1. Introduction
Network slicing is a novel technology starting from the fifth-generation (5G) mobile communication networks which has high capacity, high data rate, high energy efficiency, and low end-to-end (E2E) delay [
1]. The system architecture adopts the virtualization techniques to make the virtualized network functions (VNF) dynamically allocated to servers in a cloud computing environment [
2,
3,
4,
5,
6]. Software-defined networking (SDN) is an enabling technology for the network access management, deployment, configuration, and control of the data forwarding planes of the underlying resources [
7,
8,
9,
10]. Each slice has the logical and independent network corresponding to the quality of service (QoS) requirements for applications, such as the Internet of Things (IoT) for massive machine-type communication (mMTC) [
11,
12], emerging AR/VR media applications, UltraHD, or 360-degree streaming video for enhanced mobile broadband (eMBB) [
6], and industrial automation, intelligent transportation, or remote diagnosis and surgery for ultra-reliable low-latency communication (URLLC) [
13]. Furthermore, the challenging research problems are derived and discovered in the following aspects:
Operators always desire to develop a sustainable network with appropriate network access management mechanisms [
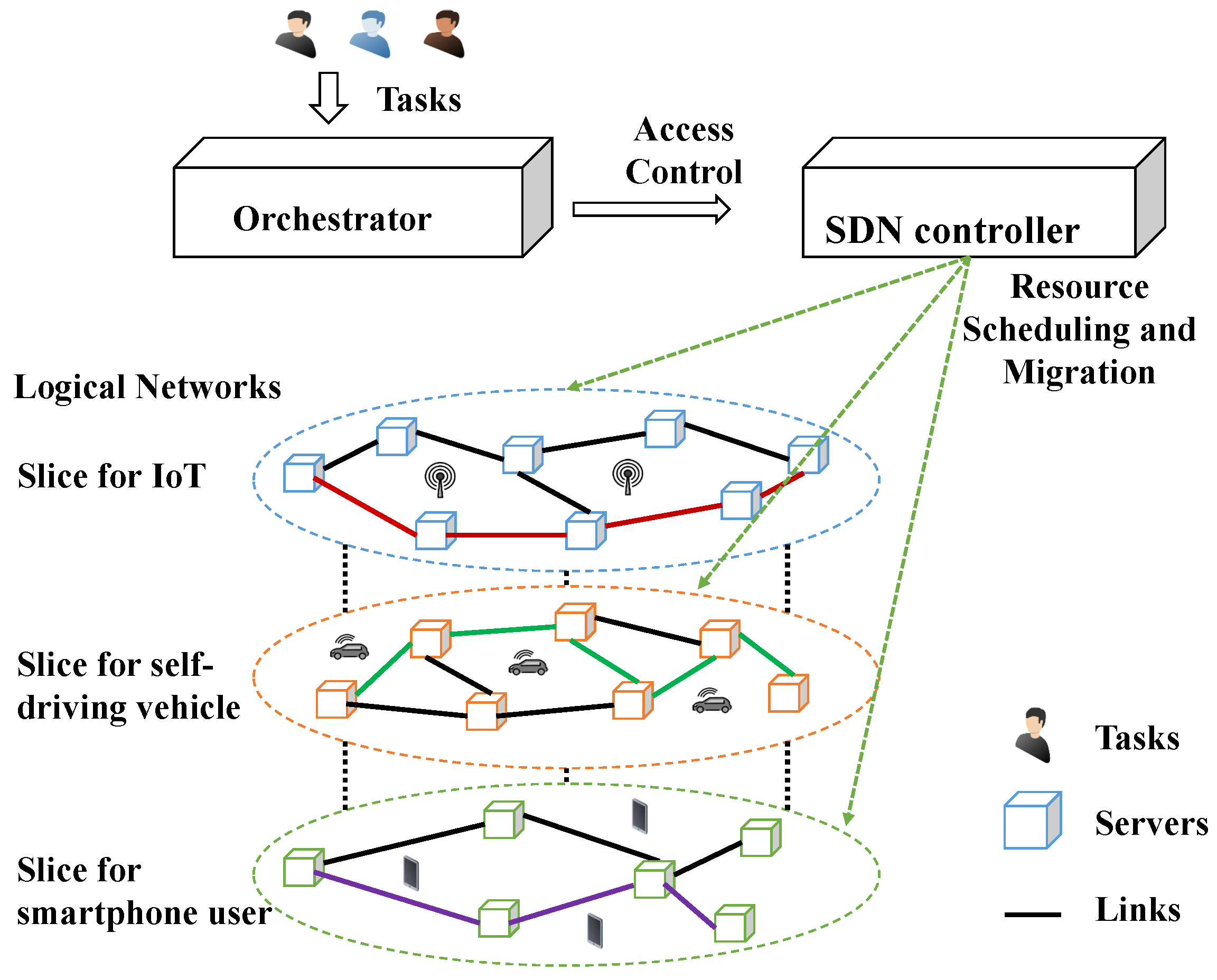
9]. A sophisticated resource orchestrator for resource allocations is a promising approach that can improve QoS and energy efficiency shown in
Figure 1. For pursuing a positive user experience, many operators also switch their focus on how to improve the QoS [
15]. An orchestrator for network operation implemented by applying resource scheduling and resource allocation strategies is crucial [
6,
13,
16].
