
SSD-EMB: An Improved SSD Using Enhanced Feature Map Block for Object Detection

Abstract
1. Introduction
- We propose a lightweight feature map concatenation stream, which consists of feature map split, three convolutional layers, and feature map concatenation.
- We present an efficient attention mechanism stream that applies channel-wise average pooling and sigmoid activation function on the input feature map.
- Combining the above two streams, the proposed model, SSD-EMB, solves the challenges associated with both small object detection and detection speed degradation.
2. Related Work
2.1. Attention Mechanism
2.2. Single-Shot Multibox Detector (SSD)
2.3. SSD-Based Object Detectors
2.4. Other Object Detectors
2.5. Low-Rank Approximation of Feature Map
3. Materials and Methods
3.1. Attention Stream
3.2. Feature Map Concatenation Stream
3.3. Combination of Two Maps
3.4. Datasets and Evaluation Metrics
3.5. Implementation Details
4. Results and Discussion
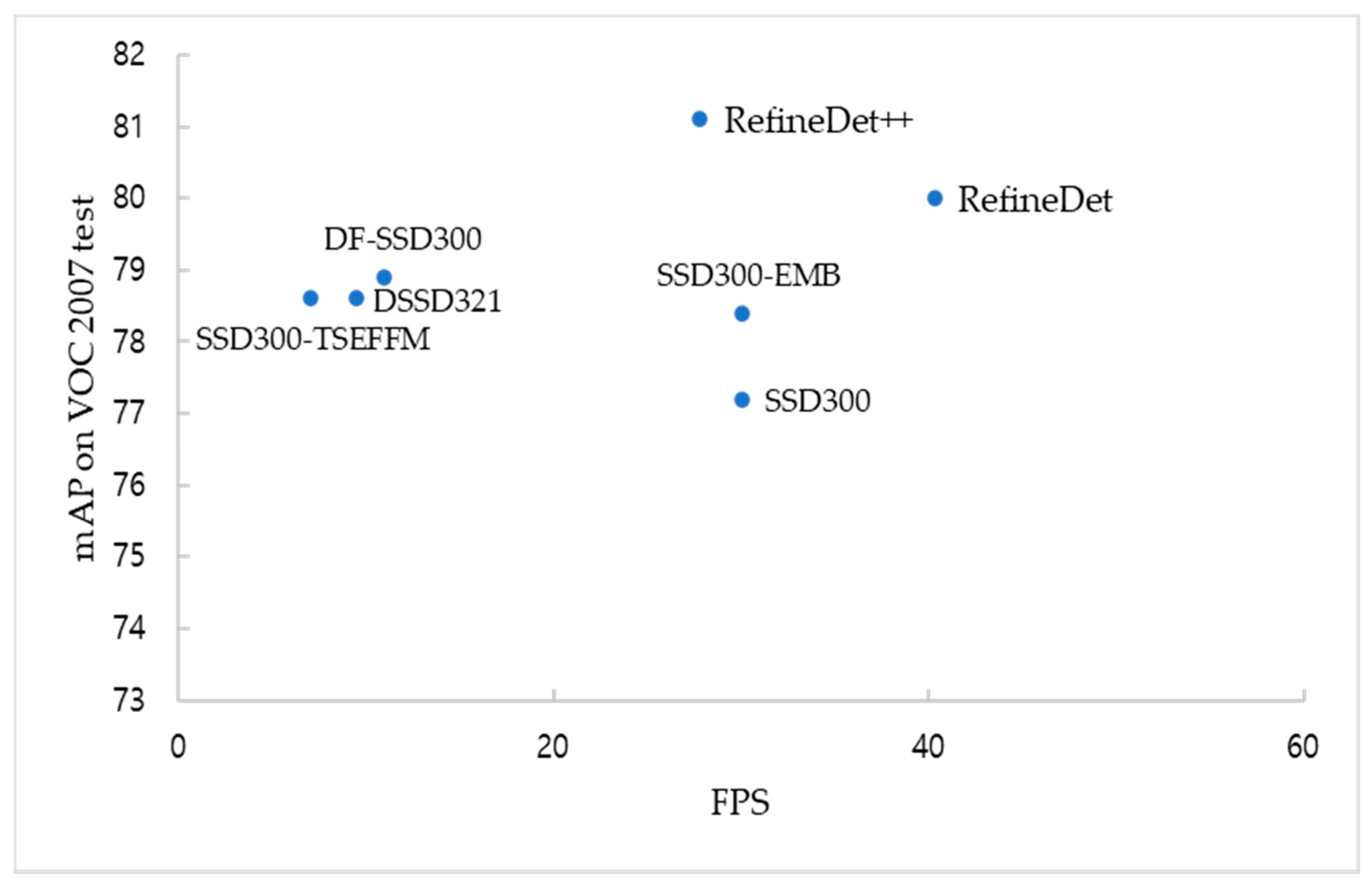
4.1. Results on PASCAL VOC 2007 Test Set
4.2. Results on PASCAL VOC 2012 Test Set
4.3. Results on Microsoft Common Objects in Context (MS COCO)
4.4. Ablation Studies
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Feng, D.; Haase-Schütz, C.; Rosenbaum, L.; Hertlein, H.; Gläser, C.; Timm, F.; Wiesbeck, W.; Dietmayer, K. Deep Multi-Modal Object Detection and Semantic Segmentation for Autonomous Driving: Datasets, Methods, and Challenges. IEEE Trans. Intell. Transp. Syst. 2020, 22, 1341–1360. [Google Scholar] [CrossRef]
- Zhang, C.; Xu, X.; Tu, D. Face Detection Using Improved Faster RCNN. arXiv 2018, arXiv:1802.02142. [Google Scholar]
- Li, Z.; Dong, M.; Wen, S.; Hu, X.; Zhou, P.; Zeng, Z. CLU-CNNs: Object detection for medical images. Neurocomputing 2019, 350, 53–59. [Google Scholar] [CrossRef]
- Hashib, H.; Leon, M.; Salaque, A.M. Object Detection Based Security System Using Machine learning algorthim and Raspberry Pi. In Proceedings of the 2019 International Conference on Computer, Communication, Chemical, Materials and Electronic Engineering (IC4ME2), Rajshahi, Bangladesh, 11–12 July 2019. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Fei-Fei, L. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft COCO: Common Objects in Context. In Proceedings of the Computer Vision—ECCV 2014, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.-Y.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Proceedings of the Computer Vision—ECCV 2016, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Fu, C.-Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. DSSD: Deconvolutional Single Shot Detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1701.06659. [Google Scholar]
