
DOE-SLAM: Dynamic Object Enhanced Visual SLAM



Abstract
1. Introduction
- We present a novel monocular vSLAM system with deep-learning-based semantic segmentation to reduce the impact of dynamic objects and use the dynamic features to improve the accuracy and robustness;
- We present a method to estimate camera pose and object motion simultaneously in addition to ORB-SLAM2 [4] for monocular cameras;
- We propose a strategy to recover the camera pose from the predicted object motion if a moving object obstructs enough background features, such that tracking from the background alone is impossible; and
- We generate a number of new test cases with ground truth for camera trajectory, object motion trajectories, and a semantic segmentation mask for each frame.
2. Related Work
2.1. Classic SLAM
2.2. Dynamic SLAM
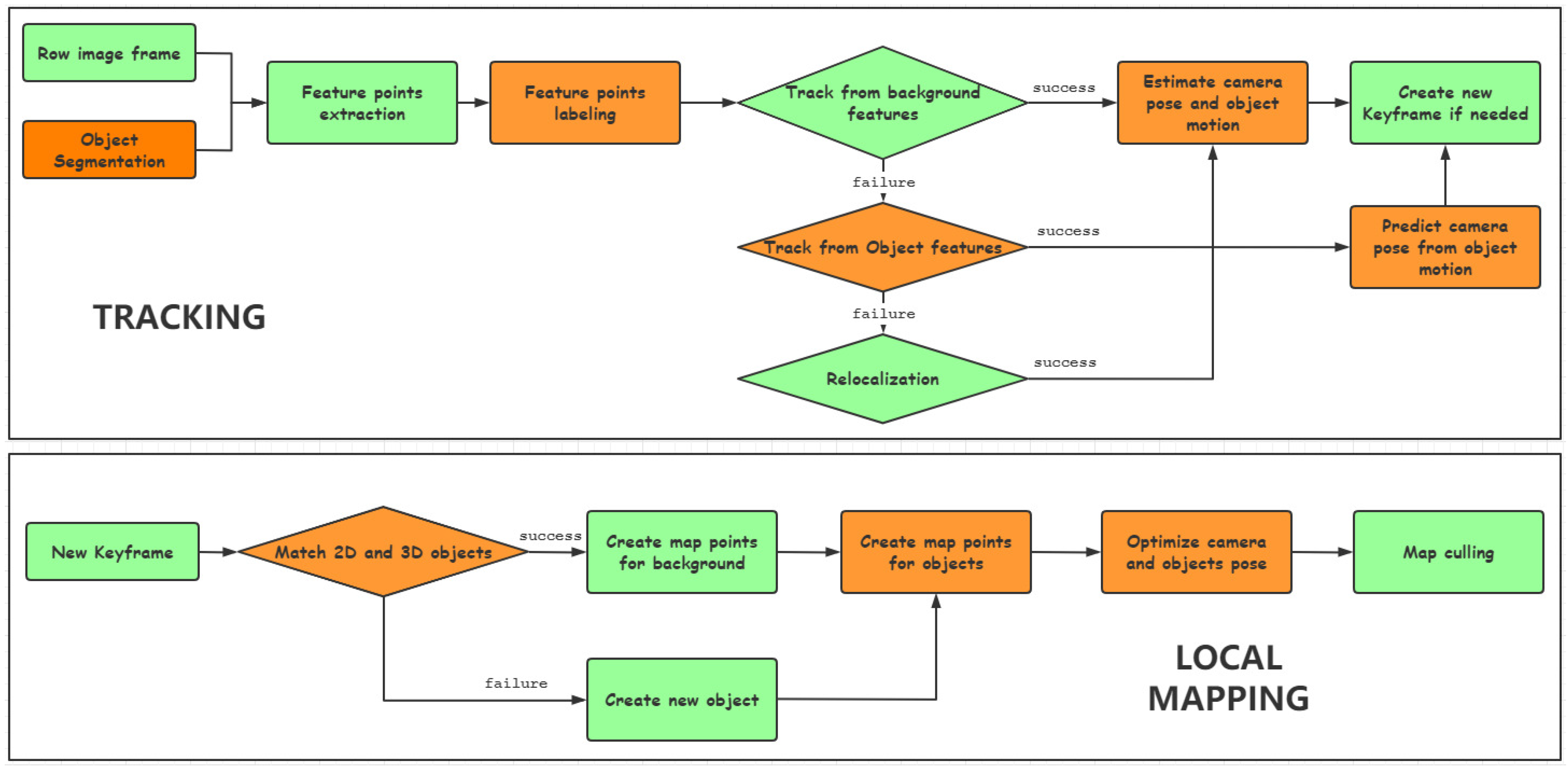
3. Method
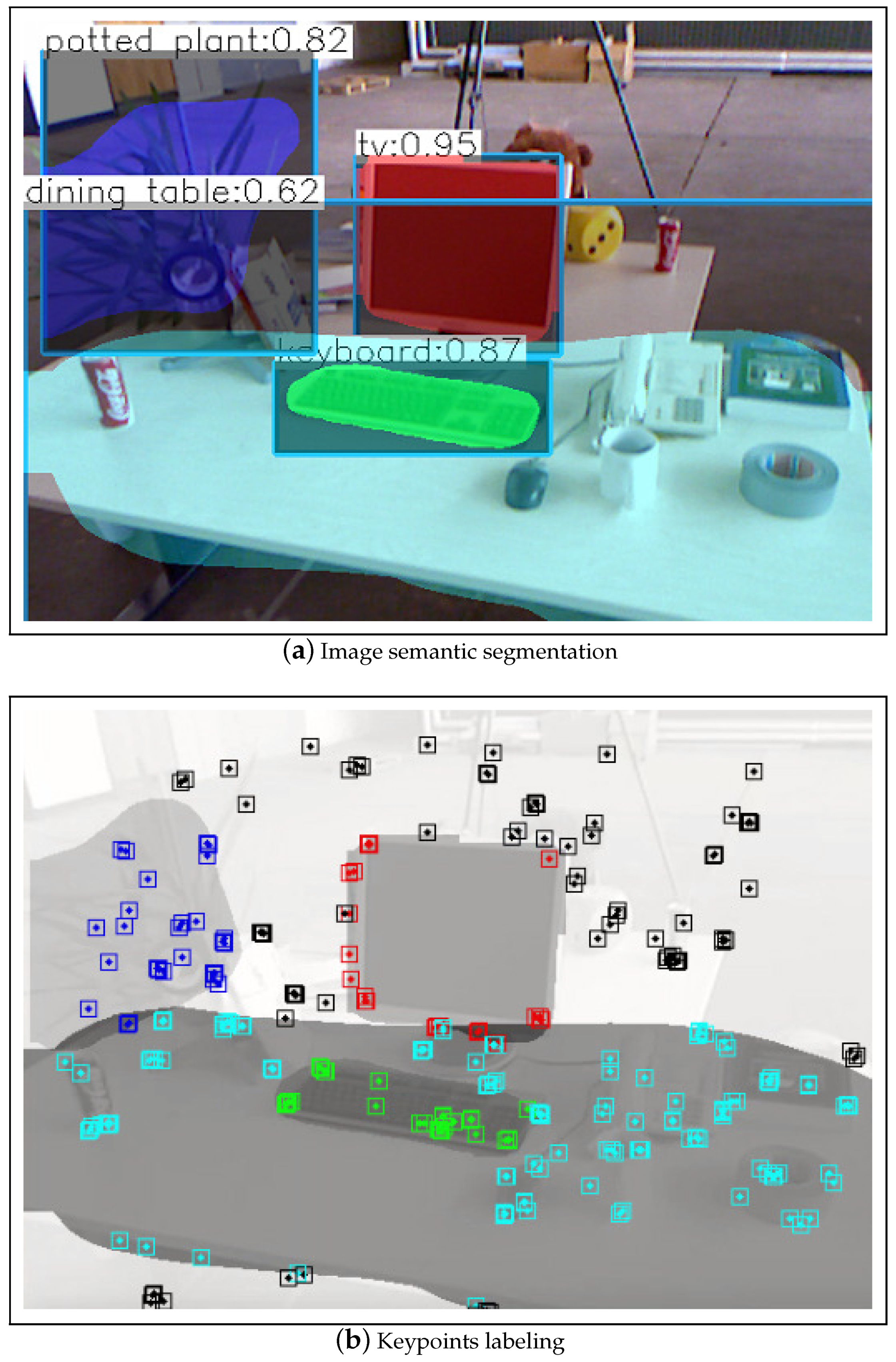
3.1. Object Modeling
3.2. Object Motion Estimation and Optimization
3.3. Camera Pose from Object Motion
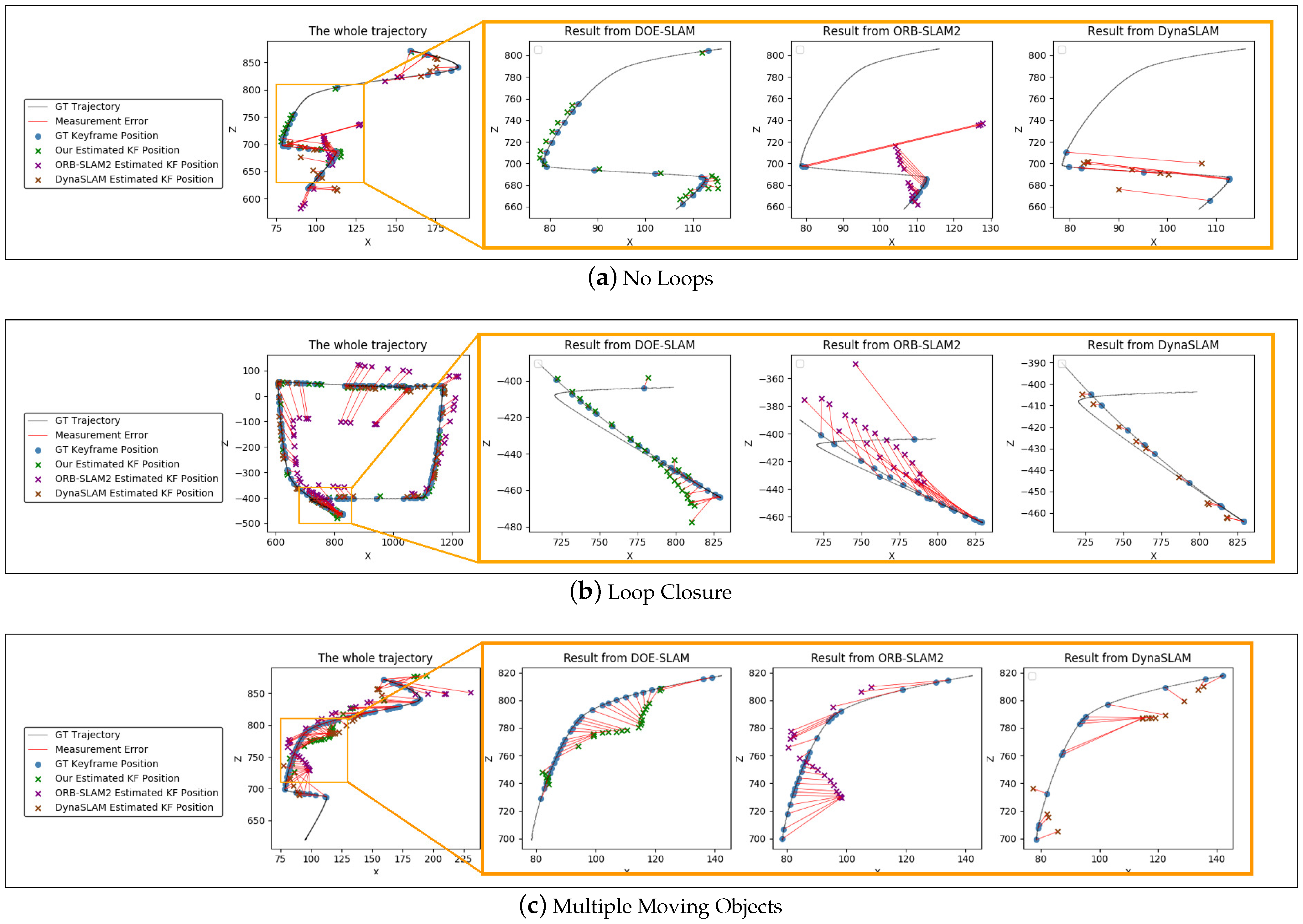
4. Experiments
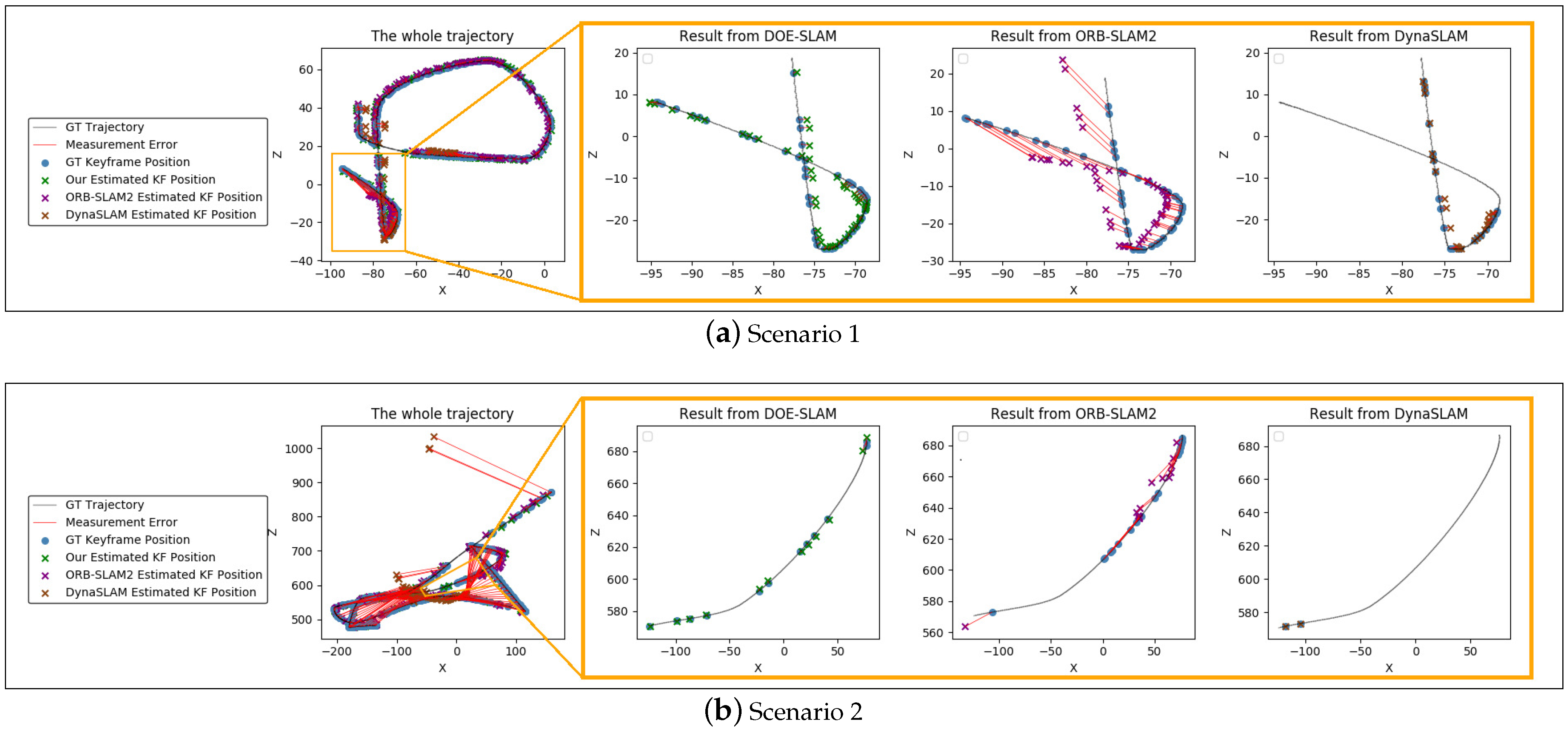
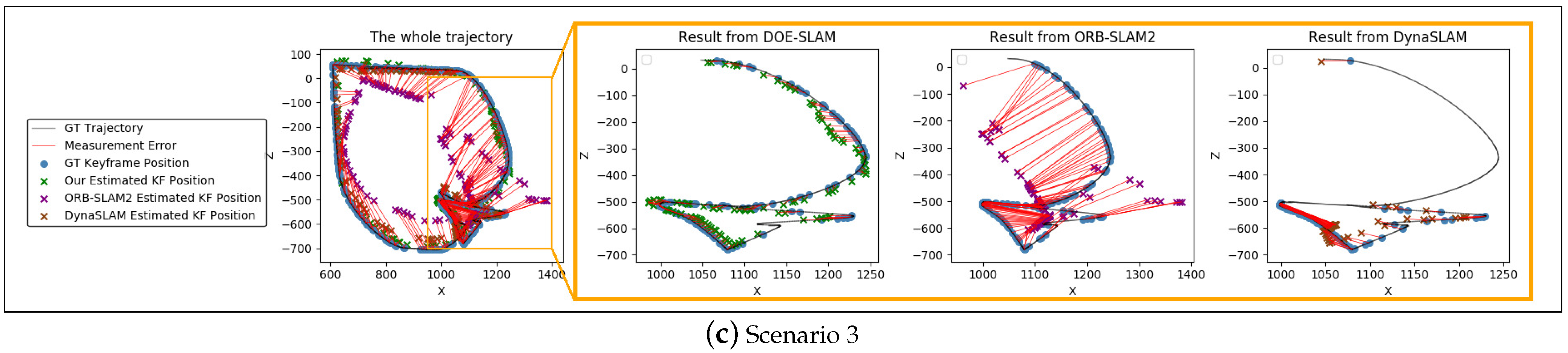
4.1. Motion of Previously Static Objects
4.2. Fully Dynamic Object
4.3. TUM Dataset
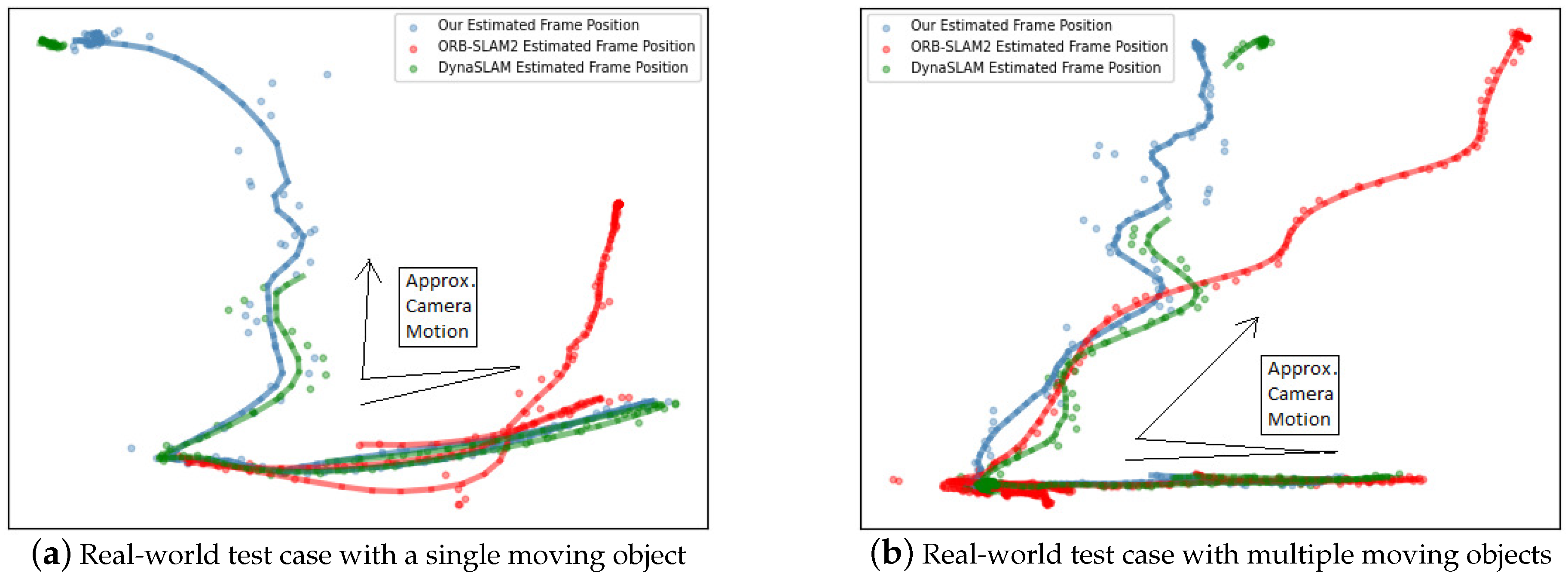
4.4. Real-World Test Cases
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- McCormac, J.; Clark, R.; Bloesch, M.; Davison, A.; Leutenegger, S. Fusion++: Volumetric object-level slam. In Proceedings of the 2018 International Conference on 3D Vision (3DV), Verona, Italy, 5–8 September 2018; pp. 32–41. [Google Scholar]
