
Random Access Using Deep Reinforcement Learning in Dense Mobile Networks

Abstract
1. Introduction
- Formulate the random access selection task as a mathematical optimization formulation.
- Define the random access selection task in terms of MDP.
- Propose a novel deep reinforcement learning algorithm that solves the random access selection problem formulated as MDP. This is performed by designing the system states, defining actions that are taken by agents, and defining a reward function.
- Test and compare the performance of the proposed deep reinforcement learning algorithm against another learning algorithm and baseline approaches.
2. AI and Recent RA Enhancements in Literature
2.1. AI for Wireless Networking
2.2. Information Redundancy for RA
2.3. Architectural Improvements for RA
2.4. Perspective
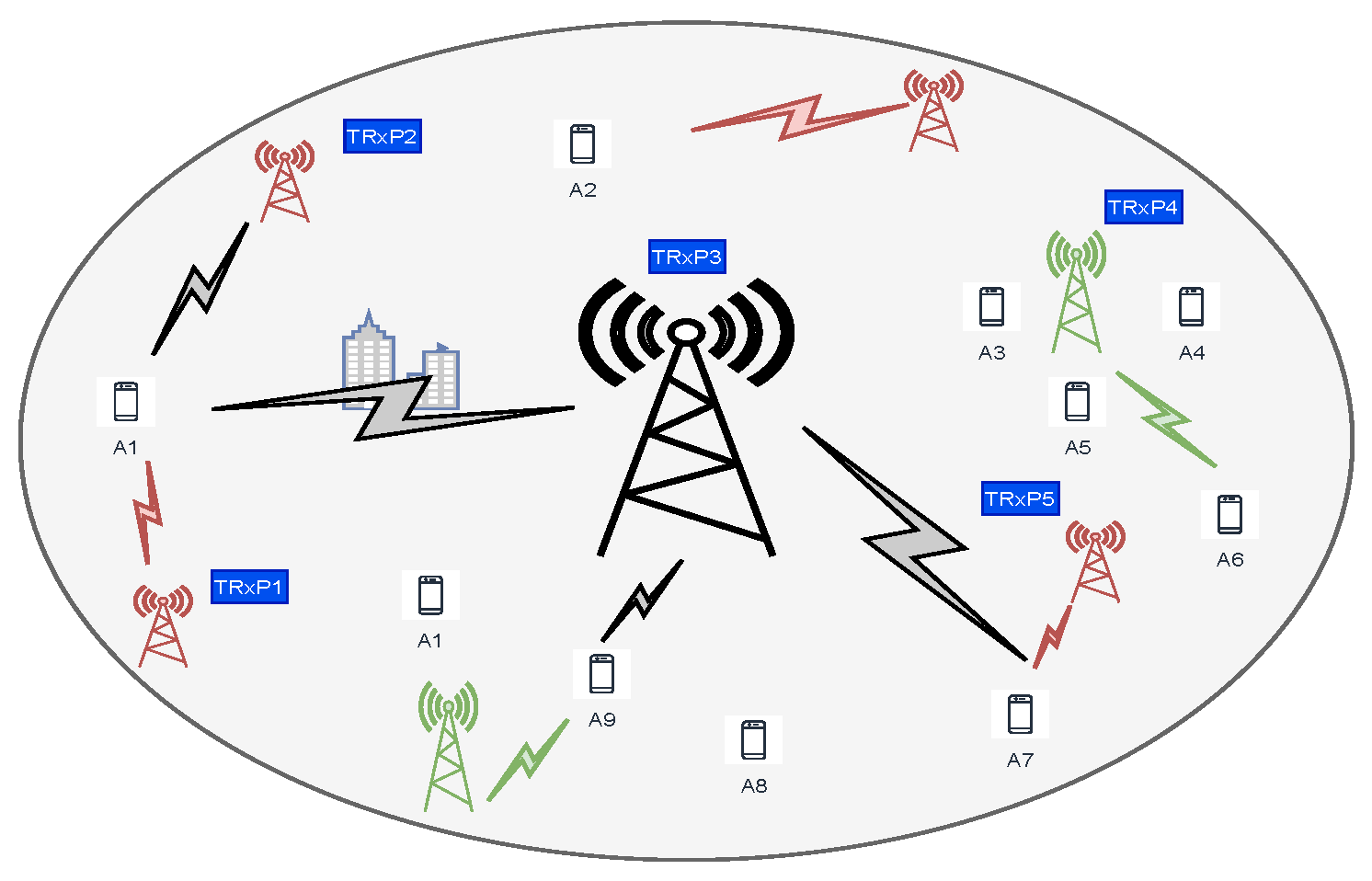
3. Problem Formulation and System Model
3.1. Traffic Model
3.2. Combined Channel Model
3.3. Problem Formulation
4. RL Based Selection of TRxPs for RA
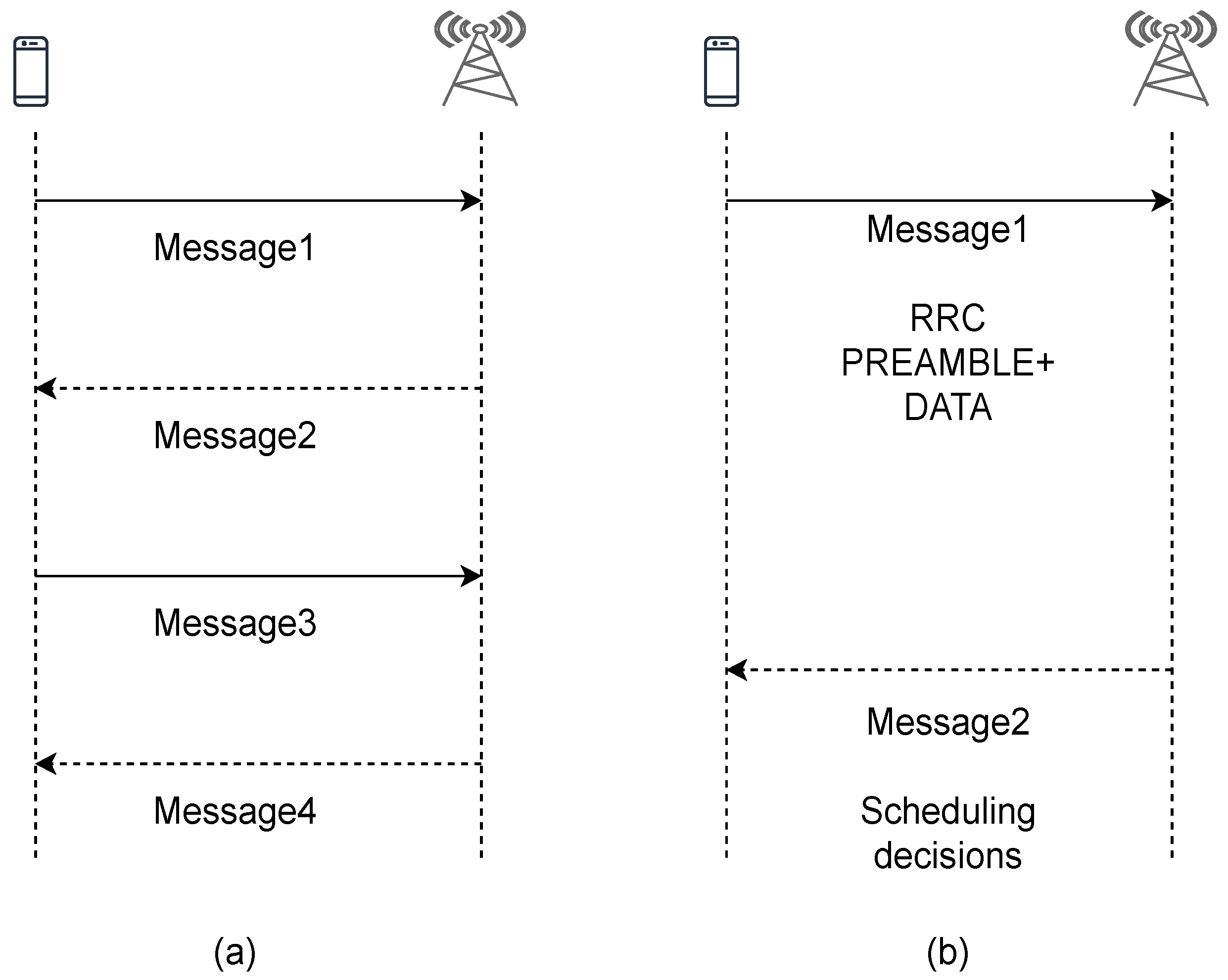
4.1. TRxPs Search and Selection
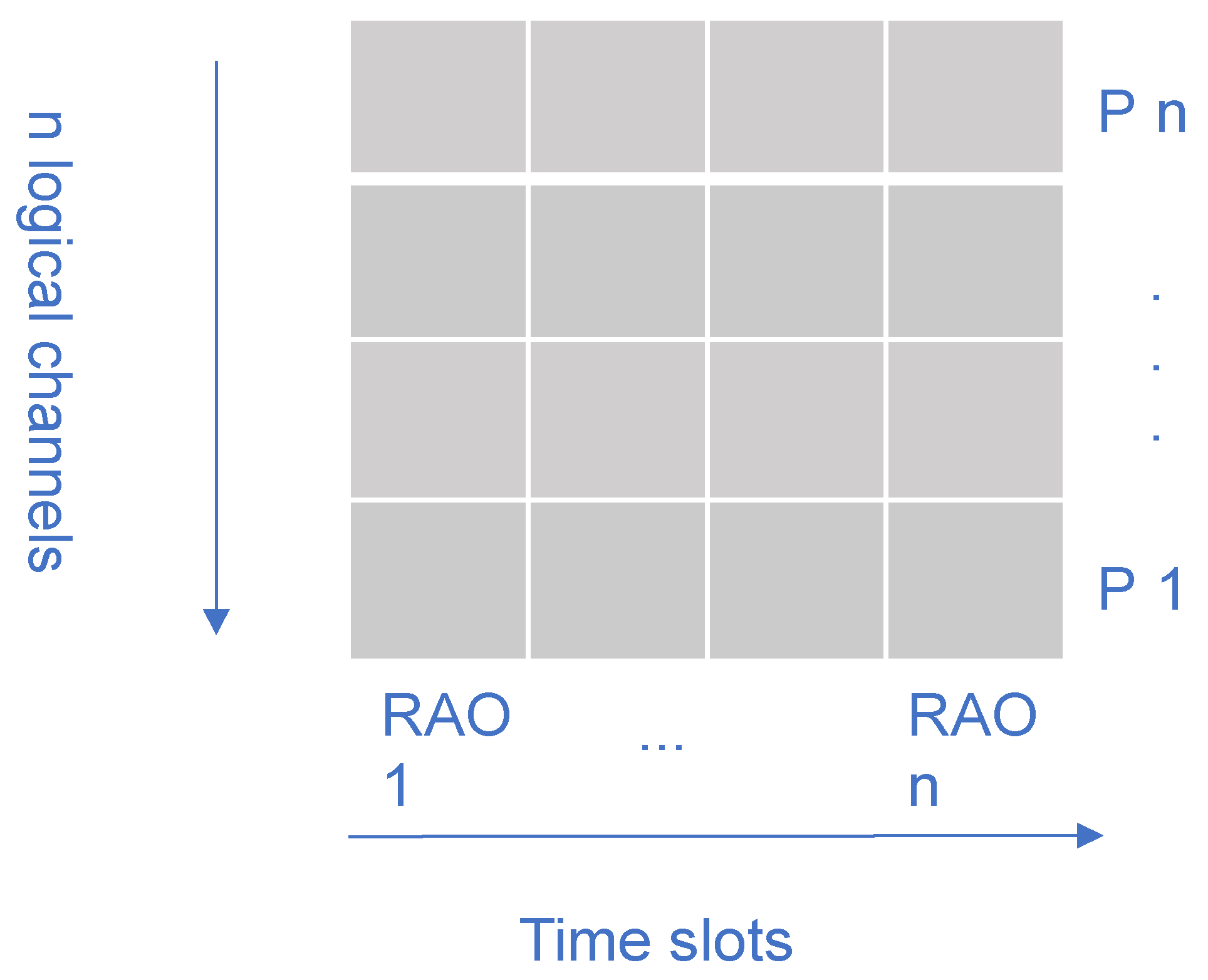
4.2. System Parameters through SIB2
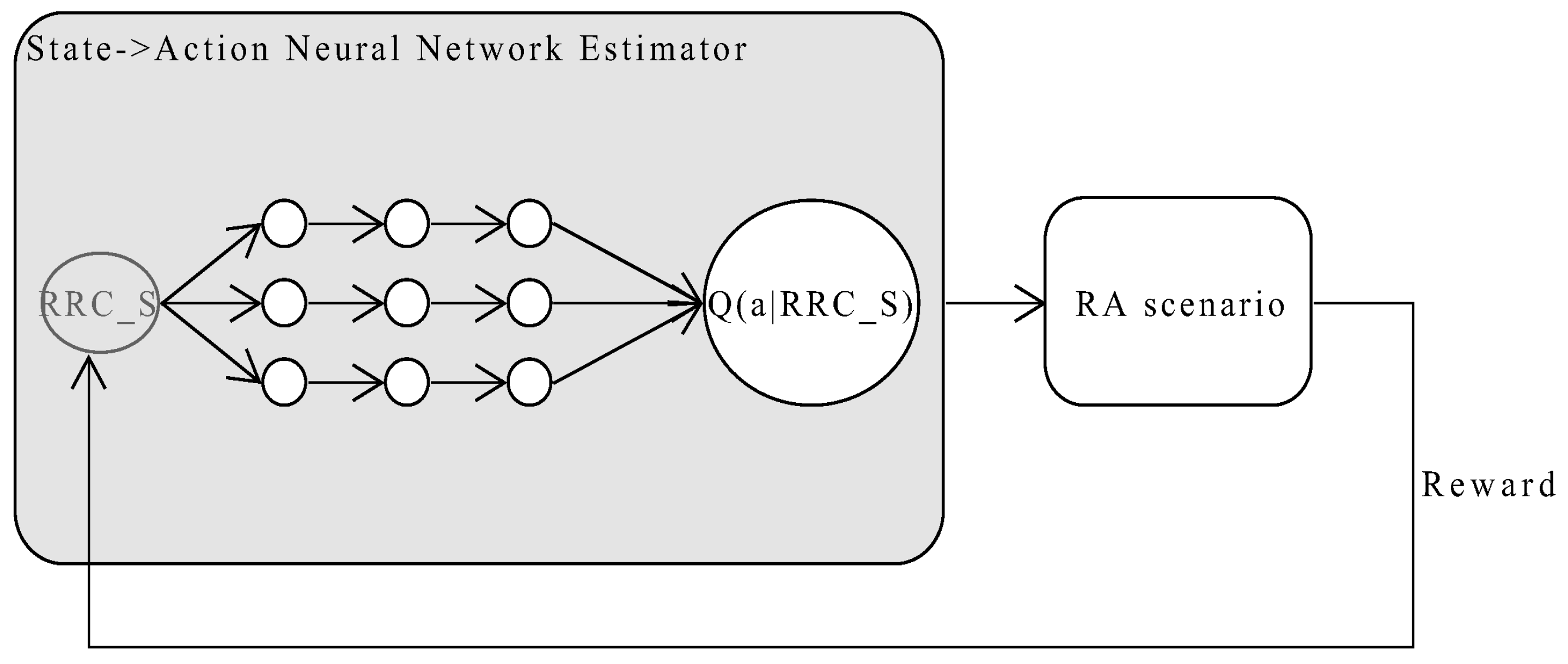
4.3. Proposed RL Based Selection for RA
4.4. Design
4.4.1. States
