
Q-Meter: Quality Monitoring System for Telecommunication Services Based on Sentiment Analysis Using Deep Learning

 , , ,
, , ,  ,
,  and
and
Abstract
1. Introduction
- A method to classify the main subscriber complaints about cellular operator services based on OSN information is proposed. This work focuses on the weak signal problem because it was the most recurrent users’ claim. However, other topics can be easily addressed.
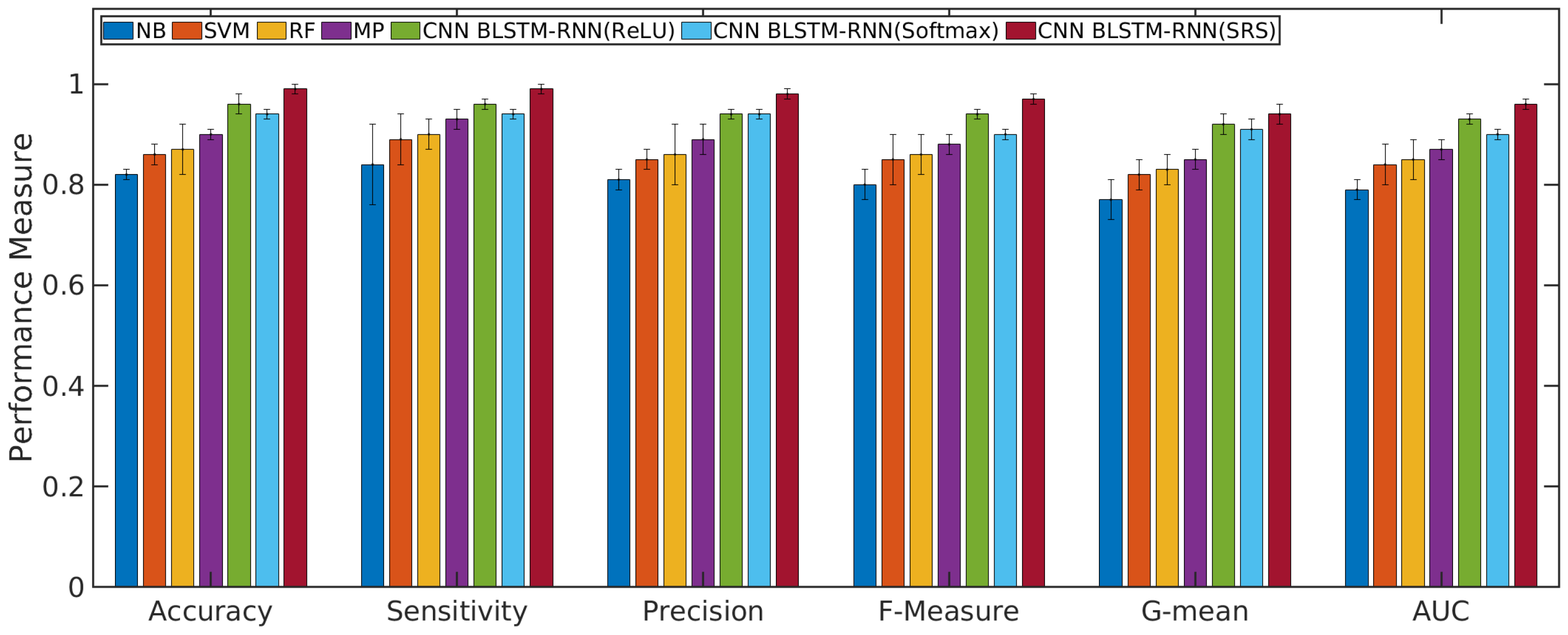
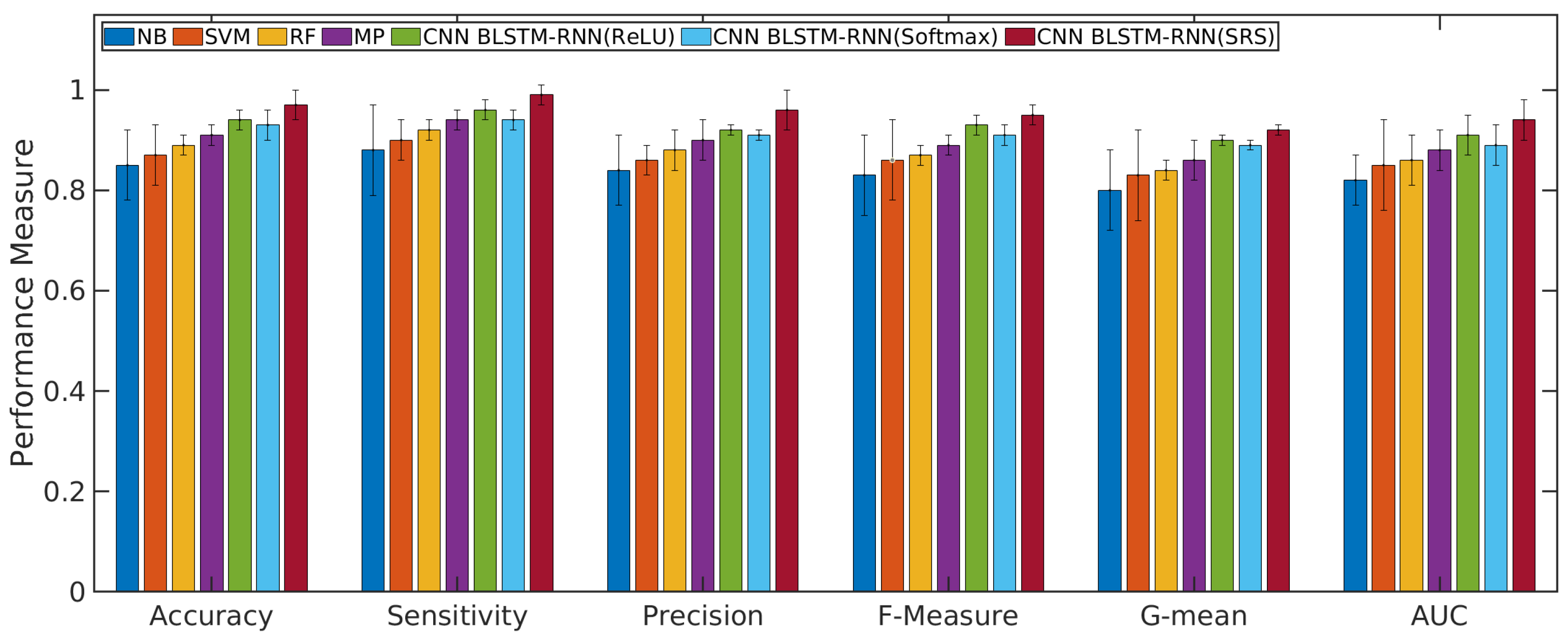
- The convolutional neural network (CNN), a bidirectional long short-term memory (BLSTM), recurrent neural network (RNN), and the soft-root-sign (SRS) activation function are tested and validated as a sentiment analysis tool in the area of telecommunication services. The proposed model overcame other similar machine learning algorithms.
