
HRDepthNet: Depth Image-Based Marker-Less Tracking of Body Joints



Abstract
1. Introduction
2. Materials and Methods
2.1. Data Preprocessing
2.2. Machine Learning
2.3. Post-Processing: Keypoint Visibility
2.4. Study Design
2.5. Preparation of the Dataset
2.6. Analysis
3. Results
3.1. Study Sample
3.2. Keypoint Detection Accuracy
3.3. Sensitivity among Models
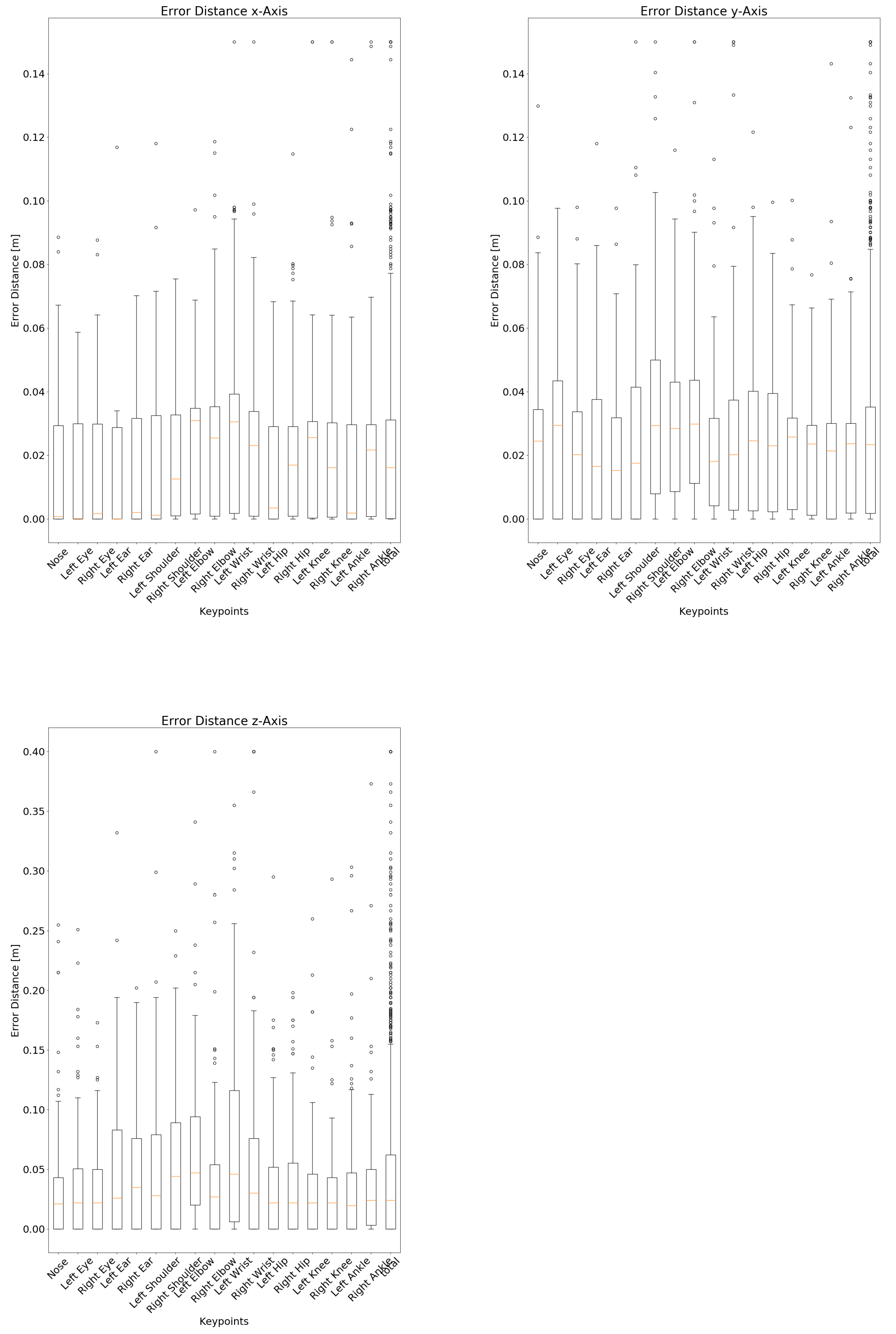
3.4. Consideration of Individual Keypoints
4. Discussion
4.1. Sensitivity of Depth Image-Based HRNet
4.2. Specific Consideration of Keypoints
4.3. Spatial Accuracy
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Merriaux, P.; Dupuis, Y.; Boutteau, R.; Vasseur, P.; Savatier, X. A Study of Vicon System Positioning Performance. Sensors 2017, 17, 1591. [Google Scholar] [CrossRef] [PubMed]
- Moreira, B.S.; Sampaio, R.F.; Kirkwood, R.N. Spatiotemporal gait parameters and recurrent falls in community-dwelling elderly women: A prospective study. Braz. J. Phys. Ther. 2015, 19, 61–69. [Google Scholar] [CrossRef] [PubMed]
- Bueno, G.A.S.; Gervásio, F.M.; Ribeiro, D.M.; Martins, A.C.; Lemos, T.V.; de Menezes, R.L. Fear of Falling Contributing to Cautious Gait Pattern in Women Exposed to a Fictional Disturbing Factor: A Non-randomized Clinical Trial. Front. Neurol. 2019, 10. [Google Scholar] [CrossRef] [PubMed]
- Eltoukhy, M.; Kuenze, C.; Oh, J.; Jacopetti, M.; Wooten, S.; Signorile, J. Microsoft Kinect can distinguish differences in over-ground gait between older persons with and without Parkinson’s disease. Med. Eng. Phys. 2017, 44, 1–7. [Google Scholar] [CrossRef] [PubMed]
- Leu, A.; Ristić-Durrant, D.; Gräser, A. A robust markerless vision-based human gait analysis system. In Proceedings of the 6th IEEE International Symposium on Applied Computational Intelligence and Informatics (SACI), Timisoara, Romania, 19–21 May 2011; pp. 415–420. [Google Scholar] [CrossRef]
- Castelli, A.; Paolini, G.; Cereatti, A.; Della Croce, U. A 2D Markerless Gait Analysis Methodology: Validation on Healthy Subjects. Comput. Math. Methods Med. 2015, 2015, 186780. [Google Scholar] [CrossRef] [PubMed]
- Fudickar, S.; Hellmers, S.; Lau, S.; Diekmann, R.; Bauer, J.M.; Hein, A. Measurement System for Unsupervised Standardized Assessment of Timed “Up & Go” and Five Times Sit to Stand Test in the Community—A Validity Study. Sensors 2020, 20, 2824. [Google Scholar] [CrossRef]
- Hellmers, S.; Izadpanah, B.; Dasenbrock, L.; Diekmann, R.; Bauer, J.M.; Hein, A.; Fudickar, S. Towards an automated unsupervised mobility assessment for older people based on inertial TUG measurements. Sensors 2018, 18, 3310. [Google Scholar] [CrossRef]