- Initial criteria: In the RA selection problem, user nodes are allowed to participate in the RA selection problem if they are in the RRC_IDLE RA mode and have a full buffer to send data in the uplink, or a request from a TRxP to receive data in the downlink. Mathematically, we use an indicator variable as follows.
- System parameters criteria: Once users pass the above criteria, the next step is to pass the ACB system parameter criteria that they receive from the serving cell. The ACB flag indicates whether users are barred from performing RA in case of insufficient resources. Initially, this parameter is represented as a real number. We use another indicator variable to check whether a user has passed this parameter as follows.where a is the ACB factor the user randomly selects and sends to the serving cell, and t is a threshold factor for admission control by the cell. Finally, the user is allowed to perform RA if the above two criteria are successfully met, which is mathematically presented as
- Set of TRxPs: We encode the set consisting of the TRxPs from which user nodes can obtain a pilot signal and measure the RSRP representing potential candidates for RA channel selection. This is given as follows.where
4.4.2. Reward Function
4.4.3. Using Replay Buffer for Stability
4.5. Algorithms
| Algorithm 1 DQN-based Intelligent TRxPs Selector Algorithm: Training. |
|
| Algorithm 2 DQN-based Intelligent TRxPs Selector Algorithm: Online. |
|
| Algorithm 3 Q-Based Intelligent TRxPs Selector Algorithm: Online. |
|
| Algorithm 4 Random TRxPs Selector Algorithm: Online. |
|
5. Evaluation
5.1. Experimental Setup
5.2. Performance Metric Measures
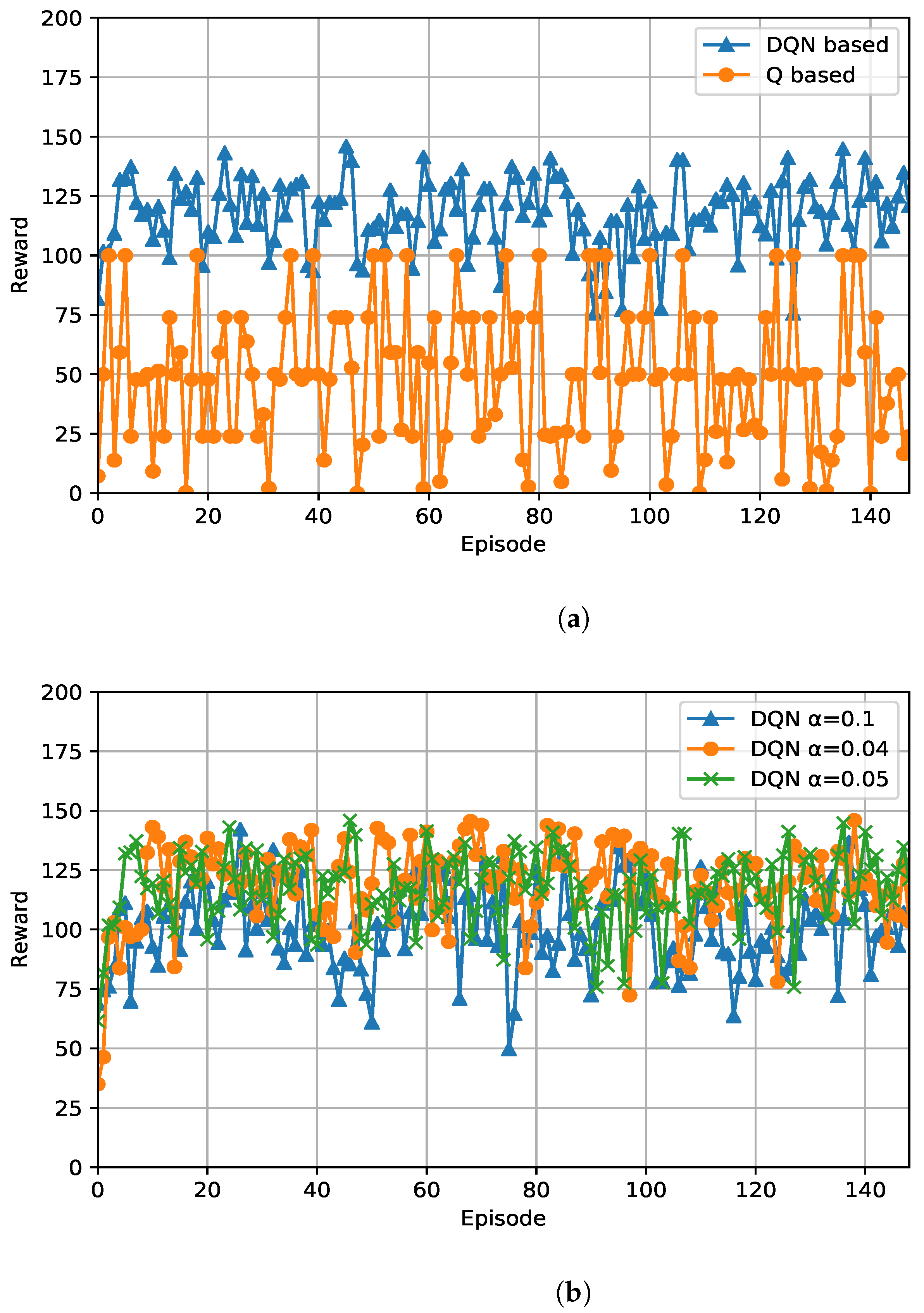
5.3. Learning Performance
5.4. Impact of Proposed Algorithm on RA KPIs
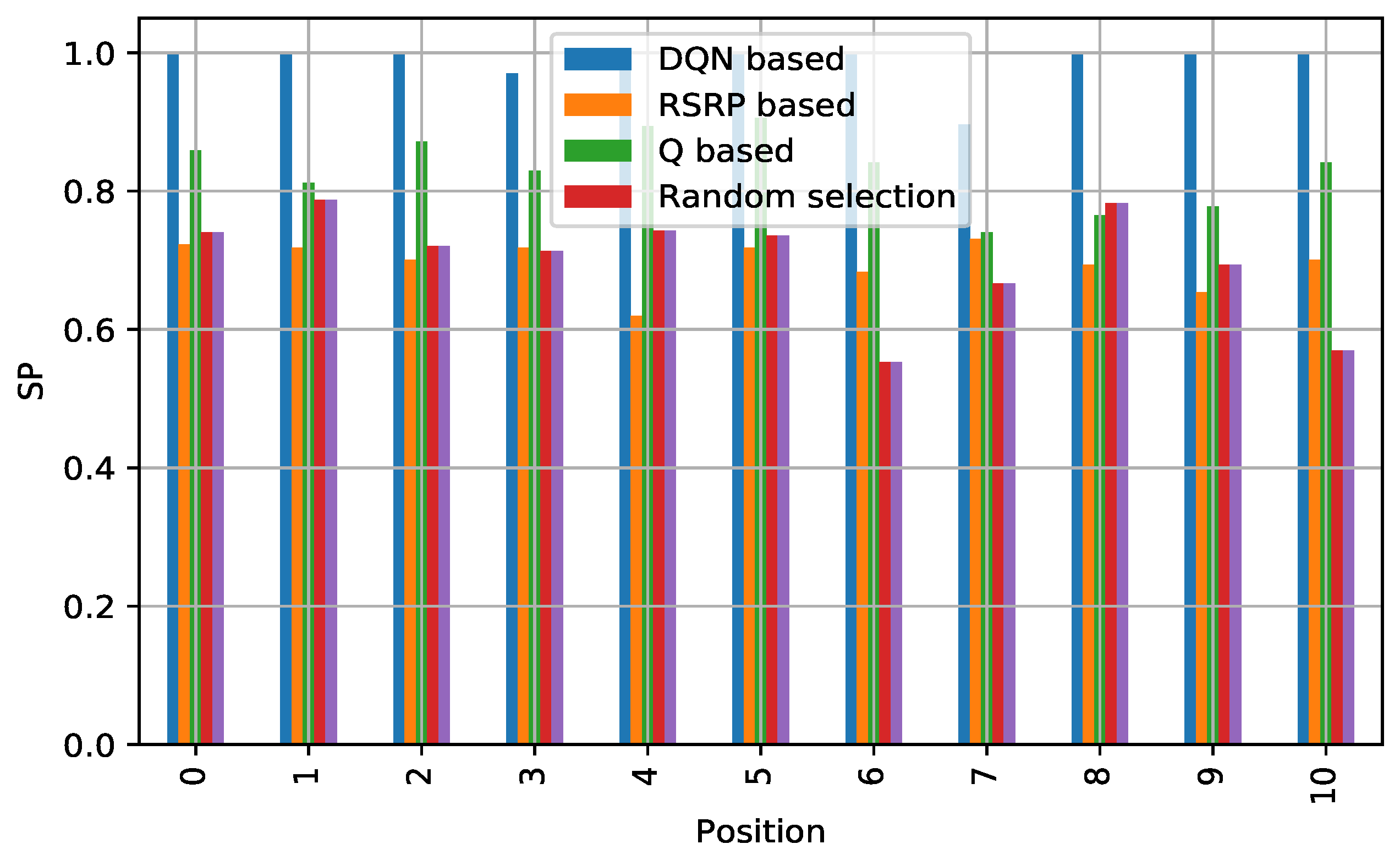
5.4.1. Reliability
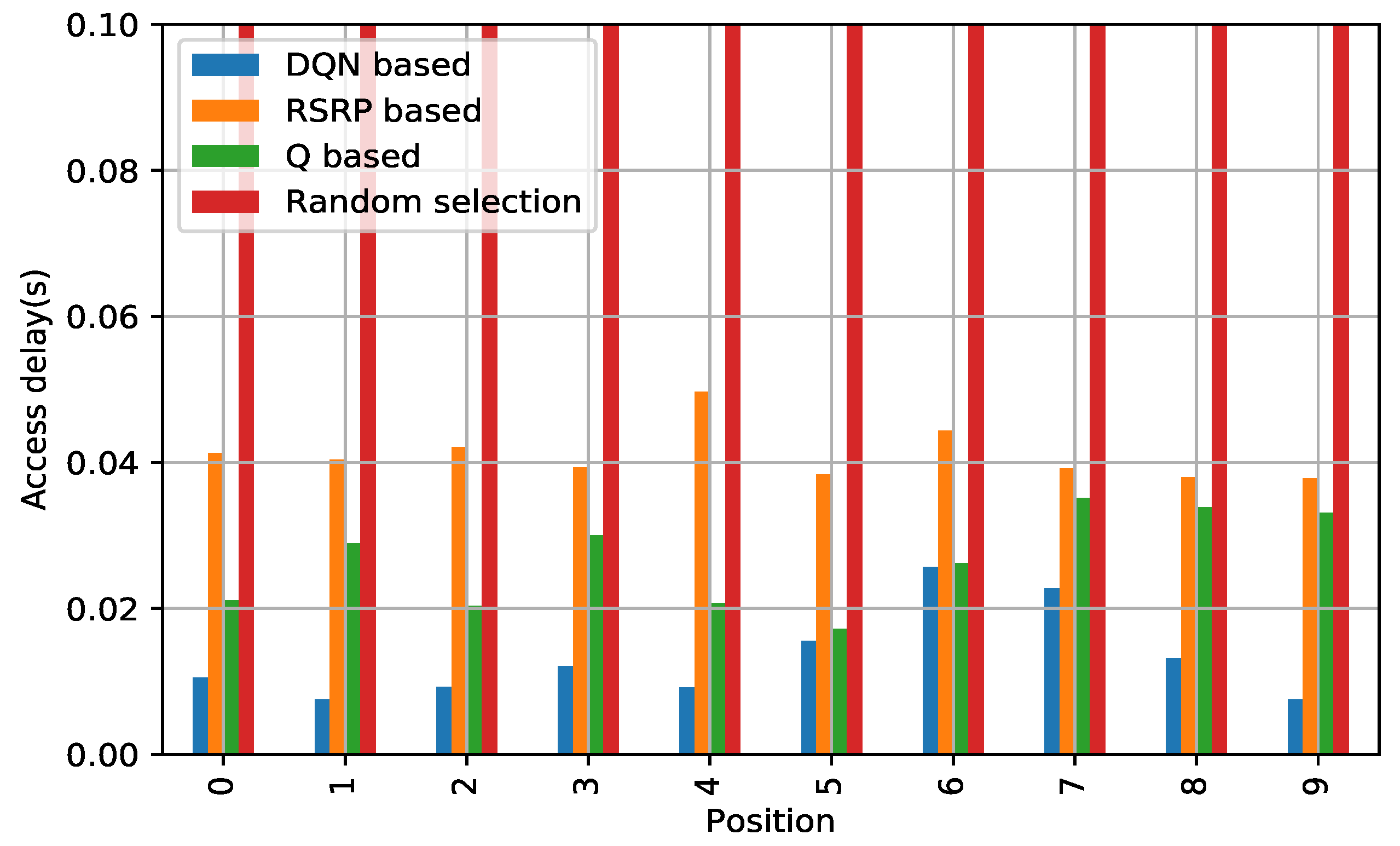
5.4.2. RA Delay
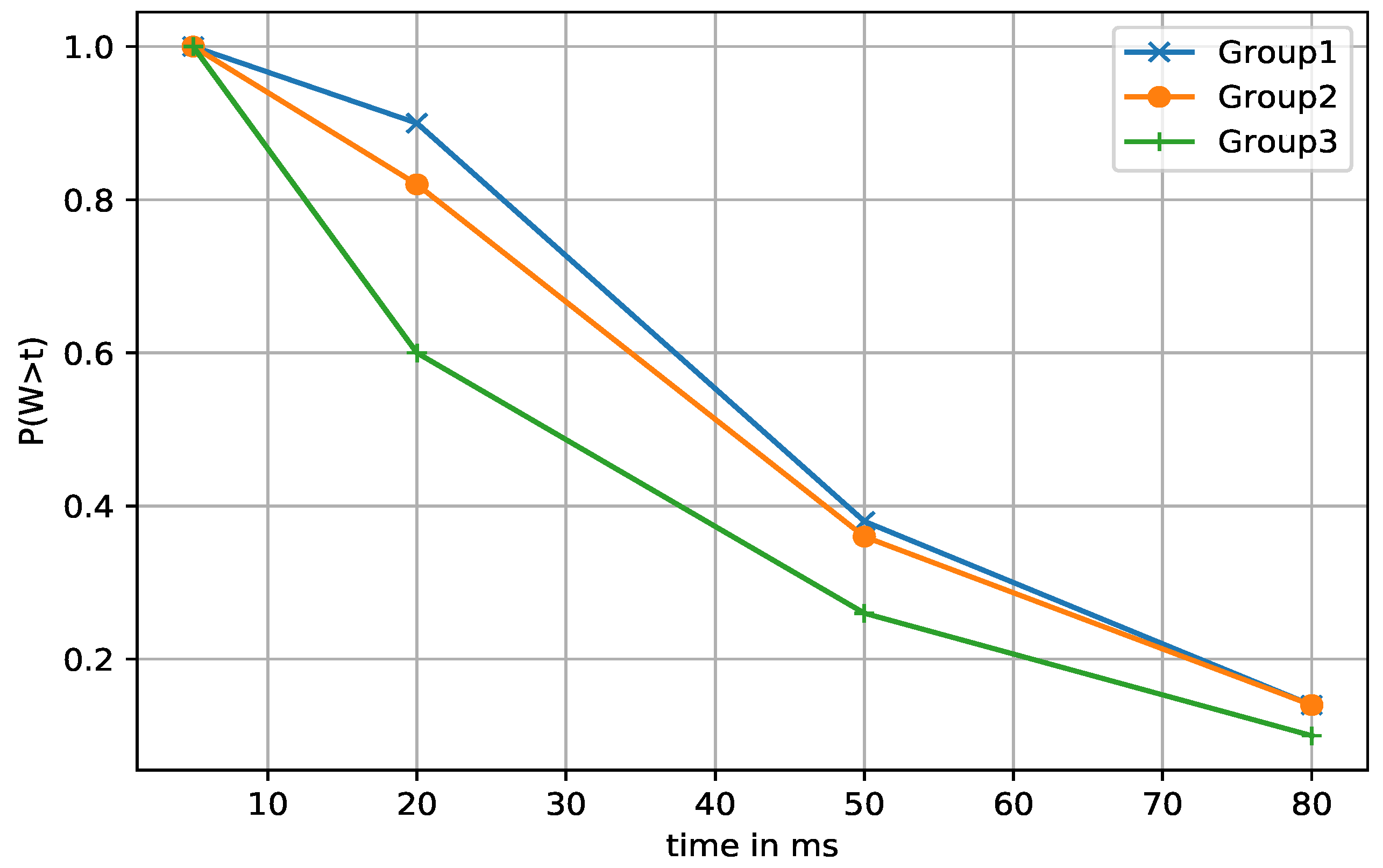
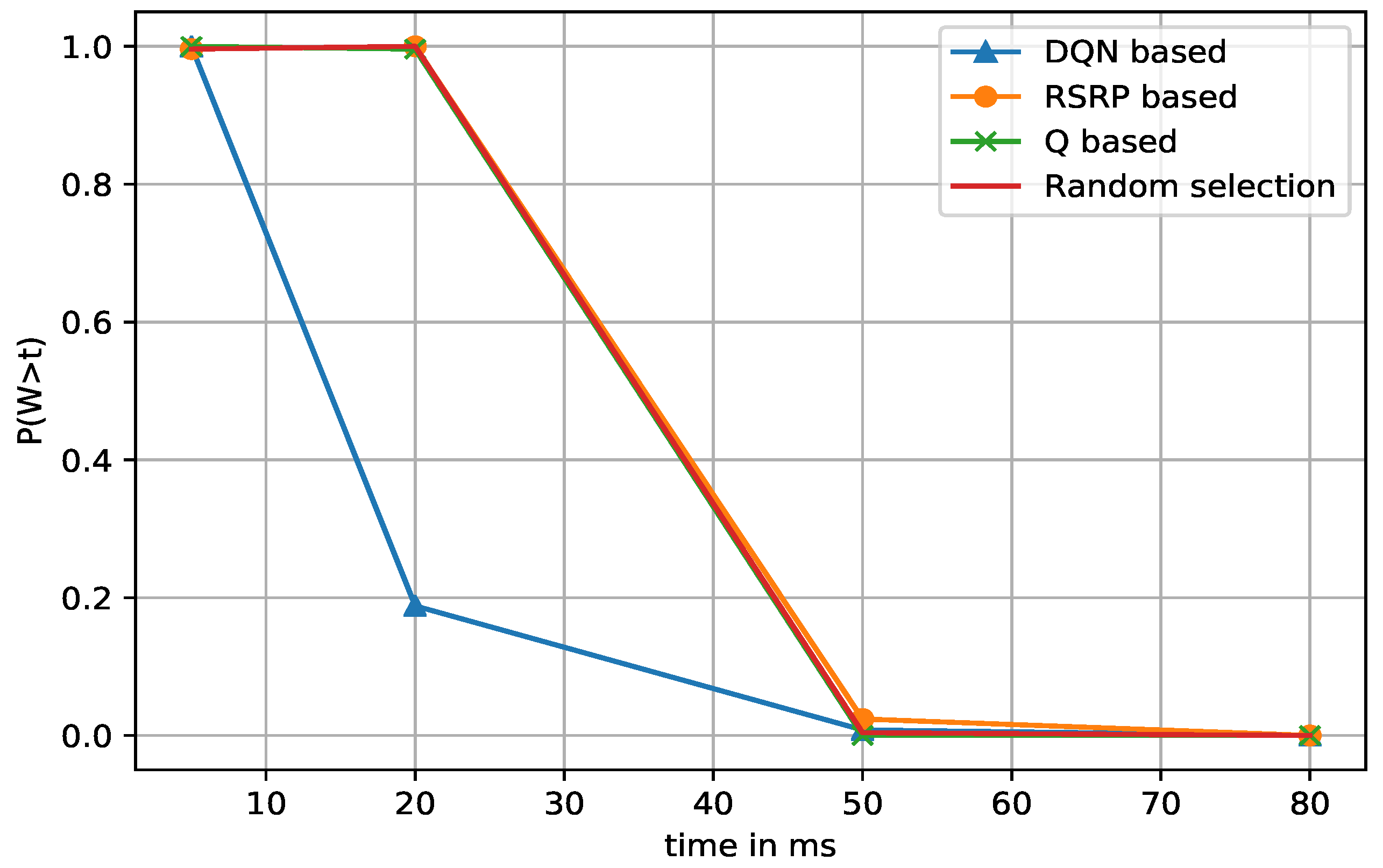
5.4.3. Waiting Time Distribution
5.4.4. Algorithm Overhead Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- 3rd Generation Partnership Project; Technical Specification Group Radio Access Network; Evolved Universal Terrestrial Radio Access (E-UTRA); Radio Resource Control (RRC); Protocol Specification. September 2011. Available online: https://www.3gpp.org/ftp/Specs/archive/36_series/36.331 (accessed on 10 March 2021).
- 3rd Generation Partnership Project; Radio Resource Control (RRC); Protocol Specification. September 2011. Available online: https://www.3gpp.org/ftp/Specs/archive/38_series/38.331 (accessed on 10 March 2021).
