
Time-Domain Joint Training Strategies of Speech Enhancement and Intent Classification Neural Models


Abstract
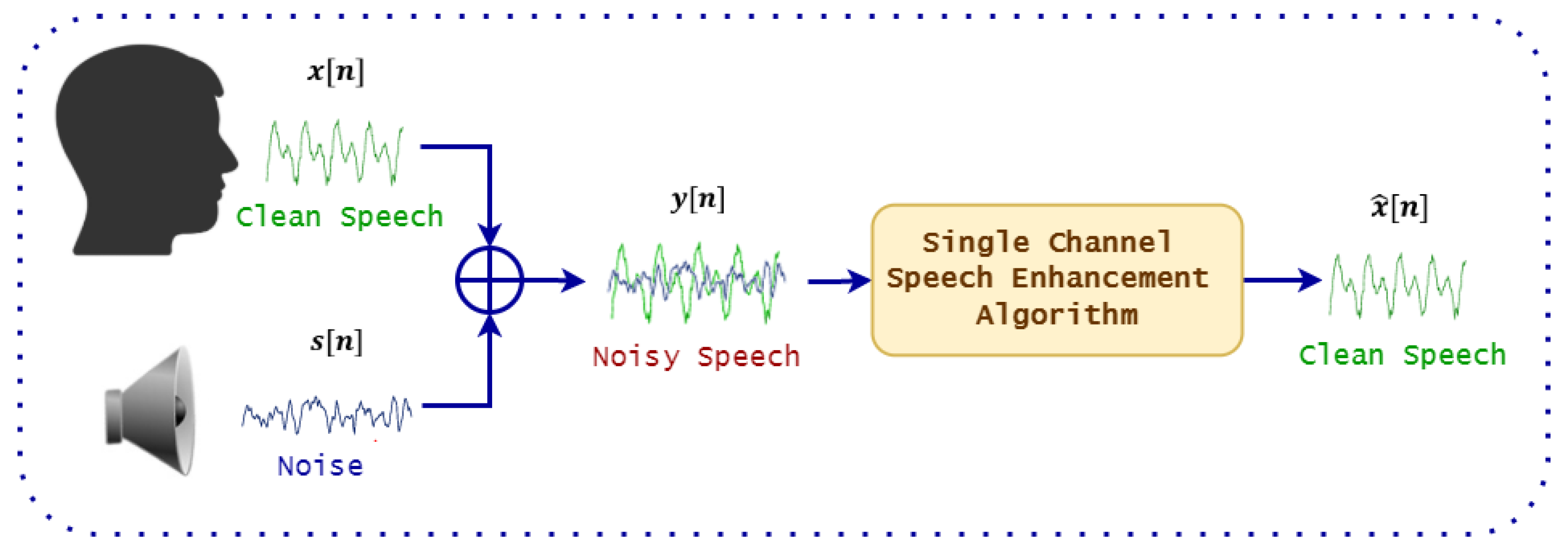
:1. Introduction
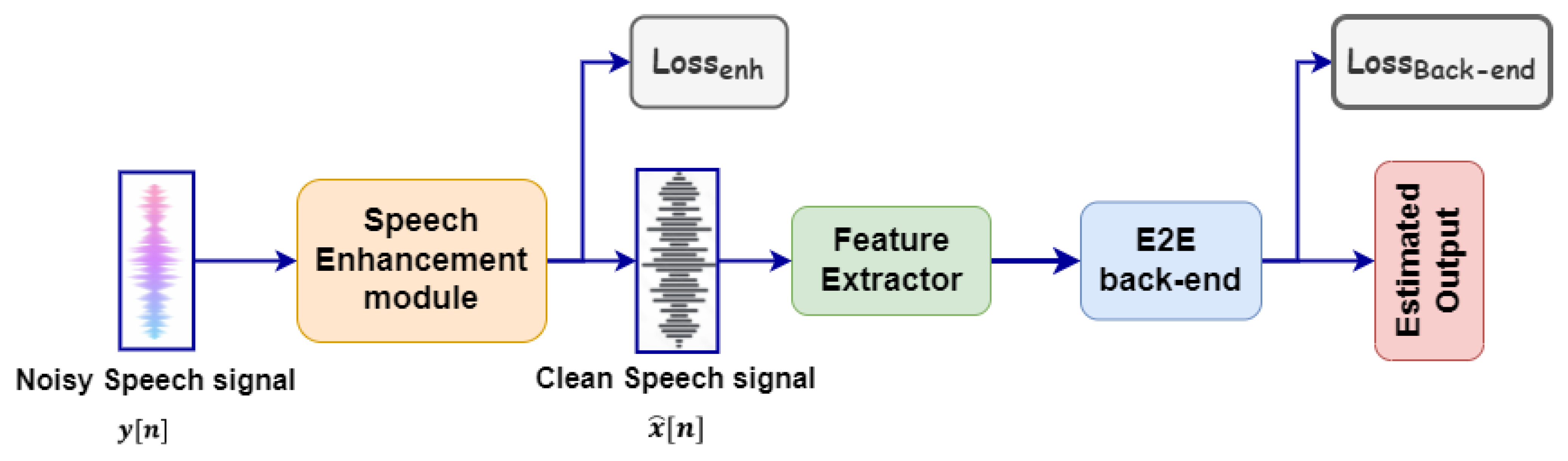
2. Related Work on Jointly Training of Speech Enhancement with Different Speech Tasks
2.1. Jointly Training Speech Enhancement with Voice Activity Detection (VAD)
2.2. Jointly Training Speech Enhancement with ASR
3. System Description
3.1. Wave-U-Net for Speech Enhancement
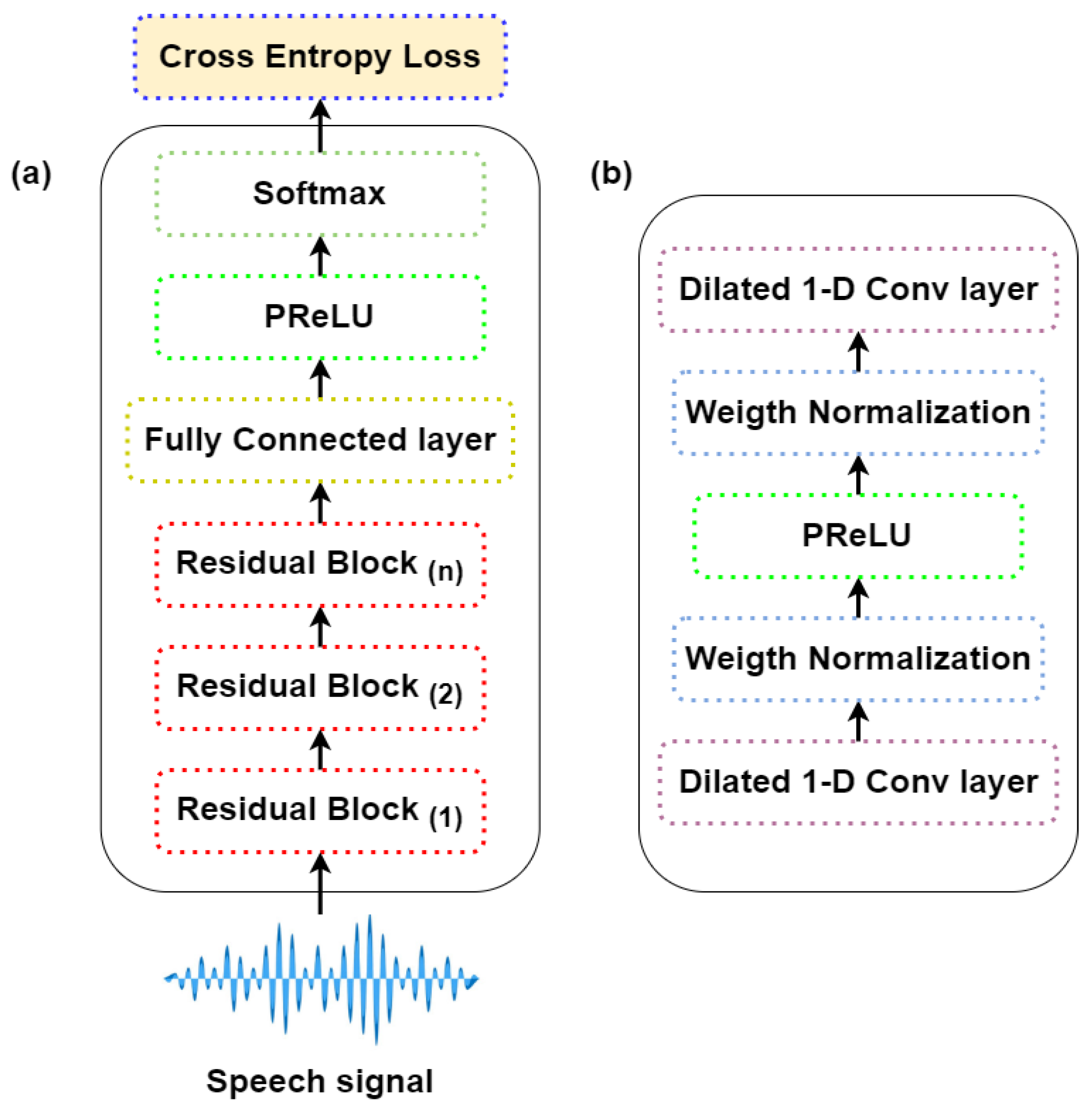
3.2. Intent Classification
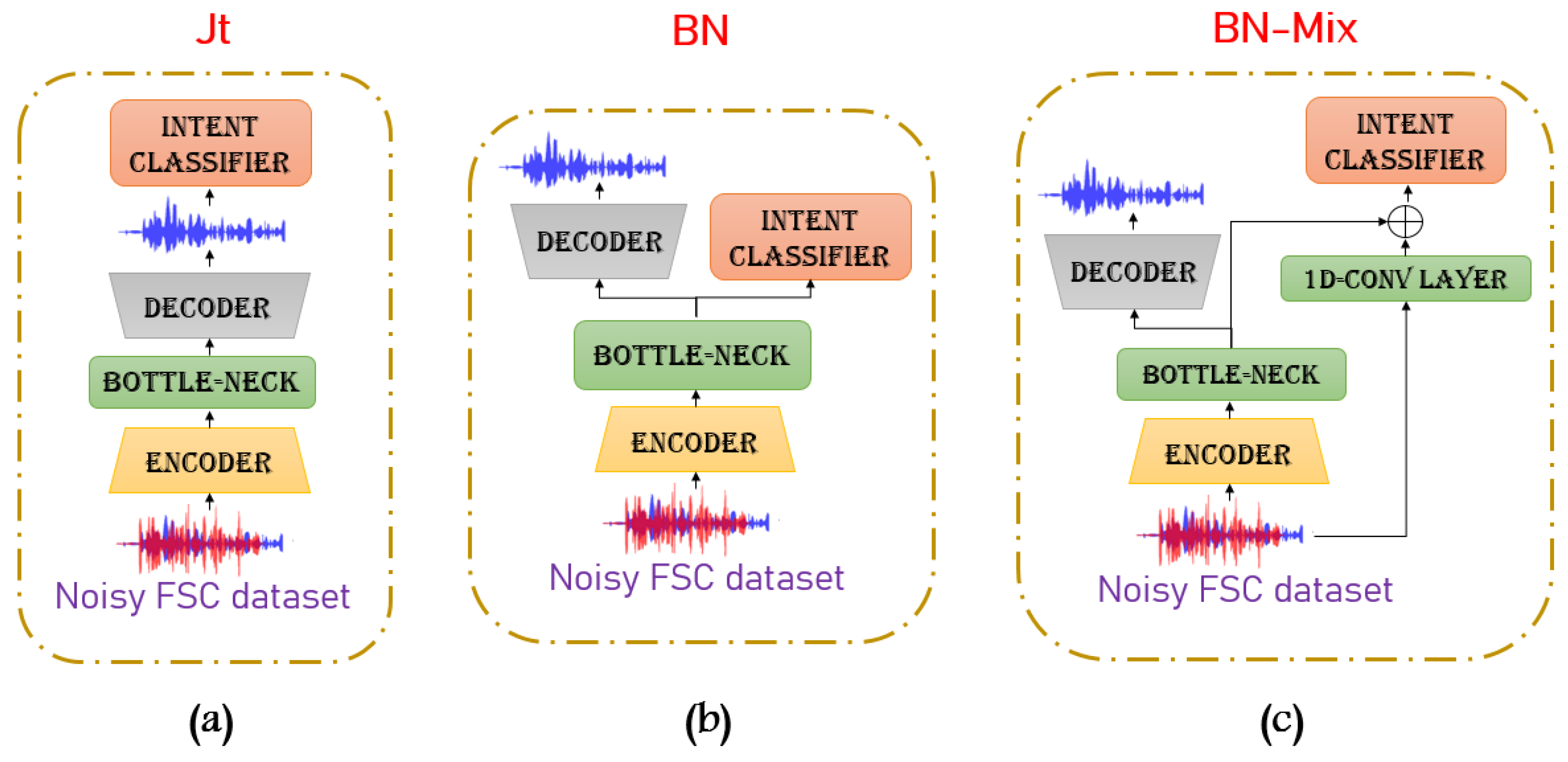
3.3. Joint Training Architectures
4. Experimental Analysis
4.1. Dataset
4.2. Experimental Results
5. Conclusions
Future Directions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Abbreviation | Meaning |
|---|---|
| ASR | Automatic Speech Recognition |
| SNR | Signal-to-Noise Ratio |
| SE | Speech Enhancement |
| MVDR | Minimum Variance Distortion Response |
| SDR | Signal-to-Distortion Ratio |
| WER | Word Error Rate |
| IBM | Ideal Binary Mask |
| IRM | Ideal Ratio Mask |
| MSE | Mean Square Error |
| TCN | Time Convolutional Neural Network |
| IC | Intent Classification |
| VAD | Voice Activity Detection |
| VAE | Variational Auto Encoder |
| DNN | Deep Neural Network |
| GAN | Generative Adversarial Network |
| GRF | Gated Recurrent Fusion |
| NLP | Natural Language Processing |
| SLU | Spoken Language Understanding |
| E2E | End-to-End |
| FSC | Fluent Speech Commands |
| PESQ | Perceptual Evaluation of Speech Quality |
| STOI | Short Time Objective Intelligibility |
References
- Morrone, G. Deep Learning Methods for Audio-Visual Speech Processing in Noisy Environments. Ph.D. Thesis, University of Modena and Reggio Emilia, Modena, Italy, 2021. [Google Scholar]
- Arons, B. A review of the cocktail party effect. J. Am. Voice I/O Soc. 1992, 12, 35–50. [Google Scholar]
- Vary, P.; Martin, R. Digital Speech Transmission: Enhancement, Coding and Error Concealment; John Wiley & Sons: Hoboken, NJ, USA, 2006. [Google Scholar]
- Bronkhorst, A.W. The cocktail party phenomenon: A review of research on speech intelligibility in multiple-talker conditions. Acta Acust. United Acust. 2000, 86, 117–128. [Google Scholar]
- Shinn-Cunningham, B.G.; Best, V. Selective attention in normal and impaired hearing. Trends Amplif. 2008, 12, 283–299. [Google Scholar] [CrossRef]
