
A Heterogeneous Hardware Accelerator for Image Classification in Embedded Systems


Abstract
:1. Introduction
- We designed a heterogeneous architecture on programmable hardware to accelerate MobileNet V2 inference with lower resource utilization and power consumption than other published work. This allows our design to be synthesized on edge devices for applications that favor low resource usage over high inference speed.
- We use loop tiling, loop unrolling, pruning, and quantization techniques to maximize the inference performance of the MobileNet V2 network and, at the same time, maintain low power consumption and resource usage on our accelerator.
- Our implementation on a Xilinx XCZU7EV FPGA running at 200 MHz consumes 29 times less power than a desktop processor, and 5 times less than an embedded GPU. It also uses 30% of the on-chip memory resources and 25% of the arithmetic resources of other published MobileNet FPGA accelerators.
2. Related Work
2.1. CNN Inference on FPGAs
2.2. Other Image Classification Algorithms on FPGAs
3. Methods
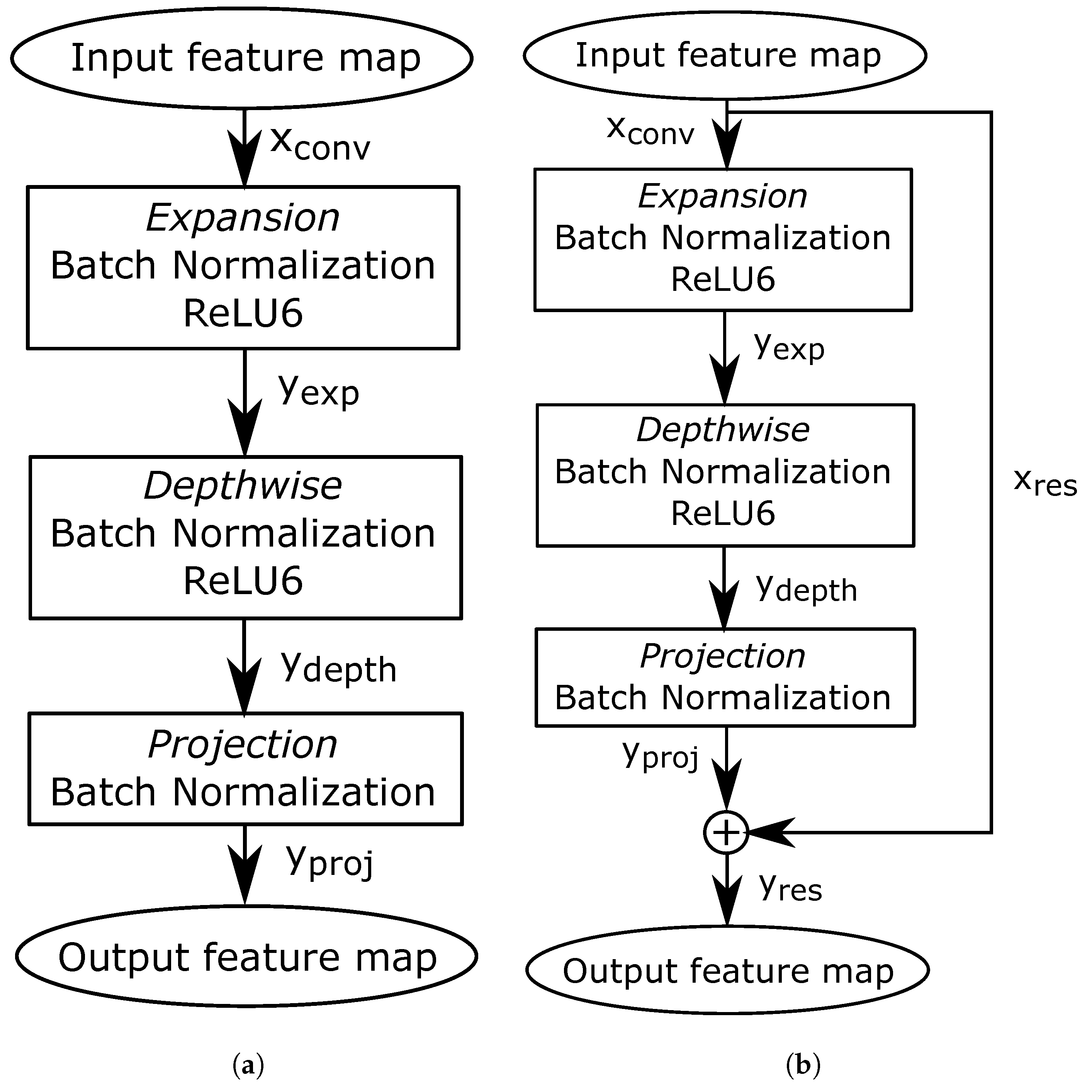
3.1. MobileNet V2
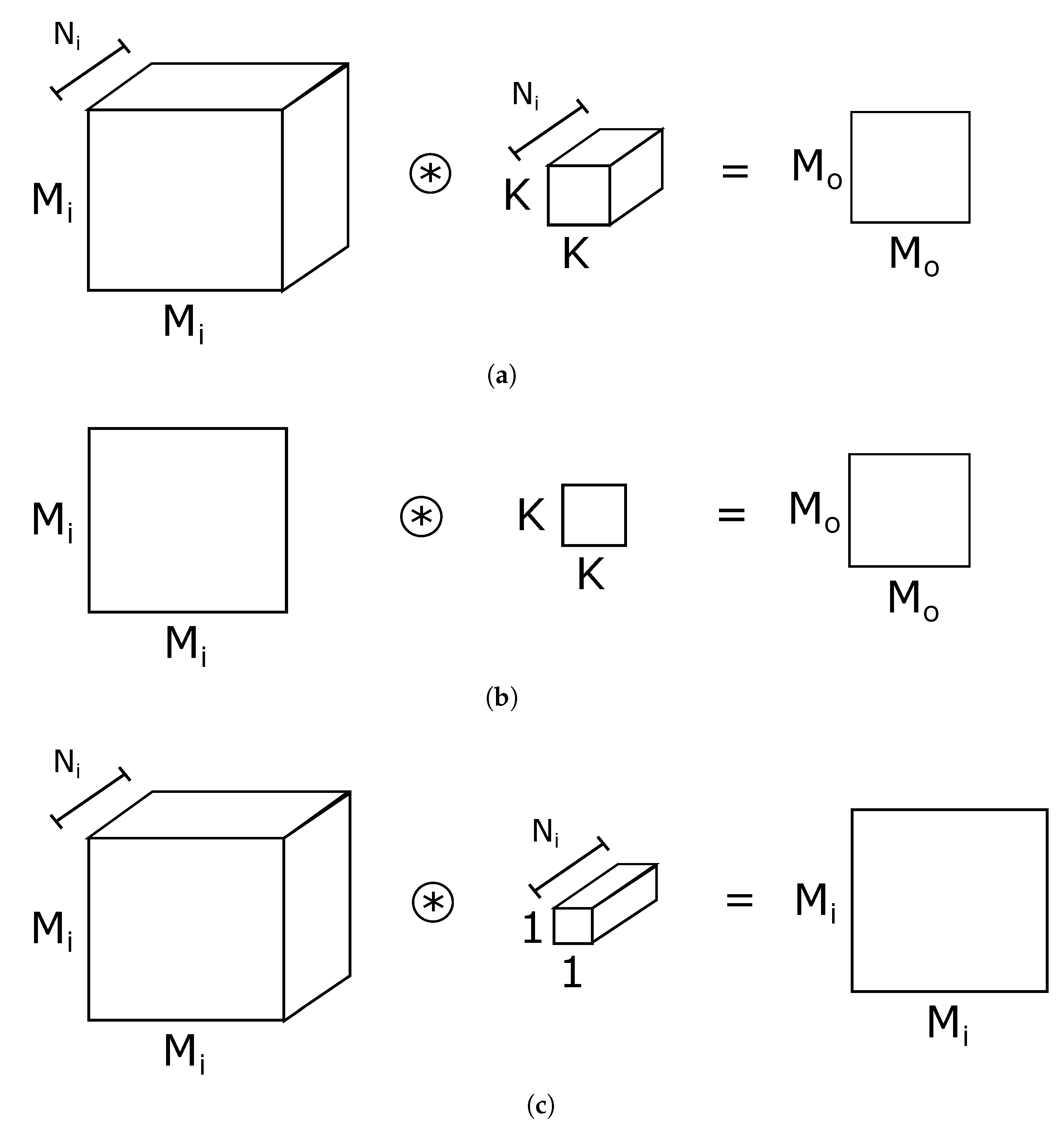
3.1.1. Convolutional Layers
3.1.2. Classification Layers
3.1.3. MobileNet V2 Model
3.2. Imagenet Dataset
3.3. Complexity-Reduction Techniques
3.3.1. Batch Normalization
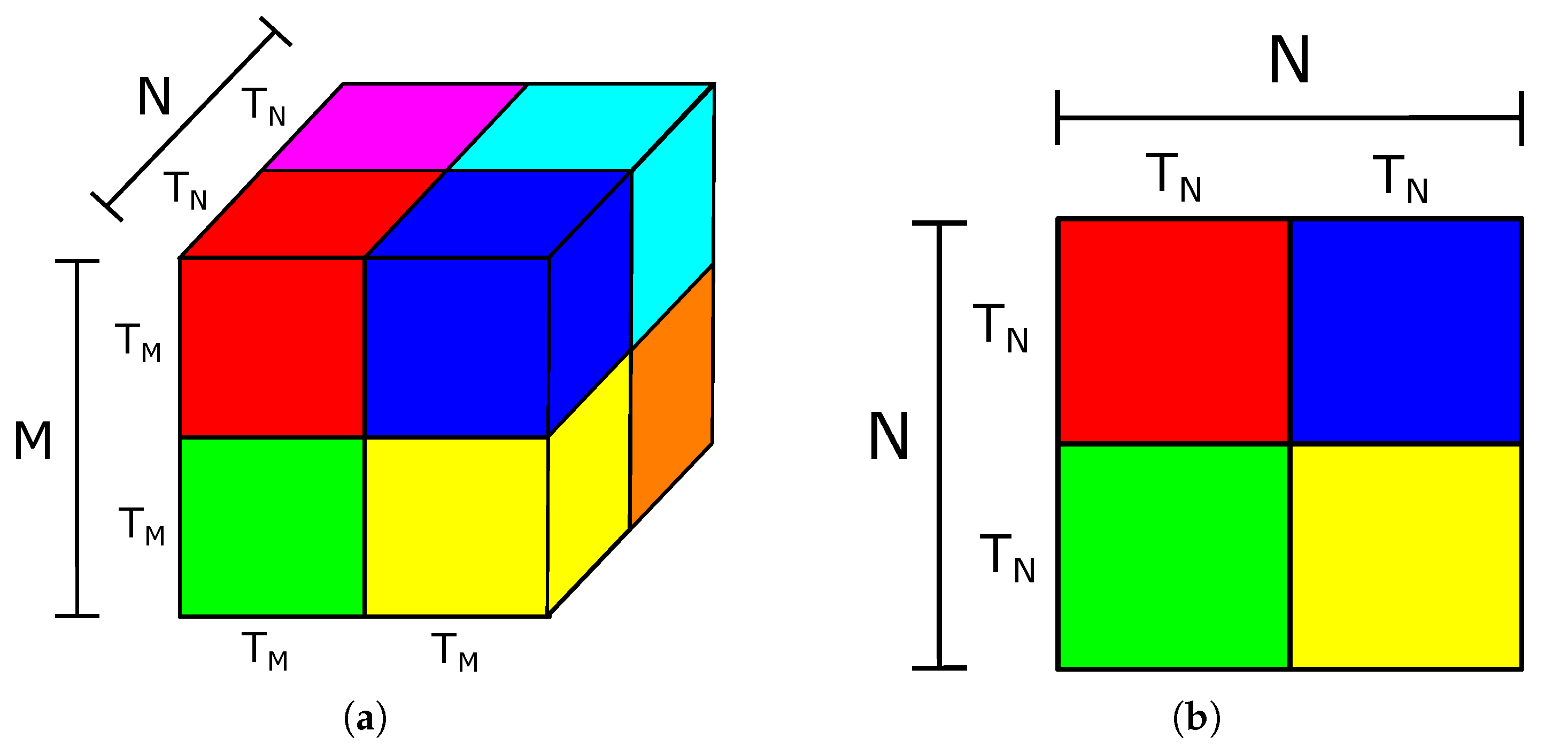
3.3.2. Loop Tiling
3.3.3. Pruning
3.3.4. Quantization
4. Hardware Architecture
4.1. MobileNet V2 Accelerator Architecture
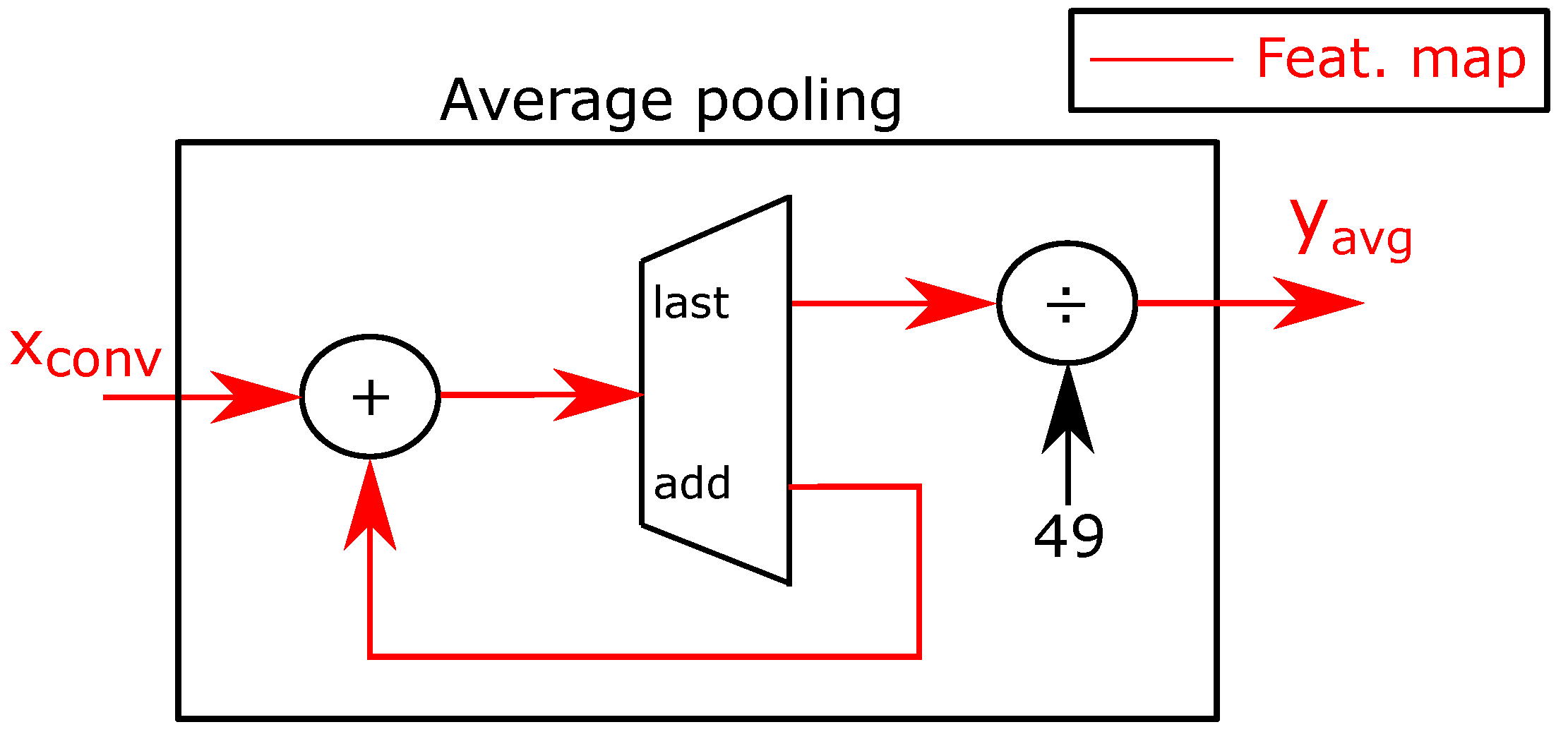
4.1.1. General Architecture
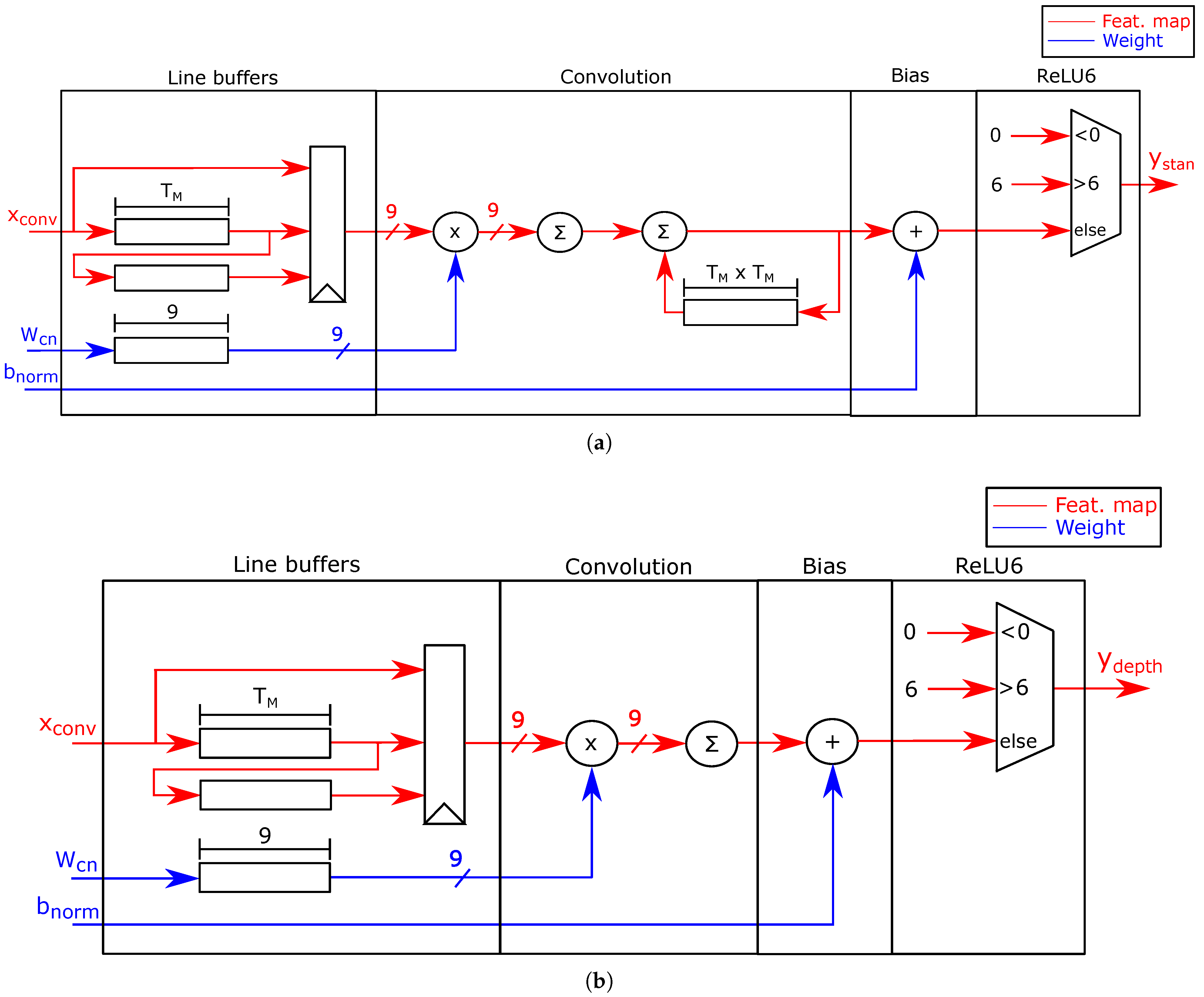
4.1.2. Processing Elements
4.1.3. Parallel Map Processing
4.2. Design Space Exploration
4.2.1. Loop Tiling Factor
4.2.2. Pipelining
4.2.3. Loop Unrolling Factor
4.2.4. Array Partitioning
5. Results
5.1. Classification Performance
5.2. Performance and Resource Utilization
5.3. Scalability
5.4. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| BRAM | Block Random Access Memory |
| CNN | Convolutional Neural Network |
| CPU | Central Processing Unit |
| DMA | Direct Memory Access |
| DSP | Digital Signal Processor |
| FIFO | First In First Out |
| FPGA | Field-Programmable Gate Array |
| fps | frames per second |
| FU | Functional Unit |
| GOPS | Giga Operations per Second |
| GPU | Graphics Processing Unit |
| HLS | High-Level Synthesis |
| KNN | K-Nearest Neighbor |
| LBP | Local Binary Patterns |
