1. Introduction
With the development of modern industrial systems and the pursuit of extreme efficiency, complex industrial systems are gradually automated, sophisticated and integrated [
1]. Mechanical failure of key components can easily lead to the collapse of the entire system. To accurately capture the internal status information of key components, high-precision industrial sensors are used to obtain time-series monitoring signals for health status assessment. Due to a large number of checkpoints, high sampling rate and long detection time, the health monitoring system has acquired massive status data. On the one hand, it has prompted the fault diagnosis of complex industrial systems to move into the “data-driven” era [
2], on the other hand, it has also brought great difficulty to fast fault diagnosis in resource-constrained industrial embedded systems [
3].
The existing research on fast fault diagnosis of the rotating components has achieved valuable results. Such as a data-driven bearing prognostic scheme that was designed based on novel health indicators and gated recurrent unit network [
4]. The work [
5] studies the statistical characteristics of the spalling propagation for rotating components, which is conducive to predicting the occurrence of failures. The work [
6] enables dynamic modeling of defect extension and appearance of rotating components, which helps us to predict service life based on defect models. However, there is still a lot of work to be done to achieve fast fault diagnosis in resource-constrained industrial embedded systems. For resource-constrained industrial embedded systems, we believe that we should first achieve lightweight data and optimize the data sampling process. Data sampling refers to monitoring the health status of the target device for a long time through a large number of sensors. The optimization of data sampling mainly adopts data compression. The sampling methods still follow the Nyquist sampling theorem [
7], and the sampled signals contain a lot of redundant information. For fault diagnosis, we pay more attention to the accuracy and timeliness in implementing fault diagnosis in embedded systems, so we optimize in terms of feature extraction and fault classification. Feature extraction refers to obtaining data features from a signal through signal processing methods. The optimization in feature extraction mainly adopts transform domain analysis, which includes principal component analysis [
8] and discrete cosine transform [
9]. Fault classification refers to predicting the fault category of unknown signals by learning data features. The research on fault classification optimization is relatively mature and includes the latest algorithms: ANN [
10], SPBO-SDAE [
11], PSO-DNN [
12] and CS-IMSNs [
13].
Starting from the above three aspects, this work further explores the three limitations:
- 1.
The original sampling signals contain a lot of redundant information, which will greatly increase the pressure for subsequent data transmission, storage and calculation.
- 2.
Features extracted from the original sampling signals have problems such as high computational complexity, long time consumption and incomplete reflection of fault features.
- 3.
Existing fault diagnosis methods cannot effectively balance efficiency and accuracy in resource-constrained environments and cannot effectively classify sparse signals.
Recently, industrial embedded systems [
14] have drawn significant attention when applied to industrial process control [
15] and monitoring [
16,
17,
18] and edge intelligent systems [
19,
20]. Unlike the loose requirements found in traditional Industrial IoT (IIoT) applications, resource-constrained industrial embedded systems set stricter requirements for low latency and small memory. The existing lightweight methods are mainly reflected in model optimization, including network pruning, weight quantization and knowledge distillation. However, there is no method designed for the whole process of fault diagnosis for data sampling, feature extraction and fault classification.