- Dubois, A.; Bihl, T.; Bresciani, J.P. Automating the Timed Up and Go Test Using a Depth Camera. Sensors 2018, 18, 14. [Google Scholar] [CrossRef] [PubMed]
- Thaler-Kall, K.; Peters, A.; Thorand, B.; Grill, E.; Autenrieth, C.S.; Horsch, A.; Meisinger, C. Description of spatio-temporal gait parameters in elderly people and their association with history of falls: Results of the population-based cross-sectional KORA-Age study. BMC Geriatr. 2015, 15, 1–8. [Google Scholar] [CrossRef] [PubMed]
- Jung, H.W.; Roh, H.; Cho, Y.; Jeong, J.; Shin, Y.S.; Lim, J.Y.; Guralnik, J.M.; Park, J. Validation of a Multi–Sensor-Based Kiosk for Short Physical Performance Battery. J. Am. Geriatr. Soc. 2019, 67, 2605–2609. [Google Scholar] [CrossRef] [PubMed]
- Hellmers, S.; Fudickar, S.; Lau, S.; Elgert, L.; Diekmann, R.; Bauer, J.M.; Hein, A. Measurement of the Chair Rise Performance of Older People Based on Force Plates and IMUs. Sensors 2019, 19, 1370. [Google Scholar] [CrossRef] [PubMed]
- Dentamaro, V.; Impedovo, D.; Pirlo, G. Sit-to-Stand Test for Neurodegenerative Diseases Video Classification. In Pattern Recognition and Artificial Intelligence; Lu, Y., Vincent, N., Yuen, P.C., Zheng, W.S., Cheriet, F., Suen, C.Y., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 596–609. [Google Scholar]
- Yang, C.; Ugbolue, U.C.; Kerr, A.; Stankovic, V.; Stankovic, L.; Carse, B.; Kaliarntas, K.T.; Rowe, P.J. Autonomous gait event detection with portable single-camera gait kinematics analysis system. J. Sens. 2016, 2016. [Google Scholar] [CrossRef]
- Arizpe-Gomez, P.; Harms, K.; Fudickar, S.; Janitzky, K.; Witt, K.; Hein, A. Preliminary Viability Test of a 3-D-Consumer-Camera-Based System for Automatic Gait Feature Detection in People with and without Parkinson’s Disease. In Proceedings of the ICHI 2020, Oldenburg, Germany, 15–18 June 2020. [Google Scholar]
- Cao, Z.; Martinez, G.H.; Simon, T.; Wei, S.E.; Sheikh, Y.A. OpenPose: Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields. IEEE Trans. Pattern Anal. Mach. Intell. 2019, 43, 172–186. [Google Scholar] [CrossRef] [PubMed]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep High-Resolution Representation Learning for Human Pose Estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, 25 February 2019; Computer Vision Foundation/IEEE: Piscataway, NJ, USA, 2019; pp. 5693–5703. [Google Scholar] [CrossRef]
