
Human Activity Recognition via Hybrid Deep Learning Based Model


Abstract
:1. Introduction
- We proposed an indoor activity recognition system to efficiently recognize different types of activities to improve the physical and mental health of an individual.
- We developed a hybrid approach for the recognition of physical activity which integrates CNN and LSTM, where CNN layers are utilized to extract spatial features followed by the LSTM network for learning temporal information.
- We performed a detailed comparative analysis of various machine learning and deep learning models to select the best optimal modal for activity recognition.
- No publicly available dataset provides home base physical activities; therefore, we contribute a new dataset comprising 12 different physical activities performed by 20 participants.
2. Literature Review
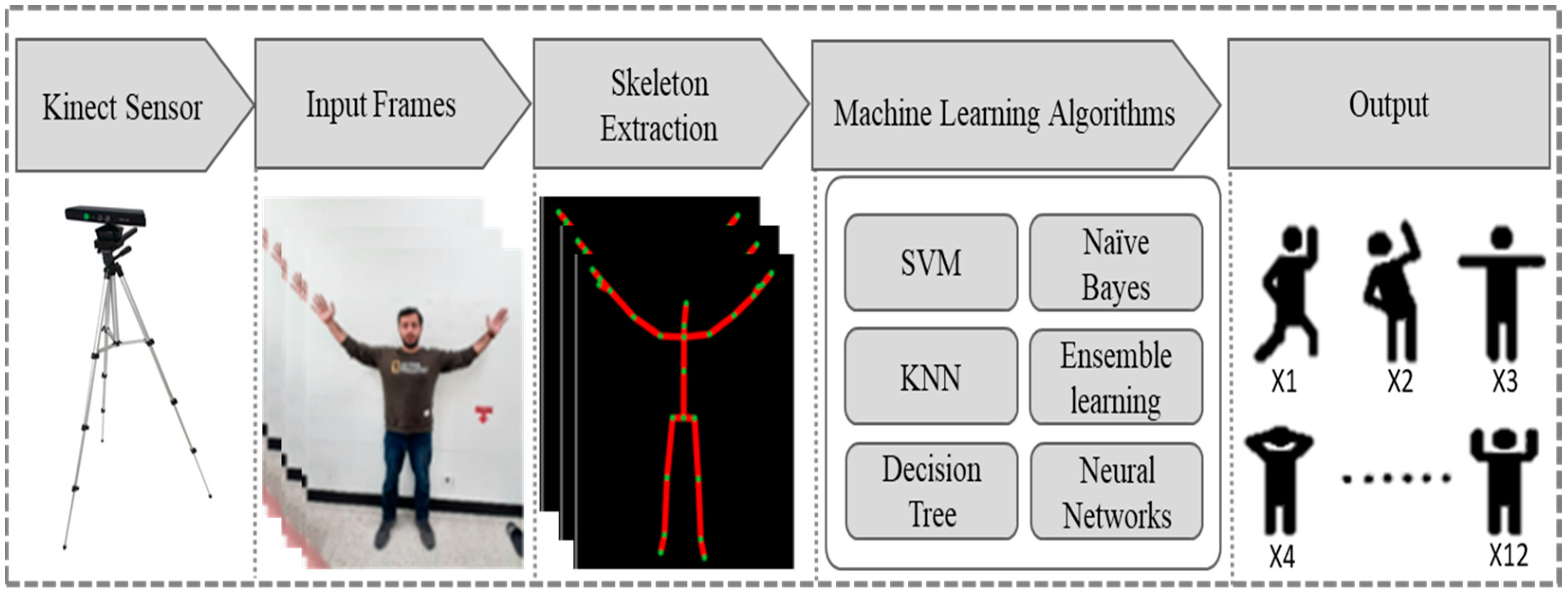
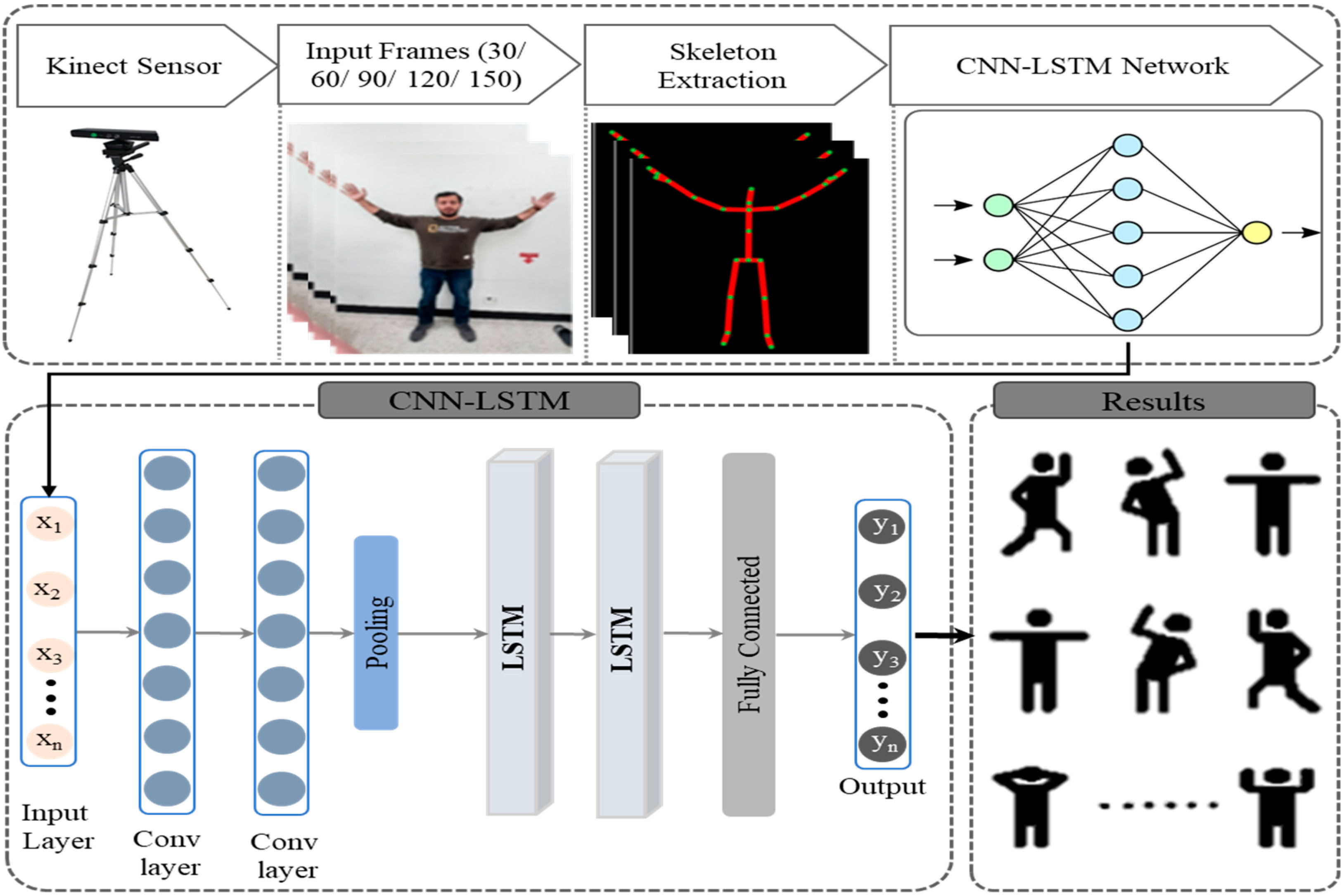
3. Proposed Method
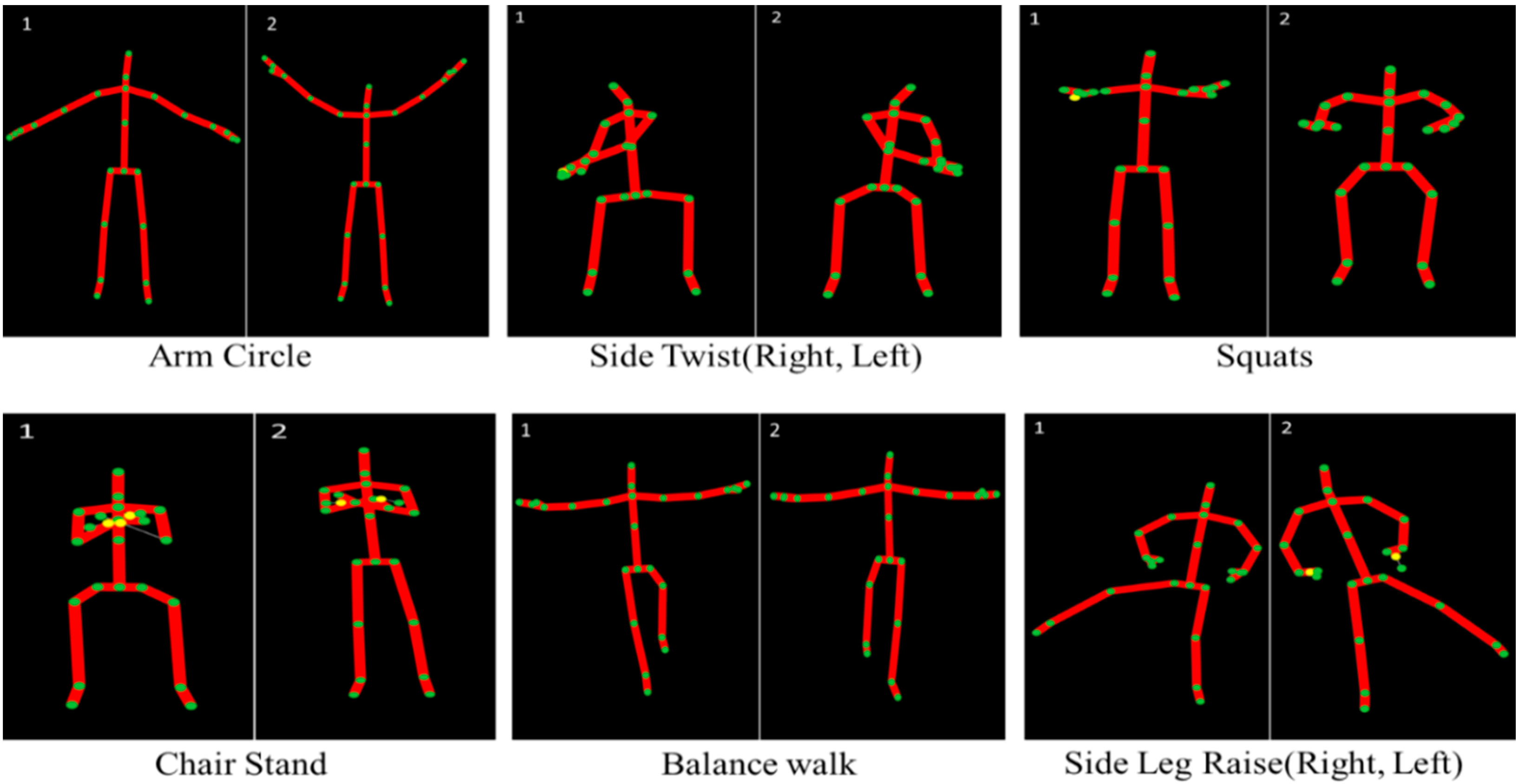
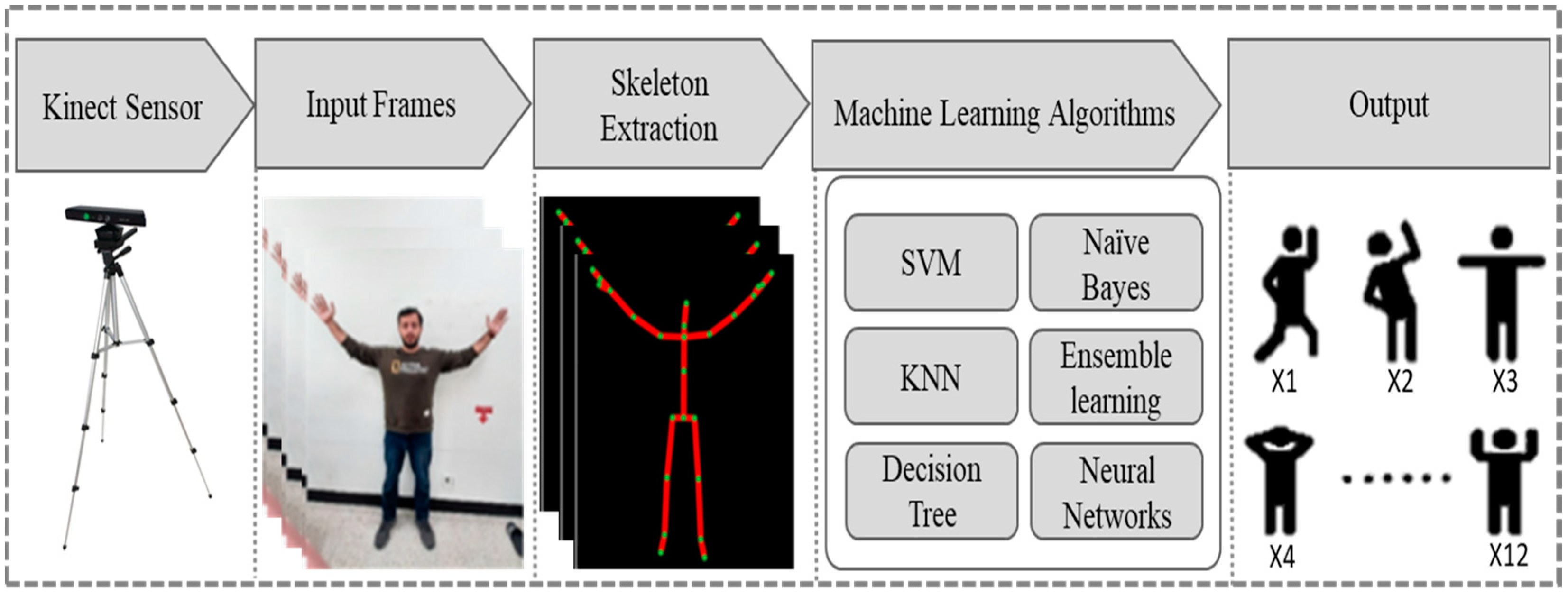