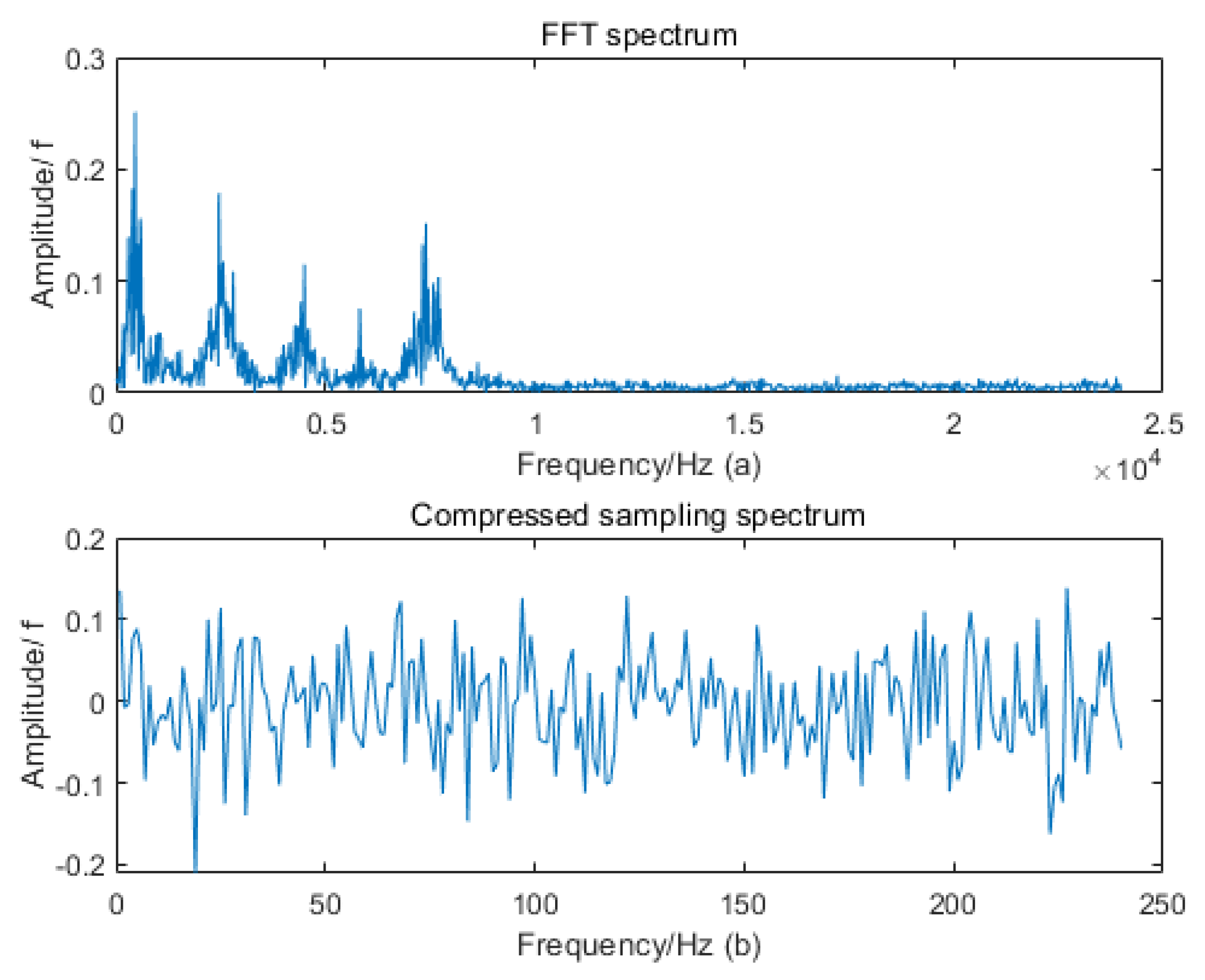
Compressing the data from the data sampling source will significantly reduce the subsequent computational complexity. Compressed sensing (CS) theory, which integrates data sampling and compression, may give us some inspiration [
21]. CS adopts an approximate optimal sampling scheme, theoretically obtains all the information contained in the original signal and effectively realizes the dimension reduction of the signal. It frees data sampling from the Nyquist theory and can achieve signal compression through nonlinear projection in the transformation domain, thereby reducing the mass of redundant data sampling into a small amount of useful information sampling. Therefore, the storage and calculation costs required for feature extraction and fault classification are greatly reduced. Integrating data sampling and data compression, the efficient information perception method provides a brand-new idea for data sampling and processing in real-time monitoring systems.
Some studies have introduced the concept of CS [
22,
23,
24], and the general process of which includes compressed sampling, data transmission and compressed signal reconstruction. Then, the reconstructed signal will be input to the feature extraction and fault classification model. Although these methods reduce the requirements for data storage and data transmission, the subsequent operations are still based on the reconstructed time-domain signals. Therefore, there is still significant room for improvement in diagnosis time if the sparse compressed sampling signal can be directly used in fault diagnosis [
25]. Since the compressed sampling signals contain the information of fault characteristics in a small amount of data, as long as a suitable fault diagnosis model is constructed, efficient fault diagnosis can be achieved.
