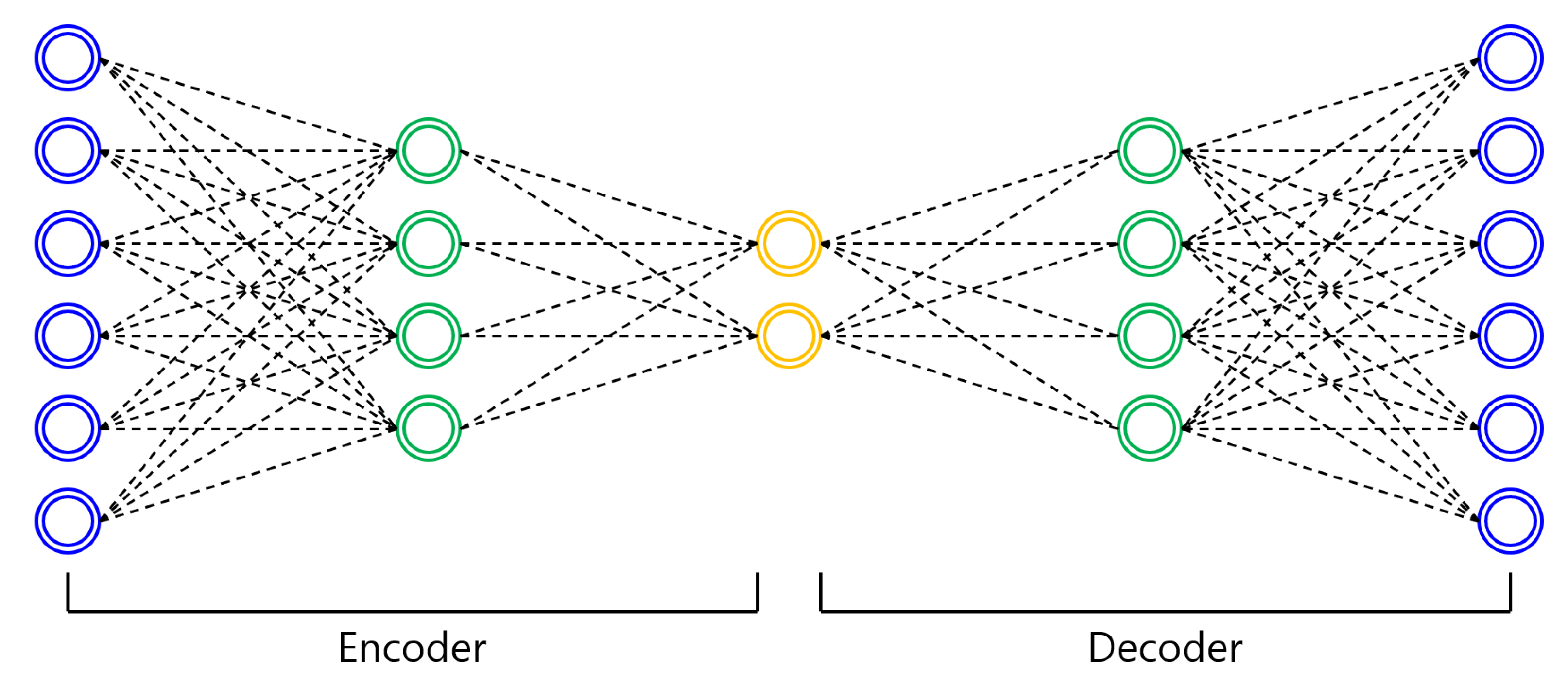
The proposed method, that is, NRA, has an autoencoder structure and research has been conducted to reduce losses that occur in the process of compressing and decompressing features and losses that occur in the process of expanding extracted features. Existing methods use the rectified linear unit (ReLU) [
12] as an activation function in the encoder process of extracting features. ReLU treats negative regions as 0, so feature loss occurs, but the learning speed is fast. Instead of using ReLU, the conventional method uses a model in the backbone network where a large dataset is trained to prevent feature loss. The backbone network requires pre-trained weights, and there is a limit to model transformation. Most of the input images are also fixed and the model becomes heavier.
The proposed method aims to improve the heaviness of the model, change the size of the input image according to the user’s computer performance, and minimize the feature loss at the encoder stage. ELU is used as an activation function to avoid the feature loss problem that occurs in ReLU. The exponential linear unit (ELU) activation function is used in the encoding process to compress and extract features and utilize them in the negative region. The NRA provided for the extracted features can be used to suppress non-object areas in the negative areas and emphasize the contour and texture information of the objects in the positive areas. The decoding process, which enlarges the extracted features to the size of the input image, utilizes the features in the encoding stage through concatenation. Through this process, an improved saliency map is generated. The detection flowchart using NRA proposed in this paper is shown in
Figure 2.