- A Al-Karawi, K.; H Al-Noori, A.; Li, F.F.; Ritchings, T. Automatic speaker recognition system in adverse conditions—Implication of noise and reverberation on system performance. Int. J. Inf. Electron. Eng. 2015, 5, 423–427. [Google Scholar] [CrossRef] [Green Version]
- Li, J.; Deng, L.; Gong, Y.; Haeb-Umbach, R. An overview of noise-robust automatic speech recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 745–777. [Google Scholar] [CrossRef]
- Yin, S.; Liu, C.; Zhang, Z.; Lin, Y.; Wang, D.; Tejedor, J.; Zhang, T.F.; Li, Y. Noisy training for deep neural networks in speech recognition. EURASIP J. Audio Speech Music. Process. 2015, 2015, 2. [Google Scholar] [CrossRef] [Green Version]
- Braun, S.; Tashev, I. Data augmentation and loss normalization for deep noise suppression. In Speech and Computer; Springer: Cham, Switzerland, 2020; pp. 79–86. [Google Scholar]
- Johnson, D.H. Array Signal Processing: Concepts and Techniques. 1993. Available online: https://silo.pub/qdownload/array-signal-processing-concepts-and-techniques.html (accessed on 29 November 2021).
- Wolfel, M.; McDonough, J. Minimum variance distortionless response spectral estimation. IEEE Signal Process. Mag. 2005, 22, 117–126. [Google Scholar] [CrossRef]
- Brandstein, M.; Ward, D. Microphone Arrays: Signal Processing Techniques and Applications; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2013. [Google Scholar]
- Guimarães, H.R.; Nagano, H.; Silva, D.W. Monaural Speech Enhancement through Deep Wave-U-Net. Expert Syst. Appl. 2020, 158, 113582. [Google Scholar] [CrossRef]
- Koizumi, Y.; Karita, S.; Wisdom, S.; Erdogan, H.; Hershey, J.R.; Jones, L.; Bacchiani, M. DF-Conformer: Integrated architecture of Conv-TasNet and Conformer using linear complexity self-attention for speech enhancement. In Proceedings of the 2021 IEEE Workshop on Applications of Signal Processing to Audio and Acoustics, New Paltz, NY, USA, 17–20 October 2021; pp. 161–165. [Google Scholar]
- Tai, W.; Lan, T.; Wang, Q.; Liu, Q. IDANet: An Information Distillation and Aggregation Network for Speech Enhancement. IEEE Signal Process. Lett. 2021, 28, 1998–2002. [Google Scholar] [CrossRef]
- Tang, C.; Luo, C.; Zhao, Z.; Xie, W.; Zeng, W. Joint time-frequency and time domain learning for speech enhancement. In Proceedings of the Twenty-Ninth International Conference on International Joint Conferences on Artificial Intelligence, Yokohama, Japan, 7–15 January 2021; pp. 3816–3822. [Google Scholar]
