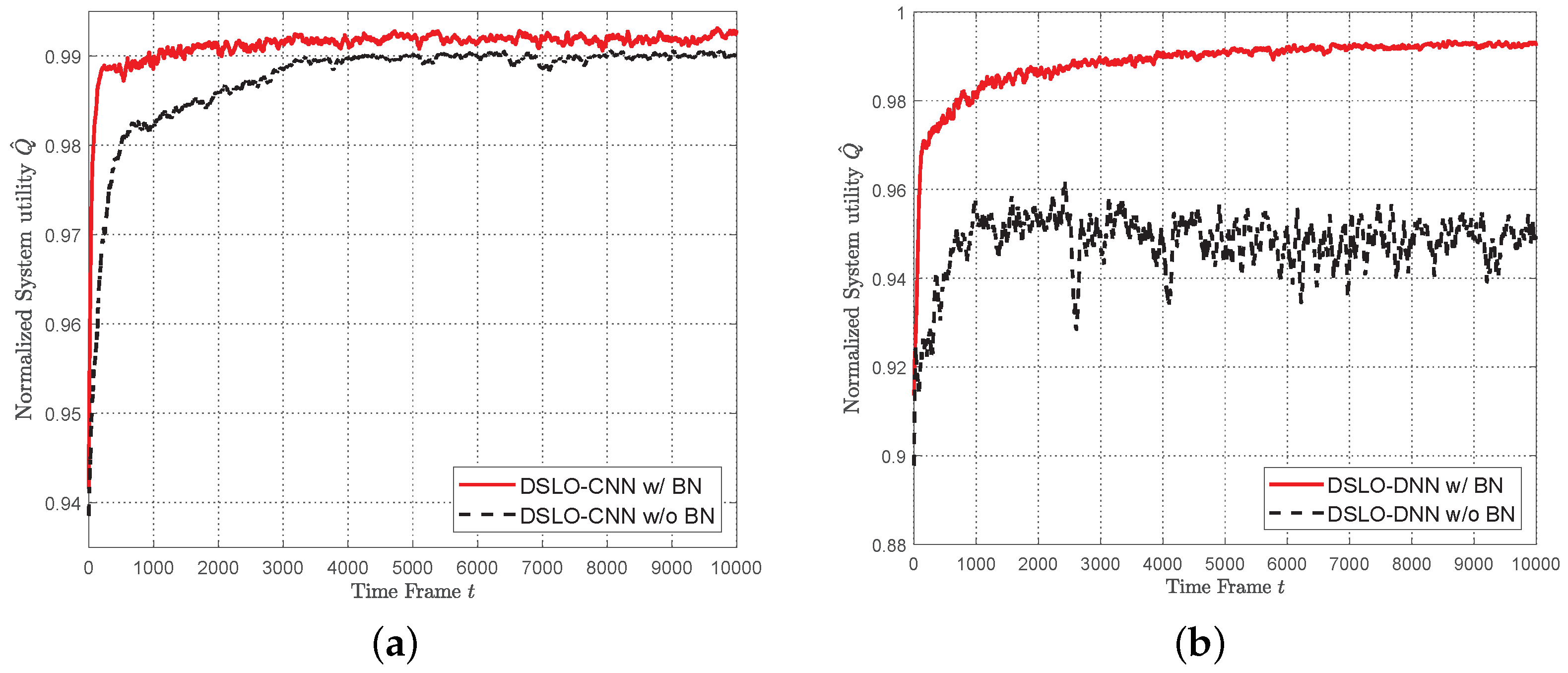
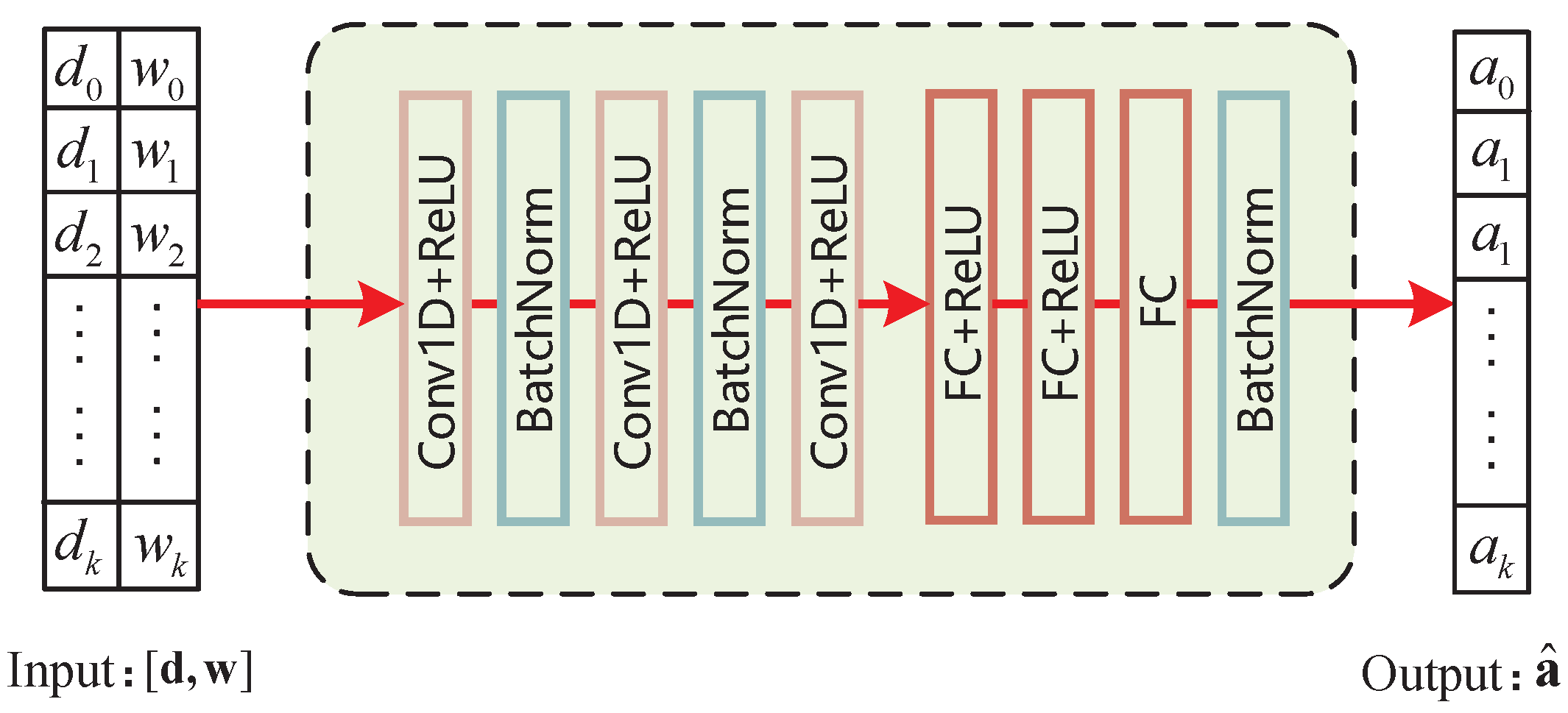
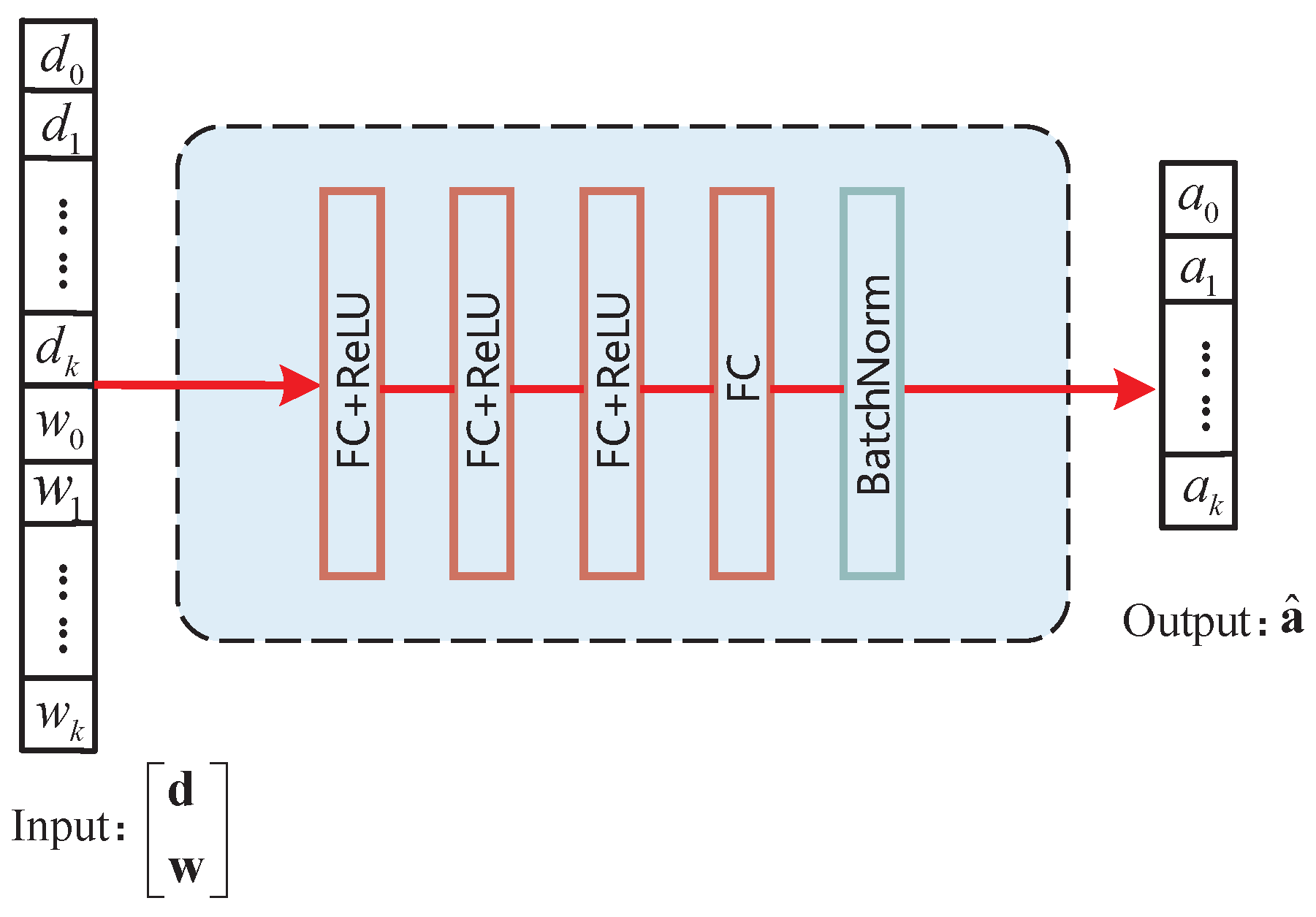
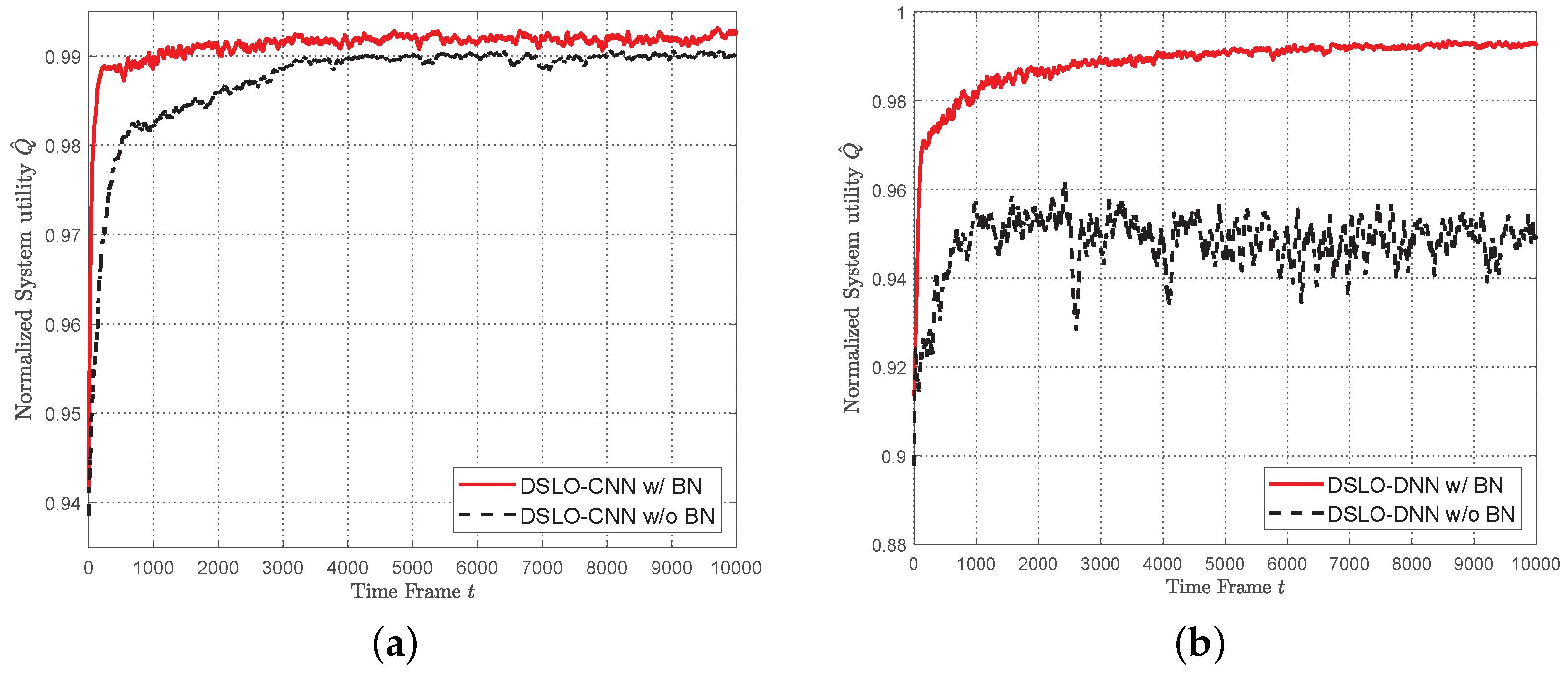
- We propose the DSLO framework to learn from a few training samples to optimize the offloading decision actions. We introduce the