- 3rd Generation Partnership Project; Technical Specification Group Radio Access Network; Evolved Universal Terrestrial Radio Access (E-UTRA) User Equipment (UE) Procedures in idle Mode. September 2011. Available online: https://www.3gpp.org/ftp/Specs/archive/36_series/36.304 (accessed on 10 March 2021).
- 3rd Generation Partnership Project; Technical Specification Group Core Network; NAS Functions related to Mobile Station (MS) in idle Mode. September 2011. Available online: https://www.3gpp.org/ftp/Specs/archive/23_series/23.122 (accessed on 10 March 2021).
- Wan, C.; Sun, J. Access Class Barring Parameter Adaptation Based on Load Estimation Model for mMTC in LTE-A. In Proceedings of the 2019 International Conference on Communications, Information System and Computer Engineering (CISCE), Haikou, China, 5–7 July 2019; pp. 512–515. [Google Scholar]
- Tello-Oquendo, L.; Vidal, J.R.; Pla, V.; Guijarro, L. Dynamic access class barring parameter tuning in LTE-A networks with massive M2M traffic. In Proceedings of the 2018 17th Annual Mediterranean Ad Hoc Networking Workshop (Med-Hoc-Net), Capri, Italy, 20–22 June 2018; pp. 1–8. [Google Scholar]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 13 November 2018. [Google Scholar]
- Watkins, C.J.; Dayan, P. Q-learning. Mach. Learn. 1992, 8, 279–292. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 529–533. [Google Scholar] [CrossRef] [PubMed]
- Kaelbling, L.P.; Littman, M.L.; Moore, A.W. Reinforcement learning: A survey. J. Artif. Intell. Res. 1996, 4, 237–285. [Google Scholar] [CrossRef]
- Puterman, M.L. Markov Decision Processes: Discrete Stochastic Dynamic Programming; John Wiley & Sons: Hoboken, NJ, USA, 2014. [Google Scholar]
- Russell, S.; Norvig, P. Artificial Intelligence: A Modern Approach. Available online: https://storage.googleapis.com/pub-tools-public-publication-data/pdf/27702.pdf (accessed on 10 March 2021).
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Van Hasselt, H.; Guez, A.; Silver, D. Deep reinforcement learning with double q-learning. In Proceedings of the AAAI Conference on Artificial Intelligence 2016, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Wang, C.X.; Di Renzo, M.; Stanczak, S.; Wang, S.; Larsson, E.G. Artificial intelligence enabled wireless networking for 5G and beyond: Recent advances and future challenges. IEEE Wirel. Commun. 2020, 27, 16–23. [Google Scholar] [CrossRef]
- Kulin, M.; Kazaz, T.; De Poorter, E.; Moerman, I. A survey on machine learning-based performance improvement of wireless networks: PHY, MAC and network layer. Electronics 2021, 10, 318. [Google Scholar] [CrossRef]
- Asadi, A.; Müller, S.; Sim, G.H.; Klein, A.; Hollick, M. FML: Fast machine learning for 5G mmWave vehicular communications. In Proceedings of the IEEE INFOCOM 2018—IEEE Conference on Computer Communications, Honolulu, HI, USA, 16–19 April 2018; pp. 1961–1969. [Google Scholar]
- Cao, X.; Ma, R.; Liu, L.; Shi, H.; Cheng, Y.; Sun, C. A Machine Learning-Based Algorithm for Joint Scheduling and Power Control in Wireless Networks. IEEE Internet Things J. 2018, 5, 4308–4318. [Google Scholar] [CrossRef]
- Zhang, C.; Patras, P.; Haddadi, H. Deep learning in mobile and wireless networking: A survey. IEEE Commun. Surv. Tutor. 2019, 21, 2224–2287. [Google Scholar] [CrossRef]
- Khan, M.A.; Kim, J. Toward Developing Efficient Conv-AE-Based Intrusion Detection System Using Heterogeneous Dataset. Electronics 2020, 9, 1771. [Google Scholar] [CrossRef]
- Luong, N.C.; Hoang, D.T.; Gong, S.; Niyato, D.; Wang, P.; Liang, Y.C.; Kim, D.I. Applications of deep reinforcement learning in communications and networking: A survey. IEEE Commun. Surv. Tutor. 2019, 21, 3133–3174. [Google Scholar] [CrossRef]
- Xiong, Z.; Zhang, Y.; Niyato, D.; Deng, R.; Wang, P.; Wang, L.C. Deep reinforcement learning for mobile 5G and beyond: Fundamentals, applications, and challenges. IEEE Veh. Technol. Mag. 2019, 14, 44–52. [Google Scholar] [CrossRef]
- Wang, J.; Zhao, L.; Liu, J.; Kato, N. Smart resource allocation for mobile edge computing: A deep reinforcement learning approach. IEEE Trans. Emerg. Top. Comput. 2019. [Google Scholar] [CrossRef]
- Orsino, A.; Galinina, O.; Andreev, S.; Yilmaz, O.N.; Tirronen, T.; Torsner, J.; Koucheryavy, Y. Improving initial access reliability of 5G mmWave cellular in massive V2X communications scenarios. In Proceedings of the 2018 IEEE International Conference on Communications (ICC), Kansas City, MO, USA, 20–24 May 2018; pp. 1–7. [Google Scholar]
- Galinina, O.; Turlikov, A.; Andreev, S.; Koucheryavy, Y. Multi-channel random access with replications. In Proceedings of the 2017 IEEE International Symposium on Information Theory (ISIT), Aachen, Germany, 25–30 June 2017; pp. 2538–2542. [Google Scholar]
- Grassi, A.; Piro, G.; Boggia, G. A look at random access for machine-type communications in 5th generation cellular networks. Internet Technol. Lett. 2018, 1, e3. [Google Scholar] [CrossRef]
- Alavikia, Z.; Ghasemi, A. Pool resource management based on early collision detection in random access of massive MTC over LTE. Ad Hoc Netw. 2019, 91, 101883. [Google Scholar] [CrossRef]
- Sinitsyn, I.E.; Zaripova, E.R.; Gaidamaka, Y.V.; Shorgin, V.S. Success Access Probability Analysis Using Virtual Preambles Via Random Access Channel. In CEUR Workshop Proceedings; CEUR: Budapest, Hungary, 2018. [Google Scholar]
