
Deep Reinforcement Learning-Based Task Scheduling in IoT Edge Computing




Abstract
1. Introduction
- Model-free DRL-based task scheduling is studied for task scheduling in edge computing, where the time scheduling and VM assignment are jointly optimized. The problem is formulated as an MDP problem, where the availability of VMs, task characteristics, and queue dynamics are taken into account.
- The action is represented as a VM-task pair, whose dimension may be extremely large. A new mechanism is designed in the MDP formulation, where the scheduling time step is decoupled from the real time step. By this mechanism, the action space stays linear with the product of the number of VMs and the queue size, and multiple tasks can be scheduled in one time step.
- Extensive simulation results demonstrate that the proposed DRL-based algorithm achieves a better task satisfaction degree in comparison with the baseline task scheduling algorithms.
2. System Model
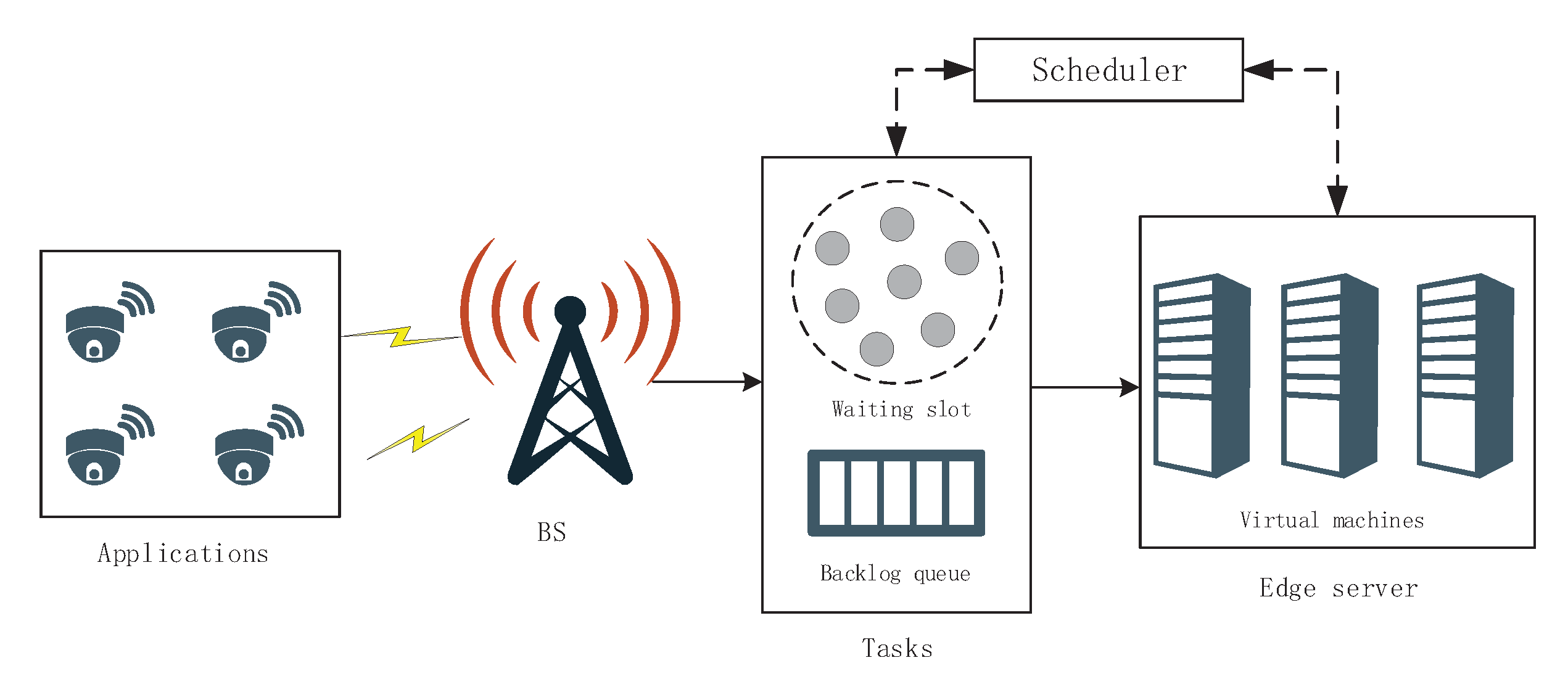
2.1. System Architecture
2.2. Task Model
2.3. Task Scheduling Mechanism
3. DRL Solution
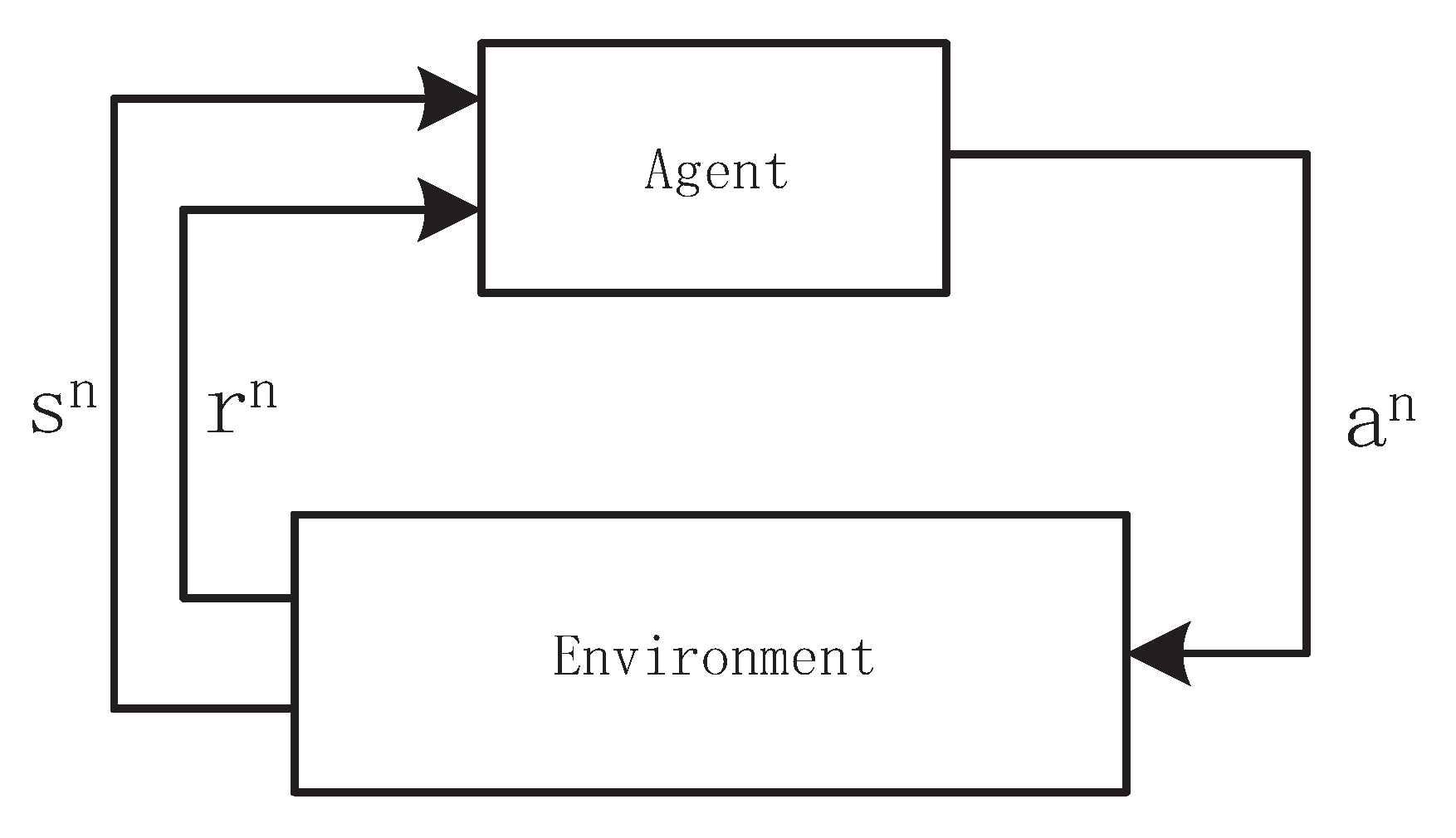
3.1. Preliminaries
3.2. MDP Formulation
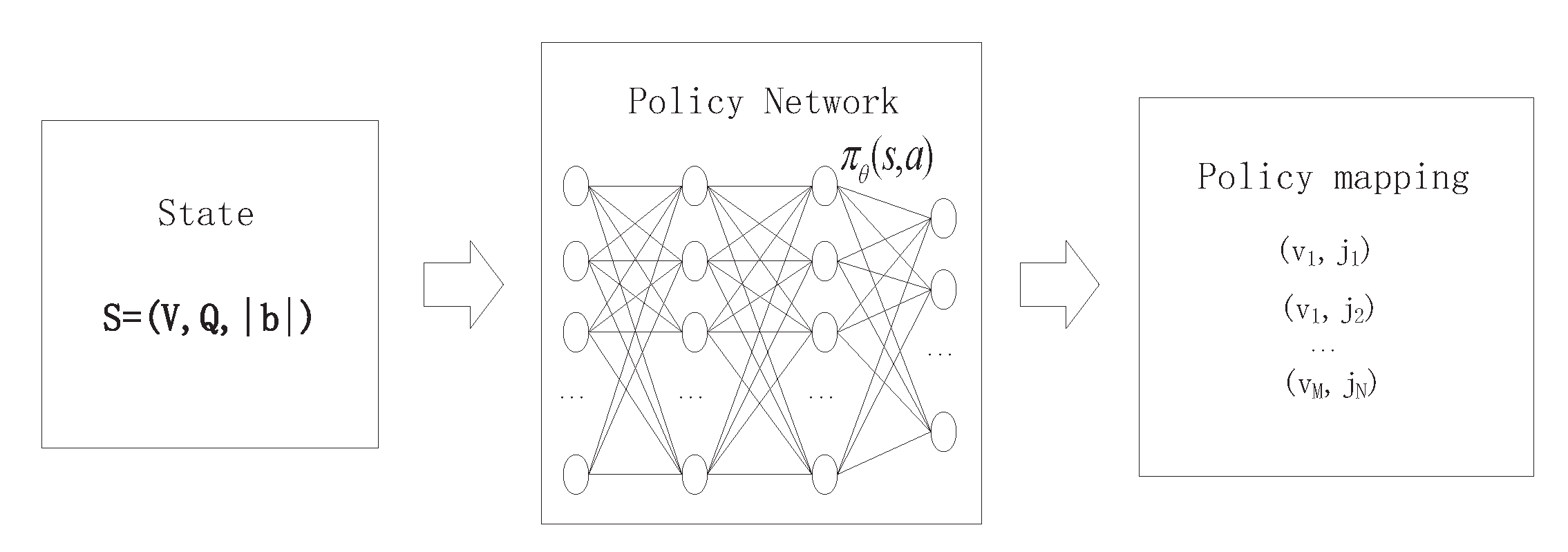
3.2.1. State Space
3.2.2. Action Space
3.2.3. State Transition
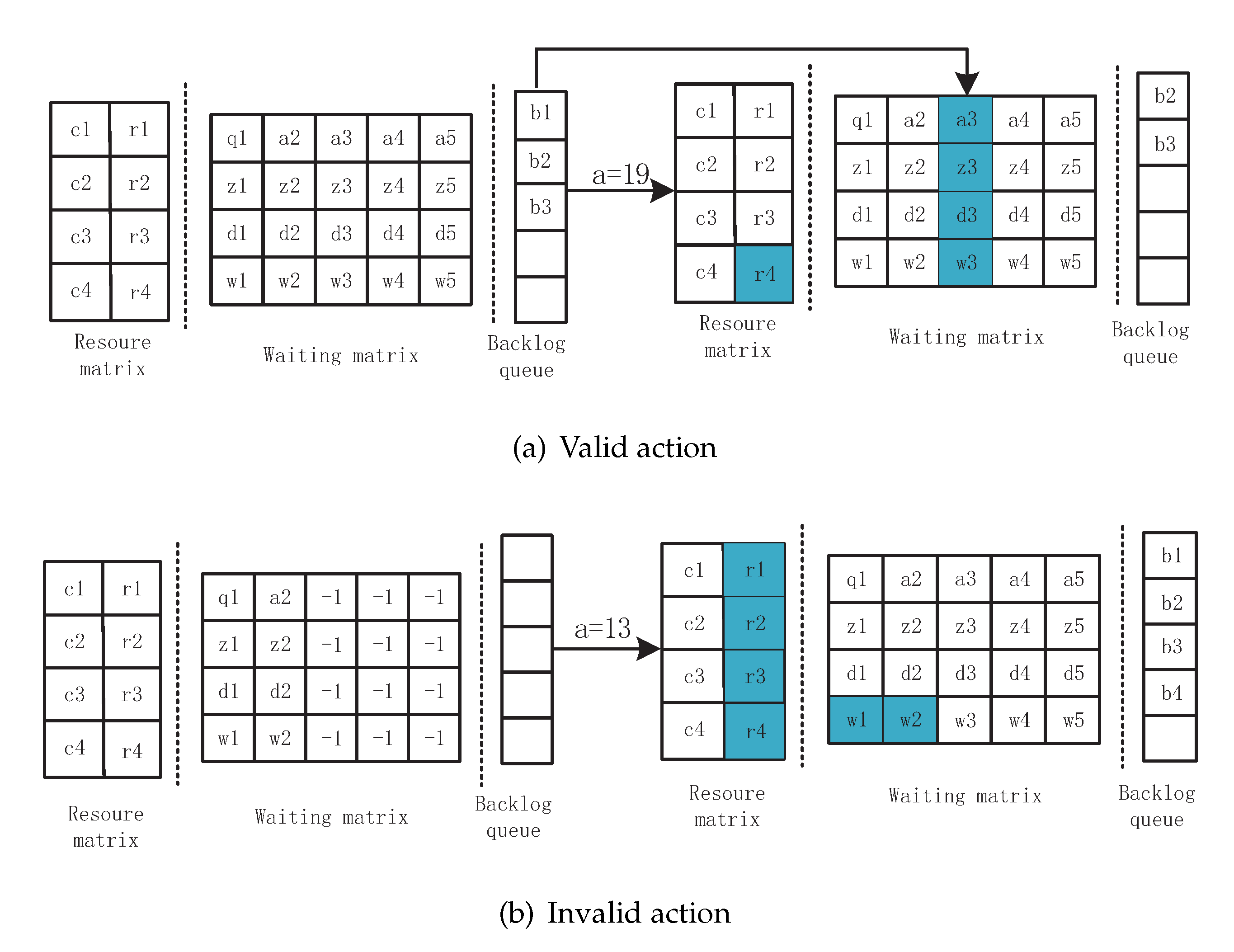
- (a)
- The scheduler selects a valid action, and the backlog queue is not empty. For example, in Figure 3a, , that is , where the subscript indicates the index of the VM and task in the waiting slot. Then, the task is scheduled to the VM and will be executed after time steps. The value of ready time for the next scheduled tasks changes by pulsing the execution time to process . Furthermore, the first tasks in the backlog queue are put into the position that just stores and the number of tasks of the backlog queue minus one simultaneously. It is noted that the waiting time of all the tasks stays unchanged within the same time step.
