
Latency-Optimal Computational Offloading Strategy for Sensitive Tasks in Smart Homes





{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- We constructed a system including local queues and edge queues and define the Lyapunov drift optimization problem to minimize the average queue length in each time slot, which ensures the stability of all queues.
- We present the back-pressure algorithm-based computational offloading strategy for minimizing delay, which can determine the task offloading decision and offloading number by computing the task delay and using the back-pressure algorithm, while also being subject to the time allowance of the task.
- We provide the theoretical analysis of the BMDCO algorithm stability, and the simulation results are given to show the stability of the BMDCO algorithm and demonstrate that the performance of this algorithm outperforms other comparison alternatives.
2. Related Work
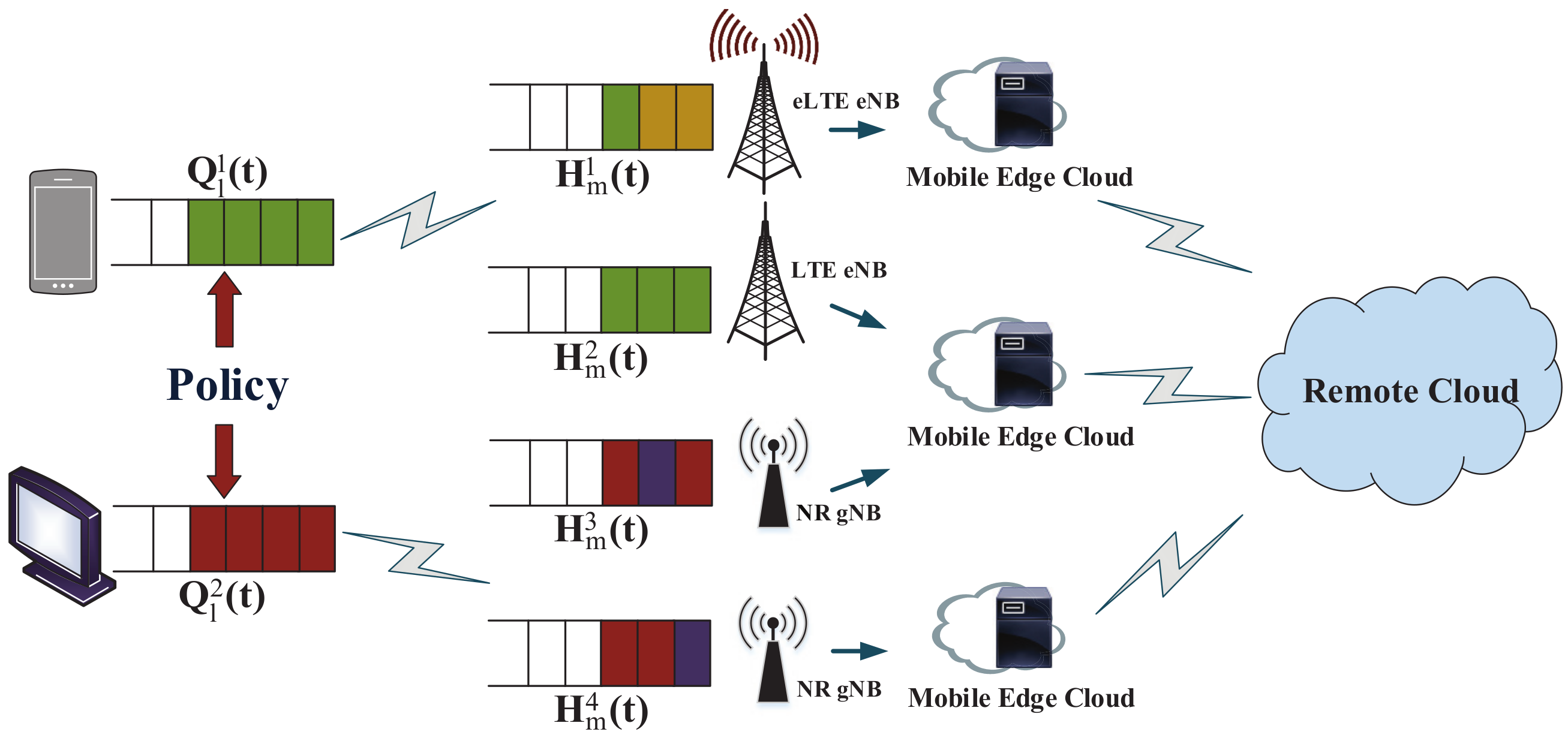
3. System Model and Problem Formulation
3.1. System Model
3.1.1. Local Smart Device and Tasks
3.1.2. Local Computing Model
3.1.3. Edge Computing Model
3.2. Queue Dynamics
3.3. Problem Formulation
4. Back-Pressure Algorithm-Based Offloading Strategy of Minimizing Delay
4.1. Algorithm Development
4.1.1. Possible Offloading Task Set
| Algorithm 1 BMDCO Algorithm |
|
4.1.2. Offloading Task Set
4.1.3. Feasibility Check
4.2. Performance of the BMDCO Algorithm
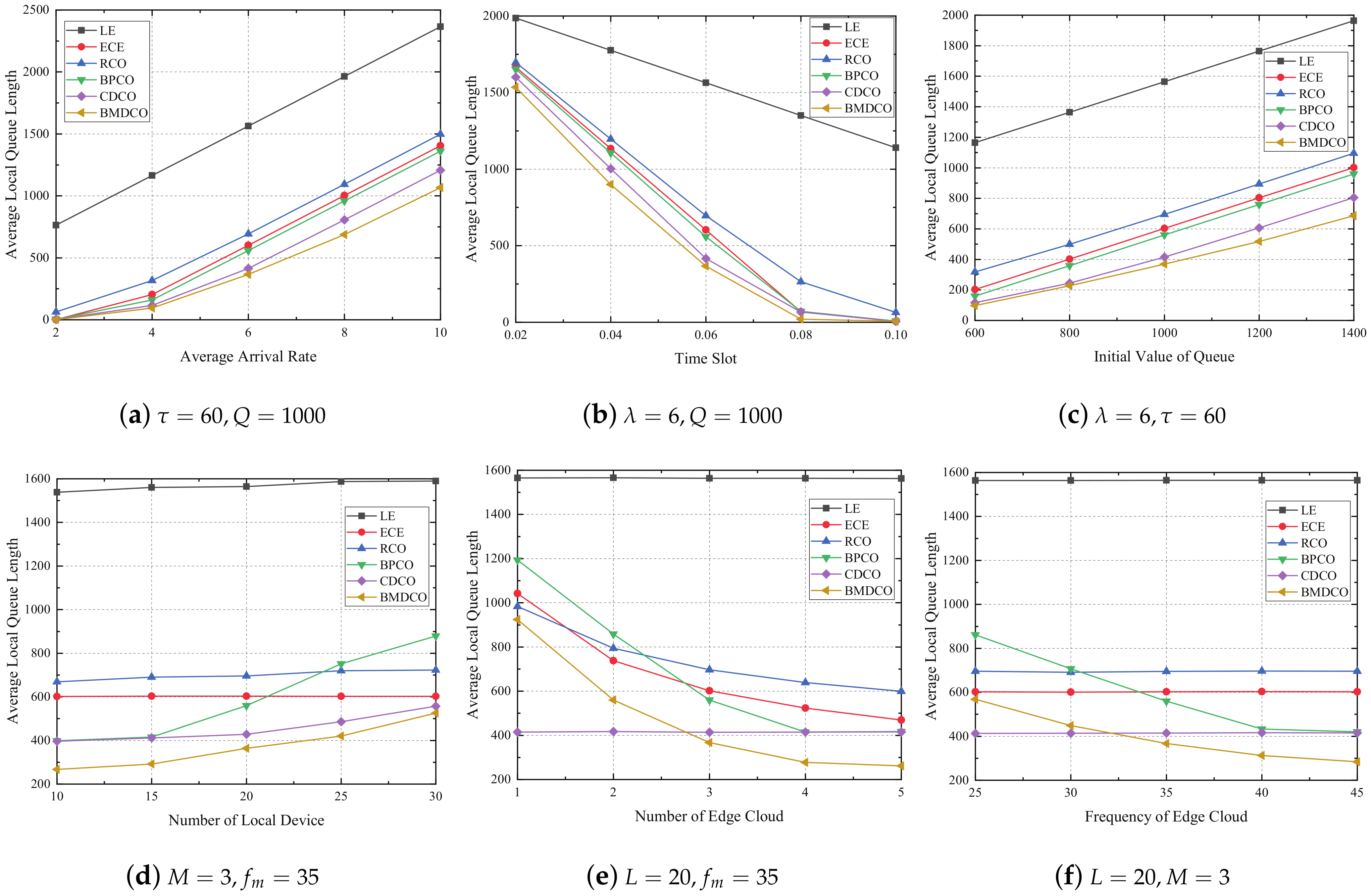
5. Numerical Results
5.1. Performance Analysis
5.2. Performance Comparison
- Only Local Execution (LE): Tasks are only executed on the local device, and only local state information is considered.
