
Remaining Useful Life Prediction of Lithium-Ion Batteries Using Neural Networks with Adaptive Bayesian Learning



Abstract
:1. Introduction
2. Training Algorithms for Neural Networks
3. Degradation Datasets
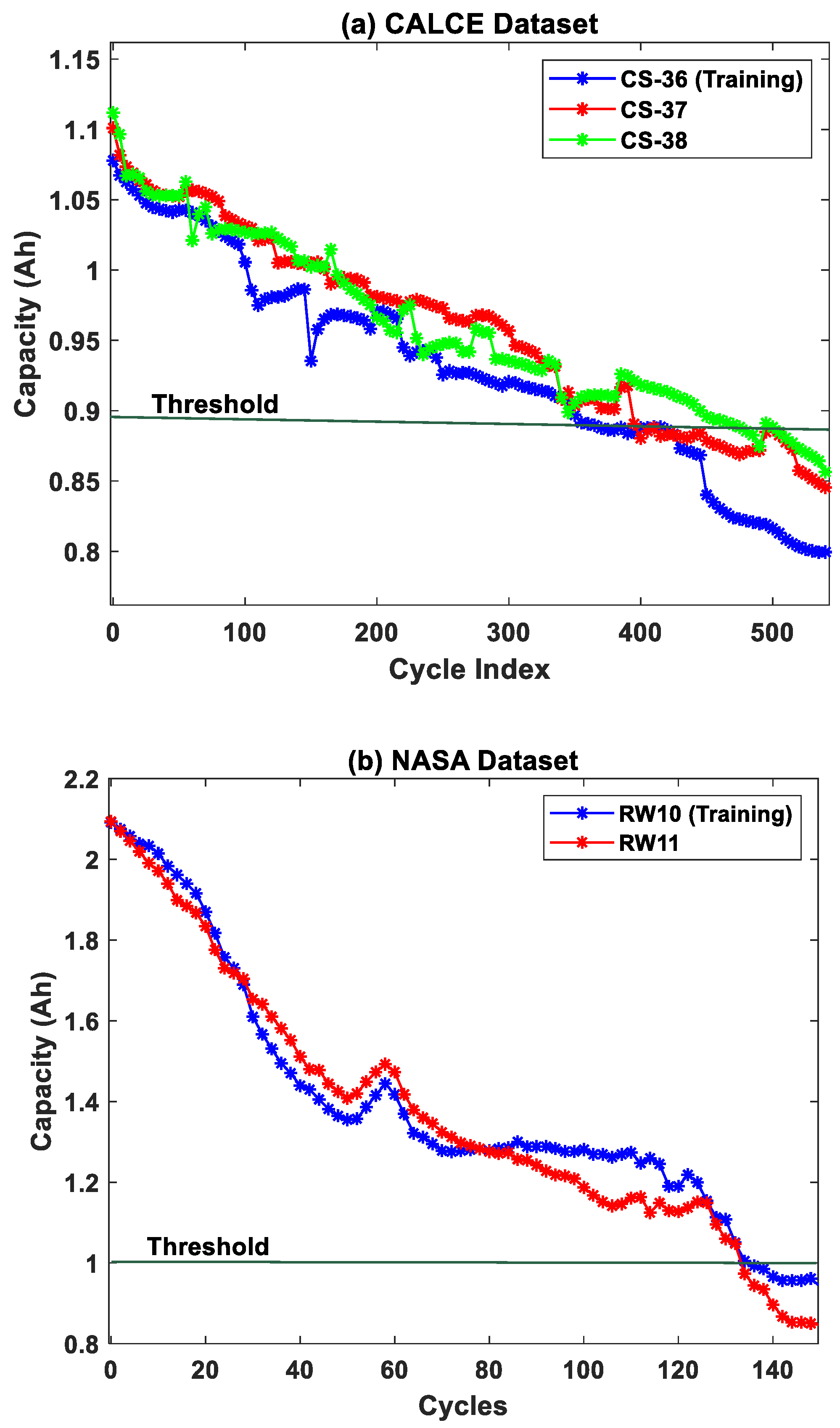
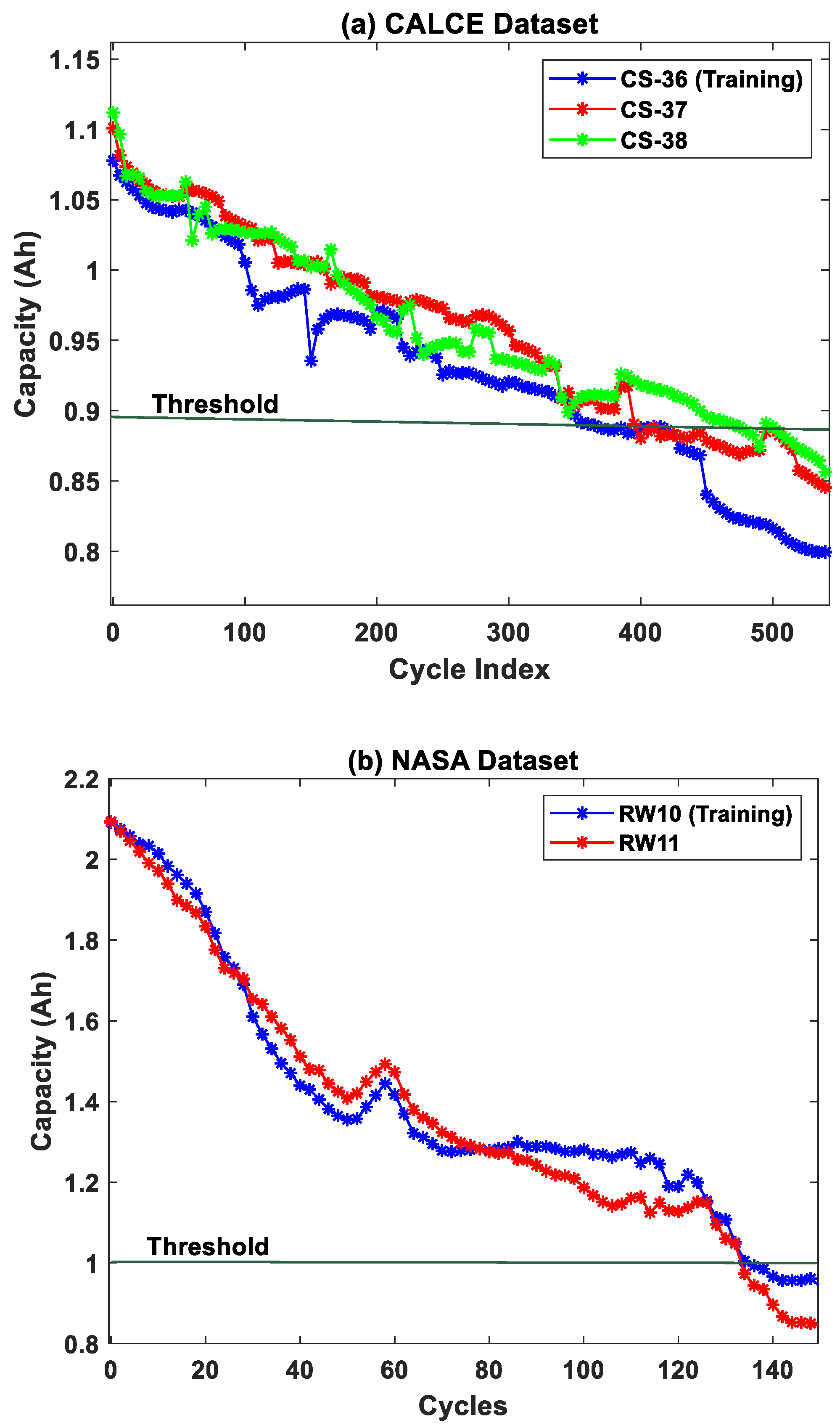
3.1. CALCE Dataset
3.2. NASA Dataset
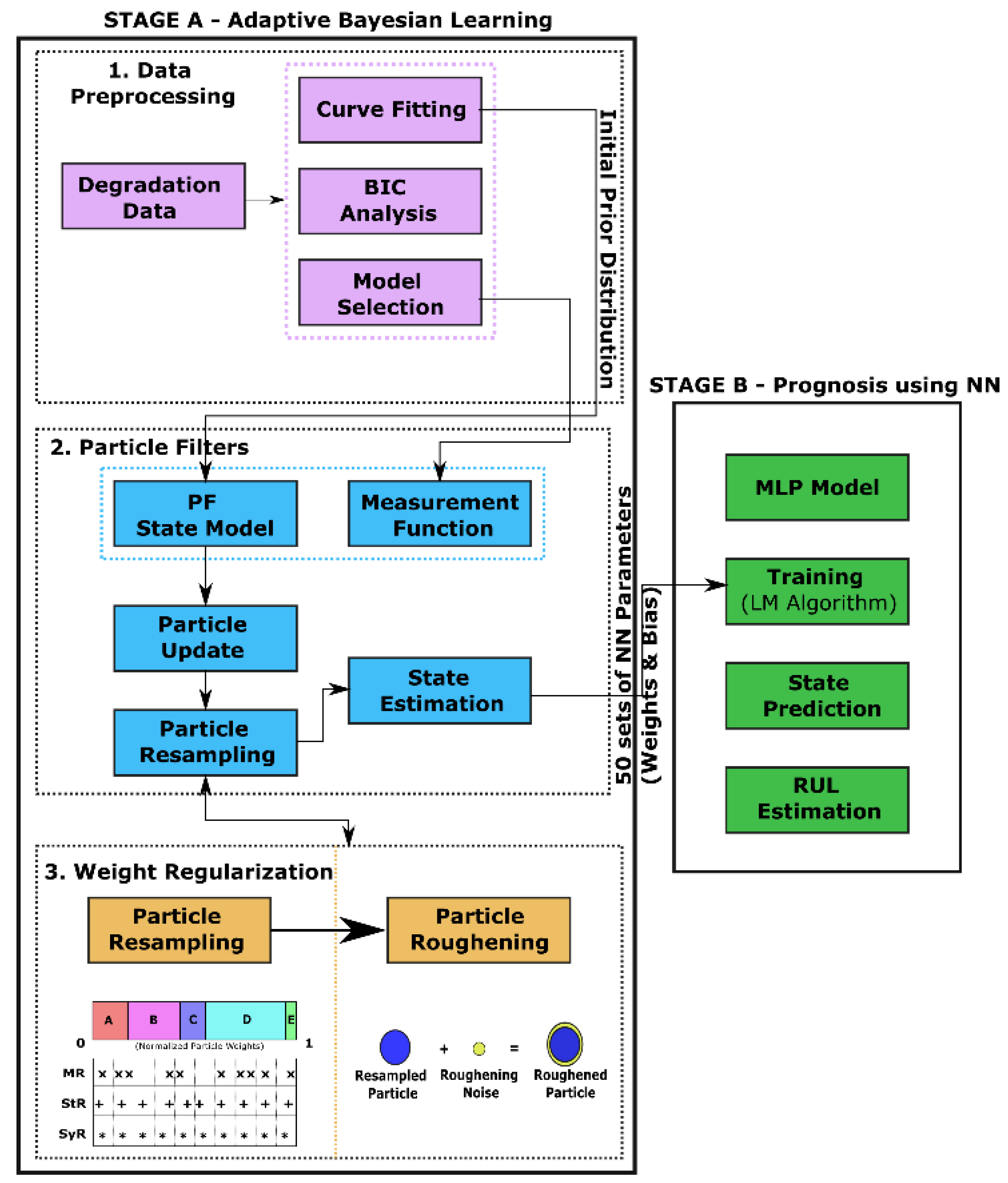
4. Methodology
4.1. Multilayer Perceptron
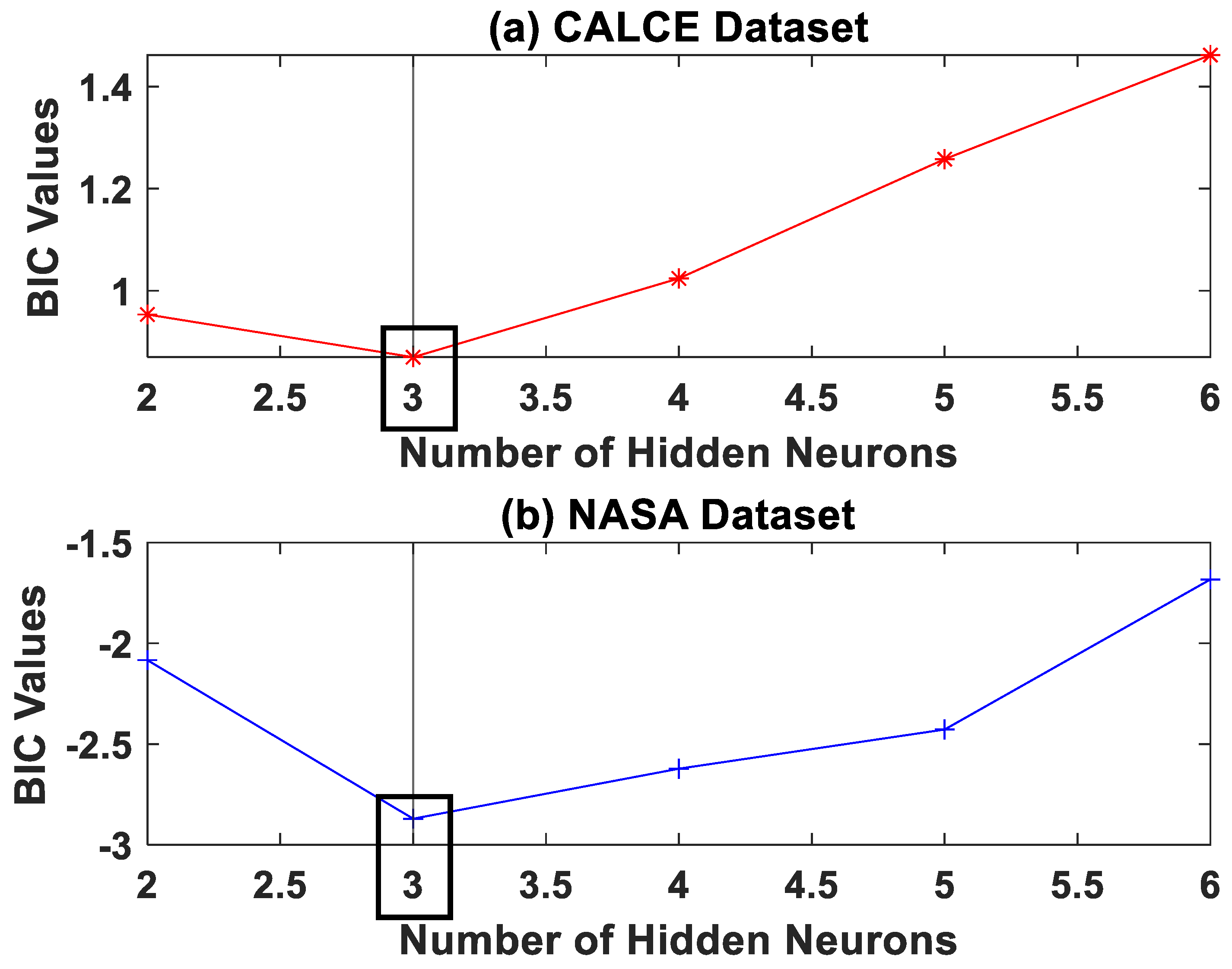
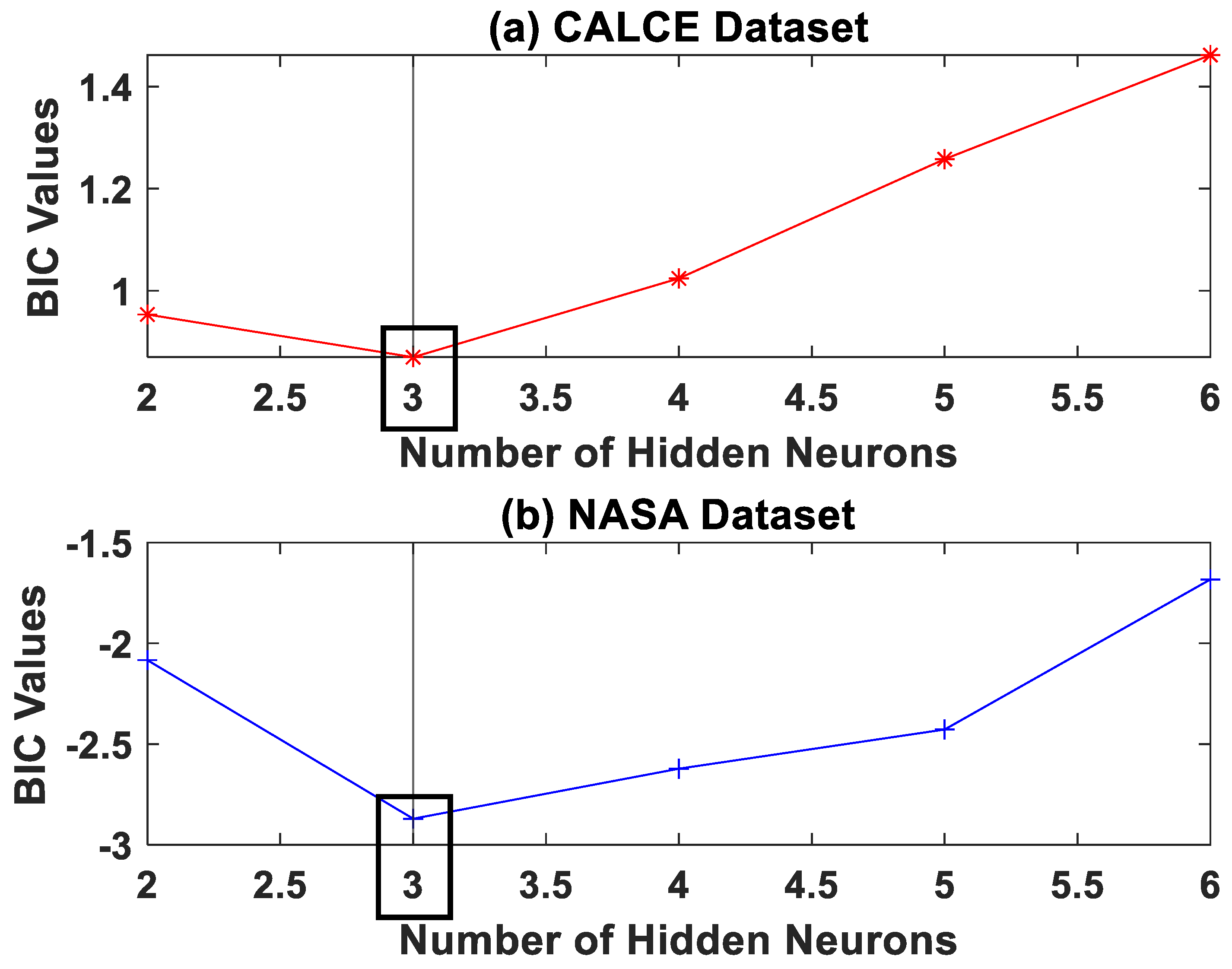
Choice of Network Architecture
4.2. Adaptive Bayesian Learning
4.2.1. Particle Filters
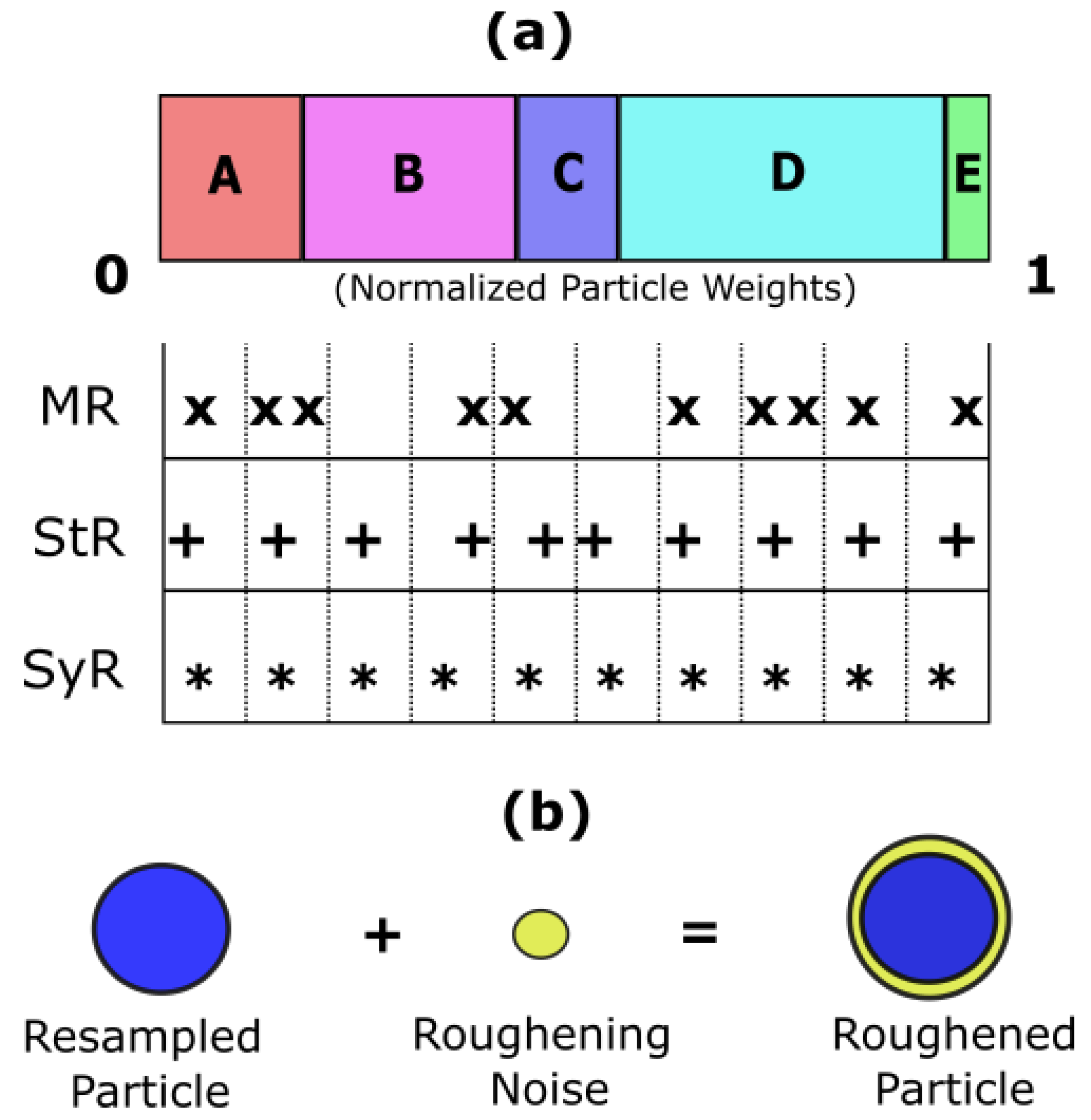
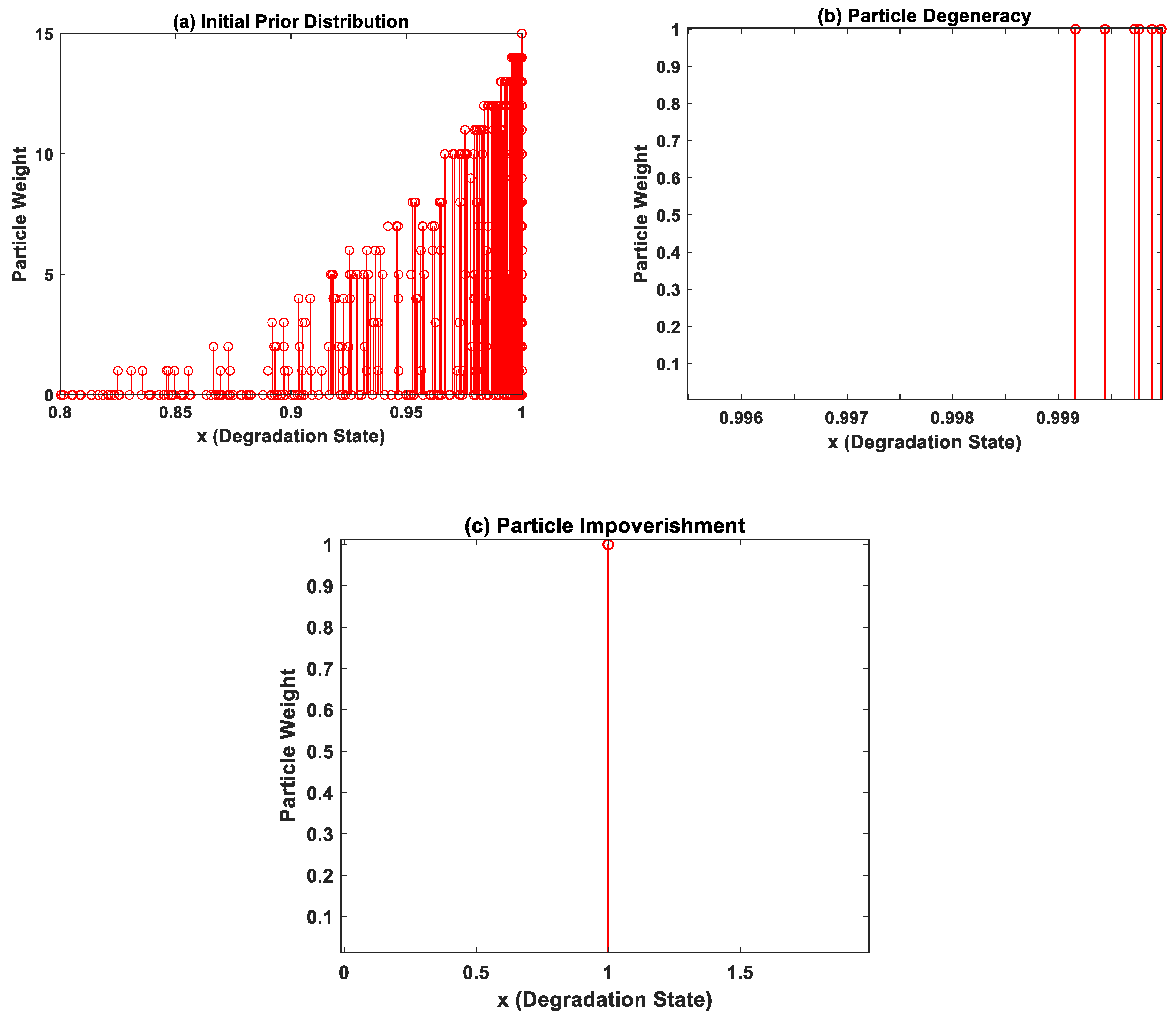
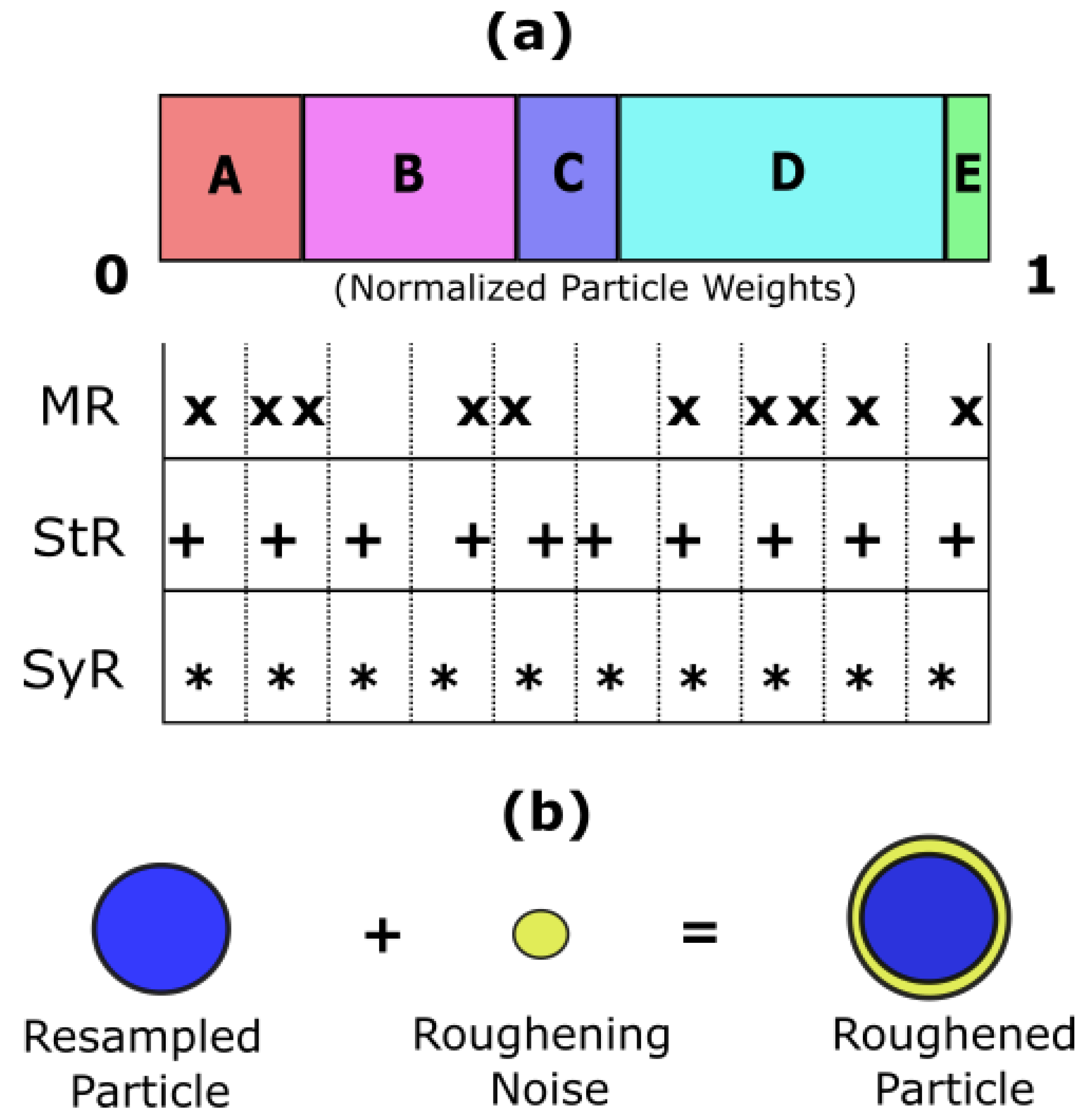