| LUT | Lookup Table |
| PE | Processing Element |
| PL | Programmable Logic |
| PS | Processing System |
| SG | Scatter Gather |
| SIFT | Scale Invariant Feature Transform |
| SVD | Singular Value Decomposition |
| SVM | Support Vector Machines |
| RTL | Register Transfer Level |
| TPU | Tensor Processing Unit |
| URAM | Ultra Random Access Memory |
References
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Shaha, M.; Pawar, M. Transfer Learning for Image Classification. In Proceedings of the 2018 Second International Conference on Electronics, Communication and Aerospace Technology (ICECA), Coimbatore, India, 29–31 March 2018; pp. 656–660. [Google Scholar]
- Makkar, T.; Kumar, Y.; Dubey, A.K.; Rocha, A.; Goyal, A. Analogizing time complexity of KNN and CNN in recognizing handwritten digits. In Proceedings of the 2017 Fourth International Conference on Image Information Processing (ICIIP), Shimla, India, 21–23 December 2017; pp. 1–6. [Google Scholar]
- Chaganti, S.Y.; Nanda, I.; Pandi, K.R.; Prudhvith, T.G.N.R.S.N.; Kumar, N. Image Classification using SVM and CNN. In Proceedings of the 2020 International Conference on Computer Science, Engineering and Applications (ICCSEA), Sydney, Australia, 19–20 December 2020; pp. 1–5. [Google Scholar]
- Pérez-Hernández, F.; Tabik, S.; Lamas, A.; Olmos, R.; Fujita, H.; Herrera, F. Object Detection Binary Classifiers methodology based on deep learning to identify small objects handled similarly: Application in video surveillance. Knowl.-Based Syst. 2020, 194, 105590. [Google Scholar] [CrossRef]
- Feng, D.; Haase-Schütz, C.; Rosenbaum, L.; Hertlein, H.; Gläser, C.; Timm, F.; Wiesbeck, W.; Dietmayer, K. Deep Multi-Modal Object Detection and Semantic Segmentation for Autonomous Driving: Datasets, Methods, and Challenges. IEEE Trans. Intell. Transp. Syst. 2021, 22, 1341–1360. [Google Scholar] [CrossRef] [Green Version]
- Afif, M.; Ayachi, R.; Said, Y.; Pissaloux, E.; Atri, M. An evaluation of retinanet on indoor object detection for blind and visually impaired persons assistance navigation. Neural Process. Lett. 2020, 51, 2265–2279. [Google Scholar] [CrossRef]
- Jiang, Q.; Tan, D.; Li, Y.; Ji, S.; Cai, C.; Zheng, Q. Object detection and classification of metal polishing shaft surface defects based on convolutional neural network deep learning. Appl. Sci. 2020, 10, 87. [Google Scholar] [CrossRef] [Green Version]