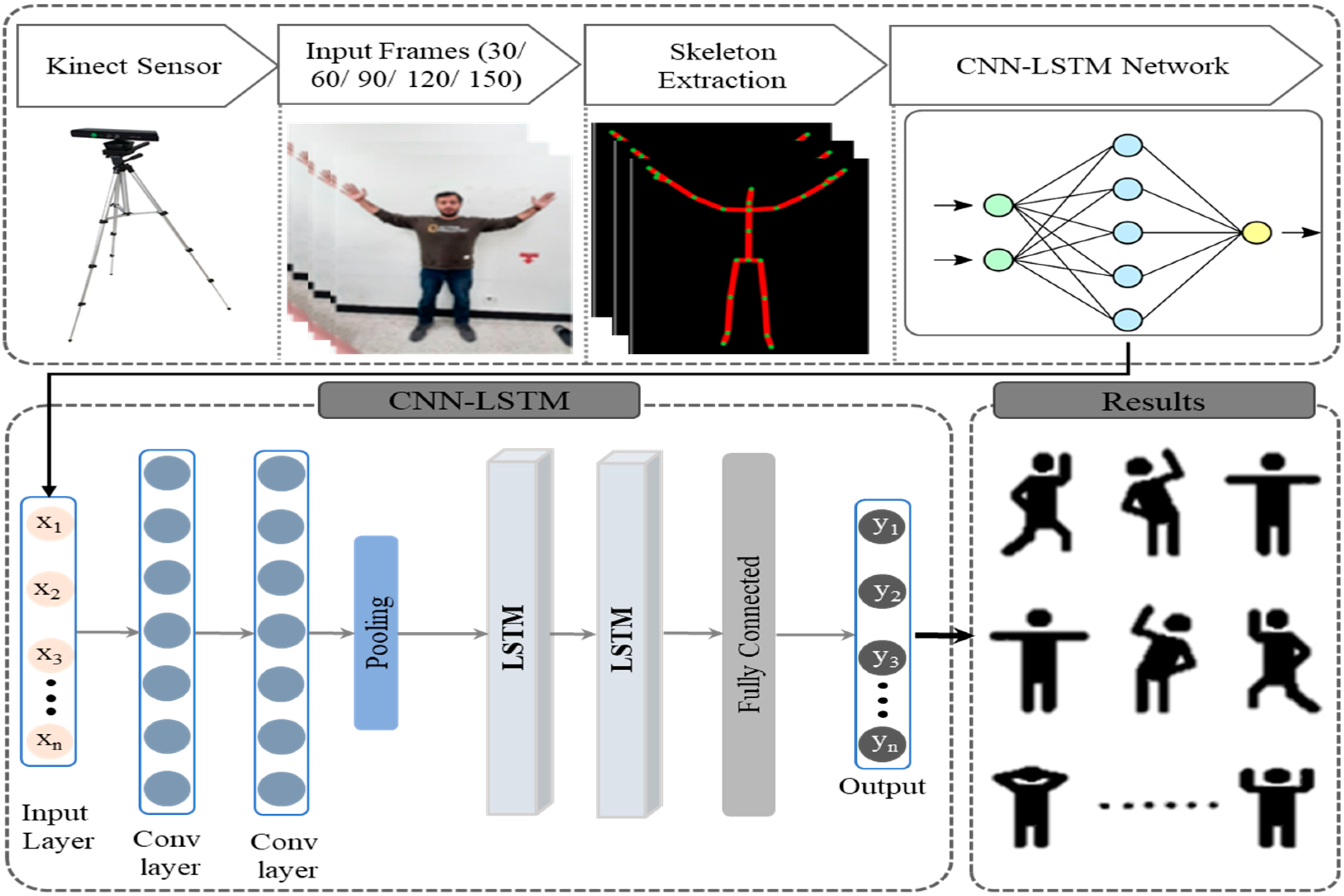
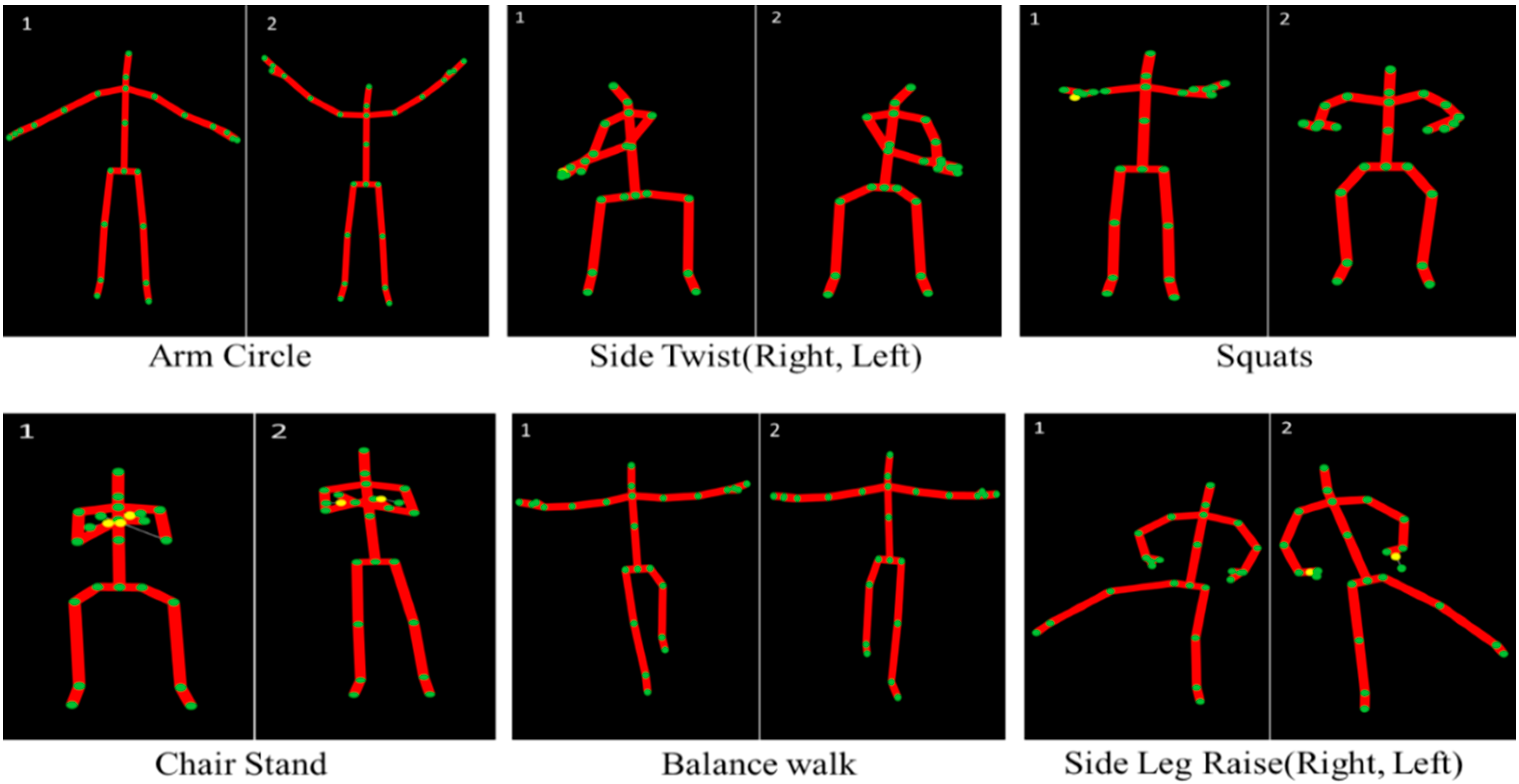
3.1. Dataset Collection & Preparation
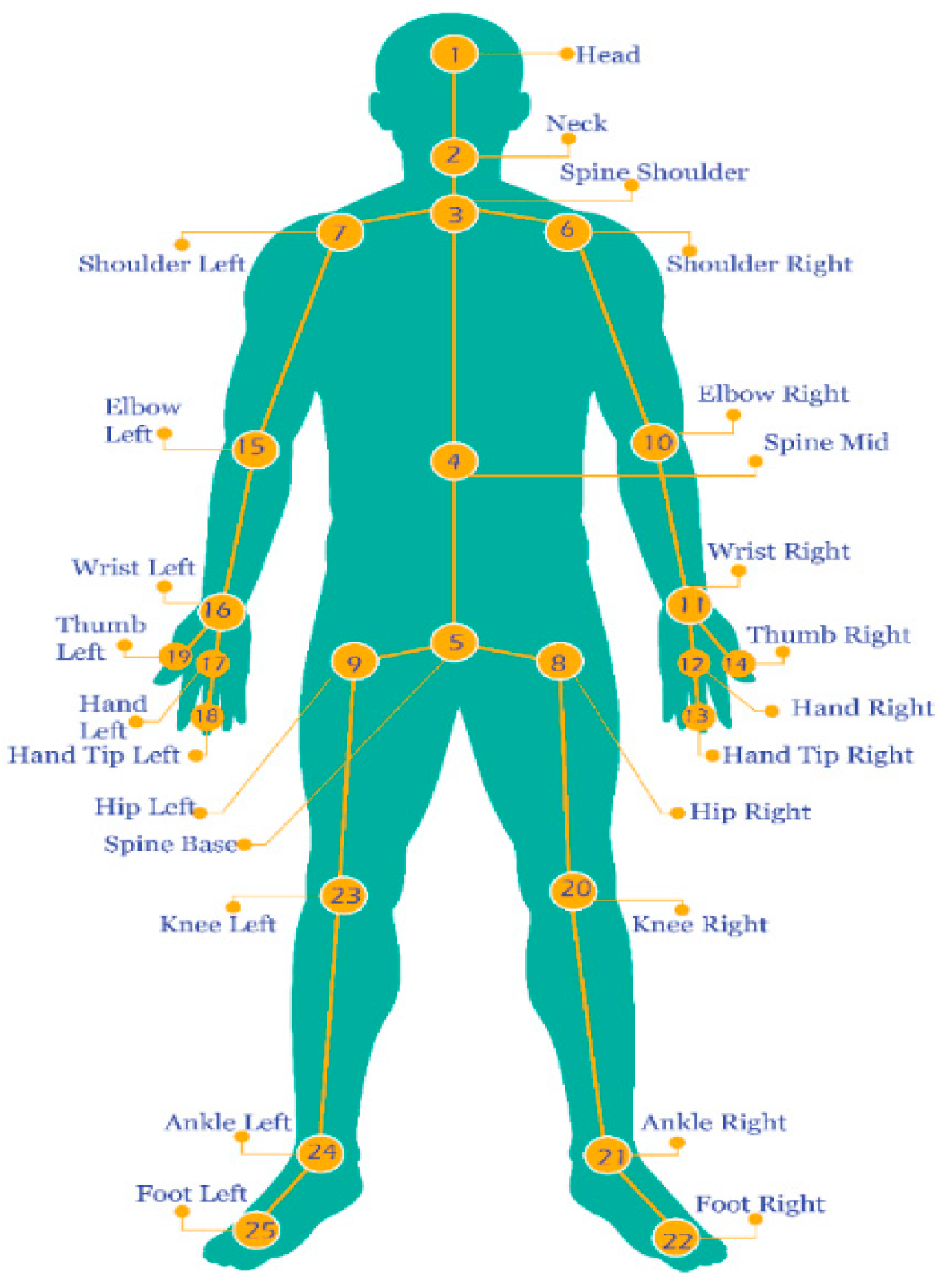
3.2. Skeleton Joints Position
3.3. Machine Learning Techniques
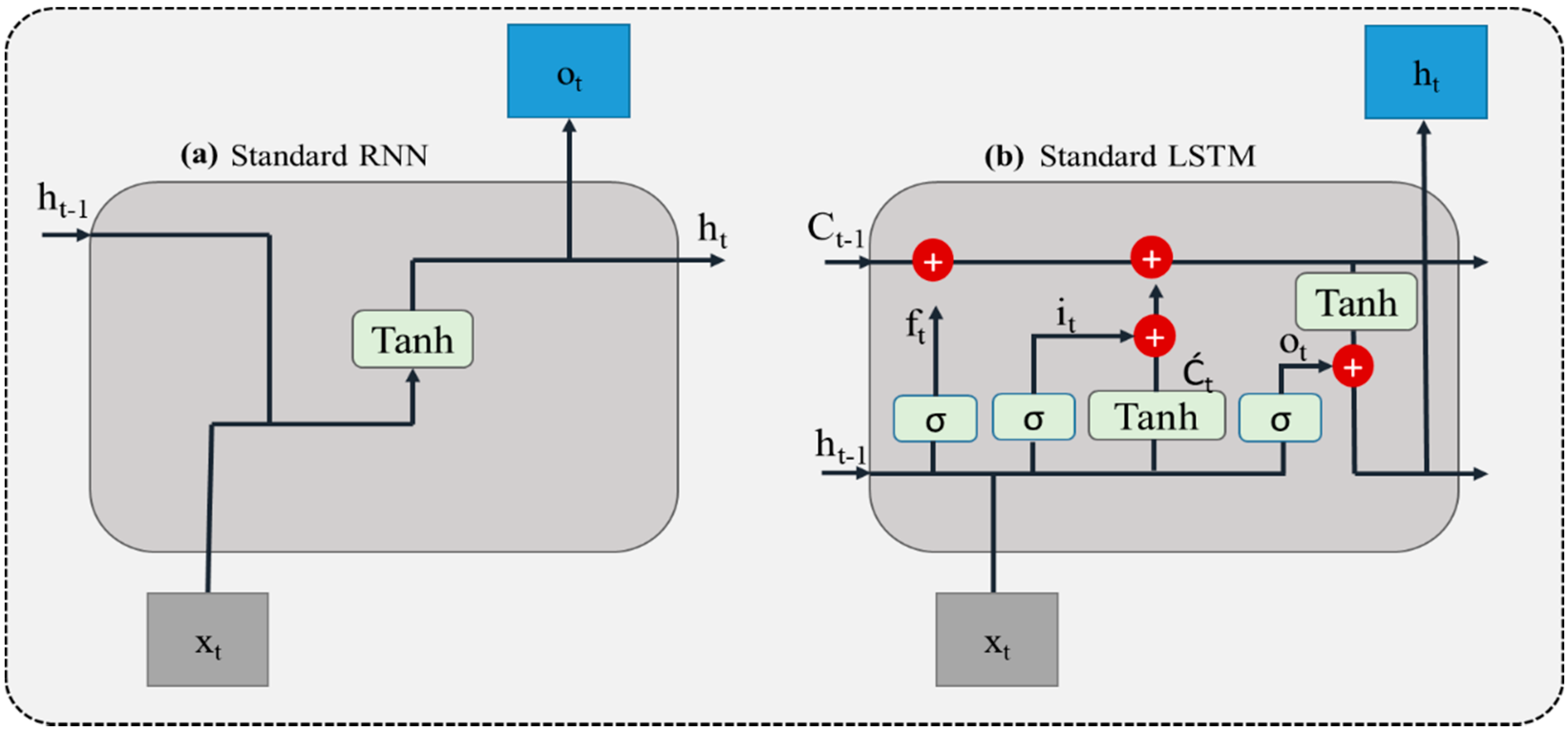
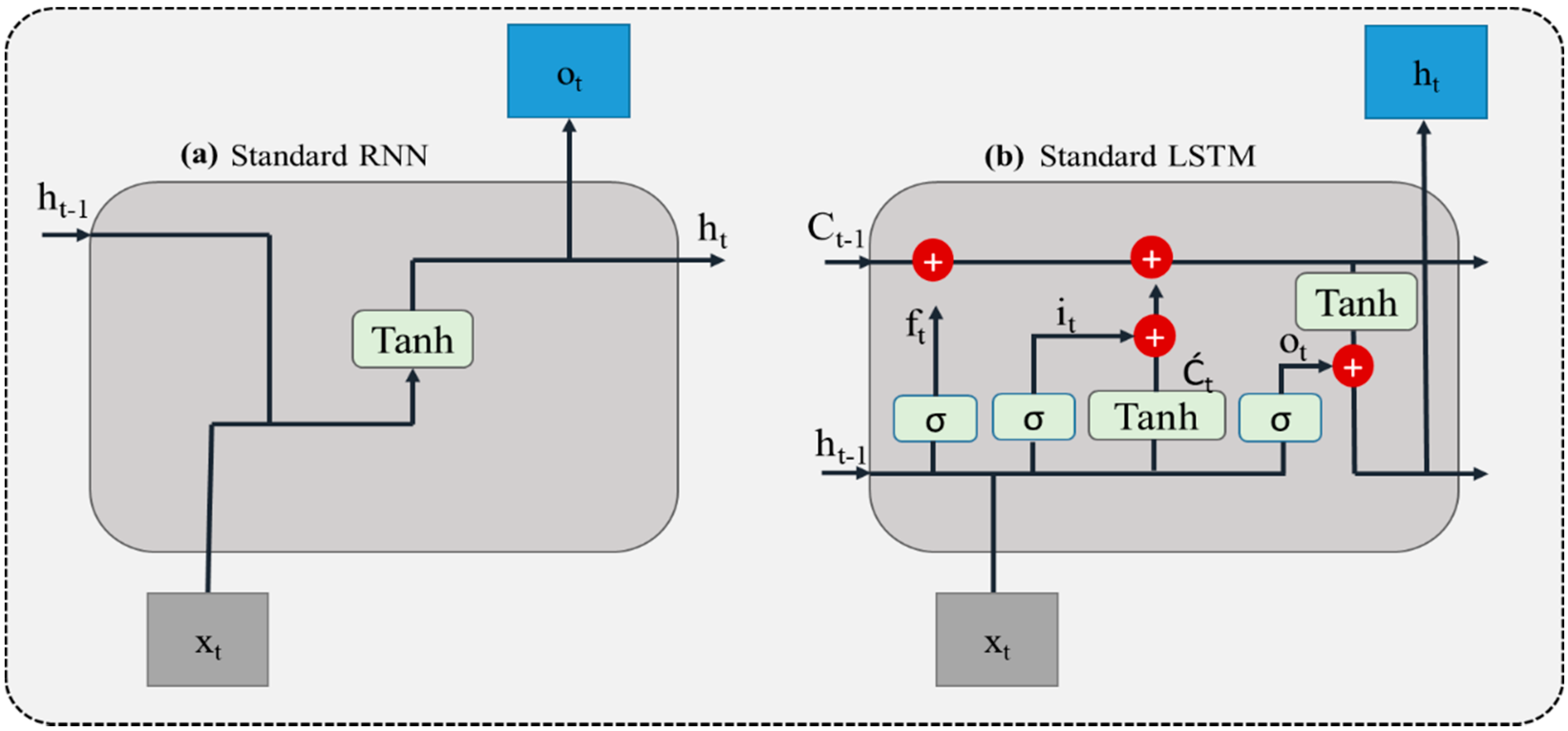
3.4. Convolutional Neural Network (CNN)
3.5. Long-Short Term Memory (LSTM)
3.6. Proposed CNN-LSTM Model
4. Experimental Results
4.1. Dataset Descriptions
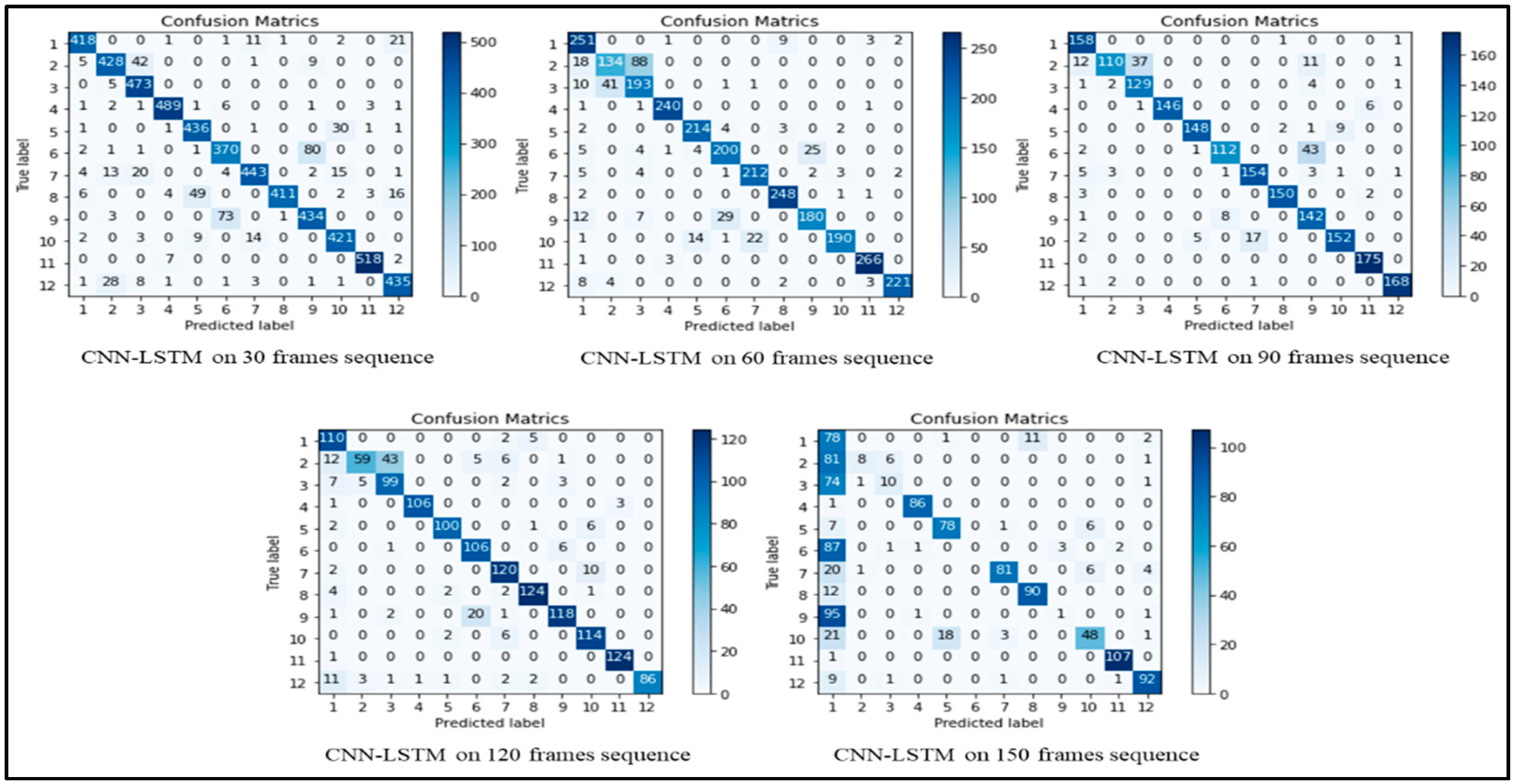
4.2. Evaluation Metrics