- a. Particle Initialization—At k = 1 time instant, the initial prior distribution is populated based on prior knowledge of the system model parameters as shown in Figure 3a. In this case, the curve fitting coefficients corresponding to one device from each device datasets are used. The initial prior probability density function p(x0) is then sampled into weighted particles.
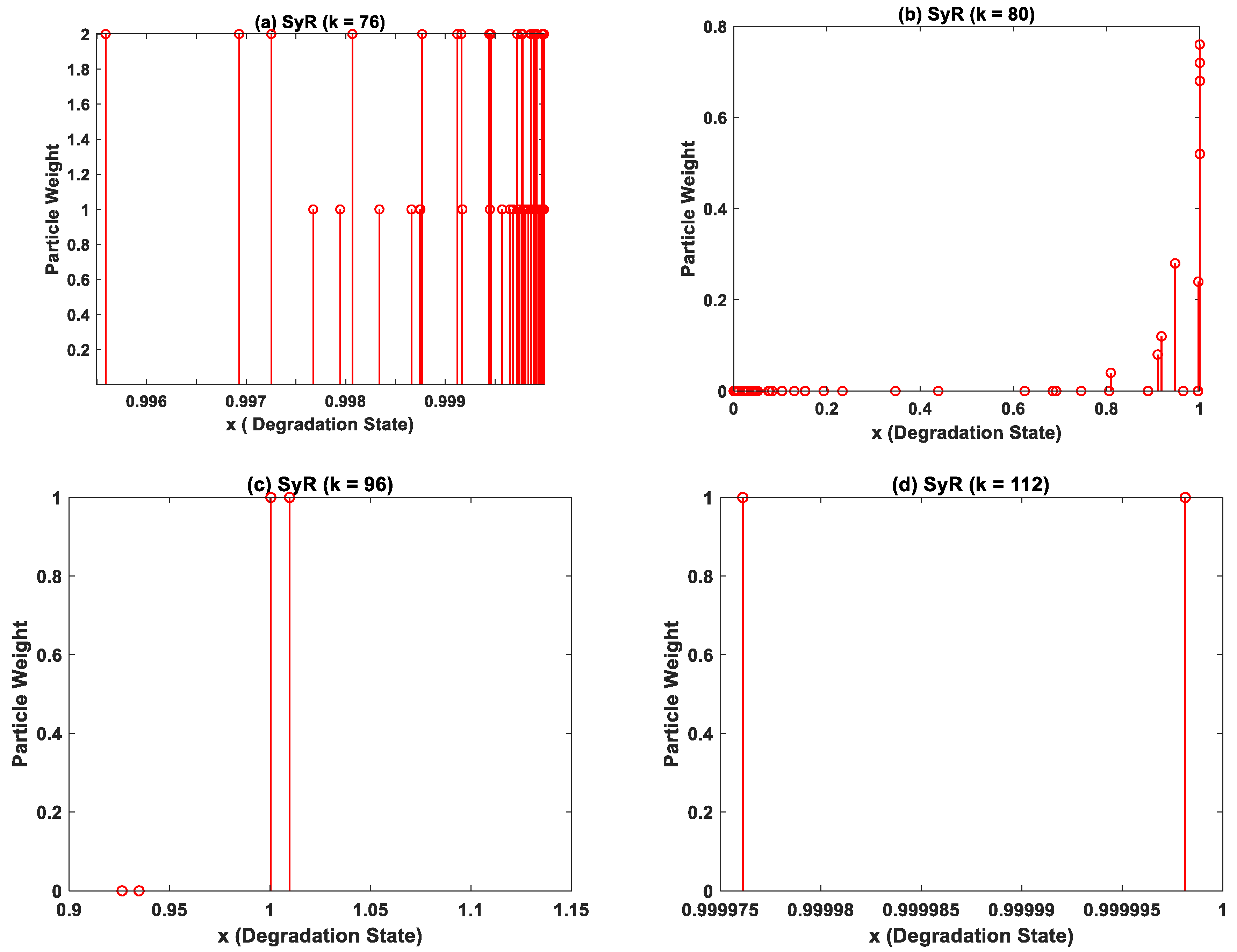
- b. Particle Update—Whenever new measurement data are available for prediction, the weights of the particles are recursively updated based on the likelihood function, as shown belowwhere is the likelihood function with representing the MLP network parameter at kth time instant, zk is the available test data, xk is the current system degradation state, and wik represents the particle weights. It is to be noted that the particle weights of the PF algorithm are different from the MLP network parameter weights.
- c. Particle Resampling—During particle update, the weights accumulate over a few particles, and the rest of the particles carry negligible weights after a few iterations as shown in Figure 3b. In order to enhance diversity amongst the particles, the smaller weight particles are replaced with large weight particles by a process called particle resampling. Thus, the basic idea of resampling is to maintain all the samples/particles at the same weight.
- d. State Estimation—Finally, the degradation state of the system at (k + 1)th time instant is evaluated based on the new set of weighted particles. The process is repeated for all available measurement data, and the posterior distribution at the current step becomes the prior distribution for the next step.