- Lyra, S.; Mayer, L.; Ou, L.; Chen, D.; Timms, P.; Tay, A.; Chan, P.Y.; Ganse, B.; Leonhardt, S.; Hoog Antink, C. A Deep Learning-Based Camera Approach for Vital Sign Monitoring Using Thermography Images for ICU Patients. Sensors 2021, 21, 1495. [Google Scholar] [CrossRef] [PubMed]
- Shibata, T.; Teramoto, A.; Yamada, H.; Ohmiya, N.; Saito, K.; Fujita, H. Automated Detection and Segmentation of Early Gastric Cancer from Endoscopic Images Using Mask R-CNN. Appl. Sci. 2020, 10, 3842. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. MobileNetV2: Inverted Residuals and Linear Bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going Deeper With Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 7–12 June 2015. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet Classification with Deep Convolutional Neural Networks. In Advances in Neural Information Processing Systems 25; Curran Associates, Inc.: Red Hook, NY, USA, 2012; pp. 1097–1105. [Google Scholar]
- Iandola, F.N.; Moskewicz, M.W.; Ashraf, K.; Han, S.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <1 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Teichmann, M.; Weber, M.; Zöllner, M.; Cipolla, R.; Urtasun, R. MultiNet: Real-time Joint Semantic Reasoning for Autonomous Driving. In Proceedings of the 2018 IEEE Intelligent Vehicles Symposium (IV), Suzhou, China, 26 June–1 July 2018; pp. 1013–1020. [Google Scholar]
- Strigl, D.; Kofler, K.; Podlipnig, S. Performance and Scalability of GPU-Based Convolutional Neural Networks. In Proceedings of the 2010 18th Euromicro Conference on Parallel, Distributed and Network-based Processing, Pisa, Italy, 17–19 February 2010; pp. 317–324. [Google Scholar]
- Kim, H.; Nam, H.; Jung, W.; Lee, J. Performance analysis of CNN frameworks for GPUs. In Proceedings of the 2017 IEEE International Symposium on Performance Analysis of Systems and Software (ISPASS), Santa Rosa, CA, USA, 24–25 April 2017; pp. 55–64. [Google Scholar]
- Li, D.; Chen, X.; Becchi, M.; Zong, Z. Evaluating the Energy Efficiency of Deep Convolutional Neural Networks on CPUs and GPUs. In Proceedings of the 2016 IEEE International Conferences on Big Data and Cloud Computing (BDCloud), Social Computing and Networking (SocialCom), Sustainable Computing and Communications (SustainCom) (BDCloud-SocialCom-SustainCom), Atlanta, GA, USA, 8–10 October 2016; pp. 477–484. [Google Scholar]
