
U-Infuse: Democratization of Customizable Deep Learning for Object Detection


Abstract
1. Introduction
Related Works
2. The U-Infuse Application
Functionalities
3. Animal Detection and Classification Using Default Models
4. Custom Model Training Using FlickR and Camera Trap Image Infusion
4.1. Dataset and Classes
4.2. Training
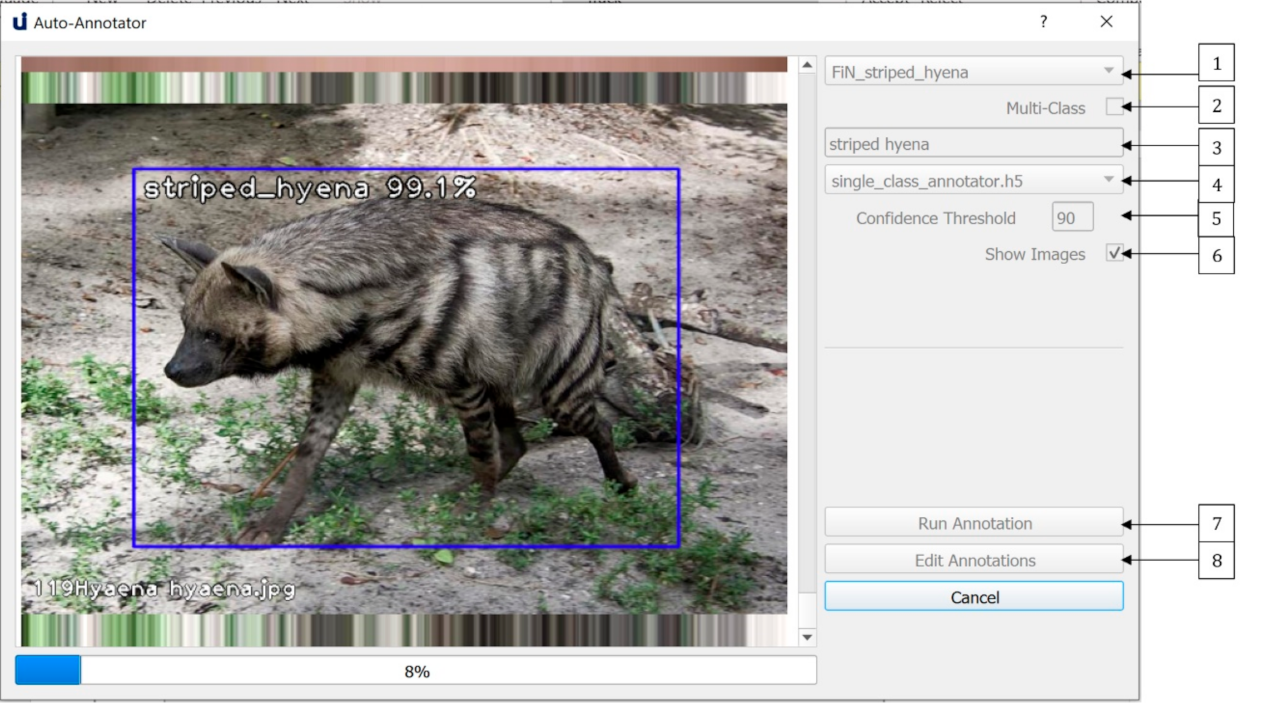
5. Auto-Annotation and Manual Annotation Editing
6. Case Study: Monitoring and Managing Feral Cats
6.1. Background
6.2. FiN-Infusion Training with U-Infuse
6.3. Per Image and Per Capture Event Performance
6.4. Discussion
7. Future Work and Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- O’Connell, A.; Nichols, J.D.; Karanth, K.U. Camera Traps in Animal Ecology: Methods and Analyses; Springer: Berlin/Heidelberg, Germany, 2011. [Google Scholar]
- Bengsen, A.; Robinson, R.; Chaffey, C.; Gavenlock, J.; Hornsby, V.; Hurst, R.; Fosdick, M. Camera trap surveys to evaluate pest animal control operations. Ecol. Manag. Restor. 2014, 15, 97–100. [Google Scholar] [CrossRef]
- Meek, P.; Fleming, P.; Ballard, G.; Banks, P.; Claridge, A.; Sanderson, J.; Swann, D. Camera Trapping in Wildlife Research and Monitoring; CSIRO Publishing: Melbourne, Australia, 2014. [Google Scholar]
- Rovero, F.; Zimmermann, F. Camera Trapping for Wildlife Research; Pelagic Publishing: Exeter, UK, 2016. [Google Scholar]
- Lashley, M.A.; Cove, M.V.; Chitwood, M.C.; Penido, G.; Gardner, B.; DePerno, C.S.; Moorman, C.E. Estimating wildlife activity curves: Comparison of methods and sample size. Sci. Rep. 2018, 8, 4173. [Google Scholar] [CrossRef]
- Li, X.; Bleisch, W.V.; Jiang, X. Using large spatial scale camera trap data and hierarchical occupancy models to evaluate species richness and occupancy of rare and elusive wildlife communities in southwest China. Divers. Distrib. 2018, 24, 1560–1572. [Google Scholar] [CrossRef]
- Ahumada, J.A.; Hurtado, J.; Lizcano, D. Monitoring the Status and Trends of Tropical Forest Terrestrial Vertebrate Communities from Camera Trap Data: A Tool for Conservation. PLoS ONE 2013, 8, e73707. [Google Scholar] [CrossRef] [PubMed]
- Zaumyslova, O.; Bondarchuk, S. The Use of Camera Traps for Monitoring the Population of Long-Tailed Gorals. Achiev. Life Sci. 2015, 9, 15–21. [Google Scholar] [CrossRef]
- Fegraus, E.H.; MacCarthy, J. Camera Trap Data Management and Interoperability. In Camera Trapping for Wildlife Research; Rovero, F., Zimmermann, F., Eds.; Pelagic Publishing: Exeter, UK, 2016; pp. 33–42. [Google Scholar]
- Rahman, D.A.; Gonzalez, G.; Aulagnier, S. Population size, distribution and status of the remote and Critically Endangered Bawean deer Axis kuhlii. Oryx 2016, 51, 665–672. [Google Scholar] [CrossRef]
- Rowcliffe, J.M.; Kays, R.; Kranstauber, B.; Carbone, C.; Jansen, P.A. Quantifying levels of animal activity using camera trap data. Methods Ecol. Evol. 2014, 5, 1170–1179. [Google Scholar] [CrossRef]