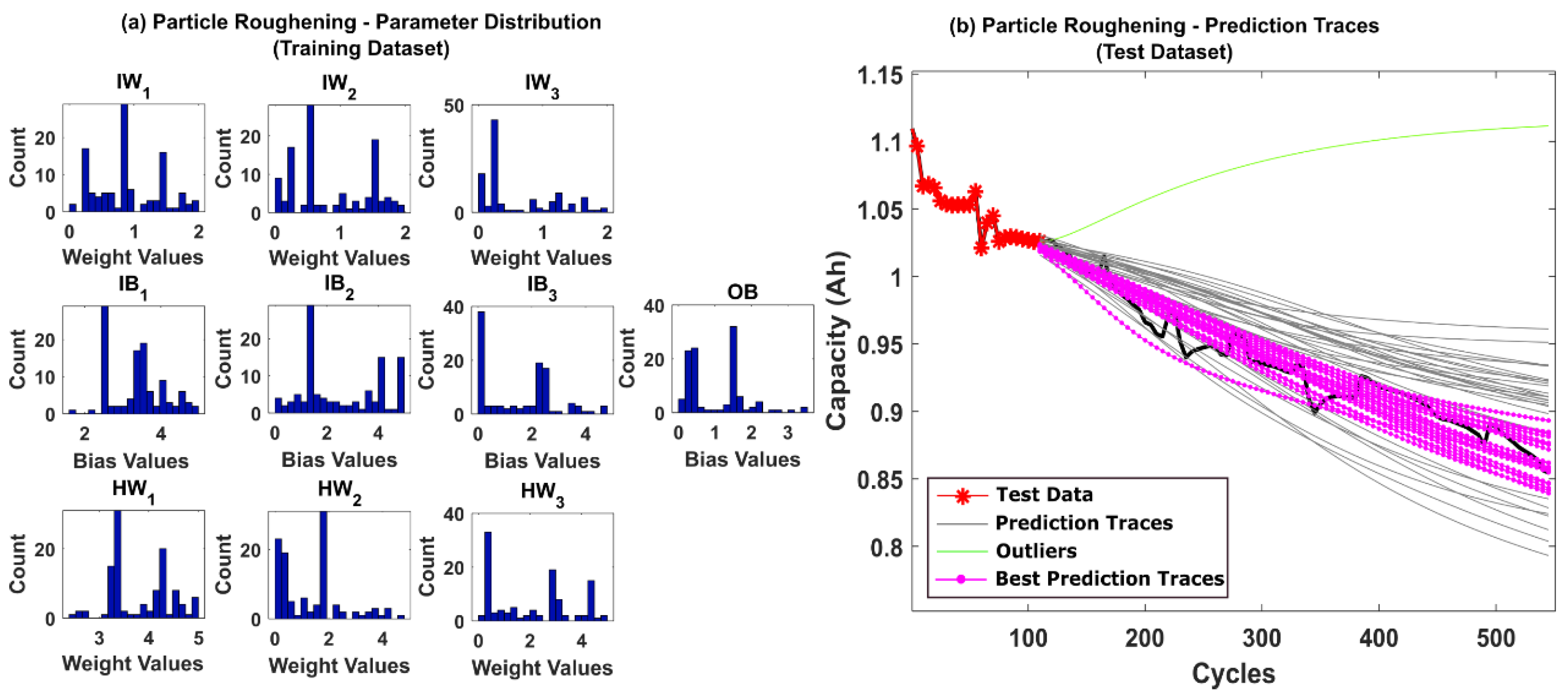
4.2.2. Weight Regularization Methods
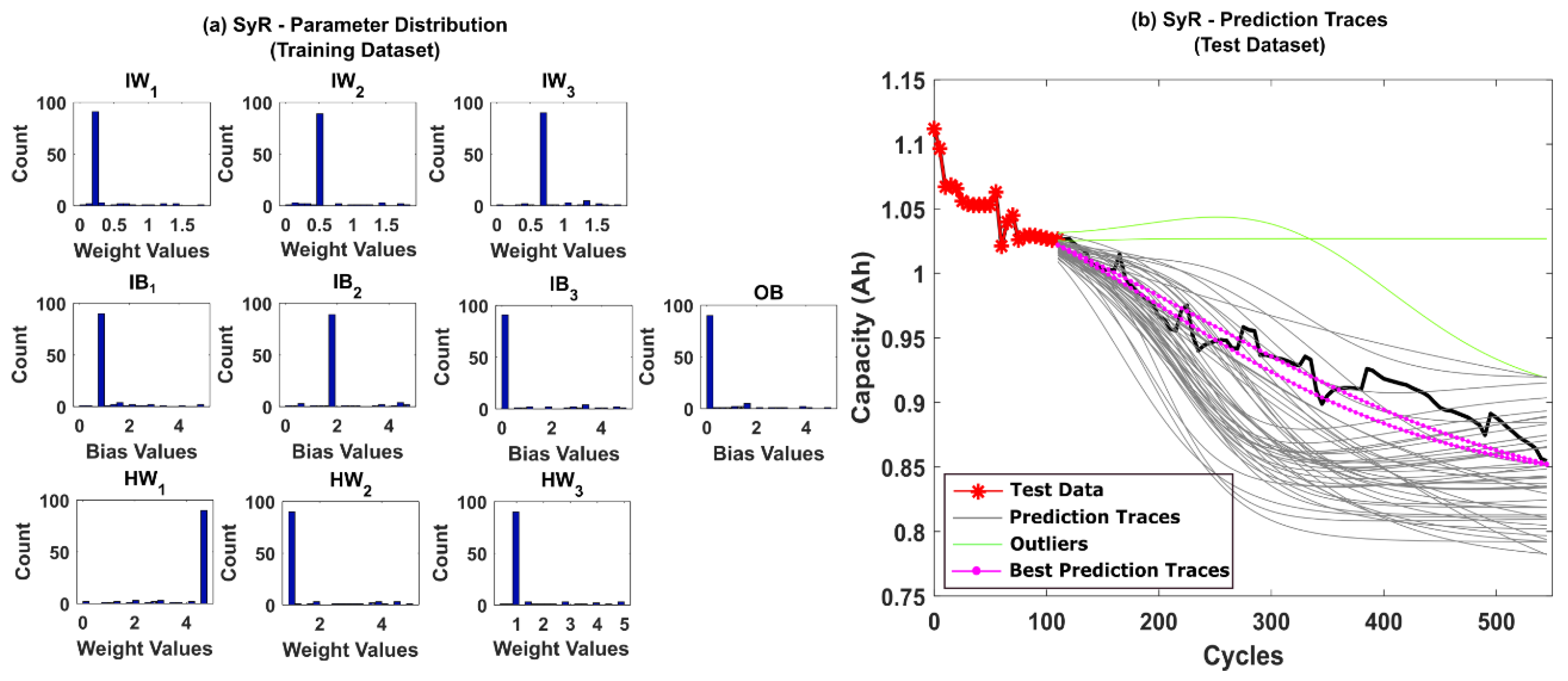
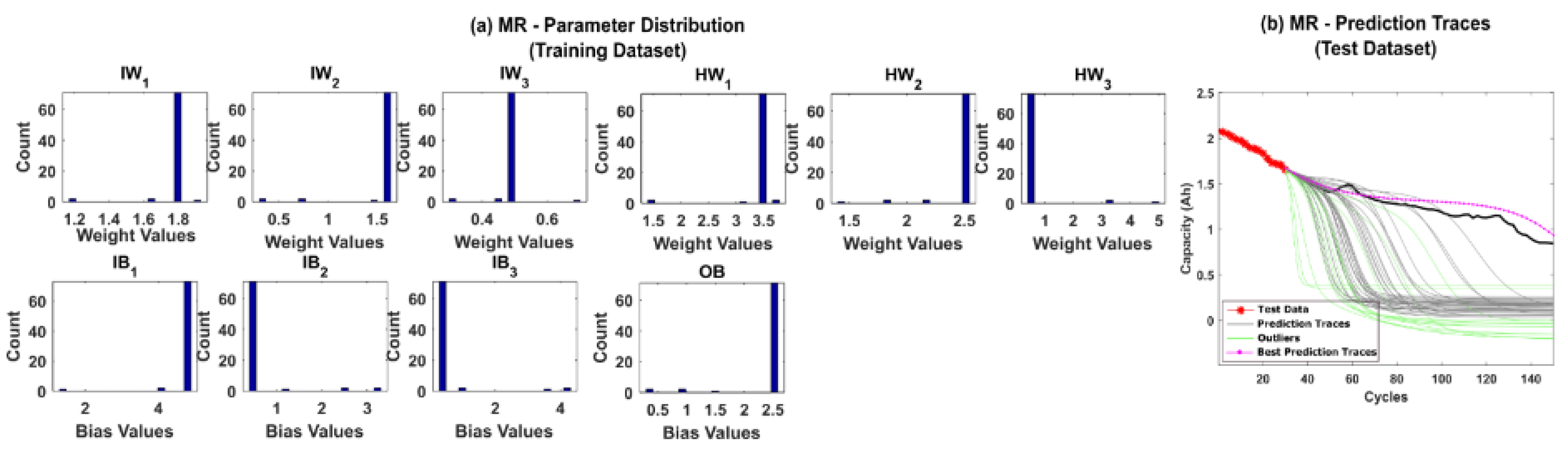
4.3. Remaining Useful Life Estimation
- Data Preprocessing—An appropriate NN model is chosen based on the BIC analysis described in previous sections.
- Particle Filters—The chosen model is used as the measurement function in the particle filter algorithm to recursively update the model parameters using the available degradation data from the training dataset.
- Weight Regularization—To overcome the particle degeneracy and impoverishment issues, suitable resampling strategies, and roughening methods are adopted for weight regularization. Additionally, resampling/roughening at every time step is unnecessary as it introduces additional variance in the posterior distribution. Hence, Effective Sample Size (ESS) is introduced to regulate the resampling/roughening process. If the ESS of the distribution is lower than a predefined threshold NT, then the particles are resampled/roughened. This reduces unnecessary additional computational load. The parameters obtained at the final time step for the training dataset is the PF estimated MLP network parameters.