- Wang, K.; He, B.; Zhu, W.-P. TSTNN: Two-Stage Transformer Based Neural Network for Speech Enhancement in the Time Domain. In Proceedings of the 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing, Toronto, ON, Canada, 6–11 June 2021; pp. 7098–7102. [Google Scholar]
- Hasannezhad, M.; Yu, H.; Zhu, W.-P.; Champagne, B. PACDNN: A phase-aware composite deep neural network for speech enhancement. Speech Commun. 2022, 136, 1–13. [Google Scholar] [CrossRef]
- Choi, H.S.; Park, S.; Lee, J.H.; Heo, H.; Jeon, D.; Lee, K. Real-Time Denoising and Dereverberation wtih Tiny Recurrent U-Net. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing, Toronto, ON, Canada, 6–11 June 2021; pp. 5789–5793. [Google Scholar]
- Li, X.; Li, J.; Yan, Y. Ideal Ratio Mask Estimation Using Deep Neural Networks for Monaural Speech Segregation in Noisy Reverberant Conditions. In Proceedings of the Interspeech 2017, Stockholm, Sweden, 20–24 August 2017; pp. 1203–1207. [Google Scholar]
- Sun, J.; Tang, Y.; Jiang, A.; Xu, N.; Zhou, L. Speech enhancement via sparse coding with ideal binary mask. In Proceedings of the 2014 12th International Conference on Signal Processing, Hangzhou, China, 26–30 October 2014; pp. 537–540. [Google Scholar]
- Xu, Z.; Elshamy, S.; Zhao, Z.; Fingscheidt, T. Components loss for neural networks in mask-based speech enhancement. EURASIP J. Audio Speech Music. Process. 2021, 2021, 24. [Google Scholar] [CrossRef]
- Wang, X.; Bao, F.; Bao, C. IRM estimation based on data field of cochleagram for speech enhancement. Speech Commun. 2018, 97, 19–31. [Google Scholar] [CrossRef]
- Defossez, A.; Synnaeve, G.; Adi, Y. Real time speech enhancement in the waveform domain. arXiv 2020, arXiv:2006.12847. [Google Scholar]
- Macartney, C.; Weyde, T. Improved speech enhancement with the wave-u-net. arXiv 2018, arXiv:1811.11307. [Google Scholar]
- Ali, M.N.; Schmalz, V.J.; Brutti, A.; Falavigna, D. A Speech Enhancement Front-End for Intent Classification in Noisy Environments. In Proceedings of the 2021 29th European Signal Processing Conference, A Coruña, Spain, 2–6 September 2021; pp. 471–475. [Google Scholar]