batch normalize (BN) layer in CNN/DNN network structure to accelerate the convergence process. It can efficiently learn the mapping from the workload and weight factors to computational offloading.
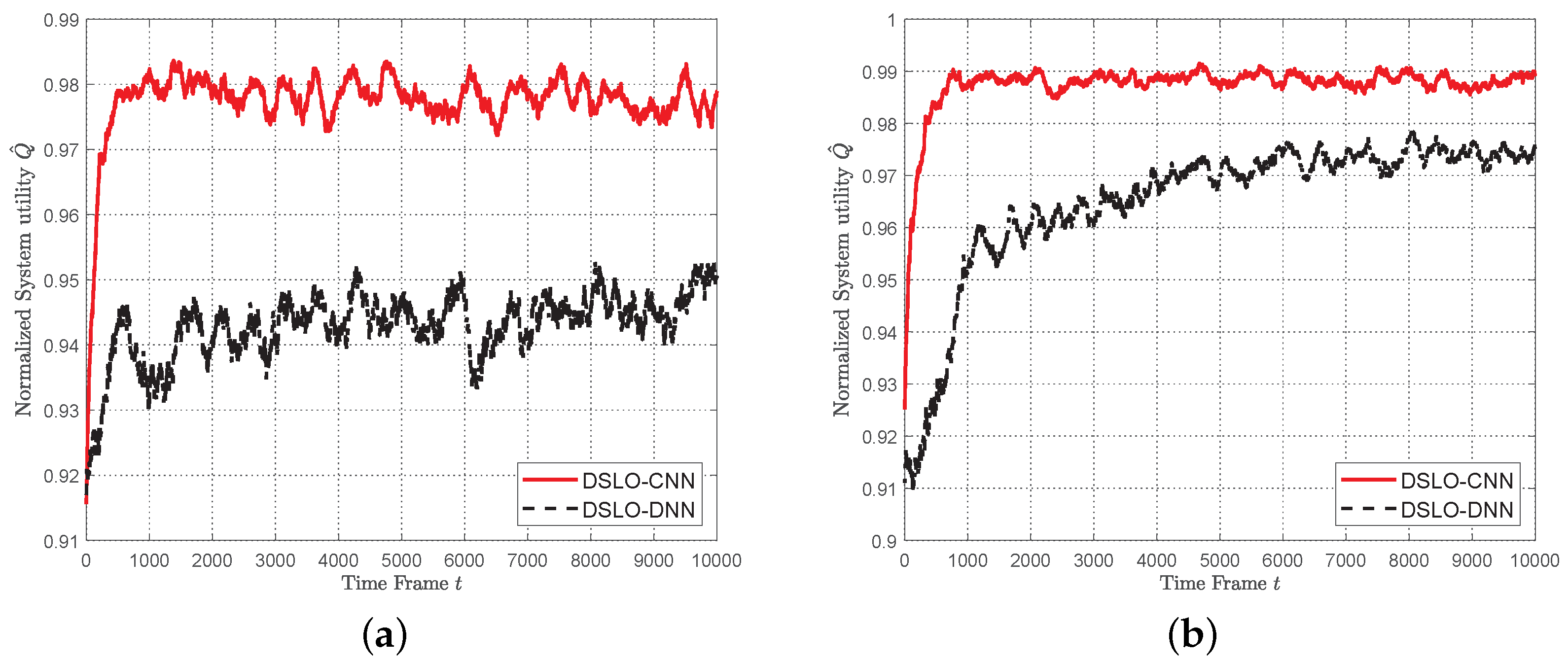
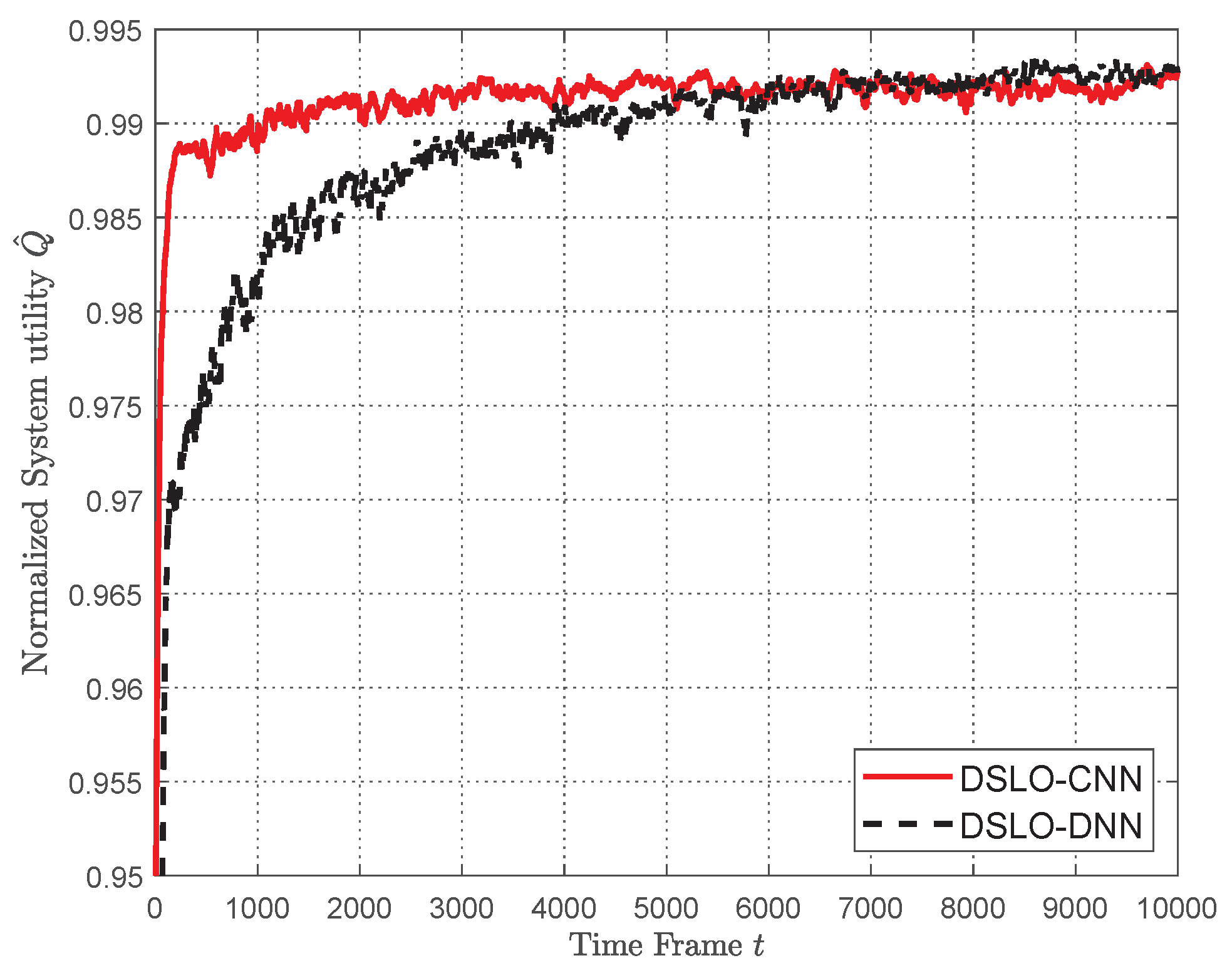