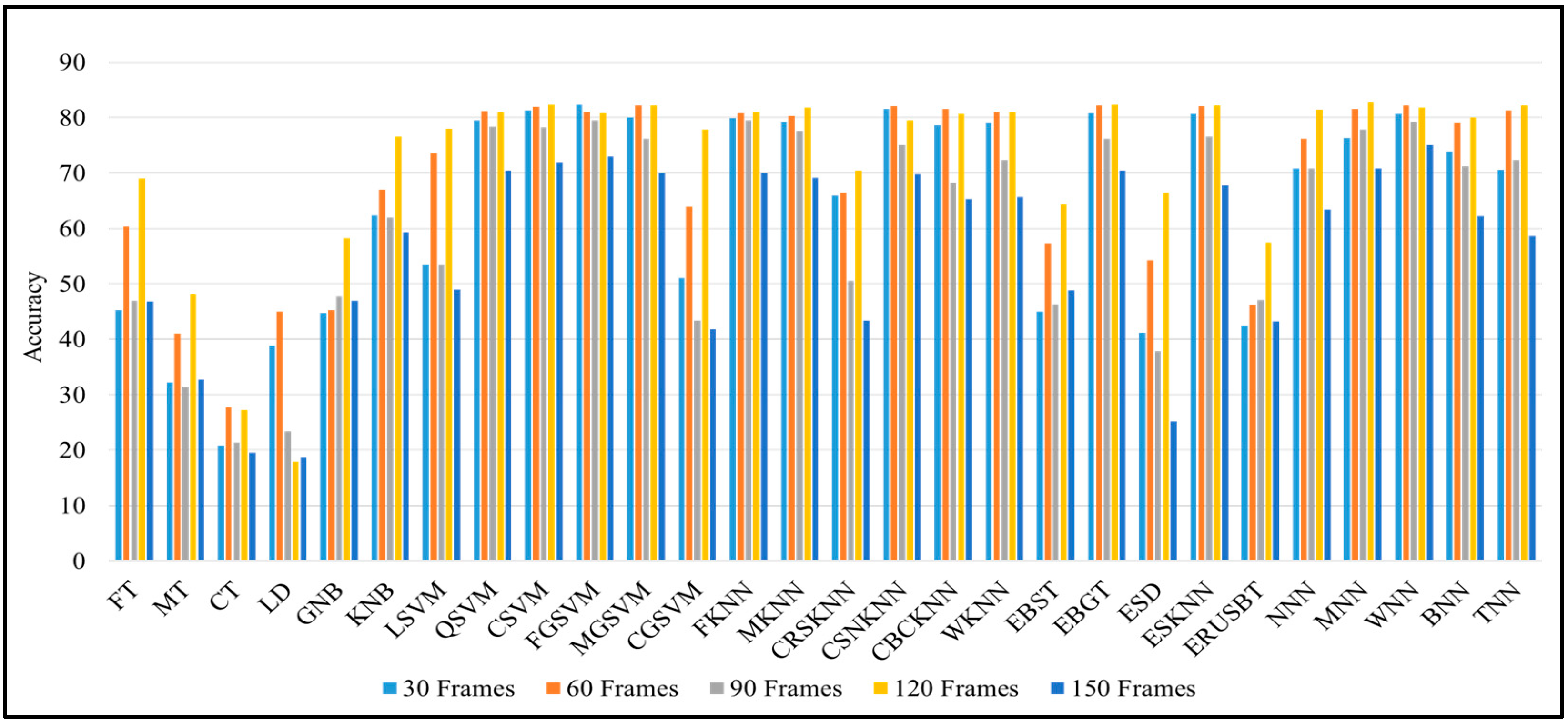
4.3. Detailed Ablation Study
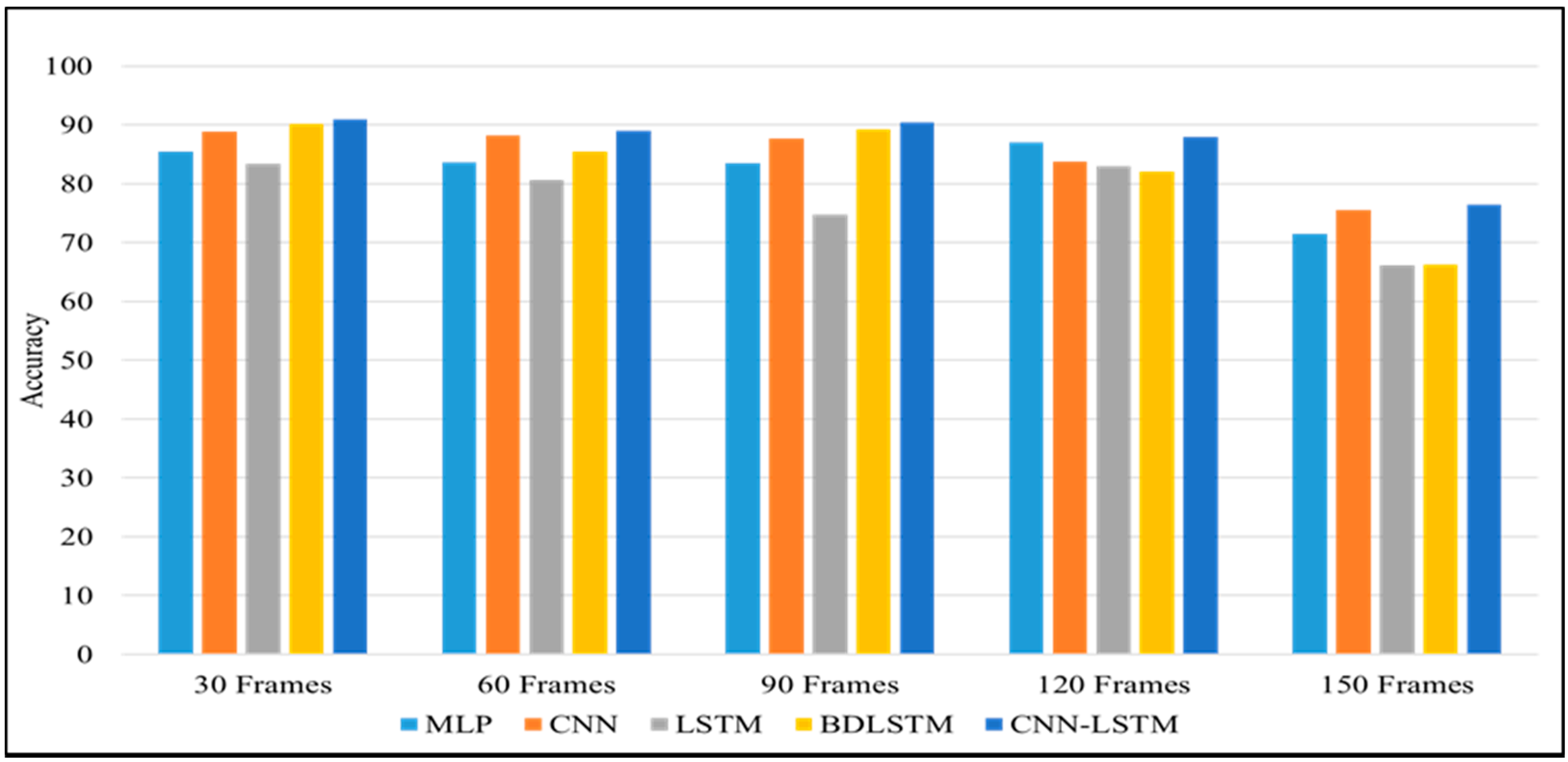
4.4. Deep Learning Techniques
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Acknowledgments
Conflicts of Interest
References
- Lin, B.-S.; Wang, L.-Y.; Hwang, Y.-T.; Chiang, P.-Y.; Chou, W.-J. Depth-camera-based system for estimating energy expenditure of physical activities in gyms. IEEE J. Biomed. Health Inform. 2018, 23, 1086–1095. [Google Scholar] [CrossRef]