- Zhu, Y.; Samajdar, A.; Mattina, M.; Whatmough, P.N. Euphrates: Algorithm-SoC Co-Design for Low-Power Mobile Continuous Vision. arXiv 2018, arXiv:1803.11232. [Google Scholar]
- Haut, J.M.; Bernabé, S.; Paoletti, M.E.; Fernandez-Beltran, R.; Plaza, A.; Plaza, J. Low–High-Power Consumption Architectures for Deep-Learning Models Applied to Hyperspectral Image Classification. IEEE Geosci. Remote Sens. Lett. 2019, 16, 776–780. [Google Scholar] [CrossRef]
- Caba, J.; Díaz, M.; Barba, J.; Guerra, R.; López, J.A. Fpga-based on-board hyperspectral imaging compression: Benchmarking performance and energy efficiency against gpu implementations. Remote Sens. 2020, 12, 3741. [Google Scholar] [CrossRef]
- Kang, P.; Jo, J. Benchmarking Modern Edge Devices for AI Applications. IEICE Trans. Inf. Syst. 2021, 104, 394–403. [Google Scholar] [CrossRef]
- Su, J.; Faraone, J.; Liu, J.; Zhao, Y.; Thomas, D.B.; Leong, P.H.; Cheung, P.Y. Redundancy-reduced mobilenet acceleration on reconfigurable logic for ImageNet classification. In Proceedings of the Applied Reconfigurable Computing. Architectures, Tools, and Applications: 14th International Symposium, ARC 2018, Santorini, Greece, 2–4 May 2018; Springer: Berlin/Heidelberg, Germany, 2018; pp. 16–28. [Google Scholar]
- Bai, L.; Zhao, Y.; Huang, X. A CNN Accelerator on FPGA Using Depthwise Separable Convolution. IEEE Trans. Circuits Syst. II Express Briefs 2018, 65, 1415–1419. [Google Scholar] [CrossRef] [Green Version]
- Hareth, S.; Mostafa, H.; Shehata, K.A. Low power CNN hardware FPGA implementation. In Proceedings of the 2019 31st International Conference on Microelectronics (ICM), Cairo, Egypt, 15–18 December 2019; pp. 162–165. [Google Scholar]
- Kim, S.; Lee, J.; Kang, S.; Lee, J.; Yoo, H. A Power-Efficient CNN Accelerator With Similar Feature Skipping for Face Recognition in Mobile Devices. IEEE Trans. Circuits Syst. I Regul. Pap. 2020, 67, 1181–1193. [Google Scholar] [CrossRef]
- Bahl, G.; Daniel, L.; Moretti, M.; Lafarge, F. Low-Power Neural Networks for Semantic Segmentation of Satellite Images. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV) Workshops, Seoul, Korea, 27 October–3 November 2019. [Google Scholar]
- Yih, M.; Ota, J.M.; Owens, J.D.; Muyan-Özçelik, P. FPGA versus GPU for Speed-Limit-Sign Recognition. In Proceedings of the 2018 21st International Conference on Intelligent Transportation Systems (ITSC), Maui, HI, USA, 4–7 November 2018; pp. 843–850. [Google Scholar]