- Cadena, C.; Carlone, L.; Carrillo, H.; Latif, Y.; Scaramuzza, D.; Neira, J.; Reid, I.; Leonard, J.J. Past, present, and future of simultaneous localization and mapping: Toward the robust-perception age. IEEE Trans. Robot. 2016, 32, 1309–1332. [Google Scholar] [CrossRef]
- Elghor, H.E.; Roussel, D.; Ababsa, F.; Bouyakhf, E.H. Planes detection for robust localization and mapping in rgb-d slam systems. In Proceedings of the 2015 International Conference on 3D Vision (3DV), Lyon, France, 19–22 October 2015; pp. 452–459. [Google Scholar]
- Mur-Artal, R.; Tardós, J.D. ORB-SLAM2: An open-source slam system for monocular, stereo, and RGB-D cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef]
- Usenko, V.; Engel, J.; Stückler, J.; Cremers, D. Direct visual-inertial odometry with stereo cameras. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–20 May 2016; pp. 1885–1892. [Google Scholar]
- Leutenegger, S.; Lynen, S.; Bosse, M.; Siegwart, R.; Furgale, P. Keyframe-based visual–inertial odometry using nonlinear optimization. Int. J. Robot. Res. 2015, 34, 314–334. [Google Scholar] [CrossRef]
- Xu, B.; Li, W.; Tzoumanikas, D.; Bloesch, M.; Davison, A.; Leutenegger, S. Mid-fusion: Octree-based object-level multi-instance dynamic SLAM. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 5231–5237. [Google Scholar]
- Zhong, F.; Wang, S.; Zhang, Z.; Wang, Y. Detect-SLAM: Making object detection and slam mutually beneficial. In Proceedings of the 2018 IEEE Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; pp. 1001–1010. [Google Scholar]
- Sturm, J.; Burgard, W.; Cremers, D. Evaluating egomotion and structure-from-motion approaches using the TUM RGB-D benchmark. In Proceedings of the 2012 Workshop on Color-Depth Camera Fusion in Robotics at the IEEE/RJS International Conference on Intelligent Robot Systems (IROS), Vila Moura, Portugal, 7–12 October 2012. [Google Scholar]