- Only Edge Cloud Execution (ECE): The algorithm offloads all tasks to the edge processor for computing and determines the offloading decision by considering the information of transmission channel and edge cloud.
- Random Computational Offloading (RCO): This algorithm uses the queue method, and the task offloading matrix is randomly generated to determine where the task is performed.
- Back-pressure Algorithm-based Computational Offloading (BPCO) [45]: This method considers a queuing system, and determines the task offloading decision by using the back-pressure algorithm to calculate the task backlog difference between the local queue and the edge queue.
- Closed-form Delay-optimal Computational Offloading (CDCO) [20]: This strategy takes into account the queue model and determines the offloading decision of tasks by minimizing the average energy cost.
5.3. Summary
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Appendix A. Lyapunov Drift Optimization Problem
Appendix B. Proof of Theorem 1
References
- Song, F.; Zhu, M.; Zhou, Y.; You, I.; Zhang, H. Smart collaborative tracking for ubiquitous power iot in edge-cloud interplay domain. IEEE Internet Things J. 2020, 7, 6046–6055. [Google Scholar] [CrossRef]
- Zhang, J.; Zhou, Z.; Li, S.; Gan, L.; Zhang, X.; Qi, L. Hybrid computation offloading for smart home automation in mobile cloud computing. Pers. Ubiquitous Comput. 2018, 22, 121–134. [Google Scholar] [CrossRef]
- Farrugia, S. Mobile Cloud Computing Techniques for Extending Computation and Resources in Mobile Devices. In Proceedings of the IEEE International Conference on Mobile Cloud Computing, Oxford, UK, 29 March–1 April 2016; pp. 1–10. [Google Scholar]
- Shi, W.; Zhang, X. Edge Computing: State-of-the-Art and Future Directions. IEEE J. Comput. Res. Dev. 2019, 56, 69–89. [Google Scholar]
- Cheng, N.; Xu, W.; Shi, W.; Zhou, Y.; Lu, N.; Zhou, H.; Shen, X. Air-ground integrated mobile edge networks: Architecture, challenges and opportunities. IEEE Commun. Mag. 2018, 56, 26–32. [Google Scholar] [CrossRef]
- Bagchi, S.; Siddiqui, M.B.; Wood, P. Dependability in edge computing. Commun. ACM 2020, 63, 58–66. [Google Scholar] [CrossRef]
- Bokhari, M.U.; Shallal, Q.; Tamandani, Y.K. Cloud computing service models: A comparative study. In Proceedings of the IEEE International Conference on Computing for Sustainable Global Development, New Delhi, India, 16–18 March 2016. [Google Scholar]
- Al-Dhuraibi, Y.; Paraiso, F.; Djarallah, N.; Merle, P. Elasticity in cloud computing: State of the art and research challenges. IEEE Trans. Serv. Comput. 2018, 11, 430–447. [Google Scholar] [CrossRef]
- Wang, J.; Pan, J.; Esposito, F.; Calyam, P.; Yang, Z.; Mohapatra, P. Edge Cloud Offloading Algorithms: Issues, Methods, and Perspectives. ACM Comput. Surv. 2019, 52, 1–23. [Google Scholar] [CrossRef]
- Mach, P.; Becvar, Z. Mobile Edge Computing: A Survey on Architecture and Computation Offloading. IEEE Commun. Surv. Tutor. 2017, 19, 1628–1656. [Google Scholar] [CrossRef]