- Narayanan, A.; Wang, D. Investigation of speech separation as a front-end for noise robust speech recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2014, 22, 826–835. [Google Scholar] [CrossRef]
- Seltzer, M.L.; Yu, D.; Wang, Y. An investigation of deep neural networks for noise robust speech recognition. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 7398–7402. [Google Scholar]
- Vincent, E.; Barker, J.; Watanabe, S.; Le Roux, J.; Nesta, F.; Matassoni, M. The second ‘CHiME’ speech separation and recognition challenge: An overview of challenge systems and outcomes. In Proceedings of the 2013 IEEE Workshop on Automatic Speech Recognition and Understanding, Olomouc, Czech Republic, 8–12 December 2013; pp. 162–167. [Google Scholar]
- Li, F.; Nidadavolu, P.S.; Hermansky, H. A long, deep and wide artificial neural net for robust speech recognition in unknown noise. In Proceedings of the Fifteenth Annual Conference of the International Speech Communication Association, Singapore, 14–18 September 2014. [Google Scholar]
- Zhang, X.L.; Wu, J. Denoising deep neural networks based voice activity detection. In Proceedings of the 2013 IEEE International Conference on Acoustics, Speech and Signal Processing, Vancouver, BC, Canada, 26–31 May 2013; pp. 853–857. [Google Scholar]
- Wang, Q.; Du, J.; Bao, X.; Wang, Z.; Dai, L.; Lee, C. A universal VAD based on jointly trained deep neural networks. In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015. [Google Scholar]
- Lin, R.; Costello, C.; Jankowski, C.; Mruthyunjaya, V. Optimizing Voice Activity Detection for Noisy Conditions. In Proceedings of the Interspeech 2019, Graz, Austria, 15–19 September 2019; pp. 2030–2034. [Google Scholar]
- Xu, T.; Zhang, H.; Zhang, X. Joint training ResCNN-based voice activity detection with speech enhancement. In Proceedings of the 2019 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Lanzhou, China, 18–21 November 2019; pp. 1157–1162. [Google Scholar]
- Tan, Z.-H.; Sarkar, A.K.; Dehak, N. rVAD: An unsupervised segment-based robust voice activity detection method. Comput. Speech Lang. 2020, 59, 1–21. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Lee, G.W.; Kim, H.K. Multi-task learning u-net for single-channel speech enhancement and mask-based voice activity detection. Appl. Sci. 2020, 10, 3230. [Google Scholar] [CrossRef]