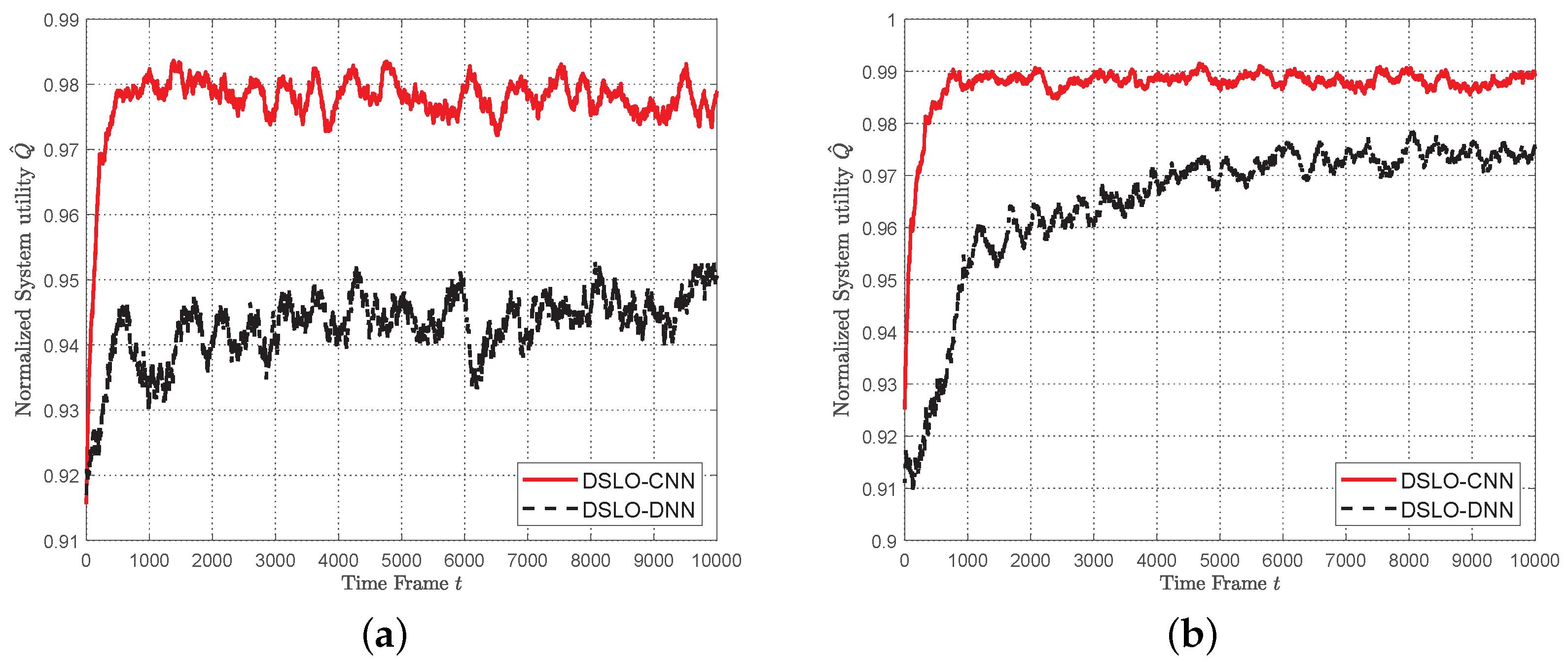
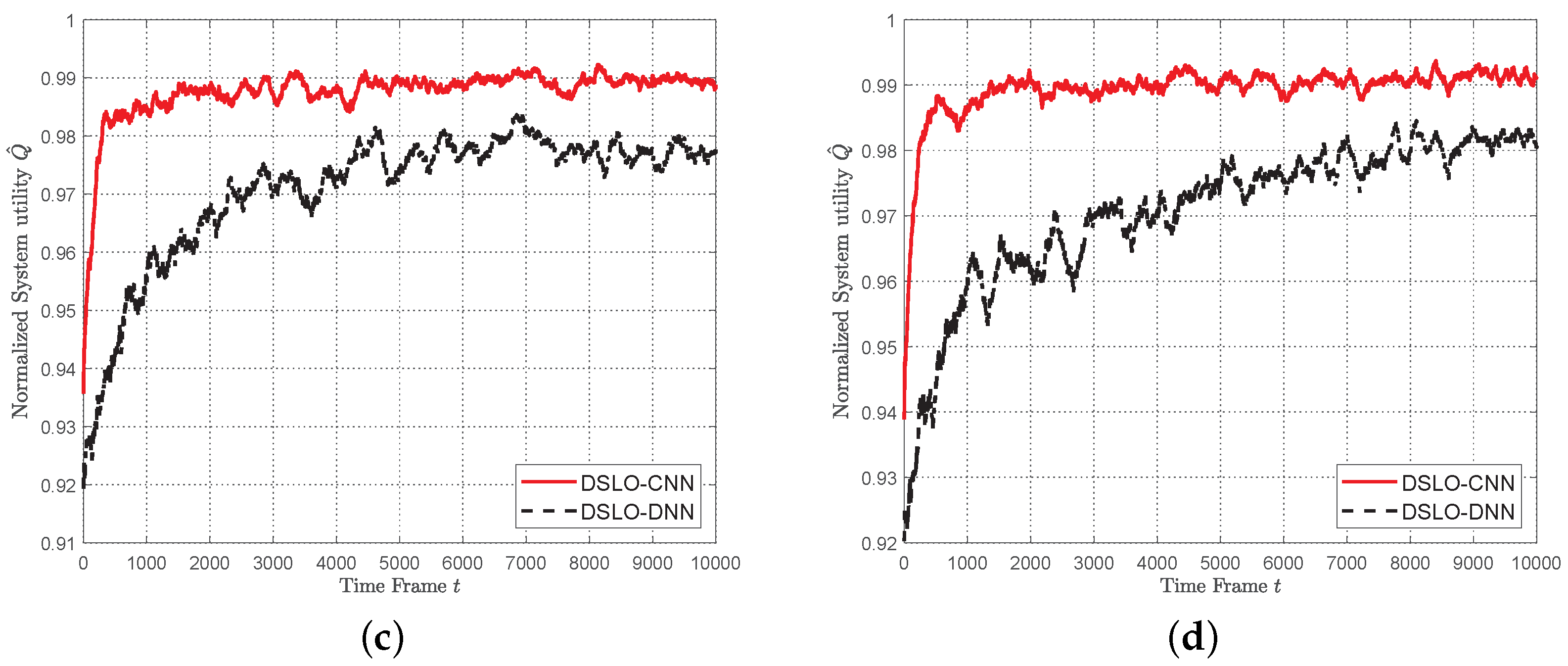
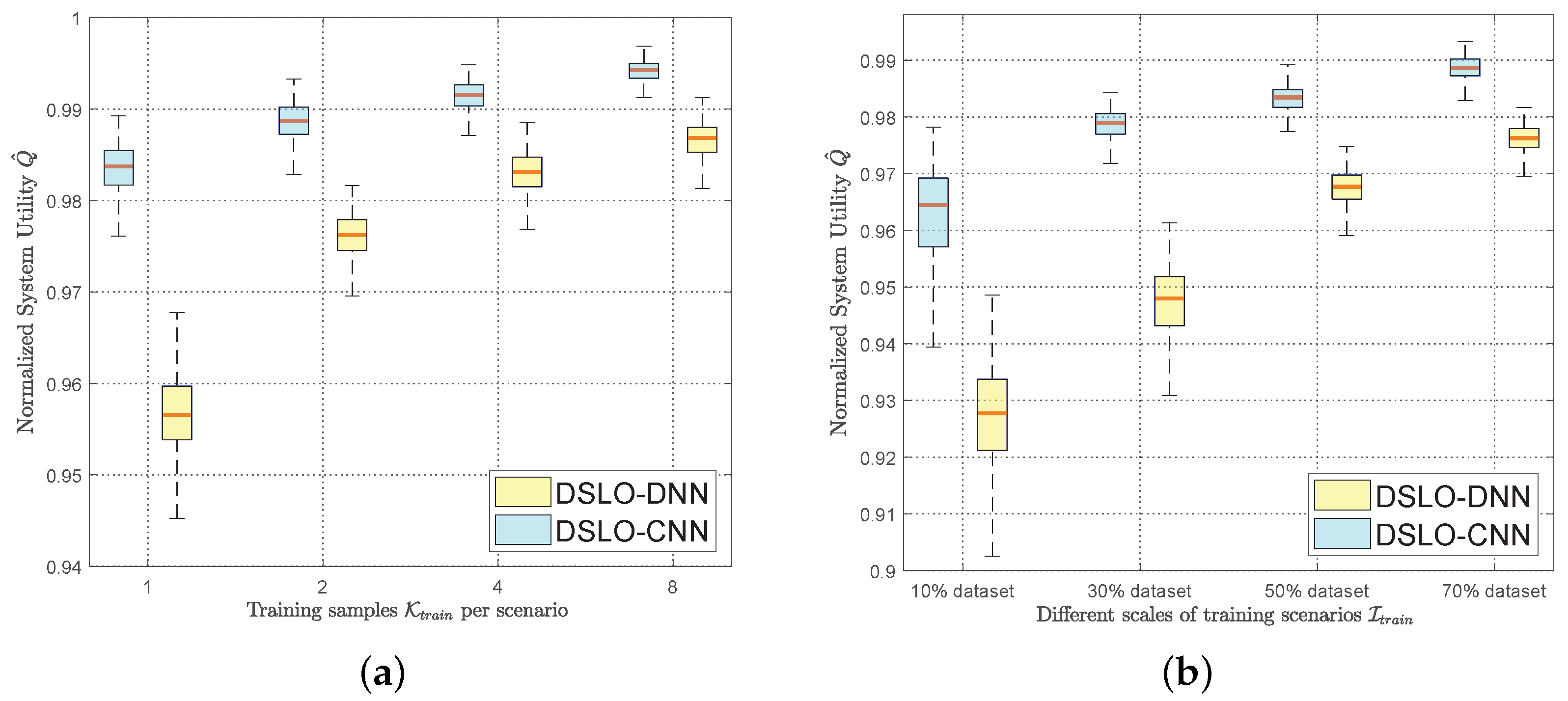
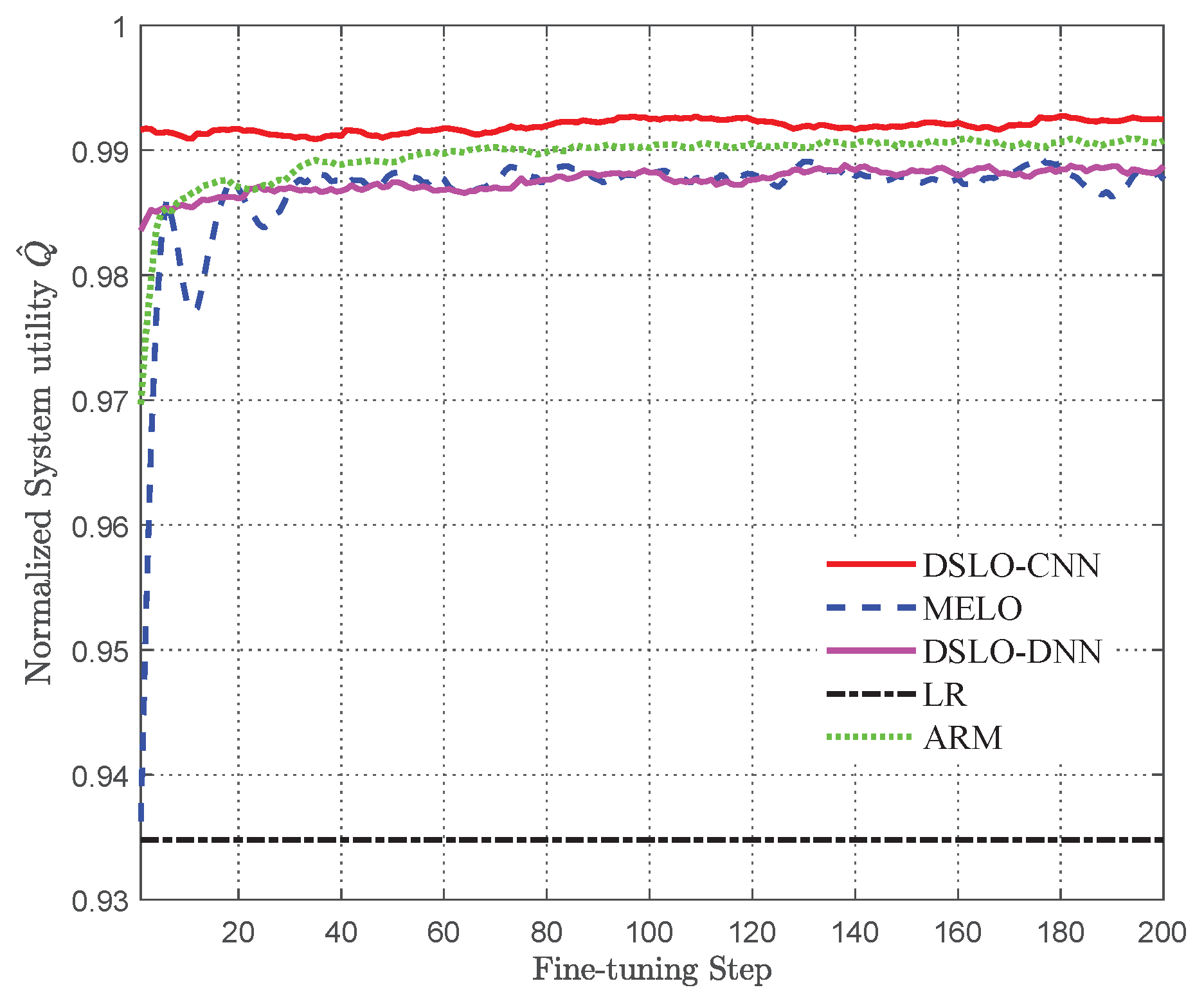
- Simulation results show that DSLO-CNN can generate near-optimal offloading decisions and outperforms DSLO-DNN under MEC scenarios training datasets of different sizes. Significantly, the normalized system utility of the DSLO-CNN algorithm achieves a median value of 96% when only 10% of MEC scenarios are included in the training dataset with two training samples per MEC scenario. In new MEC scenarios, DSLO-CNN converges faster than MELO.