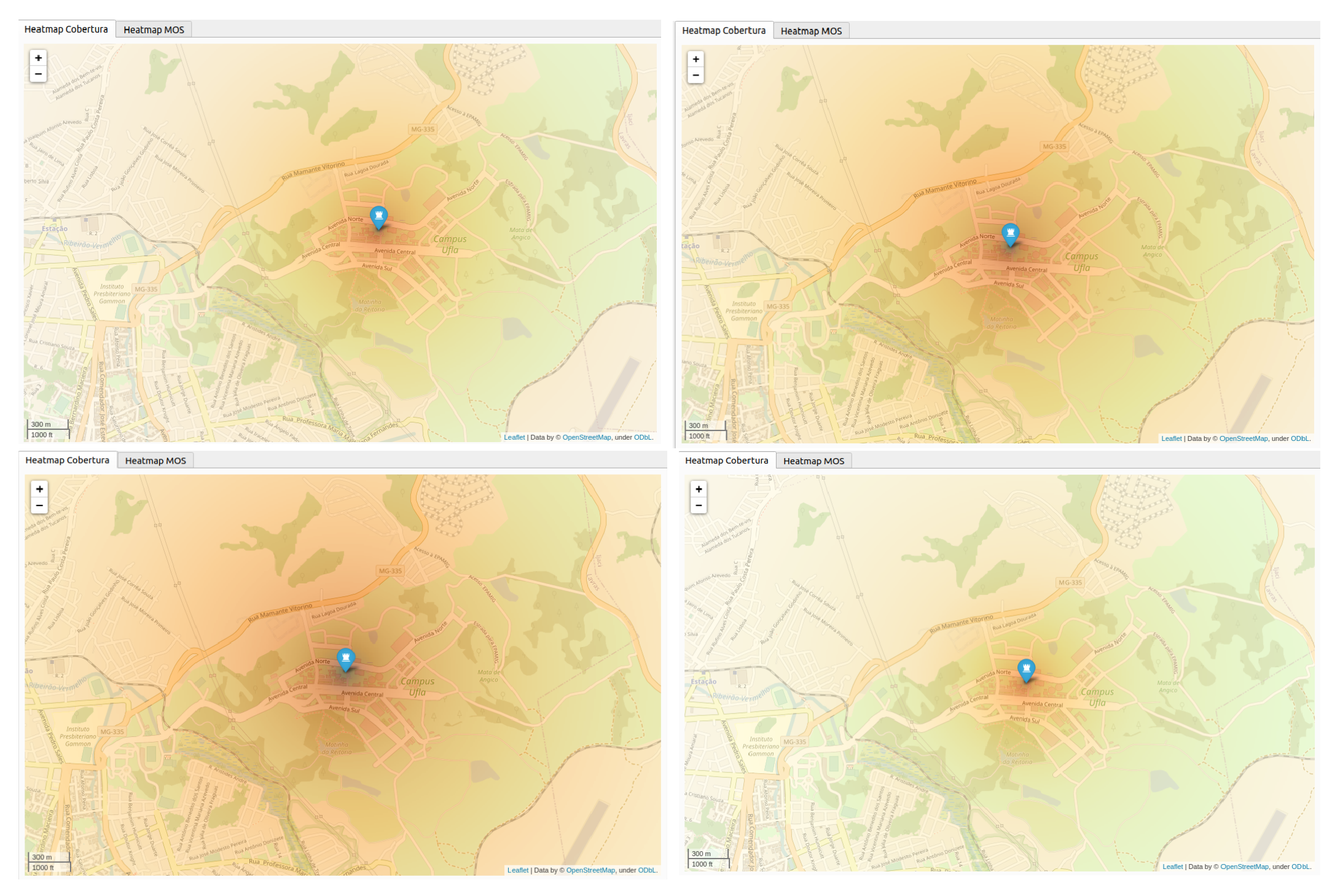
- Specific regions with possible coverage problems are automatically detected through the OSN. Thus, the Q-Meter can work as a real-time quality monitoring system for mobile communication networks.
- In general, the proposed Q-Meter will be useful for network operation and maintenance tasks, and its integration with commercial cellular networks, such as current and next generation 6G networks, will help to improve the network performance, and therefore, the users’ QoE. It is important to note that the Q-meter should not require either significant investments or complicated engineering operations.
2. Related Work
2.1. Sentiment Analysis
2.2. Monitoring System for Telecommunication Services
3. Methodology
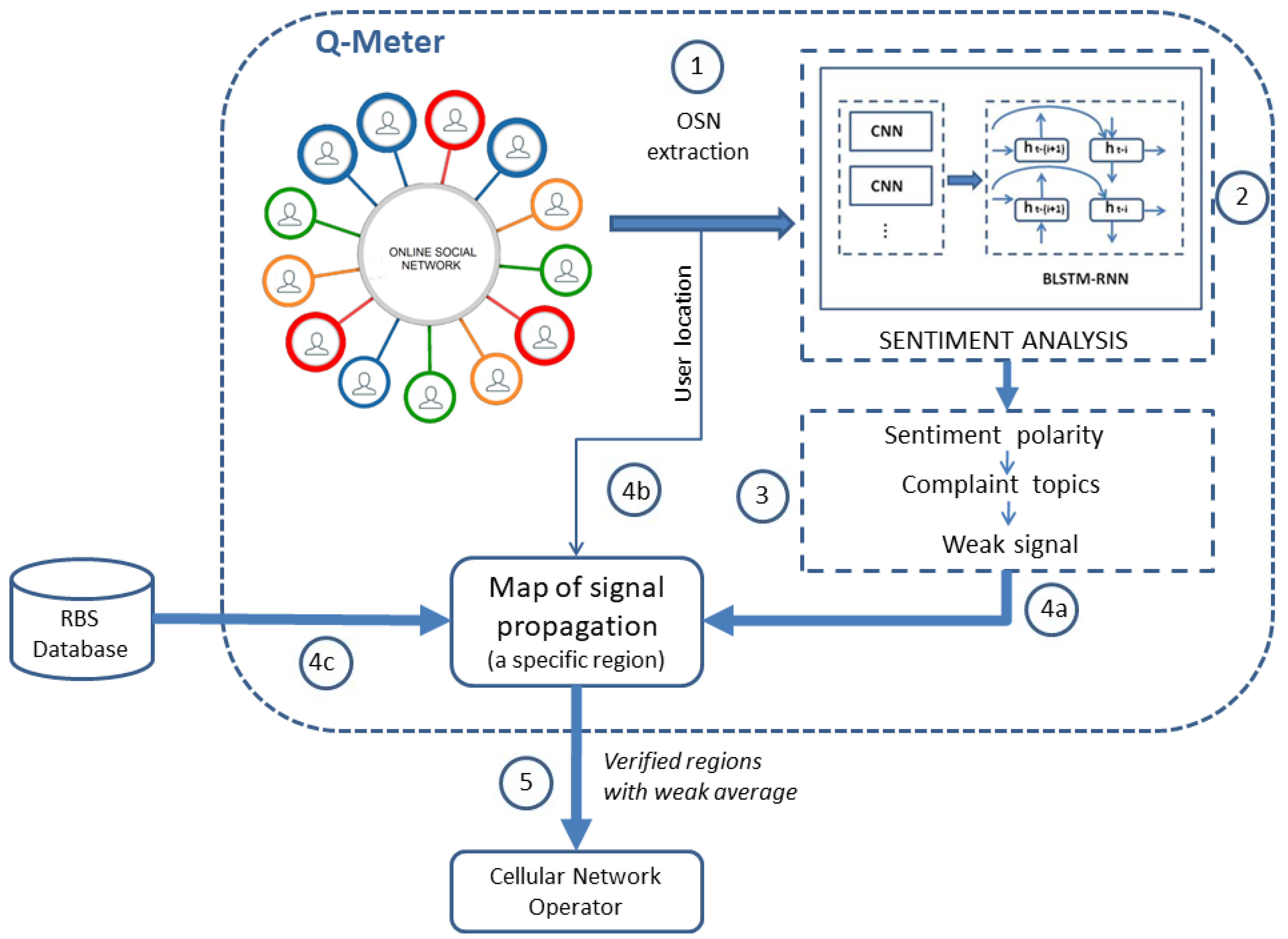
3.1. Proposed Measurement System Monitoring Telecommunication Services, Q-Meter
3.1.1. Online Social Network (OSN) Extraction
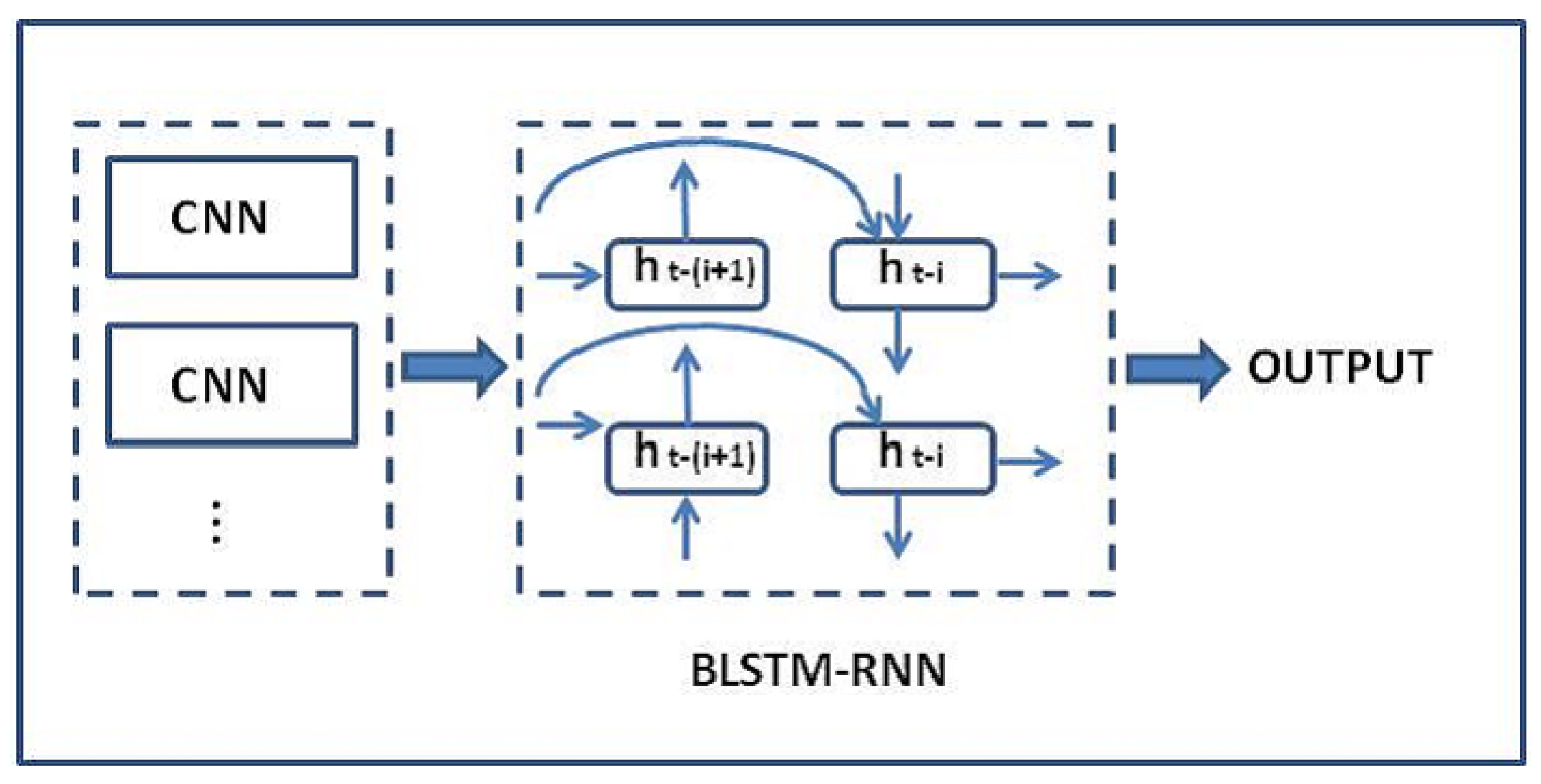
3.1.2. Sentiment Analysis
3.1.3. Complaint Topics Classification
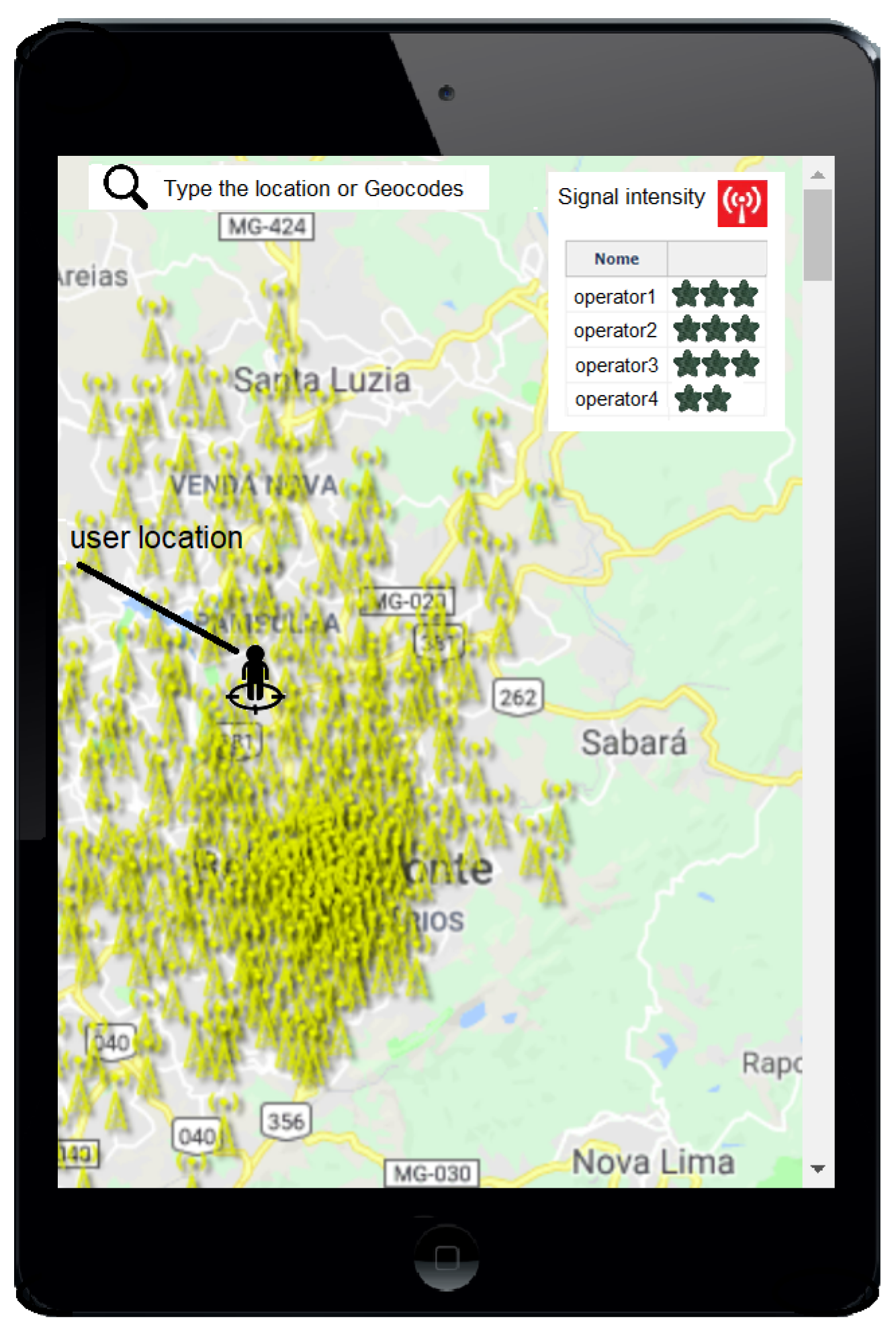
3.1.4. Map of Signal Propagation
3.1.5. Cellular Network Operator
3.2. Subjective Tests for Topic Classification and Sentiment Metric Evaluation
3.3. Performance Measures
4. Results and Discussion
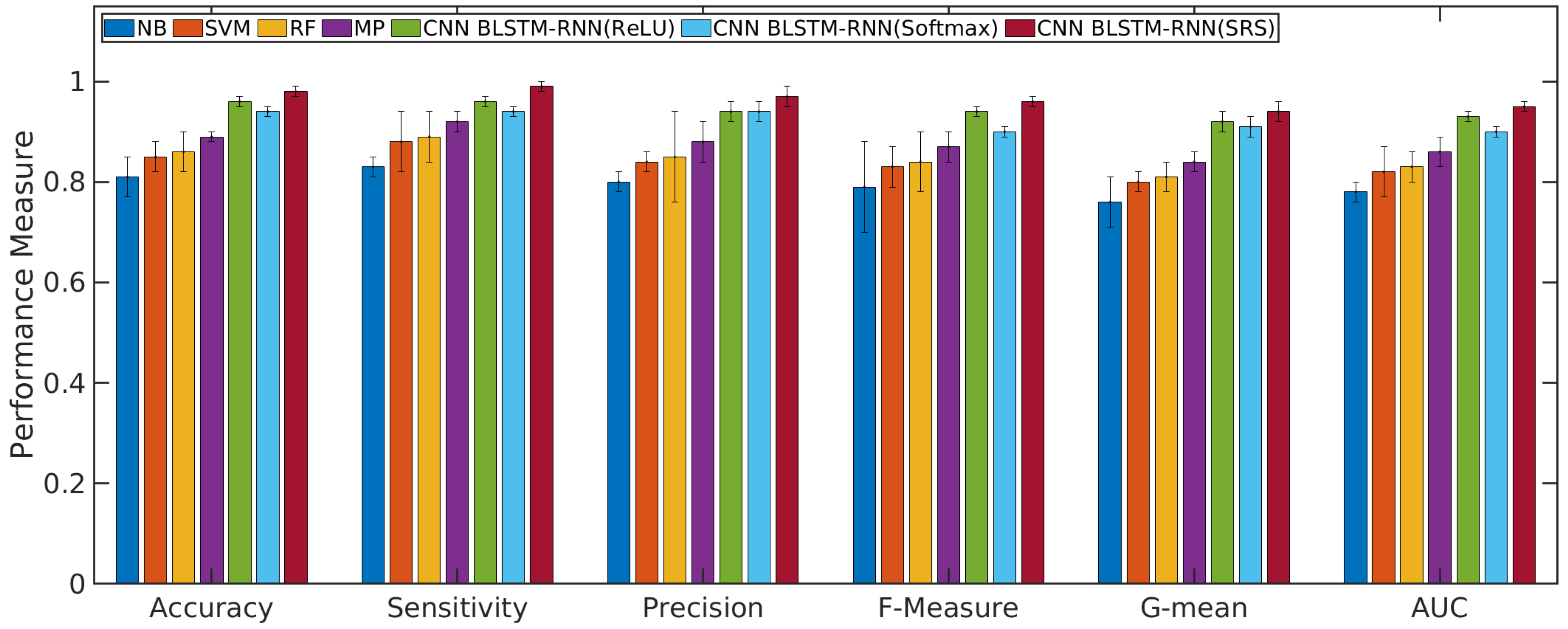
4.1. Performance Evaluation of the CNN with BLSTM-RNN and SRS Activation Function in Relation to Other Algorithms
4.2. Detection of Social Network Complaints about Telecommunication Services and Signal Coverage of the RBS
4.3. Performance Evaluation of the Sentiment Model by Subjective Tests
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Alharthi, R.; Guthier, B.; Guertin, C.; El Saddik, A. A Dataset for Psychological Human Needs Detection From Social Networks. IEEE Access 2017, 5, 9109–9117. [Google Scholar] [CrossRef]
- Rosa, R.; Rodriguez, D.Z.; Bressan, G. SentiMeter-Br: A Social Web Analysis Tool to Discover Consumers’ Sentiment. In Proceedings of the Digest of Technical Papers—IEEE International Conference on Consumer Electronics, Milan, Italy, 3–6 June 2013; pp. 153–154. [Google Scholar] [CrossRef]
- Cambria, E.; Schuller, B.; Xia, Y.; Havasi, C. New Avenues in Opinion Mining and Sentiment Analysis. IEEE Intell. Syst. 2013, 28, 15–21. [Google Scholar] [CrossRef]
- Ortigosa, A.; Martín, J.M.; Carro, R.M. Sentiment analysis in Facebook and its application to e-learning. Comput. Hum. Behav. 2014, 31, 527–541. [Google Scholar] [CrossRef]
- Zucco, C.; Bella, S.; Paglia, C.; Tabarini, P.; Cannataro, M. Predicting Abandonment in Telehomecare Programs Using Sentiment Analysis: A System Proposal. In Proceedings of the 2018 IEEE International Conference on Bioinformatics and Biomedicine (BIBM), Madrid, Spain, 3–6 December 2018; pp. 1734–1739. [Google Scholar]
- Rosa, R.L.; Rodriguez, D.Z.; Bressan, G. Music recommendation system based on user’s sentiments extracted from social networks. IEEE Trans. Consum. Electron. 2015, 61, 359–367. [Google Scholar] [CrossRef]
- Arulmurugan, R.; Sabarmathi, K.R.; Anandakumar, H. Classification of sentence level sentiment analysis using cloud machine learning techniques. Clust. Comput. 2019, 22, 1199–1209. [Google Scholar] [CrossRef]
- Guimarães, R.G.; Rosa, R.L.; De Gaetano, D.; Rodríguez, D.Z.; Bressan, G. Age Groups Classification in Social Network Using Deep Learning. IEEE Access 2017, 5, 10805–10816. [Google Scholar] [CrossRef]
- Chen, X.; Lin, X. Big Data Deep Learning: Challenges and Perspectives. IEEE Access 2014, 2, 514–525. [Google Scholar] [CrossRef]