3.1. Feature Extraction Using the Proposed Attention
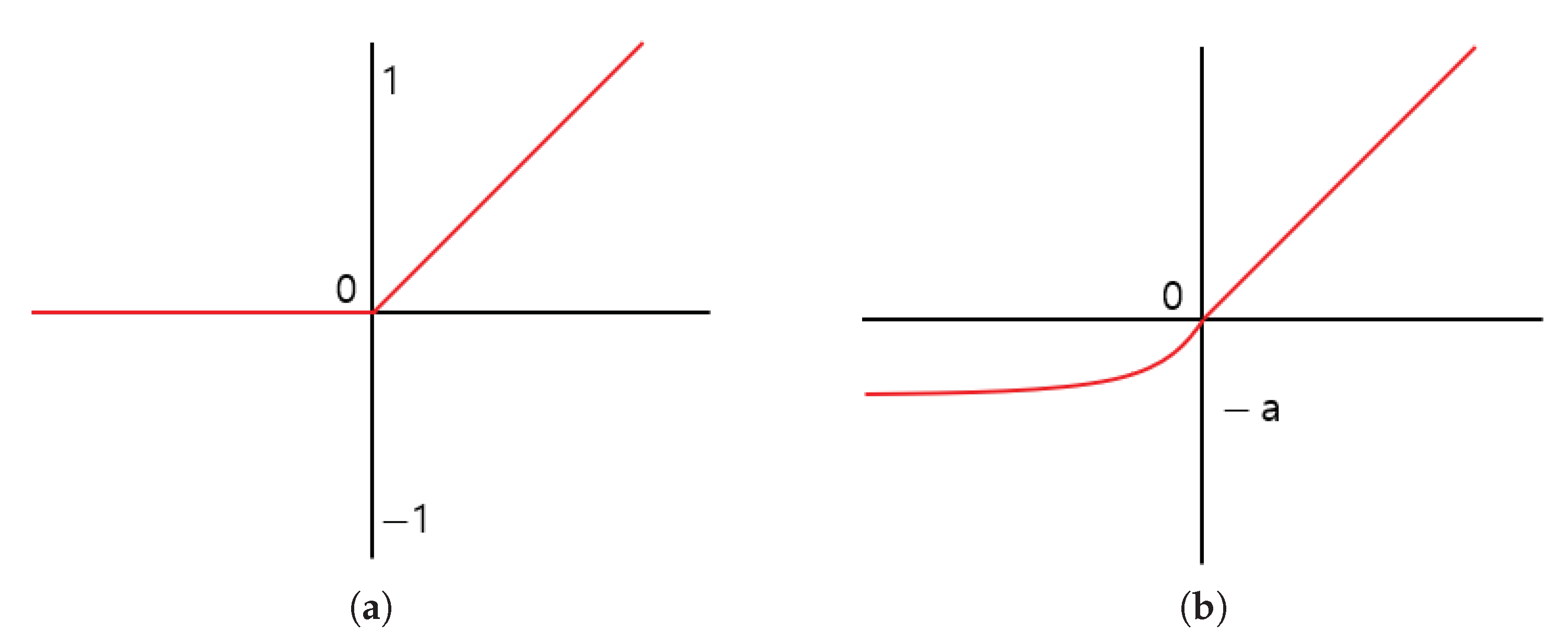
In a deep learning-based method, the convolution operation results involve negative and positive regions. The conventional method uses ReLU activation function to determine which node to pass to the next layer. The ReLU activation function treats the negative region as 0 and causes feature loss in the feature extraction process. Accordingly, the proposed method utilizes the negative region and uses the Exponential Linear Unit (ELU) [
13] activation function to prevent feature loss. The positive region of the ELU activation function is processed similarly as the ReLU activation function, and the negative region has a convergence form of (
1) and (
2). Equations (
1) and (
2) are the equations of the ReLU and ELU activation functions, respectively, where the
function was used in the negative region in ELU. The graphs of the activation functions are presented in
Figure 3.
As shown in
Figure 3, the graph of the ELU activation function directly outputs the input in the positive region, but in the negative region, it is normalized so that it is not outputted immediately and converges to
. By setting the values of a, the influence of the negative region can be limited. The proposed method uses all the characteristics of the positive and negative regions by setting a to 1, but the negative region has little effect.