2. Related Work
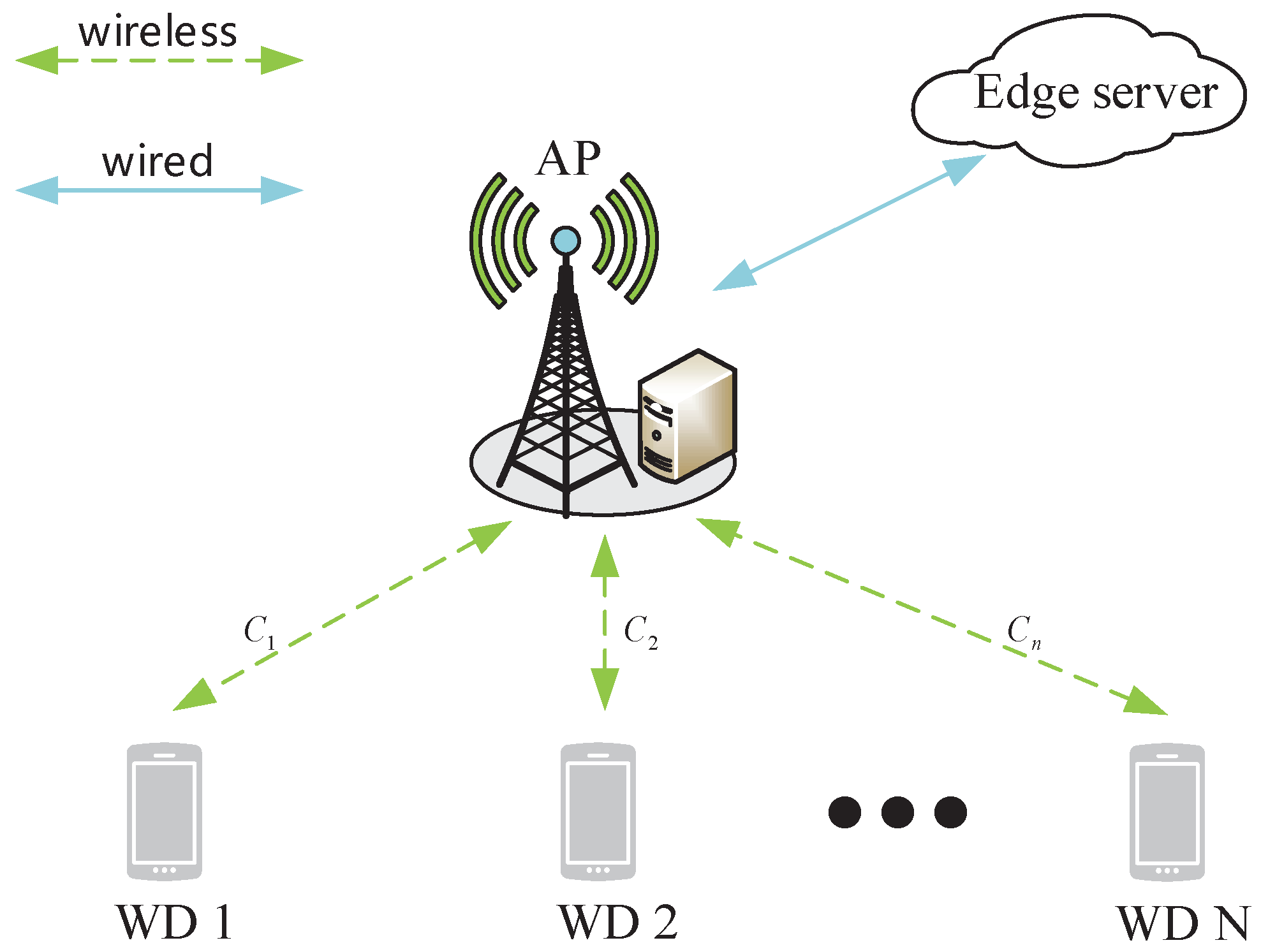
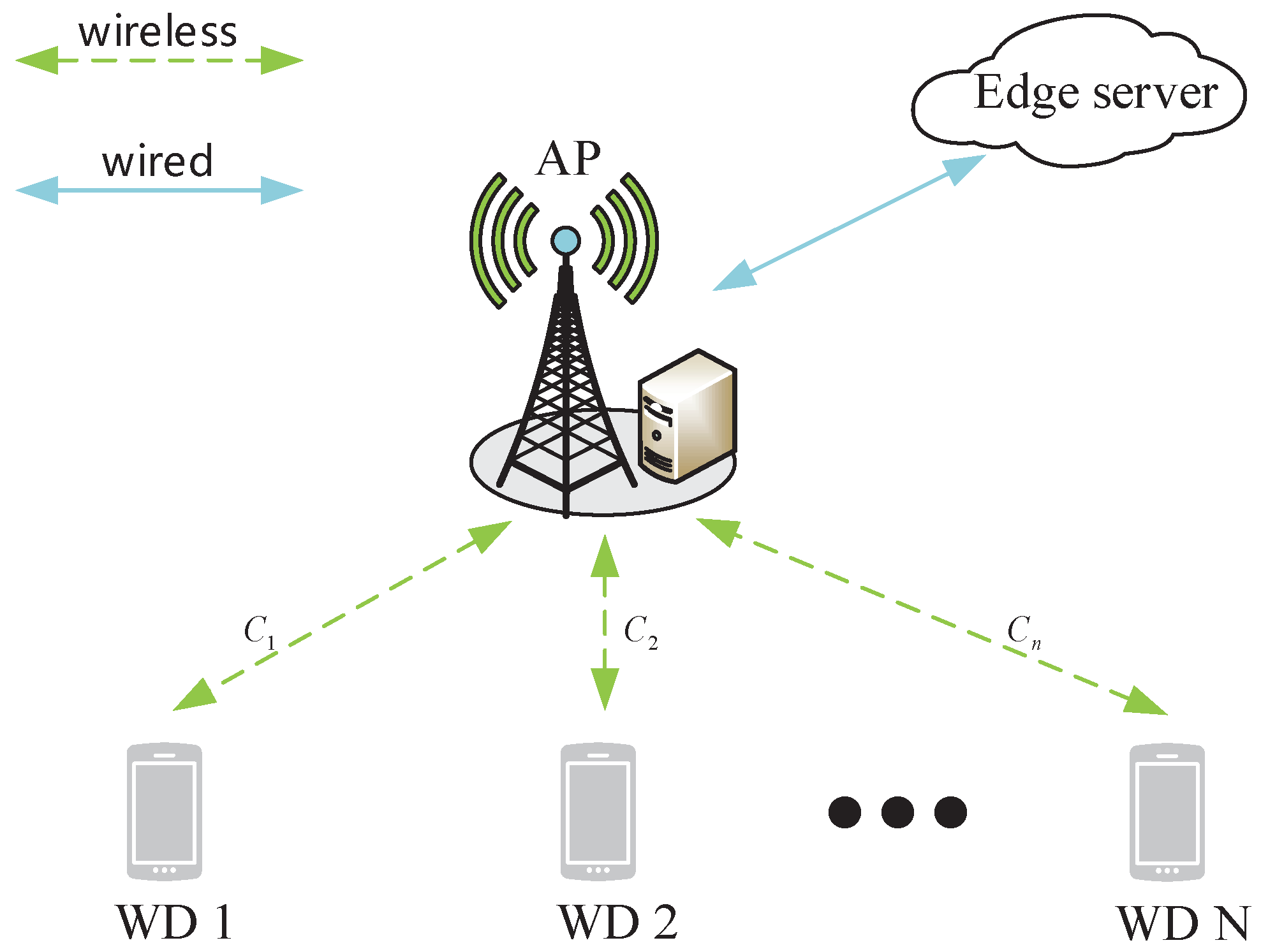
3. System Model
3.1. Energy Consumption
3.2. Time Delay
3.3. Problem Formulation
4. Deep Supervised Learning-Based Offloading Algorithm
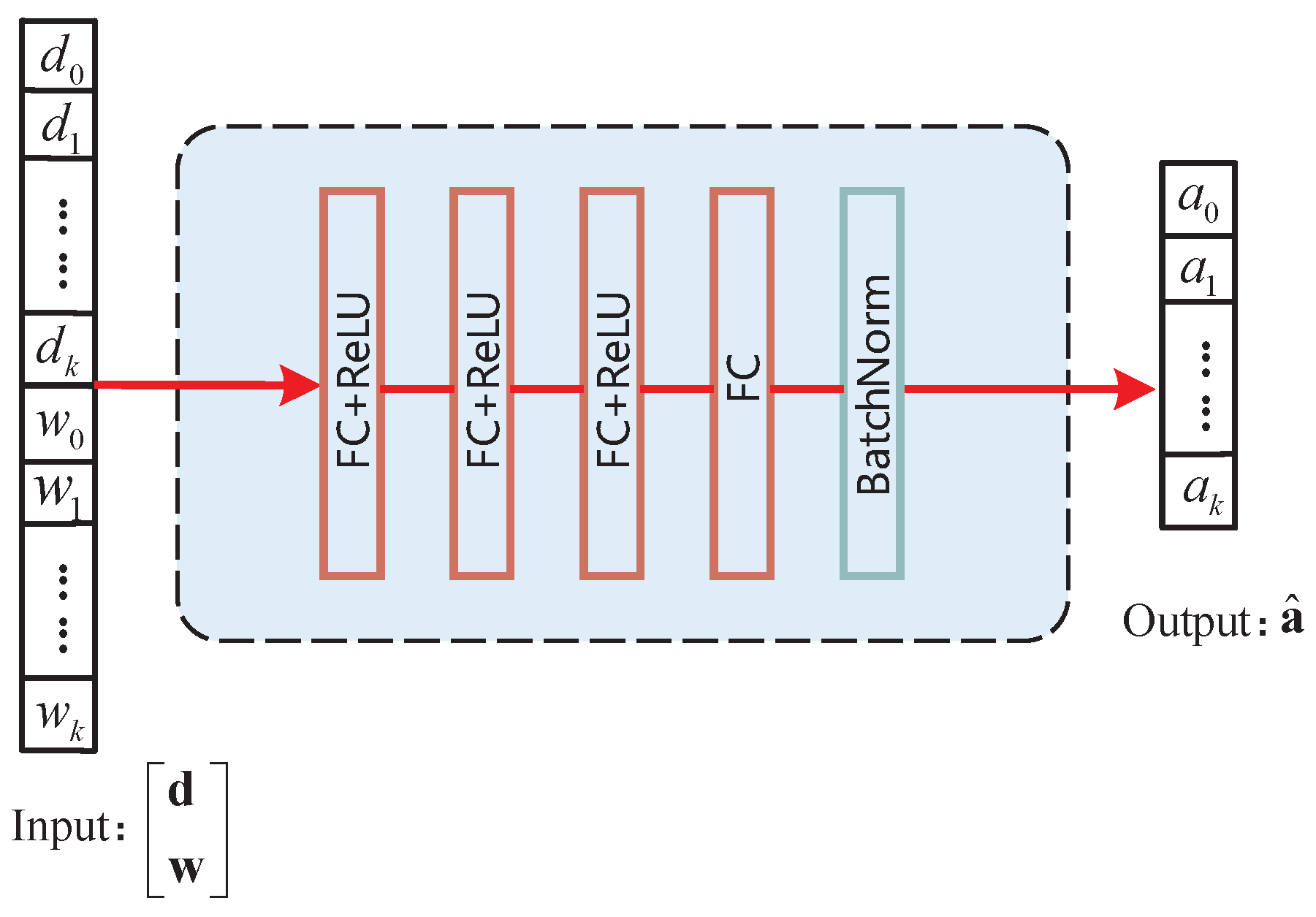
4.1. Neural Network Architecture
4.2. Train DSLO
4.3. Test DSLO
| Algorithm 1: Pseudo-code of the DSLO Algorithm. |
| Input : Dataset of different MEC scenarios and step-size hyper-parameter Output: The trained neural network model Randomly initialize