- Savva, M.; Kadian, A.; Maksymets, O.; Zhao, Y.; Wijmans, E.; Jain, B.; Straub, J.; Liu, J.; Koltun, V.; Malik, J.; et al. Habitat: A platform for embodied ai research. In Proceedings of the 2019 IEEE International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 9339–9347. [Google Scholar]
- Chang, A.; Dai, A.; Funkhouser, T.; Halber, M.; Niessner, M.; Savva, M.; Song, S.; Zeng, A.; Zhang, Y. Matterport3D: Learning from RGB-D Data in Indoor Environments. In Proceedings of the 2017 International Conference on 3D Vision (3DV), Qingdao, China, 10–12 October 2017. [Google Scholar]
- Billinghurst, M.; Clark, A.; Lee, G. A survey of augmented reality. Found. Trends Hum.-Comput. Interact. 2015, 8, 73–272. [Google Scholar] [CrossRef]
- Özyeşil, O.; Voroninski, V.; Basri, R.; Singer, A. A survey of structure from motion*. Acta Numer. 2017, 26, 305–364. [Google Scholar] [CrossRef]
- Yi, G.; Jianxin, L.; Hangping, Q.; Bo, W. Survey of structure from motion. In Proceedings of the 2014 International Conference on Cloud Computing and Internet of Things (CCIOT), Changchun, China, 13–14 December 2014; pp. 72–76. [Google Scholar]
- Choi, H.; Jun, C.; Li Yuen, S.; Cho, H.; Doh, N.L. Joint solution for the online 3D photorealistic mapping using SfM and SLAM. Int. J. Adv. Robot. Syst. 2013, 10, 8. [Google Scholar] [CrossRef]
- Engel, J.; Koltun, V.; Cremers, D. Direct sparse odometry. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 611–625. [Google Scholar] [CrossRef] [PubMed]
- Engel, J.; Schöps, T.; Cremers, D. LSD-SLAM: Large-scale direct monocular SLAM. In Proceedings of the 2014 European conference on computer vision (ECCV), Zurich, Switzerland, 6–12 September 2014; pp. 834–849. [Google Scholar]
