
HRV Features as Viable Physiological Markers for Stress Detection Using Wearable Devices



Abstract
1. Introduction
2. Related Work
3. Materials and Methods
3.1. Datasets
3.1.1. Data Pre-Processing
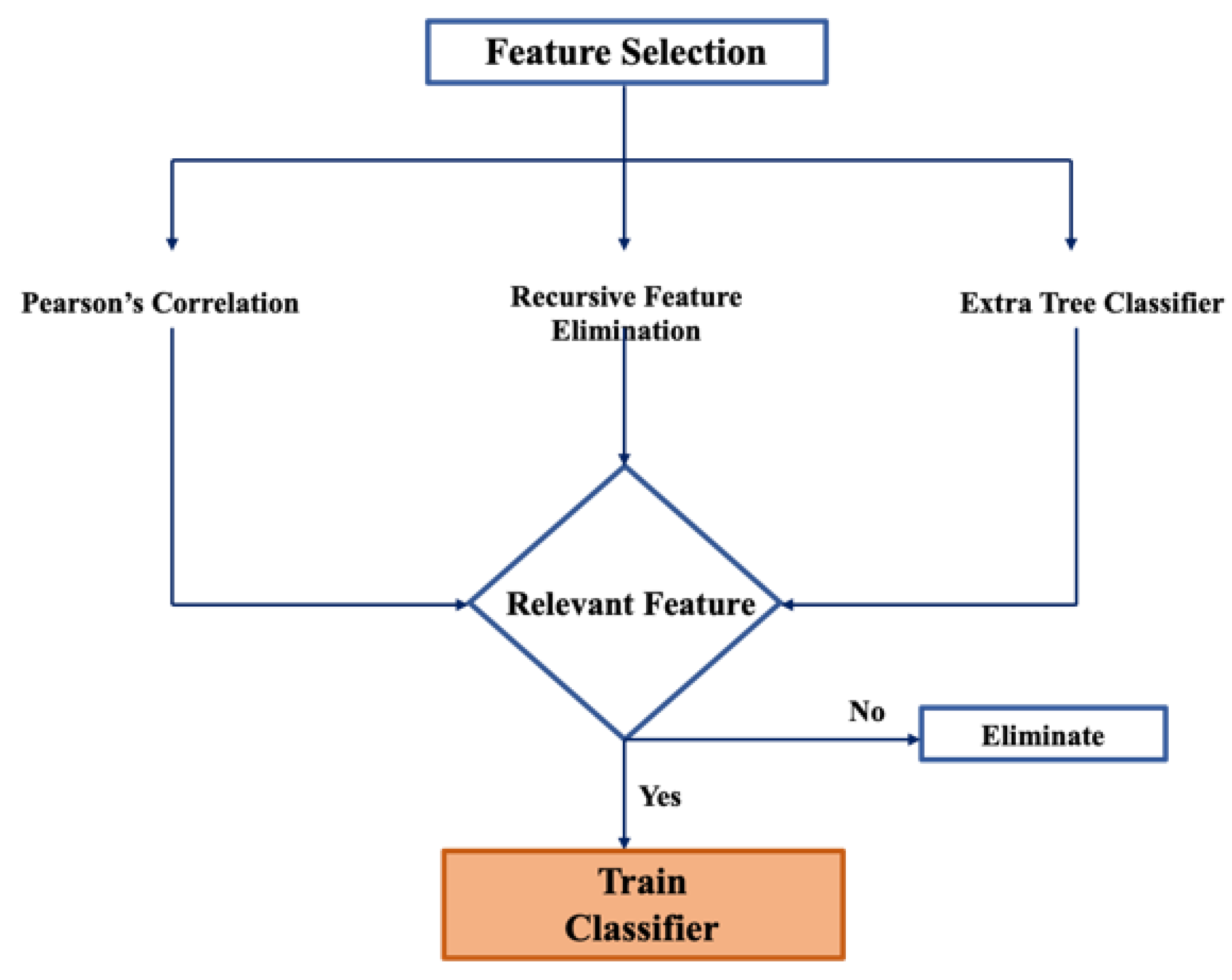
3.1.2. Feature Selection
3.2. Parameter Tuning
3.2.1. K-Nearest Neighbour
3.2.2. Support Vector Machine