- Lin, T.Y.; Patterson, G.; Ronchi, M.R.; Cui, Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; et al. COCO—Common Objects in Context—Keypoint Evaluation. Available online: http://cocodataset.org/#keypoints-eval (accessed on 16 April 2020).
- Veges, M.; Lorincz, A. Multi-Person Absolute 3D Human Pose Estimation with Weak Depth Supervision. arXiv 2020, arXiv:2004.03989. [Google Scholar]
- Ye, M.; Wang, X.; Yang, R.; Ren, L.; Pollefeys, M. Accurate 3d pose estimation from a single depth image. In Proceedings of the 2011 International Conference on Computer Vision, Barcelona, Spain, 6–11 November 2011; pp. 731–738. [Google Scholar] [CrossRef]
- Ganapathi, V.; Plagemann, C.; Koller, D.; Thrun, S. Real time motion capture using a single time-of-flight camera. In Proceedings of the 2010 IEEE Computer Society Conference on Computer Vision and Pattern Recognition, San Francisco, CA, USA, 13–18 June 2010. [Google Scholar] [CrossRef]
- Shotton, J.; Fitzgibbon, A.; Cook, M.; Sharp, T.; Finocchio, M.; Moore, R.; Kipman, A.; Blake, A. Real-time human pose recognition in parts from single depth images. In Proceedings of the CVPR 2011, Colorado Springs, CO, USA, 20–25 June 2011. [Google Scholar] [CrossRef]
- Wei, X.; Zhang, P.; Chai, J. Accurate Realtime Full-Body Motion Capture Using a Single Depth Camera. ACM Trans. Graph. 2012, 31. [Google Scholar] [CrossRef]
- Park, S.; Yu, S.; Kim, J.; Kim, S.; Lee, S. 3D hand tracking using Kalman filter in depth space. EURASIP J. Adv. Signal Process. 2012, 2012. [Google Scholar] [CrossRef]
- Shen, W.; Lei, R.; Zeng, D.; Zhang, Z. Regularity Guaranteed Human Pose Correction. In Computer Vision—ACCV 2014; Cremers, D., Reid, I., Saito, H., Yang, M.H., Eds.; Springer International Publishing: Cham, Switzerland, 2015; pp. 242–256. [Google Scholar]
- Rusu, R.B.; Cousins, S. 3D is here: Point Cloud Library (PCL). In Proceedings of the IEEE International Conference on Robotics and Automation (ICRA), Shanghai, China, 9–13 May 2011. [Google Scholar]
- Mederos, B.; Velho, L.; De Figueiredo, L.H. Moving least squares multiresolution surface approximation. In Proceedings of the 16th Brazilian Symposium on Computer Graphics and Image Processing (SIBGRAPI 2003), Sao Carlos, Brazil, 12–15 October 2003; pp. 19–26. [Google Scholar]
- Hartley, R.; Zisserman, A. Multiple View Geometry in Computer Vision; Cambridge University Press: Cambridge, UK, 2004; ISBN 9781139449144. [Google Scholar]
- Yodayoda. From Depth Map to Point Cloud. 2020. Available online: https://medium.com/yodayoda/from-depth-map-to-point-cloud-7473721d3f (accessed on 5 February 2021).