5. Results and Discussion
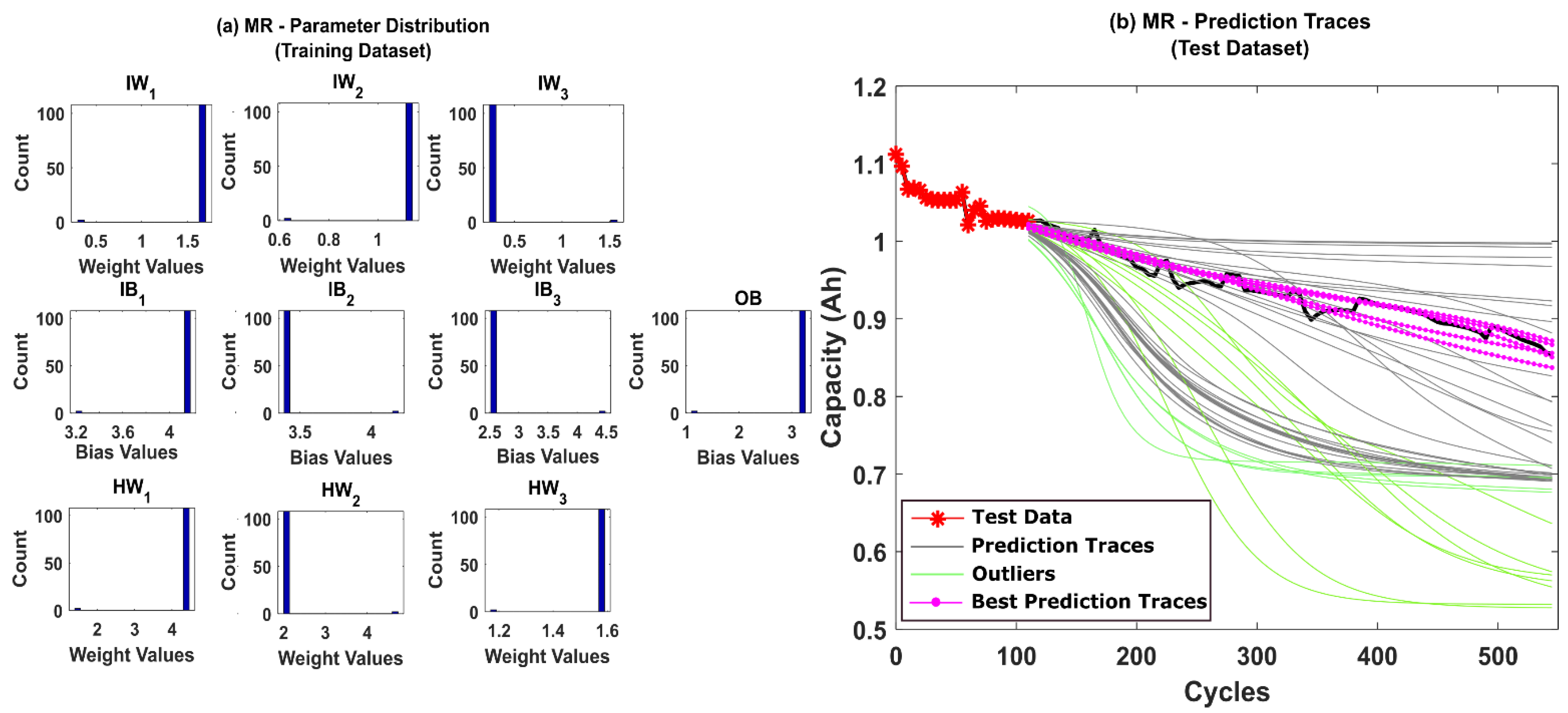
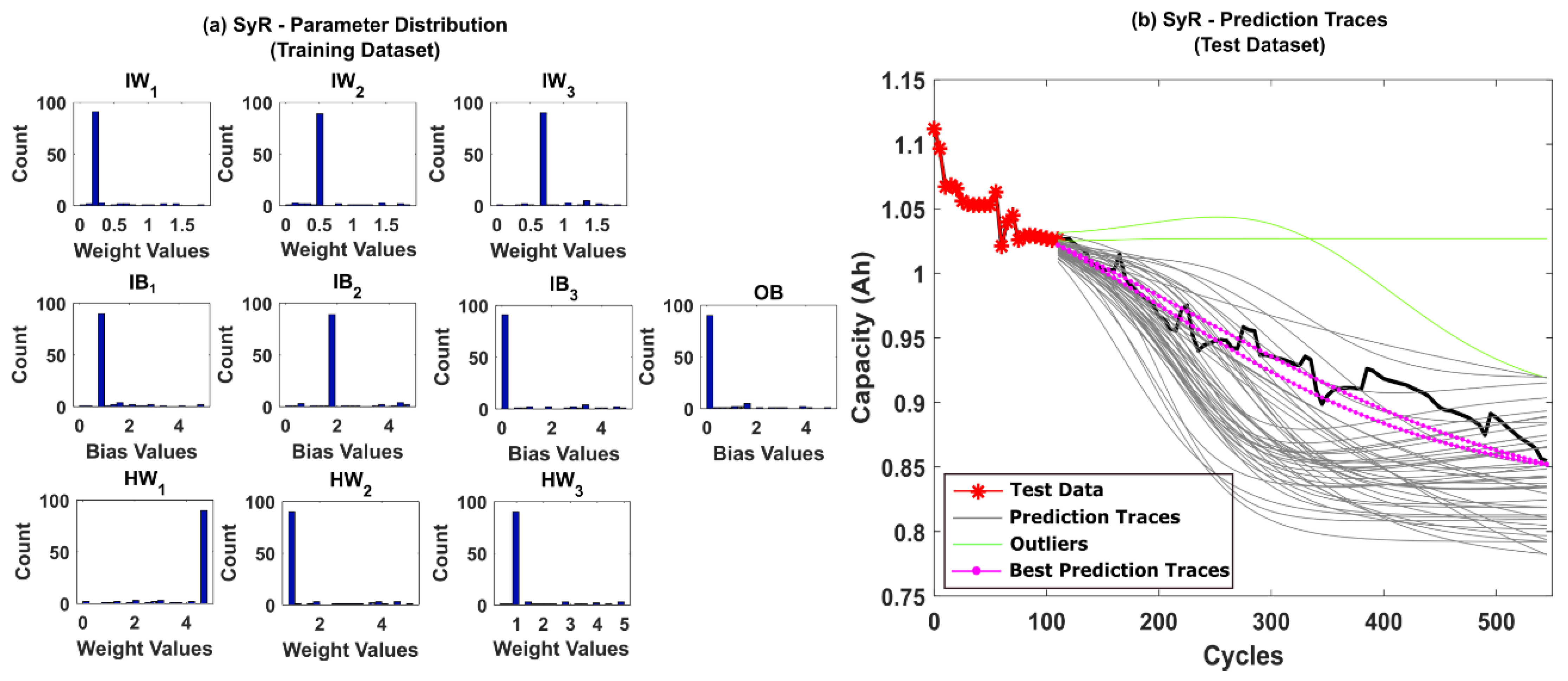
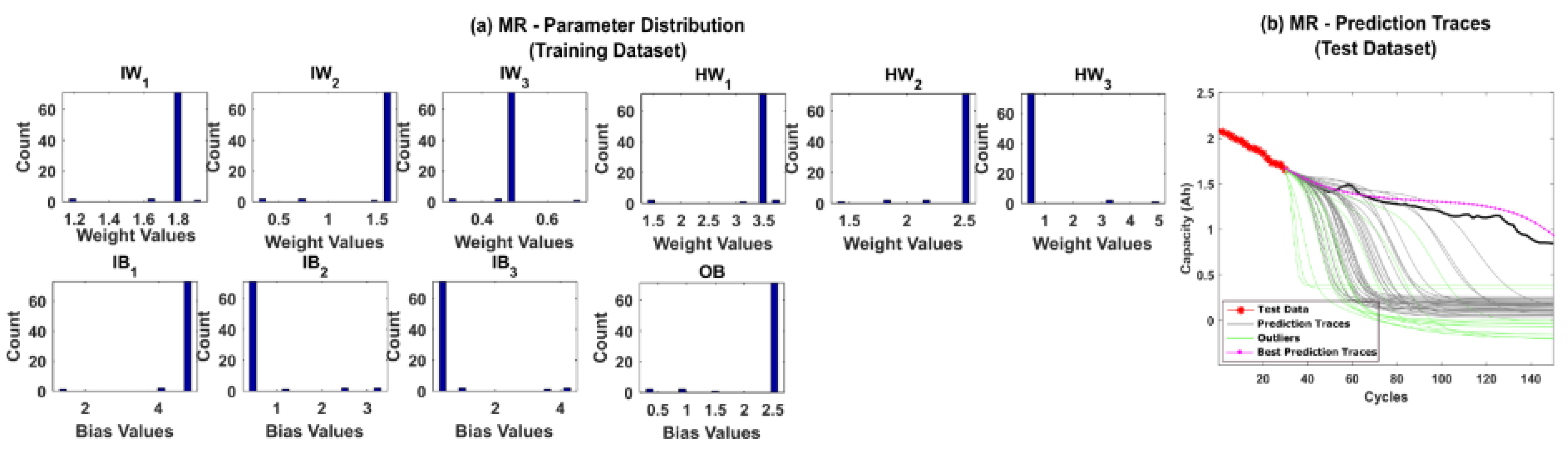
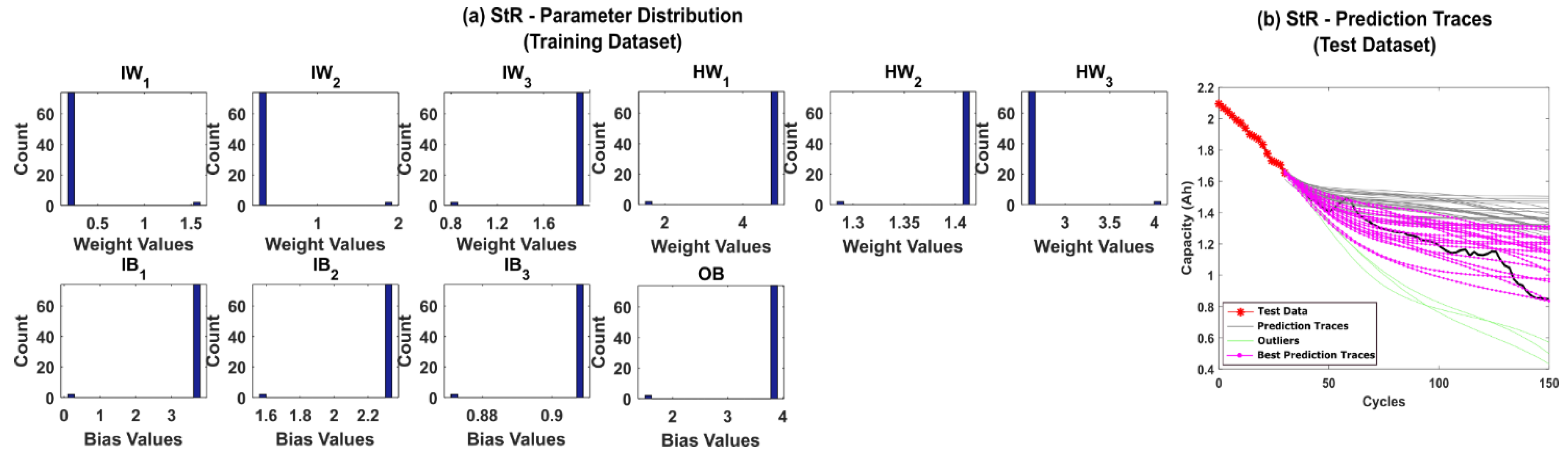
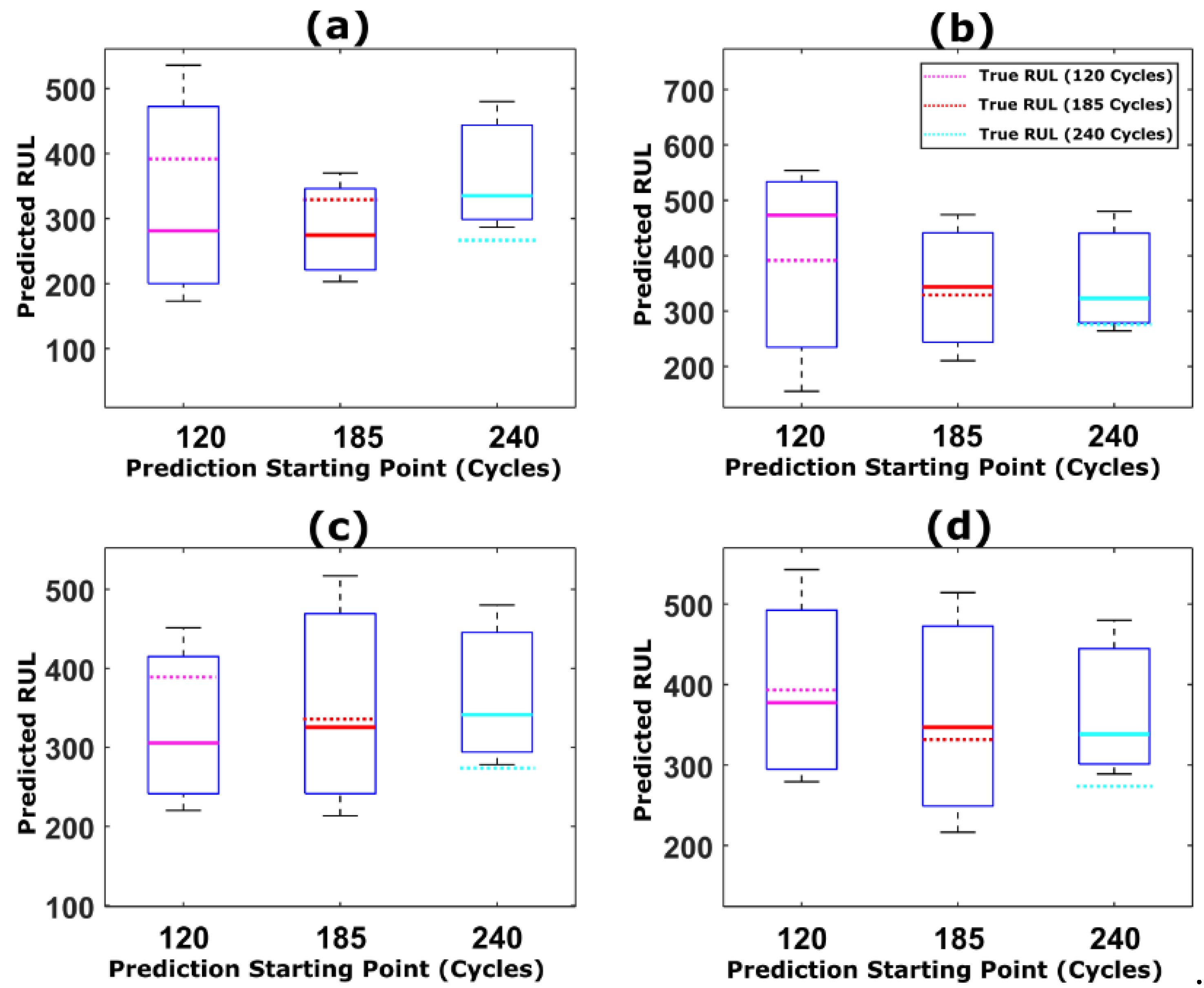
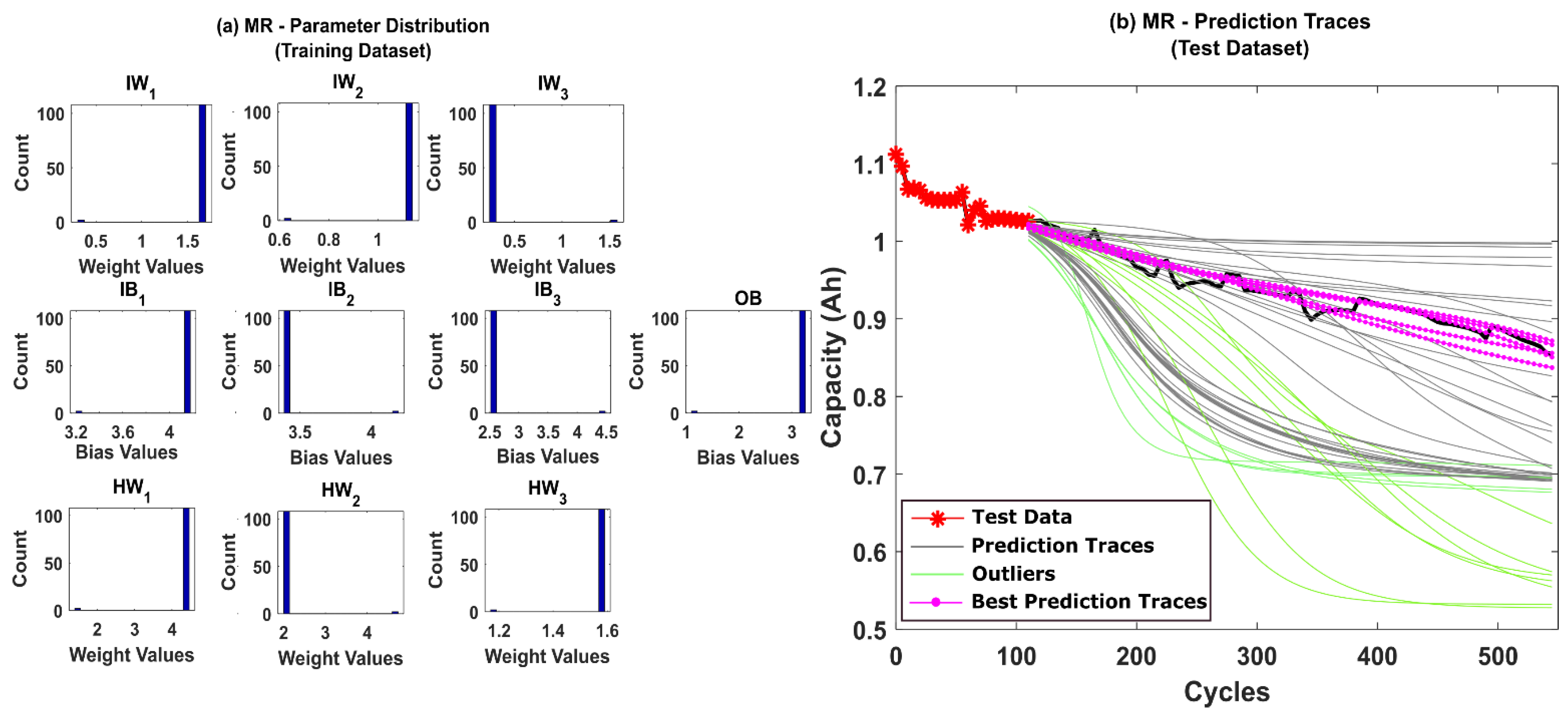
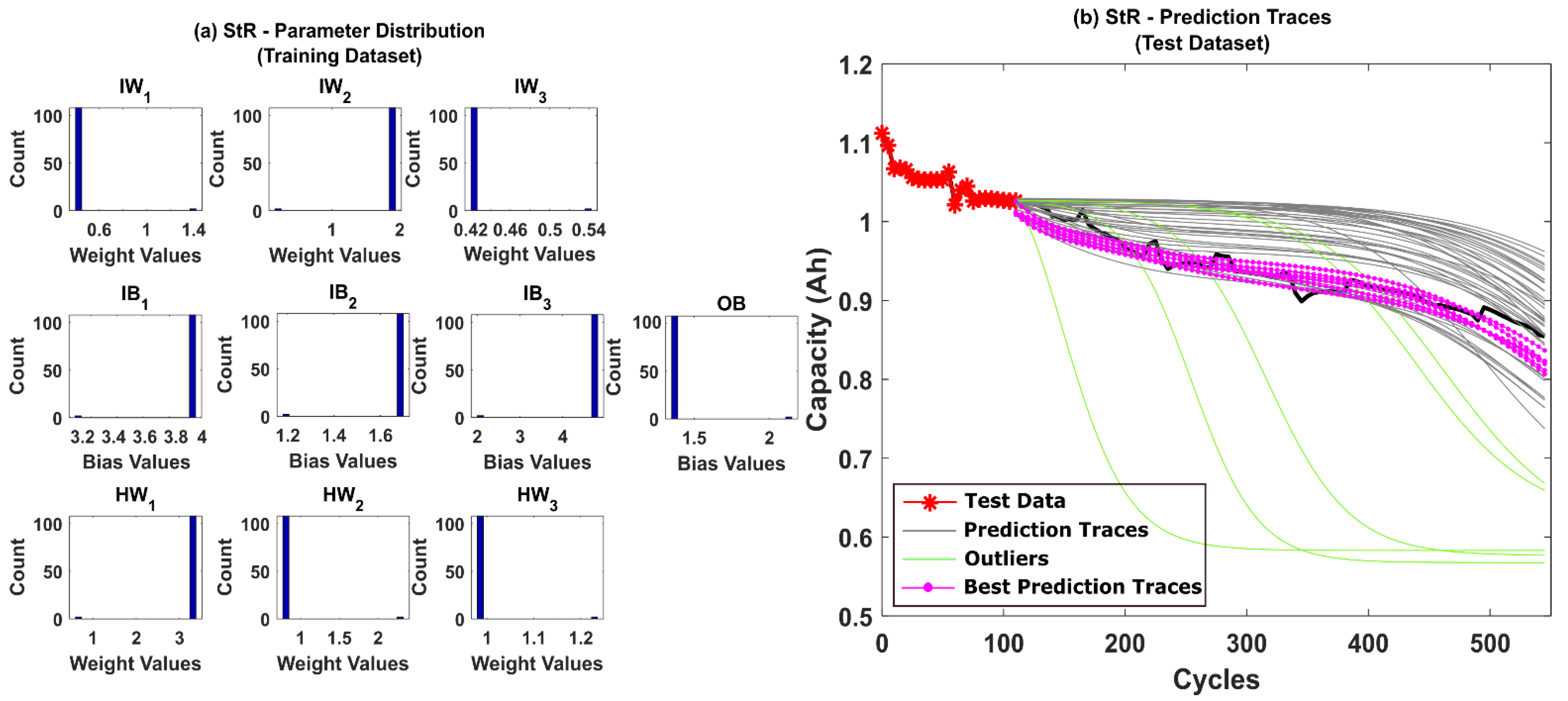
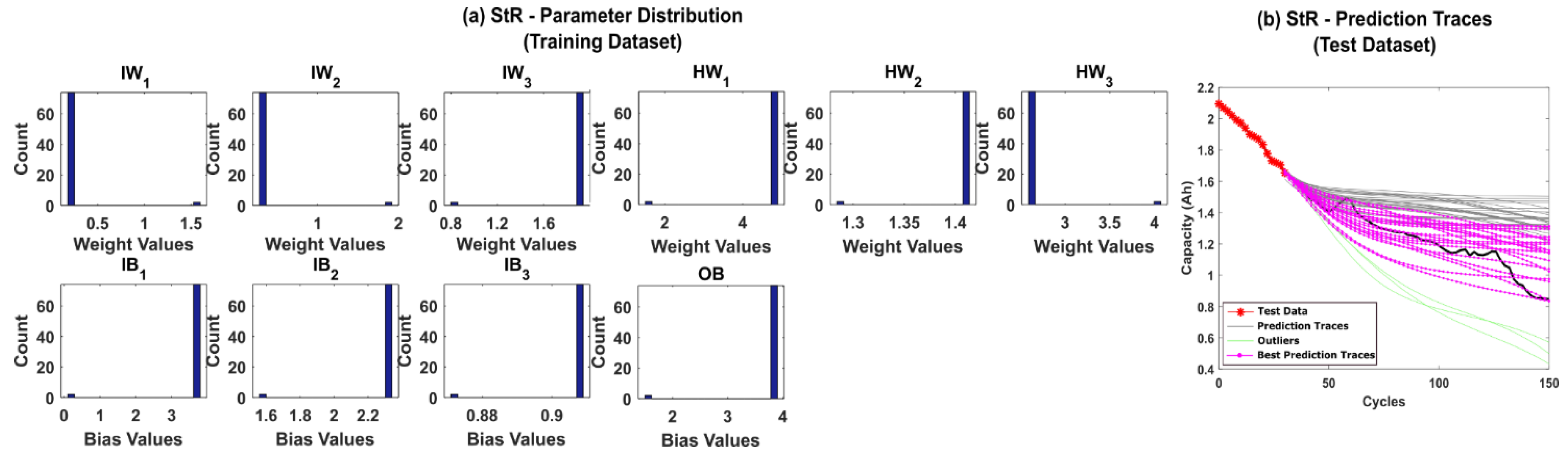
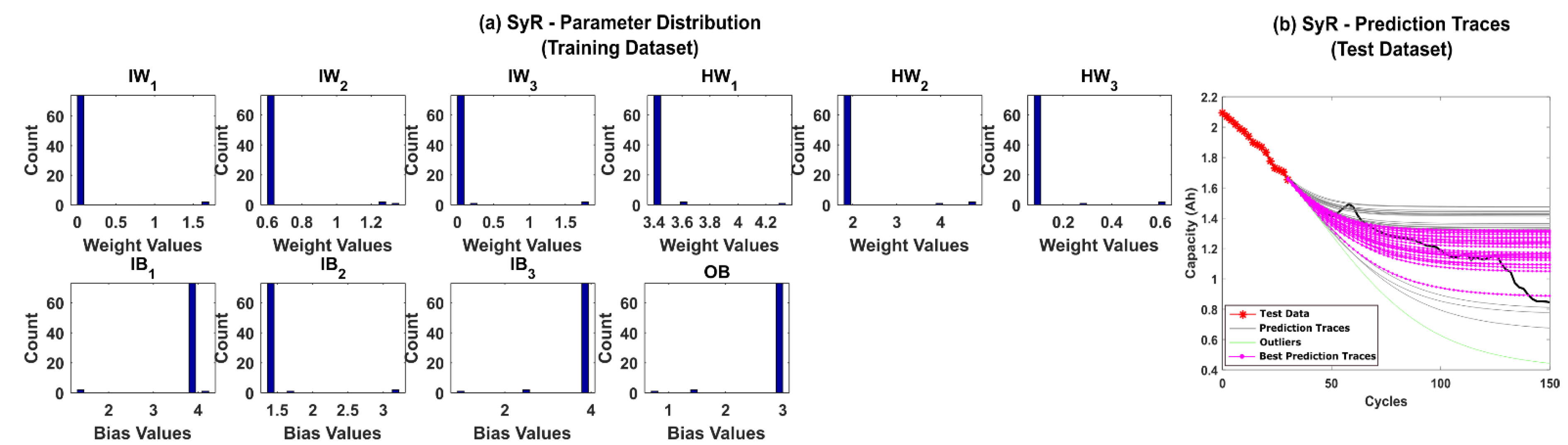
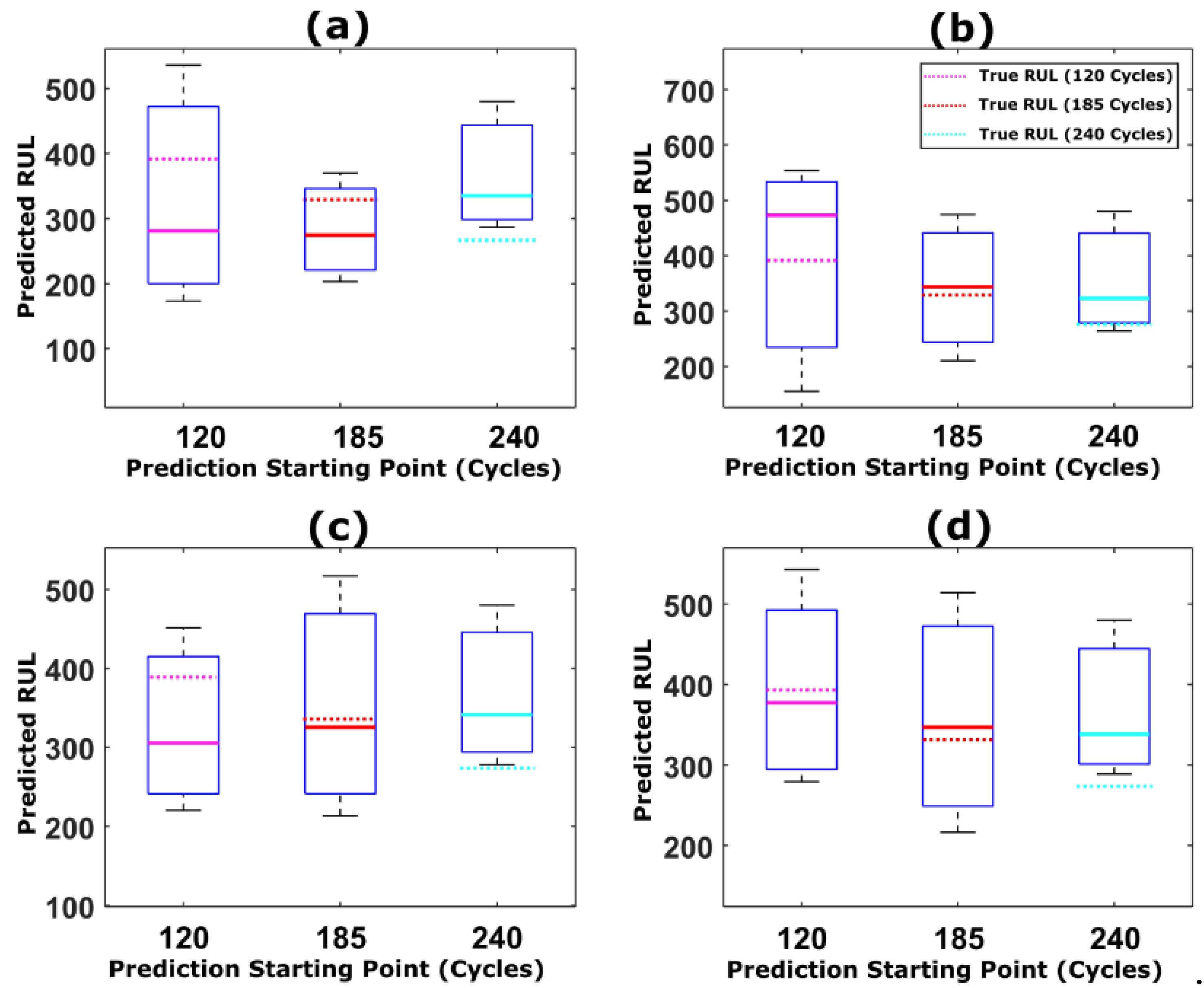
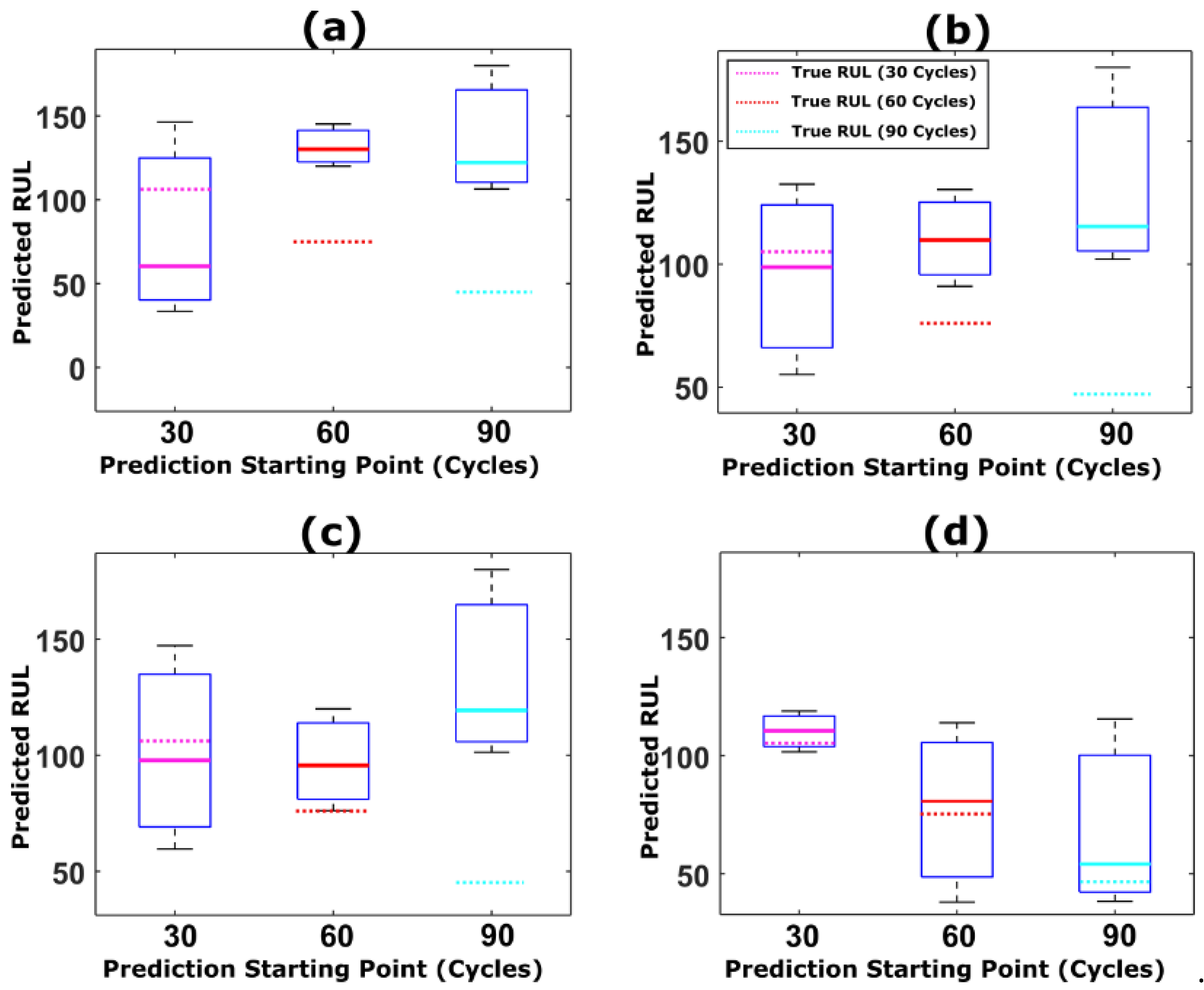
5.1. RUL Estimation Using Different Resampling Strategies
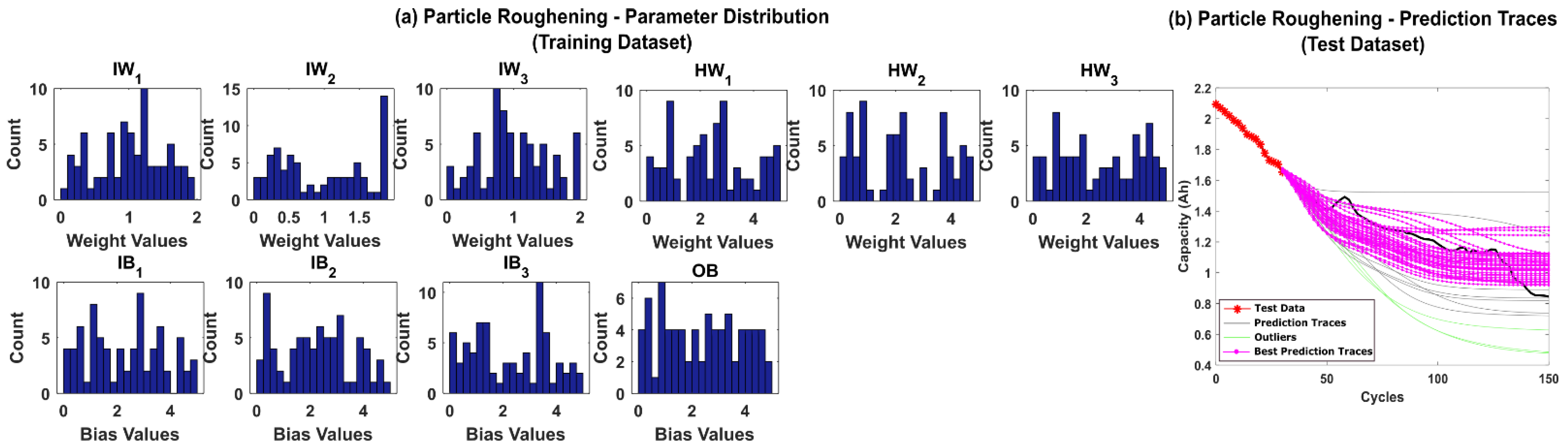
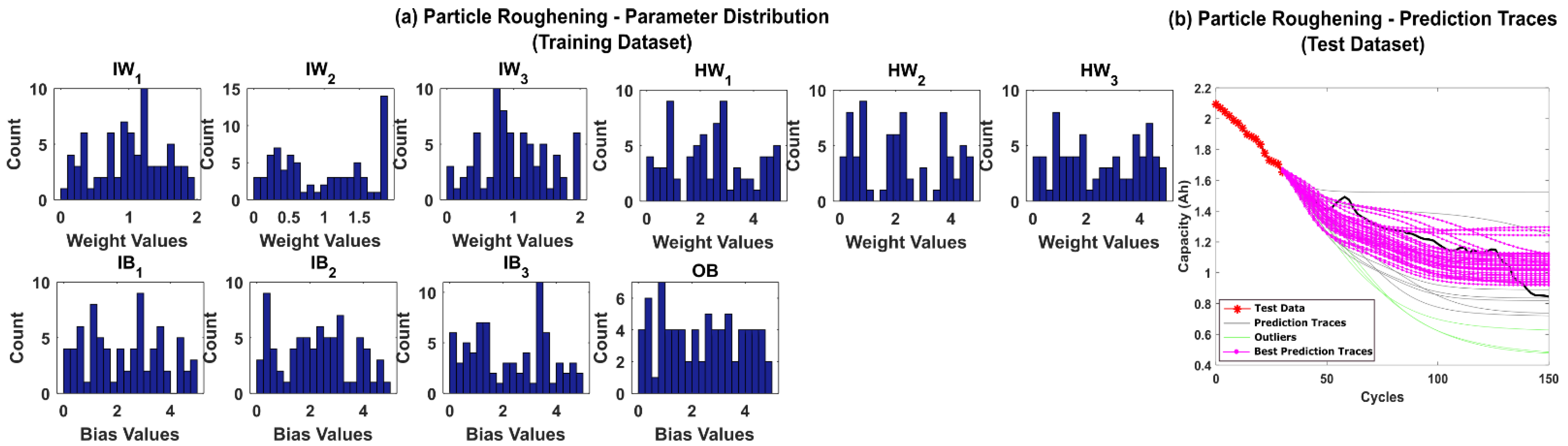
5.2. RUL Estimation Using Particle Roughening Method
5.3. Comparison of Prediction Results with Previous Works in the Literature
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Kulkarni, C.; Biswas, G.; Saha, S.; Goebel, K. A model-based prognostics methodology for electrolytic capacitors based on electrical overstress accelerated aging. In Proceedings of the Annual Conference of the PHM Society, Montreal, QC, Canada, 29 November–2 December 2021. [Google Scholar]
- Baptista, M.; Henriques, E.M.; de Medeiros, I.P.; Malere, J.P.; Nascimento, C.L., Jr.; Prendinger, H. Remaining useful life estimation in aeronautics: Combining data-driven and Kalman filtering. Reliab. Eng. Syst. 2019, 184, 228–239. [Google Scholar] [CrossRef]
- Singleton, R.K.; Strangas, E.G.; Aviyente, S. Extended Kalman filtering for remaining-useful-life estimation of bearings. IEEE Trans. Ind. Electron. 2014, 62, 1781–1790. [Google Scholar] [CrossRef]
- Celaya, J.R.; Saxena, A.; Kulkarni, C.S.; Saha, S.; Goebel, K. Prognostics approach for power MOSFET under thermal-stress aging. In Proceedings of the 2012 Annual Reliability and Maintainability Symposium, Reno, NV, USA, 23–26 January 2012. [Google Scholar]
- An, D.; Choi, J.H.; Kim, N.H. Prognostics 101: A tutorial for particle filter-based prognostics algorithm using Matlab. Reliab. Eng. Syst. Saf. 2013, 115, 161–169. [Google Scholar] [CrossRef]
- Zhang, H.; Miao, Q.; Zhang, X.; Liu, Z. An improved unscented particle filter approach for lithium-ion battery remaining useful life prediction. Microelectron. Reliab. 2018, 81, 288–298. [Google Scholar] [CrossRef]
- Ahmad, W.; Khan, S.A.; Islam, M.M.; Kim, J.M. A reliable technique for remaining useful life estimation of rolling element bearings using dynamic regression models. Reliab. Eng. Syst. Saf. 2019, 184, 67–76. [Google Scholar] [CrossRef]
- Si, X.S.; Wang, W.; Hu, C.H.; Zhou, D.H. Remaining useful life estimation–a review on the statistical data driven approaches. Eur. J. Oper. Res. 2011, 213, 1–14. [Google Scholar] [CrossRef]