The critical factors of resource management, such as access control, scheduling, and migrations, are analyzed in this paper on flexibility and scalability over cloud computing in sliced network. However, the network resource allocation based on data traffic and network performance is deployed by slices with heterogeneous QoS satisfied 5G traffic management characteristics. The optimal resource allocation algorithms embedded in an orchestrator are also implemented to optimize resource utilization in the end-to-end slices as the objective function to maximize the system value [
5,
17,
18,
19].
To address the challenges mentioned above, this study’s purpose and scope are proposed to stand on an ISP to optimize system resource utilization in operational stages. The system architecture is shown in
Figure 1. The orchestrator with a Lagrangian-Relaxation-based solution approach is a coordinator with network resource operation and scheduling to deal with resource management problems. It offers reliable QoS to users and provides flexibility and scalability over a cloud-based environment. A centralized computing resource management model is formulated as a mathematical programming problem to optimize the total system revenue through access control, weighted task scheduling, server operation, and resource migration. This work analyzes how the core networks acquire resources to satisfy various user requirements subject to budget and QoS constraints. The objectives are to find efficient and effective ways of obtaining the primal feasible solutions to the optimal.
Furthermore, the operation is divided into slices with many time slots concerned in the evaluation period—additionally, the available hosts scheduling with migration to adjust into active hosts. The operation costs are reflected in the objective function. Based on enough system capacities, the task processes with the QoS constraints are considered to satisfy user experience. However, the extra migration effort and active hosts are calculated as a
problem to migrate resources or shutdown hosts for power saving in limited resources. Accordingly, the problem formulation is extended from previous work [
20]. The objective function includes access control variables for task assignment, host on-off variables, and migration variables to maximize system revenue with the proposed scheduling heuristics among allocated time slots. Several constraints are formulated according to the research problem. The computational experiments and the scenarios are designed for an orchestrator for network operation to show how the experimental cases lead to a real-life situation. Then, the proposed heuristics can then iteratively obtain the primal feasible solutions with LR and dual problems to effectively minimize the solutions’ quality (GAP). The algorithms are embedded and implemented into the orchestrator to significantly, efficiently, and effectively apply resource scheduling and resource allocation strategies. This work is to concentrate on the detailed operation for practical evaluation. The main contributions of this work compared briefly to the previous work [
20] include.
The reminder of this paper is organized as follows. The literature review of the existing ideas and mechanisms for an orchestrator designed in the 5G network is presented in
Section 2 from communication and computation perspectives. In
Section 3, the problem definitions for the resource management are described, and a mathematical programming model is formulated.
Section 4 presents the proposed solution through
algorithms as initial solutions, Lagrangian Relaxation (LR) methods and optimization-based heuristics (SP, UP, and OI) developed to determine the primal feasible solutions.
Section 5 presents various computational experiments, and the results are correspondingly discussed and validated to support the proposed mechanisms. Finally, the discussion and conclusions based on numerical results are drawn for the orchestrator design proposed for network operation, and the future work is described in
Section 6.
3. System Model and Mathematical Formulation
Figure 1 illustrates an abstract system model in an optimization-based framework. The tasks are represented as user computing demands concerning values, amount of computational resources, processing time, and delay tolerance. The heterogeneous servers have various levels of limited computational resources. For example, an application requests diverse computational resources simulated as tasks for transmission and data processing. The orchestrator has to make acceptance or rejection to the user requirements. During the time slot after arrival and before departure, the computational resources are all reserved and allocated to resource pools even with operations in a sliced network, such as VM migrations or turning on new servers. Furthermore, traffic loads vary over time. The research problem is how to manage resources of tasks for VM allocations and system utilizations. The task access control, computing resource allocation, switching servers on and off, and task migrations are implemented as the objectives of the orchestrator design.