- Newcombe, R.A.; Lovegrove, S.J.; Davison, A.J. DTAM: Dense tracking and mapping in real-time. In Proceedings of the 2011 international conference on computer vision (ICCV), Barcelona, Spain, 6–13 November 2011; pp. 2320–2327. [Google Scholar]
- Mur-Artal, R.; Montiel, J.M.M.; Tardos, J.D. ORB-SLAM: A versatile and accurate monocular SLAM system. IEEE Trans. Robot. 2015, 31, 1147–1163. [Google Scholar] [CrossRef]
- Klein, G.; Murray, D. Parallel tracking and mapping for small AR workspaces. In Proceedings of the 2007 6th IEEE and ACM International Symposium on Mixed and Augmented Reality (ISMAR), Nara, Japan, 13–16 November 2007; pp. 1–10. [Google Scholar]
- Bescos, B.; Fácil, J.M.; Civera, J.; Neira, J. DynaSLAM: Tracking, mapping, and inpainting in dynamic scenes. IEEE Robot. Autom. Lett. 2018, 3, 4076–4083. [Google Scholar] [CrossRef]
- Sun, Y.; Liu, M.; Meng, M.Q.H. Motion removal for reliable RGB-D SLAM in dynamic environments. Robot. Auton. Syst. 2018, 108, 115–128. [Google Scholar] [CrossRef]
- Godard, C.; Mac Aodha, O.; Brostow, G.J. Unsupervised monocular depth estimation with left-right consistency. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 270–279. [Google Scholar]
- Qiu, K.; Ai, Y.; Tian, B.; Wang, B.; Cao, D. Siamese-ResNet: Implementing Loop Closure Detection based on Siamese Network. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Changshu, China, 26–30 June 2018; pp. 716–721. [Google Scholar]
- Tateno, K.; Tombari, F.; Laina, I.; Navab, N. CNN-SLAM: Real-time dense monocular SLAM with learned depth prediction. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 6243–6252. [Google Scholar]