- Khelif, R.; Chebel-Morello, B.; Malinowski, S.; Laajili, E.; Fnaiech, F.; Zerhouni, N. Direct remaining useful life estimation based on support vector regression. IEEE Trans. Ind. Electron. 2016, 64, 2276–2285. [Google Scholar] [CrossRef]
- Benkedjouh, T.; Medjaher, K.; Zerhouni, N.; Rechak, S. Remaining useful life estimation based on nonlinear feature reduction and support vector regression. Eng. Appl. Artif. Intell. 2013, 26, 1751–1760. [Google Scholar] [CrossRef]
- Liu, D.; Zhou, J.; Pan, D.; Peng, Y.; Peng, X. Lithium-ion battery remaining useful life estimation with an optimized relevance vector machine algorithm with incremental learning. Measurement 2015, 63, 143–151. [Google Scholar] [CrossRef]
- Yuchen, S.; Datong, L.; Yandong, H.; Jinxiang, Y.; Yu, P. Satellite lithium-ion battery remaining useful life estimation with an iterative updated RVM fused with the KF algorithm. Chin. J. Aeronaut 2018, 31, 31–40. [Google Scholar]
- Benker, M.; Furtner, L.; Semm, T.; Zaeh, M.F. Utilizing uncertainty information in remaining useful life estimation via Bayesian neural networks and Hamiltonian Monte Carlo. J. Manuf. Syst. 2020, 61, 799–807. [Google Scholar] [CrossRef]
- Nielsen, J.S.; Sørensen, J.D. Bayesian estimation of remaining useful life for wind turbine blades. Energies 2017, 10, 664. [Google Scholar] [CrossRef] [Green Version]
- Le, T.T.; Chatelain, F.; Bérenguer, C. Multi-branch hidden Markov models for remaining useful life estimation of systems under multiple deterioration modes. Proc. Inst. Mech. Eng. Part O J. Risk Reliab. 2016, 230, 473–484. [Google Scholar] [CrossRef]
- Saon, S.; Hiyama, T. Predicting remaining useful life of rotating machinery based artificial neural network. Comput. Math. Appl. 2010, 60, 1078–1087. [Google Scholar]
- Farsi, M.A.; Hosseini, S.M. Statistical distributions comparison for remaining useful life prediction of components via ANN. Int. J. Syst. Assur. Eng. Manag. 2019, 10, 429–436. [Google Scholar] [CrossRef]
- Li, X.; Ding, Q.; Sun, J.Q. Remaining useful life estimation in prognostics using deep convolution neural networks. Reliab. Eng. Syst. Saf. 2018, 172, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Xia, M.; Li, T.; Shu, T.; Wan, J.; De Silva, C.W.; Wang, Z. A two-stage approach for the remaining useful life prediction of bearings using deep neural networks. IEEE Trans. Industr. Inform. 2018, 15, 3703–3711. [Google Scholar] [CrossRef]