- Falzon, G.; Meek, P.D.; Vernes, K. Computer Assisted identification of small Australian mammals in camera trap imagery. In Camera Trapping: Wildlife Management and Research; Meek, P., Fleming, P., Ballard, G., Banks, P., Claridge, A., Sanderson, J., Swann, D., Eds.; CSIRO Publishing: Melbourne, Australia, 2014; pp. 299–306. [Google Scholar]
- Swanson, A.; Kosmala, M.; Lintott, C.; Simpson, R.; Smith, A.; Packer, C. Snapshot Serengeti, high-frequency annotated camera trap images of 40 mammalian species in an African savanna. Sci. Data 2015, 2, 150026. [Google Scholar] [CrossRef] [PubMed]
- Villa, A.G.; Salazar, A.; Vargas, F. Towards automatic wild animal monitoring: Identification of animal species in camera-trap images using very deep convolutional neural networks. Ecol. Inform. 2016, 41. [Google Scholar] [CrossRef]
- Norouzzadeh, M.S.; Nguyen, A.; Kosmala, M.; Swanson, A.; Palmer, M.S.; Packer, C.; Clune, J. Automatically identifying, counting, and describing wild animals in camera-trap images with deep learning. Proc. Natl. Acad. Sci. USA 2018, 115, E5716–E5725. [Google Scholar] [CrossRef]
- Schneider, S.; Taylor, G.; Kremer, S. Deep Learning Object Detection Methods for Ecological Camera Trap Data. In Proceedings of the 2018 15th Conference on Computer and Robot Vision (CRV), Toronto, ON, Canada, 8–10 May 2018; pp. 321–328. [Google Scholar]
- Willi, M.; Pitman, R.T.; Cardoso, A.W.; Locke, C.; Swanson, A.; Boyer, A.; Veldthuis, M.; Fortson, L. Identifying animal species in camera trap images using deep learning and citizen science. Methods Ecol. Evol. 2019, 10, 80–91. [Google Scholar] [CrossRef]
- Miao, Z.; Gaynor, K.M.; Wang, J.; Liu, Z.; Muellerklein, O.; Norouzzadeh, M.S.; McInturff, A.; Bowie, R.C.K.; Nathan, R.; Yu, S.X.; et al. Insights and approaches using deep learning to classify wildlife. Sci. Rep. 2019, 9, 1–9. [Google Scholar] [CrossRef] [PubMed]
- Tabak, M.A.; Norouzzadeh, M.S.; Wolfson, D.W.; Sweeney, S.J.; Vercauteren, K.C.; Snow, N.P.; Halseth, J.M.; Di Salvo, P.A.; Lewis, J.S.; White, M.D.; et al. Machine learning to classify animal species in camera trap images: Applications in ecology. Methods Ecol. Evol. 2019, 10, 585–590. [Google Scholar] [CrossRef]
- Falzon, G.; Lawson, C.; Cheung, K.-W.; Vernes, K.; Ballard, G.A.; Fleming, P.J.S.; Glen, A.S.; Milne, H.; Mather-Zardain, A.; Meek, P.D. ClassifyMe: A Field-Scouting Software for the Identification of Wildlife in Camera Trap Images. Animals 2019, 10, 58. [Google Scholar] [CrossRef]
- Ahumada, J.A.; Fegraus, E.; Birch, T.; Flores, N.; Kays, R.; O’Brien, T.G.; Palmer, J.; Schuttler, S.; Zhao, J.Y.; Jetz, W.; et al. Wildlife Insights: A Platform to Maximize the Potential of Camera Trap and Other Passive Sensor Wildlife Data for the Planet. Environ. Conserv. 2020, 47, 1–6. [Google Scholar] [CrossRef]
- Microsoft. AI for Earth Camera Trap API. Available online: https://github.com/microsoft/CameraTraps (accessed on 10 July 2020).