- Jung, Y.; Kim, Y.; Choi, Y.; Kim, H. Joint Learning Using Denoising Variational Autoencoders for Voice Activity Detection. In Proceedings of the Interspeech 2018, Hyderabad, India, 2–6 September 2018; pp. 1210–1214. [Google Scholar]
- Zhuang, Y.; Tong, S.; Yin, M.; Qian, Y.; Yu, K. Multi-task joint-learning for robust voice activity detection. In Proceedings of the 2016 10th International Symposium on Chinese Spoken Language Processing, Tianjin, China, 17–20 October 2016; pp. 1–5. [Google Scholar]
- Tan, X.; Zhang, X.L. Speech enhancement aided end-to-end multi-task learning for voice activity detection. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Toronto, ON, Canada, 6–11 June 2021; pp. 6823–6827. [Google Scholar]
- Droppo, J.; Acero, A. Joint discriminative front end and back end training for improved speech recognition accuracy. In Proceedings of the 2006 IEEE International Conference on Acoustics Speech and Signal Processing, Toulouse, France, 14–19 May 2006; Volume 1, p. I–I. [Google Scholar]
- Wang, Z.Q.; Wang, D. Joint training of speech separation, filterbank and acoustic model for robust automatic speech recognition. In Proceedings of the Sixteenth Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015. [Google Scholar]
- Gao, T.; Du, J.; Dai, L.; Lee, C. Joint training of front-end and back-end deep neural networks for robust speech recognition. In Proceedings of the 2015 IEEE International Conference on Acoustics, Speech and Signal Processing, South Brisbane, Australia, 19–24 April 2015; pp. 4375–4379. [Google Scholar]
- Ravanelli, M.; Brakel, P.; Omologo, M.; Bengio, Y. Batch-normalized joint training for DNN-based distant speech recognition. In Proceedings of the 2016 IEEE Spoken Language Technology Workshop (SLT), San Diego, CA, USA, 13–16 December 2016; pp. 28–34. [Google Scholar]
- Li, L.; Kang, Y.; Shi, Y.; Kürzinger, L.; Watzel, T.; Rigoll, G. Adversarial Joint Training with Self-Attention Mechanism for Robust End-to-End Speech Recognition. arXiv 2021, arXiv:2104.01471. [Google Scholar] [CrossRef]
- Fan, C.; Yi, J.; Tao, J.; Tian, Z.; Liu, B.; Wen, Z. Gated Recurrent Fusion With Joint Training Framework for Robust End-to-End Speech Recognition. IEEE/ACM Trans. Audio Speech Lang. Process. 2020, 29, 198–209. [Google Scholar] [CrossRef]
- Luo, Y.; Mesgarani, N. Conv-tasnet: Surpassing ideal time–frequency magnitude masking for speech separation. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 1256–1266. [Google Scholar] [CrossRef] [Green Version]