When the value of a is set large, the effect of the negative region becomes large in the complete data representation, and the texture information around the boundary information in which the amount of data change is large is expressed in various ways. The proposed method uses integrated texture information rather than various texture information in the negative area and sets the value of a to 1 to suppress non-object areas.
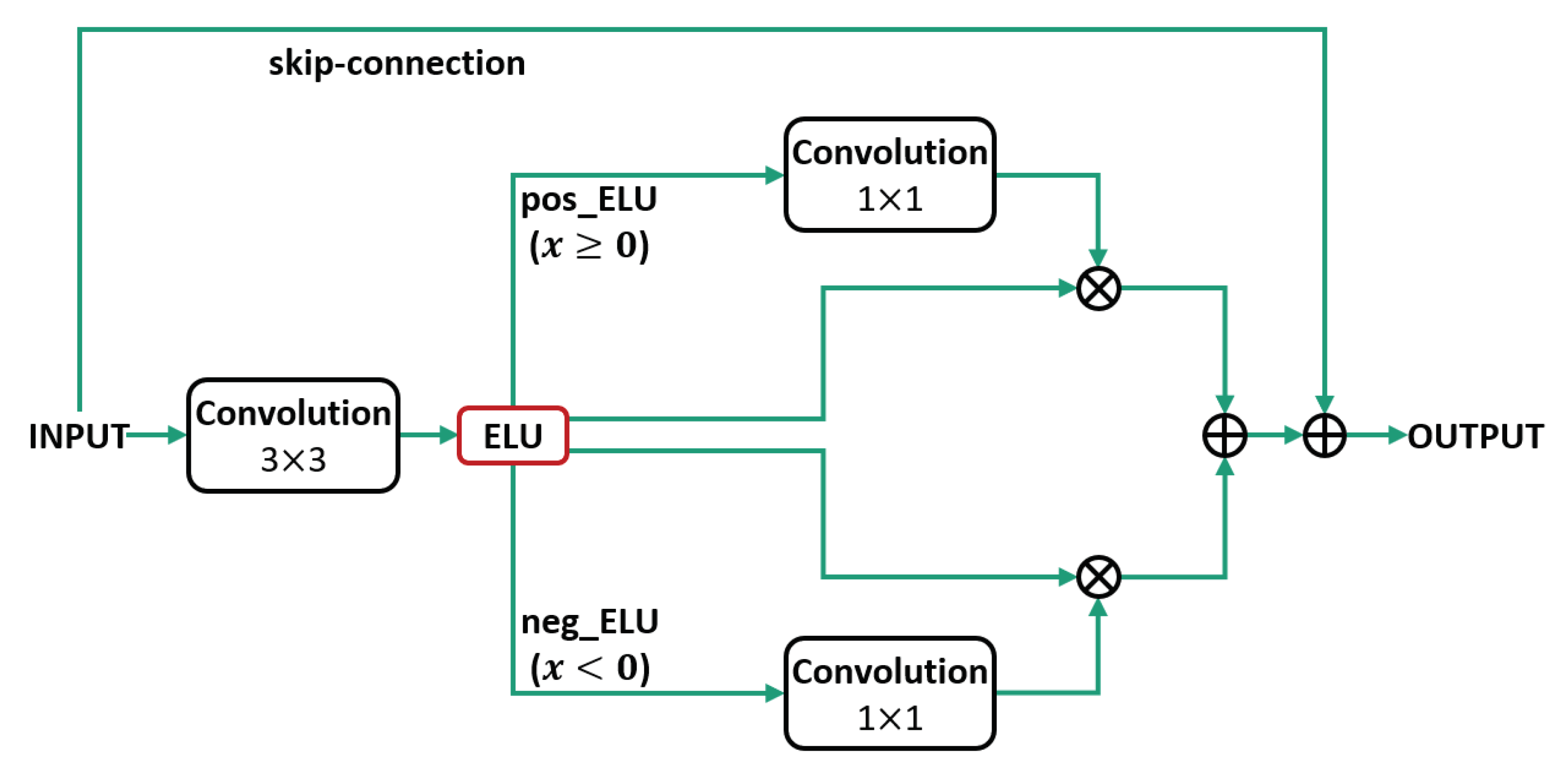
We propose NRA to suppress the non-object area of the positive region and emphasize the object area using the negative region of the ELU. The proposed method was separately emphasized in the negative and positive regions after applying the ELU activation function.
Figure 4 shows the proposed NRA structure.