- (b)
- An invalid action is chosen, meaning no task is scheduled and the backlog queue is empty at the current time step, as shown in Figure 3b. In this case, the time step proceeds to the next time step to accept new tasks. New tasks move to the waiting slot firstly, and the extra tasks are put into the backlog queue. The tasks are dropped if the number of new tasks is larger than the backlog queue size. Meanwhile, the waiting time in both the waiting matrix and the backlog plus one and the ready time of VM are set to a value of .
- (c)
- The scheduler selects a valid action. After that, both the waiting slot and the backlog queue are empty. The time step goes to the next time step and fetches new tasks. In this case, only the ready time of all the VMs changes.
3.2.4. Reward
3.3. REINFORCE Implementation
| Algorithm 1: Task scheduling and allocation with the REINFORCE algorithm. |
 |
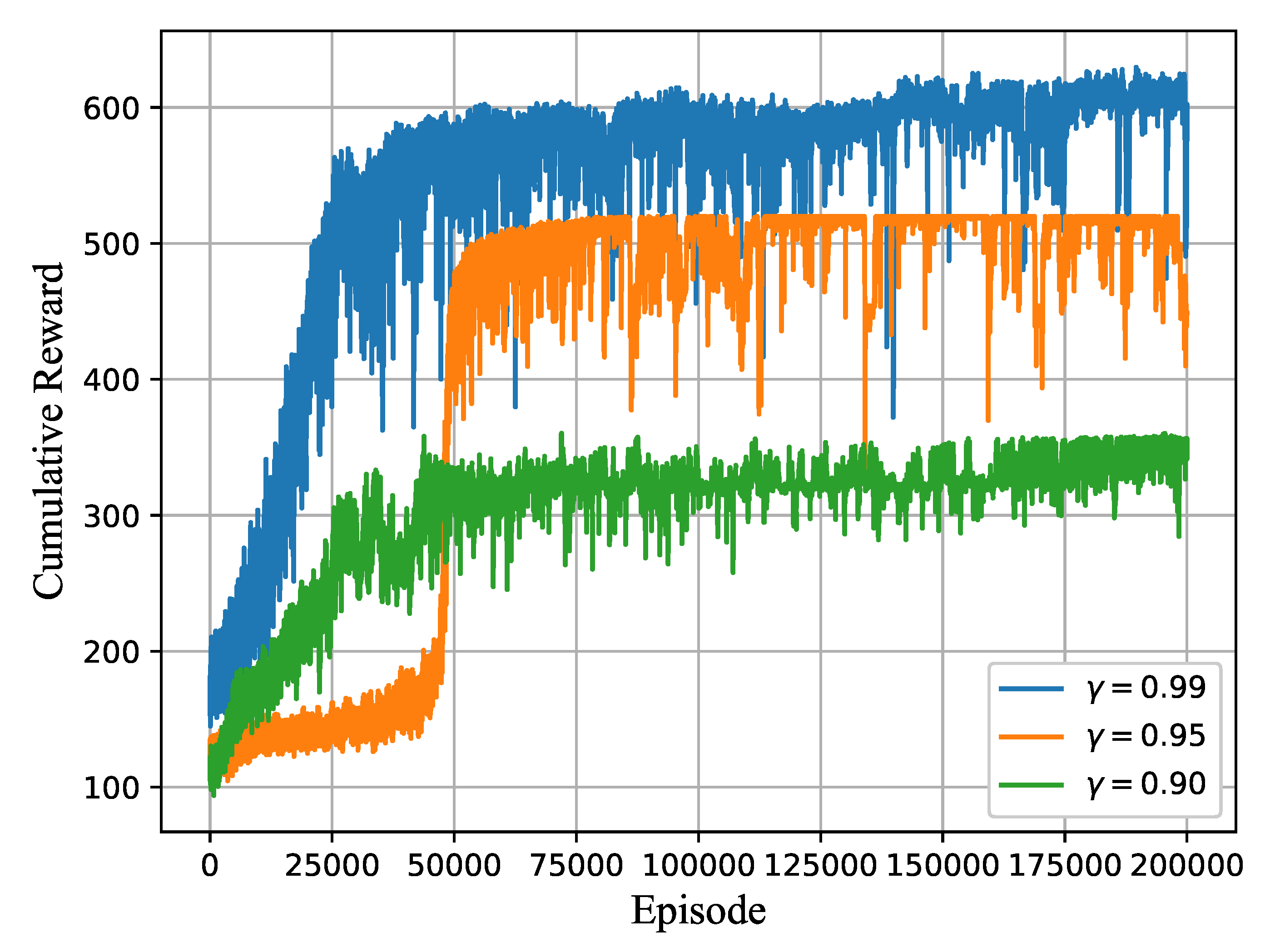