- Zhang, W.; Wen, Y.; Wu, J.; Li, H. Toward a unified elastic computing platform for smartphones with cloud support. IEEE Netw. 2013, 27, 34–40. [Google Scholar] [CrossRef]
- Mao, Y.; Zhang, J.; Song, S.; Letaief, K.B. Stochastic Joint Radio and Computational Resource Management for Multi-User Mobile-Edge Computing Systems. IEEE Trans. Wirel. Commun. 2017, 16, 5994–6009. [Google Scholar] [CrossRef]
- Chen, X.; Jiao, L.; Li, W.; Fu, X. Efficient Multi-User Computation Offloading for Mobile-Edge Cloud Computing. IEEE/ACM Trans. Netw. 2016, 24, 2795–2808. [Google Scholar] [CrossRef]
- Zhang, M.; Zhou, Y.; Quan, W.; Zhu, J.; Zheng, R.; Wu, Q. Online Learning for IoT Optimization: A Frank-Wolfe Adam-Based Algorithm. IEEE Internet Things J. 2020, 7, 8228–8237. [Google Scholar] [CrossRef]
- Cui, X.; Shan, N.; Li, Y. A Multilevel Optimization Framework for Computation Offloading in Mobile Edge Computing. IEEE/ACM Trans. Netw. 2020, 2020, 4124791. [Google Scholar]
- Josilo, S.; Dán, G. Wireless and Computing Resource Allocation for Selfish Computation Offloading in Edge Computing. In Proceedings of the IEEE Conference on Computer Communications, INFOCOM, Paris, France, 29 April–2 May 2019; pp. 2467–2475. [Google Scholar]
- Shan, F.; Luo, J.; Jin, J.; Wu, W. Offloading Delay Constrained Transparent Computing Tasks With Energy-Efficient Transmission Power Scheduling in Wireless IoT Environment. IEEE Internet Things J. 2019, 6, 4411–4422. [Google Scholar] [CrossRef]
- Li, M.; Wu, Q.; Zhu, J.; Zheng, R.; Zhang, M. A Computing Offloading Game for Mobile Devices and Edge Cloud Servers. Wirel. Commun. Mob. Comput. 2018, 2018, 2179316. [Google Scholar] [CrossRef]
- Geng, Y.; Yang, Y.; Cao, G. Energy-Efficient Computation Offloading for Multicore-Based Mobile Devices. In Proceedings of the IEEE Conference on Computer Communications, INFOCOM, Honolulu, HI, USA, 16–19 April 2018; pp. 46–54. [Google Scholar]
- Meng, X.; Wang, W.; Wang, Y.; Lau, V.K.N.; Zhang, Z. Closed-Form Delay-Optimal Computation Offloading in Mobile Edge Computing Systems. IEEE Trans. Wirel. Commun. 2019, 18, 4653–4667. [Google Scholar] [CrossRef]
- Neely, M.J.; Michael, J. Stochastic Network Optimization with Application to Communication and Queueing Systems; Morgan and Claypool Publishers: San Rafael, CA, USA, 2010. [Google Scholar]
- Li, C.P.; Modiano, E. Receiver-Based Flow Control for Networks in Overload. IEEE/ACM Trans. Netw. 2015, 23, 616–630. [Google Scholar] [CrossRef]
- Liu, M.; Cui, T.; Schuh, H.; Krishnamurthy, A.; Peter, A.; Gupta, K. Offloading distributed applications onto smartNICs using iPipe. In Proceedings of the ACM Special Interest Group on Data Communication SIGCOMM, Beijing, China, 19–23 August 2019; pp. 318–333. [Google Scholar]
- Neto, J.L.D.; Yu, S.Y.; Macedo, D.F.; Nogueira, J.M.S.; Langar, R.; Secci, S. Uloof: A user level online offloading framework for mobile edge computing. IEEE Trans. Mobile Comput. 2018, 17, 2660–2674. [Google Scholar] [CrossRef]