- Duchi, J.; Hazan, E.; Singer, Y. Adaptive subgradient methods for online learning and stochastic optimization. J. Mach. Learn. Res. 2011, 12, 2121–2159. [Google Scholar]
- Zeiler, M.D. ADADELTA: An Adaptive Learning Rate Method. arXiv 2012, arXiv:1212.5701. [Google Scholar]
- Lin, T.-Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Singh, B.; Davis, L.S. An analysis of scale invariance in object detection snip. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3578–3587. [Google Scholar]
- Singh, B.; Najibi, M.; Davis, L.S. SNIPER: Efficient Multi-Scale Training. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, Canada; Bengio, S., Wallach, H., Larochelle, H., Grauman, K., Cesa-Bianchi, N., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2018; Volume 31, pp. 9310–9320. [Google Scholar]
- Zhang, J.; Sun, J.; Wang, J.; Yue, X.-G. Visual object tracking based on residual network and cascaded correlation filters. J. Ambient Intell. Humaniz. Comput. 2020. [Google Scholar] [CrossRef]
- Yang, Z.; Liu, G.; Xie, X.; Cai, Q. Efficient dynamic domain adaptation on deep CNN. Multimed. Tools Appl. 2020, 79, 33853–33873. [Google Scholar] [CrossRef]
- Hwang, Y.-J.; Lee, J.-G.; Moon, U.-C.; Park, H.-H. SSD-TSEFFM: New SSD Using Trident Feature and Squeeze and Extraction Feature Fusion. Sensors 2020, 20, 3630. [Google Scholar] [CrossRef] [PubMed]
- Zhai, S.; Shang, D.; Wang, S.; Dong, S. DF-SSD: An Improved SSD Object Detection Algorithm Based on DenseNet and Feature Fusion. IEEE Access 2020, 8, 24344–24357. [Google Scholar] [CrossRef]
- Denton, E.; Zaremba, W.; Bruna, J.; LeCun, Y.; Fergus, R. Exploiting linear structure within convolutional networks for efficient evaluation. arXiv 2014, arXiv:1404.0736. [Google Scholar]
- Jaderberg, M.; Vedaldi, A.; Zisserman, A. Speeding up convolutional neural networks with low rank expansions. In Proceedings of the British Machine Vision Conference, Nottingham, UK, 1–5 September 2014. [Google Scholar]
- Cao, J.; Song, C.; Song, S.; Peng, S.; Wang, D.; Shao, Y.; Xiao, F. Front vehicle detection algorithm for smart car based on improved SSD model. Sensors 2020, 20, 4646. [Google Scholar] [CrossRef] [PubMed]
- Ding, F.; Zhuang, Z.; Liu, Y.; Jiang, D.; Yan, X.; Wang, Z. Detecting defects on solid wood panels based on an improved SSD algorithm. Sensors 2020, 20, 5315. [Google Scholar] [CrossRef]
- Everingham, M.; Van Gool, L.; Williams, C.K.I.; Winn, J.; Zisserman, A. The Pascal Visual Object Classes (VOC) Challenge. Int. J. Comput. Vis. 2010, 88, 303–338. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.U.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2017; Volume 30, pp. 5998–6008. [Google Scholar]