- Zhang, X.; Dong, Y.; Wen, L.; Lu, F.; Li, W. Remaining useful life estimation based on a new convolutional and recurrent neural network. In Proceedings of the 2019 IEEE 15th International Conference on Automation Science and Engineering (CASE), Vancouver, BC, Canada, 22–26 August 2019. [Google Scholar]
- Song, Y.; Li, L.; Peng, Y.; Liu, D. Lithium-ion battery remaining useful life prediction based on GRU-RNN. In Proceedings of the 2018 12th International Conference on Reliability, Maintainability, and Safety (ICRMS), Shanghai, China, 17–19 October 2018. [Google Scholar]
- Pan, Y.; Hong, R.; Chen, J.; Wu, W. A hybrid DBN-SOM-PF-based prognostic approach of remaining useful life for wind turbine gearbox. Renew. Energy 2020, 152, 138–154. [Google Scholar] [CrossRef]
- Wu, Y.; Yuan, M.; Dong, S.; Lin, L.; Liu, Y. Remaining useful life estimation of engineered systems using vanilla LSTM neural networks. Neurocomputing 2018, 275, 167–179. [Google Scholar] [CrossRef]
- Karasu, S.; Altan, A. Crude oil time series prediction model based on LSTM network with chaotic Henry gas solubility optimization. Energy 2022, 242, 122964. [Google Scholar] [CrossRef]
- Ma, G.; Zhang, Y.; Cheng, C.; Zhou, B.; Hu, P.; Yuan, Y. Remaining useful life prediction of lithium-ion batteries based on false nearest neighbors and a hybrid neural network. Appl. Energy 2019, 253, 113626. [Google Scholar] [CrossRef]
- Wu, Y.; Li, W.; Wang, Y.; Zhang, K. Remaining useful life prediction of lithium-ion batteries using neural network and bat-based particle filter. IEEE access 2019, 7, 54843–54854. [Google Scholar] [CrossRef]
- Gudise, V.G.; Venayagamoorthy, G.K. Comparison of particle swarm optimization and backpropagation as training algorithms for neural networks. In Proceedings of the 2003 IEEE Swarm Intelligence Symposium. SIS’03 (Cat. No. 03EX706), Indianapolis, IN, USA, 26–26 April 2003. [Google Scholar]
- Karaboga, D.; Akay, B.; Ozturk, C. Artificial bee colony (ABC) optimization algorithm for training feed-forward neural networks. In Proceedings of the International Conference on Modeling Decisions for Artificial Intelligence, Umeå, Sweden, Kitakyushu, Japan, 16–18 August 2007. [Google Scholar]
- CALCE Battery Dataset Repository. Available online: https://web.calce.umd.edu/batteries/data.htm (accessed on 13 December 2021).
- Randomized Battery Usage Data Set. Available online: http://ti.arc.nasa.gov/project/prognostic-data-repository (accessed on 13 December 2021).
- Vrieze, S.I. Model selection and psychological theory: A discussion of the differences between the Akaike information criterion (AIC) and the Bayesian information criterion (BIC). Psychol. Methods 2012, 17, 228. [Google Scholar] [CrossRef] [Green Version]