- Taha, A.; Zayed, H.H.; Khalifa, M.; El-Horbaty, E.-S.M. Human activity recognition for surveillance applications. Hindawi 2016, 1, 577–586. [Google Scholar]
- Mousse, M.A.; Motamed, C.; Ezin, E.C. Percentage of human-occupied areas for fall detection from two views. Vis. Comput. 2017, 33, 1529–1540. [Google Scholar] [CrossRef]
- Ullah, A.; Muhammad, K.; Ding, W.; Palade, V.; Haq, I.U.; Baik, S.W. Efficient activity recognition using lightweight CNN and DS-GRU network for surveillance applications. Appl. Soft Comput. 2021, 103, 107102. [Google Scholar] [CrossRef]
- Ullah, A.; Muhammad, K.; Hussain, T.; Baik, S.W. Conflux LSTMs network: A novel approach for multi-view action recognition. Neurocomputing 2021, 435, 321–329. [Google Scholar] [CrossRef]
- Parker, S.J.; Strath, S.J.; Swartz, A.M. Physical activity measurement in older adults: Relationships with mental health. J. Aging Phys. Act. 2008, 16, 369–380. [Google Scholar] [CrossRef] [Green Version]
- WHO. World Health Organization. Available online: https://www.who.int/emergencies/diseases/novel-coronavirus-2019 (accessed on 5 November 2021).