The research problem is formulated as a mathematical programming problem. It attempts to involve a higher amount of VMs with VNFs emulated as tasks to maximize system revenue. However, the supplied resources and required demands are not equivalent. It forces a
while deciding the tasks selected with maximum values and assigned them to servers with limited capacities through the proposed arrangement algorithms. For the finite number of tasks and servers, each VM is simulated as a task requested a CPU processing power and memory space package. Each server has the finite CPU processing power and memory for packing VMs. Each server incurs a start power cost when it is switched on. The delay in VM migration between servers is a type of cost. At least one server must be maintained active to accept VMs during the operating periods. The system revenue is set as an objective function. Algorithms of the orchestrator are designed to rely on decision variables, such as access control, resource allocation, server operation (switching on and switching off), and VM migrations. The access control and resource allocation decisions are jointly considered in three dimensions including tasks, time, and servers. The objective function is to maximize the total profits by admitting tasks subject to the budget of operating servers and migrating VMs in
. The constraints are jointly considered with task assignment, server capacity, server switching on or off, and VM migration. The given parameters and the decision variables used in this work are listed in
Table 2 and
Table 3, respectively.
The objective function is formulated as an integer programming (IP) problem to optimize the system revenue of the entire system for network operation. The objective function, , comprises the values corresponding to the maximum tasks assigned to subtract the setup cost of servers in .
The first term of the objective function represents the total values of served tasks in the system.
is the reward rate of task
i. A task blocking variable,
, is set for the task rejection into the system in the second term of the objective function. The penalty,
, is considered if a task is not admitted to be processed due to the task requests are not entirely served by task assignments. The penalty values are set to be higher than the values of the reward rate. There are three types of cost: initial cost rate
, reopening cost
, and migration cost
.
is the estimated cost per unit time for server
s. The total initial cost is estimated based on the on-going time slots, which is referred to Amazon EC2 operation.
is charged for a server to be switched on one at a time after server initialization. The value of
is designed to be greater than that of
in the experiments. The migration cost occurs when a VM process migrates to other servers. It represents a type of overhead of computational resource disturbances. The difference between time index
and
is the time scale, and
is a superset of
. The approach tries not only to get the maximum values of assigned tasks efficiently but also to control the servers in a cost-effective way in the network operation stage. The mathematical programming problem is shown as follows:
where (C. 1)–(C. 8) are task assignment constraints, (C. 9)–(C. 10) are capacity constraints, and (C. 11)–(C. 17) are switching constraints.
For task assignment constraints, the admitted task i should be assigned to one of the servers. The summation of overall servers should not be greater than one, as shown in constraint (C. 1). Constraint (C. 2) represents that the processing time slot requested by task i should be satisfied. The total assignment time slots are equal to the requested time slot. Constraint (C. 3) implies that only if task i is assigned to server s, server s must be switched on. Accordingly, both decision variables and are set to one. If task i is not assigned to any server, is set to zero, and can be a free variable. Constraint (C. 4) and (C. 5) imply that time is assigned for task i in chronological order. More precisely, task i should be processed after it arrives and needs to be earlier than its deadline. The deadline is presented by the delay tolerance, which begins in arrival time. Constraints (C. 6) and (C. 7) represent the correlation between task required time slot for assignments and the task blocking decisions. The blocking decision is set to one when the requested time slots of of processing are not satisfied. Otherwise, the decision is set to zero. Constraint (C. 8) presents that the total rate of blocking tasks should not exceed that of the system requirement. K represents the system requirement of total task-blocking rate, for example, , which implies that fewer than tasks will be blocked.
For capacity constraints, constraint (C. 9) and (C. 10) are intuitively obtained by the total requirements of tasks aggregated in server
s. The aggregated traffic should not exceed the server capacity. To put it another way, if a new amount of traffic load (CPU or memory) is arriving and is assigned to server
s. After that, it should not be greater than either the remaining CPU or memory capacities of server
s [
28].
Constraint (C. 11) is associated with a policy of system design about the number of reserved servers. That is, the number of power-on servers should be at least greater than the minimum amount, G, for each time slot of . Constraint (C. 12) shows that the decision variable is determined by , which implies server s is powered on in the time slot .