- Militani, D.; Vieira, S.; Valadão, E.; Neles, K.; Rosa, R.; Rodríguez, D.Z. A Machine Learning Model to Resource Allocation Service for Access Point on Wireless Network. In Proceedings of the 2019 International Conference on Software, Telecommunications and Computer Networks (SoftCOM), Split, Croatia, 19–21 September 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Affonso, E.T.; Nunes, R.D.; Rosa, R.L.; Pivaro, G.F.; Rodríguez, D.Z. Speech Quality Assessment in Wireless VoIP Communication Using Deep Belief Network. IEEE Access 2018, 6, 77022–77032. [Google Scholar] [CrossRef]
- Zegarra Rodriguez, D.; Bressan, G. Video Quality Assessments on Digital TV and Video Streaming services using Objective Metrics. IEEE Lat. Am. Trans. 2012, 10, 1184–1189. [Google Scholar] [CrossRef]
- Socher, R.; Perelygin, A.; Wu, J.; Chuang, J.; Manning, C.; Ng, A.; Potts, C. Recursive deep models for semantic compositionality over a sentiment treebank. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing 2013, Seattle, WA, USA, 18–21 October 2013; pp. 1631–1642. [Google Scholar]
- Navas, E.; Hernaez, I.; Iker Luengo. An objective and subjective study of the role of semantics and prosodic features in building corpora for emotional TTS. IEEE Trans. Audio Speech Lang. Process. 2006, 14, 1117–1127. [Google Scholar] [CrossRef]
- Serrano-Guerrero, J.; Olivas, J.A.; Romero, F.P.; Herrera-Viedma, E. Sentiment analysis: A review and comparative analysis of web services. Inf. Sci. 2015, 311, 18–38. [Google Scholar] [CrossRef]
- Li, J.; Qiu, L. A Sentiment Analysis Method of Short Texts in Microblog. In Proceedings of the 2017 IEEE International Conference on Computational Science and Engineering (CSE) and IEEE International Conference on Embedded and Ubiquitous Computing (EUC), Guangzhou, China, 21–24 July 2017; Volume 1, pp. 776–779. [Google Scholar] [CrossRef]
- Corchs, S.; Fersini, E.; Gasparini, F. Ensemble learning on visual and textual data for social image emotion classification. Int. J. Mach. Learn. Cybern. 2019, 10, 2057–2070. [Google Scholar] [CrossRef]
- Zhang, Z.; Zou, Y.; Gan, C. Textual sentiment analysis via three different attention convolutional neural networks and cross-modality consistent regression. Neurocomputing 2018, 275, 1407–1415. [Google Scholar] [CrossRef]
- İrsoy, O.; Cardie, C. Deep Recursive Neural Networks for Compositionality in Language. In Proceedings of the 27th International Conference on Neural Information Processing Systems, NIPS’14; MIT Press: Cambridge, MA, USA, 2014; Volume 2, pp. 2096–2104. [Google Scholar]
- Shen, Q.; Wang, Z.; Sun, Y. Sentiment analysis of movie reviews based on cnn-blstm. In Proceedings of the International Conference on Intelligence Science, Shanghai, China, 25–28 October 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 164–171. [Google Scholar]
- Piyaphakdeesakun, C.; Facundes, N.; Polvichai, J. Thai Comments Sentiment Analysis on Social Networks with Deep Learning Approach. In Proceedings of the 2019 34th International Technical Conference on Circuits/Systems, Computers and Communications (ITC-CSCC), Jeju, Korea, 23–26 June 2019; pp. 1–4. [Google Scholar] [CrossRef]
- Rosa, R.L.; Schwartz, G.M.; Ruggiero, W.V.; Rodríguez, D.Z. A Knowledge-Based Recommendation System That Includes Sentiment Analysis and Deep Learning. IEEE Trans. Ind. Inform. 2019, 15, 2124–2135. [Google Scholar] [CrossRef]
- Omerustaoglu, F.; Sakar, C.O.; Kar, G. Distracted driver detection by combining in-vehicle and image data using deep learning. Appl. Soft Comput. 2020, 96, 106657. [Google Scholar] [CrossRef]