- Ghazal, S.; Khan, U.S.; Saleem, M.M.; Rashid, N.; Iqbal, J. Human activity recognition using 2D skeleton data and supervised machine learning. IET Image Processing 2019, 13, 2572–2578. [Google Scholar] [CrossRef]
- Zhu, G.; Zhang, L.; Shen, P.; Song, J. An online continuous human action recognition algorithm based on the Kinect sensor. Sensors 2016, 16, 161. [Google Scholar] [CrossRef] [Green Version]
- Manzi, A.; Dario, P.; Cavallo, F. A human activity recognition system based on dynamic clustering of skeleton data. Sensors 2017, 17, 1100. [Google Scholar] [CrossRef] [Green Version]
- Hbali, Y.; Hbali, S.; Ballihi, L.; Sadgal, M. Skeleton-based human activity recognition for elderly monitoring systems. IET Comput. Vis. 2018, 12, 16–26. [Google Scholar] [CrossRef]
- Zanfir, M.; Leordeanu, M.; Sminchisescu, C. The Moving Pose: An Efficient 3d Kinematics Descriptor for Low-Latency Action Recognition and Detection. In Proceedings of the Computer Vision Foundation, ICCV, Computer Vison Foundation, Sydney, Australia, 3–6 December 2013; pp. 2752–2759. [Google Scholar]
- Ofli, F.; Chaudhry, R.; Kurillo, G.; Vidal, R.; Bajcsy, R. Sequence of the most informative joints (smij): A new representation for human skeletal action recognition. J. Vis. Commun. Image Represent. 2014, 25, 24–38. [Google Scholar] [CrossRef] [Green Version]
- Yang, X.; Tian, Y.L. Eigenjoints-Based Action Recognition Using Naive-Bayes-Nearest-Neighbor. In Proceedings of the 2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops, Providence, RI, USA, 16–21 June 2021; pp. 14–19. [Google Scholar]
- Tamou, A.B.; Ballihi, L.; Aboutajdine, D. Automatic learning of articulated skeletons based on mean of 3D joints for efficient action recognition. Int. J. Pattern Recognit. Artif. Intell. 2017, 31, 1750008. [Google Scholar] [CrossRef]
- Cai, X.; Zhou, W.; Wu, L.; Luo, J.; Li, H. Effective active skeleton representation for low latency human action recognition. IEEE Trans. Multimed. 2015, 18, 141–154. [Google Scholar] [CrossRef]
- Hussein, M.E.; Torki, M.; Gowayyed, M.A.; El-Saban, M. Human Action Recognition Using a Temporal Hierarchy of Covariance Descriptors on 3d Joint Locations. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 588–595. [Google Scholar]
- Arthi, L.; Priya, M.N. An Efficient Data Augmentation CNN-Network for Skeleton-based Human Action Recognition. IJARTET J. 2020, 7, 101. [Google Scholar]
- Martinez, J.; Black, M.J.; Romero, J. On human motion prediction using recurrent neural networks. Comput. Aided Geom. Des. 2021, 86, 101964. [Google Scholar]
- Li, C.; Zhong, Q.; Xie, D.; Pu, S. Co-Occurrence Feature Learning from Skeleton Data for Action Recognition and Detection with Hierarchical Aggregation. In Proceedings of the Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Li, M.; Chen, S.; Chen, X.; Zhang, Y.; Wang, Y.; Tian, Q. Symbiotic graph neural networks for 3d skeleton-based human action recognition and motion prediction. IEEE Trans. Pattern Anal. Mach. Intell. 2021, 1, 10010. [Google Scholar] [CrossRef]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Altman, N.S. An introduction to kernel and nearest-neighbor nonparametric regression. Am. Stat. 1992, 46, 175–185. [Google Scholar]
- Belson, W.A. Matching and prediction on the principle of biological classification. J. R. Stat. Soc. Ser. C (Appl. Stat.) 1959, 8, 65–75. [Google Scholar] [CrossRef]
- Fisher, R. The use of multiple measurements in taxonomic problems. Annu. Eugen. 1936, 7, 179–188. [Google Scholar] [CrossRef]
- Webb, G.I.; Sammut, C.; Perlich, C. Lazy Learning. Encyclopedia of Machine Learning, 1st ed.; Springer Science & Business Media: Sydney, Australia, 2011. [Google Scholar]
- Opitz, D.; Maclin, R. Popular ensemble methods: An empirical study. J. Artif. Intell. Res. 1999, 11, 169–198. [Google Scholar] [CrossRef]
- Ilopfield, J. Neural Networks and Physical Systems with Emergent Collective Computational Abilities. Proc. Natl. Acad. Sci. USA 1982, 79, 2554. [Google Scholar]
- Hur, T.; Bang, J.; Lee, J.; Kim, J.-I.; Lee, S.J.S. Iss2Image: A novel signal-encoding technique for CNN-based human activity recognition. Sensors 2018, 18, 3910. [Google Scholar] [CrossRef] [Green Version]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2016, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kwon, S. MLT-DNet: Speech emotion recognition using 1D dilated CNN based on multi-learning trick approach. Expert Syst. Appl. 2021, 167, 114177. [Google Scholar]
- Mustaqeem; Kwon, S. 1D-CNN: Speech Emotion Recognition System Using a Stacked Network with Dilated CNN Features. CMC-Comput. Mater. Contin. 2021, 67, 4039–4059. [Google Scholar] [CrossRef]
- Ullah, H.; Muhammad, K.; Irfan, M.; Anwar, S.; Sajjad, M.; Imran, A.S.; de Albuquerque, V.H.C. Light-DehazeNet: A Novel Lightweight CNN Architecture for Single Image Dehazing. IEEE Trans. Image Process. 2021, 30, 8968–8982. [Google Scholar] [CrossRef] [PubMed]
- Khan, N.; Ullah, A.; Haq, I.U.; Menon, V.G.; Baik, S.W. SD-Net: Understanding overcrowded scenes in real-time via an efficient dilated convolutional neural network. J. Real-Time Image Process. 2021, 18, 1729–1743. [Google Scholar] [CrossRef]
- Li, X.; Zhang, Y.; Zhang, J.; Chen, S.; Marsic, I.; Farneth, R.A.; Burd, R.S. Concurrent Activity Recognition with Multimodal CNN-LSTM Structure. Available online: https://arxiv.org/ftp/arxiv/papers/1702/1702.01638.pdf (accessed on 30 November 2021).
- Gupta, S. Deep learning based human activity recognition (HAR) using wearable sensor data. Int. J. Inf. Manag. Data Insights 2021, 1, 100046. [Google Scholar] [CrossRef]
- Ullah, W.; Ullah, A.; Hussain, T.; Khan, Z.A.; Baik, S.W. An Efficient Anomaly Recognition Framework Using an Attention Residual LSTM in Surveillance Videos. Sensors 2021, 21, 2811. [Google Scholar] [CrossRef]
- Ullah, W.; Ullah, A.; Hussain, T.; Muhammad, K.; Heidari, A.A.; del Ser, J.; Baik, S.W.; de Albuquerque, V.H.C. Artificial Intelligence of Things-assisted two-stream neural network for anomaly detection in surveillance Big Video Data. Future Gener. Comput. Syst. 2021, 1, 1001. [Google Scholar] [CrossRef]
- Kwon, S. CLSTM: Deep feature-based speech emotion recognition using the hierarchical ConvLSTM network. Mathematics 2020, 8, 2133. [Google Scholar]
- Muhammad, K.; Ullah, A.; Imran, A.S.; Sajjad, M.; Kiran, M.S.; Sannino, G.; de Albuquerque, V.H.C. Human action recognition using attention based LSTM network with dilated CNN features. Future Gener. Comput. Syst. 2021, 125, 820–830. [Google Scholar] [CrossRef]
- Khan, S.U.; Hussain, T.; Ullah, A.; Baik, S.W. Deep-ReID: Deep features and autoencoder assisted image patching strategy for person re-identification in smart cities surveillance. Multimed. Tools Appl. 2021, 1, 1–22. [Google Scholar] [CrossRef]