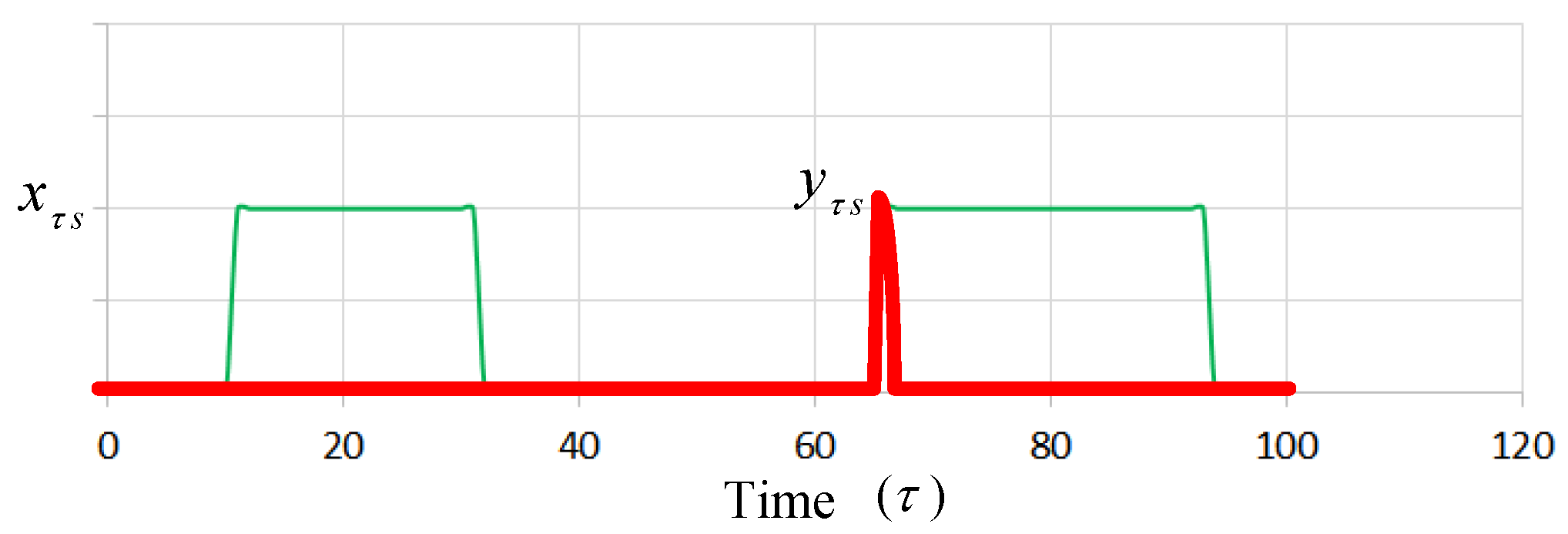
Figure 2 presents an example in which the green dotted curve is represented as
. The red pulse line, which is represented as
, is re-switched on within the time slot (
= 66). Constraints (C. 13) and (C. 14) imply that the total number of time slots the server switches on or off should not exceed the boundary condition during a time slot period. A faulty server may be caused if the operating time is over the boundary, which is
in an assumption of the proposed model. Constraint (C. 15) implies that if task
i is assigned to server
s in time slot
, then the parameter
is set to one. The time index
is a superset of
; that is, each time slot
contains one or more time slots
, if a
in this time slot is set to one,
is also set to one.
For Constraint (C. 16), each task should be only served in one server in the time slot
. Constraint (C. 17) implies the decision variable
is determined by
.
Figure 3 shows an example for calculating
for task 1 with two servers, and we can observe that the
is set to one due to the migration occurs.
4. Lagrangian Relaxation-Based Solution Procedures
The LR approach is proposed to solve large-scale mathematical programming problems in the 1970s [
29]. This approach has become a procedure for dealing with mathematical programming problems, such as integer or nonlinear programming problems, in many practical situations.
At the beginning, the idea is to relax complicated constraints into the primal problem and extend feasible solution regions to simplify the primal problem. The primal problem is transformed into an LR problem which is associated with Lagrangian multipliers [
20]. Then, the LR problem can be divided into several independent sub-problems using decomposition methods associated with their decision variables and constraints. By applying the LR method and the subgradient method to solve the problems, some heuristics are designed rigorously to solve each sub-problem optimally. We can determine theoretical lower bounds from the primal feasible solutions and find helpful hints for obtaining the primal feasible solutions.
Suppose that the set of suboptimal solutions is satisfied using the original constraints. In that case, the solutions are known as primal feasible solutions. A near-optimal primal feasible solution has to be found to solve the primal problem. Thus, the objective values of the primal problem are iteratively updated after sequentially feasible verifications.