Randomly split into and For each scenario, randomly split its data samples into and Merge all training samples into a whole training set // Training procedure  // Testing procedure Given a new sample set from , generate its offloading decision Evaluate the network utility Q by solving the subproblem (P2) |
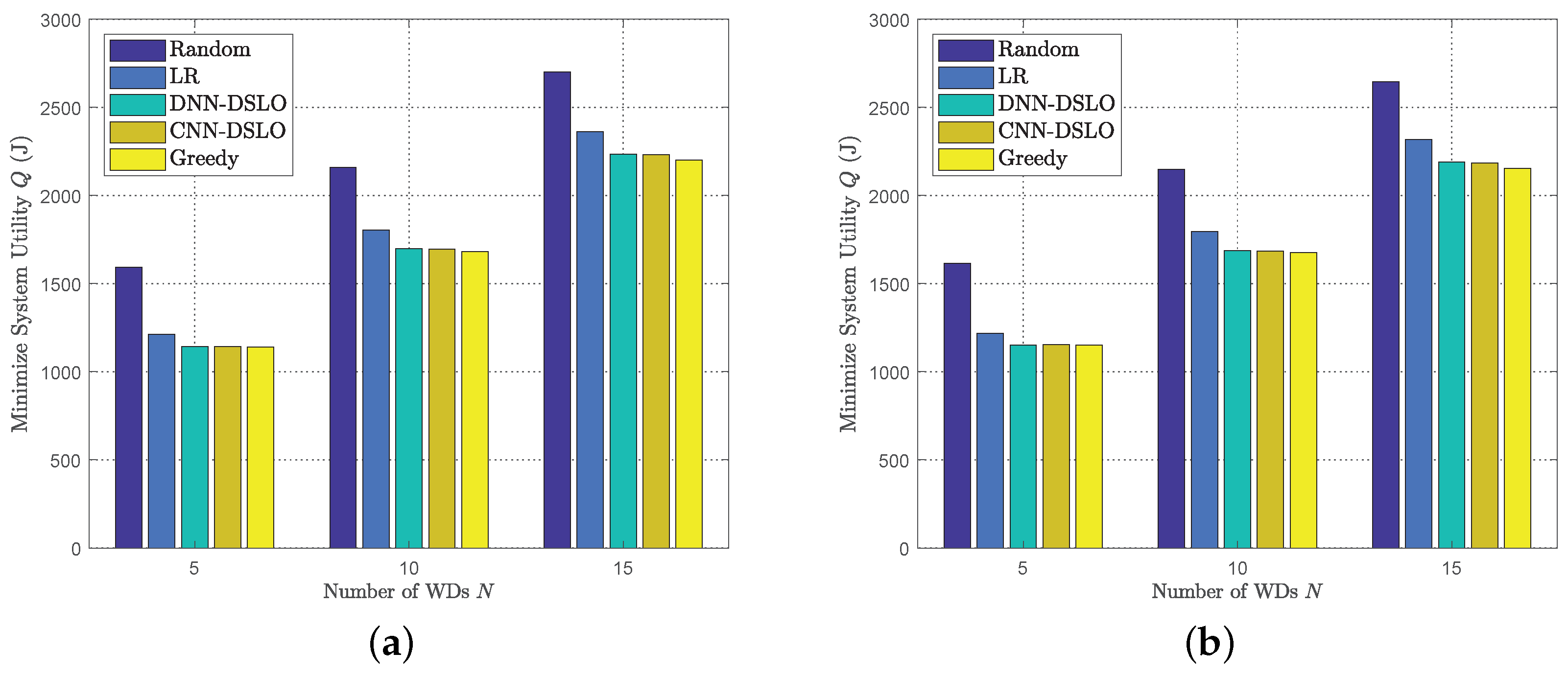
5. Performance Evaluation
5.1. Parameter Settings
- 1
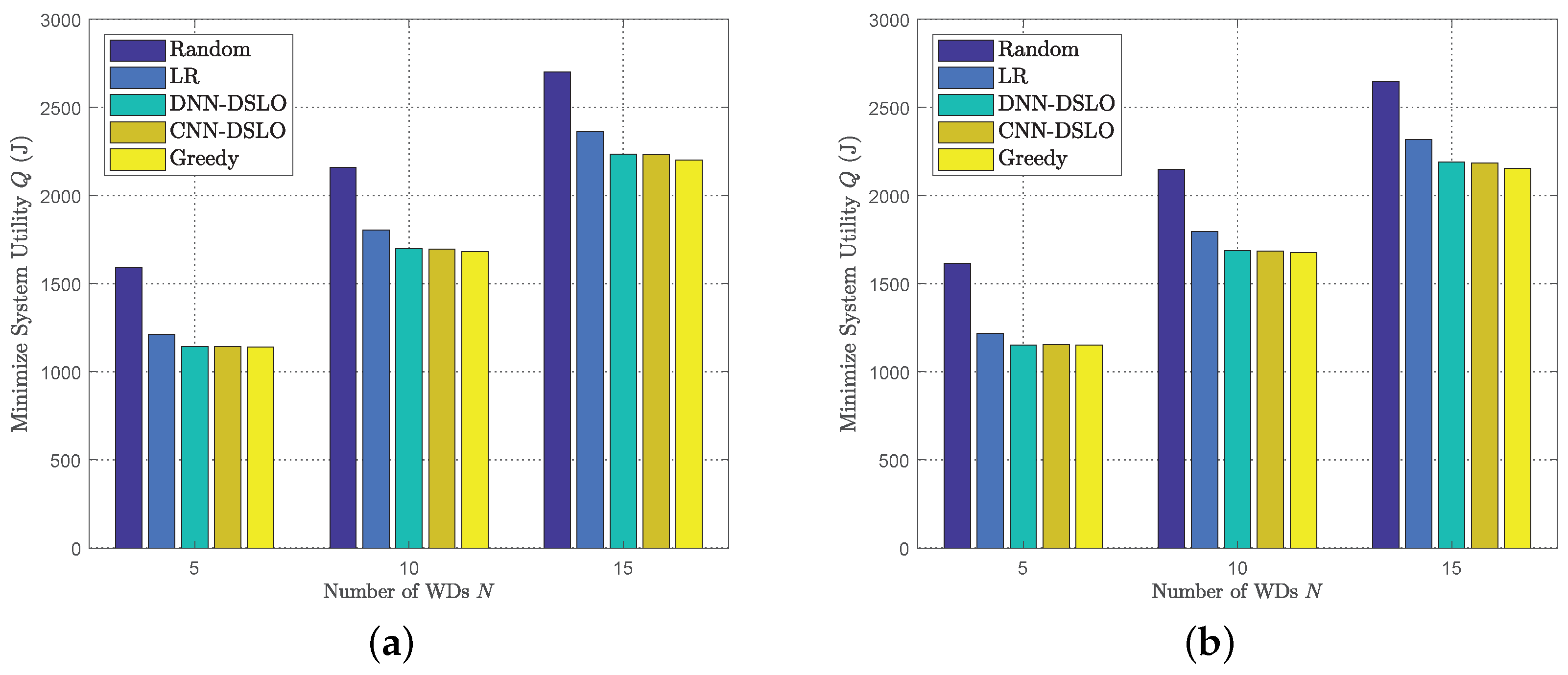
- Random offloading decision: All N WDs randomly generate 0–1 offloading decisions.