- Khan, S.U.; Haq, I.U.; Khan, Z.A.; Khan, N.; Lee, M.Y.; Baik, S.W. Atrous Convolutions and Residual GRU Based Architecture for Matching Power Demand with Supply. Sensors 2021, 21, 7191. [Google Scholar] [CrossRef]
- Khan, N.; Ullah, F.U.M.; Ullah, A.; Lee, M.Y.; Baik, S.W. Batteries state of health estimation via efficient neural networks with multiple channel charging profiles. IEEE Access 2020, 9, 7797–7813. [Google Scholar] [CrossRef]
- Sajjad, M.; Khan, S.U.; Khan, N.; Haq, I.U.; Ullah, A.; Lee, M.Y.; Baik, S.W. Towards efficient building designing: Heating and cooling load prediction via multi-output model. Sensors 2020, 20, 6419. [Google Scholar] [CrossRef]
- Khan, Z.A.; Hussain, T.; Ullah, A.; Rho, S.; Lee, M.; Baik, S.W. Towards efficient electricity forecasting in residential and commercial buildings: A novel hybrid CNN with a LSTM-AE based framework. Sensors 2020, 20, 1399. [Google Scholar] [CrossRef] [Green Version]
- Fan, A.; Bhosale, S.; Schwenk, H.; Ma, Z.; El-Kishky, A.; Goyal, S.; Baines, M.; Celebi, O.; Wenzek, G.; Chaudhary, V.; et al. Beyond english-centric multilingual machine translation. J. Mach. Learn. Res. 2021, 22, 1–48. [Google Scholar]
- Mekruksavanich, S.; Jitpattanakul, A.J.E. Deep convolutional neural network with rnns for complex activity recognition using wrist-worn wearable sensor data. Electronics 2021, 10, 1685. [Google Scholar] [CrossRef]
- Khan, N.; Ullah, F.U.M.; Haq, I.U.; Khan, S.U.; Lee, M.Y.; Baik, S.W. AB-Net: A Novel Deep Learning Assisted Framework for Renewable Energy Generation Forecasting. Mathematics 2021, 9, 2456. [Google Scholar] [CrossRef]
- Khan, N.; Haq, I.U.; Khan, S.U.; Rho, S.; Lee, M.Y.; Baik, S.W. DB-Net: A novel dilated CNN based multi-step forecasting model for power consumption in integrated local energy systems. Int. J. Electr. Power Energy Syst. 2021, 133, 107023. [Google Scholar] [CrossRef]
- Khan, S.U.; Baik, R. MPPIF-net: Identification of plasmodium falciparum parasite mitochondrial proteins using deep features with multilayer Bi-directional LSTM. Processes 2020, 8, 725. [Google Scholar] [CrossRef]
- Haq, I.U.; Ullah, A.; Khan, S.U.; Khan, N.; Lee, M.Y.; Rho, S.; Baik, S.W. Sequential learning-based energy consumption prediction model for residential and commercial sectors. Mathematics 2021, 9, 605. [Google Scholar] [CrossRef]
- Ullah, F.U.M.; Khan, N.; Hussain, T.; Lee, M.Y.; Baik, S.W. Diving Deep into Short-Term Electricity Load Forecasting: Comparative Analysis and a Novel Framework. Mathematics 2021, 9, 611. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Labels | Activity Name | Participants | Time/Activity | Samples/Activity | Frame/Per Sec |
|---|---|---|---|---|---|
| 1 | Overhead Arm Raise | 20 | 10 s | 200 | 30 |
| 2 | Front Arm Raise | 20 | 10 s | 200 | 30 |
| 3 | Arm Curl | 20 | 10 s | 200 | 30 |
| 4 | Chair Stand | 20 | 10 s | 200 | 30 |
| 5 | Balance Walk | 20 | 10 s | 200 | 30 |
| 6 | Side Leg Raise (Right, Left) | 20 | 10 s | 200 | 30 |
| 7 | Shoulder | 20 | 10 s | 200 | 30 |
| 8 | Chest | 20 | 10 s | 200 | 30 |
| 9 | Leg Raise (Forward, Backward) | 20 | 10 s | 200 | 30 |
| 10 | Arm Circle | 20 | 10 s | 200 | 30 |
| 11 | Side Twist (Right, Left) | 20 | 10 s | 200 | 30 |
| 12 | Squats | 20 | 10 s | 200 | 30 |
| Layer (Type) | Kernel Size | Filter Size | No. of Param. |
|---|---|---|---|
| 1D CNN Layer 1 | 3 | 64 | 9664 |
| 1D CNN Layer 2 | 3 | 128 | 24,704 |
| MaxPooling 1D | - | - | - |
| LSTM(64) | - | - | 46,408 |
| LSTM(64) | - | - | 33,024 |
| Flatten | - | - | - |
| Dense(12) | - | - | 780 |
| Total parameters | - | - | 117,580 |
| No. | Classifiers | Frames Sequence | ||||
|---|---|---|---|---|---|---|
| 30 | 60 | 90 | 120 | 150 | ||
| 1 | FT | 45.2 | 60.3 | 47.0 | 69.0 | 46.8 |
| 2 | MT | 32.3 | 41.0 | 31.4 | 48.1 | 32.7 |
| 3 | CT | 20.8 | 27.7 | 21.4 | 27.2 | 19.5 |
| 4 | LD | 38.9 | 45.0 | 23.4 | 17.9 | 18.7 |
| 5 | GNB | 44.7 | 45.2 | 47.7 | 58.3 | 46.9 |
| 6 | KNB | 62.3 | 67.0 | 62.0 | 76.6 | 59.3 |
| 7 | LSVM | 53.5 | 73.6 | 53.5 | 78.0 | 48.9 |
| 8 | QSVM | 79.4 | 81.2 | 78.4 | 80.9 | 70.5 |
| 9 | CSVM | 81.3 | 82.0 | 78.3 | 82.4 | 71.9 |
| 10 | FGSVM | 82.4 | 81.1 | 79.5 | 80.8 | 72.9 |
| 11 | MGSVM | 80.0 | 82.2 | 76.1 | 82.2 | 70.1 |
| 12 | CGSVM | 51.1 | 63.9 | 43.4 | 77.9 | 41.8 |
| 13 | FKNN | 79.8 | 80.8 | 79.5 | 81.0 | 70.0 |
| 14 | MKNN | 79.2 | 80.3 | 77.6 | 81.8 | 69.1 |
| 15 | CRSKNN | 65.9 | 66.4 | 50.5 | 70.5 | 43.4 |
| 16 | CSNKNN | 81.6 | 82.1 | 75.1 | 79.4 | 69.8 |
| 17 | CBCKNN | 78.6 | 81.6 | 68.2 | 80.6 | 65.3 |
| 18 | WKNN | 79.0 | 81.1 | 72.3 | 80.9 | 65.6 |
| 19 | EBST | 45.0 | 57.3 | 46.3 | 64.4 | 48.8 |
| 20 | EBGT | 80.8 | 82.3 | 76.2 | 82.4 | 70.4 |
| 21 | ESD | 41.1 | 54.2 | 37.8 | 66.5 | 25.2 |
| 22 | ESKNN | 80.7 | 82.1 | 76.6 | 82.2 | 67.8 |
| 23 | ERUSBT | 42.5 | 46.1 | 47.1 | 57.4 | 43.2 |
| 24 | NNN | 70.9 | 76.1 | 70.8 | 81.4 | 63.4 |
| 25 | MNN | 76.3 | 81.6 | 77.9 | 82.8 | 70.9 |
| 26 | WNN | 80.6 | 82.2 | 79.2 | 81.8 | 75.1 |
| 27 | BNN | 73.9 | 79.0 | 71.3 | 80.0 | 62.2 |
| 28 | TNN | 70.6 | 81.3 | 72.3 | 82.2 | 58.6 |
| No. | Model Name | Frames Sequence | ||||
|---|---|---|---|---|---|---|
| 30 | 60 | 90 | 120 | 150 | ||
| 1 | MLP | 85.45 | 83.64 | 83.47 | 87.05 | 71.51 |
| 2 | CNN | 88.82 | 88.22 | 87.65 | 83.74 | 75.47 |
| 3 | LSTM | 83.31 | 80.64 | 74.69 | 82.92 | 66.09 |
| 4 | BiLSTM | 90.15 | 85.39 | 89.30 | 82.02 | 66.26 |
| 5 | CNN-LSTM | 90.89 | 88.98 | 90.44 | 87.94 | 76.50 |
| No. | Model Name | Frames Sequence | ||||
|---|---|---|---|---|---|---|
| 30 | 60 | 90 | 120 | 150 | ||
| 1 | MLP | 86.18 | 84.37 | 85.12 | 88.54 | 74.97 |
| 2 | CNN | 89.20 | 88.48 | 88.37 | 83.93 | 78.04 |
| 3 | LSTM | 83.94 | 82.51 | 74.95 | 84.04 | 64.01 |
| 4 | BiLSTM | 90.74 | 85.90 | 89.62 | 82.52 | 70.35 |
| 5 | CNN-LSTM | 91.11 | 89.31 | 91.13 | 88.82 | 76.13 |
| No. | ModelName | Frames Sequence | ||||
|---|---|---|---|---|---|---|
| 30 | 60 | 90 | 120 | 150 | ||
| 1 | MLP | 85.39 | 83.43 | 83.58 | 86.86 | 71.92 |
| 2 | CNN | 88.86 | 88.07 | 87.77 | 83.50 | 75.36 |
| 3 | LSTM | 83.24 | 81.23 | 74.15 | 82.84 | 65.89 |
| 4 | BiLSTM | 90.05 | 85.24 | 89.41 | 82.11 | 67.16 |
| 5 | CNN-LSTM | 90.84 | 88.79 | 90.56 | 88.10 | 75.82 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, I.U.; Afzal, S.; Lee, J.W. Human Activity Recognition via Hybrid Deep Learning Based Model. Sensors 2022, 22, 323. https://doi.org/10.3390/s22010323
Khan IU, Afzal S, Lee JW. Human Activity Recognition via Hybrid Deep Learning Based Model. Sensors. 2022; 22(1):323. https://doi.org/10.3390/s22010323
Chicago/Turabian StyleKhan, Imran Ullah, Sitara Afzal, and Jong Weon Lee. 2022. "Human Activity Recognition via Hybrid Deep Learning Based Model" Sensors 22, no. 1: 323. https://doi.org/10.3390/s22010323
APA StyleKhan, I. U., Afzal, S., & Lee, J. W. (2022). Human Activity Recognition via Hybrid Deep Learning Based Model. Sensors, 22(1), 323. https://doi.org/10.3390/s22010323