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. Conference Track Proceedings. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Obdrzalek, S.; Kurillo, G.; Ofli, F.; Bajcsy, R.; Seto, E.; Jimison, H.; Pavel, M. Accuracy and robustness of Kinect pose estimation in the context of coaching of elderly population. In Proceedings of the 2012 Annual International Conference of the IEEE Engineering in Medicine and Biology Society, San Diego, CA, USA, 28 August–1 September 2012. [Google Scholar] [CrossRef]
- Association WMA. WMA Deklaration von Helsinki—Ethische Grundsätze für die Medizinische Forschung am Menschen; WMA: Ferney-Voltaire, France, 2013. [Google Scholar]
- Dutta, A.; Gupta, A.; Zissermann, A. VGG Image Annotator (VIA). 2016. Available online: http://www.robots.ox.ac.uk/~vgg/software/via/ (accessed on 14 July 2019).
- Lin, T.Y.; Patterson, G.; Ronchi, M.R.; Cui, Y.; Maire, M.; Belongie, S.; Bourdev, L.; Girshick, R.; Hays, J.; Perona, P.; et al. COCO—Common Objects in Context—What Is COCO? Available online: http://cocodataset.org/#home (accessed on 16 April 2020).
- Halmetschlager-Funek, G.; Suchi, M.; Kampel, M.; Vincze, M. An Empirical Evaluation of Ten Depth Cameras: Bias, Precision, Lateral Noise, Different Lighting Conditions and Materials, and Multiple Sensor Setups in Indoor Environments. IEEE Robot. Autom. Mag. 2019, 26, 67–77. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| AP | AP50 | AP75 | APM | APL | AR | |
|---|---|---|---|---|---|---|
| OpenPose | 0.642 | 0.862 | 0.701 | 0.61 | 0.688 | |
| HRNet | 0.77 | 0.927 | 0.845 | 0.734 | 0.831 | 0.82 |
| AP | AP50 | AP75 | APM | APL | AR | |
|---|---|---|---|---|---|---|
| All keypoints | ||||||
| Average | 0.725 | 0.919 | 0.846 | 0.756 | 0.735 | 0.783 |
| Min | 0.692 | 0.887 | 0.812 | 0.736 | 0.693 | 0.747 |
| Max | 0.755 | 0.939 | 0.893 | 0.778 | 0.775 | 0.807 |
| HRNet | 0.61 | 0.898 | 0.648 | 0.693 | 0.62 | 0.669 |
| Upper Extremities | ||||||
| Average | 0.633 | 0.906 | 0.705 | 0.713 | 0.61 | 0.724 |
| Min | 0.579 | 0.862 | 0.648 | 0.682 | 0.545 | 0.671 |
| Max | 0.669 | 0.928 | 0.738 | 0.754 | 0.65 | 0.753 |
| HRNet | 0.618 | 0.919 | 0.692 | 0.738 | 0.58 | 0.706 |
| Lower Extremities | ||||||
| Average | 0.856 | 0.933 | 0.881 | 0.974 | 0.826 | 0.883 |
| Min | 0.819 | 0.904 | 0.843 | 0.964 | 0.777 | 0.869 |
| Max | 0.884 | 0.95 | 0.909 | 0.983 | 0.862 | 0.898 |
| HRNet | 0.609 | 0.832 | 0.594 | 0.714 | 0.578 | 0.651 |
| Model | Precision | Recall | F1-Score |
|---|---|---|---|
| 1 | 0.92 | 0.882 | 0.901 |
| 2 | 0.916 | 0.88 | 0.897 |
| 3 | 0.884 | 0.88 | 0.882 |
| 4 | 0.86 | 0.883 | 0.872 |
| 5 | 0.872 | 0.88 | 0.876 |
| 6 | 0.909 | 0.88 | 0.894 |
| 7 | 0.919 | 0.88 | 0.899 |
| 8 | 0.909 | 0.881 | 0.895 |
| 9 | 0.883 | 0.88 | 0.881 |
| 10 | 0.914 | 0.88 | 0.897 |