- Chakrabarti, A.; Ghosh, J.K. AIC, BIC and recent advances in model selection. Philos. Stat. 2011, 7, 583–605. [Google Scholar]
- Pugalenthi, K.; Raghavan, N. A holistic comparison of the different resampling algorithms for particle filter based prognosis using lithium ion batteries as a case study. Microelectron. Reliab. 2018, 91, 160–169. [Google Scholar] [CrossRef]
- Pugalenthi, K.; Raghavan, N. Roughening Particle Filter Based Prognosis on Power MOSFETs Using ON-Resistance Variation. In Proceedings of the 2018 Prognostics and System Health Management Conference (PHM-Chongqing), Chongqing, China, 26–28 October 2018. [Google Scholar]
- Pugalenthi, K.; Park, H.; Hussain, S.; Raghavan, N. Hybrid Particle Filter Trained Neural Network for Prognosis of Lithium-Ion Batteries. IEEE Access 2021, 9, 135132–135143. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Sigma Label | Lower Limit (σr1) | Upper Limit (σr2) |
|---|---|---|
| Sigma—1 | 0.001 | 0.01 |
| Sigma—2 | 0.01 | 0.1 |
| Sigma—3 | 0.1 | 0.1 |
| MR | StR | SyR | Particle Roughening | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Dataset | RMSE | RA | Time (s) | Successful Iterations (%) | RMSE | RA | Time (s) | Successful Iterations (%) | RMSE | RA | Time (s) | Successful Iterations (%) | RMSE | RA | Time (s) | Successful Iterations (%) |
| CALCE (CS-37) | 0.14 | 0.85 | 47.0 | 78 | 0.06 | 0.56 | 41.9 | 90 | 0.05 | 0.92 | 42.1 | 96 | 0.04 | 0.96 | 343 | 98 |
| NASA (RW11) | 0.37 | 0.58 | 66.3 | 84 | 0.35 | 0.72 | 31.3 | 90 | 0.27 | 0.94 | 83.8 | 98 | 0.24 | 0.95 | 255 | 94 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pugalenthi, K.; Park, H.; Hussain, S.; Raghavan, N. Remaining Useful Life Prediction of Lithium-Ion Batteries Using Neural Networks with Adaptive Bayesian Learning. Sensors 2022, 22, 3803. https://doi.org/10.3390/s22103803
Pugalenthi K, Park H, Hussain S, Raghavan N. Remaining Useful Life Prediction of Lithium-Ion Batteries Using Neural Networks with Adaptive Bayesian Learning. Sensors. 2022; 22(10):3803. https://doi.org/10.3390/s22103803
Chicago/Turabian StylePugalenthi, Karkulali, Hyunseok Park, Shaista Hussain, and Nagarajan Raghavan. 2022. "Remaining Useful Life Prediction of Lithium-Ion Batteries Using Neural Networks with Adaptive Bayesian Learning" Sensors 22, no. 10: 3803. https://doi.org/10.3390/s22103803
APA StylePugalenthi, K., Park, H., Hussain, S., & Raghavan, N. (2022). Remaining Useful Life Prediction of Lithium-Ion Batteries Using Neural Networks with Adaptive Bayesian Learning. Sensors, 22(10), 3803. https://doi.org/10.3390/s22103803