- Yu, J.; Lin, Z.; Yang, J.; Shen, X.; Lu, X.; Huang, T.S. Generative image inpainting with contextual attention. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5505–5514. [Google Scholar]
- Xu, K.; Ba, J.; Kiros, R.; Cho, K.; Courville, A.; Salakhudinov, R.; Zemel, R.; Bengio, Y. Show, Attend and Tell: Neural Image Caption Generation with Visual Attention. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; pp. 2048–2057. [Google Scholar]
- Zhang, H.; Goodfellow, I.; Metaxas, D.; Odena, A. Self-Attention Generative Adversarial Networks. In Proceedings of the 36th International Conference on Machine Learning, Long Beach, CA, USA, 10–15 June 2019; Chaudhuri, K., Salakhutdinov, R., Eds.; PMLR: Long Beach, CA, USA, 2019; Volume 97, pp. 7354–7363. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Park, J.; Woo, S.; Lee, J.-Y.; Kweon, I.S. BAM: Bottleneck Attention Module. arXiv 2018, arXiv:1807.06514. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; So Kweon, I. Cbam: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Choe, J.; Lee, S.; Shim, H. Attention-based Dropout Layer for Weakly Supervised Single Object Localization and Semantic Segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2020. [Google Scholar] [CrossRef] [PubMed]
- Gao, C.; Zou, Y.; Huang, J.-B. ICAN: Instance-centric attention network for human-object interaction detection. arXiv 2018, arXiv:1808.10437. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G.; Usunier, N.; Kirillov, A.; Zagoruyko, S. End-to-end object detection with transformers. arXiv 2020, arXiv:2005.12872. [Google Scholar]
- Ning, X.; Gong, K.; Li, W.; Zhang, L.; Bai, X.; Tian, S. Feature refinement and filter network for person re-identification. IEEE Trans. Circuits Syst. Video Technol. 2020, 31. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLOv3: An Incremental Improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. EfficientDet: Scalable and Efficient Object Detection. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 13–19 June 2020; IEEE: Piscataway, NJ, USA, 2020. [Google Scholar]
- Dai, Z.; Yi, J.; Zhang, Y.; He, L. Multi-scale boxes loss for object detection in smart energy. Intell. Autom. Soft Comput. 2020, 26, 887–903. [Google Scholar] [CrossRef]
- Qayyum, A.; Ahmad, I.; Iftikhar, M.; Mazher, M. Object detection and fuzzy-based classification using UAV data. Intell. Autom. Soft Comput. 2020, 26, 693–702. [Google Scholar] [CrossRef]
