
Unsupervised Trademark Retrieval Method Based on Attention Mechanism



Abstract
:1. Introduction
2. Related Work
2.1. Unsupervised Learning
2.2. Attention Mechanism
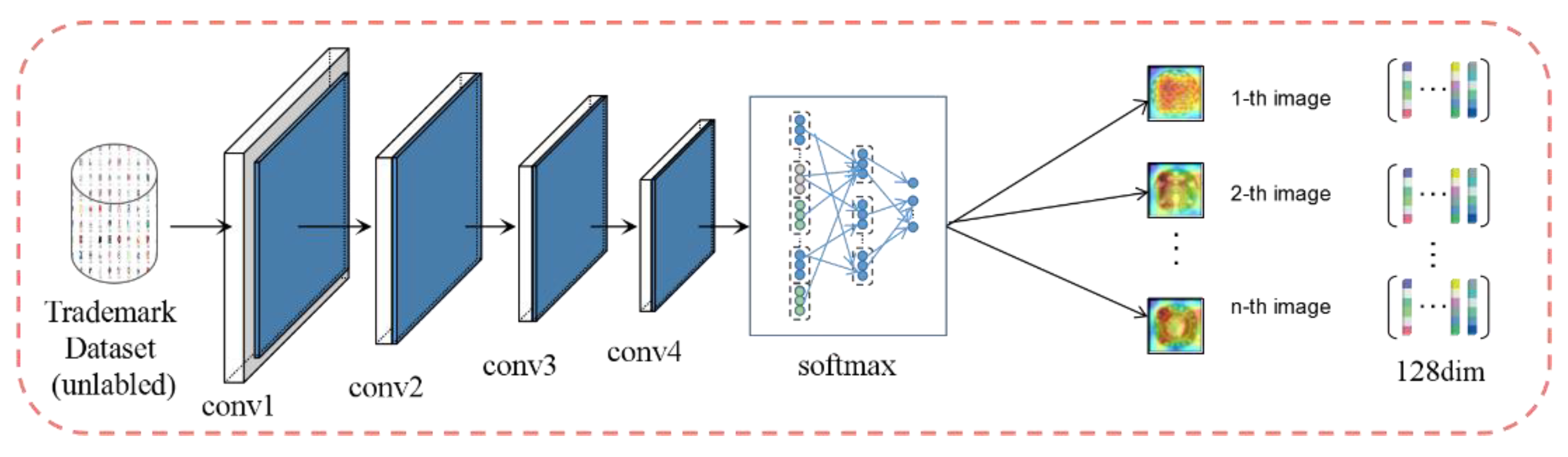
3. The Proposed Method
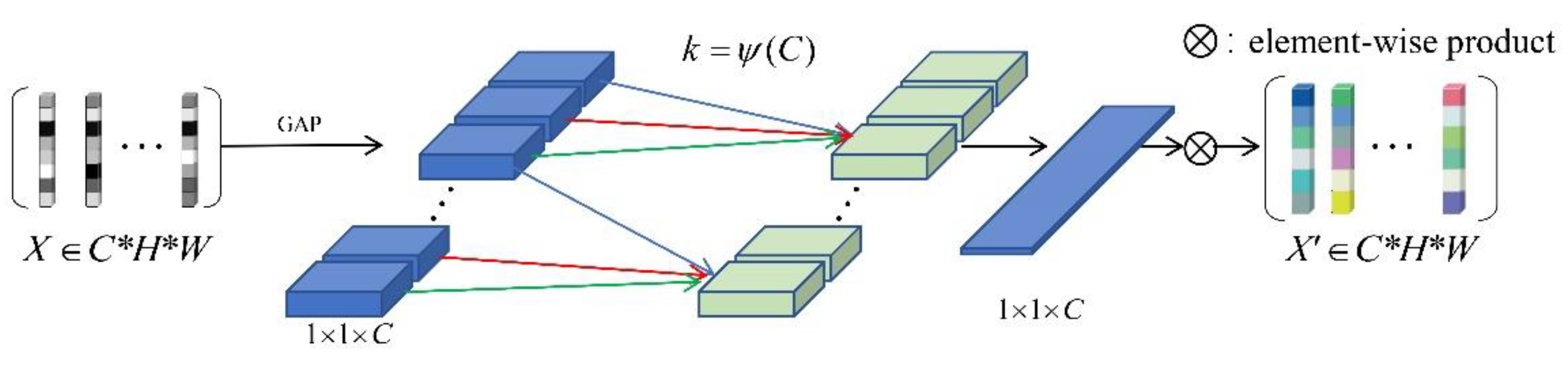
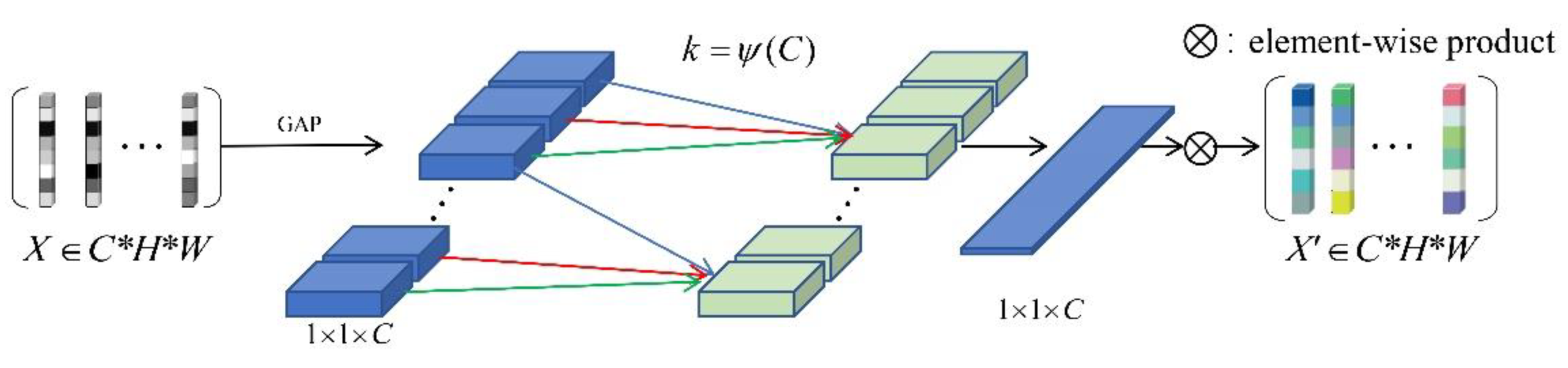
3.1. Learning about Important Features of Trademarks
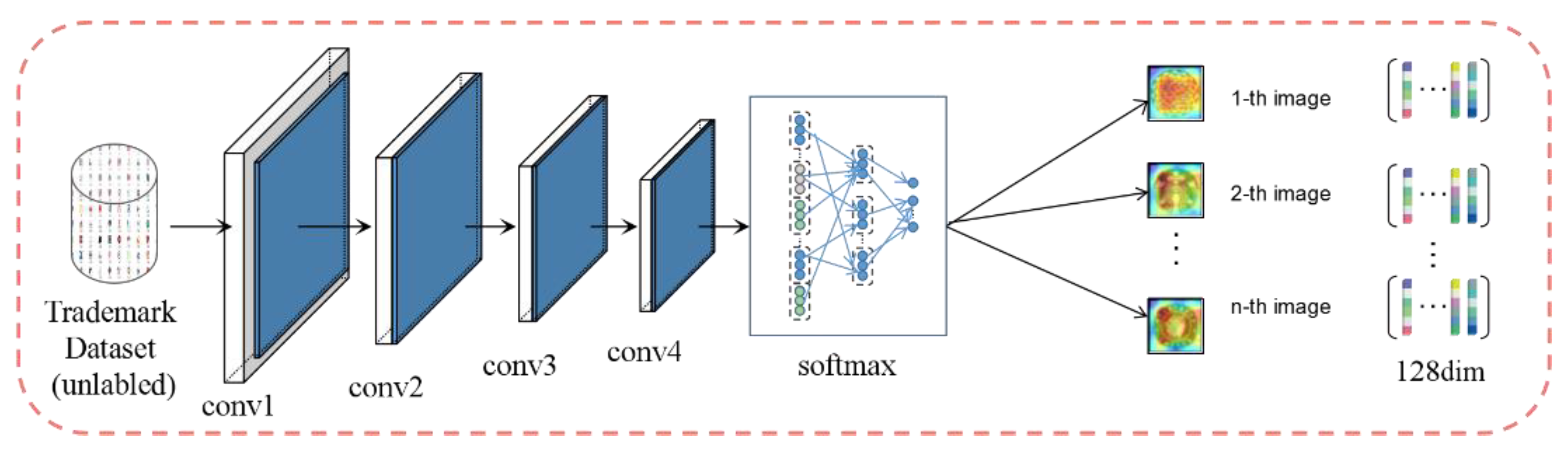
3.2. Instance Discrimination
- Select training samples from the trademark database and preprocess them to obtain , form training batches;
- Input the training set into the unsupervised network, extract the features to get the initial feature set , and store it as the corresponding feature of the current batch;
- Sample negative samples from the stored feature set s;
- Calculate the loss value of the instance sample and the noise sample collected from the memory bank;
- Use back propagation to continuously optimize the target value and update the parameters until the end of the training.