- Qiu, J.; Wang, J.; Yao, S.; Guo, K.; Li, B.; Zhou, E.; Yu, J.; Tang, T.; Xu, N.; Song, S.; et al. Going Deeper with Embedded FPGA Platform for Convolutional Neural Network. In Proceedings of the 2016 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 21–23 February 2016; pp. 26–35. [Google Scholar]
- Fowers, J.; Ovtcharov, K.; Strauss, K.; Chung, E.S.; Stitt, G. A High Memory Bandwidth FPGA Accelerator for Sparse Matrix-Vector Multiplication. In Proceedings of the 2014 IEEE 22nd Annual International Symposium on Field-Programmable Custom Computing Machines, Boston, MA, USA, 11–13 May 2014; pp. 36–43. [Google Scholar]
- Colleman, S.; Verhelst, M. High-Utilization, High-Flexibility Depth-First CNN Coprocessor for Image Pixel Processing on FPGA. IEEE Trans. Very Large Scale Integr. VLSI Syst. 2021, 29, 461–471. [Google Scholar] [CrossRef]
- Jin, Z.; Finkel, H. Population Count on Intel® CPU, GPU and FPGA. In Proceedings of the 2020 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), New Orleans, LA, USA, 18–22 May 2020; pp. 432–439. [Google Scholar]
- Zhang, C.; Li, P.; Sun, G.; Guan, Y.; Xiao, B.; Cong, J. Optimizing FPGA-based Accelerator Design for Deep Convolutional Neural Networks. In Proceedings of the 2015 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 22–24 February 2015; pp. 161–170. [Google Scholar]
- Ni, Y.; Chen, W.; Cui, W.; Zhou, Y.; Qiu, K. Power optimization through peripheral circuit reusing integrated with loop tiling for RRAM crossbar-based CNN. In Proceedings of the 2018 Design, Automation Test in Europe Conference Exhibition (DATE), Dresden, Germany, 19–23 March 2018; pp. 1183–1186. [Google Scholar]
- Abdelouahab, K.; Pelcat, M.; Sérot, J.; Berry, F. Accelerating CNN inference on FPGAs: A Survey. arXiv 2018, arXiv:1806.01683. [Google Scholar]
- Guo, K.; Sui, L.; Qiu, J.; Yu, J.; Wang, J.; Yao, S.; Han, S.; Wang, Y.; Yang, H. Angel-Eye: A Complete Design Flow for Mapping CNN Onto Embedded FPGA. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2018, 37, 35–47. [Google Scholar] [CrossRef]
- Yang, Y.; Huang, Q.; Wu, B.; Zhang, T.; Ma, L.; Gambardella, G.; Blott, M.; Lavagno, L.; Vissers, K.; Wawrzynek, J.; et al. Synetgy: Algorithm-hardware co-design for convnet accelerators on embedded fpgas. In Proceedings of the 2019 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Seaside, CA, USA, 24–26 February 2019; ACM: New York, NY, USA, 2019; pp. 23–32. [Google Scholar]