- Luo, Y.; Mesgarani, N. Tasnet: Time-domain audio separation network for real-time, single-channel speech separation. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Calgary, AB, Canada, 15–20 April 2018; pp. 696–700. [Google Scholar]
- Rethage, D.; Pons, J.; Serra, X. A wavenet for speech denoising. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Calgary, AB, Canada, 15–20 April 2018; pp. 5069–5073. [Google Scholar]
- Kim, E.; Seo, H. SE-Conformer: Time-Domain Speech Enhancement Using Conformer. In Proceedings of the Interspeech 2021, Brno, Czech Republic, 4–10 September 2021; pp. 2736–2740. [Google Scholar]
- Pandey, A.; Wang, D. Dense CNN with self-attention for time-domain speech enhancement. IEEE/ACM Trans. Audio Speech Lang. Process. 2021, 29, 1270–1279. [Google Scholar] [CrossRef]
- Pandey, A.; Wang, D. A new framework for CNN-based speech enhancement in the time domain. IEEE/ACM Trans. Audio Speech Lang. Process. 2019, 27, 1179–1188. [Google Scholar] [CrossRef]
- Ali, M.N.; Brutti, A.; Falavigna, D. Speech Enhancement Using Dilated Wave-U-Net: An Experimental Analysis. In Proceedings of the 2020 27th Conference of Open Innovations Association (FRUCT), Trento, Italy, 9–11 September 2020; pp. 3–9. [Google Scholar]
- Firdaus, M.; Golchha, H.; Ekbal, A.; Bhattacharyya, P. A deep multi-task model for dialogue act classification, intent detection and slot filling. Cogn. Comput. 2020, 13, 626–645. [Google Scholar] [CrossRef]
- Tur, G.; De Mori, R. Spoken Language Understanding: Systems for Extracting Semantic Information from Speech; John Wiley & Sons: Hoboken, NJ, USA, 2011. [Google Scholar]
- Gao, J.; Galley, M.; Li, L. Neural Approaches to Conversational AI: Question Answering, Task-oriented Dialogues and Social Chatbots; Now Foundations and Trends: Boston, MA, USA; Delft, The Netherlands, 2019. [Google Scholar]
- Lugosch, L.; Ravanelli, M.; Ignoto, P.; Tomar, V.S.; Bengio, Y. Speech model pre-training for end-to-end spoken language understanding. In Proceedings of the Interspeech 2019, Graz, Austria, 15–19 September 2019; pp. 814–818. [Google Scholar]
- Haghani, P.; Narayanan, A.; Bacchiani, M.; Chuang, G.; Gaur, N.; Moreno, P.; Prabhavalkar, R.; Qu, Z.; Waters, A. From audio to semantics: Approaches to end-to-end spoken language understanding. In Proceedings of the IEEE Spoken Language Technology Workshop, Athens, Greece, 18–21 December 2018; pp. 720–726. [Google Scholar]