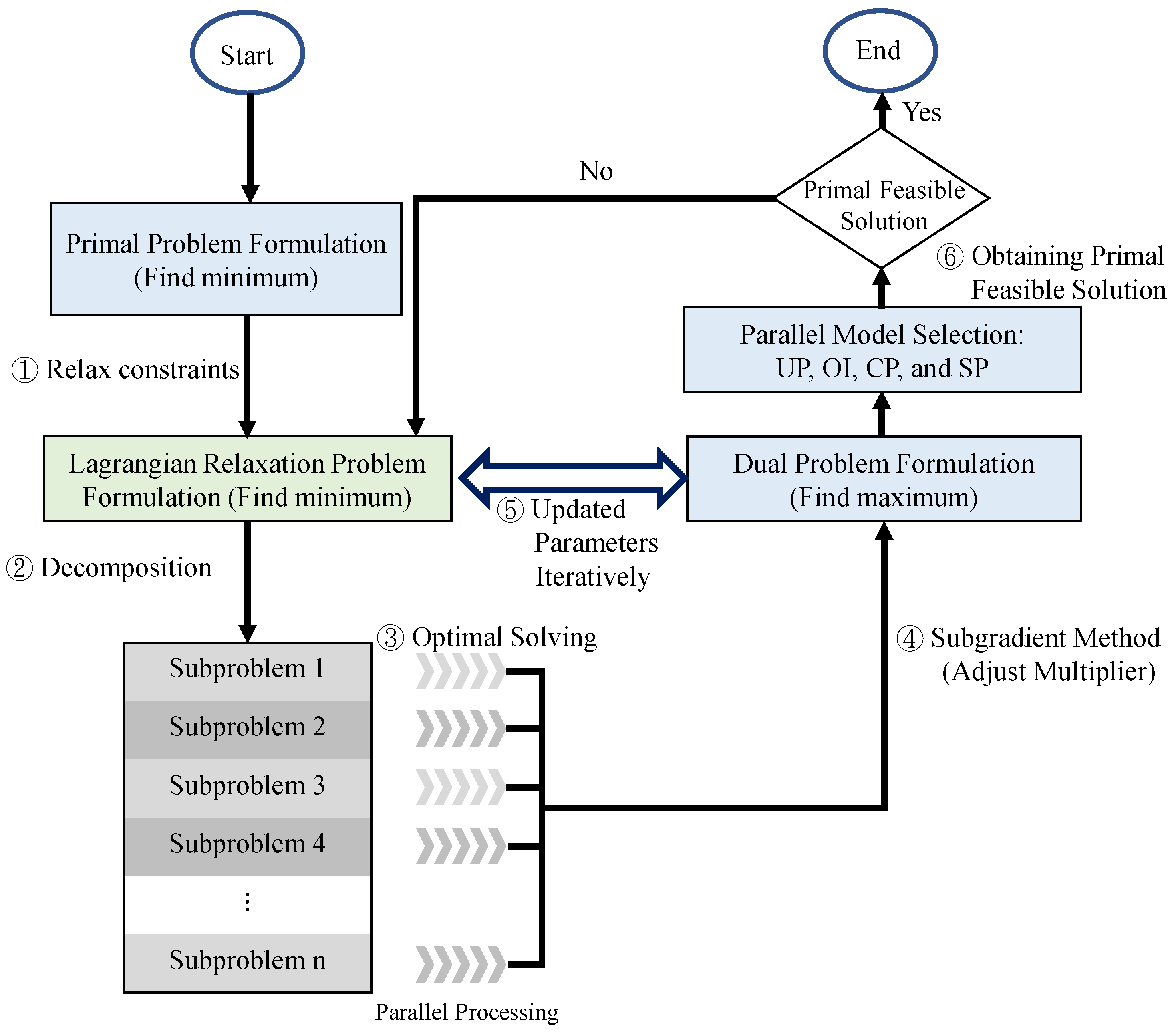
The procedure of the LR approach is presented and marked in six steps in
Figure 4. If a minimization problem is considered, the solution of the LR approach is the lower bounds. The lower bounds are iteratively improved by adjusting the multipliers set between the LR problem and the dual problem. If there is a feasible solution for the primal problem, then the solution is marked. The gap between the lower bounds and the feasible solutions is calculated for the entire process. The calculations are iteratively repeated until the termination conditions are satisfied. The subgradient optimization method is used for adjusting the multipliers in each iteration to accelerate the convergence of the minimization gap [
30].