- Greenberg, S.; Godin, T.; Whittington, J. Design patterns for wildlife-related camera trap image analysis. Ecol. Evol. 2019, 9, 13706–13730. [Google Scholar] [CrossRef] [PubMed]
- Hendry, H.; Mann, C. Camelot—intuitive software for camera-trap data management. Oryx 2018, 52, 15. [Google Scholar] [CrossRef]
- Driven Data. Project Zamba Computer Vision for Wildlife Research & Conservation. 2017. Available online: https://zamba.drivendata.org/ (accessed on 23 November 2020).
- Schneider, S.; Greenberg, S.; Taylor, G.W.; Kremer, S.C. Three critical factors affecting automated image species recognition performance for camera traps. Ecol. Evol. 2020, 10, 3503–3517. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. YOLO9000: Better, Faster, Stronger. arXiv 2016, arXiv:1612.08242. [Google Scholar]
- R Core Team. R: A Language and Environment for Statistical Computing; R Foundation for Statistical Computing: Vienna, Austria, 2018; Available online: https://www.R-project.org/labelImg (accessed on 1 April 2021).
- Yu, X.; Wang, J.; Kays, R.; Jansen, P.A.; Wang, T.; Huang, T. Automated identification of animal species in camera trap images. EURASIP J. Image Video Process. 2013, 2013, 52. [Google Scholar] [CrossRef]
- Beery, S.; Van Horn, G.; Perona, P. Recognition in Terra Incognita; Springer International Publishing: Cham, Switzerland, 2018. [Google Scholar]
- Shepley, A.; Falzon, G.; Meek, P.D.; Kwan, P. Automated Location Invariant Animal Detection in Camera Trap Images Using Publicly Available Data Sources. Ecol. Evol. 2021. [Google Scholar] [CrossRef]
- Lin, T.-Y.; Goyal, P.; Girshick, R.; He, K.; Dollar, P. Focal Loss for Dense Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 1. [Google Scholar] [CrossRef]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. TensorFlow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation, Savannah, GA, USA, 2–4 November 2016. [Google Scholar]
- Tiwary, U.S. Intelligent Human Computer Interaction: 10th International Conference, IHCI 2018, Allahabad, India, 7–9 December 2018, Proceedings; Springer: Berlin/Heidelberg, Germany, 2018. [Google Scholar]
- Nickolls, J.; Buck, I.; Garland, M.; Skadron, K. Scalable Parallel Programming with CUDA. Queue 2008, 6, 40–53. [Google Scholar] [CrossRef]
- Zhang, E.; Zhang, Y. Average Precision. In Encyclopedia of Database Systems; Liu, L., ÖZsu, M.T., Eds.; Springer: Boston, MA, USA, 2009; pp. 192–193. [Google Scholar]
- Tzutalin. LabelImg. Git Code. 2015. Available online: https://github.com/tzutalin/labelImg (accessed on 1 April 2021).