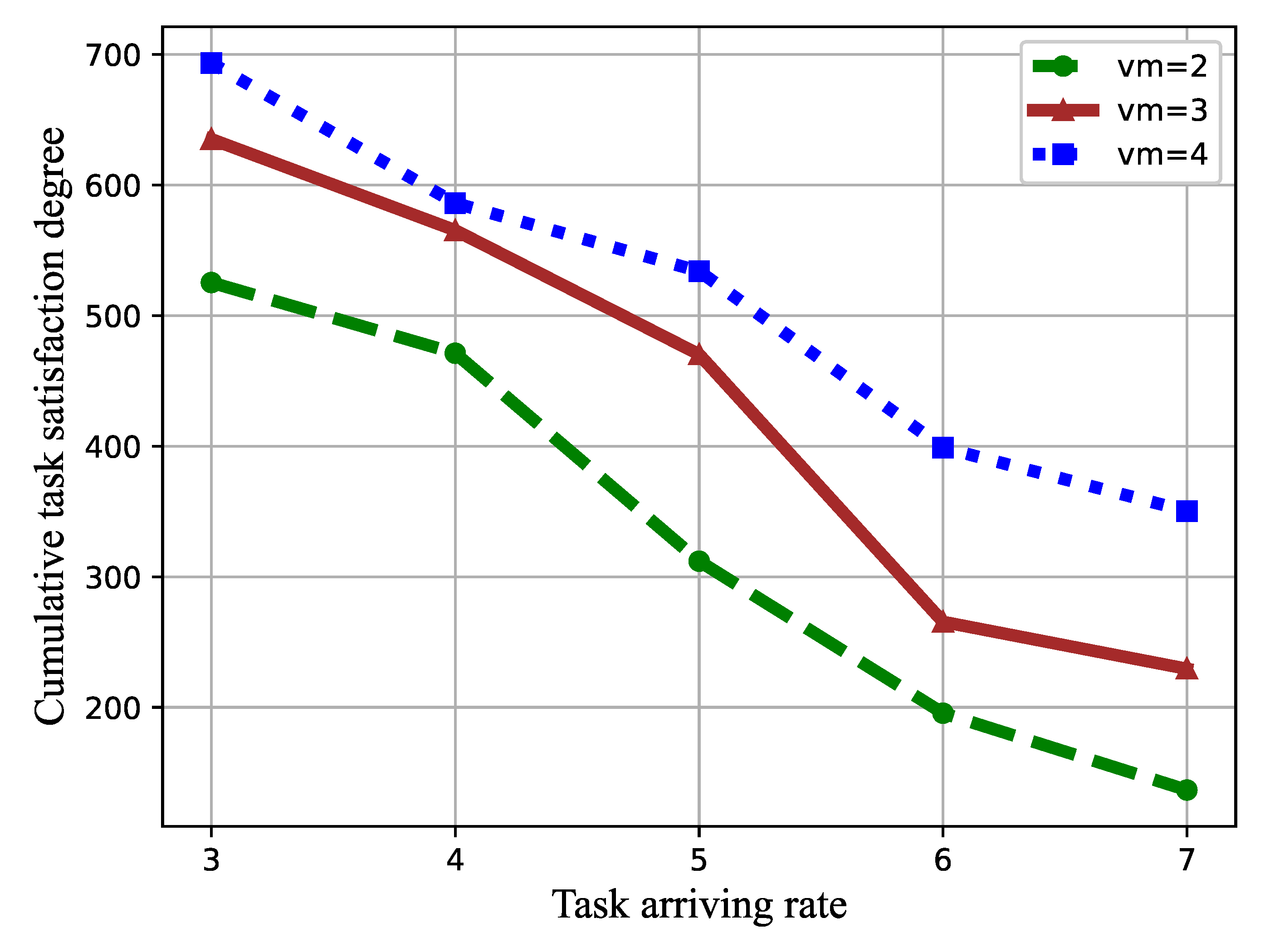
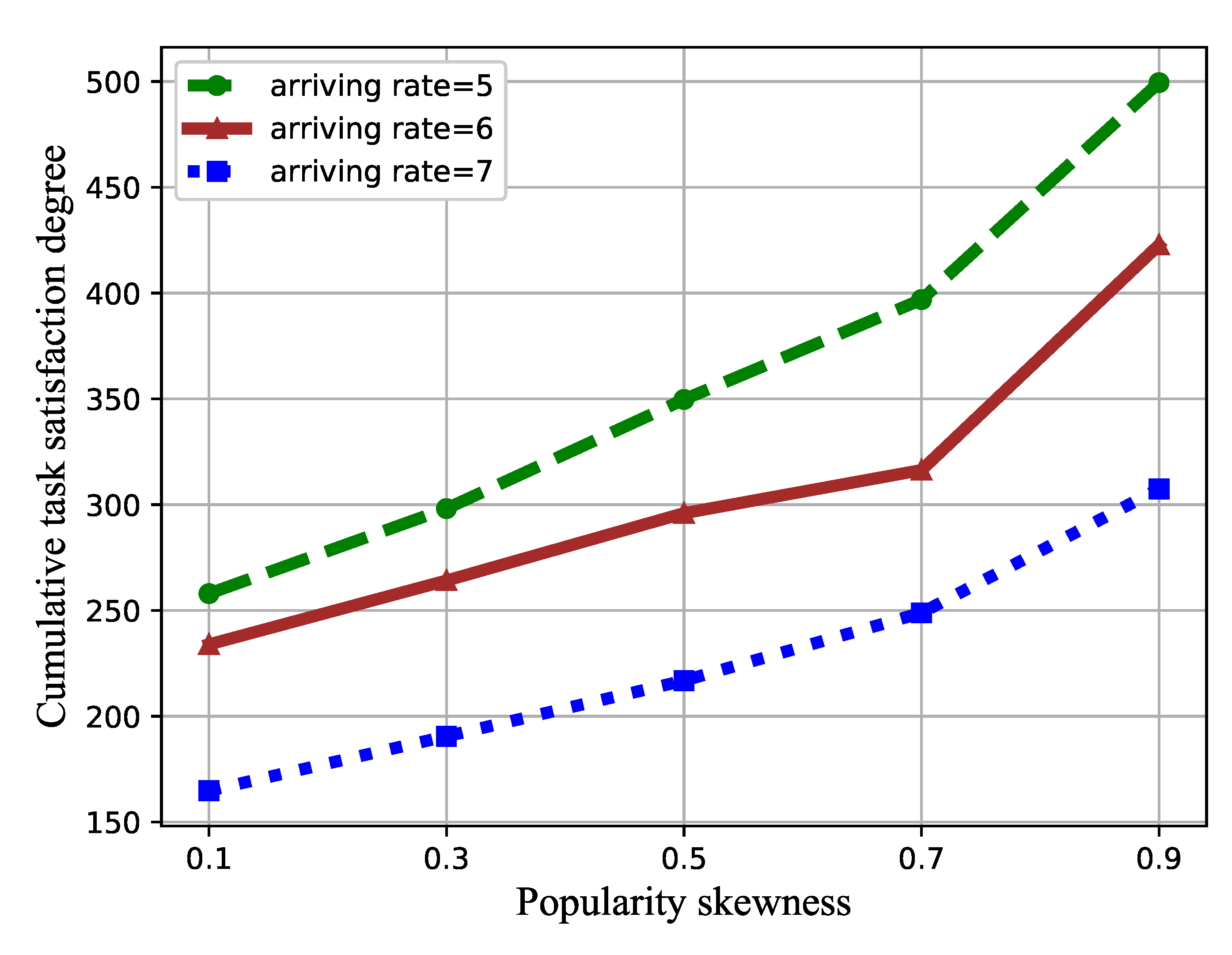
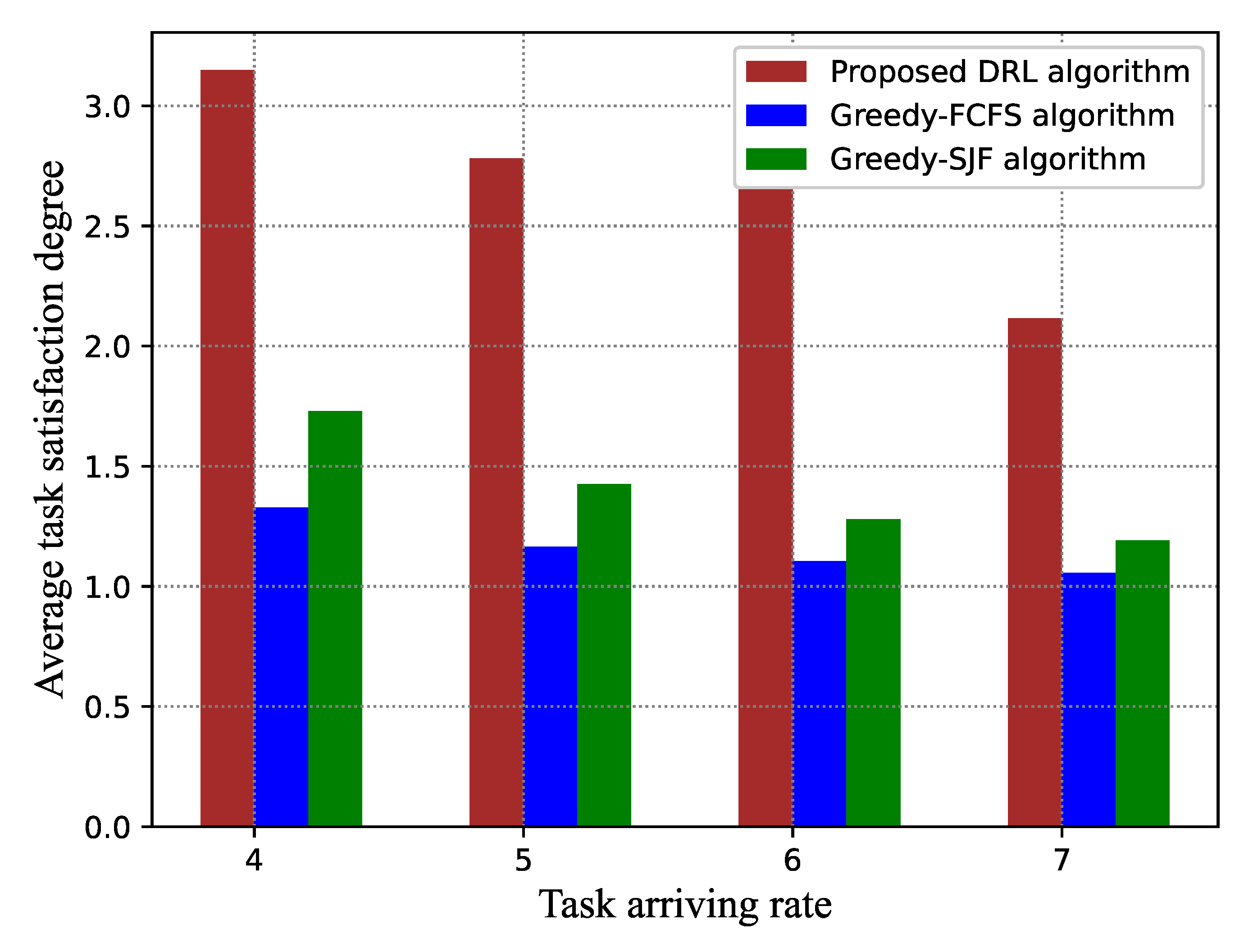
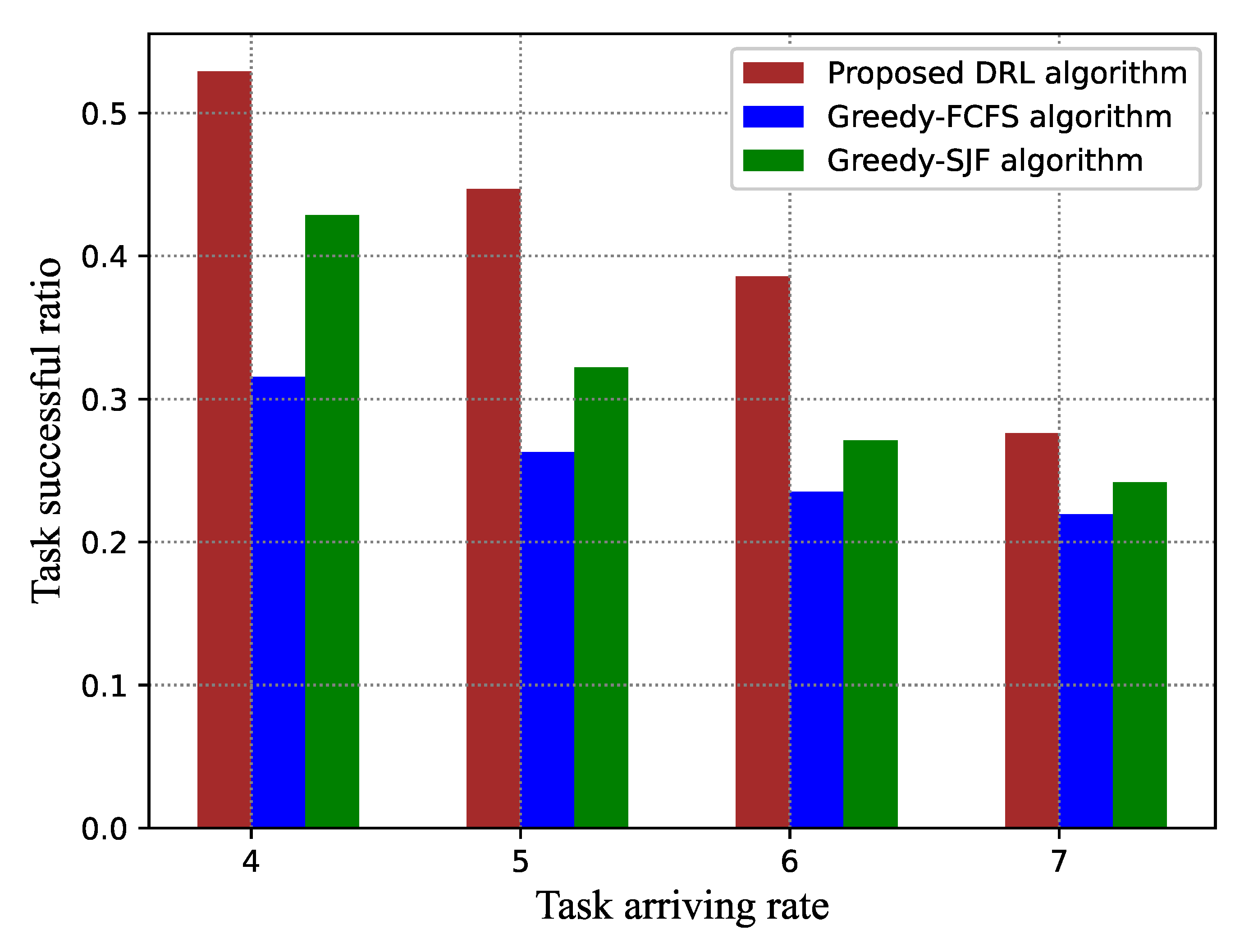
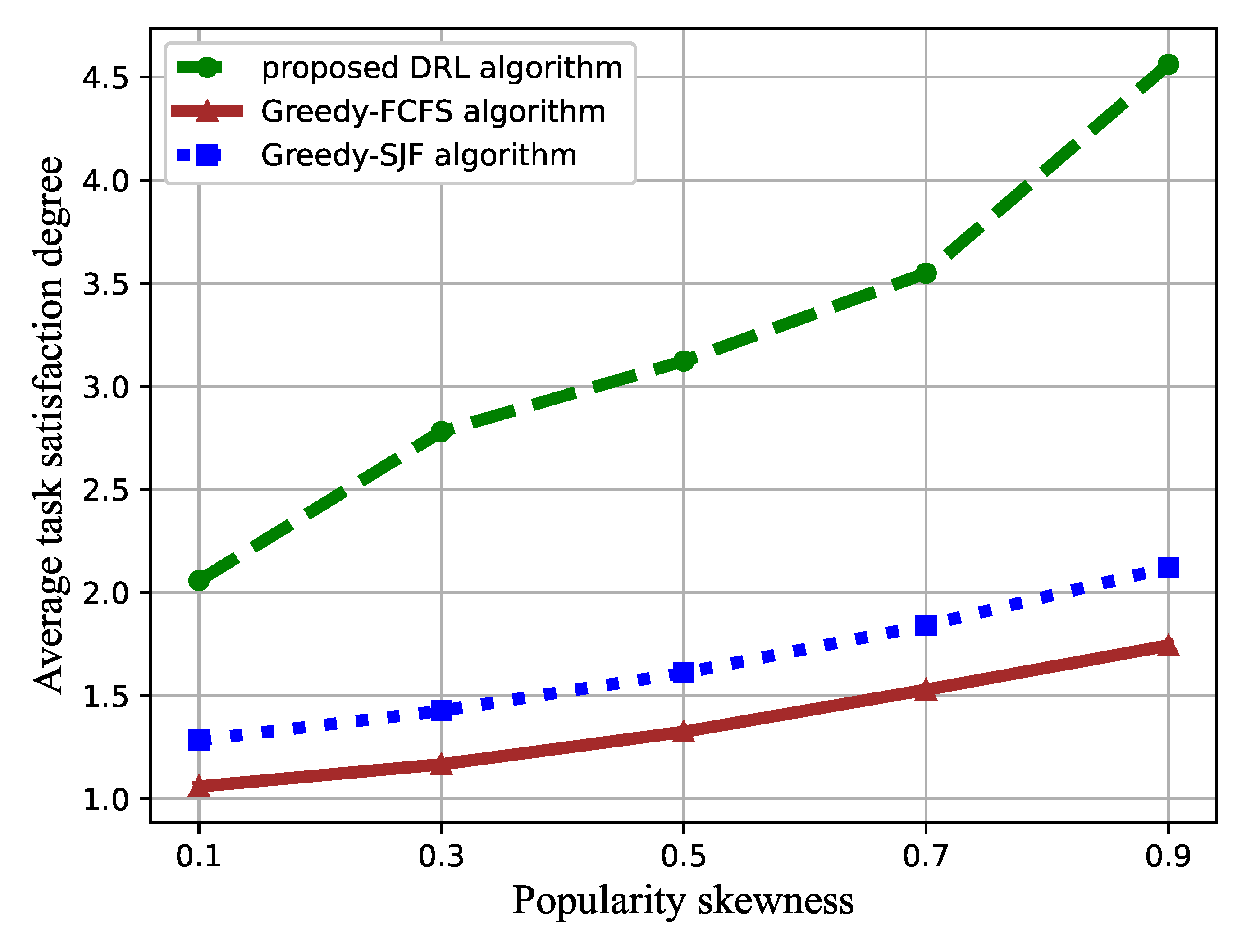
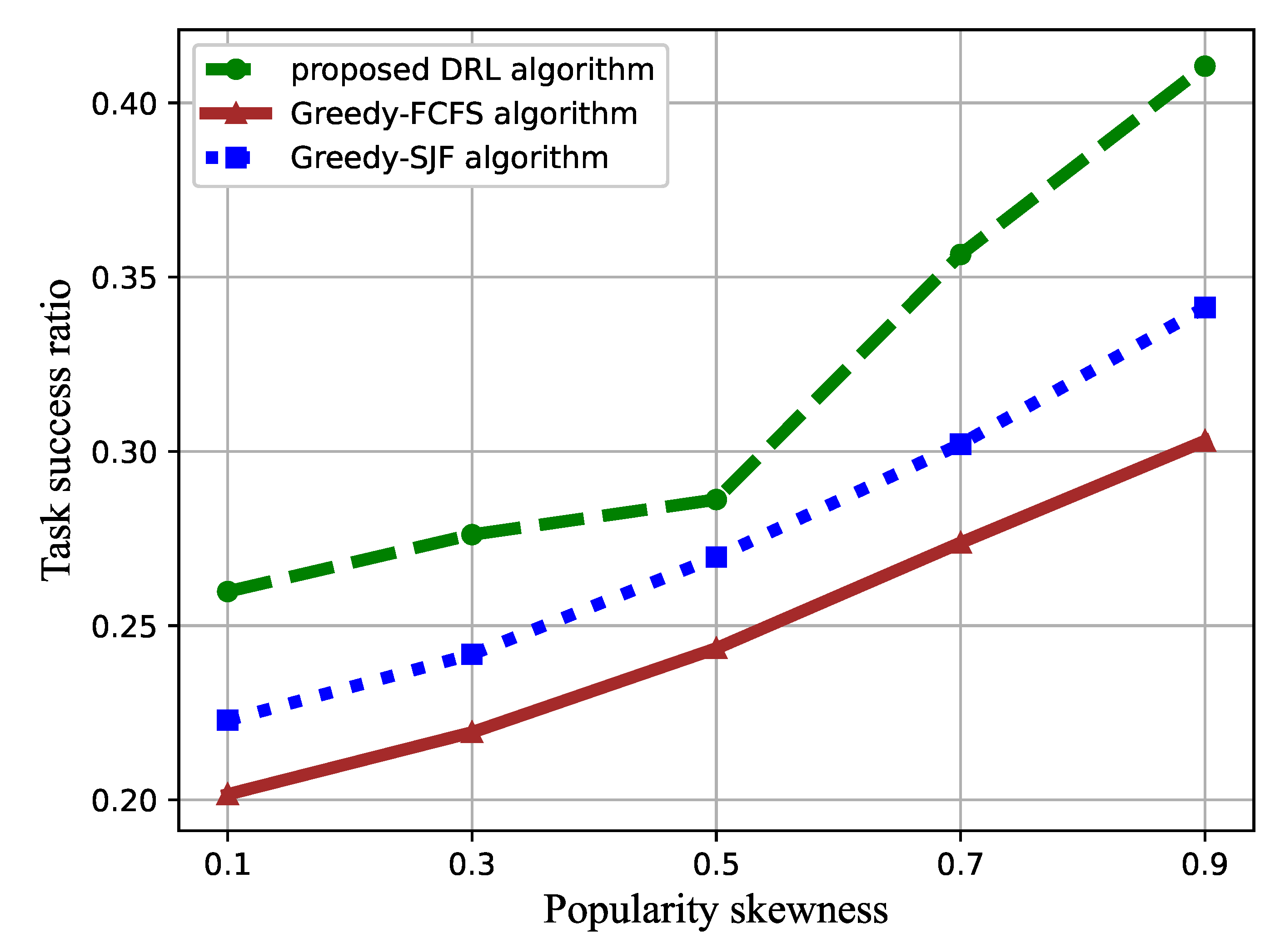
4. Simulation Results
4.1. Simulation Setting
- The tasks generated by the IoT device are sent to the BS suffer from the communication transmission and arrive at the edge server at a certain rate. We assumed that the expected latency ranges from 5 s to 10 s and the transmission delay ranges from 1 s to 5 s. The range of the task size was set as MI. In general, any arriving rate is applicable, because it is unknown in advance and is not included in the input state feature; for convenience, the tasks arrive at the edge server according to a Poisson distribution, and the average arrival rate varies from three request/s to seven requests/s, so the task arriving interval follows an exponential distribution with .