The proposed NRA method is configured as follows after applying ELU, the process of separating the negative and positive areas results in an ELU feature map and an element-wise product spatial attention course using a 1 × 1 convolution in the separated area and an element of the emphasized feature map, which consists of a joint process using an element-wise sum. In
Figure 4, neg_ELU represents the negative region of the ELU activation function and pos_ELU represents the positive region.
Equation (
2) is the process of separating into a negative region (neg_ELU) and a positive region (pos_ELU), which are respectively shown in (
3) and (
4), respectively.
Figure 5 is a graph showing the separation in the ELU.
Using the ELU activation function, the feature map was separated into a negative area and a positive area. In Equation (
3),
is the negative region of the ELU when the input is
x, and the positive region is treated as 0. Because
a is set to 1 and converges to
, it can be confirmed that the texture information with a small amount of data change is unified and displayed. In Equation (
4),
is a positive region of the ELU when the input is
x and is processed in the same way as the ReLU function. The proposed method separates the positive and negative regions to take advantage of the properties of the ELU.
Figure 6 shows the module of
Figure 4, which has a feature map separated into positive and negative regions, as shown in
Figure 5.
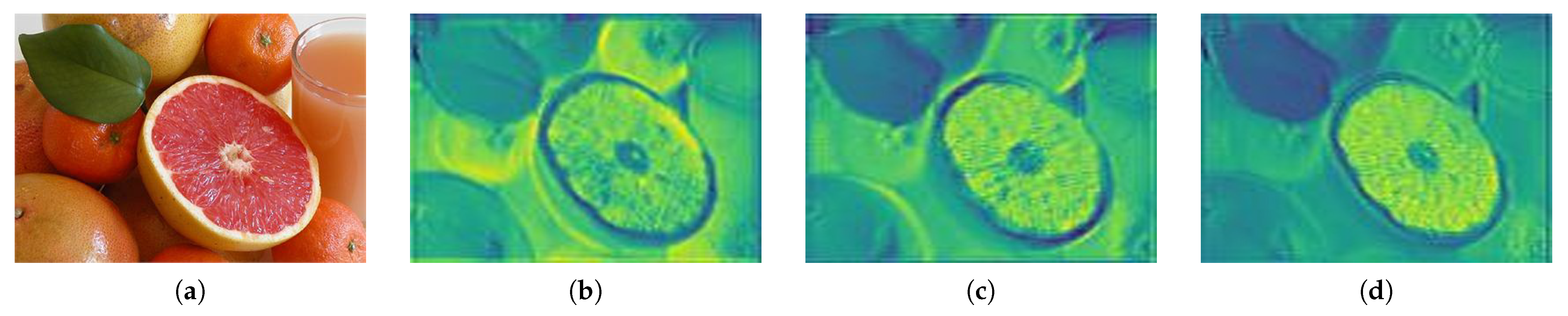
Figure 6c is a feature map showing the separation in the ELU. This map is different from that when the ReLU activation function is applied in the separation of the ELU feature map (b) into a positive region, so the normalization range is different and ReLU shows different results. In the positive region, various textures and boundary information are extracted according to the amount of data change in the image. These features are affected by color and brightness. The texture information of the salient object of lighting is extracted from the features of the non-object area, and the shadow features of the non-object area are extracted in the same way as the salient object.
Figure 6d shows the results of dividing the saliency map into negative and positive regions, where a converges to
.
3.1.1. Extraction of Attention Region from Each Region
Because the SOD needs to detect the area of the salient object, not only the boundary information but also the texture information of the object to be detected is important. Various texture information can be obtained by outputting features through an ELU function with a wide range of feature expressions. However, environmental conditions, such as light reflection, affect color and brightness, and texture information is extracted based on such conditions, resulting in a loss area. Although the loss can be minimized by unifying the various texture information through an emphasis technique, a region with texture information similar to that of a salient object is emphasized, resulting in false detection. Therefore, the proposed method does not use the ELU function as it is and proceeds with the enhancement technique by separating the saliency map into a positive region representing various texture information and a negative region containing mainly unified texture information and boundary information with a large amount of change.
Areas of objects and backgrounds in the image are separated based on the boundary information. Spatial attention can be used for positive areas that have various textures, and boundary information can be used to unify the information of various textures and emphasize the salient object area. The feature separated into the negative region is different from that in the positive region, such that the feature converges to and outputs unified texture information and boundary information with a large amount of data change. If these features are utilized without emphasis, then the area of the salient object can be suppressed as a non-object area. Spatial attention can be used to emphasize only the salient object area based on the boundary information to suppress the non-object area emphasized in the positive area.