4.1. Procedures of Step 1: Relaxation
Based on the standard form of an optimization problem proposed in Reference [
30], the objective function,
, is reformulated as a minimization problem to take from max to min and multiply with a negative sign. The constraints, (C. 3), (C. 6), (C. 7), (C. 9), (C. 10), (C. 12), (C. 14), (C. 15), and (C. 17), have decision variables on both sides of the inequality. They are selected to be relaxed and multiplied by non-negative Lagrangian multipliers. They are added to the objective functions for step 1 in
Figure 4, as shown in Equation (2), and denoted as
.
Afterwards, the optimization problem can be reformulated as
where
or 1,
or 1,
or 1,
or 1,
or 1, and
or 1.
A fewer number of remaining constraints are separated and solved in the sub-problems related to the decision variables, accordingly. By considering a subset of decision variables one at a time, six independent sub-problems are decomposed using the LR problem for Step 2 in
Figure 4. The objective function and the remaining constraints are not transformed into a complex problem. The optimal solutions can be determined one by one with Step 3 in
Figure 4, parallelly.
4.2. Procedures of Step 2 and 3: Decomposition and Solving Sub-Problems
4.2.1. Sub-Problem 1 (Related to )
By considering the variables related to
, the optimization problem is shown as
(3) is a cost minimization problem. The first observation is that the coefficients of (3) can be divided into sub-problems. If the coefficient of each sub-problem is negative, then the decision variable is set to one at index time , task i, and server s. Note that any value for is all feasible for constraints (C. 1), (C. 2), (C. 4), and (C. 5).The result is that the minimum objective value is determined. The summation of all the objective values of sub-problems with the assigned parameter is set to one, and the optimal solution is determined. The running time is , and the pseudo-code is illustrated as shown in Algorithm 1.
4.2.2. Sub-Problem 2 (Related to )
By considering the variables related to
, the optimization problem is shown as
(4) can be divided into
sub-problems, as well. If the coefficient corresponding to the sub-problem is negative, the decision variable
is set to one. For the feasible region (C. 11) of (4),
G is denoted by at least
G servers should be switched on at every time
, which is a policy of the system design. If no coefficient of (4) is less than zero, the minimal objective value of (4) is determined by setting
G numbers of
equal to one. On the contrary, the numbers are set to zero. The running time is
, and the pseudo-code is demonstrated as shown in Algorithm 2.
| Algorithm 1 Sub-problem 1 |
![Sensors 22 00100 i001]() |
4.2.3. Sub-Problem 3 (Related to )
By considering the variables related to
, the optimization problem is shown as
(5) can also be divided into
sub-problems. When the corresponding coefficient is less than zero, the decision variable
is set to one. Note that any value for
is all feasible for constraints (C. 13). The running time is
, and the pseudo-code is illustrated as shown in Algorithm 3.
| Algorithm 2 Sub-problem 2 |
![Sensors 22 00100 i002]() |
| Algorithm 3 Sub-problem 3 |
![Sensors 22 00100 i003]() |
4.2.4. Sub-Problem 4 (Related to )
By considering the variables related to
, the optimization problem is shown as
(6) can be divided into
sub-problems. In each sub-problem, the decision variable
is set to one, whereas the coefficient is less than zero. Subject to constraint (C. 8), the maximum amount of
set to one should not be greater than
. The pseudo-code is demonstrated as shown in Algorithm 4 with the running time
.
| Algorithm 4 Sub-problem 4 |
![Sensors 22 00100 i004]() |
4.2.5. Sub-Problem 5 (Related to )
By considering the variables related to
, the optimization problem is shown as
The solution process of (7) is similar to that of (4). (7) is divided into
sub-problems. The decision variable
is set to one if the coefficients corresponding to index migration time
, task
i, and server
s of the sub-problem are negative. The difference between (4) and (7) is the feasible region, constraint (C. 16); that is,
is set to one at the server
s which has negative coefficients for specific index migration time
and task
i. The running time is
, and the pseudo-code is illustrated as shown in Algorithm 5.
| Algorithm 5 Sub-problem 5 |
![Sensors 22 00100 i005]() |
4.2.6. Sub-Problem 6 (Related to )
By considering the variables related to
, the optimization problem is shown as
The objective function of (8) is also a cost minimization problem that can be divided into
sub-problems. If the coefficient of each sub-problem is negative, then the decision variable
is set to one at index migration interval
and task
i. The minimum objective value is determined by the summation of all the objective values of
sub-problems with the assigned parameter
set to one. The running time is
, and the pseudo-code is illustrated as shown in Algorithm 6.