- Zhou, A.; Yao, A.; Guo, Y.; Xu, L.; Chen, Y. Incremental Network Quantization: Towards Lossless CNNs with Low-Precision Weights. arXiv 2017, arXiv:1702.03044. [Google Scholar]
- Banner, R.; Nahshan, Y.; Soudry, D. Post training 4-bit quantization of convolutional networks for rapid-deployment. In Advances in Neural Information Processing Systems 32; Curran Associates, Inc.: Red Hook, NY, USA, 2019; pp. 7950–7958. [Google Scholar]
- Mathew, M.; Desappan, K.; Kumar Swami, P.; Nagori, S. Sparse, Quantized, Full Frame CNN for Low Power Embedded Devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Honolulu, HI, USA, 22–25 July 2017. [Google Scholar]
- Han, S.; Mao, H.; Dally, W.J. Deep compression: Compressing deep neural networks with pruning, trained quantization and huffman coding. Presented at the 4th International Conference on Learning Representations (ICLR), San Juan, Puerto Rico, 2–4 May 2016. [Google Scholar]
- Narang, S.; Undersander, E.; Diamos, G. Block-sparse recurrent neural networks. arXiv 2017, arXiv:1711.02782. [Google Scholar]
- Cao, S.; Zhang, C.; Yao, Z.; Xiao, W.; Nie, L.; Zhan, D.; Liu, Y.; Wu, M.; Zhang, L. Efficient and effective sparse LSTM on FPGA with Bank-Balanced Sparsity. In Proceedings of the 2019 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Seaside, CA, USA, 24–26 February 2019; ACM: New York, NY, USA, 2019; pp. 63–72. [Google Scholar]
- Lin, S.; Ji, R.; Yan, C.; Zhang, B.; Cao, L.; Ye, Q.; Huang, F.; Doermann, D. Towards Optimal Structured CNN Pruning via Generative Adversarial Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–21 June 2019. [Google Scholar]
- Luo, J.; Wu, J. An Entropy-based Pruning Method for CNN Compression. arXiv 2017, arXiv:1706.05791. [Google Scholar]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Zhang, M.; Li, L.; Wang, H.; Liu, Y.; Qin, H.; Zhao, W. Optimized Compression for Implementing Convolutional Neural Networks on FPGA. Electronics 2019, 8, 295. [Google Scholar] [CrossRef] [Green Version]
- Mousouliotis, P.G.; Petrou, L.P. CNN-Grinder: From Algorithmic to High-Level Synthesis descriptions of CNNs for Low-end-low-cost FPGA SoCs. Microprocess. Microsyst. 2020, 73, 102990. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.; Li, K.; Li, F.-F. ImageNet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255.