- The processing capacity of the VMs was set in the range MIPS.
- The size of the waiting slot was set as , and the length of the backlog queue was set as .
- There were five types of tasks in the simulation, and the task characteristics, including the size and the expected delay, are shown in Table 2.
4.2. Performance Evaluation
4.3. Performance Comparison with the Benchmark Methods
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Lin, J.; Yu, W.; Zhang, N.; Yang, X.; Zhang, H.; Zhao, W. A Survey on Internet of Things: Architecture, Enabling Technologies, Security and Privacy, and Applications. IEEE Internet Things J. 2017, 4, 1125–1142. [Google Scholar] [CrossRef]
- Weyrich, M.; Ebert, C. Reference Architectures for the Internet of Things. IEEE Softw. 2016, 33, 112–116. [Google Scholar] [CrossRef]
- Deng, S.; Huang, L.; Taheri, J.; Zomaya, A.Y. Computation Offloading for Service Workflow in Mobile Cloud Computing. IEEE Trans. Parallel Distrib. Syst. 2015, 26, 3317–3329. [Google Scholar] [CrossRef]
- Abbas, N.; Zhang, Y.; Taherkordi, A.; Skeie, T. Mobile Edge Computing: A Survey. IEEE Internet Things J. 2018, 5, 450–465. [Google Scholar] [CrossRef]
- Shi, W.; Cao, J.; Zhang, Q.; Li, Y.; Xu, L. Edge Computing: Vision and Challenges. IEEE Internet Things J. 2016, 3, 637–646. [Google Scholar] [CrossRef]
- Yan, J.; Bi, S.; Zhang, Y.J.A. Offloading and Resource Allocation With General Task Graph in Mobile Edge Computing: A Deep Reinforcement Learning Approach. IEEE Trans. Wirel. Commun. 2020, 19, 5404–5419. [Google Scholar] [CrossRef]
- Ren, J.; Yu, G.; He, Y.; Li, G.Y. Collaborative Cloud and Edge Computing for Latency Minimization. IEEE Trans. Veh. Technol. 2019, 68, 5031–5044. [Google Scholar] [CrossRef]
- Fan, Q.; Ansari, N. Application Aware Workload Allocation for Edge Computing-Based IoT. IEEE Internet Things J. 2018, 5, 2146–2153. [Google Scholar] [CrossRef]
- Samie, F.; Bauer, L.; Henkel, J. From Cloud Down to Things: An Overview of Machine Learning in Internet of Things. IEEE Internet Things J. 2019, 6, 4921–4934. [Google Scholar] [CrossRef]
- Lin, L.; Liao, X.; Jin, H.; Li, P. Computation Offloading Toward Edge Computing. Proc. IEEE 2019, 107, 1584–1607. [Google Scholar] [CrossRef]
- Li, Z.; Yang, Z.; Xie, S.; Chen, W.; Liu, K. Credit-Based Payments for Fast Computing Resource Trading in Edge-Assisted Internet of Things. IEEE Internet Things J. 2019, 6, 6606–6617. [Google Scholar] [CrossRef]
- Wang, P.; Yao, C.; Zheng, Z.; Sun, G.; Song, L. Joint Task Assignment, Transmission, and Computing Resource Allocation in Multilayer Mobile Edge Computing Systems. IEEE Internet Things J. 2019, 6, 2872–2884. [Google Scholar] [CrossRef]
- Zhang, J.; Hu, X.; Ning, Z.; Ngai, E.C.; Zhou, L.; Wei, J.; Cheng, J.; Hu, B.; Leung, V.C.M. Joint Resource Allocation for Latency-Sensitive Services Over Mobile Edge Computing Networks With Caching. IEEE Internet Things J. 2019, 6, 4283–4294. [Google Scholar] [CrossRef]
- Zhang, X.; Zhong, Y.; Liu, P.; Zhou, F.; Wang, Y. Resource Allocation for a UAV-Enabled Mobile-Edge Computing System: Computation Efficiency Maximization. IEEE Access 2019, 7, 113345–113354. [Google Scholar] [CrossRef]
- AlQerm, I.; Pan, J. Enhanced Online Q-Learning Scheme for Resource Allocation with Maximum Utility and Fairness in Edge-IoT Networks. IEEE Trans. Netw. Sci. Eng. 2020, 7, 3074–3086. [Google Scholar] [CrossRef]
- Tran, T.X.; Pompili, D. Joint Task Offloading and Resource Allocation for Multi-Server Mobile-Edge Computing Networks. IEEE Trans. Veh. Technol. 2019, 68, 856–868. [Google Scholar] [CrossRef]
- Tan, H.; Han, Z.; Li, X.; Lau, F.C.M. Online job dispatching and scheduling in edge-clouds. In Proceedings of the IEEE INFOCOM 2017—IEEE Conference on Computer Communications, Atlanta, GA, USA, 1–4 May 2017; pp. 1–9. [Google Scholar] [CrossRef]
- Zhang, Y.; Du, P.; Wang, J.; Ba, T.; Ding, R.; Xin, N. Resource Scheduling for Delay Minimization in Multi-Server Cellular Edge Computing Systems. IEEE Access 2019, 7, 86265–86273. [Google Scholar] [CrossRef]
- Chen, X.; Thomas, N.; Zhan, T.; Ding, J. A Hybrid Task Scheduling Scheme for Heterogeneous Vehicular Edge Systems. IEEE Access 2019, 7, 117088–117099. [Google Scholar] [CrossRef]
- Chiang, Y.; Zhang, T.; Ji, Y. Joint Cotask-Aware Offloading and Scheduling in Mobile Edge Computing Systems. IEEE Access 2019, 7, 105008–105018. [Google Scholar] [CrossRef]
- Li, C.; Tang, J.; Tang, H.; Luo, Y. Collaborative cache allocation and task scheduling for data-intensive applications in edge computing environment. Future Gener. Comput. Syst. 2019, 95, 249–264. [Google Scholar] [CrossRef]
- Saleem, U.; Liu, Y.; Jangsher, S.; Li, Y.; Jiang, T. Mobility-Aware Joint Task Scheduling and Resource Allocation for Cooperative Mobile Edge Computing. IEEE Trans. Wirel. Commun. 2021, 20, 360–374. [Google Scholar] [CrossRef]
- Alameddine, H.A.; Sharafeddine, S.; Sebbah, S.; Ayoubi, S.; Assi, C. Dynamic Task Offloading and Scheduling for Low-Latency IoT Services in Multi-Access Edge Computing. IEEE J. Sel. Areas Commun. 2019, 37, 668–682. [Google Scholar] [CrossRef]