3.3. Similarity Measure
3.4. The Process of Our Proposed Method
| Algorithm1: Unsupervised trademark retrieval method based on attention mechanism |
| Input: Retrieved image I, Trademark database M. Output: Image sequence R which is similar to I. Step1: for i←1 to maximum_epochs do 1. . 2. , put V into the instance discrimination module. 3. and optimize loss, update V iteratively. 4. Backpropagate the loss and update the parameters. 5. Repeat the above steps until the algorithm converges to get the feature extraction network N. end for step2: 1. in the retrieval module. 2. in the retrieval module. 3. , output similar image sequence R. |
4. Experiment
4.1. METU Dataset
4.2. Evaluation Method and Metrics
4.3. Experimental Settings
4.3.1. Training Parameters
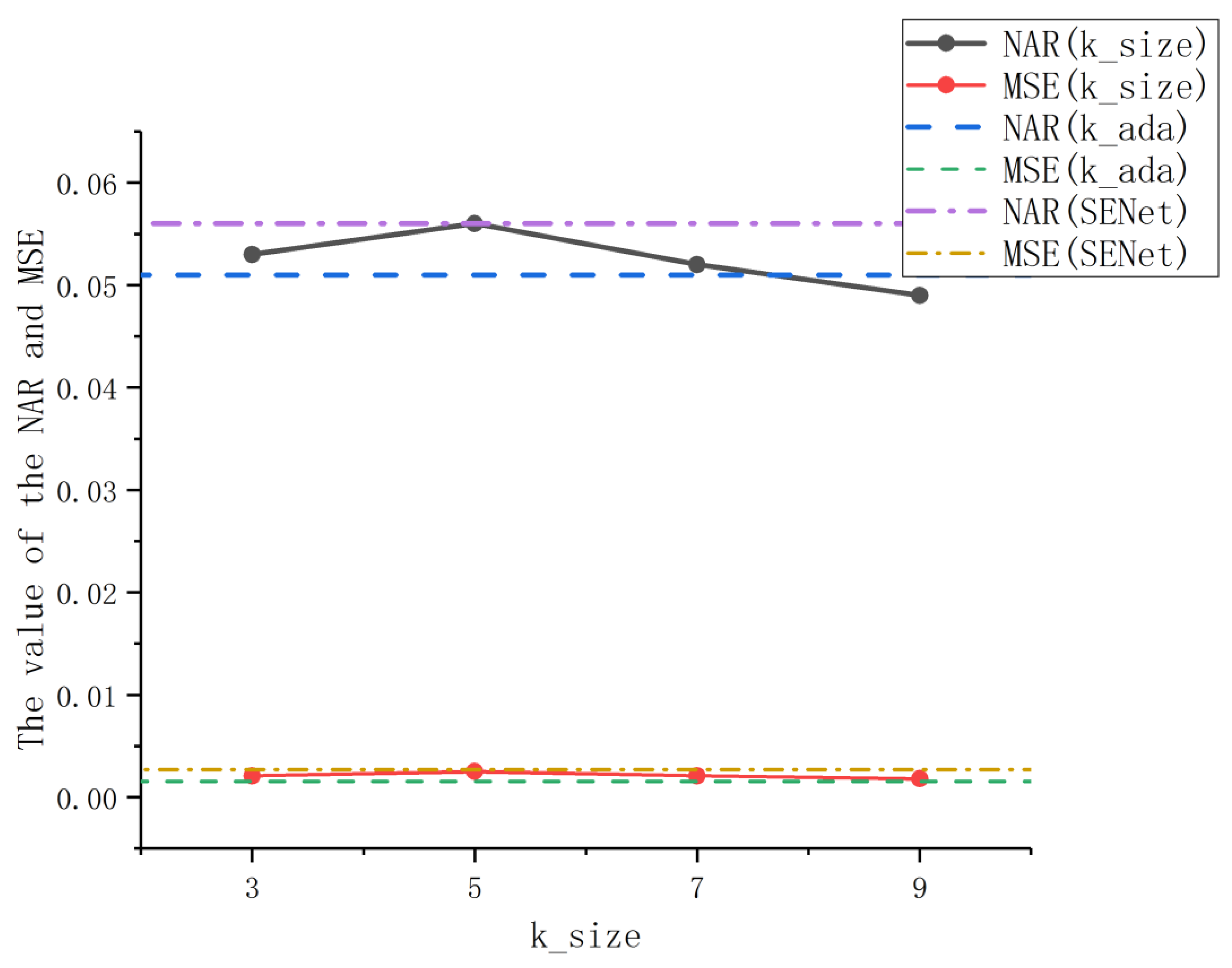
4.3.2. Effect of k on ECA Module
4.4. Experimental Results and Analysis
4.4.1. Compared with Traditional Feature Extraction Methods
4.4.2. Compared with Deep Learning Methods
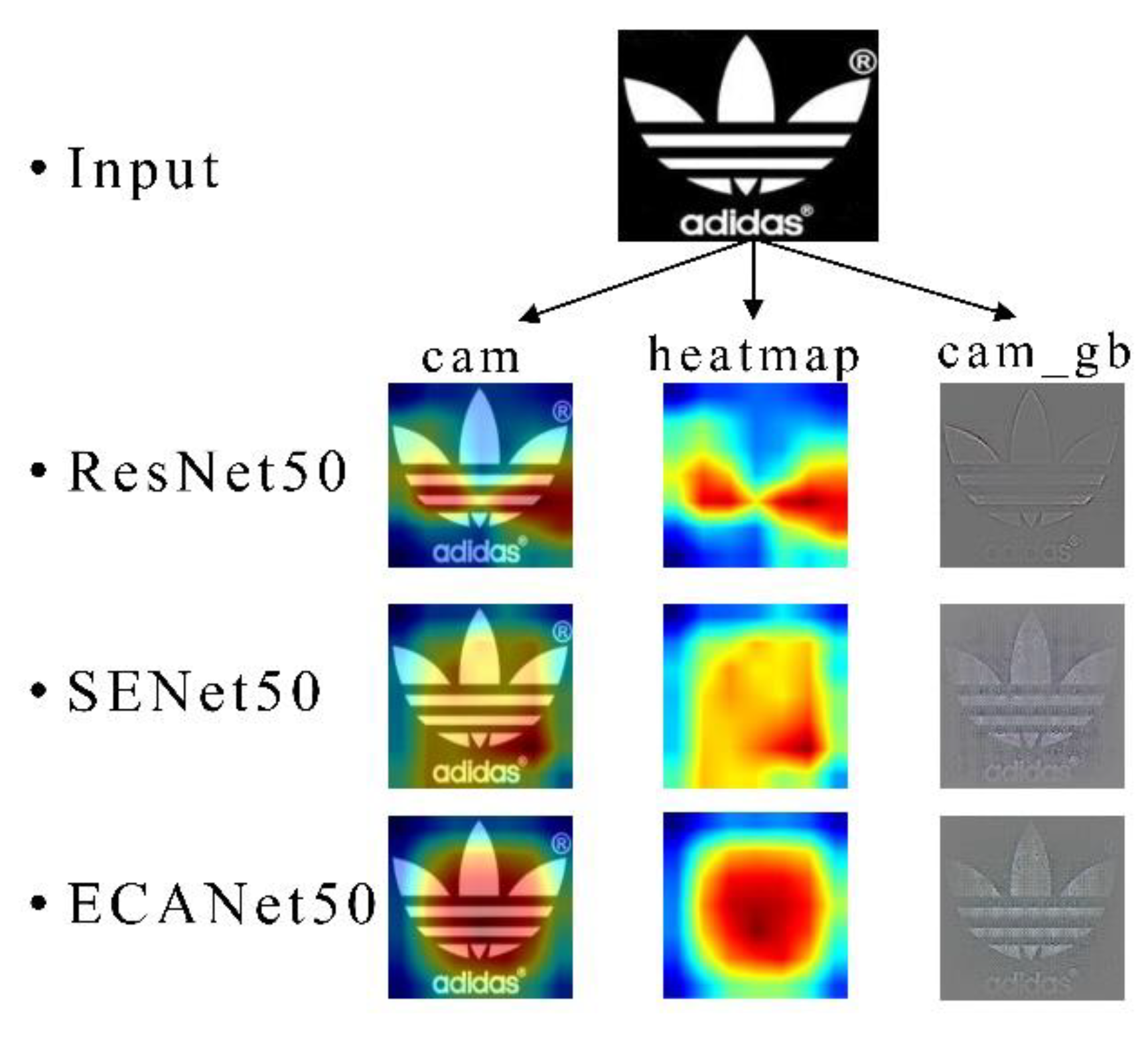
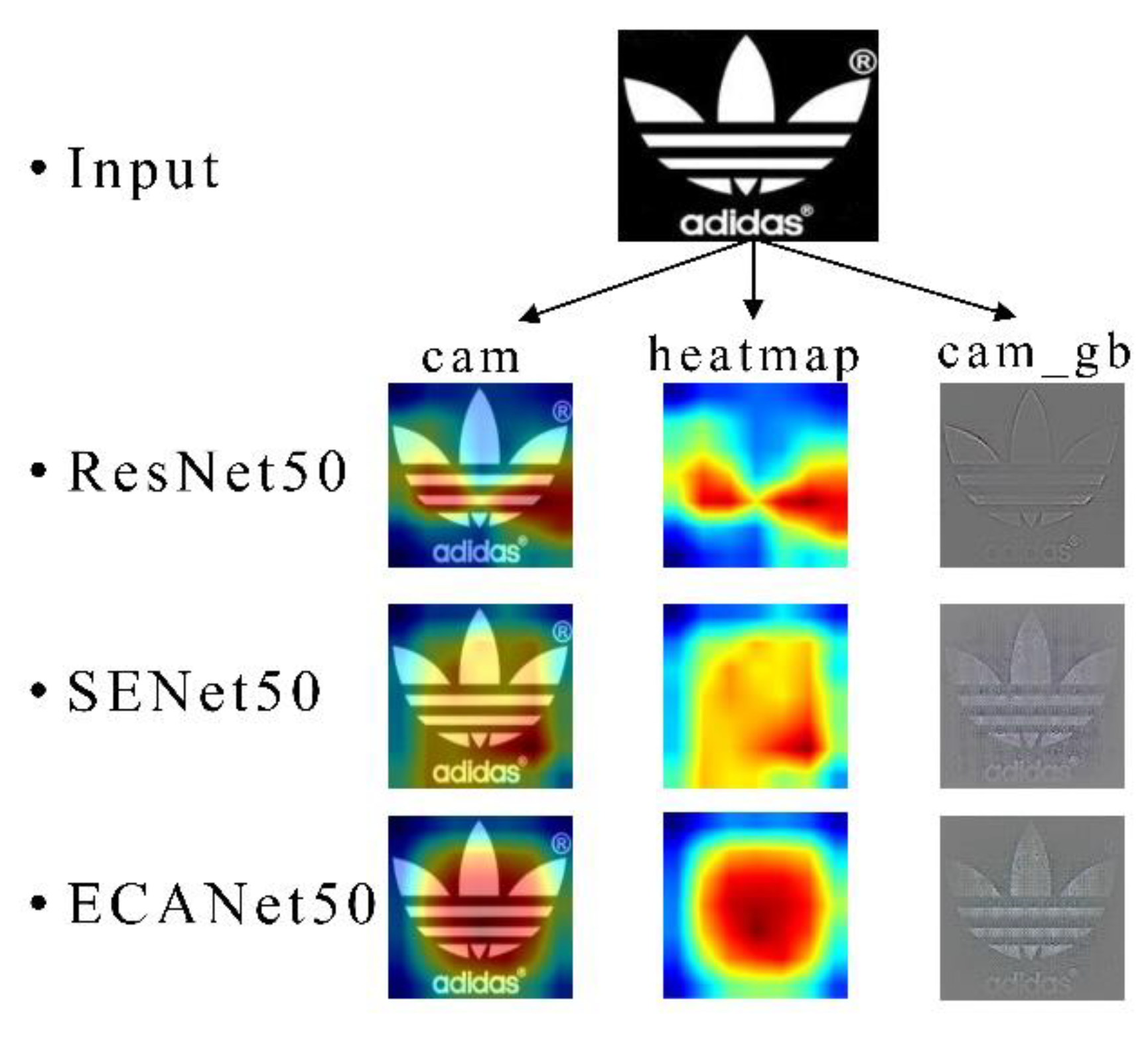
4.4.3. Visualization of the Results
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Perez, C.A.; Estévez, P.A.; Galdames, F.J.; Schulz, D.A.; Perez, J.P.; Bastías, D.; Vilar, D.R. Trademark image retrieval using a combination of deep convolutional neural networks. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–7. [Google Scholar]