- Xu, J.; Chen, L.; Zhou, P. Joint Service Caching and Task Offloading for Mobile Edge Computing in Dense Networks. In Proceedings of the IEEE Conference on Computer Communications, INFOCOM, Honolulu, HI, USA, 16–19 April 2018; pp. 207–215. [Google Scholar]
- Sundar, S.; Liang, B. Offloading Dependent Tasks with Communication Delay and Deadline Constraint. In Proceedings of the IEEE/ACM Transactions on Networking, Honolulu, HI, USA, 16–19 April 2018; pp. 37–45. [Google Scholar]
- Zhang, W.; Zhang, Z.; Zeadlally, S.; Chao, H.C.; Leung, V.C.M. MASM: A Multiple-Algorithm Service Model for Energy-Delay Optimization in Edge Artificial Intelligence. IEEE Trans. Ind. Inform. 2019, 15, 4216–4224. [Google Scholar] [CrossRef]
- Mao, Y.; Zhang, J.; Letaief, K.B. Joint Task Offloading Scheduling and Transmit Power Allocation for Mobile-Edge Computing Systems. In Proceedings of the IEEE Wireless Communications and Networking Conference, WCNC, San Francisco, CA, USA, 19–22 March 2017; pp. 1–6. [Google Scholar]
- Kuang, Z.; Li, L.; Gao, J.; Zhao, L.; Liu, A. Partial Offloading Scheduling and Power Allocation for Mobile Edge Computing Systems. IEEE Internet Things J. 2019, 6, 6774–6785. [Google Scholar] [CrossRef]
- Guo, H.; Liu, J. Collaborative Computation Offloading for Multi-Access Edge Computing over Fiber-Wireless Networks. IEEE Trans. Veh. Technol. 2018, 67, 4514–4526. [Google Scholar] [CrossRef]
- Chen, W.; Wang, D.; Li, K. Multi-User Multi-Task Computation Offloading in Green Mobile Edge Cloud Computing. IEEE Trans. Serv. Comput. 2019, 12, 726–738. [Google Scholar] [CrossRef]
- Du, W.; Lei, T.; He, Q.; Liu, W.; Lei, Q.; Zhao, H.; Wang, W. Service Capacity Enhanced Task Offloading and Resource Allocation in Multi-Server Edge Computing Environment. IEEE Int. Conf. Web Serv. ICWS 2019, 83–90. [Google Scholar]
- Guo, S.; Liu, J.; Yang, Y.; Xiao, B.; Li, Z. Energy-Efficient Dynamic Computation Offloading and Cooperative Task Scheduling in Mobile Cloud Computing. IEEE Trans. Mob. Comput. 2019, 18, 319–333. [Google Scholar] [CrossRef]
- Liu, C.F.; Bennis, M.; Debbah, M.; Poor, H.V. Dynamic Task Offloading and Resource Allocation for Ultra-Reliable Low-Latency Edge Computing. IEEE Trans. Commun. 2019, 67, 4132–4150. [Google Scholar] [CrossRef]
- Ning, Z.; Dong, P.; Kong, X.; Xia, F. A Cooperative Partial Computation Offloading Scheme for Mobile Edge Computing Enabled Internet of Things. IEEE Internet Things J. 2019, 6, 4804–4814. [Google Scholar] [CrossRef]
- Zhang, J.; Hu, X.; Ning, Z.; Ngai, C.H.; Zhou, L.; Wei, J. Energy-Latency Tradeoff for Energy-Aware Offloading in Mobile Edge Computing Networks. IEEE Internet Things J. 2018, 5, 2633–2645. [Google Scholar] [CrossRef]
- Liu, L.; Guo, X.; Chang, Z.; Ristaniemi, T. Joint optimization of energy and delay for computation offloading in cloudlet-assisted mobile cloud computing. Wirel. Netw. 2019, 25, 2027–2040. [Google Scholar] [CrossRef]