- Qasaimeh, M.; Sagahyroon, A.; Shanableh, T. FPGA-Based Parallel Hardware Architecture for Real-Time Image Classification. IEEE Trans. Comput. Imaging 2015, 1, 56–70. [Google Scholar] [CrossRef]
- Afifi, S.; GholamHosseini, H.; Sinha, R. SVM classifier on chip for melanoma detection. In Proceedings of the 2017 39th Annual International Conference of the IEEE Engineering in Medicine and Biology Society (EMBC), Jeju Island, Korea, 11–15 July 2017; pp. 270–274. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift. In Proceedings of the 32nd International Conference on Machine Learning, Lille, France, 6–11 July 2015; Volume 37, pp. 448–456. [Google Scholar]
- Krishnamoorthi, R. Quantizing deep convolutional networks for efficient inference: A whitepaper. arXiv 2018, arXiv:1806.08342. [Google Scholar]
- Nvidia Corporation. Jetson AGX Xavier: Deep Learning Inference Benchmarks. Available online: https://developer.nvidia.com/embedded/jetson-agx-xavier-dl-inference-benchmarks (accessed on 28 December 2020).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Qiu et al. [32] | Guo et al. [39] | Su et al. [26] | Bai et al. [27] | Yang et al. [40] | Zhang et al. [50] | Panagiotis et al. [51] | |
|---|---|---|---|---|---|---|---|
| Year | 2016 | 2018 | 2018 | 2018 | 2019 | 2019 | 2020 |
| FPGA | XC7Z045 | XC7Z045 | XCZU9EG | Arria 10 SX | XCZU3EG | XCZU7EV | XC7Z020 |
| Freq. (MHZ) | 150 | 214 | 150 | 133 | 250 | 300 | 100 |
| CNN | VGG-16 | VGG-16 | MobileNet | MobileNet V2 | DiracDeltaNet | AlexNet | SqueezeNet |
| Reduction | SVD | N/A | Pruning | N/A | N/A | Pruning | N/A |
| Quantization | 16 bits | 8 bits | 8–4 bits | 16 bits | 1–4 bits | 8 bits | 8 bits |
| LUT | 182,616 | 29,867 | 139,000 | 163,506 | 24,130 | 101,953 | 34,489 |
| BRAM | 486 | 85.5 | 1729 | 1844 | 170 | 198.5 | 97.5 |
| FF | 127,653 | 35,489 | 55,000 | N/A | 29,867 | 127,577 | 25,036 |
| DSP | 780 | 190 | 1452 | 1278 | 37 | 696 | 172 |
| Power (W) | 9.63 | 3.5 | N/A | N/A | 5.5 | 17.67 | N/A |
| Perf. (GOPS) | 136.97 | 84.3 | 91.2 | 170.6 | 47.09 | 14.11 | N/A |
| fps | 4.45 | 2.75 | 127 | 266 | 58.7 | 9.73 | 14.2 |
| Top-1 | N/A | 67.72% | 64.6% | 71.8% | 70.1% | 55.99% | 56.94% |
| Top-5 | 86.66% | 88.06% | 84.5% | 91.0% | 88.2% | N/A | 79.94% |
| Input () | Output () | Layer | Repeat Time | Expansion Factor | Stride | Residual | Thousands of Parameters |
|---|---|---|---|---|---|---|---|
| 224 × 224 × 3 | 112 × 112 × 32 | Standard conv | 1 | - | 2 | No | 0.8 |
| 112 × 112 × 32 | 112 × 112 × 16 | Bottleneck | 1 | 1 | 1 | No | 0.7 |
| 112 × 112 × 16 | 56 × 56 × 24 | Bottleneck | 2 | 6 | 2 | Yes | 12.9 |
| 56 × 56 × 24 | 28 × 28 × 32 | Bottleneck | 3 | 6 | 2 | Yes | 37.3 |
| 28 × 28 × 32 | 14 × 14 × 64 | Bottleneck | 4 | 6 | 2 | Yes | 177.9 |
| 14 × 14 × 64 | 14 × 14 × 96 | Bottleneck | 3 | 6 | 1 | Yes | 296.0 |
| 14 × 14 × 96 | 7 × 7 × 160 | Bottleneck | 3 | 6 | 2 | Yes | 784.2 |
| 7 × 7 × 160 | 7 × 7 × 320 | Bottleneck | 1 | 6 | 1 | No | 469.4 |
| 7 × 7 × 320 | 7 × 7 × 1280 | Expansion conv | 1 | - | 1 | No | 409.6 |
| 7 × 7 × 1280 | 1 × 1 × 1280 | Avg pooling | 1 | - | - | - | 0.0 |
| 1 × 1 × 1280 | 1 × 1 × 1000 | FC | 1 | - | - | - | 1280.0 |
| Loop Tiling Factor | Inference Time (ms) | |
|---|---|---|
| Activations | Weights | |
| 14 | 16 | 252.8 |
| 14 | 32 | 239.7 |
| 14 | 64 | 241.6 |
| 28 | 16 | 230.2 |
| 28 | 32 | 220.5 |
| Loop Unrolling Factor | Processing Cycles | |
|---|---|---|
| Min | Max | |
| Without unrolling | 53 | 788 |
| Unrolling | 30 | 114 |
| Unrolling | 15 | 57 |
| Unrolling | 8 | 29 |
| Hyper Parameter | Retraining | Inference |
|---|---|---|
| Batch size | 32 | 1 |
| Input image size | ||
| Width multiplier | 1 | 1 |
| Number of layers | 21 | 21 |
| Learning rate | 0.001 | N/A |
| Momentum | 0.9 | N/A |
| Number of epochs | 30 | N/A |
| Image id | 00041633 | 00031834 | 00023151 |
|---|---|---|---|
| Correct label | mink | walker hound | combination lock |