- Qi, H.; Li, K.; Shen, Y.; Qu, W. An effective solution for trademark image retrieval by combining shape description and feature matching. Pattern Recognit. 2010, 43, 2017–2027. [Google Scholar] [CrossRef]
- Anuar, F.M.; Setchi, R.; Lai, Y. Trademark image retrieval using an integrated shape descriptor. Expert Systems with Applications. Expert Syst. Appl. 2013, 40, 105–121. [Google Scholar] [CrossRef]
- Liu, F.; Wang, B.; Zeng, F. Trademark image retrieval using hierarchical region feature description. In Proceedings of the 2017 IEEE International Conference on Image Processing (ICIP), Beijing, China, 17–20 September 2017; pp. 3620–3624. [Google Scholar]
- Toriu, T.; Miyazaki, M.; Miyazaki, K.; Toda, K.; Hama, H. A similar trademark retrieval system based on rotation invariant local features. In Proceedings of the 2016 2nd International Conference on Frontiers of Signal Processing (ICFSP), Warsaw, Poland, 15–17 October 2017; pp. 81–86. [Google Scholar]
- Feng, Y.; Shi, C.; Qi, C.; Xu, J.; Xiao, B.; Wang, C. Aggregation of reversal invariant features from edge images for large-scale trademark retrieval. In Proceedings of the 2018 4th International Conference on Control, Automation and Robotics (ICCAR), Auckland, New Zealand, 20–23 April 2018; pp. 384–388. [Google Scholar]
- Tursun, O.; Aker, C.; Kalkan, S. A large-scale dataset and benchmark for similar trademark retrieval. arXiv 2017, arXiv:1701.05766. [Google Scholar]