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Nair, V.; Hinton, G.E. Rectified Linear Units Improve Restricted Boltzmann Machines. In Proceedings of the 27th International Conference on International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; pp. 807–814. [Google Scholar]
- Ramachandran, P.; Zoph, B.; Le, Q.V. Searching for Activation Functions. arXiv 2017, arXiv:1710.05941. [Google Scholar]
- Goodfellow, I.J.; Warde-Farley, D.; Mirza, M.; Courville, A.; Bengio, Y. Maxout Networks. arXiv 2013, arXiv:1302.4389. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 11–18 December 2015; pp. 1026–1034. [Google Scholar]
- Zhou, Y.; Li, D.; Huo, S.; Kung, S.Y. Soft-Root-Sign Activation Function. arXiv 2020, arXiv:2003.00547. [Google Scholar]
- Rodríguez, D.Z.; Rosa, R.L.; Bressan, G. A billing system model for voice call service in cellular networks based on voice quality. In Proceedings of the 2013 IEEE International Symposium on Consumer Electronics (ISCE), Hsinchu City, Taiwan, 3–6 June 2013; pp. 89–90. [Google Scholar] [CrossRef]
- Asuquo, D. An Efficient Model for Reducing Soft Blocking Probability in Wireless Cellular Networks. Int. J. Wirel. Mob. Netw. 2014, 6, 85–99. [Google Scholar] [CrossRef]
- Pierucci, L.; Micheli, D. A Neural Network for Quality of Experience Estimation in Mobile Communications. IEEE Multimed. 2016, 23, 42–49. [Google Scholar] [CrossRef]
- Grigoriou, E.; Saoulidis, T.; Atzori, L.; Pilloni, V.; Chatzimisios, P. An Agent-Based QoE Monitoring Strategy for LTE Networks. In Proceedings of the 2018 IEEE International Conference on Communications (ICC), Kansas City, MO, USA, 20–24 May 2018; pp. 1–6. [Google Scholar]
- Mathar, R.; Niessen, T. Optimum Positioning of Base Stations for Cellular Radio Networks. Wirel. Netw. 2000, 6, 421–428. [Google Scholar] [CrossRef]
- Ullah, I.; Raza, B.; Malik, A.K.; Imran, M.; Islam, S.U.; Kim, S.W. A Churn Prediction Model Using Random Forest: Analysis of Machine Learning Techniques for Churn Prediction and Factor Identification in Telecom Sector. IEEE Access 2019, 7, 60134–60149. [Google Scholar] [CrossRef]
- Almuqren, L.A.R.; Qasem, M.M.; Cristea, A.I. Using Deep Learning Networks to Predict Telecom Company Customer Satisfaction Based on Arabic Tweets. In Proceedings of the Information Systems Development: Information Systems Beyond 2020, Toulon, France, 28–30 August 2019. [Google Scholar]
- Woo, J.; Kang, S.W.; Kim, H.K.; Park, J. Contagion of Cheating Behaviors in Online Social Networks. IEEE Access 2018, 6, 29098–29108. [Google Scholar] [CrossRef]
- Liu, D.; Huang, J.; Lin, C. Recommendation With Social Roles. IEEE Access 2018, 6, 36420–36427. [Google Scholar] [CrossRef]
- Datsika, E.; Antonopoulos, A.; Zorba, N.; Verikoukis, C. Green Cooperative Device–to–Device Communication: A Social–Aware Perspective. IEEE Access 2016, 4, 3697–3707. [Google Scholar] [CrossRef]
- Huang, Q.; Yue, W.; He, Y.; Yang, Y. Secure Identity-Based Data Sharing and Profile Matching for Mobile Healthcare Social Networks in Cloud Computing. IEEE Access 2018, 6, 36584–36594. [Google Scholar] [CrossRef]
- Hew, K.F. Students’ and teachers’ use of Facebook. Comput. Hum. Behav. 2011, 27, 662–676. [Google Scholar] [CrossRef]
- Ernst, C.P.H. The Influence of Perceived Belonging on Social Network Site Usage. In Factors Driving Social Network Site Usage; Springer Fachmedien Wiesbaden: Wiesbaden, Germany, 2015; pp. 29–44. [Google Scholar]