- Liu, C.F.; Bennis, M.; Poor, H.V. Latency and Reliability-Aware Task Offloading and Resource Allocation for Mobile Edge Computing. In Proceedings of the IEEE Globecom Workshops, Singapore, 4–8 December 2017; pp. 1–7. [Google Scholar]
- Guo, Y.; Pan, M.; Gong, Y.; Fang, Y. Dynamic Multi-Tenant Coordination for Sustainable Colocation Data Centers. IEEE Trans. Cloud Comput. 2019, 7, 733–743. [Google Scholar] [CrossRef]
- Zheng, R.; Liu, K.; Zhu, J.; Zhang, M.; Wu, Q. Stochastic resource scheduling via bilayer dynamic Markov decision process in mobile cloud networks. Comput. Commun. 2019, 145, 234–242. [Google Scholar] [CrossRef]
- Chen, L.; Zhou, S.; Xu, J. Computation Peer Offloading for Energy-Constrained Mobile Edge Computing in Small-Cell Networks. IEEE/ACM Trans. Netw. 2018, 26, 1619–1632. [Google Scholar] [CrossRef]
- Mireslami, S.; Rakai, L.; Wang, M.; Far, B.H. Dynamic Cloud Resource Allocation Considering Demand Uncertainty. IEEE Trans. Cloud Comput. 2019. [Google Scholar] [CrossRef]
- Mao, Y.; Zhang, J.; Letaief, K.B. Dynamic Computation Offloading for Mobile-Edge Computing With Energy Harvesting Devices. IEEE J. Sel. Areas Commun. 2016, 34, 3590–3605. [Google Scholar] [CrossRef]
- Merluzzi, M.; Lorenzo, P.D.; Barbarossa, S. Latency-Constrained Dynamic Computation Offloading with Energy Harvesting IoT Devices. In Proceedings of the IEEE Conference on Computer Communications Workshops, INFOCOM, Paris, France, 29 April–2 May 2019; pp. 750–755. [Google Scholar]
- Destounis, A.; Paschos, G.S.; Koutsopoulos, I. Streaming big data meets backpressure in distributed network computation. In Proceedings of the IEEE International Conference on Computer Communications, INFOCOM, San Francisco, CA, USA, 10–14 April 2016; pp. 1–9. [Google Scholar]
- Safari, M.; Khorsand, R. PL-DVFS: Combining Power-aware List-based scheduling algorithm with DVFS technique for real-time tasks in Cloud Computing. J. Supercomput. 2018, 74, 5578–5600. [Google Scholar] [CrossRef]



Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Wang, L.; Zheng, R.; Zhao, X.; Liu, M. Latency-Optimal Computational Offloading Strategy for Sensitive Tasks in Smart Homes. Sensors 2021, 21, 2347. https://doi.org/10.3390/s21072347
Wang Y, Wang L, Zheng R, Zhao X, Liu M. Latency-Optimal Computational Offloading Strategy for Sensitive Tasks in Smart Homes. Sensors. 2021; 21(7):2347. https://doi.org/10.3390/s21072347
Chicago/Turabian StyleWang, Yanyan, Lin Wang, Ruijuan Zheng, Xuhui Zhao, and Muhua Liu. 2021. "Latency-Optimal Computational Offloading Strategy for Sensitive Tasks in Smart Homes" Sensors 21, no. 7: 2347. https://doi.org/10.3390/s21072347
APA StyleWang, Y., Wang, L., Zheng, R., Zhao, X., & Liu, M. (2021). Latency-Optimal Computational Offloading Strategy for Sensitive Tasks in Smart Homes. Sensors, 21(7), 2347. https://doi.org/10.3390/s21072347