- Saputra, M.R.U.; Markham, A.; Trigoni, N. Visual SLAM and structure from motion in dynamic environments: A survey. ACM Comput. Surv. (CSUR) 2018, 51, 1–36. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Bârsan, I.A.; Liu, P.; Pollefeys, M.; Geiger, A. Robust dense mapping for large-scale dynamic environments. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–26 May 2018; pp. 7510–7517. [Google Scholar]
- Jaimez, M.; Kerl, C.; Gonzalez-Jimenez, J.; Cremers, D. Fast odometry and scene flow from RGB-D cameras based on geometric clustering. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 3992–3999. [Google Scholar]
- Hachiuma, R.; Pirchheim, C.; Schmalstieg, D.; Saito, H. DetectFusion: Detecting and Segmenting Both Known and Unknown Dynamic Objects in Real-time SLAM. In Proceedings of the 2019 British Machine Vision Conference (BMVC), Cardiff, UK, 9–12 September 2019. [Google Scholar]
- Strecke, M.; Stuckler, J. EM-Fusion: Dynamic Object-Level SLAM with Probabilistic Data Association. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 5865–5874. [Google Scholar]
- Rünz, M.; Buffier, M.; Agapito, L. Maskfusion: Real-time recognition, tracking and reconstruction of multiple moving objects. In Proceedings of the 2018 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Munich, Germany, 16–20 October 2018; pp. 10–20. [Google Scholar]
- Rünz, M.; Agapito, L. Co-fusion: Real-time segmentation, tracking and fusion of multiple objects. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 4471–4478. [Google Scholar]
- Fan, Y.; Han, H.; Tang, Y.; Zhi, T. Dynamic objects elimination in SLAM based on image fusion. Pattern Recognit. Lett. 2019, 127, 191–201. [Google Scholar] [CrossRef]