| Algorithm 6 Sub-problem 6 |
![Sensors 22 00100 i006]() |
4.3. Procedure of Step 4 and 5: Dual Problem and the Subgradient Method
Based on the weak Lagrangian duality theorem [
29], the multiples are all non-negative values; that is,
and
. The objective value of the LR problem,
, is the lower bound of the primal problem,
. Construct the following dual problem
based on the LR problem to calculate the tightest boundary of steps 4 and 5 in
Figure 5, where the dual problem (9) is shown as [
31]
There are several methods to solve the dual problem (9). The most popular one of them is the subgradient method proposed in Reference [
28,
29]. First, define the multiplier vector of
k-
iteration,
, and let it to be iteratively updated by
, where
k is the number of iterations. The vector
is the subgradient of
of the
k-
iteration which represents the directions to the optimal solutions. The step size
is determined by
, where
is an objective value of the primal problem, and
is a constant,
. The optimal solutions of the LR and dual problems for each iteration are determined by solving the sub-problems and iteratively updating the multipliers by using the subgradient method, respectively.
4.4. Procedure of Step 6: Obtaining the Primal Feasible Solutions
The LR and Subgradient methods determine the theoretical bounds and provide some hints toward the primal feasible solutions. Based on the sensitivity properties in Reference [
32], the Lagrangian multipliers are represented by weights, which are also known as the cost per unit constraint violation for the objective value improvement rate. In observing the primal feasible region of the primal problem, the solutions must satisfy all the constraints. A set of primal feasible solutions to
is a subset of the solutions to
. For Step 6 in
Figure 4, the following four model selections based on the properties of Lagrangian multipliers are proposed for obtaining primal feasible solutions, parallelly.
4.4.1. Urgent and Penalty (UP) Involved
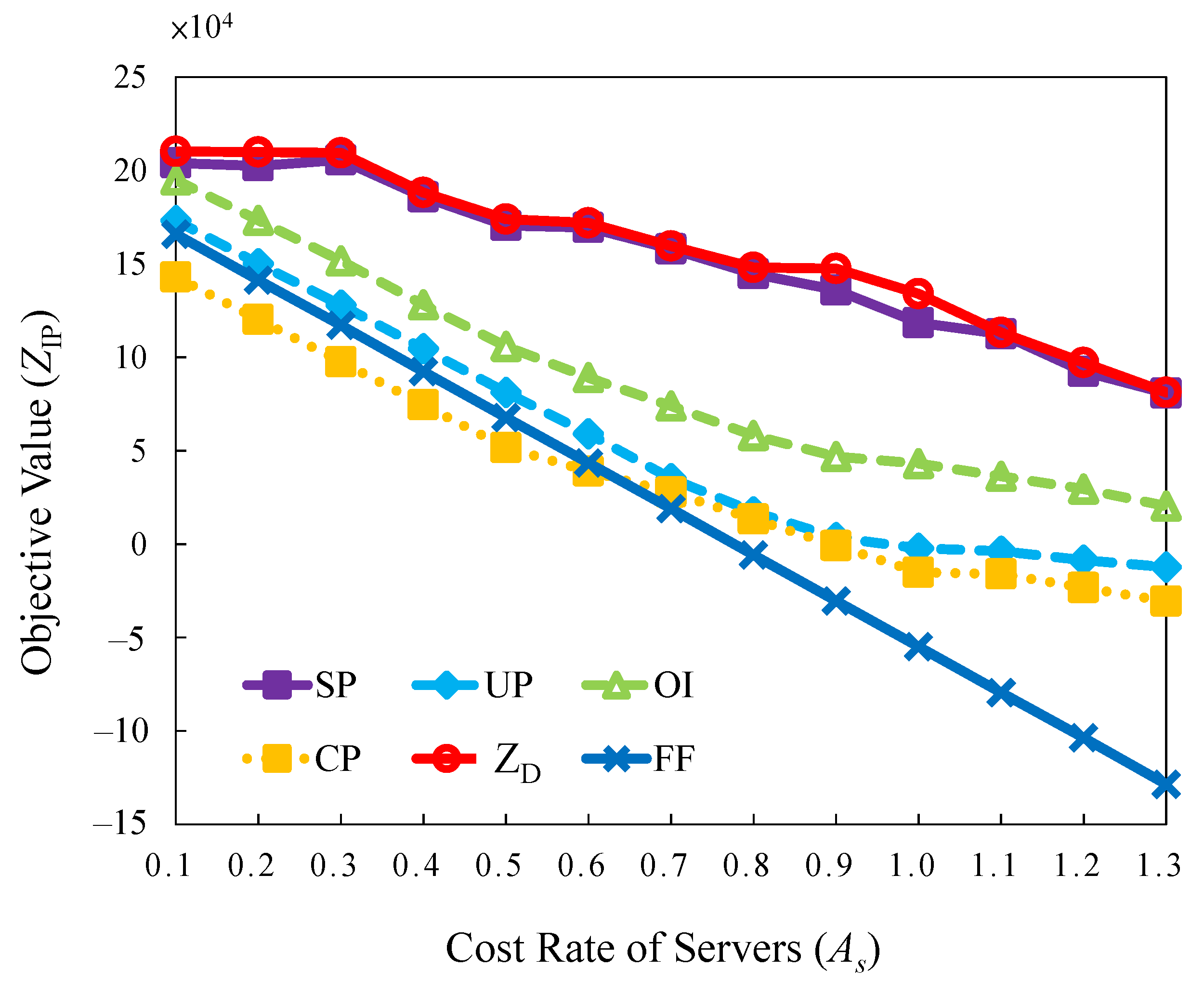
Task assignment and scheduling are considered in combination in the first step for obtaining primal feasible solutions. A heuristic is proposed to determine the order of tasks sorted by the level of significance. An index in Equation (10), urgent and penalty (UP), is created by analyzing the coefficients of SUB4 with the penalty value. A brief analysis of the coefficient of SUB4 implies the significance of tasks. However, the multipliers, and , are represented as the requested processing time’s satisfaction variables and assigned time slot. is the penalty of a task that occurs if the requested processing time is not satisfied. The orchestrator is allowed to determine the crucial decisions of rejection and each task’s assigned processing time.
According to constraints (C. 6) and (C. 7), the decision variable
is set to zero if the processing time required by task
i is satisfied. Otherwise, it is set to one if the requirement is not fulfilled. Thus, combine corresponding multipliers
and
with the penalty of rejection
as an index of processing priority.