3.2.3. Multilayer Perceptron
3.2.4. Random Forest
3.2.5. Gradient Boosting
4. Results
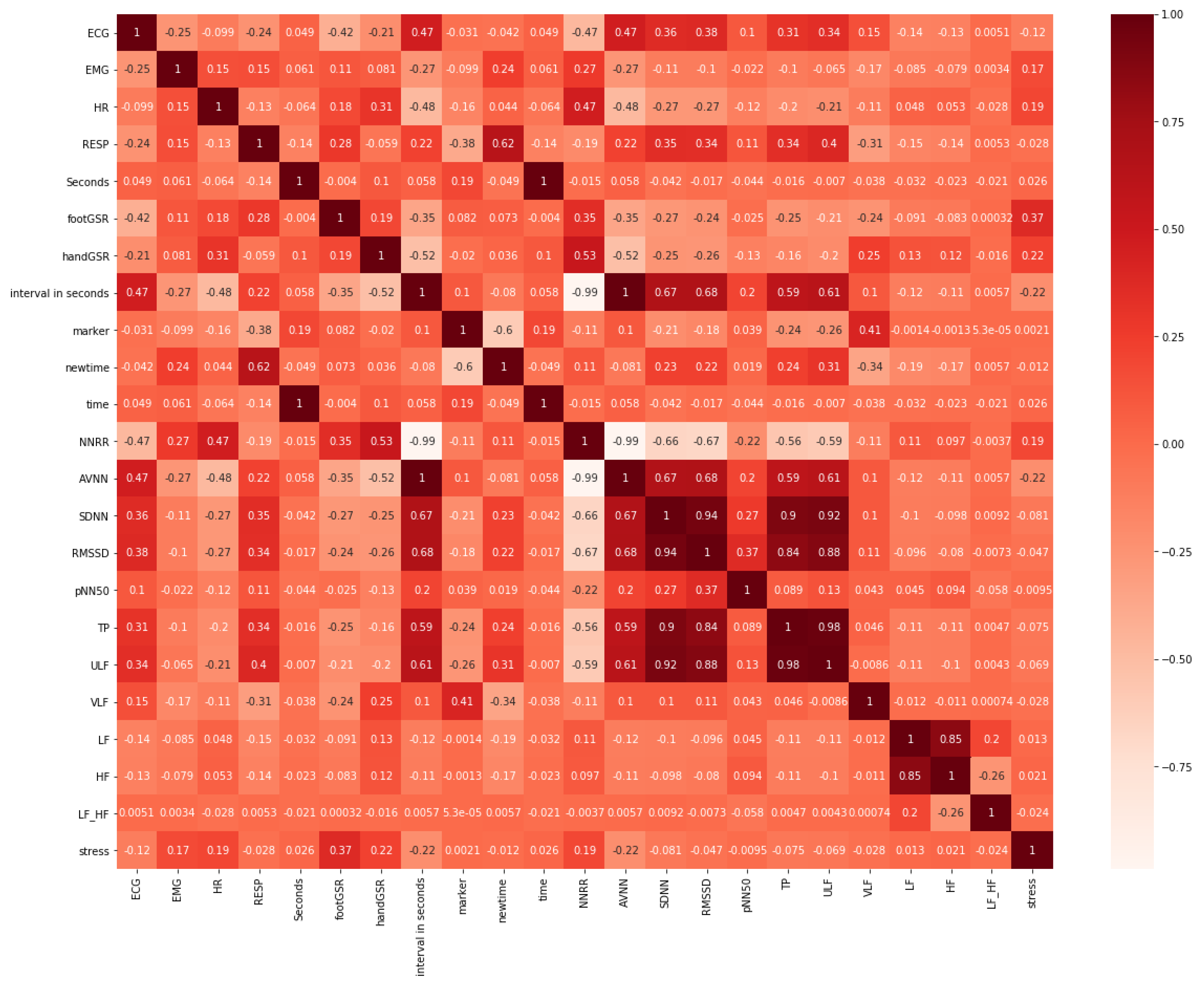
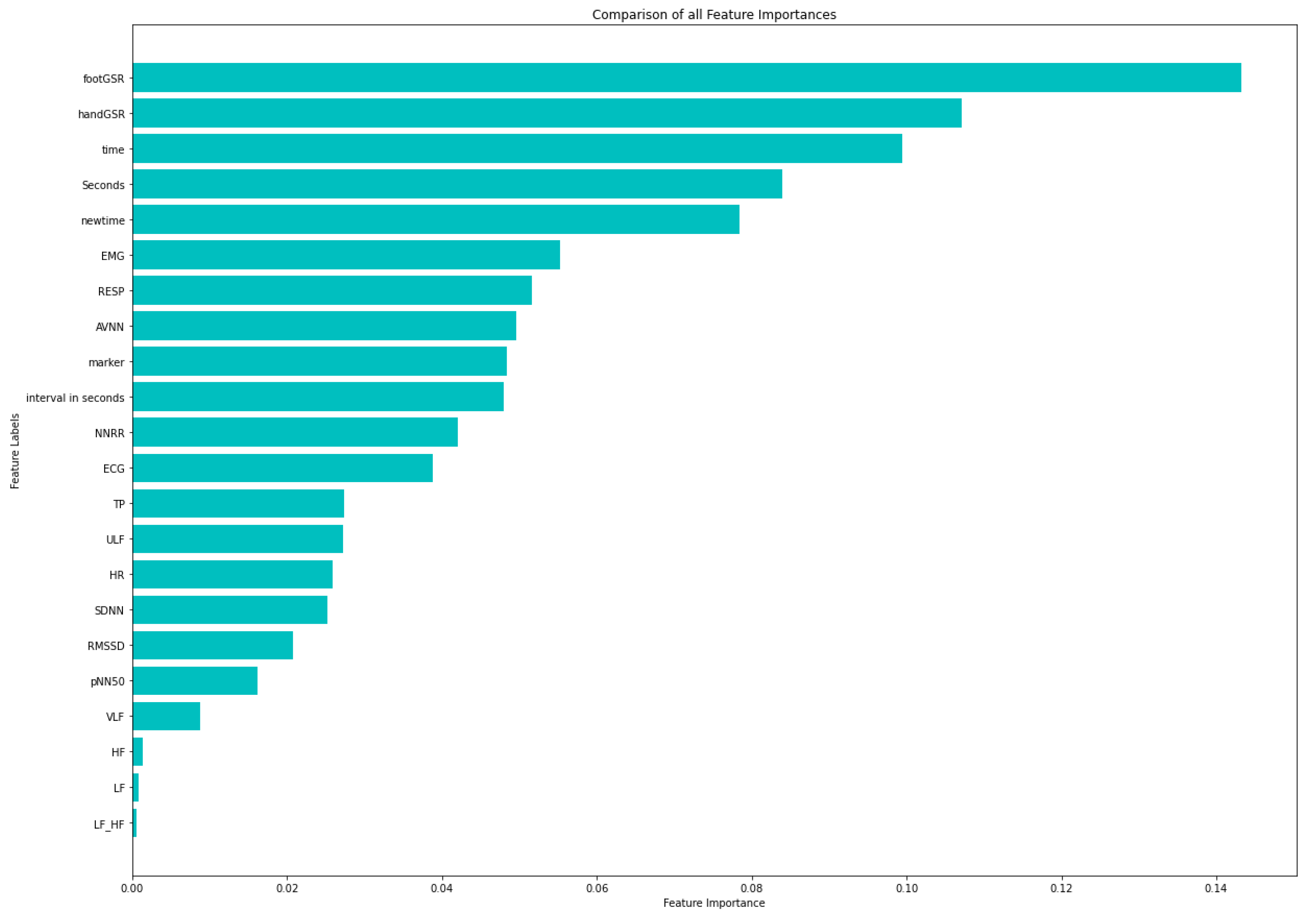
4.1. Feature Selection on Original-Dataset
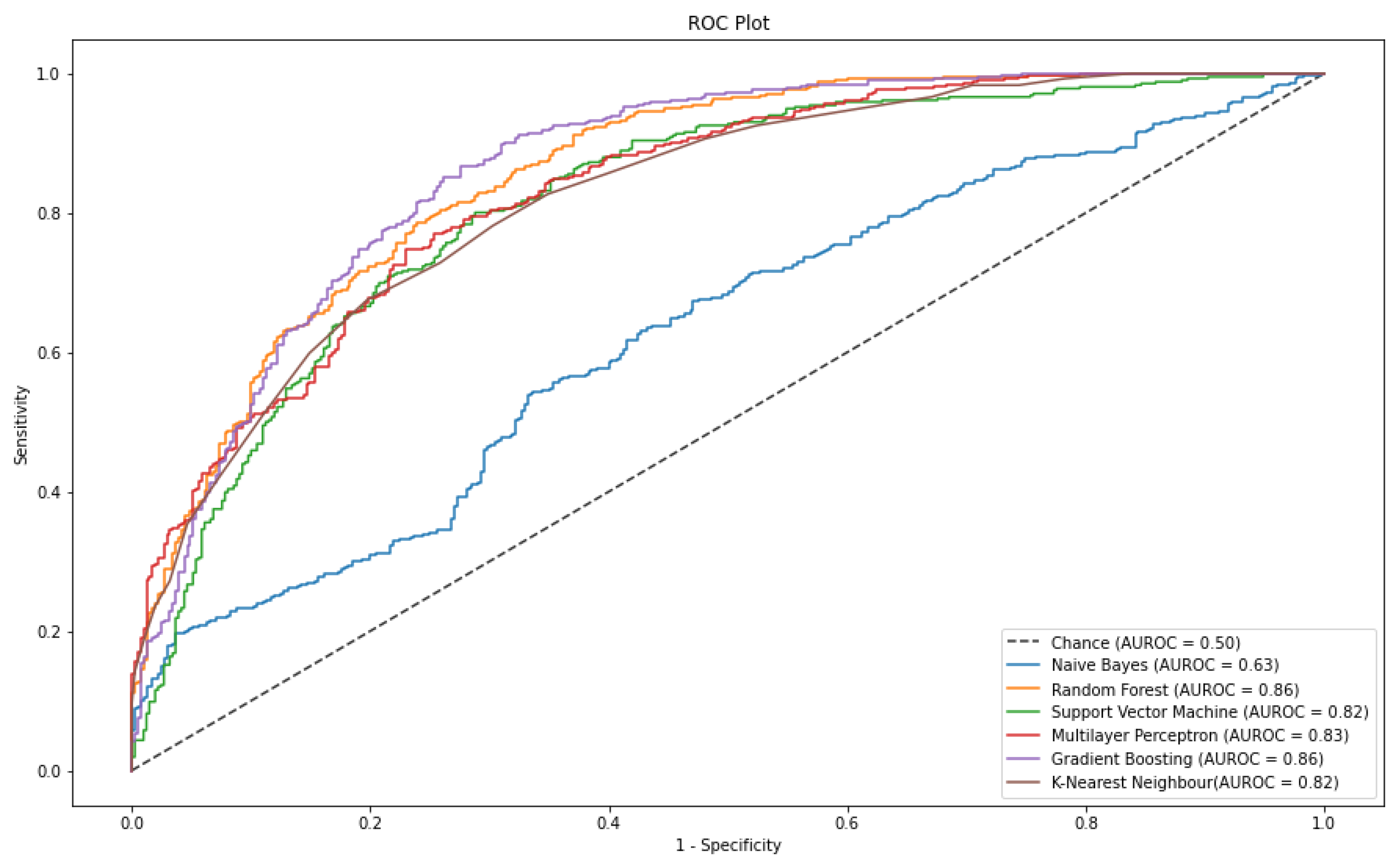
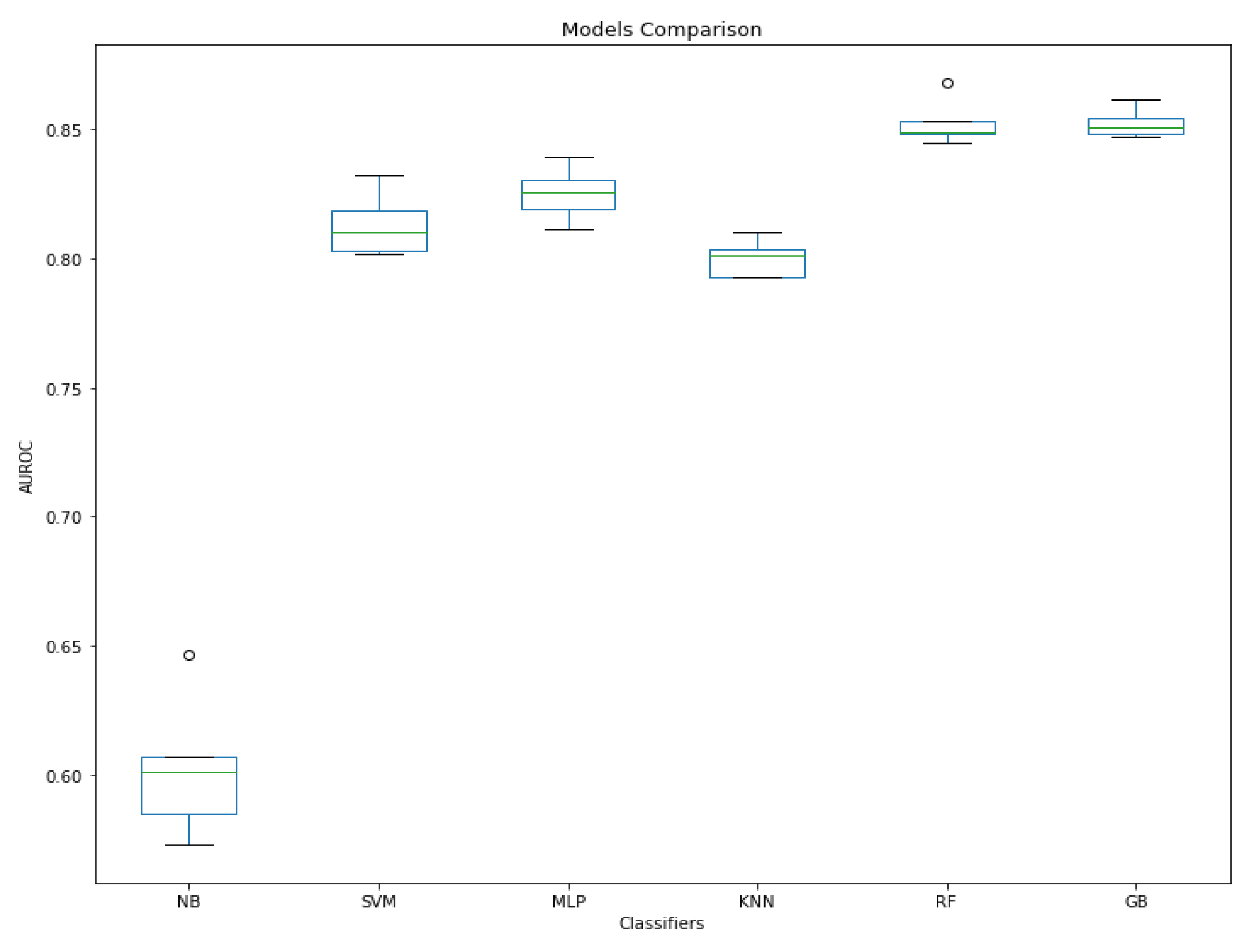
4.2. Stress Classification on Original-Dataset
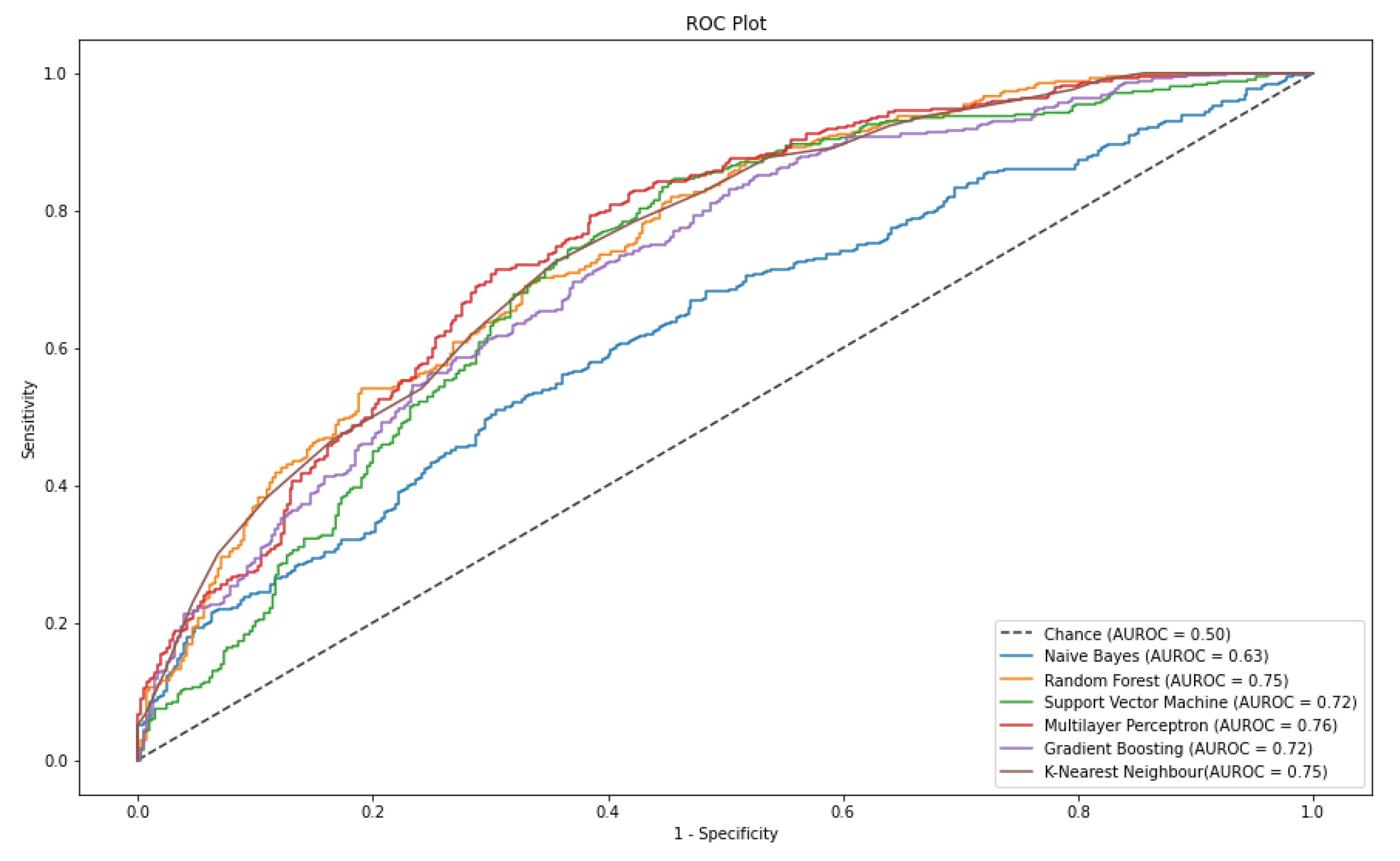