- Ciccone, V.; Ferrante, A.; Zorzi, M. Robust identification of “sparse plus low-rank” graphical models: An optimization approach. In Proceedings of the 2018 IEEE Conference on Decision and Control (CDC), Miami, FL, USA, 17–19 December 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An Imperative Style, High-Performance Deep Learning Library. arXiv 2019, arXiv:1912.01703. [Google Scholar]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S.Z. Single-shot refinement neural network for object detection. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; IEEE: Piscataway, NJ, USA, 2018. [Google Scholar]
- Zhang, S.; Wen, L.; Lei, Z.; Li, S.Z. RefineDet++: Single-shot refinement neural network for object detection. IEEE Trans. Circuits Syst. Video Technol. 2021, 31, 674–687. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | mAP | Aero | Bike | Bird | Boat | Bottle | Bus | Car | Cat | Chair | Cow | Table | Dog | Horse | Mbike | Person | Plant | Sheep | Sofa | Train | TV |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SSD300 | 77.2 | 83.4 | 85.2 | 75.0 | 71.2 | 50.8 | 85.1 | 86.1 | 87.0 | 61.4 | 80.9 | 76.5 | 84.1 | 87.1 | 83.6 | 78.3 | 47.8 | 73.5 | 77.1 | 83.2 | 76.1 |
| DSSD321 | 78.6 | 81.9 | 84.9 | 80.5 | 68.4 | 53.9 | 85.6 | 86.2 | 88.9 | 61.1 | 83.5 | 78.7 | 86.7 | 88.7 | 86.7 | 79.7 | 51.7 | 78.0 | 80.9 | 87.2 | 79.4 |
| SSD300-TSEFFM | 78.6 | 81.6 | 94.6 | 79.1 | 72.1 | 50.2 | 86.4 | 86.9 | 89.1 | 60.3 | 85.6 | 75.7 | 85.6 | 88.3 | 84.1 | 79.6 | 54.6 | 82.1 | 80.2 | 87.1 | 79.0 |
| RefineDet320 | 80.0 | 83.9 | 85.4 | 81.4 | 75.5 | 60.2 | 86.4 | 88.1 | 89.1 | 62.7 | 83.9 | 77.0 | 85.4 | 87.1 | 86.7 | 82.6 | 55.3 | 82.7 | 78.5 | 88.1 | 79.4 |
| SSD300-EMB | 78.4 | 83.6 | 85.5 | 75.9 | 71.9 | 54.2 | 87.4 | 86.8 | 87.2 | 62.8 | 82.8 | 78.8 | 85.4 | 86.4 | 85.8 | 80.2 | 51.5 | 76.9 | 81.9 | 85.7 | 77.3 |
| SSD512 | 79.5 | 84.8 | 85.1 | 81.5 | 73.0 | 57.8 | 87.8 | 88.3 | 87.4 | 63.5 | 85.4 | 73.2 | 86.2 | 86.7 | 83.9 | 82.5 | 55.6 | 81.7 | 79.0 | 86.6 | 80.0 |
| DSSD513 | 81.5 | 86.6 | 86.2 | 82.6 | 74.9 | 62.5 | 89.0 | 88.7 | 88.8 | 65.2 | 87.0 | 78.7 | 88.2 | 89.0 | 87.5 | 83.7 | 51.1 | 86.3 | 81.6 | 85.7 | 83.7 |
| SSD512-TSEFFM | 80.4 | 84.9 | 86.7 | 80.6 | 76.2 | 59.4 | 87.8 | 88.9 | 89.2 | 61.7 | 86.9 | 78.3 | 86.2 | 88.8 | 85.6 | 82.7 | 55.4 | 82.7 | 79.4 | 84.7 | 81.3 |
| RefineDet512 | 81.8 | 88.7 | 87.0 | 83.2 | 76.5 | 68.0 | 88.5 | 88.7 | 89.2 | 66.5 | 87.9 | 75.0 | 86.8 | 89.2 | 87.8 | 84.7 | 56.2 | 83.2 | 78.7 | 88.1 | 82.3 |
| SSD512-EMB | 80.4 | 85.9 | 86.2 | 81.3 | 76.8 | 59.6 | 87.1 | 88.4 | 88.2 | 67.5 | 85.3 | 76.8 | 87.1 | 89.3 | 84.9 | 83.0 | 54.2 | 81.6 | 78.7 | 87.8 | 78.3 |
| Model | Data | Backbone Network | Input Size | GPU | Framework | #Parameters | mAP | FPS |