- Wang, W.; Xu, X.; Zhang, J.; Yang, L.; Song, G.; Huang, X. Trademark Image Retrieval Based on Faster R-CNN. J. Phys. Conf. Ser. 2019, 1237, 032042. [Google Scholar] [CrossRef]
- Tursun, O.; Denman, S.; Sivapalan, S.; Sridharan, S.; Fookes, C.; Mau, S. Component-based Attention for Large-scale Trademark Retrieval. Ieee Trans. Inf. Forensics Secur. 2019, 1. [Google Scholar] [CrossRef] [Green Version]
- Lan, T.; Feng, X.; Xia, Z.; Pan, S.; Peng, J. Similar Trademark Image Retrieval Integrating LBP and Convolutional Neural Network. In Proceedings of the Constructive Side-Channel Analysis and Secure Design; Springer International Publishing: Berlin/Heidelberg, Germany, 2017; pp. 231–242. [Google Scholar]
- Xia, Z.; Lin, J.; Feng, X. Trademark image retrieval via transformation-invariant deep hashing. J. Vis. Commun. Image Represent. 2019, 59, 108–116. [Google Scholar] [CrossRef]
- Wu, Z.; Xiong, Y.; Yu, S.X.; Lin, D. Unsupervised Feature Learning via Non-parametric Instance Discrimination. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 3733–3742. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2018; pp. 7132–7141. [Google Scholar]
- Qilong, W.; Banggu, W.; Pengfei, Z.; Peihua, L. ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Seattle, WA, USA, 14–19 June 2020; pp. 11531–11539. [Google Scholar]