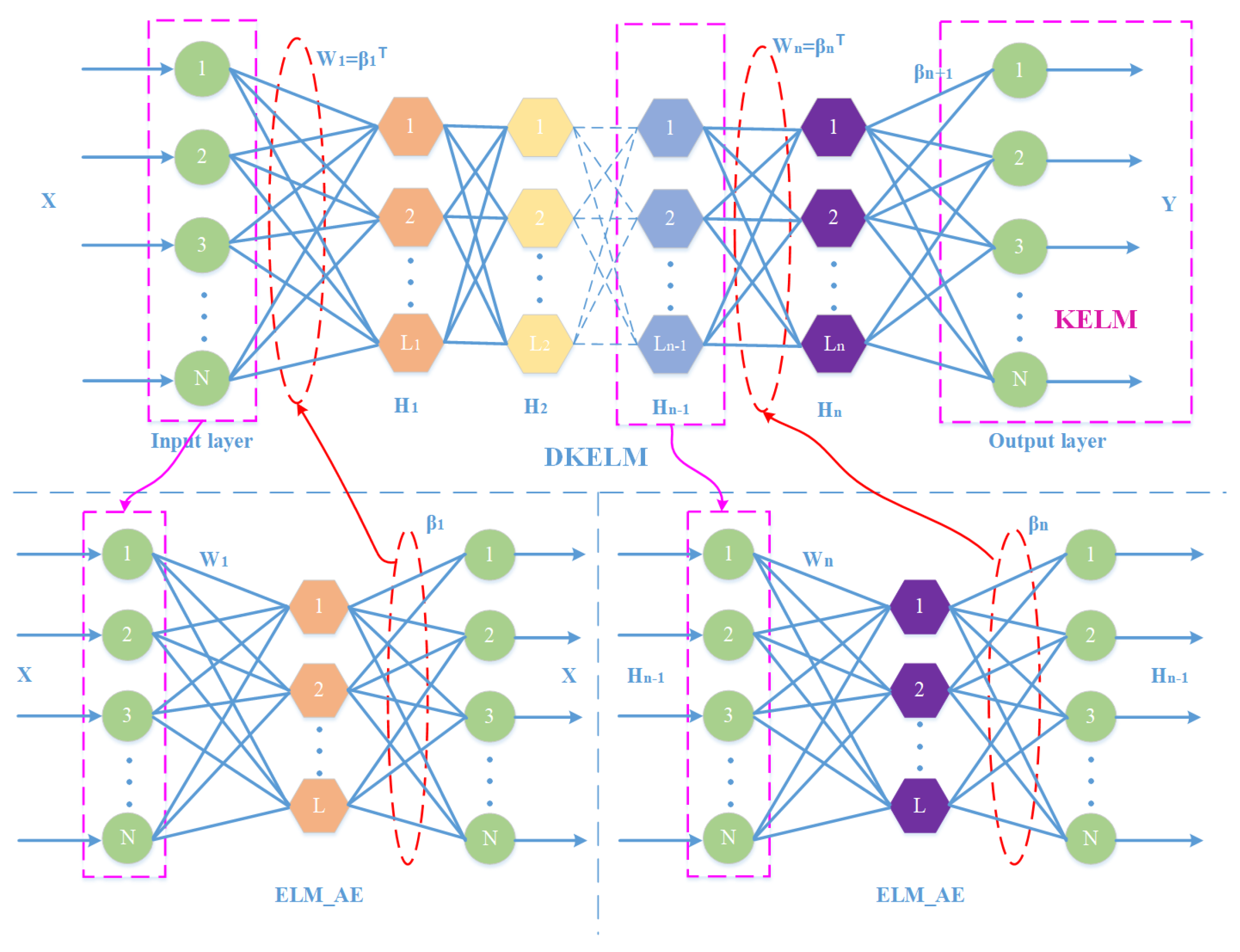
Deep Extreme Learning Machine (DELM) [
26] is a multi-layer neural network that uses Extreme Learning Machine-AutoEncoder (ELM-AE) as the basic unit of unsupervised learning, which performs greedy layer-by-layer unsupervised training on input data. It is widely used because it is faster than other deep neural networks in terms of model training and weight update of hidden layers [
27]. Compared with the ELM-AE, which has a single hidden layer, the DELM can extract more complex fault features in the low-dimensional observation signal. Therefore, the DELM is an ideal fault classification model that integrates the accuracy of DNN and the speed of traditional machine learning [
28]. In order to make more accurate fault classifications for the sparse signal after compressed sampling, this paper introduces the kernel function into DELM to obtain the fault diagnosis module DKELM. DKELM maps low-dimensional nonlinear inseparable data features to high-dimensional space to make it linearly separable, so it has better adaptability to sparse signals.