- Ai, Y.; Rui, T.; Lu, M.; Fu, L.; Liu, S.; Wang, S. DDL-SLAM: A robust RGB-D SLAM in dynamic environments combined with deep learning. IEEE Access 2020, 8, 162335–162342. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the 18th International Conference on Medical Image Computing and Computer Assisted Interventions (MICCAI), Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Sünderhauf, N.; Protzel, P. Switchable constraints for robust pose graph SLAM. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 1879–1884. [Google Scholar]
- Olson, E.; Agarwal, P. Inference on networks of mixtures for robust robot mapping. Int. J. Robot. Res. 2013, 32, 826–840. [Google Scholar] [CrossRef]
- Agarwal, P.; Tipaldi, G.D.; Spinello, L.; Stachniss, C.; Burgard, W. Robust map optimization using dynamic covariance scaling. In Proceedings of the 2013 IEEE International Conference on Robotics and Automation (ICRA), Karlsruhe, Germany, 6–10 May 2013; pp. 62–69. [Google Scholar]
- Lee, D.; Myung, H. Solution to the SLAM problem in low dynamic environments using a pose graph and an RGB-D sensor. Sensors 2014, 14, 12467–12496. [Google Scholar] [CrossRef] [PubMed]
- Yu, C.; Liu, Z.; Liu, X.J.; Xie, F.; Yang, Y.; Wei, Q.; Fei, Q. DS-SLAM: A semantic visual SLAM towards dynamic environments. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 1168–1174. [Google Scholar]
- Badrinarayanan, V.; Kendall, A.; Cipolla, R. Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 2481–2495. [Google Scholar] [CrossRef] [PubMed]