- Doersch, C.; Zisserman, A. Multi-task Self-Supervised Visual Learning. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2070–2079. [Google Scholar]
- Doersch, C.; Gupta, A.; Efros, A.A. Unsupervised Visual Representation Learning by Context Prediction. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1422–1430. [Google Scholar]
- Goodfellow, I.J.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. Stat 2014, 1050, 10. [Google Scholar]
- Kingma, D.P.; Welling, M. Auto-encoding variational bayes. arXiv 2013, arXiv:1312.6114. [Google Scholar]
- Donahue, J.; Krähenbühl, P.; Darrell, T. Adversarial feature learning. arXiv 2016, arXiv:1605.09782. [Google Scholar]
- Schroff, F.; Kalenichenko, D.; Philbin, J. FaceNet: A unified embedding for face recognition and clustering. In Proceedings of the 2015 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Boston, MA, USA, 8–12 June 2015; pp. 815–823. [Google Scholar]
- Xiao, T.; Li, S.; Wang, B.; Lin, L.; Wang, X. Joint Detection and Identification Feature Learning for Person Search. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 3376–3385. [Google Scholar]
- Dosovitskiy, A.; Springenberg, J.T.; Riedmiller, M.; Brox, T. Discriminative Unsupervised Feature Learning with Convolutional Neural Networks. NIPS. 2014. Available online: http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.748.8912&rep=rep1&type=pdf (accessed on 26 June 2020).