- Hoadley, C.M.; Xu, H.; Lee, J.J.; Rosson, M.B. Privacy as information access and illusory control: The case of the Facebook News Feed privacy outcry. Electron. Commer. Res. Appl. 2010, 9, 50–60. [Google Scholar] [CrossRef]
- Rosen, P.; Kluemper, D. The Impact of the Big Five Personality Traits on the Acceptance of Social Networking Website. Peter A. Rosen 2008, 2, 274. [Google Scholar]
- Sledgianowski, D.; Kulviwat, S. Using Social Network Sites: The Effects of Playfulness, Critical Mass and Trust in a Hedonic Context. J. Comput. Inf. Syst. 2009, 49, 74–83. [Google Scholar]
- Tan, C.; Lee, L. All Who Wander: On the Prevalence and Characteristics of Multi-community Engagement. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015. [Google Scholar]
- Ali, O.G.; Ariturk, U. Dynamic Churn Prediction Framework with More Effective Use of Rare Event Data: The Case of Private Banking. Expert Syst. Appl. 2014, 41, 7889–7903. [Google Scholar]
- Glady, N.; Baesens, B.; Croux, C. Modeling churn using customer lifetime value. Eur. J. Oper. Res. 2009, 197, 402–411. [Google Scholar] [CrossRef]
- Larivière, B.; den Poel, D.V. Investigating the role of product features in preventing customer churn, by using survival analysis and choice modeling: The case of financial services. Expert Syst. Appl. 2004, 27, 277–285. [Google Scholar] [CrossRef]
- Xie, Y.; Li, X.; Ngai, E.; Ying, W. Customer churn prediction using improved balanced random forests. Expert Syst. Appl. 2009, 36, 5445–5449. [Google Scholar] [CrossRef]
- Guillén, M.; Nielsen, J.P.; Scheike, T.H.; Pérez-Marín, A.M. Time-varying effects in the analysis of customer loyalty: A case study in insurance. Expert Syst. Appl. 2012, 39, 3551–3558. [Google Scholar] [CrossRef]
- Khan, A.A.; Jamwal, S.; Sepehri, M.M. Article:Applying Data Mining to Customer Churn Prediction in an Internet Service Provider. Int. J. Comput. Appl. 2010, 9, 8–14. [Google Scholar]
- Chen, Z.Y.; Fan, Z.P.; Sun, M. A hierarchical multiple kernel support vector machine for customer churn prediction using longitudinal behavioral data. Eur. J. Oper. Res. 2012, 223, 461–472. [Google Scholar] [CrossRef]
- Óskarsdóttir, M.; Bravo, C.; Verbeke, W.; Sarraute, C.; Baesens, B.; Vanthienen, J. Social network analytics for churn prediction in telco: Model building, evaluation and network architecture. Expert Syst. Appl. 2017, 85, 204–220. [Google Scholar] [CrossRef]
- Verbeke, W.; Dejaeger, K.; Martens, D.; Hur, J.; Baesens, B. New insights into churn prediction in the telecommunication sector: A profit driven data mining approach. Eur. J. Oper. Res. 2012, 218, 211–229. [Google Scholar] [CrossRef]
- Sv, S.; Geetha, A.; Sathiynarayanan, R. Sentiment Analysis of Twitter and RSS News Feeds and Its Impact on Stock Market Prediction. Int. J. Intell. Eng. Syst. 2017, 10, 68–77. [Google Scholar] [CrossRef]
- Fabbri, T.; Mandreoli, F.; Martoglia, R.; Scapolan, A.C. Employee Attitudes and (Digital) Collaboration Data: A Preliminary Analysis in the HRM Field. In Proceedings of the 2019 28th International Conference on Computer Communication and Networks (ICCCN), Valencia, Spain, 29 July–1 August 2019; pp. 1–6. [Google Scholar]
- Sever, N.; Humski, L.; Ilić, J.; Skočir, Z.; Pintar, D.; Vranić, M. Applying the multiclass classification methods for the classification of online social network friends. In Proceedings of the 2017 25th International Conference on Software, Telecommunications and Computer Networks (SoftCOM), Split, Croatia, 21–23 September 2017; pp. 1–6. [Google Scholar] [CrossRef]