- Serdyuk, D.; Wang, Y.; Fuegen, C.; Kumar, A.; Liu, B.; Bengio, Y. Towards end-to-end spoken language understanding. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Calgary, AB, Canada, 15–20 April 2018; pp. 5754–5758. [Google Scholar]
- Qian, Y.; Ubale, R.; Ramanaryanan, V.; Lange, P.; Suendermann-Oeft, D.; Evanini, K.; Tsuprun, E. Exploring ASR-free end-to-end modeling to improve spoken language understanding in a cloud-based dialog system. In Proceedings of the IEEE Automatic Speech Recognition and Understanding Workshop, Okinawa, Japan, 16–20 December 2017; pp. 569–576. [Google Scholar]
- Li, B.; Sainath, T.N.; Narayanan, A.; Caroselli, J.; Bacchiani, M.; Misra, A.; Shafran, I.; Sak, H.; Pundak, G.; Chin, K.K.; et al. Acoustic Modeling for Google Home. In Proceedings of the Interspeech 2017, Stockholm, Sweden, 20–24 August 2017; pp. 399–403. [Google Scholar]
- Reddy, C.K.; Beyrami, E.; Pool, J.; Cutler, R.; Srinivasan, S.; Gehrke, J. A scalable noisy speech dataset and online subjective test framework. arXiv 2019, arXiv:1909.08050. [Google Scholar]
- Santos, J.F. Maracas Is a Library for Corrupting Audio Files. 2020. Available online: https://github.com/jfsantos/maracas (accessed on 3 November 2021).
- Haos, X. Wave-U-Net-for-Speech-Enhancement. 2020. Available online: https://github.com/haoxiangsnr/Wave-U-Net-for-Speech-Enhancement (accessed on 3 November 2021).
- ITU-Telecommunication Standardization Sector. ITU, Recommendation ITU-T P. 862.2: Wideband Extension to Recommendation P. 862 for the Assessment of Wideband Telephone Networks and Speech Codecs. 2007. Available online: https://www.itu.int/rec/T-REC-P.862.2 (accessed on 25 November 2021).
- Taal, C.H.; Hendriks, R.C.; Heusdens, R.; Jensen, J. A short-time objective intelligibility measure for time-frequency weighted noisy speech. In Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, Dallas, TX, USA, 14–19 March 2010; pp. 4214–4217. [Google Scholar]
- Fu, S.; Liao, C.; Tsao, Y. Learning with learned loss function: Speech enhancement with quality-net to improve perceptual evaluation of speech quality. IEEE Signal Process. Lett. 2019, 27, 26–30. [Google Scholar] [CrossRef]