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. Adv. Neural Inf. Process. Syst. 2012, 25, 1097–1105. [Google Scholar] [CrossRef]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module. In Proceedings of the Lecture Notes in Computer Science; Springer Science and Business Media LLC: Berlin/Heidelberg, Germany, 2018; pp. 3–19. [Google Scholar]
- Gao, Z.; Xie, J.; Wang, Q.; Li, P. Global Second-Order Pooling Convolutional Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3019–3028. [Google Scholar]
- Hu, J.; Shen, L.; Albanie, S.; Sun, G.; Vedaldi, A. Gather-Excite: Exploiting Feature Context in Convolutional Neural Networks. Adv. Neural Inf. Process. Syst. 2018, 31, 9401–9411. [Google Scholar]
- Park, J.; Woo, S.; Lee, J.Y.; Kweon, I. In Proceedings of the BAM: Bottleneck Attention Module. British Machine Vision Con-ference (BMVC), Newcastle, UK, 2–6 September 2018.
- Wang, X.; Girshick, R.; Gupta, A.; He, K. Non-local Neural Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7794–7803. [Google Scholar]
- Cao, Y.; Xu, J.; Lin, S.; Wei, F.; Hu, H. GCNet: Non-Local Networks Meet Squeeze-Excitation Networks and Beyond. In Proceedings of the 2019 IEEE/CVF International Conference on Computer Vision Workshop (ICCVW), Seoul, Korea, 27–28 October 2019; pp. 1971–1980. [Google Scholar]
- Fu, J.; Liu, J.; Tian, H.; Li, Y.; Bao, Y.; Fang, Z.; Lu, H. Dual Attention Network for Scene Segmentation. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 3141–3149. [Google Scholar]
- Chen, Y.; Kalantidis, Y.; Li, J.; Yan, S.; Feng, J. A 2-Nets: Double attention networks. In Proceedings of the 32nd International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 3–8 December 2018; pp. 350–359. [Google Scholar]
- Ioannou, Y.; Robertson, D.; Cipolla, R.; Criminisi, A. Deep Roots: Improving CNN Efficiency with Hierarchical Filter Groups. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 5977–5986. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1251–1258. [Google Scholar]
- Xie, S.; Girshick, R.; Dollar, P.; Tu, Z.; He, K. Aggregated Residual Transformations for Deep Neural Networks. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1492–1500. [Google Scholar]
- Zhang, T.; Qi, G.-J.; Xiao, B.; Wang, J. Interleaved Group Convolutions. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 4383–4392. [Google Scholar]
- Hinton, G.; Vinyals, O.; Dean, J. Distilling the Knowledge in a Neural Network. Stat 2015, 1050, 9. [Google Scholar]
- Gutmann, M.; Hyvärinen, A. Noise-contrastive estimation: A new estimation principle for unnormalized statistical models. In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, JMLR Workshop and Confer-ence Proceedings, Chia Laguna Resort, Sardinia, Italy, 13–15 May 2010; pp. 297–304. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Phan, R.; Androutsos, D. Content-based retrieval of logo and trademarks in unconstrained color image databases using color edge gradient co-occurrence histograms. Comput. Vis. Image Underst. 2010, 114, 66–84. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Oliva, A.; Torralba, A. Modeling the Shape of the Scene: A Holistic Representation of the Spatial Envelope. Int. J. Comput. Vis. 2001, 42, 145–175. [Google Scholar] [CrossRef]
- Her, I.; Mostafa, K.; Hung, H.K. A hybrid trademark retrieval system using four-gray-level zernike moments and image compactness indices. Int. J. Image Process. 2011, 4, 631–646. [Google Scholar]