4.3. Stress Classification on Modified-Dataset
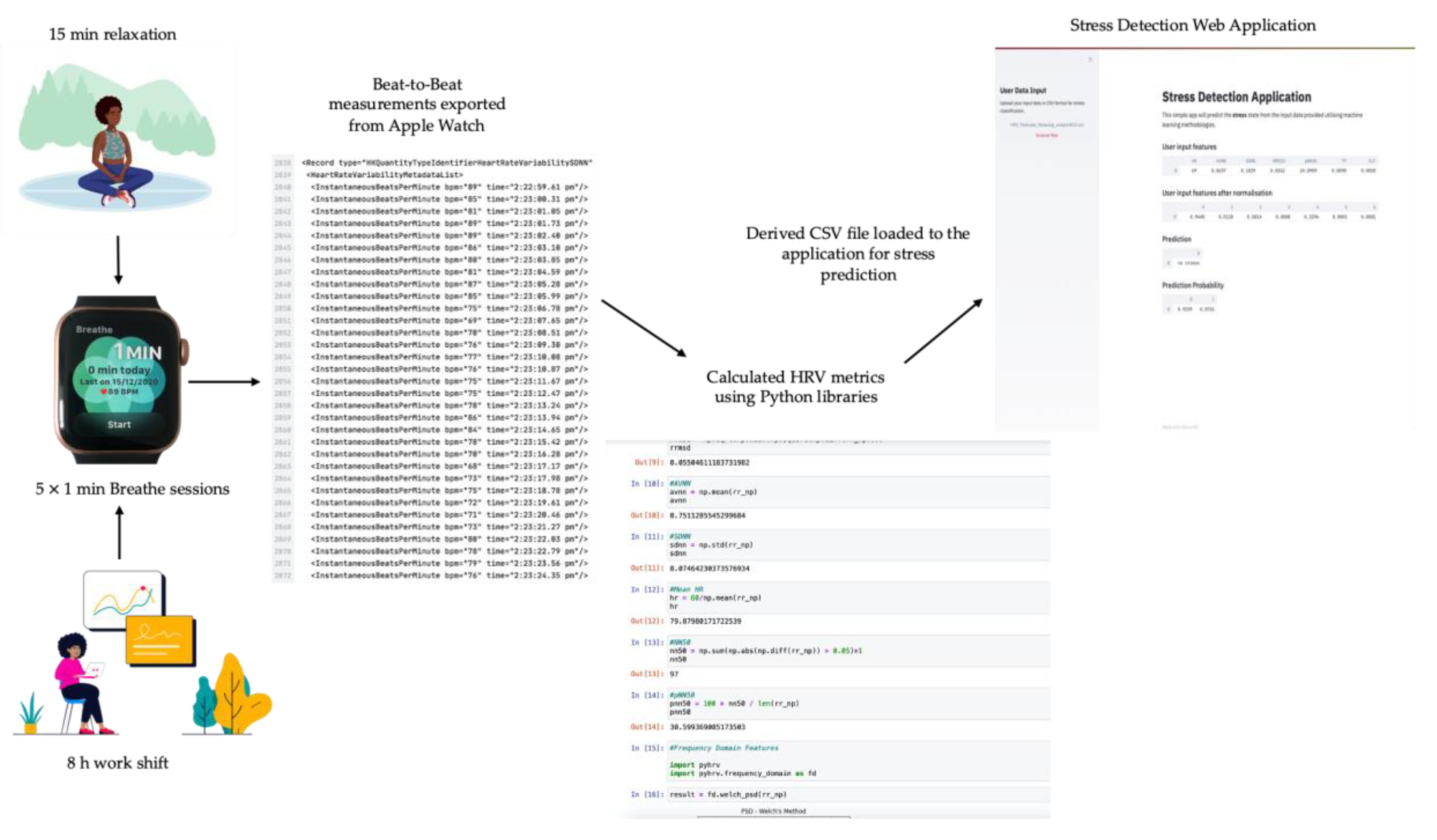
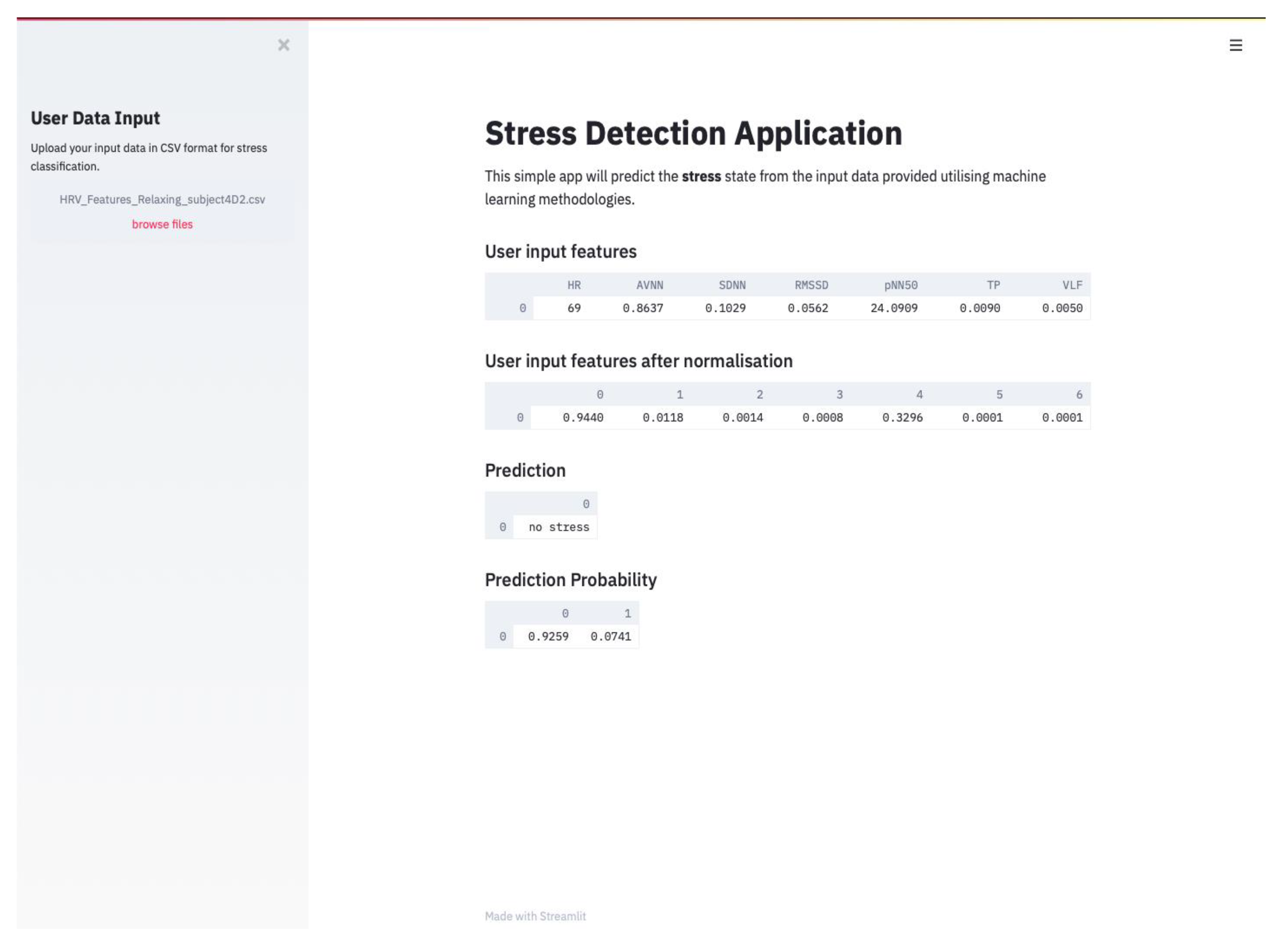
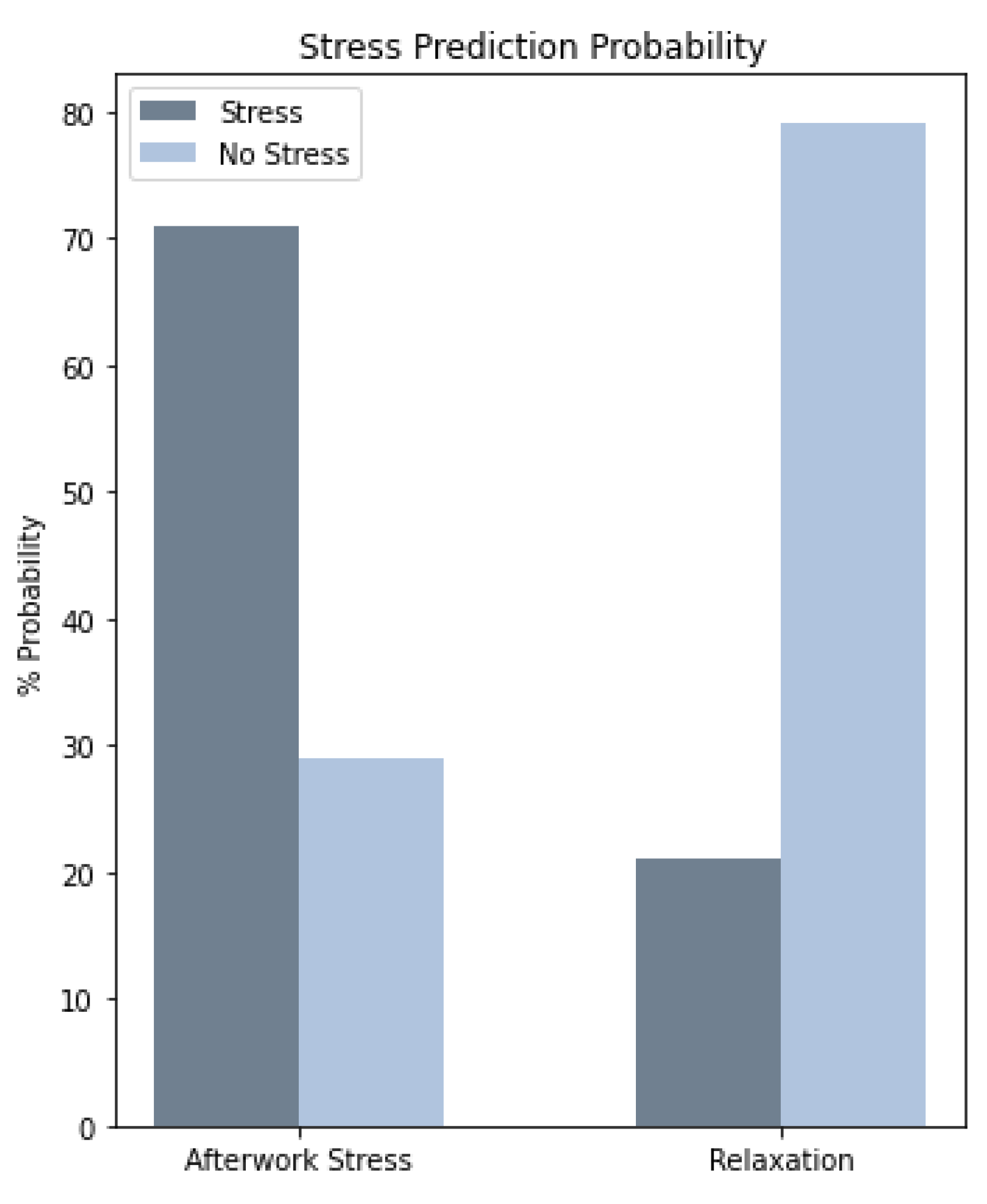
4.4. Stress Classification from HRV Measurements Obtained from Apple Watch
5. Discussion
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- McLeod, S.A. What is the stress Response. Simply Psychology. 2010. Available online: https://www.simplypsychology.org/stress-biology.html (accessed on 9 October 2020).
- Moldagulova, A.; Sulaiman, R.B. Using KNN algorithm for classification of textual documents. In Proceedings of the 8th International Conference on Information Technology (ICIT), Amman, Jordan, 17–18 May 2017; pp. 665–671. [Google Scholar]
- Sato, T.; Yamamoto, H.; Sawada, N.; Nashiki, K.; Tsuji, M.; Muto, K.; Kume, H.; Sasaki, H.; Arai, H.; Nikawa, T.; et al. Restraint stress alters the duodenal expression of genes important for lipid metabolism in rat. Toxicology 2016, 227, 248–261. [Google Scholar] [CrossRef] [PubMed]
- Salai, M.; Vassányi, I.; Kósa, I. Stress detection using low-cost heart rate sensors. J. Healthc. Eng. 2016. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, M.U.; Begum, S.; Islam, M.S. Heart rate and inter-beat interval computation to diagnose stress using ECG sensor signal. Mrtc Rep. 2010, 4. Available online: http://www.es.mdh.se/pdf_publications/1929.pdf (accessed on 16 April 2021).