- Yuan, J.; Huang, A.; Shan, H.; Quek, T.Q.; Yu, G. Design and Analysis of Random Access for Standalone LTE-U Systems. IEEE Trans. Veh. Technol. 2018, 67, 9347–9361. [Google Scholar] [CrossRef]
- Agiwal, M.; Qu, M.; Jin, H. Abstraction of Random Access Procedure for Bursty MTC Traffic in 5G Networks. In Proceedings of the 2018 24th Asia-Pacific Conference on Communications (APCC), Ningbo, China, 12–14 November 2018; pp. 280–285. [Google Scholar]
- Park, S.; Lee, S.; Choi, W. Markov Chain Analysis for Compressed Sensing based Random Access in Cellular Systems. In Proceedings of the 2019 International Conference on Computing, Networking and Communications (ICNC), Honolulu, HI, USA, 18–21 February 2019; pp. 34–38. [Google Scholar]
- Bekele, Y.Z.; Choi, Y.J. Scheduling for Machine Type Communications in LTE Systems. In Proceedings of the 2018 International Conference on Information and Communication Technology Convergence (ICTC), Jeju, Korea, 17–19 October 2018; pp. 889–891. [Google Scholar]
- Vilgelm, M.; Schiessl, S.; Al-Zubaidy, H.; Kellerer, W.; Gross, J. On the reliability of LTE random access: Performance bounds for machine-to-machine burst resolution time. In Proceedings of the 2018 IEEE International Conference on Communications (ICC), Kansas City, MO, USA, 20–24 May 2018; pp. 1–7. [Google Scholar]
- Lee, J.Y.; Noh, H.; Lee, K.; Choi, J. Comparison of one-shot and handshaking systems for MTC in 5G. In Proceedings of the 2018 IEEE 87th Vehicular Technology Conference (VTC Spring), Porto, Portugal, 3–6 June 2018; pp. 1–5. [Google Scholar]
- Cheng, R.G.; Becvar, Z.; Huang, Y.S.; Bianchi, G.; Harwahyu, R. Two-Phase Random Access Procedure for LTE-A Networks. IEEE Trans. Wirel. Commun. 2019, 18, 2374–2387. [Google Scholar] [CrossRef]
- 3GPP. Study on RAN Improvements for Machine-Type Communications; Technical Report, TR 37.868; SGPP: Paris, France, 2014. [Google Scholar]
- Akdeniz, M.R.; Liu, Y.; Samimi, M.K.; Sun, S.; Rangan, S.; Rappaport, T.S.; Erkip, E. Millimeter wave channel modeling and cellular capacity evaluation. IEEE J. Sel. Areas Commun. 2014, 32, 1164–1179. [Google Scholar] [CrossRef]
- Bekele, Y.Z.; June-Choi, Y. Access Point Selection Using Reinforcement Learning in Dense Mobile Networks. In Proceedings of the 2020 International Conference on Information Networking (ICOIN), Barcelona, Spain, 7–10 January 2020; pp. 676–681. [Google Scholar]
- NSNAM. Ns-3: A Discrete-Event Network Simulator for Internet Systems, 2006–2020. Available online: https://www.nsnam.org/ (accessed on 10 March 2021).
Short Biography of Authors
 | Yared Zerihun Bekele received the B.Sc degree in Computer Science from Addis Ababa University in 2013 and the M.Sc degree in Computer Science and Engineering from Ajou University in 2016. Currently, he is with the Intelligence Platform, Network, and Security (Intelligence PLANETs) Lab at Ajou University. His research area revolves around Artificial Intelligence, Internet of Things, and Computer Networks. |
 | Young-June Choi received his B.S., M.S., and Ph.D. degrees from the Department of Electrical Engineering and Computer Science, Seoul National University, in 2000, 2002, and 2006, respectively. From 2006 to 2007, he was a post-doctoral researcher with the University of Michigan, Ann Arbor, MI, USA. From 2007 to 2009, he was with NEC Laboratories America, Inc., Princeton, NJ, USA, as a Research Staff Member. He is currently a Professor at Ajou University, Suwon, South Korea. His research interests include beyond-mobile wireless networks, radio resource management, and cognitive radio networks. He was a recipient of the Gold Prize at the Samsung Humantech Thesis Contest in 2006, Haedong Young Researcher Award in 2015, and Best Paper Award from Journal of Communications and Networks in 2015. |










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Parameter | Value |
|---|---|
| Maximum number of retrials | 50 |
| Number of available preambles | 64 |
| Number of access points | 5 |
| Tolerable delay | 100 slots |
| Scheduler | Proportional Fair |
| Channel frequency | 28 GHz |
| Total number of users | 900 |
| Number of TRxPs | 5 |
| Mobility pattern | ConstantVelocityMobilityModel |
| Position allocator | Random uniform distribution allocator |
| Scheduler | Proportional Fair |
| Parameter (Description) | Value |
|---|---|
| m (Replay memory size) | 500,000 |
| M (Mini-batch size) | 32 |
| (Discount factor) | 0.95 |
| (0.01, 1.0) | |
| 0.0001 | |
| (Learning rate) | 0.0001 |
| (Copy rate) | 0.05 |
| Optimizer | Adam |
| Activation | 0.05 |
| Episodes | 1000 |
| Steps | 500 |
| Connected layers | 4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bekele, Y.Z.; Choi, Y.-J. Random Access Using Deep Reinforcement Learning in Dense Mobile Networks. Sensors 2021, 21, 3210. https://doi.org/10.3390/s21093210
Bekele YZ, Choi Y-J. Random Access Using Deep Reinforcement Learning in Dense Mobile Networks. Sensors. 2021; 21(9):3210. https://doi.org/10.3390/s21093210
Chicago/Turabian StyleBekele, Yared Zerihun, and Young-June Choi. 2021. "Random Access Using Deep Reinforcement Learning in Dense Mobile Networks" Sensors 21, no. 9: 3210. https://doi.org/10.3390/s21093210
APA StyleBekele, Y. Z., & Choi, Y.-J. (2021). Random Access Using Deep Reinforcement Learning in Dense Mobile Networks. Sensors, 21(9), 3210. https://doi.org/10.3390/s21093210