- 2
- Linear Relaxation (LR) algorithm [33]: The binary offloading decision variable conditioned on (11) is relaxed to a real number between 0 and 1, as . Then, the optimization problem (P1) with this relaxed constraint is convex with respect to and can be solved using the convex optimization toolbox. Once is obtained, the binary offloading decision is determined as follows
- 3
- Greedy strategy: For the greedy scheme, we enumerate all offloading decision combinations and then adopt the best one.
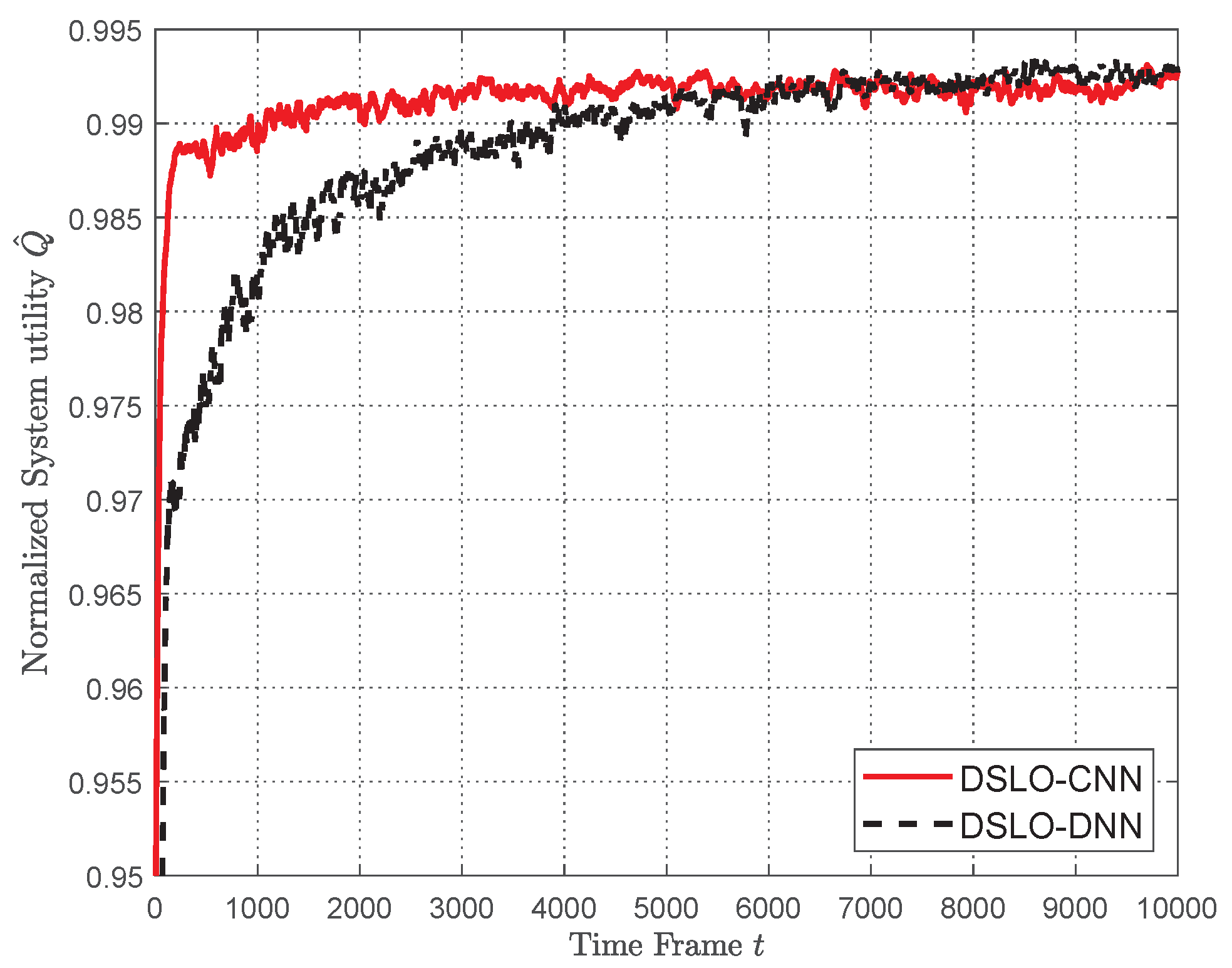
5.2. DSLO with Plenty Training Samples
5.3. DSLO with Few Training Samples
5.4. Comparisons with MELO and ARM
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| N | The number of WDs |
| The weight assigned to the n-th WD | |
| Offloading decision of the n-th WD | |
| Workload of the n-th WD | |
| Number of CPU cycles required by the n-th WD to complete tasks | |
| Energy consumption of the edge server to executing the n -th WD task | |
| Energy consumption to transfer offloading task of the n-th WD | |
| Bandwidth allocated to the n-th WD | |
| C | Total bandwidth |
| The edge processing delay of the n-th WD | |
| The processor’s computing speed of the n-th WD | |
| Local computing unit data energy consumption of the n-th WD | |
| Local computing energy consumption of the n-th WD | |
| Local unit data execution delay of the n-th WD | |
| Local execution delay of the n-th WD | |
| The system utility function | |
| Offloading policy function | |
| The training loss function of the model | |
| Scenario of MEC | |
| The training step | |
| The parameters of the model | |
| Predictive offloading decisions | |
| G | Training iterations |
| Normalized system utility | |
| Mobile Edge Computing | |
| Deep Supervised Learning-based computational Offloading algorithm | |
| MEta-Learning-based computing Offloading algorithm | |
| Wireless Device | |
| Deep Neural Network | |
| Convolutional Neural Network | |
| Batch Normalize | |
| Access Point | |
| One-dimensional Convolutional | |
| Rectified Linear activation function | |
| Linear Relaxation |
References
- Mach, P.; Becvar, Z. Mobile Edge Computing: A Survey on Architecture and Computation Offloading. IEEE Commun. Surv. Tutor. 2017, 19, 1628–1656. [Google Scholar] [CrossRef] [Green Version]
- Lin, H.; Zeadally, S.; Chen, Z.; Labiod, H.; Wang, L. A survey on computation offloading modeling for edge computing. J. Netw. Comput. Appl. 2020, 169, 102781. [Google Scholar] [CrossRef]
- Fan, B.; Wu, Y.; He, Z.; Chen, Y.; Quek, T.; Xu, C.-Z. Digital Twin Empowered Mobile Edge Computing for Intelligent Vehicular Lane-Changing. IEEE Netw. Mag. 2021, 35, 194–201. [Google Scholar] [CrossRef]
- Wang, T.; Li, Y.; Wu, Y. Energy-Efficient UAV Assisted Secure Relay Transmission via Cooperative Computation Offloading. IEEE Trans. Green Commun. Netw. 2021, 5, 1669–1683. [Google Scholar] [CrossRef]
- Zhang, S.; Kong, S.; Chi, K.; Huang, L. Energy Management for Secure Transmission in Wireless Powered Communication Networks. IEEE Internet Things J. 2022, 9, 1171–1181. [Google Scholar] [CrossRef]
- Dinh, T.Q.; Tang, J.; La, Q.D.; Quek, T.Q. Offloading in mobile edge computing: Task allocation and computational frequency scaling. IEEE Trans. Commun. 2017, 65, 571–3584. [Google Scholar]
- Wu, H.; Knottenbelt, W.J.; Wolter, K. An efficient application partitioning algorithm in mobile environments. IEEE Trans. Parallel Distrib. Syst. 2017, 65, 3571–3584. [Google Scholar] [CrossRef]
- Wang, X.; Han, Y.; Leung, V.C.M.; Niyato, D.; Yan, X.; Chen, X. Convergence of edge computing and deep learning: A comprehensive survey. IEEE Commun. Surv. Tutor. 2020, 22, 869–904. [Google Scholar] [CrossRef] [Green Version]
- Ale, L.; Zhang, N.; Fang, X.; Chen, X.; Wu, S.; Li, L. Delay-aware and energy-efficient computation offloading in mobile-edge computing using deep reinforcement learning. IEEE Trans. Cogn. Commun. Netw. 2021, 7, 881–892. [Google Scholar] [CrossRef]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 486–496. [Google Scholar]
- Huang, L.; Zhang, L.; Yang, S.; Qian, L.P.; Wu, Y. Meta-Learning Based Dynamic Computation Task Offloading for Mobile Edge Computing Networks. IEEE Commun. Lett. 2021, 25, 1568–1572. [Google Scholar] [CrossRef]
- Wang, J.; Hu, J.; Min, G.; Zomaya, A.Y.; Georgalas, N. Fast Adaptive Task Offloading in Edge Computing Based on Meta Reinforcement Learning. IEEE Trans. Parallel Distrib. Syst. 2021, 32, 242–253. [Google Scholar] [CrossRef]
- Li, X.; Huang, L.; Wang, H.; Bi, S.; Zhang, Y.-J.A. An Integrated Optimization-Learning Framework for Online Combinatorial Computation Offloading in MEC Networks. IEEE Wirel. Commun. 2022, 29, 170–177. [Google Scholar] [CrossRef]
- Huang, L.; Feng, X.; Zhang, C.; Qian, L.P.; Wu, Y. Deep reinforcement learning-based joint task offloading and bandwidth allocation for multi-user mobile edge computing. Digit. Commun. Netw. 2019, 5, 10–17. [Google Scholar] [CrossRef]
- Huang, L.; Feng, X.; Zhang, L.; Qian, L.; Wu, Y. Multi-Server Multi-User Multi-Task Computation Offloading for Mobile Edge Computing Networks. Sensors 2019, 19, 1446. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Zhu, B.; Chi, K.; Liu, J.; Yu, K.; Mumtaz, S. Efficient Offloading for Minimizing Task Computation Delay of NOMA-Based Multi-access Edge Computing. IEEE Trans. Commun. 2022, 70, 3186–3203. [Google Scholar] [CrossRef]