- Tan, W.; Liu, H.; Dong, Z.; Zhang, G.; Bao, H. Robust monocular SLAM in dynamic environments. In Proceedings of the 2013 IEEE International Symposium on Mixed and Augmented Reality (ISMAR), Adelaide, Australia, 1–4 October 2013; pp. 209–218. [Google Scholar]
- Xiao, L.; Wang, J.; Qiu, X.; Rong, Z.; Zou, X. Dynamic-SLAM: Semantic monocular visual localization and mapping based on deep learning in dynamic environment. Robot. Auton. Syst. 2019, 117, 1–16. [Google Scholar] [CrossRef]
- Bolya, D.; Zhou, C.; Xiao, F.; Lee, Y.J. Yolact: Real-time instance segmentation. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019; pp. 9157–9166. [Google Scholar]
- Sturm, J.; Engelhard, N.; Endres, F.; Burgard, W.; Cremers, D. A benchmark for the evaluation of RGB-D SLAM systems. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vilamoura, Portugal, 7–12 October 2012; pp. 573–580. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| (a) Scenario 1 | |||
| RMSE | Object RMSE | Lost Frames | |
| ORB-SLAM2 | 4.62 | n/a | 0 |
| DynaSLAM | 2.17 | n/a | 922 (46.7%) |
| DOE-SLAM | 1.67 | 5.91 | 0 |
| (b) Scenario 2 | |||
| RMSE | Object RMSE | Lost Frames | |
| ORB-SLAM2 | 23.34 | n/a | 39 (2.44%) |
| DynaSLAM | 86.19 | n/a | 197 (12.34%) |
| DOE-SLAM | 18.05 | 30.88 | 0 |
| (c) Scenario 3 | |||
| RMSE | Object RMSE | Lost Frames | |
| ORB-SLAM2 | 176.46 | n/a | 0 |
| ORB-SLAM2 (lost) | 60.97 | n/a | 554 (23.23%) |
| DynaSLAM | 39.44 | n/a | 639 (26.79%) |
| DOE-SLAM | 48.66 | 53.40 | 0 |
| Scenario 1 | Scenario 2 | Scenario 3 | |
|---|---|---|---|
| ORB-SLAM2 | 20.5 | 25.06 | 20.65 |
| DynaSLAM | 31.12 | 33.56 | 27.34 |
| DOE-SLAM | 25.21 | 29.8 | 26.13 |
| Scenario 4 | Scenario 5 | Scenario 6 | ||||
|---|---|---|---|---|---|---|
| RMSE | Lost | RMSE | Lost | RMSE | Lost | |
| ORB-SLAM2 | 31.30 | 0 | 86.98 | 0 | 30.60 | 0 |