The proposed method performs spatial attention in the positive and negative regions using Equations (
5) and (
6), respectively, and is a transformation of spatial attention. In the case of using the average and maximum pooling, a representative value is outputted in the separate positive region, resulting in a loss of various texture information. Because the sigmoid is normalized to a value between 0 and 1, the amount of data change is altered, so the boundary information is lost. Therefore, in the proposed method, spatial attention through a convolution and element-wise product is used without pooling and sigmoid.
In Equations (
5) and (
6),
and
represent the positive and negative regions of the input
x;
and
are the
and
convolutions, respectively; the ⨂ is an element-wise product;
and
are the positive and negative regions separated from the ELU in Equations (
3) and (
4), respectively; and
a was set to 1 in the ELU. The results of such a modified spatial attention equation are shown in
Figure 7.
Figure 7 shows a feature map of each region separated from the ELU and a feature map emphasizing the positive and negative regions. Spatial attention was performed on the salient object to emphasize the detailed information from
Figure 7a. Negative areas also emphasized the contour and texture information via spatial attention. Unlike the result of applying the ELU activation function, the area of the salient object was emphasized. The emphasis of the positive area emphasizes the texture information of the entire image, and the negative area suppresses the non-object area and emphasizes the contour and texture information.
3.1.2. Combination of Attention Positive and Negative Region
The texture information of the salient object was emphasized based on the boundary information between the salient object and the background, and the positive area where the shadow area was emphasized and the negative area where the non-object area was suppressed were combined with the element-wise sum. As a result of emphasizing the negative region through the combination, the shadow region, which is a non-object region, is suppressed, and the feature that the region of the salient object is emphasized through the emphasis on the positive and negative regions is obtained. Equation (
7) shows the combination of the emphasized feature maps.
The combination of the feature maps emphasized for input x is represented by . represents a feature map with emphasized positive areas, and represents a feature map with emphasized negative areas.
Figure 8 shows the result of a combination of feature maps and shows an emphasis on each area. Bases on the spatial attention results of the positive region, which contains various detailed information, we have element-wise-summed the positive and negative feature maps emphasized to suppress the shadow features that are non-object regions. By combining the results of emphasizing the unified texture information in (c) and the result of emphasizing various texture information in (b), the non-object area is suppressed, as shown in
Figure 8d. The boundary and texture information of the salient objects is also emphasized.
In the deep learning process, when the distance between the input and output increases as shown above, the slope value is saturated with a large or small value in the backpropagation process in which the weight is transmitted between layers when learning the network, resulting in an ineffective learning, a slope that slows learning, and loss problem. To prevent these problems, a structure that learns the difference between the input value and output value was constructed by applying skip connection after combining the highlighted feature maps.
Figure 9 compares the results of the highlighted feature map combination with the results of applying skip connection to the combined feature map. The problems of weights being propagated directly from the output to the input and the slope disappearing in deep structures when learning the network through a structure that applies skip connection are avoided. The final NRA result is shown in
Figure 9c, in which the non-object area is suppressed and the detailed information of the object is emphasized. Equation (
8) is the formula for NRA.
The result of NRA is represented by
on the input
x, and
and the input are element-wise-summed to utilize skip connection.
is a combination of the positive and negative feature maps emphasized in Equation (
7).
Figure 10 is a comparison of the feature map to which the ELU activation function is applied when performing the convolution operation on the input image and the result of applying the proposed NRA to the result emphasized by these feature maps. When spatial attention is applied to the feature map extracted using the ELU activation function, the texture information of the salient object is extracted in the non-object area by lighting, as shown in
Figure 10c. The proposed NRA method is separated into positive and negative regions by the ELU activation function, and then spatial attention is applied to each region to suppress non-object regions and emphasize the detailed information of salient objects.
3.2. Decoder for Extending Extracted Features
Because the decoding process is a stage where feature extraction and compressed features are expanded to the size of the input image and restored at the encoder stage, feature loss occurs during the expansion process. In this process, information on the correlation of surrounding pixels is lost. The proposed method uses concatenation to utilize the features of each stage extracted from the encoder at each stage of the decoder to prevent feature loss.
Unlike skip connection, which adds a feature map, concatenation simply follows. The number of feature maps is increasing, following the feature maps of the same size. Equation (
9) is the formula for concatenation:
is the result of performing NRA on the input x, and indicates the size of the resulting feature map. is the result of the inverse convolution of the input y with the decoder, and indicates the size of the result feature map. is the result of the concatenation of a feature map of the same size as .