- Wu, X.; Zhu, X.; Wu, G.; Ding, W. Data mining with big data. IEEE Trans. Knowl. Data Eng. 2014, 26, 97–107. [Google Scholar]
- Xie, Y.; Li, X.; Ngai, E.; Ying, W. Sentiment analysis algorithms and applications: A survey. Ain Shams Eng. J. 2014, 5, 1093–1113. [Google Scholar]
- Wilson, T.; Wiebe, J.; Hoffmann, P. Recognizing Contextual Polarity in Phrase-level Sentiment Analysis. In Proceedings of the Conference on Human Language Technology and Empirical Methods in Natural Language Processing, Vancouver, BC, Canada, 6–8 October 2005; pp. 347–354. [Google Scholar]
- Turney, P.D. Thumbs Up or Thumbs Down?: Semantic Orientation Applied to Unsupervised Classification of Reviews. In Proceedings of the 40th Annual Meeting on Association for Computational Linguistics, ACL ’02, Philadelphia, PA, USA, 6–12 July 2002; Association for Computational Linguistics: Stroudsburg, PA, USA, 2002; pp. 417–424. [Google Scholar] [CrossRef]
- Hammarström, H.; Borin, L. Unsupervised Learning of Morphology. Comput. Linguist. 2011, 37, 309–350. [Google Scholar] [CrossRef]
- Jianqiang, Z.; Xiaolin, G. Comparison Research on Text Pre-processing Methods on Twitter Sentiment Analysis. IEEE Access 2017, 5, 2870–2879. [Google Scholar] [CrossRef]
- Guimarães, R.; Rodríguez, D.Z.; Rosa, R.L.; Bressan, G. Recommendation system using sentiment analysis considering the polarity of the adverb. In Proceedings of the 2016 IEEE International Symposium on Consumer Electronics (ISCE), Sao Paulo, Brazil, 28–30 September 2016; pp. 71–72. [Google Scholar]
- Uylas Sati, N.; Ordin, B. Application of the Polyhedral Conic Functions Method in the Text Classification and Comparative Analysis. Sci. Program. 2018, 2018, 5349284. [Google Scholar] [CrossRef]
- Hasan, A.; Moin, S.; Karim, A.; Shamshirband, S. Machine Learning-Based Sentiment Analysis for Twitter Accounts. Math. Comput. Appl. 2018, 23, 11. [Google Scholar] [CrossRef]
- Thelwall, M.; Buckley, K.; Paltoglou, G. Sentiment Strength Detection for the Social Web. J. Am. Soc. Inf. Sci. Technol. 2012, 63, 163–173. [Google Scholar] [CrossRef]
- Mouthami, K.; Devi, K.N.; Bhaskaran, V.M. Sentiment analysis and classification based on textual reviews. In Proceedings of the 2013 International Conference on Information Communication and Embedded Systems (ICICES), Chennai, India, 21–22 February 2013; pp. 271–276. [Google Scholar]
- Tripathy, A.; Agrawal, A.; Rath, S.K. Classification of Sentimental Reviews Using Machine Learning Techniques. Procedia Comput. Sci. 2015, 57, 821–829. [Google Scholar] [CrossRef]
- Schuller, B.; Batliner, A.; Steidl, S.; Seppi, D. Recognising realistic emotions and affect in speech: State of the art and lessons learnt from the first challenge. Speech Commun. 2011, 53, 1062–1087. [Google Scholar] [CrossRef]
- Desai, M.; Mehta, M.A. Techniques for sentiment analysis of Twitter data: A comprehensive survey. In Proceedings of the 2016 International Conference on Computing, Communication and Automation (ICCCA), Greater Noida, India, 29–30 April 2016; pp. 149–154. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bulatov, Y.; Ibarz, J.; Arnoud, S.; Shet, V. Multi-digit Number Recognition from Street View Imagery using Deep Convolutional Neural Networks. arXiv 2013, arXiv:1312.6082. [Google Scholar]
- Safari, P.; Ghahabi, O.; Hernando, J. Feature classification by means of deep belief networks for speaker recognition. In Proceedings of the 2015 23rd European Signal Processing Conference (EUSIPCO), Nice, France, 31 August–4 September 2015; pp. 2117–2121. [Google Scholar] [CrossRef]