4.4.2. Optimization-Based Significance Index (OI)
Based on the previous index, the significance index (
OI) is also derived from the two multipliers
and
, as shown in (11). The stages for considering
and
can be observed in constraints (C. 6) and (C. 7). These two constraints are satisfied under the conditions in which a task requests appropriate assignments. The decision variables
in constraints (C. 6) and (C. 7) are both set to zero, which indicates that all the requested processing time slots are assigned. For each iteration, the absolute value of the subtraction of
and
is used to evaluate the task significance of assignments properly.
4.4.3. Cost Performance (CP)
This heuristic approach is proposed to establish the concept of the cost performance (
CP) ratio of the tasks. The
CP ratio is defined as the ratio of the task values per requested demand, as shown in (12). This heuristic concept is derived from identifying the tasks with the maximum CP value that contributes to the most objective values. The
CP values are used to determine the tasks that have to be performed or dropped. The tasks with higher
CP values than those with lower
CP values are selected to contribute to the objective values. The tasks that reflect the high
CP values in objective functions are accurately identified in the method.
4.4.4. Shortest-Path-Based Significance Index ()
We can find three independent dimension problems with time slot
, task
i, and server
s from the observation of objective function in the primal problem. The aggregation of the assigned tasks does not exceed the capacity of the servers. Furthermore, a tree data structure can be represented as a set of linked nodes for task
i in which the root is the starting time of the task assignment. The branches are the assigned servers after a global analysis of the objective function. The destination is the deadline related to the servers. Suppose there is any path available from the root to the destination. In that case, the task assignment series can be determined, as shown in
Figure 6.
The Border Gateway Multicast Protocol (BGMP) and a scalable multicast routing protocol use heuristics to select the global root of the delivery tree [
33]. We develop source-specific shortest-path distribution branches to supplant the shared tree. The arc weights are the coefficients of SUB1. The arc weights of migration are also considered. Moreover, the problem is transformed into a path length-restricted shortest path problem. We identify the paths with weights from the task arrival to departure. Furthermore, the shortest path problem can be effectively solved using the Bellman-Ford algorithm [
34]. Link constraints with server CPU and memory capacities are the restrictions set on using links to form a routing tree [
34]. The path constraints are the restrictions to initialize the time slot and select the branches related to the servers switched on or off. The detailed flowchart is shown in
Figure 7, where the decision variables are fine-tuned to feasible from the dual problem to the
SP model.


 ,
, 
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}