- Abdel-Basset, M.; Mohamed, R.; Elhoseny, M.; Bashir, A.K.; Jolfaei, A.; Kumar, N. Energy-Aware Marine Predators Algorithm for Task Scheduling in IoT-based Fog Computing Applications. IEEE Trans. Ind. Inform. 2020. early access. [Google Scholar] [CrossRef]
- Meng, J.; Tan, H.; Li, X.; Han, Z.; Li, B. Online Deadline-Aware Task Dispatching and Scheduling in Edge Computing. IEEE Trans. Parallel Distrib. Syst. 2020, 31, 1270–1286. [Google Scholar] [CrossRef]
- Hou, L.; Lei, L.; Zheng, K.; Wang, X. A Q -Learning-Based Proactive Caching Strategy for Non-Safety Related Services in Vehicular Networks. IEEE Internet Things J. 2019, 6, 4512–4520. [Google Scholar] [CrossRef]
- Xiang, H.; Peng, M.; Sun, Y.; Yan, S. Mode Selection and Resource Allocation in Sliced Fog Radio Access Networks: A Reinforcement Learning Approach. IEEE Trans. Veh. Technol. 2020, 69, 4271–4284. [Google Scholar] [CrossRef]
- Meng, F.; Chen, P.; Wu, L.; Cheng, J. Power Allocation in Multi-User Cellular Networks: Deep Reinforcement Learning Approaches. IEEE Trans. Wirel. Commun. 2020, 19, 6255–6267. [Google Scholar] [CrossRef]
- Chen, J.; Chen, S.; Wang, Q.; Cao, B.; Feng, G.; Hu, J. iRAF: A Deep Reinforcement Learning Approach for Collaborative Mobile Edge Computing IoT Networks. IEEE Internet Things J. 2019, 6, 7011–7024. [Google Scholar] [CrossRef]
- Xu, Z.; Tang, J.; Yin, C.; Wang, Y.; Xue, G.; Wang, J.; Gursoy, M.C. ReCARL: Resource Allocation in Cloud RANs with Deep Reinforcement Learning. IEEE Trans. Mob. Comput. 2020. early access. [Google Scholar] [CrossRef]
- Xiong, X.; Zheng, K.; Lei, L.; Hou, L. Resource Allocation Based on Deep Reinforcement Learning in IoT Edge Computing. IEEE J. Sel. Areas Commun. 2020, 38, 1133–1146. [Google Scholar] [CrossRef]
- Wei, Y.; Pan, L.; Liu, S.; Wu, L.; Meng, X. DRL-Scheduling: An Intelligent QoS-Aware Job Scheduling Framework for Applications in Clouds. IEEE Access 2018, 6, 55112–55125. [Google Scholar] [CrossRef]
- Baek, J.; Kaddoum, G. Heterogeneous Task Offloading and Resource Allocations via Deep Recurrent Reinforcement Learning in Partial Observable Multifog Networks. IEEE Internet Things J. 2021, 8, 1041–1056. [Google Scholar] [CrossRef]
- Guo, M.; Guan, Q.; Ke, W. Optimal Scheduling of VMs in Queueing Cloud Computing Systems With a Heterogeneous Workload. IEEE Access 2018, 6, 15178–15191. [Google Scholar] [CrossRef]
- Zhan, W.; Luo, C.; Wang, J.; Wang, C.; Min, G.; Duan, H.; Zhu, Q. Deep-Reinforcement-Learning-Based Offloading Scheduling for Vehicular Edge Computing. IEEE Internet Things J. 2020, 7, 5449–5465. [Google Scholar] [CrossRef]
- Guo, W.; Tian, W.; Ye, Y.; Xu, L.; Wu, K. Cloud Resource Scheduling with Deep Reinforcement Learning and Imitation Learning. IEEE Internet Things J. 2020, 8, 3576–3586. [Google Scholar] [CrossRef]
- Sutton, R.S.; Barto, A.G. Reinforcement Learning: An Introduction; MIT Press: Cambridge, MA, USA, 2018; pp. 54–55. [Google Scholar]
- Sutton, R.S.; McAllester, D.A.; Singh, S.P.; Mansour, Y. Policy gradient methods for reinforcement learning with function approximation. Adv. Neural Inf. Process. Syst. 1999, 99, 1057–1063. [Google Scholar] [CrossRef]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Description |
|---|---|
| the task | |
| the arriving time of | |
| the type of | |
| the size of | |
| the expected latency of | |
| the VM | |
| M | the number of VMs |
| O | the maximum tasks in the waiting slot |
| the state of the VM, with the shape of | |
| the state of the waiting tasks, with the shape of | |
| the number of tasks in the backlog queue | |
| the waiting time of scheduled to | |
| the task satisfaction degree of scheduled to | |
| the response time of scheduled to |
| Type | Size (MI) | Expect Delay (s) |
|---|---|---|
| 1 | 500 | 5 |
| 2 | 1375 | 6 |
| 3 | 2250 | 7 |
| 4 | 3125 | 8 |
| 5 | 4000 | 10 |
| Number of VMs | DRL | Greedy-FCFS | Greedy-SJF |
|---|---|---|---|
| 1.5175 | 0.9072 | 0.9752 | |
| 2.5502 | 1.4163 | 1.5091 | |
| 4.7276 | 1.9956 | 2.2305 |
| Number of VMs | DRL | Greedy-FCFS | Greedy-SJF |
|---|---|---|---|
| 0.3362 | 0.1717 | 0.1740 | |
| 0.3741 | 0.2924 | 0.3204 | |
| 0.5688 | 0.4602 | 0.5613 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sheng, S.; Chen, P.; Chen, Z.; Wu, L.; Yao, Y. Deep Reinforcement Learning-Based Task Scheduling in IoT Edge Computing. Sensors 2021, 21, 1666. https://doi.org/10.3390/s21051666
Sheng S, Chen P, Chen Z, Wu L, Yao Y. Deep Reinforcement Learning-Based Task Scheduling in IoT Edge Computing. Sensors. 2021; 21(5):1666. https://doi.org/10.3390/s21051666
Chicago/Turabian StyleSheng, Shuran, Peng Chen, Zhimin Chen, Lenan Wu, and Yuxuan Yao. 2021. "Deep Reinforcement Learning-Based Task Scheduling in IoT Edge Computing" Sensors 21, no. 5: 1666. https://doi.org/10.3390/s21051666
APA StyleSheng, S., Chen, P., Chen, Z., Wu, L., & Yao, Y. (2021). Deep Reinforcement Learning-Based Task Scheduling in IoT Edge Computing. Sensors, 21(5), 1666. https://doi.org/10.3390/s21051666