- Poria, S.; Cambria, E.; Gelbukh, A. Deep Convolutional Neural Network Textual Features and Multiple Kernel Learning for Utterance-level Multimodal Sentiment Analysis. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 2539–2544. [Google Scholar] [CrossRef]
- Zhao, H.; Hou, C.; Alrobassy, H.; Zeng, X. Recognition of Transportation State by Smartphone Sensors Using Deep Bi-LSTM Neural Network. J. Comput. Netw. Commun. 2019, 2019, 1–11. [Google Scholar] [CrossRef]
- Mishra, A.; Reddy, U.S. A Novel Approach for Churn Prediction Using Deep Learning. In Proceedings of the 2017 IEEE International Conference on Computational Intelligence and Computing Research (ICCIC), Coimbatore, India, 14–16 December 2017; pp. 1–4. [Google Scholar] [CrossRef]
- Zhang, X.; Zou, Y.; Shi, W. Dilated convolution neural network with LeakyReLU for environmental sound classification. In Proceedings of the 2017 22nd International Conference on Digital Signal Processing (DSP), London, UK, 23–25 August2017; pp. 1–5. [Google Scholar]
- Li, Y.; Fan, C.; Li, Y.; Wu, Q.; Ming, Y. Improving deep neural network with Multiple Parametric Exponential Linear Units. Neurocomputing 2018, 301, 11–24. [Google Scholar] [CrossRef]
- Jony, R.; Habib, M.A.; Mohammed, N.; Rony, R.I. Big Data Use Case Domains for Telecom Operators. In Proceedings of the IEEE International Conference on Smart City/SocialCom/SustainCom (SmartCity), Chengdu, China, 19–21 December 2015. [Google Scholar] [CrossRef]
- Zheng, K.; Yang, Z.; Zhang, K.; Chatzimisios, P.; Yang, K.; Xiang, W. Big data-driven optimization for mobile networks toward 5G. IEEE Netw. 2016, 30, 44–51. [Google Scholar] [CrossRef]
- Huang, Y.; Kechadi, T. An effective hybrid learning system for telecommunication churn prediction. Expert Syst. Appl. 2013, 40, 5635–5647. [Google Scholar] [CrossRef]
- Umayaparvathi, V.; Iyakutti, K. Automated Feature Selection and Churn Prediction using Deep Learning Models. Int. Res. J. Eng. Technol. 2017, 4, 1846–1854. [Google Scholar]
- Zhang, R.; Li, W.; Tan, W.; Mo, T. Deep and Shallow Model for Insurance Churn Prediction Service. In Proceedings of the 2017 IEEE International Conference on Services Computing (SCC), Honolulu, HI, USA, 25–30 June 2017; pp. 346–353. [Google Scholar]
- Sharma, A.; Panigrahi, P.K. A Neural Network based Approach for Predicting Customer Churn in Cellular Network Services. Int. J. Comput. Appl. 2011, 27, 26–31. [Google Scholar] [CrossRef]
- Jahromi, A.; Moeini, M.; Akbari, I.; Akbarzadeh, A. A Dual-Step Multi-Algorithm Approach for Churn Prediction in Pre-Paid Telecommunications Service Providers. J. Innov. Sustain. 2010, 1. [Google Scholar] [CrossRef]
- Amin, A.; Shah, B.; Khattak, A.M.; Moreira, F.J.L.; Ali, G.; Rocha, A.; Anwar, S. Cross-company customer churn prediction in telecommunication: A comparison of data transformation methods. Int. J. Inf. Manag. 2019, 46, 304–319. [Google Scholar] [CrossRef]
- Bakshy, E.; Hofman, J.M.; Mason, W.A.; Watts, D.J. Everyone’s an Influencer: Quantifying Influence on Twitter. In Proceedings of the Fourth ACM International Conference on Web Search and Data Mining, WSDM ’11, Hong Kong, China, 9–12 February 2011; pp. 65–74. [Google Scholar]
- Perera, R.D.W.; Anand, S.; Subbalakshmi, K.P.; Chandramouli, R. Twitter analytics: Architecture, tools and analysis. In Proceedings of the MILCOM Military Communications Conference, San Jose, CA, USA, 31 October–3 November 2010; pp. 2186–2191. [Google Scholar]
- Vaughan-Nichols, S.J. Will Mobile Computing’s Future Be Location, Location, Location? Computer 2009, 42, 14–17. [Google Scholar] [CrossRef]