- Herman, J. Neural control of chronic stress adaptation. Front. Behav. Neurosci. 2013, 7, 61. [Google Scholar] [CrossRef] [PubMed]
- Pramod, B.; Vani, M. Stress Detection with Machine Learning and Deep Learning using Multimodal Physiological Data. In Proceedings of the Second International Conference on Inventive Research in Computing Applications (ICIRCA), Coimbatore, India, 15–17 July 2020; pp. 51–57. [Google Scholar]
- Rastgoo, M.N.; Nakisa, B.; Maire, F.; Rakotonirainy, A.; Chandran, V. Automatic driver stress level classification using multimodal deep learning. Expert Syst. Appl. 2019, 138, 112793. [Google Scholar] [CrossRef]
- Goel, S.; Tomar, P.; Kaur, G. ECG Feature Extraction for Stress Recognition in Automobile Drivers. Electron. J. Biol. 2016, 12, 156–165. [Google Scholar]
- Londhe, A.N.; Atulkar, M. Heart rate variability analysis: Application overview. In Proceedings of the 2018 Second International Conference on Inventive Communication and Computational Technologies (ICICCT), Coimbatore, India, 20–21 April 2018; pp. 1518–1523. [Google Scholar]
- Reijmerink, I.; van der Laan, M.; Cnossen, F. Heart rate variability as a measure of mental stress in surgery: A systematic review. Int. Arch. Occup. Environ. Health 2020, 25, 1–17. [Google Scholar]
- Khairuddin, M.K.N.B.; Nakamoto, K.; Nakamura, H.; Tanaka, K.; Nakashima, S. Heart rate and heart rate variability measuring system by using Smartphone. In Proceedings of the 5th Intl Conf on Applied Computing and Information Technology/4th Intl Conf on Computational Science/Intelligence and Applied Informatics/2nd Intl Conf on Big Data, Cloud Computing, Data Science (ACIT-CSII-BCD), Hamamatsu, Japan, 9–13 July 2017; pp. 47–52. [Google Scholar]
- Dobbs, W.C.; Fedewa, M.V.; MacDonald, H.V.; Holmes, C.J.; Cicone, Z.S.; Plews, D.J.; Esco, M.R. The accuracy of acquiring heart rate variability from portable devices: A systematic review and meta-analysis. Sports Med. 2019, 49, 417–435. [Google Scholar] [CrossRef] [PubMed]
- Shcherbina, A.; Mattsson, C.M.; Waggott, D.; Salisbury, H.; Christle, J.W.; Hastie, T.; Wheeler, M.T.; Ashley, E.A. Accuracy in wrist-worn, sensor-based measurements of heart rate and energy expenditure in a diverse cohort. J. Pers. Med. 2017, 7, 3. [Google Scholar] [CrossRef] [PubMed]
- Hernando, D.; Roca, S.; Sancho, J.; Alesanco, Á.; Bailón, R. Validation of the apple watch for heart rate variability measurements during relax and mental stress in healthy subjects. Sensors 2018, 18, 2619. [Google Scholar] [CrossRef] [PubMed]
- Taelman, J.; Vandeput, S.; Spaepen, A.; Van Huffel, S. Influence of mental stress on heart rate and heart rate variability. In 4th European Conference of the International Federation for Medical and Biological Engineering; Springer: Berlin/Heidelberg, Germany, 2009; pp. 1366–1369. [Google Scholar]
- Munla, N.; Khalil, M.; Shahin, A.; Mourad, A. Driver stress level detection using HRV analysis. In Proceedings of the 2015 international conference on advances in biomedical engineering (ICABME), Beirut, Lebanon, 16–18 September 2015; pp. 61–64. [Google Scholar]
- Healey, J.A.; Picard, R.W. Detecting stress during real-world driving tasks using physiological sensors. IEEE Trans. Intell. Transp. Syst. 2005, 6, 156–166. [Google Scholar] [CrossRef]
- Goldberger, A.; Amaral, L.; Glass, L.; Hausdorff, J.; Ivanov, P.C.; Mark, R.; Mietus, J.E.; Moody, G.B.; Peng, C.K.; Stanley, H.E. PhysioBank, PhysioToolkit, and PhysioNet: Components of a new research resource for complex physiologic signals. Circulation 2000, 101, e215–e220. [Google Scholar] [CrossRef] [PubMed]
- Zong, W.; Moody, G.B.; Jiang, D. A robust open-source algorithm to detect onset and duration of QRS complexes. Comput. Cardiol. 2003, 30, 737–740. [Google Scholar]
- Li, K.; Rüdiger, H.; Ziemssen, T. Spectral analysis of heart rate variability: Time window matters. Front. Neurol. 2019, 10, 545. [Google Scholar] [CrossRef] [PubMed]
- Gomes, P.; Silva, H.; Margaritoff, P. pyHRV-Open-Source Python toolbox for heart rate variability. 2018. Available online: https://pypi.org/project/pyhrv/ (accessed on 16 April 2021).
- Brownlee, J. Feature Selection in Python with Scikit-Lear. Machine Learning Mastery. 2020. Available online: https://machinelearningmastery.com/feature-selection-in-python-with-scikit-learn/ (accessed on 21 March 2021).
- Sharaff, A.; Gupta, H. Extra-tree classifier with metaheuristics approach for email classification. In Advances in Computer Communication and Computational Sciences; Springer: Singapore, 2019; pp. 189–197. [Google Scholar]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. JMLR 2011, 12, 2825–2830. [Google Scholar]
- Duda, R.O.; Hart, P.E.; Stork, D.G. Pattern Classification and Scene Analysis; Wiley: New York, NY, USA, 1973; Volume 3. [Google Scholar]
- Gandhi, R. Support vector machine, Introduction to machine learning algorithms. Towards Data Science. 2018. Available online: https://towardsdatascience.com/support-vector-machine-introduction-to-machine-learning-algorithms-934a444fca47 (accessed on 16 April 2021).