|---|---|---|---|---|---|---|---|---|
| SSD300* | 07 + 12 | VGG | 2080Ti | PyTorch | 26.3 M | 77.2 | 30 | |
| SSD300* 1 | 07 + 12 | VGG | Titan X | Caffe | 26.3 M | 77.2 | 46 | |
| DSSD321 | 07 + 12 | ResNet-101 | Titan X | Caffe | - 2 | 78.6 | 9.5 | |
| SSD300-TSEFFM | 07 + 12 | VGG | 2080Ti | PyTorch | - | 78.6 | 7 | |
| DF-SSD300 | 07 + 12 | DenseNet-S-32-1 | Titan X | Caffe | 15.2 M | 78.9 | 11.6 | |
| RefineDet320 | 07 + 12 | VGG | Titan X | Caffe | - | 80.0 | 40.3 | |
| RefineDet320++ | 07 + 12 | VGG | Titan X | PyTorch | - | 81.1 | 27.8 | |
| SSD300-EMB | 07 + 12 | VGG | 2080Ti | PyTorch | 30.6 M | 78.4 | 30 |
| Model | mAP | Aero | Bike | Bird | Boat | Bottle | Bus | Car | Cat | Chair | Cow | Table | Dog | Horse | Mbike | Person | Plant | Sheep | Sofa | Train | TV |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| SSD300 | 75.8 | 88.1 | 82.9 | 74.4 | 61.9 | 47.6 | 82.7 | 78.8 | 91.5 | 58.1 | 80.0 | 64.1 | 89.4 | 85.7 | 85.5 | 82.6 | 50.2 | 79.8 | 73.6 | 86.6 | 72.1 |
| DSSD321 | 76.3 | 87.3 | 83.3 | 75.4 | 64.6 | 46.8 | 82.7 | 76.5 | 92.9 | 59.5 | 78.3 | 64.3 | 91.5 | 86.6 | 86.6 | 82.1 | 53.3 | 79.6 | 75.7 | 85.2 | 73.9 |
| DF-SSD300 | 76.5 | 89.5 | 85.6 | 72.6 | 65.8 | 51.3 | 82.9 | 79.9 | 92.2 | 62.4 | 77.5 | 64.5 | 89.5 | 85.4 | 86.4 | 85.7 | 51.9 | 77.8 | 72.6 | 85.1 | 71.6 |
| SSD300-TSEFFM | 77.1 | 88.6 | 85.9 | 76.0 | 65.4 | 46.2 | 84.0 | 79.9 | 92.7 | 58.6 | 81.9 | 65.3 | 91.5 | 87.8 | 88.8 | 82.9 | 52.6 | 79.1 | 75.4 | 87.1 | 73.8 |
| RefineDet320 | 78.1 | 90.4 | 84.1 | 79.8 | 66.8 | 56.1 | 83.1 | 82.7 | 90.7 | 61.7 | 82.4 | 63.8 | 89.4 | 86.9 | 85.9 | 85.7 | 53.3 | 84.3 | 73.1 | 87.4 | 73.9 |
| SSD300-EMB | 77.0 | 88.8 | 85.4 | 75.4 | 63.6 | 50.3 | 83.5 | 79.4 | 92.1 | 59.5 | 81.4 | 66.2 | 88.9 | 86.6 | 86.3 | 83.3 | 51.5 | 80.5 | 75.6 | 88.1 | 73.3 |
| SSD512 | 78.5 | 90.0 | 85.3 | 77.7 | 64.3 | 58.5 | 85.1 | 84.3 | 92.6 | 61.3 | 83.4 | 65.1 | 89.9 | 88.5 | 88.2 | 85.5 | 54.4 | 82.4 | 70.7 | 87.1 | 75.6 |
| DSSD513 | 80.0 | 92.1 | 86.6 | 80.3 | 68.7 | 58.2 | 84.3 | 85.0 | 94.6 | 63.3 | 85.9 | 65.6 | 93.0 | 88.5 | 87.8 | 86.4 | 57.4 | 85.2 | 73.4 | 87.8 | 76.8 |
| SSD512-TSEFFM | 80.2 | 90.1 | 88.2 | 81.5 | 68.4 | 59.1 | 85.6 | 85.5 | 93.7 | 63.0 | 86.1 | 64.0 | 90.9 | 88.6 | 89.1 | 86.4 | 59.2 | 85.9 | 73.3 | 87.8 | 75.9 |
| RefineDet512 | 80.1 | 90.2 | 86.8 | 81.8 | 68.0 | 65.6 | 84.9 | 85.0 | 92.2 | 62.0 | 84.4 | 64.9 | 90.6 | 88.3 | 87.2 | 87.8 | 58.0 | 86.3 | 72.5 | 88.7 | 76.6 |
| SSD512-EMB | 79.9 | 90.2 | 88.5 | 78.4 | 67.7 | 59.5 | 86.2 | 84.7 | 93.1 | 62.7 | 84.5 | 67.1 | 91.3 | 88.9 | 89.5 | 86.1 | 58.1 | 84.3 | 73.0 | 87.8 | 76.3 |