3.3. Residual Block in the Process of Concatenation Operation
When the NRA result of the encoder step is directly concatenated to the decoder, only the salient region is expressed because the highlighted feature is not refined. A residual block was used to generate a saliency map close to the ground truth through the feature refinement process of this highlighted region.
Figure 11 shows the results of the concatenation of the NRA without feature refinement.
The results show only the emphasized regions where the features have not been purified. The features in the residual block were reconstructed to improve the quality of the saliency maps and generate them closer to the ground truth.
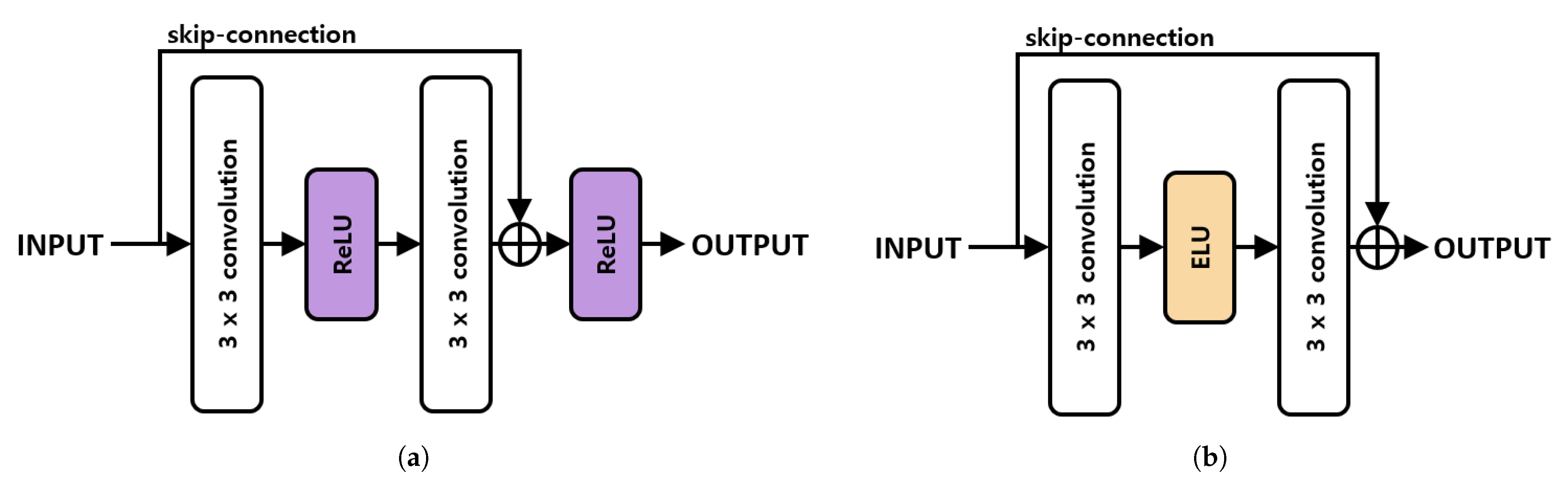
The existing residual block consists of two (
) convolutions and two ReLU activation functions. Such a structure does not take advantage of the negative region features using the ReLU activation function. Because the proposed method also utilizes features in the negative region, we used the ELU activation function to prevent the loss of features highlighted by the residual block. The information transmitted by skip connection in the proposed method emphasizes the salient area. When the ELU activation function was applied after receiving the emphasized feature information, the features in the emphasized negative region were normalized and feature loss occurred. Therefore, unlike the conventional method, the result was outputted without using the activation function after skip connection. Equation (
10) is an equation of the residual block by the proposed method.
is the result of the residual block in the proposed way of the input
x, and
is the
convolution. After extracting the features in the
convolution as the input, the features were enabled as an ELU function and the features were extracted again via a
convolution. Then, the input was added to the element-wise sum, and the skip-connection structure was used.
Figure 12 shows the structure of the residual block.
The features of the structure of these proposed residual blocks were purified. This method also avoids the problem of slope disappearance in the skip connection, reduces loss, and generates a saliency map close to the ground truth.