- Amato, F.; Mazzocca, N.; Moscato, F.; Vivenzio, E. Multilayer perceptron: An intelligent model for classification and intrusion detection. In Proceedings of the 2017 31st International Conference on Advanced Information Networking and Applications Workshops (WAINA), Taipei, Taiwan, 27–29 March 2017; pp. 686–691. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time Domain Metrics | |
| SDNN | Standard deviation of all NN intervals |
| SDANN | Standard deviation of the average NN intervals |
| AVNN | Average of NN intervals |
| RMSSD | Square root of the mean squared differences of successive RR intervals |
| pNN50 | Percentage differences of successive RR intervals larger than 50 ms |
| Frequency Domain Metrics | |
| TP | Total Power—total spectral power of all NN intervals up to 0.004 Hz |
| LF | Low Frequency—total spectral power of all NN intervals with frequency ranging from 0.04 Hz to 0.15 Hz |
| HF | High Frequency—total spectral power of all NN intervals with frequency ranging from 0.15 Hz to 0.4 Hz |
| VLF | Very Low Frequency—total spectral power of all NN intervals with frequencies >0.004 Hz |
| ULF | Ultra-Low Frequency—total spectral power of all NN intervals with frequencies <0.003 Hz |
| LF/HF | Ratio of low to high frequency |
| Feature | RFE Score |
|---|---|
| EMG | 1 |
| HR | 1 |
| footGSR | 1 |
| handGSR | 1 |
| Interval in seconds | 1 |
| NNRR | 1 |
| AVNN | 1 |
| RMSSD | 1 |
| TP | 1 |
| ULF | 1 |
| RESP | 2 |
| marker | 3 |
| SDNN | 4 |
| LF_HF | 5 |
| LF | 6 |
| ECG | 7 |
| pNN50 | 8 |
| HF | 9 |
| newtime | 10 |
| time | 11 |
| VLF | 12 |
| Seconds | 13 |
| Algorithm | AUROC | Recall | F1 Score |
|---|---|---|---|
| NB | 0.60 ± 0.02 | 0.63 ± 0.04 | 0.61 ± 0.02 |
| KNN | 0.80 ± 0.01 | 0.76 ± 0.02 | 0.74 ± 0.01 |
| SVM | 0.81 ± 0.01 | 0.79 ± 0.03 | 0.77 ± 0.01 |
| MLP | 0.83 ± 0.01 | 0.81 ± 0.07 | 0.77 ± 0.02 |
| RF | 0.85 ± 0.01 | 0.81 ± 0.03 | 0.78 ± 0.02 |
| GB | 0.85 ± 0.01 | 0.80 ± 0.02 | 0.79 ± 0.01 |
| Model A | Model B | mean (A) | mean (B) | diff | se | p-Tukey 1 |
|---|---|---|---|---|---|---|
| GB | KNN | 0.852 | 0.800 | 0.052 | 0.009 | 0.001 |
| GB | MLP | 0.852 | 0.825 | 0.027 | 0.009 | 0.039 |
| GB | NB | 0.852 | 0.603 | 0.249 | 0.009 | 0.001 |
| GB | RF | 0.852 | 0.853 | −0.001 | 0.009 | 0.9 |
| GB | SVM | 0.852 | 0.813 | 0.039 | 0.009 | 0.001 |
| KNN | MLP | 0.800 | 0.825 | −0.025 | 0.009 | 0.077 |
| KNN | NB | 0.800 | 0.603 | 0.197 | 0.009 | 0.001 |
| KNN | RF | 0.800 | 0.853 | −0.053 | 0.009 | 0.001 |
| KNN | SVM | 0.800 | 0.813 | −0.013 | 0.009 | 0.671 |
| MLP | NB | 0.825 | 0.603 | 0.222 | 0.009 | 0.001 |
| MLP | RF | 0.825 | 0.853 | −0.028 | 0.009 | 0.036 |
| MLP | SVM | 0.825 | 0.813 | 0.012 | 0.009 | 0.732 |
| NB | RF | 0.603 | 0.853 | −0.250 | 0.009 | 0.001 |
| NB | SVM | 0.603 | 0.813 | −0.210 | 0.009 | 0.001 |
| RF | SVM | 0.853 | 0.813 | 0.040 | 0.009 | 0.001 |
| Algorithm | AUROC | Recall | F1 Score |
|---|---|---|---|
| NB | 0.60 ± 0.02 | 0.69 ± 0.04 | 0.63 ± 0.02 |
| KNN | 0.74 ± 0.02 | 0.76 ± 0.02 | 0.71 ± 0.02 |
| SVM | 0.74 ± 0.01 | 0.79 ± 0.02 | 0.74 ± 0.01 |
| MLP | 0.75 ± 0.01 | 0.80 ± 0.06 | 0.72 ± 0.02 |
| RF | 0.77 ± 0.01 | 0.74 ± 0.01 | 0.72 ± 0.01 |
| GB | 0.73± 0.01 | 0.70 ± 0.02 | 0.70 ± 0.01 |
| Model A | Model B | mean (A) | mean (B) | diff | se | p-Tukey 1 |
|---|---|---|---|---|---|---|
| GB 1 | GB 2 | 0.852 | 0.731 | 0.121 | 0.008 | 0.001 |
| GB 1 | MLP 1 | 0.852 | 0.825 | 0.027 | 0.008 | 0.011 |
| GB 1 | MLP 2 | 0.852 | 0.752 | 0.100 | 0.008 | 0.001 |
| GB 1 | RF 1 | 0.852 | 0.853 | −0.001 | 0.008 | 0.9 |
| GB 1 | RF 2 | 0.852 | 0.768 | 0.084 | 0.008 | 0.001 |
| GB 2 | MLP 1 | 0.731 | 0.825 | −0.094 | 0.008 | 0.001 |
| GB 2 | MLP 2 | 0.731 | 0.752 | −0.021 | 0.008 | 0.088 |
| GB 2 | RF 1 | 0.731 | 0.853 | −0.122 | 0.008 | 0.001 |
| GB 2 | RF 2 | 0.731 | 0.768 | −0.037 | 0.008 | 0.001 |
| MLP 1 | MLP 2 | 0.825 | 0.752 | 0.073 | 0.008 | 0.001 |
| MLP 1 | RF 1 | 0.825 | 0.853 | −0.028 | 0.008 | 0.01 |
| MLP 1 | RF 2 | 0.825 | 0.768 | 0.057 | 0.008 | 0.001 |
| MLP 2 | RF 1 | 0.752 | 0.853 | −0.101 | 0.008 | 0.001 |
| MLP 2 | RF 2 | 0.752 | 0.768 | −0.016 | 0.008 | 0.313 |
| RF 1 | RF 2 | 0.853 | 0.768 | 0.085 | 0.008 | 0.001 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dalmeida, K.M.; Masala, G.L. HRV Features as Viable Physiological Markers for Stress Detection Using Wearable Devices. Sensors 2021, 21, 2873. https://doi.org/10.3390/s21082873
Dalmeida KM, Masala GL. HRV Features as Viable Physiological Markers for Stress Detection Using Wearable Devices. Sensors. 2021; 21(8):2873. https://doi.org/10.3390/s21082873
Chicago/Turabian StyleDalmeida, Kayisan M., and Giovanni L. Masala. 2021. "HRV Features as Viable Physiological Markers for Stress Detection Using Wearable Devices" Sensors 21, no. 8: 2873. https://doi.org/10.3390/s21082873
APA StyleDalmeida, K. M., & Masala, G. L. (2021). HRV Features as Viable Physiological Markers for Stress Detection Using Wearable Devices. Sensors, 21(8), 2873. https://doi.org/10.3390/s21082873