| Results | mink: 71.63% | beagle: 28.18% | syringe: 7.65% |
| weasel: 11.72% | walker hound: 14.47% | reel: 6.17% | |
| polecat: 6.79% | basset: 6.34% | fountain pen: 6.00% | |
| hamster: 2.12% | basenji: 5.90% | corkscrew: 3.91% | |
| wombat: 1.91% | pembroke: 4.81% | wine bottle: 3.34% |
| Module | Slice | Slice | BRAM | URAM | DSP |
|---|---|---|---|---|---|
| LUT | Registers | ||||
| Standard FU | 2378 | 1737 | 6 | 0 | 21 |
| Depthwise FU | 1904 | 1747 | 0 | 0 | 18 |
| Expansion/projection FU | 3668 | 1335 | 112 | 3 | 40 |
| Average pooling FU | 363 | 209 | 0 | 0 | 1 |
| Fully-connected FU | 775 | 578 | 1 | 3 | 4 |
| Read control information | 3215 | 2211 | 6 | 0 | 1 |
| Communication protocols | 3069 | 5514 | 0 | 0 | 0 |
| Total | 15,372 | 13,331 | 125 | 6 | 85 |
| Percent | 7.36% | 3.06% | 19.71% | 6.25% | 4.92% |
| Module | Slice | Slice | BRAM | URAM | DSP |
|---|---|---|---|---|---|
| LUT | Registers | ||||
| DMA | 57,072 | 75,322 | 32 | 0 | 0 |
| PEs | 61,161 | 53,292 | 500 | 24 | 340 |
| Total | 118,233 | 128,614 | 532 | 24 | 340 |
| Percent | 51.32% | 27.91% | 85.26% | 25.00% | 19.68% |
| Input () | Output () | Layer | Processor [ms] | Accelerator [ms] | Total [ms] |
|---|---|---|---|---|---|
| 224 × 224 × 3 | 112 × 112 × 32 | Standard conv | 1.5 | 18.1 | 19.6 |
| 112 × 112 × 32 | 112 × 112 × 16 | Bottleneck | 5.7 | 7.2 | 12.9 |
| 112 × 112 × 16 | 56 × 56 × 24 | Bottleneck | 29.0 | 29.9 | 58.9 |
| 56 × 56 × 24 | 28 × 28 × 32 | Bottleneck | 9.2 | 12.7 | 21.9 |
| 28 × 28 × 32 | 14 × 14 × 64 | Bottleneck | 4.0 | 12.9 | 16.9 |
| 14 × 14 × 64 | 14 × 14 × 96 | Bottleneck | 3.4 | 18.7 | 22.1 |
| 14 × 14 × 96 | 7 × 7 × 160 | Bottleneck | 3.3 | 30.1 | 33.4 |
| 7 × 7 × 160 | 7 × 7 × 320 | Bottleneck | 0.7 | 14.6 | 15.3 |
| 7 × 7 × 320 | 7 × 7 × 1280 | E × pansion conv | 0.2 | 12.9 | 13.1 |
| 7 × 7 × 1280 | 1 × 1 × 1280 | Avg pooling | 0.2 | 0.3 | 0.5 |
| 1 × 1 × 1280 | 1 × 1 × 1000 | Fc | 0.2 | 5.7 | 5.9 |
| MobileNet V2 | 57.4 | 163.1 | 220.5 | ||
| Number | Slice | Slice | BRAM | URAM | DSP | Time | fps |
|---|---|---|---|---|---|---|---|
| of PEs | LUT | Registers | [ms] | ||||
| 4 | 121,689 | 127,020 | 524 | 24 | 340 | 126.91 | 7.87 |
| 8 | 240,660 | 250,278 | 1047 | 48 | 680 | 63.45 | 15.76 |
| 12 | 368,936 | 391,517 | 1572 | 72 | 1020 | 40.65 | 24.60 |
| Implementation | CNN | Top-1 (%) | Top-5 (%) | Power (W) | fps | LUT | BRAM | FF | DSP |
|---|---|---|---|---|---|---|---|---|---|
| Qiu et al. [32] | VGG-16 | N/A | 86.7 | 9.63 | 4.45 | 182,616 | 486 | 127,653 | 780 |
| Guo et al. [39] | VGG-16 | 67.7 | 88.1 | 3.5 | 2.75 | 29,867 | 85.5 | 35,489 | 190 |
| Su et al. [26] | MobileNet | 64.6 | 84.5 | N/A | 127 | 139,000 | 1729 | 550,00 | 1452 |
| Bai et al. [27] | MobileNet V2 | 71.8 | 91.0 | N/A | 266 | 163,506 | 1844 | N/A | 1278 |
| Yang et al. [40] | DiracDeltaNet | 70.1 | 88.2 | 5.5 | 58.7 | 24,130 | 170 | 29,867 | 37 |
| Zhang et al. [50] | AlexNet | 56.0 | N/A | 17.67 | 9.73 | 101,953 | 198.5 | 127,577 | 696 |
| Panagiotis et al. [51] | SqueezeNet | 56.9 | 79.9 | N/A | 14.2 | 34,489 | 97.5 | 25,036 | 172 |
| This work | MobileNet V2 | 65.6 | 87.0 | 7.35 | 4.54 | 118,233 | 532 | 128,614 | 340 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Pérez, I.; Figueroa, M. A Heterogeneous Hardware Accelerator for Image Classification in Embedded Systems. Sensors 2021, 21, 2637. https://doi.org/10.3390/s21082637
Pérez I, Figueroa M. A Heterogeneous Hardware Accelerator for Image Classification in Embedded Systems. Sensors. 2021; 21(8):2637. https://doi.org/10.3390/s21082637
Chicago/Turabian StylePérez, Ignacio, and Miguel Figueroa. 2021. "A Heterogeneous Hardware Accelerator for Image Classification in Embedded Systems" Sensors 21, no. 8: 2637. https://doi.org/10.3390/s21082637
APA StylePérez, I., & Figueroa, M. (2021). A Heterogeneous Hardware Accelerator for Image Classification in Embedded Systems. Sensors, 21(8), 2637. https://doi.org/10.3390/s21082637