- Glover-Kapfer, P.; Soto-Navarro, C.A.; Wearn, O.R. Camera-trapping version 3.0: Current constraints and future priorities for development. Remote Sens. Ecol. Conserv. 2018, 5, 209–223. [Google Scholar] [CrossRef]
- Legge, S.; Woinarski, J.C.Z.; Dickman, C.R.; Murphy, B.P.; Woolley, L.-A.; Calver, M.C. We need to worry about Bella and Charlie: The impacts of pet cats on Australian wildlife. Wildl. Res. 2020, 47, 523. [Google Scholar] [CrossRef]
- Legge, S.; Taggart, P.L.; Dickman, C.R.; Read, J.L.; Woinarski, J.C.Z. Cat-dependent diseases cost Australia AU$6 billion per year through impacts on human health and livestock production. Wildl. Res. 2020, 47, 731. [Google Scholar] [CrossRef]
- Anton, V.; Hartley, S.; Geldenhuis, A.; Wittmer, H.U. Monitoring the mammalian fauna of urban areas using remote cameras and citizen science. J. Urban Ecol. 2018, 4. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Wen, L.; Bian, X.; Lei, Z.; Li, S. Single-Shot Refinement Neural Network for Object Detection. arXiv 2018, arXiv:1711.06897. [Google Scholar]











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model Name | Classes | Source |
|---|---|---|
| pretrained_COCO | 80 classes | MS COCO |
| Australian_Multi-class | 30 classes | FlickR |
| pig_single_class | Pig | FlickR |
| striped_hyena_single_class | Dog | FlickR |
| rhino_single_class | Cat | FlickR |
| Dataset | Description | No Images | No Capture Events | |
|---|---|---|---|---|
| Training | Positive Samples | FiN_feral_cats | 1000 | NA |
| AU_Feral_Cat_A_Grade_1 | 166 | NA | ||
| AU_Feral_Cat_A_Grade_2 | 50 | NA | ||
| Negative Samples | FiN_australian_animals | 818 | NA | |
| FiN_brushturkey | 335 | NA | ||
| FiN_deer | 340 | NA | ||
| FiN_dog | 355 | NA | ||
| FiN_fox | 292 | NA | ||
| FiN_koala | 309 | NA | ||
| FiN_quoll | 287 | NA | ||
| FiN_random_negatives_feral_cat_version | 782 | NA | ||
| infusion_AU_Unbalanced_A_Grade_Trap_Fox | 56 | NA | ||
| infusion_AU_Unbalanced_A_Grade_Trap_Other (koalas, goannas, possums, etc.) | 63 | NA | ||
| infusion_AU_Unbalanced_A_Grade_Trap_Kangaroo | 53 | NA | ||
| infusion_AU_Unbalanced_A_Grade_Trap_Feral_dog | 53 | NA | ||
| infusion_AU_Unbalanced_A_Grade_Trap_Pig | 53 | NA | ||
| blank_trap | 31 | NA | ||
| Testing | Positive Samples | NE_Gorge_trap_2_day | 130 | 128 |
| NE_Gorge_trap_2_infrared | 403 | 135 | ||
| Wellington Camera Traps (cat) | 1347 | 449 | ||
| Negative Samples | NE_Gorge_trap_Dog | 64 | NA | |
| NE_Gorge_trap_Kangaroo | 20 | NA | ||
| NE_Gorge_trap_Blank | 64 | NA | ||
| NE_Gorge_trap_Fox | 64 | NA | ||
| NE_Gorge_trap_Pig | 87 | NA | ||
| NE_Gorge_trap_Other | 162 | NA | ||
| Test Set | Per Capture Event | Per Image | |
|---|---|---|---|
| Positive | NE_Gorge_trap_2_day | 76.56% (98/128) | 75% (98/130) |
| NE_Gorge_trap_2_infrared | 84.44% (114/135) | 66% (266/403) | |
| Wellington Camera Traps (cat) | 73.94% (332/449) | 55% (743/1347)) | |
| Negative | NE_Gorge_trap_Dog | NA | 94% (60/64) |
| NE_Gorge_trap_Kangaroo | NA | 85% (3/20) | |
| NE_Gorge_trap_Blank | NA | 100% (29/29) | |
| NE_Gorge_trap_Fox | NA | 80% (51/64) | |
| NE_Gorge_trap_Pig | NA | 80% (70/87) | |
| NE_Gorge_trap_Other | NA | 86% (140/162) | |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shepley, A.; Falzon, G.; Lawson, C.; Meek, P.; Kwan, P. U-Infuse: Democratization of Customizable Deep Learning for Object Detection. Sensors 2021, 21, 2611. https://doi.org/10.3390/s21082611
Shepley A, Falzon G, Lawson C, Meek P, Kwan P. U-Infuse: Democratization of Customizable Deep Learning for Object Detection. Sensors. 2021; 21(8):2611. https://doi.org/10.3390/s21082611
Chicago/Turabian StyleShepley, Andrew, Greg Falzon, Christopher Lawson, Paul Meek, and Paul Kwan. 2021. "U-Infuse: Democratization of Customizable Deep Learning for Object Detection" Sensors 21, no. 8: 2611. https://doi.org/10.3390/s21082611
APA StyleShepley, A., Falzon, G., Lawson, C., Meek, P., & Kwan, P. (2021). U-Infuse: Democratization of Customizable Deep Learning for Object Detection. Sensors, 21(8), 2611. https://doi.org/10.3390/s21082611