- Lowe, D.G. Distinctive image features from scale-invariant keypoints. Int. J. Comput. Vis. 2004, 60, 91–110. [Google Scholar] [CrossRef]
- Bay, H.; Tuytelaars, T.; Van Gool, L. Surf: Speeded up Robust Features. European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2006; pp. 404–417. [Google Scholar]
- Dalal, N.; Triggs, B. Histograms of oriented gradients for human detection. In Proceedings of the 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, CVPR, San Diego, CA, USA, 20–25 June 2005. [Google Scholar]
- Vural, M.F.; Yardimci, Y.; Temlzel, A. Registration of multispectral satellite images with orientation-restricted SIFT. In Proceedings of the 2009 IEEE International Geoscience and Remote Sensing Symposium, Cape Town, South Africa, 12–17 July 2009. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- Li, X.; Wang, W.; Hu, X.; Yang, J. Selective Kernel Networks. In Proceedings of the 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 15–20 June 2019; pp. 510–519. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE international conference on computer vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | NAR ± MSE |
|---|---|
| CH 1 | 0.400 ± 0.175 |
| LBP 2 | 0.276 ± 0.142 |
| GIST 3 | 0.254 ± 0.173 |
| SC 4 | 0.220 ± 0.186 |
| HOG 5 | 0.262 ± 0.129 |
| SIFT 6 | 0.179 ± 0.145 |
| OR-SIFT 7 | 0.190 ± 0.151 |
| SURF 8 | 0.207 ± 0.151 |
| Our Method | 0.051 ± 0.002 |
| Method | NAR ± MSE |
|---|---|
| ResNet50 (FC1000) | 0.110 ± 0.133 |
| ResNet50 (Pool5) | 0.095 ± 0.138 |
| VGGNet16 (FC7) | 0.086 ± 0.107 |
| AlexNet (FC7) | 0.112 ± 0.171 |
| GoogleNet (77S1) | 0.118 ± 0.138 |
| VGG19v | 0.066 ± 0.130 |
| VGG19c | 0.063 ± 0.128 |
| VGG19v + VGG19c | 0.047 ± 0.095 |
| SENet | 0.056 ± 0.003 |
| SENet (ResNeXt) | 0.055 ± 0.008 |
| SKNet | 0.068 ± 0.002 |
| CBAM | 0.056 ± 0.003 |
| ResNet50 (dim = 128) | 0.063 ± 0.002 |
| Our Method | 0.051 ± 0.002 |
| Score Index | Pic1 | Pic2 | Pic3 | Pic4 |
|---|---|---|---|---|
| US_1 | 0.837 | 0.802 | 0.881 | 0.894 |
| US_2 | 0.821 | 0.744 | 0.824 | 0.731 |
| US_3 | 0.692 | 0.673 | 0.803 | 0.625 |
| US_4 | 0.667 | 0.661 | 0.752 | 0.612 |
| US_5 | 0.655 | 0.606 | 0.670 | 0.580 |
| RES_1 | 0.860 | 0.712 | 0.778 | 0.807 |
| RES_2 | 0.734 | 0.654 | 0.773 | 0.579 |
| RES_3 | 0.667 | 0.617 | 0.767 | 0.497 |
| RES_4 | 0.605 | 0.560 | 0.694 | 0.426 |
| RES_5 | 0.570 | 0.553 | 0.545 | 0.415 |
| US_AVG | 0.734 | 0.697 | 0.786 | 0.688 |
| RES_AVG | 0.687 | 0.619 | 0.711 | 0.545 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cao, J.; Huang, Y.; Dai, Q.; Ling, W.-K. Unsupervised Trademark Retrieval Method Based on Attention Mechanism. Sensors 2021, 21, 1894. https://doi.org/10.3390/s21051894
Cao J, Huang Y, Dai Q, Ling W-K. Unsupervised Trademark Retrieval Method Based on Attention Mechanism. Sensors. 2021; 21(5):1894. https://doi.org/10.3390/s21051894
Chicago/Turabian StyleCao, Jiangzhong, Yunfei Huang, Qingyun Dai, and Wing-Kuen Ling. 2021. "Unsupervised Trademark Retrieval Method Based on Attention Mechanism" Sensors 21, no. 5: 1894. https://doi.org/10.3390/s21051894
APA StyleCao, J., Huang, Y., Dai, Q., & Ling, W.-K. (2021). Unsupervised Trademark Retrieval Method Based on Attention Mechanism. Sensors, 21(5), 1894. https://doi.org/10.3390/s21051894