Combining the advantages of CS and DKELM, this paper proposes a general diagnosis method to realize the functional integration of signal compressed sampling, feature adaptive extraction and fast fault diagnosis. Meanwhile, the Particle Swarm Optimization (PSO) Algorithm [
29] is used to optimize the nodes of each hidden layer, the regularization coefficient, the penalty coefficient and the core parameters of the DKELM so as to achieve the best fault classification results. The main contributions of this paper are summarized as follows:
- 1.
A data-driven general method for fast fault diagnosis is proposed. This method only needs a small amount of compressed sampling data to achieve fast and high-accuracy fault diagnosis, which dramatically reduces diagnosis time in industrial embedded systems.
- 2.
A new adaptive feature extraction method for high-frequency monitoring signals is proposed. Our research found that not all IIoT monitoring signals are strictly sparse, a sparse basis should be added before compressed sampling, and then the transformed high-dimensional signal should be compressed by the observation matrix. This can be seen as a feature representation.
- 3.
An improved DKELM fault diagnosis module is constructed. The module can better adapt to sparse signals and provides a new idea for fast fault diagnosis in industrial embedded systems.
The remainder of this paper is organized as follows.
Section 2 introduces a fast fault diagnosis method based on CS-DKELM.
Section 3 verifies the effectiveness of the method. In addition, our method is compared with existing methods, and the effects of important factors are analyzed. Finally,
Section 4 draws the conclusions.
4. Conclusions
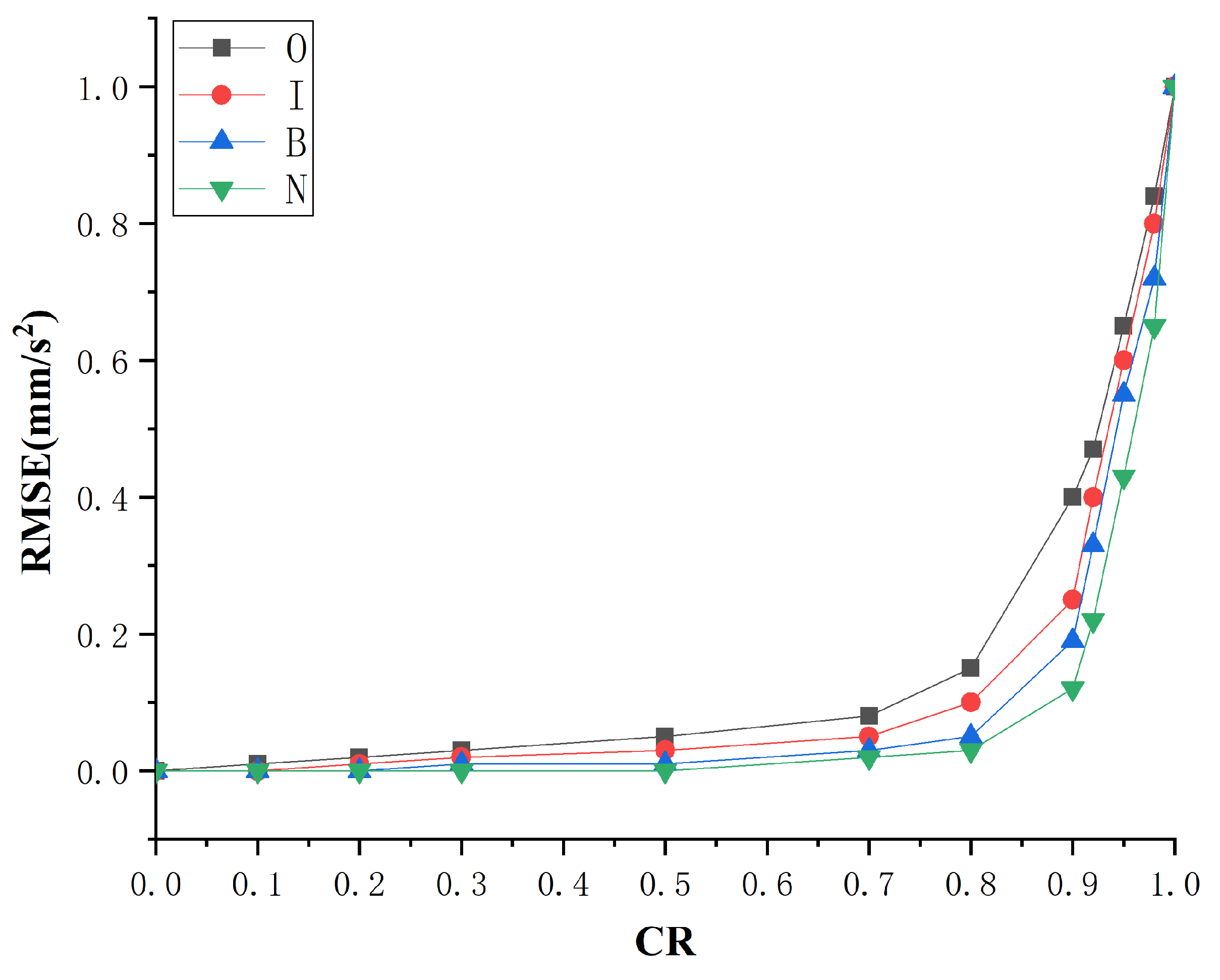
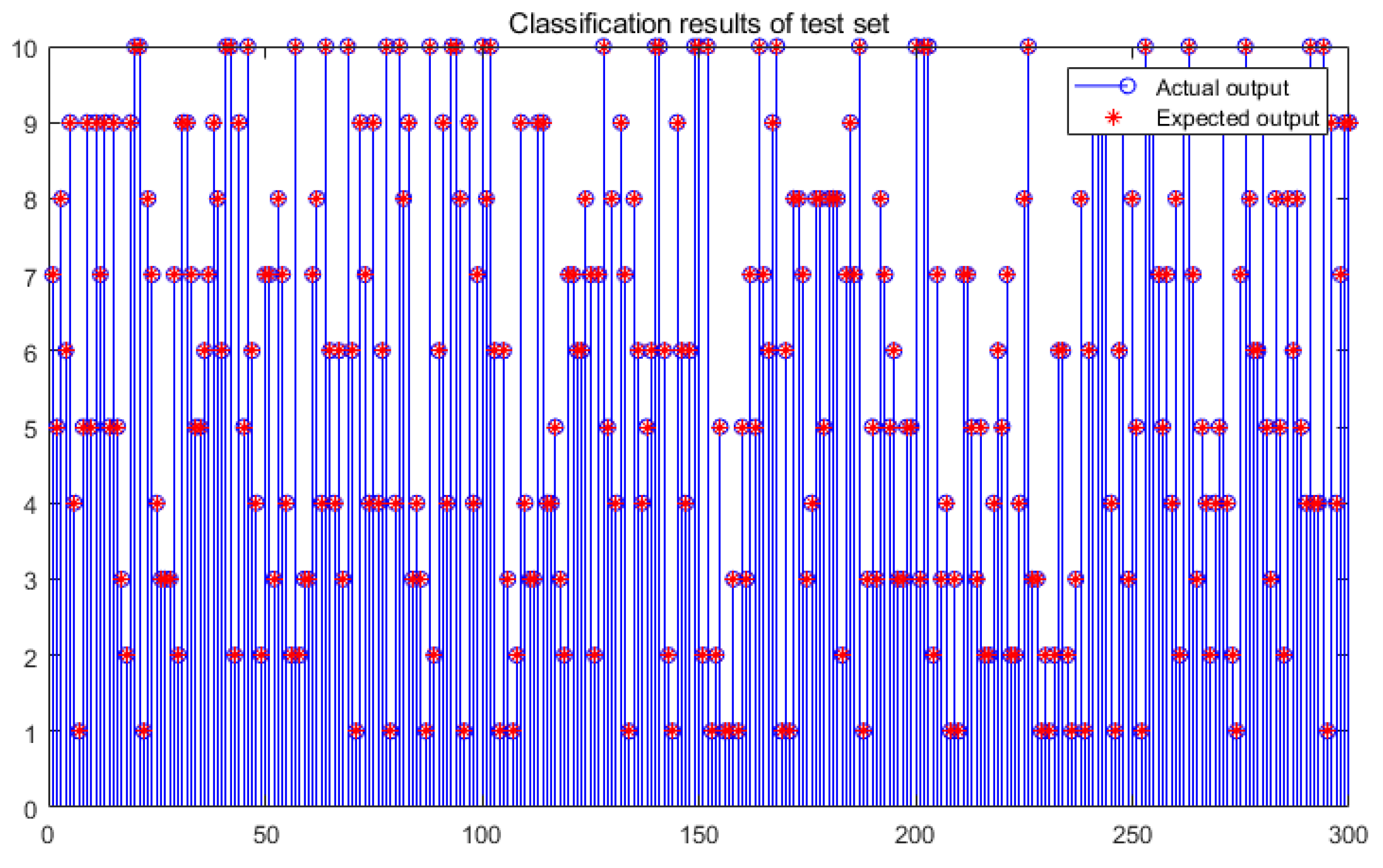
In this work, we propose an integrated method for data sampling and fast fault diagnosis based on CS and DKELM. By compressed sampling the original monitoring signal, CS-DKELM can achieve substantial compression of monitoring data while preserving fault information. This sampling method for mechanical vibration signals greatly