| DynaSLAM | 25.76 | 39 | 16.40 | 31 | 27.34 | 43 |
| DOE-SLAM | 8.61 | 0 | 16.11 | 0 | 24.73 | 0 |
| ORB-SLAM2 | DynaSLAM | Dynamic-SLAM | DOE-SLAM | |
|---|---|---|---|---|
| w_static | 1.74 | 0.49 | - | 0.58 |
| w_xyz | 1.41 | 1.53 | 1.32 | 1.05 |
| w_rpy | 6.38 | 4.81 | 6.03 | 5.71 |
| w_halfsphere | 1.79 | 1.77 | 2.14 | 1.65 |
| s_rpy | 2.40 | 2.02 | 3.45 | 1.81 |
| s_xyz | 0.99 | 1.17 | 0.60 | 0.62 |
| ORB-SLAM2 | DynaSLAM | DOE-SLAM | |
|---|---|---|---|
| w_static | 17.99 | 23.77 | 29.87 |
| w_xyz | 20.89 | 25.28 | 25.11 |
| w_rpy | 20.03 | 24.61 | 28.50 |
| w_halfsphere | 19.42 | 27.06 | 26.12 |
| s_rpy | 22.08 | 27.06 | 25.48 |
| s_xyz | 20.92 | 24.93 | 26.38 |
| Total | ORB-SLAM2 | DynaSLAM | DOE-SLAM | |
|---|---|---|---|---|
| w_static | 743 | 646 | 585 | 685 |
| w_xyz | 859 | 638 | 830 | 835 |
| w_rpy | 910 | 727 | 680 | 767 |
| w_halfsphere | 1067 | 1062 | 1061 | 1061 |
| s_rpy | 820 | 615 | 455 | 668 |
| s_xyz | 1261 | 1194 | 1194 | 1207 |
| ORB-SLAM2 | DynaSLAM | DOE-SLAM | |
|---|---|---|---|
| Single moving object | 0 | 22 | 0 |
| Multiple moving objects | 0 | 20 | 0 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hu, X.; Lang, J. DOE-SLAM: Dynamic Object Enhanced Visual SLAM. Sensors 2021, 21, 3091. https://doi.org/10.3390/s21093091
Hu X, Lang J. DOE-SLAM: Dynamic Object Enhanced Visual SLAM. Sensors. 2021; 21(9):3091. https://doi.org/10.3390/s21093091
Chicago/Turabian StyleHu, Xiao, and Jochen Lang. 2021. "DOE-SLAM: Dynamic Object Enhanced Visual SLAM" Sensors 21, no. 9: 3091. https://doi.org/10.3390/s21093091
APA StyleHu, X., & Lang, J. (2021). DOE-SLAM: Dynamic Object Enhanced Visual SLAM. Sensors, 21(9), 3091. https://doi.org/10.3390/s21093091