- You, C.; Huang, K.; Chae, H. Energy Efficient Mobile Cloud Computing Powered by Wireless Energy Transfer. IEEE J. Sel. Areas Commun. 2016, 34, 1757–1771. [Google Scholar] [CrossRef] [Green Version]
- Tran, T.X.; Pompili, D. Joint Task Offloading and Resource Allocation for Multi-Server Mobile-Edge Computing Networks. IEEE Trans. Veh. Technol. 2019, 68, 856–868. [Google Scholar] [CrossRef] [Green Version]
- Bi, S.; Huang, L.; Zhang, Y.-J.A. Joint Optimization of Service Caching Placement and Computation Offloading in Mobile Edge Computing Systems. IEEE Trans. Wirel. Commun. 2020, 19, 4947–4963. [Google Scholar] [CrossRef] [Green Version]
- Huang, L.; Bi, S.; Zhang, Y.-J.A. Deep Reinforcement Learning for Online Computation Offloading in Wireless Powered Mobile-Edge Computing Networks. IEEE Trans. Mob. Comput. 2020, 19, 2581–2593. [Google Scholar] [CrossRef] [Green Version]
- Min, M.; Xiao, L.; Chen, Y.; Cheng, P.; Wu, D.; Zhuang, W. Learning-Based Computation Offloading for IoT Devices with Energy Harvesting. IEEE Trans. Veh. Technol. 2019, 68, 1930–1941. [Google Scholar] [CrossRef] [Green Version]
- Qu, G.; Wu, H.; Li, R.; Jiao, P. DMRO: A Deep Meta Reinforcement Learning-Based Task Offloading Framework for Edge-Cloud Computing. IEEE Trans. Netw. Serv. Manag. 2021, 18, 3448–3459. [Google Scholar] [CrossRef]
- Chen, J.; Xing, H.; Xiao, Z.; Xu, L.; Tao, T. A DRL Agent for Jointly Optimizing Computation Offloading and Resource Allocation in MEC. IEEE Internet Things J. 2021, 8, 17508–17524. [Google Scholar] [CrossRef]
- Chen, X.; Jiao, L.; Li, W.; Fu, X. Efficient Multi-User Computation Offloading for Mobile-Edge Cloud Computing. IEEE/ACM Trans. Netw. 2016, 24, 2827–2840. [Google Scholar] [CrossRef] [Green Version]
- Bi, S.Z.; Huang, L.; Wang, H.; Zhang, Y.-J.A. Lyapunov-Guided Deep Reinforcement Learning for Stable Online Computation Offloading in Mobile-Edge Computing Networks. IEEE Trans. Wirel. Commun. 2021, 20, 7519–7537. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Huang, L.; Feng, X.; Feng, A.; Huang, Y.; Qian, L. Distributed deep learning-based offloading for mobile edge computing networks. Mob. Netw. Appl. 2018. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 448–456. [Google Scholar]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef] [Green Version]
- Christoffersen, P.; Jacobs, K. The importance of the loss function in option valuation. J. Financ. Econ. 2004, 72, 291–318. [Google Scholar] [CrossRef] [Green Version]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning representations by back-propagating errors. Nature 1986, 323, 533–536. [Google Scholar] [CrossRef]
- Miettinen, A.P.; Nurminen, J.K. Energy efficiency of mobile clients in cloud computing. In Proceedings of the 2nd USENIX Conference HotCloud, Boston, MA, USA, 22–25 June 2010. [Google Scholar]
- Guo, S.T.; Xiao, B.; Yang, Y.Y.; Yang, Y. Energy-Efficient Dynamic Offloading and Resource Scheduling in Mobile Cloud Computing. In Proceedings of the 35th Annual IEEE International Conference on Computer Communications (INFOCOM 2016), San Francisco, CA, USA, 10–14 April 2016. [Google Scholar]
- Zhang, M.; Marklund, H.; Dhawan, N.; Gupta, A.; Levine, S.; Finn, C. Adaptive risk minimization: Learning to adapt to domain shift. In Proceedings of the 35th Annual Conference on Neural Information Processing Systems (NeurIPS 2021), Virtual, 6–14 December 2021. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| (a) DSLO-CNN Algorithm | |||
|---|---|---|---|
| Layer | Size | Activation | BN |
| 16 | ReLU | 16 | |
| 16 | ReLU | 16 | |
| 3 | ReLU | - | |
| 21 | ReLU | - | |
| 64 | ReLU | - | |
| 10 | Sigmoid | 10 | |
| (b) DSLO-DNN algorithm | |||
| Layer | Size | Activation | BN |
| 20 | ReLU | - | |
| 120 | ReLU | - | |
| 80 | ReLU | - | |
| 10 | Sigmoid | 10 | |
| Notation | Value | Notation | Value |
|---|---|---|---|
| C | 100 Mbps | 10–30 MB | |
| s/bit | s/bit | ||
| J/bit | 1900 cycles/byte | ||
| J/bit | CPU rate | cycles/s |
| MEC Task Scenarios | Weight | ||
|---|---|---|---|
| N = 5 | N = 10 | N = 15 | |
| {1.0, 1.5, 1.0, 1.5, 1.0} | {1.0, 1.0, 1.5, 1.5, 1.0 1.5, 1.5, 1.0, 1.0, 1.5} | {1.0, 1.0, 1.5, 1.5, 1.5 1.0, 1.5, 1.0, 1.5, 1.0 1.5, 1.5, 1.5, 1.0, 1.0} | |
| {1.0, 1.5, 1.5, 1.5, 1.0} | {1.0, 1.5, 1.0, 1.5, 1.0 1.5, 1.0, 1.5, 1.0, 1.5} | {1.0, 1.5, 1.0, 1.5, 1.0 1.5, 1.5, 1.5, 1.0, 1.0 1.0, 1.0, 1.5, 1.5, 1.0} | |
| # of WDs | DSLO-CNN | DSLO-DNN | LR | ||
|---|---|---|---|---|---|
| Train | Test | Train | Test | ||
| 5 | s | s | s | s | s |
| 10 | s | s | s | s | s |
| 15 | s | s | s | s | s |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yang, S.; Lee, G.; Huang, L. Deep Learning-Based Dynamic Computation Task Offloading for Mobile Edge Computing Networks. Sensors 2022, 22, 4088. https://doi.org/10.3390/s22114088
Yang S, Lee G, Huang L. Deep Learning-Based Dynamic Computation Task Offloading for Mobile Edge Computing Networks. Sensors. 2022; 22(11):4088. https://doi.org/10.3390/s22114088
Chicago/Turabian StyleYang, Shicheng, Gongwei Lee, and Liang Huang. 2022. "Deep Learning-Based Dynamic Computation Task Offloading for Mobile Edge Computing Networks" Sensors 22, no. 11: 4088. https://doi.org/10.3390/s22114088
APA StyleYang, S., Lee, G., & Huang, L. (2022). Deep Learning-Based Dynamic Computation Task Offloading for Mobile Edge Computing Networks. Sensors, 22(11), 4088. https://doi.org/10.3390/s22114088