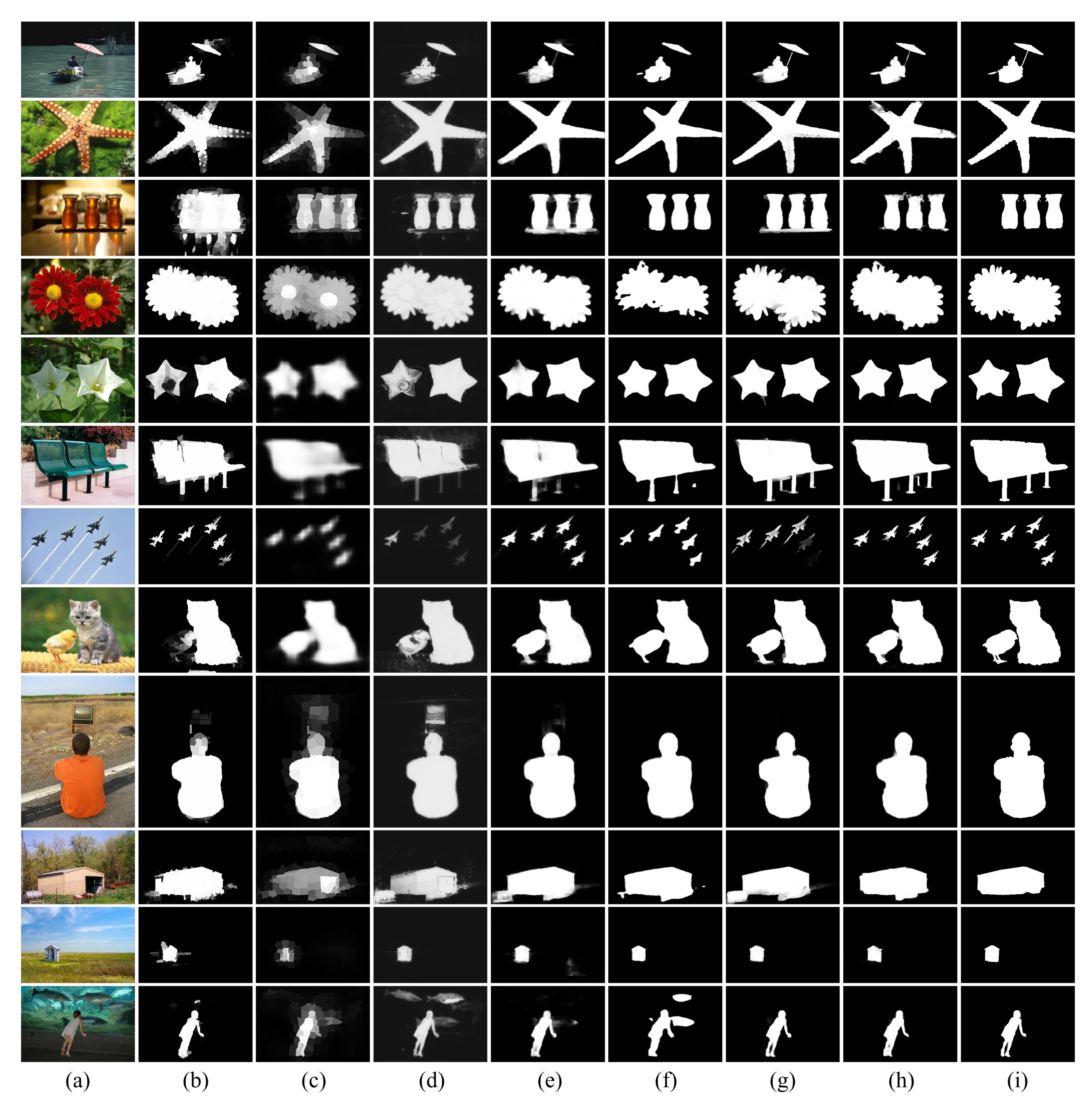
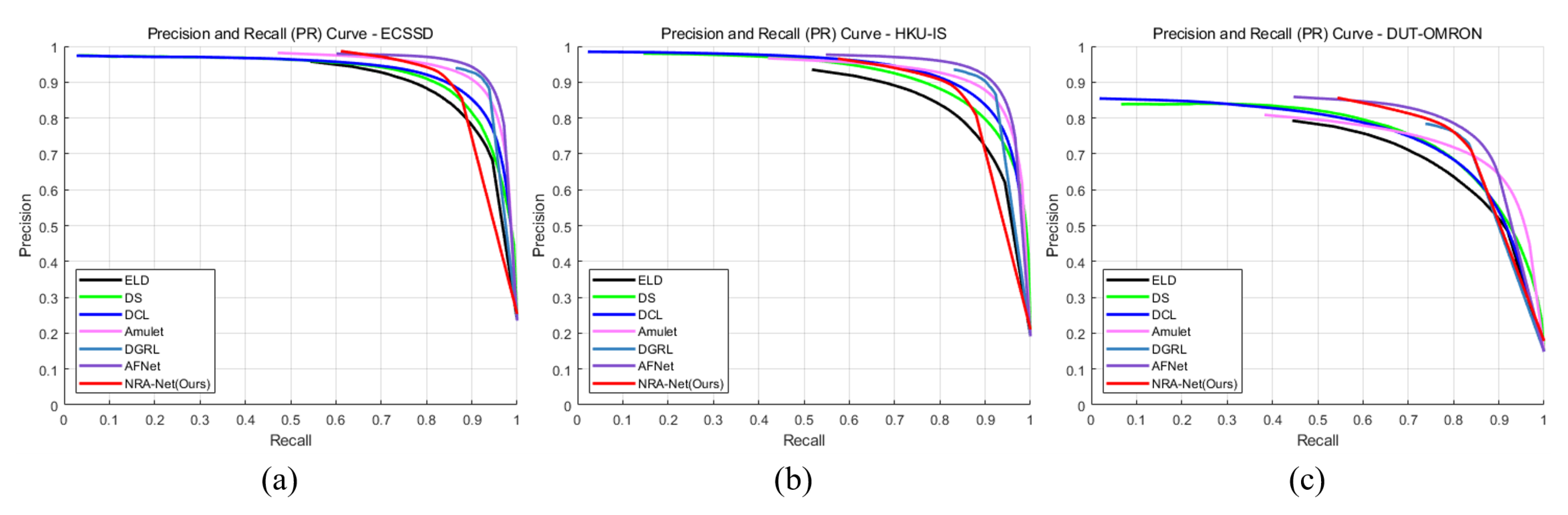
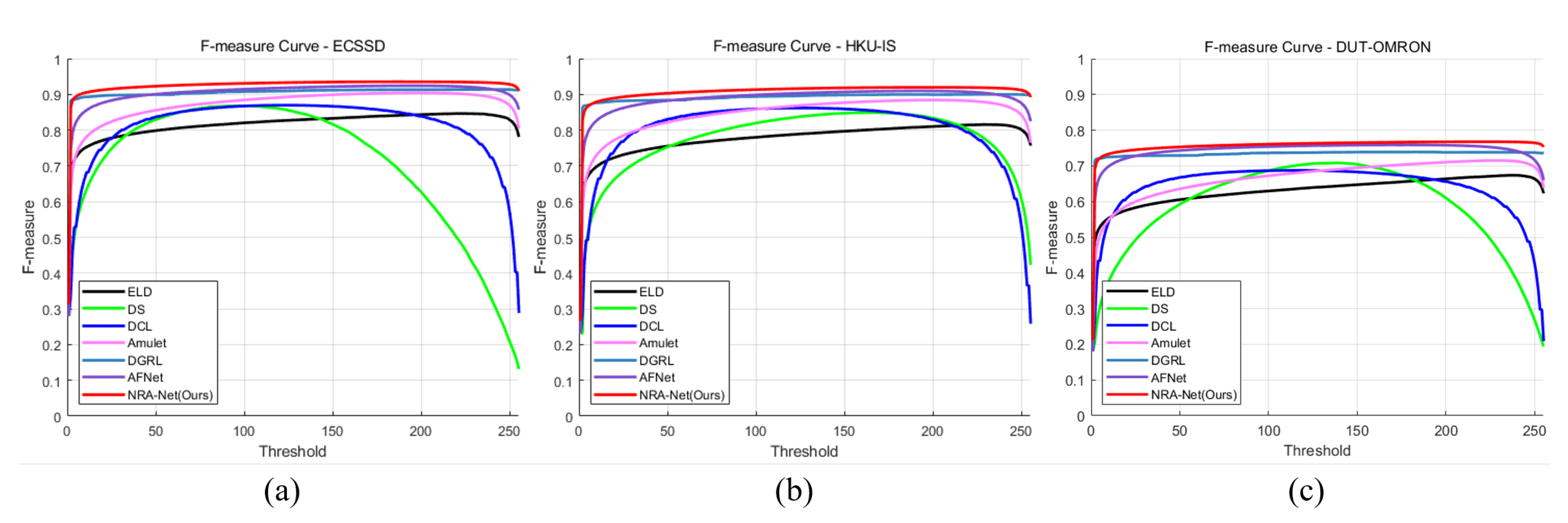
Figure 13 shows the final SOD results.























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}