- Musolesi, M. Big Mobile Data Mining: Good or Evil? IEEE Internet Comput. 2014, 18, 78–81. [Google Scholar] [CrossRef]
- Ma, X.; Hovy, E. End-to-end Sequence Labeling via Bi-directional LSTM-CNNs-CRF. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Berlin, Germany, 7–12 August 2016; pp. 1064–1074. [Google Scholar]
- Lample, G.; Ballesteros, M.; Subramanian, S.; Kawakami, K.; Dyer, C. Neural Architectures for Named Entity Recognition. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 260–270. [Google Scholar]
- Bastien, F.; Lamblin, P.; Pascanu, R.; Bergstra, J.; Goodfellow, I.; Bergeron, A.; Bouchard, N.; Warde-Farley, D.; Bengio, Y. Theano: New features and speed improvements. arXiv 2012, arXiv:1211.5590. [Google Scholar]
- Ma, H.; Mao, F.; Taylor, G.W. Theano-MPI: A Theano-Based Distributed Training Framework. In Euro-Par 2016: Parallel Processing Workshops; Desprez, F., Dutot, P.F., Kaklamanis, C., Marchal, L., Molitorisz, K., Ricci, L., Scarano, V., Vega-Rodríguez, M.A., Varbanescu, A.L., Hunold, S., et al., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 800–813. [Google Scholar]
- Fushiki, T. Estimation of prediction error by using K-fold cross-validation. Stat. Comput. 2011, 21, 137–146. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Training | Execution |
|---|---|---|
| (min) | (min) | |
| NB | 85 | 27 |
| SVM | 91 | 29 |
| RF | 101 | 31 |
| MP | 129 | 41 |
| CNN BLSTM-RNN (ReLU) | 157 | 51 |
| CNN BLSTM-RNN (Softmax) | 154 | 55 |
| CNN BLSTM-RNN (SRS) | 131 | 34 |
| Operator | Weak Signal | Other Complaint |
|---|---|---|
| 1 | 66.0% | 34.0% |
| 2 | 67.0% | 33.0% |
| 3 | 70.7% | 29.3% |
| 4 | 79.1% | 19.9% |
| Operator | Real Weak Signal |
|---|---|
| 1 | 89% |
| 2 | 91% |
| 3 | 87% |
| 4 | 92% |
| Characteristics | Values |
|---|---|
| Environment | Conservative/City |
| RBS-Latitude | −19.9190677 |
| RBS-Longitude | −43.9427914 |
| Transmission Height | 25.0 m |
| Transmission Power | 6.0 W |
| Receiving Height | 1.5 m |
| Receiving Gain | 2.14 dBi |
| Initial Frequency | 2670.00000000 MHz |
| Final Frequency | 2690.00000000 MHz |
| Sentiment Metric | % of Assertiveness |
|---|---|
| CNN with BLSTM-RNN and SRS | 98% |
| SentiMeter-Br | 89% |
| LSTM with GRU | 92% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Terra Vieira, S.; Lopes Rosa, R.; Zegarra Rodríguez, D.; Arjona Ramírez, M.; Saadi, M.; Wuttisittikulkij, L. Q-Meter: Quality Monitoring System for Telecommunication Services Based on Sentiment Analysis Using Deep Learning. Sensors 2021, 21, 1880. https://doi.org/10.3390/s21051880
Terra Vieira S, Lopes Rosa R, Zegarra Rodríguez D, Arjona Ramírez M, Saadi M, Wuttisittikulkij L. Q-Meter: Quality Monitoring System for Telecommunication Services Based on Sentiment Analysis Using Deep Learning. Sensors. 2021; 21(5):1880. https://doi.org/10.3390/s21051880
Chicago/Turabian StyleTerra Vieira, Samuel, Renata Lopes Rosa, Demóstenes Zegarra Rodríguez, Miguel Arjona Ramírez, Muhammad Saadi, and Lunchakorn Wuttisittikulkij. 2021. "Q-Meter: Quality Monitoring System for Telecommunication Services Based on Sentiment Analysis Using Deep Learning" Sensors 21, no. 5: 1880. https://doi.org/10.3390/s21051880
APA StyleTerra Vieira, S., Lopes Rosa, R., Zegarra Rodríguez, D., Arjona Ramírez, M., Saadi, M., & Wuttisittikulkij, L. (2021). Q-Meter: Quality Monitoring System for Telecommunication Services Based on Sentiment Analysis Using Deep Learning. Sensors, 21(5), 1880. https://doi.org/10.3390/s21051880