| Model | Data | Network | Avg. Precision, IoU: | Avg. Precision, Area: | Avg. Recall, #Dets: | Avg. Recall, Area: | ||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0.5:0.95 | 0.5 | 0.75 | S | M | L | 1 | 10 | 100 | S | M | L | |||
| SSD300 | trainval35k | VGG | 25.1 | 43.1 | 25.8 | 6.6 | 25.9 | 41.4 | 23.7 | 35.1 | 37.2 | 11.2 | 40.4 | 58.4 |
| DSSD321 | trainval35k | ResNet-101 | 28.0 | 46.1 | 29.2 | 7.4 | 28.1 | 47.6 | 25.5 | 37.1 | 39.4 | 12.7 | 42.0 | 62.6 |
| DF-SSD300 | trainval | DenseNet-S-32-1 | 29.5 | 50.7 | 31.3 | 9.8 | 31.1 | 46.5 | 27.1 | 41.5 | 42.7 | 17.3 | 46.8 | 64.4 |
| RefineDet320 | trainval35k | ResNet-101 | 32.0 | 51.4 | 34.2 | 10.5 | 34.7 | 50.4 | 28.0 | 44.0 | 47.6 | 20.2 | 53.0 | 69.8 |
| RefineDet320++ | trainval35k | ResNet-101 | 33.2 | 53.4 | 35.1 | 13.1 | 35.5 | 51.0 | 28.3 | 44.5 | 47.8 | 20.9 | 53.1 | 70.1 |
| DETR | trainval | ResNet-101 | 44.9 | 64.7 | 47.7 | 23.7 | 49.5 | 62.3 | - 1 | - | - | - | - | - |
| EfficientDet | train | EfficientNet | 55.1 | 74.3 | 59.9 | - | - | - | - | - | - | - | - | - |
| SSD300-EMB | train | VGG | 26.6 | 45.2 | 27.8 | 7.3 | 29.3 | 43.5 | 25.4 | 36.4 | 38.6 | 12.0 | 41.7 | 60.3 |
| Model | Conv4_3 | Conv7 | Conv8_2 | Attention stream | Concatenation stream | mAP |
|---|---|---|---|---|---|---|
| SSD300 | 77.2 | |||||
| SSD300-EMB_1 | ✔ | ✔ | ✔ | 77.8 | ||
| SSD300-EMB_2 | ✔ | ✔ | ✔ | ✔ | 77.9 | |
| SSD300-EMB_3 | ✔ | ✔ | ✔ | 78.1 | ||
| SSD300-EMB_4 | ✔ | ✔ | ✔ | 77.8 | ||
| SSD300-Attn | ✔ | ✔ | ✔ | ✔ | 77.7 | |
| SSD300-Concat | ✔ | ✔ | ✔ | ✔ | 77.9 | |
| SSD300-EMB_5 | ✔ | ✔ | ✔ | ✔ | ✔ | 78.4 |
| Model | 1/4 | 2/4 | 3/4 | 4/4 | FPS | mAP |
|---|---|---|---|---|---|---|
| SSD300-EMB_1/4 | ✔ | 30.7 | 77.9 | |||
| SSD300-EMB_2/4 | ✔ | 30.4 | 78.4 | |||
| SSD300-EMB_3/4 | ✔ | 30.2 | 78.1 | |||
| SSD300-EMB_4/4 | ✔ | 30.0 | 78.3 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Choi, H.-T.; Lee, H.-J.; Kang, H.; Yu, S.; Park, H.-H. SSD-EMB: An Improved SSD Using Enhanced Feature Map Block for Object Detection. Sensors 2021, 21, 2842. https://doi.org/10.3390/s21082842
Choi H-T, Lee H-J, Kang H, Yu S, Park H-H. SSD-EMB: An Improved SSD Using Enhanced Feature Map Block for Object Detection. Sensors. 2021; 21(8):2842. https://doi.org/10.3390/s21082842
Chicago/Turabian StyleChoi, Hong-Tae, Ho-Jun Lee, Hoon Kang, Sungwook Yu, and Ho-Hyun Park. 2021. "SSD-EMB: An Improved SSD Using Enhanced Feature Map Block for Object Detection" Sensors 21, no. 8: 2842. https://doi.org/10.3390/s21082842
APA StyleChoi, H.-T., Lee, H.-J., Kang, H., Yu, S., & Park, H.-H. (2021). SSD-EMB: An Improved SSD Using Enhanced Feature Map Block for Object Detection. Sensors, 21(8), 2842. https://doi.org/10.3390/s21082842