improves the efficiency of subsequent fault diagnosis. In the fault diagnosis stage, through the multi-layer nonlinear learning of the low-dimensional sampling values of the original signal, the adaptive extraction of fault features and the fast diagnosis of fault types are realized. We verified the accuracy and efficiency of the CS-DKELM method, and its influencing factors were studied and compared with existing methods. The analysis shows that the intelligent diagnosis method proposed in this paper has higher real-time performance and diagnostic accuracy in the resource-constrained industrial embedded systems, which are superior to the existing methods. Moreover, only a small amount of monitoring data needed to be sampled in our scheme, which greatly reduces the pressure of transmission, storage and calculation in the process of fault diagnosis. Finally, we applied this method to the actual hardware platform and achieved ideal experimental results, which verified the practical application value of the method proposed in this paper. In the future work, we will combine edge intelligence technology to study anomaly detection technology for multi-source time series data in industrial embedded platforms.







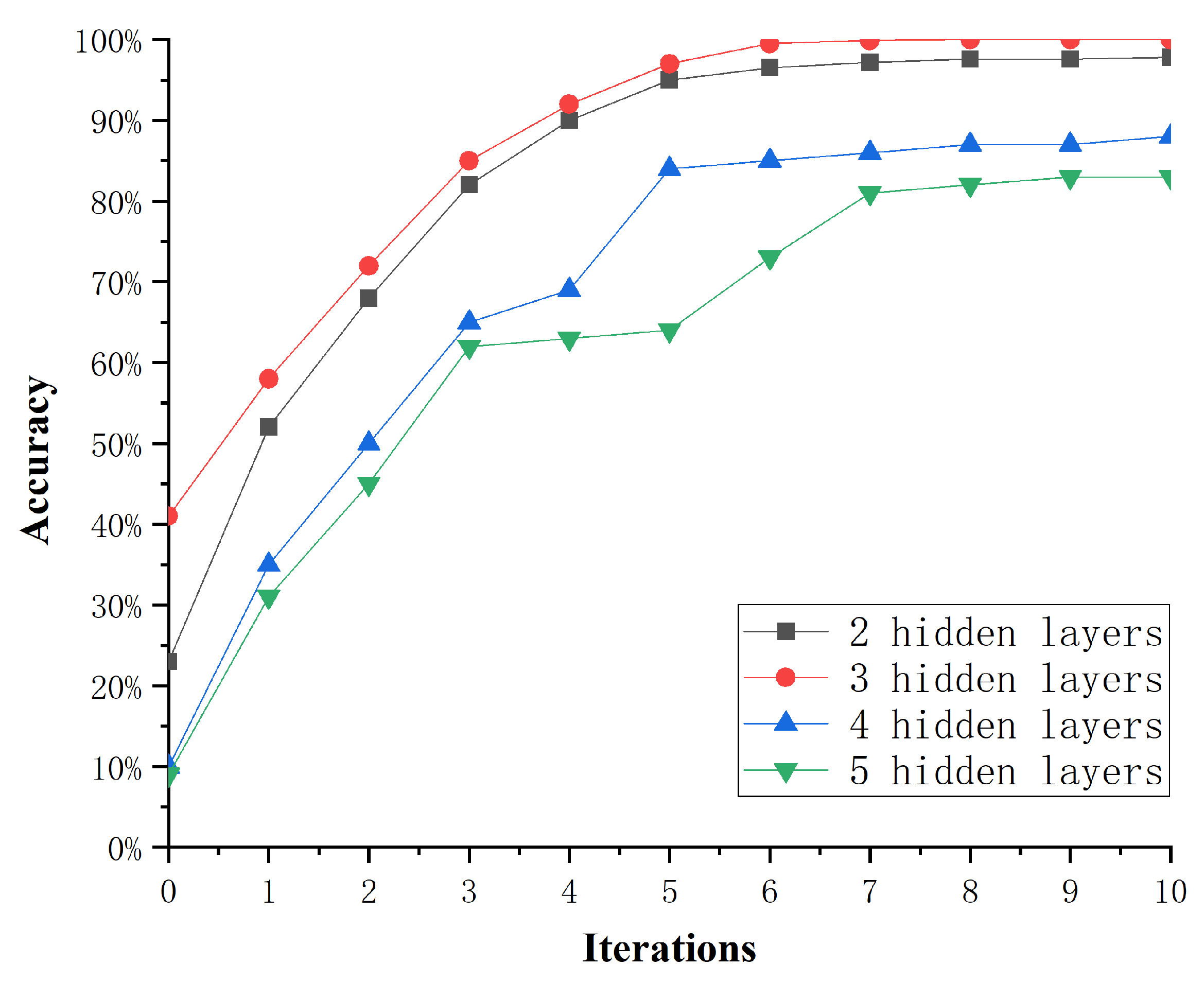

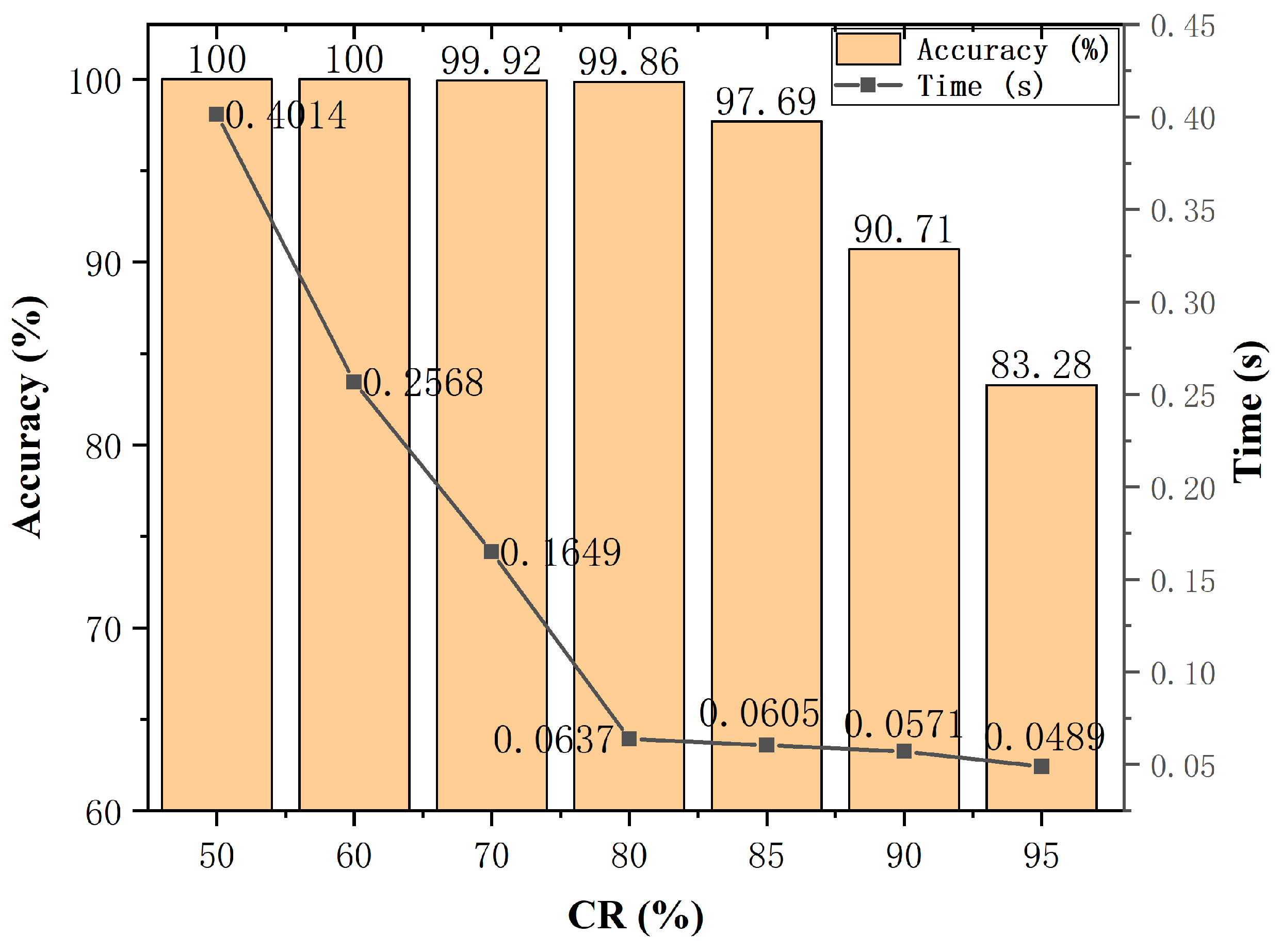

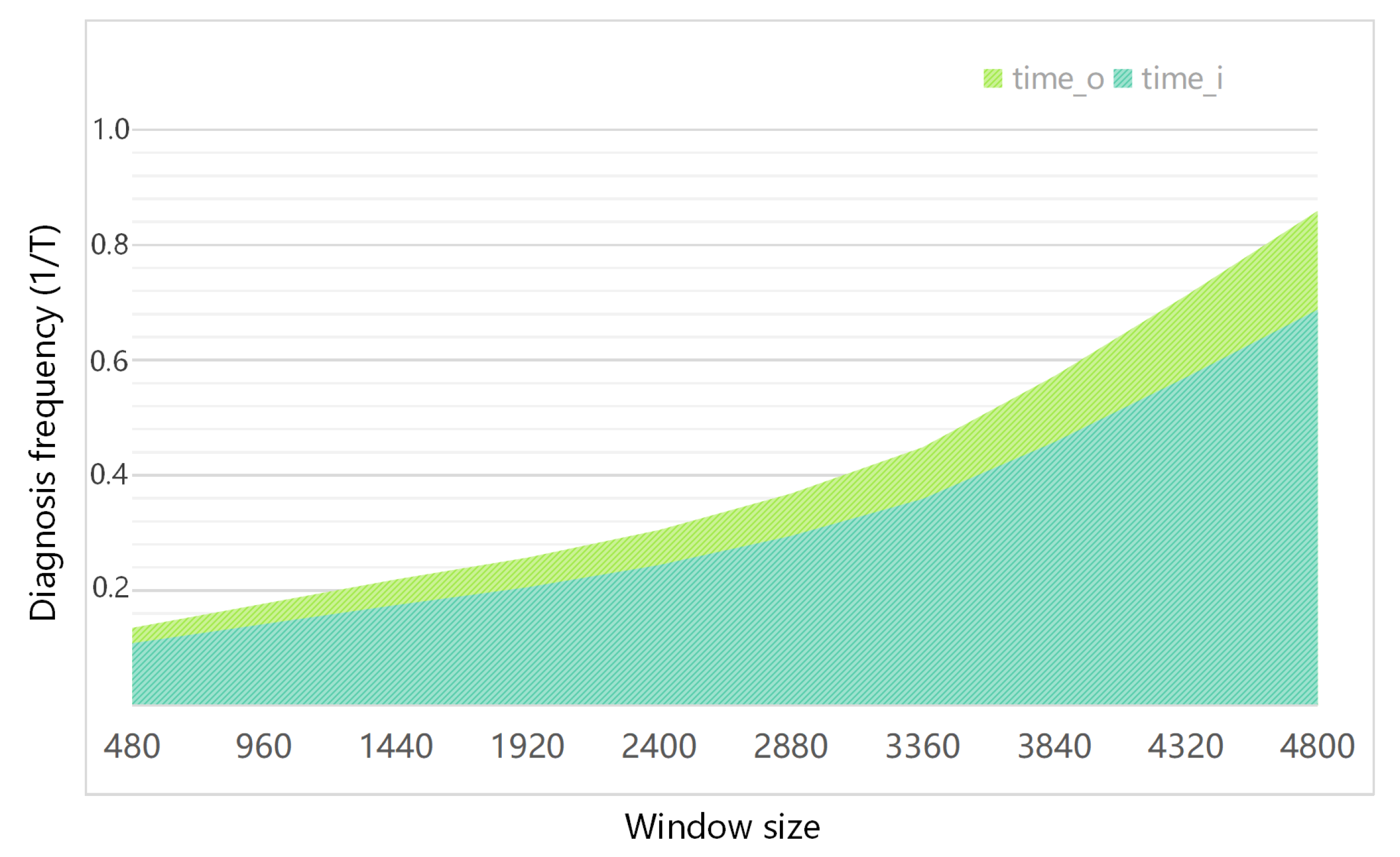


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}