| Classified Keypoints | |||
|---|---|---|---|
| Visible | Occluded | ||
| Reference Keypoints | visible | 2488 (88%) | 332 |
| occluded | 217 | 1451 (87%) | |
| Median Error Distance [cm] | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Keypoints | TP | FP | FN | TN | Sensitivity | Specificity | F1-Score | Lateral (x) | Height (y) | Depth (z) |
| Nose | 113 | 12 | 2 | 137 | 0.983 | 0.919 | 0.942 | 0.078 | 2.446 | 2.1 |
| Left Eye | 99 | 17 | 0 | 148 | 1 | 0.897 | 0.921 | 0.005 | 2.948 | 2.2 |
| Right Eye | 104 | 17 | 1 | 142 | 0.99 | 0.893 | 0.92 | 0.162 | 2.019 | 2.2 |
| Left Ear | 51 | 49 | 1 | 163 | 0.981 | 0.769 | 0.671 | 0.002 | 1.658 | 2.6 |
| Right Ear | 118 | 14 | 1 | 131 | 0.992 | 0.903 | 0.94 | 0.209 | 1.527 | 3.5 |
| Left Shoulder | 123 | 13 | 4 | 124 | 0.969 | 0.905 | 0.935 | 0.122 | 1.754 | 2.8 |
| Right Shoulder | 141 | 6 | 6 | 111 | 0.959 | 0.949 | 0.959 | 1.261 | 2.935 | 4.4 |
| Left Elbow | 154 | 12 | 17 | 81 | 0.901 | 0.871 | 0.914 | 3.09 | 2.846 | 4.7 |
| Right Elbow | 166 | 7 | 23 | 68 | 0.878 | 0.907 | 0.917 | 2.543 | 2.987 | 2.7 |
| Left Wrist | 155 | 17 | 17 | 75 | 0.901 | 0.815 | 0.901 | 3.054 | 1.815 | 4.6 |
| Right Wrist | 182 | 8 | 42 | 32 | 0.813 | 0.8 | 0.879 | 2.305 | 2.026 | 3.0 |
| Left Hip | 168 | 12 | 23 | 61 | 0.88 | 0.836 | 0.906 | 0.343 | 2.454 | 2.2 |
| Right Hip | 159 | 19 | 48 | 38 | 0.768 | 0.667 | 0.826 | 1.693 | 2.296 | 2.2 |
| Left Knee | 191 | 5 | 34 | 34 | 0.849 | 0.872 | 0.907 | 2.558 | 2.579 | 2.2 |
| Right Knee | 197 | 2 | 39 | 26 | 0.835 | 0.929 | 0.906 | 1.619 | 2.357 | 2.2 |
| Left Ankle | 178 | 6 | 39 | 41 | 0.82 | 0.872 | 0.888 | 0.182 | 2.138 | 1.95 |
| Right Ankle | 189 | 1 | 35 | 39 | 0.844 | 0.975 | 0.913 | 2.167 | 2.365 | 2.4 |
| Upper Extremities | 1406 | 172 | 114 | 1212 | 0.925 | 0.876 | 0.908 | 1.68 | 2.296 | 2.7 |
| Lower Extremities | 1082 | 45 | 218 | 239 | 0.832 | 0.841 | 0.892 | 1.537 | 2.371 | 2.2 |
| Total | 2488 | 217 | 332 | 1451 | 0.882 | 0.87 | 0.901 | 1.619 | 2.342 | 2.4 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Büker, L.C.; Zuber, F.; Hein, A.; Fudickar, S. HRDepthNet: Depth Image-Based Marker-Less Tracking of Body Joints. Sensors 2021, 21, 1356. https://doi.org/10.3390/s21041356
Büker LC, Zuber F, Hein A, Fudickar S. HRDepthNet: Depth Image-Based Marker-Less Tracking of Body Joints. Sensors. 2021; 21(4):1356. https://doi.org/10.3390/s21041356
Chicago/Turabian StyleBüker, Linda Christin, Finnja Zuber, Andreas Hein, and Sebastian Fudickar. 2021. "HRDepthNet: Depth Image-Based Marker-Less Tracking of Body Joints" Sensors 21, no. 4: 1356. https://doi.org/10.3390/s21041356
APA StyleBüker, L. C., Zuber, F., Hein, A., & Fudickar, S. (2021). HRDepthNet: Depth Image-Based Marker-Less Tracking of Body Joints. Sensors, 21(4), 1356. https://doi.org/10.3390/s21041356