- Hemphill, C.T.; Godfrey, J.J.; Doddington, G.R. The ATIS Spoken Language Systems Pilot Corpus. In Proceedings of the Workshop on Speech and Natural Language, Hidden Valley, PA, USA, 24–27 June 1990. [Google Scholar]
- Bellomaria, V.; Castellucci, G.; Favalli, A.; Romagnoli, R. Almawave-SLU: A new dataset for SLU in Italian. arXiv 2019, arXiv:1907.07526. [Google Scholar]
- Bastianelli, E.; Vanzo, A.; Swietojanski, P.; Rieser, V. SLURP: A Spoken Language Understanding Resource Package. arXiv 2020, arXiv:2011.13205. [Google Scholar]
- Schneider, S.; Baevski, A.; Collobert, R.; Auli, M. wav2vec: Unsupervised pre-training for speech recognition. arXiv 2019, arXiv:1904.05862. [Google Scholar]



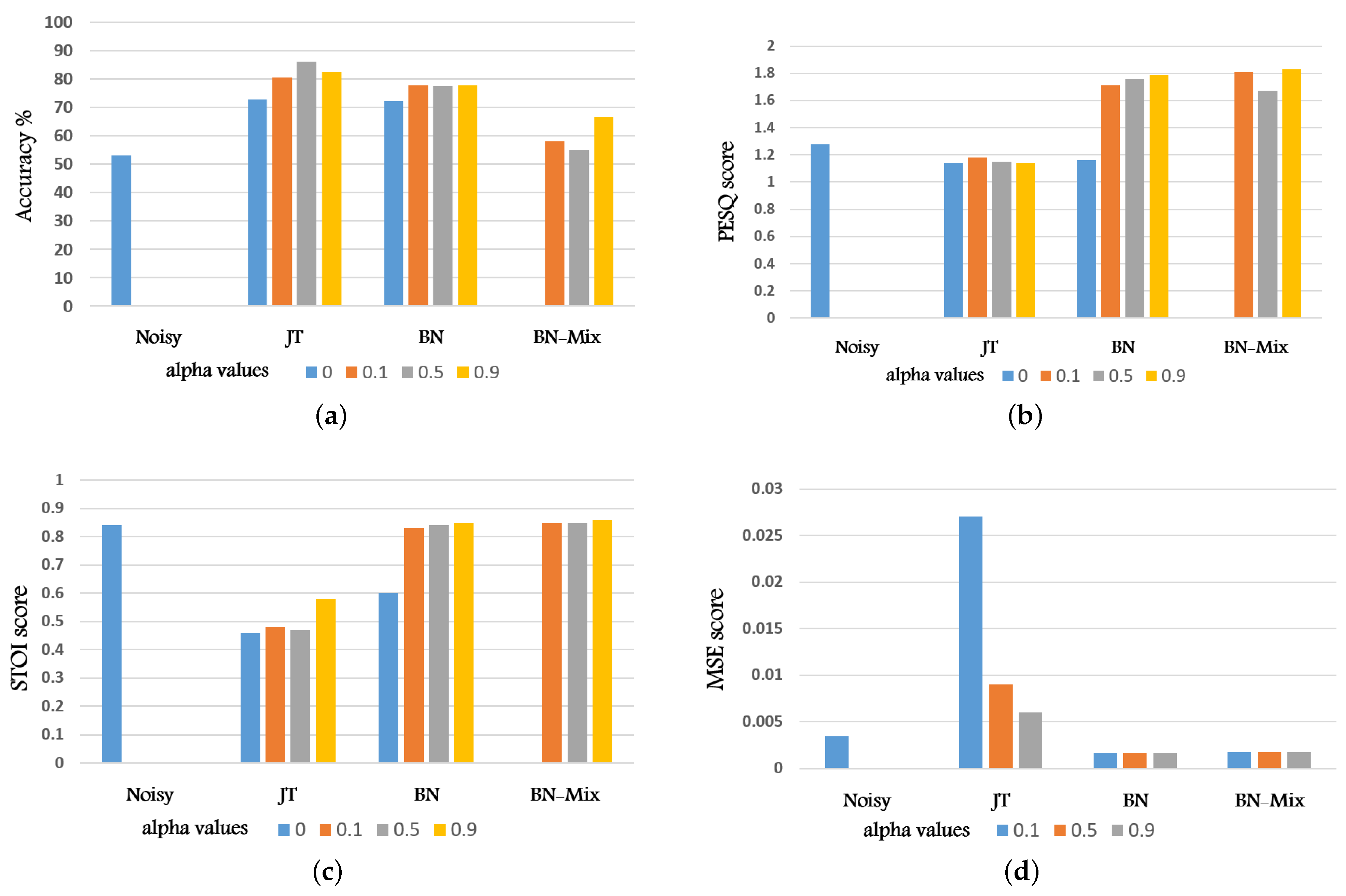
| Data | Speakers No. | Utterance No. | Total Hours |
|---|---|---|---|
| Train Data | 77 | 23,132 | 14.7 |
| Validation Data | 10 | 3119 | 1.9 |
| Evaluation Data | 10 | 3793 | 2.4 |
| Noisy | Jt-Clean | Jt | BN | BN-Mix | |
|---|---|---|---|---|---|
| 53.2% | 73.37% | 72.80% | 72.39% | - | |
| 91.53% | 80.50% | 77.80% | 58.02% | ||
| 92.77% | 86.02% | 77.53% | 54.99% | ||
| - | 82.52% | 77.90% | 66.67% |
| Noisy | JT | BN | BN-Mix | |
|---|---|---|---|---|
| 1.28 | 1.14 | 1.16 | - | |
| 1.18 | 1.71 | 1.81 | ||
| 1.15 | 1.76 | 1.67 | ||
| 1.14 | 1.79 | 1.83 |
| Noisy | JT | BN | BN-Mix | |
|---|---|---|---|---|
| 0.84 | 0.46 | 0.60 | - | |
| 0.48 | 0.83 | 0.85 | ||
| 0.47 | 0.84 | 0.85 | ||
| 0.58 | 0.85 | 0.86 |
| Noisy | JT | BN | BN-Mix | |
|---|---|---|---|---|
| - | ||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ali, M.N.; Falavigna, D.; Brutti, A. Time-Domain Joint Training Strategies of Speech Enhancement and Intent Classification Neural Models. Sensors 2022, 22, 374. https://doi.org/10.3390/s22010374
Ali MN, Falavigna D, Brutti A. Time-Domain Joint Training Strategies of Speech Enhancement and Intent Classification Neural Models. Sensors. 2022; 22(1):374. https://doi.org/10.3390/s22010374
Chicago/Turabian StyleAli, Mohamed Nabih, Daniele Falavigna, and Alessio Brutti. 2022. "Time-Domain Joint Training Strategies of Speech Enhancement and Intent Classification Neural Models" Sensors 22, no. 1: 374. https://doi.org/10.3390/s22010374
APA StyleAli, M. N., Falavigna, D., & Brutti, A. (2022). Time-Domain Joint Training Strategies of Speech Enhancement and Intent Classification Neural Models. Sensors, 22(1), 374. https://doi.org/10.3390/s22010374